
Exploration and Exploitation of Sensorimotor Contingencies for a
Cognitive Embodied Agent
Quentin Houbre, Alexandre Angleraud and Roel Pieters
Cognitive Robotics Group, Automation Technology and Mechanical Engineering, Tampere University, Tampere, Finland
Keywords:
Cognitive Robotics, Embodiment, Sensorimotor Contingencies, Dynamic Neural Fields.
Abstract:
The modelling of cognition is playing a major role in robotics. Indeed, robots need to learn, adapt and plan
their actions in order to interact with their environment. To do so, approaches like embodiment and enactivism
propose to ground sensorimotor experience in the robot’s body to shape the development of cognition. In this
work, we focus on the role of memory during learning in a closed loop. As sensorimotor contingencies, we
consider a robot arm that moves a baby mobile toy to get visual reward. First, the robot explores the continuous
sensorimotor space by associating visual stimuli to motor actions through motor babbling. After exploration,
the robot uses the experience from its memory and exploits it, thus optimizing its motion to perceive more
visual stimuli. The proposed approach uses Dynamic Field Theory and is integrated in the GummiArm, a 3D
printed humanoid robot arm. The results indicate a higher visual neural activation after motion learning and
show the benefits of an embodied babbling strategy.
1 INTRODUCTION
The role of robotics in society is increasing, and with
it comes the problem of modelling intelligence. With
more complex tasks to perform, robots need to adapt
to their environment. To address these issues, re-
searchers are focusing on cognition, autonomy, their
development in humans and how to model them in
robots.
Developmental approaches in robotics try to re-
produce experimental results observed in infants to
understand cognition. The notion of Sensorimotor
Contingency ties together perceptions and motor ac-
tions in a situated agent. For example, the mo-
tor babbling behavior provides an explanation for
the learning of sensorimotor contingencies by asso-
ciating actions with their outcomes. Piaget (Piaget
and Cook, 1952) formulated the ”primary circular-
reaction hypothesis” where children generate ”re-
flexes” and these reflexes change (even slightly) when
they produce an effect on the children’s environment.
Later, the hypothesis was experimentally confirmed
(Von Hofsten, 1982). This behavior led researchers to
investigate such early behavior as a learning mech-
anism in robotics. One cognitive architecture im-
plements this mechanism with Bayesian Belief Net-
works (Demiris and Dearden, 2005) where a robot
learns to associate motor commands with their sen-
sory consequences and how the inverse association
can be used for imitation. Other research (Saegusa
et al., 2009) applied motor babbling with neural net-
works to predict future motor states to influence the
exploration strategy, avoiding to learn all the motor
states and perception associations. Around the same
time, researchers proposed a model (Caligiore et al.,
2008) using motor babbling to support the learning of
more complex skills such as reaching with obstacles
and grasping. The problem was mainly to demon-
strate that motor babbling is suitable to generate ac-
tion sequences in time. More recent work (Mahoor
et al., 2016) proposed a neurally plausible model of
reaching by encoding the trajectory of the movements
within three interconnected neuron maps. These in-
teresting but non-exhaustive works provide interest-
ing ways on how motor babbling could be imple-
mented in robotics, allowing us to propose our own
model based on Neural Dynamics with an enactive
approach.
To understand enactivism, the notion of embod-
iment needs to be defined. Embodiment (Francisco
J. Varela and Rosch, 1991) is an approach where the
body is an interface that shapes the development of
cognition through its interactions with the environ-
ment. More than an interface, the body is a struc-
tured living organism and so must be considered em-
bodiment in robotics (Chrisley and Ziemke, 2006;
Morse et al., 2011; Ziemke, 2016). For example, in
(Laflaqui
`
ere and Hemion, 2015) researchers proposed
an architecture to ground object perception from a
robot’s sensorimotor experience. As a simple form
546
Houbre, Q., Angleraud, A. and Pieters, R.
Exploration and Exploitation of Sensorimotor Contingencies for a Cognitive Embodied Agent.
DOI: 10.5220/0008951205460554
In Proceedings of the 12th International Conference on Agents and Artificial Intelligence (ICAART 2020) - Volume 2, pages 546-554
ISBN: 978-989-758-395-7; ISSN: 2184-433X
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

of embodiment, proprioceptive signals from the robot
to improve the learning to count, was demonstrated in
(Ruci
´
nski et al., 2012). To go beyond embodiment,
some researchers proposed a new multi-disciplinary
approach named computational grounded cognition
(Pezzulo et al., 2013), where every aspect of cognition
is grounded through sensorimotor experience. Even if
such approach is beneficial to help the design of cog-
nitive architectures, the concept of autonomy needs
to be addressed and integrated with grounding. En-
activism is an answer to this issue, even if here we
distinguish sensorimotor enactivism, which puts per-
ceptual abilities at the center, with autopoietic enac-
tivism where there is a necessary link between con-
scious experiences and autopoietic processes (Dege-
naar and O’Regan, 2017). This means the grounding
of experience depends on the internal system’s orga-
nization and the ability to change it, but also on the
regulation of the system itself (Barandiaran, 2017).
The first statement remains problematic and complex
to deal with in robotics, but the second one can be
addressed. In this case, we talk about homeostasis
(Cannon, 1929), the process of self-regulation. The
design of a cognitive architecture must take into ac-
count the circular causality of the sensorimotor ex-
perience if this exhibits autonomy with an enactive
approach (Vernon et al., 2015). In order to produce
these self-regulated dynamics, the use of neural fields
is promising.
Dynamic Field Theory (DFT) is a new approach to
understand cognitive and neural dynamics (Sch
¨
oner
et al., 2016). This is suitable to deliver homeosta-
sis to the architecture and provides various ways of
learning. The most basic learning mechanism in DFT
is the formation of memory traces of positive activa-
tion of a Dynamic Neural Field (Perone and Spencer,
2013). Hebbian Learning is possible (Luciw et al.,
2013) and the learning of sequences could be done
via a structure involving elementary behaviors, inten-
tions and conditions of satisfaction (Sandamirskaya
and Sch
¨
oner, 2010).
In this work, we propose a new mechanism of ex-
ploration and exploitation with Dynamic Field The-
ory. We set up an experiment where the robot is
attached to a baby mobile toy with a rubber band,
similar to the baby mobile experiment with infants
(Watanabe and Taga, 2006). We investigate how
memory is shaping the experience of the robot and
thus how this helps to optimize the robot’s motion.
The proposed architecture is self-regulated and uses
Dynamic Neural Fields in a closed loop, meaning the
actions influence future perceptions. In particular, we
propose the following contributions:
• A dynamic exploration architecture based on mo-
tor babbling.
• The grounding of visual stimuli with motor ac-
tions in a memory field.
• A dynamic exploitation mechanism using new
neural dynamics and taking inspiration from Re-
inforcement Learning (Q-Learning).
• Implementation and experimental results of the
dynamic exploration architecture.
The paper is organized as follows. Section 2 de-
scribes the methodological background, with the dy-
namic field theory and the associated related work.
Section 3 presents the model design, that includes
the action selection strategy and the exploration and
exploitation stage that compose the learning mecha-
nism. Following, Section 4 presents the experimental
setup and the results of the experiments. Finally, Sec-
tion 5 discusses the limitations of our work, future
efforts, and concludes the paper.
2 METHODOLOGICAL
BACKGROUND
Dynamic Field Theory is a theoretical framework
that provides a mathematically explicit way to model
the evolution in time of neural population activity
(Sch
¨
oner et al., 2016). It was originally used to model
reactive motor behavior (Kopecz and Sch
¨
oner, 1995)
but demonstrated its ability to model complex cog-
nitive processes (Spencer et al., 2009). The core el-
ements of DFT are Dynamic Neural Fields (DNF)
that represent activation distributions of neural pop-
ulations. Stable peaks of activation form as a result
of supra-threshold activation and lateral interactions
within a field. A DNF can represent different fea-
tures and a peak of activation at a specific location
corresponds to the current observation. For exam-
ple, a DNF can be used to represent a visual color
space (Red, Green, Blue) and a peak at the ”blue loca-
tion” would mean a blue object is perceived. Neural
Fields are particularly suitable to represent continu-
ous space.
Dynamic Neural Fields evolve continuously in
time under the influence of external inputs and lateral
interactions within the Dynamic Field as described by
the integro-differential equation :
τ ˙u(x,t) = −u(x,t) + h + S(x,t)
+
Z
f (u(x,t))ω(x − x
0
)dx
0
,
(1)
where h is the resting level (h < 0) and S(x,t) is the
external inputs. u(x,t) is the activation field over fea-
ture dimension x at time t and τ is a time constant.
Exploration and Exploitation of Sensorimotor Contingencies for a Cognitive Embodied Agent
547

An output signal f(u(x,t)) is determined from the acti-
vation via a sigmoid function with threshold at zero.
This output is then convoluted with an interaction ker-
nel ω that consists of local excitation and surrounding
inhibition (Amari, 1977). The role of the Gaussian
kernel is crucial since different shapes influence the
neural dynamics of a field. For example, local exci-
tatory (bell shape) coupling stabilizes peaks against
decay while lateral inhibitory coupling (Mexican-hat
shape) prevents activation from spreading out along
the neural field. By coupling or projecting together
several neural fields of different features and dimen-
sions, DFT is able to model cognitive processes. If
neural fields are the core of the theory, other elements
are essential to our work.
Dynamic neural nodes are basically a 0-
dimensional neural field and follow the same dy-
namic:
τ ˙u(x,t) = −u(x, t) + h + c
uu
f (u(t)) +
∑
S(x, t). (2)
The terms are similar to a Neural Field except for c
uu
which is the weight of a local nonlinear excitatory in-
teraction. A node can be used as a boost to another
Neural Field. By projecting its activation globally, the
resting level of the neural field will rise allowing to
see the rise of peaks of activation (Figure 4).
Finally, the memory trace is another important
component of DFT:
˙v(t) =
1
τ
+
(−v(t) + f (u(t))) f (u(t))
+
1
τ
−
(−v(t)(1 − f (u(t))),
(3)
with τ
+
< τ
−
. A memory trace in DFT has two dif-
ferent time scales, a build up time τ
+
that corresponds
to the time for an activation to rise in the memory and
a decay time τ
−
which is the time decay of an activa-
tion. In our model, we use a 2-dimensional memory
trace which keeps track of visual activation.
2.1 Q-Learning
Q-Learning algorithm (Watkins and Dayan, 1992;
Sutton et al., 1998) is a model-free reinforcement
learning algorithm that learns a policy in order to
choose the best action according to a given state. The
learned action/value function Q is defined by :
Q(s
t
, a
t
) ← Q(s
t
, a
t
) + α
[R
t+1
+ γ.max
a
Q(s
t+1
, a) − Q(s
t
, a
t
)],
(4)
where s
t
and a
t
are, respectively, a state and an action
at time t, α is the learning rate, r
t+1
the reward at time
t+1 and γ the discount factor. In practice, the learn-
ing rate determines to what extent newly acquired in-
formation overrides old information and the discount
factor γ determines the importance of future rewards.
The Q-Values are stored and updated in a table (Q-
Table) divided along a state and action dimension. Af-
ter learning, and given a state s
t
, a Q-Value represents
a probability of obtaining a certain reward in time af-
ter performing an action. The next section introduces
our model and draws the parallel of the Q-Learning
inspiration with Dynamic Neural Fields.
3 MODEL
In this work, we propose a cognitive architecture al-
lowing a robot to learn a specific movement with a
visual motion detector. The robot resembles a human
arm, where the upper arm roll motor is used for ex-
ploration and exploitation. For simplicity, we split
our architecture according to the different phases: ex-
ploration with an action generation mechanism and
exploitation of the motor babbling outcomes.
3.1 Action Generation for Motor
Babbling
As described earlier, motor babbling consists of asso-
ciating motor actions with their perceptual outcome.
In this work, we show the possibility to generate ac-
tions directly from a neural field. To do so, we com-
bine two different neural mechanisms: A slow boost
of the resting level and an Inhibition of return (Fig-
ure 1). With DFT, the tuning of the resting level is
an essential component that leads to express differ-
ent neural behavior (Sch
¨
oner et al., 2016). It is well-
known that the resting membrane potential of neu-
rons can vary under different conditions (Wilson and
Kawaguchi, 1996)(Franklin et al., 1992). Here, in-
stead of defining a static resting level, we choose to
dynamically vary the resting level of two neural fields
to generate a new action. The slow boost module in-
creases the resting level of the action formation (AF)
field until a peak of activation emerges. The module
ceases to increase the activation when the stop node
is active and resets the activation to zero when the
reset node is active. The peak within the AF field
is then projected to a set of neural fields reproduc-
ing an inhibition of return. This mechanism is well
studied, especially regarding visual attention (Posner
et al., 1985), (Tipper et al., 1991), where immediately
following an event at a peripheral location, there is fa-
cilitation for the processing of other stimuli near that
location. Here, we use this effect to avoid generat-
ing the same action twice given a motor state. When
a peak emerges from the AF field and is projected to
the Inhibition Of Return excitatory field (IOR excit),
ICAART 2020 - 12th International Conference on Agents and Artificial Intelligence
548

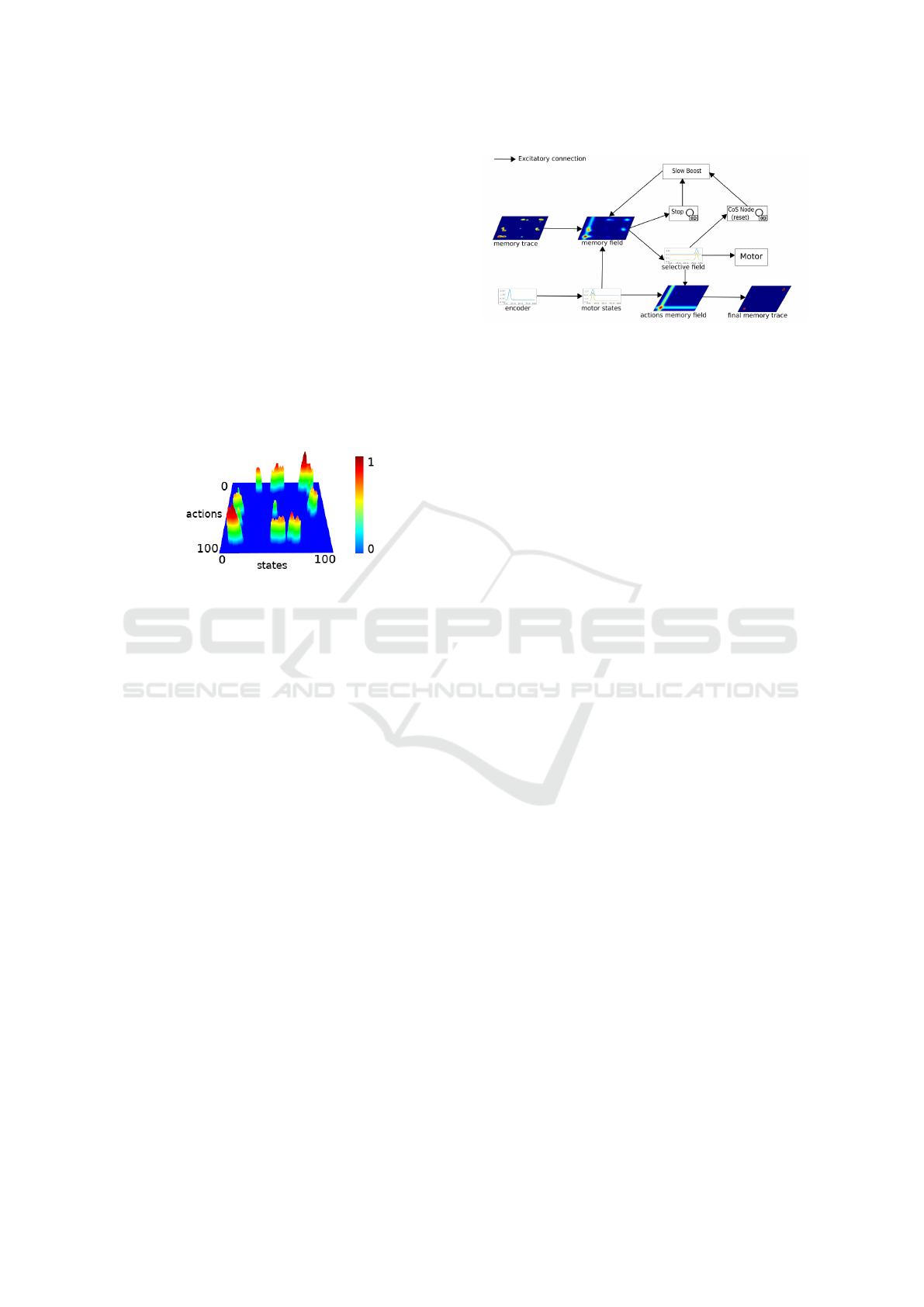
Figure 1: Exploration stage divided by the action generation mechanism with the inhibition of return (blue) and the recording
of the visual outcomes (green). A peak of activation from actions/states field spreads in memory trace only when the Rec node
is active. This means storing the visual activation exactly while an action is performing. The decay of the memory trace τ
−
is
10 seconds, and only happens when the Rec node is active. The motor module converts the neural field value to the desired
angle position.
a memory trace stores this activation. This memory
trace is recording all the actions taken during the mo-
tor babbling with a slow decay τ
−
. The memory trace
then projects all the activation into an Inhibition Of
Return field (IOR inhib). This last neural field closes
the loop of the Inhibition of Return mechanism by
projecting an inhibitory connection to the AF field.
The kernel interaction within that field allows the rise
of peaks of activation. When the slow boost module
begins to rise the resting level of both action forma-
tion and IOR Inhib field, the activation within the ac-
tion field generates a stable peak and projects it to the
selective field. In some rare cases, the neural dynam-
ics generate more than one action within the action
formation field. Thus, the selective field assures the
emergence of a single peak. The dynamics observed
within the AF field are influenced by the speed of the
increasing boost. If we increase the resting level of
the fields too quickly, they begin to oscillate between
a supra-threshold and a below-threshold states. Nev-
ertheless, this mechanism allows the generation of a
unique single action at a given state.
All neural fields are defined in the interval [0;100]
and represent a motor angle position within the inter-
val [-1;1]. The action formation field is divided along
the state space on the horizontal dimension and the
action space along the vertical dimension. If a peak
emerges at position [50;90], that means at motor state
50, the action 90 is taken. The encoder module cor-
responds to the motor value from the upper arm roll
motor (e.g motor angle with the interval [-1;1]).
The Condition of Satisfaction (CoS) field receives
inputs from the encoder and the motor intention field.
When both of them reach the same location within the
CoS field, the activation goes beyond threshold and
activates a node that will reset the slow boost module.
3.2 Exploration
The first stage of our model consists of exploring the
sensorimotor space (Figure 1) with the action genera-
tion mechanism. The purpose of exploration is quite
simple: generate an action to perform and store the
visual outcome into a 2-dimensional memory trace.
Thus, the architecture performs an action, stores the
neural activation within a memory trace while execut-
ing the action, then stops storing the activation when
the action is over.
The actions/states field, memory trace and record
(Rec) node are the core components of the explo-
ration. As stated earlier, the condition of satisfaction
field (CoS Field) is a one dimensional neural field
representing the motor space and basically indicates
when an action is over. It receives activation from
both the motor intention field and the encoder. When
a new action is selected, the CoS field receives an ac-
tivation from the intention field. The motor module
performs the action and the encoder’s new value is
updated. This causes a peak to rise within the CoS
field and activates a node that resets the slow boost
component.
Concerning the reward peak module, it receives
input from the motion detector and the motor inten-
tion field. This is where the grounding of visual per-
ception is happening. The implementation gathers the
motor state position and the visual perception value to
form a Gaussian curve centered on the motor’s posi-
tion with an amplitude corresponding to the the mo-
tion detector’s value.
The actions/states field is a 2-dimensional neural
field where the horizontal axis represents the motor
states and the vertical axis the motor actions. When a
new action is executed, the grounding of vision/action
Exploration and Exploitation of Sensorimotor Contingencies for a Cognitive Embodied Agent
549
peak field projects along the horizontal axis of the ac-
tion/state field while the current motor state projects
along the vertical axis. This creates a 2 dimensional
peak of activation depending of the strength of the vi-
sual input. Finally, the memory trace field stores ac-
tivation from the action state neural field. A convolu-
tion (gaussian kernel) is applied to the output of the
actions/states field to smooth the peak of activation
in the memory trace. The rec node plays the role of
trigger for the storage of neural activation since it al-
lows them to happen only when the node is active. In
our design, the rec node is active only when an action
is generated (peak within the motor intention field).
This way, the memory trace accepts input from the
actions/states field only when an action is currently
being executed (Figure 2).
Figure 2: 3D view of the Memory Trace after exploration
with 100ms of build up activation (τ
+
) and 10 seconds de-
cay (τ
−
).
The inspiration from Q-Learning comes from the
memory trace storing the visual outputs. Since the
actions/states field is divided along, respectively, the
vertical and horizontal space, the memory trace stores
peaks with the amplitude of a visual activation given
a specific action taken at a specific state. Similarly
to a Q-Value that represent a probability to get a re-
ward from a state/action pair, the amplitude of a peak
within the memory trace reflect the probability of get-
ting a high visual neural activation. The memory trace
is then analogous to a Q-Table where the highest peak
along the current state dimension represents the ac-
tion with the highest visual outcome. Contrary to
Q-Learning, the actions/states neural field is updated
with the current visual activation, without a discount
factor and a learning rate. The goal of exploration
is purely to observe all sensorimotor outcomes after
performing an action.
3.3 Exploitation
The last step of our architecture is the exploitation
phase (Figure 3). The architecture runs by following
the different activations within the memory trace. The
goal is to follow the ”path” left by every high activa-
tion until reaching an optimal sequence of actions.
Figure 3: Exploitation phase. The slow boost node slowly
rises the resting level of the memory field provoking a peak
at the location of the best action taken during exploration.
The memory trace from the exploration serves as
input to a 2-dimensional neural field. This memory
field is the core component of the exploitation mech-
anism. First, a motor state field spans the current mo-
tor state over the horizontal dimension of the mem-
ory field which rises the neural activation of taken
actions during the exploration stage at that particular
state. The neural activation within the memory field
remains below the threshold of activation. To see the
rise of the highest activation, we apply a slow boost.
This component remains the same seen during the ac-
tion generation dynamics. This slow boost stops to
increase the resting level when an activation appears
(Stop node). The 2-dimensional memory field then
projects the output activation to a 1-dimensional se-
lective action field. Finally, the selective field repre-
sents the best action taken (the best visual outcome)
at that state (Figure 4).
The activation within the selective action field is
projected into the motor module that will perform the
corresponding action. The selective field will emit the
action’s ending to a Condition of Satisfaction (CoS)
node then to the slow boost. The boost already re-
ceives an activation from the Stop node to block the
increase of the resting level. The signal coming from
the CoS node resets the iterative boost to its initial
resting level. The CoS node is mainly a trigger in-
forming the boost module that an action has been per-
formed and the selection of a new action from the new
state can take place.
Finally, the actions memory field forms a peak of
activation at each action taken if the visual outcomes
are strong enough. It then stores it into a final mem-
ory trace field that represents the optimal sequence
of actions. During the exploitation phase, the mo-
tion takes some time to reach the stabilized sequence
of motor state transitions. At the beginning, it might
go through some motor states that will not be visited
again and this is why we use a final memory trace.
With an arbitrary chosen activation decay of 4 sec-
onds (τ
−
), the motor states that are visited only once
ICAART 2020 - 12th International Conference on Agents and Artificial Intelligence
550

Figure 4: Top panel: projection of the current motor state
on the memory field, the slow boost node is active and
stopped. Bottom left: results of the sigmoid activation when
the boost is active and stopped. Bottom right: projection of
the action dimension to a 1-dimensional selective field. In
the rare case where two peaks have exactly the same activa-
tion, only one of them will remain above threshold.
during the whole exploitation step disappear, while
the most used motor states are kept active. One could
see the final memory trace as a clean (for a given ex-
ploration) sequence of actions since the unused acti-
vations are pulled off.
The exploitation phase in our architecture is anal-
ogous to exploitation with Q-Learning. Indeed, the
choice of the next action to perform within the mem-
ory field is always the highest peak given a motor
state. With Q-Learning, this would mean choosing
the action with the highest Q-value.
4 EXPERIMENT AND RESULTS
In order to validate our approach, a set of 10 ex-
plorations and 10 exploitations are performed with a
robot arm that mimics a human arm and torso.
4.1 Setup
The gummiArm robot (Stoelen et al., 2016) is a 7 de-
grees of freedom (+2 for the head) 3D printed arm. In
our case, only the upper arm roll joint will be used for
demonstration of the architecture. A rubber band is
attached from the palm of the hand to one of the mov-
ing toys in the baby mobile (Figure 5). The motor
space of the upper arm roll joint is an angle position
situated within the interval [-1;1] where -1 and 1 rep-
resent respectively the extreme left and extreme right
position of the end-effector. The motor space interval
is scaled along the Motor Intention Field from 0 to
100.
Figure 5: GummiArm robot in initial position, with the
palm of the hand attached to the baby mobile (grey balloon).
The camera mounted inside the head (Intel Re-
alSense D435), is used for the motion detector
that subtracts two consecutive images and applies a
threshold to observe the changed pixels. The result re-
turns the sum of changed pixels which is scaled from
0 to 3 and represents the visual neural activation. The
toys hanging from the baby mobile are within the vi-
sual field of the camera whereas the arm itself is out
of sight. Despite the noisiness of the motion detector,
the exploration mechanism allows the emergence of a
pattern during motor babbling.
The exploration phase begins with the robot’s arm
at 0 position (50 over the motor intention field). As al-
ready mentioned, the memory field applies the decay
time τ
−
only when the trigger node associated is also
active. The exploration and exploitation stages run
for 210 seconds each. The length of these two stages
were chosen according to the memory trace’s decay
(τ
−
) and the slow boost mechanism. For exploration,
we apply a decay τ
−
of 10 seconds. This is enough to
see a pattern emerging and thus support the exploita-
tion of the sensorimotor contingencies. As mentioned
earlier, the slow boost module slowly increases the
resting level of the memory field, strongly influenc-
ing the time needed to choose an action. Since we
use the same parameters to increase the resting level
for both stages, the time needed to generate an action
remain the same.
For exploring, we record the visual neural acti-
vation happening during an action (when the mem-
ory node is active) every 50ms. In the meantime, we
record the activation within the motor intention field
module to keep track of the actions taken with the
same rate (50ms). We apply the same procedure for
the exploitation (a vision module is used in the archi-
tecture to record the visual activation the exact same
way as for the first phase). We run 10 explorations,
then apply the exploitation stage to each of these runs.
Exploration and Exploitation of Sensorimotor Contingencies for a Cognitive Embodied Agent
551
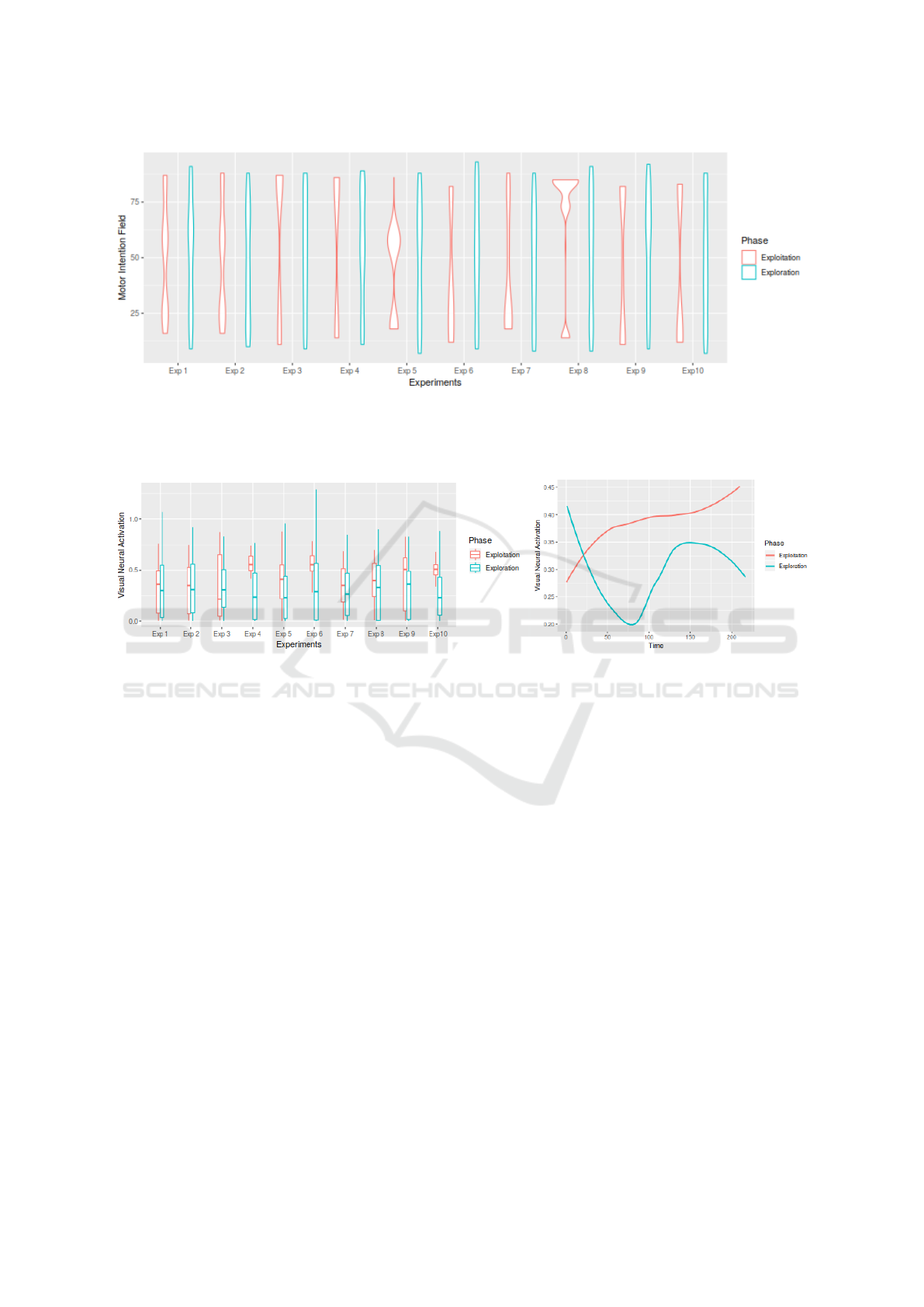
Figure 6: Violin plots for the distribution of Motor Intention. The plots show a specific motor space distribution during
exploitation, while the exploration stage motor distribution is more uniform. The distribution of motor intention demonstrate
a focus at three particular interval corresponding to the extreme left, center and extreme right position of the gummiArm.
Figure 7: The figure shows the visual activation for the 10 experiments, for both exploration and exploitation. Left figure
depicts that, for each experiment, a gain of visual neural activation during exploitation can be seen. Right figure depicts the
sum of visual activation in time for each experiment and represented by a linear regression. This indicates a general higher
neural activation during the exploitation of the sensorimotor contingencies.
4.2 Results
Figure 6 depicts the motor distribution of actions dur-
ing the 10 experiments. These reflect the particu-
lar setting of the experiment, however, the motor in-
tentions during exploitation show a preferred motor
space to three different intervals: [10;30],[48;65] and
[70;85]. This corresponds respectively to the extreme
left, center and extreme right location of the arm.
These motor positions represent the actions with a
high neural visual activation.
For only one action performed there are many vi-
sual activations recorded. The distribution of the vi-
sual neural activation per experiment are presented in
Figure 7-left. It can be seen that the visual activation
is higher during exploitation than during exploration
for most of the experiments. For the first three ex-
periments, there is no clear gain of visual activation
during exploitation. This is mostly due to the noisi-
ness of the motion detector.
The average neural activation of the 10 experi-
ments in time is shown in Figure 7-right and depicts
the benefits of exploitation. It is difficult to analyse
why the linear regression of visual activation for ex-
ploration follows such dynamics. The experiment’s
dynamics represent this particular set up (head cen-
tered on the baby mobile) and would evolve differ-
ently with a different setting. If these results represent
the dynamics of this particular settings, they still show
an improvement of the visual activation when exploit-
ing the ”knowledge” gathered during motor babbling.
To conclude, experimental demonstration shows that
there is a gain of visual activation during the exploita-
tion stage.
5 DISCUSSION AND
CONCLUSION
This work proposes a cognitive architecture with an
embodiment approach that allows a robotic arm to op-
ICAART 2020 - 12th International Conference on Agents and Artificial Intelligence
552

timize its motion based on the neural activation com-
ing from a motion detector. As such, the approach
is grounding the sensorimotor experience within Dy-
namic Neural Fields. The intrinsic properties of the
latter provides a certain level of homeostasis, mean-
ing that a self regulation of the system is realized.
In experiments, a GummiArm robot is moving a
baby mobile and observes the outcome of the action
taken to optimize its motion. After the selection of
an action, the model records the visual outcome in a
visual memory trace. Indeed, the sensorimotor con-
tingencies can be encoded as neural activation within
neural fields and explored through motor babbling.
Then, an exploitation mechanism optimizes the mo-
tion of the robot, following the path left by high neu-
ral activation. Exploiting the high neural activations
means choosing actions leading to the best visual re-
ward.
Furthermore, the robot observes the outcomes of
every action taken during exploration. The exploita-
tion phase then selects only the actions with the high-
est visual outcomes. The results validate our approach
by showing a restricted motor space during exploita-
tion and demonstrates higher neural activation. The
purpose of this work serves as a proof of concept and
justifies further investigation on dynamical learning
in a closed-loop fashion, with an embodied approach.
However, few issues remain.
Firstly, the exploration does not stop indepen-
dently. It was expected that the action selection mech-
anism will stop by itself when all motor positions
were selected given a motor state. This was not con-
clusive since the IOR inhib field does not project
enough inhibition to stop the emergence of a new peak
within the action formation field. This is therefore a
current limitation of the model. Future work will in-
vestigate the tuning of the kernel interaction of the
IOR Inhib field as well as the excitatory connections
coming from the memory trace actions field to resolve
this. During experiments, it was noted that influence
from the inhibition of return and tuning it could lead
to different exploratory behavior. Future work will
determine how the strength of the inhibition could
help the exploitation stage to converge faster toward
an optimal sequence of actions.
Secondly, the motor babbling behavior remains
divided between the exploration and the exploitation
stage. The exploration of the sensorimotor space di-
rectly influences the exploitation process. The gen-
eral architecture will be further investigated to allow
a switch from exploration to exploitation and vice
versa. In general, the switch from exploration to ex-
ploitation is a major issue in unsupervised learning
or reinforcement learning. This would mean inves-
tigating how such switch mechanism could be im-
plemented dynamically, and more specifically, decide
when the exploration ceases to improve the exploita-
tion stage.
In this work, only a single degree of freedom was
utilized to drive the baby mobile. This demonstrates
the work as a proof of concept, with a focus on the
motor babbling strategies. In a future work, we intend
to use the whole robotic arm with an inverse kinemat-
ics model. Practically, this will mean dealing with 3D
Cartesian space instead of motor position. In terms
of embodiment, this will result in grounding the 3D
position of the robot’s end-effector with the neural
activation from the motion detector. With the nec-
essary cognitive transformation and gain modulation
(Sch
¨
oner et al., 2016), the different motor spaces will
be reduced to be explored with motor babbling.
Finally, the embodiment of the sensorimotor expe-
rience within neural fields is promising for the learn-
ing of skills. Here, the task is only to shake a baby
mobile toy with the feedback of a motion detector,
but a certain pattern of neural activation can still be
observed and exploited. In the future, we will investi-
gate the grounding of more complex stimulis such as
the orientation or the movement of an object and see if
it supports the learning of higher cognitive tasks such
as reaching, pushing or pulling objects.
REFERENCES
Amari, S.-I. (1977). Dynamics of pattern formation in
lateral-inhibition type neural fields. Biological Cyber-
netics, 27(2):77–87.
Barandiaran, X. E. (2017). Autonomy and Enactivism:
Towards a Theory of Sensorimotor Autonomous
Agency. Topoi, 36(3):409–430.
Caligiore, D., Ferrauto, T., Parisi, D., Accornero, N.,
Capozza, M., and Baldassarre, G. (2008). Using mo-
tor babbling and hebb rules for modeling the devel-
opment of reaching with obstacles and grasping. In
International Conference on Cognitive Systems, pages
E1–8.
Cannon, W. B. (1929). Organization for physiological
homeostasis. Physiological reviews, 9(3):399–431.
Chrisley, R. and Ziemke, T. (2006). Embodiment. In Ency-
clopedia of Cognitive Science. American Cancer So-
ciety.
Degenaar, J. and O’Regan, J. K. (2017). Sensorimotor The-
ory and Enactivism. Topoi, 36(3):393–407.
Demiris, Y. and Dearden, A. (2005). From motor babbling
to hierarchical learning by imitation: a robot develop-
mental pathway. In International Workshop on Epi-
genetic Robotics: Modeling Cognitive Development
in Robotic Systems, volume 123, pages 31–37. Lund
University Cognitive Studies.
Exploration and Exploitation of Sensorimotor Contingencies for a Cognitive Embodied Agent
553

Francisco J. Varela, E. T. and Rosch, E. (1991). The Em-
bodied Mind | MIT CogNet. MIT Press.
Franklin, J., Fickbohm, D., and Willard, A. (1992). Long-
term regulation of neuronal calcium currents by pro-
longed changes of membrane potential. Journal of
Neuroscience, 12(5):1726–1735.
Kopecz, K. and Sch
¨
oner, G. (1995). Saccadic motor
planning by integrating visual information and pre-
information on neural dynamic fields. Biological cy-
bernetics, 73(1):49–60.
Laflaqui
`
ere, A. and Hemion, N. (2015). Grounding ob-
ject perception in a naive agent’s sensorimotor experi-
ence. In 2015 Joint IEEE International Conference on
Development and Learning and Epigenetic Robotics
(ICDL-EpiRob), pages 276–282.
Luciw, M., Kazerounian, S., Lakhmann, K., Richter, M.,
and Sandamirskaya, Y. (2013). Learning the percep-
tual conditions of satisfaction of elementary behav-
iors. In Robotics: science and systems (RSS), work-
shop “active learning in robotics: exploration, curios-
ity, and interaction”.
Mahoor, Z., MacLennan, B. J., and McBride, A. C. (2016).
Neurally plausible motor babbling in robot reach-
ing. In 2016 Joint IEEE International Conference on
Development and Learning and Epigenetic Robotics
(ICDL-EpiRob), pages 9–14.
Morse, A. F., Herrera, C., Clowes, R., Montebelli, A.,
and Ziemke, T. (2011). The role of robotic mod-
elling in cognitive science. New Ideas in Psychology,
29(3):312–324.
Perone, S. and Spencer, J. P. (2013). Autonomy in action:
Linking the act of looking to memory formation in in-
fancy via dynamic neural fields. Cognitive Science,
37(1):1–60.
Pezzulo, G., Barsalou, L. W., Cangelosi, A., Fischer,
M. H., McRae, K., and Spivey, M. (2013). Com-
putational Grounded Cognition: a new alliance be-
tween grounded cognition and computational model-
ing. Frontiers in Psychology, 3.
Piaget, J. and Cook, M. (1952). The origins of intelligence
in children, volume 8. International Universities Press
New York.
Posner, M. I., Rafal, R. D., Choate, L. S., and Vaughan, J.
(1985). Inhibition of return: Neural basis and func-
tion. Cognitive Neuropsychology, 2(3):211–228.
Ruci
´
nski, M., Cangelosi, A., and Belpaeme, T. (2012).
Robotic model of the contribution of gesture to learn-
ing to count. In 2012 IEEE International Confer-
ence on Development and Learning and Epigenetic
Robotics (ICDL), pages 1–6. IEEE.
Saegusa, R., Metta, G., Sandini, G., and Sakka, S. (2009).
Active motor babbling for sensorimotor learning. In
2008 IEEE International Conference on Robotics and
Biomimetics, pages 794–799.
Sandamirskaya, Y. and Sch
¨
oner, G. (2010). Serial order in
an acting system: A multidimensional dynamic neu-
ral fields implementation. In 2010 IEEE 9th Inter-
national Conference on Development and Learning,
pages 251–256.
Sch
¨
oner, G., Spencer, J., and Group, D. F. T. R. (2016). Dy-
namic Thinking: A Primer on Dynamic Field Theory.
Oxford University Press. Google-Books-ID: ySex-
CgAAQBAJ.
Spencer, J., Perone, S., and Johnson, J. (2009). Dynamic
Field Theory and Embodied Cognitive Dynamics.
Stoelen, M. F., Bonsignorio, F., and Cangelosi, A. (2016).
Co-exploring actuator antagonism and bio-inspired
control in a printable robot arm. In From Animals to
Animats 14, pages 244–255, Cham. Springer Interna-
tional Publishing.
Sutton, R. S., Barto, A. G., et al. (1998). Introduction to
reinforcement learning, volume 135. MIT press Cam-
bridge.
Tipper, S. P., Driver, J., and Weaver, B. (1991). Short re-
port: Object-centred inhibition of return of visual at-
tention. The Quarterly Journal of Experimental Psy-
chology Section A, 43(2):289–298.
Vernon, D., Lowe, R., Thill, S., and Ziemke, T. (2015). Em-
bodied cognition and circular causality: on the role
of constitutive autonomy in the reciprocal coupling
of perception and action. Frontiers in Psychology,
6:1660.
Von Hofsten, C. (1982). Eye–hand coordination in the new-
born. Developmental psychology, 18(3):450.
Watanabe, H. and Taga, G. (2006). General to specific de-
velopment of movement patterns and memory for con-
tingency between actions and events in young infants.
Infant Behavior and Development, 29(3):402–422.
Watkins, C. J. and Dayan, P. (1992). Q-learning. Machine
learning, 8(3-4):279–292.
Wilson, C. and Kawaguchi, Y. (1996). The origins of two-
state spontaneous membrane potential fluctuations of
neostriatal spiny neurons. Journal of Neuroscience,
16(7):2397–2410.
Ziemke, T. (2016). The body of knowledge: On the role
of the living body in grounding embodied cognition.
Biosystems, 148:4–11.
APPENDIX
We would like to thank Mathis Richter and Jan
Tek
¨
ulve from the Institut f
¨
ur Neuroinformatik. The
code, parameters and architecture files are available
at https://github.com/rouzinho/DynamicExploration/
wiki
ICAART 2020 - 12th International Conference on Agents and Artificial Intelligence
554
