
Intention Indication for Human Aware Robot Navigation
Oskar Palinko
a
, Eduardo R. Ramirez
b
, William K. Juel
c
, Norbert Kr
¨
uger
d
and Leon Bodenhagen
e
SDU Robotics, Maersk Mc-Kinney Moller Institute, University of Southern Denmark,
Campusvej 55, 5230 Odense, Denmark
Keywords:
Human Aware Navigation, Mobile Robots, Intention.
Abstract:
Robots are gradually making their ways from factory floors to our everyday living environments. Mobile
robots are becoming more ubiquitous in many domains: logistics, entertainment, security, healthcare, etc. For
robots to enter the everyday human environment they need to understand us and make themselves understood.
In other words, they need to make their intentions clear to people. This is especially important regarding
intentions of movement: when robots are starting, stopping, turning left, right, etc. In this study we explore
three different ways for a wheeled mobile robot to communicate its intentions on which way it will go at
a hallway intersection: one analogous to automotive signaling, another based on movement gesture and as
a third option a novel light signal. We recorded videos of the robot approaching an intersection with the
given methods and asked subjects via a survey to predict the robot’s actions. The car analogy and turn gesture
performed adequately, while the novel light signal less so. In the following we describe the setup and outcomes
of this study, as well as give suggestions on how mobile robots should signal in indoor spaces based on our
findings.
1 INTRODUCTION
Mobile robots are having widespread success in con-
strained, industrial environments, executing various
logistic tasks and both freeing human resources as
well as providing additional flexibility compared to
solutions based on conveyors. However, in other do-
mains such as healthcare, robots are still rarely found,
although they are considered to be one of the means to
mitigate the demographic challenge (Riek, 2017) and
a large variety of technical challenges can be solved
with existing technology already (Bodenhagen et al.,
2019). In healthcare, unlike the industrial domain,
robots are expected to encounter humans that are both
unfamiliar with the robot and vulnerable. However,
besides operating safely, which can be achieved by
utilizing adequate safety mechanism, it is also re-
quired to operate robustly – for mobile robots this im-
plies in particular to adapt the navigation strategies
with respect to humans that share the environment.
a
https://orcid.org/0000-0002-4513-5350
b
https://orcid.org/0000-0002-6575-7202
c
https://orcid.org/0000-0001-5046-8558
d
https://orcid.org/0000-0002-3931-116X
e
https://orcid.org/0000-0002-8083-0770
In this paper we will in particular investigate how in-
tention can be conveyed and aid humans in anticipat-
ing the actions of the robot without prior instruction.
Understanding the intention of the robot allows for
adjusting the own behaviour accordingly and thereby
to minimize interference with the robot. It should be
clarified that robots of course do not have intentions
like humans, but as they are perceived as agents, we
should focus on displaying signals that will be per-
ceived as intentions by people. This understanding is
important for the acceptance of robots in our everyday
environments.
2 BACKGROUND
Mobile robots are entering into less constrained envi-
ronments such as public institutions and even private
homes. This shift is caused by technological progress
enabling robots to be reactive and responsive to hu-
mans in their environment (Svenstrup et al., 2009) and
to adjust the planned path online accordingly.
In the following, we will investigate prior work
relevant for the communication of intention since the
understanding of the robots’ intention by humans can
64
Palinko, O., Ramirez, E., Juel, W., Krüger, N. and Bodenhagen, L.
Intention Indication for Human Aware Robot Navigation.
DOI: 10.5220/0009167900640074
In Proceedings of the 15th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2020) - Volume 2: HUCAPP, pages
64-74
ISBN: 978-989-758-402-2; ISSN: 2184-4321
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

help avoiding conflicting situations which can impose
challenges to traditional navigation solutions and lead
to poor acceptance of robots (Hameed et al., 2016;
Beer et al., 2011). There are several approaches to
provide clues about the intention of robots including
the use of embodiment, physical attributes, or expres-
sive light (Juel et al., 2018). In the following, we
will summarize how humans anticipate the intention
of others (section 2.1) and use this to relate to rele-
vant research focusing on how robots communicate
their intentions (section 2.2).
2.1 Human Anticipation of Intention
Human-human interaction is often successful because
we can respond and react to the intention and action of
other humans. For this, we make use of the contextual
information within the nearby environment where ac-
tions are performed. If a teacup is on a kitchen table
with a tea-bag in it and a person reaches for a pot with
boiling water, we predict that he is probably going to
pour the boiling water into the cup. This type of con-
textual information surrounding an action allows us to
limit the possible outcomes of human intentions (Kil-
ner, 2011).
When the context in the environment cannot be
used or is not present, we use other techniques to pre-
dict intentions. Experiments by (Castiello, 2003) sug-
gest that the intentions of a human can be inferred
by monitoring gaze. If both contextual information
and gaze are absent it has been shown that from body
motion we can predict intentions of humans (Sciutti
et al., 2015) and that human actions translate into dif-
ferent kinematic patterns. (Ansuini et al., 2008) show
that depending on the end goal, we grasp the same ob-
ject differently which means we can use body motion
to anticipate intention.
The different techniques humans use to antici-
pate intention and action are naturally also used when
we want to understand the intention of robots. This
means that we first and foremost will try to use con-
textual information to anticipate the intention or state
of the robot. If contextual information is absent it
is the robot’s task to provide us with clues about
its intentions. In the following section, we will de-
scribe how this has been done via anticipatory motion,
augmented reality, animation techniques, expressive
light, animated light, and biological inspired lights.
2.2 Communication of Robot’s
Intentions
(Gielniak and Thomaz, 2011) show that anticipatory
motion can be used to communicate motion intent
earlier than motion without anticipation. They find
that when robots are displaying their anticipatory mo-
tion, humans have more time to respond in interactive
tasks. (Ferreira Duarte et al., 2018) show that when a
robot arm overemphasizes a motion, the intentions of
the robotic arms motion becomes predictable. In con-
trast, they also show that when adding gaze and reduc-
ing the motion of the robotic arm to normal the overall
readability of the intention increases. This suggests
that a combination of signaling modalities is stronger
than an overemphasized signal alone which could in-
crease the acceptability of the robot.
A number of HRI studies have employed anima-
tion techniques to improve robots’ intention legibil-
ity. These techniques are borrowed from animated
movies (cartoons). Some of these methods are: antic-
ipation (reaching back before throwing a ball), squash
and stretch (a falling character will squash at landing),
secondary action (a character puts on a jacket while
leaving a house), etc. For a detailed overview of the
field, see (Schulz et al., 2019).
Augmented reality can also be used to display
a mobile robot’s intentions of movement. (Coovert
et al., 2014) looked at a robot projecting an arrow
in front of itself signaling its intended direction of
movement. Experiment participants correctly inter-
preted these projections and rated such a robot more
favorably. (Chadalavada et al., 2015) designed an
augmented reality signaling system where the robot
projected a line representing its exact intended path.
People interacting with this robot thought that it was
much more communicative, predictable and transpar-
ent compared to the same robot but without intention
projection.
(P
¨
ortner et al., 2018) hypothesized that colored
light is a suitable feedback mechanism for mobile
robots. They test which of six chosen colors repre-
sent three categories: Active, help needed from hu-
man, and error. They find that a green signal should
be used to report active robot behavior, yellow/orange
signal for reporting that the robot needs help and red
signaling if an error occurs. Their results show that
humans interpret light on robots in very specific ways
and that it can be used to express the internal state of
robots.
Utilizing colored light to signal a robot’s state and
action is supported by (Baraka and Veloso, 2018) that
use light arrays to create both periodic and aperiodic
expressive light signals on a mobile robot. Their re-
sults suggest that the presence of lights on a mobile
robot can significantly increase people’s understand-
ing of the robot’s intentions. They completed a user
study where they demonstrate that when using ex-
pressive light to show that the robot needs help more
Intention Indication for Human Aware Robot Navigation
65

humans would help it and understand that the robot
needed help. This shows that expressive light has an
impact on the behavior of humans around the robot.
Interestingly, their results also suggest that by using
expressive light the trust between humans and robots
increases.
(P
¨
ortner et al., 2018) and (Baraka and Veloso,
2018) suggest that expressive light and animated light
can be used to signal in what operating state the robot
is in while also compelling humans to partake in in-
teractions with a robot.
(Szafir et al., 2015) investigate how expressive
light can be used to communicate directional flight
intention in drones. They apply design constraints to
a drone’s flight behaviors, using gaze, lighthouse bea-
con, blinkers, and airplane flight as inspiration and
thereby design a set of signaling mechanisms to signal
directionality. In a user study, they asked participants
to predict the drone’s behavior. They find that using
expressive light to signal directional movements sig-
nificantly improves the understanding of the drone’s
directional flight, where they found the gaze behavior
to be especially useful in communicating the intention
of the drone. (Hart et al., 2019) has made a user study
with a mobile robot that drives towards participants of
the study and the robot signals a lane switch. On the
mobile robot, they mount a virtual head that can turn
and have a gaze. They compare the performance of
the gaze from the virtual agent head against an LED
turn signal. They show that the gaze signal more often
prevents the human and robot from choosing conflict-
ing trajectories. This suggests that gaze has some an
advantage in being more explicit than expressive light
but with the essential problem of only being visual
when facing the robot which in turns are very limited
for its overall usability in public spaces because in
many scenarios humans would be interested in know-
ing the intention of the robot from both of its sides and
from behind which could be possible with e.g. expres-
sive lights. Another problem is the level of anthro-
pomorphism required for being able to convey gaze.
A very high level of anthropomorphism might not be
suitable for mobile robots performing logistic tasks
at e.g. hospitals. In general, the literature by (Fer-
reira Duarte et al., 2018), (Hart et al., 2019), (Szafir
et al., 2015) suggests that using signaling mechanisms
that follow known and human-aware conventions and
biological signals (gaze) increased the understanding
of both drone’s and robot’s intentions.
Inspired by the design methodology by (Szafir
et al., 2015) we investigate in this paper the use of
signaling schemes from the automobile domain. The
benefit of employing such signals for mobile robots is,
as suggested by (P
¨
ortner et al., 2018) and (Baraka and
Figure 1: Robot test platform used for the experiments
(left); top view of the robot with standard car light pattern
(right).
Veloso, 2018), that animated lights occur (blinking,
etc.) and they follow well-known conventions. We
also incorporate anticipatory motion by using the em-
bodiment of the robot to signal directional movement
(turn cue) and we combined the usage of expressive
light and anticipatory motion.
3 METHODOLOGY
This section covers all details of the research ap-
proach that was taken in this paper. First we will
describe the mobile robot platform with the signal-
ing unit (Section 3.1) and the implementation of the
signals (Section 3.2). Finally we will detail the exper-
imental design including the recording of the videos,
online survey and data collection in Section 3.3.
3.1 Experimental Platform - The Robot
In order to perform the experiments, we built a test
platform, using a MiR100 autonomous mobile robot
as the base due to its stability, payload capacity and
off the shelf implementation. We made electrical
modifications to control the LEDs around the robot.
Figure 2: Robot system architecture.
HUCAPP 2020 - 4th International Conference on Human Computer Interaction Theory and Applications
66

(a) (b) (c) (d) (e)
Figure 3: Signaling behaviors. Each image shows a robot top view where the lines in the perimeter represent the bottom
LEDs, and the circles inside the rectangle represent the top LED ring arrays. The arrow in the top indicates the front side of
the robot. (a) Standard car lights (b) Left blinking signal (c) Right blinking signal (d) Left rotating signal (yellow LEDs move
in the arrow direction) e) Right rotating signal (yellow LEDs move in the arrow direction).
On top of the mobile platform, a chest of drawers was
placed to emulate a logistic use case and design of
the Health-CAT robot. Atop the drawers we installed
four LED ring arrays. Both, the bottom and top sets
of LEDs, could be addressed individually by a con-
troller, giving the possibility of defining the custom
patterns needed for the experiments (see Figure 1).
The system architecture is outlined in Figure 2.
We used an Intel NUC as the master computer. It had
ROS (Robot Operating System) framework installed,
and it provided an interface between the mobile plat-
form and the microcontroller. In order to trigger the
robot behaviors needed for the experiment, we used
a Logitech Wireless Gamepad F710. This remote
controller was constantly sending an array filled with
0 and 1 (buttons array), representing which buttons
from the gamepad were pressed. The array was then
read by the master computer, which, based on the but-
tons pressed, ran the corresponding robot behavior.
A robot behavior consisted of both, sending veloc-
ity commands (velocity cmd) to the robot platform to
move and pattern commands (pattern cmd) with the
light pattern ID to the microcontroller in charge of
the light control. The communication between these
two devices followed the MQTT messaging protocol,
with the master computer being the MQTT server.
The light control was implemented on a ESP8285
microcontroller, which provides not only a digital
I/O interface, but also a wireless communication with
other devices. Following the master computer re-
quirements, the microcontroller was programmed as
a MQTT client. For the light control, we pro-
grammed the patterns, first, in a way they emulated
car lights: white for the headlights, red for the tail
lights and yellow for the signal lights (Figure 3a).
Along with the car signals (Figure 3b), an extra pat-
tern was programmed, showing a LED rotation mo-
tion in each of the rings and the base strip in the
direction of the turn (Figure 3d). Further explana-
tion about the robot signals can be found in Section
3.2. Based on the reading from the pattern cmd, it
was selected which pattern to run, which was later
decomposed into light commands that were sent to
both, the LED strip (led strip cmd) and the LED
rings (led ring cmd). The commands transmission
followed a NZR communication protocol managed
by open source libraries specific for each LED type
(Fast LED for the strip and Adafruit NeoPixel for the
rings). The structure of those commands consisted of
the LED position and the color to light on.
3.2 Experimental Conditions - Robot
Signals
It is important for a mobile robot intended for hospital
use like ours, to communicate its intentions clearly.
In the following sections, three potential solutions are
outlined: blinking lights, rotating lights, and a turning
gesture.
1
3.2.1 Blinking Lights
This solution for signaling was designed as an anal-
ogy with standard signaling on cars for making turns.
In this, the outer halves of the top lights were blinking
with yellow light at a frequency of about 1Hz. The
blink frequency was designed to comply with auto-
motive industry standards. The inner halves of the
top front lights were kept constant white, while the
1
See a video of the implemented conditions here https:
//youtu.be/J6jtDH6ZSuw
Intention Indication for Human Aware Robot Navigation
67

inner parts of the top back lights were constantly red
(Figures 3b, 3c and 4b). These patterns were emulat-
ing the front and back lights on cars. Using this setup
also adds information about which end is the front of
the robot (white inner lights) and which the back (red
inner lights), again in analogy with cars. The bot-
tom LED strip was also blinking at the corner position
with the same color LEDs.
3.2.2 Rotating Lights
We implemented a rotation of the top and bottom
lights as a novel signaling method. In this condition
only two LEDs of each top light ring were on at one
time. The lit LEDs kept changing to create an ef-
fect of rotating lights. All four lights were moving in
the same direction. This direction was correspondent
with the future turn of the robot: the lights were turn-
ing clockwise when the robot wanted turn right and
anti-clockwise when it intended to turn left. The bot-
tom lights were displaying a ”running” pattern around
the base of the robot, corresponding to the future turn
direction of the robot Figures 3d, 3e and 4c.
3.2.3 Turn Gesture
A final signaling option was implemented in the form
of movement: when the robot reached the intersec-
tion, it made a turning gesture of about 30 degrees
towards the side it wanted to turn to (Figure 4a). We
considered this the strongest signal indicating the in-
tention of the robot: there was no reason why a turn
gesture to one side would be interpreted as an inten-
tion to move in the other direction. In the experiment
itself we used this signal in two ways: 1) by itself
without additional indicators and 2) in combination
with the above mentioned two other signaling meth-
ods.
3.2.4 Combination of Conditions
The main independent variable of our study was the
signaling method with conditions: blinking light, ro-
tating light and turn gesture. The last of the condi-
tions could be administered either by itself or in com-
bination with the first two methods. We also wanted
to show movements of the robot using a standard car
light pattern without any turn signals (none), to estab-
lish a baseline behavior. A secondary necessary in-
dependent variable we considered was turn direction
with levels: left and right. All these combinations of
conditions are represented in Table 1.
For the combination of no-turn and no-light the
left and right conditions are the same, i.e. the robot
just approaches the intersection without any turning
Table 1: Combination of conditions.
without turn gesture with turn gesture
blink rotate none blink rotate none
left • • • • •
right • •
•
• • •
(a) (b) (c)
Figure 4: Signaling behaviors on real robot. (a) Right turn
gesture with standard car lights (b) Blinking signal to left
(c) Rotating signal.
lights or gestures. Therefore these two cases are con-
joined into one condition. This give us a total of 11
combinations of conditions.
3.3 Experimental Design
We ran a human subject study to investigate which
signaling approach would be the most appropriate for
our robot. In order to ensure repeatability and effi-
cient gathering of human data, we opted for recording
videos of the robot’s signaling movements and show-
ing them to human participants via online surveys. As
it was essential for all subjects to see exactly the same
robot behaviors, video recordings were the best op-
tion.
3.3.1 Video Recordings
One video was recorded for each of the 11 combina-
tions of conditions mentioned above. The videos were
shot with a Motorola moto G7 Plus mobile phone’s
primary camera in 4K resolution with 30 frames per
second. The recording was done from an initial dis-
tance to the robot of 3,5 m. At the end of the video
the robot approached the intersection and was at a dis-
tance of 2,3 m to the camera, see Figure 5. The mo-
bile phone was mounted on a fixed tripod at a height
of 1,7 m, thus simulating the point of view of a per-
son. The location of the video recording was exactly
the same in all clips. We made a careful selection of a
location that represents a symmetrical intersection of
hallways at the university. The robot always started
from the same position of 1,25 m from the intersec-
HUCAPP 2020 - 4th International Conference on Human Computer Interaction Theory and Applications
68

tion. It always ended its movement just at the bor-
derline of the intersection box. It was always in the
center of the corridor allowing the same amount of
space on both of its sides. The width of the hallway
at the entrance to the intersection was 2,22 m. The
width of the robot is 0,58 m. This allowed a space of
0,82 m on both sides of the robot for passing around
it. In the conditions where the robot also performed
a turning gesture, this space somewhat decreased, be-
cause of its rectangular geometry. The videos ended
at the point when the robot stops at the intersection
and has performed the turn gesture and light actions.
We intentionally cut it off before the robot performed
the actual turn at the intersection, because we wanted
to ask our participants to tell us what their prediction
would be on what will happen next, thus giving us
insight on the effectiveness of our signaling methods
in conveying information about the robot’s future ac-
tions.
3.3.2 Online Survey
An online survey was created to test the designed ex-
perimental conditions with human subjects. As a sur-
vey platform, we selected the site soscisurvey.de be-
cause of its high customizability. Among other things,
most importantly it allows many options for random-
izing the order of presentation of the videos. The sur-
vey started with a quick explanation of the experiment
without giving away its scientific purpose. After the
initial slide, we presented the 11 videos, each on a
separate page, in pseudo-random order. It was de-
signed to be counter-balanced, but not all fields of the
procedure were covered because there were 120 com-
binations of order and 30 subjects. The videos were
Figure 5: Video recordings setup layout. Dimensions are in
mm.
Figure 6: The last frame of the video, representing the route
options in the multiple choice questions.
divided in two groups:
1. With turn gesture,
2. Without turn gesture.
The randomized first group was always shown before
the randomized second group. The videos contain-
ing the turn gesture were selected to be shown later,
because when they were in combination with either
of the light signals, they could influence the subjects’
subsequent decision on light signals appearing with-
out the turn gesture. This could happen as we ex-
pected the turn gesture to be the strongest indicator for
the turning intention of the robot. The questions we
asked the participants right after showing each video
are shown in Table 2.
Table 2: Questions about the videos.
QA1
Which way would you go around the robot to get
to the end of the hallway ahead?
QA2
Which way will the robot turn after the end of the
video?
For the first question we offered multiple choice
radio buttons with the labels: a,b,c,d,e,f,g,h,i,j. These
labels represented ten possible routes of movement
for people to take and corresponded to arrow repre-
sentations of these paths at the end of the video, which
were added in a video editing application, see Fig-
ure 6. The second question’s answers were three radio
buttons with the labels m, n and o. These were also
represented by arrows at the last frame of the video.
The videos only played once (of which the subjects
were informed at the initial page) and stopped at the
last frame with the arrow representations.
After the survey pages with the videos the subjects
Intention Indication for Human Aware Robot Navigation
69
had two more pages with questions to fill out: one
about the experiment and another about demographic
information. The experimental page started with two
questions for validating if subjects paid attention to
the videos.
Table 3: Validation questions about the experiment.
QB1 What was the color of the robot?
QB2 What was the general shape of the robot?
The first of these questions had an open text field,
so people could enter the name of the color they per-
ceived. The second question was a multiple choice
one with the following options: cylindrical, box-
shaped, ball-shaped, snake-shaped, humanoid, other.
The correct choice was ’box-shaped’. The follow-
ing 9 questions were in the form of statements with
7-point Likert-scaled answers ranging from ’strongly
disagree’ to ’strongly agree’, see Table 4.
With these statements we expected to learn more
about people’s preference for the conditions we were
suggesting. This page ended with a comments sec-
tion. We asked subjects in a large textual field to let
us know about their thoughts, observations, and sug-
gestions concerning the experiment. The last input
page asked for demographic information, see Table 5.
3.3.3 Data Collection
We opted for collecting data using Mechanical Turk.
Thirty-one participants were recruited with MTurk
Master qualification and at least 90 percent job quality
approval rating. They were all located int the United
States. We opted for this country as our questionnaire
was in English and the USA is the largest English
speaking country (as their native language), thus we
could get quick high quality responses. One of the
subjects showed irregular behavior according to our
survey collection system: she spent very little time
on each slide (around 11,7 seconds per slide, while
the average was 25,7 seconds), i.e. she didn’t pay at-
tention to the videos, thus we elimiated her from the
results. Out of the leftover 30, 10 were female and
20 male. The average age was 41,9. Two people were
left-handed and 28 right-handed. They all had driver’s
licenses except one. Twelve subjects never interacted
with robots before, 16 a few times, while two experi-
enced robots a number of times.
4 RESULTS
Results can be categorized into a number of groups.
First we’ll discuss subjective responses, then partici-
pants’ movements as reactions to the robot and finally
people’s understanding of robot’s intentions.
4.1 Subjective Results
This section will discuss the Likert-scaled agreements
of participants with the statements found in Table 4.
The first analysis focuses on opinions about the three
basic signaling methods: blink, rotate and turn. These
refer to statements QC1, QC2 and QC3. There is
some disagreement in the literature on how Likert-
scaled values should be analyzed. The more con-
servative approaches suggest non-parametric statisti-
cal methods as the Friedman test and the Wilcoxon
signed-rank test, which we will use here.
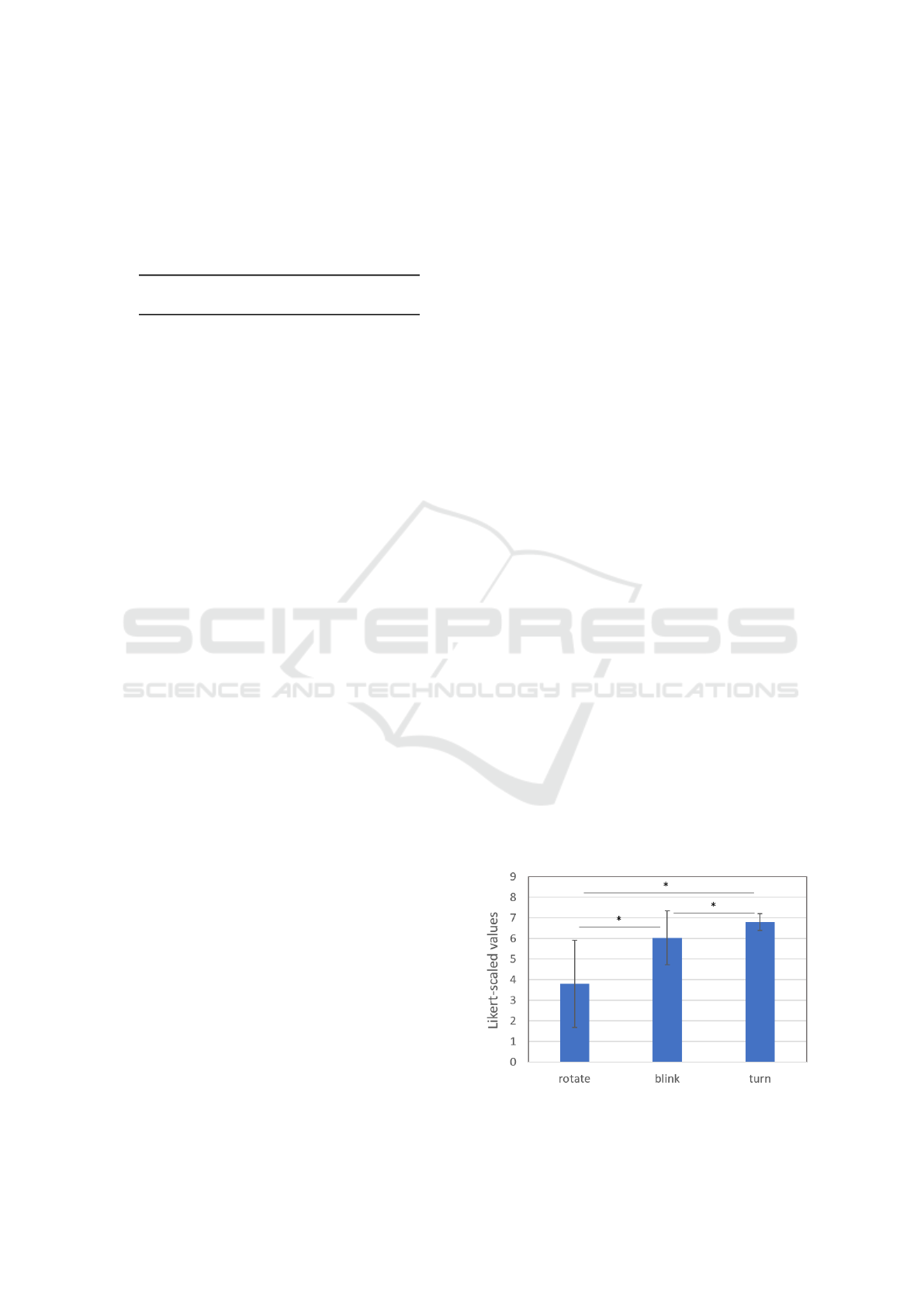
Figure 7 shows the averages of responses to state-
ments QC1, QC2 and QC3 about the clearness of sig-
nals when using rotating lights, blinking lights and
turn gesture. We applied a Friedman test to assess
the difference between these. The results show a sta-
tistically significant difference between the signaling
methods, χ
2
(2) = 44.1, p < 0.001. Post-hoc analy-
sis using Wilcoxon signed-rank test was conducted
with a Bonferroni correction. This has shown signif-
icant differences between all pairs of conditions: ro-
tate compared to blink (Z = -3.781, p < 0.001), blink
compared to turn (Z = -3.13, p = 0.002) and rotate
compared to turn (Z = -4.475, p < 0.001). This means
that participants found the rotating lights the least in-
formative, and the blinking more informative than ro-
tation but less than the turning gesture. Therefore, the
turning gesture was the strongest signal, followed by
blinking, followed by rotating lights.
We intended to explore participants’ preference
of the LED rings on the top versus the LED strips
near the bottom of the robot, statements QC6 and
QC7 in Table 4. Figure 8 shows the averages and
standard deviations for this comparison. Adapting a
Wilcoxon signed-rank test we did not find statistically
Figure 7: Averages of opinions on clearness of signaling
with rotating lights, blinking lights and turning. +/- 1SD.
HUCAPP 2020 - 4th International Conference on Human Computer Interaction Theory and Applications
70
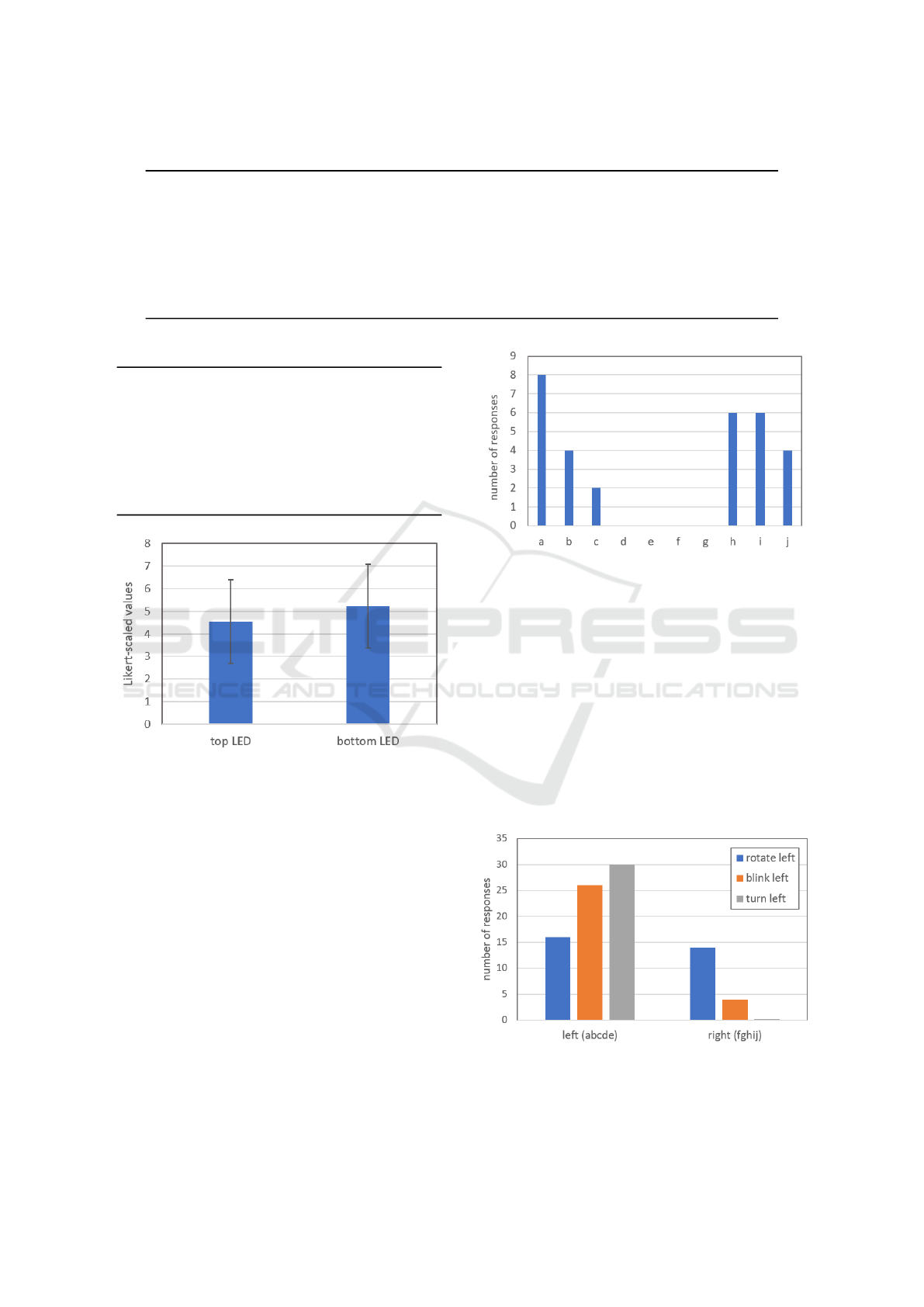
Table 4: Likert-scaled questions about the experiment.
QC1 The blinking lights on the robot in some of the videos made it very clear which way it would want to go.
QC2 The rotating lights on the robot in some of the videos made it very clear which way it would want to go.
QC3 The turning of the robot at the end of some videos made it very clear which way it would want to go.
QC4 The combination of blinking lights and turning made it very clear which way the robot would go
QC5 The combination of rotating lights and turning made it very clear which way the robot would go.
QC6 The lights on the top of the robot were very useful in understanding where it would go.
QC7 The lights near the bottom of the robot were very useful in understanding where it would go.
QC8 I did not notice any difference between the videos.
QC9 The different signals were insufficient for one to understand which way the robot would go.
Table 5: Demographic information questions.
QD1 What is your gender?
QD2 What is your age?
QD3 Are you left-handed or right-handed?
QD4
How many times have you interacted with robots
before?
QD5 Do you have a driver’s license?
QD6
In your country of residence, which side of the
road do cars drive on?
QD7 Have you participated in this experiment before?
Figure 8: Averages of opinions on usefulness of top LED
lights vs. bottom LED lights. +/- 1SD.
significant difference between the two conditions (Z
= −1.668, p = 0.095). Even though this results is not
significant, we report it because our expectation was
that the top LEDs would be preferred, which was not
the case at all.
4.2 Participant Movement Intentions
This section will present the results derived from par-
ticipants’ answer to question QA1 in Table 2: Which
way would you go around the robot to get to the end
of the hallway ahead? This question was asked once
for each of the 11 videos, showing the 11 conditions.
The answers were in the form of multiple choices
(a,b,...,j). These letters refer to paths proposed in the
last frame of the videos, see Figure 6. Paths a,b,c,d,e
led around the robot from the left side, while paths
f,g,h,i,j went around from the right. Figure 9 con-
Figure 9: Histogram of participants’ bimodal choices on
which way to go around the robot that doesn’t show any
signals.
tains the histogram of answers to this question while
showing the video of the robot with no signals. This
was the baseline condition administered to investigate
people’s default preference of sides.
Participants were fairly evenly divided between
left and right sides. On the left they tended to stay
further away from the robot while on the right, they
approached somewhat closer. There were still more
people (16) circumventing from the right, as opposed
to left (14). This makes intuitive sense, if the robot
Figure 10: Histogram on participants’ binomial choices on
which side to take to go around the robot while displaying
rotation, blinking lights and turning gesture to the left.All
direction labels (left, right) are from the subject’s point of
view.
Intention Indication for Human Aware Robot Navigation
71
is perceived as a vehicle and right-hand-side driving
road rules apply. It was noticed that these histograms
have an irregular bimodal distribution. Therefore we
opted to reduce the complexity by clustering all left
side paths (a,b,c,d,e) together and all right side paths
(f,g,h,i,j) together, thus simplifying the bimodal to a
binomial (left, right) distribution. This allowed us to
apply simpler statistical methods, while keeping the
most important part of the data. With this new ap-
proach, we compared which way people want to cir-
cumvent the robot when it is signaling to the left and
right. Figure 10 shows the binomial distributions of
side selection when the robot wants to turn to its own
left side. It can be noticed that for blinking and turn-
ing, people follow the expected route, to their left,
because they are correctly perceiving the robot’s in-
tention to turn to its own left and want to avoid col-
lision. However, for the rotating light, we don’t see
the same ’keep left’ distribution. Rather, it is split be-
tween going left and right. This might be because the
rotating light was not perceived as an intention to turn
to that side. To check for differences between these
three binomial distributions we ran a 3x2 Chi-squared
test and found significant difference between the three
conditions χ
2
(2,N=30)=21.67, p<0.001. Post-hoc
analysis of adjusted residuals with Bonferroni correc-
tion revealed (p<0.001) that it was the rotating light
condition that was significantly different compared to
the other conditions.
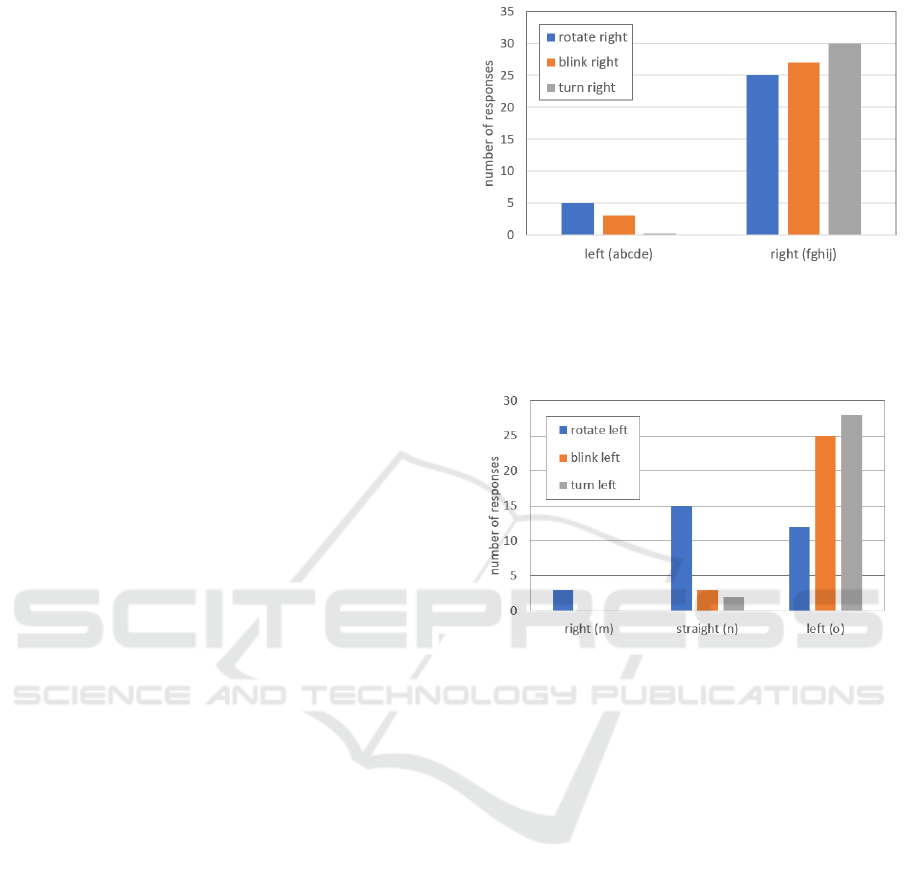
We also investigated the analogous situation, but
when the robot is signaling for a right turn, Figure 11.
Here we do not see a deviation from the expected
choice even for the rotating light. Most people chose
to go to the right side from their point of view, to
avoid the robot which was signaling a turn towards
its own right. Indeed, a Chi-squared test also did not
report a significant difference between conditions for
this case, χ
2
(2,N=30)=5.21, p<0.074.
4.3 Understanding of Robot’s Intention
In this section we report on question QA2 from Ta-
ble 2: Which way will the robot turn after the end of
the video? This question had three possible answers:
paths m,n and o (see Figure 6). It was asked to see if
the subject can make correct robot movement predic-
tions based on the signaling methods. Similarly as in
the previous section we see that blinking and turning
are adequately interpreted, but the rotating light signal
is not. Half of the participants thought that the robot
will continue going straight even though it was rotat-
ing to signal a right turn. We conducted a Chi-squared
analysis on this dataset too and found significant dif-
ferences between levels χ
2
(4,N=30)=27.6, p<0.001,
Figure 11: Histogram on participants’ binomial choices on
which side to take to go around the robot while displaying
rotation, blinking lights and turning gesture to the right.All
direction labels (left, right) are from the subject’s point of
view.
Figure 12: Histogram on participants’ opinions on which
way the robot will go for different signaling methods.
Right, straight, left is from the robot’s point of view. Ro-
tate left, blink left and turn left are from the subject’s point
of view.
indicating that the rotation signal is improperly inter-
preted.
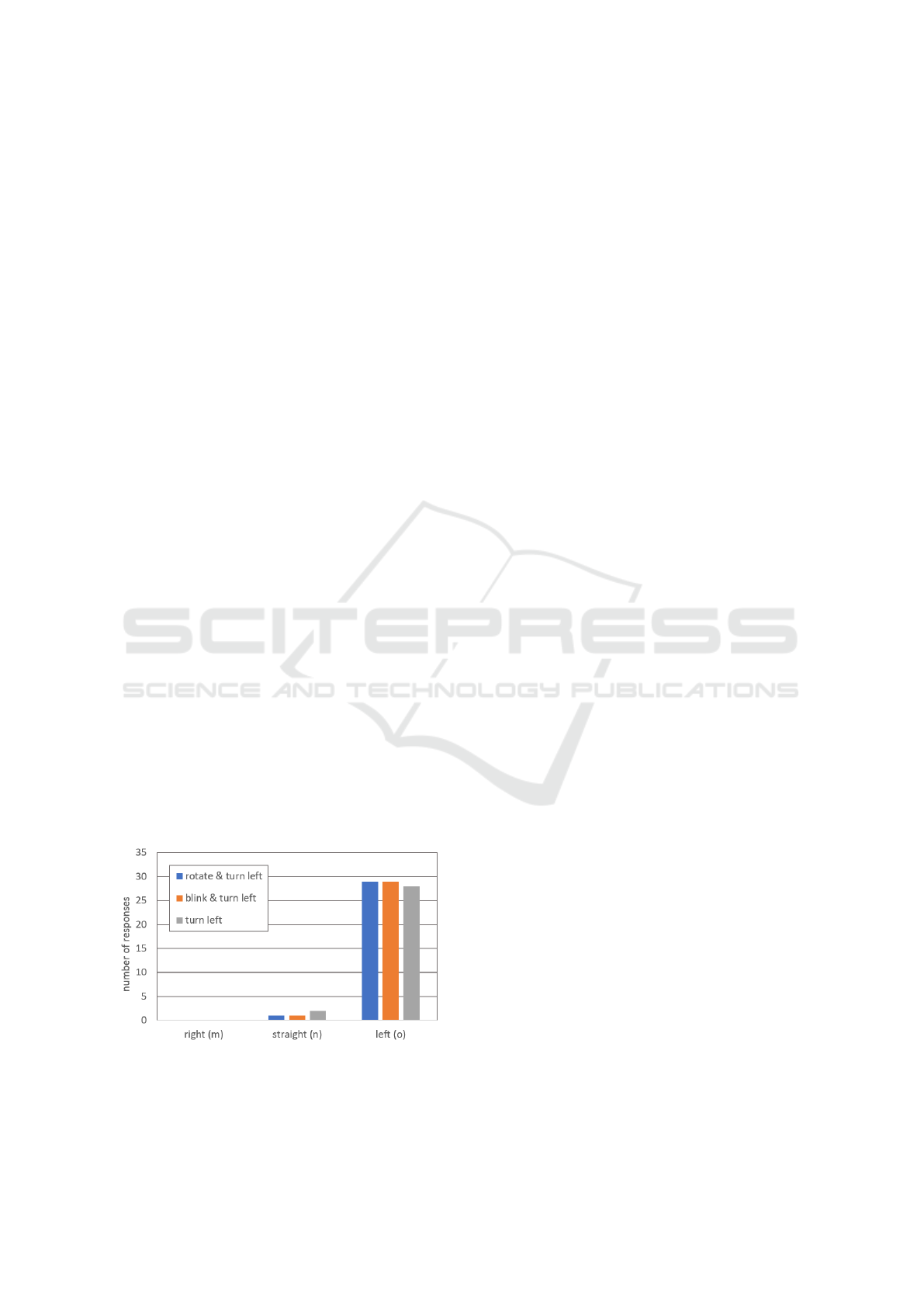
Regarding the signals in combination with turn,
they were very correctly interpreted by almost all
participants. Figure 13 shows three conditions ”ro-
tate&turn”, ”blink&turn” and ”turn”. It can be no-
ticed that the turning signal already provides all in-
formation for making a right decision. The addi-
tion of the two light signals doesn’t change the out-
come. As expected, a Chi-squared test did not show
and significant difference between these conditions
χ
2
(2,N=30)=0.36, p=1. The results in this section
tell us that all subsequent robot movements were cor-
rectly predicted by the subjects, except the rotating
light.
5 DISCUSSION
Section 4.1 demonstrated that people found the ro-
tating lights the least informative, the blinking lights
HUCAPP 2020 - 4th International Conference on Human Computer Interaction Theory and Applications
72
more and the turn gesture the most informative. These
differences were also statistically very significant. We
did expect that the turn gesture will be the most
prominent indicator for the intention of the robot, but
we did not expect the rotating lights to be evaluated
so poorly. It was thought, that a rotational signal
would clearly communicate the robot’s intention to
turn. However this was not reflected in the data. It
might be the case that people associate rotating lights
with heavy machinery or oversized vehicles on the
road, which utilize similar signals, but only for at-
tracting people’s attention and not for signaling di-
rection. Even the running lights on the bottom LED
strips did not help in clarifying the intention. The
blinking light performed quite well, as expected. As
we were aiming for analogy with regular vehicles in
terms of lights, we expected that people will easily
make the connection between the robot and a car on
the road. Even the turning gesture can be associ-
ated with vehicular traffic: in many situations at in-
tersections cars will turn towards their intended final
goal, especially for right turns in right-hand-side traf-
fic countries. We emphasize that the turn gesture was
not the turn itself. After the gesture, the robot made
a full stop before performing the actual turning ac-
tion. The actual turn was not part of our videos, as we
wanted subjects to predict this.
Next, we looked at the preference of top or bottom
lights. We expected that the top lights would be pre-
ferred as there were more of them and they were more
in the line of sight of passers by. The ring LEDs were
also more expressive, thanks to their numbers and
customizability. However, this expectation was not
supported by the results. Figure 8 shows participants’
opinions on this matter: the average opinion was even
better for the bottom lights, than top, even though this
difference was not statistically significant. One of the
possible explanations for this kind of outcome might
Figure 13: Histogram on participants’ opinions on which
way the robot will go for combined signals. Right, straight,
left is from the robot’s point of view. Rotate&turn left,
blink&turn left and turn left are from the subject’s point of
view.
be the similar position of the bottom lights to lights
on regular cars. Although, we designed the top lights
to emulate car signals in one condition, maybe their
location on the top was not appropriate for making a
closer connection with automotive lights.
Regarding the analysis of participants’ intention to
go around the robot from the right or left, we looked at
their answers to question QA1, see Table 2, Figure 10
and Figure 11. There is an inconsistency between the
left and right turns. The leftward rotating condition
produced an even outcome between taking either the
right or left routes. This tells us that the rotating lights
were not a good indicator of turning intention. On the
other hand, for the rightward turn, rotation behaved
as expected. This might be caused by the fact that
more people tend to choose passing on the right (see
Figure 9) in analogy with passing an oncoming car
from the right. Figure 12 might give some insight on
this: it shows people’s prediction of the robot’s turn-
ing intention under the basic conditions. It can be no-
ticed that the leftward rotation signal is interpreted as
an intention to go straight mostly and going left sec-
ondly. Thus, people who think that the robot will con-
tinue straight can go around the robot from their own
right side, even though in the designer’s intention this
would lead them to collision with the robot. Finally,
Figure 13 showed us that the turn gesture overpowers
any additional light signal that might occur contem-
poraneously.
Regarding the number of experiment participants
(30), we acknowledge that their number could have
be higher for even more convincing results, but on the
other hand most of our results showed very high levels
of significance (p=0.001), thus adding more subject
most likely wouldn’t have changed these outcomes.
6 CONCLUSION AND FUTURE
WORK
Signaling movement intention is essential for mobile
robots in public environments like hospitals, univer-
sities, airports, etc. Finding an effective signal for
indicating direction at a hallway intersection is cru-
cial for the acceptance of such robots. In this paper,
we discussed three such signals and their combina-
tions. One was a turning gesture which was expected
and proven to be the strongest indicator. Next there
were the blinking signals in analogy with automo-
tive signaling, which performed quite well too. Fi-
nally there was the newly designed rotational signal
which proved to be the least efficient for the purpose,
as some participants misinterpreted it as a general at-
tention signal.
Intention Indication for Human Aware Robot Navigation
73

All in all, as expected we found that using car sig-
nals on vehicle-shaped mobile robots is a good idea
and a design recommendation for the robotics com-
munity. What we did not expect was that the less vis-
ible bottom lights were at least as important for sig-
naling as the top LED rings, which we expected to
be more informative. We also noticed a tendency of
people passing by an oncoming robot from the right
side, as in vehicular traffic. We might have expected
this to be more significant, which it was not, because
many participants chose to go on the left side of the
robot too. As future work it might be interesting to
compare this effect with populations where the driv-
ing is on the left-hand-side of streets. We will also
consider redesigning our robots lights and enforcing
the ones near the bottom of the robot, according to our
findings. Finally, based on the conclusions from this
controlled study on the most efficient ways to signal
turning intent, we plan to drive the robot on the uni-
versity hallways and collect data in this uncontrolled
environment and analyze how people flow around it
depending on turn signaling.
ACKNOWLEDGEMENTS
This work was supported by the project Health-CAT,
funded by the European Regional Development Fund.
REFERENCES
Ansuini, C., Giosa, L., Turella, L., Alto
`
e, G., and Castiello,
U. (2008). An object for an action, the same object for
other actions: effects on hand shaping. Experimental
Brain Research, 185(1):111–119.
Baraka, K. and Veloso, M. M. (2018). Mobile service robot
state revealing through expressive lights: Formalism,
design, and evaluation. International Journal of So-
cial Robotics, 10(1):65–92.
Beer, J. M., Prakash, A., Mitzner, T. L., and Rogers, W. A.
(2011). Understanding robot acceptance. Technical
report, Georgia Institute of Technology.
Bodenhagen, L., Suvei, S.-D., Juel, W. K., Brander, E.,
and Kr
¨
uger, N. (2019). Robot technology for future
welfare: meeting upcoming societal challenges – an
outlook with offset in the development in scandinavia.
Health and Technology, 9(3):197–218.
Castiello, U. (2003). Understanding other people’s ac-
tions: Intention and attention. Journal of experimen-
tal psychology. Human perception and performance,
29:416–30.
Chadalavada, R. T., Andreasson, H., Krug, R., and Lilien-
thal, A. J. (2015). That’s on my mind! robot to human
intention communication through on-board projection
on shared floor space. In 2015 European Conference
on Mobile Robots (ECMR), pages 1–6. IEEE.
Coovert, M. D., Lee, T., Shindev, I., and Sun, Y. (2014).
Spatial augmented reality as a method for a mobile
robot to communicate intended movement. Comput-
ers in Human Behavior, 34:241–248.
Ferreira Duarte, N., Tasevski, J., Coco, M., Rakovi
´
c, M.,
and Santos-Victor, J. (2018). Action anticipation:
Reading the intentions of humans and robots. IEEE
Robotics and Automation Letters, PP.
Gielniak, M. J. and Thomaz, A. L. (2011). Generating an-
ticipation in robot motion. In 2011 RO-MAN, pages
449–454.
Hameed, I., Tan, Z.-H., Thomsen, N., and Duan, X. (2016).
User acceptance of social robots. In The Ninth In-
ternational Conference on Advances in Computer-
Human Interactions.
Hart, J., Mirsky, R., Tejeda, S., Mahajan, B., Goo, J., Bal-
dauf, K., Owen, S., and Stone, P. (2019). Unclogging
our arteries: Using human-inspired signals to disam-
biguate navigational intentions.
Juel, W., Kr
¨
uger, N., and Bodenhagen, L. (2018). Robots
for elderly care institutions: How they may affect
elderly care. In Coeckelbergh, M., Loh, J., Funk,
M., Seibt, J., and Nørskov, M., editors, Envisioning
Robots in Society – Power, Politics, and Public Space,
pages 221–230. IOS Press.
Kilner, J. (2011). More than one pathway to action under-
standing. Trends in cognitive sciences, 15:352–7.
P
¨
ortner, A., Schroder, L., Rasch, R., Sprute, D., Hoffmann,
M., and Koenig, M. (2018). The power of color: A
study on the effective use of colored light in human-
robot interaction. In 2018 IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS),
pages 3395–3402.
Riek, L. D. (2017). Healthcare robotics. Commun. ACM,
60(11):68–78.
Schulz, T., Torresen, J., and Herstad, J. (2019). Anima-
tion techniques in human-robot interaction user stud-
ies: A systematic literature review. ACM Transactions
on Human-Robot Interaction (THRI), 8(2):12.
Sciutti, A., Ansuini, C., Becchio, C., and Sandini, G.
(2015). Investigating the ability to read others’ inten-
tions using humanoid robots. Frontiers in Psychology,
6.
Svenstrup, M., Tranberg, S., Andersen, H. J., and Bak, T.
(2009). Pose estimation and adaptive robot behaviour
for human-robot interaction. In 2009 IEEE Interna-
tional Conference on Robotics and Automation, pages
3571–3576.
Szafir, D., Mutlu, B., and Fong, T. (2015). Communicating
directionality in flying robots. 2015 10th ACM/IEEE
International Conference on Human-Robot Interac-
tion (HRI), pages 19–26.
HUCAPP 2020 - 4th International Conference on Human Computer Interaction Theory and Applications
74
