
Incremental Learning for Real-time Partitioning for FPGA Applications
Belhedi Wiem, Kammoun Ahmed and Hireche Chabha
Department of Research, Altran Technologies, Rennes, France
Keywords:
Hardware/Software Partitioning, Incremental Learning, Classification, Incremental Kernel SVM (InKSVM),
Online Learning.
Abstract:
The co-design approach consists in defining all the sub-tasks of an application to be integrated and distributed
on software or hardware targets. The introduction of conventional cognitive reasoning can solve several prob-
lems such as real-time hardware/software classification for FPGA-based applications. However, this requires
the availability of large databases, which may conflict with real-time applications.
The proposed method is based on the Incremental Kernel SVM (InKSVM) model. InKSVM learns incremen-
tally, as new data becomes available over time, in order to efficiently process large, dynamic data and reduce
computation time. As a result, it relaxes the assumption of complete data availability and provides fully au-
tonomous performance.
Hence, in this paper, an incremental learning algorithm for hardware/software partitioning is presented. Start-
ing from a real database collected from our FPGA experiments, the proposed approach uses InKSVM to
perform the task classification in hardware and software. The proposal has been evaluated in terms of classi-
fication efficiency. The performance of the proposed approach was also compared to reference works in the
literature.
The results of the evaluation consist in empirical evidence of the superiority of the InKSVM over state-of-the-
art progressive learning approaches in terms of model accuracy and complexity.
1 INTRODUCTION
Hardware/software partitioning consists of dividing
the application’s computations between those which
will be performed by conventional software (that are
sequential instructions) and those that run parallel cir-
cuits which will be performed by specific hardware.
This is referred to as co-design, the design is twofold,
a software design and a hardware design. The co-
design approach is then to define all the sub-tasks of
an application to integrate and to distribute them on
software or hardware targets (Kammoun et al., 2018).
The automatic partitioning of a system specifica-
tion is a complex issue (considered as a NP-hard prob-
lem) due to the high number of parameters to account
for. In addition, it requires adapted computing pow-
ers. The problem gets more complicated when work-
ing on embedded systems that will be subject to real-
time constraints, surface consumption, etc.
Faced with the complexity of the software / hard-
ware partitioning problem, several approaches have
adopted manual methods to assign each task to the
corresponding entity on architecture.
Others have been made in regard of hard-
ware/software partitioning (Shui-sheng et al., 2006),
(Wang et al., 2016), (Zhang Tao and Zhichun, 2017),
(Ouyang et al., 2017), (Wijesundera et al., 2018),
(Yousuf and Gordon-Ross, 2016).
All these approaches are unique in nature and
each offers advantages of its own. However, real-
time applications require unsupervised learning in or-
der for a fully autonomous performance (Skliarova
and Sklyarov, 2019). Hence, in this paper, we
proposed an unsupervised learning algorithm for
hardawre/software partitioning. Starting for a real
database that was collected from our experimenta-
tions on FPGA, the proposed work makes the use of
Incremental Kernel-SVM in order to perform task-
classification into hardware and software. The pro-
posal was evaluated in terms of its classification ef-
ficiency and its performance was also compared to
benchmark approaches.
The partitioning category uses an automatic
method; in this case an optimization algorithm, which
takes into account all the parameters of the problem,
will be adopted.
In this work, our goal is to develop an algorithm
that will naturally group the data into two groups:
598
Wiem, B., Ahmed, K. and Chabha, H.
Incremental Learning for Real-time Partitioning for FPGA Applications.
DOI: 10.5220/0010202705980603
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 2, pages 598-603
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

hardware tasks and software tasks. Fore this, we use
in incremental Kernel SVM (InKSVM) to perform the
task classification in hardware and software.
The overall organization of the paper is as follows.
After the introduction, we present the various Incre-
mental learning methods algorithms that were used
for real-time classification applications in section 2.
In section 3, the proposed learning strategy of unsu-
pervised hardawre/software partitioning is presented.
In Section 4, experimental results of the proposed ap-
proach are presented and compared to those given by
benchmark approaches. In Section 5, we summarize
results from different perspectives and we conclude
the paper.
2 RELATED WORK:
INCREMENTAL LEARNING
METHODS FOR REAL-TIME
CLASSIFICATION
Artificial intelligence has drawn great attention in re-
cent years and it can be found in many practical ap-
plications, such as (Belhedi and Hannachi, 2020).
However, in real world problems, not all the
data is always always available at the very begin-
ning. For instance, this is the case for autonomous
systems(e.g.,autonomous driving and robotics) which
need a continuous adjustment, as new data is avail-
able. Moreover, other systems need human feed-
back. In such situations, classic or batch models re-
train from scratch, which requires high computational
complexity and training time.
Hence incremental-learning-based algorithms
were proposed in the literature in order to solve
real-time challenges.
More precisely, for the sake of solving classifica-
tion problems for non-linearly separable data, many
incremental classifiers have been proposed in the lit-
erature. The rest of this section reviews and discusses
a selection of Incremental classifiers that are namely:
Online Random Forest (ORF)(Lakshminarayanan
et al., 2014), incremental Learning Vector Quan-
tization (ILVQ)(Shui-sheng et al., 2006), Learn++
(LPP)(Polikar et al., 2001), Stochastic Gradient De-
scent (SGD)(Bottou, 2010), and Incremental Extreme
Learning Machine (IELM). A performance compara-
ison of these classifiers with respect to the proposed
approach is presented in section 4
Online Random Forest (ORF) (Lakshminarayanan
et al., 2014) is an incremental version of the Extreme
Random Forest. In fact, it goes a step further in order
to refine the prediction.
A predefined number of trees grows continuously
by adding splits whenever enough samples are gath-
ered within one leaf. Tree ensembles are very popular,
due to their high accuracy, simplicity and paralleliza-
tion capability.
In fact, instead of using a predetermined set of
data at the start, the ORF injects new data during
the process. It works by creating new trees when-
ever there are enough sample based on the result of
existing trees and adds those to the forest.
Incremental Learning Vector Quantization (ILVQ)
(Shui-sheng et al., 2006) extends the Generalized
Learning Vector Quantization (GLVQ) to a dynami-
cally growing model by continuous insertion of new
prototypes. The (GLVQ)(Liang et al., 2006) is an im-
provement of the basic method in which reference
vectors are updated based on the steepest descent
method in order to minimize the cost function. The
cost function is determined so that the obtained learn-
ing rule satisfies the convergence condition.
Learn++ (LPP) (Polikar et al., 2001) utilizes an
ensemble of classifiers by generating multiple hy-
potheses using training data sampled according to
carefully tailored distributions. The outputs of the re-
sulting classifiers are combined using a weighted ma-
jority voting procedure. In essence, both Learn++ and
AdaBoost which is it inspired by generating an en-
semble of weak classifiers, each trained using a dif-
ferent distribution of training samples. The outputs of
these classifiers are then combined using Littlestone’s
majority-voting scheme to obtain the final classifica-
tion rule.
Stochastic Gradient Descent (SGD) (Bottou,
2010) As the data size and means of stocking it had
gone up over the last decade, the SGD is an attempt to
help processing these faster and thus reduces the com-
puting time, which is the limiting factor in the current
statistical machine learning methods. A more precise
analysis uncovers qualitatively different tradeoffs for
the case of small-scale and large-scale learning prob-
lems. The large-scale case involves the computational
complexity of the underlying optimization algorithm
in non-trivial ways. Unlikely optimization algorithms
such as stochastic gradient descent show amazing per-
formance for large-scale problems. In particular, sec-
ond order stochastic gradient and averaged stochas-
tic gradient are asymptotically efficient after a single
pass on the training set.
Incremental Extreme Learning Machine (IELM)
(Liang et al., 2006) is a variant of the ELM algorithm,
which are feedforward neural networks for classifica-
tion and feature learning with a single layer or mul-
tiple layers of hidden nodes, where the parameters of
hidden nodes (not just the weights connecting inputs
Incremental Learning for Real-time Partitioning for FPGA Applications
599

to hidden nodes) need not be tuned. In OS-ELM, the
parameters of hidden nodes (the input weights and bi-
ases of additive nodes or the centers and impact fac-
tors of RBF nodes) are randomly selected and the out-
put weights are analytically determined based on the
sequentially arriving data. One of the main strength
of IELM is its versatility, as it can both handle data
arriving one by one or chunk-by-chunk with varying
chunk size.
3 PROPOSED APPROACH
Let x
i
be the training vectors and y
i
= ±1 are their
corresponding labels. The goal of the SVM-based
classification is to find the optimal separating func-
tion that reduces to a linear combination of kernels on
the training data as follows:
f (x) =
N
∑
j=1
α
j
K(x
j
,x) + b (1)
The coefficients α
j
are obtained by minimizing the
following quadratic objective function subject to the
lagrange multiplier (b) and with the symmetric posi-
tive definite matrix (Q) constrains:
min
0≤α
j
≥C
: W =
∑
i, j
α
i
Q
i j
α
j
−
∑
i
α
i
+ b
∑
i
y
i
α
i
(2)
Hence, as Q = y
i
y
j
K(x
i
,x
j
) is positive definite, and
K are positive-definite, then the Karush-Kuhn-Tucker
(KKT) condition on the loss function W are sufficient
for optimality and are written as:
g
i
=
dW
dα
i
=
∑
i
Q
i j
α
j
+ y
i
f (x
i
) − 1
≥ 0,i f α
i
= 0
= 0,
i f 0 < α
i
< C
≤ 0,otherwise
dW
db
=
∑
i
y
j
α
j
= 0
(3)
Hence, the KKT condition divides the dataset into
three sets as:
• The first set, S, consists of support vectors that are
strictly located on the margin (y
i
f (x
i
) = 1).
• The second set consists of error support vectors
that exceed the margin.
• The third set consists of non-support vectors.
Before a new data is added, the KKT condition is sat-
isfied for all the training samples. The key idea is
to maintain equilibrium on all data points by updating
the Lagrange multiplier α
i
in order to satisfy the KKT
condition that can be also expressed as:
(
∆g
i
= Q
ic
∆α
c
+
∑
j∈S
Q
i j
∆
j
+ y
i
∆b,
∀i ∈ {1,...,l}∪ {c}
∆
dW
db
= y
c
∆α
c
+
∑
j∈S
∆α
j
= 0
(4)
where α
c
is the coefficient being incremented of the
new data point x
c
outside the initial database. Since
g
i
= 0 for the margin vectors inside S, the equation 4
can be rewritten in matrix form as:
∆g
c
∆g
s
∆g
0
0
=
y
c
Q
c,s
y
s
Q
s,s
y
0
Q
0,s
0 y
T
s
∆b
∆α
s
+∆α
c
Q
T
c,c
Q
T
c,s
Q
T
c,0
y
c
(5)
Hence, in equilibrium:
∆b = β∆α
c
(6)
and
∆α
j
= β
j
∆α
j
,∀ j ∈ D (7)
where the sensitivity coefficients are give by
β
β
s1
.
.
.
β
sl
s
= −A
y
c
Q
s1c
.
.
.
Q
sl
s
c
(8)
Where A = Q
−1
and β
j
= 0 for all j outside S. Hence,
according to the equation 4, the margin change ac-
cording to:
∆g
i
= γ
i
∆α
c
,∀i ∈ ∪{c} (9)
where the margin sensitivity γ
i
is expressed as:
γ
i
= Q
ic
+
∑
j∈S
Q
i j
β
j
+ y
i
β,∀i /∈ S (10)
γ
i
= 0 for all i in S.
Hence, IKSVM efficiently updates the previously
trained model.
4 EVALUATION
4.1 Comparison with Incremental
Learning Methods
In order to provide empirical evidence of the supe-
riority of the proposed model, several experiments
are conducted. First we have compared it with state-
of-the-art incremental learning approaches in terms
of accuracy and model complexity. This experiment
shows the advantages of incremental learning over
batch learning. For this experiment, tests were con-
ducted using several artificial databases whose de-
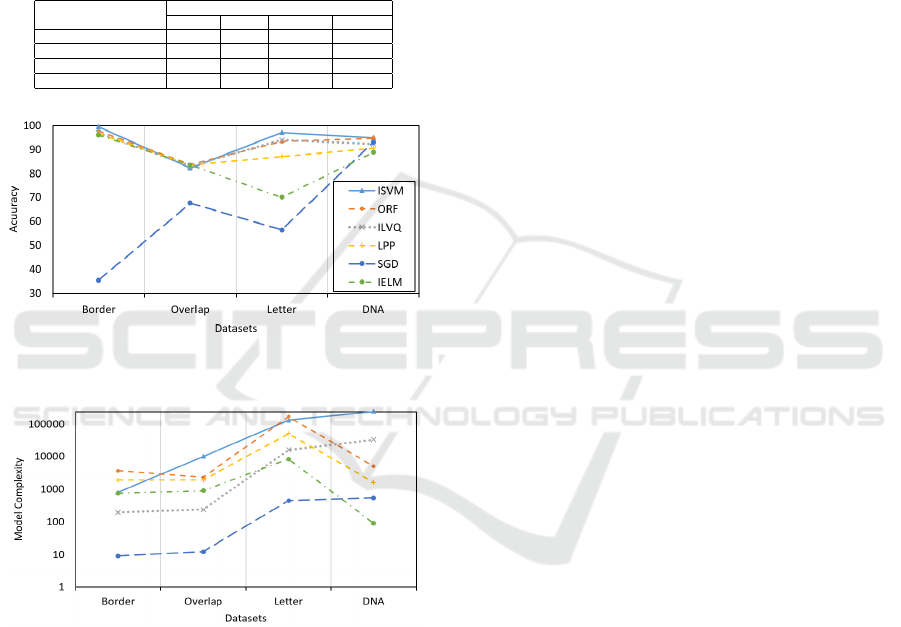
scriptions are reported in Table 1. According to Fig-
ure 1 and Figure 2, the proposed approach provides
better accuracy compared to batch in terms of accu-
racy values, since incremental models yield a cleaner
solution.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
600
In addition, the proposed method is applied for
solving industry applications: hardawre/software par-
titioning for FPGA-based applications. For this, the
database is of a collection of experiments that were
conducted in Altran Technologies.
The studied incremental methods are namely:
Online Random Forest (ORF), Incremental Learn-
ing Vector Quantization (ILVQ), Learn++ (LPP), In-
cremental Extreme Learning Machine (IELM) and
Stochastic Gradient Descent (SGD).
Table 1: Evaluated datasets.
Incremental Method Description
Train Test Features Classes
Border 4000 1000 2 3
Overlap 3960 990 2 4
Letter 16000 4000 16 26
DNA 1400 1186 180 3
Figure 1: Comparison against incremental learning meth-
ods in terms of accuracy.
Figure 2: Comparison against incremental learning meth-
ods in terms of model complexity.
4.2 Application of Real-time
Hardawre/Software Partitioning for
FPGA-based Applications (Wiem
et al., 2018)
4.2.1 Database
The database is of a collection of experiments that
were conducted in Altran Technologies. As described
in (Belhedi and Hannachi, 2020), it consists of sev-
eral tasks with their respective Execution time (ET),
Energy, Allocation, and type (Hardware or Software).
The allocation step is one of the most important
in the partitioning process. In fact, by definition, the
Allocation is to find the best set of components which
allows to implement the functionalities of a given sys-
tem. However, the sheer number of available software
and hardware makes the task extremely complex.
4.2.2 Comparison of Partitioning Results with
Conventional Approaches
The comparison of partitioning results with respect
to conventional Approaches is illustrated in Table 2.
Results are reported for the proposed method as well
as 1)Lee(Lee et al., 2007), 2)Lin(Lin et al., 2006),
3)GHO(Lee et al., 2009), 4)GA(Zou et al., 2004), as
well as the Hardware orient partition (HOP).
The results illustrated in Table 2 show the superi-
ority of the proposed approach in terms of both accu-
racy and execution time.
5 CONCLUSIONS AND FUTURE
WORK
The problem of software / hardware partitioning is
approached in many ways depending on the applica-
tion and architecture models considered. In this pa-
per, this problem was effectively solved based on AI
algorithms.
In this paper, IKSVM was used. In fact, InKSVM
learns incrementally, as new data becomes available
over time, in order to efficiently process large, dy-
namic data and reduce computation time. As a result,
it relaxes the assumption of complete data availabil-
ity and provides fully autonomous performance as it
efficiently updates the previously trained model.
In order to provide empirical evidence of the su-
periority of the proposed model, several experiments
are conducted. First we have compared it with state-
of-the-art incremental learning approaches in terms
of accuracy and model complexity. This experiment
shows the advantages of incremental learning over
batch learning. For this experiment, tests were con-
ducted using several artificial databases whose de-
scriptions are reported in Table 1. According to Fig-
ures 1 and 2, the proposal provides better accuracy
compared to batch in terms of accuracy values, since
incremental models yield a cleaner solution.
In addition, the proposed method is applied for
solving industry applications: hardawre/software par-
titioning for FPGA-based applications. For this, the
database is of a collection of experiments that were
conducted in Altran Technologies.
Incremental Learning for Real-time Partitioning for FPGA Applications
601

Table 2: Comparison of partitioning results against conventional Approaches.
Partitioning results
Methods T
1
T
2
T
3
T
4
T
5
T
6
T
7
T
8
T
9
T
10
T
11
T
12
T
13
T
14
T
15
T
16
T
17
T
18
T
19
T
20
T
21
T
22
Exec time (us)
Proposed 1 1 -1 -1 1 1 1 1 1 -1 1 1 1 1 1 -1 1 -1 1 1 1 -1 20021.60
Lee(Lee et al., 2007) 1 -1 -1 1 1 1 1 1 -1 1 1 1 1 1 1 1 1 -1 1 1 1 1 20022.26
Lin(Lin et al., 2006) -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 1 20151.58
GHO(Lee et al., 2009) 1 -1 1 -1 1 1 1 1 1 1 1 1 -1 1 1 1 1 1 1 1 1 1 20021.66
GA(Zou et al., 2004) -1 -1 1 -1 -1 1 -1 1 -1 1 1 1 -1 1 1 -1 1 1 1 -1 1 -1 20111.26
HOP -1 1 -1 -1 1 1 1 1 1 -1 1 -1 1 1 1 -1 1 -1 1 1 1 -1 20066.64
As future work, InKSVM will be implemented on
FPGA for a fully autonomous real-time HW/SW par-
titioning.
REFERENCES
Belhedi, W. and Hannachi, M. (2020). Supervised hardware
software partitioning algorithms for fpga based appli-
cations. the 12th International Conference on Agents
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
602

and Artificial Intelligence (ICAART 2020), 2:860–
864.
Bottou, L. (2010). Large-scale machine learning with
stochastic gradient descent. In Proceedings of COMP-
STAT’2010, pages 177–186. Springer.
Kammoun, A., Hamidouche, W., Belghith, F., Nezan, J.-F.,
and Masmoudi, N. (2018). Hardware design and im-
plementation of adaptive multiple transforms for the
versatile video coding standard. IEEE Transactions
on Consumer Electronics, 64(4):424–432.
Lakshminarayanan, B., Roy, D. M., and Teh, Y. W. (2014).
Mondrian forests: Efficient online random forests. In
Advances in neural information processing systems,
pages 3140–3148.
Lee, T.-Y., Fan, Y.-H., Cheng, Y.-M., and Tsai, C.-C.
(2009). Hardware-software partitioning for embed-
ded multiprocessor fpga systems. International Jour-
nal of Innovative Computing, Information and Con-
trol, 5(10):3071–3083.
Lee, T.-Y., Fan, Y.-H., Cheng, Y.-M., Tsai, C.-C., and
Hsiao, R.-S. (2007). Enhancement of hardware-
software partition for embedded multiprocessor fpga
systems. In Third International Conference on In-
telligent Information Hiding and Multimedia Signal
Processing (IIH-MSP 2007), volume 1, pages 19–22.
IEEE.
Liang, N.-Y., Huang, G.-B., Saratchandran, P., and Sun-
dararajan, N. (2006). A fast and accurate online se-
quential learning algorithm for feedforward networks.
IEEE Transactions on neural networks, 17(6):1411–
1423.
Lin, T.-Y., Hung, Y.-T., and Chang, R.-G. (2006). Efficient
hardware/software partitioning approach for embed-
ded multiprocessor systems. In 2006 International
Symposium on VLSI Design, Automation and Test,
pages 1–4. IEEE.
Ouyang, A., Peng, X., Liu, J., and Sallam, A. (2017).
Hardware/software partitioning for heterogenous mp-
soc considering communication overhead. Interna-
tional Journal of Parallel Programming, 45(4):899–
922.
Polikar, R., Upda, L., Upda, S. S., and Honavar, V. (2001).
Learn++: An incremental learning algorithm for su-
pervised neural networks. IEEE transactions on sys-
tems, man, and cybernetics, part C (applications and
reviews), 31(4):497–508.
Shui-sheng, Z., Wei-wei, W., and Li-hua, Z. (2006). A new
technique for generalized learning vector quantization
algorithm. Image and Vision Computing, 24(7):649–
655.
Skliarova, I. and Sklyarov, V. (2019). Hardware/software
co-design. In FPGA-BASED Hardware Accelerators,
pages 213–241. Springer.
Wang, R., Hung, W. N., Yang, G., and Song, X. (2016). Un-
certainty model for configurable hardware/software
and resource partitioning. IEEE Transactions on Com-
puters, 65(10):3217–3223.
Wiem, B., Mowlaee, P., Aicha, B., et al. (2018). Unsuper-
vised single channel speech separation based on opti-
mized subspace separation. Speech Communication,
96:93–101.
Wijesundera, D., Prakash, A., Perera, T., Herath, K., and
Srikanthan, T. (2018). Wibheda: framework for
data dependency-aware multi-constrained hardware-
software partitioning in fpga-based socs for iot de-
vices. In 2018 IEEE 26th Annual International Sym-
posium on Field-Programmable Custom Computing
Machines (FCCM), pages 213–213. IEEE.
Yousuf, S. and Gordon-Ross, A. (2016). An automated
hardware/software co-design flow for partially recon-
figurable fpgas. In 2016 IEEE Computer Society
Annual Symposium on VLSI (ISVLSI), pages 30–35.
IEEE.
Zhang Tao, Zhao Xin, A. X. Q. H. and Zhichun,
L. (2017). Using blind optimization algorithm
for hardware/software partitioning. IEEE Access,
5:1353–1362.
Zou, Y., Zhuang, Z., and Chen, H. (2004). Hw-sw parti-
tioning based on genetic algorithm. In Proceedings
of the 2004 Congress on Evolutionary Computation
(IEEE Cat. No. 04TH8753), volume 1, pages 628–
633. IEEE.
Incremental Learning for Real-time Partitioning for FPGA Applications
603
