
Test Oracle using Semantic Analysis from Natural Language
Requirements
Maryam Imtiaz Malik, Muddassar Azam Sindhu
a
and Rabeeh Ayaz Abbasi
b
Department of Computer Science, Quaid-i-Azam University, Islamabad, 45320, Pakistan
Keywords:
Natural Language Requirements, Software Testing, Test Oracle, Semantic Analysis.
Abstract:
Automation of natural language based applications is a challenging task due to its semantics. This challenge
is also confronted in the software testing field. In this paper, we provide a systematic literature review related
to the semantic analysis of natural language requirements in the software testing field. The literature review
assisted us in the identification of the substantial research gap related to the semantics-based natural language
test oracle. To the best of our knowledge, we have not found any technique in which the semantics of test oracle
from natural language requirements can be solved using Word Sense Disambiguation techniques. We have
discussed our proposed approach to generate semantics-based test oracle from natural language requirements.
Our proposed approach can be applied to any domain.
1 INTRODUCTION
Software testing is an important phase in the software
development life cycle (SDLC). The software testing
field has many research areas including test case gen-
eration, test case prioritization, software bug localiza-
tion, test oracle, etc. In all areas, the requirements
are given as input for proceeding the respective ap-
proach. These requirements are expressed either for-
mally or informally. The informal software require-
ments are written in natural language by requirement
engineers. Although, the natural language require-
ments are easy to understand without requiring any
technical skills, but these requirements are ambiguous
and often incomplete. Moreover, natural language re-
quirements have another problem that is related to
its semantics. The level of semantics can be taken
broadly into two categories: word level and sentence
level. As the meaning of words varies from context to
context therefore the word and sentence level seman-
tics should deal within a particular context.
Many researchers proposed different approaches
regarding the semantics of natural language require-
ments. Therefore, in this position paper, we con-
ducted a study in which semantics of natural lan-
guage requirements in the software testing field are
discussed. Further based on the research gap, we have
a
https://orcid.org/0000-0002-3411-9224
b
https://orcid.org/0000-0002-3787-7039
also discussed our proposed approach.
In the rest of the paper, Section 2 provides the state
of the art related to the semantics of natural language
requirements in the software testing field. Section 3
discusses the motivation behind our research work.
Section 4 and 5 discuss the research problem and pro-
posed approach. And the last section 6 concludes the
position paper along with discussing future directions
of work.
2 STATE OF THE ART
In this section, we have discussed state of the art in
the field of software testing related to the semantic
analysis of natural language requirements. We have
searched literature by the following set of keywords
on Google Scholar.
• Natural Language Requirement
• Semantic analysis
• Software testing
• Semantic based Test oracle / Test oracle
• Test case generation
• Test case execution
• Natural Language Processing (NLP)
We further restricted our search to publication year
since 2017, 2018, 2019, 2020 and any time. We also
Malik, M., Sindhu, M. and Abbasi, R.
Test Oracle using Semantic Analysis from Natural Language Requirements.
DOI: 10.5220/0009471903450352
In Proceedings of the 22nd International Conference on Enterprise Information Systems (ICEIS 2020) - Volume 2, pages 345-352
ISBN: 978-989-758-423-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
345

checked the citation and references of most relevant
papers. In the later subsections, we discuss the stud-
ies related to systematic literature review. Further, we
discuss literature related to semantics of natural lan-
guage in the respective field by categorizing them into
seven broad categories that are discussed in the sub-
sections.
2.1 Systematic Study
The authors of (Dadkhah et al., 2020) provide the lit-
erature review of software testing using semantic web.
(Garousi et al., 2018) discuss several papers re-
lated to natural language processing in the software
testing field. (Garousi et al., 2018) also categorize
some papers based on semantic analysis.
(Mustafa et al., 2017) also discuss literature for
test case generation approaches from the models and
specifications.
(Ahsan et al., 2017) discuss literature related to
test case generation using natural language processing
techniques.
2.2 Testing Framework
The authors of (Atefi and Alipour, 2019) have worked
on an approach for automated testing of the con-
versational agent. The approach highlighted the
test oracle for natural languages. The approach se-
mantically compared the utterances using word2vec,
Google's Universal Sentence Encoder and Facebook’s
InferSent sentence embeddings.
(Wang et al., 2018) proposed an approach for au-
tomatically generating Object Constraint Language
(OCL) constraints from the Use Case Modelling
for System Tests Generation (UMTG) and domain
model. The approach used semantic role labeling,
Wordnet, and Verbnet for the generation of OCL con-
straints. These automated OCL constraints are used
for system testing.
(Lin et al., 2017) proposed an approach in which
the topic of the input field, GUI state, and clickable
document object model (DOM) element are identified
using latent semantic indexing. In the proposed ap-
proach the vectors are generated from DOM. These
vectors are used for feature extraction by applying
TF-IDF. The TF-IDF vector is used for singular value
decomposition. The approach has used cosine simi-
larity for assigning the topic to the DOM element.
(Masuda et al., 2015) proposed an approach for
logic retrieval from Japanese specifications. The mor-
phological and dependency parsing is used for logic
retrieval.
(Sunil Kamalakar, 2013) proposed a behavioral
driven development (BDD) approach for automatic
generation of glue code from the natural language re-
quirement. The approach takes application code/stub
and BDD specification as an input. Reflection tech-
niques are applied to code for the extraction of infor-
mation related to class and methods. The probabilis-
tic matcher is used for matching the specification with
the properties of code. The probabilistic matcher in-
cludes edit distance, cosine, and cosine WordNet sim-
ilarity, and Disco.
(Torres et al., 2006) proposed an approach for the
extraction of natural language description from test
cases in Communicating Sequential Processes. The
ontology and case frames are used for storing domain
classes and thematic roles respectively. Further, the
lexicon is used for storing nouns, verbs, and modi-
fiers.
2.3 Test Case Generation
(Mai et al., 2019) proposed an approach for the gen-
eration of security-based executable test cases. The
test cases are generated using misuse case specifica-
tion and test driver API. The approach used NLP tech-
niques for security testing and also mapped the test
API into ontology. Further, semantic role labeling is
used for the generation of executable code.
(Wang et al., 2019), (Wang et al., 2015a), (Wang
et al., 2015b) proposed an approach to generate sys-
tem test cases from the use case specification. The
authors have used the extended Restricted Use Case
Modeling (RUCM) template along with the domain
model as an input. The NLP techniques are applied
to identify the RUCM steps, domain entities, alter-
native flows and references. Further, semantic role
labeling is used to generate OCL constraints. These
constraints are then used to generate a use case test
model. The scenarios and input are generated from
the use case test and domain model. These scenarios
and input along with the mapping table are used to
generate test cases.
(Moitra et al., 2019) proposed an approach to gen-
erate executable test cases from structured natural lan-
guage requirement and domain ontology. These test
cases are derived using formal analysis techniques.
In (Silva et al., 2019) the test cases are generated
from requirements through colored Petri nets (CPN).
The syntax tree and requirements frames are gener-
ated from controlled natural language requirements.
These frames are used to create Data-Flow Reactive
Systems (DFRS) and CPN models for test case gen-
eration.
(Mahalakshmi et al., 2018) proposed an approach
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
346

for the generation of test cases from use cases. (Ma-
halakshmi et al., 2018) extracted the named-entity list
from the use case by feeding features into the machine
learning algorithm. The features are extracted us-
ing n-gram, term frequency, WordNet reference, etc.
These named-entities are used to identify data ele-
ments in the decision table. Further, the scenario ma-
trix and data elements are used to generate test cases.
(Anjalika et al., 2018) proposed an approach to
generate test cases from user stories and ontology.
The user story along with its corresponding epic num-
ber is provided as an input. The triplets are generated
from user stories using natural language processing.
The triplet contains the actor, action, and object. Fur-
ther, human intervention is required to develop an on-
tology. The test cases are generated from these triplets
and ontology.
(Mai et al., 2018) proposed an approach for the
generation of executable test cases. The approach has
taken misuse case specification, test driver API and
an initial ontology as an input. The test diver API is
mapped onto the provided ontology. They also used
semantic role labeling for test input identification and
executable test case generation. Further, the concrete
test values are provided by the test engineers.
(Rane, 2017) proposed an approach to generate
test cases from natural language requirements. They
have used user story, test scenario description, dictio-
nary and acceptance criteria as an input for the gener-
ation of test cases. The NLP techniques are applied to
the input to generate frames. These frames are used
for the generation of an activity graph and test cases.
Although, the authors have claimed that the test cases
are generated directly from user stories or through an
activity diagram. But they have only discussed the
generation of test cases through an activity diagram
in detail.
(Carvalho et al., 2012) proposed an approach to
analyze the CNLParser tool syntactically and produce
a syntax tree as an output. In this approach, the
output of Controlled Natural Language (CNL) parser
is given as input to the Syntax Tree to Case Frame
(ST2CF) tool. This tool is used to analyze the syn-
tax tree semantically and generated the case frame.
The case frame represents the thematic role of each
element in a sentence based on the main verb. Fur-
ther, the test vectors are generated using the Software
Cost Reduction (SCR) tool. This approach is used
for test case generation in (Carvalho et al., 2013),
(Silva et al., 2016), (Carvalho et al., 2014b), (Car-
valho et al., 2015) and model-based testing (Carvalho
et al., 2014a).
(Santiago Junior and Vijaykumar, 2012), (de San-
tiago Junior, 2011) proposed an approach for the gen-
eration of abstract and executable test cases from nat-
ural language requirements. The approach modeled
state chart for the generation of test cases. The mod-
eled state chart is refined using the domain and word
sense disambiguation (WSD). The WSD is used to re-
move the states containing self-transition. Besides,
the pair of verbs is semantically analyzed using graph
indegree and Jiang and Conrath similarity measures.
2.4 Test Case Prioritization
(Yang et al., 2017) provided an empirical performance
evaluation of three NLP based test case prioritiza-
tion techniques that are Risk, Div, and DivRisk. It
is calculated using the average percentage of detected
faults among the available test cases. In this study,
the test cases are written in the Chinese language.
These test cases are categorized into testing and train-
ing. The keywords from the training set are added
into the dictionary of the testing set. These keywords
are extracted using the Language Technology Plat-
form (LTP) platform. Further, the nouns and verbs
are selected and synonyms are manually identified.
The words whose frequency is greater than average
word frequency are added into the dictionary for per-
formance evaluation. The result shows that Risk strat-
egy has good performance as compared to others.
(Islam et al., 2012) proposed an approach to
automatically prioritize test cases using the multi-
objective function. (Islam et al., 2012) also prioritized
the test cases based on the cost, code and requirement
coverage. Moreover, the latent semantic indexing is
used for traceability.
2.5 Software Duplicate Bug Detection
and Localization
(Zhao and Harris, 2019) proposed an approach to gen-
erate assertions from the specification document. The
sentences written in English language are semanti-
cally analyzed for the generation of formal assertions.
(Khatiwada et al., 2018) proposed an approach for
automatic bug localization. (Khatiwada et al., 2018)
semantically localize the software bug using normal-
ized google distance and pointwise mutual informa-
tion.
(Du et al., 2017) proposed an approach for classi-
fication of bug reports on the basis of fault types. The
word2vec is used for classification.
(Lukins et al., 2010) proposed an approach for au-
tomatic bug localization. The approach has used the
latent Dirichlet allocation technique for the identifi-
cation of the topic and the query formation. These
queries are created through the extraction of keywords
Test Oracle using Semantic Analysis from Natural Language Requirements
347

from the bug report, title, and addition of words like
synonyms.
(Runeson et al., 2007) proposed an approach
to detect duplicate reports using NLP techniques.
Among other NLP techniques and similarity mea-
sures, the synonyms are also used for duplicate de-
tection.
Similarly, there are multiple studies including
(Chen et al., 2018), (Yang et al., 2016), (Dit et al.,
2008), (Kang, 2017) in which bug reports are detected
using semantic similarity.
2.6 Test Oracle and Assertion
Generation
(Goffi, 2018) also used their work (Blasi et al., 2017)
in a thesis for generation of test oracles from Java
comments present in source code. Further they have
also suggested generation of test oracles from un-
structured natural language as a future work.
The authors of (Blasi et al., 2017) extended their
approach proposed in (Goffi et al., 2016). In this
approach, the Java elements are compared syntacti-
cally and semantically with comments for the genera-
tion of the assertion. For semantical analysis, the ap-
proach has used Word Mover’s Distance, Word2Vec
and GloVe model.
Several NLP techniques are applied to the soft-
ware artifact in (Ernst, 2017). The cosine similar-
ity and TF-IDF are used to display error messages
with the appropriate details. Further, edit distance or
WordNet are used for the identification of the word
similarity. The oracle assertions are also automati-
cally generated from the Javadoc using parse trees,
pattern matching, and lexical similarity. In (Ernst,
2017) English specifications are also converted into
bashed commands through the translation process.
(Hu et al., 2011) proposed a semantic oracle using
ontology and rule-based specification. The rules have
antecedents and consequent which provide the test in-
puts and expected output respectively. These outputs
are compared by oracle reasoner.
2.7 Functional Dependency and
Traceability
(Tahvili et al., 2019) proposed an approach to detect
and clustered the functionally dependent test cases.
The authors have used Doc2vec for generating fea-
ture vectors. These feature vectors are clustered using
the hierarchical density-based spatial clustering of ap-
plications with noise and fuzzy c-means clustering al-
gorithms.
(Csuvik et al., 2019) proposed an approach for
tracing the test with code using latent semantic index-
ing and word2vec.
3 MOTIVATION
The semantic analysis has extensive applicability in
different areas including text mining, information re-
trieval, knowledge extraction etc. The extensive re-
search in the literature revealed that semantic analysis
also plays a vital role in the software testing field.
In the literature, the authors discussed a tool
named DrQA for question answering (King et al.,
2019) and (Makela, 2019). The tool used semantic
analysis techniques like word embedding. The au-
thors claim that the DrQA tool can be used to gen-
erate automated test oracle for testing AI systems.
They also recommended that the models can be cre-
ated from requirements and specifications to automate
the test oracle (Makela, 2019). DrQA tool and differ-
ent semantic analysis techniques within the software
testing field motivated us to compare expected and ob-
served outputs semantically from natural language re-
quirements.
4 RESEARCH PROBLEM
In this position paper, we have provided an exten-
sive literature on the applicability of semantic analy-
sis in the software testing field. From the literature,
it has been observed that there is an immense gap
in providing semantic test oracle for natural language
requirements-based test cases. We have retrieved only
one relevant paper from literature in which utterances
are semantically compared (Atefi and Alipour, 2019).
In this paper, the testing framework is limited for
conversational agents only. And the context module
has used the design patterns. This approach relies on
the determination of appropriate data set for semantic
analysis.
In addition, many researchers proposed ap-
proaches for the generation of test cases from natu-
ral language requirements but these approaches do not
perform semantic analysis of test oracle from natural
language requirements.
There is no automated approach in which the test-
ing framework leads from natural language require-
ments to semantic-based test oracle. Therefore, we
are planning to generate automated semantic test ora-
cle for natural language requirements.
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
348
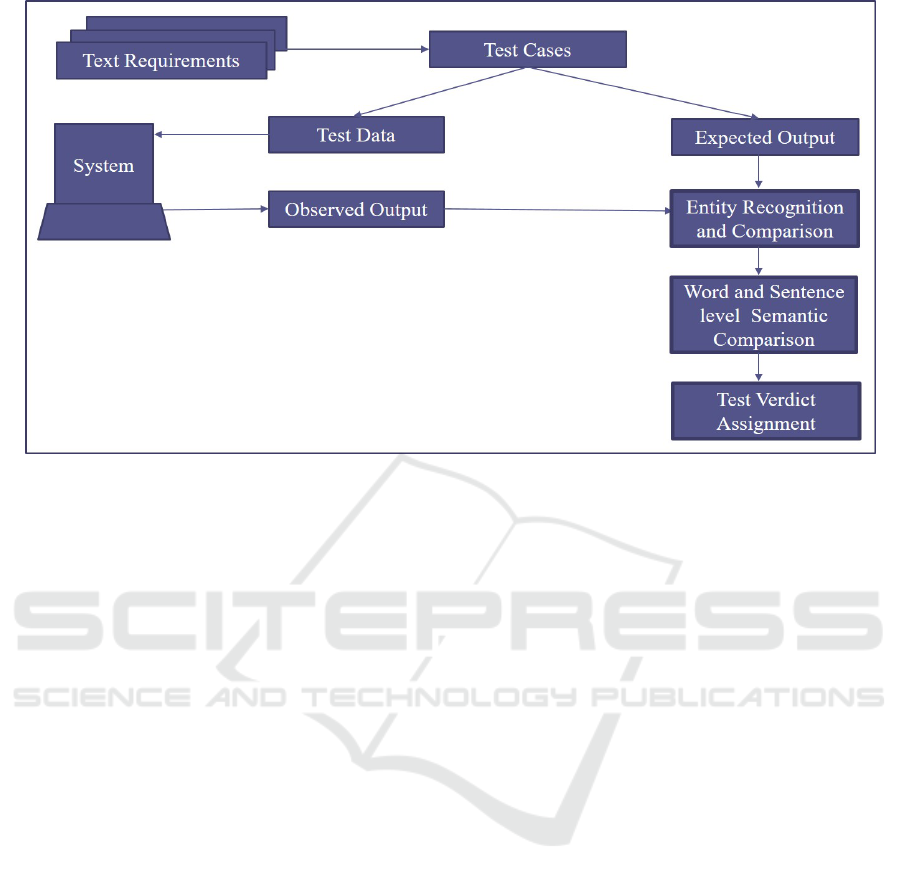
Figure 1: Proposed Approach.
5 PROPOSED APPROACH
Our proposed approach will generate test cases from
natural language requirements and then compare the
expected and observed outputs. Our proposed ap-
proach is not restricted to some particular domain.
And it does not require additional dataset for semantic
comparison. Figure 1 shows our proposed approach.
The proposed test oracle part is divided into mul-
tiple phases. The first phase is responsible for the
identification of entities from outputs that do not re-
quire semantic similarity comparison. These entities
may comprise a person’s name, place, digits, etc. The
named entity recognition or semantic role labeling
will be applied for the identification of these enti-
ties. These entities are omitted or replaced by a con-
stant word for further processing. The test oracle then
compares these entities through some other proposed
methodology.
In the second phase, we will apply semantic simi-
larity both at word and sentence level. Our approach
establishes the context using requirements for seman-
tic similarity. Relying on requirements saves the extra
effort and time of testers.
We will use WSD techniques for semantic com-
parison. WSD deals with different senses of a word.
(Navigli, 2012) discussed three types of WSD: Su-
pervised WSD, Unsupervised WSD, and Knowledge-
based WSD. Supervised WSD approaches have ap-
plied machine learning techniques, knowledge-based
WSD has used knowledge resources, and Unsuper-
vised WSD has used unlabeled corpora for identify-
ing the word sense in a context.
In our proposed approach we will evaluate sev-
eral knowledge-based techniques and select the most
suitable technique. The intuition behind using the
knowledge-based technique is to not rely on the cor-
pus for semantic similarity. WSD is AI-complete
problem (Navigli, 2009). Consequently, to achieve
better accuracy, we may use knowledge-based tech-
niques along with other WSD techniques. As a super-
vised learning method requires human intervention
for labeling therefore, we are not using supervised
WSD. In the future, we will also use the word2vec
approach by training on requirement documents.
In the third phase, our proposed approach will as-
sign a test verdict based on the comparison of ex-
pected and observed outputs.
The proposed test oracle is illustrated using the
following expected and observed outputs:
Expected Output: John's data is deleted from the
system.
Observed Output: John's data is removed from the
system.
The first phase of the proposed approach identifies
John as an entity from expected and observed outputs.
These entities are compared and replaced with a con-
stant word. In the second phase, the expected and ob-
served outputs are semantically compared. The parser
identifies ‘delete’and ‘remove’as semantically similar
words. Finally, a test pass verdict is assigned.
Test Oracle using Semantic Analysis from Natural Language Requirements
349

6 CONCLUSION
In this position paper, we raised an important problem
related to the semantics of natural language require-
ments. We have discussed literature related to the se-
mantics of natural language requirements in the soft-
ware testing field. It is observed from the literature
that there is little research carried on the automation
of test oracle semantically. We plan to address these
research gaps as the research problem in the software
testing field. To solve the mentioned research prob-
lems, we have proposed an approach to automate the
semantic test oracle from natural language require-
ments. The worthiness of our research work can be
clarified from the research gap which originates after
an extensive literature review. Our proposed approach
is the first step towards the use of WSD techniques
for solving a significant problem. Our approach can
be applied to all applications dealing with natural lan-
guage requirements.
In the future, we will automate the proposed ap-
proach. We will also evaluate the proposed approach
from several case studies. We will also extend the lit-
erature review by covering some other search engines
with additional keywords.
REFERENCES
Ahsan, I., Butt, W. H., Ahmed, M. A., and Anwar, M. W.
(2017). A comprehensive investigation of natural lan-
guage processing techniques and tools to generate au-
tomated test cases. In Proceedings of the Second In-
ternational Conference on Internet of Things, Data
and Cloud Computing, ICC ’17, pages 132:1–132:10,
New York, NY, USA. ACM.
Anjalika, H. N., Salgado, M. T. Y., and Siriwardhana, P. I.
(2018). An ontology based test case generation frame-
work.
Atefi, S. and Alipour, M. A. (2019). An automated testing
framework for conversational agents.
Blasi, A., Kuznetsov, K., Goffi, A., Castellanos, S. D.,
Gorla, A., Ernst, M. D., and PEZZ, M. (2017).
Semantic-based analysis of javadoc comments.
Carvalho, G., Barros, F., Carvalho, A., Cavalcanti, A.,
Mota, A., and Sampaio, A. (2015). Nat2test tool:
From natural language requirements to test cases
based on csp. In Calinescu, R. and Rumpe, B., editors,
Software Engineering and Formal Methods, pages
283–290, Cham. Springer International Publishing.
Carvalho, G., Barros, F., Lapschies, F., Schulze, U., and
Peleska, J. (2014a). Model-based testing from con-
trolled natural language requirements. In Artho, C.
and
¨
Olveczky, P. C., editors, Formal Techniques for
Safety-Critical Systems, pages 19–35, Cham. Springer
International Publishing.
Carvalho, G., Falc
˜
ao, D., Barros, F., Sampaio, A., Mota,
A., Motta, L., and Blackburn, M. (2013). Test case
generation from natural language requirements based
on scr specifications. In Proceedings of the 28th An-
nual ACM Symposium on Applied Computing, SAC
’13, pages 1217–1222, New York, NY, USA. ACM.
Carvalho, G., Falc
˜
ao, D., Barros, F., Sampaio, A., Mota,
A., and Motta, L. (2012). Nlreq2tvectors: A tool for
generating test vectors from natural language require-
ments. Technical report, Technical report, UFPE.
Carvalho, G., Falc
˜
ao, D., Barros, F., Sampaio, A., Mota, A.,
Motta, L., and Blackburn, M. (2014b). Nat2testscr:
Test case generation from natural language require-
ments based on scr specifications. Science of Com-
puter Programming, 95:275 – 297. Special Section:
ACM SAC-SVT 2013 + Bytecode 2013.
Chen, M., Hu, D., Wang, T., Long, J., Yin, G., Yu,
Y., and Zhang, Y. (2018). Using document embed-
ding techniques for similar bug reports recommenda-
tion. In 2018 IEEE 9th International Conference on
Software Engineering and Service Science (ICSESS),
pages 811–814.
Csuvik, V., Kicsi, A., and Vid
´
acs, L. (2019). Source
code level word embeddings in aiding semantic test-
to-code traceability. In 2019 IEEE/ACM 10th Inter-
national Symposium on Software and Systems Trace-
ability (SST), pages 29–36.
Dadkhah, M., Araban, S., and Paydar, S. (2020). A sys-
tematic literature review on semantic web enabled
software testing. Journal of Systems and Software,
162:110485.
de Santiago Junior, V. A. (2011). SOLIMVA: A methodol-
ogy for generating model-based test cases from natu-
ral language requirements and detecting incomplete-
ness in software specifications. PhD thesis, PhD the-
sis, Instituto Nacional de Pesquisas Espaciais (INPE).
Dit, B., Poshyvanyk, D., and Marcus, A. (2008). Measuring
the semantic similarity of comments in bug reports.
Proc. of 1st STSM, 8:64.
Du, X., Zheng, Z., Xiao, G., and Yin, B. (2017). The au-
tomatic classification of fault trigger based bug report.
In 2017 IEEE International Symposium on Software
Reliability Engineering Workshops (ISSREW), pages
259–265.
Ernst, M. D. (2017). Natural Language is a Programming
Language: Applying Natural Language Processing to
Software Development. In Lerner, B. S., Bod
´
ık, R.,
and Krishnamurthi, S., editors, 2nd Summit on Ad-
vances in Programming Languages (SNAPL 2017),
volume 71 of Leibniz International Proceedings in
Informatics (LIPIcs), pages 4:1–4:14, Dagstuhl, Ger-
many. Schloss Dagstuhl–Leibniz-Zentrum fuer Infor-
matik.
Garousi, V., Bauer, S., and Felderer, M. (2018). Nlp-
assisted software testing: a systematic review. arXiv
preprint arXiv:1806.00696.
Goffi, A. (2018). Automating test oracles generation. PhD
thesis, Universita della Svizzera italiana.
Goffi, A., Gorla, A., Ernst, M. D., and Pezz
`
e, M. (2016).
Automatic generation of oracles for exceptional be-
haviors. In Proceedings of the 25th International
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
350

Symposium on Software Testing and Analysis, ISSTA
2016, pages 213–224, New York, NY, USA. ACM.
Hu, L., Bai, X., Zhang, Y., Lu, H., Ye, H., and Hou,
K. (2011). Semantic-based test oracles. In 2011
IEEE 35th Annual Computer Software and Applica-
tions Conference(COMPSAC), volume 00, pages 640–
649.
Islam, M. M., Marchetto, A., Scanniello, G., and Susi, A.
(2012). A multi-objective technique to prioritize test
cases based on latent semantic indexing. In 2012 16th
European Conference on Software Maintenance and
Reengineering(CSMR), volume 00, pages 21–30.
Kang, L. (2017). Automated duplicate bug reports
detection-an experiment at axis communication ab.
Master’s thesis.
Khatiwada, S., Tushev, M., and Mahmoud, A. (2018). Just
enough semantics: An information theoretic approach
for ir-based software bug localization. Information
and Software Technology, 93:45 – 57.
King, T. M., Arbon, J., Santiago, D., Adamo, D., Chin, W.,
and Shanmugam, R. (2019). Ai for testing today and
tomorrow: Industry perspectives. In 2019 IEEE Inter-
national Conference On Artificial Intelligence Testing
(AITest), pages 81–88.
Lin, J., Wang, F., and Chu, P. (2017). Using seman-
tic similarity in crawling-based web application test-
ing. In 2017 IEEE International Conference on
Software Testing, Verification and Validation (ICST),
pages 138–148.
Lukins, S. K., Kraft, N. A., and Etzkorn, L. H. (2010). Bug
localization using latent dirichlet allocation. Informa-
tion and Software Technology, 52(9):972 – 990.
Mahalakshmi, G., Vijayan, V., and Antony, B. (2018).
Named entity recognition for automated test case gen-
eration. INTERNATIONAL ARAB JOURNAL OF IN-
FORMATION TECHNOLOGY, 15(1):112–120.
Mai, P. X., Pastore, F., Goknil, A., and Briand, L. C.
(2018). A natural language programming approach
for requirements-based security testing. 29th IEEE
International Symposium on Software Reliability En-
gineering (ISSRE 2018).
Mai, P. X., Pastore, F., Goknil, A., and Briand, L. C.
(2019). Mcp: A security testing tool driven by require-
ments. In 2019 IEEE/ACM 41st International Confer-
ence on Software Engineering: Companion Proceed-
ings (ICSE-Companion), pages 55–58.
Makela, M. (2019). Utilizing artificial intelligence in soft-
ware testing. Master’s thesis.
Masuda, S., Iwama, F., Hosokawa, N., Matsuodani, T., and
Tsuda, K. (2015). Semantic analysis technique of
logics retrieval for software testing from specification
documents. In 2015 IEEE Eighth International Con-
ference on Software Testing, Verification and Valida-
tion Workshops (ICSTW), pages 1–6.
Moitra, A., Siu, K., Crapo, A. W., Durling, M., Li, M.,
Manolios, P., Meiners, M., and McMillan, C. (2019).
Automating requirements analysis and test case gen-
eration. Requirements Engineering, 24(3):341–364.
Mustafa, A., Wan-Kadir, W. M., and Ibrahim, N.
(2017). Comparative evaluation of the state-of-art
requirements-based test case generation approaches.
International Journal on Advanced Science, Engi-
neering and Information Technology, 7:1567–1573.
Navigli, R. (2009). Word sense disambiguation: A survey.
ACM Comput. Surv., 41(2).
Navigli, R. (2012). A quick tour of word sense disambigua-
tion, induction and related approaches. In Bielikov
´
a,
M., Friedrich, G., Gottlob, G., Katzenbeisser, S., and
Tur
´
an, G., editors, SOFSEM 2012: Theory and Prac-
tice of Computer Science, pages 115–129, Berlin, Hei-
delberg. Springer Berlin Heidelberg.
Rane, P. (2017). Automatic generation of test cases for agile
using natural language processing. Master’s thesis,
Virginia Tech.
Runeson, P., Alexandersson, M., and Nyholm, O. (2007).
Detection of duplicate defect reports using natural lan-
guage processing. In 29th International Conference
on Software Engineering (ICSE’07), pages 499–510.
Santiago Junior, V. A. d. and Vijaykumar, N. L. (2012).
Generating model-based test cases from natural lan-
guage requirements for space application software.
Software Quality Journal, 20(1):77–143.
Silva, B. C. F., Carvalho, G., and Sampaio, A. (2016). Test
case generation from natural language requirements
using cpn simulation. In Corn
´
elio, M. and Roscoe,
B., editors, Formal Methods: Foundations and Appli-
cations, pages 178–193, Cham. Springer International
Publishing.
Silva, B. C. F., Carvalho, G., and Sampaio, A. (2019). Cpn
simulation-based test case generation from controlled
natural-language requirements. Science of Computer
Programming, 181:111 – 139.
Sunil Kamalakar, F. (2013). Automatically generating tests
from natural language descriptions of software behav-
ior. Master’s thesis, Virginia Tech.
Tahvili, S., Hatvani, L., Felderer, M., Afzal, W., and Bohlin,
M. (2019). Automated functional dependency detec-
tion between test cases using doc2vec and clustering.
In 2019 IEEE International Conference On Artificial
Intelligence Testing (AITest), pages 19–26.
Torres, D., Leitao, D., and Barros, F. (2006). Motorola
specnl: A hybrid system to generate nl descriptions
from test case specifications. In 2006 Sixth Inter-
national Conference on Hybrid Intelligent Systems
(HIS’06), pages 45–45.
Wang, C., Pastore, F., and Briand, L. (2018). Automated
generation of constraints from use case specifications
to support system testing. In 2018 IEEE 11th Inter-
national Conference on Software Testing, Verification
and Validation (ICST), pages 23–33.
Wang, C., Pastore, F., Goknil, A., Briand, L., and Iqbal, Z.
(2015a). Automatic generation of system test cases
from use case specifications. In Proceedings of the
2015 International Symposium on Software Testing
and Analysis, ISSTA 2015, page 385–396, New York,
NY, USA. Association for Computing Machinery.
Wang, C., Pastore, F., Goknil, A., and Briand, L. C. (2019).
Automatic generation of system test cases from use
case specifications: an nlp-based approach.
Test Oracle using Semantic Analysis from Natural Language Requirements
351

Wang, C., Pastore, F., Goknil, A., Briand, L. C., and Iqbal,
Z. (2015b). Umtg: A toolset to automatically generate
system test cases from use case specifications. In Pro-
ceedings of the 2015 10th Joint Meeting on Founda-
tions of Software Engineering, ESEC/FSE 2015, page
942–945, New York, NY, USA. Association for Com-
puting Machinery.
Yang, X., Lo, D., Xia, X., Bao, L., and Sun, J. (2016). Com-
bining word embedding with information retrieval to
recommend similar bug reports. In 2016 IEEE 27th
International Symposium on Software Reliability En-
gineering (ISSRE), pages 127–137.
Yang, Y., Huang, X., Hao, X., Liu, Z., and Chen, Z. (2017).
An industrial study of natural language processing
based test case prioritization. In 2017 IEEE Inter-
national Conference on Software Testing, Verification
and Validation (ICST), pages 548–549.
Zhao, J. and Harris, I. G. (2019). Automatic assertion gener-
ation from natural language specifications using sub-
tree analysis. In 2019 Design, Automation Test in Eu-
rope Conference Exhibition (DATE), pages 598–601.
ICEIS 2020 - 22nd International Conference on Enterprise Information Systems
352
