
CP-ABE Scheme Satisfying Constant-size Keys based on ECC
Nishant Raj and Alwyn Roshan Pais
Department of Computer Science and Engineering, National Institute of Technology Karnataka,
Surathkal, Karnataka, India
Keywords:
Ciphertext-policy Attribute-based Encryption, Elliptic Curve based Cryptography, Cloud Computing,
Security, Constant-size Secret Key.
Abstract:
Cloud-based applications, especially on IoT devices, is one of the desired fields to apply Ciphertext-Policy
Attribute-Based Encryption (CP-ABE). Most of the IoT devices are with the low-end configuration; hence,
they need better time and computation efficient algorithms. There are existing algorithms, but none of the
systems are based on conventional cryptosystems as well as secure at the same time. Here, we propose a
CP-ABE scheme based on the elliptic curve cryptosystem with a constant-size secret key, which is capable of
addressing the collusion attack security issue.
1 INTRODUCTION
With the emergence of cloud computing, it becomes
the need of the hour to design a mechanism that facil-
itates faster encryption and decryption (D.Pharkkavi
and Maruthanayagam, 2018). One such scheme is
CP-ABE, which is based on ABE proposed in (Sahai
and Waters, 2005). CP-ABE allows the user to de-
fine an access policy associated with every message,
thereby defining a set of users who can correctly de-
crypt the message. This makes CP-ABE a convenient
mechanism to transfer messages in the cloud comput-
ing environment(Zhang et al., 2014)(Li et al., 2014).
Also, CP-ABE should be cost-efficient to work on
battery constrained devices.
In recent times many CP-ABE schemes have
been proposed, which are based on bi-linear maps,
which are computationally intensive than those based
on conventional cryptosystems, such as (Vergnaud,
2016)(Li et al., 2014). Hence, there is a need to de-
sign a cost-efficient access structure CP-ABE cipher-
texts using conventional public-key cryptosystems,
with constant-size secret keys. One such attempt was
made by (Odelu et al., 2016).
A security flaw was shown in the scheme of(Odelu
et al., 2016) by (Herranz, 2017). It was proven that the
scheme could be broken using collusion of non-policy
satisfying users. This is based on the observation that
the attack is possible if the union of users attribute set
satisfies access policy.
Here, we have proposed a modified scheme, orig-
inally proposed by (Odelu et al., 2016). The proposed
scheme is based in ECC, so cost-efficient in both en-
cryption and decryption, and follows the AND-gate
access structure, with a constant-size secret key.
We divide the rest of the paper into different sec-
tions. First, we discuss the various mathematical def-
initions and preliminaries, which are a prerequisite to
understanding the scheme in 2. Following this, in 3,
we propose our CP-ABE scheme. Then in 4, we dis-
cuss the security aspects of the scheme. Then, we
discuss the implementation detail of the scheme in 5.
Finally, in 6, we provide a few concluding remarks.
2 MATHEMATICAL
PRELIMINARIES AND
DEFINITIONS
In this section, we explain the various definitions and
preliminaries related to CP-ABE scheme.
2.1 Attribute Definition and Access
Structure
We follow a similar definition for attributes and access
policy, as provided in (Guo et al., 2014). Assume that
we have n attributes in U, set of all attributes in the
universe, so we have U = {A
1
,A
2
,A
3
,...A
n
}, where
A
i
represents the ith attribute in the universe. Also,
for convenience we represent A, attribute set associ-
Raj, N. and Pais, A.
CP-ABE Scheme Satisfying Constant-size Keys based on ECC.
DOI: 10.5220/0009590905350540
In Proceedings of the 17th International Joint Conference on e-Business and Telecommunications (ICETE 2020) - SECRYPT, pages 535-540
ISBN: 978-989-758-446-6
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
535

ated with a user, so we have A ⊆ U, as a n-bit string
a
1
a
2
a
3
...a
n
, where
(
a
i
= 1, A
i
∈ A
a
i
= 0, A
i
6∈ A
For example, if we have n = 5, then U =
{A
1
,A
2
,A
3
,A
4
,A
5
}. Also, if the user has the fol-
lowing attributes {A
1
,A
3
,A
4
}, then it’s correspond-
ing five-bit string takes the value 10110. Similarly,
we represent P be the access policy associated with a
message(P ⊆ U) as an n-bit string b
1
b
2
b
3
...b
n
, same
assignment as A.
Now we shall define the AND gate access struc-
ture on a given set universal set of n attributes U. Let,
attribute set A be associated with a user, and in the bit
string, it is a
1
a
2
a
3
...a
n
. Similarly, for access policy
P be b
1
b
2
b
3
...b
n
. If a
i
≥ b
i
∀i, then we say A satis-
fies P, in other words, P ⊆ A. From here, A and P are
represented as n-bit-string.
2.2 Compuational Hard Problem
This section describes the computationally hard prob-
lems.
q-Generalized Diffie-Hellman (q-GDH) Assump-
tion. It is hard to compute (a
1
a
2
a
3
...a
q
)P ∈ G,
given a
1
P,a
2
P,a
3
P...a
q
P ∈ G where P is a base point
in E
p
(a,b) and (
∏
i∈S
a
i
)P ∈ G for all proper sub-
sets S ⊂ {1, . . . , q}. The access to all the above-
mentioned subset products, which are exponential
in q, is provided by an oracle. For a vector a =
(a
1
,a
2
...a
q
) ∈ (Z
p
)q , define O
P,a
to be an oracle that
for any proper subset S ⊂ {1,2,...,q} responds with
O
P,a
= (
∏
i∈S
a
i
)P.
Definition 2.2.1. q-GDH Assumption: The (t,q,ε)-
GDH assumption is satisfied by G if the advan-
tage of all the t-time algorithms A is given by
ADV
GDH
A,q
= Pr[A
O
P,a
= (a
1
...a
q
)P] < ε, where a =
(a
1
,a
2
,a
3
...a
q
) ← (Z
p
)
q
for any sufficiently small
ε > 0.
q-DHI Problem. The q-Diffie-Hellman Inver-
sion problem states that given a (q + 1)-tuple
(P,xP,x
2
P,...,x
q
P) ∈ G
q+1
as input, output (1/x)P ∈
G where x ∈ Z
∗
p
.
Definition 2.2.2. q-DHI Assumption (Boneh and
Boyen, 2004): The (t, q, ε)-GDI assumption is satis-
fied by G if the advantage of all the t-time algorithms
A is given by
ADV
DHI
A,q
= Pr[A (P,xP,x
2
P,..., x
q
P) = (1/x)P] < ε
for any sufficiently small ε > 0. where the probability
is considered over the random choices of x in Z
∗
p
and
random bits of A .
2.3 Definition of CP-ABE Scheme
There are four major algorithms in a CP-ABE
scheme. They are Setup, Encrypt, KeyGen, and De-
crypt. These algorithms are defined in Table 1, sim-
ilarly as in (Guo et al., 2014). We have introduced
Validate Phase for our scheme.
For any given (MPK,MSK), the ciphertext gen-
erated using Encrypt algorithm and the access policy
P, the plain text message M, and the user secret key
k
u
associated with attributes A. If P ⊆ A then the De-
crypt algorithm should always output the correct plain
text message M, otherwise, user cannot decrypt M.
2.4 Security Model - Selective Game for
CP-ABE Scheme
In this section, we have defined a selective game to
show restiveness against the chosen cipher-text attack.
In the game, after the challenge phase, an adversary
R. issues multiple secret key queries. The game is
described as follows between the challenger B and an
adversary R.
Game is the same as mentioned in (Cheung and
Newport, 2007).
In the game, the advantage ε of R, adversary, is
given by,
ε =
Pr[c
0
= c] −
1
2
For the above scheme to be secure ε must be neglegi-
ble function of ρ(security parameter).
3 PROPOSED CP-ABE-CSSK
SCHEME
Here, we propose a CP-ABE scheme with
constant-size secret keys based on ECC, i.e., CP-
ABE-CSSK-ECC. Other notations we use are enlisted
in Table 2.
The scheme consists of five phases, as follows:
3.1 Setup Phase
In this phase,
Input: Security parameter ρ and the universe of
attributes U = {A
1
,A
2
,...A
n
,A
n+1
}.
Output: Master Secret Key MSK and Master
Public Key MPK.
Note: Here, we add one extra attribute A
n+1
,
which is 1 for every user and 0 for every access
policy in bit strings.
The algorithm works the same as in (Odelu et al.,
2016).
SECRYPT 2020 - 17th International Conference on Security and Cryptography
536
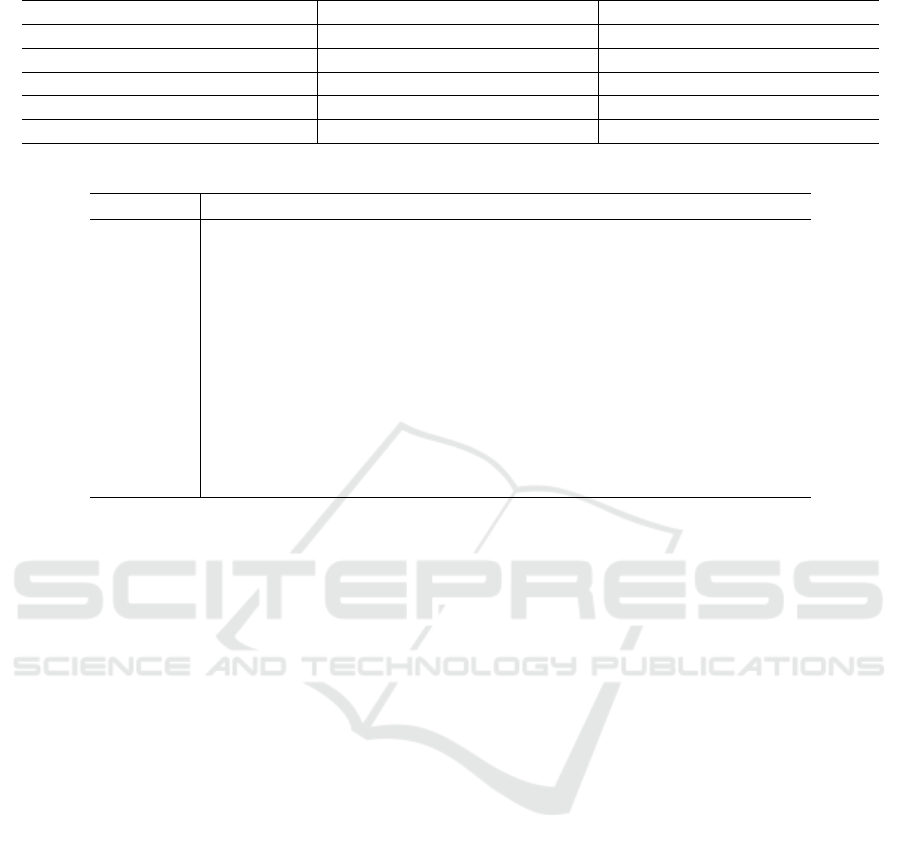
Table 1: Inputs and Outputs for various phases in Defination Scheme.
Phase Input Output
Setup Phase U,ρ MSK, MPK
KeyGen Phase A,MSK, MPK k
u
= (u
1
,u
2
)
Encrypt Phase P,MPK, M message C = {P, P
m,i
,K
1m
,K
2m
,C
σ
m
,C
m
}
Validate Phase (Only our scheme) C = {P, P
m,i
,K
1m
,K
2m
,C
σ
m
,C
m
} C or (fail/no transmit)
Decrpyt Phase C,k
u
,A,MPK message M or ⊥
Table 2: Notations.
Notation Description
”(α,k
1
,k
2
) System private keys
p A large prime number
E
p
(a,b) An elliptic curve y
2
= x
3
+ ax + b(mod p) defined over the finite field Z
p
;
Z
p
{0,1,..., p − 1}
P A base point in E
p
(a,b) whose order is a 160-bit number in Z
p
xP P + P + . . . P(x times), scalar multiplication, P ∈ E
p
(a,b)
G Elliptic curve group {p, E
p
(a,b),P} generated by P
U Universe of (n + 1) attributes
{A
1
,A
2
,A
3
,... , A
n
,A
n+1
}
A User set attributes, A ⊆ U
P Access policy, P ⊆ (U \ A
n+1
)” (Odelu et al., 2016)
3.2 Encrypt Phase
The Encrypt phase is the same as in (Odelu et al.,
2016), with taking into changes of value of A
n+1
.
In encryption algorithm,
Input: An access policy P ⊆ U where |P| = 0, the
Master Public Key MPK and a plaintext message M.
Output: The ciphertext C as C =
{P,P
m,i
,K
1m
,K
2m
,C
σ
m
,C
m
}.
The algorithm works the same as in (Odelu et al.,
2016).
3.3 Validate Phase
In this phase, the ciphertext C is sent to a centralized
server for validation after the encrypt phase. The steps
are as follows:
1. First, we check if the attribute A
n+1
is in the pol-
icy P of the ciphertext C or not. If the attribute
is present, then the security of the system is com-
promised as the attack shown in (Herranz, 2017)
is possible. So, we discard the message and notify
the user to do the encryption again.
2. If the attribute A
n+1
is not present in the ciphertext
C, then it is transmitted to all the users.
3.4 Key-gen Phase
In this phase,
Input:The Master Secret Key MSK and the Mas-
ter Public Key MPK.
Output:The user secret key k
u
corresponding to
the user attributes A
The algorithm works the same as in (Odelu et al.,
2016).
3.5 Decrypt Phase
In this phase,
Input: The ciphertext C =
{P,P
m,i
,K
1m
,K
2m
,C
σ
m
,C
m
} corresponding to a
given access policy P, the user secret key k
u
corresponding to the user attribute A.
Output: Original message M, if successful, else
⊥.
The algorithm works the same as in (Odelu et al.,
2016).
Assumption: All transmissions of data between
phases are completely secure.
4 SECURITY ANALYSIS
Here, we provide proof of security against some pos-
sible known attacks. Then, prove our intuition regard-
ing why we choose the extra attribute to prevent the
attack(Herranz, 2017) with proof.
CP-ABE Scheme Satisfying Constant-size Keys based on ECC
537

4.1 Security against Collusion Attack
We analyze the situation where multiple adversaries,
having valid secret keys corresponding to their at-
tributes, collaborate, and try to generate the system’s
private keys (k
1
,k
2
).
Theorem 4.1. The scheme is secure against col-
lusion attacks by adversaries who aim at deriving the
system’s private key pair (k
1
,k
2
).
Proof as mentioned in (Odelu et al., 2016) and in-
cludes proof in section 4.6
4.2 Security against Key Recovery
Attack
This section provides an analysis of the proposed
scheme where an adversary attempts to obtain a valid
user secret key corresponding to the attribute set A.
Theorem 4.2. This scheme is secure against an
adversary who tries to derive valid user secret key
k
u
= (k
1
,k
2
) corresponding to the attribute set A.
Proof as mentioned in (Odelu et al., 2016) and in-
cludes proof in section 4.6
4.3 Security against Adversary Deriving
Original Message without Secret
User Keys
In this subsection, we discuss what adversary can de-
rive from the ciphertext without knowing a valid user
secret key.
Theorem 2.4.3. Our proposed scheme is secure
against an adversary who executes a message recov-
ery attack and tries to derive the original message
without knowing the secret user key k
u
= (u
1
,u
2
).
The proof is the same as mentioned in (Odelu
et al., 2016).
4.4 Description of the CP-ABE Scheme
(Odelu et al., 2016)
Our CP-ABE scheme differs from the CP-ABE
Scheme (Odelu et al., 2016), as we have added one
extra attribute as A
n+1
, where A
n+1
∈ A
i
and A
i
is the
attribute set of i
th
user.
KeyGen (A, MSK, PMS): Step to compute gener-
ate key (Key-Gen Phase):
1. Select two random numbers, r
u
,t
u
∈ Z
p
2. Choose s
u
such that
1
f (α,A)
= (k
1
s
u
+k
2
r
u
) mod p.
That is:
s
u
=
1
k
1
.
1
f (α,A)
− k
2
r
u
mod p (1)
3. Compute u
1
= r
u
+ k
1
t
u
mod p and u
2
= s
u
− k
2
t
u
mod p. We have the secret key as sk
A
= (u
1
,u
2
).
Note (1): The attack was possible from the fact
that entropy of the secret key, sk
A
= (u
1
,u
2
), is not
enough. Even though they used two random and
independent values r
u
,t
u
, the final secret key sk
A
=
(u
1
,u
2
) is not independent.
Proof: Let us write the relation between the pairs
(r
u
,t
u
) and (u
1
,u
2
), we get
u
1
u
2
=
1 k
1
k
2
k
1
−k
2
.
r
u
t
u
+
0
1
k
1
f (α,A)
mod p
(2)
The matrix is not invertible: the first one multiplied
with −
k
2
k
1
equals the second row. Thus, we have
u
2
= −
k
2
k
1
u
1
+
1
k
1
f (α,A)
mod p. (3)
4.5 Attack on CP-ABE Scheme (Odelu
et al., 2016) by (Herranz, 2017)
According to the paper (Herranz, 2017), the attack is
based on three simple observations, of which the first
and third are not relevant to our solution. Here is the
second:
(b). Pair information (X,Y
B
) (derived as in (Herranz,
2017)) is enough for each subset of attributes B to
create a valid secret key sk
B
for subset B. Again, using
the Note (1) in previous subsection i.e., equation (1),
we choose a random u
1
∈ Z
p
and compute:
u
2
= −
k
2
k
1
u
1
+
1
f (α,B)
= X u
1
+Y
B
mod p (4)
Proof using Example. Let us take n = 4 and
the subsets of attributes defined by bit strings A
1
=
0011,A
2
= 1100,A
3
= 0100,B = 1011, where, A
i
is
i
th
user’s attribute set and B is access policy. We can
easily see the equality holds:
f (α,B) =
f (α,A
1
). f (α,A
2
)
f (α,A
3
)
mod p. (5)
Now, for above subsets of attributes, we get:
Y
B
=
1
k
1
f (α,B)
=
1
k
1
f (α,A
1
). f (α,A
2
)
f (α,A
3
)
=
1
k
1
f (α,A
1
)
.
1
k
1
f (α,A
2
)
1
k
1
f (α,A
3
)
=
Y
A
1
.Y
A
2
Y
A
3
mod p.
(6)
Using all three observation (Herranz, 2017) have
shown a possible attack.
Note. The above attack is a key recovery attack that
is even stronger than an attack against the IND-CPA
property.
SECRYPT 2020 - 17th International Conference on Security and Cryptography
538

4.6 Security Analysis of Our Solution
As in equation (6) we have established:
Y
B
=
1
k
1
f (α,B)
=
Y
A
1
.Y
A
2
Y
A
3
mod p.
where, A
1
= 1100,A
2
= 0011,A
3
= 0100 and B =
1011.
To Proof. The above equation is not possible in our
scheme, as it is essential to perform attack as in (Her-
ranz, 2017).
As mentioned before, we have introduced one
more attribute, which is included in every user’s at-
tribute set and excluded from the access policy at-
tribute set. So, new A
1
= 11001, A
2
= 00111, A
3
=
01001 and B = 10110, now, the bit string length is
n+1.
As mentioned earlier,
f (x,A) =
n+1
∏
i=1
(x + H
4
(i))
1−a
i
,
with degree of n + 1 − |A|
Let a
1
a
2
...a
n
a
n+1
be the bit string of attribute set A,
for values of a
i
= 0 : 1 <= i <= n + 1, we have α +
H
4
(i) in f (α, A), otherwise it is 1. Now, f (α,A) can
be redefined as:
f (α,A) =
n+1
∏
i=1
(
(α + H
4
(i)), if a
i
= 0
1, otherwise
(7)
Folowing equation (7), we can say, f (α, A
1
), f (α,A
2
)
and f (α,A
3
) doesn’t contains (α + H
4
(n + 1)),
whereas, f (α, B) contains (α + H
4
(n + 1)).
Proposition:In our CP-ABE scheme with any al-
gebraic combination of Y
A
i
we cannot generate Y
B
.
Proof to the proposition: We know,
Y
A
i
=
1
k
1
f (α,A
i
)
and Y
B
=
1
k
1
f (α,B)
.
Hence, Y
A
i
∝
1
f (α,A
i
)
and Y
B
∝
1
f (α,B)
.
Considering equation,
Y
B
= (Product and Division combination
of any Y
A
i
) mod p.
(8)
In the left-hand side of equation (6) contains (α +
H
4
(n + 1)), whereas, any term in right-hand side
doesn’t contain (α + H
4
(n + 1)) term. So, the gen-
eration of the left-hand side from the right-hand side
is highly improbable. So, we have,
Y
B
6= (Product and Division combination
of any Y
A
i
) mod p.
with overwhelming probability.
Hence, it proved the proposition.
So, equation (8) doesn’t hold good for our CP-
ABE scheme; hence, the attack mentioned in (Her-
ranz, 2017), also in section 4.5, is not possible on our
CP-ABE scheme, as 4.5.(b) does not give value Y
B
,
and the rest of the attack would be unsuccessful.
5 IMPLEMENTATION DETAILS
We have implemented the proposed scheme in C++,
using Crypto++, an open-source, the cryptographic li-
brary. System configuration that we used: Intel Core
i5-4210U CPU, 8 GB RAM, processor speed 2.7GHz
× 4, and 64-bit Linux-based OS.
The bottleneck will be in calculating the i
th
co-
efficient of polynomial f (x, P). To compute the co-
efficient of x
i
of these polynomials, we can have the
following methods with time complexity:
• Brute Force: O(2
n
)
• Dynamic Programming approach: O(n
2
)
• Divide and conquer approach: O(n
log
2
(3)
)
– Karatsuba Method (modified)
5.1 Dynamic Programming Approach
We have defined the sub problem in co-efficent calcu-
lation of polynomial, f (x) =
∏
n
0
k=1
(x + c
k
), of degree
n
0
.
Table(i, j) = coefficient of x
i− j
in the polynomial
i
∏
k=1
(x + c
k
)
!
for i, j = 0, 1, 2, . . . n
0
. Where
∏
i
k=1
(x + c
k
)
is the
product of first i terms of f (x).
The time and space complexity of the above ap-
proach is O(n
02
) and O(n
0
), respectively.
5.2 Divide and Conquer Approach
Karatsuba Algorithm. We extend this approach
to find coefficients of polynomial function f (x) =
∏
n
0
k=1
(x + c
k
). Let polynomials two A(x) and B(x) be
defined as:
A(x) = A
0
+ A
1
x + A
2
x
2
+ ··· + A
n
0
x
n
0
B(x) = B
0
+ B
1
x + B
2
x
2
+ ··· + B
n
0
x
n
0
Let A(x) be expressed in terms of two polynomial
A
0
(x) and A
00
(x) as described below:
A(x) = A
0
(x) + x
n
0
/2
A
00
(x) and
B(x) = B
0
(x) + x
n
0
/2
B
00
(x)
CP-ABE Scheme Satisfying Constant-size Keys based on ECC
539

Now, the Karatsuba algorithm recursively computes
the following three products:
• X(x) = A
0
(x) × B
0
(x)
• Y (x) = A
00
(x) × B
00
(x)
• Z(x) = (A
0
(x) + A
00
(x)) × (B
0
(x) + B
00
(x))
The product of A(x) and B(x) will be given by,
A(x) × B(x) = X(x) + x
n
0
/2
(Z(x) − X(x) −Y (x)) + x
n
0
Y (x)
The recurrence relation formulated to be:
T (n
0
) = 3T (n
0
/2) + O(n
0
)
So the time complexity for polynomial multiplication
by Karatsuba algorithm is O(n
0(log
2
(3))
) where n
0
is the
degree of polynomials.
Figure 1: Execution Time of different phases in proposed
scheme - Calculating coefficients of f (x) =
∏
n
0
k=1
(x + c
k
)
using Divide and conquer approach (Karatsuba Method) for
|U| = n
0
= 2000.
Figure 2: Execution time comparison of Dynamic Program-
ming algorithm and Karatsuba algorithm for all 5 phase to-
gether for |U| = n
0
= 4000.
6 CONCLUSION
With the boom in cloud-based applications and IoT
devices in the market, and an efficient CP-ABE
scheme is a necessity. We have proposed a secure
ECC based CP-ABE scheme with constant-size se-
cret keys. Further, we have also provided the security
analysis and the intuition for the same.
In this paper, we require a centralized server to
perform the Validate Phase. This, however, may be
the cause for a bottleneck or an extra overhead. For
future work, we can look into removing this validation
phase and thereby making the scheme more robust.
REFERENCES
Boneh, D. and Boyen, X. (2004). Efficient selective-id
secure identity-based encryption without random or-
acles.
Cheung, L. and Newport, C. (2007). Provably secure ci-
phertext policy abe. In Proceedings of the 14th ACM
Conference on Computer and Communications Secu-
rity, CCS ’07, pages 456–465, New York, NY, USA.
ACM.
D.Pharkkavi and Maruthanayagam, D. D. (2018). Time
complexity analysis of rsa and ecc based security al-
gorithms in cloud data. International Journal of Ad-
vanced Research in Computer Science, 9(3).
Guo, F., Mu, Y., Susilo, W., Wong, D. S., and Varadhara-
jan, V. (2014). Cp-abe with constant-size keys for
lightweight devices. IEEE Transactions on Informa-
tion Forensics and Security, 9(5):763–771.
Herranz, J. (2017). Attribute-based encryption implies
identity-based encryption. IET Information Security,
11(6):332–337.
Li, H., Lin, X., Yang, H., Liang, X., Lu, R., and Shen, X.
(2014). Eppdr: An efficient privacy-preserving de-
mand response scheme with adaptive key evolution in
smart grid. IEEE Transactions on Parallel and Dis-
tributed Systems, 25(8):2053–2064.
Odelu, V., Das, A. K., and Goswami, A. (2016). An effi-
cient cp-abe with constant size secret keys using ecc
for lightweight devices. ACM, 9(17):4048–4059.
Sahai, A. and Waters, B. (2005). Fuzzy identity-based en-
cryption. In Proceedings of the 24th Annual Inter-
national Conference on Theory and Applications of
Cryptographic Techniques, EUROCRYPT’05, pages
457–473, Berlin, Heidelberg. Springer-Verlag.
Vergnaud, D. (2016). Comment on ”a strong provably se-
cure ibe scheme without bilinear map” by m. zheng,
y. xiang and h. zhou j. comput. syst. sci. 81 (2015)
125-131. J. Comput. Syst. Sci., 82(5):756–757.
Zhang, Y., Zheng, D., Chen, X., Li, J., and Li, H. (2014).
Computationally efficient ciphertext-policy attribute-
based encryption with constant-size ciphertexts. In
Chow, S. S. M., Liu, J. K., Hui, L. C. K., and Yiu,
S. M., editors, Provable Security, pages 259–273,
Cham. Springer International Publishing.
SECRYPT 2020 - 17th International Conference on Security and Cryptography
540
