
Machine Learning based Video Processing for Real-time Near-Miss
Detection
Xiaohui Huang, Tania Banerjee, Ke Chen, Naga Venkata Sai Varanasi, Anand Rangarajan
and Sanjay Ranka
Modern Artificial Intelligence and Learning Technologies (MALT) Lab, University of Florida, U.S.A.
Keywords:
Near-Miss Detection, Fisheye Camera, Intersection Video, Calibration, Thin-plate Spline, Deep Learning.
Abstract:
Video-based sensors are ubiquitous and are therefore indispensable in understanding traffic behavior at inter-
sections. Deriving near-misses from large scale video processing is extremely useful in assessing the level
of safety of intersections. In this paper, we develop real-time or near real-time algorithms for detecting near-
misses for intersection video collected using fisheye cameras. We propose a novel method consisting of the
following steps: 1) extracting objects and multiple object tracking features using convolutional neural net-
works; 2) densely mapping object coordinates to an overhead map; 3) learning to detect near-misses by new
distance measures and temporal motion. The experimental results demonstrate the effectiveness of our ap-
proach with real-time performance at 40 fps and high specificity.
1 INTRODUCTION
The advent of nominally priced video-based systems,
open source tools for video processing and deep
learning, and the availability of low-cost GPU proces-
sors have opened the door for their use in real-time
transportation decision systems. While video-based
systems for intersection traffic measurement can per-
form multiple object detection and tracking, their use
for more complex tasks such as anomaly detection
and near-misses is limited. The recent proposed AI
city challenge (Tang et al., 2019) also focuses on sim-
ilar applications. In general, monitoring activities
of road users and understanding traffic events have
shown to be useful for modeling, analyzing and im-
proving road-based transportation.
In order to derive intersection scenes with wider
angles, omnidirectional fisheye cameras are widely
installed and used for street video surveillance [also
known as closed-circuit television (CCTV)]. It is non-
trivial to directly apply learning-based methods to de-
tect near-misses in fisheye videos as they suffer from
two types of distortions: fisheye lens distortion and
perspective distortion. Due to both these distortions,
road users (pedestrians, cars, etc.) can appear to be
very close to each other in image space and to the
human eye while remaining far apart in the physical
world. Figure 1 illustrates a real fisheye traffic scene
and one false near-miss case that can easily mislead.
Figure 1: Illustration of near-Miss Detection Problem.
The focus of our work is on building a platform
that allows one to collect sufficient samples and vi-
sual cues corresponding to near-misses, intending to
detect and even anticipate dangerous scenarios in real-
time so that appropriate preventive steps can be un-
dertaken. In particular, we focus on near-miss prob-
lems from large-scale intersection videos collected
from fisheye cameras. The goal is to temporally and
Huang, X., Banerjee, T., Chen, K., Varanasi, N., Rangarajan, A. and Ranka, S.
Machine Learning based Video Processing for Real-time Near-Miss Detection.
DOI: 10.5220/0009345401690179
In Proceedings of the 6th International Conference on Vehicle Technology and Intelligent Transport Systems (VEHITS 2020), pages 169-179
ISBN: 978-989-758-419-0
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
169
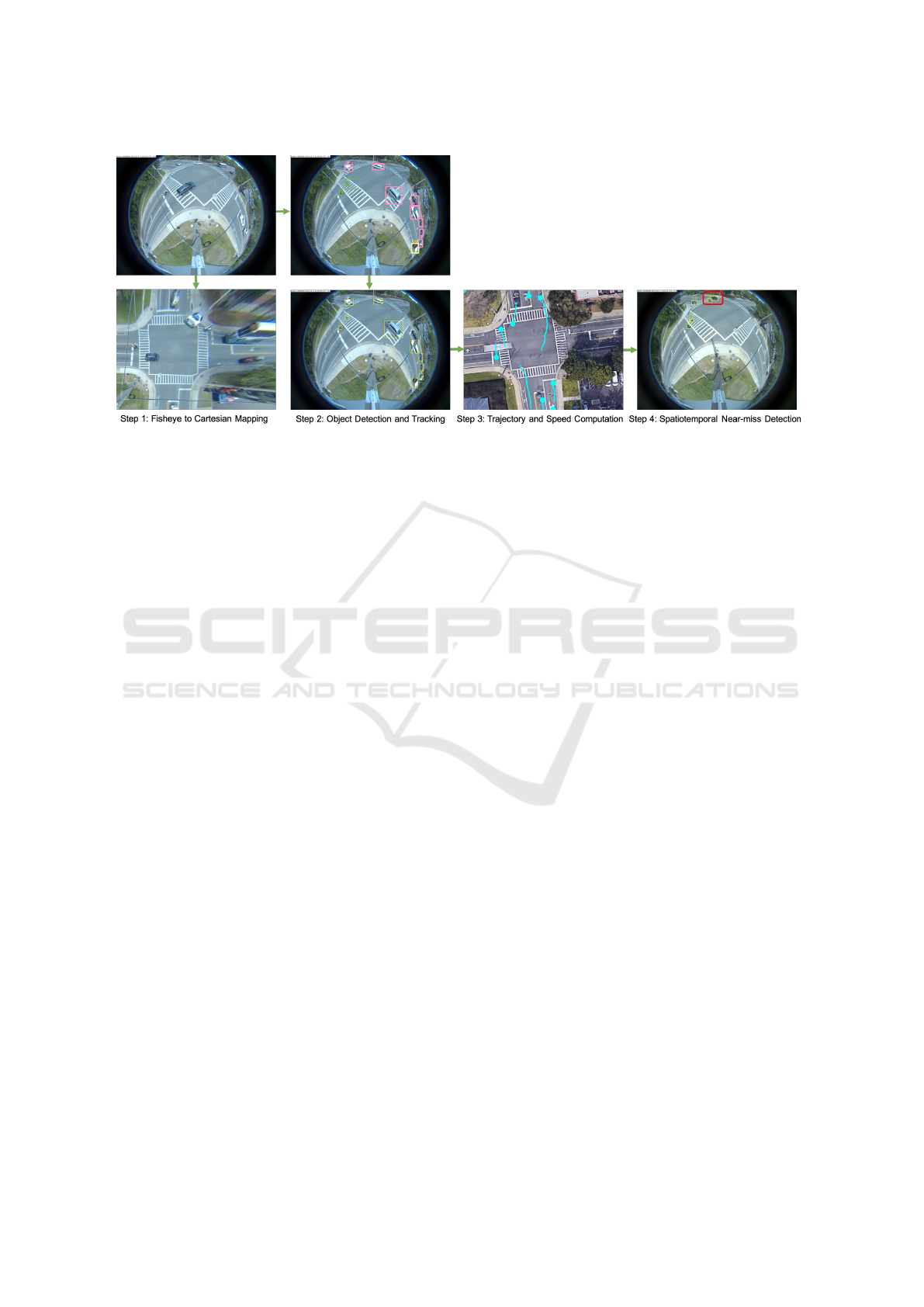
Figure 2: The Pipeline Overview of the Proposed Framework.
spatially localize and recognize near-miss cases from
fisheye video. The main motivation for resolving dis-
tortion instead of using original fisheye videos are to
compute accurate distance among objects as well as
their accurate speeds using rectangular coordinates
that better represent the real-world. The projections
are done on an overhead satellite map of the intersec-
tion. We specify five categories of objects of interest:
pedestrians, motorbikes, cars, buses and trucks. The
overhead satellite maps of intersections are derived
from Google Earth
R
. The main steps of our detection
framework (Figure 2) can be summarized as follows:
1. Fisheye to Cartesian Mapping: We first apply
camera calibration methods on a fisheye back-
ground image (with no road objects) to make an
initial correction. We take the calibrated image as
the target image, an overhead satellite map as the
reference image and select corresponding land-
mark points in both images for mapping. Given
these landmark points, we adopt the thin-plate
spline (TPS) (Bookstein, 1989; Chui and Ran-
garajan, 2003) as basis function for coordinate
mappings from the reference to the target and
store the point-to-point outputs.
2. Object Detection and Multiple Object Tracking:
We train an object detector using deep learning
techniques and design a vehicle re-identification
model with deep cosine metric learning to han-
dle occlusion problems. We integrate these two
models into our multiple-object tracking pipeline.
Given fisheye videos as the input, the framework
supports real-time object detection and multiple
object tracking.
3. Trajectory and Speed Computation: Using the
point-to-point TPS mappings, we correct and
scale road object trajectories and speed informa-
tion from the perspective of the overhead satellite
map with learned deep features. As the complex-
ity of coordinates transfer is O(1), it allows us to
process data both online and offline.
4. Spatial and Temporal Near-Miss Detection We
define two scenarios for near-misses in videos: 1)
spatial scenario: proximity of road objects in im-
age space, 2) temporal scenario: a dramatic speed
decrease to avoid near-misses (a sudden break).
We use the distance-based and speed-based mea-
sures to compute the near-miss probabilities of
road objects and aggregate scores via averaging
as the final output.
The main contributions of this paper can be sum-
marized as follows:
• We propose a novel method that combines dis-
tance measures and temporal motion to detect
near-misses in fisheye traffic video.
• We propose a combined calibration and spline-
based mapping method that maps fisheye video
features to an overhead map to correct fisheye lens
distortion and camera perspective distortion.
• We present a unified approach that performs real-
time object recognition, multiple object tracking,
and near-miss detection in fisheye video.
• We show a promising pipeline to be customized to
several fisheye video understanding applications
such as accident anticipation, anomaly detection,
and trajectory prediction.
We have obtained accurate and real-time object
detection and multiple object tracking results for
long-duration video. The object detector has good
performance to localize and classify road objects even
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
170

for tiny pedestrians. With cosine metric learning, the
tracker generates more consistent and robust tracks
and trajectories. With aid of calibration and TPS map-
ping, the location and speed information of objects
has been corrected and scaled to a large extent. Com-
pared to non-mapping based methods, the experimen-
tal results demonstrated that our methods have better
performance in filtering out non-near-miss cases.
The overall organization of the paper is as fol-
lows: Section 1 introduces the significant challenges
in near-miss detection from fisheye video, and sum-
marizes the proposed method. Section 2 discusses re-
lated work on video-based near-miss detection. Sec-
tion 3 presents preliminary and methodology details
for the proposed method. Section 4 describes the
dataset and demonstrates qualitative and quantitative
evaluation. Section 5 gives an overall summary of the
work in this paper and discussion of future opportuni-
ties for extending this work to other applications.
2 RELATED WORK
We have conducted a literature survey on near-miss
or accident detection. However, these methods have
limitations to process large-scale video data due to
performance issues and difficulties in handling the
distortion characteristics of omnidirectional fisheye
videos. Therefore, we proposed a method with real-
time performance and distortion correction. Future
opportunities consist of extending our method to near-
miss anticipation and/or applying specific spherical
coordinate-based deep learning models.
Near-Miss or Accident Detection. In general, we
have two types of methods for near-miss or accident
detection: sensor-based and video-based. Sensor-
based methods typically use data collected from loop
detectors or multi-sensors and most of them apply
machine learning or signal processing techniques:
Kalman filters, time series analysis and decision trees
etc. in (Ohe et al., 1995; Srinivasan et al., 2001;
Srinivasan et al., 2003; Ghosh-Dastidar and Adeli,
2003; Srinivasan et al., 2004; Zeng et al., 2008; Chen
et al., 2010). Video-based methods attempt to rec-
ognize near-miss events from image and video and
this is the focus of the present work. The litera-
ture in this area uses a variety of machine learning
and computer vision technologies (Jiansheng et al.,
2014; Kamijo et al., 2000; Saunier et al., 2010; Chen
et al., 2020; Banerjee et al., 2020; He et al., 2020).
Specific techniques include histograms of flow gra-
dients (HFG) (Sadeky et al., 2010), smoothed parti-
cles hydrodynamics (SPH) (Ullah et al., 2015), ma-
trix approximation (Xia et al., 2015), optical flow
and scale-invariant feature transform (SIFT) (Chen
et al., 2016), adaptive traffic motion flow model-
ing (Maaloul et al., 2017) and convolutional neural
networks (CNNs) and stacked autoencoders (Singh
and Mohan, 2018). However, these methods are re-
stricted to offline processing and not really applicable
for the real-time analysis of fisheye video.
Near-Miss or Accident Anticipation. The early
work in accident prediction is mainly based on
anomaly detection.With advances in deep neural net-
works and object detection, several automatated traf-
fic accident anticipation methods based on deep learn-
ing have been proposed. (Chan et al., 2016) proposed
a method for anticipating accidents in dashcam videos
using a Dynamic-Spatial-Attention (DSA) recurrent
neural network (RNN). Meanwhile, more large-scale
annotated video accident datasets have been proposed
along with these learning based methods such as
surveillance videos (Sultani et al., 2018; Shah et al.,
2018) or drive (dashcam) videos (Chan et al., 2016).
In our work, we detect near-misses 5 to 20 frames
ahead of an actual near-miss or accident.
Fisheye Video Processing. A few deep network
models have been proposed to learn and handle spher-
ical representations in fisheye videos for problems
such as object detection, tracking and segmentation.
(Lee et al., 2019) proposed a method to directly apply
CNNs to omnidirectional images. (Li et al., 2019)
proposed a method with a CNN (trained on a synthetic
distortion dataset) to predict displacement fields be-
tween distorted images and corrected images. (Wei
et al., 2011) presented an interactive fisheye correc-
tion method that integrates natural scene appearance
and use energy minimization of time-varying distor-
tion. (Dhane et al., 2012) presented a fisheye cor-
rection method using non-linear radial stretching and
scaling down of pixels in X and Y directions. (Yin
et al., 2018) proposed a multi-context collaborative
deep network to rectify distortions from single fisheye
images. These approaches process videos offline and
are not applicable for real-time traffic applications.
3 METHODOLOGY
Figure 3 demonstrates the pipeline and the overall ar-
chitecture of the proposed method.
Machine Learning based Video Processing for Real-time Near-Miss Detection
171
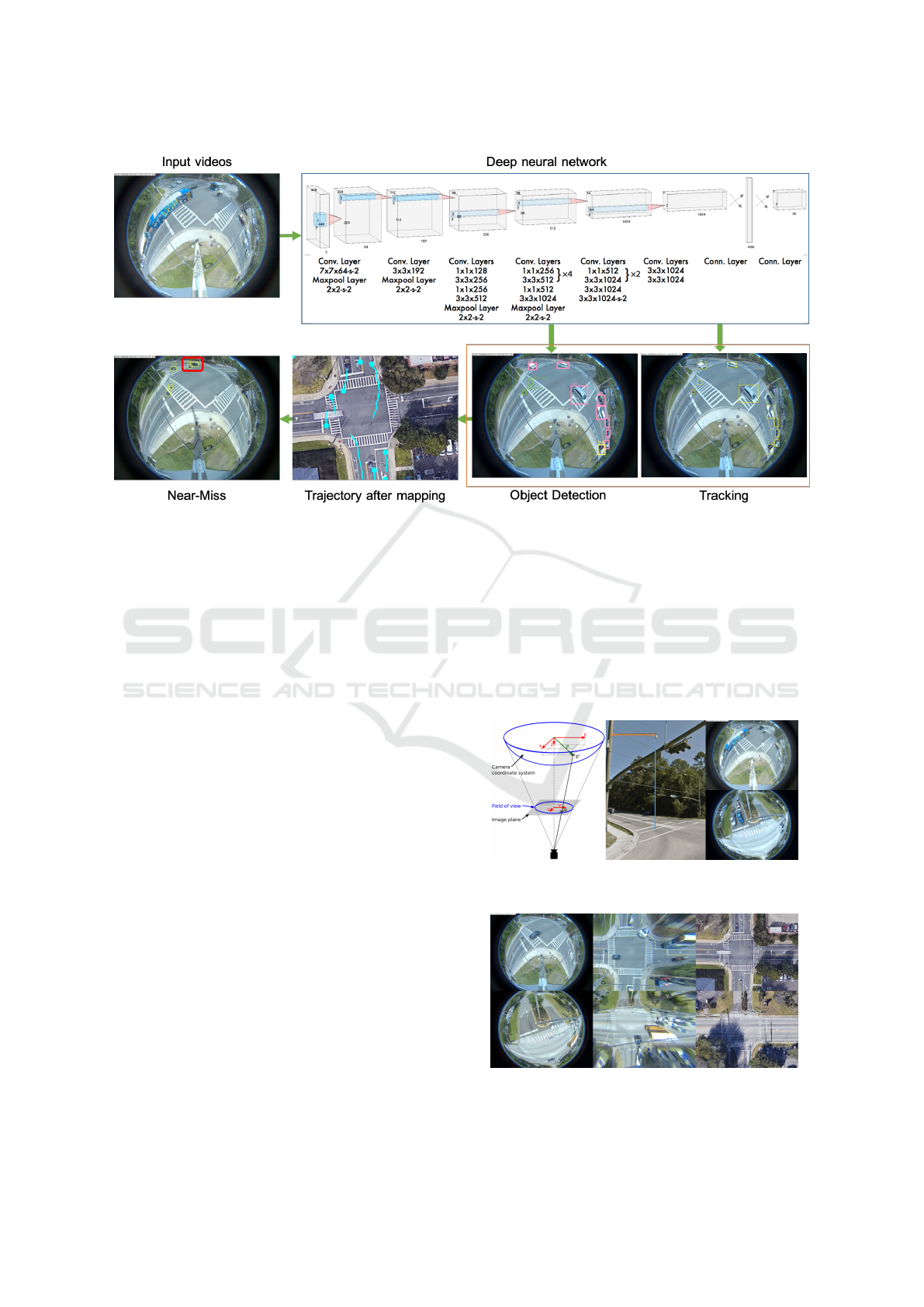
Figure 3: The Pipeline and the Deep Model Architecture of the Proposed Method.
3.1 Fisheye to Cartesian Mapping
3.1.1 Calibration and Perspective Correction
Due to fisheye lens distortion and perspective distor-
tion, we found that directly applying mapping meth-
ods between fisheye images and satellite maps does
not result in good quality mappings. Therefore, we
wish to utilize fisheye camera parameters to make
an initial calibration. For our fisheye camera model,
points in real 3D world are first transformed to fish-
eye coordinates via extrinsic parameters (rotation and
translation), and these fisheye coordinates are mapped
into the 2D image plane via the intrinsic parameters
(including the polynomial mapping coefficients of the
projection function). For a point P in the 3D world,
the transformation from world points to points in the
camera reference image is:
x
y
z
=
Xc
Y c
Zc
= R
Xw
Y w
Zw
+ T (1)
where R is the rotation matrix and T is for transla-
tion. The pinhole projection coordinates of P is (a,b)
where a = x/z, b = y/z, r
2
= a
2
+ b
2
, θ = atan(r).
The fisheye distortion is defined as
θ
distortion
= θ(1 + k
1
θ
2
+ k
2
θ
4
+ k
3
θ
6
+ k
4
θ
8
) (2)
where the vector of distortion coefficients is
(k
1
,k
2
,k
3
,k
4
) and camera matrix is
A =
f
x
0 c
x
0 f
y
c
y
0 0 1
(3)
The distorted point coordinates are (x
0
= (θ
d
/r)a, y
0
=
(θ
d
/r)b). The final pixel coordinates vector is (u,v)
where u = f
x
(x
0
+ αy
0
) + c
x
and v = f
y
y
0
+ c
y
, where
skew coefficient α is set to zero and stay zero.
Figure 4: Illustration of Omnidirectional Fisheye Camera
Used for Data Collection and Examples of Fisheye Video.
Figure 5: Calibration and TPS Mapping Are Used for Fish-
eye to Cartesian Mapping. left: Original Fisheye Image.
middle: Mapping Result. right: Reference Satellite Map.
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
172

The procedure of distortion correction involves
three major stages—Calibration correction, Perspec-
tive correction, and TPS mapping—in order to trans-
form the object location in fisheye to Cartesian co-
ordinates. The calibration process involves getting
parameters using a checkerboard reference. The im-
age obtained after the calibration has a noticeable per-
spective distortion which is adjusted by selecting four
points in the output image of the first stage and then
mapping them to a reference satellite image. There
are small but noticeable distortions in the image after
perspective correction which are caused by the geo-
graphic structure of the road like ridges and grooves
or may be due to small errors caused in the calibra-
tion. To address these distortions, the TPS mapping is
used, where multiple points are selected on the image
obtained after perspective transformation and mapped
to points on the satellite map. It approximates the
transformation using a spline-based method. Thus
by performing TPS, we get an image whose ground
(road) and the map ground almost overlap. As our
application goes beyond distortion correction, we can
actually track the vehicles and get the exact location
in Cartesian coordinates.
3.1.2 Thin-plate Spline Mapping
After calibration and perspective correction steps, we
can compute an initial fisheye to cartesian mapping.
To refine the mapping between the corrected fisheye
image and satellite map, we adopt the thin-plate spline
(TPS) as the parameterization of the non-rigid spatial
mapping connecting fisheye geometry to a Cartesian
grid. The choice of TPS to handle the spatial warping
in our problem is driven by the fact that it is a natural
non-rigid extension of the affine map. Furthermore,
we do not have any information regarding physics-
based mappings that can augment fisheye calibration.
Therefore, we adopt the TPS to generate mappings.
Given the point-sets V and Y in 2D (D = 2) consist-
ing of points v
a
,a = 1, 2,...,K and y
a
,a = 1, 2,...,N
respectively, the TPS fits a mapping function f (x,y)
using corresponding landmark sets y
a
and v
a
by mini-
mizing the following energy function (Chui and Ran-
garajan, 2003):
E
T PS
( f ) =
K
∑
a=1
ky
a
− f (v
a
)k
2
+
λ
Z Z
(
∂
2
f
∂x
2
)
2
+ 2(
∂
2
f
∂x∂y
)
2
+ (
∂
2
f
∂y
2
)
2
dxdy.
(4)
Homogeneous coordinates are used for the landmarks
with each point y
a
represented as a vector (1,y
ax
,y
ay
).
With a fixed regularization parameter λ, a unique
minimizer f can be obtained as follows (Chui and
Rangarajan, 2003):
f (v
a
,d,w) = v
a
· d + φ(v
a
) · w (5)
where d is a (D+1)×(D + 1) matrix representing the
affine transformation and w is a K × (D + 1) warping
coefficient matrix representing the nonaffine deforma-
tion. The vector φ(v
a
) is a 1 × K vector related to the
TPS kernel. When combined with the warping coeffi-
cients w, the TPS generates a non-rigid warping.
Figure 4 illustrates the omnidirectional fisheye
camera model, camera placement and examples of
collected video data. We present mapping results of
two intersections in Figure 5.
3.2 Object Detection and Multiple
Object Tracking
The pipeline of our framework is to first detect and
track road objects using deep learning models and
then compute distortion corrected speeds followed by
map-based trajectories. The deep object detector—
trained on fisheye video samples—is based on the
architecture of YOLO (Redmon and Farhadi, 2017).
According to the intersection attributes, we specify
five object categories: pedestrian, motorbike, car, bus,
and truck.
The multiple object tracker is built upon Deep-
Sort (Wojke et al., 2017), which uses a conven-
tional single hypothesis tracking method with recur-
sive Kalman filtering (Kalman, 1960) and frame-by-
frame data association. However, there exists an
occlusion problem when the intersection becomes
crowded or when big buses or trucks appear. There-
fore, some road objects can get a new identification
after occlusion disappears and this forces us to inte-
grate object signatures or object re-identification fea-
tures. We introduce a deep cosine metric learning
component to learn the cosine distance between road
objects and integrated it as the second metric measure
for the assignment problem in multiple object track-
ing. The cosine distance includes appearance infor-
mation of road objects to provide useful cues for re-
covering identities when the motion feature is less dis-
criminative. We trained the deep cosine metric learn-
ing model on the VeRi dataset (Liu et al., 2016).
Given the dataset D = {(x
x
x
i
,y
i
)}
N
i=1
of N train-
ing samples x
x
x
i
∈ R
D
and associated class labels y
i
∈
{1,. ..,C}, it fits a parametrized deep neural net-
work encoder function r
r
r = f
Θ
(x
x
x) with parameters Θ
project input images x
x
x ∈ R
D
into a feature representa-
tion r
r
r ∈ R
d
that follows a predefined notion of cosine
similarity. We modified a standard softmax classifier
Machine Learning based Video Processing for Real-time Near-Miss Detection
173

Figure 6: Example of Superpixel Segmentation on Fisheye
Video. It Is Used for Extracting More Detailed Object Fea-
tures (with Object Boundaries and Shapes) than Detection.
into a cosine softmax classifier as (Wojke et al., 2017)
p(y = k | r
r
r) =
exp
κ ·
˜
w
w
w
T
k
r
r
r
∑
C
n=1
exp
κ ·
˜
w
w
w
T
n
r
r
r
, (6)
where κ is a free scale parameter. The training of
the cosine metric encoder network can also be carried
out using the cross-entropy loss.
3.3 Trajectory and Speed Computation
We leverage tracking results to generate a trajectory
for each object in terms of frame, track id, class, x, y
coordinates. We transform the x, y coordinates from
fisheye image space to overhead satellite map space
using the point-to-point mapping matrix obtained in
the mapping pipeline. We estimate the speed of ob-
jects using distance after mapping. In order to lever-
age more accurate and compact object masks than
rectilinear bounding boxes, we also investigate the
(Huang et al., 2020) use of gSLICr (Ren et al., 2015),
a GPU-based implementation of SLIC (Achanta et al.,
2012)—a superpixel segmentation method—instead
of standard rectangular bounding boxes. Figure 6
demonstrates the use of superpixels for generating ob-
ject masks. This integration performed in real-time
results in better distance measures that can be utilized
for detecting near-misses.
3.4 Near-Miss Detection
Our method performs object detection and multiple
object tracking in real-time and has the capability to
handle large-scale and city-scale intersection video
for traffic understanding and analysis. Using our TPS-
based non-rigid mapping tool we can do both online
and offline coordinates correction to project road ob-
ject locations to satellite maps and then form refined
trajectories for near-miss detection.
Two near-miss scenarios are defined for videos:
1) spatial scenario: road objects collide or are very
close in image space, 2) temporal scenario: a dramatic
speed decrease to avoid near-misses (a sudden break).
We use distance-based measures and speed measures
to compute the near-miss probability of road objects
with the average of two scores serving as the final out-
put as described below.
Spatial Distance Measure We use tracks data to
form trajectories of road objects and compute dis-
tances between two road objects using center coor-
dinates of detected bounding boxes in image space at
frame level. The probability of a spatial near-miss is
computed using the Euclidean distance of road ob-
jects with ratio to the size of object according to ob-
ject class (vehicles size of each class does not varies
much) and is computed as follows:
P
spatial
(b
p
t
,b
q
t
) =
1
2
·
(w
p
t
+ w
p
t
+ h
q
t
+ h
q
t
)
p
(x
p
t
− x
q
t
)
2
+ (y
p
t
− y
q
t
)
2
(7)
where b
p
t
and b
q
t
denote the detected bounding boxes
for the p-th and q-th objects in the t-th frame. w
p
t
,
h
q
t
, w
p
t
, h
q
t
denote the object width, object height, x
coordinate, and y coordinates for the p-th object in
the t-th frame respectively.
Temporal motion measure The speed of the road
object is computed by adjacent displacement over
multiple time frames. The probability of motion-
based near-miss is computed by the fractional de-
crease in speed and is computed as follows:
P
temporal
(b
p
k:t
) =
max
∑
t
i=k
(s
p
i+1
− s
p
i
)
average(s
p
k:t
)
(8)
where b
p
1:t
denotes the detected bounding boxes for
the p-th from its first frame (k-th frame) to its last
frame (t-th frame). s
p
i
denotes speed for the p-th ob-
ject in the i-th frame.
We use a weighted average of the above two prob-
abilities of near-miss to compute the overall score.
4 EXPERIMENTS
We first describe the dataset used for our experimental
evaluation. We then present qualitative performance
and quantitative evaluation of our methods for object
detection, multiple object tracking, superpixel seg-
mentation, thin-plate spline, and near-miss detection.
For near-miss detection, we present a performance
comparison between non-mapping-based method and
our proposed calibration+TPS-based method.
4.1 Fisheye Video Data
We have collected large-scale fisheye traffic video
from omnidirectional cameras at several intersections.
Figure 7 shows gallery images of the dataset with sev-
eral collected fisheye video samples at multiple inter-
sections under different lighting conditions. We col-
lected 8 hours of videos on a daily basis for each
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
174

Figure 7: Gallery Images of Fisheye Video with a Variety of Different Locations (4 Cameras) and Different Lighting Condi-
tions.
Figure 8: Qualitative Results of Detection, Tracking and Segmentation Tasks. left: Object Detection, Outputs Object Class
(Car, Pedestrian, Bus, Motorbike, Etc.) and Localization (Bounding Box). middle: Multiple Object Tracking, Associates
Object in Consecutive Video Frames (Track Id). right: Superpixel Segmentation, Aids to Compute Object Boundaries and
Shapes.
intersection, 2 hours for the morning, noon, after-
noon, evening time respectively. The total video
datasets used the experiments has a duration of more
than 100 hours. As discussed earlier, fisheye inter-
section videos are more challenging than videos in
other datasets collected by surveillance cameras for
reasons including fisheye distortion, multiple object
types (pedestrians and vehicles) and diverse lighting
conditions. For generating ground truth for object de-
tection, tracking, and near-miss detection, we manu-
ally annotated the spatial location (bounding boxes)
and temporal location (frames) for each object and
near-miss. We also annotated the corresponding ve-
hicle class.
4.2 Qualitative Performance
Fisheye to Cartesian Mapping. The results for cal-
ibration+TPS pipeline (Figure 5) shows that fisheye
distortion and perspective distortion are effectively
addressed by our method. The qualitative results in
terms of performance for object detection, multiple
object tracking, and superpixel segmentation (Fig-
ure 8) show that the deep learning based detector
is effective in classifying objects even when the im-
age footprint is small ( e.g. pedestrians and motor-
bikes). The use of deep cosine metric learning al-
lows the tracker to generate more consistent and sta-
ble tracks. The superpixel segmentation assists in out-
Machine Learning based Video Processing for Real-time Near-Miss Detection
175

Table 1: Quantitative Evaluation of Speed Performance.
Methods CPU/GPU
Speed
TPS mapping CPU 10 s
SLIC segmentation NVIDIA TITAN V 400 fps
Overall pipeline NVIDIA TITAN V 40 fps
Table 2: Quantitative Performance of Object Detection and Multiple Object Tracking.
Methods TP FN FP Precision Recall F1-score
Object Detection 7649 102 82 0.98940 0.98684 0.98812
Multiple Object Tracking 7540 483 314 0.96002 0.93980 0.94980
Figure 9: Qualitative Results of Object Trajectories Map-
ping to Satellite Map. left: Tracking in Fisheye Video.
right: Trajectories after Mapping. Different Color Repre-
sents Different Object Class (Red for Bus, Green for Pedes-
trian, Blue for Car).
putting compact contours of objects. The latter can
then be used for an effective signature for tracking.
Trajectory and near-Miss Detection. The trajec-
tories of road objects projected on the satellite map
along with referenced tracking frames are shown in
Figure 9. These trajectory maps give an easier to un-
derstand traffic pattern for the intersection than that
from the perspective of the original fisheye camera.
Samples of near-miss we detected at different inter-
sections are presented in Figure 10. The first example
shows a spatial near-miss between two road objects.
The second example shows a temporal near-miss as
the front white car suddenly stopped in the middle of
the intersection, forcing a sudden break for the car
that was following.
4.3 Quantitative Evaluation
We present a quantitative evaluation of the overall
performance of our proposed method in terms of
speed performance, improvement object speed mea-
sures based on mapping, and the precision and recall
for each subtask of the pipeline.
Computational Requirements. We present speed
performance for the tested methods in Table 1. The
fisheye video resolution is 1280 × 960 and our im-
plementation for thin-plate spline takes 10s for one-
to-one corresponding mapping for 1,228,800 points.
This is one-time setup cost.
After getting mapping point-sets, all video pro-
cessing experiments have been performed on a sin-
gle GPU (NVIDIA TITAN V). The GPU-based SLIC
segmentation (Achanta et al., 2012) has excellent
speed performance and can process 400 fps on fisheye
videos. The overall pipeline of our methods (object
detection, multiple object tracking, and near-miss de-
tection) achieve about 40 fps. This rate is sufficient to
address a variety of real traffic surveillance and near-
miss detection for large-scale daily video data.
Trajectory and near-Miss Detection. A quantita-
tive prediction of object representation and near-miss
is achieved by comparing predicted detection with the
ground truth at frame level. A true positive corre-
sponds to a high level of overlap between prediction
and ground truth detection pair. It is computed using
an Intersection over Union (IoU) score. If this over-
lap exceeds a predefined threshold (e.g 0.7) then the
track is correctly associated. A true negative means
no prediction and no associated ground truth. A false
positive is that a prediction had no associated ground
truth. A false negative is that a ground truth had no
associated prediction. The true negative rate (TNR)
also refers to specificity and false positive rate (FPR)
refers to fall-out. The specificity, fall-out, precision,
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
176
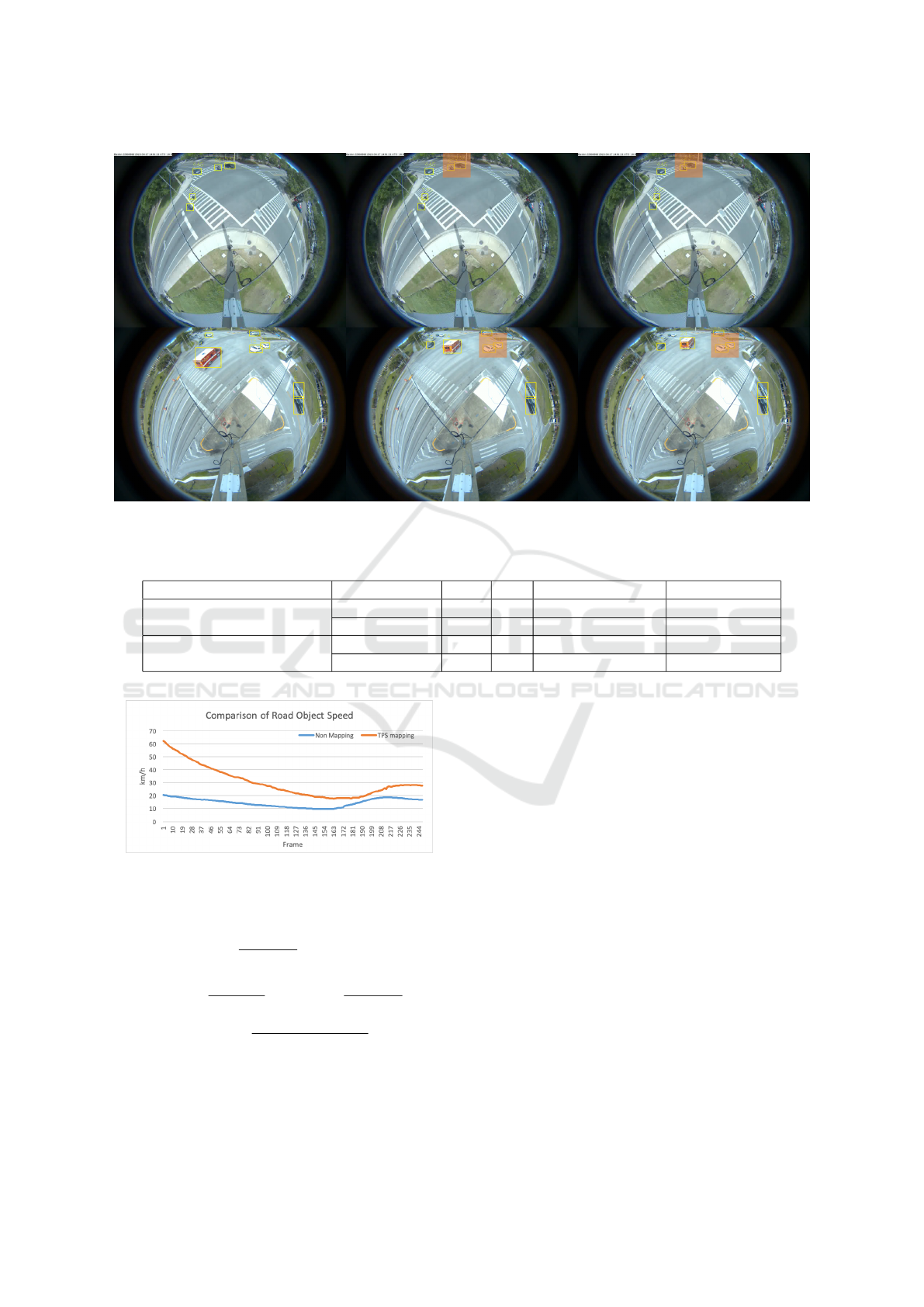
Figure 10: Qualitative Results of Two Types of near-Miss Detected. top 3 Images: a Spatial near-Miss Case: A Motorbike
and a Car Are Colliding. bottom 3 Images: a Temporal near-Miss Case Caused a Sudden Break.
Table 3: Quantitative comparison of near-miss detection between non-mapping and calibration+TPS-based method.
Methods Intersection TN FP Specificity (TNR) Fall-out (FPR)
Non-mapping based
(Baseline)
intersection 01 2869 32 0.98897 0.01103
intersection 02 2659 162 0.94257 0.05743
Calibration + TPS mapping
intersection 01 2895 6 0.99793 0.00207
intersection 02 2818 3 0.99894 0.00106
Figure 11: Quantitative Comparison of Computed Object
Speed between Non-Mapping and Proposed Methods.
recall, and F1-score are defined as
T NR =
T N
T N + FP
= 1 − FPR (9)
Precision =
T P
T P + FP
Recall =
T P
T P + FN
(10)
F1 = 2 ×
Precision ∗ Recall
Precision + Recall
(11)
We compute object speed information based on
trajectories by converting pixels to actual meters and
frame intervals to seconds. Figure 11 shows an ex-
ample of the comparison of computed object speed
information where a car is approaching the intersec-
tion with speed decreasing from 60 km/h to 20 km/h
and then back to 30 km/h. With non-mapping meth-
ods, object speed computing suffers from fisheye and
perspective distortion and yields inaccurate results.
We also present accuracy evaluation for object detec-
tion and multiple object (cosine metric learning) in
Table 2. As real near-miss is rare in terms of two
camera video data in a week, it is more reasonable
to exam specificity (selectivity or true negative rate)
and fall-out (false positive rate) for near-miss detec-
tion. In Table 3, we present the comparison of non-
mapping based detection and calibration+TPS map-
ping based detection in terms of true negative rate
(TNR) and false positive rate (FPR). The quantitative
evaluation demonstrates the overall effectiveness of
our proposed method for near-miss detection in large-
scale fisheye traffic videos.
Machine Learning based Video Processing for Real-time Near-Miss Detection
177
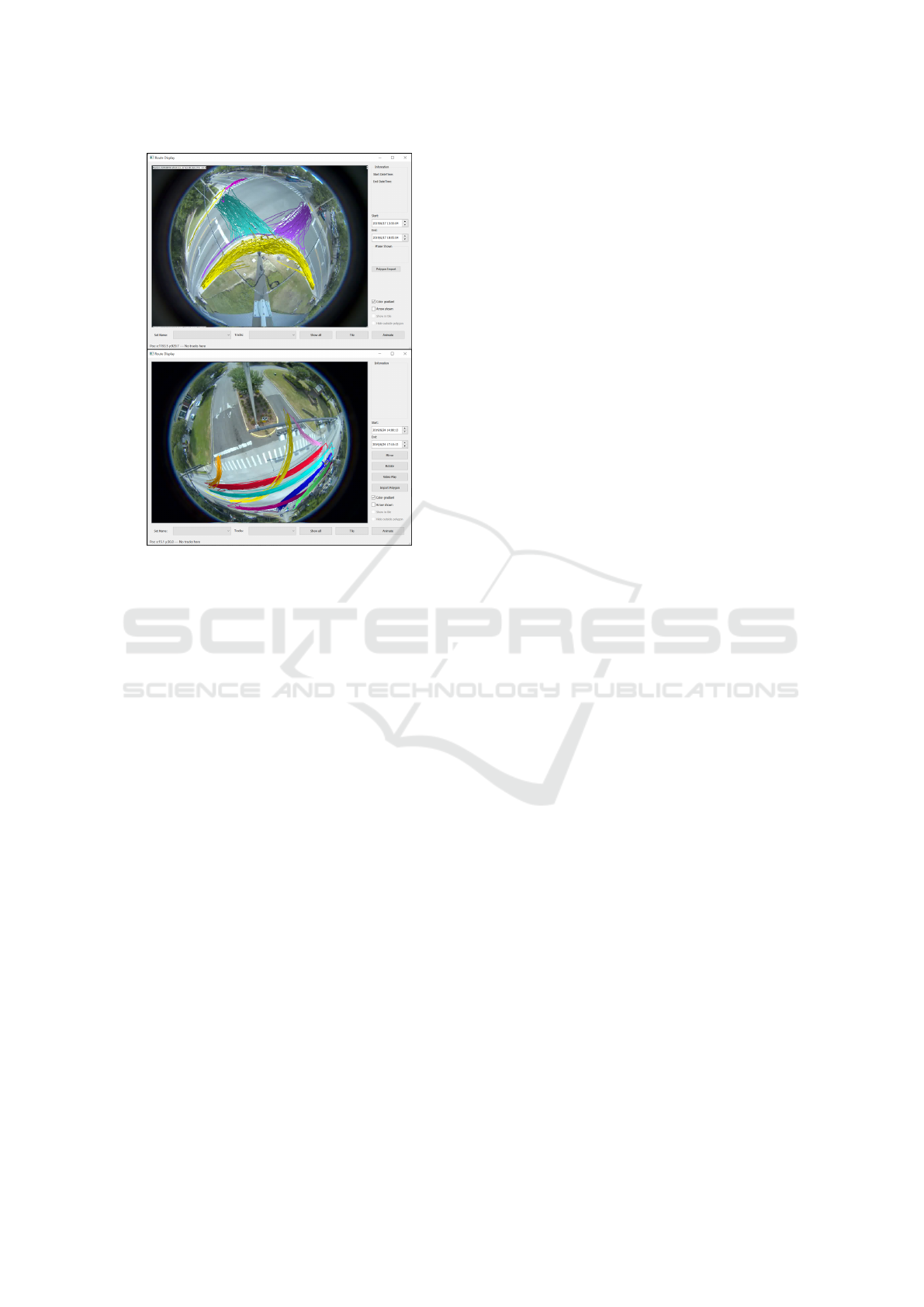
Figure 12: Example of Trajectory Visualization Used in Our
Visualization Tool. top: Pedestrian Trajectories in Intersec-
tion 01. bottom: Vehicle Trajectories in Intersection 02.
Color Means Different Clusters after Clustering.
5 CONCLUSIONS
We presented a novel unsupervised method to de-
tect near-misses in fisheye intersection video using
an end-to-end deep learning model integrated with a
combined camera calibration and spline-based map-
ping method. It maps road objects coordinates in
fisheye images to a satellite based overhead map to
correct fisheye lens distortion and camera perspec-
tive distortion. This allows for computing distance
and speed more accurately. This unified approach
performs real-time object recognition, multiple object
tracking, and near-miss detection in fisheye video. It
is efficient and robust to handle geometry and uncer-
tainty on object-level analysis in fisheye video, result-
ing in more accurate near-miss detection. The exper-
imental results demonstrate the effectiveness of our
approach and we show a promising pipeline broadly
applicable to fisheye video understanding applica-
tions such as accident anticipation, anomaly detec-
tion, and trajectory prediction.
Intersection SPAT data can be integrated with
video data to develop interesting traffic analyses, e.g.
cars crossing the intersection during a red light. The
generated tracks can be plotted over extended periods
(shown in Figure 12) to visualize macro trends.
ACKNOWLEDGMENTS
This research was supported, in part, by the Florida
Department of Transportation (FDOT) and NSF CNS
1922782. The opinions, findings, and conclusions ex-
pressed in this publication are those of the Author(s)
and not necessarily those of the Florida Department
of Transportation or the U.S. Department of Trans-
portation. The authors would like to thank the City
of Gainesville for access to the fisheye video data that
was used in this paper.
REFERENCES
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., and
S
¨
usstrunk, S. (2012). SLIC superpixels compared to
state-of-the-art superpixel methods. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
34(11):2274–2282.
Banerjee, T., Huang, X., Chen, K., Rangarajan, A., and
Ranka, S. (2020). Clustering object trajectories for
intersection traffic analysis. In 6th International Con-
ference on Vehicle Technology and Intelligent Trans-
port Systems (VEHITS 2020).
Bookstein, F. L. (1989). Principal warps: Thin-plate splines
and the decomposition of deformations. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence,
11(6):567–585.
Chan, F.-H., Chen, Y.-T., Xiang, Y., and Sun, M. (2016).
Anticipating accidents in dashcam videos. In Asian
Conference on Computer Vision, pages 136–153.
Springer.
Chen, K., Banerjee, T., Huang, X., Rangarajan, A., and
Ranka, S. (2020). A Visual Analytics System for Pro-
cessed Videos from Traffic Intersections. In 6th Inter-
national Conference on Vehicle Technology and Intel-
ligent Transport Systems (VEHITS 2020).
Chen, L., Cao, Y., and Ji, R. (2010). Automatic incident de-
tection algorithm based on support vector machine. In
2010 Sixth International Conference on Natural Com-
putation, volume 2, pages 864–866. IEEE.
Chen, Y., Yu, Y., and Li, T. (2016). A vision based traffic
accident detection method using extreme learning ma-
chine. In 2016 International Conference on Advanced
Robotics and Mechatronics (ICARM), pages 567–572.
IEEE.
Chui, H. and Rangarajan, A. (2003). A new point matching
algorithm for non-rigid registration. Computer Vision
and Image Understanding, 89(2-3):114–141.
Dhane, P., Kutty, K., and Bangadkar, S. (2012). A generic
non-linear method for fisheye correction. Interna-
tional Journal of Computer Applications, 51(10).
Ghosh-Dastidar, S. and Adeli, H. (2003). Wavelet-
clustering-neural network model for freeway incident
detection. Computer-Aided Civil and Infrastructure
Engineering, 18(5):325–338.
VEHITS 2020 - 6th International Conference on Vehicle Technology and Intelligent Transport Systems
178

He, P., Wu, A., Huang, X., Rangarajan, A., and Ranka,
S. (2020). Video-based machine learning system for
commodity classification. In 6th International Con-
ference on Vehicle Technology and Intelligent Trans-
port Systems (VEHITS 2020).
Huang, X., He, P., Rangarajan, A., and Ranka, S. (2020). In-
telligent intersection: Two-stream convolutional net-
works for real-time near-accident detection in traffic
video. ACM Trans. Spatial Algorithms Syst., 6(2).
Jiansheng, F. et al. (2014). Vision-based real-time traf-
fic accident detection. In Proceeding of the 11th
World Congress on Intelligent Control and Automa-
tion, pages 1035–1038. IEEE.
Kalman, R. E. (1960). A new approach to linear filtering
and prediction problems. Journal of basic Engineer-
ing, 82(1):35–45.
Kamijo, S., Matsushita, Y., Ikeuchi, K., and Sakauchi, M.
(2000). Traffic monitoring and accident detection at
intersections. IEEE Transactions on Intelligent Trans-
portation Systems, 1(2):108–118.
Lee, Y., Jeong, J., Yun, J., Cho, W., and Yoon, K.-J. (2019).
Spherephd: Applying cnns on a spherical polyhedron
representation of 360deg images. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition, pages 9181–9189.
Li, X., Zhang, B., Sander, P. V., and Liao, J. (2019). Blind
geometric distortion correction on images through
deep learning. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
4855–4864.
Liu, X., Liu, W., Ma, H., and Fu, H. (2016). Large-scale ve-
hicle re-identification in urban surveillance videos. In
2016 IEEE International Conference on Multimedia
and Expo (ICME), pages 1–6. IEEE.
Maaloul, B., Taleb-Ahmed, A., Niar, S., Harb, N., and
Valderrama, C. (2017). Adaptive video-based algo-
rithm for accident detection on highways. In 2017
12th IEEE International Symposium on Industrial
Embedded Systems (SIES), pages 1–6. IEEE.
Ohe, I., Kawashima, H., Kojima, M., and Kaneko, Y.
(1995). A method for automatic detection of traf-
fic incidents using neural networks. In Pacific Rim
TransTech Conference. 1995 Vehicle Navigation and
Information Systems Conference Proceedings. 6th In-
ternational VNIS. A Ride into the Future, pages 231–
235. IEEE.
Redmon, J. and Farhadi, A. (2017). YOLO9000: better,
faster, stronger. In Proceedings of the IEEE Con-
ference on Computer Vision and Pattern Recognition,
pages 7263–7271.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster R-
CNN: Towards real-time object detection with region
proposal networks. In Advances in Neural Informa-
tion Processing Systems, pages 91–99.
Sadeky, S., Al-Hamadiy, A., Michaelisy, B., and Sayed, U.
(2010). Real-time automatic traffic accident recogni-
tion using hfg. In 2010 20th International Conference
on Pattern Recognition, pages 3348–3351. IEEE.
Saunier, N., Sayed, T., and Ismail, K. (2010). Large-scale
automated analysis of vehicle interactions and colli-
sions. Transportation Research Record: Journal of
the Transportation Research Board, (2147):42–50.
Shah, A., Lamare, J. B., Anh, T. N., and Hauptmann, A.
(2018). Accident forecasting in cctv traffic camera
videos. arXiv preprint arXiv:1809.05782.
Singh, D. and Mohan, C. K. (2018). Deep spatio-temporal
representation for detection of road accidents using
stacked autoencoder. IEEE Transactions on Intelli-
gent Transportation Systems.
Srinivasan, D., Cheu, R. L., and Poh, Y. P. (2001). Hy-
brid fuzzy logic-genetic algorithm technique for au-
tomated detection of traffic incidents on freeways. In
ITSC 2001. 2001 IEEE Intelligent Transportation Sys-
tems. Proceedings (Cat. No. 01TH8585), pages 352–
357. IEEE.
Srinivasan, D., Jin, X., and Cheu, R. L. (2004). Evalua-
tion of adaptive neural network models for freeway
incident detection. IEEE Transactions on Intelligent
Transportation Systems, 5(1):1–11.
Srinivasan, D., Loo, W. H., and Cheu, R. L. (2003). Traffic
incident detection using particle swarm optimization.
In Proceedings of the 2003 IEEE Swarm Intelligence
Symposium. SIS’03 (Cat. No. 03EX706), pages 144–
151. IEEE.
Sultani, W., Chen, C., and Shah, M. (2018). Real-world
anomaly detection in surveillance videos. Center for
Research in Computer Vision (CRCV), University of
Central Florida (UCF).
Tang, Z., Naphade, M., Liu, M.-Y., Yang, X., Birchfield,
S., Wang, S., Kumar, R., Anastasiu, D., and Hwang,
J.-N. (2019). Cityflow: A city-scale benchmark
for multi-target multi-camera vehicle tracking and re-
identification. In The IEEE Conference on Computer
Vision and Pattern Recognition (CVPR).
Ullah, H., Ullah, M., Afridi, H., Conci, N., and De Natale,
F. G. (2015). Traffic accident detection through a hy-
drodynamic lens. In 2015 IEEE International Confer-
ence on Image Processing (ICIP), pages 2470–2474.
IEEE.
Wei, J., Li, C.-F., Hu, S.-M., Martin, R. R., and Tai, C.-
L. (2011). Fisheye video correction. IEEE Trans-
actions on Visualization and Computer Graphics,
18(10):1771–1783.
Wojke, N., Bewley, A., and Paulus, D. (2017). Simple on-
line and realtime tracking with a deep association met-
ric. In 2017 IEEE International Conference on Image
Processing (ICIP), pages 3645–3649. IEEE.
Xia, S., Xiong, J., Liu, Y., and Li, G. (2015). Vision-
based traffic accident detection using matrix approx-
imation. In 2015 10th Asian Control Conference
(ASCC), pages 1–5. IEEE.
Yin, X., Wang, X., Yu, J., Zhang, M., Fua, P., and Tao, D.
(2018). Fisheyerecnet: A multi-context collaborative
deep network for fisheye image rectification. In Pro-
ceedings of the European Conference on Computer Vi-
sion (ECCV), pages 469–484.
Zeng, D., Xu, J., and Xu, G. (2008). Data fusion for traffic
incident detection using ds evidence theory with prob-
abilistic svms. Journal of computers, 3(10):36–43.
Machine Learning based Video Processing for Real-time Near-Miss Detection
179
