
The Use of Ensemble Classification and Clustering Methods of Machine
Learning in the Study of Internet Addiction of Students
Oksana V. Klochko
1 a
, Vasyl M. Fedorets
2 b
, Vitalii I. Klochko
3 c
and Maryna V. Kormer
4 d
1
Vinnytsia Mykhailo Kotsiubynskyi State Pedagogical University, 32 Ostrozhskogo Str., Vinnytsia, 21100, Ukraine
2
Vinnytsia Academy of Continuing Education, 13 Hrushevskoho Str., Vinnytsia, 21050, Ukraine
3
Vinnytsia National Technical University, 95 Khmelnytsky Highway, Vinnytsia, 21021, Ukraine
4
State University of Economics and Technology, 5 Stepana Tilhy Str., Kryvyi Rih, 50006, Ukraine
Keywords:
Machine Learning, Clustering Classification, Internet Addiction, Detection of Internet Addiction, Internet
Disorders, Internet Addiction of Students, Expectation Maximization, Farthest First, K-Means, AdaBoost,
Bagging, Random Forest, Vote.
Abstract:
One of the relevant current vectors of study in machine learning is the analysis of the application peculiarities
for methods of solving a specific problem. We will study this issue on the example of methods of solving
the clustering and classification problem. Currently, we have a considerable number of machine learning al-
gorithms – e.g. Expectation Maximization, Farthest First, K-Means, Expectation-Maximization, Hierarchical
Clustering, Support vector machines, K-nearest neighbor, Logistic regression, Random Forest etc. – which can
be used for clustering and classification. However, not all methods can be used for solving a specific task. The
article describes the technology of empirical comparison of methods of clustering and classification problems
solving using WEKA free software for machine learning. Empirical comparison of data clustering methods
was based on the results of a survey conducted among students majoring in Computer Studies and dedicated
to detecting signs of Internet Addiction (IA) (Internet Addiction is a behavioural disorder that occurs due to
Internet misuse). As a continuation of the study of Internet Addiction of students, a survey of students of other
specialties was conducted. Ensemble methods of machine learning classification were used to analyze these
data. Empirical comparison of clustering algorithms (Expectation Maximization, Farthest First and K-Means)
and ensemble classification algorithms (AdaBoost, Bagging, Random Forest and Vote) with the application
of the WEKA machine learning system had the following results: it described the peculiarities of application
of these methods in feature clustering and classification, the authors developed data instances’ clustering and
classification models to detect signs of Internet addiction among students, the study concludes that these meth-
ods may be applicable to development of models detecting respondents with signs of IA related disorders and
risk groups.
1 INTRODUCTION
One of the areas of research, particularly, such as
education, healthcare and life safety, is the empiri-
cal analysis of methods of solving a specific problem
with the using of the machine learning (Zahorodko
et al., 2021; Zelinska, 2020). Let us study this issue
on the example of methods of solving the clustering
and classification problems (Tarasenko et al., 2019).
a
https://orcid.org/0000-0002-6505-9455
b
https://orcid.org/0000-0001-9936-3458
c
https://orcid.org/0000-0002-9415-4451
d
https://orcid.org/0000-0002-6509-0794
Clustering methods are statistic methods of data
analysis that enable people to group the given selec-
tion of data samples into clusters, classes, taxons de-
pending on the value of their attributes; each of these
groups has certain characteristics. The main idea is
to use several clustering methods in order to carry out
an empirical comparison study and determine which
methods ensure the most optimal data grouping while
solving a specific problem.
Machine learning classifies clustering problems as
problems for unsupervised learning. Currently, there
is a considerable number of machine learning algo-
rithms that can be used for clustering, for instance,
Expectation Maximization, Farthest First, K-Means,
Klochko, O., Fedorets, V., Klochko, V. and Kormer, M.
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students.
DOI: 10.5220/0010923500003364
In Proceedings of the 1st Symposium on Advances in Educational Technology (AET 2020) - Volume 1, pages 241-260
ISBN: 978-989-758-558-6
Copyright
c
2022 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
241

K-Medians, Hierarchical Clustering etc. But not all
of them are suitable for solving a specific problem.
Data clustering algorithms differ by the cluster model
type, the algorithm model type, the nesting hierarchy
of clusters, the way of implementation depending on
the data set etc. Because of this, there are also certain
requirements to the data set parameters.
Classification tasks are considered to be a differ-
ent group of machine learning tasks – namely, super-
vised learning. However, nowadays, there are devel-
oped classification algorithms based on a combina-
tion of supervised learning and unsupervised learning
(e.g., Learning Vector Quantization) the classification
algorithm in machine learning is built on the basis of
the preset finite number of objects divided into groups
and allows to classify an arbitrary object, if it is un-
known which group it belongs to. There is a con-
siderable number of machine learning algorithms that
can be applied to solve classification tasks, e.g. Sup-
port vector machines (SVMs), Logistic regression, K-
nearest neighbor, Linear discriminant analysis (LDA),
etc. However, currently, one can get more accurate re-
sults by using ensemble methods.
Popular software products used in machine learn-
ing include TensorFlow, WEKA, MATLAB, MXNet,
Torch, PyTorch, Microsoft Azure Machine Learning
Studio and others.
In this study, we use the WEKA (Waikato Envi-
ronment for Knowledge Analysis) free machine learn-
ing software (Weka, 2021). The free WEKA machine
learning system gives direct access to the library of
implemented algorithms written in Java.
Analysis of contemporary studies and publica-
tions shows that the issue of analysis and selection
of the machine learning method, which would be op-
timal for processing a concrete data set, is popular in
the scientific circles. A considerable number of these
studies is dedicated to the application of machine
learning methods in the fields of education, healthcare
and life safety.
In healthcare and education sentiment analysis be-
comes more and more popular. Thus, Pacol and
Palaoag (Pacol and Palaoag, 2020) conducted the sen-
timent analysis of the Textual Feedback of students
regarding the work of the professors using Machine
Learning Techniques. In the sentiment classification
study, the Random Forest algorithm proved to be most
effective; it proved to be more effective than base
models of Support vector machines, Naive Bayes, Lo-
gistic regression algorithms and their ensembles (Pa-
col and Palaoag, 2020).
Klochko et al. (Klochko et al., 2020) applied clus-
tering algorithms of machine learning for the anal-
ysis of typical mistakes pupils make, the selection
and adaptation of the content of learning to concrete
groups of pupils that was then supposed to be used for
flipped learning with the use of virtual learning envi-
ronment. The analysis was done through the compar-
ison of clusters, defined by learning results demon-
strated by the pupils, using Canopy, Expectation Max-
imization and Farthest First algorithms.
Souri et al. (Souri et al., 2020) suggested a model
based on the Internet of Things technologies for mon-
itoring the indicators of students’ health in order to
detect biological and behavioral changes. The de-
veloped model, when used together with the Support
Vector Machine (SVM) algorithm, reaches the high-
est accuracy of 99.1% (Souri et al., 2020).
Hussain et al. (Hussain et al., 2019) studied
the application of the machine learning classification
methods to find ways to ensure independent daily liv-
ing of people who have Alzheimer’s disease. The idea
of the study is to analyze the data registered by differ-
ent equipment in order to determine the changes in a
person’s behavior that are relevant for the daily life
and social interaction. The paper gives a comparison
of the efficiency levels of five machine learning clas-
sification techniques used for the recognition of a per-
son’s activity (and his/her psychological status). Ex-
perimental findings show that compared to traditional
methodologies, these approaches give better results in
determining the activity of the person and his/her psy-
chological and behavioral peculiarities.
Kr
¨
amer et al. (Kr
¨
amer et al., 2019) studied the
speed and efficiency of medical aid provision us-
ing the databases of the Hospital ER. Applying the
Random forest algorithm, the authors developed the
model based on the data about the patient’s pro-
visional diagnosis. The use of the controlled ma-
chine learning method and model training based on
the opinion of a specialized doctor allowed them to
achieve high forecasting accuracy (96%) as well as
the area under the receiver operating curve (>0.99).
Subasi et al. (Subasi et al., 2019) developed a hy-
brid model of detecting epileptic fits using the Ge-
netic Algorithm (GA) and Particle Swarm Optimiza-
tion (PSO) to determine the optimal parameters of ap-
plication of the Support Vector Machine (SVM) algo-
rithm. The hybrid algorithm that they suggested can
demonstrate data set classification accuracy of up to
99.38%.
A considerable number of papers appeared, which
are dedicated to diagnosing Internet addiction (IA)
and studying the mechanisms of this disorder among
various social groups. The appearance and use of
the Internet has many benefits. However, at the same
time, disorders related to pathological use of the Inter-
net are becoming a social as well as a psychological
AET 2020 - Symposium on Advances in Educational Technology
242

problem. Currently, we face an important psycholog-
ical, sociocultural and educational issue of detection
and prevention of certain pathologies and steady pre-
morbid conditions (state before the disease) caused by
inadequate Internet use. Cases of IA were first men-
tioned in 1995 and attracted considerable attention.
Issues related to this one became the research subject
of Yuryeva and Bolbot (Yuryeva and Bolbot, 2006),
Derhach (Derhach, 2016) and others. Internet Ad-
diction Disorder (IAD) is also called Pathological In-
ternet Use (PIU). The term “Internet Addiction” was
first suggested by Ivan K. Goldberg in 1995. He de-
scribes net addiction as a specific pathology charac-
terized by a wide spectrum of behavioral and impulse
control disorders (lack of control, absence of volun-
tary regulation) (Abbott et al., 1995). In 1996 Gold-
berg made the first attempt to determine groups of be-
havioural and psychological signs and symptoms of
IA (Wallis, 1997), namely: tolerance; abstinence syn-
drome; difficulties in voluntary regulation of Internet-
behaviour; increase of time and financial investments
in things related to Internet or computer use; a shift
of a person’s interests towards Internet-related ac-
tivities; extensive Internet use that leads to malad-
justment. In 1998 Young (Young, 1998a,b) defined
IAD as an impulsive-compulsive disorder, which has
specific signs or addictions: cyber-sexual addiction,
cyber-relationship addiction, net compulsions, infor-
mation overload and computer addiction. IAD is
not officially included into ICD-11 for Mortality and
Morbidity Statistics (Version: 09/2020), however, in
section 6C51 Gaming disorder the “Gaming disor-
der” is described as a “pattern of persistent or recur-
rent gaming behaviour (‘digital gaming’ or ‘video-
gaming’), which may be online (i.e., over the Inter-
net)” (ICD-11 for Mortality and Morbidity Statistics ,
Version: 09/2020).
Even though the problem of IA is becoming more
and more relevant, there are not enough scientific pa-
pers dedicated to the study of this issue with the help
of machine learning methods. Let us look at some
of them. On the basis of the Support Vector Ma-
chine algorithm, including the C-SVM and v-SVM,
and applying the Student’s t-test to the data set of the
survey conducted among 2,397 Chinese students, Di
et al. (Di et al., 2019) proved the utility of using ma-
chine learning methods for detecting and forecasting
the risk of IA. Hsieh et al. (Hsieh et al., 2019) sug-
gested using the EMBAR protected system of web-
services based on the ensemble classification meth-
ods and case-based reasoning to study the IA of the
users and prevent the development of this disorder at
the initial stages. Ji et al. (Ji et al., 2019) are cur-
rently continuing their research, which aims to cre-
ate an IA detector that would work in a real-time
mode. The authors suggest studying this issue using
an adapted system of continuous real-coded variables
(XCSR), which determines the level of Internet ad-
diction (high-risk and low-risk) on the basis of the in-
formation about the Internet users using the Chen In-
ternet addiction scale (CIAS) or respiratory instanta-
neous frequency (IF). Suma et al. (Suma et al., 2021)
studied the possibilities for predicting IA based on a
set of predictor variables using the Random forest al-
gorithm.
Thus, based on the above presented statement of
the problem as well as taking into consideration the
insufficient amount of research on the application of
machine learning methods to IA diagnosing, we de-
termine the aim of our research, which is to determine
the fields of use and conduct an empirical comparison
of ensemble classification and clustering methods of
machine learning in the study of IA disorder of stu-
dents.
2 SELECTION OF METHODS
AND DIAGNOSTICS
The study of IA disorder of pupils had two stages.
The first sage was conducted in 2019, its purpose was
to determine the possible fields of use as well as an
empirical comparison of clustering methods of ma-
chine learning for studying IA disorders of students.
During the second stage, in 2019–2021, the authors
studied possible fields of use as well as an empir-
ical comparison of ensemble classification methods
of machine learning for studying IA disorders of stu-
dents.
At the first stage, data regarding the spread and
severity of IA among students majoring in Computer
Sciences were received from an online survey, which
used a questionnaire drafted with the help of Google
Forms. 262 students majoring in Computer Sciences
and coming from different regions of Ukraine partic-
ipated in the experimental study. The data set is pre-
sented in the ARFF format and consists of 8 attributes
(figure 1) (Klochko and Fedorets, 2019). The data set
contains the fields described in table 1.
Cluster analysis is one of the tasks of database
mining. Cluster analysis is a set of methods of mul-
tidimensional observations or objects classification,
based on defining the concept of distance between the
objects and their subsequent grouping (into clusters,
taxons, classes). The selection of a concrete cluster
analysis method depends on the purpose of classifica-
tion (Klochko, 2019). At the same time, one does not
need a priori information about the statistical popula-
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
243

Table 1: Data structure on the state of IA among students majoring in Computer Sciences.
Attributes Contents/Questions Type Statistics
age Age of the student Numeric Minimum 16
Maximum 59
Mean 19.756
StdDev 6.806
sex Student’s sex Nominal Female 199
Male 63
3 Can’t imagine my life without the Internet Nominal yes 184
undefined 39
no 39
4 When I cannot use the Internet I feel anxiety, irritation Nominal yes 81
undefined 134
no 47
5 I like “surfing” the Net without a clearly defined purpose Nominal yes 121
undefined 112
no 29
6 I can give up from food, sleep, going to classes, if a have a Nominal yes 248
chance to use the Internet for free undefined 7
no 7
7 I prefer meeting new people over the Internet rather than Nominal yes 185
in real life undefined 37
no 40
8 I often feel that I’ve spent not enough time playing Nominal yes 178
computer games over the Internet, I constantly wish undefined 61
to play longer no 23
Figure 1: Data set on the state of IA among students major-
ing in Computer Sciences, presented in the ARFF format.
tion. This approach is based on the following presup-
positions: objects that have a certain number of sim-
ilar (different) features group in one segment (clus-
ter). The level of similarity (difference) between the
objects that belong to one segment (cluster) must be
higher than the level of their similarity with the ob-
jects that belong to other segments (Klochko, 2019).
Let us look at one of cluster analysis algorithms
(Klochko, 2019).
Output matrix:
X =
x
11
. . . x
1n
.
.
.
.
.
.
.
.
.
x
m1
. . . x
mn
.
Let us move to the matrix of standardized Z values
with elements:
z
i j
=
x
i j
− ¯x
j
s
j
;
where j = 1, 2, ·· · ,n — index number, i = 1, 2, ··· ,m
– observation number;
¯x
j
=
1
m
m
∑
i=1
x
i j
;
s
j
=
s
1
m
m
∑
i=1
(x
i j
− x
j
)
2
=
q
(x
2
i j
) − (x
j
)
2
.
There are several ways to define the distance be-
tween two observations z
i
and z
v
: weighted Euclidean
AET 2020 - Symposium on Advances in Educational Technology
244

distance, which is determined by the formula
ρ
BE
(z
i
, z
v
) =
s
n
∑
l=1
w
l
(z
il
− z
vl
)
2
,
where w
l
is the “weight” of index; 0 < w
l
≤ 1; if
w
l
= 1 for all l = 1, 2, . . . ,n, then we get the usual
Euclidean distance
ρ
BE
(z
i
, z
v
) =
s
n
∑
l=1
(z
il
− z
vl
)
2
.
Hamming distance:
ρ
BH
(z
i
, z
v
) =
n
∑
l=1
|z
il
− z
vl
|,
in most cases this way of distance measuring gives the
same result as the usual Euclidean distance, but in this
case the influence of non-systemic large differences
(runouts) decreases.
Chebyshev distance:
ρ
BCH
(z
i
, z
v
) = max
1≤l≤n
|z
il
− z
vl
|,
it is best to apply this distance in order to determine
the differences existing between the two objects using
only one dimension.
Mahalanobis distance:
ρ
BM
(z
i
, z
v
) =
q
(z
i
− z
v
)
T
S
−1
(z
i
− z
v
),
where S is covariance matrix; this distance measure-
ment gives good results when applied to a concrete
data group, but it does not work very well, if the co-
variance matrix is calculated for the whole data set.
Distance between peaks:
ρ
BL
(z
i
, z
v
) =
1
n
n
∑
l=1
|z
il
− z
vl
|
z
il
+ z
vl
,
presupposes independence of random variables,
which indicates the distance in the orthogonal space.
It is best to choose from the above described dis-
tance measures after the consideration of the structure
and characteristics of the data sample.
Let us present the received measurements in the
form of distance matrix:
R =
0 ρ
12
ρ
13
. . . ρ
1m
ρ
21
0 ρ
23
. . . ρ
2m
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
ρ
i1
ρ
i2
ρ
i3
. . . ρ
im
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
ρ
m1
ρ
m2
ρ
m3
. . . 0
.
As the R matrix is symmetric, i.e. ρ
iv
= ρ
vi
,
we may confine ourselves to off-diagonal matrix el-
ements. Using the distance matrix, we can imple-
ment the agglomerative hierarchic procedure of clus-
ter analysis. Distances between clusters are deter-
mined as the closest or the farthest ones. In the first
case, the distance between the clusters is the one be-
tween the closest elements of these clusters, in the
second case, it is the one between the two farthermost
located. The principle of the work of agglomerative
hierarchic procedures lies in a consequent grouping of
elements, starting from the ones closest to each other
and those that are farther and farther apart. During
the first step of the algorithm, every observation z
i
(i = 1, 2, ..., m) is viewed as a separate cluster. Then,
during every next step of the work of the algorithm,
two closest located clusters are grouped together and
then once again the distance matrix is built, but its
dimension decreases by one. The algorithm stops its
work when all the observations are grouped into clus-
ters.
Let us look at the algorithms we used while clus-
tering the data set regarding the state of IA disorder
among students majoring in Computer Sciences:
EM (Expectation Maximization):
Determines the probability distribution for every
object, which indicated its belongingness to each
cluster. EM methods (Keng, 2016): Maximum Like-
lihood Estimation (MLE) or Maximum a Posteriori
(MAP). Description of the algorithm is shown in fig-
ure 2 (Keng, 2016): at the E-stage (expectation) we
calculate the estimated likelihood; at the M-stage
(Maximization) we calculate the maximum likelihood
estimation, increasing the expected likelihood, calcu-
lated at the E-stage; its value is used for the E-stage at
the next iteration. The algorithm is repeated until its
convergence.
K-Means algorithm:
Aims to partition n observations into k clusters in
such a way that each observation belongs to the clus-
ter with the nearest mean value. The shortest distance
between the observations and the nearest mean value
may be calculated by minimizing the sum of squares
of the distances (Linoff and Berry, 2011) (figure 3).
Farthest First algorithm:
This is a modification of a K-Means algorithm, in
which the initial selection of centroids is 2 and higher.
Centroids are determined following the remoteness
principle, i.e. the point farthest from the rest is se-
lected first. The Farthest First algorithm is described
in figure 4 (Dasgupta and Long, 2005).
During the second stage of the survey on the sit-
uation with IA among students of various specialties
was conducted with the help of Google Forms. 363
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
245

Figure 2: Description of how the algorithm EM works from 10,000 feet (Keng, 2016).
Figure 3: K-Means algorithm (Linoff and Berry, 2011).
students from different regions of Ukraine took part
in the survey. The data set is presented in the ARFF
format and consists of 9 attributes (figure 5). The data
set contains the fields described in table 2.
Cluster analysis is one of the tasks of database
mining. Cluster analysis is a set of methods of mul-
tidimensional observations or objects classification,
based on defining the concept of distance between the
objects and their subsequent grouping (into clusters,
taxons, classes). The selection of a concrete cluster
analysis method depends on the purpose of classifica-
tion (Klochko, 2019). At the same time, one does not
need a priori information about the statistical popula-
tion. This approach is based on the following presup-
positions: objects that have a certain number of sim-
ilar (different) features group in one segment (clus-
ter). The level of similarity (difference) between the
objects that belong to one segment (cluster) must be
higher than the level of their similarity with the ob-
jects that belong to other segments (Klochko, 2019).
In order to analyze the IA phenomenon, we di-
vide the respondents into three groups (Significant
Risk (SR), Insignificant Risk (IR), No Risk (NR)).
The division is based on the integrative use of qual-
itative and quantitative characteristics of the IA phe-
nomenon. The SR group is formed on the basis of
detecting and analysis of those IA features, which sig-
nify qualitative changes of the psychological status of
a personality. The selection of such features is car-
ries out on the basis of traditional understanding of
the fact that in-depth psychic changes related to the
formation of addictive behavior concern, primarily,
vital (Balatskiy, 2008) and existential “foundations”
of a personality. Such vital and existential (ontologi-
cal) “foundations” are relatively stable and are subject
to “external” transformation if the influence is sig-
nificant and long-lasting. The changes concern the
existential dimension (Frankl, 1985), vital resources
(Balatskiy, 2008) and intentions as well as attitudes
and behavioral stereotypes aimed at survival and life
preservation. They are linked with the vital “founda-
tions” of life itself.
The questions which reflect the above stated life
“foundations” or vital resources are (table 2): “I can
give up food, sleep, going to classes, if I have a chance
to use the Internet for free” (1
st
SR) and “When I
cannot use the Internet, I feel anxiety, irritation” (2
nd
SR). The 1
st
SR seems to be more important as food
and sleep are system organizing and basic vital needs.
The ability to give them up indicates not only the “to-
tal”, in-depth and comprehensive change of the hier-
archy of vital needs, values and senses (Frankl, 1985;
AET 2020 - Symposium on Advances in Educational Technology
246

Figure 4: Farthest-first traversal of a data set (Dasgupta and Long, 2005). Take the distance from a point x to a set S to be
d(x, S) = min
y∈S
d(x, y) (Dasgupta and Long, 2005).
Figure 5: Data set on the state of IA of students, presented
in the ARFF format.
Leontyev, 2017), but also the deformation of very vi-
tal “foundation” of a personality. The stated issues of
food and sleep indirectly reflect the existential prob-
lems of a person. The is caused by the fact these
issues concern the existential problem of “life and
death” and the “I am” existential phenomenon. That
is why, while IA is being formed, the existential prob-
lem is also being developed, which is temporarily and
compensatory solved with a “potential possibility of
Internet access”.
In the first (1
st
SR) question, the “can give up
classes” part is an important social and personal-
ity oriented aspect. If the answer is positive, that
means that the content embedded in the afore men-
tioned fragment is ignored and desemantized. This
discloses the presence of desemantization and depre-
ciation of the possible socio-economically “settled”
future and a conscious self-limitation in the field of
self-actualization in studying and professional activ-
ity. Another relevant point is ignoring communica-
tion, social ties, possibilities for self-improvement
and “construction” of self in the educational dis-
course. The stated needs and aims are partially
changed and substituted by the Internet. At the same
time the “real” reality is replaced, deactualized and
desemantized. The second (2
nd
SR) question reflects
the presence of neurotic anxiety, which is a mani-
festation of ”exhaustion” and ”overstrain” of the ner-
vous system as well as of certain changes in the sys-
tem of emotions and volition. Moreover, in this case,
the problem of sense formation and understanding
occurs as well as the corresponding changes in the
value-conceptual field. This is what V. Frankl (Frankl,
1985) described and logoneurosis – the loss and / or
absence of sublime and vital senses. The presence
of a neurotic aspect in the form of neurotic anxiety
is particularized through actualization in the 2
nd
SR
question of the irritation phenomenon (“. . . feel . . .
irritation”).
In general, the 2
nd
SR question supplements, par-
ticularizes and “strengthens” the deficit and “narrow-
ing” of vitality, life creativity, nature correspond-
ing existence, healthy life preservation instinct (food,
sleep, communication). The stated vital resources and
life creativity, which are actualized and problematized
in the 1
st
SR and 2
nd
SR question, act as a com-
plex diagnostic sub-system. It is aimed at detect-
ing systemic, comprehensive stable, in-depth, vital,
personal-psychological problems (i.e. disorders). The
stated problems may develop and together transform
into AI.
The 1
st
SR and 2
nd
SR questions, which reflect
the vitality pf a person and his/her existence, disclose
the qualitative difference of the SR group from IR and
NR groups, which do not have the stated peculiarities.
Thus, with a certain degree of certainty, the SR group
may be represented as well as diagnosed with a rel-
atively limited number of questions (1
st
SR and 2
nd
SR). The questions, which represent the SR group in-
dicate that the Internet has “penetrated” deep into the
consciousness and into the core of a personality, in
his/her vitality, into human existence (figure 6).
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
247

Table 2: Data structure on the state of IA of students.
Attributes Contents/Questions Type Statistics
age Age of the student Numeric Minimum 15
Maximum 59
Mean 20.306
StdDev 7.238
sex Student’s sex Nominal Female 260
Male 103
3 Can’t imagine my life without the Internet Nominal yes 245
undefined 53
no 65
4 When I cannot use the Internet I feel anxiety, irritation Nominal yes 110
undefined 194
no 59
5 I like “surfing” the Net without a clearly defined purpose Nominal yes 169
undefined 156
no 38
6 I can give up from food, sleep, going to classes, if a have a Nominal yes 343
chance to use the Internet for free undefined 8
no 12
7 I prefer meeting new people over the Internet rather than Nominal yes 263
in real life undefined 48
no 520
8 I often feel that I’ve spent not enough time playing Nominal yes 243
computer games over the Internet, I constantly wish undefined 86
to play longer no 343
IA IA disorder Nominal nr 113
ir 217
sr 33
Thus, the SR group is qualitatively different from
IR and NR. The SR group represents either a con-
siderable risk of IA development or a transitive (pre-
morbid) state or even the presence of the actual IA
pathology whereas the IR and NR groups indicate a
greater or lesser possibility of its development.
The IR group is diagnosed by questions 3, 5, 7 and
8 of table 2, which reflect “weak” signs. The signs re-
flected in these questions are not attributive or essen-
tial. Accordingly, they do not represent the in-depth
personality-psychological, vital and existential aspect
of IA. That is why, these questions, by summing up a
certain number of them (in this case, three), may form
a certain degree of probability for having IA risks.
These questions get a certain level of “consistency”
when there is a certain number of them, in this case,
not less than three.
Thus, the IR group is characterized (diagnosed)
by the presence of three questions out of questions
3 (1
st
IR), 5 (2
nd
IR), 7 (3
rd
IR) and 8 (4
th
IR) of
table 2. The 1
st
IR question discloses contemporary
reality of professional activity and communication, in
which the Internet component id relevant, systemic,
environmental and significant. Thus, taking into con-
sideration current systemic Internet-oriented socio-
technological and technological contexts, this ques-
tion does not reveal the totality and explicitness of
personality-psychological changes. It primarily indi-
cates considerably high level or significance and even
value of the Internet in the life of a person. The 2
nd
IR question characterizes the peculiarity of the con-
temporary Internet-culture. It reflects the fact that
the person has an actualized orientation-searching re-
flex and a corresponding search and cognitive behav-
ior, and not just that possibility of IA development.
While disclosing the peculiarities of modern-day In-
ternet communication, the 3
rd
IR question also par-
tially characterizes the problem of the insufficiently
developed communicative competence and commu-
nicative culture of a personality, which, in turn, is ef-
fectively compensated with Internet-communication.
As for the 4
th
IR, the significant question is the one
which indicates an integrative manifestation of the
activity (leading aspect), cognitive, value-conceptual,
creative and communicative dimensions of the psy-
chic reality. The positive answer partially indicates
AET 2020 - Symposium on Advances in Educational Technology
248
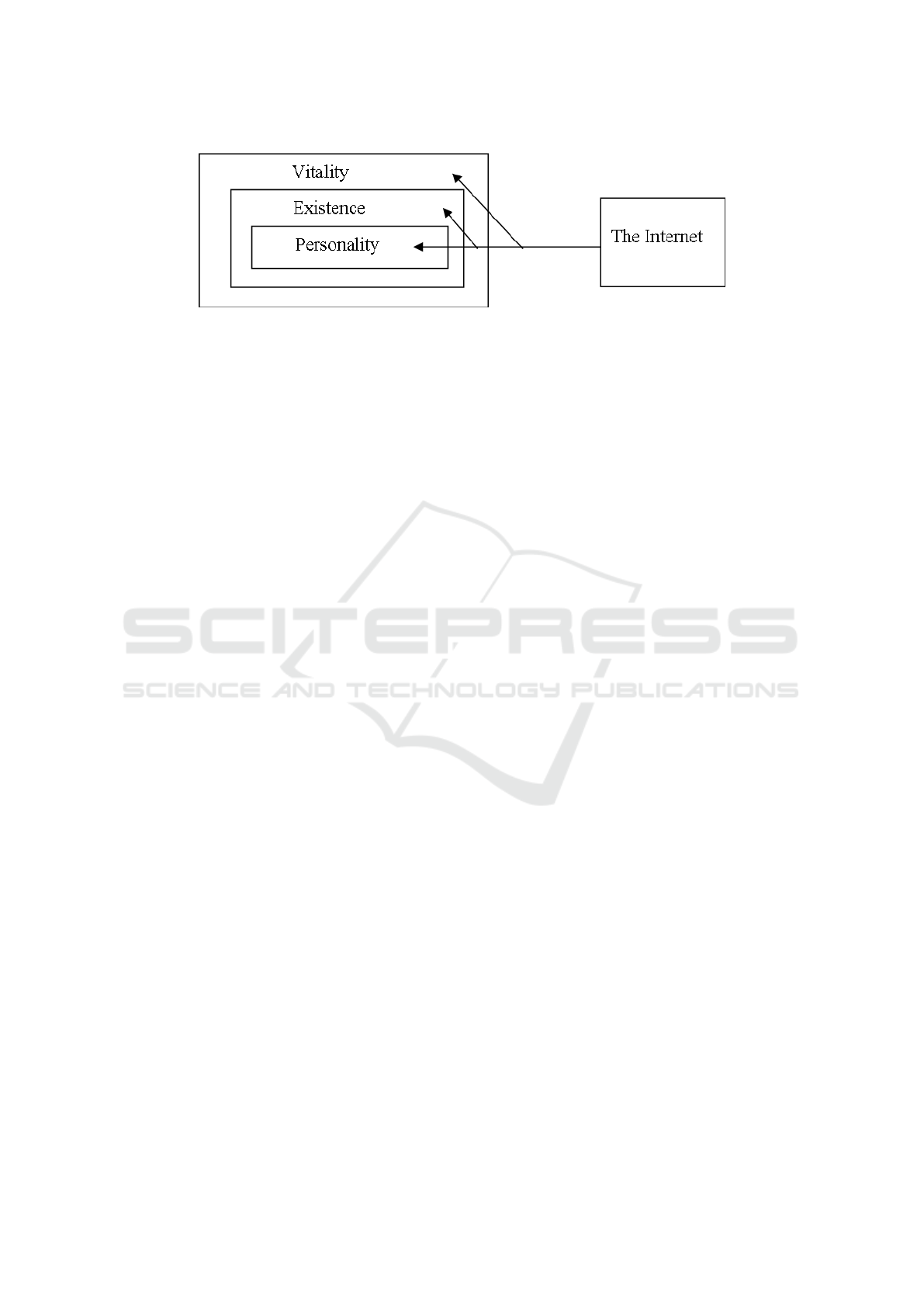
Figure 6: “Penetration” of the Internet into the core of a personality, into vitality, into existence, which illustrates the psycho-
logical mechanisms of risk formation in the SR group.
the presence of insufficient risks. At the same time,
in its essence, a person is a creature that plays –
Homo ludens (Huizinga, 2016). What is important,
is the fact that at an early childhood a game is a spe-
cific integrative and integrating form of activity and
the essence of human existence. The states gaming
essence of a person can manifest itself in course of
solving complicated tasks, studying as well as dur-
ing leisure time. A computer game has a consider-
able mobilizing, emotional, orientation-search poten-
tial. A computer game can become addictive, both
due to the “gaming” peculiarities of human nature and
as a result of the professionally developed games that
take human psychology into account. A computer
game addiction thus indicates not only not as much
the risks of IA development, but rather the presence
of the “gaming essence” of Homo ludens. In addition,
a considerable number of teenagers and grown-up de-
velop computer game addiction as a consequence of
the fact that they did not have a chance to fully real-
ize their gaming potential in early childhood. This
often happens due to intense early learning, which
competes with gaming activity. The stated principle
of competition between different forms of activity is
described in Anokhin (Anokhin, 1968) study on func-
tional systems (Sudakov, 2011). At the same time,
constant interest in playing computer games poses a
certain threat of the development of a computer game
and Internet addictions as it “touches” different psy-
chic spheres.
At the same time, if a person gives at least three
positive answers to the 1
st
IR, 2
nd
IR, 3
rd
IR and 4
th
IR questions, this indicates a certain risk of IA devel-
opment. This is caused by the fact that each question
characterizes the influence of the Internet on a certain
aspect of a personality: the 1
st
IR – on the need and
value-conceptual aspect, the 2
nd
– on the cognitive as-
pect, including the orientation ability; the 3
rd
– on the
communicative aspect, the 4
th
– on the activity com-
ponent. Thus, actualization of the Internet as a need,
value-conceptual, cognitive, communicative and ac-
tivity phenomenon that is significant for a personal-
ity speaks of its certain “spread” and “rootedness” in
the stated aspects (spheres) as well as about its corre-
sponding significance and value. A certain “Internet
locus” is formed in various spheres of a personality.
Thus, as a result of systemic interiorization processes,
the Internet “integrates” into a person’s conscious-
ness, becoming a significant phenomenon (figure 7).
At the same time, the stated “integration” is “super-
ficial”, reversal, unstable, and such that does not lead
to maladaptation or personality-psychological and be-
havioral changes.
The totality of the “spread” or “expansion” of the
Internet on the psychic reality, as a significant phe-
nomenon for several spheres of consciousness, cre-
ates certain (but considerably insignificant) risks of
IA development. At the same time, the more spheres
“contain” the “Internet locus”, the higher the risks are
as this means the increase of the number of opportuni-
ties for forming the summing up and synergy effects,
which lead to qualitative changes.
NR is a group of questions, which characterize
separate features of Internet influence. The personal-
ity demonstrates local, superficial, reactive reactions.
That is why the people that fall into this group, the
risks are almost absent or are rather insignificant.
The classification ensemble methods of machine
learning were used to study the presence of IA dis-
order in students. The ensemble methods combine
a few algorithms that learn simultaneously and com-
pensate or correct mistakes of one another. Such ap-
proaches as stacking, bagging (bootstrap aggregat-
ing) and boosting are used while developing ensem-
ble methods. Stacking used the approach of meta-
learning in order to best combine a few machine
learning models. On the basis of the basic-level mod-
els, the algorithm is taught. Using these results, the
meta-model learns to better combine the predictions
of basic models. Bagging uses multiple teaching of
an ensemble of classifiers on random data sets, which
is conducted simultaneously but independently from
one another. Then, a determined averaging of results
is conducted. The results are averaged on the basis of
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
249

Figure 7: Influence of the Internet on various spheres of human psychic.
a determined strategy. Boosting carries out a consec-
utive adaptive algorithm teaching. The next algorithm
learns through focusing on classification mistakes of
the first algorithm. In this research, the authors used
such ensemble classification algorithms as AdaBoost,
Bagging, Random Forest and Vote.
The WEKA machine learning system uses the Ad-
aBoost algorithm.M1 (figure 8) (Freund and Schapire,
1996; Santos and de Barros, 2020). The Ad-
aBoost meta-algorithm improves the efficiency of ba-
sic learning algorithms by building their combination.
It uses adaptive boosting, building every next classi-
fier according to the instance that were badly clas-
sified by previous classifiers. Having determined a
weak classifier in the cycle, AdaBoost re-assigns the
weights, and at every iteration the weights of incor-
rectly classified instances increase. By testing classi-
fiers in such a way, the AdaBoost algorithm selects a
classifier that better identifies the instances.
The Bagging (bootstrap aggregation) meta-
algorithm uses compositions of algorithms each of
which learns independently from one another; to
determine the final result, the process called voting is
being implemented, as a result of which, the mistakes
of the classifiers are compensated (Breiman, 1996;
Tuysuzoglu and Birant, 2020) (figure 9).
According to Leo Breiman’s definition, “a Ran-
dom Forest is a classifier consisting of a collection of
tree-structured classifiers {h(x, Θ
k
), k = 1, ... } where
the {Θ
k
} are independent identically distributed ran-
dom vectors and each tree casts a unit vote for the
most popular class at input x” (figure 10) (Breiman,
2001; Zhong et al., 2020).
The voting classifier combines different classifiers
that learn and are assessed simultaneously (Kittler
et al., 1998; Kuncheva, 2014). The final decision
regarding the prediction is taken by a majority vote
following two strategies. In hard voting (majority
voting), the class label is predicted, which is deter-
mined by a majority of votes of every classifier (Kit-
tler et al., 1998; Kuncheva, 2014). In soft voting,
probability vectors for every predicted class (for all
classifiers) are summed up and averaged and the class
with the highest value is selected (Kittler et al., 1998;
Kuncheva, 2014).
3 RESULTS AND DISCUSSION
To cluster data using the WEKA platform, we will use
Weka.clusterers.EM, Weka.clusterers.SimpleKMeans
and Weka.clusterers.FarthestFirst algorithms (Weka,
2021).
We check the application of clustering algorithms
that can be assigned to two classes of clustering al-
gorithms, i.e. distribution based (Expectation Max-
imization) and centroid-based (K-Means, Farthest
First). Such selection is motivated by the fact these
algorithms have long been used to cluster different
types of data in many fields and are considered to be
effective.
Dunn, DB, SD, CDbw and S Dbw were selected
as validity indices for testing (da Silva et al., 2019;
Moshtaghi et al., 2019) (table 3). In the CDbw in-
dex the distance from the point to multitude set in
the course of selecting cluster element can be calcu-
lated in different ways. In this study, we use the sum
of distances of already existing “representatives” of
the cluster to each cluster element to calculate this
distance. The element, on which the maximum was
reached, was selected as the next “representative” of
the cluster.
If the data set has no cluster structure, then such
situation is not determined with the help of validity
metrics. While using K-Means and Farthest First (ta-
ble 2) the numbers of clusters for the two algorithms
that were selected as optimal by the majority of in-
dices, can only nominally be defined as cluster struc-
ture. As the work of Expectation Maximization algo-
rithm is based on determining the probability of eval-
uating maximum similarity, the indices calculated for
this algorithm are more homogenous. The structure,
which is characterized by a small number of clusters
that also have to be compact and separable, is deter-
mined to be the best one. Judging by the results of
evaluation of clustering using the validity indices, we
may consider that k-Means and Farthest First algo-
rithms are most likely to give worse clustering results
than the Expectation Maximization algorithms.
To cluster the data, we select training/testing using
the percentage split option. As a data set for training
(model building) we select 66% of data from the set.
AET 2020 - Symposium on Advances in Educational Technology
250

Figure 8: The algorithm AdaBoost.M1 (Freund and Schapire, 1996).
Figure 9: The algorithm Bagging (Breiman, 1996; Lee et al., 2020).
As a data set for testing we select 34% of data from
the set. In addition, we select number of clusters “3”
in algorithm settings.
We received the following results:
In the course of application of the EM cluster-
ing algorithm, according to the built clustering model
based on the training data set, three clusters were de-
termined, their characteristics are given in table 4.
Cluster 0 (63% of respondents): The average age
of respondents in this cluster is 17. The group consists
predominantly of women. The characteristic feature
of the representatives of this group is that they are un-
able to imagine their life without the Internet. There
are variations in the levels of anxiety and irritation,
if there is no possibility to use the Internet. There
are also varying opinions regarding the aimless use of
the Internet. As for other attributes, disorders related
to IA may be observed in the insignificant number
of respondents, who belong to this cluster. The be-
havioural model of the representatives of this cluster
demonstrated Internet centration in the psychic real-
ity of a personality, which is accordingly reflected in
their activity and behavior, other life interests as well
as significance of everyday activities lose their impor-
tance. The stated tendencies are linked to IA.
Cluster 1 (13% of respondents): For the represen-
tatives of this group the average value of the age at-
tribute is 36 and it varies greatly. This is the oldest
age group if compared with other clusters. This group
has the largest share of women. Representatives of
this group, predominantly, cannot imagine their life
without the Internet. Thus, according to the centroid
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
251

Figure 10: The algorithm Random Forest (Breiman, 2001).
Table 3: Optimal number of clusters, calculated with the help of quality indices.
Index
Algorithms
Expectation Maximization k-Means Farthest First
Dunn 3 6 6
DB 3 6 4
SD 3 3 3
CDbw 3 3 3
S Dbw 3 5 4
Table 4: Model and evaluation on test split by EM algo-
rithm.
Attributes Indications
Clusters
0 1 2
(0,63) (0,13) (0,24)
112.1491 24.7781 44.0727
age
mean 17.4469 36.2459 19.2906
std. dev. 1.5994 10.0785 2.243
sex
female 108.8714 16.0638 5.0648
male 2.2778 7.7143 38.0079
3
no 22.7034 3.1864 10.1102
undefined 16.0405 6.4026 4.5569
yes 73.4052 15.1891 29.4057
4
no 54.392 13.8263 27.7817
undefined 23.6012 5.1903 7.2085
yes 34.156 5.7615 9.0825
5
no 45.3302 19.3167 26.3531
undefined 15.1791 2.1415 5.6794
yes 51.6398 3.32 12.0403
6
no 106.1573 22.7561 41.0866
undefined 1.0117 1.0098 1.9785
yes 4.9802 1.0122 1.0076
7
no 81.1224 20.5492 27.3284
undefined 11.5501 2.168 11.282
yes 19.4767 2.061 5.4624
8
no 89.4444 19.3333 9.2223
undefined 7.2533 1.1937 9.553
yes 15.4514 4.2512 25.2975
values of the attributes, we may diagnose IA related
Internet centration in the psychic reality of a personal-
ity, which is accordingly reflected in their activity and
behavior; other life interests as well as significance of
everyday activities lose their importance. There are
predominantly no other signs of IA related disorders.
Cluster 2 (24% of respondents): The probabilis-
tic average of the age attribute among the representa-
tives of this group is middle-aged in comparison with
other groups and is 19. Male representatives signifi-
cantly dominate in this group. Regarding the inabil-
ity to imagine their life without the Internet, opinions
differed, however, predominantly respondents believe
they have this addiction. Judging by the values of
attributes 4, 5, 6 and 7, the vast majority of this
group’s representatives declare that they do not have
other signs of IA. However, the feeling of the lack
of time spent playing computer games over the In-
ternet, which was confirmed by the vast majority of
respondents, is a warning signal that may signify the
existence of IA related disorders. Thus, the charac-
teristic feature of this group is that most of its rep-
resentatives have IA related disorders such as: Inter-
net centration in the psychic reality of a personality;
behavioral impulse control disorders related to online
gaming. These people are in the risk group for devel-
oping IA related disorders.
In the course of application of the Farthest First al-
gorithm, according to the built clustering model based
on the training data set, there have also been three
clusters formed; their characteristics are given in ta-
ble 5.
Table 5: Model and evaluation on test split by Farthest First
algorithm.
Attributes
Clusters
0 1 2
age 16.0 22.0 20.0
sex female male male
3 yes undefined yes
4 undefined no yes
5 no yes undefined
6 no no undefined
7 no undefined undefined
8 no undefined no
AET 2020 - Symposium on Advances in Educational Technology
252

Cluster 0: Contains data instances of the youngest
age group, whose age centroid attribute is 16. Ac-
cording to the value of the sex centroid attribute, the
group is made up of mostly female data instances.
The representatives of this group cannot imagine their
life without the Internet, i.e. there is obvious Internet
centration in the psychic reality of a personality. Re-
spondents cannot clearly determine whether they feel
either anxiety or irritation if they do not have the pos-
sibility to use the Internet. Judging by other attributes,
data instances of this cluster do not have IA related
disorders.
Cluster 1: This cluster contains data instances of
an older age group, the age attribute centroid of which
is 22. The value of the sex attribute centroid in this
cluster is male. A characteristic feature of the cluster
is undecidedness regarding the vital need to use the
Internet, prevalence of Internet relations over actual
real interactions, feeling the lack of time spent play-
ing computer games over the Internet (attributes 3, 7,
8 equal undefined). The value of the yes centroid of
attribute 5 shows inclination to use the Internet with-
out a concrete purpose. To give an overall character-
istic, this group has signs of IA, i.e. behavior control
disorders related to Internet use.
Cluster 2: By the value of the age attribute cen-
troid, 20, this cluster contains data instances of the
middle age group if compared with other clusters.
The sex attribute centroid in this cluster is male. The
representatives of this cluster cannot imagine their life
without the Internet and feel anxiety and irritation
when they do not have the possibility to use the In-
ternet. They are characterized by their undecidedness
regarding the vital need to use the Internet; giving up
other life interests and everyday activities for the sake
of free Internet use; prevalence of online relations of
real-life interactions (value of attributes 5, 6, 7 is un-
defined). Thus, the representatives of this cluster have
signs of IA, the priority significance of the Internet
and behavior control disorders, related to Internet use.
Compared to other groups, they are in the risk group
for developing IA related disorders.
In the course of application of the K-Means algo-
rithm to the clustering model built on the basis of the
training data set three clusters have also been formed,
their characteristics are presented in table 6.
Cluster 0: Contains data instances of the youngest
age group, whose age attribute centroid is about 18.
According to the sex attribute centroid, mostly female
data instances are present in the groups. The represen-
tatives of this group cannot clearly determine whether
they have a vital need to use the Internet. As for other
indices, respondents state absence of signs of IA re-
lated disorders.
Table 6: Model and evaluation on test split by K-Means
algorithm.
Attributes
Clusters
0 1 2
age 18.4194 21.8605 20.9552
sex female male female
3 undefined yes yes
4 no no no
5 no no no
6 no no no
7 no no no
8 no yes no
Cluster 1: This cluster contains data instances of
the older age group, whose age attribute centroid is
about 22. The value of the sex attribute centroid in
this cluster is male. Characteristic features of data
instances that belong to this cluster include the vi-
tal need to use the Internet, feeling the lack of time
spent playing online computer games as well as the
systemic need to play longer. The overall characteris-
tic of this cluster is the presence of signs of IA, i.e. be-
havior control issues related to Internet use, namely,
gaming Internet addiction. If compared with other
cluster, they belong to the risk group that may develop
IA related disorders.
Cluster 2: By the value of age attribute centroid,
which is about 21 years, compared to other clusters,
this cluster contains data instances of medium age
group. The sex attribute centroid is female. The rep-
resentatives of this cluster cannot imagine their life
without the Internet. Judging by centroids of other
characteristics, respondents of this cluster do not have
Internet-related disorders. Thus, the representatives
of this cluster have only IA signs associated with the
utmost significance of the Internet.
The cluster distribution of test data in the course of
application of the three algorithms – the Expectation
Maximization, Farthest First and K-Means – using the
built training models is presented in table 7. Thus,
as it can be seen from the table, the algorithms have
determined three data groups. Clusters were formed,
which included 71:12:7, 67:4:19 and 33:15:42 data
instances respectively. There is a cluster that has
the largest number of data instances; a group, which
has the least data instances (exceptions); a group that
includes several times more data instances than the
smallest group.
Figures 11, 12 and 13 present a graphic repre-
sentation of clusters by age characteristic of data in-
stances, which are built using the training data set
and received in the course of implementation of the
Expectation Maximization, the Farthest First and the
K-Means algorithm respectively. As we can see, the
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
253
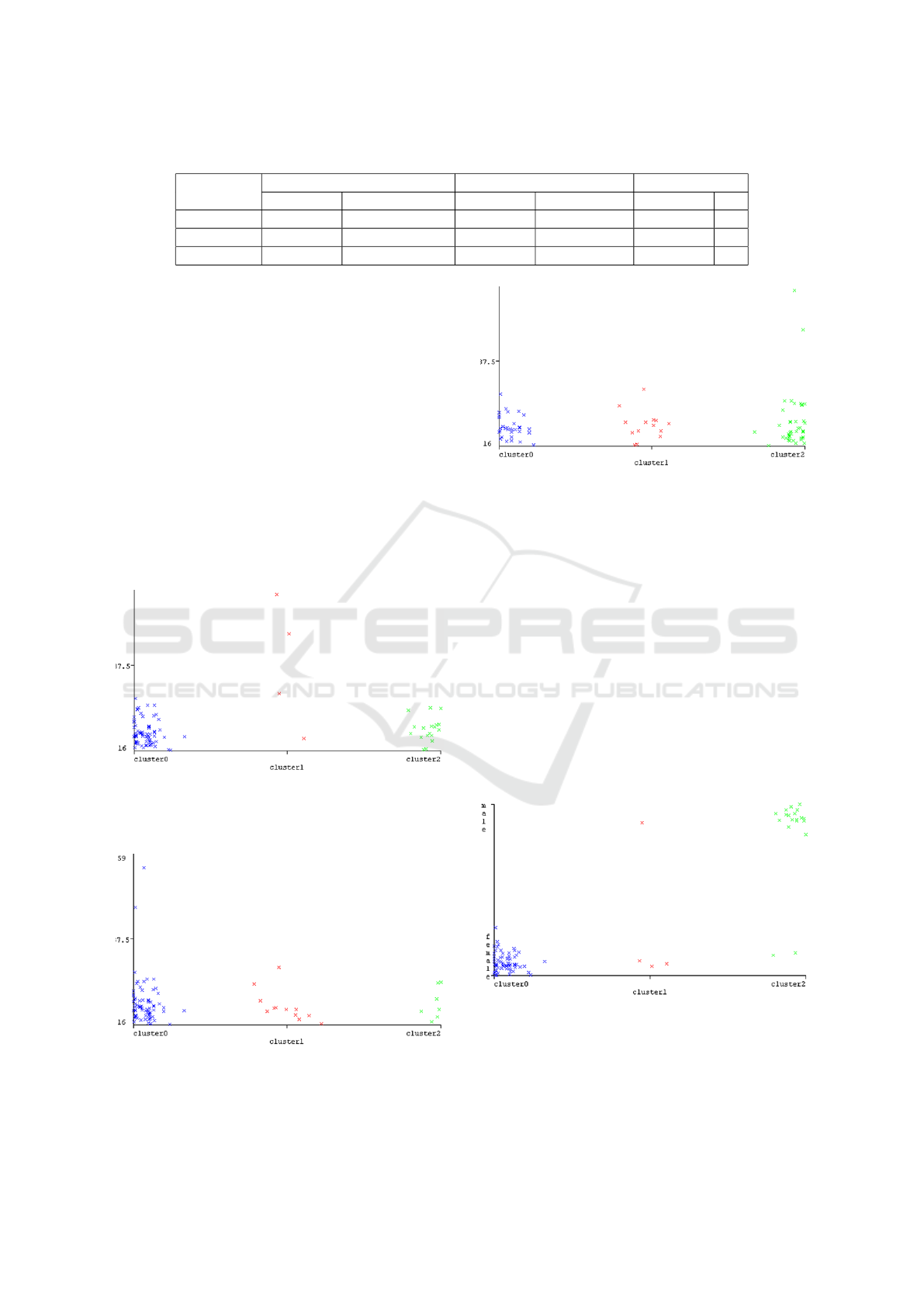
Table 7: Clustered Instances determined using Expectation Maximization, K-Means and Farthest First algorithms.
Attributes
Expectation Maximization Farthest First algorithm K-Means
Instances % Instances % Instances %
0 67 74 71 79 33 37
1 4 4 12 13 15 17
2 19 21 7 8 42 47
formed clusters differ from each other by the age at-
tribute. For instance, Cluster 0, which contains most
data instances, contains instances of respondents of a
younger age, if formed through the application of the
Expectation Maximization algorithm (figure 11). On
the other hand, the same cluster received through the
implementation of the Farthest First algorithm, con-
tains data instance of various age groups (figure 12).
Also, a small number of data instances of various
age groups is present in Cluster 2, received in the
course of implementation of the K-Means algorithm
(figure 13). Cluster 0 and Cluster 2 formed with the
Expectation Maximization algorithm as well as Clus-
ter 1 and Cluster 2 formed with the Farthest First algo-
rithm contain homogeneous age groups, and Cluster 0
and Cluster 1, formed with K-Means algorithm.
Figure 11: Plot of cluster distribution applying the Expec-
tation Maximization algorithm depending on the age group
attribute.
Figure 12: Plot of cluster distribution applying the Farthest
First algorithm depending on the age group attribute.
Figures 14, 15 and 16 present a graphic represen-
Figure 13: Plot of cluster distribution applying the K-Means
algorithm depending on the age group attribute.
tation by sex attribute of clusters formed through the
application of the Expectation Maximization, Farthest
First and K-Means algorithm respectively. The analy-
sis of figure 14, which visualizes clustering through
application of the Expectation Maximization algo-
rithm, shows that Cluster 0 contains only female data
instances. Clusters 1 and 2 have date instances of both
sexes. Female data instances prevail in Cluster 1 and
male ones in Cluster 2. Unlike Clusters formed by the
Expectation Maximization algorithm, all the clusters
formed by the Farthest First algorithm contain data
instances of both sex groups (figure 15). Female data
instances significantly prevail in Cluster 0. All the
clusters built using the K-Means algorithm, contain
both male and female data instances (figure 16).
Figure 14: Plot of cluster distribution applying the Expecta-
tion Maximization algorithm depending on the sex attribute.
To classify a data set that contains 363 data sets,
we break it with the help of random choice into a
training set, which contains 70% (254) data sets and a
test set, which contains 30% (109) data sets.
AET 2020 - Symposium on Advances in Educational Technology
254
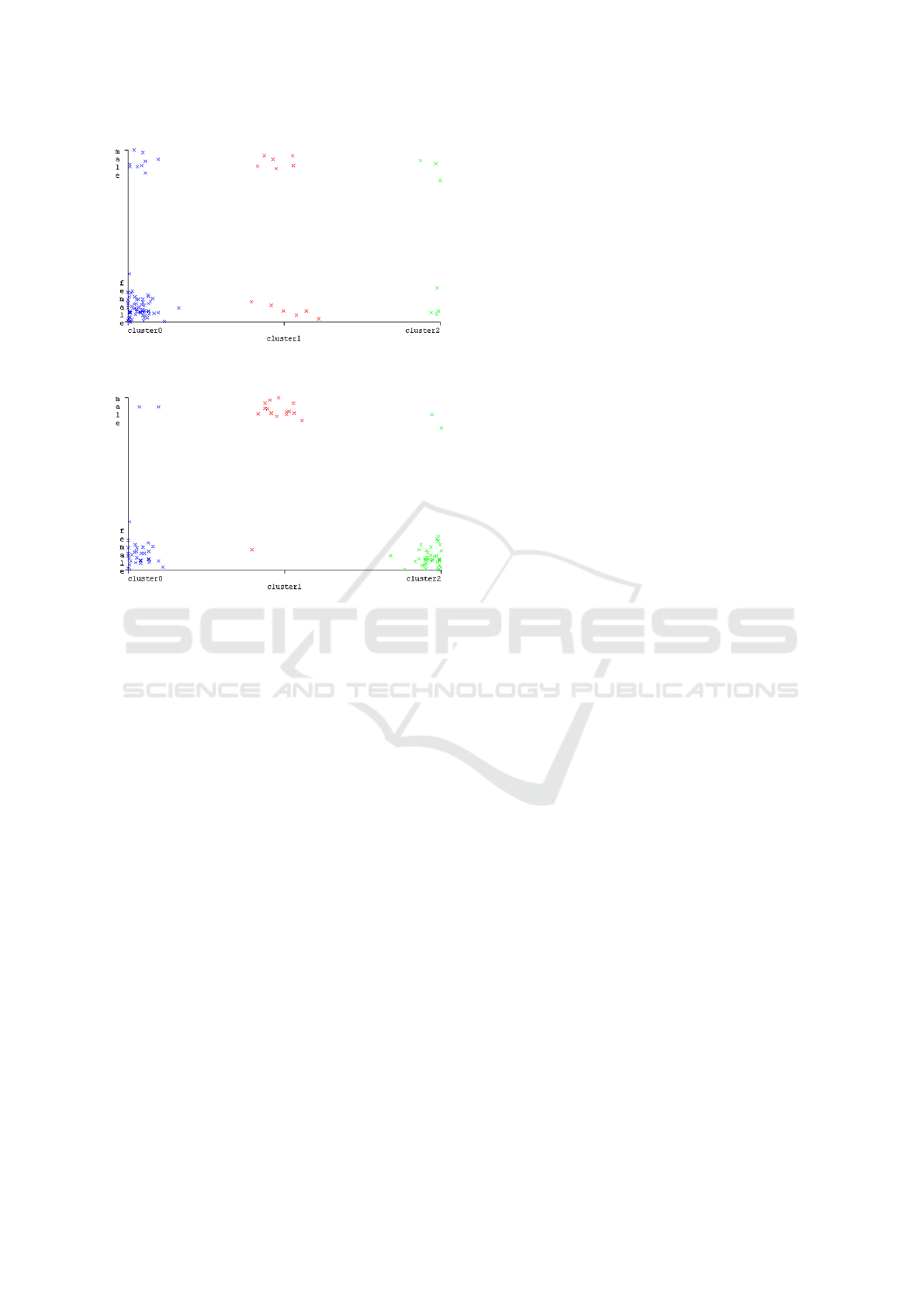
Figure 15: Plot of cluster distribution applying the Farthest
First algorithm depending on the sex attribute.
Figure 16: Plot of cluster distribution applying the K-Means
algorithm depending on the sex attribute.
To classify using the WEKA machine learning
system, we create classification models on the basis
of the training set with the help of AdaBoost, Bag-
ging, Random Forest and Vote algorithms.
The results are shown in tables 8, 9, 10, 11, 12,
13.
According to the results, that are reflected in ta-
bles 8-13, the highest percent of correctly classified
instances both by the results of the training model as
well as by the prediction results are received while
applying the Bagging (classification algorithm classi-
fiers.trees.REPTree) and Random Forest algorithms,
with 94.4882% (testing – 96.3303%) and 96.8504%
(testing – 99.0826%) respectively. In this case, over-
fitting is not observed as the stated models demon-
strate a higher level of efficiency on test data rather
than on training data. In addition, these models
demonstrate the highest Kappa statistic and ROC
Area indexes. At the same time, the best results are
received while using the Random Forest algorithm.
The results received in the course of application of the
Ada Boost (classifiers.trees.DecisionStump) model
are somewhat worse by all the criteria, but are still ac-
ceptable. According to the indexes provided in Tables
8 and 11, the worst results are received in the course
of application of the Vote (classifiers.rules.ZeroR)
model.
According to the Mean absolute error (MAE),
the data forecast that is closes to the actual results
both in the process pf learning as well as in the pro-
cess of testing was built using the Random Forest
0.0597 (testing – 0.0405) and Bagging 0.0728 (test-
ing – 0.0478) models; the worst result according to
this indicator is received in the course of application
of the Vote 0.3643 (testing – 0.3569) model. The ap-
proximately twice higher MAE value was received in
course of building and testing the Ada Boost model,
which is 0.1309 and 0.1029 respectively.
The Root mean squared error (RMSE) values also
indicate the supremacy of the Random Forest 0.1391
(testing – 0.0964) and Bagging 0.1765 (testing –
0.1362) algorithms. The worst value was received as a
result of building a model based on Vote 0.4263 (test-
ing – 0.4176).
According to the Relative absolute error (RAE)
and Root relative squared error (RRSE) the assess-
ment prioritization of classification models is pre-
served with Random Forest and Bagging. It should
be noted that the worst indexes are received as a re-
sult of classification using the M model (RAE=100%,
RSE=100%), which characterizes an almost random
prediction.
4 CONCLUSION
In the course of determine the fields of use and con-
duct an empirical comparison of ensemble classifi-
cation and clustering methods using the WEKA ma-
chine learning system to study the signs of IA related
disorders of students, the following conclusions have
been made:
1. As a result of empirical comparison of Expecta-
tion Maximization, Farthest First and K-Means al-
gorithms using the WEKA machine learning sys-
tem, we developed models of data instances’ clus-
tering to determine the signs of internet addiction
disorders among students majoring in Computer
Sciences.
2. The implementation of the Expectation Maxi-
mization, the K-Means and the Farthest First algo-
rithms each resulted in the formation of 3 clusters.
The results of clustering demonstrate that Internet
centration in the psychic reality of a personality
is a characteristic feature of the respondents that
took part in the survey. This also reflects accord-
ingly in their activity and behavior, diminishing
other life interests and the significance of every-
day activities. In addition, in the course of im-
plementation of the Expectation Maximization al-
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
255
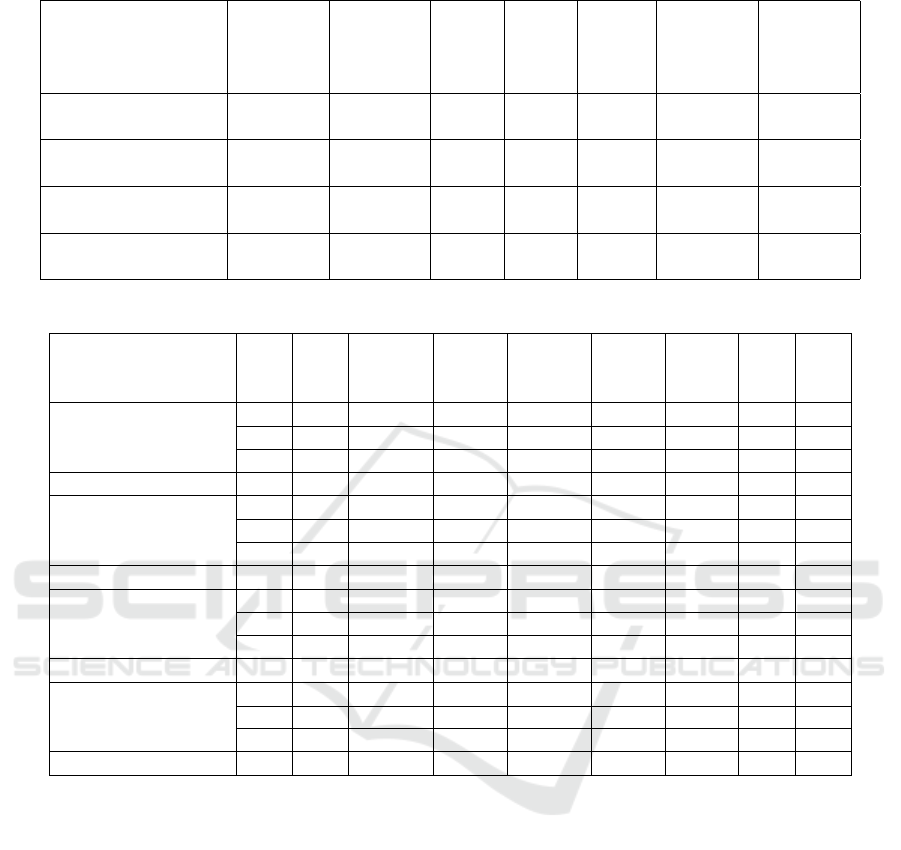
Table 8: Evaluation of the results of the work of WEKA ensemble classification training models.
Ensemble classifi-
cation algorithm
scheme
Correctly
Classified
Instances
Incorrectly
Classified
Instances
Kappa
statis-
tic
Mean
abso-
lute
error
Root
mean
squared
error
Relative
absolute
error
Root
relative
squared
error
weka.classifiers.
meta.AdaBoostM1
224
(88.189%)
30
(11.811%)
0.7583 0.1309 0.2355 35.9359% 55.2562%
weka.classifiers.
meta.Bagging
240
(94.4882%)
14
(5.5118%)
0.8962 0.0728 0.1765 19.9917% 41.3999%
weka.classifiers.
trees.RandomForest
246
(96.8504%)
8
(3.1496%)
0.9411 0.0597 0.1391 16.375% 32.6236%
weka.classifiers.
meta.Vote
152
(59.8425%)
102
(40.1575%)
0 0.3643 0.4263 100% 100%
Table 9: Detailed Accuracy by Class of the WEKA ensemble classification training models.
Ensemble classifi-
cation algorithm
scheme
TP
Rate
FP
Rate
Precision Recall F-
Measure
MCC ROC
Area
PRC Area
Class
weka.classifiers.
meta.AdaBoostM1
0.973 0.000 1.000 0.973 0.986 0.981 0.978 0.982 SR
1.000 0.294 0.835 1.000 0.910 0.768 0.958 0.961 NR
0.000 0.000 - 0.000 - - 0.922 0.620 IR
Weighted Average 0.882 0.176 - 0.882 - - 0.960 0.929
weka.classifiers.
meta.Bagging
0.973 0.000 1.000 0.973 0.986 0.981 0.975 0.981 SR
0.980 0.108 0.931 0.980 0.955 0.886 0.972 0.965 NR
0.679 0.013 0.864 0.679 0.760 0.741 0.975 0.852 IR
Weighted Average 0.945 0.066 0.944 0.945 0.943 0.898 0.974 0.957
weka.classifiers.
trees.Random Forest
0.973 0.000 1.000 0.973 0.986 0.981 0.998 0.996 SR
0.993 0.069 0.956 0.993 0.974 0.935 0.994 0.995 NR
0.821 0.004 0.958 0.821 0.885 0.875 0.995 0.971 IR
Weighted Average 0.969 0.042 0.969 0.969 0.968 0.942 0.995 0.993
weka.classifiers.
meta.Vote
0.000 0.000 - 0.000 - - 0.484 0.285 SR
1.000 1.000 0.598 1.000 0.749 - 0.475 0.586 NR
0.000 0.000 - 0.000 - - 0.466 0.103 IR
Weighted Average 0.598 0.598 - 0.598 - - 0.477 0.445
gorithm, a cluster was formed, whose represen-
tatives have behavior control disorders, related to
online gaming. These respondents are in the risk
group for developing IA related disorders.
3. Expectation Maximization, Farthest First and K-
Means algorithms of data clustering differ by their
algorithm model, however, from the point of char-
acteristic features, they produce relatively simi-
lar clusters, thus implementing optimized clus-
tering. At the same time, when a data set was
grouped into three clusters by implementing these
algorithms, the clusters differed by cluster model,
namely, by the number of data instances in each
cluster, their structure and value of attribute cen-
troids.
4. Judging by the evaluation results of clustering va-
lidity using the validity indices, we can state that
most likely the K-Means and Farthest First algo-
rithms show worse clustering results than the Ex-
pectation Maximization algorithm.
5. Respondents are divided into three groups (Signif-
icant Risk (SR), Insignificant Risk (IR), No Risk
(NR)). Such division gives the possibility of pri-
mary general assessment of risks of IA develop-
ment based on the significance of Internet influ-
ence on the psychic of a person. The Signif-
icant Risk (SR) group is determined by asking
questions, which reflect the signs of “in-depth”,
maladaptive and, accordingly, a relatively long-
lasting influence of the Internet on the psychic,
vital resources, vitality, the existential level, the
personality in general in its vital and conceptual
basis. The Insignificant Risk (IR) is determined
by asking question, which disclose the signs of
“superficial”, local, adaptive even though a rather
significant influence on the psychic. In this group
AET 2020 - Symposium on Advances in Educational Technology
256

Table 10: Table of confusion matrix of WEKA ensemble classification testing models.
Actual class
Ensemble classification algorithm scheme Area Class SR NR IR
Predicted
class
weka.classifiers.meta.AdaBoostM1
SR 72 2 0
NR 0 152 0
IR 0 28 0
weka.classifiers.meta.Bagging
SR 72 2 0
NR 0 149 3
IR 0 9 19
weka.classifiers.trees.RandomForest
SR 72 2 0
NR 0 151 1
IR 0 5 23
weka.classifiers.meta.Vote
0 74 0
NR 0 152 0
IR 0 28 0
Table 11: Evaluation of the results of testing the WEKA ensemble classification models.
Ensemble classifi-
cation algorithm
scheme
Correctly
Classified
Instances
Incorrectly
Classified
Instances
Kappa
statis-
tic
Mean
abso-
lute
error
Root
mean
squared
error
Relative
absolute
error
Root
relative
squared
error
weka.classifiers.
meta.AdaBoostM1
103
(94.4954%)
6
(5.5046%)
0.8869 0.1029 0.1729 28.8318% 41.399%
weka.classifiers.
meta.Bagging
105
(96.3303%)
4
(3.6697%)
0.9276 0.0478 0.1362 13.3815% 32.6122%
weka.classifiers.
trees.RandomForest
108
(99.0826%)
1
(0.9174%)
0.982 0.0405 0.0964 11.3566% 23.0819%
weka.classifiers.
meta.Vote
65
(59.633%)
44
(40.367%)
0 0.3569 0.4176 100% 100%
the spheres, influence by the Internet are the cog-
nitive, activity, value-conceptual, need, commu-
nicative spheres of the psychic. The No Risk (NR)
group indicates the absence of risks for IA devel-
opment. Belongingness to this group is defined
y asking questions, which reflect an insignificant,
local and short-tern influence of the Internet on
the psychic.
6. The model that gave the results that are the
closest ones to the actual classification re-
sults is the model built using the Random
Forest algorithm. According to all the as-
sessments, the classification model built us-
ing the Bagging algorithm (classification al-
gorithm classifiers.trees.REPTree) is close to
it. Somewhat lower classification indexes
are received in the course of building a
model using the Ada Boost algorithm (classi-
fiers.trees.DecisionStump). These models can be
considered suitable for diagnosing IA disorders
among students. The model built with the help of
the Vote algorithm (classifiers.rules.ZeroR) is not
suitable for use. Such a result indicates that the
application of this algorithm requires additional
modifications.
7. Intellectual analysis of the data set regarding the
situation with IA among students majoring in
Computer Sciences with the application of en-
semble classification and clustering methods has
shown that the methods studied above may be
considered suitable for developing models for de-
tecting IA disorders and respondent groups with
the signs of IA related disorders.
8. The results of the research indicate the expedience
of the application of the intellectual data analy-
sis in medical research using the machine learning
systems. The presented methods may serve as the
basis for a strategic development of new vectors
of medical data processing as well as decision-
making in this field.
The present-day medicine needs non-standard ap-
proaches to intellectual data analysis, complex appli-
cation of methods, their modification, application the
ensemble of methods in order to be able to process
large data sets in digital systems. Our conclusions
may help to determine the signs of IA related disor-
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
257
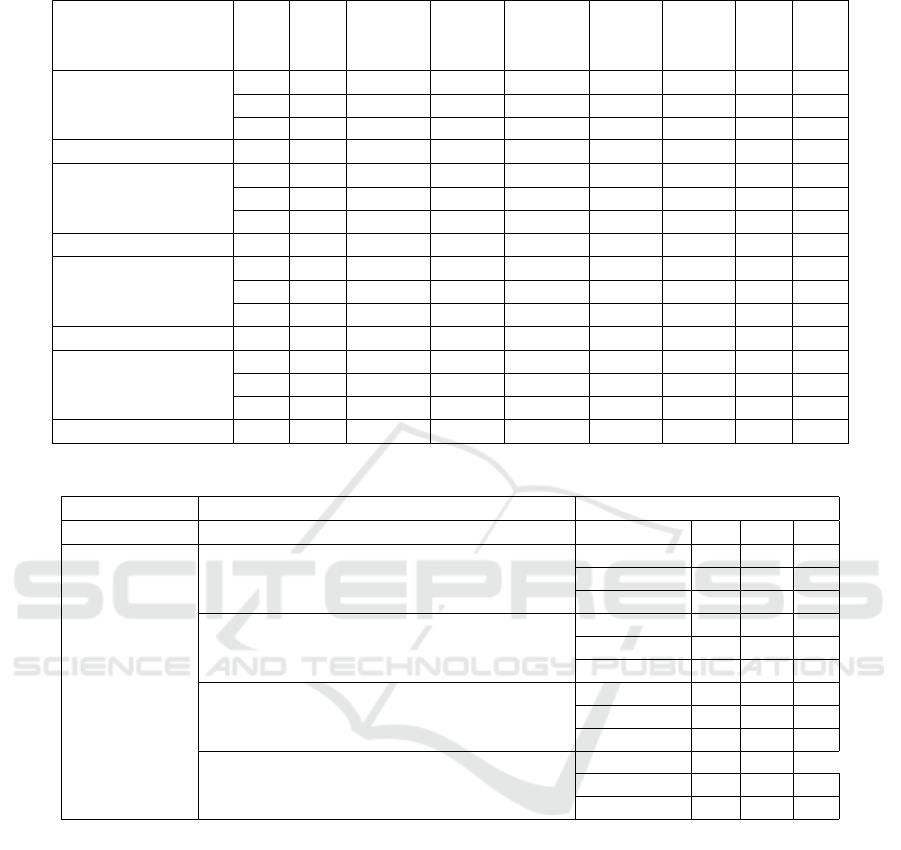
Table 12: Detailed Accuracy by Class of testing the WEKA ensemble classification models.
Ensemble classifi-
cation algorithm
scheme
TP
Rate
FP
Rate
Precision Recall F-
Measure
MCC ROC
Area
PRC Area
Class
weka.classifiers.
meta.AdaBoostM1
0.974 0.000 1.000 0.974 0.987 0.980 0.983 0.984 SR
1.000 0.136 0.915 1.000 0.956 0.889 0.976 0.971 NR
0.000 0.000 - 0.000 - - 0.946 0.540 IR
Weighted Average 0.945 0.081 - 0.945 - - 0.977 0.956
weka.classifiers.
meta.Bagging
0.974 0.000 1.000 0.974 0.987 0.980 1.000 1.000 SR
0.985 0.068 0.955 0.985 0.970 0.924 0.995 0.997 NR
0.600 0.010 0.750 0.600 0.667 0.657 0.975 0.750 IR
Weighted Average 0.963 0.041 0.962 0.963 0.962 0.932 0.996 0.987
weka.classifiers.
trees.Random Forest
1.000 0.000 1.000 1.000 1.000 1.000 1.000 1.000 SR
1.000 0.023 0.985 1.000 0.992 0.981 0.999 1.000 NR
0.800 0.000 1.000 0.800 0.889 0.890 0.998 0.967 IR
Weighted Average 0.991 0.014 0.991 0.991 0.990 0.984 0.999 0.998
weka.classifiers.
meta.Vote
0.000 0.000 - 0.000 - - 0.500 0.358 SR
1.000 1.000 0.596 1.000 0.747 - 0.500 0.596 NR
0.000 0.000 - 0.000 - - 0.500 0.046 IR
Weighted Average 0.596 0.596 - 0.596 - - 0.500 0.486
Table 13: Table of confusion matrix of testing the WEKA ensemble classification models.
Actual class
Ensemble classification algorithm scheme Area Class SR NR IR
Predicted
class
weka.classifiers.meta.AdaBoostM1
SR 38 1 0
NR 0 65 0
IR 0 5 0
weka.classifiers.meta.Bagging
SR 38 1 0
NR 0 64 1
IR 0 2 3
weka.classifiers.trees.RandomForest
SR 39 0 0
NR 0 65 0
IR 0 1 4
weka.classifiers.meta.Vote
0 39 0
NR 0 65 0
IR 0 5 0
ders among students majoring in Computer Sciences,
forecasting the risk of IA and development of services
aimed at IA prevention.
REFERENCES
Abbott, D. A., Cramer, S. L., and Sherrets, S. D. (1995).
Pathological gambling and the family: Practice impli-
cations. Families in Society, 76(4):213–219.
Anokhin, P. (1968). Cybern
´
etique, neurophysiologie et psy-
chologie. Social Science Information, 7(1):169–197.
Balatskiy, E. V. (2008). Vitalnyye resursy i kontury soz-
naniya (Vital resources and circuits of consciousness).
Vestnik Rossiyskoy akademii nauk, 78(6):531–537.
Breiman, L. (1996). Bagging predictors. Machine learning,
24(2):123–140.
Breiman, L. (2001). Random forests. Machine learning,
45(1):5–32.
da Silva, L. E. B., Melton, N. M., and au2, D. C. W. I.
(2019). Incremental cluster validity indices for hard
partitions: Extensions and comparative study.
Dasgupta, S. and Long, P. M. (2005). Performance guaran-
tees for hierarchical clustering. Journal of Computer
and System Sciences, 70(4):555 – 569.
Derhach, M. (2016). Cyber-addiction of students majoring
in computer science. Science and Education, (7):92–
98.
Di, Z., Gong, X., Shi, J., Ahmed, H. O. A., and Nandi, A. K.
(2019). Internet addiction disorder detection of Chi-
nese college students using several personality ques-
tionnaire data and support vector machine. Addictive
Behaviors Reports, 10:100200.
Frankl, V. E. (1985). Man’s search for meaning. Simon and
Schuster.
AET 2020 - Symposium on Advances in Educational Technology
258

Freund, Y. and Schapire, R. E. (1996). Experiments with
a new boosting algorithm. In Proceedings of the
Thirteenth International Conference on International
Conference on Machine Learning, ICML’96, page
148–156, San Francisco, CA, USA. Morgan Kauf-
mann Publishers Inc.
Hsieh, W.-H., Shih, D.-H., Shih, P.-Y., and Lin, S.-B.
(2019). An ensemble classifier with case-based rea-
soning system for identifying internet addiction. Inter-
national journal of environmental research and public
health, 16(7):1233.
Huizinga, J. (2016). Homo Ludens: A Study of the Play-
Element in Culture. Angelico Press.
Hussain, R. G., Ghazanfar, M. A., Azam, M. A., Naeem, U.,
and Ur Rehman, S. (2019). A performance compari-
son of machine learning classification approaches for
robust activity of daily living recognition. Artificial
Intelligence Review, 52(1):357–379.
ICD-11 for Mortality and Morbidity Statistics (Ver-
sion: 09/2020) (2020). 6C51 Gaming disor-
der. https://icd.who.int/browse11/l-m/en#/http://id.
who.int/icd/entity/1448597234.
Ji, H.-M., Chen, L.-Y., and Hsiao, T.-C. (2019). Real-
time detection of internet addiction using reinforce-
ment learning system. In Proceedings of the Genetic
and Evolutionary Computation Conference Compan-
ion, pages 1280–1288.
Keng, B. (2016). The expectation-maximization algo-
rithm. http://bjlkeng.github.io/posts/the-expectation-
maximization-algorithm.
Kittler, J., Hatef, M., Duin, R. P., and Matas, J. (1998). On
combining classifiers. IEEE transactions on pattern
analysis and machine intelligence, 20(3):226–239.
Klochko, O. and Fedorets, V. (2019). An empirical com-
parison of machine learning clustering methods in the
study of Internet addiction among students majoring
in Computer Sciences. CEUR Workshop Proceedings,
2546:58–75.
Klochko, O., Fedorets, V., Tkachenko, S., and Maliar, O.
(2020). The use of digital technologies for flipped
learning implementation. CEUR Workshop Proceed-
ings, 2732:1233–1248.
Klochko, O. V. (2019). Matematychne modeliuvannia
system i protsesiv v osviti/pedahohitsi (Mathemat-
ical modeling of systems and processes in educa-
tion/pedagogy). Druk.
Kr
¨
amer, J., Schrey
¨
ogg, J., and Busse, R. (2019). Classifica-
tion of hospital admissions into emergency and elec-
tive care: a machine learning approach. Health Care
Management Science, 22(1):85–105.
Kuncheva, L. I. (2014). Combining pattern classifiers:
methods and algorithms. John Wiley & Sons.
Lee, T.-H., Ullah, A., and Wang, R. (2020). Bootstrap ag-
gregating and random forest. In Fuleky, P., editor,
Macroeconomic Forecasting in the Era of Big Data:
Theory and Practice, pages 389–429. Springer Inter-
national Publishing, Cham.
Leontyev, D. A. (2017). Psikhologiya smysla: priroda.
stroyeniye i dinamika smyslovoy realnosti (The psy-
chology of meaning: nature, structure and dynamics
of meaningful reality). Litres.
Linoff, G. S. and Berry, M. J. A. (2011). Data mining tech-
niques: for marketing, sales, and customer relation-
ship management. John Wiley & Sons.
Moshtaghi, M., Bezdek, J. C., Erfani, S. M., Leckie, C.,
and Bailey, J. (2019). Online cluster validity indices
for performance monitoring of streaming data clus-
tering. International Journal of Intelligent Systems,
34(4):541–563.
Pacol, C. A. and Palaoag, T. D. (2020). En-
hancing sentiment analysis of textual feedback in
the student-faculty evaluation using machine learn-
ing techniques. In 3rd International Confer-
ence On Academic Research in Science, Technology
and Engineering. https://www.dpublication.com/wp-
content/uploads/2020/11/3-3003.pdf.
Santos, S. G. T. d. C. and de Barros, R. S. M. (2020).
Online AdaBoost-based methods for multiclass prob-
lems. Artificial Intelligence Review, 53(2):1293–
1322.
Souri, A., Ghafour, M. Y., Ahmed, A. M., Safara, F.,
Yamini, A., and Hoseyninezhad, M. (2020). A new
machine learning-based healthcare monitoring model
for student’s condition diagnosis in Internet of Things
environment. Soft Computing, 24(22):17111–17121.
Subasi, A., Kevric, J., and Abdullah Canbaz, M. (2019).
Epileptic seizure detection using hybrid machine
learning methods. Neural Computing and Applica-
tions, 31(1):317–325.
Sudakov, K. V. (2011). Funktsionalnyye sistemy (Func-
tional systems). Izdatelstvo RAMN.
Suma, S. N., Nataraja, P., and Sharma, M. K. (2021). Inter-
net addiction predictor: Applying machine learning in
psychology. In Advances in Artificial Intelligence and
Data Engineering, pages 471–481. Springer.
Tarasenko, A., Yakimov, Y., and Soloviev, V. (2019). Con-
volutional neural networks for image classification.
CEUR Workshop Proceedings, 2546:101–114.
Tuysuzoglu, G. and Birant, D. (2020). Enhanced bagging
(ebagging): A novel approach for ensemble learning.
The International Arab Journal of Information Tech-
nology, 17(4):515–528.
Wallis, D. (1997). Just click no: Talk story about Dr. Ivan K.
Goldberg and the internet addiction disorder. The New
Yorker. http://www.newyorker.com/magazine/1997/
01/13/just-click-no.
Weka (2021). Weka 3: Machine Learning Software in Java.
http://old-www.cms.waikato.ac.nz/ ml/weka/.
Young, K. S. (1998a). Caught in the net: How to recognize
the signs of internet addiction–and a winning strategy
for recovery. John Wiley & Sons.
Young, K. S. (1998b). Internet addiction: The emergence of
a new clinical disorder. CyberPsychology & Behav-
ior, 1(3):237–244. https://www.liebertpub.com/doi/
pdf/10.1089/cpb.1998.1.237.
Yuryeva, L. N. and Bolbot, T. Y. (2006). Kompyuter-
naya zavisimost: formirovaniye, diagnos-
tika, korrektsiya i profilaktika (Computer ad-
diction: formation, diagnostics, correction
The Use of Ensemble Classification and Clustering Methods of Machine Learning in the Study of Internet Addiction of Students
259

and prevention). Porogi, Dnepropetrovsk.
http://kingmed.info/media/book/3/2673.pdf.
Zahorodko, P. V., Semerikov, S. O., Soloviev, V. N.,
Striuk, A. M., Striuk, M. I., and Shalatska, H. M.
(2021). Comparisons of performance between
quantum-enhanced and classical machine learning al-
gorithms on the IBM quantum experience. Journal of
Physics: Conference Series, 1840(1):012021.
Zelinska, S. (2020). Machine learning: Technologies and
potential application at mining companies. E3S Web
of Conferences, 166:03007.
Zhong, Y., Yang, H., Zhang, Y., and Li, P. (2020).
Online random forests regression with memories.
Knowledge-Based Systems, 201:106058.
AET 2020 - Symposium on Advances in Educational Technology
260
