
Identity Linking in Computer Networks
Libor Pol
ˇ
c
´
ak
a
, Ond
ˇ
rej Ry
ˇ
sav
´
y
b
and Petr Matou
ˇ
sek
c
Brno University of Technology, Faculty of Information Technology, Centre of Excellence IT4Innovations,
Bo
ˇ
zet
ˇ
echova 2, 612 66 Brno, Czech Republic
Keywords:
Cross-layer Identity Linking, Identifiers, Graph of Identifiers, Applications of Labeled Property Graphs.
Abstract:
Lawful interception, network forensics, and security incident investigations require cross-layer linking of iden-
tification information to link different activities of a particular person. This paper presents a model called
graphs of identifiers that allows cross-layer linking of identifiers detected by various methods. Graphs of iden-
tifiers provide operations that link identifiers according to the constraints provided in the queries. The goal is
to employ the linking during early stages of the network forensic investigations when an investigator searches
for leads. The tools that implement the proposed model are publicly available.
1 INTRODUCTION
Identifiers appearing in the network identify differ-
ent subjects (Pfitzmann and Hansen, 2010), for exam-
ple, human beings, legal persons, or computers. For
many network-related tasks spanning lawful intercep-
tion, network forensics, and security incident inves-
tigation, it is necessary to link identities of different
subjects. The linking is necessary to answer questions
such as Who was using the computer with a particular
IP address last Friday at 5 PM?
An IP address identifies a computer interface.
However, an IP address is not stable (Pol
ˇ
c
´
ak et al.,
2014b) and can be hidden behind a network address
translation (NAT). At the application layer, users au-
thenticate to various services. They open sessions,
each of which is carried over one or more TCP
or UDP connections. All communication can be
identified with identifiers occurring inside the traffic
flow (FIDIS project, 2008b).
This paper proposes graphs of identifiers based on
undirected labeled property graphs (Robinson et al.,
2015). A graph of identifiers can link identifiers
used by a particular subject and link different subjects
based on the relationships between the subjects. The
model and operations in the model described in this
paper are available in a tool called linking
1
.
This work enhances the graph model established
a
https://orcid.org/0000-0001-9177-3073
b
https://orcid.org/0000-0001-9652-6418
c
https://orcid.org/0000-0003-4589-2041
1
https://github.com/polcak/linking
by (Pol
ˇ
c
´
ak et al., 2014b). Comparably, this paper rep-
resents identifiers as nodes in a graph. The novelty
of the model presented in this paper lays in assign-
ments of key-value pairs to both nodes and relation-
ships. This improves the information that can be re-
vealed by the model:
• Time is an inherent component of graphs of iden-
tifiers. Hence, it is possible to track and investi-
gate time-related identifier linking which is cru-
cial for fields such as network forensics and secu-
rity incident investigations.
• The model supports probabilistic identification
methods (Pfitzmann and Hansen, 2010) — meth-
ods that are not able to indisputably reveal the sub-
ject represented by an identifier. Instead, such
method reveals the identity with some degree of
certainty. Graphs of identifiers support linking of
identifiers detected by probabilistic identification.
Hence, during network forensics, it is possible to
treat all identification information as inaccurate,
see (Casey and Jaquet-Chiffelle, 2017) for more
information on the need for careful examination
during network forensics.
• The model considers resources such as web pages
or chat rooms. The underlying labeled property
graphs allow a definition of additional categories
of identifiers.
• We provide more operations compared to the orig-
inal model with the possibility to define even more
operations. The operations are defined as walks in
the labeled property graphs.
Pol
ˇ
cák, L., Ryšavý, O. and Matoušek, P.
Identity Linking in Computer Networks.
DOI: 10.5220/0009783500450052
In Proceedings of the 17th International Joint Conference on e-Business and Telecommunications (ICETE 2020) - DCNET, OPTICS, SIGMAP and WINSYS, pages 45-52
ISBN: 978-989-758-445-9
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
45

This paper primarily uses the terminology established
by (Pfitzmann and Hansen, 2010). An identifier is
a unique attribute value of the subject. FIDIS project
introduced a concept of natural persons and virtual
persons (FIDIS project, 2008a). According to the ter-
minology established by FIDIS, the model established
in this paper links identifiers in the virtual world only.
This paper is organized as follows. Section 2
overviews scenarios that benefit from identifier link-
ing. Section 3 positions this paper to the related work.
Section 4 reviews methods and information sources
that reveals identifiers used in the network. Revealed
identifiers are used to build graphs of identifiers as de-
scribed in Section 5. Section 5 also defines operations
in graphs of identifiers. Section 6 describes the vali-
dation of the method. Section 7 concludes the paper.
2 SCENARIOS
This section lists several scenarios that benefit from
identifier linking.
Lawful Interception. (ATIS/TIA, 2006; ETSI,
2009) allows an authorized law enforcement agency
(LEA) to capture network traffic of criminal suspects.
For each intercept, the LEA provides an identifier that
identifies the suspect to a service provider or a net-
work operator. However, the network of the operator
can be designed in a way in which it is not straight-
forward to carry the interception. For example, a law-
ful interception system has to be able to determine all
IP addresses used by devices in the network and link
them to the suspect.
Nevertheless, sometimes the warrant authoriz-
ing lawful interception provides some restrictions on
the identifiers allowed for the interception. For ex-
ample, a warrant can list an IP address and allow in-
terception of data identified by the particular IP ad-
dress only. Any other address even if it is certain that
the other address belongs to the same computer can-
not be intercepted. Other warrants may allow inter-
ception of all traffic of the computer. Hence, the link-
ing should be customizable.
Data Retention. (ETSI, 2015): providers of elec-
tronic communications services or public communi-
cation networks collect metadata about all communi-
cation in the network. Authorized LEA can obtain
metadata about communication. A service provider or
a network operator that receives a data retention war-
rant has to find all identifiers used by the suspect dur-
ing a listed period. Hence, it is crucial that the linking
mechanism support time-related queries.
Network Forensics. entails the separation of sus-
pect traffic from other communication to reduce
the amount of information that needs to be analyzed
and to avoid privacy infringements of benign users.
Nevertheless, as (Casey and Jaquet-Chiffelle, 2017)
note, there is always an uncertainty in confidence
in the online traces. Malware, identity thefts, and
the integrity of the input data are a significant con-
cern. Hence, during network forensic investigation,
it is necessary to take into account the confidence in
the identification data.
Security Incident Investigation. Computer emer-
gency response teams (CERTs) and computer se-
curity incident response teams (CSIRTs) investigate
network security incidents. One of the tasks of
the CERT/CSIRT team investigating an incident is to
learn the identity of the attacker. For the investigation
of the security incident, it can be necessary to link
identifiers stored in different sources, sometimes even
including end stations.
3 RELATED WORK
Identification in digital environment faces several is-
sues. It is common that a single natural person
has multiple online identities (Furnell, 2010; FIDIS
project, 2009; Casey and Jaquet-Chiffelle, 2017).
Also, identity theft and the use of false identity com-
plicates the identification. The challenge in the cur-
rent forensic investigation is to prove that the suspect
was using the device at the incriminated time, so it is
possible to link her responsibility for the actions taken
by the device (Jones and Martin, 2010). This paper
does not address the linking between natural persons
and virtual persons. Nevertheless, the operations al-
lows linking different virtual identities which can be
helpful for the identification of the suspect.
(Casey, 2011) emphasizes the need to link iden-
tifiers based on specific network parameters and
the limits imposed by law. The graphs of identifiers
link information revealed from various information
sources. Moreover, the operations can limit the scope
of allowed linking on a per-query basis. Each query
can be limited by time and inaccuracy constraints.
(Da-Yu Kao, 2015) proposes People-Process-
Technology-Strategy model to investigate advanced
persistent threats, that is stealthy network attacks in
which unauthorized persons gain access to a network
and remain undetected for a long period. As Da-Yu
Kao explains, the technology part of the model ben-
efits from identity linking. Graphs of identifiers help
DCNET 2020 - 11th International Conference on Data Communication Networking
46

to achieve the goal to provide tools to execute time-
dependent queries.
(Atsa Etoundi Roger and Mboupda Moyo Achille,
2012) describe a network forensic model for proac-
tive, reactive, and active investigation. One of
the steps during the forensics is the analysis of gath-
ered evidence. As the evidence is coming from many
sources, the analysis can benefit from graphs of iden-
tifiers. Nevertheless, expertise supervision on the re-
sults of queries in the model is necessary.
Evidence revealed during a forensic investigation
has only a limited level of certainty (Casey, 2011;
Casey and Jaquet-Chiffelle, 2017). Graphs of iden-
tifiers support both accurate and inaccurate relation-
ships. The linking operations consider the inaccu-
racy and queries can limit linking of inaccurate evi-
dence. Nevertheless, the intended use of the tools is in
the early phases of the investigative process (Jackson
et al., 2006) when the investigator is looking for leads.
The investigator can provide thresholds for acceptable
inaccuracy using linking
1
. It is up to the investiga-
tor to link revealed partial identities (Pfitzmann and
Hansen, 2010) and virtual persons (FIDIS project,
2008a) to the physical world entities.
(Carmagnola et al., 2010; Ye Na et al., 2013;
Peled et al., 2013) focus on identity linking of iden-
tities in social network websites. This paper provides
a method of generalized linking that covers various
information sources. Moreover, the linking methods
that detect profiles of the same person on different so-
cial network websites can be used as another source
of relationships between identifiers. The profile iden-
tification on a social network is an account identifier
of category L7User as specified in Section 5.
The main contribution of this paper is the graph
model that links identifiers learned from various
sources that can be distributed in the network envi-
ronment. Graphs of identifiers extend previous work
introduced by (Pol
ˇ
c
´
ak et al., 2014b). Graphs of iden-
tifiers described in this paper provide multiple ad-
vantages compared to the previous work, such as the
extensibility, time-related queries, support for iden-
tification methods with limited certainty. The en-
hanced model described in this paper is implemented
in the tool linking
1
.
4 DETECTION OF IDENTIFIERS
Identifiers can be detected from many sources in
the network and network hosts. Current research al-
ready considers various options to learn identification
information. Let us summarize the options.
• Network traffic: network protocols usually rely on
identifiers (FIDIS project, 2008b). The presence
of a source and destination identifier is often nec-
essary to enable the communication between re-
mote parties. Netflow/IPFIX data provide meta-
data about the traffic flows in the network.
• Log files, temporary and cache files, and his-
tory files reflect events that occurred on a com-
puter system. Events in server logs are typically
connected to network-related identifiers (Casey,
2011). See Figure 1 for example of log entries.
• Locally stored information such as hard drives
and other storage mediums. Tools such as
Autopsy
2
or AUDIT (Karabiyik and Aggarwal,
2014) analyze the content of hard drives includ-
ing deleted files. Besides the content of the files,
metadata, such as the owner, group, or last modi-
fication time are also available.
• Hidden identifiers are unique characteristics that
are specific to the deployed software or hard-
ware of a unique user, site, or a small set of
users. For example, hidden identifiers are browser
fingerprints (Laperdrix et al., 2020), communi-
cation patterns (Banse et al., 2012; Herrmann
et al., 2012; Kirchler et al., 2016), and clock skew
(Kohno et al., 2005; Pol
ˇ
c
´
ak and Frankov
´
a, 2015) .
(a) 192.168.9.5 - - [04/Nov/2016:15:21:02 +0000]
”GET /phpMyAdmin/scripts/setup.php HTTP/1.1”
403 237 ”-” ”ZmEu”
(b) Nov 4 15:06:41 server dhcpd: DHCPACK on
192.168.9.5 to fc:55:47:00:4f:90 (R1) via em0
(c) Nov 4 15:22:52 server postfix/smtpd[1234]:
Anonymous TLS connection established from
dhcp1.example.com[192.168.9.5]: TLSv1.2 with
cipher AECDH-AES256-SHA (256/256 bits)
Figure 1: An example of log files: (a) web server, (b) DHCP
server, (c) SMTP server.
Many sources of identification are scattered in
the network environment. Even though a single in-
vestigation case typically employs only a subset of
the discussed identification methods, there is a need
to link the scattered information. Graphs of identifiers
proposed in Section 5 can utilize any source of iden-
tifiers. Each detected relationship between identifiers
can be limited in time. Additionally, the identification
method should report the uncertainty of the relation-
ship as inaccuracy. The identification method is in
the best position to quantify the possible inaccuracy
of the provided information as it knows the trustwor-
thiness of its sources and its detection abilities. Re-
call that in some scenarios, such as network forensics,
2
https://www.sleuthkit.org/autopsy/
Identity Linking in Computer Networks
47

all sources have some level of uncertainty depending
on the possibility to alter the information (Casey and
Jaquet-Chiffelle, 2017).
5 IDENTIFIER LINKING
Section 4 identified various sources of identification
information in the network and on network hosts.
However, the mere knowledge that some identifiers
do exist or did exist at some time is only of limited
use for the use cases established in Section 2. This
section provides the main contribution of this paper
— the model that links the information based on user-
specified queries. Subsection 5.1 divides the iden-
tifiers into categories according to their similarities,
such as durability and the identified subject. Sub-
section 5.2 defines the graphs of identifiers based on
undirected labeled property graphs (Robinson et al.,
2015). Finally, Subsection 5.3 defines operations in
the graphs of identifiers as implemented by linking
1
.
5.1 Categories of Identifiers
Even though the identifiers can be learned by various
methods, there are some similarities between iden-
tifiers. We divide identifiers into categories; each
contains identifiers of the same subject — a per-
son, a computer, or a resource. The categories also
reflect the occurrence of the identifiers, for exam-
ple, the identifier appears in each network packet, or
the identifier appears during an authentication phase
of a protocol only. Last but not least, the categories re-
flect the duration of the identifiers: long-term or short-
term. We consider virtual identifiers (FIDIS project,
2008a) only. The goal of the categories is to gener-
alise the similarities in identifiers so that it is possible
to define useful operations. The categories are based
on categories established by (Pol
ˇ
c
´
ak et al., 2014b)
with two differences: (1) the categories are labeled
and (2) we add the category L7Resource.
We distinguish the following categories:
L4Flow — Bi-directional TCP and UDP flows.
IPAddr — IP addresses (typically short-term dura-
tion and dynamically assigned) identify an inter-
face of a network node.
IfcOrComp — Long-term identifiers of computers
or network interfaces, such as MAC addresses,
DUIDs, and hidden identifiers, such as clock skew
values and browser fingerprints.
AAAUser — Usernames of authentication protocols
such as RADIUS, or PPP that identify a set of net-
work devices controlled by a unique virtual per-
son or a household depending on the network.
L7User — Application layer usernames (for exam-
ple, login names, account identifiers, e-mail ad-
dresses) identify a unique virtual person in a spe-
cific context or a role. Usually, application layer
usernames appear at least once in each session
of an application layer protocol. Nevertheless,
such session may be composed of several trans-
port layer flows (for example, SIP, FTP).
L7Resource — An application layer resource such as
a chat room or a web page URI.
AAAUser and L7User identifiers are very close to
the natural person whereas L4Flow and IPAddr iden-
tify devices. As the use cases often seek for trans-
lation between natural persons and devices or vice
versa, such identifiers are common input or output
identifiers of the queries in the proposed model.
5.2 Graph Model for Identifier Linking
For identifier linking, we store identifiers in an undi-
rected labeled property graph (Robinson et al., 2015).
A labeled property graph consists of nodes (vertices)
and relationships between nodes; each relationship
is represented as an oriented edge connecting two
nodes. A labeled property graph allows multiple rela-
tionships between a pair of nodes. Both nodes and re-
lationships can contain properties as key-value pairs.
In the proposed model, each node (vertex) repre-
sents a single identifier. Additionally, each node con-
tains the category of the node as a property. The edges
of the proposed model have no orientation.
When an identity source detects a connection be-
tween identifiers, the relationship is inserted into
the graph of identifiers as an edge. Each relation-
ship is valid during a specific period; the relationship
can have an inaccuracy quantified by the detection
method. The detection method, validity, and inaccu-
racy are stored as properties of the relationships in
undirected labeled property graphs.
For example, the IP address of a computer of John
Doe can be configured through a dynamic protocol
such as RADIUS. In that case, the virtual person au-
thenticates a device to the network, and the network
assigns the device a dynamic IPv4 address. Such as-
signment is stored in a RADIUS server log files; it
can also be learned from an analysis of RADIUS traf-
fic. In addition, the device might obtain an IPv6 pre-
fix through DHCPv6. Figure 2 shows the graph con-
structed in this example.
DCNET 2020 - 11th International Conference on Data Communication Networking
48
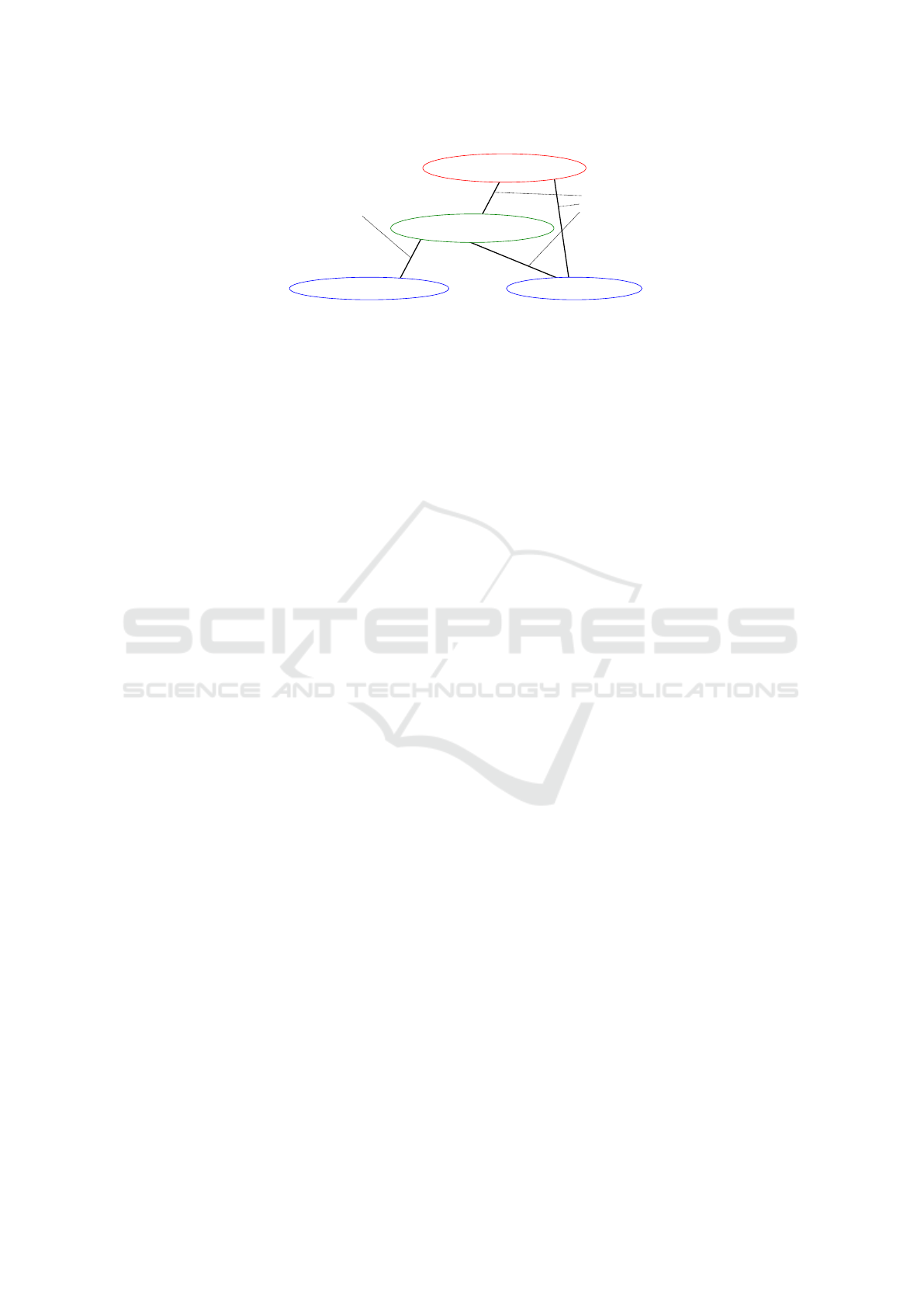
AAAUser
RadiusLogin: JohnDoe
IfcOrComp
MAC: aa:bb:cc:00:11:22
IPv4: 10.0.0.1
IPAddr
source RADIUS log
valid from
2017-01-01T12:00
valid to
2017-01-01T13:00
inaccuracy 0
IPv6: 2001:db8::/64
source DHCPv6 log
valid from 2017-01-01T12:01
valid to 2017-01-01T12:31
inaccuracy 0
Figure 2: An example of a simple graph of detected identifiers.
5.3 Operations in Graphs of Identifiers
This subsection specifies the operations designed for
queries during lawful interception, data retention, net-
work forensics, and security incident investigation.
For lawful interception, we define operations reflect-
ing the specific wording of a warrant. Note that it
is possible to limit queries in graphs of identifiers
by multiple constraints at the same time. A query
with multiple constraints yields identifiers that are ac-
cepted by all constraints.
The queries are defined as walks in the graph.
For mathematical definitions of most of the opera-
tions presented in this paper refer to the Ph.D. the-
sis (Pol
ˇ
c
´
ak, 2017).
5.3.1 Constraining Relations between Identifiers
For both network forensics and lawful interception,
it is essential to limit identifier linking based on
the relationship between the identifiers. For example,
(1) Were all linked identifiers used by the same com-
puter? (2) Do all linked identifiers identify the same
virtual person?
Based on the restrictions on allowed relation-
ships (edges) between identifiers (nodes), the identity
graphs support the following constraints:
Other Corresponding Identifiers. This constraint
aims at cases like a warrant to intercept network traffic
linkable to a DHCPv6 DUID. The intercept should
cover all IP addresses leased to the DHCPv6 DUID,
but it must not cover other IP addresses even if they
are assigned to the same interface.
Identifiers of a Specific Computer. The goal is to
detect identifiers belonging to the same computer. For
example, a lawful interception warrant may require
capturing all traffic of a computer, or, a forensic inves-
tigator analyses if two IP addresses belong to the same
computer.
Note that the input identifier for this constraint has
to be an identifier of a computer or a computer net-
work interface(IPAddr or IfcOrComp).
Identifiers of Computers Where a Specific Virtual
Person Was Authenticated or Logged in. Some-
times, a lawful interception warrant orders intercep-
tion of all traffic of all computers authenticated by
a specific virtual person or a digital forensic inves-
tigator needs such identifiers.
The input identifier of this constraint is an iden-
tifier of a virtual person, hence, only AAAUser or
L7User identifiers are allowed.
Identifiers of All Virtual Persons Accessing
a Specific Resource. When network forensics in-
vestigator needs to know what users have seen a spe-
cific resource, this constrain reveals the information.
All IP Addresses Accessing a Specific Resource.
For network forensics focusing on a resource, it is
usually beneficial to learn all IP addresses that ac-
cessed the resource.
All Login Aliases. A single person can use multiple
L7User identifiers in parallel. Hence, it is beneficial
to have an operation to learn all detected names be-
longing to a single person — aliases.
All User Accounts Logged in or Authenticated
from a Computer or a Set of Computers. The
goal is to reveal all virtual person identifiers linkable
to an identifier of a computer identified by a category
IPAddr or IfcOrComp identifier, or a set of computers
linkable to a category AAAUser or L7User identifier.
All Accessed Resources. The goal is to determine
all resources accessed by a particular virtual person
(identified by a category AAAUser or L7User identi-
fier) or a particular computer (identifier by a category
IPAddr or IfcOrComp) identifier.
Identity Linking in Computer Networks
49

5.3.2 Time Restrictions
The time limitations are essential for all considered
scenarios. Consider the following constraints:
• The investigator is interested only in identifiers
active during a particular period determined by
the investigator. Finding such identifiers in
a graph of identifiers consists of finding a path be-
tween the input identifier and the linked identifier,
such as all the relationships (edges) on the path
are valid during the whole period.
• The investigator is interested only in identifiers
active at any time during a particular period deter-
mined by the investigator. In this case, the path
consists of relationships (edges) that are valid
at some moment of the previous relationship on
the path and during the input period.
5.3.3 Path Inaccuracy
In case that some linking information is based on in-
accurate sources such as hidden identifiers (see Sec-
tion 4) or in case of network forensics investiga-
tion (Casey and Jaquet-Chiffelle, 2017), the linking is
not transitive. Let us define a cumulative inaccuracy
for a path in a graph of identifiers as the sum of the in-
accuracy of all edges on the path. Then, the query
in the graph can be limited with a threshold specify-
ing the maximal inaccuracy of the path from the input
identifier to the linked identifier. Another inaccuracy
constraints is to ignore all paths with an edge with a
cost higher than a threshold.
Note that the model expects that the accuracy is
specified by all detection methods with the same met-
ric and that the metric is additive. We leave the defi-
nition of a universal metric for future research.
6 VALIDATION
The original mechanism (Pol
ˇ
c
´
ak et al., 2014b) to link
identities is a part of the lawful interception system
3
developed at our university. The extended model pro-
posed in Section 5 released as open source software
linking
1
.
As a part of the lawful interception system,
graphs of identifiers were able to link identities that
were learned from many sources including DHCP,
DHCPv6, SLAAC (and IPv6 neighbor discovery in
general), PPPoE, RADIUS, XMPP, OSCAR, IRC,
YMSG, and SMTP. Identifiers from these protocols
3
http://www.fit.vutbr.cz/
∼
ipolcak/prods.php.en?id=
397¬itle=1
were linked with IP addresses; which in turn were
used by custom 1 and 10 Gbps probes to capture traf-
fic of the suspects.
Validation in Simulated Network. Consider an ex-
ample of a simulated network of an IPv6-enabled in-
ternet provider network. The provider authenticates
the MAC address of all devices by RADIUS. Each
device leases an IPv4 address and generates IPv6 ad-
dresses as the device needs (Narten et al., 2007). Fig-
ure 3 shows results of a complex forensic investiga-
tion in the simulated network. The example consid-
ers two monitoring scenarios: local and remote. In
the local monitoring scenario, the graph of identifiers
is constructed from information in local networks, in
this case, RADIUS log files, DHCP log files, and IPv6
neighbor discovery tracking (Pol
ˇ
c
´
ak et al., 2014a). In
a remote scenario, the data in Figure 3 reflects the in-
ability to obtain the data used for local monitoring;
instead, the graph of identifiers for remote monitor-
ing is based on inaccurate data sources.
• The number of active IP addresses in the network
equals to a sum of the number of IP addresses re-
vealed by learning other corresponding identifiers
to each RADIUS login at a particular time.
• The average number of IP addresses linked to
each active IPv4 address in local monitoring is
computed by learning active IPv4 addresses at
each evaluation time t
e
and the number of linked
IP addresses to the input address by learning iden-
tifiers of a specific computer at the time t
e
.
• To present comparable results, the average num-
ber of IP addresses linked to each active IPv4 ad-
dress in remote monitoring is computed by learn-
ing active IPv4 addresses at each evaluation time
t
e
and the number of linked IP addresses evaluat-
ing the same query with an inaccuracy thresholds
of 3, 5, and 10 for the whole path.
As obvious from the Figure 3, the local and re-
mote monitoring use case provides the forensic inves-
tigator with different results. By modifying the inac-
curacy threshold, the forensic investigator can focus
only on data that most probably belong to the subject
of the investigation.
7 CONCLUSION
There are many sources of identifiers in computer net-
works. One of the challenges is to link information re-
vealed by several sources and methods. The linking is
DCNET 2020 - 11th International Conference on Data Communication Networking
50
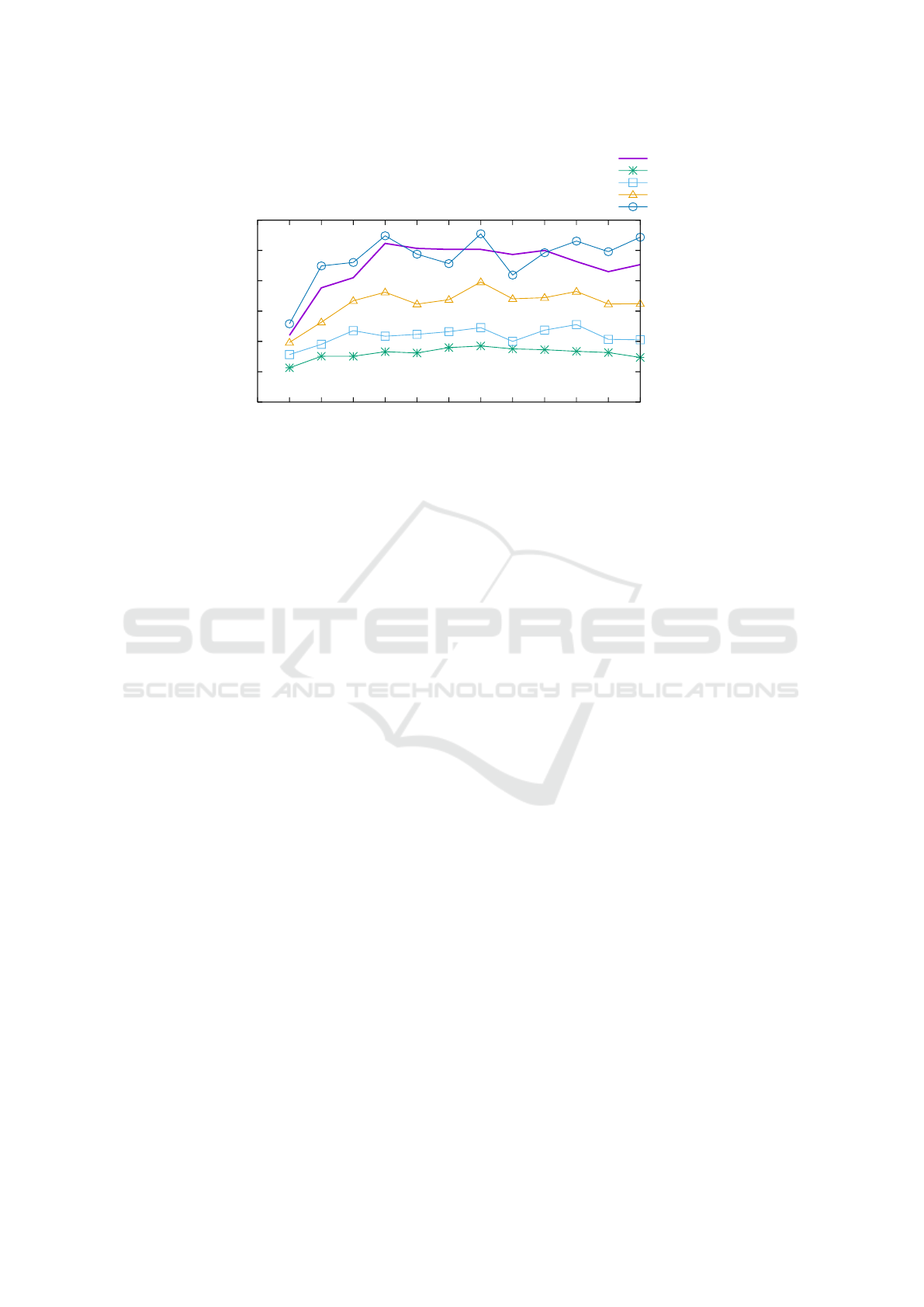
0
1
2
3
4
5
6
0 30 60 90 120 150 180 210 240 270 300 330 360
0
30
60
90
120
150
180
Avg number of linked IP addresses
Count of detected IP addresses
Time of the monitoring [minutes]
Detected number of IP addresses
Local: average number of linked IP addresses
Remote: average number of linked IP addresses (max inacc. 3)
Remote: average number of linked IP addresses (max inacc. 5)
Remote: average number of linked IP addresses (max inacc. 10)
Figure 3: The number of detected IP addresses (right y axis) and linked average number of IP addresses (left y axis) in
the simulated internet service provider network.
applicable in (1) lawful interception as a lawful inter-
ception system has to identify traffic of an intercep-
tion target according to the warrant allowing the in-
tercept, (2) data retention queries, (3) early stages of
network forensic investigative process, and (4) secu-
rity incident investigations.
This paper describes graphs of identifiers that ex-
tend the work of (Pol
ˇ
c
´
ak et al., 2014b). Graphs of
identifiers can be built based on information from var-
ious sources, including traffic traces, log files, and
inaccurate identification methods. One of the essen-
tial extensions to the previous work is the time that
is an inherent part of graphs of identifiers. Conse-
quently, the investigation queries support time-related
queries. Another significant extension is the support
of inaccurate identification methods which quantify
the inaccuracy for each reported relation between two
identifiers.
The tool linking
1
is freely available and imple-
ments queries in graphs of identifiers as described in
this paper. We also provide an extensible log files con-
verter that currently allows processing log files of ISC
DHCP server and NCSA common/combined log for-
mat.
ACKNOWLEDGEMENTS
This work was supported by The Ministry of Ed-
ucation, Youth and Sports of the Czech Republic
from the National Programme of Sustainability (NPU
II); project IT4Innovations excellence in science -
LQ1602. We thank Frank Breitinger for his help dur-
ing the preparation of this paper.
REFERENCES
ATIS/TIA (2006). Lawfully Authorized Electronic Surveil-
lance. J-STD-025-B. Alliance for Telecommunica-
tions Industry Solutions/Telecommunications Indus-
try Association Joint Standard.
Atsa Etoundi Roger and Mboupda Moyo Achille (2012).
Multi-perspective cybercrime investigation process
modeling. International Journal of Applied Informa-
tion Systems, 2(2):14–20.
Banse, C., Herrmann, D., and Federrath, H. (2012). Track-
ing users on the internet with behavioral patterns:
Evaluation of its practical feasibility. In Information
Security and Privacy Research, volume 376 of IFIP
Advances in Information and Communication Tech-
nology, pages 235–248. Springer Berlin Heidelberg,
DE.
Carmagnola, F., Osborne, F., and Torre, I. (2010). User
data distributed on the social web: How to identify
users on different social systems and collecting data
about them. In Proceedings of the 1st International
Workshop on Information Heterogeneity and Fusion
in Recommender Systems, HetRec ’10, pages 9–15,
New York, NY, USA. ACM.
Casey, E. (2011). Digital Evidence and Computer Crime:
Forensic Science, Computers and the Internet. Aca-
demic Press, Elsevier Inc., USA. Third Edition.
Casey, E. and Jaquet-Chiffelle, D.-O. (2017). Do identities
matter? Policing: a Journal of Policy and Practice,
(Special Issue):1–14.
Da-Yu Kao (2015). Performing an APT investigation: Us-
ing people-process-technology-strategy model in dig-
ital triage forensics. In 2015 IEEE 39th Annual
Computer Software and Applications Conference, vol-
ume 3, pages 47–52.
ETSI (2009). ETSI TR 101 331: Lawful Interception (LI);
Requirements of Law Enforcement Agencies. Euro-
Identity Linking in Computer Networks
51

pean Telecommunications Standards Institute. Ver-
sion 1.3.1.
ETSI (2015). ETSI TS 102 657: Lawful Interception
(LI); Retained data handling; Handover interface for
the request and delivery of retained data. Euro-
pean Telecommunications Standards Institute. Ver-
sion 1.17.1.
FIDIS project (2008a). D2.13: Virtual Persons and Identi-
ties. David-Oliver Jaquet-Chiffelle (ed.), Version 1.0,
Available online at http://www.fidis.net/resources/
fidis-deliverables/identity-of-identity/#c2162.
FIDIS project (2008b). D3.8: Study on protocols with
respect to identity and identification — an insight
on network protocols and privacy-aware communi-
cation. Marit Hansen and Ammar Alkassar (ed.),
Version 0.8. Available online at http://www.fidis.net/
resources/fidis-deliverables/hightechid/#c2216.
FIDIS project (2009). D17.4: Trust and Identification in
the Light of Virtual Persons. David-Oliver Jaquet-
Chiffelle and Hans Buitelaar (ed.), Version 1.2. Avail-
able online at http://www.fidis.net/resources/fidis-
deliverables/identity-of-identity/#c2596.
Furnell, S. (2010). Online identity: Giving it all away?
Information Security Technical Report, 15(2):42–46.
Identity Theft and Reconstruction.
Herrmann, D., Gerber, C., Banse, C., and Federrath, H.
(2012). Analyzing characteristic host access patterns
for re-identification of web user sessions. In Infor-
mation Security Technology for Applications, volume
7127 of Lecture Notes in Computer Science, pages
136–154. Springer Berlin Heidelberg, DE.
Jackson, G., Jones, S., Booth, G., Champod, C., and Evett,
I. (2006). The nature of forensic science opinion —
a possible framework to guide thinking and practicce
in investigation and in court proceedings. Science &
Justice, 46(1):33–44.
Jones, A. and Martin, T. (2010). Digital forensics and the
issues of identity. Information Security Technical Re-
port, 15(2):67–71. Identity Theft and Reconstruction.
Karabiyik, U. and Aggarwal, S. (2014). Audit: Auto-
mated disk investigation toolkit. The Journal of Digi-
tal Forensics, Security and Law, 2014(2):129–143.
Kirchler, M., Herrmann, D., Lindemann, J., and Kloft, M.
(2016). Tracked without a trace: Linking sessions
of users by unsupervised learning of patterns in their
DNS traffic. In Proceedings of the 2016 ACM Work-
shop on Artificial Intelligence and Security, AISec
’16, pages 23–34, New York, NY, USA. ACM.
Kohno, T., Broido, A., and Claffy, K. C. (2005). Remote
physical device fingerprinting. IEEE Transactions on
Dependable and Secure Computing, 2(2):93–108.
Laperdrix, P., Bielova, N., Baudry, B., and Avoine, G.
(2020). Browser fingerprinting: A survey. ACM
Trans. Web, 14(2):8:1–8:33.
Narten, T., Draves, R., and Krishnan, S. (2007). Privacy
Extensions for Stateless Address Autoconfiguration in
IPv6. IETF. RFC 4941 (Draft Standard).
Peled, O., Fire, M., Rokach, L., and Elovici, Y. (2013). En-
tity matching in online social networks. In 2013 In-
ternational Conference on Social Computing, pages
339–344.
Pfitzmann, A. and Hansen, M. (2010). A terminol-
ogy for talking about privacy by data minimiza-
tion: Anonymity, unlinkability, undetectability, un-
observability, pseudonymity, and identity manage-
ment. Technical report. Version 0.34, Available
online at https://dud.inf.tu-dresden.de/literatur/Anon
Terminology v0.34.pdf.
Pol
ˇ
c
´
ak, L. (2017). Lawful Interception: Identity Detection.
PhD thesis, Brno University of Technology, Faculty of
Information Technology.
Pol
ˇ
c
´
ak, L. and Frankov
´
a, B. (2015). Clock-skew-based
computer identification: Traps and pitfalls. Journal
of Universal Computer Science, 21(9):1210–1233.
Pol
ˇ
c
´
ak, L., Holkovi
ˇ
c, M., and Matou
ˇ
sek, P. (2014a). Host
Identity Detection in IPv6 Networks. In Communica-
tions in Computer and Information Science. Springer
Berlin Heidelberg, DE.
Pol
ˇ
c
´
ak, L., Hranick
´
y, R., and Mart
´
ınek, T. (2014b). On
identities in modern networks. The Journal of Digital
Forensics, Security and Law, 2014(2):9–22.
Robinson, I., Webber, J., and Eifrem, E. (2015). Graph
Databases. O’Reilly Media, Inc., 1005 Gravenstein
Highway North, Sebastopol, CA, USA. Second Edi-
tion.
Ye Na, Zhao Yinliang, Dong Lili, Bian Genqing, Liu, E.,
and Clapworthy, G. J. (2013). User identification
based on multiple attribute decision making in social
networks. China Communications, 10(12):37–49.
DCNET 2020 - 11th International Conference on Data Communication Networking
52
