VIP Blowfish Privacy in Communication Graphs
Mohamed Nassar
1 a
, Elie Chicha
2,3
, Bechara AL Bouna
2
and Richard Chbeir
3
1
Computer Science Department, American University of Beirut, Lebanon
2
TICKET Lab., Antonine University, Hadat-Baabda, Lebanon
3
Univ. Pau & Pays Adour, UPPA - E2S, LIUPPA, Anglet, France
Keywords:
Blowfish Privacy, Social Networks.
Abstract:
Communication patterns analysis is becoming crucial for global health security especially with the spread of
epidemics such as COVID-19 by the means of social contact. At the same time, personal privacy is considered
an essential human right. Privacy-preserving frameworks enable communication graph analysis within formal
privacy guarantees. In this paper, we present a summary of Blowfish privacy and explore the possibility
of applying it in the context of undirected communication graphs. Communication graphs represent social
contact or call detail records databases. We define the notions of neighborhood, discriminative secrets, and
policies for these graphs. We study several examples of queries and compute their sensitivity. Even though not
addressed in the original Blowfish privacy paper, we explore the idea of having a discriminative secret graph
per individual. This allows us to treat some persons as VIP and put their privacy on top priority, where other
persons can have lower privacy constraints. This may help to offer privacy as a service and increase the utility
of the anonymized communication graph to an appropriate level.
1 INTRODUCTION
Communication patterns analysis is becoming crucial
for global health security especially with the spread
of epidemics such as COVID-19 by the means of
social contact. In the same time, personal privacy
is considered as an essential human right. Privacy-
preserving frameworks enable communication graph
analysis within formal privacy guarantees. Differen-
tial Privacy (DP) provides ways for trading-off the
privacy of individuals in a statistical database for the
utility of data analysis.
DP has a single tuning knob, namely ε, sometimes
two (ε and δ). For example, increasing ε means more
utility and less privacy. The idea of Blowfish privacy
(BP) is to provide more tuning knobs by introducing
policies He et al. (2014). In BP, a policy specifies:
• secrets: information that must be kept secret. Since not
all the information has to be secret, we can increase the
utility of the data by lessening the protection of certain
properties.
• and constraints: known properties about the data. Con-
straints add protection against an adversary who knows
these constraints.
DP can be considered as an instance of BP where:
a
https://orcid.org/0000-0001-8857-4436
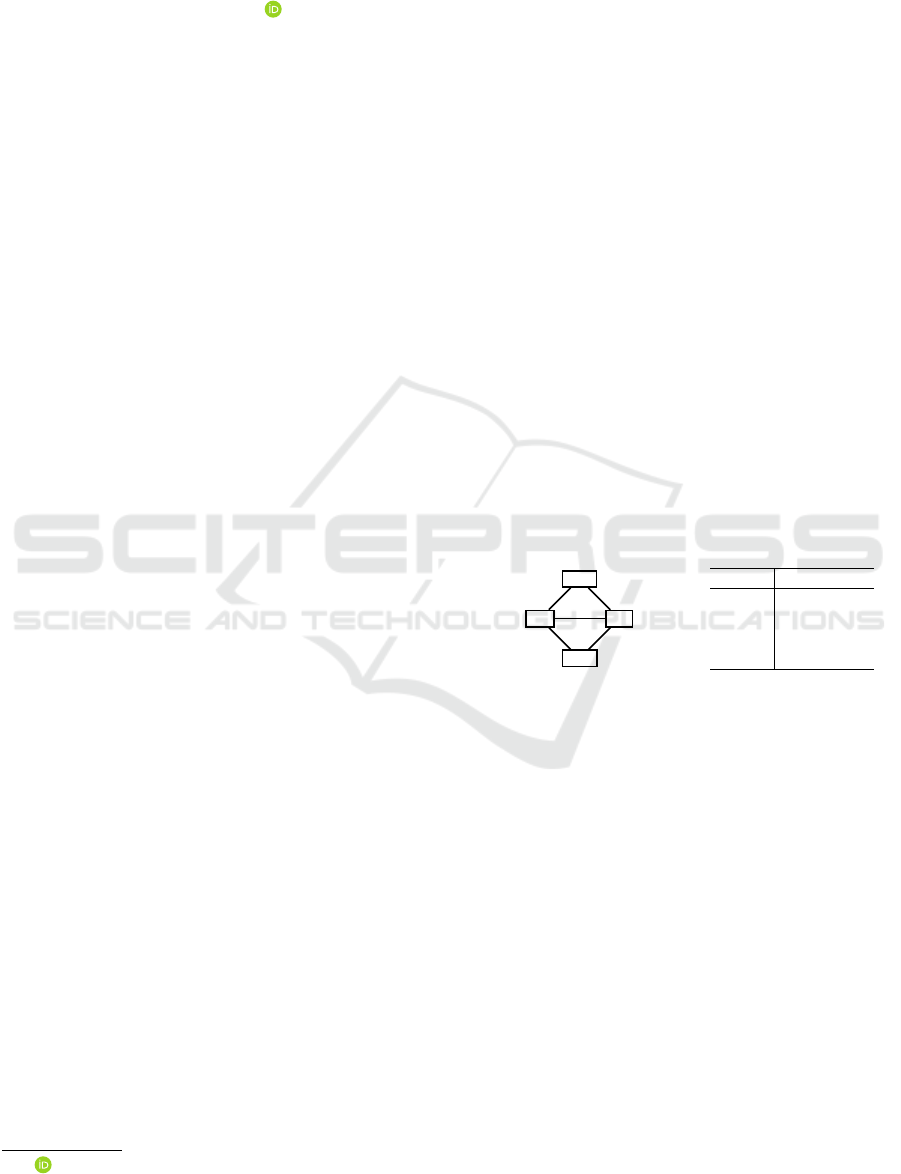
Bob
Alice
Eve
Carol
id tuple
Bob (0, 1, 1, 1)
Alice
(1, 0, 1, 0)
Eve (1, 1, 0, 1)
Carol (1, 0, 1, 0)
Figure 1: Communication graph and its database.
• every property about an individual’s record is protected,
• every individual is independent of all the other individ-
uals in the dataset. There is no correlations.
Because of its generalized framework and powerful
expressiveness of adversarial knowledge, we expect
that BP can solve privacy challenges in graph-based
databases. In this paper, we explore the application of
BP to communication graphs such as social networks
and call detail records databases. We model the se-
crets and the auxiliary knowledge in terms of the BP
model and give numerous examples.
2 BP FOR COMMUNICATION
GRAPHS
A communication graph is a graph where vertices
represent individuals and an edge between two in-
Nassar, M., Chicha, E., Al Bouna, B. and Chbeir, R.
VIP Blowfish Privacy in Communication Graphs.
DOI: 10.5220/0009875704590467
In Proceedings of the 17th International Joint Conference on e-Business and Telecommunications (ICETE 2020) - SECRYPT, pages 459-467
ISBN: 978-989-758-446-6
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
459
dividuals exists if a communication has happened
in between the individuals corresponding to the ver-
tices. Social networks and call detail records can
be modeled as communication graphs. One way to
anonymize the data of a communication graph is to
remove the identifiers at the vertices. The goal of an
adversary is therefore to discover the individual cor-
responding to a node in the graph.
A communication graph G
c
(V
c
,E
c
) can be repre-
sented as a database D of size n = |V
c
| where each
tuple t of D corresponds to an individual id. The tu-
ple dimension is m = |V
c
| as well. The ith attribute
of t is 1 if t. id has communicated with the individual
corresponding to node i, and 0 otherwise. A row in D
represents the ego network of a vertex.
An example of a communication graph and its cor-
responding database is shown in Figure 1. Note that
we consider a binary communication event (0 or 1).
Other models might be explored in future work, for
instance annotating the edges with call frequency, av-
erage duration, call time or other meta-data. since the
BP framework is defined over categorical data, bin-
ning might be used if the meta data is not categorical.
The BP notation is based on the DP notation as
summarized in Table 1.
2.1 Secrets
In addition, BP defines secrets and discriminative
pairs of secrets as shown in Table 1. We give exam-
ples of secrets and pairs of secrets over a communica-
tion graph in Table 2.
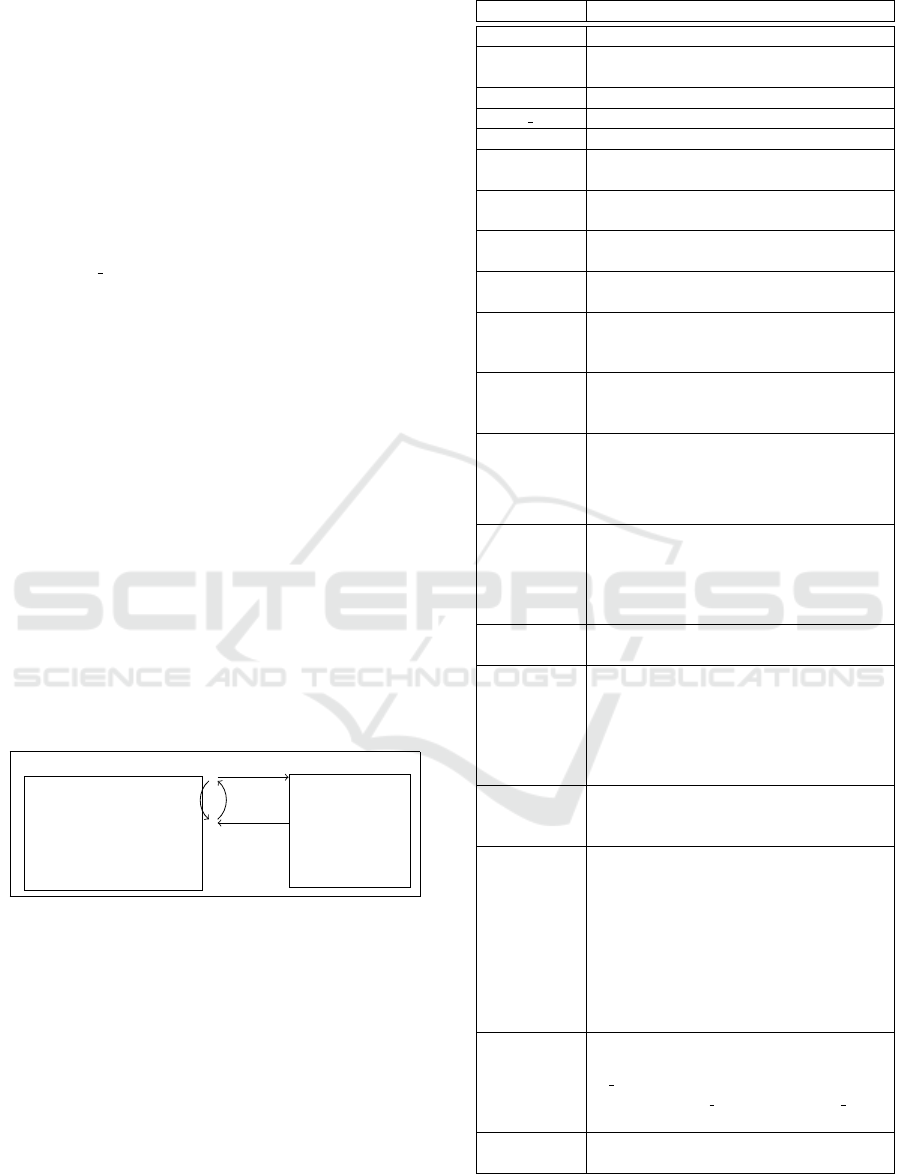
Guess
the real t
Adversary
Pick a secret pair
(s
id
t
0
,s
id
t
1
) from S
pairs
Challenger
id,t
0
,t
1
b(0 or 1)
Repeat
Figure 2: Discriminative pair of secrets as a game.
The discriminative secret graph generalizes the speci-
fication of discriminative pairs of secrets. It is a graph
where vertices represent secrets and edges link only
the discriminative pairs of secrets. More formally it
is denoted G = (V, E) where V = T and E ⊆ T × T .
Even though not addressed in the original BP paper,
we explore the idea of having a discriminative secret
graph per individual. This allows us to treat some
persons as VIP and put their privacy on top prior-
ity, where other persons can have lower privacy con-
straints. This may help increase the utility of the com-
munication graph to an appropriate level.
Table 1: Notation of BP, secrets, and discriminative pairs.
Symbol Description
D Database of n tuples
T = A
1
×
A
2
×. .. ×A
m
Domain of m categorical attributes
t ∈ T A single tuple
t. id Id of the tuple’s real owner
t.A
i
Value of the ith attribute in tuple t
I
n
Set of all possible datasets with size n (|D| =
n)
(D
1
,D
2
) ∈ N
In DP, D
1
and D
2
are neighbors, they differ
in the value of one tuple
M
A randomized mechanism, for example
adding random noise to the result of a query
S ⊆
range(M )
A set of the outputs generated by M
ε-DP
For every S and every two neighbors
(D
1
,D
2
): Pr[M (D
1
) ∈ S] ≤ e
ε
Pr[M (D
2
) ∈
S]
f : I
n
−→ R
d
A function that takes a database as input and
returns a vector of real numbers as output,
for example a countIf query
S( f )
The global sensitivity of f is the max
Manhattan distance between the outputs
for any two neighbor databases: S( f ) =
max
(D
1
,D
2
)∈N
|| f (D
1
) − f (D
2
)||
1
M
Lap
The Laplace Mechanism adds η ∈ R
d
to
f (D), where η is a vector of independent
random variables. Each η
i
is drawn from the
Laplace distribution with parameter S( f )/ε:
Pr[η
i
= z] ∝ e
−z.ε/S( f )
P =
(P
1
,. .. ,P
k
)
A partitioning of the domain T
h
P
: I
n
−→ Z
k
A histogram query. h
P
(D) outputs for each
P
i
the number of times values in P
i
appear
in D. The sensitivity of histogram queries is
S(h
P
) = 2 since replacing a tuple by another
one may decrease the count of a partition and
increase the count of another partition.
h
T
The complete histogram query, it outputs for
each t ∈ T the number of times it appears in
D
E
M
(D)
The expected mean squared error of M :
E
M
(D) =
∑
i
E[( f
i
(D) −
¯
f
i
(D))
2
] where
f
i
(D) and
¯
f
i
(D) are the ith components of
the true answer and the noisy answer, re-
spectively. For Laplace mechanism and his-
togram queries, this error is: E
M
Lap
h
P
(D) =
|T |.E(Laplace(2/ε))
2
= 8|T |/ε
2
. A large
epsilon means less error, hence more utility.
s
An arbitrary statement over the val-
ues in the database. Example1:
t. id = ’Bob’ ∧ t.disease = ’cancer’.
Example2: t.
id = ’Bob’ ∧ t
2
. id =
’Alice’ ∧t
1
.disease = t
2
.disease
S
A set of secrets that the data owner would
like to protect, e.g. {Example1, Example2}
SECRYPT 2020 - 17th International Conference on Security and Cryptography
460
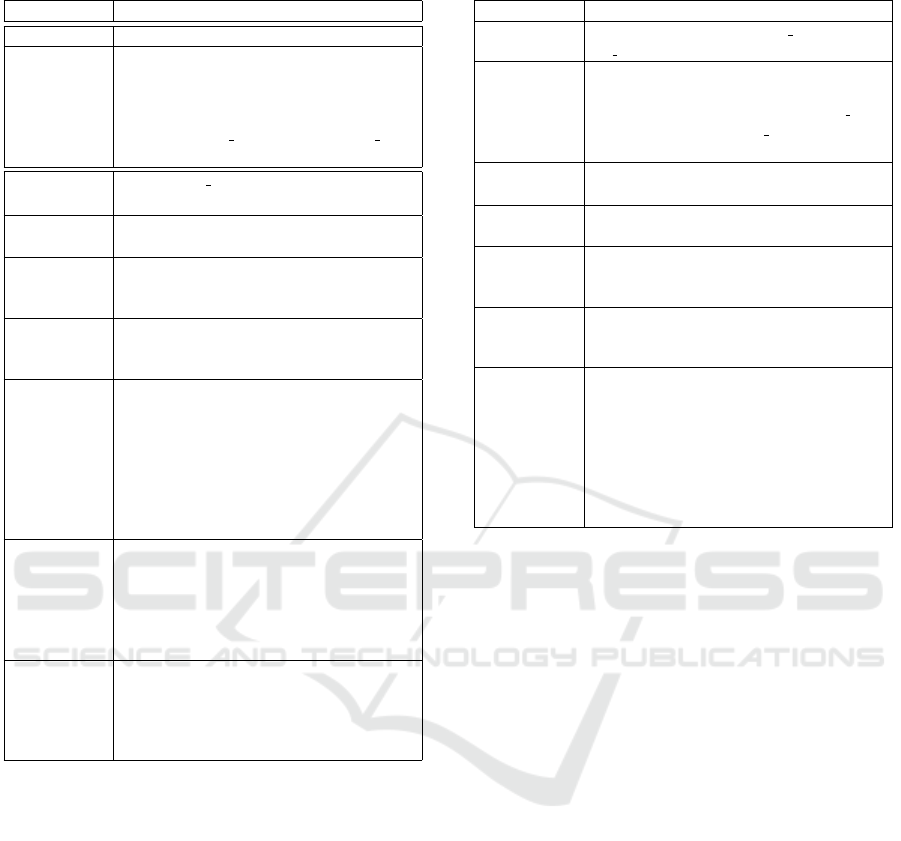
Table 1: Notation of BP, secrets, and discriminative pairs.
(cont.)
Symbol Description
(s,s
0
) ∈ S ×S A pair of secrets, e.g. (Example1, Example2)
A discrimi-
native pair of
secrets (s,s
0
)
A mutually exclusive pair of secrets. Two
statements that cannot be true at the same
time. An adversary must not be able to dis-
tinguish which one is true and which one
is false, e.g. (t. id = ’Bob’ ∧ t = x, t. id =
’Bob’ ∧t = y)
s
i
x
The secret t. id = i ∧t = x where x ∈ T , e.g.
s
’Bob’
(’cancer’,65)
S
pairs
A set of discriminative pairs of secrets, e.g.
S
full
pairs
, S
attr
pairs
, S
P
pairs
, S
d,θ
pairs
S
G
pairs
A set of discriminative pairs of se-
crets based on graph G(V,E), i.e.
{(s
i
x
,s
i
y
)|∀i,∀(x, y) ∈ E}
Full domain:
S
full
pairs
For every individual, the value
is not known to be x or y, i.e.
{(s
i
x
,s
i
y
)|∀i,∀(x, y) ∈ T × T }
Attributes:
S
attr
pairs
For every individual and every two tu-
ples differing in the value of only one
attribute A where one of them is real,
the real tuple is not known. The privacy
definition is weaker than in full domain
S
full
pairs
since the real tuple is distinguish-
able if more than one attribute differs, i.e.
{(s
i
x
,s
i
y
)|∀i,∃A, x[A] 6= y[A] ∧ x[
¯
A] = y[
¯
A]}
Partitioned:
S
P
pairs
For every individual and every two tuples
coming from the same partition where one
of them is real, the real tuple is not known,
i.e.
{(s
i
x
,s
i
y
)|∀i,∃ j,(x , y) ∈ P
j
× P
j
}.
This
privacy definition is very useful for location
data.
Distance
threshold:
S
d,θ
pairs
For every individual and every two tuples
having their distance less than or equal
to a threshold θ where one of them is
real, the real tuple is not known, i.e.
{(s
i
x
,s
i
y
)|∀i,d(x,y) ≤ θ}
In this direction, the idea of a discriminative secret is
very similar to what consists a game in cryptography.
We prefer to call it a privacy game here and represent
it as shown in Figure 2. In this game, a challenger
picks an Id (e.g. Bob) and a pair of discriminative se-
crets at random (e.g. ”Bob has called Alice” or ”Bob
has not called Alice”). The pair is represented by two
tuples, or an edge in the discriminative secret graph
of the Id. The edge vertices identify the two tuples.
The challenger sends the Id and the two tuples to the
adversary (e.g. which one does belong to Bob?). The
adversary has to guess which of the two tuples be-
longs to the id and responds with only 1 bit b. b = 0
is chosen for t
0
and b = 1 for t
1
.
Our goal is to make the probability of the adver-
sary guessing the assumed right tuple not significantly
different than a coin flip.
An important remark about undirected communi-
Table 2: Examples of notions of secrets for a communica-
tion database.
Symbol Description - Example
Secret: s
Bob has talked to Alice: t
i
. id = ’Bob’ ∧
t
j
. id = ’Alice’ ∧t
i
[ j] = t
j
[i] = 1
A discrimi-
native pair of
secrets (s,s
0
)
Given two communication tuples (ego net-
works), we cannot distinguish which one of
them belongs to Bob, for example, (t. id =
’Bob’ ∧ t = (0,1, 1,1), t. id = ’Bob’ ∧ t =
(0,0, 0,1))
s
i
x
The secret where individual i has ego net-
work x, for example, s
’Bob’
(0,1,1,1)
S
full
pairs
For an individual, all ego networks are dis-
criminative
S
attr
pairs
For an individual and two vectors that differ
in only one communication, we cannot tell
which one is real.
S
P
pairs
For an individual and two tuples belonging
to the same partition, we cannot tell which
tuple is the real one.
S
(d,θ)
pairs
Given a distance metric and a threshold. The
privacy game is to challenge the adversary
with one individual and two records having
their distance less than or equal to thresh-
old. A suitable distance for communication
graphs is the Hamming distance (or the num-
ber of different bits), which is equivalent to
the Manhattan distance in this case.
cation graphs is that not all the graphs are feasible. If
Bob has talked to Alice, it means that Alice has talked
to Bob. The database matrix is symmetric. Another
constraint is that t
i
[i] must be 0, and all other entries
are either 0 or 1. The BP framework allows to de-
fine constraints about the dataset, and redefines the
notion of neighborhood databases by excluding inter-
mediate, yet infeasible ones. Therefore, we suggest
that BP is a more suitable framework for communica-
tion graphs than its DP predecessor.
2.2 Auxiliary Knowledge
Auxiliary knowledge is usually formalized using cor-
relations, for example c(R = r
1
) + c(R = r
2
) = a
1
where c(r
1
) is the count of records having the attribute
R equal to r
1
, c(r
2
) is the count of records having
the attribute R equal to r
2
, and a
1
is known. BP sug-
gests to formalize auxiliary knowledge in terms of a
set of constraints Q that a database D must satisfy.
It denotes I
Q
⊂ I
n
the subset of all possible database
instances. In the case of undirected communication
graphs, we have two inherent constraints:
• the matrix of D is symmetric: t
i
j
= t
j
i
• the ego attributes are zero: t
i
i
= 0
It is also possible to use directed communication
graphs where a directed edge from Bob to Alice
VIP Blowfish Privacy in Communication Graphs
461
means that Bob has called Alice. In this case the
first constraint above is not considered. Additional
constraints which are not necessarily inherent to the
graph representation can be considered, for example:
• Count Queries. The number of individuals that have 5
neighbors.
• Marginal Constraints. A marginal is the projection of
the database on a given subset of columns. Rows hav-
ing the same projection are grouped in one record along
with their count. In our context we project on a subset
of nodes. For example let’s project the database in Fig-
ure 1 on Bob and Eve only (columns 1 and 3). Alice and
Carol have the same projection since both have called
Bob and Eve. Therefore the projection have 3 rows:
(Bob,1), (Eve,1) and (Alice-Carol,2).
• Meta-node Constraints. A meta-node is a node repre-
senting a sub-graph or a group of individuals. Meta-
node auxiliary knowledge is for example the number of
people calling a group of individuals, or the number of
calls in between two groups of individuals. The adver-
sary may know that the group Bob-Carol and the group
Alice-Eve have three calls linking them.
• Clique Constraints. A clique is a complete graph. The
adversary may know that a group of nodes makes a
clique. For example Bob, Alice and Eve form a clique.
2.3 Policy and Privacy Definitions
To apply BP, one must define a policy P(T ,G,I
Q
)
which is composed of a set of tuples T , a discrimi-
native secret graph G(V,E) based on sets of discrim-
inative pairs S
pairs
, and a set of possible database in-
stances I
Q
under the auxiliary knowledge constraints.
One also has to devise a randomized mechanism M
that satisfies (ε,P)-BP. Concretely, for every pair of
neighboring databases, denoted (D
1
,D
2
) ∈ N(P), and
every set of outputs S ⊆ range(M ), we have:
Pr[M (D
1
) ∈ S] ≤ e
ε
Pr[M (D
2
) ∈ S]
To see how it differs from DP, let’s consider D
1
=
D ∪ {x} and D
2
= D ∪ {y}, two databases that dif-
fer in one tuple, and suppose P = (T ,G,I
n
), i.e., no
constraints. D
1
and D
2
are not considered neighbors
unless (s
i
x
,s
i
y
) ∈ S
G
pairs
. Otherwise, having M that sat-
isfies (ε,P)-BP means that:
Pr[M (D
1
) ∈ S] ≤ e
ε.d
G
(x,y)
Pr[M (D
2
) ∈ S]
since BP is shown to satisfy sequential composition.
Similarly to increasing ε, the chance of an attacker
to distinguish between pairs farther apart in the graph
is higher. We gain overall utility by scarifying local
privacy of some users.
The Laplace mechanism M
Lap
ensures
(ε, P(T , G, I
Q
))-BP for any query function,
f : I
Q
−→ R
d
, by outputting f (D) + η where
η ∈ R
d
is a vector of independent random num-
bers drawn from Lap(S( f ,P)/ε). S( f , P) is the
policy-specific global sensitivity and is defined as
max
(D
1
,D
2
)∈N(P)
k
f (D
1
) − f (D
2
)
k
1
.
Following the definition of neighbors in He et al.
(2014), let T (D
1
,D
2
) the set of discriminative pairs
(s
i
x
,s
i
y
) such as the ith tuples in D
1
and D
2
are x and
y. Let ∆(D
1
,D
2
) = D
1
\D
2
∪ D
2
\D
1
. D
1
and D
2
are neighbors, if: (1) they both comply to the con-
straints, (2) T 6=
/
0, and (3) T has the smallest size,
there is no feasible database D
3
such that T (D
1
,D
3
) ⊂
T (D
1
,D
2
) or T (D
1
,D
3
) = T (D
1
,D
2
) & ∆(D
1
,D
3
) ⊂
∆(D
1
,D
2
). In our communication graph representa-
tion, two databases are candidate neighbors if they
differ by the ego network of one individual, and this
difference is represented in the security graph of that
individual. Note that this means that one or several
edges might be added or removed between two neigh-
bor communication graphs.
To give an example, the two graphs in Figure 3
are different in three tuples: |∆(D
1
,D
2
)| = 6. If only
one of the different pairs is in the security graph, for
instance Bob’s pairs, we have |T | = 1. There is no
database having a non-empty subset of T , and no fea-
sible database with same T and a subset of ∆. (To do
so, we need to make Alice’s ego network indifferent,
or Eve’s ego network indifferent, which is not possi-
ble due to symmetry constraints). We consider that
these two graphs are neighbors.
Bob
Alice
Eve
Carol
id tuple
Bob (0, 0, 1, 1)
Alice (0, 0, 1, 0)
Eve (1, 1, 0, 1)
Carol (1, 0, 1, 0)
Bob
Alice
Eve
Carol
id tuple
Bob (0, 1, 0, 1)
Alice (1, 0, 1, 0)
Eve (0, 1, 0, 1)
Carol (1, 0, 1, 0)
Figure 3: Neighboring graphs and their databases. The ego
network of Bob has changed, and Bob has a G
full
policy.
Under P(T ,G
full
,I
Q
), we can obtain two neigh-
bor communication graphs by taking one vertex and
changing its ego network. Any two communication
graphs that differ in n + 1 tuples where n tuples differ
in one bit and one tuple differs in n bits are considered
neighbors under G
full
.
To make the concept of neighbor databases
used throughout the paper more straightforward, we
demonstrate the following result:
Theorem 1. Given G
c
(V
c
,E
c
), its database/matrix rep-
resentation M(G
c
) and the policy P(T , G,I
Q
), where T
represents all binary vectors of size |V
c
|, G represents the
SECRYPT 2020 - 17th International Conference on Security and Cryptography
462

overall graph of discriminative secret graphs for all the
nodes, and I
Q
constrains the possible databases to have:
(1) ∀i 6= j,M
i, j
= M
j,i
= 0 or M
i, j
= M
j,i
= 1 and (2)
∀i,M
i,i
= 0. If G = G
attr
or G is any non-empty subset of
G
attr
, we have that: Two graphs G
1
c
and G
2
c
are neighbors,
i.e., (G
1
c
,G
2
c
) ∈ N(P), if they differ by one and only one edge
e(i, j) = e( j, i) and for at least one vertex of the edge (either
i or j) the discriminative secret pair (s
i
x
,s
i
y
) (where x and y
differ at the bit j) or (s
j
a
,s
j
b
) (where a and b differ at the bit
i) is in the security graph G.
Proof. G
attr
means that two tuples form a discriminative
secret pair if they differ by only one attribute. This differ-
ence is reflected in the communication graph by the addition
or removal of one edge.
If G
1
C
and G
2
C
differ by one or more edges that do not
correspond to discriminative pairs in the security graph G,
then T (G
1
C
,G
2
C
) =
/
0 and the graphs are not neighbors.
If G
1
C
and G
2
C
differ by many edges that affect many
secret pairs in G, then we can build a graph G
3
C
that takes
only one of these edges that affects one (or two) secret pairs
in G to form a subset of T (G
1
C
,G
2
C
), and therefore the two
graphs are not neighbors.
For the case where G
1
C
and G
2
C
differ by many edges and
for only one of them e(i, j ) we have (s
i
x
,s
i
y
) ∈ G or (s
j
a
,s
j
b
) ∈
G or both, then T (G
1
C
,G
2
C
) is the minimal possible set. But
we can find a sub-graph G
3
C
of G
2
C
where T (G
1
C
,G
2
C
) =
T (G
1
C
,G
3
C
) by removing the extra edges which do not have
any discriminative secret pairs that belong to the security
graph. Then, G
1
C
and G
2
C
are not neighbors.
For the case where G
1
C
and G
2
C
differ by only one edge
e(i, j), and we have (s
i
x
,s
i
y
) ∈ G or (s
j
a
,s
j
b
) ∈ G or both, then
T (G
1
C
,G
2
C
) is minimal and there is no feasible intermediate
database. Only in this case G
1
C
and G
2
C
are neighbors.
2.4 BP with Individualized Security
Graphs
We consider the possibility that different individuals
may have different security graphs. For example, we
can divide the users into two extreme sub-groups: VIP
and Standard. The discriminative secret graph for a
VIP user is complete or attribute-based. The discrim-
inative secret graph for a standard user has 0 edges.
The application of Theorem 1 to the case where
standard nodes’ security graph is G
empty
and VIP
nodes’ security graph is G
attr
can be explained as fol-
lows. Take two communication graphs that differ by
only one edge:
• Case I. If the vertices of the edge are standard nodes,
then T (G
1
C
,G
2
C
) =
/
0 and the graphs are not neighbors.
• Case II. If one of the vertices is VIP and the other is
standard, then the size of T is 1 and the graphs are
neighbors.
• Case III. If the vertices of the edge are two VIP nodes,
then the size of T is 2 and the graphs are neighbors. Any
intermediate database that makes | T |= 1 is infeasible.
3 EXAMPLES OF QUERIES AND
BP MECHANISMS
To apply BP given a query or a function f over the
protected database D, one has to determine first the
global sensitivity Dwork et al. (2006) of f , based on
the privacy policy P = (T ,G,I
Q
):
S( f ,P) = max
(D
1
,D
2
)∈N(P)
|| f (D
1
) − f (D
2
)||
1
Once the global sensitivity S( f , P) is identified, out-
putting f (D) + η ensures (ε,P)-BP if η ∈ R
d
is a
vector of independent random numbers drawn from
Lap(S( f ,P)/ε).
3.1 Example 1: Histogram Query for
Degrees of Vertices
Under P
attr
, two graphs G
1
C
and G
2
C
are neighbors if
G
2
C
= G
1
C
∪ {e}. Assume DV = dv
1
,...,dv
|DV |
is the
set of all degrees for the vertices in these graphs.
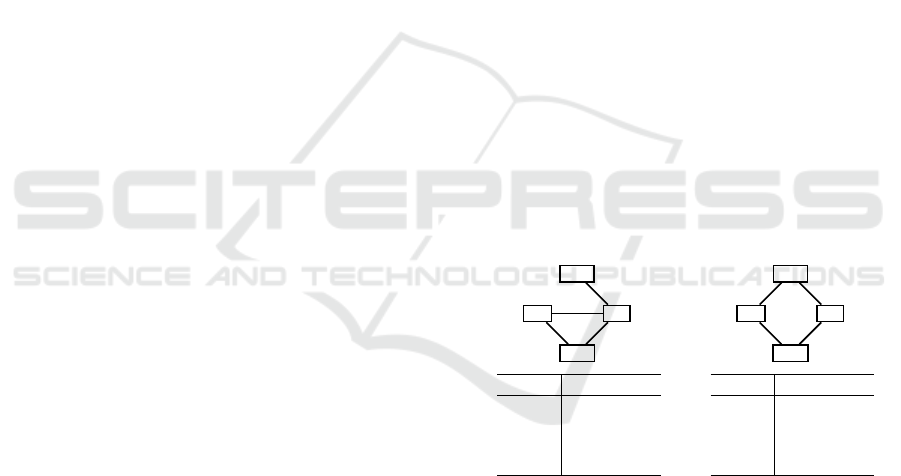
If the edge e is added between node a having de-
gree dv
i
and node b with degree dv
j
, i 6= j, then the
count of dv
i
and dv
j
will decrease each by 1 while
dv
i+1
and dv
j+1
will increase each by 1. Also the
cumulative count of dv
i
(respectively dv
j
) decreases
by 1, yet the cumulative count of dv
i+1
(respectively
dv
j+1
) stays unchanged, as shown in Figure 4.
If the edge e is added between two nodes both
having the same degree dv
i
, then the count of dv
i
will decrease by 2 and dv
i+1
will increase by 2.
Also the cumulative count of dv
i
decreases by 2, yet
the cumulative count of dv
i+1
stays unchanged, as
shown in Figure 5. Taking both cases into account,
the global sensitivity of complete histogram query is
S( f
complete
,P
attr
) = 4, and the global sensitivity of a
cumulative histogram query is S( f
cumulative
,P
attr
) = 2.
Under P
full
, two graphs G
1
C
and G
2
C
are neighbors
if they differ by the ego network of one vertex. In the
worst case, the vertex passes from degree 0 to degree
n − 1, where n is the number of vertices in the graph.
All the other vertices have their degrees shifted by +1.
In total, 2n bins are affected and the sensitivity is 2n.
In cumulative histogram query, in a worst case sce-
nario, n vertices change their degrees and move from
one bin to another, however the receptive bin does not
change its count. The sensitivity is n.
VIP Blowfish Privacy in Communication Graphs
463

3.2 Example 2: Histogram of Degrees of
Vertices for Standard Nodes
In this exercise, we divide the communication graph
vertices into two groups: VIP nodes and standard
nodes. The discriminative secret graph for a VIP node
is built as follows: There is no edge between two
tuples if they differ by more than one attribute (i.e.
G
attr
). In addition, we consider only attributes that
belong to a VIP vertex. Two tuples differing by an at-
tribute corresponding to a standard node are not con-
nected in the discriminative secret graph. We denote
this set of secret pairs: S
attr,VIP
pairs
.
Consider the following query: ”Histogram of de-
grees of vertices for standard nodes”. To compute
their sensitivity we examine the three cases: (a) the
edge we add/remove is between two VIP nodes: noth-
ing will change in the histogram of the query; (b) the
edge we add/remove is between one VIP node and
one standard node: one of the bins in the histogram
will decrease by 1 and its right-hand neighbor will in-
crease by 1; (c) the edge we add/remove is between
two standard nodes. This edge does not correspond to
a secret pair. It means that this case will not occur for
two neighbor graphs and can therefore be ignored.
It follows that the sensitivity of this query under
S
attr,VIP
pairs
is only 2. The sensitivity is reduced by 50%
in comparison to the full histogram query. By limiting
the privacy focus to the VIP nodes, we gain in terms
of utility for queries over the standard nodes.
3.3 Example 3: Histogram of the
Number of Connections between
VIP Nodes and Standard Nodes
Bob
Alice
Eve
Carol
degree 0 1 2 3 0 1 2 3
count 1 2 1 0 0 3 0 1
cumul-
ative count
1 3 4 4 0 3 3 4
Figure 4: Counts and cumulative counts of node degree for
graphs G
1
C
and G
2
C
(with dashed red edge), the added edge
e connects two nodes of different degrees.
A similar query is the ”Histogram of the number of
connections between a VIP node and standard nodes”
or ”Histogram of the number of connections between
a standard node and VIP nodes” . To compute their
sensitivity we examine the three cases:
(a) the edge we add/remove is between two VIP nodes:
nothing will change in the query’s result,
(b) the edge we add/remove is between one VIP node and
Bob
Alice
Eve
Carol
degree 2 3 2 3
count 2 2 0 4
cumulative
count
2 4 0 4
Figure 5: Counts and cumulative counts of node degree for
graphs G
1
C
and G
2
C
(with dashed red edge), the added edge
e connects two nodes of the same degree.
one standard node: two of the bins in the histogram
will vary by ±1,
(c) the edge we add/remove is between two standard
nodes. This edge does not correspond to a secret pair
and does not change the query result in the same time.
The sensitivity of these queries under S
attr,VIP
pairs
is 2.
These queries are useful in a graph where the stan-
dard nodes are the members of a company’s support
team and the VIP nodes are the customers. The calls
between a support team member and the customers
are the target. We aim to study, for example, if a load
balancing strategy works well, or how many clients a
support member is serving in average. At the same
time, we are protecting the privacy of the customers.
4 EXPERIMENTS AND RESULTS
In this section, we present the results of our exper-
iments to evaluate the BP on graphs both in terms
of utility and privacy. We compare G
attr
and G
full
for histogram queries. In addition, we show the
utility of some queries under G
attr,VIP
. Our exper-
iments use three graph datasets collected from the
music streaming service Deezer Rozemberczki et al.
(2019). These datasets represent the friendship Net-
work of users from Croatia (HR) of 54,573 nodes and
498,202 edges, Hungary (HU) of 47,538 nodes and
222,887 edges and Romania (RO) of 41,773 nodes
and 125,826 edges.
4.1 MSE of Complete Histogram
The Mean Squared Error (MSE) for complete his-
togram queries under G
attr
and G
full
are:
E
M
Lap
h
P
attr
(D) = bE[Laplace(4/ε)
2
] = 32b/ε
2
E
M
Lap
h
P
full
(D) = bE[Laplace(2n/ε)
2
] = 8n
2
b/ε
2
where n is the number of vertices and b is the number
of bins. We empirically sample the MSE of the com-
plete histogram query for a given ε by generating the
real histogram of each graph (HR, HU, and RO) and
k noisy versions. We compute the MSE of the noisy
SECRYPT 2020 - 17th International Conference on Security and Cryptography
464

(a) Full Policy
Complete Histogram.
(b) Attribute Policy
Complete Histogram.
Figure 6: MSE of complete histograms queries under Full
and Attribute Policies (k = 10).
versions as follows:
MSE(H,H
ε
) =
b
∑
i=1
mean
k
[(H(i) − H
ε
(i))
2
]
where H is the original histogram and H
ε
is its
ε-noisy version. We choose ten epsilon values:
0.1, 0.2, ..., 1. The number of bins b is equal to
421, 113 and 113 for the graphs HR, HU and RO re-
spectively. The results are shown in Figure 6a under
G
full
and in Figure 6b under G
attr
. G
full
has null util-
ity whereas for G
attr
we expect the standard deviation
per bin to be around 32 to 56 (depending on ε). Using
coarser bins may reduce this error by decreasing b.
4.2 MSE of Cumulative Histogram
MSE for cumulative histogram under G
attr
and G
full
:
E
M
Lap
h
P
attr
(D) = bE(Laplace(2/ε))
2
= 8b/ε
2
E
M
Lap
h
P
full
(D) = bE(Laplace(n/ε))
2
= 2n
2
b/ε
2
The difference in MSE under G
full
and G
attr
is also
clear for cumulative histogram queries as shown in
Figure 7a and Figure 7b.
4.3 Simulating Sensitivity Results
In this experiment, we sample neighbors of our input
graphs and compute the difference in the values of the
histogram queries. We compare the obtained values
with our derived sensitivity formulas. We sample the
sensitivity values for our input graphs as follows:
(a) take an input graph, and compute its histogram H,
(b) take a vertex at random,
(c) randomly change the ego network of the vertex for
G
full
, change the value of only one edge for G
attr
,
(d) compute the histogram query for the obtained graph
H
0
, and compute the L1-norm ||H − H
0
||
1
,
(e) repeat starting at (c),
(a) Full Policy
Cumulative Histogram.
(b) Attribute Policy
Cumulative Histogram.
Figure 7: MSE of cumulative histograms queries under Full
and Attribute Policies (k = 10).
(f) take max ||H −H
0
||
1
and compare to the corresponding
sensitivity: 2n for G
full
and just 4 for G
attr
,
(g) repeat starting at (a),
Different strategies can be adopted to change the ego
network under G
full
:
• Take-out: The chosen vertex is taken out by removing
all its connections similarly to node-based DP.
• Random Ego Network: The chosen vertex samples
a Bernoulli distribution with predefined probability p
(e.g. 0.5) to decide on linking to each node in the graph.
• Flipped Ego Network: The chosen vertex deletes all its
neighbors and connects to all non-neighbors.
We apply the above strategies to the complete his-
togram queries and vertices of different degrees. The
results are shown in Figure 8a. In addition we show
the derived sensitivity formula and the worst case
take-out difference (2 × (deg
v
+ 1)). It is clear that
G
full
is unreasonably pessimistic about the sensitiv-
ity of complete histograms queries. We can gain
more utility by deriving more specific secret graphs
(based on the strategy of ego network manipulation)
or adding constraints and auxiliary knowledge to the
policy. For instance, it is unreasonable that a single
node would be connected to all the nodes in the graph.
Similar experiments for the cumulative histogram
queries are shown in 8b. In contrast, random and
flipped ego network values are very close to the de-
rived sensitivity formula.
4.4 Extrapolation of Queries under
G
attr
We have shown that limiting privacy to some VIP
nodes provides utility for queries such as ”Histogram
of degrees of vertices for standard nodes” and ”His-
togram of the number of connections between a VIP
node and standard nodes”. In this experiment, we
show that these queries can be exploited to esti-
mate information about the complete graph. For in-
stance, the histogram of degrees of vertices for stan-
VIP Blowfish Privacy in Communication Graphs
465
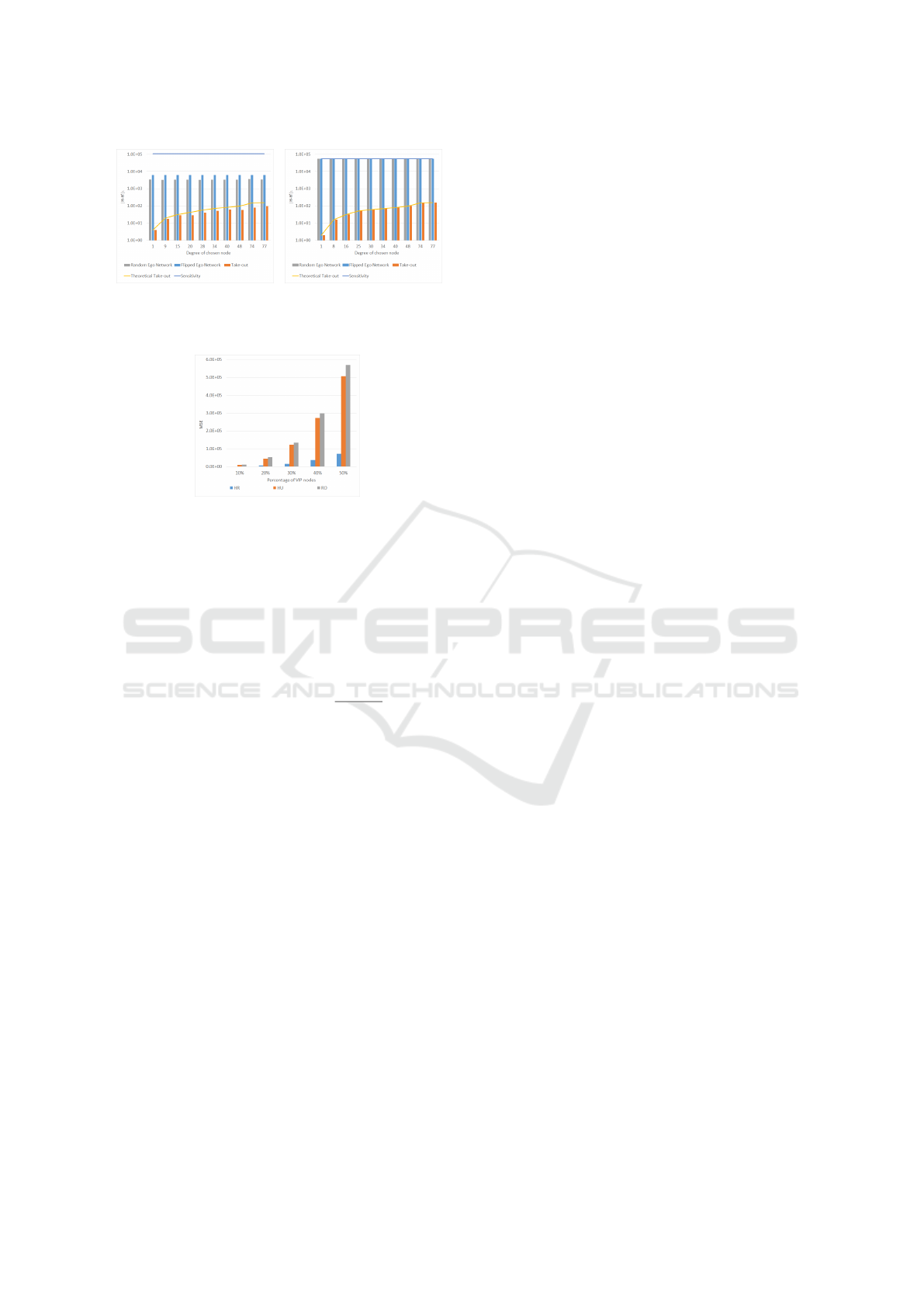
(a) Complete Histogram. (b) Cumulative Histogram.
Figure 8: Simulation of the queries under Full Policy.
Figure 9: MSE of extrapolation for complete histogram
queries under VIP/Standard partition.
dard nodes can be extrapolated to estimate the his-
togram of degrees of vertices for all the nodes. The
histogram of the number of connections between a
VIP node and standard nodes can be extrapolated to
estimate the histogram of degrees of VIP nodes, and
so on. The histogram of degrees of vertices for stan-
dard nodes can be extrapolated as follows:
H
all nodes
(i) = H(i)
standard
×
100
100−%
V IP
The MSE of the extrapolated histogram query com-
pared to the complete histogram query is shown in
Figure 9. Naturally, the error depends on the ratio of
the number of VIP nodes to the total number of ver-
tices in the graph.
5 RELATED WORK
The authors of this paper are recently conducting re-
search in secure outsourcing of computations Nassar
et al. (2013, 2016) and privacy preserving applica-
tions Barakat et al. (2016); Chicha et al. (2018). To
our knowledge, no previous work concerning BP to-
wards graph datasets has been considered in the liter-
ature. However, many DP mechanisms were prosped
for graphs. In Hay et al. (2009), Hay et al. divide
these mechanisms into two types: edge-DP and node-
DP.
Usually, a node in a graph represents a person
while an edge represents a connection between two
persons. The purpose of edge-DP Blocki et al. (2012)
is to prevent the usage of these connections for reveal-
ing the identity of a person. On the other hand, node-
DP achieve similar data protection by blurring node
appearance in the graph. Node-DP is much more sen-
sitivity than edge-DP, which is usually preferable.
Graph projection is a technique to apply node-DP.
A parameter α is used to transform a graph to be α-
degree-bounded. In Kasiviswanathan et al. (2013), all
the nodes with a higher degree than α are removed,
which causes a much higher number of edges to be
removed than necessary.
In Raskhodnikova and Smith (2015), Raskhod-
nikova et al. use a Lipschitz extension tool and a
generalized exponential mechanism to release an ap-
proximate histogram of degree distribution in a graph
under node-DP with a sensitivity of 6α. Many works
propose to generate noisy degree distributions from
graphs under DP. Generative methods are then used
to create output graphs fulfilling noisy input distribu-
tions Day et al. (2016). Qin et al. Qin et al. (2017)
propose LDPGen for decentralized social networks.
It collects neighbor lists of the nodes and reconstructs
the graph in two phases under local edge-DP.
Local and smooth sensitivity achieves less noise
than the global sensitivity Nissim et al. (2007). Fi-
nally, Karma et al. Karwa et al. (2011) presents ef-
ficient algorithms to provide noisy answers to sub
graph counting queries under a relaxed version of
edge-DP. Our work is a departure from previous
works, first because it employs the framework of
BP, and second because it allows a per-identity cus-
tomized privacy policy for individuals in the graph.
6 CONCLUSION
In this paper, we have summarized BP, its formal
model and the enhanced privacy-utility trade-off that
it brings with respect to its predecessor, DP. We en-
rolled examples of its application to communication
graph databases and their typical queries. We further
studied the idea of privacy as a service with differ-
entiation among different groups of individuals. We
showed that this relaxation is formally feasible and
proved its utility through the enrollment of several
queries and computing their sensitivity. We work un-
der the settings of binary differentiation (standard vs.
VIP) and binary communication status (0 or 1).
ACKNOWLEDGMENTS
The authors would like to acknowledge the National
Council for Scientific Research of Lebanon (CNRS-
SECRYPT 2020 - 17th International Conference on Security and Cryptography
466

L) and Univ. Pau & Pays Adour, UPPA - E2S,
LIUPPA for granting a doctoral fellowship to Elie
Chicha. This work is also partially suported by a grant
from the University Research Board of the Ameri-
can University of Beirut (URB-AUB-2019/2020), the
National Council for Scientific Research of Lebanon,
and the Antonine University.
REFERENCES
S. Barakat, B. A. Bouna, M. Nassar, and C. Guyeux. On
the evaluation of the privacy breach in disassociated
set-valued datasets. arXiv preprint arXiv:1611.08417,
2016.
J. Blocki, A. Blum, A. Datta, and O. Sheffet. The johnson-
lindenstrauss transform itself preserves differential
privacy. In Foundations of Computer Science (FOCS),
2012 IEEE 53rd Annual Symposium on, pages 410–
419. IEEE, 2012.
E. Chicha, B. Al Bouna, M. Nassar, and R. Chbeir. Cloud-
based differentially private image classification. Wire-
less Networks, pages 1–8, 2018.
W.-Y. Day, N. Li, and M. Lyu. Publishing graph degree dis-
tribution with node differential privacy. In Proceed-
ings of the 2016 International Conference on Manage-
ment of Data, pages 123–138, 2016.
C. Dwork, F. McSherry, K. Nissim, and A. Smith. Cali-
brating noise to sensitivity in private data analysis. In
Theory of cryptography conference, pages 265–284.
Springer, 2006.
M. Hay, C. Li, G. Miklau, and D. Jensen. Accurate esti-
mation of the degree distribution of private networks.
In Data Mining, 2009. ICDM’09. Ninth IEEE Interna-
tional Conference on, pages 169–178. IEEE, 2009.
X. He, A. Machanavajjhala, and B. Ding. Blowfish pri-
vacy: Tuning privacy-utility trade-offs using policies.
In Proceedings of the 2014 ACM SIGMOD inter-
national conference on Management of data, pages
1447–1458. ACM, 2014.
V. Karwa, S. Raskhodnikova, A. Smith, and G. Yaroslavt-
sev. Private analysis of graph structure. Proceedings
of the VLDB Endowment, 4(11):1146–1157, 2011.
S. P. Kasiviswanathan, K. Nissim, S. Raskhodnikova, and
A. Smith. Analyzing graphs with node differential pri-
vacy. In Theory of Cryptography Conference, pages
457–476. Springer, 2013.
M. Nassar, A. Erradi, F. Sabri, and Q. M. Malluhi. Secure
outsourcing of matrix operations as a service. In 2013
IEEE Sixth International Conference on Cloud Com-
puting, pages 918–925. IEEE, 2013.
M. Nassar, N. Wehbe, and B. Al Bouna. K-nn classi-
fication under homomorphic encryption: application
on a labeled eigen faces dataset. In 2016 IEEE Intl
Conference on Computational Science and Engineer-
ing (CSE) and IEEE Intl Conference on Embedded
and Ubiquitous Computing (EUC) and 15th Intl Sym-
posium on Distributed Computing and Applications
for Business Engineering (DCABES), pages 546–552.
IEEE, 2016.
K. Nissim, S. Raskhodnikova, and A. Smith. Smooth sen-
sitivity and sampling in private data analysis. In Pro-
ceedings of the thirty-ninth annual ACM symposium
on Theory of computing, pages 75–84. ACM, 2007.
Z. Qin, T. Yu, Y. Yang, I. Khalil, X. Xiao, and K. Ren. Gen-
erating synthetic decentralized social graphs with lo-
cal differential privacy. In Proceedings of the 2017
ACM SIGSAC Conference on Computer and Commu-
nications Security, pages 425–438, 2017.
S. Raskhodnikova and A. Smith. Efficient lipschitz ex-
tensions for high-dimensional graph statistics and
node private degree distributions. arXiv preprint
arXiv:1504.07912, 2015.
B. Rozemberczki, R. Davies, R. Sarkar, and C. Sutton.
Gemsec: Graph embedding with self clustering. In
Proceedings of the 2019 IEEE/ACM International
Conference on Advances in Social Networks Analysis
and Mining 2019, pages 65–72. ACM, 2019.
VIP Blowfish Privacy in Communication Graphs
467
