
An Ontology-based Approach for Building and Querying ICH Video
Datasets
Sihem Belabbes
1
, Yacine Izza
1
, Nizar Mhadhbi
1
, Tri-Thuc Vo
2
, Karim Tabia
1
and Salem Benferhat
1
1
CRIL, Université d’Artois & CNRS, Lens, France
2
CICT, Can Tho University, Vietnam
Keywords:
Ontology, Dance Video Annotation, Inconsistency Handling.
Abstract:
The diversity of Southeast Asian Intangible Cultural Heritage (ICH) is showcased in many art forms and
notably in traditional dances. We focus on the preservation of Vietnamese ICH by building an ontology
for Tamia đwa buk dances. We propose a completion of the ontology by semantically enriching traditional
dance videos through manual annotation. Once annotated video datasets are built, we propose strategies for
processing user queries. In particular, we address inconsistencies which emerge when the same video receives
conflicting annotations from multiple sources. We also take into account different reliability levels of the
sources in order to prioritize query answers.
1 INTRODUCTION
This study is conducted in the context of a Euro-
pean research project called AniAge
1
, that focuses on
the digital preservation of Southeast Asian Intangible
Cultural Heritage (ICH), using high dimensional het-
erogeneous data-based animation techniques.
Indeed, Southeast Asia is known for its abundance
of natural resources as well as for its rich ethnic and
cultural diversity. Vietnam is no exception with its
ancient histor y and its 54 ethnic groups (Luyên N. T.,
2013). Traditional dances play a crucial role in spiri-
tual and cultural life (Sakaya, 2010). They are one of
the living art forms that the UNESCO
2
organization
considers as ICH which should be preserved.
Ontologies play a key role in ICH digital preser-
vation. In this paper, we build an OWL ontology
for a Vietnamese traditional dance called Tamia đwa
buk (a.k.a. Jar Dance), which is performed by fe-
male dancers holding jars. The ontology then serves
as a backbone for semantic enrichment of Jar Dance
videos, through a process of manual annotation. In-
deed, domain experts annotate dance videos by pro-
viding descriptions of the cultural content conveyed
in a Jar Dance. This is expressed by elements such as
dancer postures and movements, costumes, jar posi-
tion, as well as the symbolism portrayed in the dance.
1
http://www.cril.univ-artois.fr/aniage/
2
https://ich.unesco.org/en/lists
In the field of knowledge representation and rea-
soning within AI, ontologies are formalised with lan-
guages based on Description Logics (Baader et al.,
2007), such as DL-Lite (Calvanese et al., 2007), a
lightweight fragment known for its expressive power
and good computational properties. The ontology is
translated into an axiomatic knowledge base (a ter-
minological box, a.k.a. TBox), whereas annotations
are translated into a set of ground facts (an assertional
box, a.k.a. ABox). The TBox together with the ABox
form a knowledge base (KB).
Recently, a tool has been developed for manual
annotation of traditional dance videos (Lagrue et al.,
2019). Domain experts may use such tool to anno-
tate a video by decomposing it into segments (i.e.,
sets of frames). Several experts may annotate the
same video, but they may not share the same opin-
ion about dance elements showcased in some video
segments. Thus the exper ts may disagree in their an-
notations. This may lead to inconsistencies (or con-
flicts) in the ABox with respect to the TBox, making
the whole KB inconsistent. Standard query answer-
ing tools cannot be used in such a case as anything
can be derived from an inconsistent KB. Furthermore,
experts may assign confidence degrees to their an-
notations, reflecting various reliability levels of the
information. This corresponds to defining a priority
relation, namely a total preorder, over the assertions
contained in the ABox. In this paper, we propose
meaningful strategies for answering queries from in-
Belabbes, S., Izza, Y., Mhadhbi, N., Vo, T., Tabia, K. and Benferhat, S.
An Ontology-based Approach for Building and Querying ICH Video Datasets.
DOI: 10.5220/0009176804970505
In Proceedings of the 12th International Conference on Agents and Artificial Intelligence (ICAART 2020) - Volume 1, pages 497-505
ISBN: 978-989-758-395-7; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
497

consistent KBs that also take into account pr iorities to
compute the answers.
After a brief overview of related work in Section 2,
we present our ontology for Vietnamese Jar Dance in
Section 3. We discuss query answering from fully re-
liable information in Section 4. We deal with conflict-
ing and prior itized information and show how to rank-
order query answers in Section 5, before concluding.
2 RELATED WORK
In (Saaw et al., 2012), an OWL ontology for move-
ment in videos is built and an approach is proposed
for the semantic annotation of movements using the
Benesh Movement Notation. Ontology completion
supports video retrieval through SPARQL queries.
In (El Raheb and Ioannidis, 2011), a dance ontol-
ogy is built in OWL-2 to represent and archive dance
choreographies. SPARQL queries were applied for
searching the steps and movements of dances within
the ontology. In (Goienetxea Urkizu et al., 2012), a
representation of folk song metadata is described us-
ing OWL. Based on using and extending the CIDOC
CRM
3
, a method is proposed to encode and structure
metadata of folk song collections. In (El Raheb et al.,
2016), OWL is used to represent ballet movements.
A system is built to annotate dance videos based on
concepts from a predefined ontology of ballet termi-
nology and to search videos based on movement con-
cepts. In (Bertini et al., 2008), OWL is used to sup-
port automatic semantic annotation and retrieval of
video sequences. A Dance Video Semantic Model
(DVSM) is proposed in (Ramadoss and Rajkumar,
2007). It models dance video objects at various levels
of detail which are determined by components of the
accompanying song, and takes into account the mean-
ing conveyed both by the song and movements.
The use of ontologies for modelling Vietnamese
folk dances has been investigated in (Ma et al., 2018),
with a focus on a popular dance in Vietnam known
as Mõ folk dance. An ontology is proposed to de-
fine a taxonomy of dance movement classes and their
relationships, for the traditional Vietnamese dances
of type Mõ, taking into account the semantics of
its art and its cultural anthropology. A subsequent
study (Bourahla et al., 2019) extends the work in (Ma
et al., 2018), by building a searchable knowledge
base. This enables the search for non-elementary
movements in Mõ dances. The ontology is aug-
mented with classification rules, which are built with
3
Conceptual Reference Model for cultural heritage doc-
umentation.
the OWL complementary language SWRL (Seman-
tic Web Rule Language), to entail movement phrases
having complete meaning. Furthermore, in (Ma-Thi
et al., 2017), an approach is presented for annotat-
ing automatically movement phrases, mainly dancer
movements, in Vietnamese folk dance videos. In this
approach, annotation of videos is performed in three
steps: movement phrase detection, movement phrase
classification and movement phrase annotation.
To the best of our knowledge, there have been no
studies dealing with an ontology-based modelling of
Tamia đwa buk dances. In (Belabbes et al., 2019),
very early steps were taken into the investigation of
query answering from annotated videos of traditional
Malaysian dances. The originality of the present work
compared to the existing literature lies in the provision
of query answering strategies that take into account
conflicts and various reliability levels of the informa-
tion to rank-order query answers. This corresponds to
situations where different experts may provide con-
flicting annotations for a given video and may attach
various confidence degrees to their annotations.
3 AN ONTOLOGY FOR
VIETNAMESE TRADITIONAL
DANCE TAMIA DWA BUK
3.1 Overview of Vietnamese Traditional
Dances
Vietnamese traditional dances, with their wide va-
riety, are rooted in the country’s rich natural, his-
toric, cultural, regional and ethnic diversity. Most of
Vietnamese traditional dances are preserved through
transmission in local communities and documents are
extremely rare. Cham people are one of the 54 eth-
nic groups of Vietnam (Luyên N. T., 2013), located in
the south of the country. Their traditional dances play
a crucial role in spiritual and cultural life (Sakaya,
2010). Some popular dances of Cham people in-
clude: Tamia đwa buk (a.k.a. Jar Dance), Tamia
tadik (dance with paper fan), Tamia (towel dance) and
Tamia jwak apwei (fire dance) (Ngô V. D., 2002).
These traditional dances can be classified into four
main categories, namely: daily activity dances, reli-
gious dances, dances with props and dances without
props. This paper focuses on the dance type Tamia
đwa buk, later referred to as Jar Dance, in which fe-
male dancers hold jars, as illustrated in Figure 1.
A session of Jar Dance usually lasts between 3
and 5 minutes, and is performed by 4 to 8 female
dancers. Jar Dance movements include: dancers
ARTIDIGH 2020 - Special Session on Artificial Intelligence and Digital Heritage: Challenges and Opportunities
498

Figure 1: Tamia đwa buk dancers with traditional costumes.
standing, sitting, leaning and carrying a jar on the
head (without holding it with the hand). Traditional
costumes include: long dress (áo dài Chăm), long
skirt (váy), a belt called “talei ka-in” (dây thắt lưng
ngang), a scarf on the right shoulder called “talei
kabak”, head scarf (khăn đội đầu), earrings (khuyên
tai) and jewellery around the neck.
3.2 The JARDANCE Ontology
We have built an ontology for Jar Dance using
the free and open source tool Protégé
4
. The ob-
tained OWL ontology, called JARDANCE.OWL, com-
prises 38 classes, 2 object properties and 54 logical
axioms, making a total of 94 axioms. The correspond-
ing OWL document JARDANCE.OWL is available for
download from the link http://www.cril.univ-artois.fr/
aniage/ICAART19.
Figure 2 gives an overview of the concepts in the
ontology JARDANCE.OWL. It consists of a main class
“JarDance”, from which classes representing dance
concepts are derived. There are three main concepts,
namely: jar position, dancer body and dancer posture.
The jar’s position in a Jar Dance has an impor-
tant significance. Each position symbolises a daily
life task performed by women in the community of
Cham people. For instance, a dancer lifting the jar on
her head refers to women carr ying water. There are
five jar positions as can be seen in Figure 2, namely:
• Jar on Hand: dancer holds the jar in her hands.
• Jar over Head: dancer carries the jar with both
hands and lifts it up over the head.
• Jar on Floor: jar is on the floor and dancer moves
around it and makes a gesture like an activity of
getting water.
• Jar on Hip: left or right hand holds the jar on
same side hip. The free hand moves following the
music played by a traditional instrument.
• Jar on Head: dancer carries the jar on the head
without holding it with her hands.
Similarly to jar position, dancer postures have differ-
ent symbolic meanings. They can be divided into
4
https://protege.stanford.edu/
Figure 2: Overview of JARDANCE Ontology.
six categories: arm posture, hand posture, leg pos-
ture, foot posture, standing posture and sitting posture.
These are described below.
• Arm Posture: it can be either with or without hold-
ing the jar. There are five arm postures, shown in
Figure 3, as follows:
– Hold jar: hold the jar either on the head, or over
the head, or on the hip or on the hand.
– Diagonal: hands aligned and tilted diagonally.
– Orthogonal Forearm: both hands are open and
forearms are orthogonal to upper arms.
– Parallel: both arms are parallel and straightfor-
ward, or parallel on the left/right side and point
to the ground in a 45 degrees angle.
– Pray: hold arms in front of chest like a prayer.
• Hand Posture: it has three sub-classes as shown
in Figure 4, where Orthogonal-Straight Fingers
means that index to baby finger are straight while
thumb is orthogonal to the other four fingers. No-
tice that Hold Jar has two super-classes: Arm Pos-
ture and Hand Posture.
An Ontology-based Approach for Building and Querying ICH Video Datasets
499
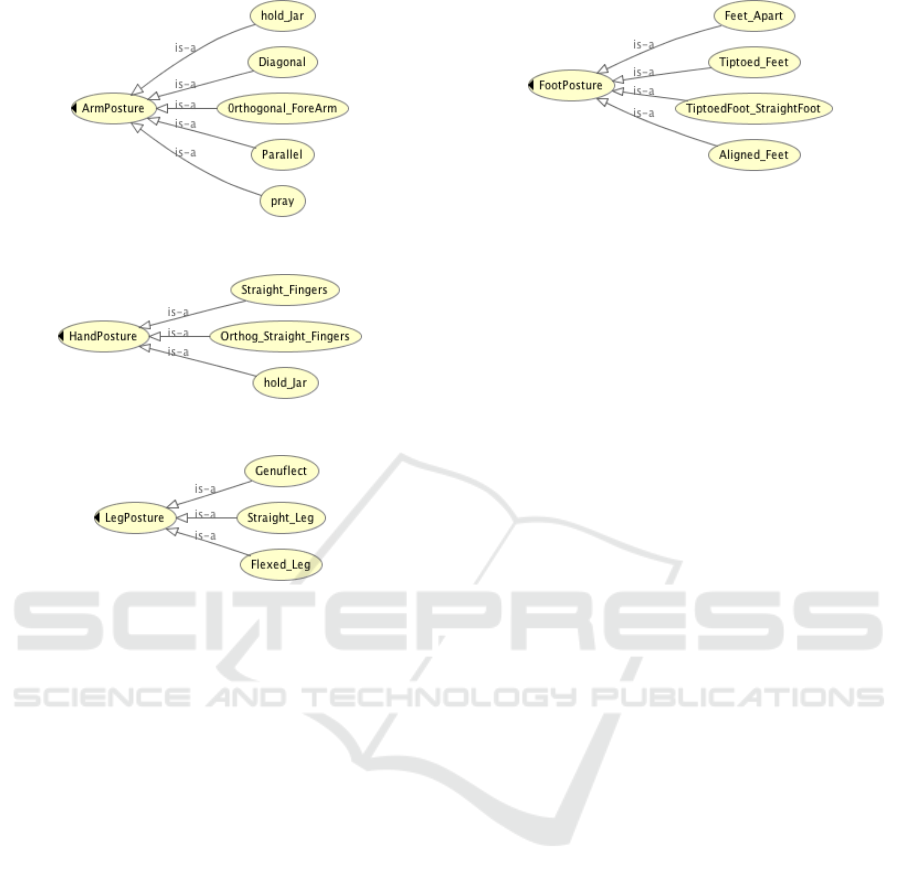
Figure 3: Arm Posture class and its sub-classes.
Figure 4: Hand Posture class and its sub-classes.
Figure 5: Leg Posture class and its sub-classes.
• Leg Posture: this depends on whether the dancer
is in sitting posture or standing posture. Genu-
flect posture corresponds to sitting posture, while
flexed and straight leg postures are per formed
within standing posture. (See Figure 5)
• Foot Posture: there are four sub-classes as shown
in Figure 6, where Tiptoed Foot Straight Foot
means one foot is tiptoed and the other is straight.
• Standing Posture: it can be of two types. Buck-
led standing posture combines buckled leg pos-
tures (one buckled leg and one straight leg, or both
buckled legs) and arm postures. Straight stand-
ing posture combines straight leg postures (tiptoed
foot or straight foot) and arm postures.
• Sitting Posture: it includes genuflection, rotated
body and upright body. Genuflections on the floor
are combined with arm movements.
In the rest of this paper, we discuss how an ontology
can be used in answering queries from ICH digital
content. We distinguish the case where information
is consistent (i.e., conflict-free) and fully reliable, and
the case where it is inconsistent and prioritized.
Figure 6: Foot Posture class and its sub-classes.
4 QUERYING CONSISTENT
ASSERTIONS
Ontology-Mediated Query Answering (OMQA) is an
active research area that takes advantage of the se-
mantic knowledge specified in an ontology to answer
queries about data (Bienvenu and Ortiz, 2015). Typ-
ically, querying is performed on a knowledge base
(KB) which is composed of an ontology (a TBox)
and a dataset of assertional facts (an ABox). De-
scription Logic languages are widely used to en-
code, integrate and maintain ontologies (Baader et al.,
2017). In this paper, we formalise our ontology using
the lightweight fragment DL-Lite (Calvanese et al.,
2007), since it provides a good trade-off between ex-
pressive power and computational complexity. For
lack of space, we do not provide the full transcription
of our ontology in DL-Lite, but we mention some ax-
ioms in the examples when needed. We first provide a
brief reminder on DL-Lite languages which are used
for formalising lightweight ontologies, followed by a
small illustrative example issued from our ontology,
then a section on querying fully reliable assertions.
4.1 A Brief Reminder on DL-Lite
The basic notions of DL-Lite languages are as fol-
lows. Consider finite sets of concept names, role
names and individual names. Let B (resp. C) denote a
basic (resp. complex) concept. Let R (resp. E) denote
a basic (resp. complex) role. An inclusion axiom on
concepts (resp. on roles) is a statement of the form
B v C (resp. R v E). Inclusion axioms with ¬ in the
right-hand side are called negative inclusions.
A TBox T is a finite set of inclusion axioms. An
ABox A is a finite set of assertions, that is, concept or
role names defined over individual names. A knowl-
edge base (KB) is a tuple K = hT , Ai. A KB is said
to be consistent if it admits at least one model, it is in-
consistent otherwise. A TBox T is incoherent if there
is a concept name that is empty in every model of T ,
it is coherent otherwise.
ARTIDIGH 2020 - Special Session on Artificial Intelligence and Digital Heritage: Challenges and Opportunities
500

Figure 7: Frame f
1
of a Jar Dance video.
Figure 8: Frame f
2
of a Jar Dance video.
We refer the reader to the work of (Calvanese et al.,
2007) for further details on DL-Lite.
4.2 Illustrative Example
In order to build a dataset for enriching our ontology,
we consider a set of Jar Dance videos. Domain ex-
perts are asked to semantically annotate each video in
terms of the concepts and roles defined in the ontol-
ogy. Annotations are then translated into assertions
of an ABox. We use the following running example
to illustrate query answering from annotated videos.
Example 1. Assume a video v
1
annotated by three
experts, E
1
, E
2
and E
3
. For the sake of simplicity, we
focus only on annotations associated with one video
segment, denoted by [ f
1
, f
2
], where f
1
represents its
first frame and f
2
its last frame. Let frames f
1
and f
2
be those of Figure 7 and Figure 8, respectively.
Annotations of experts E
1
, E
2
and E
3
for segment
[ f
1
, f
2
] are listed in Tables 1 to 3.
Table 1: Expert E
1
’s annotations of segment [ f
1
, f
2
].
Expert E
1
Annotation (assertion) Confidence degree
Sitting([ f
1
, f
2
]) 1
Jar_on_Head([ f
1
, f
2
]) 1
Straight_Bust([ f
1
, f
2
]) α
1
Orthogonal_FA([ f
1
, f
2
]) α
2
For instance, annotations in Table 1 depict: dancers
sitting (i.e., [ f
1
, f
2
] is an instance of the concept Sit-
ting), holding a jar on the head (i.e., [ f
1
, f
2
] is an
instance of the concept Jar_on_Head), and having a
Table 2: Expert E
2
’s annotations of segment [ f
1
, f
2
].
Expert E
2
Annotation (assertion) Confidence degree
Sitting([ f
1
, f
2
]) 1
Jar_on_Head([ f
1
, f
2
]) 1
Genuflect([ f
1
, f
2
]) 1
Pray([ f
1
, f
2
]) β
1
Table 3: Expert E
3
’s annotations of segment [ f
1
, f
2
].
Expert E
3
Annotation (assertion) Confidence degree
Sitting([ f
1
, f
2
]) 1
Jar_on_Head([ f
1
, f
2
]) 1
Tilted_Bust([ f
1
, f
2
]) γ
1
posture of straight bust and orthogonal forearms (i.e.,
[ f
1
, f
2
] is an instance of concepts Straight_Bust and
Orthogonal_FA).
The tables also contain confidence degrees at-
tached to annotations. Values α
1
, α
2
, β
1
and γ
1
are
positive numbers defined over a totally ordered un-
certainty scale, where “1” is the highest value and “0”
is the lowest value. As we shall see later, assertional
facts with confidence degrees can actually be repre-
sented by a totally pre-ordered (or prioritized) ABox.
For lack of space, we do not provide the full tran-
scription of the ontology (TBox) in DL-Lite and men-
tion only some axioms when needed.
Next, we discuss query answering in the case
where the ABox is consistent w.r.t. the TBox (i.e.,
all experts agree in their annotations), and the ABox
is non-pr ioritized or flat (i.e., experts are fully confi-
dent in their annotations).
4.3 Non-prioritized Consistent ABoxes
Let us assume that all experts agree in their annota-
tions of any given video and that they are fully confi-
dent about their own annotations. Namely, we assume
values α
1
, α
2
, β
1
, γ
1
(given in Tables 1 to 3) are all
equal to 1. This means that the ABox is consistent
w.r.t. the TBox, and that no priorities are assigned to
assertions (i.e., the ABox is f lat). Then query answer-
ing (QA) simply amounts to using any standard QA
tool (for instance, a DL-Lite QA tool when the TBox
and ABox are expressed in DL-Lite).
In this case, the input of the QA tool consists of
a set of annotated videos (an ABox), an ontology (a
TBox) and a conjunctive query q(
#»
x ). The output of
the QA tool is a set of answers X. Note that when
#»
x
is empty, then q(.) is a boolean query and its answer
is either yes or no.
An Ontology-based Approach for Building and Querying ICH Video Datasets
501

Example 1 (continued). Consider the TBox T con-
tains at least two axioms: T ⊃ {Straight_Bust v
Standing, Standing v ¬Sitting}. In other words, con-
cept Straight_Bust is a type of Standing, and concepts
Standing and Sitting are disjoint.
Consider annotations of video v
1
by expert E
1
and
ignore confidence degrees. Thus:
A
1
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Straight_Bust([ f
1
, f
2
]), Orthogonal_FA([ f
1
, f
2
])}
Consider the boolean query q(.) ← ∃x, Standing(x).
ABox A
1
contains assertion Straight_Bust([ f
1
, f
2
]),
but it also contains assertion Sitting([ f
1
, f
2
]. Accord-
ing to T , Standing and sitting are disjoint, then the
query’s answer is no.
One may want to rank-order videos instead of an-
swers. This can be achieved by first collecting the
answers associated with each video, and then rank-
ordering the sets of answers, as follows:
Definition 1. Let v
1
, v
2
be two videos. Then v
1
is
presented to the user before v
2
, denoted v
1
> v
2
, iff
|X(v
1
)| > |X(v
2
)|, where |X(v
i
)|, i = 1, 2, is the size of
the set of answers obtained from v
i
and the ontology.
Example 1 (continued). Consider a video v
2
with a
segment [ f
3
, f
4
], annotated by some expert. Let the
corresponding ABox be:
A
2
= {Standing([ f
3
, f
4
]), Jar_on_Floor([ f
3
, f
4
])}.
Consider now a query q(x) ← ∃x, Jar_on_Head(x),
asking for all individuals holding a jar on the head.
Querying A
1
of video v
1
returns X(v
1
) = {[ f
1
, f
2
]},
while querying A
2
of video v
2
returns X(v
2
) =
/
0.
Since |X (v
1
)| > |X(v
2
)|, then video v
1
is ranked first
and shown to the user because its component better
fits the query.
When different experts are asked to annotate the
same video, their annotations may potentially be con-
flicting since the experts may disagree about some el-
ements depicted in video segments. This issue is ad-
dressed in the next section.
5 QUERYING CONFLICTING
ASSERTIONS
In this section, we assume that any given video may
receive conflicting annotations obtained from multi-
ple experts. Hence, there may be conflicts between
assertions of the ABox w.r.t. the TBox, resulting in an
inconsistent KB. Moreover, we assume that experts
can express confidence in their own annotations. This
can be captured by applying a priority relation over
ABox assertions.
Here, we go beyond standard OMQA and pro-
pose strategies for querying inconsistent KBs when
the ABox is prioritized. We take the reasonable as-
sumption stating that the TBox is stable, coherent and
reliable, and distinguish two cases as follows:
1. The ABox contains conflicting assertions and all
experts are fully confident in their annotations.
2. The ABox contains conflicting assertions and ex-
perts may assign confidence degrees to their an-
notations.
5.1 Non-prioritized Conflicting ABoxes
Let us take a closer look at the case where experts
may disagree with one another in their annotations of
a given video, but they are fully confident about their
own annotations. Here we still consider that the con-
fidence degrees α
1
, α
2
, β
1
and γ
1
used in Tables 1, 2
and 3 are all equal to 1. Hence the KB is inconsis-
tent and the ABox is flat. In this case, one may not
use standard QA tools because every tuple would be
returned as a query answer from the inconsistent KB.
In what follows, we explain how to circumvent this
situation and introduce some definitions. We first de-
fine an assertional conflict.
Definition 2. Let T be a TBox, A be a flat ABox and
K = hT , Ai be an inconsistent KB. A sub-base C ⊆ A
is an assertional conflict of K iff hT , C i is inconsis-
tent and ∀g ∈ C , hT , C \{g}i is consistent.
Example 2. Consider annotations on video v
1
by ex-
perts E
1
to E
3
from Tables 1 to 3, without confidence
degrees. The resulting ABox, denoted by A, is:
A = {Sit ting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Straight_Bust([ f
1
, f
2
]), Genu f lect([ f
1
, f
2
]),
Pray([ f
1
, f
2
]), Orthogonal_FA([ f
1
, f
2
]),
Tilted_Bust([ f
1
, f
2
])}
The TBox T also contains the following two ax-
ioms: T ⊃ {Straight_Bust v ¬ Tilted_Bust, Pray v
¬Orthogonal_FA}. The first negative axiom means
that Straight_Bust and Tilted_Bust are disjoint con-
cepts. The second negative axiom means that Pray
and Orthogonal_FA are disjoint concepts.
This implies that {Straight_Bust([ f
1
, f
2
]),
Tilted_Bust([ f
1
, f
2
])} and {Pray([ f
1
, f
2
]),
Orthogonal_FA([ f
1
, f
2
])} are two assertional
conflicts of ABox A.
A pivotal notion when dealing with an inconsistent
KB is that of a repair (Lembo et al., 2010). Formally:
Definition 3. Let T be a TBox, A be a flat ABox and
K = hT ,Ai be an inconsistent KB. A sub-base R ⊆
A is a repair iff hT , R i is consistent, and ∀R
0
⊆ A:
ARTIDIGH 2020 - Special Session on Artificial Intelligence and Digital Heritage: Challenges and Opportunities
502

R ( R
0
,hT , R
0
i is inconsistent.
Furthermore if hT , Ai is consistent, then there exists
only one repair R = A.
It follows that a repair is a maximal subset of A
that is consistent w.r.t. T . Usually, there are several
repairs for any given ABox, as shown in this example:
Example 2 (continued). Assertions involved in a con-
flict may not appear in the same repair. Thus the re-
pairs of A are:
R
1
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Straight_Bust([ f
1
, f
2
]), Genu f lect([ f
1
, f
2
]),
Pray([ f
1
, f
2
])}
R
2
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Straight_Bust([ f
1
, f
2
]), Genu f lect([ f
1
, f
2
]),
Orthogonal_FA([ f
1
, f
2
])}
R
3
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Genu f lect([ f
1
, f
2
]), Pray([ f
1
, f
2
]),
Tilted_Bust([ f
1
, f
2
])}
R
4
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Genu f lect([ f
1
, f
2
]), Orthogonal_FA([ f
1
, f
2
]),
Tilted_Bust([ f
1
, f
2
])}
For answering queries from several repairs of an
ABox, one needs to define some strategy for select-
ing repairs. Let us define the notion of a cardinality-
preferred repair.
Definition 4. Let T be a TBox, A be a flat ABox and
K = hT , Ai be an inconsistent KB. Let R
1
, R
2
be two
repairs of A. Then R
1
is cardinality-preferred to R
2
iff |R
1
| > |R
2
|.
Note the difference between Definitions 3 and 4.
In the former, a repair is a maximal set in terms
of consistency, namely, adding any new assertion
makes the set inconsistent. In the latter, a repair is
cardinality-preferred to another one in terms of set
cardinality, namely, it is a maximal consistent set con-
taining a larger number of assertions.
Let CR(A) = {R
1
⊆ A, R
1
is a repair s.t. @R
2
⊆
A : R
2
is a repair and |R
2
| > |R
1
|} denote the set of
cardinality-preferred repairs of an ABox A, i.e., those
with the largest number of assertions. We then define
a query answer as follows:
Definition 5. Let A be an ABox and CR(A) be the set
of cardinality-preferred repairs. Given a query q(
#»
x ),
an answer
#»
x is valid iff it can be derived from every
repair R ∈ CR(A).
Example 2 (continued). All repairs of A contain five
assertions. Hence, the set of cardinality-preferred re-
pairs of A is CR(A) = {R
1
, R
2
, R
3
, R
4
}.
Consider the query q(.) ← ∃x, Jar_on_Head(x).
Since all repairs of A contain Jar_on_Head([ f
1
, f
2
]),
then the answer is yes.
Consider now the query q(.) ← ∃x, Pray(x). Then the
answer is no, since there is no individual d such that
Pray(d) can be derived from repairs R
2
and R
4
.
Now the question is how to rank-order videos.
Let us define X
CR
(v) as the set of answers based on
CR(A), where the ABox A encodes annotations of
video v. Thus we are also able to compare videos by
applying a variant of Definition 1 in which X (v
i
) is
replaced with X
CR
(v
i
). Formally:
Definition 6. Let v
1
, v
2
be two videos. Then v
1
> v
2
iff |X
CR
(v
1
)| > |X
CR
(v
2
)|, i = 1, 2.
Example 3. Consider a video v
3
with a segment
[ f
5
, f
6
], of which annotations produce ABox A
3
:
A
3
= {Standing([ f
5
, f
6
]), Jar_on_Floor([ f
5
, f
6
]),
Straight_Bust([ f
5
, f
6
]), Tilted_Bust([ f
5
, f
6
])}
There are two repairs, R
0
1
and R
0
2
, for A
3
. Namely:
R
0
1
= {Standing([ f
5
, f
6
]), Jar_on_Floor([ f
5
, f
6
]),
Straight_Bust([ f
5
, f
6
])}
R
0
2
= {Standing([ f
5
, f
6
]), Jar_on_Floor([ f
5
, f
6
]),
Tilted_Bust([ f
5
, f
6
])}.
Consider the query q(x) ← ∃x, Jar_on_Head(x). The
answer is yes with ABox A
1
of video v
1
(from Exam-
ple 1), while it is no with ABox A
3
of video v
3
. Then
video v
1
is ranked first and presented to the user.
5.2 Prioritized Conflicting ABoxes
Let us assume that the experts disagree with one an-
other in their annotations and that they are not fully
confident about their own annotations, so some an-
notations are deemed as more reliable than others.
Hence the KB is inconsistent and the ABox is no
longer flat. In fact, the introduction of confidence de-
grees requires adapting the notions of ABox, repairs
and query answers.
As stated previously, the assessment of confidence
degrees is done on a totally ordered uncertainty scale
(a qualitative uncertainty scale). Hence, for any given
video v, the corresponding ABox A is partitioned into
strata like so: A = (S
1
, . . . , S
n
), where S
1
(resp. S
n
)
contains the most (resp. least) reliable assertions. As-
sertions of the same stratum have the same confidence
degree. In this case, Definition 3 of a repair still holds.
Example 4. Consider annotations of experts E
1
, E
2
and E
3
of video v
1
(given in Example 1), together with
their confidence degrees, where:
An Ontology-based Approach for Building and Querying ICH Video Datasets
503

1 > α
1
> β
1
> α
2
= γ
1
.
Here, a total preorder applied to ABox assertions pro-
duces a partitioning of A into four strata. Namely:
S
1
= {Sitting([ f
1
, f
2
]), Jar_on_Head([ f
1
, f
2
]),
Genu f lect([ f
1
, f
2
])}
S
2
= {Straight_Bust([ f
1
, f
2
])}
S
3
= {Pray([ f
1
, f
2
])}
S
4
= {Orthogonal_FA([ f
1
, f
2
]), Tilted_Bust([ f
1
,
f
2
])}
The repairs of A remain the same as in Example 2,
namely: R
1
, R
2
, R
3
, R
4
.
When the ABox is stratified, the definition of a
preferred repair needs to be adapted in order to take
into account priorities. We introduce the notion of
a PC-preferred repair (where PC stands for priori-
ties and cardinality), first proposed in the context of
propositional logic (Benferhat et al., 1993).
Definition 7. Let A = (S
1
, . . . , S
n
) be a prioritized
ABox and R
1
, R
2
be two repairs of A. Then R
1
is PC-
preferred to R
2
iff ∃i, 1 ≤ i ≤ n, |R
1
∩ S
i
| > |R
2
∩ S
i
|
and ∀ j, 1 ≤ j < i, |R
1
∩ S
j
| = |R
2
∩ S
j
|.
Similarly to the case discussed in Section 5.1, let
PCR(A) denote the set of PC-preferred repairs.
Example 4 (continued). Recall that the TBox con-
tains these two axioms: T ⊃ {Straight_Bust v
¬ Tilted_Bust, Pray v ¬Orthogonal_FA}. Since
Straight_Bust([ f
1
, f
2
]) is in S
2
, it is strictly preferred
to Tilted_Bust([ f
1
, f
2
]) which is in S
4
. Similarly,
since Pray([ f
1
, f
2
]) is in S
3
, it is strictly preferred to
Orthogonal_FA([ f
1
, f
2
]) which is in S
4
. Then A has
a single PC-preferred repair, namely :
PCR(A) ={{Sitting([ f
1
, f
2
]), Genu f lect([ f
1
, f
2
]),
Jar_on_Head([ f
1
, f
2
]), Pray([ f
1
, f
2
]),
Straight_Bust([ f
1
, f
2
])}}.
Given a query q(
#»
x ), an answer
#»
x is PC-valid (or
PC-consequence) if it can be derived from every re-
pair R ∈ PCR(A). Furthermore, let X
PCR
(v) be the
set of answers based on PCR(A), where the ABox A
encodes the annotated video v. Now, one may assign
to each answer
#»
x a priority degree, denoted α
#»
x
, as
the first rank (the most important rank) from which
#»
x is derived. More precisely, assume that
#»
x is a PC-
consequence. Then a priority α
#»
x
associated with
#»
x
is α
#»
x
= i obtained as follows:
i)
#»
x is a PC-valid answer of PCR(S
1
∪ ··· ∪ S
i
), and
ii) ∀ j > i,
#»
x is not a PC-valid answer of PCR(S
j
∪
··· ∪ S
n
).
Thanks to the priorities associated with answers,
X
PCR
(v) can be split into: X
1
PCR
(v) ∪ ··· ∪ X
n
PCR
(v),
where X
i
PCR
(v) are answers obtained with priority i.
Thus, we are able to compare videos like so:
Definition 8. Let v
1
, v
2
be two videos. Then v
1
> v
2
iff ∃i, 1 ≤ i ≤ n, |X
i
PCR
(v
1
)| > |X
i
PCR
(v
2
)| and ∀ j, 1 ≤
j < i, |X
j
PCR
(v
1
)| = |X
j
PCR
(v
2
)|.
Namely, answers with the highest priority degree
are the most preferred ones. Note that Definition 8
extends Definition 6 when all answers have the same
priority level.
Example 5. Consider a video v
4
(similar to v
1
) of
which the corresponding ABox A
4
is stratified into:
S
0
1
= {Sitting([ f
7
, f
8
]), Jar_on_Head([ f
7
, f
8
]),
Genu f lect([ f
7
, f
8
])}
S
0
2
= {Straight_Bust([ f
7
, f
8
]), Pray([ f
7
, f
8
])}
S
0
3
= {Orthogonal_FA([ f
7
, f
8
]), Tilted_Bust([ f
7
,
f
8
])}
One can check that A
4
admits a single PC-preferred
repair, similarly to A in Example 4. Thus:
PCR(A
4
) ={{Sitting([ f
7
, f
8
]), Genu f lect([ f
7
, f
8
]),
Jar_on_Head([ f
7
, f
8
]), Pray([ f
7
, f
8
]),
Straight_Bust([ f
7
, f
8
])}}
Consider the query q(x) = ∀x.Pray(x). Clearly,
#»
x =
{[ f
1
, f
2
]} and
#»
x
0
= {[ f
7
, f
8
]} are both answers from A
and A
4
, respectively. However, [ f
1
, f
2
] is obtained
with rank 3 (i.e., from stratum S
3
of Example 4), while
[ f
7
, f
8
] is obtained with rank 2 (i.e., from stratum S
0
2
).
Using Definition 8, video v
4
is preferred to video v
1
,
hence it is presented first to the user.
6 CONCLUSION
In this paper, we first proposed an ontology, that
can be represented in Description Logic languages,
to capture the cultural knowledge conveyed by Viet-
namese traditional dances Tamia đwa buk. We then
proposed to enrich our ontology by manually anno-
tating dance videos. A tool for manual annotation of
videos, based on ontologies, has been developed (La-
grue et al., 2019) and used in this study. Lastly,
we proposed strategies for querying ontologies in the
presence of conflicting and prioritized data.
Enriching ontologies by annotating videos is a
crucial task for query answering. This task may ap-
pear to be daunting for large datasets. In this work, we
ARTIDIGH 2020 - Special Session on Artificial Intelligence and Digital Heritage: Challenges and Opportunities
504

took the first steps towards developing a comprehen-
sive tool for automatic annotations of videos and for
querying their content using machine lear ning. The
idea is to build a training set from a set of manually
annotated videos, then to use machine learning tech-
niques to train machine learning models to annotate
videos automatically.
ACKNOWLEDGEMENTS
Work supported by H2020-MSCA-RISE European
project: AniAge (High Dimensional Heterogeneous
Data-based Animation Techniques for Southeast
Asian Intangible Cultural Heritage Digital Content).
REFERENCES
Baader, F., Calvanese, D., Mcguinness, D., Nardi, D., and
Patel-Schneider, P. (2007). The Description Logic
Handbook: Theory, Implementation, and Applica-
tions.
Baader, F., Horrocks, I., Lutz, C., and Sattler, U. (2017). An
Introduction to Description Logic. Cambridge Univer-
sity Press.
Belabbes, S., Tan, C.-W., Vo, T.-T., Izza, Y., Tabia, K., and
Benferhat, S. (2019). Query-answering from tradi-
tional dance videos: Case study of zapin dances. In
Proceedings of the 31st International Conference on
Tools with Artificial Intelligence (ICTAI), pages 1630–
1634. IEEE.
Benferhat, S., Cayrol, C., Dubois, D., Lang, J., and Prade,
H. (1993). Inconsistency management and priori-
tized syntax-based entailment. In International Joint
Conference on Artificial Intelligence, pages 640–647.
Morgan Kaufmann.
Bertini, M., Del Bimbo, A., and Serra, G. (2008). Learn-
ing ontology rules for semantic video annotation. In
Proceedings of the 2nd ACM Workshop on Multimedia
Semantics, pages 1–8, Vancouver, Canada. ACM.
Bienvenu, M. and Ortiz, M. (2015). Ontology-mediated
query answering with data-tractable description log-
ics. In Reasoning Web. Web Logic Rules - 11th Inter-
national Summer School, Berlin, Germany, Tutorial
Lectures, pages 218–307.
Bourahla, M., Telli, A., Benferhat, S., and Chau, M. T.
(2019). Classifying non-elementary movements in
vietnamese mõ dances. In Digital Human Modeling
and Applications in Health, Safety, Ergonomics and
Risk Management. Human Body and Motion - 10th
International Conference, DHM 2019, Held as Part
of the 21st HCI International Conference, HCII 2019,
Orlando, FL, USA, July 26-31, 2019, Proceedings,
Part I, pages 128–139.
Calvanese, D., De Giacomo, G., Lembo, D., Lenzerini,
M., and Rosati, R. (2007). Tractable reasoning and
efficient query answering in description logics: The
DL-Lite family. Journal of Automated Reasoning,
39(3):385–429.
El Raheb, K. and Ioannidis, Y. (2011). A labanotation based
ontology for representing dance movement. In Inter-
national Gesture Workshop, pages 106–117. Springer.
El Raheb, K., Papapetrou, N., Katifori, V., and Ioannidis, Y.
(2016). BalOnSe: ballet ontology for annotating and
searching video performances. In Proceedings of the
3rd International Symposium on Movement and Com-
puting, pages 1–8. ACM.
Goienetxea Urkizu, I., Arrieta, I., Bag
¨
ués, J., Cuesta, A.,
Lei
˜
nena, P., and Conklin, D. (2012). Ontologies
for representation of folk song metadata. Technical
Report EHU-KZAA-TR-2012-01, University of the
Basque Country.
Lagrue, S., Chetcuti-Sperandio, N., Delorme, F., Ma-
Thi, C., Ngo-Thi, D., Tabia, K., and Benferhat, S.
(2019). An ontology web application-based annota-
tion tool for intangible culture heritage dance videos.
In Proceedings of the 1st Workshop on Structuring
and Understanding of Multimedia heritAge Contents,
SUMAC ’19, pages 75–81. ACM.
Lembo, D., Lenzerini, M., Rosati, R., Ruzzi, M., and Savo,
D. F. (2010). Inconsistency-tolerant semantics for de-
scription logics. In International Conference on Web
Reasoning and Rule Systems, volume 6333 of LNCS,
pages 103–117.
Luyên N. T. (2013). Giáo trình Trang phục các dân tộc Việt
Nam. Nhà xuất bản Đại học Quốc gia TP.HCM.
Ma, T., Benferhat, S., Bouraoui, Z., Tabia, K., Do, T., and
Nguyen, H. (2018). An ontology-based modelling of
vietnamese traditional dances (S). In The 30th In-
ternational Conference on Software Engineering and
Knowledge Engineering, Redwood City, USA, July 1-
3, 2018, pages 64–67.
Ma-Thi, C., Tabia, K., Lagrue, S., Le-Thanh, H., Bui-The,
D., and Nguyen-Thanh, T. (2017). Annotating move-
ment phrases in vietnamese folk dance videos. In
Advances in Artificial Intelligence: From Theory to
Practice, pages 3–11. Springer.
Ngô V. D. (2002). Văn hóa Cổ Chămpa. Nhà xuất bản văn
hóa dân tộc Publishers.
Ramadoss, B. and Rajkumar, K. (2007). Modeling and an-
notating the expressive semantics of dance videos. In
International Journal "Information Technologies and
Knowledge" Vol.1.
Saaw, S., Beul, D. D., Said, M., and Manneback, P. (2012).
An ontology for video human movement representa-
tion based on benesh notation. In International Con-
ference on Multimedia Computing and Systems, pages
77–82. IEEE.
Sakaya (2010). Văn hóa Chăm: Nghiên cứu và Phê bình,
Tập I. Nhà xuất bản Phụ nữ Publishers.
An Ontology-based Approach for Building and Querying ICH Video Datasets
505
