
Towards a Data Science Framework Integrating Process and Data
Mining for Organizational Improvement
Andrea Delgado, Adriana Marotta, Laura Gonz
´
alez, Libertad Tansini and Daniel Calegari
Instituto de Computaci
´
on, Facultad de Ingenier
´
ıa, Universidad de la Rep
´
ublica,
Montevideo, 11300, Uruguay
Keywords:
Process Mining, Data Mining, Data Science Framework, Organizational Improvement, Business Intelligence.
Abstract:
Organizations face many challenges in obtaining information and value from data for the improvement of
their operations. For example, business processes are rarely modeled explicitly, and their data is coupled with
business data and implicitly managed by the information systems, hindering a process perspective. This paper
presents a proposal of a framework that integrates process and data mining techniques and algorithms, process
compliance, data quality, and adequate tools to support evidence-based process improvement in organizations.
It aims to help reduce the effort of identification and application of techniques, methodologies, and tools in
isolation for each case, providing an integrated approach to guide each operative phase, which will expand the
capabilities of analysis, evaluation, and improvement of business processes and organizational data.
1 INTRODUCTION
Over the last years the ”data explosion” phenomenon
characterized by the amount of data available in in-
ternet and organizations, from several sources such
as personal/enterprise computers, social media, dig-
ital cameras, servers, sensors, and others, has been
impacting the world and the way data is perceived,
stored, collected and analyzed (van der Aalst, 2016).
Organizations face many challenges in managing
these large volumes of data, being one of the most
important ones to obtain information and value from
the data in their information systems.
Although business processes (BPs) are the basis
for the operation of organizations no matter which
is their domain (i.e. banking, health, e-government)
they are rarely modeled explicitly to guide the activ-
ities to perform, and they are implicitly stored and
managed within the organizational information sys-
tems and associated with the business data. Both or-
ganizations and their processes, as well as the soft-
ware systems that support such processes and data,
are increasingly complex, defining ecosystems in
which it is necessary to integrate different visions,
techniques, and tools for the management of informa-
tion, processes, and associated systems.
Data science (van der Aalst, 2013; IEEE, 2020)
has emerged in recent years as a discipline in itself, in-
terdisciplinary, to respond to the problem of manage-
ment, analysis and discovery of information in large
volumes of data that are generated at high speed (ve-
locity) and with great variety (the three V) (Furht and
Villanustre, 2016), also considering the veracity of the
data (Ong et al., 2016), which is stored in structured
or unstructured form. Organizations are increasingly
incorporating tools and techniques for managing and
analyzing the large volumes of data they have, but due
to the variety of approaches, tools, and objectives,
they often lack conceptual and objective guides that
allow them to identify the solutions that best suit their
needs and capabilities.
In this context, the compartmentalized vision of
processes on the one hand and organizational data
on the other are not adequate to provide the organi-
zation with the evidence-based business intelligence
necessary to improve their daily operation. What
is more, in inter-organizational collaborative envi-
ronments business processes include several partic-
ipants with their own internal processes (orchestra-
tions) with their own internal data, which makes the
scenario of data integration and analysis more com-
plex. Also, a key element in data manipulation, both
of the event logs from processes execution and of the
organizational data that these processes manipulate,
refers to their quality analysis, data cleaning, and as-
suring that the data analyzed complies with a mini-
mum quality, in different dimensions. In light of the
above, one of the main lines of research that remains
492
Delgado, A., Marotta, A., González, L., Tansini, L. and Calegari, D.
Towards a Data Science Framework Integrating Process and Data Mining for Organizational Improvement.
DOI: 10.5220/0009875004920500
In Proceedings of the 15th International Conference on Software Technologies (ICSOFT 2020), pages 492-500
ISBN: 978-989-758-443-5
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

open in this area refers precisely to the integrated sup-
port for the analysis of processes and data in organi-
zations.
This paper presents a proposal of an integrated
framework for organizational Data Science, that in-
cludes process and data mining techniques and algo-
rithms, the integration of process and organizational
data, data quality assessment, process compliance as-
sessment, methodologies and guides to support all of
the above, and adequate tool support, for the improve-
ment of organizations based on evidence. The main
objective of this framework is to help reduce the ef-
fort of identification and application of techniques,
methodologies, and tools in isolation for each case,
providing an integrated package to guide each phase
of the data analytic operation, which will expand the
possibilities of analysis, evaluation, and improvement
of the organizational business processes and corre-
sponding data.
The main contributions of our work are as fol-
lows: i) an integrated view and complete support (el-
ements mentioned above) for the manipulation and
analysis of process and organizational data, that will
serve as a basis to guide analytic efforts in organi-
zations, ii) models and tools for process and organi-
zational data integration, from different sources and
scenarios, iii) models and tools for process and orga-
nizational data quality assessment and improvement,
iv) adapted and new techniques and algorithms for
integrated process and data mining analysis over the
integrated data within different scenarios, and corre-
sponding tool support, v) models, techniques, algo-
rithms, and tools to support compliance analysis on
business processes, over different scenarios.
As a research methodology, we follow Design Sci-
ence guidelines (Hevner et al., 2004; Wieringa, 2014),
where knowledge and understanding of a problem and
its solution are based on two main processes: build-
ing and assessment (of the application) of an arti-
fact. Artifacts that are useful to solve problems not
yet solved are built, and they are assessed with re-
spect to their usefulness in the solution of the defined
problem (Hevner et al., 2004). For the evaluation of
artifacts we will carry out experimentation on algo-
rithms and their results as we build them, Action-
Research (Iivari and Venable, 2009) and case study
research (Yin, 2014) within the organization, to val-
idate artifacts and the proposal with our counterpart.
We are working with a team from the e-Government
in our countrywhich has real processes and organi-
zational data for our research work. We also carried
out a systematic literature review (Kitchenham, 2004;
Kitchenham and Charters, 2007) at the beginning of
our research, to review existing work on the integrated
view we are proposing and the main sub-topics. To
the best of our knowledge, there are no other initia-
tives that integrate all of the dimensions of process
and data analysis as we are in our framework.
The rest of the article is organized as follows: In
Section 2 we introduce key concepts related to the
main elements included in our proposal. In Section 3
we discuss related work. In Section 4 we describe
our proposal including the definition of the frame-
work and the main elements it comprises, as well as
preliminary results. Finally in Section 5 we present
some conclusions and future work.
2 BACKGROUND
Business Process Management (BPM) (van der Aalst
et al., 2003; Weske, 2019; Dumas et al., 2018) refers
to the activities that organizations perform for the ex-
plicit management and improvement of their business
processes according to their organizational needs. In
these terms, a business process (BP) is a set of activ-
ities carried out in coordination in an organizational
and technical environment, to achieve a business ob-
jective (Weske, 2019). Its life cycle (e.g.: analysis
& design, configuration, execution, and evaluation
phases (Weske, 2019)) is usually supported by a Busi-
ness Process Management System (BPMS) (Chang,
2016).
Process discovery is a complex task, especially
when trying to describe not only the activities but also
the participants and resources involved in a BP. In this
context, organizations not only use strategies based
on interviews with process participants, but also au-
tomatic methods based on learning from the infor-
mation systems that support BPs. Process mining
(van der Aalst, 2016) exploits the data registered by
such information systems when supporting the real
executions of BPs to discover process models. Com-
plimentary, process archaeology (P
´
erez-Castillo et al.,
2011) can be used to extract information from the
source code of such information systems, when avail-
able.
Using runtime information from information sys-
tems it is possible not only to describe a BP, but also
to verify the compliance of the enacted BP concern-
ing the expected one (the one that can be modeled
from interviews). Moreover, it is possible to obtain
key execution measures, e.g., about bottlenecks, used
resources, time duration, etc. In this context, in previ-
ous works (Delgado et al., 2014; Delgado et al., 2012)
we have presented a framework and methodology for
BPs continuous improvement to define and analyze
execution measures with the Business Process Exe-
Towards a Data Science Framework Integrating Process and Data Mining for Organizational Improvement
493

cution Measurement Model (BPEMM), including a
plug-in for the ProM tool
1
.
In turn, compliance management aims to ensure
that organizations act following multiple established
regulations (e.g. laws, standards) (Tran et al., 2012).
It comprises several activities including the modeling,
implementation, maintenance, verification, and re-
porting of compliance requirements (Ramezani et al.,
2012)(El Kharbili, 2012). In particular, compliance
control involves assessing the fulfillment of such re-
quirements and acting accordingly. In general, most
current approaches control compliance at design time,
execution (i.e. runtime), or after execution (Hashmi
et al., 2018). Also, compliance controls may be
preventive, detective, or corrective (Elgammal et al.,
2016).
To monitor processes execution including pro-
cess compliance, BPMS platforms may be integrated
with middleware infrastructures such as the enter-
prise service bus (ESB) (Gonz
´
alez and Ruggia, 2011),
and complex event processing (CEP) engines (Flouris
et al., 2017), for example, to signal an alarm when a
violation of policies occur during process execution.
Furthermore, the traceability of collaborative BPs be-
tween participants is another important element for
the discovery as well as monitoring and analysis of
processes execution (Delgado et al., 2017).
Another perspective on the operation of the or-
ganization can be obtained by analyzing the data in-
volved in the execution of these BPs, adding the extra
information on when, how and by whom these data
were created, modified, deleted, etc.
Data mining techniques allow exploring large
databases to find repetitive patterns, trends, or rules
that explain the behavior of the data in a given con-
text (Sumathi and Sivanandam, 2006). Given the
large amount of data that organizations generate in
their daily activity and the need to take advantage of
it, data mining techniques have become fundamental
tools to assist in business decision making involving
methods at the intersection of artificial intelligence,
machine learning, statistics, and database systems. A
wide range of algorithms or methods is used to carry
out data mining functions based on data mining tech-
niques. For example, the Apriori algorithm, Naıve
Bayesian, k-Nearest Neighbour, k-Means, CLIQUE,
STING, etc. (Gupta and Chandra, 2020). Data min-
ing has been used in a variety of domains, such as
time-series data mining, web mining, temporal data
mining, spatial data mining, tempo-spatial data min-
ing, educational data mining, business, medical, sci-
ence, and engineering, etc. Each domain can have
one or more applications of data mining (Han et al.,
1
ProM: http://www.promtools.org/
2011).
Finally, a key element in data manipulation, both
of the event logs from processes execution and of the
data that these processes manipulate, refers to their
quality. As remarked in (van der Aalst, 2016), data
quality is of great importance in process mining, since
its results are less valuable if the data is not complete
enough or trustful. The author focuses on event logs
data quality, providing some basic guidelines for ad-
dressing this problem. Data quality evaluation, data
cleaning, and enforcement of a minimum quality of
the managed data, according to several quality dimen-
sions, are the kind of tasks that should be present in
this context. Quality management in a data set in-
volves the complex tasks of evaluating, improving,
and monitoring its data quality (Batini and Scanna-
pieco, 2016). To carry out these tasks it is necessary
to define a quality model that works as a base and
conducts all the processes involved. A quality model
is a set of quality dimensions and metrics, where the
former represent general aspects of data quality and
the latter define how these dimensions are measured
to evaluate the quality in a particular data set.
3 RELATED WORK
Although process mining (van der Aalst, 2016) and
data mining (Sumathi and Sivanandam, 2006) are ex-
tensive research areas in which many techniques, al-
gorithms, and tools are being currently developed,
the exploitation of both process data and organiza-
tional data altogether has not been analyzed much yet.
When dealing with process execution, the problem is
mostly observed from the perspective of process min-
ing. In (van der Aalst and Damiani, 2015) the rela-
tion between data science and process science through
process mining is explored, and in (van der Aalst,
2013) a process cube is defined to analyze and explore
processes interactively based on a multidimensional
view on event data.
In line with our interests, in (de Murillas et al.,
2019) the authors propose a comprehensive integra-
tion of process and organizational data in a consis-
tent and unified format through the definition of a
metamodel. However, they focus on the extraction of
read/write event logs from a database, thus business-
level activities are hidden, and the analysis is focused
on the lower level of database operations. In (Tsoury
et al., 2018) the authors discuss the aforementioned
problem and define a conceptual framework for a
deep exploration of process behavior, combining in-
formation from three sources: the event log (business-
level), the database (low level), and the transaction
ICSOFT 2020 - 15th International Conference on Software Technologies
494

(redo) log, as we do, but they do not provide a uni-
form way of expressing all the information. Finally,
in (Radesch
¨
utz et al., 2008; Radesch
¨
utz et al., 2015)
the authors describe concrete matching techniques be-
tween process and organizational data, that are later
integrated into a business impact analysis framework
based on a data warehouse. To support our vision, we
are extending the unified model for process execution
in (Delgado et al., 2016) to include mining concepts,
and link it with other metamodels such as for business
data (de Murillas et al., 2019), inter-organizational
collaborative processes (Delgado et al., 2020), and
process compliance (Gonz
´
alez and Ruggia, 2018).
In turn, during the last two decades, a large body
of knowledge has been developed in the field of busi-
ness process compliance, mostly focusing on control-
ling compliance within intra-organizational processes
(Fdhila et al., 2015), at design time and runtime (Fell-
mann and Zasada, 2014)(Hashmi et al., 2018). The
COMPAS project defined a model-driven approach
for runtime compliance governance in the context
of a process-driven SOA (Tran et al., 2012). The
approach proposed languages and tools for model-
ing compliance requirements, linking them to busi-
ness processes, monitoring process execution using
CEP, displaying the current state of compliance, and
analyzing cases of non-compliance (Birukou et al.,
2010). The C
3
Pro Project focused on providing a
theoretical framework for enabling change and com-
pliance of collaborative business processes, at design
time, runtime, and a-posteriori (i.e. after execution)
by processing execution logs (Knuplesch et al., 2017).
Finally, in our previous work, we proposed a policy-
based approach to compliance management within
inter-organizational integration platforms (Gonz
´
alez
and Ruggia, 2018). This approach enables com-
pliance control at runtime in collaborative business
processes, by leveraging an integration platform and
a compliance policy language (PL4C)(Gonz
´
alez and
Ruggia, 2018). This language enables specifying how
the platform has to control compliance requirements
for each one of the processes.
Regarding data quality, in recent years a wide
set of data quality dimensions has been defined, cur-
rently, there is a sub-set used by most of the authors
(Scannapieco and Catarci, 2002; Shankaranarayanan
and Blake, 2017), but without reaching total agree-
ment about the set of dimensions that characterize
data quality. In (Batini and Scannapieco, 2016) the
existing quality dimensions are organized and 6 clus-
ters have proposed that try to cover the main dimen-
sions: accuracy, completeness, redundancy, readabil-
ity, accessibility, consistency, usefulness and trust.
The definition of quality dimensions for process min-
ing, focusing only on event logs data, was also stud-
ied. In (Verhulst, 2016) the author proposes a set of
dimensions for a generic model, discarding the di-
mensions that depend on specific domains or users.
These dimensions are selected taking into account
previous proposals and following the guidelines pro-
posed in (van der Aalst, 2016). In (Andrews et al.,
2019) an approach for process mining and practical
experience is presented, where data quality is an es-
sential step, and certain dimensions and metrics are
selected.
4 FRAMEWORK PROPOSAL
The framework integrates process and data mining
techniques and algorithms for the analysis of process
execution and organizational data, and tool support,
to help improve an organization’s operation based
on evidence. We have named it PRICED for Pro-
cess and Data sCience for oRganIzational improvE-
ment, and although we integrate elements for intra-
organizational business processes (orchestrations) we
focus on inter-organizational collaborative business
processes.
4.1 Framework Definition
The framework defines a general strategy including
methodologies, techniques, and tools, both existing
and new, to provide organizations with key elements
to analyze their processes and data in an integrated
manner. The framework will help organizations re-
ducing the effort of identifying and applying suitable
techniques, methodologies, and tools to analyze op-
erational data (event logs and organizational data) in
order to evaluate and improve their daily operation. It
provides an integrated and accessible package of pro-
posals for each operative phase, which will translate
in better possibilities for analysis, evaluation, and im-
provement of processes and related data in organiza-
tions. In the following, we describe the dynamic and
static views of the framework.
4.1.1 Dynamic View
Figure 1 presents the dynamic view of the framework
including the three phases we have defined.
In the Enactment Phase, several different sys-
tems are operating in the organization, which can be
categorized in two main types: i) Systems that are
Process-Aware (PAIS) where business processes are
explicit and generally enforced within a process en-
gine, and ii) traditional Systems where processes are
Towards a Data Science Framework Integrating Process and Data Mining for Organizational Improvement
495
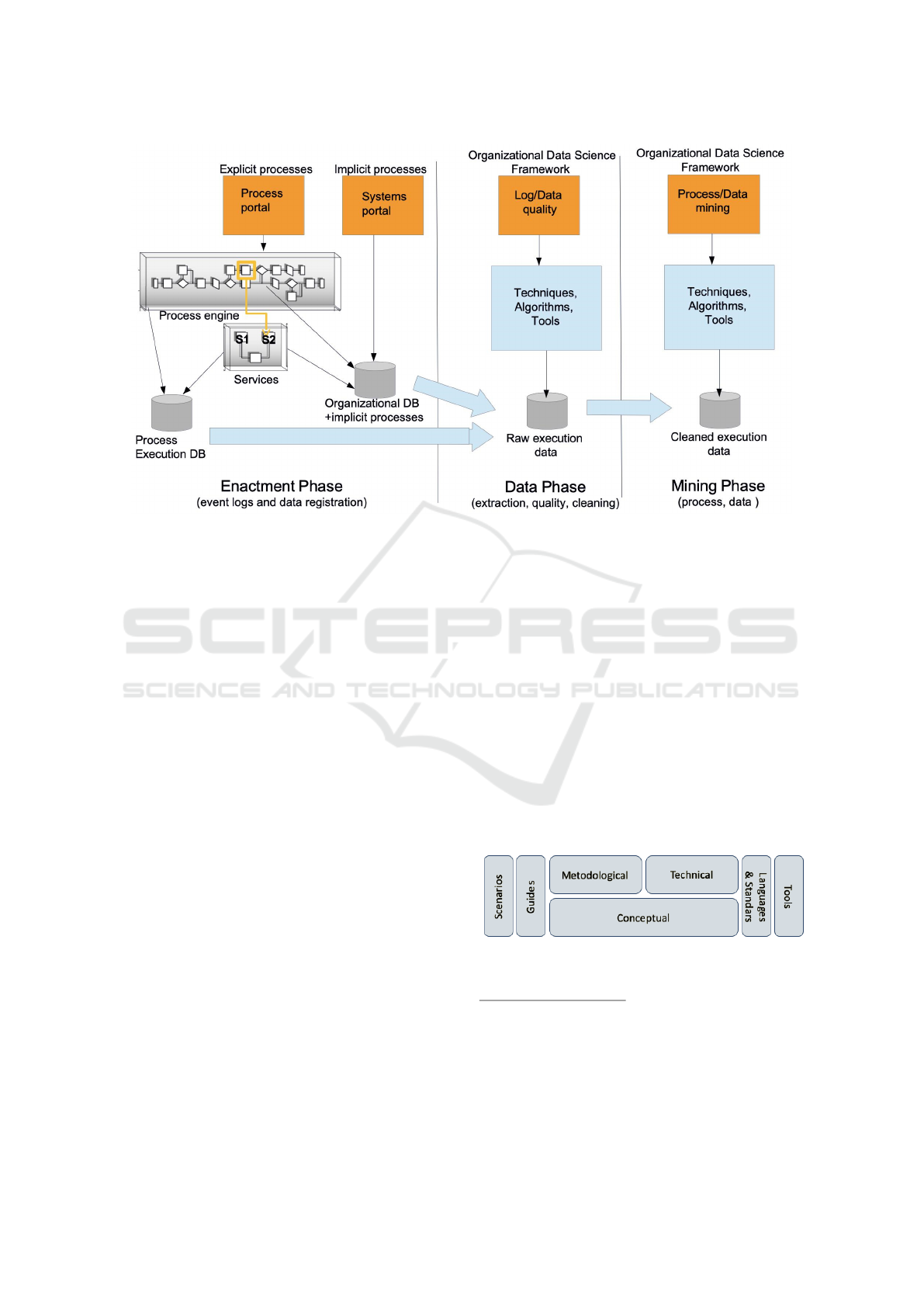
Figure 1: Framework proposal Phases.
implicitly defined and embedded in it. Traces of pro-
cess execution (user tasks, services, business rules)
are registered in the process engine database (i.e. in a
BPMS), whereas organizational data are registered in
the organizational database, along with data from the
implicit processes.
Although some organizational data is registered
in the process engine database, the complete data
is often implemented within activities and regis-
tered directly into the organizational database, with-
out knowledge of the process engine. Then, at least
two (internal) data sources should be taken into ac-
count as input for analysis and evaluation of organi-
zational processes and data. These sources are not
automatically connected (i.e. records in a process -
event log- and the business data that flows with it -
organizational data-) for which the first challenge to
tackle refers to linking enhanced event logs with the
corresponding data in the organizational database.
The Data Phase deals with all aspects of data
preparation, in order to be used as input in the next
phase for process and data mining. The first step
refers to extract data from the sources and put it to-
gether in event logs and database query results. Af-
ter the data is in place and in the correct format, data
quality aspects are reviewed, in order to remove un-
desirable elements before the mining phase, cleaning
the data. Regarding event log data quality aspects we
consider an existing work (Verhulst, 2016), and for
data quality aspects we integrate a data quality frame-
work already defined within the participating research
groups. Finally, in the Mining Phase an integrated
view on process and data mining is used, to provide
organizations with the complete information regard-
ing the operation of their processes and the associ-
ated data. For this, we are working on mining both
processes and data based on existing algorithms and
techniques, enhanced with the correlation of data and
their visualization in an integrated manner.
4.1.2 Static View
The framework comprises seven dimensions in which
elements are defined. These elements are used within
the phases to go from input data to output informa-
tion and business value regarding the real operation
of the organization. In Figure 2 these dimensions are
presented.
Figure 2: Framework proposal dimensions.
Conceptual Dimension: includes the definition of key
concepts for process and data mining, data quality,
and process compliance, that are used within the
framework. Elements such as process traces, event
logs, quality dimensions, policies specification, tech-
niques, and algorithms for process and data mining
such as process discovering and conformance, data
clustering analysis, decision trees, regression, among
ICSOFT 2020 - 15th International Conference on Software Technologies
496

others, are included with detailed definitions and ex-
amples.
Technical Dimension: builds upon the conceptual di-
mension, and includes an exhaustive list of ap-
proaches, techniques, and algorithms used for process
and data mining and their categorization, including
description and operation of each one, data quality,
and process compliance approaches and techniques.
Methodological Dimension: it also builds upon the
conceptual dimension and provides methodological
guides to carry out process and data mining activities,
data quality activities, and process compliance activi-
ties. It defines support processes, roles, artifacts, and
guides for the selection and use of techniques and al-
gorithms, among others. All processes will be spec-
ified in the Eclipse Process Framework (EPF)
2
and
published on the web site of the framework.
Languages & Standards: includes a description of
languages and standards that are used for process and
data mining, such as MXML and XES, BPMN 2.0,
Petri nets, and others for data quality and process
compliance.
Tools: includes a list and description of existing tools
(open source and proprietary) that provide support for
process and data mining, such as the ProM framework
or Disco, and tools for data quality and process com-
pliance.
Guides: includes guides, templates, FAQs, best prac-
tices, and general knowledge management to support
carrying out the activities defined within the frame-
work, as well as related artifacts and documents.
Scenarios: in this dimension, scenarios, and examples
of different identified use cases are provided, in order
to illustrate the adoption of the framework in organi-
zations.
4.2 Preliminary Results
The main preliminary result is the definition and con-
ceptualization of the framework itself, its phases,
and dimensions, as presented above. We have iden-
tified several scenarios for the integration of pro-
cess and organizational data, which includes intra-
organizational processes (orchestrations) and inter-
organizational collaborative processes, and defined
and initial metamodel to support this integration. In
Figure 3 b) we present the initial definition of the in-
tegrated metamodel which extends existing metamod-
els from the previous works (Delgado et al., 2016;
Delgado et al., 2020).
The integrated metamodel is composed of a pro-
cess view and a data view, both of them with two lev-
els of information: definition of elements and their
2
https://www.eclipse.org/epf/
instances. The left-hand side focuses on the defini-
tion of elements such as process which are composed
of process elements (tasks, messages, etc.), variables,
roles, the variables that can refer to data entities com-
posed by attributes. The right-hand side focuses on
the instances of elements defined in the left-hand side,
such as cases (process instances) which are composed
of element instances, variable instances connected
with entity and attribute instances, and users, which
are related within each other in the same way as their
definitions. These elements specify values that evolve
over time. The ElementDefinition concept is used to
connect this metamodel with the specification of pro-
cesses (e.g. BPMN 2.0) and compliance requirements
(described below). The definition of this metamodel
is part of ongoing work.
The aim of this metamodel is to build an ex-
tended event log which contains not only the tradi-
tional process data regarding process execution and
related variables, such as case id, tasks (business
tasks), events (start, complete), timestamps, the orig-
inator (resource), variables data, but also elements
from services execution (internal, external), organiza-
tional data objects (in external BDs such as client, or-
der, etc.), messages exchanged between process par-
ticipants and the associated data, among others. For
doing this, we added concepts for data elements defi-
nition (Entity, Attribute) related to the corresponding
instances (EntityInstance, AttributeInstance) in the
organizational database. We are automating the inte-
gration of data from all the sources mentioned to pop-
ulate the integration metamodel, as well as algorithms
to generate and analyze the extended event log from
these integrated data, including inter-organizational
collaborative process records with several partici-
pants.
Regarding business process compliance, we are
working on processing event logs in a post mortem
fashion in order to analyze each case execution, and
checking whether it presents a violation of the com-
pliance requirements that were specified for the pro-
cess. We are exploring the definition of clusters of
traces that presents the same behavior with respect to
the compliance requirements, in order to further an-
alyze the causes of the violations (i.e. by the orga-
nization, employee, among others) as well as to be
able, for example, to perform preventive actions. For
compliance elements definition we use PL4C specifi-
cations (Gonz
´
alez and Ruggia, 2018).
On the modeling side, we are extending the Busi-
ness Process Model and Notation (BPMN 2.0) to
specify compliance requirements directly over BPMN
2.0 business processes and choreographies, with a
focus on inter-organizational collaborative business
Towards a Data Science Framework Integrating Process and Data Mining for Organizational Improvement
497
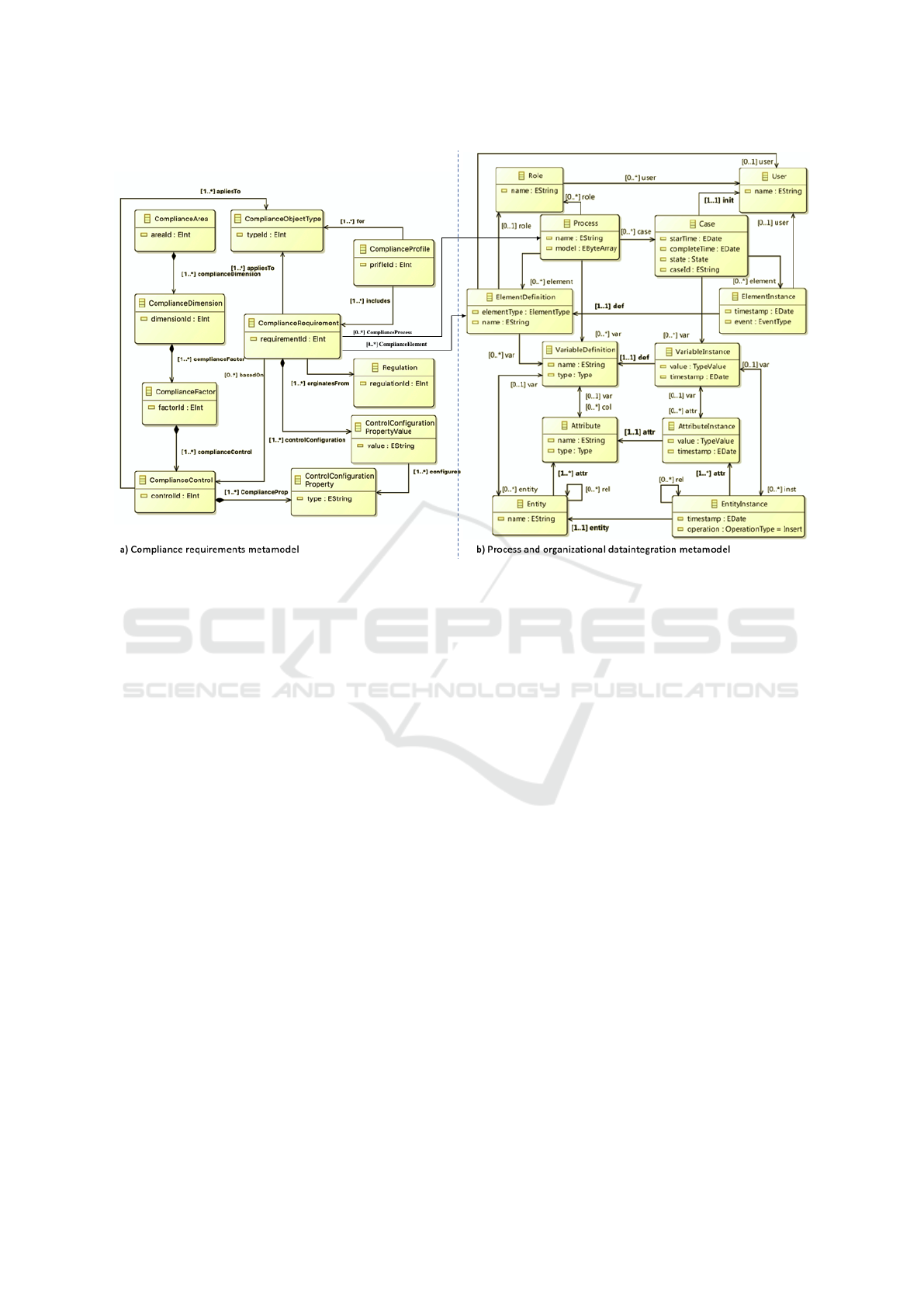
Figure 3: Defined metamodels for: a) compliance requirements, b) process and organizational data integration.
processes. Figure 3 a) presents the compliance
requirements metamodel defined in the context of
(Gonz
´
alez and Ruggia, 2018), where the Compli-
anceRequirements element references the Element-
Definition concept which abstracts the main modeling
elements from BPMN 2.0. Based on this specifica-
tion, we will automatically generate the PL4C speci-
fications which would enable compliance control not
only at runtime but also after execution, by processing
event logs with our process mining approach.
Compliance models define the focal compliance
areas (e.g. Quality of Service, Data quality) and rele-
vant characteristics within these areas (e.g. availabil-
ity, completeness). Compliance requirements specify
general requirements (e.g. response time greater than
1ms) applicable to specific objects types (e.g. opera-
tion, service). Compliance profiles define a set of re-
quirements for the same object type enabling a more
agile specification of a set of requirements for differ-
ent objects of the same type. Applicable regulations
are also managed, which allows relating requirements
with the regulations from which they come from.
Data quality dimensions and factors are mostly
universal, but depending on the specific data under
analysis some aspects will be more important than
others. As we are working with an extended event
log, we consider several elements that are not usually
present in a traditional event log, such as organiza-
tional data, services, messages, etc. We are working
on defining the specific dimensions and factors to in-
tegrate into the framework for the extended event log.
These elements will be added to the previous meta-
model to specify quality requirements over the log.
5 CONCLUSION
We have presented a proposal towards an integrated
framework that helps to analyze execution data in an
integrated manner, both from processes and organiza-
tional data that are handled by those processes, with a
focus on inter-organizational collaborative processes.
The framework aims to support and guide organiza-
tions in the complete process of analyzing their data,
from data extraction, data quality assessment, data
format and selection, data integration, application of
process and data mining techniques and algorithms,
and tool support.
Although initial definitions and conceptualiza-
tions have been made for the framework proposal
which we presented here, many challenges remain.
We are working on obtaining an integrated vision of
execution data from any source within the organi-
zation and from other participant organizations, and
how to apply process and data mining techniques to
the extended execution log we are building. For doing
so, we are extending our previously defined metamod-
els to provide support for that integrated view, includ-
ICSOFT 2020 - 15th International Conference on Software Technologies
498

ing adding specific data quality elements and process
compliance elements to analyze processes behavior.
We believe the framework will help organizations
in getting the most of their data, in an integrated man-
ner, and to use the best tools to support the activities
within each phase, which will be accessible within the
framework.
ACKNOWLEDGEMENTS
Supported by project ”Miner
´
ıa de procesos y datos
para la mejora de procesos en las organizaciones”
funded by Comisi
´
on Sectorial de Investigaci
´
on
Cient
´
ıfica, Universidad de la Rep
´
ublica, Uruguay.
REFERENCES
Andrews, R., Wynn, M., Vallmuur, K., ter Hofstede, A.,
Bosley, E., Elcock, M., and Rashford, S. (2019).
Leveraging data quality to better prepare for process
mining: An approach illustrated through analysing
road trauma pre-hospital retrieval and transport pro-
cesses in queensland. Int. Journal Environment Re-
search and Public Health, 16(7):1138.
Batini, C. and Scannapieco, M. (2016). Data and Informa-
tion Quality - Dimensions, Principles and Techniques.
Data-Centric Systems and Applications. Springer.
Birukou, A., D’Andrea, V., Leymann, F., Serafinski, J., Sil-
veira, P., Strauch, S., and Tluczek, M. (2010). An in-
tegrated solution for runtime compliance governance
in SOA. In SOC, pages 122–136. Springer.
Chang, J. (2016). Business Process Management Systems:
Strategy and Implementation. CRC Press.
de Murillas, E. G. L., Reijers, H. A., and van der Aalst, W.
M. P. (2019). Connecting databases with process min-
ing: a meta model and toolset. Software and Systems
Modeling, 18(2):1209–1247.
Delgado, A., Calegari, D., and Arrigoni, A. (2016). To-
wards a Generic BPMS User Portal Definition for the
Execution of Business Processes. Electronic Notes in
Theoretical Computer Science, 329:39 – 59. CLEI
2016 - The Latin American Computing Conference.
Delgado, A., Calegari, D., Gonz
´
alez, L., Montarnal, A., and
Benaben, F. (2020). Towards a metamodel supporting
e-government collaborative business processes man-
agement within a service-based interoperability plat-
form. In The 53rd Hawaii International Conference
on System Sciences (HICSS-53).
Delgado, A., Gonz
´
alez, L., and Calegari, D. (2017). To-
wards setting up a collaborative environment to sup-
port collaborative business processes and services
with social interactions. In Service-Oriented Comput-
ing - ICSOC Work. and Sat. Events, Revised Selected
Papers, volume 10797, pages 308–320. Springer.
Delgado, A., Ruiz, F., de Guzm
´
an, I. G.-R., and Piattini, M.
(2008-2012). MINERVA: Model drIveN and sErvice
oRiented framework for the continuous business pro-
cess improVement & relAted tools. http://alarcos.esi.
uclm.es/MINERVA/.
Delgado, A., Weber, B., Ruiz, F., de Guzm
´
an, I. G. R., and
Piattini, M. (2014). An integrated approach based on
execution measures for the continuous improvement
of business processes realized by services. Informa-
tion and Software Technology, 56(2):134–162.
Dumas, M., Rosa, M. L., Mendling, J., and Reijers, H. A.
(2018). Fundamentals of BPM, 2nd Edition. Springer.
El Kharbili, M. (2012). Business process regulatory com-
pliance management solution frameworks: A compar-
ative evaluation. In Procs. Eighth Asia-Pacific Conf.
on Conceptual Modelling, APCCM ’12, pages 23–32.
Australian Comp. Soc., Inc.
Elgammal, A., Turetken, O., van den Heuvel, W.-J., and
Papazoglou, M. (2016). Formalizing and appling
compliance patterns for business process compliance.
Software & Systems Modeling, 15(1):119–146.
Fdhila, W., Rinderle-Ma, S., Knuplesch, D., and Reichert,
M. (2015). Change and compliance in collaborative
processes. In 2015 IEEE International Conference on
Services Computing. IEEE.
Fellmann, M. and Zasada, A. (2014). State of the art of
business process compliance approaches. a survey. In
22nd European Conference on Information Systems.
Flouris, I., Giatrakos, N., Deligiannakis, A., Garofalakis,
M. N., Kamp, M., and Mock, M. (2017). Issues in
complex event processing: Status and prospects in
the big data era. Journal of Systems and Software,
127:217–236.
Furht, B. and Villanustre, F. (2016). Introduction to big
data. In Furht, B. and Villanustre, F., editors, Big Data
Technologies and Applications, pages 3–11. Springer.
Gonz
´
alez, L. and Ruggia, R. (2011). Addressing qos issues
in service based systems through an adaptive ESB in-
frastructure. In Proc. 6th Workshop on Middleware for
Service Oriented Computing, MW4SOC 2011, page 4.
ACM.
Gonz
´
alez, L. and Ruggia, R. (2018). A comprehen-
sive approach to compliance management in inter-
organizational service integration platforms. In Procs.
13th International Conference on Software Technolo-
gies, ICSOFT 2018, pages 722–730. SciTePress.
Gonz
´
alez, L. and Ruggia, R. (2018). Policy-based compli-
ance control within inter-organizational service inte-
gration platforms. In Procs. 11th Conference on Ser-
vice Oriented Computing and Applications (SOCA).
IEEE.
Gupta, M. and Chandra, P. (2020). A comprehensive survey
of data mining. International Journal of Information
Technology.
Han, J., Pei, J., and Kamber, M. (2011). Data mining: con-
cepts and techniques. Elsevier.
Hashmi, M., Governatori, G., Lam, H.-P., and Wynn, M. T.
(2018). Are we done with business process compli-
ance: state of the art and challenges ahead. Knowledge
and Information Systems, 57(1):79–133.
Hevner, A. R., March, S. T., Park, J., and Ram, S. (2004).
Towards a Data Science Framework Integrating Process and Data Mining for Organizational Improvement
499

Design science in information systems research. MIS
Quarterly, 28(1):75–105.
IEEE (2020). Task Force on Data Science and Advanced
Analytics. http://www.dsaa.co/.
Iivari, J. and Venable, J. (2009). Action research and design
science research - seemingly similar but decisively
dissimilar. In 17th European Conference on Informa-
tion Systems, ECIS, Verona, Italy, pages 1642–1653.
Kitchenham, B. (2004). Procedures for performing system-
atic reviews. Technical Report TR/SE-0401, Keele
University.
Kitchenham, B. and Charters, S. (2007). Guidelines for per-
forming systematic literature reviews in software en-
gineering. Technical Report EBSE-2007-01, EBSE.
Knuplesch, D., Reichert, M., and Kumar, A. (2017). A
framework for visually monitoring business process
compliance. Information Systems, 64:381–409.
Ong, K.-L., De Silva, D., Boo, Y. L., Lim, E. H., Bodi, F.,
Alahakoon, D., and Leao, S. (2016). Big Data Appli-
cations in Eng. and Science, pages 315–351. Springer.
P
´
erez-Castillo, R., de Guzm
´
an, I. G. R., and Piattini, M.
(2011). Business process archeology using MAR-
BLE. Journal of Information and Software Technol-
ogy, 53(10):1023–1044.
Radesch
¨
utz, S., Mitschang, B., and Leymann, F. (2008).
Matching of process data and operational data for a
deep business analysis. In Procs. 4th Int. Conference
on Interoperability for Enterprise SW and Applica-
tions, IESA, pages 171–182. Springer.
Radesch
¨
utz, S., Schwarz, H., and Niedermann, F. (2015).
Business impact analysis - a framework for a com-
prehensive analysis and optimization of business pro-
cesses. Computer Science and Research Development,
30(1):69–86.
Ramezani, E., Fahland, D., van der Werf, J. M., and
Mattheis, P. (2012). Separating compliance manage-
ment and bpm. In BPM Workshops, pages 459–464.
Springer.
Scannapieco, M. and Catarci, T. (2002). Data quality under
a computer science perspective. Archivi & Computer,
page 2:1–15.
Shankaranarayanan, G. and Blake, R. (2017). From content
to context: The evolution and growth of data quality
research. J. Data and Inf. Quality, 8(2):9:1–9:28.
Sumathi, S. and Sivanandam, S. N. (2006). Introduction to
Data Mining and its Applications, volume 29 of Stud-
ies in Computational Intelligence. Springer.
Tran, H., Zdun, U., Holmes, T., Oberortner, E., Mulo,
E., and Dustdar, S. (2012). Compliance in service-
oriented architectures: A model-driven and view-
based approach. Information and Software Technol-
ogy, 54(6):531–552.
Tsoury, A., Soffer, P., and Reinhartz-Berger, I. (2018).
A conceptual framework for supporting deep explo-
ration of business process behavior. In Conceptual
Modeling - 37th Int. Conference, ER 2018, Procs.,
volume 11157 of LNCS, pages 58–71. Springer.
van der Aalst, W. M. P. (2013). Process cubes: Slicing, dic-
ing, rolling up and drilling down event data for process
mining. In Asia Pacific BPM Conf. AP-BPM, Selected
Papers, volume 159 of LNBIP, pages 1–22. Springer.
van der Aalst, W. M. P. (2016). Process Mining - Data
Science in Action, 2nd Edition. Springer.
van der Aalst, W. M. P. and Damiani, E. (2015). Processes
meet big data: Connecting data science with process
science. IEEE Transactions on Services Computing,
8(6):810–819.
van der Aalst, W. M. P., ter Hofstede, A. H. M., and Weske,
M. (2003). Business process management: A sur-
vey. In Business Process Management, International
Conference, BPM 2003, Proceedings, volume 2678 of
LNCS, pages 1–12. Springer.
Verhulst, R. (2016). Evaluating quality of event data within
event logs: an extensible framework. Master’s thesis,
TU/e Eindhoven University of Technology.
Weske, M. (2019). BPM - Concepts, Languages, Architec-
tures, 3rd Edition. Springer.
Wieringa, R. J. (2014). Design Science Methodology for
Inf. Systems and Software Engineering. Springer.
Yin, R. K. (2014). Case Study Research: Design and Meth-
ods, 5th edition. SAGE Publications, Inc.
ICSOFT 2020 - 15th International Conference on Software Technologies
500
