
Towards Data-driven Services in Vehicles
Milan Koch
1
, Hao Wang
2
, Robert B
¨
urgel
1
and Thomas B
¨
ack
2
1
BMW Group, Munich, Germany
2
Leiden University, Leiden, The Netherlands
Keywords:
Data-driven Service, Machine Learning, Damage Prediction, Connected Car, Vehicle Network, Online
Learning.
Abstract:
Numerous recent studies show the prosperous future of data-driven business models. Some key challenges
have to be dealt with when moving towards the development of data-driven car services. In this paper, a new
data-driven customer service is proposed for the settlement of vehicle low speed accidents. Beyond that, we
present a more general approach towards the development of data-driven car services. We point out its main
challenges and suggest a method for developing new customer-oriented data-driven services. This approach
illustrates key points in developing a practical service, from a technical and business related perspective. Such
data-driven services are developed mostly on a small number of initial test data, which results often in a limited
prediction performance. Therefore, based on an optimized CRISP-DM approach, we propose a methodology
for developing initial prediction models with limited test data and stabilizing the models with newly gained
data after deployment by online learning. On-board and off-board services are discussed with the result that
especially off-board running services offer a large potential for future data-driven business models in a digital
ecosystem. The flexibility of such an ecosystem depends on the degree of the integration of the vehicle in the
ecosystem - in other words, the car needs to be enabled to deliver data on demand according to GDPR and to
any applicable regional law and in cooperation with the customer. The presented method, together with the
ecosystem, enables fast developments of various data-driven services.
1 INTRODUCTION
Robotics and transportation have been underpinned
by artificial intelligence since its early beginning. In
1969, Nilsson discussed the use of artificial intelli-
gence in integrated robot systems (Nilsson, 1969). In
the late 1970s pioneering discussions were made on
the first autonomous vehicles with artificial intelli-
gence (Tsugawa et al., 1979). Across the end of the
1970s to the 1990s, first prototypes were developed
by different scientists and organizations (Schmidhu-
ber, 2018). Such technical progresses continued until
2000 and the autonomous driving was feasible for the
first time, sparking major developments in both re-
search and industry (Stone et al., 2018; Huber et al.,
2008; Aeberhard et al., 2019; Ardelt et al., 2012).
In autonomous driving, data from different sensors
are combined by computers deployed in the car (Liu
et al., 2017). Using methods of artificial intelligence
(specifically deep learning techniques), these comput-
ers predict the car actions that are required to han-
dle situations. Due to the large data volume, those
artificial intelligence models are mainly deployed on
on-board-systems (embedded) in the car (Aeberhard
et al., 2019). Beyond autonomous driving functional-
ities, certain types of car data, especially the one re-
lated to self-driving, are combined with a car internet
interface and a robust internet connection, offering a
new era of data-driven services. Most of these ser-
vices require no additional car hardware and operate
only with the vehicle data that is available. As such
services are mainly driven by small data volumes, the
data set used can be transferred to a back-end sys-
tem, complying with data protection regulations and
customer’s consent. This enables running the data-
driven service outside of the car (off-board). Hence,
new services do not require any changes in the hard-
ware, which significantly simplifies the service devel-
opment. It allows for the continuous and faster cre-
ation of new services, even within the lifetime of cars.
Therefore, off-board running services are much more
powerful than in-car computations: A car interface
sends data on request to a back-end system, which
uses data-driven models for a prediction and sends the
output, e.g., back to the car. This is combined with
full transparency and involvement of the customer re-
Koch, M., Wang, H., Bürgel, R. and Bäck, T.
Towards Data-driven Services in Vehicles.
DOI: 10.5220/0009458700450052
In Proceedings of the 6th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2020), pages 45-52
ISBN: 978-989-758-419-0
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
45

garding certain data. The interconnection of vehicle
and back-end system builds a so-called digital ecosys-
tem, which integrates all aforementioned methods to
provide car services. It enables faster service devel-
opment and deployment, even within the lifetime of
cars.
The revenue from mobility services and connected
car services are projected to reach USD 1,087 billion
by 2030 (Seiberth and Gruendinger, 2018). This is
not only a large business for OEMs (Original Equip-
ment Manufacturer), but also for suppliers as well
as ecosystem developers and other parties involved
(Seiberth and Gruendinger, 2018). Data availabil-
ity, its protection and privacy of an open (e.g. to
third parties) digital ecosystem, is of key importance
to integrate cars more seamlessly into our lives with
more digital services. This paper mainly illustrates
the technical approach with its challenges for devel-
oping new data-driven customer services, going from
the idea to a running service.
The remainder of the paper is organized as fol-
lows: First, existing work that is related to our ap-
proach is discussed in section 2. Second, we present
an example of a data-driven service in section 3. Our
proposed methodology with its six main steps is then
introduced in section 4. In section 5, we provide con-
clusions and an outlook.
2 RELATED WORK
Recent studies illustrate new data-driven business
models in the car industry by means of a digital vehi-
cle ecosystem. In this context, Seiberth et al. present
a definition of data-driven business models: ”data [...]
as primary business resource to deliver value to cus-
tomers and to convert this value into revenue and/or
profit” (Seiberth and Gruendinger, 2018, p. 8). They
declare that in 2050 car manufacturers will achieve
50 % of the revenue from data-driven services. The
growing digitalization with its disruption process de-
stroys many traditional business models (Weill and
Woerner, 2014). The authors also picture more gen-
eral business models and the possibilities of digital
ecosystems for different industries. Car manufactur-
ers have different approaches to deal with digital ser-
vices and many tech start-ups are already develop-
ing sustainable business models with digital services.
Furthermore, OEMs enter already strategic partner-
ships and invest into such connected vehicle start-ups
(Kaiser et al., 2017).
Seiberth et al. discuss the available car data,
e.g. from sensors for autonomous driving, and high-
light the possible revenues when creating services
based on it (Seiberth and Gruendinger, 2018). In addi-
tion, there is a growing need for building trust towards
the customers regarding the use of their data for ser-
vices and therefore for the transparency of the data,
its use, and privacy and security (Kilian et al., 2020).
Beyond that, they present a figure of the connectiv-
ity ecosystem, which describes roughly a connectiv-
ity platform: it communicates with the data source
(car) and receives external data like weather, traffic
etc. The connectivity platform is connected to the
OEM’s back-end system, as well as to third party ser-
vices and apps.
Many studies present new business models en-
abled by data (Seiberth and Gruendinger, 2018; Weill
and Woerner, 2014; Kilian et al., 2020). In most
cases, new service ideas are superficially mentioned
and it is only briefly discussed how to really benefit
from each individual service. Some of the studies dis-
cuss the design of (vehicle) ecosystems, e.g. (Immo-
nen et al., 2016; Immonen et al., 2018), but a method-
ology for creating data-driven (customer) vehicle ser-
vices has not been a major topic of scientific research
yet.
3 A DATA-DRIVEN SERVICE FOR
CRASH DAMAGE PREDICTION
The variety of possible data-driven services is large.
A data-driven car service often assists the customer
(like a car pooling service) or the car (like predic-
tive maintenance services). Based on historical data
and with methods of artificial intelligence, models are
trained to predict behavior, e.g. in car pooling to pre-
dict the best possible route to carry the most passen-
gers or if a certain part of the car needs to be main-
tained in the nearby future.
Another example of a data-driven service is
a crash damage prediction system. Based on a
machine-learning model, such a system predicts the
damaged parts of a vehicle in a low speed crash. An
accident with a velocity difference below approxi-
mately 16 km/h is usually considered as low speed
crash. The baseline of this service is to use only on-
board data. Therefore, data from serial car sensors are
used for the prediction (e.g. acceleration). To gener-
ate an initial data set, low speed crash tests are per-
formed and certain on-board data are recorded. These
recordings are used together with the occurred dam-
age on the vehicle for training first initial models. The
benefit of such a data-driven service is e.g. immediate
transparency of the damage, which allows initiating
a faster and more convenient repair for the customer
(Seiberth and Gruendinger, 2018; Koch et al., 2018;
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
46

Koch and B
¨
ack, 2018).
However, the machine-learning model itself is
only one unit of the car service. When striving to cre-
ate seamless customer experiences with a data-driven
service, it is essential to consider the whole customer
journey. Such a journey describes the way how a
customer experiences the whole service. The overall
objective should be creating something which is so-
called convenient to the customer at all levels. This
can be achieved by designing the end-to-end service
with its technical challenges like data transfer or in-
tuitiveness of its handling as a whole picture. Based
on this, in the following we propose a general path to-
wards data-driven services to tackle and consider the
challenges with the one and only goal to create cus-
tomer value.
4 METHODOLOGY TOWARDS
DATA-DRIVEN SERVICES
In this section we propose a methodology for devel-
oping data-driven car services. This interdisciplinary
method is illustrated in Fig. 1. The horizontal axis
shows the time of the development while the vertical
one describes the level of development, i.e. the matu-
rity of the service. The origin presents the time of the
initial idea about the service and the beginning of its
development. The methodological approach consists
of six overlapping phases:
1. Idea.
2. Potentials.
3. Modeling.
4. Deployment.
5. Process.
6. Finalization.
All phases are linked to each other. In order to
allow short development times the phases are partially
executed in parallel. The phases are described in the
following sections.
4.1 Idea
The first phase of Fig. 1 is referred as idea. This pic-
tures the timeline from the first idea about the service
to very concrete solution concepts. Principally, there
are many motivations or ideas for thinkable services,
but for successful and seamless services the business
potential and customer benefits have to be evaluated
continuously in the next phase, the evaluation of the
potential.
Figure 1: The methodological approach: From the idea to a
deployed data-driven service.
4.2 Potentials
Seiberth et al. state that new car services follow
mainly two objectives: improvement of the brand im-
age or increase of profit (Seiberth and Gruendinger,
2018). This shows that the motivation to create those
is based on image or profit reasons or a combina-
tion of both. Therefore, data-driven services can
have strong impacts on the brand and can be used
for strengthening images with creating so-called cus-
tomer experience by building positive experiences
followed by an emotional bond between user and
product (Glattes, 2016).
Next to retail customers other stakeholders like,
e.g., fleet operators, insurance companies or other par-
ties can strongly support such services with their own
advantages (Seiberth and Gruendinger, 2018). Cre-
ating a service with many benefiting parties exploits
its potentials and is key for a successful and seam-
less service. Therefore, in case of promising ideas, in
phase 2 of Fig. 1, it is important to analyze and contin-
uously evaluate all aspects of the data-driven service
regarding the own objectives and the targets of part-
ners. However, it is mostly very ambitious to evaluate
the real potential of a new service in an ad-hoc man-
ner. Therefore, it is important to quickly develop pro-
totypes for experiments, get customer feedback and
constantly monitor the need for the service and decide
continuously to proceed or cancel the development.
In this context, after revealing an initial potential
of the idea, data scientists begin the phase of model-
ing with collecting data and designing first models.
4.3 Modeling
In the beginning of the modeling phase, data scientists
have to prove the feasibility of describing the desired
relations by the available data with methods from the
field of artificial intelligence. A feasibility study helps
to quickly assess the practicability of the idea.
To start the modeling phase, an initial data set
is crucial. In some cases, the data has been already
Towards Data-driven Services in Vehicles
47
collected and is available or can be gathered quickly.
However, in most cases the data has to be generated
manually. When considering the damage prediction
system, data from low speed crash tests are required.
Performing large numbers of such tests is very tedious
and expensive. Therefore, in such cases only small
initial data sets are generated in order to evaluate the
feasibility. Prediction models based on small data sets
are often of poor prediction quality. In order to in-
crease its quality and especially to have informative
results for the feasibility study, the use of optimiza-
tion techniques is key.
Shearer proposed an approach to run data mining
projects in industry, the cross industry standard pro-
cess for data mining (CRISP-DM) (Shearer, 2000).
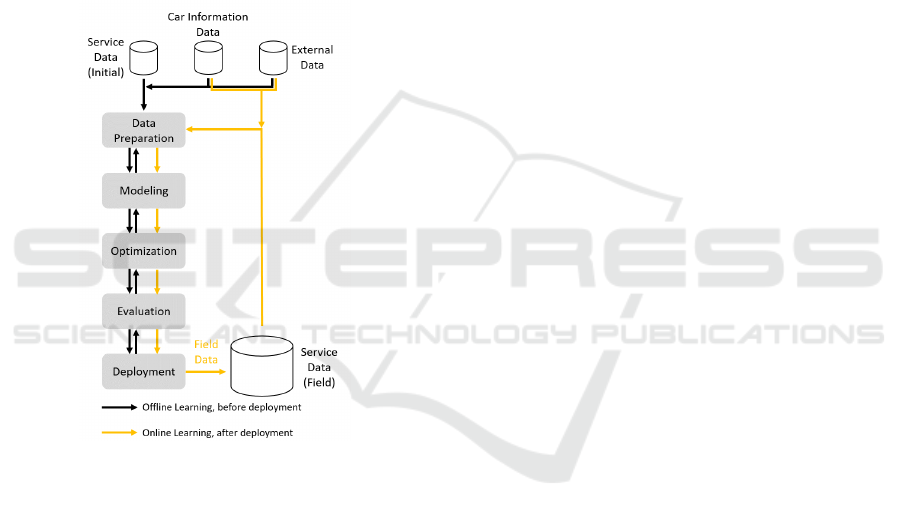
Figure 2: The modified CRISP-DM approach with opti-
mization and online learning components. Note that the
offline learning part follows the methodology proposed in
(Shearer, 2000).
This approach has become a very known standard
process to perform industrial data science projects.
Roughly, it describes the process from the business
understanding to data understanding, data prepara-
tion, modeling, evaluation until its deployment. We
have modified parts of the CRISP-DM and added op-
timization between modeling and evaluation in order
to enhance the model performance. Furthermore, we
have separated the data into initial data and field data,
as well as the process streams into offline learning
(black) and online learning (yellow) (see Fig. 2). Of-
fline learning describes the process of learning mod-
els with an offline generated (initial-) data set (Ser-
vice Data) to create an (initial-) prediction model. In
addition, car information data like the car type, the
equipment of the vehicle and geometry information,
as well as external data like, e.g. weather or traffic are
used as additional data resource, because such data of-
ten contain valuable information for the service. Af-
ter deploying the initial model in an offline learning
process, we are updating it by online learning (yellow
stream). This means that the initial model is stabilized
step by step after deployment with newly generated
field data.
We have developed this modified CRISP-DM ap-
proach, when we were dealing with the modeling
of the crash damage prediction system. Its required
crash data is extremely difficult to generate at large
volume, because either crash tests or simulations have
to be performed. Therefore, we only created a small
test data set containing just enough observations to
verify whether it is feasible to use on-board data to
predict the damaged parts. We obtained a data set
with 100 observations. The number of damages of
some parts is less than 5 among the 100 tests. This
indicates a very small and class-imbalanced data set.
Due to the character of our data set, first results with,
e.g., multi-label classification methods were not lead-
ing to promising results. More and more we have tai-
lored our approach: we developed a part-wise classi-
fication, i.e., we generated individual prediction mod-
els for each part of the vehicle. This was very promis-
ing, because each model has its own set of charac-
terizing features and its own set of hyper-parameters.
However, creating hand-crafted predicting models for
each vehicle part is a very time consuming process.
As a result, we developed our own automatic ap-
proach for time series classification, a so-called ma-
chine learning pipeline (Koch et al., 2018). The input
of our pipeline are time series with the correspond-
ing label. The outputs are predictive model perfor-
mance measures such as accuracy or F1-score, which
describe the quality of the prediction.
Our automated machine learning pipeline for time
series classification consists of four steps:
1. Feature Extraction from Time Series,
2. Feature Selection,
3. Modelling and
4. Hyperparameter Optimization of the Classifier.
This pipeline describes the modeling and optimiza-
tion part of our modified CRISP-DM approach more
in detail. It consists of the following components: fea-
ture extraction, feature selection, training of a classi-
fier and hyperparameter optimization. When dealing
with time series instead of non-temporal data, repre-
sentations (features) from time series need to be ex-
tracted. Traditionally, time series features are identi-
fied manually by a very time consuming process. To
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
48

generalize and automate this process, we take the ad-
vantage of tsfresh package (Christ et al., 2018) that
automatically extracts a potentially large number of
features. In tsfresh, there are 63 built-in feature func-
tions and in our scenario 794 features are generated
by parameterizing those functions differently.
In a next step, a feature selection algorithm
searches in the generated features space for the ones
that contain significant information about the damage:
some of those 794 features per time series describe the
relation better than others. Common methods for fea-
ture selection are, e.g., forward selection or RFE (re-
cursive feature elimination) (Guyon et al., 2008). In a
forward selection process, models are computed iter-
atively, starting with no features. Subsequently, fea-
tures are added in each iteration and those improving
the model performance are kept until no enhancement
can be achieved anymore (Guyon et al., 2008). Alter-
natively, in RFE, a predictive model is firstly built us-
ing all features and the weakest feature is removed ac-
cording to some well-defined importance metric. The
model is re-trained after the removal and such a pro-
cess is repeated until the specified number of features
is reached (Guyon et al., 2006).
In the next step, after selecting the most important
features, these are used to train a random forest classi-
fier. Due to our small number of observations, model
optimization strategies are indispensable. Therefore,
the hyper-parameters of this random forest classifier
are optimized. Common hyper-parameter optimiza-
tion techniques are, e.g., grid search or randomized
search (Geron, 2017).
We developed this pipeline to efficiently gener-
ate individual models predicting the damage for each
part and, more importantly, the pipeline can be used
for automatically enhancing and stabilizing the ini-
tial model performance after deployment by online
learning following the methodology of our modified
CRISP-DM approach.
Our initial pipeline models have achieved F1-
scores between 0% and 94%. This indicates, that
based on the small number of data points the pre-
dictability depends strongly on the part, i.e., the dam-
age of some parts can be predicted more precisely
than of others. Additional methods like frequent
pattern mining could help analyzing which parts are
likely to be damaged together within one crash. This
is especially important for parts with a low prediction
quality. Furthermore, by considering, e.g., the learn-
ing curves from our results we were able to foresee
an improvement of the performance with increasing
data (Koch et al., 2018). Among other things, this
helped us to evaluate the feasibility for practical use.
The solution space for such modeling problems
is usually large and often the combination of differ-
ent methods is leading to usable results in practice.
In our opinion automatic machine learning methods
(AutoML) like our pipeline approach are very promis-
ing, because of its practical use and due to its perfor-
mance and its efficiency (short computation times).
Modern vehicles employ many different sensors
and can produce large amounts of data. Sometimes
it is not obvious what data would be promising for
modeling. Therefore, from a possibly large number
of sensors, the most promising ones for the task at
hand have to be discovered.
As mentioned, after the data generation a feasibil-
ity study shows the practicability of the data-driven
service. When receiving results matching the expec-
tations, the models for the serial application can be
developed.
In conclusion, the key of the modeling phase is to
generate efficient predictive models and to check the
validity of the service model approach by assessing
the quality of the models that can be learned from the
data. After the feasibility is identified and confirmed,
the deployment of the service should be prepared.
4.4 Ecosystem/Deployment
The deployment of a data-driven service in an auto-
motive environment depends mainly on whether it re-
quires on-board or off-board running services. On-
board services are deployed on embedded systems in
the car. This needs data storage and computing power
on control units of the vehicle. Off-board services
are running in back-end systems. In this case, data
is transferred via the internet interface from the car
to the back-end, provided a sufficient bandwidth is
available. In both off-board and on-board running
services the car needs to provide the required data.
In this regard, in the deployment phase the electronic
components of the car have to be enabled to deliver
the needed data. Fig. 3 shows a typical vehicle net-
work of a passenger car. Such architecture consists
of different communication systems like Ethernet and
more traditional bus systems like FlexRay, CAN or
LIN. Ethernet is a local area network (LAN). It is
designed to transmit data between computers (Spur-
geon, 2000). BES are bridged end stations (switches),
which can send and receive transmissions. Bridges
communicate to other bridges, to the gateway (router)
and to end stations (ES), which is in an automotive
environment, e.g., the head unit (Spurgeon, 2000;
Spurgeon and Zimmerman, 2013). Bus systems like
FlexRay, CAN or LIN differ in various bandwidths
and each system transfers data between components,
called electronic control units (ECU). ECUs are em-
Towards Data-driven Services in Vehicles
49
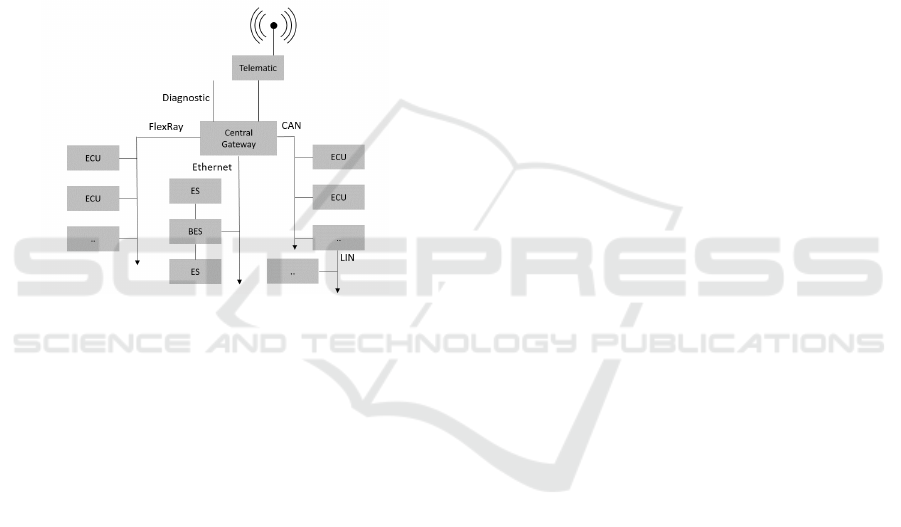
bedded systems, which control electrical systems in
the vehicle. A car contains many ECUs like the en-
gine control unit, the airbag control unit, the bat-
tery management system or the telematic control unit,
which sends and receives data via the mobile network.
All bus systems are connected via gateways (Robert
Bosch GmbH, 2014; Matheus and K
¨
onigseder, 2015).
Sensors are connected to the ECUs, which process the
sensor raw data and route it partly to the bus system.
This bus data can be used from other ECUs within
the connected bus or by the gateway. In some cases,
data from one bus is required on another bus. Then,
the gateway routes this data from one bus to another.
However, mostly data is only available in the ECUs
or on the initial bus system.
Figure 3: A typical schematic in-vehicle network.
Deploying a service on-board in an ECU de-
mands a high effort regarding receiving/delivering the
needed data, matching the data quality requirements
and the general deployment of the software within the
automotive system. This additional software needs to
harmonize with all car systems and thus implies very
costly technical security. In addition, the capacity
of storage within the ECU and its computing power
is limited for additional services due to the fact that
ECUs serve most likely other essential vehicle func-
tions. Furthermore, it is very challenging to deploy
on-board services in the lifetime of cars due to com-
patibility issues and the additional technical security
required.
A more flexible way is established by transmit-
ting the data from the car to a back-end system and
running the data-driven system off-board. As soon
as the required data is available on a bus system, this
data is routed by the gateway to the bus where the
sending unit (telematic) is located and it transfers the
data from the car to a back-end system. The back-end
computes the results and transmits it to the involved
systems of the stakeholders. In this regard, the inter-
net interface (telematic) of the car needs to be enabled
to transmit different data package sizes in order to
provide efficiently the required data (Arena and Pau,
2019). One crucial baseline is, that the bandwidth of
the mobile network allows such data transfers.
As mentioned before, the deployment of a service
on-board (embedded) is complex, time consuming
and not as flexible as a data-driven service is meant
to be. Some services need to run on embedded sys-
tems like autonomous driving (Liu et al., 2017). The
functionality of most of the other services allows run-
ning outside of the car like in case of the damage pre-
diction system. Off-board car services provide, next
to their simpler deployment, more flexibility regard-
ing faster model updates and adaptations. The key for
off-board services is the availability of data: The car
has to be able to send the required data on demand,
according to GDPR (General Data Protection Regu-
lation) and any applicable regional law and after the
confirmation of the customer, i.e., the electronic ar-
chitecture of the vehicle must be enabled to provide
the requested data. This is the foundation of a digital
ecosystem, which can collect demanded data and al-
lows deploying new services and interactions with the
car and other involved parties quickly.
Fig. 4 shows the basic principle of a vehicle
ecosystem for data-driven services. When develop-
ing a new service, the requested data is sent via mo-
bile network from the car to a data layer, called ser-
vice data, of a protected service cloud (security layer).
This service cloud is a part of the whole vehicle back-
end system. Next to the service data, the back-end
system receives external data from third parties like
traffic, weather and other service important informa-
tion. Furthermore, the back-end contains car infor-
mation like, e.g., the car type, the equipment of the
vehicle, the drive technology, geometry information,
service information. Such information are often very
valuable for a data-driven service. Hence, using these
additional data can increase the prediction perfor-
mances. The data-driven model (AI-unit) is deployed
to the back-end system, as well as other units (flex-
ible units) like data processing. This back-end sys-
tem communicates on demand with the car. Beyond
that, the architecture of the ecosystem allows train-
ing the models with newly collected data from time to
time or automatic (see Fig. 2). Such a digital ecosys-
tem gives even the possibility to provide partly ac-
cesses to third parties to create new valuable services,
e.g. (BMW GROUP, 2018). Generated customer in-
formation from the service cloud are provided to cus-
tomer devices in the car (control panel) or outside the
car, e.g. mobile applications.
When considering an example like the damage
prediction system, this would in concrete terms imply
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
50

Figure 4: A digital ecosystem to run data-driven service.
Note that this illustration follows partly the methodology of
the BCG analysis (Kilian et al., 2020).
the following sequence of events: after a low speed
crash event and a confirmation of the customer, a
small data package is transmitted to the data-driven
prediction model in the back-end. With the data
package as input the model predicts, based on his-
torical data, the damaged parts and the repair costs.
This information can be provided to participants like,
e.g., the customer, the insurance companies for seam-
less claim settlements or the workshops for faster re-
pair (Koch et al., 2018).
In all cases, before any data is transmitted, the
customer has to confirm the certain service with an
overview of the transmitted data. Furthermore, a gen-
eral transparency of the service and its intuitiveness in
understanding and handling must be provided within
seconds to the customer. A confirmation can be can-
celed anytime. In this context, recent studies show
that 94 % of connected car owners are interested in
apps and services. Out of those 94 %, 84 % are will-
ing to share personal automotive data for new services
(Otonomo, 2018).
An ecosystem with seamlessly operating data-
driven services requires data exchange from the
ecosystem not only to the car but also to other stake-
holders/participants. These processes need to be de-
signed in regards to the business processes. This is
described below.
4.5 Process
Running a service requires an interconnection of all
stakeholders/participants. Without data transfer to all
involved parties the potential of the service can not
be exploited. Therefore, shortly after having a rough
idea about the deployment, the business process needs
to be designed with taking all necessary stakeholders
into account.
When looking at the example of the damage pre-
diction system, the data of the damaged parts and the
cost for repair are computed in the back-end system.
It can be beneficial for the customer to send certain
information to other participants like the workshop to
order the parts immediately and to prepare the work-
shop visit. Beyond that, with detailed damage infor-
mation the insurance company could approve the re-
pair immediately, which simplifies the whole insur-
ance claim settlement and would avoid an interaction
of customer and insurance company. Such connec-
tions are identified and designed in the process phase.
Furthermore, business architects establish customer
oriented processes for running the data-driven system
with all necessary parties connected. Often, the whole
potential can be only reached when all parties are con-
nected in a beneficial way.
4.6 Finalization
Fig. 1 indicates that the finalization phase starts ap-
proximately half-way of the process phase. More pre-
cisely, when having first working systems, the final-
ization phase starts with testing, validating and im-
proving the service. In most cases, it is indispensable
to test the service with, e.g. defined customer groups
to use this feedback for further improvements. In this
phase it is key to consider and connect the five pre-
vious phases seamlessly with each other in order to
create a customer experience.
5 CONCLUSIONS AND
OUTLOOK
Nowadays, the expectations regarding data-driven
business models in the car industry are massive. This
paper illustrates a track towards an efficient develop-
ment and deployment approach for data-driven ser-
vices in vehicles. It presents the important steps, as
well as the main challenges. Through the explanation
of the methodology, examples are drawn to show pre-
cisely the key points. A flexible and various service
generation can be reached with a full integration of
vehicles in a digital ecosystem, which means that the
car delivers data according to GDPR (General Data
Protection Regulation) and any applicable regional
law and in cooperation with the customer to a back-
end system. The main service runs on this back-end
system, processes the data and transfers the results to
the participants like the customer or other involved
parties like, e.g., fleet operators. The shown method
enables generating fast data-driven services in order
to integrate cars more seamlessly into our lives.
Towards Data-driven Services in Vehicles
51

As an outlook, we mention that data enables much
more than creating data-driven services: data is trans-
forming car manufacturers from traditional engineer-
ing companies to data-driven companies. This indi-
cates that not only service creation but also car devel-
opment in general is progressively based on data.
REFERENCES
Aeberhard, M., K
¨
uhbeck, T., and et al. (Retrieved May
6, 2019). Automated driving with ros at bmw.
https://roscon.ros.org/2015/presentations/ROSCon-
Automated-Driving.pdf.
Ardelt, M., Coester, C., and Kaempchen, N. (2012). Highly
automated driving on freeways in real traffic using a
probabilistic framework. IEEE Transactions on Intel-
ligent Transportation Systems, 13(4):1576–1585.
Arena, F. and Pau, G. (2019). An overview of vehicular
communications. Future Internet, 11(2).
BMW GROUP (Retrieved November 19, 2018). BMW
group launches BMW cardata: new and innova-
tive services for customers, safely and transpar-
ently. https://www.press.bmwgroup.com/global/
article/detail/T0271366EN/bmw-group-launches-
bmw-cardata:-new-and-innovative-services-for-
customers-safely-and-transparently?language=en.
Christ, M., Braun, N., Neuffer, J., and Kempa-Liehr, A. W.
(2018). Time series feature extraction on basis of scal-
able hypothesis tests (tsfresh a python package). Neu-
rocomputing, 307:72 – 77.
Geron, A. (2017). ”Hands-on machine learning with
scikit-learn & tensorflow”. O’Reilly Media, Inc., Se-
bastopol, CA, USA.
Glattes, K. (2016). ”Der Konkurrenz ein Kundenerleb-
nis voraus: Customer Experience Management –
111 Tipps zu Touchpoints, die Kunden begeistern”.
Springer.
Guyon, I., Gunn, S., Nikravesh, M., and Zadeh, L. (2006).
”Feature Extraction: Foundations and Applications”.
Studies in Fuzziness and Soft Computing. Springer.
Guyon, I., Gunn, S., Nikravesh, M., and Zadeh, L. (2008).
”Feature Extraction: Foundations and Applications”.
Studies in Fuzziness and Soft Computing. Springer.
Huber, W., Steinle, J., and Marquardt, M. (2008). Der
Fahrer steht im Mittelpunkt - Fahrerassistenz Aktive
Sicherheit bei der BMW Group. Integrierte Sicher-
heit und Fahrerassistenzsysteme, 2048:123–138.
Immonen, A., Ovaska, E., Kalaoja, J., and Pakkala, D.
(2016). A service requirements engineering method
for a digital service ecosystem. Service Oriented
Computing and Applications, 10(2):151–172.
Immonen, A., Ovaska, E., and Paaso, T. (2018). Towards
certified open data in digital service ecosystems. Soft-
ware Quality Journal, 26(4):1257–1297.
Kaiser, C., Stocker, A., and Viscusi, G. (2017). Digi-
tal vehicle ecosystems and new business models: An
overview of digitalization perspectives. In Platform
Economy & Business Models workshop at i-KNOW
2017.
Kilian, R., Gauer, C., Stein, J., and Scherer, M. (Retrieved
March 7, 2020). Connected vehicles and the road
to revenue. https://image-src.bcg.com/Images/BCG-
Connected-Vehicles-and-the-Road-to-Revenue-Dec-
2017 tcm9-179631.pdf.
Koch, M. and B
¨
ack, T. (2018). Machine learning for
predicting the impact point of a low speed vehicle
crash. In 2018 17th IEEE International Conference on
Machine Learning and Applications (ICMLA), pages
1432–1437.
Koch, M., Wang, H., and B
¨
ack, T. (2018). Machine learn-
ing for predicting the damaged parts of a low speed
vehicle crash. In Proceedings of Thirteenth Inter-
national Conference on Digital Information Manage-
ment (ICDIM 2018), pages 179–184.
Liu, S., Li, L., Tang, J., Wu, S., and Gaudiot, J. L. (2017).
”Creating Autonomous Vehicle Systems”. Synthesis
Lectures on Computer Science. Morgan & Claypool
Publishers.
Matheus, K. and K
¨
onigseder, T. (2015). Automotive Ether-
net. Cambridge University Press.
Nilsson, N. J. (1969). A mobile automaton: An applica-
tion of artificial intelligence techniques. In 1st Inter-
national Conference on Template Production, pages
509–520.
Otonomo (Retrieved November 19, 2018). Are con-
sumers willing to share connected car data?
https://otonomo.io/are-consumers-willing-to-share-
connected-car-data/.
Robert Bosch GmbH (2014). ”Bosch Automotive Electrics
and Automotive Electronics: Systems and Compo-
nents, Networking and Hybrid Drive”. Springer,
Wiesbaden, 5th edition.
Schmidhuber, J. (Retrieved November 30, 2018). Prof.
Schmidhuber’s highlights of robot car history.
http://people.idsia.ch/∼juergen/robotcars.html.
Seiberth, G. and Gruendinger, W. (2018). Data-driven busi-
ness models in connected cars, mobility services &
beyond. In BVDW Research, volume 01.
Shearer, C. (2000). The crisp-dm model: the new blueprint
for data mining. J Data Warehouse, 5:13–22.
Spurgeon, C. (2000). ”Ethernet: The Definitive Guide”.
Definitive Guide Series. O’Reilly.
Spurgeon, C. and Zimmerman, J. (2013). ”Ethernet
Switches: An Introduction to Network Design with
Switches”. O’Reilly Media.
Stone, P., Brooks, R., and et al. (Retrieved Novem-
ber 5, 2018). Artificial intelligence and life in
2030. one hundred year study on artificial intel-
ligence: Report of the 2015-2016 study panel.
http://ai100.stanford.edu/2016-report.
Tsugawa, S., Yatabe, T., and et al. (1979). An automo-
bile with artificial intelligence. In Proceedings of the
6th International Joint Conference on Artificial Intel-
ligence - Volume 2, pages 893–895, San Francisco,
CA, USA. Morgan Kaufmann Publishers Inc.
Weill, P. and Woerner, S. L. (2014). Thriving in an increas-
ingly digital ecosystem. MIT sloan management re-
view, 56(4):27–34.
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
52
