
Micro-YOLO: Exploring Efficient Methods to Compress CNN based
Object Detection Model
Lining Hu
a
and Yongfu Li
b
Department of Micro-Nano Electronics, MoE Key Lab of Artificial Intelligence, Shanghai Jiao Tong University, China
Keywords:
Object Detection, YOLO, MobileNets, Depthwise Separable Convolution, Model Compression, Prune.
Abstract:
Deep learning models have made significant breakthroughs in the performance of object detection. How-
ever, in the traditional models, such as Faster R-CNN and YOLO, the size of these networks make it too
difficult to be deployed on embedded mobile devices due to limited computation resources and tight power
budgets. Hence, we propose a new light-weight CNN based object detection model, Micro-YOLO based on
YOLOv3-Tiny, which achieves a signification reduction in the number of parameters and computation cost
while maintaining the detection performance. We propose to replace convolutional layers in the YOLOv3-tiny
network with the Depth-wise Separable convolution (DSConv) and the mobile inverted bottleneck convolution
with squeeze and excitation block (MBConv), and design a progressive channel-level pruning algorithm to
minimize the number of parameters and maximize the detection performance. Hence, the proposed Micro-
YOLO network reduces the number of parameters by 3.46× and multiply-accumulate operation (MAC) by
2.55× while slightly decreases the mAP evaluated on the COCO dataset by 0.7%, compared to the original
YOLOv3-tiny network.
1 INTRODUCTION
The accelerated growth in the deep learning field has
greatly promoted the development of the object de-
tection with its widespread applications in face de-
tection, autonomous driving, robot vision and video
surveillance (Borji et al., 2019; Pan et al., 2020). With
the vigorous development in object detection, there
are several deep convolutional neural network models
proposed in the recent years, .e.g. R-CNN, SSD, and
YOLO (Girshick et al., 2014; Liu et al., 2016; Red-
mon and Farhadi, 2018). However, as the network
becomes more complicated, the size of these mod-
els continues to increase, which makes it increasingly
difficult to deploy these models on embedded devices
in real life (Cheng et al., 2017). Therefore, it is of vi-
tal importance to develop an efficient and fast object
detection model to reduce the parameter size without
affecting the object detection quality.
The goal of object detection is to detect objects of
a certain class (such as humans, animals, or cars) in
digital images (Borji et al., 2019). One of the most
famous object detection network is “You Only Look
a
https://orcid.org/0000-0003-3506-7873
b
https://orcid.org/0000-0002-6322-8614
Once” (YOLO) architecture. After years of improve-
ment for YOLO, it has evolved into the fourth gen-
eration, YOLOv4 architecture (Bochkovskiy et al.,
2020). It achieves average precision (AP) of 43.5%
(65.7% AP50) for the MS COCO dataset at a real
time speed of 65 frames per second (FPS) on Tesla
V100(Bochkovskiy et al., 2020). However, it con-
tains more than 60 million parameters and requires to
perform more than 107 billion floating number mul-
tiplications when processing an image. Besides, the
faster version of YOLOv3, the previous version of
YOLOv4, YOLOv3-tiny is proposed where its param-
eters and multiplication requirements have reduced
by 7.5× and 13×, respectively(Redmon and Farhadi,
2018). The new model has achieved 33.1% mAP with
220FPS on Titan X. However, it remains challenging
to deploy this model for several embedded devices.
In this work, we propose a lightweight version of
the objection detection model, Micro-YOLO, which
is based on YOLOv3-tiny architecture (Redmon and
Farhadi, 2018). We proposed three effective methods
to optimize the Micro-YOLO architecture. The key
contributions of our work are as follows:
1) We propose to replace the standard convolutional
layers (Conv) in the YOLOv3-tiny network with
depth-wise separable convolutions (DSConv) and
Hu, L. and Li, Y.
Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model.
DOI: 10.5220/0010234401510158
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 2, pages 151-158
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
151

Kernel Size Exploration
Progressive Pruning
YOLOv3-tiny
(block replaced)
3×3
3×3
3×3
3×3
3×3
3×3
3×3
3×3
3×3
5×5
5×5
5×5
5×5
5×5
5×5
. . .
Channel Pruning
Conv1×1 (channel×3)
Dwise k×k
SE Layer
Conv1×1 (channel/3)
Dwise 3×3
Point wise1×1
YOLOv3-tiny
DSConv 3×3
MBConv k×k
Mobilenets Block-Based Network
Figure 1: The proposed optimization techniques adopted in Micro-YOLO.
inverted bottleneck convolution with squeeze and
excitation block (MBConv), reducing the weight
parameters with slightly degrading the detection
accuracy.
2) We explore and identify the optimal kernel sizes in
MBConv to achieve the best trade-off between the
weight parameters and detection accuracy on the
Micro-YOLO architecture.
3) We propose a progressive pruning algorithm to
perform a coarse-grained pruning on the DSConv
and MBConv layers, which further reduce the
weight parameters with slightly degrading the
detection accuracy. After pruning, we further
decrease the size to 1.92M parameters and the
computation cost to 0.87GMAC with 3.1% mAP
degradation.
The rest of this paper is organized as follows. Section
2 provides a understanding of the state-of-arts model
compression techniques and its evaluation methods
and problem statement. Section 3 provides details
of our proposed Micro-YOLO network and its model
compression methods. Section 4 discusses the exper-
imental setup and result and followed by the com-
parison with state-of-the-art works. We conclude our
work in Section 5.
2 PRELIMINARIES
2.1 Model Compression Techniques for
Object Detection Networks
As the family of object detection networks continues
to become more complicated, it is important to reduce
the weight parameters and computational cost. The
model compression methods are categorized into low-
rank factorization, knowledge distillation, pruning,
and quantization (Fernandez-Marques et al., 2020),
where pruning has shown to be an effective method
in reducing the network complexity by removing re-
dundant parameters (Cheng et al., 2017).
To address the object detection network problem,
there are several state-of-art works techniques to re-
duce the number parameters in YOLO architecture.
(Huang et al., 2018) developed the YOLO-lite net-
work, where batch normalization layer is removed
from YOLOv2-tiny to speed up the object detection.
This network has achieved a mAP of 33.81% and
12.26% on PASCAL VOC 2007 and COCO dataset,
respectively. (Wong et al., 2019) created a highly
compact network, YOLO-nano, which is a 8-bit quan-
tized model based on YOLO network and is opti-
mized on PASCAL VOC 2007 dataset. This network
has achieved 3.18M model size and 69.1% mAP on
the PASCAL VOC 2007 dataset.
2.2 Evaluation Methods
We evaluate the effectiveness of object detection net-
work based on three aspects: model size, computation
cost and accuracy performance on the COCO dataset
(Lin et al., 2014).
Definition 1 (Model Size). Model size is defined as
the number of parameters in a neural network, which
is the sum of trainable elements in each layer. It is
formulated as follows:
Model Size =
N
∑
i=1
l
i
, (1)
where l
i
denotes the number of trainable elements in
the i-th layer and N represents the total number of
layers in the neural network.
Definition 2 (Computation Cost). We define Compu-
tation Cost as the number of multiply-accumulate op-
erations (MACs) which is the count of operation units
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
152

in which the product of two numbers is computed and
that product is added to an accumulator.
Definition 3 (Mean average precision (mAP)). The
most common evaluation method for object detection
is “Average Precision” (AP), which is defined as the
average detection precision under different recalls.
Precision measures how accurate is the model pre-
dictions. Recall measures how good the model finds
all the positives. mAP (mean average precision) is
the average of AP. For COCO dataset, we evaluate
the mAP on 80 categories.
2.3 Problem Formulation
With the above definitions, the problem is formulated
as follows:
[Model Compression for Object Detection Problem]
Given an object detection neural network model, the
objective is to utilize efficient compression schemes
on the model to achieve small Model Size and Com-
putation Cost while maintaining the network’s mAP.
3 OUR PROPOSED METHOD
As shown in Fig. 1, we propose three methods on the
YOLOv3-tiny network and obtain a lightweight ver-
sion of the network, named Micro-YOLO: (1) To re-
duce the convolutional network blocks in the YOLO
network, we propose to replace the standard con-
volution (Conv) layers with two types of convolu-
tional blocks: (a) the depth-wise separable convolu-
tion (DSConv) used in MobileNetv1 (Howard et al.,
2017) and (b) mobile inverted bottleneck convolution
with squeeze and excitation block (MBConv) used in
MobileNetv3(Howard et al., 2019); (2) We explore
and identify the optimal kernel sizes in MBConv to
achieve the best trade-off between the weight param-
eters and detection accuracy on the network; (3) We
propose a progressive structured pruning method to
further shrink the Model Size.
3.1 MobileNets Block-based Network
To reduce the size of the network, we have explored
alternative lightweight convolutional layers to replace
the convolutional layers Conv in the YOLO network.
The MobileNet networks (Howard et al., 2017; San-
dler et al., 2018; Howard et al., 2019) adopt two
lightweight convolutional layers (a) the Depth-wise
separable convolution (DSConv) layer and (b) mo-
bile inverted bottleneck convolution with squeeze and
excitation block (MBConv)) layer. As shown in the
Fig. 2(a), DSConv layer performs two types of con-
volutions: (i) the depthwise convolution and (ii) the
pointwise convolution, which can significantly reduce
the Model Size and Computation Cost of the net-
work (Howard et al., 2017). As shown in the Fig.
2(b), the structure of MBConv is a 1×1 channel ex-
pansion convolution followed by depthwise convolu-
tions and a 1×1 channel reduction layer. It utilizes
squeeze and excitation block, which is a branch con-
sisting of a global average pooling operation in the
squeeze phase and two small FC layers in the excita-
tion phase (Hu et al., 2019) between depthwise con-
volution and channel reduction layer. Since the num-
ber of output channels is not equal to the number of
input channels, we remove the residual connection in
MBConv. MBConv layer provides a compact repre-
sentation at the input and output while expanding the
input to a higher-dimensional feature space internally
to increase the expressiveness of nonlinear transfor-
mations. Hence, the MBconv layer provides a better
compressed network without degrading the detection
accuracy as compared to the DSconv layer.
To evaluate the Model Size amongst these layers,
the number of parameters in the Conv (N
s
), in the
DSConv (N
ds
), and in the MBConv (N
mb
) can be com-
puted with (2), (3) and (4), respectively.
N
s
= k
2
× C
in
× C
out
, (2)
N
ds
= k
2
× C
in
+ 1 × 1 × C
in
× C
out
, (3)
N
mb
= C
in
× αC
in
× 1 × 1 + k
2
× αC
in
+ 2 × αC
in
× αC
in
/β + αC
in
× C
out
,
(4)
where k denotes kernel size, C
in
denotes number of
input channels, C
out
denotes number of output chan-
nels, α and β denotes expansion factor and reduction
factor in MBConv, respectively.
The Computation Cost amongst these layers, i.e.
the Conv layer (C
s
), the DSConv layer (C
ds
), and the
MBConv layer (C
mb
) can be expressed with the fol-
lowing (5), (6), (7), respectively.
C
s
=
1
2
k
2
× W × H × C
in
× C
out
, (5)
C
ds
=
1
2
(k
2
× W × H × C
in
+W × H × C
in
× C
out
),
(6)
C
mb
=
1
2
(W × H × C
in
× αC
in
+ k
2
× W × H × αC
in
+ 2 × αC
in
× αC
in
/β +W × H × αC
in
× C
out
),
(7)
where k denotes kernel size, C
in
denotes number of in-
put channels, C
out
denotes number of output channels,
W and H denote width and height of feature maps, α
and β denotes expansion factor and reduction factor
in MBConv, respectively.
Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model
153
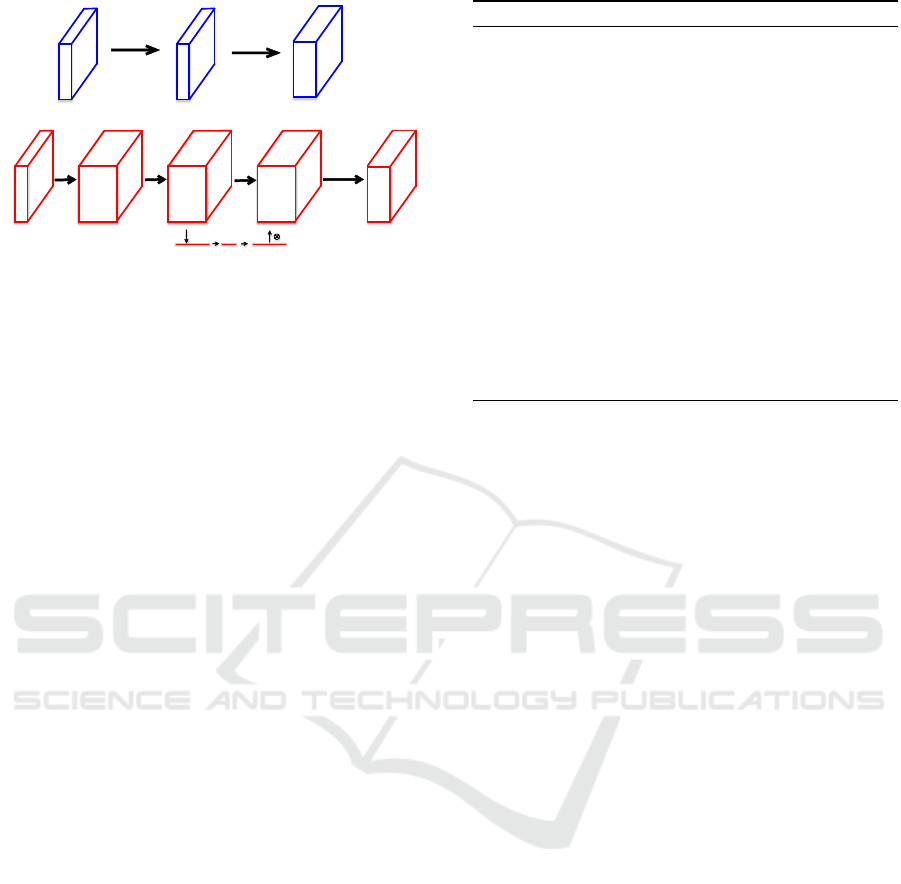
Depth-wise
convolution
Point-wise
convolution
(a) DSConv: Depth-wise separable convolution
1×1 channel
expansion
Depth-wise
convolution
1×1 channel
reduction
(b) MBConv: Inverted linear bottleneck
with squeeze and excitation layer
G-Pool
FC,relu
FC,hard-σ
Figure 2: Two types of convolutions used in our work.
3.2 Kernel Size Exploration
To further reduce the weight parameters in the convo-
lutional layer without compromising the accuracy, we
propose a kernel size optimization technique. Most
of the traditional convolutional neural network de-
sign uses 3×3 convolutional kernel (Howard et al.,
2017; Sandler et al., 2018). Similarly, YOLOv3-
tiny network also uses convolution kernel size of 3×3
in the Conv layers. However, the emergent of net-
work architecture search algorithms changed the sit-
uation. For example, (Cai et al., 2019) highlighted
that the first few convolutional layers prefer to us-
ing smaller kernel sizes while the deep convolutional
layer prefers to using larger kernel sizes. Further-
more, recent works on network exploration (Tan and
Le, 2019) have shown a similar result that the com-
bination of multiple kernel sizes leads to better detec-
tion accuracy. Hence, it is necessary to explore the
optimization space between the use of different con-
volutional kernel size and the mAP of our proposed
Micro-YOLO network. The details of our experiment
will be discussed in Section 4.
3.3 Progressive Channel Pruning
After finalizing the architecture of our proposed
Micro-YOLO network, we can further reduce the
weight parameters by using the pruning technique. In
our proposed work, we have adopted coarse-grained
pruning because the DSConv and MBConv layers are
mostly composed of 1×1 kernel size, which left min-
imal room for fine-grained pruning. (Liu et al., 2019)
indicates that the pruned architecture itself, rather
than a set of inherited “important” weights, is more
crucial to the efficiency in the final model, which sug-
gests that in some cases pruning can be useful as an
architecture search paradigm. Hence, we proposed a
progressive pruning method to search for a “thinner”
Algorithm 1: Progressive Channel Pruning Algorithm.
Input: The original network structure
Net(C
1
...C
N
).
Output: The pruned network structure
ˆ
Net.
1: for i = 1 to N do
2: Train Net for 20 epochs;
3: Evaluate mAP
origin
of Net;
4: OldC
i
= C
i
, mAP
old
= mAP
origin
;
5: repeat
6: NewC
i
= OldC
i
− 1/16C
i
;
7: OldC
i
= NewC
i
;
8: Initialize a new network
ˆ
Net(C
1
...C
N
);
9: Train
ˆ
Net for 20 epochs;
10: Evaluate mAP
new
of
ˆ
Net;
11: mAP
old
= mAP
new
12: until mAP
new
< mAP
origin
− 0.5%
13: end for
architecture in the modified network. The details of
the proposed progressive channel pruning algorithm
are shown in Algorithm 1. We first train the original
network Net and evaluate the mAP
original
before prun-
ing (Lines 2-3). The numbers of current pruned con-
volution layer channels OldC
i
are recorded (Line 4).
During the pruning of convolutional layer i, we reduce
the number of output channels by 1/16 each time since
this pruning step balances the pruning speed and ac-
curacy. Note that when the output channel of layer i is
pruned, the corresponding input channel of layer i+1
also needs to be pruned. Then the number of chan-
nels of convolutional layer i is updated, and a new
network (
ˆ
Net) with the reduced number of channels is
initialized (Lines 6-8).
ˆ
Net is retrained for 20 epochs
to evaluate the new mAP
new
(Lines 9-11). The prun-
ing procedure for layer i is repeated until mAP
new
is
0.5% lower than the original mAP
origin
since our ex-
periment shows a threshold of 0.5% ensure that chan-
nel pruning will not decrease the detection accuracy
severely (Line 12). Then, we begin to prune the next
convolutional layer until all the convolutional layers
are pruned, and the pruned network is returned.
4 EXPERIMENTAL RESULTS
We implemented and evaluated our Micro-YOLO net-
work using Python programming language with Py-
torch (Paszke et al., 2017) library on a 2.50GHz 12
cores Xeon Intel Linux machine, 128GB memory, and
2 Nvidia GTX 2080Ti graphics cards.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
154

Conv
3×3
MaxPool
MBConv
3×3
MaxPool
MBConv
5×5
MaxPool
MBConv
3×3
MBConv
5×5
MaxPool
MaxPool
MaxPool
MBConv
3×3
DSConv3×3
Conv
1×1
MBConv
3×3
Conv
1×1
Conv
1×1
Upsample
Conv
1×1
Concat
MBConv
3×3
2
1
3 4 5
6
7
8
9
10
11
12 13
14 15 16
19 20 21 22 23
Figure 3: Our proposed object detection neural network architecture. MBConvk×k denotes mobile inverted bottleneck con-
volution with squeeze and excitation block with kernel size k×k, DSConv×k denotes depth-wise separable convolution with
kernel size k×k.
4.1 Micro-YOLO Network
Optimization
In our proposed Micro-YOLO network, the choice of
convolution type in each layer and kernel size in the
convolutional layer have a great influence on the de-
tection accuracy. Thus, we conduct experiments to
determine the architecture for the Micro-YOLO net-
work.
4.1.1 The Choice of Convolution Types
As discussed in Section 3.1, there are great differ-
ences among the number of parameters in the Conv,
DSConv and MBConv layers. As shown in Table 1, we
compute the number of parameters required for differ-
ent layer types and different input channels with the
same kernel size according to (2)-(7). Note that the
number of output channels is twice the number of in-
put channels. As shown in the last two columns of the
table, the number of parameters used in MBConv and
DSConv layers are significantly smaller than Conv
layer.
To understand the impact of different convolution
types on Model Size, Computation Cost and mAP,
we replace Conv of YOLOv3-tiny with our proposed
strategies. Table 2 shows Model Size, Computation
Cost of networks composed of different convolution
types and mAP evaluated on COCO dataset. As
shown in the table, networks that with only DSConv
layers have far smaller Model Size and Computa-
tion Cost compared to networks consists of MBConv
layers only. However, using the MBConv layer is
more effective in maintaining the mAP while DSConv
can be applied to reduce the number of parameters.
Hence, it is necessary to choose an optimal trade-off
between Model Size and mAP of the network.
As shown in Tables 1 and 2, the increase in the
number of input channel and convolutional layers
leads to the increase of Model Size. For example, in
the YOLOv3-tiny model, the 10th, 12th, and 14th lay-
ers have a total weight parameters of 6.63M, which
accounts for 74.95% of the entire network. We use
DSConv in the 12th layer and MBConv in the remain-
ing layers since the 12th layer contains the largest
amount of parameters. This leads to the Model size
reduction by 3.46× while the mAP only degrades by
1.7%. Hence, the final form of our proposed Micro-
YOLO network is shown in Fig. 3.
4.1.2 Kernel Size Exploration
As discussed in Section 3.2, the choice of kernel
size is very essential to improve mAP. Therefore, we
choose the 3rd, 5th, 7th, 9th, and 11th layers, which
are layers before the detection part of YOLOv3-tiny,
to explore the effect of different kernel sizes on those
layers. For each layer, we choose kernel size from
3×3 and 5×5, thus leading to 2
5
=32 different per-
mutations and combinations. To save our training
time, we train each experiment for 20 epochs from
scratch and find the best combination of these per-
mutations and combinations. As shown in Figure 4,
among the 32 kinds of combinations, the quality of
the networks which interleaving 3×3 and 5×5 ker-
nel sizes is the best. Thus, this indicates that the best
mAP is achieved by using convolution kernels of size
3,5,3,5,3 in the 3rd, 5th, 7th, 9th, 11th layers, respec-
tively.
Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model
155
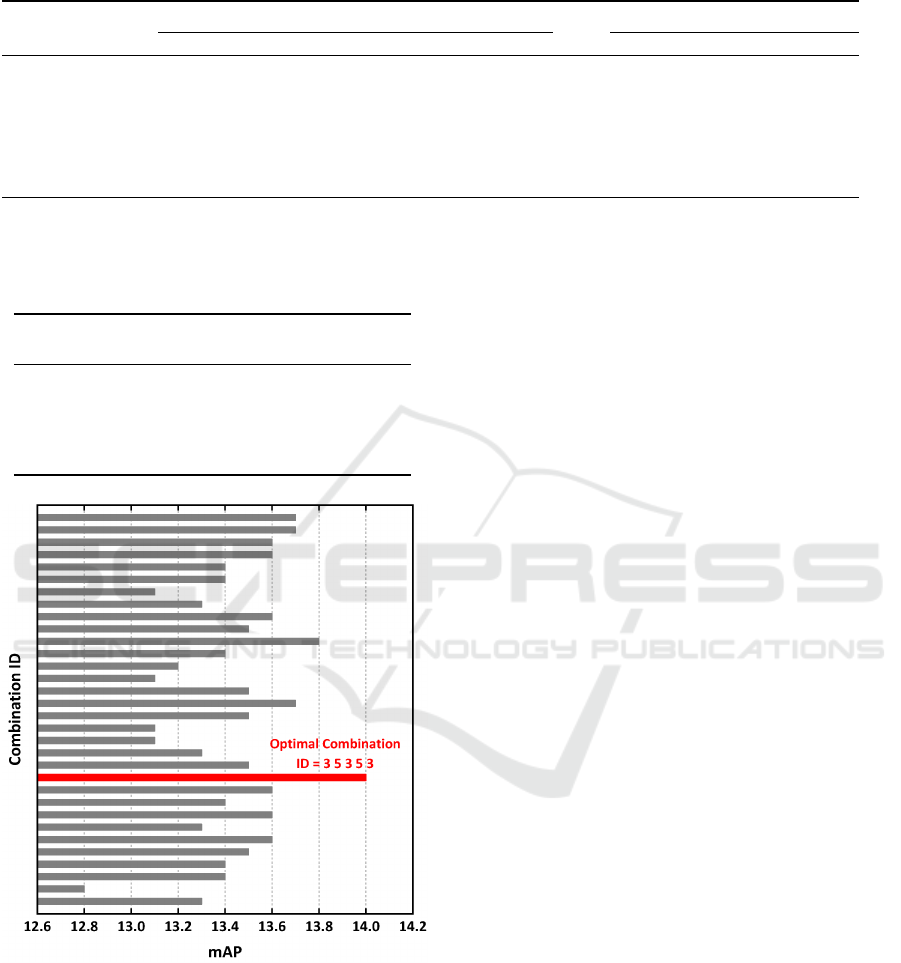
Table 1: Number of parameters required for different convolution types and different input channels with the same kernel size
3×3.
No. of Parameters Redution Multiples
1
No. of Input
Channels Conv DSConv MBConv DSConv MBConv
16 4,068 656 3,888 7.02 × 1.19 ×
32 18,432 2,336 14,688 7.89 × 1.25 ×
64 73,728 8,768 57,024 8.41 × 1.29 ×
128 294,912 33,920 224,640 8.69 × 1.31 ×
256 1,179,648 133,376 891,648 8.84 × 1.32 ×
512 4,718,592 528,896 3,552,768 8.92 × 1.33 ×
1
Reduction Multiples denote the reduced multiples of parameters compared to standard convolution.
Table 2: The amount of parameters of the YOLOv3-tiny
network composed of different convolution types.
Network
Model Size
(M)
Computation
Cost (G)
mAP
%
YOLOv3-tiny 8.85 2.81 33.1
All DSconv 3 × 3 1.44 0.52 24.6
All DSconv 5 × 5 1.47 0.55 25.4
All MBconv 3 × 3 6.45 2.08 30.4
All MBconv 5 × 5 6.53 2.16 31.5
Figure 4: Kernel size exploration result. Different bars indi-
cate different combinations of kernel sizes. For simplicity,
we only show the optimal kernel size combination in red.
4.2 Pruning Results
To further compress our model, we have applied our
progressive pruning algorithm for the first 7 convolu-
tion layers. The pruning results are presented in Table
3, where the x/16 indicates the pruning step of each
layer. For example, the 3rd layer contains 32 chan-
nels, which we first prune 2 channels based on the
1/16 of the initial number of channels calculation. At
the second step, we prune 4 channels, which is 2/16 of
32 channels. When pruning 3/16 of the initial number
of channels, compared with the initial value, the mAP
decreased by 1.4%, which is greater than 0.5%, then
we stop pruning this layer and move on to the next
layer.
As shown in Table 3, most of the convolution lay-
ers cannot be further pruned when we perform prun-
ing on 2/16 of the number of channels. If we continue
to perform pruning, the mAP starts to degrade signif-
icantly. Hence, the results shown in Table 3 has also
confirmed our conjecture: As the depth of the network
and the number of convolutional layer channels in-
crease, the convolutional layer’s “tolerance” to prun-
ing gradually increases, enabling us to prune more
channels in deeper layers, such as 11th and 13rd lay-
ers. In particular, we even prune 6/16 of the number
of channels, that is, 384 channels, in the 13th layer
without decreasing mAP. However, in the 15th layer,
we observe an exception situation where even 1/16 of
the number of channels cannot be pruned. We suspect
that the reason may be that this layer is too close to
the detection layer.
4.3 Benchmark and Comparisons
We have made a comparison between our proposed
Micro-YOLO against YOLO-nano(Huang et al.,
2018), YOLO-lite(Wong et al., 2019) and YOLOv3-
tiny (Redmon and Farhadi, 2018). We trained all of
the networks from scratch for 500,200 batches, simi-
lar to the training method used in YOLOv3-tiny (Red-
mon and Farhadi, 2018). Table 4 illustrates the Model
size, Computation cost, mAP on COCO datasets and
FPS of YOLOv3-tiny, YOLO-lite, YOLO-nano and
Micro-YOLO.
As compared with the YOLOv3-tiny network,
the initial version of our Micro-YOLO has already
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
156

Table 3: Pruning results with progressive channel pruning algorithm.
Layer
ID
Kernel
Size
No. of
Channels
mAP %
Original 1/16 2/16 3/16 4/16 5/16 6/16 7/16
3 3 32 17 16.8 16.8 15.6 - - - -
5 5 64 16.8 16.8 16.4 15.3 - - - -
7 3 128 16.4 16.1 16.2 16.1 16 16.2 15 -
9 5 256 16.2 16.2 16 15.9 14 - - -
11 3 512 15.9 15.6 15.5 15 - - - -
13 3 1024 15.5 15.5 15.4 15.5 15.6 15.6 15.7 14.7
15 3 512 15.7 15.0 - - - - - -
Table 4: Model’s amount of parameters, computation cost,
mAP, and latency of YOLOv3-tiny, YOLO-lite, YOLO-
nano, and Micro-YOLO (original and pruned). The input
size is 416×416 for all networks.
Model
Model
Size
(M)
Computation
Cost
(GMAC)
mAP %
(CO-
CO)
mAP %
(VOC
2007)
FPS
YOLOv3-tiny 8.85 2.81 33.1 - 313
YOLO-lite 0.46 0.93 12.3 33.6 378
YOLO-nano 3.18 3.49 14.5 69.1 240
Micro-YOLO 2.56 1.10 32.4 - 328
Micro-YOLO
(pruned)
1.92 0.87 29.3 - 357
achieved a significant reduction of the parameters by
3.46× and the number of operations by 2.55× with
slightly decrease of 0.7% mAP on COCO dataset.
After applying coarse-grained pruning technique, the
Micro-YOLO has reduced the weight parameters by
4.61× and computation cost by 3.23× with a slight
drop of 3.8% mAP compared with YOLOv3-tiny.
YOLO-lite model has a size of 0.46M parameters
and requires a computation cost of 0.93GMAC and
achieves 12.3% mAP on the COCO dataset. YOLO-
nano model has a size of 3.18M parameters and re-
quires a computation cost of 3.49GMAC and achieve
14.5% mAP and 69.1% mAP on COCO and PASCAL
VOC 2007 datasets, respectively, it’s because YOLO-
nano is optimized based on the PASCAL VOC 2007
dataset, it does not perform very well on the COCO
dataset. As for the latency, we re-evaluate the FPS
of all the networks on a single Nvidia GTX 2080Ti
graphics card. Our Micro-YOLO and pruned Micro-
YOLO achieve 328 and 357 FPS respectively, second
only to YOLO-lite. Since YOLO-nano is optimized
based on the PASCAL VOC 2007 dataset, it does not
perform very well on the COCO dataset.
5 CONCLUSIONS
In this paper, we explore several model compres-
sion methods and propose an improved object detec-
tion architecture, Micro-YOLO, based on YOLOv3-
tiny. We analyze several types of convolutional layers,
such as depth-wise separable convolution (DSConv)
and inverted bottleneck convolution with squeeze and
excitation block (MBConv), to determine the optimal
layer for our Micro-YOLO network. We also explore
the effect of different kernel sizes in these convolu-
tional layers on Micro-YOLO performance. Further-
more, we propose a new progressive channel prun-
ing method to minimize the number of parameters
and computation costs with slightly mAP reduction
of the original network. The Micro-YOLO only re-
quires 2.56M parameters and 1.10GMAC of Compu-
tation Cost to achieve the mAP of 32.4% and 328 FPS,
which is slightly lower than the original YOLOv3-
tiny network. After applying the pruning technique,
we can further reduce the number of parameters and
computation cost to 1.92M and 0.87GMAC with mAP
of 29.3% and 357 FPS. We also compare our work
with other variety of YOLO-based networks for ob-
ject detection and achieve promising results. We be-
lieve that our methodology to compress YOLOv3-
tiny can be highly applicable to the future version of
YOLO or other object detection models.
ACKNOWLEDGEMENTS
This research is supported in part by the National
Key Research and Development Program of China
under Grant No. 2019YFB2204500 and in part by
the Science, Technology and Innovation Action Plan
of Shanghai Municipality, China under Grant No.
1914220370.
Micro-YOLO: Exploring Efficient Methods to Compress CNN based Object Detection Model
157

REFERENCES
Bochkovskiy, A., Wang, C.-Y., and Liao, H.-Y. M. (2020).
YOLOv4: Optimal Speed and Accuracy of Object De-
tection. arXiv preprint arXiv:2004.10934.
Borji, A., Cheng, M.-M., Hou, Q., Jiang, H., and Li, J.
(2019). Salient object detection: A survey. Compu-
tational Visual Media, 5(1):117–150.
Cai, H., Zhu, L., and Han, S. (2019). Proxylessnas: Direct
neural architecture search on target task and hardware.
arXiv preprint arXiv:1812.00332.
Cheng, Y., Wang, D., Zhou, P., and Zhang, T. (2017). A sur-
vey of model compression and acceleration for deep
neural networks. arXiv preprint arXiv:1710.09282.
Fernandez-Marques, J., Whatmough, P. N., Mundy, A., and
Mattina, M. (2020). Searching for Winograd-aware
Quantized Networks. MLSys.
Girshick, R., Donahue, J., Darrell, T., and Malik, J. (2014).
Rich feature hierarchies for accurate object detection
and semantic segmentation. In IEEE CVPR, pages
580–587.
Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B.,
Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V.,
et al. (2019). Searching for Mobilenetv3. IEEE ICCV,
pages 1314–1324.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D.,
Wang, W., Weyand, T., Andreetto, M., and Adam,
H. (2017). Mobilenets: Efficient convolutional neu-
ral networks for mobile vision applications. arXiv
preprint arXiv:1704.04861.
Hu, J., Shen, L., Albanie, S., Sun, G., and Wu, E.
(2019). Squeeze-and-Excitation Networks. IEEE
PAMI, 5(1):117–150.
Huang, R., Pedoeem, J., and Chen, C. (2018). YOLO-LITE:
a real-time object detection algorithm optimized for
non-GPU computers. In IEEE Big Data, pages 2503–
2510.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ra-
manan, D., Doll
´
ar, P., and Zitnick, C. L. (2014). Mi-
crosoft coco: Common objects in context. In ECCV,
pages 740–755. Springer.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.,
Fu, C.-Y., and Berg, A. C. (2016). Ssd: Single shot
multibox detector. In ECCV, pages 21–37.
Liu, Z., Sun, M., Zhou, T., Huang, G., and Darrell, T.
(2019). Rethinking the value of network pruning.
arXiv preprint arXiv:1810.05270.
Pan, M., Zhu, X., Li, Y., Qian, J., and Liu, P. (2020). MR-
Net: A Keypoint Guided Multi-scale Reasoning Net-
work for Vehicle Re-identification. In Yang, H., Pa-
supa, K., Leung, A. C., Kwok, J. T., Chan, J. H.,
and King, I., editors, Neural Information Processing,
ICONIP 2020, volume 1332, pages 469–478.
Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E.,
DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., and
Lerer, A. (2017). Automatic differentiation in Py-
Torch. In NIPS Autodiff Workshop.
Redmon, J. and Farhadi, A. (2018). Yolov3: An incremental
improvement. arXiv preprint arXiv:1804.02767.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and
Chen, L.-C. (2018). Mobilenetv2: Inverted residuals
and linear bottlenecks. In IEEE CVPR, pages 4510–
4520.
Tan, M. and Le, Q. V. (2019). Efficientnet: Rethink-
ing model scaling for convolutional neural networks.
ICML.
Wong, A., Famuori, M., Shafiee, M. J., Li, F., Chwyl, B.,
and Chung, J. (2019). Yolo nano: a highly compact
you only look once convolutional neural network for
object detection. arXiv preprint arXiv:1910.01271.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
158
