
Towards Ontology Driven Provenance in Scientific Workflow Engine
Anila Sahar Butt
1 a
, Nicholas Car
2 b
and Peter Fitch
1 c
1
CSIRO Land and Water, Canberra, Australia
2
SURROUND Australia Pty Ltd, Brisbane, Australia
Keywords:
Workflow Provenance, Provenance Ontology, Provenance from Event Logs.
Abstract:
Most workflow engines automatically capture and provide access to their workflow provenance, which enables
its users to trust and reuse scientific workflows and their data products. However, the deed of instrumenting
a workflow engine to capture and query provenance data is burdensome. The task may require adding hooks
to the workflow engine, which can lead to perturbation in execution. An alternative approach is intelligent
logging and a careful analysis of logs to extract critical information about workflows. However, rapid growth
in the size of the log and the cloud-based multi-tenant nature of the engines has made this solution increas-
ingly inefficient. We have proposed ProvAnalyser, an ontology-based approach to capture the provenance of
workflows from event logs. Our approach reduces provenance use cases to SPARQL queries over captured
provenance and is capable of reconstructing complete data and invocation dependency graphs for a workflow
run. The queries can be performed on nested workflow executions and can return information generated from
one or various executions.
1 INTRODUCTION
The Oxford English Dictionary defines provenance as
“the source or origin of an object; its history and
pedigree; a record of the ultimate derivation and pas-
sage of an item through its various owners.” In the
context of computer applications, provenance is an es-
sential component to allow for result reproducibility,
sharing, and knowledge reuse for different stakehold-
ers. It facilitates the users in interpreting and under-
standing results by examining the sequence of steps
that led to a result (Curcin, 2017).
With the realisation of data-driven science, scien-
tists are increasingly adopting workflows to specify
and automate repetitive experiments that retrieve, in-
tegrate, and analyse datasets to produce scientific re-
sults (Belhajjame et al., 2015). In recent years, the
scientific community has developed various scientific
workflow engines to provide an environment for spec-
ifying and enacting workflows (e.g., Taverna, Kepler,
Daliuge, and Airflow). Among those, Senaps
1
is a
custom build workflow engine designed through the
need of hosting applications from multiple domains
a
https://orcid.org/0000-0002-3508-6049
b
https://orcid.org/0000-0002-8742-7730
c
https://orcid.org/0000-0002-9813-0588
1
https://research.csiro.au/dss/research/senaps/
(e.g., marine sensing, water management, and agri-
culture). The focus of Senaps is on hosting, adapting,
and sharing existing scientific models or analysis code
across organisations and groups who use the sensor,
climate, and other time-series data.
Due to the dynamic nature of the platform, Senaps
must consider its workflow provenance, which con-
cerns the reliability and integrity of workflows and
their potentially complex data processes. Understand-
ing workflow provenance is crucial for Senaps users
to identify bottlenecks, inefficiencies, learn how to
improve them, and trust in data produced by these
workflows. Moreover, to gain an understanding of
a workflow, and how it may be used and repro-
duced for their needs, scientists require access to ad-
ditional resources, such as annotations describing the
workflow, datasets used and produced by this work-
flow, and provenance traces recording workflow exe-
cutions. With the realisation of the value, provenance
can bring to the overall architecture of Senaps; its de-
velopment team is planning to integrate a provenance
collection and querying component into Senaps.
Senaps can integrate provenance component,
which is an elegant solution but requires a signifi-
cant effort to implement. It requires adding hooks
to Senaps architecture to capture provenance data,
which can lead to perturbation in execution. There-
fore, the Senaps team decided to thoroughly under-
Butt, A., Car, N. and Fitch, P.
Towards Ontology Driven Provenance in Scientific Workflow Engine.
DOI: 10.5220/0008963701050115
In Proceedings of the 8th International Conference on Model-Driven Engineering and Software Development (MODELSWARD 2020), pages 105-115
ISBN: 978-989-758-400-8; ISSN: 2184-4348
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
105

11
Grains
Forecast
location
parameters
grid
initial_sw
output
Figure 1: An abstract workflow to forecast a grain produc-
tion on a location.
stand the provenance capturing, storage, and access
requirements before integrating the provenance so-
lution into Senaps to avoid any performance issues.
Moreover, the team needed to comprehend the means
of collecting provenance of already executed work-
flows using their event log. Since workflow prove-
nance is event-based, i.e., capturing the significant
events within a system, the event log is an essential
source of provenance data. Logs are traditionally used
for auditing and identifying the root causes of failure
in large systems. However, logs also contain essen-
tial information about the events within a system that
result in the generation of data objects. It has been
shown that intelligent logging and careful analysis of
logs support to extract critical information about the
system (Oliner and Stearley, 2007). Currently, the
team answers the provenance related queries through
the analysis of workflows and their execution traces
using their event log. However, the rapid growth in
the size of the event log and the cloud-based multi-
tenant nature of the platform has made this solution
increasingly inefficient.
In this paper, we show our work capturing work-
flow provenance from event logs of Senaps. For a
workflow, as shown in Figure 1, we would like to:
(a) enable scientists and developers to ask questions
about a workflow run by providing convenient queries
against the captured provenance traces; (b) have the
engine track the exact data dependencies within a run
so that answers to such scientific questions may be
as accurate as possible. For this, we present Prov-
Analyser
2
, an ontology-based approach for prove-
nance capturing and querying system for Senaps. It
transforms Senaps event logs into knowledge graphs
using an ontology that supports a set of provenance
queries. Our approach reduces provenance use cases
to SPARQL
3
queries over the knowledge graph, and
is capable of reconstruction complete data and invo-
cation dependency graphs for a workflow run. In this
regard, we:
- detail the design of SENProv – an ontology
to model provenance data of Senaps workflows
specification and execution with the main goal of
2
https://github.com/CSIRO-enviro-informatics/
ProvAnalyser
3
https://www.w3.org/TR/sparql11-query/
9
Log Parsing & Filtering
Workflow Execution
Mapping &Transformation
SENProv
Events log
Retrospective
Provenance
Workflow Specification Mining &
Transformation
Prospective
Provenance
Exploration and
Analysis
Provenance Capturing
Provenance Analytics
RDF Store
Raw provenance
Structured provenance
Provenance
Queries
Results
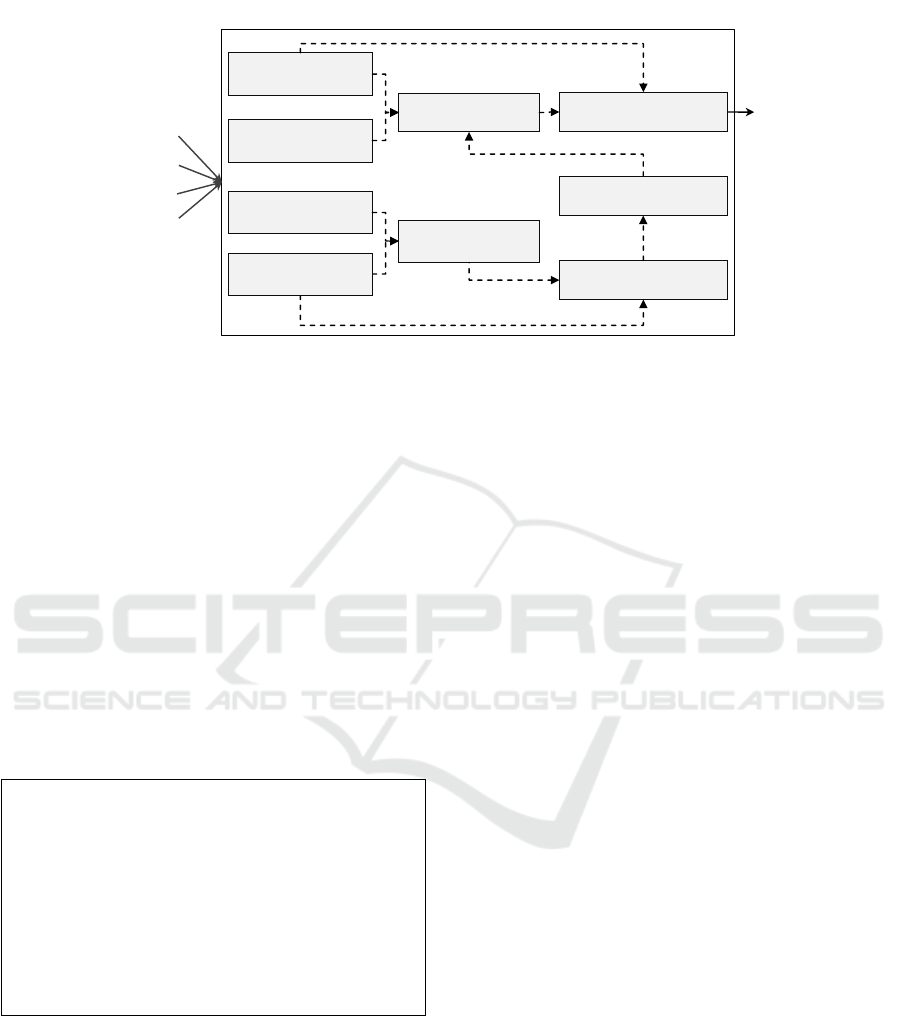
Figure 2: The ProvAnalyser Architecture.
empowering provenance data to be interoperable.
- show capturing raw provenance data from the
event log, their mapping to SENProv, and
the storage of structured provenance data in a
database.
- describe the design and running of provenance
use cases
4
to analyse the impact of provenance on
Senaps and its client applications.
The rest of the paper is organised as follows. In Sec-
tion 2, we discuss ProvAnalyser in terms of its ar-
chitecture, information model (SENProv ontology),
and its provenance extraction, structuring, and storage
mechanisms. In Section 3, we present the provenance
use cases and their results. In Section 4, we discuss
the steps required for large-scale deployment of the
technology within the organisation. In Section 5, we
review state-of-the-art and in Section 6, we conclude
outlining future directions of research and develop-
ment.
2 ProvAnalyser
Figure 2 shows the architecture of our proposed
approach. ProvAnalyser captures provenance from
Senaps event logs containing the workflows’ event ex-
ecution traces and stores it in an RDF store. On this
stored provenance data, one can perform analysis and
exploration through predefined provenance queries. It
works as follows:
1. For each workflow execution request, all traces re-
lated to that request are parsed and provenance in-
formation (i.e., execution time, workflowId, oper-
4
We store all the use cases and the correspond-
ing SPARQL queries developed for this work in
the code repository https://github.com/CSIRO-enviro-
informatics/senprov-usecases
MODELSWARD 2020 - 8th International Conference on Model-Driven Engineering and Software Development
106

atorNodeId, model, ports, and data nodes) is fil-
tered. It transforms a verbose event log into con-
cise raw provenance data.
2. The raw provenance data is mapped to SEN-
Prov and is transformed into a structured prove-
nance for that particular execution trace. It gener-
ates the RDF
5
description of retrospective prove-
nance (Herschel et al., 2017) (i.e., workflow exe-
cution) and stores in an RDF store.
3. It infers prospective provenance (Herschel et al.,
2017) (i.e., workflow structure) from the retro-
spective provenance extracted from event log us-
ing SENProv. It then links the retrospective
provenance associated with the prospective prove-
nance and stores both in the RDF store.
4. ProvAnalyser allows users to explore and analyse
provenance by designing provenance use cases,
running them as SPARQL queries over RDF store,
and displaying the results to their clients.
ProvAnalyser supports a range of provenance use
cases, such as explaining and reproducing the out-
come of a workflow, tracing the effect of a change,
and provenance analytics. It provides a structure to
provenance information, which makes it machine-
readable and interoperable. Therefore, the prove-
nance data can also be used and integrated with other
provenance solutions. Moreover, it reduces the time
needed for analysing workflow execution traces and
allows semantic web experts to perform the task, thus
distributing the load.
2.1 Workflows in Senaps
The UML diagram in Figure 3 represents the concep-
tual model for a workflow specification and execution
in Senaps. We confirmed the model during a meeting
(Joe and Charman 2018, personal communication, 13
September).
Here workflow is a multi-directed acyclic graph
6
made up of vertices and edges, which are referred
as nodes and connections in Senaps. A node can ei-
ther be a data node or an operator node. An opera-
tor node hosts a model (executable code and its sup-
porting files). The operator node has multiple ports,
whereas a data node can only connect to an operator
node through a port. Currently, a data node supports
multi-stream, document, and grid data formats A user
group or an organisation put a workflow execution
request. With a workflow execution request, a user
needs to specify the workflow to execute, the data
5
https://www.w3.org/RDF/
6
https://en.wikipedia.org/wiki/Directed acyclic graph
Senaps Workflow Execution Conceptual Model: UML
Diagram
hasPort
isConnectedTo
senaps:Document
[*]
[1..*]
[1..1]
senaps:Stream
senaps:Port
portId
direction
senaps:Workflow
name
[*]
[1..1]
senaps:Grid
label
Catalog
dataset
senaps:DataNode
dataId
senaps:Data
value
[*]
[*]
senaps:Model
modelId
include
host
[1..1]
senaps:User
senaps:Organisation
organisationId
senaps:Group
groupId
senaps:OperatorNod
eExecution
opExecutionId
opExecutionTime
executedBy
[*]
[1..1]
[*]
[1..1]
definedBy
[1..1]
[*]
has
senaps:WorkflowExe
cution
wfExecutionId
wfExecutionTime
[1..1]
[*]
executedBy
isPartOf
[*]
[1..1]
[*]
[1..1]
[0..1]
[1..1]
senaps:OperatorNode
operatorNodeId
Figure 3: Senaps Workflow Specification (constructs in
blue) and Execution (constructs in grey) Conceptual Model
UML Diagram.
node (i.e., input data), and the port on which a data
node is connecting to an operator node. A workflow
execution id is assigned to the run when it executes.
Each operator node of the workflow is executed and
has its operator node execution id, and corresponding
input and output data nodes. Therefore, one work-
flow execution is composed of all its operator nodes
executions.
2.2 Provenance Ontology
To capture the provenance of Senaps workflows, we
require a data model capable of capturing all the meta-
data (i.e., Senaps constructs) shown in Figure 3. Some
generic and extendable provenance models already
exist in the literature to capture data and(or) workflow
provenance.
PROV-DM is the World Wide Web Consor-
tium (W3C)-recommended data model for the inter-
operable provenance in heterogeneous environments,
such as the Web (Moreau and Missier, 2013). PROV-
DM is generic and domain-independent and does not
cater to the specific requirements of particular sys-
tems or domain applications; rather, it provides exten-
sion points through which systems and applications
can extend PROV-DM for their purposes.
However, Senaps is concerned with capturing
provenance from complex computational pipelines
commonly referred to as scientific workflows. Sev-
eral recent community efforts have culminated with
the development of generic models to represent the
provenance of scientific workflows. We have eval-
uated ProvONE, OPMW, and Wf4Ever as the most
expressive of these models (Oliveira et al., 2018a)
for their capability to reuse for the design of a
data model for Senaps. OPMW (Garijo and Gil,
2011) is a conceptual model for the representation
of prospective and retrospective provenance collected
Towards Ontology Driven Provenance in Scientific Workflow Engine
107

Table 1: Senaps Constructs Mapping to ProvONE and
PROV-DM Constructs.
Senaps Construct Senaps ProvONE/
Aspect Type Concept PROV-DM
Workflow
Class
Workflow provone:Workflow
OperatorNode provone:Program
DataNode provone:Channel
Port provone:Port
Model prov:Plan
Property
include provone:has-
SubProgram
hasPort provone:hasInPort
provone:hasOutPort
isConnectedTo provone:connectTo
Workflow Execution
Class
WorkflowExecution provone:Execution
OperatorNode- provone:Execution
Execution
Organisation provone:User
Group provone:User
Document prov:Entity
Stream prov:Entity
Grid prov:Entity
Property
initiatedBy provone:agent
prov:wasAssociat-
edWith
isPartOf provone:wasPartOf
wfExecutionTime prov:atTime
opExecutionTime prov:atTime
value prov:value
from the execution of scientific workflows. It is
a specialisation of PROV and the OPM provenance
model. Wf4Ever (Belhajjame et al., 2015) has ex-
tended PROV to present wfdesc and wfprov ontolo-
gies for the description of prospective and retrospec-
tive provenance respectively. ProvONE (Cuevas-
Vicentt
´
ın et al., 2016) is a data model, built on PROV-
DM, for scientific workflow provenance representa-
tion. It provides constructs to model workflow spec-
ification provenance (i.e., a set of instructions spec-
ifying how to run a workflow) and workflow execu-
tion provenance (i.e., the record of how the workflow
is executed). ProvONE is a widely accepted work-
flow provenance model and is capable of capturing
all the characteristics shown in Figure 3; therefore,
we specialise ProvONE in SENProv to capture the
provenance of Senaps workflows. SENProv takes an
event-centric perspective and revolves around work-
flow specification and workflow execution events.
To reuse ProvONE and PROV-DM in SENProv,
we need to model the relationship of Senaps con-
structs shown in Figure 3 with PROM-DM and
ProvONE constructs. Table 1 shows the mapping be-
tween Senaps and PROV-DM or ProvONE. In SEN-
Prov, each Senaps class shown in ‘Senaps Concept’
column extends from its corresponding class pre-
sented in ‘ProvONE/PROV-DM’ column of the table,
and ProvONE or PROV-DM associations are used to
model the corresponding Senaps associations. Based
on the Senaps conceptual model and its mapping to
ProvONE and PROV-DM, we present SENProv - an
ontology to capture and represent Senaps workflow
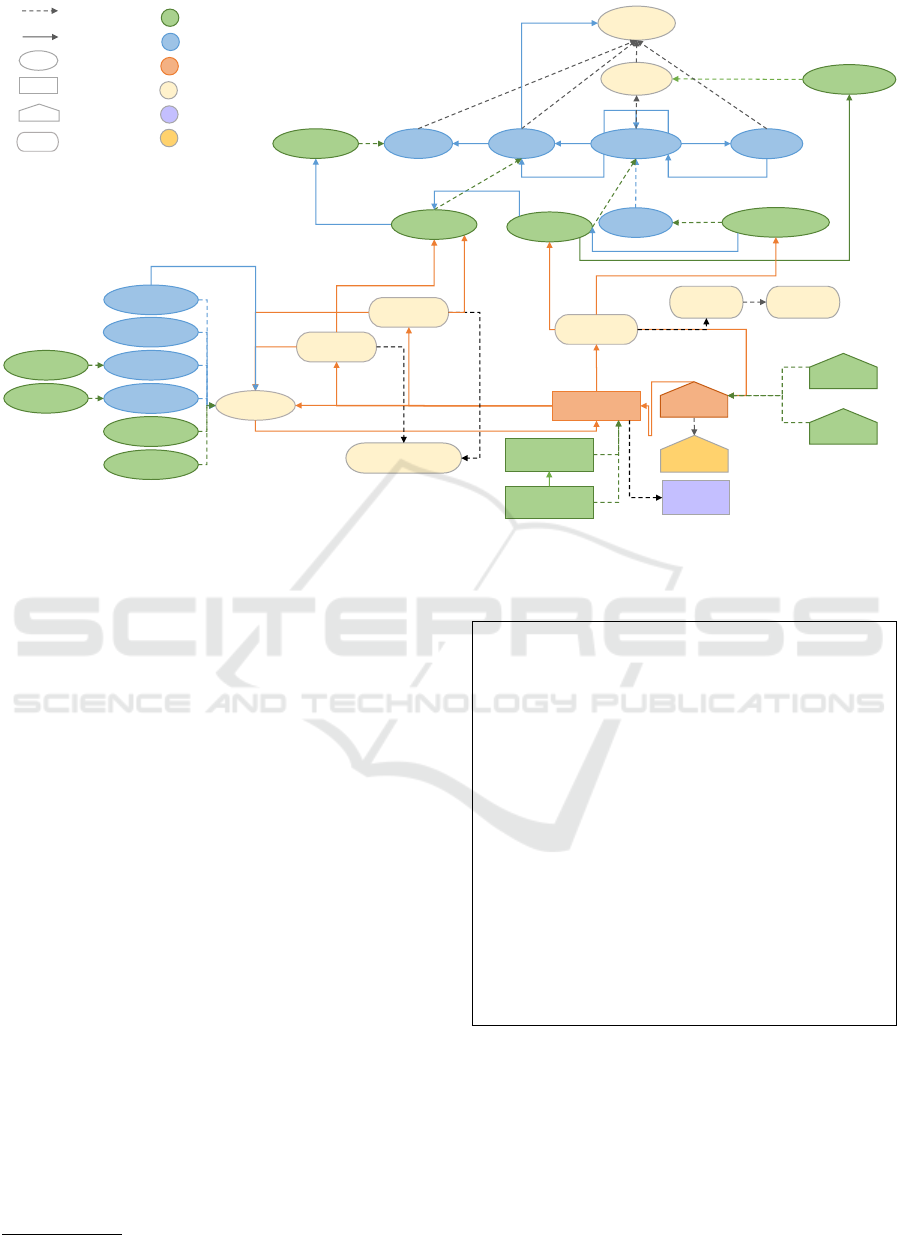
provenance. Figure 4 highlights the most impor-
tant classes and relationships that make up the SEN-
Prov ontology. The green ovals (i.e., PROV En-
tities), rectangles (i.e., PROV Activities), and pen-
tagons (i.e., PROV Agents) represent the concepts in
Senaps whereas yellow and blue presents PROV-DM
and ProvONE concepts, respectively.
2.3 Provenance from Event Logs
Provenance captured from the event logs of Senaps,
which are configured for INFO level logging. At
INFO level, informational messages that are most
useful are logged for monitoring and managing an
application during execution. For example, an INFO
level message describes the event type, the time, data
used, and data generated by a workflow. Moreover, it
considers an operator node and the model as a black
box. Hence, INFO level logging enables the collec-
tion of coarse-grained provenance (Herschel et al.,
2017).
An entry in a Senaps event log comprises of three
main components: DateTime– Date and time of an
event, EventType– the type of the event (e.g., Empty-
WorkflowCreatedEvent, OperatorNodeAddedEvent,
and DataUpdateEvent), and Payload– contains the in-
formation of the event including workflow and oper-
ator node execution ids, operator node, data nodes,
ports, and data type (depending upon the event type).
When a workflow executes in Senaps, the event log
records twelve to fourteen different events for each
operator node of the workflow. However, all the in-
formation required to capture provenance of an op-
erator node execution is available from the payload
of ‘ExecutionRequestedEvent’ entry of the exe-
cution. Other event type entries of the operator node
execution record incomplete and(or) duplicate infor-
mation. Therefore, ProvAnalyser extracts the prove-
nance from the payload of ‘ExecutionRequestedE-
vent’ and ignores other entries for the same oper-
ator node execution id while capturing provenance.
The current implementation records the provenance
of successfully executed workflows; however, in the
future, we plan to capture unsuccessful workflow
provenance to understand the root causes of workflow
execution failure. This information is obtained from
‘ExecutionSuccessfulEvent’ entry for an opera-
tor node execution of the workflow.
Provenance extraction from the log files is carried
out by the Log Parser and Filter component of
ProvAnalyser. The entries with event type ‘Execu-
tionSuccessfulEvent’ are filtered from the file, the
MODELSWARD 2020 - 8th International Conference on Model-Driven Engineering and Software Development
108
provone:Execution
prov:Association
prov:Usage
prov:Generation
qualifiedUsage
qualifiedAssociation
agent
wasAssociatedWith
qualifiedGeneration
prov:Entity
used
hadEntity
hadEntity
wasGeneratedBy
hadPlan
hadInPort
hadOutPort
prov:Activity
prov:Agent
prov:InstantaneousEvent
Prov:AgentInfl
uence
Prov:Influence
provone:User
senaps:WorkflowEx
ecution
senaps:Organi
sation
senaps:Group
provone:Prog
ram
provone:
Controller
controls
controlledBy
provone:
Port
hasInPort
hasOutPort
connectTo
connectTo
Prov:Entity
provone:
Workflow
wasDerivedFrom
hasSubProgram
senaps:Oper
atorNode
provone:
Channel
senaps:Port
senaps:Workflow
senaps :Model
senaps:Data
Node
Prov:Plan
hasSubProgram
hasOutPort/
hasInPort
hasDefaultParam
host
provone:Data
provone:Docu
ment
Provone:Visual
ization
Provone:Colle
ction
<<hadMember>>
senaps:Stream
senaps:Grid
senaps:Docu
ment
Senaps:Data
senaps:OperatorNo
deExecution
wasPartOf
hadPlan
subClassOf
association
Entity
Agent
Activity
Qualified
Influence
Senaps Constructs
ProvONE Prospective Constructs
ProvONE Retrospective Constructs
Prov Constructs
Prov Constructs
Prov Constructs
Figure 4: Core Structure of SENProv, showing relationship to PROV-DM and ProvONE - The constructs are represented in
this diagram using PROV-like elements.
workflow execution Id for each such event is extracted
from the payload and recorded into a ‘Successful
workflows list’. Next, the entries with event type
‘ExecutionRequestedEvent’ are selected to retrieve
the provenance of successfully executed workflows.
The information about operator node, connected data
nodes, model and ports are retrieved from the payload
as raw provenance data, as shown in Listing 1. Using
the SENProv, raw provenance data is transformed
into structured provenance (i.e., an RDF document).
ProvAnalyser retrieves prospective and retrospective
provenance according to the SENProv model, as
shown in Listing 2 and 3, respectively. The structured
provenance is subsequently stored in the Jena TDB
7
.
Implementation and Performance. The
Provenance Capturing module, implemented in
Java (jdk-1.8.0), processes the log files and uses
Apache’s Jena RDF API (apache-jena-3.7.0) to
transform and store the structured provenance.
For the evaluation and testing purposes, we ex-
tracted provenance from the Senaps event log of 90
days. All the processing was performed on a 64-bit
Windows 10 Enterprise computer using an Intel Core
i7 6600U CPU with 2 cores and 8 GB memory. We
processed log files of variable sizes ( i.e., from 3 to
410 MBs), and the execution takes between 2 to 38
7
https://jena.apache.org/documentation/tdb/
Listing 1: Raw Provenance.
{" wo rk fl owE xe cI d " : " c 49ff 96d - c c5 77 1b5 d6 89 " ,
" op No de Exe cI d " : " c 49f f 96d -f or eca st . t emp lat e " ,
" op Ex ec ut ion Ti me " : " 20 18 -0 7 -1 7 T03 : 43 :1 1.4 74 Z " ,
" op er at or N od eI d " : " fo rec ast . t empl ate -s el ect or " ,
" mo del Id " : " apsi m - te mpl a te - s el e ct or " ,
" Po r ts " : [
{
" po rtI d " : " l oc a ti on " ,
" po rt Di rec ti on " : " I n put " ,
" co nn ec ted Da ta " : {
" da ta Nod eI d " : " 02 b5 ff de3 e1 8 ",
" da ta No deT yp e " : " D oc ume nt " }
}
{
" po rtI d " : " p ar ame te rs " ,
" po rt Di rec ti on " : " I n put " ,
" co nn ec ted Da ta " : {
" da ta Nod eI d " : " 7 09 619 5 c3 61f " ,
" da ta No deT yp e " : " D oc ume nt " }
}
{
" po rtI d " : " a ps im _t e mp la te " ,
" po rt Di rec ti on " : " O utp ut " ,
" co nn ec ted Da ta " : {
" da ta Nod eI d " : " 6 7 3 ae b3 356 02 " ,
" da ta No deT yp e " : " D oc ume nt " }
} ]
}
seconds to parse a log file, extract provenance from
the file and store it in the RDF store.
However, the time ProvAnalyser takes to process
a log file depends on the number of successfully
executed workflows in the file and not on its size.
Moreover, we collected provenance for 4658 work-
flow runs and 246,224 operator node executions in
the RDF store of 2.29GB from log files of 6.29GB by
Towards Ontology Driven Provenance in Scientific Workflow Engine
109

Listing 2: Prospective Provenance.
< c49f f96 d - c c57 71b 5d 6 89 > a se nap s : Wor kf l ow ;
< fo r ec ast . t empl ate -s elec tor > a se na p s : Op er ato rN od e ;
se nap s : h o st < apsi m -t empl ate -s elec tor >;
pr ovo ne : h asI nP ort < loca tio n >;
pr ovo ne : h asI nP ort < par ame ter s >;
pr ovo ne : h asO ut Por t < ap sim _t e mp lat e > .
< a psim - te mpl ate - s elec tor > a s e na p s : Mod el .
< loca tio n > a se nap s : Port ;
pr ovo ne : c onn ec tTo [ a se nap s : Do c um ent ].
< par ame ter s > a s e na p s : Por t;
pr ovo ne : c onn ec tTo [ a se nap s : Do c um ent ].
< aps im _te mpl at e > a s ena ps : Por t ;
pr ovo ne : c onn ec tTo [ a se nap s : Do c um ent ].
Listing 3: Retrospective Provenance.
< c49f f96 d - c c57 71b 5d 6 89 > a se nap s : Wo rk f lo wE xe cu tio n ;
< c49f f96 d - f or eca st . te mpla te > a se nap s : Op era to rN od eE x ec ;
se nap s : par tOf < c49f f96d - cc5 771 b5d 689 >
pr o v : atT ime 2 018 - 07 -1 7 T03 : 43 :11 ;
pr o v : qu al if ied As so ci at io n < c49f f96 d -a ss oc - for ecas t >;
pr o v : qu al i fi ed Us age < c49 ff96 d - 0 2 b5 ffd e3e1 8 - fo reca st > ;
pr o v : qu al i fi ed Us age < c49 ff96 d - 09 619 5 c361 f - fo rec a st >;
pr o v : qu ali fi ed Gen < c49 f f 96d -67 3 ae b335 602 -f ore c ast >;
pr o v : used < 02 b 5ff de3 e18 >;
pr o v : used < 7096 195 c 36 1f >.
< c49f f96 d - as so c - f o rec ast > a pr o v : A ss oc iat io n ;
pr o v : had Pl a n < fo rec as t . t emp late -s ele ctor >;
pr o v : age nt < Gra inc ast >.
< c49f f96 d -0 2 b5f fde 3e1 8 - fo r eca st > a p rov :Usage;
pr ovo ne : h adI nP ort < loca tio n >;
pr o v : ha d En tit y <02 b 5ff d e3e 18 >.
< c49f f96 d - 096 19 5 c3 6 1f - for eca s t > a p rov :Usage;
pr ovo ne : h adI nP ort < par ame ter s >;
pr o v : ha d En tit y <09 6195 c 3 6 1f >.
< c49f f96 d - 6 73 a eb3 3 560 2 - fo r eca st > a p rov : G en e ra ti on ;
pr ovo ne : h adO ut Por t < ap sim _t e mp lat e > ;
pr o v : ha d En tit y <6 7 3 aeb 335 6 02 >.
<673 a eb3 3560 2 > a s en aps : D ocu me n t ;
pr o v : wa sG e ne ra te dBy < c49 ff96 d - fo re c as t . temp lat e > .
<02 b5 ffd e3e 18 > a se nap s : Doc um e nt ;
<7 0 961 95 c36 1 f > a se nap s : Doc um ent ;
< Gra inca st > a se nap s :Group;
pr o v : wa sA sso ci at ed Wi th < c4 9ff9 6d - f ore ca st . tem pla t e >.
using ProvAnalyser. This result of the provenance-
enhanced RDF data being smaller in size than the raw
logs echos other log-to-PROV experiences (Car et al.,
2016).
3 QUERYING WORKFLOW
PROVENANCE
ProvAnalyser can answer a wide range of relevant
questions using the provenance ontology described
in Section 2.2, including What actors (organisations
or groups) were involved in executing a workflow?
Which workflow was the most popular during a spe-
cific period? Find all the workflows which used a
particular model. And list the parameters used in a
particular workflow run.
Understanding a scientific workflow and repro-
ducing its results are essential requirements to trust
workflows and their results. These two requirements
lead to the reuse of workflows and data generated by
them across or within organisations. Therefore, our
focus in this work is on use cases related to these two
essential requirements. For instance, ProvAnalyser
should be able to answer queries like ‘track the lin-
eage of the final output of a workflow’. The lineage
of output should explain which workflow generated
it, when the output was generated, who is responsi-
ble for it, what dataset(s) and models are used while
generating this output. How did the process use the
input data, and how were the steps configured? The
result of this query will enable a user to repeat a series
of steps on original data to reproduce outcomes. This
capability of a workflow engine is useful for both the
clients and the developers of the workflow. A scientist
needs provenance knowledge to assess the reliability
of the outcomes or reuse a model in another work-
flow. Likewise, a workflow developer could be inter-
ested in investigating whether the workflow execution
traces conform to the workflow structure by executing
specific models in a particular order.
In this paper, we also discuss two additional use
cases related to traceability and provenance analytics.
This brings us to discuss four primary use cases for
ProvAnalyser and provide their sample queries.
Use Case 1: Understandability– Explain a Work-
flow. This use case helps in understanding the work-
flow by producing the leading intermediate operators
or models used in the execution of a particular work-
flow. A scientist could demand to examine workflow
processes in detail to assess the reliability of results
or to reuse operators in another workflow. A sample
query is as follows:
What structure was followed by a given work-
flow execution trace? A typical understandability
question to be addressed to understand the outcome
of a complex scientific process. Listing 4 shows a
SPARQL query to retrieve the structure of a workflow
execution trace.
For a workflow execution, the query constructs
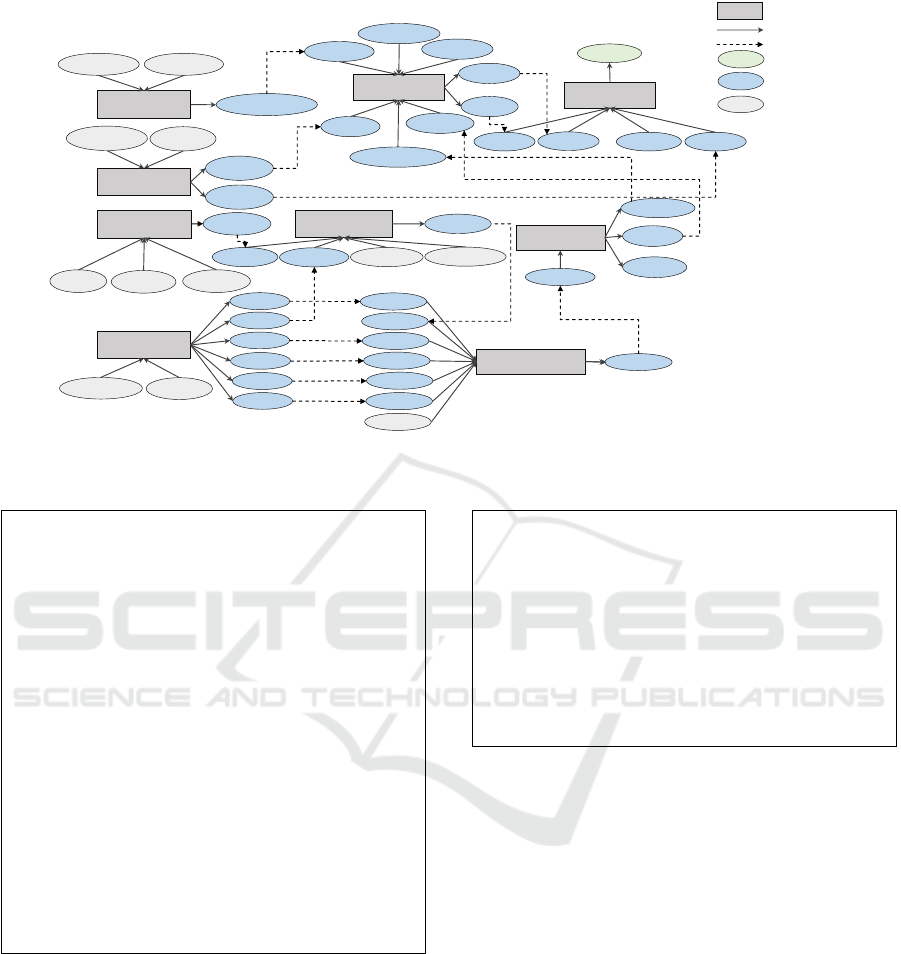
the detail of a workflow structure. Consider an ex-
ample of an execution of Forecast Grains workflow
shown in Figure 1. For this execution, the result of
the query identifies all intermediate operator nodes,
their ports, and how the data was routed among the
operator nodes as shown in Figure 5. Consequently,
MODELSWARD 2020 - 8th International Conference on Model-Driven Engineering and Software Development
110
…..
……..
“apsim_template”
forecast.template-
selector
“location”“parameters”
“file”
forcaste.apsoil
“location”
“pawc”
“parameters”
“stream”
forecast.metfile-
generator.extract-solar
“location”
“grid”
“variable”
“met_file”
forecast.metfile-
generator.metfile-generator
“maxt”
“vp”
“radn”
“rain”
“location”
“pan”
“mint”
“yield_1”
forecast.apsim-
scenario-year.apsim
“initial_sw”
“met_file”
“template”
“met_file_meta”
“parameters”
“apsoil”
“paw”
forecast.output-
formatter
“yield-1”
“paw” “pawc”
“output”
“yield-30”
forecast.climatology-
generator
“yield-1”
“metadata”
“met_file”
forecast.metfile-
generator.splice-solar
“output”
“before”
“threshold”
“splice_date”
“after”
“yield-30”
“vp”
forecast. metfile-
generator.get-silo
“t_max”
“evap”
“radn”
“rain”
“location”
“parameters”
“t_min”
Port direction
Data flow
Operator Nodes
Input Port
Data communicating Port
Out Port
Figure 5: A graphical view of a SPARQL query result; the query is given in Listing 4.
Listing 4: SPARQL to get workflow specification.
PREFIX s e na p s :< h t t p :// www . c s iro . au / on to log ie s / sen aps # >
PREFIX rdf : < htt p :/ / www . w3 . or g / 199 9/0 2/2 2 - rdf - synt ax - ns #>
PREFIX p rov one : < htt p :// p url . d a ta one . or g/ p ro von e #>
PREFIX pr ov :< h t tp :/ / www . w3 .o rg /n s/ pr ov #>
CONSTRUCT {
? so ur ce OpN od e p rov one : h as Ou tPo rt ? o utp or t .
? de sO pNo de pr ovo ne : h asI np ort ? i np o rt .
? so ur ce OpN od e p rov one : c on tr ol l ed By ? c on tr oll er UR I .
? co nt ro lle rU RI pr ov one : c ont ro ls ? d e sO pNo de .
? co nt ro lle rU RI rdf : ty pe p rov on e : Con tr oll er . }
WHERE {
< wfEx ecI d > s en a ps : h as S ub Pr og ram ? s ou rc e Op No de .
? so ur ce OpN od e s ena ps : op er at or Nod eI d ? so ur ce OpN od eI d ;
pr ovo ne : h asO ut Por t ? ou tpo rt .
? ou tpo rt se nap s : por tId ? o ut por tI d .
? en ti tyG en pr ovo ne : h adO ut Po r t ? ou tpo rt ;
pr ovo ne : h adE nt ity ? e nti ty .
? en ti tyU se d p rov one : h ad Ent it y ? e nt i ty ;
pr ovo ne : h adI nP ort ? i npo rt .
? in por t se na p s : por tI d ? in por tI d .
< wor kf low Exe cI d > pr ovo ne : h asS ub Pr ogr am ? d esO pN ode .
? de sO pNo de pr ovo ne : h asI nP ort ? i np o rt ;
se nap s : op era to rN od eId ? d es OpN od eI d .
BIND (URI(CONCAT(STR ( ? s our ce Op Nod e ) ,\" .\ " ,
STR(? o ut por tI d ), \ " _to _ \" , STR( ? de sO pN o de Id ) ,
\" .\ " ,STR(? in po rtI d ))) AS ? c on tr o ll er UR I )}
upon the query outcome, a user can comprehend the
detailed structure of the workflow as shown in Fig-
ure 6.
Use Case 2: Reproducibility– Find Information to
Reproduce. Organisations may want to reproduce
their own or others’ work. A scientist should be able
to begin with, the same inputs and methods (models)
used previously and observe if a prior result can be
confirmed. This is a particular case of repeatability
where a complete set of information is obtained to
Listing 5: SPARQL to find input information.
PREFIX s e na p s :< h t t p :// www . c s iro . au / on to log ie s / sen aps # >
PREFIX p rov one : < htt p :// p url . d a ta one . or g/ p ro v on e #>
PREFIX pr ov :< h t tp :/ / www . w3 .o rg /n s/ pr ov #>
SELECT DISTINCT ? mod el (? po rtI d AS ? va r ia bl eN a me ) ? dat a
WHERE {
<output> ( pro v: wa sG en era te dB y / prov : u s ed )* ? da t a .
OP TI O NA L {? da ta p rov : w a sG en er ate dB y ?exec.}
OP TI O NA L {?usage p rov on e : had En tit y ? dat a.
?usage pr ov o ne : h adI nP ort ? por t.
? por t se nap s : por tId ? p or t Id .
? op Nod e p r ov one : h as InP or t ? p ort .
? op Nod e se na p s : hos t ? m ode l . }
FI LTE R (! b o und (?exec)) }
verify a final or intermediate result. In the process
of repeating, and especially in reproducing, an output
the scientist needs to know which models were used
to derive an output and how the model used the input
data. A sample query of the use case is:
Find what and how to use input data to result
in a specific yield prediction. Listing 5 presents a
SPARQL query to answer this question.
The query returns the details of the inputs to a
workflow to generate a specific output, including
input ids, ports the inputs were connecting to an
operator node, and the model hosted by the oper-
ator node. For instance, for an output (outputId:
<42b838a7-786c-42a0-a4b9-f7dbed9df292>)
generated by an execution of Forecast Grains work-
flow the query returns all input ports in Figure 5,
input data provided to these input ports, and models
that used these input data.
Towards Ontology Driven Provenance in Scientific Workflow Engine
111
forecast.template-
selector
forcaste.apsoil
forecast.metfile-
generator.extract-solar
forecast.metfile-
generator.metfile-generator
forecast.apsim-
scenario-year.apsim
forecast.output-formatter
forecast.climatology-
generator
forecast.metfile-
generator.splice-solar
forecast. metfile-
generator.get-silo
location
parameters
grid
initial_sw
output
Grains Forecast
Figure 6: A detailed workflow for forecasting grains production on a location.
Use Case 3: Traceability– Trace the Effect of a
Change. This use case traces the effect of a change.
It identifies the scope of the change by determining
workflows and their executions that are (or have been)
affected. Moreover, tracing the effect can be used to
minimise the re-computations to only those parts of
a workflow that are involved in the processing of the
changed data or model. A traceability related query is,
Identify all workflow executions that used (a spe-
cific version of) the APSIM model and group them
by their organisations. The result of this query helps
to communicate all the organisations which are likely
to be affected by a change in the APSIM model. List-
ing 6 shows the SPARQL syntax of this query.
Listing 6: SPARQL to trace the affect of change.
PREFIX s e na p s :< h t t p :// www . c s iro . au / on to log ie s / sen aps # >
PREFIX rdf : < htt p :/ / www . w3 . or g / 199 9/0 2/2 2 - rdf - synt ax - ns #>
PREFIX p rov one : < htt p :// p url . d a ta one . or g/ p ro von e #>
PREFIX pr ov :< h t tp :/ / www . w3 .o rg /n s/ pr ov #>
SELECT DISTINCT ? org s ? w or kf l ow Ex ec
WHERE {
? op Nod es se nap s : h ost se nap s : gr ain ca st . ap sim .
? as s oc p rov : h adP lan ? o pN ode s ;
pr o v : age nt ? org s .
? org s rdf : ty pe s ena ps : O r ga ni sa t io n .
? op Ex ec u ti on pr o v : qu al if ied As so ci at io n ? a sso c ;
se nap s : par tOf ? w or kf low Ex ec .
} Group By ? or gs ? wo rk fl o wE xe c
Use Case 4: Provenance Analytics. Provenance-
based analytics help scientists to discover new re-
search opportunities, identify new problems, and
challenges hidden in the traces of workflow execu-
tions. Most importantly, it helps scientists discover
and address anomalies. ProvAnalyser’s current im-
plementation can partially answer some provenance
analytics related queries. For instance, a scientist may
like to know:
Is the behavior in a second workflow execution
conformant with the workflow’s behavior in the
first? This query helps impact (due to intentional
changes in workflows) and(or) cause (due to acci-
dental changes in workflows) analysis in case of any
change in the behavior of workflow on two separate
days. To date, ProvAnalyser can partially answer the
query by providing the implicit workflow structure
of two workflow executions using query presented in
Listing 4.
4 DISCUSSION
ProvAnalyser achieved satisfactory performance in
answering a range of relevant provenance queries and
exhibits high usability compared to event logs. Nev-
ertheless, some issues are planned to be addressed in
the future.
4.1 Limitations
A significant concern is that ProvAnalyser currently
captures retrospective provenance through an event
log and infers partial prospective provenance using
SENProv; it does not record exact prospective and
workflow evolution provenance. Workflow specifica-
tion and evolution provenance are required to address
many provenance analytic queries. For instance, a sci-
entist faces divergent outcomes during reproducibil-
ity analysis, i.e., two executions of the same work-
flow produce different results. The scientist is in-
terested to know what is (are) the reason(s) of di-
vergent results of two executions of a workflow?
One such reason could be the data or workflow evolu-
tion, or it could be some unintentional changes in the
MODELSWARD 2020 - 8th International Conference on Model-Driven Engineering and Software Development
112

workflow. For ProvAnalyser to identify the cause, it
should capture the workflow evolution and prospec-
tive provenance. Moreover, ProvAnalyser is capable
of producing implicit prospective provenance through
reverse engineering, as shown in Listing 4. However,
for conformance checking (Moreau, 2015), a user is
required to compare the implicit workflow specifi-
cations with explicit workflow specifications manu-
ally. The ProvAnalyser needs to capture workflow
retrospective provenance explicitly to automate con-
formance checking.
Another limitation is the unavailability of a user-
friendly provenance exploration and analysis mecha-
nism. ProvAnalyser uses SPARQL as the only mech-
anism to query stored provenance. Although query-
based access mechanisms (e.g., SPARQL, SQL,
XPath or XQuery) are amongst the most popular
provenance access methods (Oliveira et al., 2018b),
it is usable for expert users (people with query lan-
guage expertise) or, for na
¨
ıve users, to answer pre-
formulated queries. An appropriate method of prove-
nance data visualisation or exploration can improve
the data interpretation, facilitate decision making, and
lead scientists to unexpected science discovery from
the provenance traces.
4.2 Next Steps
Senaps users have well received ProvAnalyser, but
its integration within the Senaps architecture requires
some additional steps.
First, we intend to automatise the process of im-
porting and processing the most recent event log. Cur-
rently, we update our provenance data weekly by im-
porting new log files and extracting structured prove-
nance from them. This solution has two limitations:
it requires human intervention, and the system is up-
dated only every week. We plan to fully automate
the process of importing a new event log daily and
extracting provenance from them. At a later stage,
we intend to introduce hooks in the system to capture
provenance directly from Senaps at the time when a
workflow is submitted or executed instead of the event
log.
Secondly, we plan to store provenance knowledge
graph in PROMS (Car et al., 2014) that provides built-
in features for provenance data validation and privacy.
It allows detailed, system-specific, and less detailed
system- independent descriptions provenance to vali-
date through rulesets.
Finally, we plan to extend ProvAnalyser to ad-
dress the limitations in Section 4.1 including cap-
turing and storing workflow prospective & evolution
provenance; and a visualization tool for interactively
exploring provenance.
5 RELATED WORK
Workflow provenance has been studied in a variety
of domains, including experimental science, business,
and data analytics (Herschel et al., 2017). The mo-
tivation for employing workflow provenance in sci-
ence is its ability to reproduce results from earlier
runs, explain unexpected results, and prepare results
for sharing and understanding. State-of-the-art scien-
tific workflow engines Kepler (Altintas et al., 2006)
Taverna (Oinn et al., 2004), WINGS/Pegasus (Kim
et al., 2008), Galaxy (Goecks et al., 2010) and Vis-
Trails (Bavoil et al., 2005) automatically capture
workflow provenance in the form of execution traces.
Moreover, there exist stand-alone approaches for
provenance capturing and analytics (Oliveira et al.,
2018b). However, most of the solutions often rely on
proprietary formats that make interchanging prove-
nance information difficult. Furthermore, these sys-
tems and approaches harvest provenance directly
from the system at runtime workflow execution traces
rather than log files, which requires systems’ source
code instrumentation.
For employing log files to understand the root
causes of failures, LogMaster (Fu et al., 2012) uses
system logs for extracting event correlations to build
failure correlation graphs. SherLog (Yuan et al.,
2010) leverages large system logs to analyse source
code of the system. Jiaang et al. (Jiang et al., 2009)
proposes a mechanism for root cause analysis of fail-
ure in large systems by combining failure messages
with event messages. Xu et al.(Xu et al., 2009) detect
problems in large scale systems by mining logs com-
bined with the source code that generated the logs.
Gaaloul et al. (Gaaloul et al., 2009) analyse work-
flow logs to discover workflow transaction behaviors
and to improve and correct related recovery mech-
anism subsequently. Likewise, NetLogger (Gunter
et al., 2000) collects and analyses event logs for the
performance of distributed applications, but it needs
source code instrumentation. However, all these sys-
tems do not explicitly collect provenance information
from log files. Although logs contain pertinent infor-
mation for error analysis, they can also be employed
for garnering the relevant information about work-
flows execution and data objects.
While most previous log analysis has been done to
understand the root causes of failures, little work ex-
ists on extracting workflow provenance information
from log files. Car et al. (Car et al., 2016) extracted
PROV-O compliant provenance from Web service log
Towards Ontology Driven Provenance in Scientific Workflow Engine
113

to generate web service request citation. Ghoshal and
Plale (Ghoshal and Plale, 2013) presented the most
relevant approach to ProvAnalyser. They explore the
options of deriving workflow provenance from exist-
ing log files. However, their focus is on collecting
provenance from different types of logs of distributed
applications. Our approach leverages Senaps event
log to capture interoperable provenance and analyse
it to understand and reproduce workflow outputs.
6 CONCLUSION
This work shows that provenance data can be captured
from scientific workflow systems’ event logs that can
verify the quality of their data products and allow the
analysis of workflows execution traces to make them
understandable and reusable. The logs can be filtered
and transformed into standardised provenance data
using a specialised model. This transformation allows
the recording of valuable information into a standard-
ised and workflow system-independent format that is
both interoperable and intelligible to the provenance
users. Also, the storage volumes of the provenance
required to perform data and workflow quality assess-
ments and analysis are smaller than the log size, indi-
cating the practical scalability of this transformation
process. While the workflow execution provenance
recorded from the event log can answer most of the
user queries, it is not always enough and, where it is
not, workflow prospective provenance can be inferred
and used. However, to enable comprehensive prove-
nance analytics, the systems should consider captur-
ing prospective and evolution provenance information
in their logs.
REFERENCES
Altintas, I., Barney, O., and Jaeger-Frank, E. (2006). Prove-
nance collection support in the kepler scientific work-
flow system. In Provenance and Annotation of Data,
pages 118–132, Berlin, Heidelberg. Springer.
Bavoil, L., Callahan, S. P., Crossno, P. J., Freire, J., Schei-
degger, C. E., Silva, C. T., and Vo, H. T. (2005). Vis-
trails: enabling interactive multiple-view visualiza-
tions. In VIS 05 IEEE Visualization, pages 135–142.
Belhajjame, K., Zhao, J., Garijo, D., Gamble, M., Hettne,
K., Palma, R., Mina, E., Corcho, O., G
´
omez-P
´
erez,
J. M., Bechhofer, S., et al. (2015). Using a suite of on-
tologies for preserving workflow-centric research ob-
jects. Journal of Web Semantics, 32:16–42.
Car, N. J., Stanford, L. S., and Sedgmen, A. (2016). En-
abling web service request citation by provenance in-
formation. In Provenance and Annotation of Data and
Processes - 6th International Provenance and Anno-
tation Workshop, McLean, VA, USA, June 7-8, 2016,
Proceedings, pages 122–133.
Car, N. J., Stenson, M. P., and Hartcher, M. (2014).
A provenance methodology and architecture
for scientific projects containing automated
and manual processes. [accessed through:
http://academicworks.cuny.edu/cc conf hic/57].
Cuevas-Vicentt
´
ın, V., Lud
¨
ascher, B., Missier, P., Belhaj-
jame, K., Chirigati, F., Wei, Y., Dey, S., Kianmajd,
P., Koop, D., Bowers, S., et al. (2016). Provone:
A prov extension data model for scientific workflow
provenance (2015). https://purl.dataone.org/provone-
v1-dev. [Online; accessed 12-Dec-2019].
Curcin, V. (2017). Embedding data provenance into the
learning health system to facilitate reproducible re-
search. Learning Health Systems, 1(2):e10019.
Fu, X., Ren, R., Zhan, J., Zhou, W., Jia, Z., and Lu, G.
(2012). Logmaster: Mining event correlations in logs
of large-scale cluster systems. In 2012 IEEE 31st Sym-
posium on Reliable Distributed Systems, pages 71–80.
Gaaloul, W., Gaaloul, K., Bhiri, S., Haller, A., and
Hauswirth, M. (2009). Log-based transactional work-
flow mining. Distributed and Parallel Databases,
25(3):193–240.
Garijo, D. and Gil, Y. (2011). A new approach for publish-
ing workflows: Abstractions, standards, and linked
data. In Proceedings of the 6th Workshop on Work-
flows in Support of Large-scale Science, WORKS ’11,
pages 47–56, New York, NY, USA. ACM.
Ghoshal, D. and Plale, B. (2013). Provenance from log
files: A bigdata problem. In Proceedings of the Joint
EDBT/ICDT 2013 Workshops, EDBT ’13, pages 290–
297, New York, NY, USA. ACM.
Goecks, J., Nekrutenko, A., and Taylor, J. (2010). Galaxy:
a comprehensive approach for supporting accessible,
reproducible, and transparent computational research
in the life sciences. Genome biology, 11(8):R86.
Gunter, D., Tierney, B., Crowley, B., Holding, M., and Lee,
J. (2000). Netlogger: A toolkit for distributed sys-
tem performance analysis. In Proceedings 8th Inter-
national Symposium on Modeling, Analysis and Sim-
ulation of Computer and Telecommunication Systems
(Cat. No. PR00728), pages 267–273. IEEE.
Herschel, M., Diestelk
`
amper, R., and Ben Lahmar, H.
(2017). A survey on provenance: What for? what
form? what from? The VLDB Journal-The Interna-
tional Journal on Very Large Data Bases, 26(6):881–
906.
Jiang, W., Hu, C., Pasupathy, S., Kanevsky, A., Li, Z., and
Zhou, Y. (2009). Understanding customer problem
troubleshooting from storage system logs. In Proc-
cedings of the 7th Conference on File and Storage
Technologies, FAST ’09, pages 43–56, Berkeley, CA,
USA. USENIX Association.
Kim, J., Deelman, E., Gil, Y., Mehta, G., and Ratnakar, V.
(2008). Provenance trails in the wings/pegasus sys-
tem. Concurrency and Computation: Practice and
Experience, 20(5):587–597.
Moreau and Missier (2013). World Wide Web Consortium
”PROV-DM: The PROV Data Model” W3C Recom-
MODELSWARD 2020 - 8th International Conference on Model-Driven Engineering and Software Development
114

mendation . https://www.w3.org/TR/prov-dm/. [On-
line; accessed 12-Dec-2019].
Moreau, L. (2015). Aggregation by provenance types: A
technique for summarising provenance graphs. arXiv
preprint arXiv:1504.02616.
Oinn, T., Addis, M., Ferris, J., Marvin, D., Senger, M.,
Greenwood, M., Carver, T., Glover, K., Pocock,
M. R., Wipat, A., and Li, P. (2004). Taverna: a tool
for the composition and enactment of bioinformatics
workflows. Bioinformatics, 20(17):3045–3054.
Oliner, A. and Stearley, J. (2007). What supercomput-
ers say: A study of five system logs. In 37th An-
nual IEEE/IFIP Int’l Conf on Dependable Systems
and Networks, pages 575–584. IEEE.
Oliveira, W., Oliveira, D. D., and Braganholo, V. (2018a).
Provenance analytics for workflow-based computa-
tional experiments: A survey. ACM Computing Sur-
veys (CSUR), 51(3):53.
Oliveira, W., Oliveira, D. D., and Braganholo, V. (2018b).
Provenance analytics for workflow-based computa-
tional experiments: A survey. ACM Comput. Surv.,
51(3):53:1–53:25.
Xu, W., Huang, L., Fox, A., Patterson, D., and Jordan,
M. I. (2009). Detecting large-scale system prob-
lems by mining console logs. In Proceedings of
the ACM SIGOPS 22Nd Symposium on Operating
Systems Principles, SOSP ’09, pages 117–132, New
York, NY, USA. ACM.
Yuan, D., Mai, H., Xiong, W., Tan, L., Zhou, Y., and Pasu-
pathy, S. (2010). Sherlog: Error diagnosis by con-
necting clues from run-time logs. SIGPLAN Not.,
45(3):143–154.
Towards Ontology Driven Provenance in Scientific Workflow Engine
115
