
A Lightweight Secure Image Super Resolution using Network Coding
Quoc-Tuan Vien
1 a
, Tuan T. Nguyen
2 b
and Huan X. Nguyen
1 c
1
Faculty of Science and Technology, Middlesex University, The Burroughs, London NW4 4BT, U.K.
2
School of Computing, Buckingham University, Hunter St., Buckingham MK18 1EG, U.K.
Keywords:
Image Communication, Deep Learning, Super-resolution, Network Coding.
Abstract:
Images play an important part in our daily life. They convey our personal stories and maintain meaningful ob-
jects, events, emotions etc. People, therefore, mostly use images as visual information for their communication
with each other. Data size and privacy are, however, two of important aspects whilst transmitting data through
network like internet, i.e. the time prolongs when the amount of data are increased and the risk of exposing
private data when being captured and accessed by irrelevant people. In this paper, we introduce a unified
framework, namely Deep-NC, to address these problems seamlessly. Our method contains three important
components: the first component, adopted from Random Linear Network Coding (RLNC), to protect the shar-
ing of private image from the eavesdropper; the second component to remove noise causing to image data due
to transmission over wireless media; and the third component, utilising Image Super-Resolution (ISR) with
Deep Learning (DL), to recover high-resolution images from low-resolution ones due to image sizes reduced.
This is a general framework in which each component can be enhanced by sophisticated methods. Simulation
results show that an outperformance of up to 32 dB, in terms of Peak Signal-to-Noise Ratio (PSNR), can be
obtained when the eavesdropper does not have any knowledge of parameters and the reference image used in
the mixing schemes. Various impacts of the method are deeply evaluated to show its effectiveness in secur-
ing transmitted images. Furthermore, the original image is shown to be able to downscale to a much lower
resolution for saving significantly the transmission bandwidth with negligible performance loss.
1 INTRODUCTION
Deep Learning (DL) has recently received increas-
ing attention and achieves impressive results across
a spectrum of domains such as medicine, automation,
transportation, security, and so forth. It is a specific
sub-field of machine learning that uses neural network
with multiple layers. Each layer represents a deeper
level of knowledge. DL learns representations from
data through successive layers to increase meaningful
representations.
The reasons for the success of DL can be at-
tributed to two folds: first, the feature learning (Good-
fellow et al., 2016) capacity of its hierarchical archi-
tecture allows for automatically extracting meaning-
ful features from data, in which lower layers identify
basic features, and deeper layers synthesize higher-
level features in terms of learned lower-level ones;
second, the development of high-performance com-
a
https://orcid.org/0000-0001-5490-904X
b
https://orcid.org/0000-0003-0055-8218
c
https://orcid.org/0000-0002-4105-2558
puters with Graphic Processing Units and Tensor Pro-
cessing Units enable to perform a large number of op-
erations in reduced CPU times. Moreover, with the in-
creasing digitisation transformation, the applicability
of DL is more pronounced as the bigger data become,
the larger DL architecture is expected, and vice versa,
to capture underlying patterns better.
Research has proven that DL is one of effective
techniques for Super Resolution (SR) tasks with the
development of multiple DL based architectures. SR
is the process of recovering a High-Resolution (HR)
image from a given Low-Resolution (LR) image (Kim
et al., 2016). An LR image is an image which has a
reduced dimension or contains noise or blurring re-
gions. The relationship between an HR image and an
LR image can be represented by a function which al-
lows us to invert the LR image back to the HR im-
age. If the invert function is known, the HR im-
age can be easily reconstructed from the LR image.
In reality, this is, however, not the case. The core
problem of the SR is to create a mapping between
the LR and HR images. Although there are a va-
riety of approaches, they can be grouped into four
Vien, Q., Nguyen, T. and Nguyen, H.
A Lightweight Secure Image Super Resolution using Network Coding.
DOI: 10.5220/0010212406530660
In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021) - Volume 4: VISAPP, pages
653-660
ISBN: 978-989-758-488-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
653

main architecture types (Wang et al., 2020) includ-
ing: i) Pre-upsampling with bi-cubic (Keys, 1981)
and bi-linear interpolation (Smith, 1981); ii) Post-
upsampling at the last learnable layer; iii) Progressive
Upsampling with Laplacian pyramid SR framework
(LapSRN) (Lai et al., 2017); and iv) Iterative Up and
Down Sampling SR with back-projection (Irani and
Peleg, 1991), DBPN (Haris et al., 2018) and SRFBN
(Li et al., 2019b).
Nowadays, data transfer is a crucial part of our
daily life and in multiple areas. Multiple tech-
niques have been introduced to transmit data effi-
ciently. Network coding (NC) is one of them. Its con-
cept (Ahlswede et al., 2000) has been well exploited
in a vast number of research work from networking
and communications perspective aiming to increase
the system throughput by allowing the intermediate
nodes to perform encoding the incoming data rather
than operating simply as store-and-forward switches.
Specifically, an algebraic approach of NC, namely
random linear NC (RLNC), was developed in (Koet-
ter and Medard, 2003) where the intermediate nodes
can perform random linear operations on the incom-
ing data packets from different transmission source
nodes. The sink nodes with a sufficient number of
mixed data packets along with all RLNC coefficients
can recover the data of all source nodes.
Digital images contain quite a lot of essential in-
formation and are widely used to communicate be-
tween people over internet. Several issues encounter
during transmission such as data privacy and reducing
amount of data transferred to lessen the transmission
time. Various methods are developed to protect them
such as stenography, encryption, and watermarking.
Stenography is a method to hide data inside an image.
In the encryption approach, one image is converted
into an encrypted image by using the secret key. The
core idea of the encrypted image is to turn understand-
able data into incomprehensible data which are hard
to realise. On the other hand, watermarking tech-
niques are to embed the signature into an image to
visualise or hide the ownership of the image.
In general, steganography and encryption are dif-
ferent but they serve one main purpose, protecting
necessary data from irrelevant people. Encryption is
more flexible and secure (Xie et al., 2019; Guerrini
et al., 2020; Peng et al., 2020). Human, however, is
always curious and tries to see what messages when
they receive encrypted information. In such cases,
steganography is a better option because the hidden
message can be embedded so that the change of im-
age will not be noticed and does not draw attention
(Bender et al., 1996; Franz et al., 1996; Chen and
Lin, 2006). This technique nevertheless requires the
hidden message to have a smaller size than the cover
image’s, meaning that hiding an image into another
image is not easily achievable.
Different from multiple works solely focusing on
data security, or interested in data compression, our
work integrates both techniques together to gain a bet-
ter information protection. This aim is to develop a
simple yet efficient method to conceal and reduce the
file size whilst transmitting image data through net-
work. When the data is received, it can be easily re-
covered at the other end. Inspired by the NC concept,
a secure Image SR (ISR) using DL and NC, namely
Deep-NC, is proposed and demonstrated in the sce-
nario for an image communication between Alice and
Bob.
In the proposed Deep-NC, the downscaled image,
i.e. LR version of the original image, is incorporated
with the reference image by RLNC encoding prior to
transmitting to Bob. Over noisy channel, the received
image at Bob is denoised, followed by RLNC decod-
ing using the shared reference image and VDSR for
recovering the original image of high resolution. The
performance of the proposed Deep-NC is evaluated
in terms of Peak Signal-to-Noise Ratio (PSNR) tak-
ing into account additive white Gaussian noise model.
The impacts of RLNC, shared image dataset, noise
and scaling factor on the performance are assessed
through simulation to validate the effectiveness of the
proposed scheme. Simulation results show that Bob
achieves a far better performance than Eve with the
employment of Deep-NC, especially when the Eve
has no knowledge of the reference image shared be-
tween Alice and Bob. Additionally, both VDSR and
bicubic interpolation are shown to provide a better
performance at Bob compared to Eve. Furthermore,
the proposed Deep-NC allows the image to be down-
scaled to a much lower resolution to save the trans-
mission bandwidth, while still maintaining a signifi-
cantly higher performance than Eve.
2 SYSTEM MODEL
A typical secure image communication model is con-
sidered where Alice (A ) wants to send a private image
to Bob (B) in the existence of Eve (E ) trying to eaves-
drop the image.
Let I
A
denote the original image of size M × N
that Alice wants to send. Considering typical colour
images with three channels, i.e. red, green and blue,
I
A
can be defined as an M × N × 3 array, i.e.
I
A
: f (x
A
,y
A
) → R
3
, (1)
where f (x
A
,y
A
) ∈ R is the intensity of the image pixel
at point (x
A
,y
A
). Over the transmission media, the
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
654

noise is inevitable, which causes image degradation.
Generally, Gaussian noise model has been regarded
as the best fit in representing the additive noise in the
undesired signal at the receiver in most of commu-
nication systems due to its simplicity with dominant
central limit theorem.
Considering additive noise model, the image re-
ceived at node X , X ∈ {B ,E}, is given by
I
X
= I
A
+ N
X
, (2)
where N
X
, X ∈ {B,E}, is additive white Gaussian
noise (AWGN) at X having mean µ
X
and variance σ
2
X
.
In order to denoise an image with AWGN, a deep
neural network can be employed, e.g. a pretrained
DnCNN network (Zhang et al., 2017).
3 PROPOSED SECURE ISR
Our proposed approach is shown in the flowchart,
Fig. 1, which consists of the following main steps:
1
3.1 Downscaling at Alice
In order to save the transmission bandwidth, a LR ver-
sion of the original image is firstly generated using
bicubic interpolation. The bicubic filter is employed
for downscaling due to its low computational com-
plexity, while preserving image details with smooth
interpolated surface.
2
After downscaling the original image, i.e. I
A
, from
Alice, we have a LR image I
0
A
having size dM/δe ×
dN/δe × 3 where δ denotes the scaling factor and dxe
denotes the ceiling function of x.
3.2 RLNC Encoding at Alice
Following the concept of RLNC (Koetter and Medard,
2003), in the proposed scheme, the downscaled im-
age at Alice is linearly mixed with a reference image
using random scalar coefficients, a.k.a. RLNC coeffi-
cients. The reference image is acquired from an im-
age datastore which is assumed to be shared between
users as a common image dataset.
3
1
Note that common blocks at Bob and Eve to represent
the same steps are combined in the following discussion.
2
There exist different downscaling methods, e.g. Box
sampling, Nearest-neighbour interpolation, Lanczos Filter-
ing (Duchon, 1979), or CNN based downscaling like (Li
et al., 2019a); however, we do not need a sophisticated
downscaling method in this work.
3
Notice that only RLNC coeffients and the index of the
reference image are shared between Alice and Bob prior to
transmission as private keys in key-agreement protocols.
In order to mix two images, the shared image is
first downscaled to the same size of the original LR
image. Let I
S
and I
0
S
denote the HR and LR shared
image, respectively. I
0
S
should have the same size of
I
0
A
, i.e. an dM/δe × dN/δe × 3 array.
The mixing of the original image and the shared
image can be realised as follows:
I
T
= α
A
I
0
A
+ α
S
I
0
S
, (3)
where I
T
denotes the transmitted image at Alice, α
A
and α
S
are RLNC coefficients having α
A
> 0, α
S
≥ 0
and α
A
+ α
S
= 1. Here, α
A
and α
S
represent the
fractions of original image and shared image, respec-
tively, in the mixed image.
Remark 1 (Image Decodability-security Tradeoff)
A higher α
A
results in a better performance at Bob
with an enhanced image decodability, while a higher
α
S
helps secure the original image from Eve. In fact,
a higher α
A
means more information of the original
image in the mixed image, and thus Bob can recover
the desired image with higher decodability. However,
Eve also overhears the same amount of information
to be able to extract the original image, which means
more information at the same time is leaked to Eve.
On the other hand, a higher α
S
, i.e. a lower α
A
, causes
degradation of the image decodability at Bob, but it
helps improve the secrecy of the image communica-
tions due to less information of the original image in
the image mixture. Therefore, it is crucial to find α
A
(or α
S
) to balance the tradeoff between the image de-
codability and security.
3.3 Denoise at Bob and Eve
Over the noisy channel, the image transmitted from
Alice is deteriorated caused by Gaussian noise. It is
assumed that Eve experiences the same noisy envi-
ronment as Bob.
The images received at B and E over Gaussian
noise model can be obtained as in (2), i.e.
I
X
= I
T
+ N
X
, (4)
where X ∈ {B,E} and I
T
is the transmitted image
at Alice given by (3). Both B and E then remove
the Gaussian noise using the same pretrained DnCNN
network.
Let us denote the denoised images at B and E af-
ter filtering by
˜
I
B
and
˜
I
E
, respectively.
3.4 RLNC Decoding at Bob
Given the index of the reference image in the shared
image datastore and RLNC coefficients, i.e. α
A
or α
S
,
A Lightweight Secure Image Super Resolution using Network Coding
655
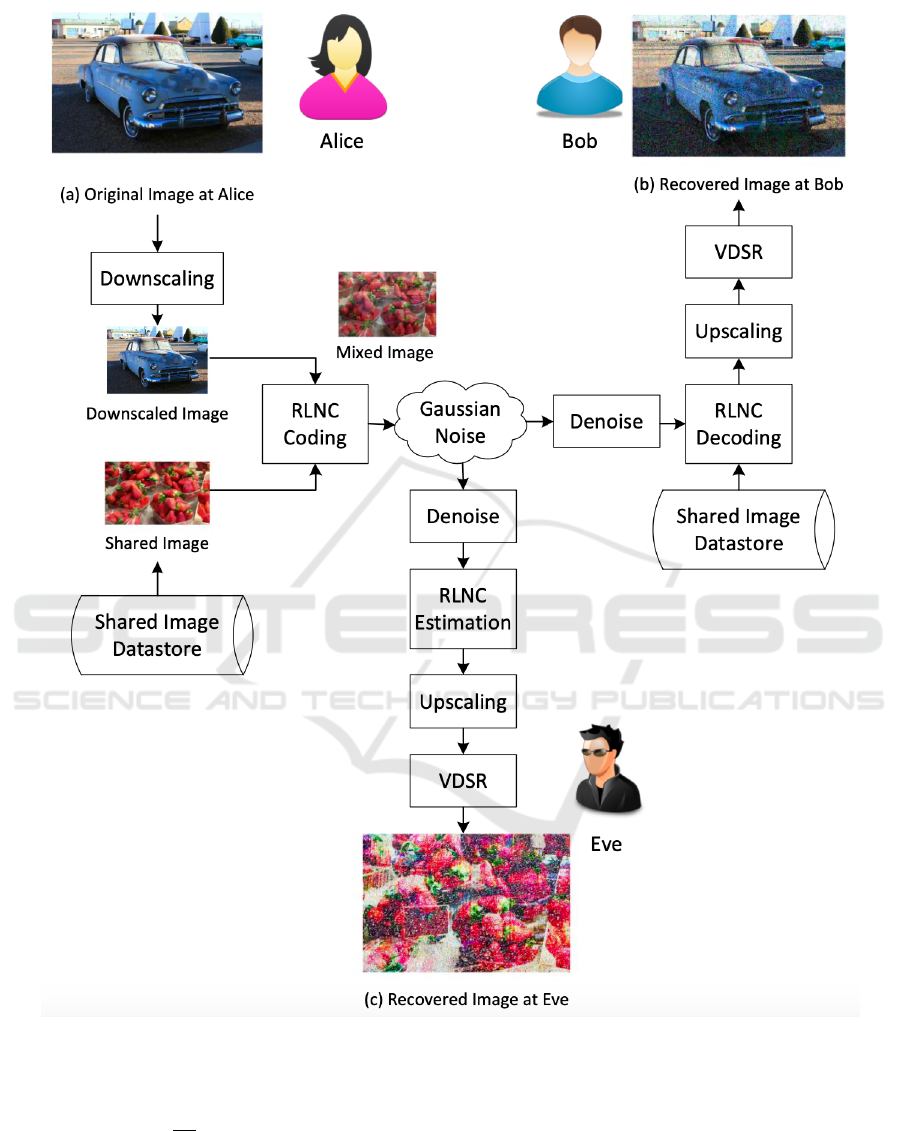
Figure 1: Proposed Deep-NC for secure ISR.
Bob can recover the image transmitted from Alice as
ˆ
I
0
B
=
1
α
A
˜
I
B
− α
S
I
0
S
, (5)
where I
0
S
is the LR version of the shared image and
ˆ
I
0
B
is the decoded image at B.
3.5 RLNC Estimation at Eve
Trying to decode the image shared from Alice, Eve
however does not know the RLNC coefficients, i.e.
α
A
and α
S
, and the index of the image in the shared
datastore, i.e. I
S
, which was used at Alice for mixing
it with the original image. Therefore, Eve has to esti-
mate the RLNC parameters and select the right image
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
656

in the datastore to recover the image.
The RLNC coefficients estimated at Eve can be
written by
ˆ
α
A
= α
A
± ε
A
, (6)
ˆ
α
S
= 1 −
ˆ
α
A
, (7)
where
ˆ
α
A
and
ˆ
α
S
are estimated RLNC coefficients of
α
A
and α
S
, respectively, and ε
A
denotes the estimation
error of α
A
at Eve knowing the fact that
ˆ
α
A
+
ˆ
α
S
= 1.
In addition to the RLNC coefficients, Eve needs to
predict the image in the shared datastore that was used
for encoding at Alice. Letting
ˆ
I
0
S
denote the predicted
image, Eve can decode the image following the same
method at Bob in Subsection 3.4.
3.6 VDSR at Bob and Eve
To be able to recover original images from decoded
images by RLNC, the VDSR framework, mentioned
in (Kim et al., 2016), was implemented. VDSR
was, then, trained with a public available IAPR TC-12
Benchmark dataset. We use simiar hyper-parameters
described in (Kim et al., 2016). More specific, the
training used batches of size 64, 100 epochs. The
learning rate is initially 0.1 and decreased by a fac-
tor of 10 every 10 epochs. The VDSR was trained
with the scaling factor δ = 4.
Then, the decoded images by RLNC decoding at
Bob, i.e.
ˆ
I
0
B
, and at Eve, i.e.
ˆ
I
0
E
, are fed into VDSR
model to obtain the upscaled images at Bob and Eve,
denoted by
ˆ
I
B
and
ˆ
I
E
. respectively. The upscaled im-
ages at Bob and Eve can be written by
ˆ
I
B
= V DSR(
ˆ
I
0
B
), (8)
ˆ
I
E
= V DSR(
ˆ
I
0
E
), (9)
respectively, where V DSR(·) denotes the operator
function to reconstruct the images with the scaling
factor δ trained before.
It is worth to mention that other SR methods can
be exploited to replace VDSR.
4 EVALUATION METHOD OF
THE PROPOSED DEEP NC
In order to evaluate the effectiveness of the proposed
Deep-NC for secure VDSR, Peak Signal-to-Noise Ra-
tio (PSNR) is presented in this section as a perfor-
mance metric to compare the quality of the recovered
image at Bob and Eve, i.e.
ˆ
I
B
and
ˆ
I
E
, with the original
HR image transmitted from Alice, i.e. I
A
.
The peak signal-to-noise ratio (PSNR) is the ra-
tio between a signal’s maximum power and the power
of the signal’s noise. Engineers commonly use the
PSNR to measure the quality of reconstructed images
that have been compressed. Each picture element
(pixel) has a color value that can change when an im-
age is compressed and then uncompressed. Signals
can have a wide dynamic range, so PSNR is usually
expressed in decibels, which is a logarithmic scale.
As a well-known image comparison metric, the
PSNR is considered to evaluate the loss of the image
quality. In the proposed secure ISR, the loss is due to
not only the noise at Bob, but also the lack of details
in the LR downscaled image and the training loss in
the VDSR network.
The PSNR, in dB, of the recovered image
ˆ
I
B
at
Bob with respect to the original image I
A
is defined
as
4
PSNR , 10log
10
1
MSE
, (10)
where MSE is the mean square error between
ˆ
I
B
and
I
A
given by
MSE , E
h
I
A
−
ˆ
I
B
2
i
. (11)
Here, E[·] denotes the expectation operator.
Considering RGB colour images having size M ×
N with three RGB values per pixel, the MSE can be
calculated by
MSE =
1
3MN
M
∑
x=1
N
∑
y=1
3
∑
z=1
I
A
(x,y,z) −
ˆ
I
B
(x,y,z)
2
.
(12)
Note that the PSNR at Eve is also evaluated using
(10). However, the quality of the recovered image is
further degraded due to the unknown reference image
and the lack of the information of RLNC coefficients
which are only shared between Alice and Bob.
5 SIMULATION RESULTS
In this section, we present the simulation results of the
proposed Deep-NC in terms of PSNR. We first com-
pare the performance at Bob with that at Eve when
employing either bicubic interpolation or VDSR
5
for
converting the received LR images to the original HR
images. The impacts of shared image dataset, Gaus-
sian noise, RLNC coefficients and scaling factor on
the performance are then sequentially evaluated to
show the enhancement of the proposed scheme in se-
curing the private image from the Eve. The results
4
In this work, the image is in double-precision floating-
point data type having maximum possible pixel value of 1.
5
It is worth to notice that the VDSR is selected as a typ-
ical ISR to validate the effectiveness of the proposed Deep-
NC in securing the image. A comparison of different ISR
schemes is beyond the scope of this work.
A Lightweight Secure Image Super Resolution using Network Coding
657

Figure 2: Images for evaluation of the proposed Deep-NC.
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
Noise variance (
2
)
-10
-5
0
5
10
15
20
25
30
PSNR [dB]
Bicubic (at Bob)
VDSR (at Bob)
Bicubic (at Eve) (known reference image)
VDSR (at Eve) (known reference image)
Bicubic (at Eve) (15th)
VDSR (at Eve) (15th)
Bicubic (at Eve) (16th)
VDSR (at Eve) (16th)
At Eve
Figure 3: PSNR versus noise variance with respect to dif-
ferent shared images at Eve.
are obtained by simulation in MATLAB. The training
is performed on an image dataset of the IAPR TC-12
benchmark with 20,000 still natural images which are
available free of charge and without copyright restric-
tions (Grubinger et al., 2006). In the following exper-
iment, the scaling factor is set as δ = 4, unless other-
wise stated. For validation of the proposed scheme,
20 undistorted images of the Image Processing Tool-
box in MATLAB are used as shown in Fig. 2 in which
the last image is selected as a reference image.
5.1 Impacts of Shared Image Dataset
In order to decode the original image, apart from the
RLNC coefficients, the reference image in the datas-
tore is required to be known at the receiver. Consid-
ering the scenario when Eve may not know the ref-
erence image used at Alice or may use the incorrect
image, Fig. 3 plots the PSNR of the proposed scheme
as a function of the noise variance, i.e. σ
2
, with re-
spect to different shared images at Eve including the
15th, 16th and 20th reference images. Here, the 20th
image is used for the RLNC encoding at Alice. Bicu-
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
Noise variance (
2
)
-5
0
5
10
15
20
25
30
PSNR [dB]
Bicubic (at Bob)
VDSR (at Bob)
Bicubic (at Eve)
VDSR (at Eve)
Figure 4: PSNR versus noise variance in Gaussian white
noise model.
bic interpolation and VDSR are employed as typical
ISR for upscaling. It can be observed in Fig. 3 that
the PSNR at Eve is considerably degraded when the
wrong reference image is selected for decoding. For
instance, in the noise-free environment with VDSR
upscaling, the PSNR at Eve decreases by 7 dB when
using the 15th or 16th image instead of the 20th im-
age. A further notice is the fact that, without knowl-
edge of the RLNC coefficient, Eve can only achieve
a close performance to Bob even with the right refer-
ence image. This accordingly reflects the effective-
ness of the proposed scheme in securing the origi-
nal image. Furthermore, as shown in Fig. 3, Bob
achieves a much better performance than Eve of up
to 32 dB when Eve implements only bicubic interpo-
lation. This is due to the fact that no SR is involved in
the image processing at Eve in this case along with es-
timation error of RLNC coefficient and the unknown
reference image.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
658
0.3 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7
RLNC coefficient of original image (
A
)
9
10
11
12
13
14
15
16
17
18
PSNR [dB]
v = 0.1 (at Bob)
v = 0.1 (at Eve)
v = 0.2 (at Bob)
v = 0.2 (at Eve)
Figure 5: PSNR versus RLNC coefficient of original image.
5.2 Impacts of Noise
Considering AWGN model in image communication
over wireless medium, Fig. 4 plots the PSNR of the
proposed scheme versus noise variance, i.e. σ
2
with
the assumption that Bob and Eve experience the same
noise model. Two typical upscaling schemes, i.e. the
bicubic interpolation and VDSR, are employed at Bob
and Eve. The reference image shared to Bob is also
leaked to Eve. Intuitively, it can be seen that the
PSNR decreases as the noise variance increases. Over
the wireless medium, the VDSR is shown to be bene-
ficial providing a higher PSNR than the bicubic inter-
polation. Similarly, Bob is shown to achieve a better
performance than Eve over the whole range of noise
variance with both bicubic interpolation and VDSR,
though the performance gap is smaller in the more
lossy environment. For instance, with the VDSR up-
scaling, the PSNR at Bob is 3 dB and 2 dB higher than
that at Eve, while a considerable enhancement of 14
dB and 13 dB can be achieved with the bicubic inter-
polation when σ
2
= 0.1 and σ
2
= 0.2, respectively.
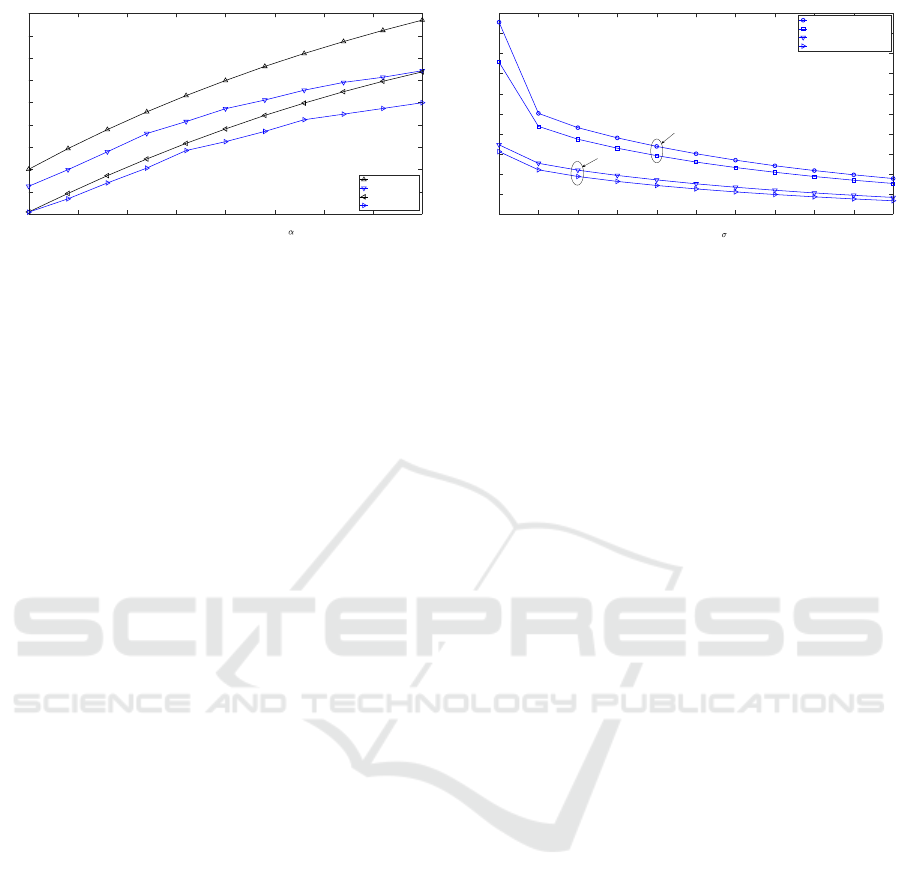
5.3 Impacts of RLNC Coefficients
Investigating the impacts of RLNC coefficients on the
performance of the proposed scheme, Fig. 5 plots the
PSNR of the proposed scheme versus the RLNC co-
efficient of the original image, i.e. α
A
, with respect to
different noise variances at Bob and Eve. Specifically,
two noise variances, i.e. σ
2
B
= σ
2
E
= σ
2
= {0.1,0.2},
are considered. It can be seen that Bob achieves a bet-
ter performance than Eve for all RLNC coefficients.
Also, the PSNR at both Bob and Eve increases as α
A
increases. This is due to the fact that there is more
information of the original image in the mixed im-
age. As noted in Remark 1, the RLNC coefficients
should be selected so as to restrict Eve from recover-
ing the original image, while maintaining the higher
image decodability at Bob. For instance, α
A
should
be less than 0.5 to limit the PSNR at Eve by 14 dB
when σ
2
= 0.1. The PSNR coefficients should be
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18 0.2
Noise variance (
2
)
8
10
12
14
16
18
20
22
24
26
28
PSNR [dB]
VDSR (at Bob) - scale=4
VDSR (at Bob) - scale=10
VDSR (at Eve) - scale=4
VDSR (at Eve) - scale=10
At Bob
At Eve
Figure 6: PSNR versus noise variance with respect to dif-
ferent scaling factors.
thus selected depending also on the noise variance.
As shown in Fig. 5, with the same requirement of the
maximal PSNR at Eve by 14 dB, α
A
should not be
greater than 0.5 and 0.7 when σ
2
= 0.1 and σ
2
= 0.2,
respectively.
5.4 Impacts of Scaling Factor
The impacts of scaling factor are shown in Fig. 6
where the PSNR at Bob and Eve of the proposed
scheme is plotted against noise variance in AWGN
model, i.e. σ
2
, with different scaling factors, i.e. δ = 4
and δ = 10. VDSR is considered with the same set-
tings as in Fig. 4. It can be seen in Fig. 6 that the
PSNR at Bob decreases considerably in the noiseless
environment as the scale increases, while there is not
much difference in the PSNR in the noisy environ-
ment. For instance, 4 dB is reduced when σ
2
= 0,
while less than 1 dB when σ
2
> 0.1. This means that
over the noisy medium, the image can be downscaled
with a higher scaling factor to save the bandwidth
with negligible performance loss.
6 CONCLUSIONS
In this paper, we have proposed a Deep-NC pro-
tocol for secure ISR communication between Alice
and Bob taking into account Gaussian noise model.
Specifically, RLNC has been adopted to protect the
secret image from Eve. It has been shown that Bob
achieves a much higher PSNR than Eve of up to 32
dB with the proposed Deep-NC protocol. Addition-
ally, an enhanced performance has been shown to
achieve at Bob over the whole range of noise vari-
ance in Gaussian model. Furthermore, the Deep-NC
protocol enables the original image to be downscaled
to a much lower resolution prior to transmitting over
the lossy environment, which accordingly implies the
effectiveness of the proposed scheme in saving the
transmission bandwidth.
A Lightweight Secure Image Super Resolution using Network Coding
659

ACKNOWLEDGMENT
This work was supported in part by a UKIERI grant,
ID ‘DST UKIERI-2018-19-011’, and in part by an
Institutional Links grant, ID 429715093, under the
Newton Programme Vietnam partnership.
REFERENCES
Ahlswede, R., Ning Cai, Li, S. . R., and Yeung, R. W.
(2000). Network information flow. IEEE Transac-
tions on Information Theory, 46(4):1204–1216.
Bender, W., Gruhl, D., Morimoto, N., and Lu, A. (1996).
Techniques for data hiding. IBM Systems Journal,
35(3.4):313–336.
Chen, P.-Y. and Lin, H.-J. (2006). A DWT based approach
for image steganography. International Journal of Ap-
plied Science and Engineering, pages 275–290.
Duchon, C. E. (1979). Lanczos Filtering in One and
Two Dimensions. Journal of Applied Meteorology,
18(8):1016–1022.
Franz, E., Jerichow, A., M
¨
oller, S., Pfitzmann, A., and
Stierand, I. (1996). Computer based steganography:
How it works and why therefore any restrictions on
cryptography are nonsense, at best. In Anderson, R.,
editor, Information Hiding, pages 7–21, Berlin, Hei-
delberg. Springer Berlin Heidelberg.
Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep
learning. MIT press.
Grubinger, M., Clough, P. D., M
¨
uller, H., and Deselaers,
T. (2006). The IAPR TC-12 benchmark: A new
evaluation resource for visual information systems.
https://www.imageclef.org/photodata.
Guerrini, F., Dalai, M., and Leonardi, R. (2020). Minimal
information exchange for secure image hash-based
geometric transformations estimation. IEEE Transac-
tions on Information Forensics and Security, 15:3482–
3496.
Haris, M., Shakhnarovich, G., and Ukita, N. (2018). Deep
back-projection networks for super-resolution. In
2018 IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 1664–1673.
Irani, M. and Peleg, S. (1991). Improving resolution by
image registration. CVGIP: Graphical Models and
Image Processing, 53(3):231 – 239.
Keys, R. (1981). Cubic convolution interpolation for digital
image processing. IEEE Transactions on Acoustics,
Speech, and Signal Processing, 29(6):1153–1160.
Kim, J., Kwon Lee, J., and Mu Lee, K. (2016). Accurate
image super-resolution using very deep convolutional
networks. In Proceedings of the IEEE conference on
computer vision and pattern recognition, pages 1646–
1654.
Koetter, R. and Medard, M. (2003). An algebraic approach
to network coding. IEEE/ACM Transactions on Net-
working, 11(5):782–795.
Lai, W., Huang, J., Ahuja, N., and Yang, M. (2017).
Deep laplacian pyramid networks for fast and accurate
super-resolution. In 2017 IEEE Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
5835–5843.
Li, Y., Liu, D., Li, H., Li, L., Li, Z., and Wu, F. (2019a).
Learning a convolutional neural network for image
compact-resolution. IEEE Transactions on Image
Processing, 28(3):1092–1107.
Li, Z., Yang, J., Liu, Z., Yang, X., Jeon, G., and Wu,
W. (2019b). Feedback network for image super-
resolution. In 2019 IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), pages
3862–3871.
Peng, H., Yang, B., Li, L., and Yang, Y. (2020).
Secure and traceable image transmission scheme
based on semitensor product compressed sensing in
telemedicine system. IEEE Internet of Things Jour-
nal, 7(3):2432–2451.
Smith, P. (1981). Bilinear interpolation of digital images.
Ultramicroscopy, 6(1):201 – 204.
Wang, Z., Chen, J., and Hoi, S. C. H. (2020). Deep learning
for image super-resolution: A survey. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence,
pages 1–1.
Xie, X.-Z., Chang, C.-C., and Lin, C.-C. (2019).
Reversibility-oriented secret image sharing mecha-
nism with steganography and authentication based on
code division multiplexing. IET Image Processing,
13(9):1411–1420.
Zhang, K., Zuo, W., Chen, Y., Meng, D., and Zhang, L.
(2017). Beyond a Gaussian denoiser: Residual learn-
ing of deep CNN for image denoising. IEEE Transac-
tions on Image Processing, 26(7):3142–3155.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
660
