
It Means More if It Sounds Good: Yet Another Hypothesis Concerning
the Evolution of Polysemous Words
Ivan P. Yamshchikov
1 a
, Cyrille Merleau Nono Saha
1
, Igor Samenko
2
and J
¨
urgen Jost
1
1
Max Planck Institute for Mathematics in the Sciences, Inselstrasse 22, Leipzig, Germany
2
Institute of Computational Technologies SB RAS, Russia
Keywords:
Evolution of Language, Semantic Structures, Polysemy.
Abstract:
This position paper looks into the formation of language and shows ties between structural properties of
the words in the English language and their polysemy. Using Ollivier-Ricci curvature over a large graph of
synonyms to estimate polysemy it shows empirically that the words that arguably are easier to pronounce also
tend to have multiple meanings.
1 INTRODUCTION
Starting form the second half of the nineteenth cen-
tury (Schleicher, 1869) various researchers address
historic development of language from evolutionary
grounds.
A considerable proportion of the works in this
field use word frequency as an important proxy of
the word fitness. For example, (Pagel et al., 2007)
demonstrate across several languages that frequently
used words evolve at slower rates, whereas infre-
quently used words evolve more rapidly. (Newberry
et al., 2017) state that a possible explanation for this
phenomenon could be a stronger stochastic drift of
rare words. In the meantime, (Adelman et al., 2006)
notice that word frequency is confounded with poly-
semy, i.e., the number of contexts in which a word has
been seen. They also show that this contextual diver-
sity is a crucial factor that determines word-naming
and lexical decision times.
(Lee, 1990) demonstrates that older words are
more polysemous than recent words and that fre-
quently used words are more polysemous than infre-
quently used words. This goes in line with (MacCor-
mac, 1985) theory of semantic conceptual change that
states that words evolve additional meanings through
metaphor. It seems that the frequency of the word is
confounded with its semantics.
(Bybee, 2002) reviews results on how a sound
change affects the lexicon and documents that a
sound change affects high-frequency words and low-
a
https://orcid.org/0000-0003-3784-0671
frequency words differently. This shows that the fre-
quency of the word is confounded with its phonetic
properties. The ideas that there is a subtle corre-
spondence between phonetics and semantics were en-
tertained by literary theorists (Shklovsky, 1917) and
artists (Kruchenykh, 1923) at least from the beginning
of the twentieth century. In a massive study across
nearly two-thirds of the world’s languages (Blasi
et al., 2016) managed to demonstrate that a consid-
erable proportion of 100 essential vocabulary items
carry strong associations with specific kinds of human
speech sounds, occurring persistently across conti-
nents and linguistic lineages. (Yamshchikov et al.,
2019) showed that modern methods of computational
linguistics could be used to highlight such associative
structures within a language.
This position paper develops these ideas, and
states that the phonetic simplicity of a word is to some
extent correlated with the number of its semantic con-
texts. We also speculate on possible cognitive mech-
anisms underlying this connection.
2 DATA
To relate polysemous properties of the words with
their phonetic structure, we use two different datasets
represented as graphs with words as vertices.
(Smerlak, 2020) reconsidered Maynard Smith’s
toy model of protein evolution (Smith, 1970) in con-
text of neutral evolution. We use this dataset here for
a different purpose. Let us consider a set of all pos-
Yamshchikov, I., Saha, C., Samenko, I. and Jost, J.
It Means More if It Sounds Good: Yet Another Hypothesis Concerning the Evolution of Polysemous Words.
DOI: 10.5220/0009582801430148
In Proceedings of the 5th International Conference on Complexity, Future Information Systems and Risk (COMPLEXIS 2020), pages 143-148
ISBN: 978-989-758-427-5
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
143

sible four-letter words and assume that two words are
connected with an edge if the second word can be de-
rived from the first one with an edit of one letter. We
further call this graph a graph of edits. One could
interpret the degree of the vertices in this graph as a
proxy of the word’s phonetic simplicity. Indeed, if a
word has more one-letter edits that produce a mean-
ingful word, one can assume that it consists of the
letters or sounds with higher joined probabilities. We
discuss this hypothesis further in Section 4.
We provide
1
a large dataset of English synonyms
that is based on WordNet
2
. Here two words are con-
nected with an edge if they are synonymous. Figure
1 shows the frequency of the word usage (estimated
on a large chunk of English Wikipedia
3
) as a function
of the number of synonyms that it has in the graph.
This is a well-known fact that is important for us here,
since to a certain extent it validates the dataset of syn-
onyms as a representative one.
Figure 2 shows that the connection between word
frequencies and degrees in the graph of synonyms is
even stronger for the four-letter words that form the
graph of edits.
The sheer number of synonyms adjacent to a given
word does not necessarily correspond to the number
of various semantic contexts in which it can occur. It
is well known that polysemic words have more syn-
onyms and tend to have higher frequencies, but one
can not infer the number of possible semantic con-
texts in which a word can occur our of the number of
its synonyms. Further, we discuss how one can esti-
mate polysemy of a word using the geometry of the
graph of synonyms.
3 OLLIVIER-RICCI CURVATURE
AND POLYSEMY
Ollivier-Ricci curvature (Ollivier, 2009) is commonly
used for community detection (Ni et al., 2015), (Sia
et al., 2019). In this paper we use it in a way that
is novel for mathematical linguistic and claim that it
could be used as a proxy for the word’s polysemy
measure in the language. Yet before we get into the
details let us briefly describe Ollivier-Ricci curvature
itself.
Here we use the method that (Ni et al., 2019) pro-
vide for calculation of the curvature
4
. One considers
1
https://github.com/i-samenko/Triplet-net/tree/master/
data
2
https://wordnet.princeton.edu/
3
https://www.kaggle.com/rtatman/english-word-
frequency
4
https://github.com/saibalmars/GraphRicciCurvature
a particular probability distribution m
x
, which has pa-
rameter α, and a graph G. For a vertex x ∈ G with
degree k, let Γ(x) = {x
1
,x
2
,...,x
k
} denote the set of
neighbors of x. For any α ∈ [0,1] the probability mea-
sure m
α
x
is defined as:
m
α
x
(x
i
) =
α if x
i
= x
(1 − α)/k if x
i
∈ Γ(x)
0 otherwise
(1)
The intuition behind the curvature of a given edge in
our case is rather intuitive. Once an edge is within a
dense community it has positive curvature, whereas
edges that connect separate communities have nega-
tive curvature. This property of Ollivier-Ricci curva-
ture directly leads to the detection of polysemy of a
given word. Indeed, every incident edge with a posi-
tive Ollivier-Ricci curvature would connect the word
to a synonym within the same semantic context, how-
ever, an incident edge with negative Ollivier-Ricci
curvature points to a synonym within a drastically dif-
ferent semantic field. Therefore, one can use the num-
ber of incident edges with negative Ollivier-Ricci cur-
vature or the average Ollivier-Ricci curvature across
incident edges as a measure of the polysemy of the
word. Figure 3 shows that words with lower average
Ollivier-Ricci curvature of incident edges tend to have
a higher degree in the graph of synonyms. This also
goes in line with the statement that word frequency is
confounded with polysemy.
Further, we show that the situation is more nu-
anced and that there is a connection between the lo-
cation of the word within the graph of edits and its
polysemy.
4 POLYSEMY AND PHONETICS
Figure 4 shows how the degree of a word in the graph
of synonyms depends on its polysemy, i.e., the num-
ber of incident edges with negative Ollivier-Ricci cur-
vature in the graph of synonyms. This connection is
well known and can be seen in the proposed dataset.
Let us now discuss the graph of edits. One can re-
gard the formation of actual words as a purely random
process. The (Smith, 1970) toy-model is based on
the assumption that if we regard all possible one-letter
edits of a word, any combination of letters is equally
’lucky’ to become be another meaningful word. How-
ever, (Nowak and Krakauer, 1999) show that intro-
duction of an error in sound recognition on the stage
of a protolanguage makes it very limited: ”Adding
new sounds increases the number of objects that can
be described but at the cost of an increased probability
COMPLEXIS 2020 - 5th International Conference on Complexity, Future Information Systems and Risk
144
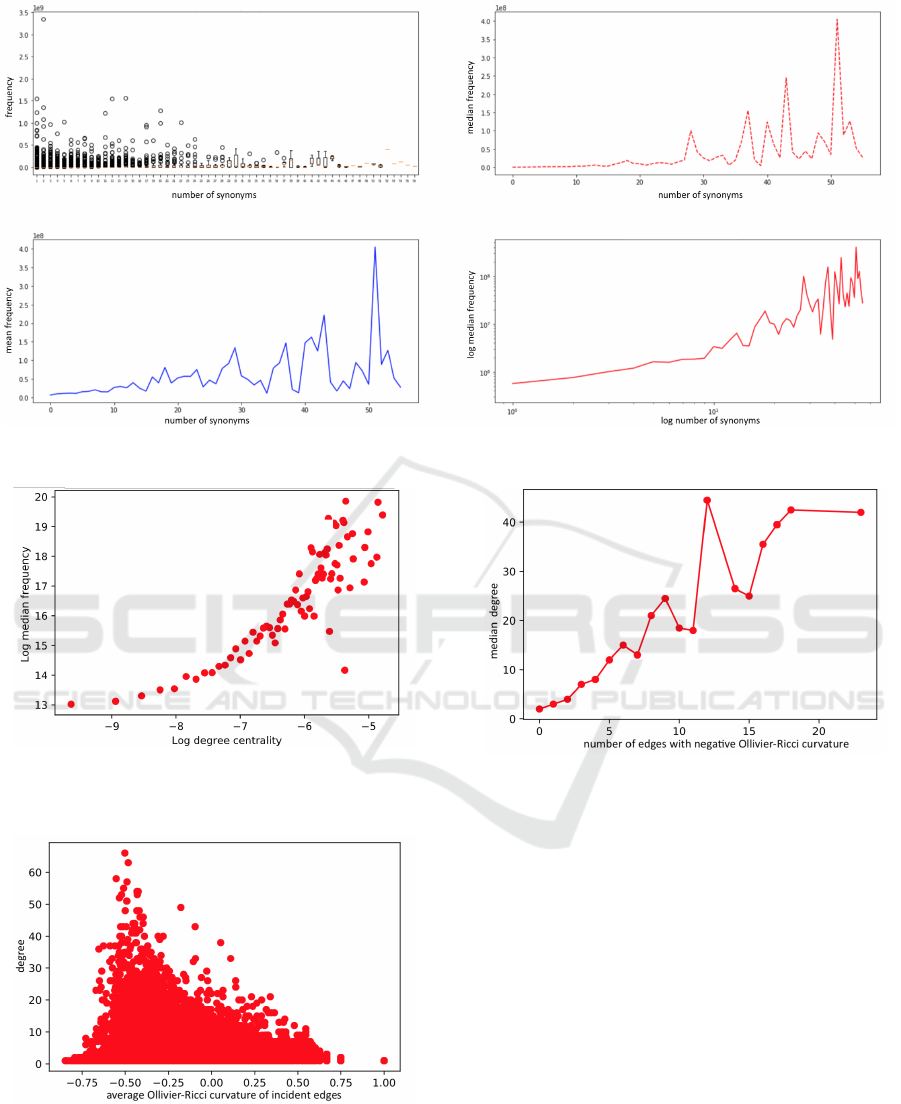
Figure 1: Word frequency tends to be higher for the words that have more synonyms.
Figure 2: Log of degree centrality in the graph of synonyms
and frequency of use for the four-letter words that form the
graph of edits.
Figure 3: Words with lower average Ollivier-Ricci curva-
ture of incident edges tend to have higher degree in the
graph of synonyms.
of making mistakes; the overall ability to transfer in-
formation does not improve”. The authors show that
Figure 4: Median degree of the words in the synonym graph
as a function of the number of incident edges with negative
Ollivier-Ricci curvature. The words with more synonyms
tend to be more polysemous.
combining sounds into words is a way to overcome
such error limit. In line with this reasoning we sug-
gest to look at the graph of edits from a phonetic per-
spective. Indeed, one should remember that there are
certain phonetic structures that are more characteristic
for a given language. Moreover, if a combination of
letters is ’not pronounceable’ it definitely can not be
a meaningful word. Therefore, one can suppose that
the degree in the graph of edits corresponds to the so-
called ’phonetic simplicity’ of a word. The words that
are easier to pronounce would probably have a higher
degree in the graph edits. Figure 5 partially illustrates
this supposition.
Figure 5 and Figure 6 show that as the degree of
the words in the graph of edits gets higher the words
tend to have two vowels rather than one. Also ”u” and
”i” are less frequent among densely connected words,
It Means More if It Sounds Good: Yet Another Hypothesis Concerning the Evolution of Polysemous Words
145
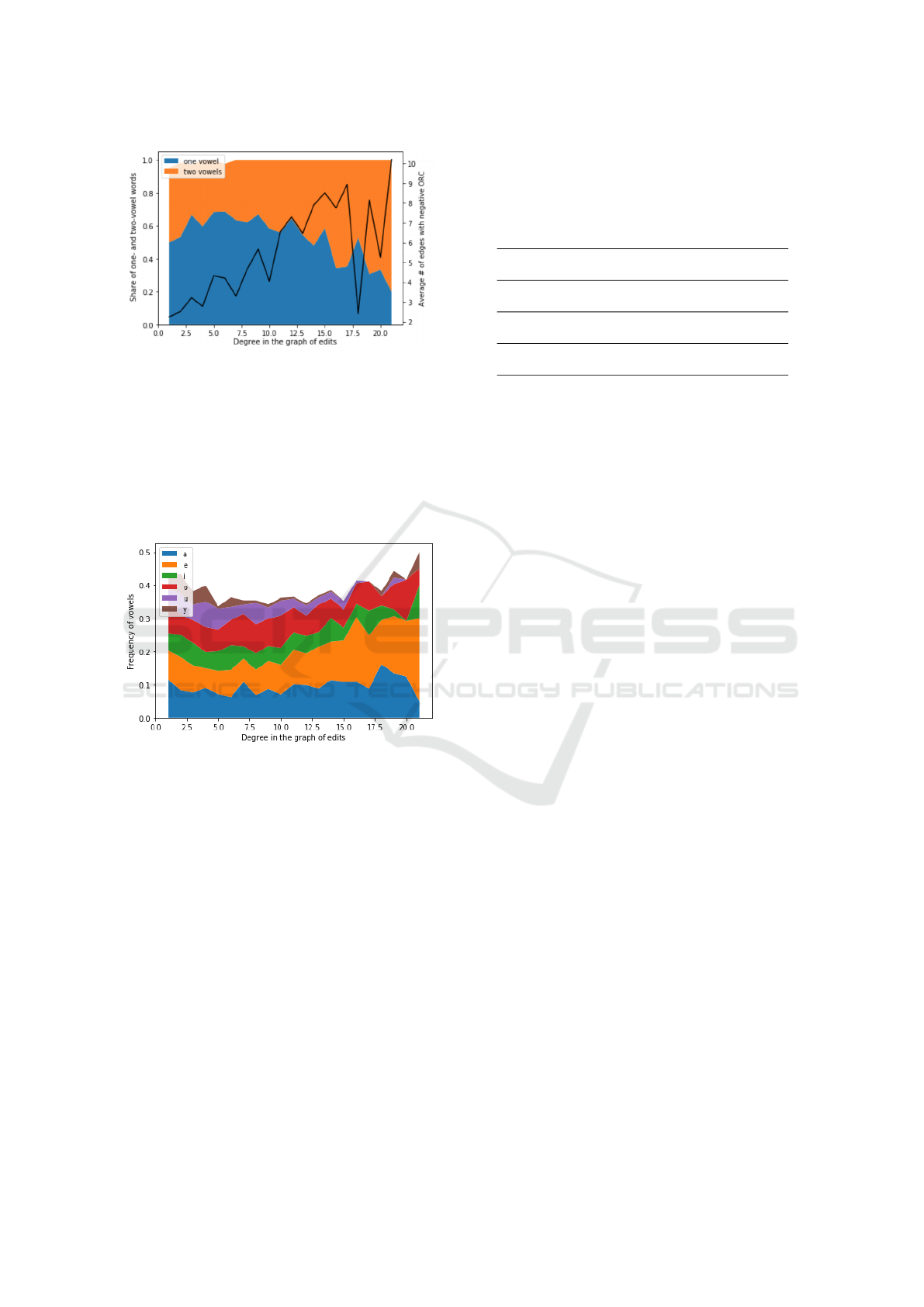
Figure 5: The words with a higher degree in the graph of ed-
its tend to have two vowels rather than one. This words also
tend to be more polysemous, since a higher number of inci-
dent edges with negative Ollivier-Ricci curvature could be
associated with more separate semantic contexts in which a
word could be used.
however ”a” and ”e” seem to occur more often. ”y”
already vanishes as the degree of the words gets big-
ger than ten.
Figure 6: Relative frequencies of vowels are different for
words with different degrees in the graph of edits. ”i” and
”u” tend to occur less often in highly connected words,
whereas ”e” and ”a” are more common.
Table 1 shows that the frequency of two-vowel words
that are arguably more robust in terms of phonetic
simplicity correlates with the degree of the corre-
sponding word in the graph of synonyms. It also
correlates with the number of incident edges with
negative Ollivier-Ricci curvature in the graph of syn-
onyms. Finally, there is a strong correlation between
the frequency of the two-vowel words and their de-
gree in the graph of edits.
All these observed correlations allow speculating
that the structure of the graph of edits is affected by
certain phonetic properties of the English language. A
higher degree of a word in this graph seems to capture
certain phonetic usability of this word.
Table 1: Both number of incident edges with negative
Ollivier-Ricci curvature and degree in the graph of syn-
onyms correlate with frequencies of two-vowel words in the
graph of edits. Degree in the graph of edits shows even
stronger correlation with the frequency of the two-vowel
words.
Value correlation with frequency
of two-vowel words
# of incident edges 59.5%
with negative ORC
degree in the graph 57.9%
of synonyms
degree in the graph 74.7%
of edits
5 DISCUSSION
This position paper demonstrates an interesting em-
pirical fact: there is a connection between the struc-
ture of the graph of edits that is based on purely for-
mal reasoning and a graph of synonyms that to a cer-
tain extent captures semantic complexity of the lan-
guage. This fact in itself is thought-provoking. It mo-
tivates a search for a phonetically inspired notion of
fitness that could be applied to the problems of the
evolution of language. However, the discussion of
such a notion is out of the scope of this work. Here
we would only like to highlight the role of negatively
curved incident edges in the graph of synonyms. We
hope that this geometric approach could be further
used to study polysemy.
Let us now briefly discuss the final interesting
connection between the phonetic structure of the
words and their polysemy. Out of Table 1 we know
that the correlation between the degree in the graph of
edits and the frequency of two vowel words is above
74%. We also know that the frequency of two-vowel
words correlates with a number of incident negatively
curved edges in the graph of synonyms and with the
degree of the word in the graph of synonyms. These
two quantities are also strongly correlated. In fact, the
degree of the word in the graph of synonyms and the
number of its incident negatively curved edges cor-
relate with a coefficient of 0.97. Indeed, a number of
synonyms, polysemy, and frequency of use are known
to be correlated. However, we would like to discuss
another interesting empiric connection here that could
highlight the connection between these properties of
the words and their phonetics.
Let us regard all the words with a given degree in
the graph of edits. For a given word i let us count all
incident edgers with negative Olliver-Ricci curvature
in the synonym graph and let us denote this number
as N
i
. Let us also denote the degree of this word in
COMPLEXIS 2020 - 5th International Conference on Complexity, Future Information Systems and Risk
146
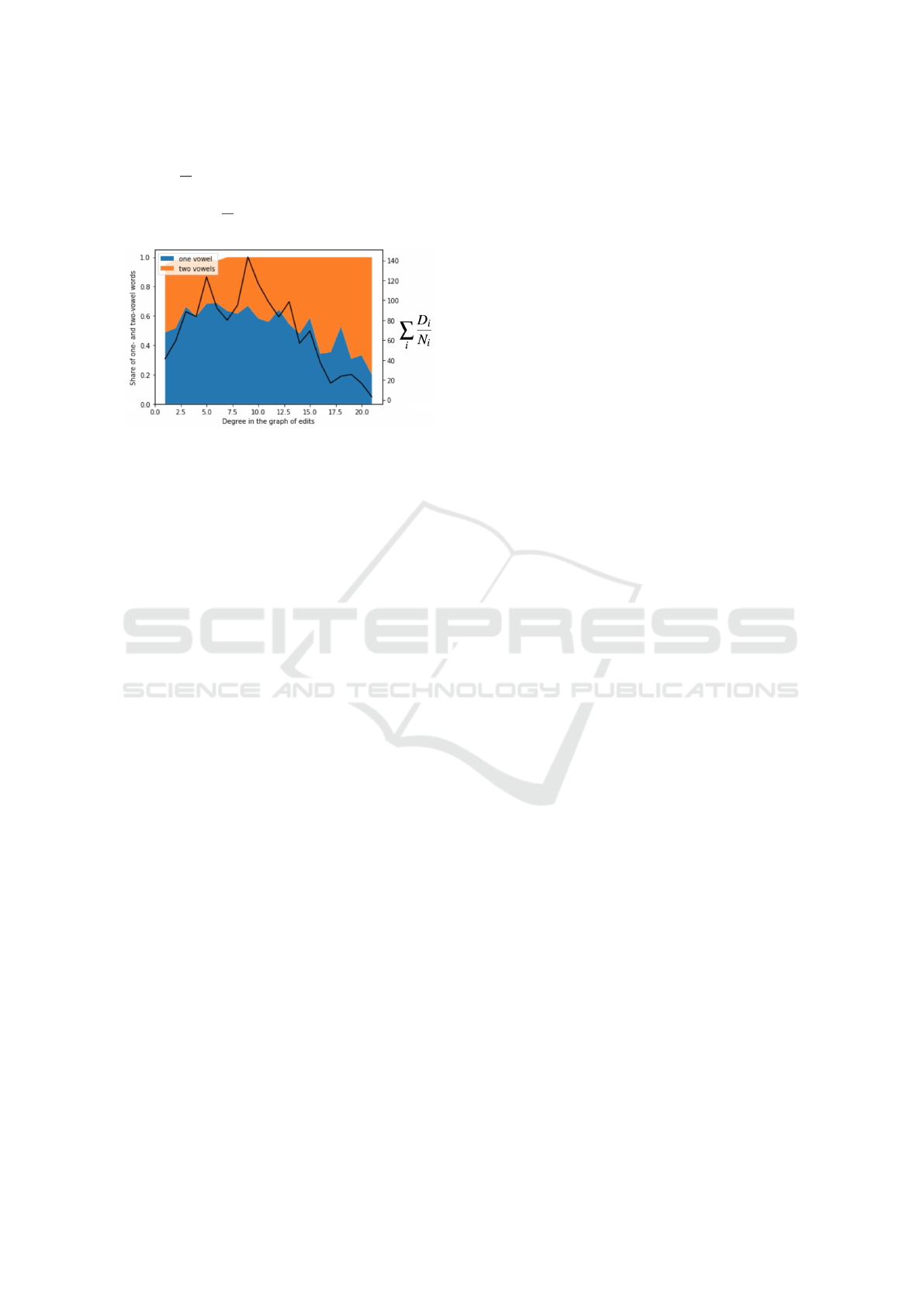
the graph of synonyms as D
i
. Let us then calculate
the ration
D
i
N
i
. Figure 7 demonstrates how the sum of
these ratios across all words with a fixed degree in the
graph of edits
∑
i
D
i
N
i
depends on this degree.
Figure 7: Sum of the ratios between degree and number of
incident edges with negative Ollivier-Ricci curvature across
all words with a fixed degree in the graph of edits correlates
with the frequency of two-vowel words.
Metric in Figure 7 correlates with the frequency of
two vowel words with -83.4%. In our opinion,
this might highlight the importance of Ollivier-Ricci
curvature-based polysemy measure as a tool to high-
light the connection between polysemy and phonetic
properties of the words. It stands to reason that the
words that are easier to pronounce would be used
more often and acquire more synonyms with time.
This highlights the possibility that polysemy could be
associated with certain acoustic simplicity. Therefore
it develops the idea of evolution through metaphor
stated in (MacCormac, 1985), showing that the words
that are easier to pronounce could be more prone to
such evolution and, as time proceeds, could end up
with more semantic fields.
6 CONCLUSION
This position paper demonstrates empirically a con-
nection between polysemy of the words and their for-
mal structure. We propose to use Ollivier-Ricci cur-
vature over a graph of synonyms as an estimate for
polysemy of the word. We speculate that the afore-
mentioned connection between polysemy and formal
structure is rooted in the phonetic properties of the
language. We empirically demonstrate that certain
phonetic properties of the words are correlated with
their polysemy.
ACKNOWLEDGEMENTS
Authors are extremely grateful to Matteo Smerlak and
Massimo Warglien for the help, support and construc-
tive discussions.
REFERENCES
Adelman, J. S., Brown, G. D., and Quesada, J. F. (2006).
Contextual diversity, not word frequency, determines
word-naming and lexical decision times. Psychologi-
cal science, 17(9):814–823.
Blasi, D. E., Wichmann, S., Hammarstr
¨
om, H., Stadler,
P. F., and Christiansen, M. H. (2016). Sound-meaning
association biases evidenced across thousands of lan-
guages. In Proceedings of the National Academy of
Sciences, volume 113:39, pages 10818–10823.
Bybee, J. (2002). Word frequency and context of use in
the lexical diffusion of phonetically conditioned sound
change. Language variation and change, 14(3):261–
290.
Kruchenykh, A. (1923). Phonetics of theatre. M.:41,
Moscow.
Lee, C. J. (1990). Some hypotheses concerning the evolu-
tion of polysemous words. Journal of Psycholinguis-
tic Research, 19(4):211–219.
MacCormac, E. R. (1985). A cognitive theory of metaphor.
Journal of Aesthetics and Art Criticism, 45(4):418–
420.
Newberry, M. G., Ahern, C. A., Clark, R., and Plotkin,
J. B. (2017). Detecting evolutionary forces in lan-
guage change. Nature, 551(7679):223–226.
Ni, C.-C., Lin, Y.-Y., Gao, J., Gu, X. D., and Saucan, E.
(2015). Ricci curvature of the internet topology. In
2015 IEEE Conference on Computer Communications
(INFOCOM), pages 2758–2766. IEEE.
Ni, C.-C., Lin, Y.-Y., Luo, F., and Gao, J. (2019). Commu-
nity detection on networks with ricci flow. Scientific
reports, 9(1):1–12.
Nowak, M. A. and Krakauer, D. C. (1999). The evolution
of language. Proceedings of the National Academy of
Sciences, 96(14):8028–8033.
Ollivier, Y. (2009). Ricci curvature of markov chains
on metric spaces. Journal of Functional Analysis,
256(3):810–864.
Pagel, M., Atkinson, Q. D., and Meade, A. (2007). Fre-
quency of word-use predicts rates of lexical evo-
lution throughout indo-european history. Nature,
449(7163):717–720.
Schleicher, A. (1869). Darwinism tested by the science of
language. JC Hotten.
Shklovsky, V. (1917). Art as technique. Literary theory: An
anthology, pages 15–21.
Sia, J., Jonckheere, E., and Bogdan, P. (2019). Ollivier-
ricci curvature-based method to community detection
in complex networks. Scientific reports, 9(1):1–12.
Smerlak, M. (2020). Localization of neutral evolution: se-
lection for mutational robustness and the maximal en-
tropy random walk. BioRxiv.
It Means More if It Sounds Good: Yet Another Hypothesis Concerning the Evolution of Polysemous Words
147

Smith, J. M. (1970). Natural selection and the concept of a
protein space. Nature, 225(5232):563–564.
Yamshchikov, I. P., Shibaev, V., and Tikhonov, A. (2019).
Dyr bul shchyl. proxying sound symbolism with word
embeddings. Proceedings of the 3rd Workshop on
Evaluating Vector Space Representations for NLP,
pages 90–94.
COMPLEXIS 2020 - 5th International Conference on Complexity, Future Information Systems and Risk
148
