
Automatic Detection of Cyber Security Events from Turkish Twitter
Stream and Newspaper Data
¨
Ozg
¨
ur Ural
1 a
and Cengiz Acart
¨
urk
1,2 b
1
Informatics Institute, Cyber Security Graduate Program, Middle East Technical University, Ankara, Turkey
2
Informatics Institute, Cognitive Science Graduate Program, Middle East Technical University, Ankara, Turkey
Keywords:
Cyber Security, Event Detection, Turkish, Twitter, H
¨
urriyet Newspaper.
Abstract:
Cybersecurity experts scan the internet and face security events that influence user and institutions. An in-
formation security analyst regularly examines sources to stay up to date on security events in the domain of
expertise. This may lead to a heavy workload for the information analysts if they do not have proper tools
for security event investigation. For example, an information analyst may want to stay aware of cybersecurity
events, such as a DDoS (Distributed Denial of Service) attack on a government agency website. The earlier
they detect and understand the threats, the longer the time remaining to alleviate the obstacle and to investi-
gate the event. Therefore, information security analysts need to establish and keep situational awareness active
about the security events and their likely effects. However, due to the large volume of information flow, it may
be difficult for security analysts and researchers to detect and analyze security events timely. It is important
to detect security events timely. This study aims at developing tools that are able to provide timely reports of
security incidents. A recent challenge is that the internet community use different languages to share infor-
mation. For instance, information about security events in Turkey is mostly shared on the internet in Turkish.
The present study investigates automatic detection of security incidents in Turkish by processing data from
Twitter and news media. It proposes an automatic prototype, Turkish-specific software system that can detect
cybersecurity events in real time.
1 INTRODUCTION
1.1 Motivation and Objectives
Security awareness tools help security analysts to pro-
tect an institution’s sensitive and mission-critical data
from being stolen, damaged, or compromised by at-
tackers. The duration between the disclosure of a new
vulnerability and the moment when the security ana-
lyst becomes aware of it is crucial for taking appro-
priate countermeasures in a timely manner.
Twitter is a major source of up to date information.
Twitter has 330 million monthly active users world-
wide (Phan et al., 2020). Turkey is the fifth country
in the list of leading countries with nearly 9 million
active users, as of January 2019 (Okay et al., 2020).
Twitter users can tweet in any languages they select.
Although there are no statistics about the use of Turk-
ish by Twitter users, it is very likely that most of the
a
https://orcid.org/0000-0003-1329-4303
b
https://orcid.org/0000-0002-5443-6868
Turkish Twitter users share their tweets in their native
language.
A review of the literature and recent state of tech-
nology reveal that most of the research conducted on
security event detection has been developed for ana-
lyzing text in English or other popular languages such
as Portuguese language (Duarte et al., 2018) using
Big Data (Seth et al., 2017). As of our knowledge, re-
search is lacking on real-time security event detection
in Turkish language streams. Given the significant
share of the use of the Turkish language on the Inter-
net, it is necessary to develop security event detection
tools that process Turkish data. Internet usage pene-
tration in Turkey is %72 with 59.36 million internet
users, and active social media penetration in Turkey
is %63 with 52 million people (Alan, 2020). With
emerging internet adoption in Turkey, there are much
timely information shared in Turkish. Recent event
detection systems which developed for English texts
are not useful for Turkish texts mining. Therefore, in
order to use Turkish texts at detection of cybersecurity
events, we should develop Turkish language-specific
66
Ural, Ö. and Acartürk, C.
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data.
DOI: 10.5220/0010201600660076
In Proceedings of the 7th International Conference on Information Systems Security and Privacy (ICISSP 2021), pages 66-76
ISBN: 978-989-758-491-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

methods and algorithms.
Social media is not the only option to extract infor-
mation as such. A security analyst has a wide range
of sources available such as the specialized press,
blogs, forums, news agencies, newspapers, and so on
to gather cyber threat information. Although, their
initial source of information for detecting such secu-
rity events is usually social networks.An alternative
way to extract information about security events is
newspapers. After the emergence of a trending event,
users increasingly share posts about it on social me-
dia. For instance, a DDoS attack to a service or a
website is usually recognized and reported by social
media users first, and they share the information on
online platforms, by posting tweets such as “X web-
site is unreachable”.
An autonomous system which can use various
data sources for security event detection has the po-
tential to be beneficial for a security analyst. We de-
signed and developed a software system capable of
detecting and monitoring cybersecurity-related events
over the Twitter Stream in Turkish. Int its recent ver-
sion, it can process several millions of documents per
day and detect security events. To gain more accu-
rate results, we added the H
¨
urriyet Turkish newspaper
stream to Twitter, for analyzing and detecting security
events. The software solution’s infrastructure sup-
ports adding new data resources, thus providing flex-
ibility. For example, it is possible to expand the sys-
tem by adding LinkedIn, Facebook website streams to
gain more complete and accurate results.
We designed the system as a framework to make it
useable for further research. Turkish datasets are used
in various research areas like text classification, au-
thor detection, automatic question answering. How-
ever, finding datasets in Turkish is difficult since there
are limited accessible datasets online. By means of
this research software framework, researchers will
be able to access security event datasets in Turkish.
Moreover, they will be able to select and modify their
queries by changing keyword vectors, thus changing
the content of information to be extracted from online
sources. We validated the proposed approach using
several detected events already shared in Turkish-in
online platforms. By means of automatic event detec-
tion systems, a security analyst establishes situation
awareness in cyberspace and take countermeasures
against new threats. For example, a security analyst
who is working for a Turkish institution may use local
websites APIs like Eksisozluk API e-Devlet API or
libraries/frameworks developed for focused Turkish
people. If these API’s, libraries or frameworks have
vulnerabilities, and someone discovers them, they are
probably discussed and announced within social me-
dia like Twitter in Turkish. It is likely that Turkish
newspapers publish it as breaking news too. To detect
such events automatically, the software system must
listen to Turkish data sources and process the text in
Turkish. Our research aims at meeting these require-
ments by proposing a software system and framework
for security event detection.
1.2 Routine Tasks of an Information
Security Analyst
Information security analyst’s the primary respon-
sibility is to take countermeasures for protecting
organizational-level, mission-critical and sensitive in-
formation, as well as being prepared for cyber-
attacks(Sohime et al., 2020). To be prepared for a
cyber-attack, they use various tools and systems. One
of their responsibilities is to analyze data and to rec-
ommend changes to managers. However, security an-
alysts are not authorized to implement changes. Their
main job is to keep cyber-attacks out.
In practice, a security analyst spends approxi-
mately one hour per a working day to get caught
up on the latest security news through bulletins, fo-
rums, news, social networks and so on to identify
new threats. They further spend two to three hours
by repeated investigation of potential security inci-
dents using online resources. They spend the rest of
their daily time with manually copying and pasting
information from disparate and siloed tools to cor-
relate data. They generally face with ten to twenty
challenges daily such as monitoring security access,
analyzing security breaches to identify the root cause,
verifying the security of third-party vendors and col-
laborating with them to meet security requirements
and so on. (Sohime et al., 2020) Their investiga-
tion time gives cyber attackers advantages if it is long
enough, and it is challenging for a security analyst to
keep up with threats. A manual investigation of se-
curity events is not sustainable without automation.
To make it sustainable, automated Natural Language
Processing analysis tools and text mining methods
need to be used.
1.3 Relevant Work
The identification of victims affected by cyber-attacks
is a major subdomain of research in cybersecurity.
One of the research field focuses on cybersecurity
events detection using English text in Twitter. For
example “Automatic Detection of Cyber Security Re-
lated Accounts on Online Social Networks: Twitter as
an Example”. In that paper (Aslan et al., 2018), they
use machine learning techniques; they investigated to
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data
67

find a method of whether social media accounts re-
lated to cybersecurity. To prepare their dataset to use
in their research, they develop a crawler with Twitter
API using Python programming language. Another
notable paper in this domain is ”Processing tweets for
cybersecurity threat awareness”(Alves et al., 2021).
They tested a quantitative evaluation considering all
tweets from 80 accounts over 8 months (more than
195,000 tweets), it shows that their approach timely
and successfully finds most of the security-related
tweets related to an example IT infrastructure (rate
positive rate greater than 90 %), incorrectly selects a
small number of tweets as relevant (false positive rate
less than 10 %).
Another subdomain of research is event forecast-
ing. The researches try to estimate the DDoS at-
tacks that have not yet taken place by processing Twit-
ter data. They tried to obtain this information us-
ing six popular supervised classification models. To
illustrate, one of the models which they used is the
“negative term count.”. Neg-Term-count is the base-
line sentiment-based model. They count the negative
words from tweets each day, forecasting an attack if
the number of negative words is more significant than
a threshold, which is the average number of negative
words on training data.
Another subdomain of research is Drive-by
Download Attack Prediction. Cyber attackers may
use the URL abbreviation method to show malicious
websites as if a harmless website and share them on
twitter as an abbreviated URL. Twitter users may be-
lieve in this deception and click on such website ab-
breviations, and these links can harm the users. “Pre-
diction of Drive-by Download Attacks on Twitter” is
an example which researches this field. (Javed et al.,
2019) They have explored what we can do to prevent
such malicious websites from being clicked like a safe
website due to this kind of abbreviation. They try var-
ious methods such as detecting malicious software in-
fection from the increase in the use of CPU or RAM
with using Honeypot.
Another subdomain of research is cyberattack de-
tection using social media. A sample study on this
field is “SONAR: Automatic Detection of Cyber Se-
curity Events Over the Twitter Stream”. They devel-
oped a self-learning framework called Sonar. (Pe-
tersen, ) Sonar can automatically capture events re-
lated to cybersecurity by processing twitter data. De-
velopers give the system some keywords to follow.
The system can find other keywords to followed re-
lated to cybersecurity with the help of previously
given keywords. They have also benefited from big
data technologies. For the architectural design of
our system, we use this research in our present re-
search. Another example is “Crowdsourcing Cyber-
security: Cyber Attack Detection using Social Me-
dia”. (Khandpur et al., 2017) It is another study on
detecting cybersecurity attacks by processing Twitter
data.
2 SYSTEM ARCHITECTURE,
DESIGN AND METHODOLOGY
In this chapter, we explain the software system’s ar-
chitecture and design and methodology. Firstly, we
explain the general approach. Then we present data
collection using Standard Twitter API, Twitter Pre-
mium API, Hurriyet API, and Selenium. After that
we mention how we can preprocess and process the
data. Then we present how we detect a cybersecurity
event with using anomaly detection which is one of
the machine learning techniques.
2.1 The Approach
Figure 1 presents a general overview of the archi-
tecture and design. First, we need real-time stream-
ing data to process. In order to establish a Twitter
stream connection, the software uses statically de-
fined the configuration file values. To gather the
data in real-time, we use Standard Twitter API. We
create cybersecurity-related Turkish keyword vector
with using Term Frequency - Inverse Term Frequency
analysis of past security incidents. We use this key-
word vector to gather useful Twitter stream and Hur-
riyet Newspaper stream for our research. We use
the language filter feature of the Twitter API in or-
der to fetch only the Turkish Tweets. Hurriyet is a
Turkish newspaper, therefore we did not need a lan-
guage filter for it. To establish the Hurriyet News-
paper stream connection, the software also uses the
configuration file. The architecture of the software
system is implemented considering new data sources
may be wanted to add. Before writing the fetched data
to the database, both fetched data of Hurriyet News-
paper and Twitter are formatted to a suitable form for
writing database.
After the normalization step, we move forward to
Named Entity Recognition step of our pipeline. In
this state, we use the predefined string vector, which
currently includes institution names, government or-
ganization name, and country names. These strings
represent the potential victims of security events. Af-
ter that step, the software counts the number of men-
tions of the potential victims with searching the pre-
defined string vector elements in the normalized texts
which are stored in the database. We add daily
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
68
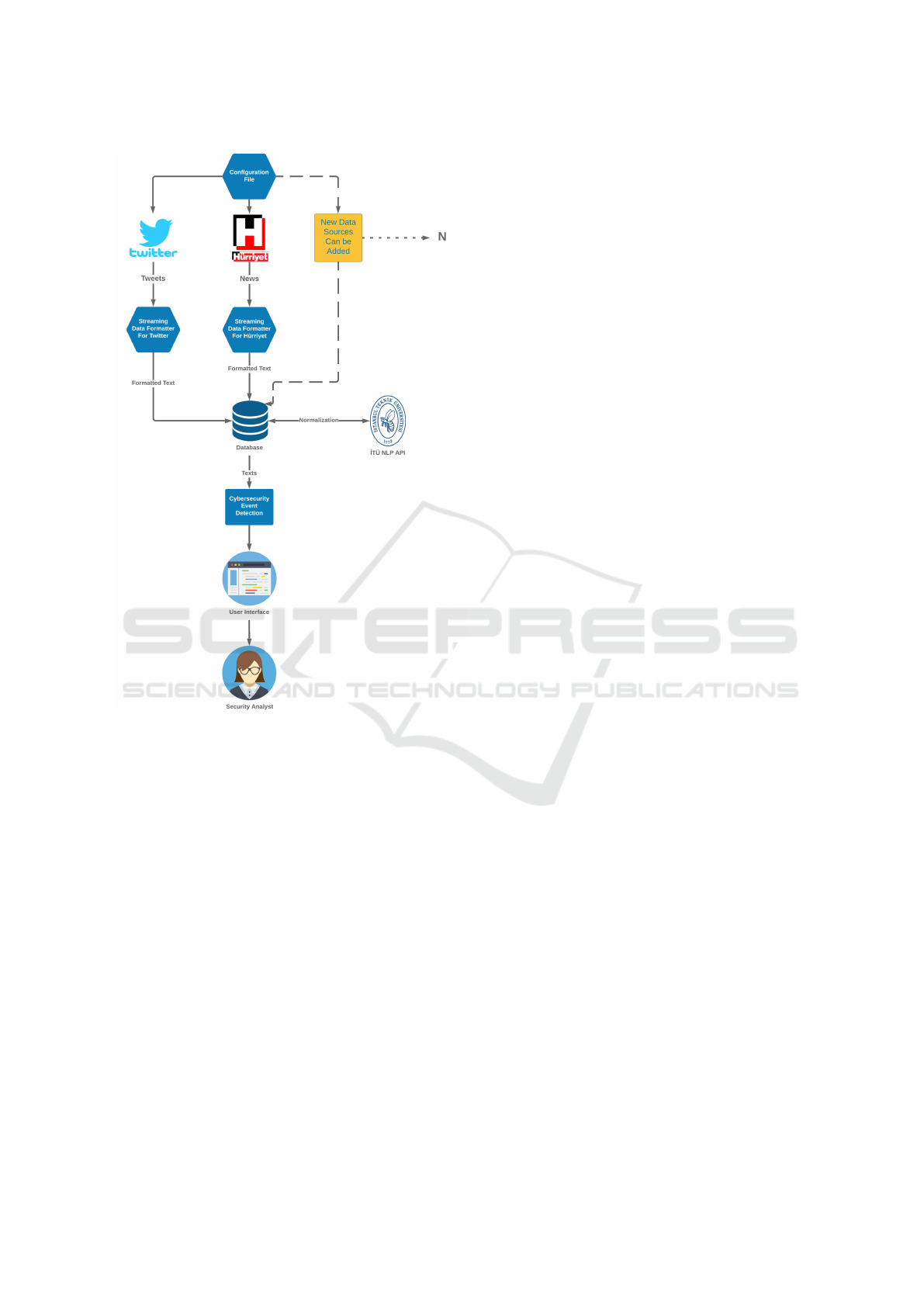
Figure 1: The General Overview of The System.
threshold values which is calculated dynamically. If
the number of mentions is more than the thresh-
olds value, we share this detected cybersecurity event
within the user interface. The software repeatedly
checks the database and analyzes new texts for detect-
ing new cybersecurity events. If one of the possible
victim’s numbers of mentions in the cybersecurity-
related database texts exceeds the threshold limit per
day, the software system adds them to the table too.
We show these detected events in a dynamically cre-
ated HTML file. Security Analysts can see the de-
tected security events from browser.
2.2 Selection of Cybersecurity Related
Keywords Vector and Data
Collection
To create an optimum version of cybersecurity-related
keyword vector, we used term frequency-inverse doc-
ument frequency(TF-IDF) technique, keyword-based
analysis, the statistical technique, and A/B testing.
Even if the Tweets or the news are in Turkish lan-
guage, there are widespread English cybersecurity
terms used in Turkish texts. Therefore we create
the vector using both English and Turkish keywords.
It is a numerical statistic that intends to reflect im-
portance a keyword or phrase is for within a doc-
ument or a Web page in a corpus or in a collec-
tion. (Rajaraman et al., 2014) In order to identify our
cybersecurity-related keywords vector, we used the
Term frequency–Inverse document frequency tech-
nique. Firstly, we find one of the past important cyber-
security events related to Turkey from history. We se-
lect “nic.tr DDOS attack” as the cybersecurity event.
Then we create three different training databases re-
lated to this attack with using Twitter Premium API.
We select “nic.tr” as keyword and filter only the Turk-
ish Tweets. With using tf-idf technique, we identify
the most important words in these databases. Then
we select the cybersecurity-related ones from the re-
sults of the tf-idf technique, and then add them to the
cybersecurity-related keyword vector. The first query
includes tweets containing nic.tr keyword at the dates
between 10.12.2014 and 13.12.2015. These dates are
the one year period of time before the nic.tr attack.
Then we created another training database. We se-
lect the Tweets only at the day of the nic.tr attack
on 14 December 2015. We analyze the tweets in the
database with TF-IDF frequency analysis and do A/B
test to select words from them to our cybersecurity-
related keyword vector. Lastly, we created another
training database. It includes the Tweets between 14
December 2015 and 28 December 2015. Within two
weeks period of time, nearly 1000 Tweet had been
tweeted related with ”nic.tr”.
We analyzed their results and create
cybersecurity-related keyword lists for each one
of them. Then we used these keywords lists for A/B
testing.The A/B test is a randomized experiment with
two variants, A and B. It includes the application of
the statistical hypothesis test or “two-sample hypoth-
esis test” used in the field of statistics. The A/B test
is a method of comparing two versions of the same
variable and determining which of the two variants
is more effective. (Fabritius, 2017) We compare the
results of the A/B test and update the elements in the
keyword vector according to their success rate. For
A/B test we used the number of false-positive cyber-
security event detection and number of cybersecurity
event detection. If a keyword significantly increases
the number of false-positive detection, we do not add
it to our cybersecurity-related keyword vector. On
the other hand, if a keyword does not affect so much
the false positive detection but increases the number
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data
69

of detection we add it to our cybersecurity-related
keyword vector list.
In order to collect data, we use Twitter and
H
¨
urriyet newspaper. Both H
¨
urriyet API and Twitter
API need seed keywords to query them. In order to
collect Turkish stream data, we need Turkish cyberse-
curity terms. However, we cannot find a Turkish cy-
bersecurity terms dictionary. Therefore, we research
the Turkish cybersecurity terms and gather them as a
list to use them in the query. Then we implemented
a Python code to parse the Twitter website with using
Selenium automation tool and chrome browser web
driver and, created our desired training datasets. The
selenium solution for fetching Twitter data is not a
known method and it is firstly implemented by us.
Twitter is an online social networking service,
which was created in October 2006 by Jack Dorsey,
Even Williams, and Biz Stone. People use Twitter for
various purposes. (Huberman et al., 2009) First of all,
One of its usage examples is as a social messaging
service. Users can interact with the other users, com-
municate with their friends and family, and share de-
tails of their lives. Secondly, users can use it as a mi-
croblogging service for sharing details of a person’s
life. Thirdly, users can use Twitter as a marketing
tool for public relations. Many celebrities and politi-
cians use Twitter for interacting with their audience.
Lastly, Twitter is an information platform on which
users can get news via broadcasting agents’ or jour-
nalists’ accounts fast and efficiently. Moreover, there
are Twitter bots created by developers for a precise
function like Bitcoin ticker bot will tweet every hour
the price of Bitcoin in Turkish Lira. According to the
first quantitative study on Twitter “What is Twitter,
a Social Network or a News Media?” which is pub-
lished in 2010 (Kwak et al., 2010), Twitter is more an
information-sharing network than a social network.
They found that result while working on Twitter fol-
lower graph. They decided that because of the low
rate of reciprocated ties. People tend to use Twitter as
a news feed by following multiple online news media,
but other Twitter users will only follow “real” users.
Twitter users can post a short message called tweet,
which is limited to 280 characters, or retweet another
user tweet. Photos, videos, or URLs can be added to
the tweets. Users can follow other accounts and cre-
ates their networks. They can mention each other or
reply to each other within their tweets. To identify
what the tweet is about, users use word preceded by
a hash sign (#). Twitter uses these hashtags to define
trending topics, both locally and globally. Users use
the trending topic lists to identify favorite subjects at
that time on Twitter. In default settings, all Twitter ac-
counts are public. Users can interact with each other
like replying other user’s tweets, sending a private di-
rect message, and so on. The Twitter API is a set of
URLs. The URLs cant take parameters and let users
access Twitter features like finding tweets which con-
tain a set of specific words and so on. Twitter pro-
vides several APIs to get tweets. Twitter’s Standart
API allows users to get tweets which includes spe-
cific parameters. Moreover, the resulting stream can
be filtered according to Tweet languages, geolocation
and so on.
Our second data source, H
¨
urriyet Newspaper.
H
¨
urriyet is one of the major Turkish newspapers,
founded in 1948. As of January 2018, it had the high-
est circulation of any newspaper in Turkey at around
319,000. We can make 12,000 request per day in
H
¨
urriyet Newspaper API. Therefore, the keyword list
is essential to get relevant data in the result streams.
H
¨
urriyet API is an interface which enables the usage
of H
¨
urriyet data programmatically in web, mobile, or
desktop applications. Developers can access H
¨
urriyet
newspaper data via standard HTTP requests. The re-
sultant set of results is in JSON format.
2.3 Data Processing
Before writing the streaming data to our database, we
need to format the collected texts. Firstly, we should
select the needed keys from JSON streams of Twitter
API and H
¨
urriyet API. For example, H
¨
urriyet API re-
quests return related news in a JSON which has “Title
of the News” key. The key can be useful for repre-
senting the detected event. On the other hand, there
are unrelated or unuseful data in the JSON too, so we
filter them and do not write in our database. We filter
the Twitter API stream’s JSON keys too and select the
useful and relevant keys too. In our database, we have
a ‘Status’ column. When we first write the texts to our
database, we set the text’s status with ‘0’. ‘0’ means
that the text is not processed yet, and it is raw data.
We sent the raw data to ITU NLP API to normalize
it. After the normalization step, we update the text
with normalized text and update the Status column of
the row which has the text with “1”. After the row
is processed to detect cybersecurity events, the Status
column is set with “2”. “2” means that the data pro-
cessed before and there is nothing to do with that row
of the table.
In the present research, we used a few Natural
Language Processing techniques and Istanbul Tech-
nical University’s Natural Language Processing API
(Eryi
˘
git, 2014) for normalization of the texts. In or-
der to develop automated systems, Natural Language
Processing is one of the actively used concepts in text
mining. It uses Natural Language Processing to de-
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
70

liver the system in the information extraction phase
as an input. (Tan et al., 1999)
Turkish Natural Language Processing Tools and
APIs developed by the Natural Language Processing
group at Istanbul Technical University are available
at “tools.nlp.itu.edu.tr” website. To be able to use the
API, we used access token and an account for the to-
ken upon permission. The platform operates as a Soft-
ware as a Service and provides the researchers and the
students the state of the art NLP tools in many layers:
preprocessing, morphology, syntax, and entity recog-
nition. It is a web API, developers can access it with
an HTTP request and can use GET or post method.
Text mining consists of a broad variety of meth-
ods and technologies. (Gaikwad et al., 2014) In this
research, we used Keyword-based technologies and
statistics technologies. Keyword-based technologies
use the input based on a selection of keywords in text
that are filtered as a series of character strings, not
words nor concepts. (Wu et al., 2006) Statistics tech-
nologies leverage a training set of documents used as
a model to manage and categorize text. In this re-
search, we used keyword-based analysis and statis-
tical techniques. We use two keyword vectors for
keyword-based analysis. One of the keyword vectors
stores possible victims who are tracked by our soft-
ware solution. The other keyword vector stores the
possible useful cybersecurity-related Turkish terms
such as “hacklendi” and “eris¸ilemiyor”. We analyze
the results by comparing the past frequency statistics
and current results as described in the Approach sec-
tion. The text required for text mining for cybersecu-
rity event detection purposes is gathered from online
platforms.
From the previous steps of the software system,
we get the possible cybersecurity-related texts from
different sources. Then preprocess and process them
and store them in our database. In order to detect the
events and find the possible victim of those events,
we prepared a named entity vector. This vector in-
cludes possible victims which we want to track. Cur-
rently, this list includes institution names, govern-
ment organization names, and country names. The
vector can be updated from changing the configura-
tion file to change tracked entities. Then with us-
ing term frequency-inverse document frequency (TF
- IDF) technique, keyword-based analysis, the sta-
tistical technique, and A/B testing; we analyze past
cybersecurity events and create cybersecurity-related
keywords vector.
As we explained in Approach section, we analyze
real-time Turkish text data to detect cybersecurity
events. In order to do this, we send requests to Twit-
ter and Hurriyet newspaper with our cybersecurity-
related keywords vector and we add Turkish language
filter to our request. The possible victim vector of the
solution periodically checked in the database in terms
of the number of occurrences. If the number of occur-
rences of a victim shows anomaly1 according to its
historical values, our solution detects them as a po-
tential cybersecurity event and shows that events in
the user interface portal.
3 IMPLEMENTATION
3.1 Multi-process Architecture
We use multi-processed system architecture in the im-
plementation of the project. There are four processes
as described in the subchapters below. These are
Twitter API Stream to Database, Hurriyet API Stream
to Database, ITU NLP API Normalization and Secu-
rity Events Web Portal Processes. Twitter API Stream
to Database Process continually gathers Twitter API
stream. Then preprocess the data and write them to
the database.Hurriyet API Stream to Database Pro-
cess continually gathers Hurriyet API stream. Then
preprocess the gathered data and write them to the
database. ITU NLP API Normalization Process con-
tinually checks the database. If the process can find
columns with status 0, then sent the columns to ITU
NLP API servers to normalize them. After the nor-
malization, the process writes back the texts to the
database and update their status row with “1”. Secu-
rity Events Web Portal Process continually checks the
database to find columns with status row set with “1”.
If it can find, it processes them to add the HTML page
which security analysts can monitor the events from
that page.
3.2 Microservice Architecture
Microservices are small, and independent services fo-
cus on doing a task at a time and ability to work to-
gether. Because the project has the potential to grow,
we design it with following microservice architecture.
With this design, our software became resilient. Fail-
ure in one service does not impact the other services
of our project. For example, assume that ITU NLP
API service stops to work for a while and does not re-
spond to our project’s requests. Due to the microser-
vice architecture of our software, the other services
can continue to work even if our software has mono-
lithic or bulky service errors in one service. Hurriyet
API can still gather the streaming data, preprocess
them, and write them to the database; Twitter API
can still gather the streaming data, preprocess them,
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data
71

and write them to the database and so on. More-
over, it has scalability. For example, if our database
technology becomes insufficient for our software, we
can change the database technology with a more suit-
able one. Furthermore, our software has less depen-
dency and easy to modify its code and test them. Our
software can understand by other developers since
the processes represent the small piece of function-
ality. It is vital because our software solution will
be an open-source project and will be used by other
developers and researchers. Lastly, this architecture
method gives us the freedom to choose technology.
We can choose the best-suited technology for each of
functionalities.
3.3 User Interface of the System
It is a simple dynamically generated HTML page
which will be used by security analysts as a portal
page of the system. A process continuously checks
the database per minute to detect new data and use
them to show the new cybersecurity events in this user
interface.
4 RESULTS
In this chapter, we discuss the results of the cyber-
security events which are discovered by our software
solution. We focus on what our software system suc-
ceeded and what it did not achieve. We share success-
ful cybersecurity event detection samples and share
the not successful cybersecurity event detection sam-
ples. As described in the previous subsection, it is
a dynamically created HTML page. We divide the
events by their dates. As cybersecurity event informa-
tion, we represent an entity, a representative news title
or tweet and a count which shows how many times the
entity is seen in the data on the same day.
4.1 Historical Cybersecurity Event
Detection Test with an Independent
Dataset: Nic.tr DDOS Attack
To reach the best version of our software solution, we
train our software with training data. In order to do
that, we select an important cybersecurity event test
that can our solution detect that cybersecurity event.
Turkish Internet hit with massive DDoS attack started
on 14.12.2015 and continues about two weeks long.
Turkey’s official domain name servers (Nic.tr) have
been under a Distributed Denial of Service (DDoS) at-
tack. We created 3 separate databases using existing
keywords. 2310 tweets were found when we pulled
the tweets during the 1-year period before the attack.
Then we analyzed these data, our solution can suc-
cessfully find the cybersecurity events that took place
for a year.
28 tweets were found when we pulled the tweets at
the start day of the nic.tr DDOS attack. Results of this
day data were important for us because we wanted to
see that our solution could detect the event just after
the attack happened. Then we analyzed these data,
our solution can successfully detect the nic.tr attack
as you can see in Figure 2.
Figure 2: Nic.tr Attack Start Day Detected Security Events
Samples.
The nic.tr attack lasted for about two weeks.
Therefore, we analyze that two weeks period
(14.12.2015 – 28.12.2015) and we expected to detect
the nic.tr attack. About 400 tweets were found when
we pulled the tweets for the given period. After run-
ning our software solution with that database, the re-
sults were satisfactory. Our solution successfully de-
tected the nic.tr attack as you can see in Figure 3.
As we explained before, we used one of the past
cybersecurity incidents. We used Term Frequency -
Inverse Document Frequency (TF-IDF) analysis of
the news and tweets just before the cybersecurity
event (premise) and immediately after the event. For
immediately after phase, we used two different time
intervals for testing. First one is the attack day, and
the second one is the two weeks period after the at-
tack. We used the attack day for sensitivity test. Our
solution is accepted as successful in terms of sensi-
tivity if it can detect the cybersecurity event at the at-
tack day. We used two weeks of period after attack
for certainty. Our solution is accepted as successful
in terms of certainty if there is not so many (more
than %30) false-positive cybersecurity event detection
within two weeks period after a cybersecurity event.
According to these success criteria, we train our soft-
ware solution with the datasets and cybersecurity-
related keyword lists. Then update our keyword lists
according to the results. With using these lists, we
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
72

Figure 3: Detected Security Events Samples between 14
and 28 December 2015.
tested the method and its accuracy in independent data
set which is nic.tr DDOS attack dataset in the present
section. As can be seen in Figure 2 and Figure 3,
our software solution can successfully detect the nic.tr
DDOS attack in terms of sensitivity and certainty and
passed our test.
4.2 Successful Cybersecurity Event
Detection Samples
In the following subsections, we share successful cy-
bersecurity event detection samples and briefly try to
explain how a security analyst can use this informa-
tion.
4.2.1 WhatsApp Spyware Attack
As can be seen in the Figure 4, our software system
can detect this event on 5 May 2019. However, there
are two different entities about the same event.
Assume that a security analyst wants to track se-
curity events related to countries. When the security
analyst sees the “WhatsApp Spyware Attack” event in
Figure 4: WhatsApp Spyware Attack Detection.
the user interface page with a country name entity, he
should check the news or tweets to control whether it
is a positive or false positive event detection. If it is a
positive and useful cybersecurity event detection, the
security analyst takes the required actions. There are
two entities as “meksika” which is the Turkish syn-
onym of Mexico, and “israil” which is the Turkish
synonym of Israel. When we control the related news
and tweets, we can see that an Israel firm named NSO
Group performs the cyber-attack. Therefore “israil”
is passing six times in the detected news and tweets.
A Mexican journalist is affected by the cyber-attack.
That is why we capture the “meksika” entity. The
security analyst can notice such attack with follow-
ing our software solutions user interface and can learn
what the new WhatsApp cyberattack is, how one can
protect from such attacks and so on from the related
news and tweets.
4.2.2 Vulnerabilities in Remote Patient Tracking
System Applications
STM is a Turkish software company which does re-
searches about cybersecurity domain. They find a vul-
nerability about Remote Patient Tracking System Ap-
plications and share this information from Twitter and
with using newspapers. Our software could detect the
security incident which is happened on 26.04.2019
about ”STM Warns about Remote Patient Tracking
System Applications” successfully. If our software
solution were to have used English texts as a data
source, we could not detect such a cybersecurity event
published in Turkish. Because of our software solu-
tion can analyze Turkish texts, we can detect such a
cybersecurity event. This is an excellent example to
show what our solution can do while the other solu-
tions in the literature cannot do.
4.3 Unsuccessful Cybersecurity Event
Detection Samples
Sometimes our software solution can detect false-
positive events, or even it is a cybersecurity event, the
detection may not be a useful event for security an-
alysts. The following subsections examine such sce-
narios.
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data
73

4.3.1 Sample False Positive Cybersecurity Event
Detection
A sample not useful cybersecurity event de-
tection detected by our software is like ”
¨
Omer
bey inanamıyorum, gerc¸ekten bunları siz mi
s
¨
oyl
¨
uyorsunuz yoksa hesabınız mı hacklendi?”. Even
the tweet has “hacklendi” word, which is one of our
keywords from our keyword vector; the event is not
a real cybersecurity event. Analyzing such tweets to
realize that it is not a real security event is hard for an
automated system.
4.3.2 Sample Not Useful Cybersecurity Event
Detection
Sometimes, even the detected event is a cybersecu-
rity event; it may be a personal status primarily if it
is published on Twitter. Security analysts should read
the detected event from the user interface and decide
that it is useful or not for her/him. Even if the de-
tected event is not a personal cybersecurity event, the
detected event may not be useful for security events.
For example, an event may occur months ago, but a
Twitter user or a Twitter bot may share the event in a
Tweet as if it occurred newly. The time frame is con-
figurable in our software system. Security analysts
should configure the software detection timeframe ac-
cording to their needs. For example, if a security an-
alyst works for a big cybersecurity technology com-
pany and he/she wants to know more detected security
events, he/she can set the timeframe longer. How-
ever, if another security analyst wants to know only
the latest security events, he/she should set smaller
timeframe in our software solution.
4.4 Evaluation of the Results
When we run our software with too much the
cybersecurity-related seed keywords vector, our soft-
ware system might receive more tweets than it can
handle. Only about %20 of Twitter users are post-
ing informative messages (Kr
´
al and Rajtmajer, 2017).
Moreover, the false-positive cybersecurity event de-
tection may significantly increase. It decreases the
certainty of our software solution. On the other hand,
if we run our software with too few cybersecurity-
related seed keywords, our software system might not
detect some cybersecurity events as fast as we expect
from our software. It decreases the sensitivity. We
expect that we can detect an attack on the day of the
attack.
Although we can verify with other sources that the
detected events are indeed occurring, or occurred, be-
ing sure that we have missed any events is very diffi-
cult. During our tests, we realized that we could miss
small events. However, our solution does not miss
any serious attack as far as we know. Sometimes our
solution detects an already detected event as if it is a
new cybersecurity event. Because our software uses
one day as a period for its frequency calculation. For
each day, all calculations start from zero again.
For a limited time, we run our software for test-
ing purposes. At a sample test run of our software
solution, our database of the software includes 437
entries. 186 of them is Twitter Tweets, and 251 of
them is from H
¨
urriyet Newspaper. After analyzing
the entries in our database, our software solution can
detect 29 cybersecurity events. 22 of them are pos-
itive detection, and 7 of them are false positive de-
tection. Our software solution’s success rate is ap-
proximately %76.15 These statistics show that this
methodology works in the detection of cybersecurity
events from Turkish texts with an acceptable success
rate in term of certainty and sensitivity. Cybersecu-
rity analysts can use our software with preparing our
cybersecurity-related keyword vector and named en-
tity vector and selecting a suitable time frame. More-
over, they can modify the keyword vector or named
entity vector as they wish. If we add new data sources
in the future, our software can work with bigger
datasets and this leads to more accurate detection and
it may increase the success rate percent of our soft-
ware solution in terms of certainty and sensitivity.
5 CONCLUSION AND FUTURE
WORK
5.1 Conclusion
In the last few decades, automation has been increas-
ingly used in various field of people’s life due to its
benefits like cost reduction, productivity, availability,
reliability, and performance. Cybersecurity is one of
the fields which automation is often used. However,
every automation software system has unique require-
ments to achieve its purposes. It leads to lots of re-
search areas and unique automation systems. Auto-
matic event detection is one of these research fields.
Social media is one of the fastest ways to detect cy-
bersecurity events because people and bots share such
events in there. Newspapers are also shared such
cybersecurity events and processing the newspaper
data is relatively more straightforward because false-
positive cybersecurity events are rarely shared in the
newspaper websites.
In this research, we investigated automatic event
detection of cybersecurity events from Turkish Twit-
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
74

ter Stream and Turkish newspaper data. We work on
real-time data to achieve that our research can be used
by security analysts. Existing publications about real-
time cybersecurity event detection system generally
use English texts to analyze and detect the events.
We cannot find any research which use Turkish data
sources to detect cybersecurity events. Using Turk-
ish data sources for cybersecurity event detection is a
new topic for literature. We believe that this research
contributes to the literature by filling an uninvesti-
gated field. We proposed an automated software sys-
tem which works using different data sources, named
entities, text mining methods, and ”state of art” soft-
ware techniques. Then we analyze the results of our
software system. Even if our software system detects
few false-positive cybersecurity events, it was often
able to detect a useful cybersecurity event. For ex-
ample, our software system can detect cybersecurity
events such as WhatsApp Spyware, MuddyWater At-
tack, the Remote Patient Tracking System Applica-
tions vulnerability, Pirate Matryoshka Virus, Zombie
Cookies threat. We concluded that event detection
with using Turkish texts is applicable, and security
analysts can use such a system like our software sys-
tem as a helper tool.
5.2 Limitations and Future Work
Currently, our software system works on a local com-
puter. When we move the software to a server(i.e.
AWS), our software can work 7x24, which will be
useful for detection success. If our software can
work with bigger data, it will detect more events
with more accurate event detection. To increase the
streaming data, we are planning to add new Turk-
ish data sources from other websites like Eksisozluk,
Linkedin, Facebook, and so on. This improvement
will make our datasets an excellent resource for fu-
ture work. After these improvements, our datasets
can be useful not only for us but also the other re-
searchers work on cybersecurity, cognitive science
or computer science field. We shared our software
solution as an open source project via Github un-
der Apache-2.0 license and it can be reachable from
”https://github.com/ozzgural/MSThesis” link. We are
also planning to share our future works on there and
according to users feedback, we are planning to refine
our software tool. The developed scenario may be ap-
plied to the other languages with necessary modifica-
tions and this work is also in our future plans. More-
over, we do not handle the named entity recognition
ambiguities yet. We are planning to handle them in
the future.
REFERENCES
Alan, G. A. E. (2020). The importance of marketing public
relations for “new” consumers. New Communication
Approaches in the Digitalized World, page 157.
Alves, F., Bettini, A., Ferreira, P. M., and Bessani, A.
(2021). Processing tweets for cybersecurity threat
awareness. Information Systems, 95:101586.
Aslan, c. B., Sa
˘
glam, R. B., and Li, S. (2018). Automatic
detection of cyber security related accounts on online
social networks: Twitter as an example. In Proceed-
ings of the 9th International Conference on Social Me-
dia and Society, SMSociety ’18, page 236–240, New
York, NY, USA. Association for Computing Machin-
ery.
Duarte, F., Pereira, O., and Aguiar, R. (2018). Discovery of
newsworthy events in twitter. pages 244–252.
Eryi
˘
git, G. (2014). ITU Turkish NLP web service. In
Proceedings of the Demonstrations at the 14th Con-
ference of the European Chapter of the Association
for Computational Linguistics (EACL), Gothenburg,
Sweden. Association for Computational Linguistics.
Fabritius, M. (2017). How to motivate colouring app users.
Gaikwad, S. V., Chaugule, A., and Patil, P. (2014). Text
mining methods and techniques. International Jour-
nal of Computer Applications, 85(17).
Huberman, B., Romero, D., and Wu, F. (2009). Social net-
works that matter: Twitter under the microscope. First
Monday, 14.
Javed, A., Burnap, P., and Rana, O. (2019). Prediction
of drive-by download attacks on twitter. Information
Processing & Management, 56(3):1133 – 1145.
Khandpur, R. P., Ji, T., Jan, S., Wang, G., Lu, C.-T., and
Ramakrishnan, N. (2017). Crowdsourcing cybersecu-
rity: Cyber attack detection using social media. In
Proceedings of the 2017 ACM on Conference on In-
formation and Knowledge Management, CIKM ’17,
page 1049–1057, New York, NY, USA. Association
for Computing Machinery.
Kr
´
al, P. and Rajtmajer, V. (2017). Real-time data harvesting
method for czech twitter. pages 259–265.
Kwak, H., Lee, C., Park, H., and Moon, S. (2010). What is
twitter, a social network or a news media? In Proceed-
ings of the 19th International Conference on World
Wide Web, WWW ’10, page 591–600, New York, NY,
USA. Association for Computing Machinery.
Okay, A., Gole, P. A., and Okay, A. (2020). Turkish and
slovenian health ministries’ use of twitter: a compar-
ative analysis. Corporate Communications: An Inter-
national Journal.
Petersen, J. K. Handbook of surveillance technologies.
CRC Press,, Boca Raton, Fla., 3rd edition.
Phan, H. T., Tran, V. C., Nguyen, N. T., and Hwang,
D. (2020). Improving the performance of sentiment
analysis of tweets containing fuzzy sentiment using
the feature ensemble model. IEEE Access, 8:14630–
14641.
Rajaraman, A., Leskovec, J., and Ullman, J. (2014). Mining
of Massive Datasets.
Automatic Detection of Cyber Security Events from Turkish Twitter Stream and Newspaper Data
75

Seth, A., Nayak, S., Mothe, J., and Jadhay, S. (2017). News
dissemination on twitter and conventional news chan-
nels. pages 43–52.
Sohime, F. H., Ramli, R., Rahim, F. A., and Bakar, A. A.
(2020). Exploration study of skillsets needed in cyber
security field. In 2020 8th International Conference
on Information Technology and Multimedia (ICIMU),
pages 68–72.
Tan, A.-H. et al. (1999). Text mining: The state of the art
and the challenges. In Proceedings of the pakdd 1999
workshop on knowledge disocovery from advanced
databases, volume 8, pages 65–70. Citeseer.
Wu, S.-T., Li, Y., and Xu, Y. (2006). Deploying approaches
for pattern refinement in text mining. In Sixth Interna-
tional Conference on Data Mining (ICDM’06), pages
1157–1161. IEEE.
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
76
