
Optimizing Leak Detection in Open-source Platforms with Machine
Learning Techniques
Sofiane Lounici
1
, Marco Rosa
1
, Carlo Maria Negri
1
, Slim Trabelsi
1
and Melek Önen
2
1
SAP Security Research, France
2
EURECOM, France
Keywords:
Data Mining, Security Tool, Machine Learning.
Abstract:
Public code platforms like GitHub are exposed to several different attacks, and in particular to the detection and
exploitation of sensitive information (such as passwords or API keys). While both developers and companies
are aware of this issue, there is no efficient open-source tool performing leak detection with a significant
precision rate. Indeed, a common problem in leak detection is the amount of false positive data (i.e., non
critical data wrongly detected as a leak), leading to an important workload for developers manually reviewing
them. This paper presents an approach to detect data leaks in open-source projects with a low false positive
rate. In addition to regular expression scanners commonly used by current approaches, we propose several
machine learning models targeting the false positives, showing that current approaches generate an important
false positive rate close to 80%. Furthermore, we demonstrate that our tool, while producing a negligible false
negative rate, decreases the false positive rate to, at most, 6% of the output data.
1 INTRODUCTION
Data protection has become an important issue over
the last few years. Despite the multiplication of
awareness campaigns and the growth of good devel-
opment practices, we observe a major rise of data
leaks in 2019, with passwords representing 64% of
all data compromised
1
. It has become a huge concern
for companies to protect themselves and to efficiently
detect these data leaks.
GitHub
2
is a hosting platform for software devel-
opment version control. With more than 100 million
repositories (with at least 28 million public ones), it is
the largest host of source code in the world. Users can
use GitHub to publish their code, to collaborate on
open-source projects, or simply to use publicly avail-
able projects. In such an environment, one of the most
critical threats is represented by hardcoded (or plain-
text) credentials in open-source projects (MITRE,
2019). Indeed, when developers integrate an authen-
tication process in their source code (e.g., a database
access), a common practice is the use of password
or authentication tokens (also known as API Keys).
In this process, there is a risk that secrets may be
unintentionally published in publicly available open-
source projects, possibly leading to data breaches. For
1
https://preview.tinyurl.com/y7bygg8d
2
https://www.github.com
instance, Uber sustained in 2016 a massive data leak
3
,
affecting 57 million customers by revealing personal
data such as names, and phone numbers. This attack
was originating from a password found in a private
GitHub repository.
Several tools are already available to detect leaks
in open-source platforms such as GitGuardian
4
or
TruffleHog
5
. Nevertheless, the diversity of creden-
tials, depending on multiple factors such as the pro-
gramming language, code development conventions,
or developers’ personal habits, is a bottleneck for
the effectiveness of these tools. Their lack of preci-
sion leads to a very high number of pieces of code
detected as leaked secrets, even though they consist
in perfectly legitimate code. Data wrongly detected
as a leak is called false positive data, and compose
the huge majority of the data detected by currently
available tools. Thus, various companies (including
GitHub itself
6
), are starting to automate the detection
of leaks while reducing false positive data.
In this paper, we present a novel approach to ana-
lyze GitHub open-source projects for data leaks, with
a significant decrease in false positives thanks to the
use of machine learning techniques. First, a Regex
3
https://tinyurl.com/yd3c37lc
4
https://www.gitguardian.com/
5
https://github.com/dxa4481/truffleHog
6
https://preview.tinyurl.com/ycnllvfd
Lounici, S., Rosa, M., Negri, C., Trabelsi, S. and Önen, M.
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques.
DOI: 10.5220/0010238101450159
In Proceedings of the 7th International Conference on Information Systems Security and Privacy (ICISSP 2021), pages 145-159
ISBN: 978-989-758-491-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
145

Scanner searches through the source code for po-
tential leaks, looking for any correspondence with a
set of programming patterns. Then, machine learn-
ing models filter the potential leaks by detecting false
positive data, before a human reviewer can check the
classified data manually to correct possible wrongly
classified data. These machine learning models are
using various techniques such as data augmenta-
tion (Shorten and Khoshgoftaar, 2019), code stylom-
etry (Long et al., 2017; Quiring et al., 2019) and rein-
forcement learning (Watkins and Dayan, 1992).
The main contributions of this paper can be sum-
marized as follows.
• We present an automated leak detector for pass-
words and API Keys in open-source platforms,
with low false positive rate.
• We evaluate our solution by scanning 1000 pub-
lic GitHub and 300 company-owned repositories,
and we show that the classic regular expression
approaches generate a high false positive rate, that
we estimate close to 82%.
• We manually assess the results of this scan, prov-
ing that our solution reaches a negligible false
negative rate.
• We investigate the false positives induced by the
machine learning models, and we show it is be-
tween 5% and 32% of the filtered data (hence be-
tween 1% and 6% of the overall data)
Outline. We introduce an overview of the prob-
lem of leak detection in Section 2.1, alongside an ar-
chitecture of our framework in Section 2.2. We fur-
ther detail the different modules: We describe the Path
Model in Section 3, the Snippet models in Section 4,
and the Similarity model in Section 5. We present an
evaluation of our approach, focusing on the false pos-
itive rate induced by the machine learning models, in
Section 6. We discuss the related work in Section 7.
We finally address potential privacy concerns in Sec-
tion 8.
2 OVERVIEW
2.1 Problem Statement
A leak is a piece of information in a source code, pub-
lished on open-source platforms such as GitHub, dis-
closing personal and sensitive data. Data leaks can be
caused by any type of developer, such as independent
developers or important corporations. For instance,
a password published on GitHub by an Uber’s em-
ployee led to the disclosure of personal information
of 57 millions customers
7
.
Several types of data leaks exist: API Keys (e.g.,
AWS credentials), email passwords, database creden-
tials, etc. Although detection techniques exist, cur-
rent approaches do not achieve a satisfying precision
rate, leading to a high false positive rate, i.e., non-
negligible part of data is wrongly classified as leak. A
high false positive rate implies an important workload
for reviewers who manually check the accuracy of the
classification.
In this paper, we present an automated leak detec-
tor for open-source platforms with low false positive
rate, powered by machine learning.
We identify three main problems we intend
to tackle. To begin with, we notice that open-
source projects often provide the documentation of
their code, together with tutorials, tests, and ex-
ample files. These situations are easily recogniz-
able by the actual path name (e.g., src/Example.py,
connectionTutorial.java, etc.). An important
amount of passwords or database credentials are lo-
cated in these type of files and are never used in pro-
duction, increasing the false positive rate.
Moreover, current solutions such as GitGuardian,
Trufflehog, S3Scanner, GitHub Token Scanning or
others in (Sinha et al., 2015) consist of regular expres-
sion classifiers and exclusively focus on API Keys,
ignoring passwords as a category of leak. Indeed,
the detection of API Keys creates a negligible amount
of false positive data (due to the particular patterns).
Thus, it is easier to handle them with simple regu-
lar expression classifiers. Passwords, on the other
hand, are difficult to identify with classic methods,
even though they account for the majority of leaks,
leading to a high false positive rate. Current solutions
offer little to no automated false positive filtering (ex-
cept with simple heuristics) because they discard the
most important source of false positive data in their
analysis.
Additionally, the detection of leaks with low false
positive rate is usually performed using supervised
machine learning techniques which by definition in-
cur the need for labelled training data. The collec-
tion of leak data in this context remains a challenge
for several reasons: (i) on a theoretical point of view,
passwords/credentials are privacy sensitive data, (ii)
on a practical point of view the training dataset needs
to satisfy general properties such as balance or diver-
sity, and current machine learning approaches cannot
guarantee these properties while maintaining a rea-
sonable manual workload to sanitize, anonymize and
label data.
7
https://tinyurl.com/yd3c37lc
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
146
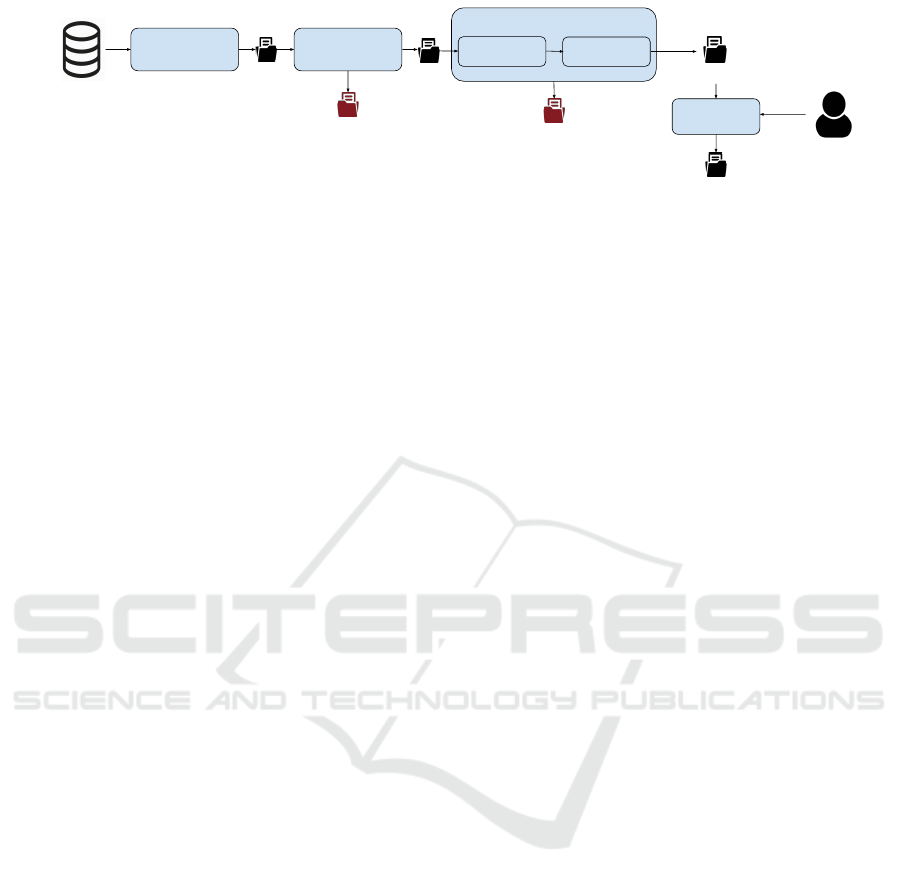
Regex Scanner
Path Model
Snippet Models
Extractor
Classifier
discoveries
repository
Path false positives
Similarity Model
output after review
Code snippet false positives
output before review
Figure 1: Architecture of our approach.
2.2 Our Approach
In order to detect leaks with high precision and low
false positive rate, we begin with the use of a regu-
lar expression scanner similar to classical approaches.
We further propose to make the distinction between
two sources of false positives: Path false positives
(e.g., data located in documentation or example files)
and Code snippet false positives (e.g., dummy creden-
tials or initialization variables). These two sources
of false positives can be tackled by two separate ma-
chine learning models: the Path model and the Snip-
pet model. Consequently, our solution regroups the
following components.
Regex Scanner. Given an open-source repository, the
Regex Scanner searches through the source code his-
tory to detect any credential, API Key or plaintext
password, and is considered as the default component
in classic approaches. The Regex Scanner analyzes
each source code modification by a developer over
time, retrieving the link between these modifications
and a set of regular expressions. The output of the
Regex Scanner over a repository R is a set of m dis-
coveries D = {d
1
, ..., d
m
}, each discovery containing
a path f
i
and a code snippet s
j
.
Path Model. The Path model analyzes each path f
i
to reduce Path false positives, and outputs a list of
filtered discoveries. We propose to make use of the
Linear Continous Bag-of-Words model to represent
and link words to the actual context. Thanks to this
model, we already reduce false positives by 69%.
The Snippet models filter false positives related
to code snippets. A code snippet is more complex to
analyze than a file path (more diversity, more irreg-
ular patterns, etc.), and may contain non-negligible
amount of irrelevant data for leak classification (func-
tion names, type names, method names, symbols,
etc.). Compared to the Path model, an additional pre-
processing step is needed before the actual leak de-
tection. Therefore, the Snippet models consist of two
main components:
Extractor. The Extractor identifies relevant informa-
tion in the snippets, i.e., the variable name and the
value assigned. As mentioned before, it is difficult
to collect relevant data to train the Extractor. Thus,
we implement data augmentation techniques through
reinforcement learning.
Classifier. The Classifier takes the relevant informa-
tion extracted as inputs to classify a code snippet as
a leak or as a false positive. At this step, we con-
sider again a LCBOW model, leading to a reduction
of 13% of the discoveries with the combination of the
Extractor and the Classifier.
As a final step, once automated components out-
put the leaks they have detected, a human reviewer
manually checks the accuracy of the classification
by flagging (i.e., re-classifying manually) a leak as a
false positive.
Similarity Model. The Similarity model can assist
the human reviewer by flagging similar discoveries as
false positives to reduce her workload.
Figure 1 gives an overview of the architecture of
the proposed framework. In the following sections,
we describe the design choices for each of these com-
ponents while illustrating their use with three example
scenarios.
Scenario 1. Consider the code snippet String
password = "Ub4!l", located in the file
src/Example.py. The Regex Scanner identi-
fies the key word password, so that the discovery is
classified as a leak. Then, the Path model analyzes
the file path, and discards the leak as a Path false
positive (due to the word Example).
Scenario 2. Consider the code snippet String
password = "Ub4!l", located in the file
src/run.py. The Regex Scanner still identifies
the key word password, while the Path model does
not discard the leak due to its Path. The Extractor
outputs the combination (password, Ub4!l), and the
Classifier classifies this code snippet as a leak.
Scenario 3. Consider the code snippet String
password = "INSERT_CREDENTIAL_HERE",
located in the file src/run.py. The Extrac-
tor outputs the combination (password, IN-
SERT_CREDENTIAL_HERE), and the Classifier
classifies the code snippet as a false positive.
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
147

3 PATH MODEL
The goal of the Path model is to reduce the Path false
positives. This model analyzes where a leak is identi-
fied in an open-source repository (i.e., its file path),
and gives a first classification on whether the leak
is relevant or not. The Path model relies on a basic
machine learning technique called Linear Continous
Bag-of-Words (LCBOW).
3.1 LCBOW Model
In the field of Natural Language Processing, there
exist many possible choices for a text represen-
tation method among which the word embedding
one where words are mapped to vectors like in
word2vec (Mikolov et al., 2013b) or Bag-of-Words
(BoW) (Ma et al., 2019) representations. In this work,
we consider the use of the Linear Continuous Bag-
of-Words (LCBOW) model (Mikolov et al., 2013a;
Joulin et al., 2016), especially for its efficiency. We
briefly explain how the LCBOW model is built.
Let’s denote a list of words as a document corpus
of size N. A sentence in the document corpus is com-
posed of N-gram features {w
1
, w
2
, ..., w
N
}. We obtain
the feature representations via a weight matrix U to
obtain x
i
= U · w
i
. Then, we define y as the linear
Bag-of-Words of the document, by averaging all the
feature representations x
i
:
y =
1
N
N
∑
i=1
x
i
y is the input of a hidden layer associated to a
weight matrix V, such that output z = V · y. We
can compute the probability that a word vector be-
longs to the j
th
class as p
j
= σ(z
j
), with σ(z
j
)
8
be-
ing the softmax function. Finally, the weight matri-
ces U and V are computed by minimizing the nega-
tive log-likelihood of the probability distribution, us-
ing stochastic gradient descent, namely:
−
1
N
N
∑
k=1
y
k
· log
σ(V ·U ·w
i
)
In the remaining of the paper, we will use the nota-
tion LCBOW (w) to describe the vector representation
of the word w.
3.2 Data Pre-processing
The Regex Scanner outputs a list of discoveries, each
discovery containing a path f
i
(used as an input for
thePath model) and a code snippet s
j
(used as an input
8
σ(z
j
) =
e
z
j
∑
m
k=1
e
z
k
for the Snippet models). Some pre-processing phase
is needed for both these data: First, we remove non-
alphanumerical characters, before applying stemming
and lemmatization, which are natural language pro-
cessing techniques (Sun et al., 2014). We split the
input data in words to obtain f
preprocc
= { f
1
i
, ..., f
k
f
i
}.
In order to respect common coding conventions while
standardizing the input data, we apply the Java coding
convention to each word in f
i
(the choice of coding
convention is irrelevant as long as it is standardized
for all inputs).
Example. If we consider Scenario 1, with
f = src/Example.py and s = String
password = "Ub4!l", the pre-processing
phase outputs f
preproc
= {src, Example, py} and
s
preproc
= {String, password,Ub4!l}
3.3 Training Phase
The workload to gather sufficient training data and to
review labeled items can be handled by a human re-
viewer. Since the path name is not a sensitive piece
of information, the data sanitization aspect can be re-
duced to a minimum. We collected 100k file names
from 1000 GitHub repositories (analyzed in our eval-
uation in Section 6), which we labeled using regular
expressions and manual checks. We applied the data
pre-processing techniques and we train a LCBOW
model, achieving 99% of accuracy on this dataset.
4 SNIPPET MODELS
In this section, we detail the design choices for the
Snippet models: the Extractor and the Classifier. To
fully understand our approach, we propose to intro-
duce several concepts, aimed to be used as building
blocks for these models.
4.1 Building Blocks
4.1.1 Code Stylometry
Each developer has her own coding habits, depend-
ing on many factors such as the coding language or
the occurrences of given key words. We introduce a
concept called code stylometry, aiming to encapsulate
into a vector the main characteristics of these coding
habits.
Example. Consider a Python developer, focused on
software development. This developer will probably
use key words such as password or pass_word to do
password assignments (e.g., password = "Ub4!l").
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
148

A different developer, focused on database manage-
ment, might prefer keywords such as root or db (like
db.root = "Ub4!l". These design choices will re-
sult in two different code stylometry vectors.
Supposing that we have extracts of code belong-
ing to a developer (denoted E ), we compute her code
stylometry based of these extracts
9
.
4.1.2 Data augmentation
As previously mentioned in Section 2.1, obtaining a
dataset for leaks on GitHub is complicated. Indeed,
since we are dealing with sensitive data, we have to
follow and comply with privacy guidelines, e.g., per-
forming data sanitization. The collected data also
needs to be labelled, which may require a signifi-
cant manual workload. In addition, the diversity of
leaks in open-source repositories usually follows the
Pareto rule, meaning that 80% of the data leaks are
originating from the same few programming patterns
(for instance, password="1234" is extremely com-
mon). Therefore, collecting a diverse dataset in order
to train a machine learning model (to have good gen-
eralization properties and avoid overfitting (Shorten
and Khoshgoftaar, 2019)) would be difficult to reach
from a practical point of view. For these reasons, we
propose to use data augmentation techniques in order
to enhance the size and the diversity of the dataset
with no extra cost in labelling or sanitization.
Data augmentation is a set of techniques to en-
hance the diversity of a dataset without new data. It
is particularly used in image processing (Shorten and
Khoshgoftaar, 2019), by applying filters to images in
order to produce new training samples. The main ben-
efit is to expand a dataset (fixing class imbalance or
adding diversity in the training samples) with limited
pre-processing cost. Data augmentation can also pre-
vent overfitting (i.e, when a machine learning model
is not able to generalize from the training data).
Example. Consider two leaks password="Ub4!" and
mypass="1234". If we switch the variable names to
obtain password="1234" and mypass="Ub4!", we
have in fact created two new leaks. In general, given
a pattern key="value", any pair of (key, value) can
be chosen to obtain a new leak. Every time another
variable name is collected, data augmented leaks can
be obtained by the re-arrangement of already exist-
ing data. More specifically, when a new program-
ming pattern is collected for password assignment
(e.g., DataBase.key="value") additional leaks can
be obtained, creating diversity from limited dataset.
9
The complete list of the features we consider for code
stylometry can be found in the Appendix
Data: D , π, style
re f
Result: Training Data for π T
π
while condition is True do
style ← choose_actions(π, D );
reward
sim
← similarity(style,style
re f
);
update_choices(reward
sim
);
end
T
π
← choose_actions(π, D )
Algorithm 1: Q-learning algorithm.
Data: Collected data D , patterns Π, extracts
E
Result: model
style
re f
← stylometry(E );
for π in Π do
T
π
← QLearning(π, D , E , style
re f
);
T
tot
← T
π
∪ T
tot
end
model ← train
LCBOW
(T
tot
);
Algorithm 2: Extractor model algorithm.
In the context of this work, we have an important
number of alternatives to enhance our dataset, such
as replacing variable names by synonyms, modify-
ing function names (e.g., from set_password() to
os.setPass()), or replacing ’[]’ with ’()’. Since
there is no clear algorithm to choose which actions
(or combination of actions) will output the best suited
dataset for the training phase, we consider the Q-
learning algorithm (Watkins and Dayan, 1992).
4.1.3 Q-learning
Q-learning algorithm is a reinforcement learning al-
gorithm, where an agent learns, through interactions
with its environment, actions to take to maximize a
reward. A classic example is a game of chess: the Q-
learning algorithm will compute the list of moves the
player needs to perform to win the game (to check-
mate her opponent).
Similarly, in the data augmentation process, some
actions can be applied to the collected data, such as
modifying variable names (like in Example A), select-
ing different functions names, or considering object-
oriented programming patterns. Since different com-
binations of actions lead to different datasets, it will
also lead to different code stylometry vectors. The
goal for data augmentation is to converge to a particu-
lar code stylometry of the transformed dataset, called
reference stylometry.
We define three primitives to build the Q-learning
algorithm, that we show in Algorithm 1.
• style ← choose_actions(π,D): The agent can
choose a combination of actions she intends to
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
149

perform on data D (collected data from an em-
pirical study) for a given pattern π. These actions
produce a new dataset, from which we can com-
pute the resulting stylometry style. In this paper,
we consider a list of 28 programming patterns
10
• similarity(style, style
re f
): The similarity function
computes the cosine distance between the current
stylometry and the reference stylometry (com-
puted through extracts E ). The output corre-
sponds to the reward (which we want to maxi-
mize)
• update_choices(reward
sim
): Based on the re-
ward, the Q-learning algorithm will update the
available choices of actions. This update is ruled
by the Bellman equation (Bellman, 1957).
After several iterations of the algorithm, the Q-
learning will apply the optimal choices of combina-
tions of actions, to compute the training dataset for
a given programming pattern T
π
. The stopping con-
dition can be time-based (e.g., maximum number of
iterations) or a threshold reward value.
4.2 Extractor
The main objective for the Extractor is to remove un-
necessary elements in a code snippet, taking as inputs
a list of discoveries (corresponding to the output of
the Path model), and it outputs, for each code snip-
pet, a tuple containing a variable name and a variable
value. If no tuple can be found in a code snippet, then
it is automatically discarded (because no variable as-
signment has been found).
The training data for the Extractor is obtained
through the augmentation of collected data D from
GitHub, like variable names, function names, etc.,
used for variable assignments. Data augmentation is
performed before the training phase. Simultaneously,
the Extractor has access to a collection of code ex-
tracts E ; these extracts are not discoveries, but simply
randomly chosen pieces of code, from which we can
compute a reference code stylometry. Hence, an Ex-
tractor model can be trained for every developer (be-
cause each of them has a different code stylometry)
or for a group of developers (considering their global
code stylometry).
The training phase for the Extractor is shown in
Algorithm 2. For each collected programming pattern
π, we apply the Q-learning algorithm, while consid-
ering the stylometry of the developer (style
re f
) as the
reference stylometry. We obtain the training data T
tot
10
see Appendix. The list of actions can also be found in
the Appendix.
Table 1: FP by models (in millions of discoveries).
Repository type Discoveries File path FP Code snippet FP Total FP
public 13.6 9.35 (69%) 1.79 (13%) 11.11 (82%)
proprietary 0.259 0.091 (35%) 0.064 (25%) 0.155 (60%)
on which a LCBOW model is trained to obtain
the Extractor.
4.3 Classifier
The Classifier takes as input a list of tuples, each of
them containing a variable name and a variable value
(which corresponds to the output of the Extractor) and
classifies the tuple as a leak or as a Code snippet false
positive. The training data for the Classifier is dif-
ferent from the training data of the Extractor. We
retrieved an open-source list of the most commonly
used passwords
11
(used by multiple tools when at-
tempting to guess credentials for a given targeted ser-
vice), and collected (through an empirical study) a list
of commonly used variable names (such as root, ad-
min, pass, etc.). The design of the Classifier is simi-
lar to the design of the Path model, with a LCBOW
model. The Classifier achieves on this dataset of
(variable name, variable value) 98% of accuracy.
5 SIMILARITY MODEL
In the manual review phase, a user can classify a po-
tential leak containing a code snippet s
j
as false pos-
itive. We assume that we have the set of LCBOW
word representations of code snippets of discoveries
{LCBOW (s
1
), ...LCBOW (s
k
)}. To reduce the work-
load of a human reviewer, we introduce a Similar-
ity model, taking the code snippet LCBOW (s
j
) as in-
put and automatically classifying discoveries contain-
ing similar code snippets as false positives, denoted
{LCBOW (s
i
), ...LCBOW (s
k
0
)} with 0 ≤ k
0
≤ k.
Definition. Let η be a similarity threshold.
Two code snippets LCBOW representation
LCBOW (s
i
) and LCBOW (s
j
) are similar if
cosine(LCBOW (s
i
), LCBOW (s
j
)) ≤ η
A similarity threshold η = 1 means that, for a
flagged discovery { f
i
, s
j
}, the Similarity model flags
all the duplicates of the code snippets. The impact of
η is analyzed in Section 6.3.
6 EXPERIMENTS
In this section, we present an evaluation of our solu-
tion, divided into three major parts. Firstly (in Sec-
11
https://github.com/danielmiessler/SecLists/tree/
master/Passwords/Common-Credentials
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
150

Figure 2: Most common files containing secrets.
tion 6.1), we evaluate the rate of false positive data
on the output of the Regex Scanner (as proposed by
the solutions in the literature). With this goal, we
scan a dataset of 1000 repositories from the pub-
lic GitHub (i.e., github.com), and 300 repositories
from a GitHub-like code versioning platform owned
by a private company. In the remainder of this sec-
tion, we refer to github.com as public github and to
the repositories publicly available on this platform as
public repositories, while we refer to the privately
owned GitHub platform as proprietary github and to
its repositories as proprietary repositories. Next, in
Section 6.2, we manually assess the false positive rate
as well as the false negative rate induced by the ma-
chine learning models, and we show that the false
negative rate is negligible (meaning that no leak on
the output of the Regex Scanner is discarded by the
models). Finally, in Section 6.3 we estimate the im-
pact of the data augmentation algorithm parameters
on the precision of our solution.
The tool that we have developed, and that we have
used for the experimental evaluation of our proposal,
is available open source together with the machine
learning models
12
.
6.1 Regex Scanner False Positive Rate
For this experiment, we randomly selected and
scanned 1000 public repositories on GitHub. The list
of regular expressions used by the Regex Scanner can
be found in the Appendix. Over 14 million discov-
eries have been found, with 13.6 million in 579 out
of 1000 public GitHub repositories (58%) and 260k
discoveries in 268 out of 300 proprietary reposito-
ries (89%). Our discoveries cover more than 30 pro-
gramming languages, and represent more than 300
file types. Figure 2 shows the 10 most common file
extensions containing leaks in our dataset. The num-
ber of contributors and the sizes of the repositories
have been chosen equally distributed.
We notice that API keys are still widely published
12
https://github.com/SAP/credential-digger
Table 2: Manual assessment of 2000 discoveries.
classification
machine learning models
potential leak non critical data
manual
leak
20%
(true positives)
1%
(false negatives)
non critical data
80%
(false positives)
99%
(true negatives)
in open-source projects, as shown also in (Meli et al.,
2019). Nevertheless, they do not represent the major-
ity of the discoveries. Indeed, in our study, we notice
a more important number of passwords giving access
to local and remote databases, or to e-mail accounts.
We observe that the vast majority of these passwords
is not critical (i.e., false positives), which seriously in-
creases the load of a developer to review each of them
manually. These passwords are mostly undetectable
by traditional scanning tools, but they are still easy
to find for someone using a simple search tool in the
commit message (with keywords such as remove cre-
dentials, delete password, etc.). We found many pass-
words that we suppose to be real (even if we cannot
have the certainty of this, since we are not allowed
to test these passwords). This is a very important
concern not only because passwords are still widely
reused (Pearman et al., 2019), but also because two-
factor authentication is still scarcely known (and thus
activated) (Milka, 2018; Center, 2019), and scarcely
supported by services (Bursztein, ).
To summarize, the vast majority of the discover-
ies detected with the Regex Scanner consists of false
positive data. In order to reduce the false positive rate,
as described in section 3, we apply the Path model
and the Snippet models sequentially, and finally eval-
uate the newly obtained false positive rates. As shown
in Table 1, the Path model classifies almost 70% of
the discoveries as false positives in the public dataset.
This score is halved with the proprietary dataset. To-
gether with the Snippets models, we see that up to
82% of the discoveries are classified as false positives
without a human intervention.
6.2 Models False Negatives
In order to assess the behavior of our models, we de-
cided to perform a manual review of a limited num-
ber of discoveries (we recall that the Regex Scanner
found 14 millions discoveries in the previous exper-
iment). To do so, we consider a sampling method,
randomly selecting 100 discoveries classified as po-
tential leaks by the models and 100 discoveries clas-
sified as non critical data by the models, and we man-
ually analyze each of them. We repeat this process
10 times (covering 0.01% of all the discoveries from
the previous experiment). The results are shown in
Table 2.It is visible that 99% of the discoveries clas-
sified as non critical data by the models are real-
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
151
{R1, R2, R3}
Augmentation
𝛱: patterns
rfp: poisoning rate
Train/Test split
𝛱*: patterns
Similarity Model
η: threshold
output after review
output before review
D
D’
Figure 3: Data augmentation on D to assess the performance of the Extractor with the train/test split technique.
Table 3: Description of the three repositories.
Repository Language Contributors
rhiever/MarkovNetwork
13
Python 3
bradtraversy/vanillawebprojects
14
Javascript 8
AGWA/git-crypt
15
C++ 15
Table 4: Impact of data augmentation with Π
∗
0.80
.
Situation Precision Recall
Pre-trained Extractor 55.56 100
Extractor with Q-learning 71.66 100
Extractor + Similarity model 74.52 99.71
life true negatives. The remaining percentage (cor-
responding to false negatives) corresponds to edge
cases, where developers inserted (seemingly) real cre-
dentials in dummy files. Thus, in the scope of our
study, we can state that the unclassified leak rate is
negligible. Given the discoveries classified as poten-
tial leaks, 80% of them are non critical (i.e., false pos-
itives non detected by the models), and 20% of them
are actual leaks (i.e., true positives). If we project the
results of this manual assessment to the complete list
of discoveries, we can assume that (i) our models do
not create false negatives and (ii) they provide an effi-
cient reduction of the false positive data on the output
of the Regex Scanner.
6.3 Models False Positives
In the previous section, we notice that it is difficult
to assess the false positive rate of the Snippet Models
(especially the Extractor) with precise metrics since
we do not have a ground truth for the majority of
the leaks detected in open-source repositories. In the
previous section, we had to consider other evaluation
techniques (e.g., sampling) to evaluate the false pos-
itive rate in real-life conditions, or to manually label
the discoveries, which represents an important work-
load. Furthermore, due to the limited size of labeled
data that we manage to collect, we cannot apply the
train/test split (Bronshtein, 2017) technique in order
to evaluate our models on them. The train/test split
technique is a well-known process to assess the va-
lidity of machine learning models, splitting the data
into two distinct subsets: training data (on which we
will fit our model) and testing data (on which we will
evaluate our model). As mentioned before, the size of
the collected labeled data D is too small to accurately
evaluate the Extractor using the train/split technique.
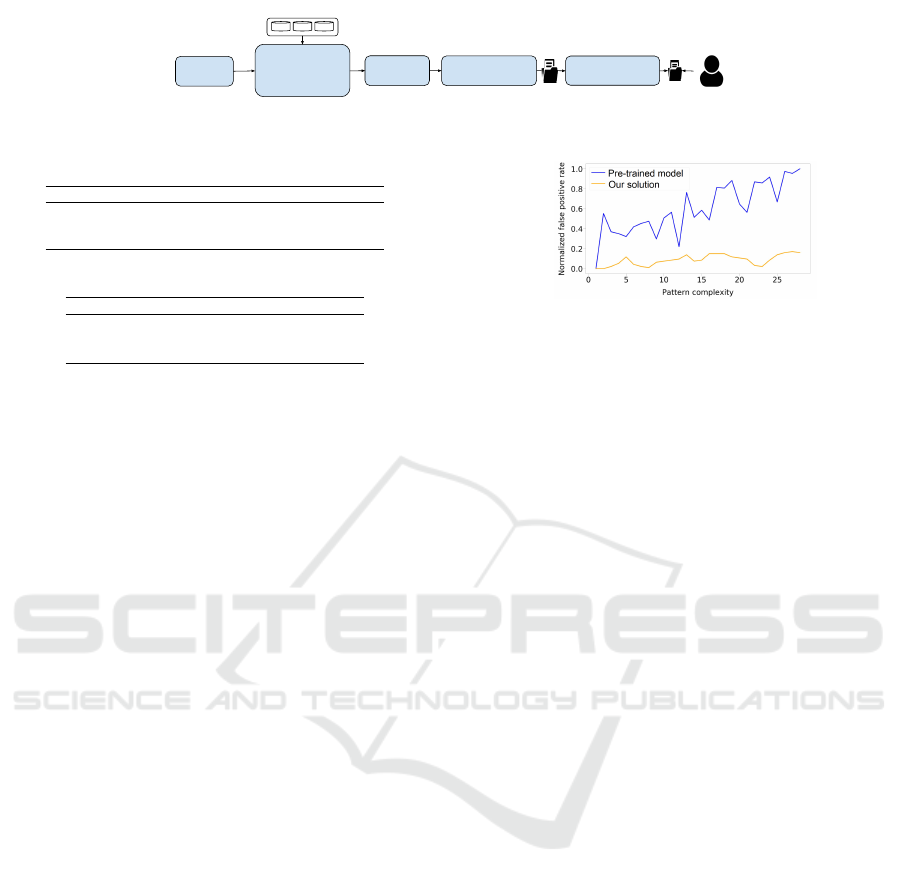
Nevertheless, Section 4.2 shows that we can ap-
Figure 4: Normalized FP rate by pattern for the pre-trained
model and the Extractor trained with Q-learning.
ply data augmentation techniques to expand the size
of our training dataset, as long as we have a ref-
erence stylometry. Hence, the goal of this section
is to evaluate the false positive rate induced by the
Extractor itself (independently from the false posi-
tives induced by the Regex Scanner) on several open-
source repositories, with a train/test split approach
commonly used in supervised learning on an data
augmented dataset. To achieve this goal, we consider
three different repositories {R
1
, R
2
, R
3
}, each of them
containing source code written in different program-
ming languages by different developers (and different
code stylometries) as shown in Table 3. The main
idea is to use the stylometries of these repositories to
obtain an augmented dataset where the train/test split
technique is possible, and to see the impact of the aug-
mentation process on accuracy metrics such as preci-
sion or recall.
6.3.1 Train/Test Split
We propose an experiment to evaluate the false pos-
itive rate on the Snippet Models with respect to R ∈
{R
1
, R
2
, R
3
}, as illustrated in Figure 3.
• To begin with, we obtain an augmented dataset D
0
from the collected data D, the patterns Π, and the
extracts E of the repository R. We can select the
leak percentage in D
0
with parameter r
f p
(r
f p
=
0.5 corresponds to a balanced dataset).
• Next, we split D
0
into a training and a testing
dataset. We also perform the split on the pat-
terns to obtain Π
∗
⊂ Π: this ensures that the pat-
terns used to perform the training (Π
∗
) are differ-
ent from the patterns used to do data augmentation
(Π).
• Finally, after the training phase, we compute met-
rics such as precision, recall, and f
1
score on the
testing dataset. A manual reviewer manually flags
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
152

the false positives, and she is assisted by the simi-
larity model (with threshold η). We consider that
the manual reviewer flags 0.1% of the discoveries.
There are mainly three hyper-parameters that have
an impact on the precision of the Extractor: r
f p
(the
percentage of leaks over the size of D
0
), how we
choose the subset of patterns Π
∗
used to train the
Extractor in the train/test phase, and the similarity
threshold η from the similarity model. In the follow-
ing subsections, we show the effects of these three
hyper-parameters on the accuracy of our solution. We
propose to first study the impact of the Q-learning al-
gorithm on the precision of the Extractor, and show
that this technique significantly increases the preci-
sion (thus decreasing the false positive rate). We fur-
ther evaluate the impact of the three hyper-parameters
on the precision, recall and false positive rate of our
approach.
6.3.2 Pre-trained Model
To begin with, we study the impact of the data aug-
mentation process. On the one hand, we have an Ex-
tractor model, pre-trained on the data we collected
without any data augmentation process (called pre-
trained Extractor). On the other hand, we have an Ex-
tractor model, trained with the Q-learning algorithm
for data augmentation where Π
∗
= Π
∗
0.8
(correspond-
ing to a set of patterns, randomly chosen including
80% of the patterns in Π). In Table 4, we see the
impact of the Q-learning algorithm, with a high pre-
cision score as opposed to the pre-trained model (it
increases from 55.56% to 71.66%).
A recall close to 100% means that we detect al-
most all the leaks. However, when the user flags a
discovery as false positive, the similarity model (with
threshold parameter η) may classify an actual leak as
non relevant (i.e., it may cause a false negative). If we
select η = 1, we reach a recall of 100% but without
any significant improvement of the precision score.
To fix the recall drop, a possible remediation is to in-
form the user on what discoveries have been classified
as non relevant by the similarity model, so that she can
check whether or not an actual leak has been wrongly
classified (it will improve the recall score, but will in-
crease the manual workload also).
We also compare the precision score per pattern.
Each pattern has a complexity value associated with
its index (i.e., the pattern with index 1 is the simplest,
and the pattern with index 28 is the most complex).
As shown in Figure 4, we can observe a linear rela-
tionship between the pattern complexity and the false
positive rate when we use the pre-trained Extractor
(which seems natural for a global model, since more
complex patterns are harder to detect, leading to more
false positives). With the Extractor trained with the Q-
learning algorithm, the false positive rate is indepen-
dent from the complexity of the pattern (which means
that no particular pattern will lead a higher false pos-
itive rate).
6.3.3 Extractor with Q-learning
In this section, we solely consider the Extractor
trained with the Q-learning algorithm (excluding the
pre-trained model), by presenting the impact of r
f p
and Π
∗
on the false positive rate.
Impact of r
f p
: First, we analyze the impact r
f p
on
the false positive rate in three different situations, i.e.,
with r
f p
= 0.5 (balanced situation between leaks and
false positive), r
f p
= 0.2, and r
f p
= 0.05 (unbalanced
situation where leaks are scarce), while fixing the pa-
rameter Π
∗
. We present the results in Table 5a. We
observe that:
• in a balanced situation, we achieve a false positive
rate of 5.97%, considerably reducing the part of
false positive data in the discoveries;
• in unbalanced situations, the results show that we
manage an acceptable rate of false positives, be-
low 12%.
Impact of Π
∗
: Next, we analyze the impact of the
choice of Π
∗
on the false positive rate in several sit-
uations, while fixing the poisoning rate r
f p
= 0.5.
As mentioned before, each pattern has a complexity
value. Thus, we can define the complexity of a set of
patterns Π as the average complexity of these patterns
(therefore, in our experiments, the complexity of our
set of 28 patterns Π, is equal to 14.5). Let Π
∗
0.5
be a
set of patterns representing 50% of the set of patterns
in Π, with an equivalent pattern complexity. Table 5b
presents the results.
For Π
∗
= Π
∗
0.5
, we obtain a false positive rate of
18.35% in this setting. Compared to Π
∗
0.8
, a 30% de-
crease in the number of patterns leads to a 15% in-
crease of the false positive, proving that our approach
is able to generalize unseen patterns while preserving
low false positive rate. We also consider Π
∗
0.25
cor-
responding to 25% of the patterns with an equivalent
overall pattern complexity.
Furthermore, we decide to study set of patterns
without conserving the overall pattern complexity,
splitting Π
∗
into two sets Π
∗
= Π
∗
simple
∪ Π
∗
complex
,
corresponding respectively to the first 14 patterns and
to the last 14 patterns. The results of the experiment
with Π
∗
simple
, Π
∗
complex
, Π
∗
simple
and Π
∗
0.25
are also pre-
sented in Table 5b.
Although Π
∗
0.5
, Π
∗
simple
and Π
∗
complex
contain the
same number of programming patterns, the pattern
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
153

Table 5: Poisoning experiments. Results in bold in (a) correspond to experiments with identical parameters in (b).
Π
∗
0.80
Π
∗
0.5
Situation
Precision Recall F1 Precision Recall F1
Before review 89.33 100 94.36 71.66 100 84.89
After review 89.69 99.96 94.55 74.52 99.71 85.30
(a) Impact on the manual review on the metrics
Situation
Π
∗
= Π
∗
0.80
r
f p
= 0.5 r
f p
= 0.20 r
f p
= 0.05
FP Rate 5.97 12.09 11.03
Situation
r
f p
= 0.5
Π
∗
complex
Π
∗
0.5
Π
∗
simple
Π
∗
0.25
FP Rate 9.36 18.35 31.99 27.86
(b) Impact of Π
s
and r
f p
on the FP rate
complexity distribution greatly impacts the false pos-
itive rate. We reach an acceptable false positive rate
with only 25% of the patterns, but more equally dis-
tributed in complexity. It is worth noting that the high-
est score is reached with the Π
complex
pattern set, with
results close to the full pattern experiment. Indeed, as
shown in Figure 4, the false positive rate per pattern is
higher, on average, for complex patterns (i.e., with in-
dex above 14). Therefore, targeting only this class of
patterns leads to a decrease of the global false positive
rate.
With respect to Π
∗
and r
f p
, we estimate the false
positive rate induced by the Extractor between 6%
and 32%. In Section 6.1, we showed that more than
80% of the false positive data (induced by the Regex
Scanner) has already been discarded. Overall, we
showed that the false positive rate of the whole so-
lution (including the Regex Scanner and the machine
learning models) represents between 1% and 6% of
the output.
7 RELATED WORK
7.1 Research Work
An important amount of work targets GitHub open-
source projects, from vulnerability detection(Russell
et al., 2018) to sentiment analysis (Guzman et al.,
2014). Empirical studies also provide a more global
overview of the data on GitHub (Kalliamvakou et al.,
2014) and how to facilitate its access (Gousios et al.,
2014).
With the advent of machine learning techniques
in the researchers’ toolkits, approaches for source
code representation have been developed, propos-
ing a language-agnostic representation of source
code (Alon et al., 2018; Gelman et al., 2018). Leak
detection can be also considered as a branch of data
mining or code search tasks. Works on evaluating the
state of the semantic code search (Husain et al., 2019),
as well as works on deep learning applications for
code search (Cambronero et al., 2019), emphasize the
need for developing machine learning techniques for
source code analysis. However, these previous works
have different purposes from ours, especially regard-
ing the criticality of the datasets, and they consider
token-based representations (so language dependent)
as opposed to our purely semantic approach.
Leak detection is connected to malware detec-
tion (Dahl et al., 2013; Pendlebury et al., 2019) ad-
dressing similar issues to solve privacy concerns in
realistic settings, where the testing samples are not
representative of real world distributions. Contrary
to malware classification, we do not have a reference
dataset to benchmark language specific approaches.
Code transformations based on stylometry have
been tackled by other works (Long et al., 2017;
Quiring et al., 2019). In particular, in (Quiring
et al., 2019), the authors, given a list of code ex-
tracts {e
1
, ..e
n
} developed by a list of developers
{D
1
, ...D
m
} and an authorship attribution classifier,
transform each e
i
to fool the classifier concerning the
authorship of e
i
. To do so, they use a Monte-Carlo
Tree Search algorithm to compute the most optimal
code transformations to perform the authorship attri-
bution attack. In our work, we leverage the ideas
developed in (Quiring et al., 2019) to perform our
own code transformation to do data augmentation.
We choose Temporal Difference (TD) learning over
Monte-Carlo, due to its incremental aspect. Indeed,
in the description of the Q-learning algorithm, there is
a stopping condition in order to obtain the augmented
data, whereas Monte-Carlo algorithms have to be run
completely. We suppose that in our case the condi-
tions for the convergence of TD algorithms are satis-
fied (Van Hasselt et al., 2018).
Two different studies have considered the state
of data leakage in GitHub repositories. (Sinha et al.,
2015) focuses on API Keys detection but the scope
of their study is limited to Java files, and the remedi-
ation techniques are mainly composed of heuristics.
In a more recent work (Meli et al., 2019), Meli et al.
propose a study on the leak of API Keys, focusing on
possible correlations between multiple features in a
GitHub project to find root causes. Nevertheless, this
work is limited to API Keys: it is explicitly stated that
their analysis does not apply to passwords. Moreover,
the focus of their study was on the characteristics of
true secrets, with indications on contributors or per-
sistence of secrets. Our focus dwells instead, on the
false positive data, since it represents the vast major-
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
154

Category Tool Scanning process User experience Adoption
Regex
Entropy check
Heuristics
Path FP detection
Password detection
Machine learning
Free
User interface
Open-source
Repository management
Scan of private repositories
Authentication not required
Community
Scalability
Regular updates
Known algorithms TruffleHog G# - - - - - - G#
Git-secrets - - - - - - G# G#
Gitrob - - - - - - G# G#
(Meli et al., 2019) G# - - - - - - - - - - -
Commercial offers GitGuardian - - - - G# - - G#
Nighfall AI - - - - - - - -
Our approach - -
= provides property; G# = partially provides property; - = does not provide property;
Figure 5: Comparison of available tools.
ity of discoveries of any open-source project. Finally,
they provide an extensive study of GitHub API Keys
leaks by scanning an important number of reposito-
ries, close to 700,000. In our work, we chose not
to conduct our GitHub leak status study with such a
high number of repositories, because it would have
led to a tremendous number of false positive discov-
eries, which would not have been possible to process.
7.2 Comparison with Other Tools
Since the problem of leak detection in public open-
source projects is not new, open-source tools such as
GitHub Token Scanning
16
, GitLeaks
17
or S3Scanner
18
have been developed to tackle it alongside com-
mercial platforms, namely GitGuardian and Gamma.
However, to the best of our knowledge, there is no
open-source tool which scans GitHub repositories and
applies machine learning to decrease the false positive
rate. Therefore, since the existing tools do not work
in the same paradigm as our approach (not consid-
ering passwords, for instance), we do not provide a
comparison of metrics to avoid any bias. Still, we can
compare our approach with several tools we selected.
TruffleHog
19
is a very popular (5k stars on
GitHub, at the time of writing) and open-source scan-
ning tool. The user has to provide her own set of reg-
ular expressions to the tool in order to detect possible
leaks. This tool does not use machine learning, and
it is mostly targeted to detect API Keys. Its main ad-
vantage is surely its simplicity for developers. Simi-
lar tools have emerged with the same characteristics,
such as Gitrob
20
and git-secrets
21
.
16
https://preview.tinyurl.com/ycnllvfd
17
https://github.com/zricethezav/gitleaks
18
https://github.com/sa7mon/S3Scanner
19
https://github.com/dxa4481/truffleHog
20
https://github.com/michenriksen/gitrob
21
https://github.com/awslabs/git-secrets
GitGuardian
22
is a tool provided by the name-
sake company founded in 2016 and specialized in de-
tection of leaks in open-source resources. Alongside
their commercial offer, they provide free services to
scan one’s own GitHub repositories. They claim their
tool is machine learning powered and that they can
identify more than 200 API Keys patterns, but they do
not mention passwords.
TruffleHog and its variants aim to be a strong
baseline for scanning tools. For example, in (Meli
et al., 2019) authors offer improvements to its core
algorithm. Various heuristics can be implemented
to improve the accuracy of the tool, such as entropy
check: if a string has high entropy, which means it
consists of seemingly random characters, the proba-
bility that this string is an API Key is high. We per-
form several manual tests on the GitGuardian plat-
form on various API Keys patterns and on plaintext
passwords in order to understand the possibilities and
the limitations of such a tool. According to our tests,
the platform is not able to detect plaintext passwords,
and it only detects a reduced sample of API Keys,
excluding big API Keys providers such as Facebook
and Paypal. We only tested the free version of Git-
Guardian, so it might be possible that the full capa-
bilities of the platform are only enabled in the com-
mercial offer. Another commercial tool called Night-
fall AI
23
(formerly known as Watchtower) offers the
same services, but no free version is available to test
the platform.
We compared several tools, on different criteria,
and show our results in Figure 5. For each scan-
ning tool, we compare what techniques are used, and
if there is any false positive reduction. The open-
source tools do not perform false positive reduction
(since most of them do not detect passwords), favor-
ing the usage of heuristics which need less compu-
22
https://www.gitguardian.com/
23
https://www.nightfall.ai/
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
155

tational power. However, most of the heuristics are
not adapted to all use cases, so the developer has to
manually configure the tool without efficiency guar-
antees. In our approach, we choose to adapt the scan-
ning process to each developer, thus the fine-tuning
is performed by the Leak Generator rather than the
user herself. The continuous training parameter is
the ability for the tool to re-train the machine learn-
ing models when the user flags a discovery, so to im-
prove future classifications. Open-source solutions
are more focused on single use cases, offering lim-
ited interactions with the developers. Our approach,
similar to the GitGuardian platform, is to improve the
accuracy while reviewing, decreasing the monitoring
time. The user experience is also a key point in order
to be used efficiently. The price could represent an
important barrier for small companies willing to pro-
tect themselves, encouraging bad development habits.
Commercial products provide a user interface, mak-
ing the tool more accessible to developers, and even
to non-technical people. Since the origin of a leak
does not depend on the level of expertise of the devel-
opers (Meli et al., 2019), tools with a user interface
could be easily used also by beginners to protect their
code.
8 PRIVACY CONCERNS
DISCLOSURE
In this paper, we deal with critical data, which could
harm users’ privacy in case they were used for mali-
cious purposes. Thus, we need to discuss privacy is-
sues in the scope of our research. First, with regard to
the experiment shown in Section 6.1, public reposito-
ries represent open-source data found in public web-
sites (in particular, github.com), while the access to
the proprietary platform has been granted by the com-
pany that owns all the rights on it. In both cases, no
intrusion or hacking techniques were used to obtain
data. We ensure that data collected are only accessi-
ble to our working team, for analysis purposes only,
and that sensitive information have not been used to
train predictive models. The training of the models,
together with the evaluation of our approach shown in
Section 6.3, has been achieved using sanitized data.
Furthermore, we did not attempt to use any actual
leaks we discovered to verify their authenticity, and
we tried, when possible, to notify the developer re-
sponsible for publishing credentials. Finally, all the
real data we collected have been deleted after the ex-
perimental evaluation of our approach.
9 CONCLUSION
We proposed an approach to detect data leaks in open-
source projects with a low false positive rate. Our
solution improves classic regular expression scanning
methods by leveraging machine models, filtering an
important number of false positives. Through our se-
ries of experiments, we show that our approach out-
performs classic scanning methods, produces a negli-
gible amount of undetected leaks and results in a false
positive rate of at most 6% of the output data.
ACKNOWLEDGMENTS
We would like to thank Sabrina Kall for her help dur-
ing the writing of this paper. We also would like to
thank the Institue for artificial intelligence 3IA and
the Councel of Industrial Resarch for Artificial Intel-
ligence ICAIR for their support.
REFERENCES
Alon, U., Zilberstein, M., Levy, O., and Yahav, E. (2018).
code2vec: Learning distributed representations of
code.
Bellman, R. (1957). Dynamic Programming.
Bronshtein, A. (2017). Train/test split and cross validation
in python. Understanding Machine Learning.
Bursztein, E. The bleak picture of two-factor authentication
adoption in the wild. https://tinyurl.com/yctk4aja.
Cambronero, J., Li, H., Kim, S., Sen, K., and Chandra, S.
(2019). When deep learning met code search.
Center, P. R. (2019). Americans and digital knowledge.
https://tinyurl.com/y8ftudoh.
Dahl, G. E., Stokes, J. W., Deng, L., and Yu, D. (2013).
Large-scale malware classification using random pro-
jections and neural networks. In ICASSP.
Gelman, B., Hoyle, B., Moore, J., Saxe, J., and Slater,
D. (2018). A language-agnostic model for semantic
source code labeling. In MASES.
Gousios, G., Vasilescu, B., Serebrenik, A., and Zaidman, A.
(2014). Lean ghtorrent: Github data on demand. In
MSR, pages 384–387.
Guzman, E., Azócar, D., and Li, Y. (2014). Sentiment
analysis of commit comments in github: an empirical
study. In MSR, pages 352–355.
Husain, H., Wu, H.-H., Gazit, T., Allamanis, M., and
Brockschmidt, M. (2019). Codesearchnet challenge:
Evaluating the state of semantic code search.
Joulin, A., Grave, E., Bojanowski, P., and Mikolov, T.
(2016). Bag of tricks for efficient text classification.
Kalliamvakou, E., Gousios, G., Blincoe, K., Singer, L., Ger-
man, D. M., and Damian, D. (2014). The promises and
perils of mining github. In MSR.
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
156

Long, F., Amidon, P., and Rinard, M. (2017). Automatic
inference of code transforms for patch generation. In
FSE, pages 727–739.
Ma, S., Sun, X., Wang, Y., and Lin, J. (2019). Bag-of-Words
as target for neural machine translation.
Meli, M., McNiece, M. R., and Reaves, B. (2019). How
bad can it git? characterizing secret leakage in public
github repositories. In NDSS.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a).
Efficient estimation of word representations in vector
space.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and
Dean, J. (2013b). Distributed representations of words
and phrases and their compositionality. In NIPS.
Milka, G. (2018). Anatomy of account takeover. In Pro-
ceedings of Enigma.
MITRE (2019). 2019 cwe top 25 most dangerous software
errors. https://tinyurl.com/y73xa6qk.
Pearman, S., Zhang, S. A., Bauer, L., Christin, N., and Cra-
nor, L. F. (2019). Why people (don’t) use password
managers effectively. In USENIX SOUPS.
Pendlebury, F., Pierazzi, F., Jordaney, R., Kinder, J., and
Cavallaro, L. (2019). TESSERACT: Eliminating ex-
perimental bias in malware classification across space
and time. In USENIX Security Symposium, pages 729–
746.
Quiring, E., Maier, A., and Rieck, K. (2019). Misleading
authorship attribution of source code using adversarial
learning.
Russell, R., Kim, L., Hamilton, L., Lazovich, T., Harer,
J., Ozdemir, O., Ellingwood, P., and McConley, M.
(2018). Automated vulnerability detection in source
code using deep representation learning. In ICMLA.
Shorten, C. and Khoshgoftaar, T. M. (2019). A survey on
image data augmentation for deep learning. Journal
of Big Data, 6:60.
Sinha, V. S., Saha, D., Dhoolia, P., Padhye, R., and Mani,
S. (2015). Detecting and mitigating secret-key leaks
in source code repositories. In MSR, pages 396–400.
Sun, X., Liu, X., Hu, J., and Zhu, J. (2014). Empirical
studies on the nlp techniques for source code data pre-
processing. In EAST, pages 32–39.
Van Hasselt, H., Doron, Y., Strub, F., Hessel, M., Sonnerat,
N., and Modayil, J. (2018). Deep reinforcement learn-
ing and the deadly triad.
Watkins, C. J. and Dayan, P. (1992). Q-learning. Machine
learning, 8:279–292.
APPENDIX
A list of 29 regular expression used in the Regex
Scanner is presented in Table 7. We collected 15 API
Keys patterns, 3 RSA Key patterns and 1 access to-
ken pattern from (Meli et al., 2019). In addition to
these, we also used patterns from TruffleHog. We
augmented this dataset with 2 ssh-related patterns,
alongside 8 passwords (or keywords) patterns. We
did not optimize our regular expressions, since we im-
plemented the scanner with Hyperscan, i.e., a regular
expression library offering integrated optimization.
In Table 6 and Table 8, we present respectively the
list of possible transformations on source code and the
list of programming patterns used for the data aug-
mentation process. We group the actions by class
of actions: identity action (no modification on the
source code), actions expanding (or reducing) the in-
put length, actions changing the hypothetical type of
an input, and actions impacting the pattern complex-
ity.
Table 6: Actions which could be applied to a source code
extract.
Actions
identity
longer_key
longer_ f unction
longer_method
longer_ob ject
smaller_key
smaller_ f unction
smaller_method
smaller_ob ject
change_type
more_complex_pattern
simpler_pattern
We present the list of features considered to com-
pute the stylometry of an extract in Figure 6.
Features
Word occurrences in the code snippet
List of keywords in the code snippet
Number of total symbols
Average length in characters
Standard Deviation length in characters
Number of spaces
Ratio between number of spaces and number of characters
Occurrences of specific symbols (parentheses, brackets, etc.)
Figure 6: Features used to compute the stylometry vector.
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
157

Table 7: Regular expression patterns.
Type Pattern Source
—–BEGIN RSA PRIVATE KEY—–
RSA Private Key [\r\n]+(?:\w+:.+)*[\s]*(?:[0-9a-zA-Z+=]
{64,76}[\r\n]+)+[0-9a-zA-Z+=]+[\r\n]+ Meli et. al
—–END RSA PRIVATE KEY—-
—–BEGIN EC PRIVATE KEY—–
RSA EC Key [\r\n]+(?:\w+:.+)*[\s]*(?:[0-9a-zA-Z+=]
{64,76}[\r\n]+)+[0-9a-zA-Z+=]+[\r\n]+ Meli et. al
—–END EC PRIVATE KEY—-
—–BEGIN PGP PRIVATE KEY BLOCK—–
RSA PGP Key [\r\n]+(?:\w+:.+)*[\s]*(?:[0-9a-zA-Z+=]
{64,76}[\r\n]+)+[0-9a-zA-Z+=]+[\r\n]+ Meli et. al
—–END PGP PRIVATE KEY BLOCK—-
Access token ((?:\? | \& | \" | \’)(?:access_token)(?:\" | \’)?\s*(?:= | :)) Meli et. al
Token EAACEdEose0cBA[0-9A-Za-z]+ Meli et. al
Token AIza[0-9A-Za-z\-_]{35} Meli et. al
Token [0-9]+-[0-9A-Za-z_]{32}\.apps\.googleusercontent\.com Meli et. al
Token sk_live_[0-9a-z]{32} Meli et. al
Token sk_live_[0-9a-zA-Z]{24} Meli et. al
Token rk_live_[0-9a-zA-Z]{24} Meli et. al
Token sq0atp-[0-9A-Za-z\-_]{22} Meli et. al
Token sq0csp-[0-9A-Za-z\-_]{43} Meli et. al
Token access_token\$production\$[0-9a-z]{16}\$[0-9a-f]{32} Meli et. al
Token SK[0-9a-fA-F]{32} Meli et. al
Token key-[0-9a-zA-Z]{32} Meli et. al
Token AKIA[0-9A-Z]{16} Meli et. al
Token (xox[p|b|o|a]-[0-9]{12}-[0-9]{12}-[0-9]{12}-[a-z0-9]{32}) TruffleHog
Token https://hooks.slack.com/services/T[a-zA-Z0-9_]{8} TruffleHog
/B[a-zA-Z0-9_]{8}/[a-zA-Z0-9_]{24}
Key word sshpass Our contribution
Key word sshpass -p.*[’|\"] Our contribution
Password (root|admin|private_key_id|client_email|client_id|token_uri) Our contribution
\s*((?:=|:| − >|< − |=>|<=|==|<<))
Password (password|new_pasword|username Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
Password (user|email|User|Pwd|UserName|user_name Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
Password (access_token|access_token_secret|consumer_key |consumer_secret Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
Password (FACEBOOK_APP_ID|ANDROID_GOOGLE_CLIENT_ID) Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
Password (authTokenToken|oauthToken|CODECOV_TOKEN Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
Password (IOS_GOOGLE_CLIENT_ID Our contribution
\s*(?:=|:|->|<-|=>|<=|==|«))
Password (sk_live|rk_live Our contribution
\s*(?:=|:| − >|< − |=>|<=|==|<<))
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
158

Table 8: Programming patterns used for the data augmentation process.
Id Pattern
1 key = "value"
2 key[’value’]
3 key « object.method("value")
4 key.method(’value’)
5 Object.key = ’value@gmail.com’
6 key = type_1 function Password(’value’)
7 public type_1 type_2 int key = ’value’
8 key => method(’value’)
9 type_1 key = ’value’
10 Object[’key’] = ’value’
11 method.key : "value"
12 object: {email: user.email, key: ’value’}
13 key = setter(’value’)
14 key = os.env(’value’)
15 Object.method :key => ’value’"
16 key = Object.function(’value’)
17 User.function(email: ’name@gmail.com’, key: ’value’)
18 User.when(key.method_1()).method_2(’value’)
19 key.function().method_1(’value’)
20 type_1 key = Object.function_1(’value’)
21 method(’key’=>’value’)
22 public type_1 key { method_1 { method_2 ’value’ } }
23 private type_1 function_1 (type_1 key, type_2 password=’value’)
24 protected type_1 key = method(’value’)
25 type_1 key = method_1() credentials: ’value’.function_1()
26 type_1 key = function_1(method_1(type_2 credentials = ’value’))
27 Object_1.method_1(type_1 Object_2.key = Object_1.method_2(’value’) )
28 type_1 Object_1 = Object_2.method(type_2 key_1=’value_1, type_3 key_2=’value_2’)
Optimizing Leak Detection in Open-source Platforms with Machine Learning Techniques
159
