
Use of Text Mining Techniques for Recommender Systems
Yanelys Betancourt
1
and Sergio Ilarri
2 a
1
Universidad de Zaragoza, Edificio Ada Byron, Mar
´
ıa de Luna, 1, 50018 Zaragoza, Spain
2
I3A, Universidad de Zaragoza, Edificio Ada Byron, Mar
´
ıa de Luna, 1, 50018 Zaragoza, Spain
Keywords:
Recommender Systems, Text Mining, Opinion Mining.
Abstract:
Recommender systems help users to reduce the information overload they may suffer in the current era of
Big Data, by offering them recommendations of relevant items according to their tastes/preferences and/or
context (location, weather, time of the day, etc.). We argue that text mining techniques can be exploited for the
development of recommender systems. Thus, they can be applied to detect user preferences (user profiling)
and also to extract context data. For this purpose, text mining can be applied on user reviews, text descriptions
associated to the items, and other texts written by the user (e.g., posts in social networks). In this paper,
we provide an overview of works exploiting text mining techniques in the field of recommender systems,
characterizing them according to their purpose and the type of textual data analyzed.
1 INTRODUCTION
Nowadays, recommender systems (RS) (Ricci et al.,
2011; Ricci et al., 2015) have become very popu-
lar, as they can help users to reduce the information
overload they may suffer in today’s Big Data era,
where advanced data management techniques are re-
quired. These systems provide recommendations to
the users according to their tastes and preferences, al-
lowing them to filter, from a great amount of differ-
ent types of items (e.g., music, movies, news, books,
places, services, shopping areas, restaurants, points
of interest, etc.), those that can be of special rele-
vance to them. Given their current specialization,
recommender systems keep being a hot area of re-
search. In mobile environments in particular, rec-
ommender systems that take into account not only
the user’s preferences but also their context (location,
time, weather, traffic conditions, etc.) are of particular
interest, which has given rise to the so-called context-
aware recommender systems (CARS) (Adomavicius
and Tuzhilin, 2011).
We argue that the use of text mining tech-
niques (Berry, 2004; Gupta et al., 2009) can be ex-
ploited for the development of recommender systems
from various perspectives. Popular text mining tasks
include text clustering, text classification, informa-
tion extraction, text summarization, sentiment analy-
sis/opinion mining, etc. For example, sentiment anal-
a
https://orcid.org/0000-0002-7073-219X
ysis techniques could be applied to quantify user pref-
erences based on their comments expressed in natu-
ral language or even to detect possible inconsisten-
cies (opinion spam) if a user provides both a textual
comment and a numerical rating (mining of opinions
about items). In addition, they can be used to ex-
ploit textual descriptions of the different elements to
recommend (mining of items’ textual data). Finally,
the possible analysis of other texts written by the
user himself/herself (e.g., in blogs, social networks,
his/her agenda, etc.) may reveal information about
his/her preferences, interests, and even his/her con-
text.
A relevant complement of text mining techniques
is the use of semantic techniques, usually based on
the use of ontologies. As an explicit formal speci-
fication of a shared conceptualization (Gruber et al.,
1993), an ontology contains a shared vocabulary to
denote the types, properties and interrelations of those
concepts (Subramaniyaswamy et al., 2019). Besides
the possibility to use ontologies as a support for data
mining tasks such as information extraction, ontolo-
gies can also be exploited directly by a recommender
system (Subramaniyaswamy et al., 2019; Tarus et al.,
2018), for example to establish the relationships be-
tween users and their preferences on the recommen-
dation topic (Tarus et al., 2018). Ontology-based
recommender systems using text mining often use a
topic ontology with associated controlled vocabulary
to identify topics from text messages written in nat-
780
Betancourt, Y. and Ilarri, S.
Use of Text Mining Techniques for Recommender Systems.
DOI: 10.5220/0009576507800787
In Proceedings of the 22nd International Conference on Enterprise Information Systems (ICEIS 2020) - Volume 1, pages 780-787
ISBN: 978-989-758-423-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

ural language (comments, descriptions, opinions, re-
views, etc.).
In this paper, we provide an overview of works
that exploit text mining techniques in the field of rec-
ommender systems (see Figure 1). The structure of
the rest of this paper is as follows. In Section 2, we fo-
cus on works in the field of recommender systems that
apply text mining techniques on user reviews. In Sec-
tion 3, we consider recommender systems that per-
form text mining on other texts written by the user. In
Section 4, we consider works using textual data about
the items themselves. Finally, in Section 5, we sum-
marize our conclusions and future work.
2 RECOMMENDER SYSTEMS
USING TEXT MINING ON
USER REVIEWS
In this section, we focus on text mining of user re-
views (see Table 1). Sometimes users provide opin-
ions about the items they consume, through text de-
scriptions posted in blogs, microblogs (like Twitter),
product review websites, chat rooms, online feed-
back systems of companies, and different user com-
munities or social networks (such as Facebook, Twit-
ter, LinkedIn, or Instagram). These opinions contain
very valuable information to detect the interests of
the users, which can be exploited for recommenda-
tion purposes (Roul and Arora, 2019; Kim and Chun,
2019).
As these opinions are provided in natural lan-
guage, they cannot be directly exploited to learn the
user preferences and recommend the user other items
that he/she is expected to like. Therefore, a typical
use of text mining for recommender systems is to try
to transform textual user reviews into scores (e.g., in
a range of 0 to 5) or predefined categories such as
positive opinion, neutral opinion, or negative opin-
ion, that can be used to build the user-item matrices
that recommender systems use in the recommenda-
tion process; specifically, sentiment analysis or opin-
ion mining techniques (Liu and Zhang, 2012; Hegde
and Padma, 2017) can be applied.
In (Aciar et al., 2007), text mining techniques are
used to transform opinions into structured data, us-
ing a translation ontology that encompasses both the
user’s skill and the user’s experience with the product.
Scores for each feature are computed in order to rank
the products according to the comments available
about that product. The system requires users to ex-
plicitly request a recommendation/assessment about a
specific product they are interested in, and they have
to select the features that interest them most. Beyond
that, it should be noted that this type of recommenda-
tion is not personalized, as the individual preferences
of the user are not considered when making the rec-
ommendation. The proposal takes into account the
level of experience of the reviewers to ensure a reli-
able recommendation.
The reliability of the reviews is also a key as-
pect considered in other proposals. Thus, (Abuein
et al., 2017) presents the design and implementa-
tion of a recommender system based on informa-
tion provided by trusted people using the concept of
trust level (LoT) (Abuein et al., 2016). In (Roul and
Arora, 2019), the reviewer’s credibility is also consid-
ered, but in this case the focus is on generating sum-
maries of multiple reviews for a given product and the
credibility (computed by analyzing how much the re-
viewer’s rating deviates from most people’s ratings)
is used to decide on the importance of a sentence. For
the automatic summarization of user reviews, fuzzy
c-means clustering is used to group similar sentences
and then one representative sentence from each group
is selected in order to compose the final summary.
This work’s goal is to generate a representative sum-
mary of reviews to provide along with the recommen-
dation of a product, rather than proposing a novel rec-
ommender system.
In (Musto et al., 2019), the authors present an ap-
proach to generate natural language justifications to
support the suggestions returned by a generic recom-
mendation algorithm, based on natural language pro-
cessing and sentiment analysis techniques to identify
the relevant and distinctive aspects that characterize
an item. The experimental results included in the pa-
per show that the justifications generated can be rich
and satisfying and that the users prefer review-based
justifications as opposed to other explanation strate-
gies (feature-based explanations); in particular, the
authors’ proposal is compared experimentally with
ExpLOD (Musto et al., 2016). As a final example, a
recommender system applying text mining on opin-
ions written in Chinese is presented in (Miao and
Lang, 2017). An item-feature matrix is built to calcu-
late the similarity of item characteristics, with the goal
to improve the accuracy of item similarity and so the
quality of the recommendations. A technique called
ItemCF is used to generate the recommendation (Shi
et al., 2014), which supports the pre-calculation of
similar items.
There are other works that exploit both numerical
ratings provided by the users and textual user reviews,
based on the hypothesis that this joint use can lead
to more accurate recommendations. Thus, in (Jakob
et al., 2009), that focuses on the domain of movies,
Use of Text Mining Techniques for Recommender Systems
781
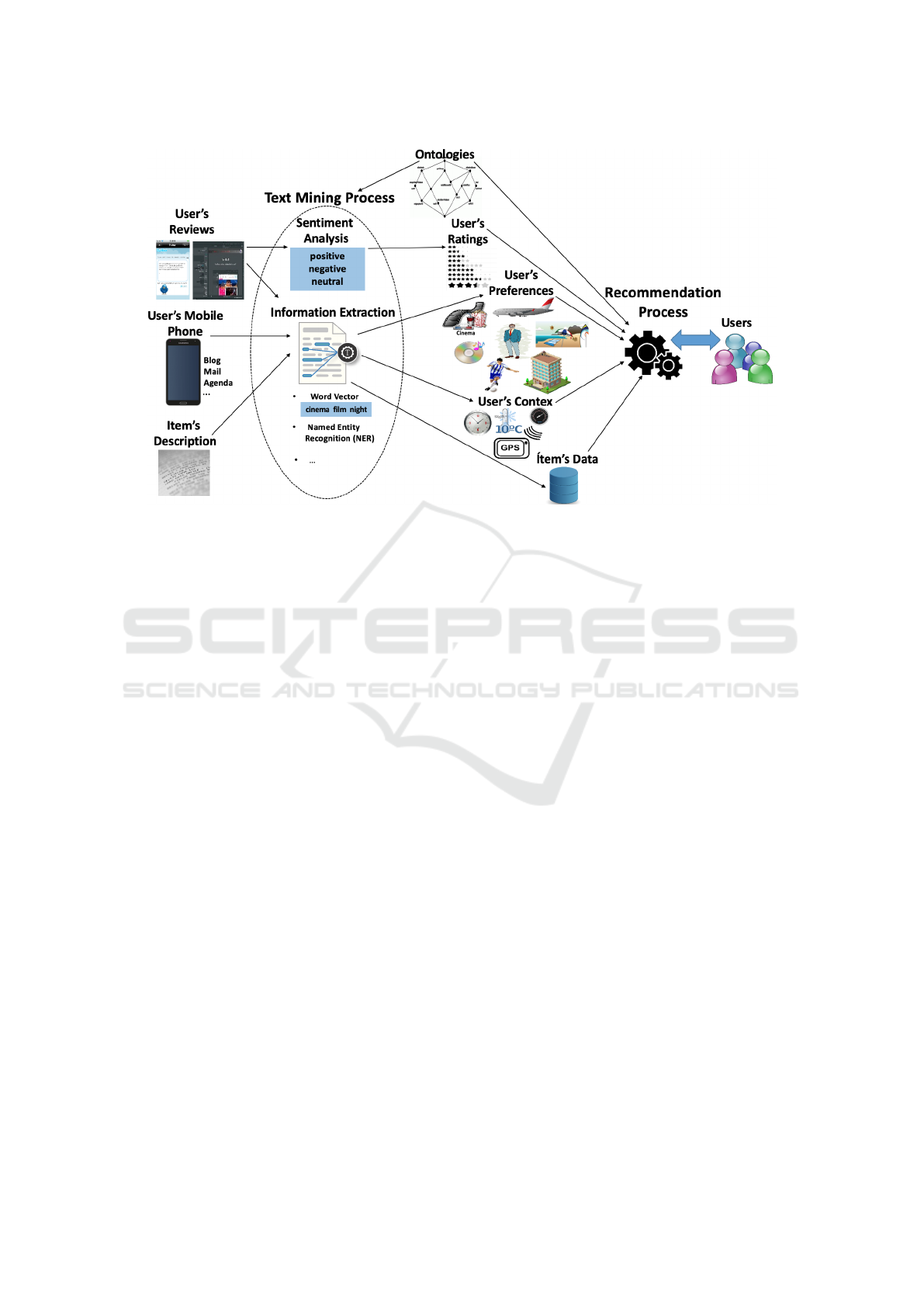
Figure 1: Using text mining in recommender systems: general framework.
a phrase-level opinion extraction from free-text film
reviews is performed to identify statements with posi-
tive and negative opinions, and this information is in-
corporated into a recommender system called HYRES
(HYbrid REcommendation System). Several movie
aspect clusters are defined and global numerical val-
ues are computed for each cluster. The experimen-
tal results show that the Latent Dirichlet Allocation
(LDA) clustering approach leads to the best results.
User reviews could also be analyzed to extract
contextual information. For example, (Li et al., 2010),
which focuses on reviews about restaurants, uses text
mining techniques to extract information about 4 dif-
ferent context attributes: companion (whether the
user is alone or with other people), occasion for the
event (e.g., whether it is a holiday or a birthday), time
of the day, and location (in this case extracted from
the user profile, as the authors argue that it is usu-
ally not available in the review texts). Then, the au-
thors propose a Probabilistic Latent Relational Model
(PLRM) to integrate the context data and provide the
recommendations.
3 RECOMMENDER SYSTEMS
USING TEXT MINING ON
OTHER USER’S TEXTS
In this section, we review works that mine textual data
written by the user (other than reviews about items,
which were already analyzed in Section 2) in order
to retrieve useful information for the recommenda-
tion process (see Table 2). This could mean analyz-
ing texts to obtain information about the user’s con-
text, such as his/her location (Drymonas and Pfoser,
2010; Feldman et al., 2015), and/or information about
his/her preferences (e.g., the topics he/she is inter-
ested in). The input textual data could be, for ex-
ample, tweets written by the user. Besides, many re-
cent studies have begun to explore other sources of in-
formation, such as social networks, where larger text
messages can be posted and shared. The diary of the
user could be another relevant text source. Finally,
several recent studies have also demonstrated the ef-
fectiveness of leveraging collective knowledge to en-
rich the users’ interest profiles (Faralli et al., 2015).
Twitter can be an interesting data source to try to
infer the interests of users (Piao and Breslin, 2018).
As an example (Xu et al., 2011), starts from the idea
that users often post noisy messages about their lives
or create conversations with friends that are not re-
ally related to their topics of interest. Therefore, they
propose a framework to address this problem by in-
troducing a modified author-subject model called the
Twitter user model, which is a generative model that
extends LDA to include information about authorship.
A latent variable is used to indicate if a tweet is related
to the author’s interests. According to the authors, this
model can be considered as an initial work for many
tasks in Twitter, such as recommending friends, rat-
ing users, and analyzing social networks. As another
example, in the proposal presented in (Zarrinkalam
et al., 2015) each topic of interest is a conjunction of
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
782

Table 1: Examples of recommender systems using text mining on user reviews.
Items Data used
Recommendation
Approach
Supporting
tools
Text mining
techniques
Reference
Products
Reviews
Collaborative Filtering
Ontology, measures
such as the OFQ
(Overall Feature Quality)
Rule-based
classification techniques,
TMSK (Text-Miner
Software Kit),
Riktext software,
ontology (opinion quality
and product quality).
(Aciar et al., 2007)
Items
Reviews
(written in
Chinese)
Collaborative Filtering
Euclidean distance,
ItemCF
(Shi et al., 2014)
Word segmentation
(jieba), stop words
removal, POS Templates,
HowNet (emotional
dictionary), clustering,
chi-square statistics,
logistic regression
(Miao and Lang, 2017)
Tourist
attractions
Reviews Knowledge-based
Supervised algorithms
Probit algorithm, binomial
logistic regression,
decision trees
(CHAID, C&RT and
Random Forest)
IBM SPSS Modeler
Text Analytics, removing
non-linguistic entities
(Guerreiro and Rita, 2019)
Shoppings Reviews
TRS LoT (approach based
on the trust level)
LoT (Level of Trust)
Stop-word removal,
word indexing,
word comparison
(Abuein et al., 2017)
Movies
Reviews,
ratings
Collaborative Filtering HYRES recommender
Clustering, stop
word removal,
Explicit Semantic Analysis
(ESA), LDA-based clustering,
subjectivity clue lexicon
(Jakob et al., 2009)
Restaurants
Restaurant’s
review
CARS (recommendation
based on contextual
information)
Boolean model,
Probabilistic Latent
Relational Model (PLRM)
Bag of words,
rule-based classifiers,
GATE tools (ANNIE,
which is a time named
entity recognizer)
(Li et al., 2010)
several concepts, which are temporarily correlated on
Twitter. Based on this, active themes within a given
time interval are extracted and the user’s inclination
towards those themes is determined. Based on this
idea, a concept graph is built and community detec-
tion methods are applied to detect active topics of in-
terest in a given time interval, considering that the re-
lationships between two topics in a social network can
change over time. Besides, a technique to determine
the standpoint of a given user with respect to the ac-
tive topics is proposed. The proposal presented was
applied to design a personalized news recommender
system, which was evaluated experimentally.
Due to the existing information overload in Twit-
ter, recommender systems have also been created to
recommend useful tweets in which users could be re-
ally interested. For example, in (Chen et al., 2012),
the following elements are considered for the recom-
mendation: factors related to the thematic/topic level
of the tweet (used to capture users’ common interests
in the content of the tweets), factors of the social rela-
tionships of the user, and explicit characteristics such
as the authority of the editor and the quality of the
tweet. The experimental results show that the combi-
nation of all these elements can help to improve the
performance of tweet recommendations.
Besides tweets, another popular type of user-
written data can be text messages posted on social
networks. KBRS (Rosa et al., 2019) is a knowledge-
based recommender system that, based on ontologies
and the analysis of feelings, is able to analyze sen-
tences published on online social networks with the
purpose of detecting users with potential psychologi-
cal disorders (depression and stress). Then, if needed,
a recommender system is used to send messages of
happiness, calm, relaxation, or motivation. Text sen-
tences are analyzed using machine learning algo-
rithms, including the CNN model, BLSTM-RNN, and
considering the feeling metric (eSM2). eSM2 was
modeled to improve the performance of KBRS, tak-
ing into account parameters of the user profile, his/her
geographic location, and the subject of the sentence,
Use of Text Mining Techniques for Recommender Systems
783
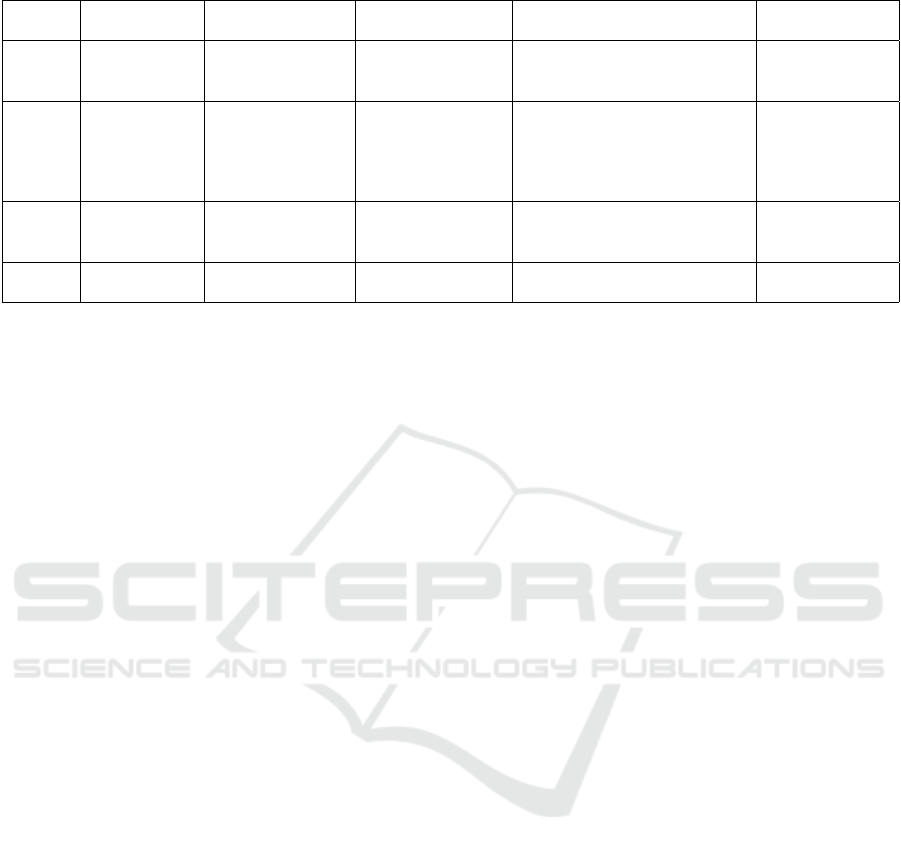
Table 2: Examples of recommender systems using text mining on other user’s texts.
Items Data used
Recommendation
Approach
Supporting
tools
Text mining
techniques
Reference
Tweets
Tweets, user
social relations
and other features
Collaborative Filtering
Factorization model,
Jaccard similarity
Latent factors (Chen et al., 2012)
Messages
Messages,
user profile
parameters,
geographical
location
Knowledge-based
Deep Learning,
recurrent neural
networks (RNN),
BLSTM-RNN model,
the Nuadu ontology
Machine learning algorithms,
sentiment metric (eSM2)
(Rosa et al., 2019)
Tourism
POIs
Textual
messages in
a web chat
Content-Based
Filtering
Probabilistic techniques
(fuzzy reasoning)
ontology
Rocchio’s and Naive Bayes algorithms,
tourism ontology
(Loh et al., 2003)
Tags Text in tags Collaborative Filtering
Association
rules, LDA
TF-IDF (Krestel et al., 2009)
to identify the intensity of the feeling identified in a
message. The paper shows the effectiveness of using
an ontology and a personalized feeling analysis.
Text mining techniques can also be used to dis-
cover user interests from text exchanged in a chat con-
versation. For example, (Loh et al., 2003) exploits
texts in chats between a customer and a travel agent to
discover and recommend travel options for customers,
especially for those who do not really know where to
go and what to do there. The proposed system queries
a tourism ontology to identify key topics in the text
messages and then queries a database to retrieve ap-
propriate touristic options (such as cities and attrac-
tions). In this case the recommender system is hidden
from the customer, as it is the travel agent the one who
receives the recommendations, that support him/her
to better guide the client. Rather than using extensive
forms with options, attributes, and requirements, the
needs and desires of the customer arise during a natu-
ral conversation, and the data retrieved by the system
can complement the potential lack of experience or
knowledge of the travel agent regarding the specific
interests of the customer.
Some work has also been done to extract infor-
mation from texts written by users in informal com-
munications (instant messaging, recordings, meeting
minutes, emails) as a potential source of knowledge
within an organization. This could be very useful,
for example, to create user profiles for use in rec-
ommender systems. In (Gentile et al., 2011), the au-
thors claim that it is possible to model the experience
of people automatically by tracking informal commu-
nication exchanges (e-mails) and through the seman-
tic annotation of their content to derive dynamic user
profiles. The profiles are then used to estimate the
similarity between people (using the Jaccard index).
A tool called SimNET (Similarity and Network Ex-
ploration Tool) interactively displays content and user
networks as part of the search and navigation capa-
bilities provided by the knowledge management sys-
tem. Three techniques are used to build the profiles:
Profile based on keywords, using the Java Automatic
Term Recognition Toolkit (JATR v1.02) for keyword
extraction; Profile based on the Entity, using the Open
Calais web service for the extraction of named enti-
ties; and Profile based on the Concept, using the Wik-
ify web service for concept extraction.
Another relevant type of written text that can be
considered is text present in tags. Tagging systems
have become important for the Web, as they allow
users to create tags that annotate and categorize dif-
ferent types of contents and share them with oth-
ers. However, an important difficulty is that tags are
not limited by a controlled vocabulary and annotation
guidelines, and they tend to be noisy and sparse. The
aim of the approach presented in (Krestel et al., 2009)
is to overcome the problem of cold start for tagging
new resources. Specifically, LDA is used to obtain
latent topics from texts and, based on this, other tags
belonging to those themes can also be recommended.
According to the experimental evaluation presented,
this approach achieves a better performance (in terms
of accuracy and recall) than an alternative approach
using association rules.
4 RECOMMENDER SYSTEMS
USING TEXT MINING ON
ITEMS’S DATA
In this section, we review some works that apply text
mining on data associated to the items that can be rec-
ommended (see Table 3).
With geo-positioning and geo-tagging of objects
that have both a geographic location and a text de-
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
784
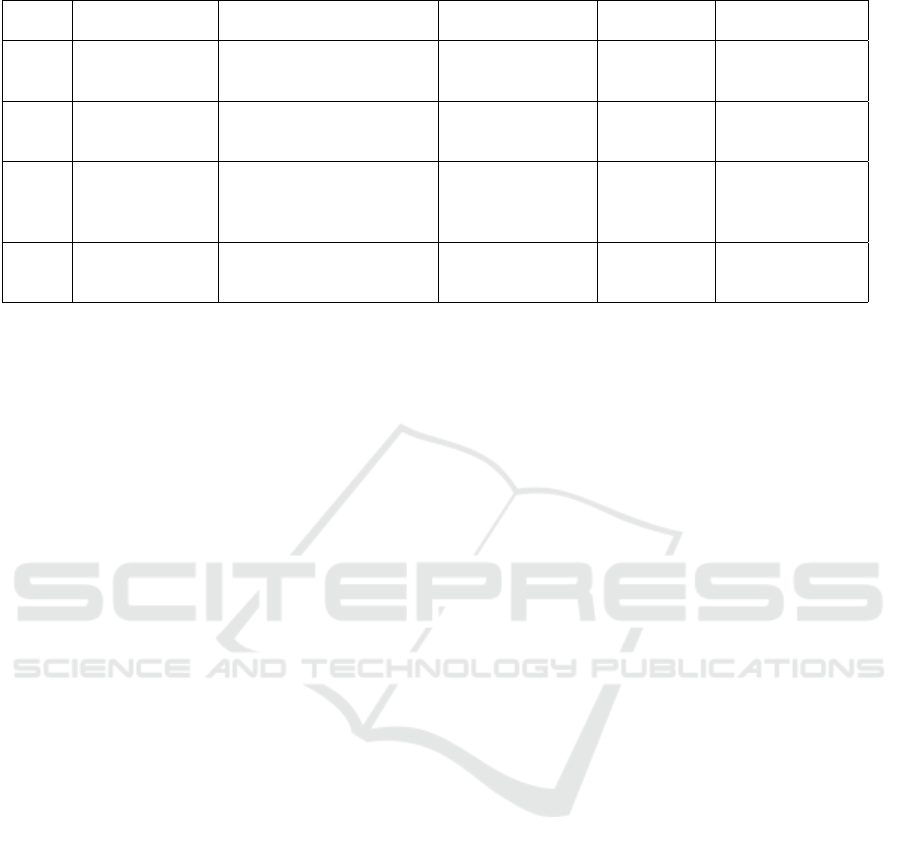
Table 3: Examples of recommender systems using text mining on item’s data.
Items Data used
Recommendation
Approach
Supporting
tools
Text mining
techniques
Reference
Tourism
POIs
Keywords,
GPS location,
POIs’ descriptions
ReCoSKQ CoSKQ
Any text mining
technique
(Hermoso et al., 2019)
Apps
Version metadata,
textual descriptions
Hybrid
Semi-supervised
topic model, PMF,
LDA
Topic-word
distribution,
latent topics
(Lin et al., 2014)
Apps
Context’s description,
app’s title and
description,
app’s metadata
IR-based (context-aware) approach
Lucene search engine,
Context-Aware Browser
(Coppola et al., 2010)
TF-IDF,
clustering
(Mizzaro et al., 2014)
Events
GPS location,
news
Location-aware
Learning model
disambiguation
and matching
sLDA, SVM
(polynomial,
Gaussian, lineal)
(Ho et al., 2012)
scription, the so-called spatial keyword queries that
exploit both the locations and the text descriptions are
attracting growing attention (Cao et al., 2011). More
specifically, the aim of a Collective Spatial Keyword
Query (CoSKQ) is to retrieve, from a spatial database,
a group of spatial elements in such a way that the de-
scription of the elements included in that set, based on
keywords, is completely covered by the keywords of
the query and also that the elements retrieved are as
close as possible to the location of the query and have
the smallest possible distances between the elements
themselves. In (Hermoso et al., 2019), the authors ar-
gue that the use of this concept could be useful for the
development of recommender systems for tourism, in
order to provide the user with a set of points of in-
terest (POIs) that satisfy his/her query (e.g., a query
expressing his/her current interest or need) both geo-
graphically and semantically; the idea of Re-CoSKQ
is presented, which is an adaptation of CoSKQ for the
field of recommender systems. Although text mining
techniques are not explicitly applied in Re-CoSKQ,
they are expected to be needed as a pre-processing
step, in order to obtain the keywords that describe the
different items and/or the user profile.
A recommender system of mobile applications
that exploits the description of the application and as-
sociated metadata is presented in (Lin et al., 2014).
As an updated version of an app may bring signif-
icant changes, it first generates latent themes from
the version’s features using a semi-supervised theme
model to characterize each version. Themes are dis-
criminated based on metadata and a recommenda-
tion technique called VSR (version-sensitive recom-
mendation) is proposed. For experimental evaluation,
two alternative recommendation approaches are con-
sidered as baselines: probability matrix factorization
(PMF), which is a collaborative filtering (CF) tech-
nique, and LDA, which is a content-based filtering
(CBF) technique. The authors show the accuracy
of the recommendations obtained when these tech-
niques are used independently and also when they
are combined (CF+CBF, CF+VSR, CBF+VSR, and
CF+CBF+VSR). This work reports that a hybrid rec-
ommender system incorporating the version-sensitive
model proposed achieves better results.
Other mobile app recommender systems also take
into account the context of the user. Thus, App-
CAB (Mizzaro et al., 2014) is a recommender system
of mobile apps that provides a proactive and fully au-
tomated procedure for querying the mobile app mar-
ket, capable of retrieving a set of applications and
classifying them according to the user’s current situa-
tion. The description of the user’s context is generated
by a Context-Aware Browser (Coppola et al., 2010) to
find the suitable applications for the user’s needs in
that specific context. To categorize contexts, all the
words in the title and description of the applications
that have the same category are grouped, creating sev-
eral sets of words that represent the categories of the
market. The word indexing process is performed us-
ing Lucene to build a category index. When the sys-
tem analyzes the current context, it checks each word
that describes the context in the index in order to com-
pute relevance scores and obtain a list of potentially-
relevant categories. In this way it is possible to weigh
the pertinence of different types of applications for
the given context. Besides, if a word that appears in
the context is part of the title of the application, then
+10% is added to the original score, to emphasize the
importance of a match at the level of the application
name. Finally, a filtering step is applied to eliminate
duplicate results before presenting them to the users.
Finally, in (Ho et al., 2012), an approach to extract
future space-time events from the Web, to be used
as candidate items in a location-aware recommender
system of events, is presented. This work proposes
Use of Text Mining Techniques for Recommender Systems
785

a procedure for the extraction of events from news
articles, which consists of two main steps: recogni-
tion and matching. In the recognition stage, place
names and future time patterns are identified and ex-
tracted. In the matching stage, operations for spatial-
temporal disambiguation, de-duplication and match-
ing, are performed. A sentiment variable (positive,
negative or neutral) is attached to each event, as an
aid for the recommendation application. So, the fu-
ture event identified consists of its geographic loca-
tion, time pattern, sentiment variable, news title, key
phrase, and URL of the news article.
5 CONCLUSIONS
In this paper, we have provided an overview of works
exploiting text mining techniques in the field of rec-
ommender systems, characterizing them according to
the type of textual data analyzed (user reviews, other
texts written by the user, or textual data associated
to the items) and considering their purpose (extract
information about the context of the user or perform
user profiling).
Beyond user reviews, exploiting other types of
texts written by the user seems to be an area that re-
mains quite unexplored, particularly concerning more
personal textual data such as emails received or sent,
the user’s personal agenda, or the user’s diary; this
could be partly due to privacy concerns. Besides,
most works focus only on a specific type of text. As
future work, we intend to propose an integrated ap-
proach that combines and adapts several text mining
techniques as a support tool to build a context-aware
recommender and evaluate its performance.
ACKNOWLEDGEMENTS
This work has been supported by the project
TIN2016-78011-C4-3-R (AEI/FEDER, UE) and
DGA-FSE (COSMOS research group).
REFERENCES
Abuein, Q., Shatnawi, A., and Al-Sheyab, H. (2017).
Trusted recomendation system based on level of trust
(TRS LoT). In 2017 International Conference on En-
gineering and Technology (ICET), pages 1–5.
Abuein, Q., Shatnawi, M., Bani Yassein, M., and Batiha,
R. (2016). A framework for social media and text-
based content analysis for event management pur-
poses. International Review on Computers and Soft-
ware, 11:388–394.
Aciar, S., Zhang, D., Simoff, S., and Debenham, J. (2007).
Informed recommender: Basing recommendations on
consumer product reviews. IEEE Intelligent Systems,
22(3):39–47.
Adomavicius, G. and Tuzhilin, A. (2011). Recommender
Systems Handbook, chapter Context-Aware Recom-
mender Systems, pages 217–253. Springer US,
Boston, MA.
Berry, M. W., editor (2004). Survey of Text Mining. Springer
New York.
Cao, X., Cong, G., Jensen, C. S., and Ooi, B. C. (2011).
Collective spatial keyword querying. In ACM SIG-
MOD International Conference on Management of
Data (SIGMOD 2011), pages 373–384, New York,
NY, USA. ACM.
Chen, K., Chen, T., Zheng, G., Jin, O., Yao, E., and Yu,
Y. (2012). Collaborative personalized tweet recom-
mendation. In 35th International ACM SIGIR Con-
ference on Research and Development in Information
Retrieval (SIGIR 2012), pages 661–670. ACM.
Coppola, P., Della Mea, V., Di Gaspero, L., Menegon, D.,
Mischis, D., Mizzaro, S., Scagnetto, I., and Vassena,
L. (2010). The context-aware browser. IEEE Intelli-
gent Systems, 25(1):38–47.
Drymonas, E. and Pfoser, D. (2010). Geospatial route ex-
traction from texts. In First ACM SIGSPATIAL Inter-
national Workshop on Data Mining for Geoinformat-
ics (DMG 2010), pages 29–37. ACM.
Faralli, S., Stilo, G., and Velardi, P. (2015). Recommenda-
tion of microblog users based on hierarchical interest
profiles. Social Network Analysis and Mining, 5(1).
Feldman, D., Sung, C., Sugaya, A., and Rus, D. (2015).
IDiary: From GPS signals to a text- searchable diary.
ACM Transactions on Sensor Networks, 11(4):60:1–
60:41.
Gentile, A. L., Lanfranchi, V., Mazumdar, S., and
Ciravegna, F. (2011). Extracting semantic user net-
works from informal communication exchanges. In
Aroyo, L., Welty, C., Alani, H., Taylor, J., Bernstein,
A., Kagal, L., Noy, N., and Blomqvist, E., editors, The
Semantic Web – ISWC 2011, pages 209–224. Springer.
Gruber, T. R. et al. (1993). A translation approach to
portable ontology specifications. Knowledge Acqui-
sition, 5(2):199–221.
Guerreiro, J. and Rita, P. (2019). How to predict ex-
plicit recommendations in online reviews using
text mining and sentiment analysis. Journal of
Hospitality and Tourism Management. DOI:
10.1016/j.jhtm.2019.07.001. In Press, Corrected
Proof.
Gupta, V., Lehal, G. S., et al. (2009). A survey of text min-
ing techniques and applications. Journal of Emerging
Technologies in Web Intelligence, 1(1):60–76.
Hegde, Y. and Padma, S. K. (2017). Sentiment analysis
using random forest ensemble for mobile product re-
views in kannada. In 2017 IEEE 7th International
Advance Computing Conference (IACC), pages 777–
782.
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
786

Hermoso, R., Ilarri, S., and Trillo-Lado, R. (2019). Re-
CoSKQ: Towards POIs recommendation using collec-
tive spatial keyword queries. In ACM RecSys Work-
shop on Recommenders in Tourism (RecTour 2019),
in conjunction with the 13th ACM Conference on Rec-
ommender Systems (RecSys 2019), Copenhagen (Den-
mark), volume 2435, pages 42–45. CEUR Workshop
Proceedings, ISSN 1613-0073.
Ho, S.-S., Lieberman, M., Wang, P., and Samet, H. (2012).
Mining future spatiotemporal events and their senti-
ment from online news articles for location-aware rec-
ommendation system. In First ACM SIGSPATIAL In-
ternational Workshop on Mobile Geographic Infor-
mation Systems (MobiGIS 2012), pages 25–32, New
York, NY, USA. ACM.
Jakob, N., Weber, S. H., M
¨
uller, M. C., and Gurevych, I.
(2009). Beyond the stars: Exploiting free-text user
reviews to improve the accuracy of movie recom-
mendations. In First International CIKM Workshop
on Topic-Sentiment Analysis for Mass Opinion (TSA
2009), pages 57–64, New York, NY, USA. ACM.
Kim, E.-G. and Chun, S.-H. (2019). Analyzing online car
reviews using text mining. Sustainability, 11(6):1611.
Krestel, R., Fankhauser, P., and Nejdl, W. (2009). Latent
Dirichlet Allocation for tag recommendation. In Third
ACM Conference on Recommender Systems (RecSys
2009), pages 61–68. ACM.
Li, Y., Nie, J., Zhang, Y., Wang, B., Yan, B., and Weng,
F. (2010). Contextual recommendation based on text
mining. In 23rd International Conference on Compu-
tational Linguistics (COLING 2010): Posters, pages
692–700. Association for Computational Linguistics.
Lin, J., Sugiyama, K., Kan, M.-Y., and Chua, T.-S. (2014).
New and improved: Modeling versions to improve
app recommendation. In 37th International ACM SI-
GIR Conference on Research & Development in Infor-
mation Retrieval (SIGIR 2014), pages 647–656, New
York, NY, USA. ACM.
Liu, B. and Zhang, L. (2012). A Survey of Opinion Mining
and Sentiment Analysis, pages 415–463. Springer US,
Boston, MA.
Loh, S., Lorenzi, F., Salda
˜
na, R., and Licthnow, D. (2003).
A tourism recommender system based on collabora-
tion and text analysis. Information Technology &
Tourism, 6(3):157–165.
Miao, D. and Lang, F. (2017). A recommendation system
based on text mining. In 2017 International Confer-
ence on Cyber-Enabled Distributed Computing and
Knowledge Discovery (CyberC), pages 318–321.
Mizzaro, S., Pavan, M., Scagnetto, I., and Zanello, I.
(2014). A context-aware retrieval system for mo-
bile applications. In 4th Workshop on Context-
Awareness in Retrieval and Recommendation (CARR
2014), pages 18–25. ACM.
Musto, C., Lops, P., de Gemmis, M., and Semeraro, G.
(2019). Justifying recommendations through aspect-
based sentiment analysis of users reviews. In 27th
ACM Conference on User Modeling, Adaptation and
Personalization, UMAP ’19, pages 4–12, New York,
NY, USA. ACM.
Musto, C., Narducci, F., Lops, P., De Gemmis, M., and Se-
meraro, G. (2016). ExpLOD: A framework for ex-
plaining recommendations based on the Linked Open
Data Cloud. In 10th ACM Conference on Rec-
ommender Systems (RecSys 2016), pages 151–154.
ACM.
Piao, G. and Breslin, J. G. (2018). Inferring user interests in
microblogging social networks: a survey. User Mod-
eling and User-Adapted Interaction, 28(3):277–329.
Ricci, F., Rokach, L., and Shapira, B. (2011). Recommender
Systems Handbook, chapter Introduction to Recom-
mender Systems Handbook, pages 1–35. Springer US,
Boston, MA.
Ricci, F., Rokach, L., and Shapira, B. (2015). Recommender
Systems Handbook, chapter Recommender Systems:
Introduction and Challenges, pages 1–34. Springer
US, Boston, MA.
Rosa, R. L., Schwartz, G. M., Ruggiero, W. V., and
Rodr
´
ıguez, D. Z. (2019). A knowledge-based rec-
ommendation system that includes sentiment analysis
and deep learning. IEEE Transactions on Industrial
Informatics, 15(4):2124–2135.
Roul, R. K. and Arora, K. (2019). A nifty review to
text summarization-based recommendation system for
electronic products. Soft Computing, 23(24):13183–
13204.
Shi, Y., Larson, M., and Hanjalic, A. (2014). Collaborative
filtering beyond the user-item matrix: A survey of the
state of the art and future challenges. ACM Computing
Surveys, 47(1).
Subramaniyaswamy, V., Manogaran, G., Logesh, R., Vi-
jayakumar, V., Chilamkurti, N., Malathi, D., and
Senthilselvan, N. (2019). An ontology-driven person-
alized food recommendation in IoT-based healthcare
system. The Journal of Supercomputing, 75(6):3184–
3216.
Tarus, J. K., Niu, Z., and Mustafa, G. (2018). Knowledge-
based recommendation: a review of ontology-based
recommender systems for e-learning. Artificial intel-
ligence review, 50(1):21–48.
Xu, Z., Ru, L., Xiang, L., and Yang, Q. (2011). Discov-
ering user interest on Twitter with a modified author-
topic model. In 2011 IEEE/WIC/ACM International
Conferences on Web Intelligence and Intelligent Agent
Technology, volume 1, pages 422–429.
Zarrinkalam, F., Fani, H., Bagheri, E., Kahani, M., and Du,
W. (2015). Semantics-enabled user interest detection
from twitter. In 2015 IEEE/WIC/ACM International
Conference on Web Intelligence and Intelligent Agent
Technology (WI-IAT), volume 1, pages 469–476.
Use of Text Mining Techniques for Recommender Systems
787
