
Generating Commonsense Ontologies with Answer Set Programming
Stefan Jakob, Alexander Jahl, Harun Baraki and Kurt Geihs
Distributed Systems Department, University of Kassel, Wilhelmsh
¨
oher Allee 71-73, Kassel, Germany
Keywords:
Knowledge Representation and Reasoning, Knowledge-based Systems, Ontologies.
Abstract:
The use of commonsense knowledge is essential for the interaction of humans and robots in a smart environ-
ment. This need arises from the way humans naturally communicate with each other, in which most details
are usually omitted due to common background knowledge. To enable such communication with a robot, it
has to be equipped with a commonsense knowledge representation that supports reasoning. Ontologies could
be a suitable approach. However, current ontology frameworks lack dynamic adaptability, are monotonous,
are missing negation as failure, and are not designed for huge amounts of data. This paper presents a new way
to model ontologies based on a non-monotonic reasoning formalism. Our ontology modelling framework,
called ARRANGE, allows for the automatic integration of graph-based knowledge sources to generate on-
tologies and provides corresponding tools. The presented experiments show the applicability of the generated
ontologies and the performance of the ontology generation, the ontology reasoning, and the query resolution.
1 INTRODUCTION
Smart environments have become a part of our every-
day life. In general, they are distributed IT systems
that support humans in their daily chores by providing
information via services or by physically supporting
them via robots. A typical example is a Smart Home.
It contains IoT devices, services either on local Edge
devices or in the Cloud, different kinds of robots, and
humans interacting with its components. Currently,
robots for the Smart Home are mainly built for a sin-
gle purpose, e. g., lawnmowers or vacuum cleaners.
While these robots are particularly suited for their
purpose, the focus in the field of service robots is set
on the development of multi-purpose robots (Brady
et al., 2015). To allow the safe cooperation of ser-
vices, robots, and humans, key features like commu-
nication, knowledge representation and sharing, as
well as reasoning, are needed. Since there is a vast
amount of existing communication frameworks, the
focus of this paper is set to knowledge sharing, knowl-
edge representation, and reasoning. A straightforward
solution for knowledge sharing would be the use of a
central database in the smart environment. However,
this would introduce a single-point-of-failure and a
bottleneck to the system. Furthermore, the distance
to the central database would increase the latency and
could cause network congestions if too many parties
access the central point simultaneously. Thus, a cen-
tral database would not scale and not be suited for
large-scale environments like Smart Cities. There-
fore, a distributed multi-agent based knowledge reg-
istry has been proposed in (Jakob et al., 2020). In
brief, the agents organise themselves in a B*-tree.
While the inner nodes of the tree manage the struc-
ture of the tree, forward queries, and incorporate fur-
ther nodes, the leaf nodes maintain the knowledge and
answer queries. The distributed knowledge registry is
based on a non-monotonic reasoning formalism, that
supports efficient knowledge representation, storage,
and reasoning.
A further challenge in a smart environment in
which humans and robots interact is the use of com-
monsense knowledge and the symbolic representa-
tion of the environment. Humans rely on their com-
monsense knowledge to solve everyday tasks (Davis,
2014) and rely on symbols to abstract their environ-
ment. For example, a cup is a symbol for an object,
which can hold liquids, is used for drinking, is often
made of pottery, and has a handle. Hence, a service
robot, which interacts with a human should have ac-
cess to a source of commonsense knowledge, such
as ConceptNet (Speer et al., 2017). These sources
represent knowledge as a graph of symbols, that are
connected by relations. However, these sources are
typically not able to reason about the represented
knowledge. We claim that the combination of non-
monotonic reasoning with such symbols is particu-
larly suited for communication between robots and
humans. A non-monotonic approach allows for the
538
Jakob, S., Jahl, A., Baraki, H. and Geihs, K.
Generating Commonsense Ontologies with Answer Set Programming.
DOI: 10.5220/0010191905380545
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 2, pages 538-545
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

dynamic adaptation of the knowledge during run-
time, which is an important requirement in dynamic
environments. For example, a robot has to its knowl-
edge or retract derived knowledge if human provides
further information.
The main contribution of this paper is, therefore,
a non-monotonic ontology generation method which
supports the dynamic incorporation of commonsense
knowledge. Furthermore, the resulting ontology can
be altered during run-time without any need to rebuild
the complete ontology.
Section 2 introduces the non-monotonic ontology
generation, which is evaluated in Section 3. Related
works are discussed in Section 4. Section 5 sum-
marises the paper and presents future work.
2 ASP ONTOLOGY MODELLING
This section presents the main contribution of this
paper, which is the automatic generation of com-
monsense ontologies with Answer Set Programming
(ASP) (Gelfond and Kahl, 2014). Section 2.1 shows
the first step, namely the extraction of the common-
sense knowledge from a hypergraph-based knowl-
edge source like ConceptNet 5 (CN5) (Speer et al.,
2017) and the translation into basic ontology rules.
This is followed by a description of the ontology in-
ference rules in Section 2.2 and the characterization
of facets in Section 2.3. A graphical tool to adjust the
resulting ontology is discussed in Section 2.4.
2.1 Ontology Extraction
The first step in the automatic generation of the com-
monsense knowledge is the extraction and translation
of the knowledge from a hypergraph-based knowl-
edge source. The general approach is to provide a
root concept for the ontology and to traverse the hy-
pergraph until no further edges adhere to a given set of
stopping criteria. Algorithm 1 presents this automatic
extraction and translation.
This algorithm receives a root concept c
r
, a set of
ontology relations R
o
, a set of relations that represent
synonyms R
s
, a set of relations denoting properties
R
p
, and stopping criteria SC as input. In the first step,
an adapted breadth-first search (BFS) is applied. Dur-
ing this step, the BFS starts at c
r
and selects edges,
which are annotated with the relations given in R
o
and
adhere to the stopping criterion SC
o
. For example, a
taxonomy could be created by only using the IsA re-
lation of CN5 and relying on the edge weight of CN5
as a stopping criterion. By adjusting SC
o
, edges could
Algorithm 1: Ontology Extraction.
Input : Root Concept c
r
,
Set of Ontology Relations R
o
,
Set of Synonymic Relations R
s
,
Set of Property Relations R
p
,
Set of Stopping Criteria SC
Output: ASP Commonsense Ontology o
asp
1 <C, E>:=
adaptedBreadthFirstSearch(c
r
, R
o
, SC
o
)
2 E := E ∪ getSynonyms(C, R
s
, SC
s
)
3 E := E ∪ getProperties(C, R
p
, SC
p
)
4 o
asp
:= translate(C, E)
be included into or excluded from the taxonomy. Af-
ter the BFS, sets of all encountered concepts C and
edges E are returned. Since synonyms are an impor-
tant part of natural language, synonyms for all con-
cepts in C are determined and the resulting edges that
adhere to SC
s
are added to E. One example is shown
in Figure 1. Pup is a synonym for puppy and hence
added in this step. In the third step, the properties of
each concept are extracted using the relations given
in R
p
. After these steps, the gathered edges in E and
concepts in C are translated into ASP.
1 # e xte rnal cs_is A (" d og " , " pe t " ,136 ) .
2 weight (136 ,668 ,0) : - cs _ i s A ( " dog " ,
" pet " ,136) .
3 # e x ter n al cs_isA (" p u ppy " , " do g " ,139) .
4 weight (139 ,568 ,0) : - cs _ i s A ( " p u ppy " ,
" dog " ,139) .
Listing 1: Excerpt from the Commonsense Ontology.
Listing 1 shows an excerpt from the edges in Fig-
ure 1 translated into ASP. Each edge is represented
by an External Statement and an auxiliary rule. Ex-
ternal Statements are a feature provided by the ASP
solver Clingo (Gebser et al., 2014), which enables
the dynamic adaptation of the truth value of a pred-
icate. Line 1 expresses that it is commonsense (cs )
that a dog is a pet. The External Statement contains
a unique identifier, which is used to link it with the
head of the auxiliary rule. This rule is used to repre-
sent the dynamically adaptable weight, for example,
the edge weight in the case of CN5 since it can be
seen as the reliability of the knowledge represented by
the edge. As long as the External Statement is set to
true, the weight predicate in the head can be derived.
The weight predicate has three values. The first is the
unique id. The second is the weight multiplied with
100 since ASP can only handle integer values. The
last value is a timestamp, which will be used in the
ontology inference rules presented in Section 2.2. If
the External Statement is set to false, the weight and
Generating Commonsense Ontologies with Answer Set Programming
539
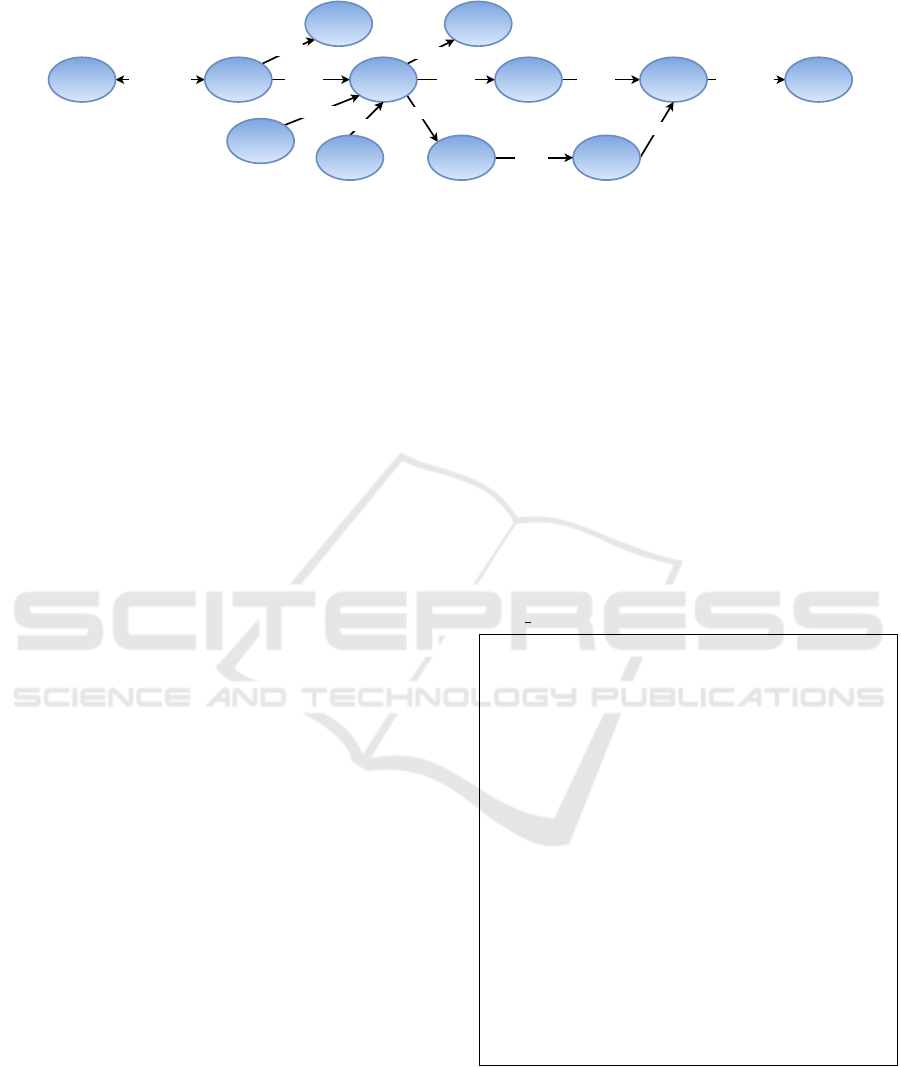
Synonym 2.0pup IsA 5.68
IsA 2.86
puppy
immature
dog
loyal
friend
IsA 3.17
IsA 6.65
IsA 6.68
dog
IsA 4.56
pet
Has
Property 4.0
animal alive
IsA 1.0
quadruped
IsA 1.0
four
legged
animal
IsA 5.60
poodle
IsA 4.17
beagle
Figure 1: Excerpt from the CN5 Hypergraph.
the External itself will not be derived in the next solv-
ing step.
2.2 Ontology Inference Rules
After the generation of ASP rules representing the
commonsense knowledge, inference rules are needed
to create an ontology and allow the application of the
commonsense knowledge to individuals. These in-
ference rules are summarized in a second ASP pro-
gram. It consists of six major parts: weight handling,
commonsense propagation, determination of subsets,
classification, facet handling, and Answer Set size re-
duction. Due to limited space, only excerpts from the
weight handling, the commonsense propagation, clas-
sification, and Answer Set size reduction are shown.
Listing 2 presents an excerpt from these infer-
ence rules. Line 1 is used to determine the current
weight for each translated edge based on the maxi-
mum timestamp (MaxTS). This enables the dynami-
cal adaption of edge weights, for example, by human
interaction. The use of a unique id allows mapping
the resulting predicates to the corresponding edges.
Line 2 and 3 are used to propagate commonsense
knowledge. In Line 2, the predicate is is used to
mark an initial classification of an individual (Ind),
e. g., given by a human user or an image classifica-
tion. If the initial classification fits a commonsense
knowledge predicate via the FromC variable, further
classifications can be derived. For example, consid-
ering the initial classification is("rex","puppy")
and that it is commonsense knowledge that a puppy
is a dog (Figure 1), it can be derived that rex is a
dog, too. Line 3 shows further commonsense prop-
agation, which is achieved by using already derived
propagations and further commonsense knowledge.
To stop this propagation, the stopping criteria are
used. For example, the edge weights extracted from
CN5. Since these weights represent the reliability of
the edge, only those edges with an increasing weight
one should be used for the propagation to achieve
reliable results. Following lower or equal weights
could result in an exhaustive traversal of the hyper-
graph and, thus, an impractical or cyclic classifica-
tion. Line 4 and 5 are used to represent the final
classification in a human and machine-readable for-
mat. Therefore, the rules like the one presented in
Line 4 create an internal representation of the clas-
sification. Based on this internal classification, the
rule in Line 5 derives the final classification annotated
with the highest weight for each classification. The
last part of this excerpt is the reduction of the Answer
Set size. Therefore, the #show directive of Clingo is
used, which limits its output to the respective predi-
cates with the given arity. Thus, Line 6 reduces the
output to all classifiedAs predicates, which have
the arity three. Applying these rules on the common-
sense knowledge presented in Figure 1 and the ini-
tial classification is("rex","puppy") will result in
the following classification: rex is a puppy, a dog, a
loyal friend, and a pet.
1 cu r re n tW e ig h t ( Id ,Weight , M a xTS ) : -
MaxTS = # max { Time S t ep :
weigh t ( Id ,_ , Ti m e Ste p ) } ,
weigh t ( Id , Weight , MaxTS ) .
2 isA ( Ind , ToC , Weigh t ): - is ( Ind , FromC ) ,
cs_is A ( FromC ,ToC , Id ) ,
cu r re n tW e ig h t ( Id , Weight , MaxTS ) .
3 isA ( FromC , ToC , Weight 2 ) : - isA ( FromC ,
InterC , W e i ght 1 ) , cs_i s A ( Inter C ,
ToC , Id ) , cur r e n tW e ig h t ( Id ,
Wei g ht2 , M axTS ) , W eight1 < W e igh t 2 .
4 cl a s s i f ie d A s I n te r n a l ( FromC ,ToC ,
Max W eig h t ) : - M a xW e i gh t = # ma x {
Weigh t : isA ( FromC , ToC , Weig h t ) } ,
isA ( FromC ,ToC , _ ) , is ( FromC , _ ) .
5 cl a ss i fi e dA s ( FromC , ToC , Ma x We i g ht ): -
Max W eig h t = # max { Weigh t :
cl a s s if i e d A s In t e r n a l ( FromC , ToC ,
Weigh t )} , c l a s s if i e d A s In t e r na l (
FromC ,ToC , _ ) .
6 # show c la s si f ie d As / 3.
Listing 2: Excerpt from the Inference Rules.
2.3 Facets
Facets are an important part during the creation of
an ontology since they allow the definition of types,
values, ranges, sub-properties, and domains. Hence,
they provide the tools to further describe concepts and
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
540

their properties given in an ontology. To demonstrate
the creation of facets, the ontology shown in Figure 1
is expanded with the edge stating that a dog has the
property coat colour. An example set of facets for
the property coat colour is shown in Listing 3.
1 # e x ter n al facet O f ( " colo u r " ,
" c oa t _c o lo u r " ) .
2 # e x ter n al typeOf (" co lour " ,
" c oa t _c o lo u r " ," stri n g ") .
3 # e x ter n al va l ue R an g eO f ( " colou r " ,
" c oa t _c o lo u r " ," 0{ black ; grey ;
brown ; white ; bri n d le }1 ") .
4 pr o p e rt y V i ol a t i on ( I n d i v i d ual ,
" c o l our " , " co a t_ c ol o ur " , " To o
many Val u e s " ) : - X = # c ount {
Value : ha s Val u e ( I n dividual , "
colou r " ," c oa t _c o lo u r " ,Value ,_ ) } ,
has V a lue ( I n d i v i d u al , " colo u r " ,"
co a t _c o lo u r " ,_ , _ ) , X > 1 ,
va l ue R an g eO f ( " colou r " ,
" c oa t _c o lo u r " ," 0{ black ; grey ;
brown ; white ; bri n d le }1 ") .
5 # e x ter n al hasV a lue (" rex " , " colo u r " ,
" c oa t _c o lo u r " ," brown " ,0) .
Listing 3: Example Facets.
Line 1 of this example is the actual definition of the
facet. In this case, the property coat colour has the
facet colour, which has the type string as defined in
Line 2. The range of this value can be restricted. This
is achieved by adding Line 3 and the auxiliary rule in
Line 4. Informally speaking, this External Statement
defines, that the facet colour has to have at least 0
values and at max 1 value for this facet. Either a set
of values or a range can be defined to further restrict
the facet. The colour is restricted to the values inside
the curly brackets. The auxiliary rule in Line 4 is used
to check if the minimum and maximum cardinality of
the values are satisfied by counting the respective val-
ues and comparing the count with the cardinalities. A
restriction to the values is granted by a graphical user
interface, which is presented in Section 2.4. The value
of the coat colour of rex is given alongside a times-
tamp in Line 5. Due to limited space, sub-property
and domain facets are omitted in this example.
2.4 Graphical User Interface
To ease the generation and usage of an ASP ontol-
ogy, ARRANGE (Answer set pRogRAmming oNtol-
oGy gEneration) provides a graphical user interface
(GUI) as shown in Figure 2. It supports the auto-
matic extraction of a commonsense knowledge ontol-
ogy (Section 2.1), generates ontology inference rules
(Section 2.2), and supports the creation of facets (Sec-
tion 2.3).
Figure 2: Graphical User Interface.
On the left side, a list of all concepts that are part
of the ontology is given. By selecting one of these
concepts, all edges connected to it are displayed.
Here, new edges can be added, existing ones can
be edited or deleted. Tabs for facets and individ-
uals are available. The last three tabs provide an
overview of the current ASP ontology, the inference
rules, and the results of a solving step, which is
available via the solver menu. The output of the
solver is twofold. The first output is the Answer
Set, which is a set of predicates and can be used
for further reasoning processes. It contains all deriv-
able facets, subset relations, and classifications. Us-
ing the example presented in the previous sections,
the Answer Set includes, amongst others, the pred-
icates hasPropertyValue("rex","coat colour",
"brown") and classifiedAs("rex","pet",668).
The second output is a graph representation of the
Answer Set, which provides an overview of its pred-
icates. The graph representing the Answer Set of the
example used in the previous sections is shown in Fig-
ure 3. Blue arrows indicate facets, black arrows prop-
erties and green arrows subsets. Red arrows denote
the classification, for example, rex is classified as a
dog with a weight of 568.
3 EXPERIMENTS
The evaluation has been conducted on a Lenovo
workstation equipped with an Intel
®
Core™ i7-7500U
@ 2.70 GHz Dual-Core processor and 16 GB DDR4-
2133 RAM running Ubuntu 18.04.4 with kernel ver-
sion 4.15.0-112-generic. ConceptNet 5.7 and Clingo
version 5.3.1 with gringo 5.3.1 and clasp 3.3.4 were
used.
3.1 Ontology Extraction and Reasoning
The selection of the root concept as well as the set
of stopping criteria (minimal weights when using
CN5) applied in Algorithm 1 determine the size of
the resulting ontology and the run time of its gener-
ation. Therefore, this section analyses three different
Generating Commonsense Ontologies with Answer Set Programming
541

"colour"
"coat_colour"
facetOf
"string"
typeOf
"1{black;grey;brown;white;bridle}1"
valueRangeOf
"dog"
"loyal_friend"
subSetOf[isA, 665]
"pet"
subSetOf[isA, 668]
"rex"
hasFacet
hasProperty[300]
hasPropertyValue["brown"]
"puppy"
subSetOf[is, 1]
classifiedAs[568]
"immature_dog"
classifiedAs[286]
classifiedAs[665]
classifiedAs[668]
subSetOf[isA, 286]
subSetOf[isA, 568]
classifiedAs[568]
propertyInheritedFrom[subClassOf,300]
Figure 3: Graph Representation of the Classification.
root concepts originating from three different areas:
animal, person, and thing. Additionally, different
minimal weight sets are used.
The smallest ontologies have been extracted for a
minimal weight of 2.5. With CN5 as a knowledge
source, this means that at least two verified sources
were the origin of the edge. Furthermore, only the
minimal weight for the isA relation is changed since
it has the highest number of edges. The remaining re-
lations have a fixed weight of 2.0. The selected root
concept has a big influence on the size of the extracted
ontology since it determines in which area of the hy-
pergraph the extraction starts. The concept animal
has the highest number of edges (522), the concept
thing has 196 edges, and person the lowest number
of edges (17). Lowering the minimal weight has a
major impact on the size of the ontology since more
edges can be added. Hence, extensive parts of the
hypergraph can be extracted. A minimal weight of
2.0 results in an identical size for all tested root con-
cepts (95353 edges). Lowering the minimal weight
even further results in an additional expansion of the
ontology (201148 edges). Higher minimal weights
are suited to create domain-specific ontologies while
lower minimal weights will result in more general
commonsense knowledge ontologies.
Besides the size of the ontology, the selection
of the root concept, and the minimal weight affect
the run time of the ontology generation. Again, the
weight for the isA relation is adapted, while the re-
maining weights are fixed at 2.0. The tests have been
executed 20 times and the average has been deter-
mined. The average run time of the ontology genera-
tion mainly depends on the selected minimal weights.
While small ontologies are generated in a few seconds
(animal 142 s, person 4 s, thing 51 s), the genera-
tion for the medium size requires 8097 s for animal,
8199 s for person, and 8142 s thing. The genera-
tion of the largest ontologies takes roughly four hours
(animal 13506 s, person 13341 s, thing 13134 s).
Considering the sizes of these ontologies, the result-
ing run times are acceptable and show the viability
of our approach. On average, the standard deviation
of the measured run times is below 1 %. The genera-
tion of the ontology for the root concept person with
a minimal weight of 2.5 has a standard deviation of
4 %, which is caused by its low run time.
The reasoning process of the presented framework
is divided into seven distinct steps. These include the
adding and grounding of the ontology edges, which
are modelled as External Statements. Since Clingo
assumes External Statements as false after they are
added, they are set to true in the third step. Finally,
the ontology is solved. The queries are ASP programs
themselves, hence, they have to be added, grounded,
and solved, too. In contrast to the ontology, they do
not use External Statements. Table 1 presents the ex-
perimental results for different ontology sizes. The
query used is the classification of rex as discussed in
Section 2.2. Again, the values are averaged over 20
measurements.
The lowest run times were measured for a mini-
mal weight of 2.5. Lowering the minimal weight will
result in larger ontologies as explained above. The
measured run times increase linearly with the size of
the measured ontologies, hence, the proposed ontol-
ogy representation is scalable. Adding and grounding
of the ontology have the highest impact on the run
time of the ontology reasoning. This is caused by the
number of ASP rules, which have to be considered.
The run time of the External Statement assignment is
almost neglectable since no reasoning is needed. The
final solving step of the ontology reasoning has a low
run time since no complex rules have to be considered
during the ontology reasoning. In general, the run
time of a query is lower than the run time of the ontol-
ogy reasoning. This is caused by the number of rules
that have to be considered in both processes. While
the number of rules increases with the selected mini-
mal weight and root concept, the number of rules for
a query is fixed. Thus, the run time for adding a query
is not influenced by the ontology size and is almost
identical for all tested combinations. The grounding
and solving steps of a query are affected by the size
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
542

Table 1: Run Time of Ontology Solving and Classification Query in [ms].
Min. Weight 2.5 2.0 1.0
Concept animal person thing animal person thing animal person thing
Add Ont. 98.7 9.3 47.6 15730.4 15616.4 15716.7 36300 37003 37020
Ground Ont. 78.9 11.4 30.5 14800.2 14679.5 14769.4 31525 31721.1 31823
Assign Ext. 1.4 0.15 0.6 256.5 247.7 262.9 523.9 520.9 521.7
Solve Ont. 3.9 0.5 1.5 1010.8 1000.3 1005.2 2257.5 2272.3 2271.6
Add Q. 11.6 13.5 11 11.8 11.7 11.8 12.7 13.1 13.1
Ground Q. 78.5 28.5 46.3 9299.6 9331.4 9350.1 19320.3 19566.8 19525.8
Solve Q. 3.5 0.3 1.1 743.1 735.8 740.2 1635.6 1650.1 1637.2
of the ontology. Again, their run times scale linearly
with the size of the ontology. On average, the stan-
dard deviation of all measured run times is lower than
1 % for the largest ontologies and increase to roughly
2.5 % for the smaller ontologies, which is caused by
the low run times. The only outlier is the standard de-
viation of query solving for the concept Person and a
minimal weight of 2.5. Since the measured run time
is extremely low and thus can be influenced by any
process running on the test system, the standard devi-
ation is roughly 7 %.
3.2 Comparison to OWL
Let us compare the run time of OWL to the run time
of an ASP ontology created by ARRANGE. We trans-
late the well-known Pizza Ontology
1
into ASP. Her-
miT with version 1.4.3.456 and Protege 5.5.0 are used
for OWL ontology reasoning. An individual with the
class margherita is created in both formalisms and
a classification query is applied. In both cases, new
solver instances have been used for each measure-
ment. The shown results are the average of 20 mea-
surements. The ontology reasoning took 82.15 ms
and query resolution 66.01 ms for the created ASP on-
tologies. In comparison, HermiT required 588.15 ms
for the reasoning step and 154.55 ms for the query
resolution. Hence, the reasoning process of the ASP
ontology is roughly seven times faster than the OWL
reasoning. On the one hand, this is caused by the un-
derlying reasoning technique. While SAT-solvers, as
used in ASP, provide fast results, the tableau algo-
rithm of OWL is generally slower but provides bet-
ter support in case of errors. The ASP query is twice
as fast as the OWL description logic query. Both in-
clude the classification of an individual, as well as, all
super- and sub-classes.
OWL is the de facto standard for knowledge rep-
resentation in the Semantic Web and is widely used
to model ontologies. OWL in its full specification
1
https://protege.stanford.edu/ontologies/pizza/pizza.owl
(December 3, 2020)
is based on first-order logic and undecidable. Thus,
most applications rely on one of the decidable sub-
sets such as OWL DL. The different specifications of
OWL have in common that no unique names are as-
sumed, that the resulting ontologies are monotonous,
and, that the open-world assumption holds. Since the
unique name assumption is not given in OWL, distinct
names can be given to one individual. Monotonous
reasoning prevents the loss of already derived knowl-
edge; thus, subsequent adaptations of the ontology
may not contradict derived knowledge. The open-
world assumption restricts the reasoning to statements
that are explicitly modelled in the ontology. De-
fault assumptions that may be overwritten by derived
knowledge cannot be defined.
In contrast to OWL, ASP adheres to the unique
name assumption. On the one hand, this prevents to
model distinct individuals with the same name. On
the other hand, it reduces the overall modelling ef-
fort, since explicitly stating that all occurrences of a
name refer to the same individual is unnecessary. Ad-
ditionally, ASP provides non-monotonous reasoning
and supports the closed world assumption enabling
the definition of defaults which is particularly use-
ful when modelling commonsense knowledge. Fi-
nally, state-of-the-art ASP solvers like Clingo provide
mechanisms to adapt an ontology dynamically and to
enumerate all possible solutions. Hence, the usage of
ASP is suited to model and reason about common-
sense knowledge.
3.3 Applicability
The application of the ontologies extracted from CN5
provides good classifications as depicted in Figure 3.
However, considering the excerpt from the CN5 hy-
pergraph shown in Figure 1, the classification is miss-
ing the classes, e. g., animal. This is caused by
the classification rules presented in Section 2.2, since
they consider edges with increasing weight to prevent
impractical classifications. To tackle this issue, AR-
RANGE provides two ways. The first is the adap-
Generating Commonsense Ontologies with Answer Set Programming
543

tation of the corresponding weight with its GUI. It
provides an overview of all edges that are part of the
ontology and enables the adaptation of all weights
during design time. The second option is applied by
adding an additional rule that adjusts the weight of the
corresponding edge. This rule has to be modelled like
the Lines 2 or 4 of Listing 1 and has to have a higher
timestamp than the current weight rule. For exam-
ple, the weight of the edge between pet and animal
shown in Figure 1 could be set to 7.0. Subsequently,
rex is classified as an animal and inherits the prop-
erty alive.
4 RELATED WORK
The presented related work is divided into two main
categories. The first one focusses on the extrac-
tion of ontologies from existing knowledge sources,
while the second category focusses on ASP as on-
tology language and reflects upon tool support for
the generation of ontologies. The general idea of
an ontology is to provide a standardised terminology
to represent knowledge which supports the collabo-
ration of different parties. In comparison to other
knowledge sources like databases, data warehouses,
and knowledge graphs, ontologies support the def-
inition of properties, the restriction of values, arbi-
trary logic constraints, and automatic reasoning. Fur-
thermore, ontologies are declarative and do not rely
on customized interpretations. They provide formal
axioms and well-defined semantics, which is essen-
tial for the interaction of agents in heterogeneous and
human-populated environments. However, the afore-
mentioned knowledge sources can serve as a seed for
the creation of an ontology, which is a reason for
extensive research on automatic and semi-automatic
converters.
A common approach to store and manage data is
the use of databases or data warehouses. Databases
and data warehouses contain tables, which consist
of named columns and store data points in the cor-
responding rows. Columns of different tables can
refer to each other and, thus, establishing relations
between them. Relying on this scheme, ontologies
can be generated. There are numerous approaches
that realise this methodology using relational SQL
databases and data warehouses (Zhou et al., 2010;
Kiong et al., 2009; Al Khuzayem and McBRIEN,
2016; da Silva et al., 2016; El Idrissi et al., 2013).
In general, these works build upon a set of predefined
rules which are used to transform a database scheme
into an ontology. This includes the translation of table
names into ontology classes, field or column names
into properties, and rows into individuals. Further-
more, semantics are added to the ontology. For exam-
ple, Kiong et al. (Kiong et al., 2009) mark, amongst
others, bridge tables, reference tables, and reference
fields. Zhou et al. (Zhou et al., 2010) identify these
references automatically and map them to the corre-
sponding relations. Additionally, they set the cardi-
nality of unique, nullable, and not-nullable properties
accordingly. In (Al Khuzayem and McBRIEN, 2016),
further features such as subclass relations and sym-
metric and reflexive properties are added.
Although the presented approaches achieve good
results, the expressive power of the resulting ontolo-
gies and the flexibility of their methodology is lim-
ited. Databases usually comprise a small number
of tables and, thus, only a few classes are gener-
ated. Hence, the number of resulting relations is re-
stricted to a few references between tables, if they
are explicitly stated. Furthermore, the generated on-
tology strongly depends on the design decisions for
the database and will mainly consist of individuals in-
stead of classes. ARRANGE, in comparison, gener-
ates ontologies consisting of a vast amount of classes
based on a given hypergraph.
As opposed to these approaches, ARRANGE
automatically extracts a commonsense ontology
from a given hypergraph. Similar to OntoHar-
vester (Mousavi et al., 2013), it relies on a given seed
class to start the ontology extraction but is able to de-
rive subclasses based on the structure of the used hy-
pergraph. ARRANGE supports the manual adaption
of ontology parts during the design time and the run
time of the ontology. Furthermore, ARRANGE en-
ables reasoning, since it utilises ASP.
In general, numerous approaches exist that ex-
tract knowledge graphs, which are hypergraphs, from
a given free text or from semi-structured knowl-
edge (Paulheim, 2017). Many of these may be re-
fined by crowds-based approaches or experts such as
in case of CN5.
However, there is no axiomatic semantics and no
reasoning support. Thus, it is beneficial to transfer the
hypergraph to an appropriate knowledge representa-
tion. In (Kr
¨
otzsch, 2017), Kr
¨
otzsch lists requirements
for such a knowledge representation. One of them
is the existence of negation, which, for example, en-
ables the definition of a class based on the absence
of information. Description logics such as OWL do
not provide negation as failure, are monotonic, and
adhere to the open-world assumption. Kr
¨
otzsch em-
phasises that description logics do not sufficiently ad-
dress these requirements and recommends a declara-
tive symbolic knowledge representation in the context
of a computation paradigm instead of pure represen-
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
544

tation (Kr
¨
otzsch, 2017). ASP with its non-monotonic
reasoning capabilities, different kinds of negation,
support of the closed world assumption, and its sym-
bolic representation is a suitable formalism to tackle
these issues. Hence, ARRANGE uses ASP to repre-
sent commonsense knowledge as ontologies, to sup-
port reasoning, and declarative programming.
OntoDLV (Ricca et al., 2009) uses an extension
to basic ASP (OntoDLP) to model ontologies. For
example, classes are declared by expanding predicate
names with the key phrase class. OntoDLP supports
the definition of individuals, relations, modules, and
the creation of lists and sets. Besides these constructs,
OntoDLP allows to model taxonomies by adding the
keyword isa enabling the generation of a class based
on inheritance and a set of attributes. Furthermore,
OntoDLV provides a graphical modelling tool to sup-
port the creation of an ontology and allows the incor-
poration of OWL atoms.
In contrast to OntoDLV, ARRANGE does not rely
on an extended version of ASP and uses the ASP-
Core-2 standard. Additionally, External Statements
provided by Clingo are used to create an ontology,
which can be dynamically altered during run time.
5 CONCLUSIONS
In this paper, we have presented a framework to auto-
matically extract ontologies from a hypergraph-based
knowledge source like CN5. The resulting ontolo-
gies are formulated using the non-monotonic reason-
ing formalism ASP that supports dynamic adaptations
of the ontology during run-time and the definition of
defaults. The presented experiments proved that the
combination of ARRANGE
2
with the commonsense
knowledge source CN5 results in an adaptable and ex-
tensive commonsense knowledge ontology. The gen-
eration process itself is configurable and allows to ex-
tract different parts of the hypergraph.
Due to the size of the resulting ontologies, we plan
in the future work to create an efficient distributed ac-
cess and automatic distribution of individuals based
on the ontology using the distributed and multi-agent-
based knowledge management presented in (Jakob
et al., 2020). This knowledge management will be
evaluated in a search and rescue scenario, which in-
corporates several heterogeneous robots and UAVs.
Furthermore, we extend the comparison to OWL by
translating further ontologies.
2
https://bitbucket.org/sjakob872/arrange/src/master/,
(December 3, 2020).
REFERENCES
Al Khuzayem, L. and McBRIEN, P. (2016). OWLRel:
Learning Rich Ontologies from Relational Databases.
Baltic Journal of Modern Computing, 4(3):466.
Brady, G., Sterritt, R., and George, W. (2015). Mobile
Robots and Autonomic Ambient Assisted Living. Pal-
adyn: Journal of Behavioral Robotics, 6.
da Silva, T. O., Bai
˜
ao, F. A., and Revoredo, K. (2016). On-
toDW: An Approach for Extraction of Conceptualiza-
tions from Data Warehouses. In ONTOBRAS, pages
83–94.
Davis, E. (2014). Representations of Commonsense Knowl-
edge. Morgan Kaufmann.
El Idrissi, B., Ba
¨
ına, S., and Ba
¨
ına, K. (2013). Automatic
Generation of Ontology from Data Models: A Practi-
cal Evaluation of Existing Approaches. In IEEE 7th
International Conference on Research Challenges in
Information Science (RCIS), pages 1–12. IEEE.
Gebser, M., Kaminski, R., Kaufmann, B., and Schaub,
T. (2014). Clingo=ASP+Control: Extended Report.
Technical report, Knowledge Processing and Informa-
tion Systems.
Gelfond, M. and Kahl, Y. (2014). Knowledge Representa-
tion, Reasoning, and the Design of Intelligent Agents:
The Answer-Set Programming Approach. Cambridge
University Press, Cambridge, USA.
Jakob, S., Jahl, A., Baraki, H., and Geihs, K. (2020). A Self-
Organizing Multi-Agent Knowledge Base. Accepted
for publication at IEEE ICWS 2020.
Kiong, Y. C., Palaniappan, S., and Yahaya, N. A. (2009).
Health Ontology Generator: Design And Implemen-
tation. IJCSNS, 9(2):104.
Kr
¨
otzsch, M. (2017). Ontologies for Knowledge Graphs?
In 30th Int. Workshop on Description Logics, volume
1879. CEUR-WS.org.
Mousavi, H., Kerr, D., Iseli, M., and Zaniolo, C. (2013).
Ontoharvester: An Unsupervised Ontology Generator
from Free Text. Technical report, InCSD Technical-
Report 130003, UCLA.
Paulheim, H. (2017). Knowledge Graph Refinement: A
Survey of Approaches and Evaluation Methods. Se-
mantic web, 8(3):489–508.
Ricca, F., Gallucci, L., Schindlauer, R., Dell’Armi, T.,
Grasso, G., and Leone, N. (2009). OntoDLV: An ASP-
based System for Enterprise Ontologies. Journal of
Logic and Computation, 19(4):643–670.
Speer, R., Chin, J., and Havasi, C. (2017). ConceptNet 5.5:
An Open Multilingual Graph of General Knowledge.
In Proceedings of the 31st AAAI Conference on Artifi-
cial Intelligence, pages 4444–4451.
Zhou, S., Ling, H., Han, M., and Zhang, H. (2010). On-
tology Generator from Relational Database Based on
Jena. Computer and Information Science, 3(2):263–
267.
Generating Commonsense Ontologies with Answer Set Programming
545
