
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete
Data in the Internet of Things
Benjamin Agbo, Yongrui Qin and Richard Hill
School of Computing and Engineering, University of Huddersfield, U.K.
Keywords:
Missing Values, Imputation, Internet of Things (IoT), Best Fit Missing Value Imputation (BFMVI).
Abstract:
The noticeable growth in the adoption of Internet of Things (IoT) technologies, has led to the generation of
large amounts of data usually from sensor devices. When dealing with massive amounts of data, it is very
common to observe databases with large amounts of missing values. This is a challenge for data miners
because various methods for data analysis only work well on complete databases. A popular way to deal with
this challenge is to fill-in (impute) missing values using adequate estimation techniques. Unfortunately, a good
number of existing methods rely on all the observed values in the entire dataset to estimate missing values,
which significantly causes unfavourable effects (low accuracy and high complexity) on imputed results. In this
paper, we propose a novel imputation technique based on data clustering and a robust selection of adequate
imputation equations for each missing datapoint. We evaluate our proposed method using six University of
California Irvine (UCI) datasets, and relevant comparison with five recently proposed imputation methods.
The results presented showed that the performance of the proposed imputation method is comparable with the
Local Similarity Imputation (LSI) technique in terms of imputation accuracy, but is significantly less complex
than all the existing methods identified.
1 INTRODUCTION
The Internet of Things (IoT) can be described as a net-
work of multiple devices that can sense, process and
share data generated from their surroundings (Singh
et al., 2018). The adoption of IoT in various plat-
forms has enabled easy communication and access to
a wide range of devices such as sensors, actuators,
home appliances, surveillance cameras, vehicles, etc.
Therefore, there is a need to deploy more applications
that will adapt to the potentially increasing amount
and variety of data that will be generated by IoT de-
vices (Agbo et al., 2019).
In order to ensure the usefulness of data gener-
ated by IoT devices in various data mining tasks, re-
searchers have attempted to curb the popular chal-
lenge of incompleteness associated with sensor gen-
erated data. According to (Lata and Chakraverty,
2014), data is often incomplete due to a number of
factors such as: human errors, erroneous measure-
ments, communication malfunctions or faulty equip-
ment e.g. sensors. Failure to account for missing data
will significantly compromise the validity of findings
from a dataset. In general, it could undermine the
conclusions of a study by reducing the sample size
which introduces bias (Read, 2015). Popular meth-
ods that have been used in research to handle the issue
of missing data include: list-wise deletion, pair-wise
deletion, hot decking, mean imputation and regres-
sion imputation. Despite the fact that these methods
are straightforward to implement, they may lead to
loss of information or introduce bias in the results ob-
tained (Inman et al., 2015). In addition, most imputa-
tion methods consider the values of an entire dataset
before estimating missing values. This could have un-
favorable effects on the imputation process (e.g. high
complexity or low accuracy).
One of the leading reasons for handling missing
values is to improve the accuracy of clustering and
classification tasks (Silva-Ram
´
ırez et al., 2015). How-
ever, most imputation methods are computationally
intensive and therefore, take time to estimate and im-
pute missing values. This may be inconsequential for
training processes but it will not be practical to spend
much time in estimating values for incomplete in-
stances during clustering or classification tasks. This
is most especially true for complex imputation tech-
niques such as Multiple Imputation by Chained Equa-
tions (MICE), which rebuilds an imputation structure
from every training instance and new instance (Tran
130
Agbo, B., Qin, Y. and Hill, R.
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete Data in the Internet of Things.
DOI: 10.5220/0009578201300137
In Proceedings of the 5th International Conference on Internet of Things, Big Data and Security (IoTBDS 2020), pages 130-137
ISBN: 978-989-758-426-8
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

et al., 2018). Although recent literature has shown
significant increase in the accuracy of advanced im-
putation methods, the high costs associated with these
methods in various tasks has often raised concerns.
Therefore, it has become paramount to address the
question of how the computation time of new meth-
ods could be reduced without sacrificing their accu-
racy (Tran et al., 2018).
In recent years, various machine learning (ML) al-
gorithms have been introduced to handle the issue of
data incompleteness which often occurs as a result of
missing values (Angelov, 2017). These algorithms are
designed to handle this issue by imputing the most
plausible values in instances with missing values. In
contrast to popular statistical methods for filling in
missing values, machine learning algorithms use ex-
isting data in a dataset to train and develop a model
that will be used to impute missing values. Various
ML algorithms for imputing missing values have been
identified in literature such as probabilistic methods,
decision trees, rule based methods etc. (Farhangfar
et al., 2008).
In this paper, we propose a novel imputation tech-
nique which utilizes the similarity between observed
values to perform imputation. This is achieved by par-
titioning an incomplete dataset in the first instance.
Then the similar records within cluster are used to
estimate the missing values. However, some chal-
lenging issues have been identified with the proposed
method including how to perform clustering on the
incomplete dataset before imputation. To solve this
problem, we initially assign distinctive values to re-
place all the missing values. This reduces the effect
of missing values in the datasets and enhances clus-
tering on the incomplete datasets.
We evaluate the performance of our pro-
posed BFMVI technique against existing techniques
namely- LSI, FIMUS, FCM, DMI and EMI, on six
datasets obtained from University of California Irvine
(UCI) machine learning repository.
2 RELATED WORKS
Many research efforts have been channelled towards
addressing the issue of data incompleteness by at-
tempting to develop more accurate and reliable im-
putation techniques. In this section, we will review
various related research and recent efforts aimed at
addressing this problem.
A framework for the imputation of missing values
using co-appearance, correlation and similarity anal-
ysis (FIMUS) was proposed by (Rahman and Islam,
2014). The overal idea behind this method is to make
educated guesses based on the correlation between at-
tributes, co-appearance of values and the similarity
between values that belong to an attribute. Unlike var-
ious existing technique, FIMUS can also be used to
impute missing categorical variables. To compute co-
appearances between values that belong to different
attributes, FIMUS first of all summarizes the values
of numerical attributes into various categories. For in-
stance, the algorithm groups the values of an attribute
A
p
into
p
|A
p
| number of categories, where |A
p
| is
the domain size of A
p
. This strategy of grouping is
advantageous due to its simplicity. However, it may
not always detect natural groups due to the fact that
it artificially makes the range of values for each cate-
gory equal.
Various missing value imputation techniques have
approached imputation using clustering schemes such
as k-means and FCM. Another technique proposed by
(Zhang et al., 2018) approaches imputation firstly by
partitioning a dataset into k clusters. This will re-
sult in the formation of membership values for items
within a particular cluster or cluster centroid. Then,
all the missing values are evaluated using the mem-
bership degree of objects that fall within the same
cluster centroid. The simplicity of this method con-
stitutes a major advantage. However, the accuracy of
the FCM imputation may be significantly affected by
clustering results in usual situations when the selec-
tion of a suitable number of k clusters is challenging
for data miners.
The Expectation maximization imputation (EMI),
proposed by (Schneider, 2001; Dempster et al., 1977)
is one of the most popular missing value imputation
techniques identified in literature. To impute miss-
ing numerical values, this technique estimates the
mean and covariance matrix from observed values in
a dataset and iterates until no considerable change is
noticed in the values of the imputed data, mean and
covariance matrix, from one iteration to another. Ac-
cording to research, the EMI algorithm only works
best in datasets with values that are missing at ran-
dom. The main disadvantage of this method however,
is that it relies on the information from other values in
the dataset. Therefore, this method is only suitable for
datasets with high correlation among attributes (Deb
and Liew, 2016).
Another technique used to handle the issue of
missing data is the Decision tree based missing value
imputation (DMI) algorithm proposed by (Rahman
and Islam, 2013). This technique incorporates the de-
cision tree and the EMI algorithm for imputing miss-
ing values. The authors argue that attributes within
the horizontal partition of a dataset can have higher
correlation than the correlation of attributes over the
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete Data in the Internet of Things
131

entire dataset. The processes involved in DMI are de-
scribed below: firstly, it divides the complete dataset
(D
f ull
) into two smaller datasets with one having in-
complete data i.e. with missing values (D
miss
) and the
other, (D
complete
) having complete records. Next, it
builds up decision trees based on (D
complete
), taking
the attributes with incomplete values in (D
miss
) as the
class attributes. After that step, it further assigns ev-
ery record having missing values in (D
miss
) to the leaf
it falls on the tree, which takes the attribute having the
missing value as the class attribute. Finally, the DMI
algorithm employs the EMI algorithm to fill-in miss-
ing numerical values and majority of the class values
within each leave to impute missing categorical val-
ues.
Another method used to handle the issue of miss-
ing data is the Local Similarity Imputation (LSI) tech-
nique proposed by (Zhao et al., 2018). Here, miss-
ing values are estimated using top k-nearest neigh-
bours and fast clustering. Firstly, a dataset with miss-
ing values is partitioned into clusters, then the most
similar records from each cluster are used to estimate
the missing values. To enhance the accuracy of clus-
tering, this technique uses a two-layer deep learning
algorithm to detect important features within a clus-
ter. Therefore, this will enable the fast clustering al-
gorithm to effectively read important records from a
dataset one time. Lastly, the top k-nearest neighbour
algorithm is used to evaluate and impute missing val-
ues in individual clusters.
Though these methods show good performance in
terms of their imputation accuracy, their huge compu-
tation time will reduce their efficiency when dealing
with increasing volumes of data.
3 ROBUST BFMVI FOR
INCOMPLETE DATA
The structure of our method is represented under two
stages: firstly, the incomplete dataset is partitioned
into different groups and at the second stage, miss-
ing values within each partition is imputed using the
BFMVI algorithm.
3.1 Arbitrary Clustering
To partition our datasets, we first of all fill in all miss-
ing values with distinctive values. To enable fast exe-
cution of our algorithm, we stored the sample of our
dataset with pre-imputed records in a array. An arbi-
trary number (γ) of items were taken from the dataset
to form different groups, containing similar records.
According to (Zhang et al., 2015), better imputation
results could be achieved when similar samples are
used to evaluate missing values. However, (Zhao
et al., 2018) argued that existing clustering algorithms
perform minimally in incomplete datasets due to the
fact that missing values pose serious uncertainties and
affect the accuracy and usability of existing cluster-
ing algorithms. Although, more prospects still remain
for the improvement of our clustering approach, the
strength of our contribution however, lies in our im-
putation method.
Algorithm 1: Clustering Algorithm.
Input: Dataset with missing values, D ∈ X
n∗m
. Parameter
γ, β.
Output: Dataset Clusters and their number k
i
.
1: D ← PreImp (dv, D); //initially fill missing values with
distinctive value
2: Arr ← GetValuesIn (D); //get preimputed values of D
and store in array
3: for i = 1 to l do
4: [Cluster, γ] ← Partition (Arr [γ], Clusters.β ;// Par-
tition arbitrary values of Arr [γ] into β groups.
5: end for
6: Return Clusters and their number k
i
.
3.2 BFMVI based on Arbitrary
Clustering
As stated earlier, the first phase of our technique in-
volves partitioning our datasets into groups of items
with similar records, then the missing values are es-
timated using the observed values of records present
in each cluster. The strength of our contribution lies
in the ability of our model to choose the most suit-
able imputation method for each missing datapoint.
Lets assume [k
1
, k
2
,. . . , k
n
] to be k clusters gener-
ated from the pre-imputed dataset D and [x
1
, x
2
,. . . ,
x
n
] is a non-nominal distribution with missing values.
In the imputation process, the algorithm develops six
imputation results as seen in equation 1-6 and selects
a suitable imputation equation for each missing data-
point based on a defined criteria.
Imputation 1: The average value of observed
records in each cluster are used to fill in each miss-
ing datapoint. Our parameters γ and λ are set to 3 and
0.4 respectively.
p
i
=
n
k
∑
i=1
x
i
n
k
(1)
Imputation 2: For each partition with missing val-
ues x
i
k
, missing values are imputed as follows:
d
i
=
1
n
k
n
k
∑
i=1
r
i
k
(2)
IoTBDS 2020 - 5th International Conference on Internet of Things, Big Data and Security
132
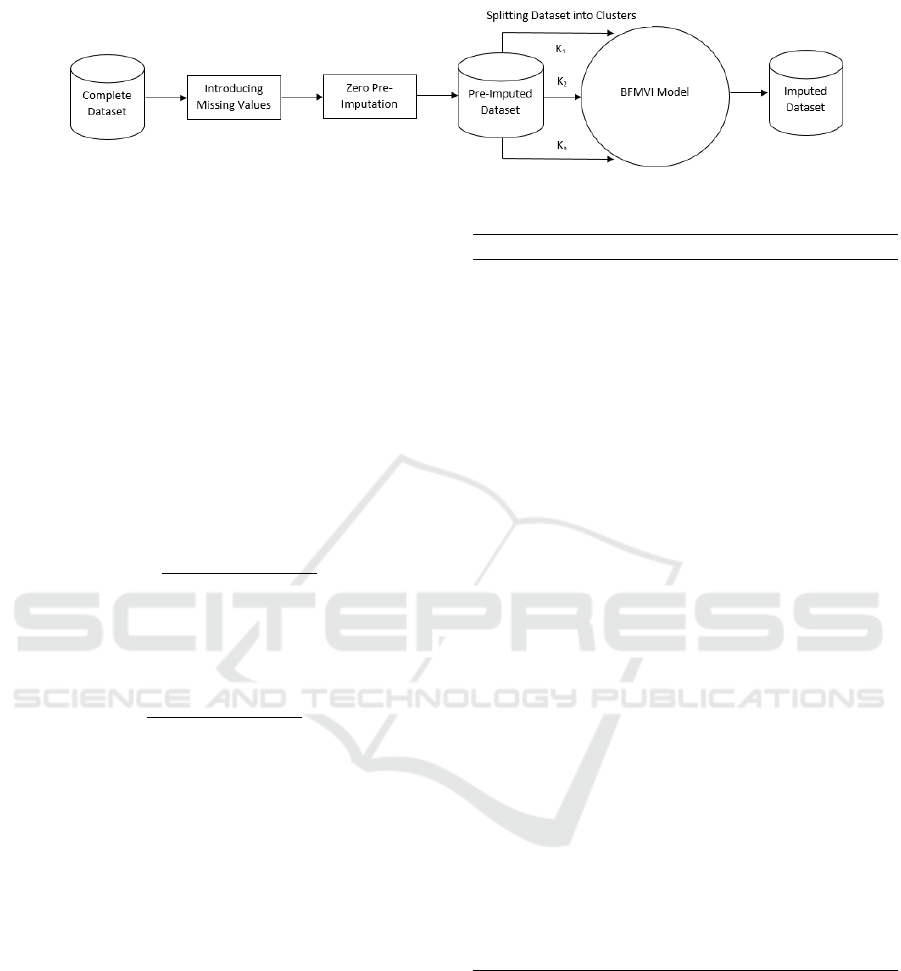
Figure 1: Framework for Imputation Model.
where r
i
k
is the corresponding mode value of x
i
k
and
n
k
represents the distribution size.
Imputation 3: The log of d
i
is computed and the
parameter γ which is set to 3, is multiplied by the re-
sulting value.
R = logd
i
(γ) (3)
Imputation 4: For each missing value within clusters,
imputed values are also evaluated by:
I = log p
i
(γ) (4)
Imputation 5: The sum of I and R is computed and
their resulting average is used to fill in the missing
values within each group.
N
k
i
=
logd
i
(γ) + log p
i
(γ)
2
(5)
Imputation 6: Finally, our parameter λ is added to the
resulting value of N
k
i
and Missing values within each
group is imputed using O
k
i
.
O
k
i
= (
logd
i
(γ) + log p
i
(γ)
2
) + λ (6)
After computing all the values for the missing in-
stances using equation (1-6), the error between each
previous imputation (r
pre
) and the six imputations
(α
curr
) are estimated using the following equation:
err = r
pre,i
− α
curr,i
(7)
For each missing data point, the value of r
pre,i
is com-
pared with all the values estimated from equations (1-
6). The difference between each α
curr,i
and the previ-
ous imputation r
pre,i
is computed and the value with
the lowest error shows a higher similarity with r
pre,i
and is used to impute the value for a particular miss-
ing data point within a cluster.
Considering further improvement and more ap-
plications in dynamic environments, our proposed
method would have the potential to handle dynamic
changes in a dataset as it selects the most appropriate
value for each missing data point.
Algorithm 2: Best Fit Missing Value Imputation.
Input: Dataset with missing values, D ∈ X
n∗m
. Parameters
α.
Output: Dataset with Imputed values P.
1: while 1 do
2: [Clusters,k
i
]← Clustering alg (D); // partitioning
the incomplete dataset using Algorithm 1.
3: for i = 1 to k
i
do
4: [InData, p] ← GetFromData(Clusters.k) ;// get
subsets with incomplete records p;
5: for j = 1 to p do
6: r1 = mean (InData[j], (Clusters.k);
7: r2 = (mode/length)(InData[j],
8: r3 = (log(r2)*3))(InData[j], Clusters.k)
9: r4 = (log(r1)*3)(InData[j], Clusters.k)
10: r5 = r3 + r4/2
11: r6 = r5 + 0.4
12: end for
13: Get set of imputation results r
curr
of Clus-
ters.k
14: α
curr
← GetSet (r
curr
) ;// get current set of
imputation results
15: end for
16: Calculate err between previous and current impu-
tations via (5)
17: Let α
γ
= err(α
curr
)
18: for each α
curr
do
19: if r
γ
= min α
γ
then
20: P ← Out putDataset(D, r
curr
) ;// r
curr
with
lowest error is used for imputation
21: Stop
22: end if
23: end for
24: end while
25: Return complete dataset P;
4 EXPERIMENTS AND ANALYSIS
4.1 Experimental Design
To assess the plausibility of our technique against
other existing techniques, namely LSI, FIMUS, FCM,
DMI and EMI, we used six UCI machine learning
datasets with no missing values as ground truth. Then,
the missing values were artificially imposed on the
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete Data in the Internet of Things
133

Table 1: Description of Six UCI Datasets.
Dataset Records Attributes Classes
Iris 150 4 3
Pima 768 8 2
Wine 178 13 3
Yeast 1484 9 10
Housing 506 14 Null
Adult 48842 14 Null
Table 2: d
2
and average execution time (sec) of the six imputation techniques on the six UCI datasets (at 3, 6, 9, 12 and 15%
missing data).
Datasets
Imputation Methods Iris Pima Wine Yeast Housing Adult
d
2
(t) d
2
(t) d
2
(t) d
2
(t) d
2
(t) d
2
(t)
BFMVI 0.977 (0.031) 0.907 (0.145) 0.959 (0.043) 0.946 (0.258) 0.967 (0.105) 0.9657 (6.89)
LSI 0.983 (0.358) 0.914 (2.439) 0.952 (0.331) 0.948 (15.557) 0.983 (1.654) 0.971 (35.65)
FIMUS 0.966 (1.154) 0.90 (313.248) 0.938 (1.393) 0.854 (1412.75) 0.940 (7.257) 0.954 (1923.35)
FCM 0.964 (0.256) 0.882 (0.874) 0.788 (0.242) 0.929 (13.974) 0.916 (0.301) 0.751 (23.75)
DMI 0.954 (2.683) 0.860 (412.386) 0.864 (12.363) 0.936 (73.146) 0.912 (84.552) 0.881 (103.04)
EMI 0.957 (0.173) 0.848 (1.674) 0.868 (0.549) 0.911 (5.417) 0.905 (2.785) 0.713 (19.78)
datasets in order to test the accuracy of the six im-
putation techniques. Since the original values of the
datasets are known, we can easily evaluate the accu-
racy of the missing data imputation techniques by ob-
serving how close the imputed values are to the origi-
nal (Zhao et al., 2018). Each of the UCI datasets were
then regenerated into five unique data sets with differ-
ent percentages of missing values: 3%, 6%, 9%, 12%
and 15% respectively on each dataset.
The six imputation methods are then used to fill
in the different percentages of missing values in each
dataset. For the purpose of our simulation, we used
a dimensionality reduction technique called Princi-
pal Component Analysis (PCA) to reduce interrelated
components, thereby retaining the variation of values
present in each dataset. This led to the generation
of new sets of uncorrelated records called principal
components, which were used to simulate the differ-
ent percentages of missing data. The criteria that are
used to quantify the performance of the imputation
methods are RMSE and d
2
. We further computed the
execution time for each technique to evaluate their
performance in resource constraint scenarios. From
equation 8 and 9, N represents the number of values
missing. P
i
and O
i
are the respective imputed and ac-
tual values of the ith missing values, and
¯
O represents
the average of the actual values. The RMSE value can
range from 0 to ∞, with a lower value indicating bet-
ter imputing performance. The value of d
2
can range
from 0 to 1 with a higher value indicating better re-
semblance (Zhao et al., 2018).
RMSE =
r
1
N
N
∑
i=1
(P
i
− O
i
)
2
(8)
d
2
= 1 − [
∑
N
i=1
(P
i
− O
i
)
2
∑
N
i=1
(|P
i
−
¯
O| + |O
i
−
¯
O|)
2
] (9)
4.2 Results and Analysis
Figure 2-7 presents the accuracy of our BFMVI tech-
nique against LSI, FIMUS, FCM, DMI and EMI tech-
niques on iris, wine, boston housing, yeast, pima and
adult datasets in terms of their RMSE for 5 missing
data ratios.
Table 2 further shows the index of agreement (d
2
)
and execution time (in seconds) for the six imputation
techniques on the six UCI datasets.
From the results, it can be observed that the pro-
posed method shows a low error rate and good impu-
tation accuracy but does not completely outperform
the LSI technique. However, it shows the best per-
formance in terms of execution time compared to the
five other methods. Although, the popular EMI tech-
nique considers the entire instances in a dataset before
performing imputation, it still has the lowest accuracy
among all the six methods that were tested.
IoTBDS 2020 - 5th International Conference on Internet of Things, Big Data and Security
134
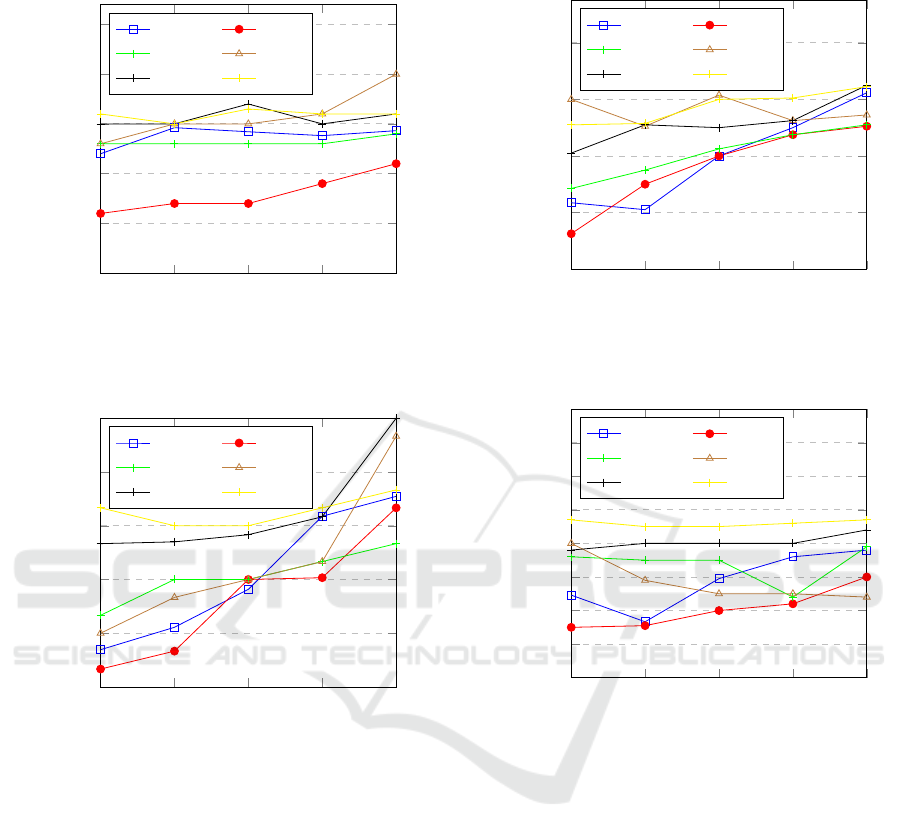
3
6
9 12
15
0
0.05
0.1
0.15
0.2
0.25
Missing Data Ratio (%)
RMSE
Boston Housing Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 2: RMSE of imputation methods on Housing Data.
3
6
9 12
15
0
0.03
0.06
0.09
0.12
0.15
Missing Data Ratio (%)
RMSE
Iris Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 3: RMSE of imputation methods on Iris Data.
In contrast, the LSI technique shows the best per-
formance in terms of imputation accuracy but fails to
completely outperform FCM, EMI and our method in
terms of execution time.
FIMUS is another hybrid method that considers
every record in a dataset before imputation. The ac-
curacy of this method is better than FCM DMI and
EMI in all five datasets and sometimes outperforms
our method when a higher percentage of missing-
ness is observed in a dataset. However, the execu-
tion time of this method is poor compared to LSI,
FCM, EMI and our method. From our observation,
the performance of the execution time reduced signif-
icantly when more records were observed ( e.g. in the
pima and yeast datasets). The DMI and FCM tech-
niques partition the datasets into small groups with
similar records which could have a positive effect on
the imputation of missing values when closely related
3
6
9 12
15
0
0.04
0.08
0.12
0.16
Missing Data Ratio (%)
RMSE
Wine Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 4: RMSE of imputation methods on Wine Data.
3
6
9 12
15
0.08
0.09
0.1
0.11
0.12
0.13
0.14
0.15
Missing Data Ratio (%)
RMSE
Yeast Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 5: RMSE of imputation methods on Yeast Data.
records are used to estimate missing records. How-
ever, DMI and FCM completely rely on the accuracy
of clustering or classification and therefore perform
minimally due to clustering or classification inaccu-
racy.
Overall, the accuracy of our proposed method ran
close to the LSI method on five out of six datasets
but showed a clear distinction from the LSI method
on the boston housing dataset. This was largely in-
fluenced by the accuracy of the fast clustering algo-
rithm using a two-layer deep learning algorithm in the
LSI method. We will attempt to address these lim-
itations by improving the similarity between records
used to estimate these missing values in our proposed
method.
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete Data in the Internet of Things
135

3
6
9 12
15
0.1
0.12
0.14
0.16
0.18
Missing Data Ratio (%)
RMSE
Pima Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 6: RMSE of imputation methods on Pima Data.
3
6
9 12
15
0
1
2
3
4
5
6
7
8
Missing Data Ratio (%)
RMSE
Adult Data
BFMVI
LSI
FIMUS FCM
DMI EMI
Figure 7: RMSE of imputation methods on Adult Data.
5 CONCLUSION AND FUTURE
WORKS
Inferences drawn from various data mining tasks
(such as prediction, clustering, classification etc.) can
significantly be affected by the presence of missing
data. Therefore, to ensure the validity of information
drawn from these tasks, the imputation of missing val-
ues using adequate techniques is paramount. In this
paper, we present a BFMVI technique for handling
incomplete static databases. The proposed method
first of all fills in missing data points with distinc-
tive values and partitions the pre-imputed dataset us-
ing arbitrary values. Secondly, based on the similar-
ity between values in each cluster, missing values are
estimated using the BFMVI algorithm. From the ex-
periments, it is observed that our proposed method is
less complex that other identified methods and shows
considerable performance in terms of imputation ac-
curacy, which makes it a good fit for resource con-
straint scenarios.
Considering the characteristics of IoT data and its
contribution to the big data era, more work still needs
to be done with regards to developing robust and less
complex algorithms for handling missing values ob-
served in streams of continuously generated data. Our
future research will be based on the improvement of
the proposed imputation method and its adoption in
more dynamic scenarios.
REFERENCES
Agbo, B., Qin, Y., and Hill, R. (2019). Research directions
on big iot data processing using distributed ledger
technology: A position paper. In IoTBDS.
Angelov, B. (2017). Working with missing data in machine
learning.
Deb, R. and Liew, A. W.-C. (2016). Missing value impu-
tation for the analysis of incomplete traffic accident
data. Information sciences, 339:274–289.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977).
Maximum likelihood from incomplete data via the em
algorithm. Journal of the Royal Statistical Society:
Series B (Methodological), 39(1):1–22.
Farhangfar, A., Kurgan, L., and Dy, J. (2008). Impact of
imputation of missing values on classification error
for discrete data. Pattern Recognition, 41(12):3692–
3705.
Inman, D., Elmore, R., and Bush, B. (2015). A case
study to examine the imputation of missing data to
improve clustering analysis of building electrical de-
mand. Building Services Engineering Research and
Technology, 36(5):628–637.
Lata, K. and Chakraverty, S. (2014). Handling data incom-
pleteness using rough sets on multiple decision sys-
tems. In 2014 International Conference on Data Min-
ing and Intelligent Computing (ICDMIC), pages 1–6.
IEEE.
Rahman, M. G. and Islam, M. Z. (2013). Missing value im-
putation using decision trees and decision forests by
splitting and merging records: Two novel techniques.
Knowledge-Based Systems, 53:51–65.
Rahman, M. G. and Islam, M. Z. (2014). Fimus:
A framework for imputing missing values using
co-appearance, correlation and similarity analysis.
Knowledge-Based Systems, 56:311–327.
Read, S. H. (2015). Applying missing data methods to rou-
tine data using the example of a population-based reg-
ister of patients with diabetes.
Schneider, T. (2001). Analysis of incomplete climate data:
Estimation of mean values and covariance matrices
and imputation of missing values. Journal of climate,
14(5):853–871.
IoTBDS 2020 - 5th International Conference on Internet of Things, Big Data and Security
136

Silva-Ram
´
ırez, E.-L., Pino-Mej
´
ıas, R., and L
´
opez-Coello,
M. (2015). Single imputation with multilayer per-
ceptron and multiple imputation combining multilayer
perceptron and k-nearest neighbours for monotone
patterns. Applied Soft Computing, 29:65–74.
Singh, M., Singh, A., and Kim, S. (2018). Blockchain:
A game changer for securing iot data. In Internet
of Things (WF-IoT), 2018 IEEE 4th World Forum on,
pages 51–55. IEEE.
Tran, C. T., Zhang, M., Andreae, P., Xue, B., and Bui, L. T.
(2018). Improving performance of classification on
incomplete data using feature selection and clustering.
Knowledge-Based Systems, 154:1–16.
Zhang, L., Pan, H., Wang, B., Zhang, L., and Fu, Z. (2018).
Interval fuzzy c-means approach for incomplete data
clustering based on neural networks. Journal of Inter-
net Technology, 19(4):1089–1098.
Zhang, Q., Yang, L. T., Chen, Z., and Xia, F. (2015). A
high-order possibilistic c-means algorithm for cluster-
ing incomplete multimedia data. IEEE Systems Jour-
nal, 11(4):2160–2169.
Zhao, L., Chen, Z., Yang, Z., Hu, Y., and Obaidat, M. S.
(2018). Local similarity imputation based on fast clus-
tering for incomplete data in cyber-physical systems.
IEEE Systems Journal, 12(2):1610–1620.
Best Fit Missing Value Imputation (BFMVI) Algorithm for Incomplete Data in the Internet of Things
137
