
Supporting Named Entity Recognition and Document Classification in a
Knowledge Management System for Applied Gaming
Philippe Tamla
1
, Florian Freund
1
and Matthias Hemmje
2
1
Faculty of Multimedia and Computer Science, Hagen University, Germany
2
Research Institute for Telekommunikation and Cooperation, Dortmund, Germany
Keywords:
Named Entity Recognition, Document Classification, Rule-based Expert System, Social Network, Knowledge
Management System.
Abstract:
In this research paper, we present a system for named entity recognition and automatic document classifica-
tion in an innovative knowledge management system for Applied Gaming. The objective of this project is
to facilitate the management of machine learning-based named entity recognition models, that can be used
for both: extracting different types of named entities and classifying textual documents from heterogeneous
knowledge sources on the Web. We present real-world use case scenarios and derive features for training and
managing NER models with the Stanford NLP machine learning API. Then, the integration of our developed
NER system with an expert rule-based system is presented, which allows an automatic classification of textual
documents into different taxonomy categories available in the knowledge management system. Finally, we
present the results of a qualitative evaluation that was conducted to optimize the system user interface and
enable a suitable integration into the target system.
1 INTRODUCTION
The European research project Realizing and Applied
Gaming Ecosystem (RAGE) is an innovative online
portal and service-oriented platform for accessing and
retrieving reusable software components and other re-
lated knowledge contents from the Web, such as re-
search publications, source code repositories, issues,
and online discussions. RAGE is used to support soft-
ware reuse in the domain of applied gaming. Applied
games (AG) or serious games (SG) aim at training,
educating and motivating players, instead of pure en-
tertainment (David R. and Sandra L., 2005). RAGE
supports the integration with various social networks
like Stack Exchange (“Hot questions”), or GitHub
(“Build software better”). For instance, RAGE in-
cludes facilities to connect with the Stack Exchange
REST API which enables an easy import of online
discussions into its ecosystem. RAGE users can eas-
ily import multiple discussions from, for instance, the
Stack Overflow social site, describe them with further
meta information, classify them using an integrated
taxonomy management system, and then finally re-
trieve useful information with faceted search that en-
ables drilling down large set of documents.
Currently, the classification of text documents into
existing taxonomies in RAGE is done manually. The
user has to, first, analyze the content of each docu-
ment manually to understand the context in which this
document is used. This is done by consulting the title
and description of each imported document, as well
as, analyzing all related meta-information (like key-
words and tags), which are associated with this doc-
ument. Once done, the user has to search for tax-
onomies that may be used to classify the imported
document based on its content and metadata. This
process can be very hard and requires the full at-
tention of the user, because he or she needs to con-
sult the document and taxonomy each time manu-
ally. With a large number of documents and multiple
hierarchical taxonomies, it can very time-consuming
to classify documents in RAGE. To solve this prob-
lem, named entity recognition (NER) is generally ap-
plied because it can extract various knowledge con-
tents (like named entities) from natural language texts
(Nadeau and Sekine, 2007). The extracted knowledge
content can then be used to automate the process of
classifying text documents from various domains on
the Web, using, for instance, an expert rule-based sys-
tem.
NER has been widely used to recognize named en-
tities in medical reports (K et al., 2017), news articles
108
Tamla, P., Freund, F. and Hemmje, M.
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming.
DOI: 10.5220/0010145001080121
In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2020) - Volume 2: KEOD, pages 108-121
ISBN: 978-989-758-474-9
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

(Newman et al., 2006), and software web documents
(Ye et al., 2016; Tamla et al., 2019a). Techniques
for NER vary from rule-based, over machine learn-
ing (ML), to hybrid methods. But, ML-based NER
methods are more efficient on Web contents, because
they include statistical models that can automatically
recognize and classify named entities from very large
and heterogeneous contents on the Web. The train-
ing of a machine learning-based NER model is how-
ever very challenging. It requires, besides very good
programming knowledge, dealing with different tech-
nologies and pipelines for text analysis, natural lan-
guage processing (NLP), machine learning and rule-
based operations (Konkol, 2015). Errors in the initial
stages of the pipeline can have snowballing effects
on the pipeline’s end performance. Therefore, facil-
itating the development, management, and execution
of all necessary NER related tasks and pipelines will,
not only reduce the effort to train new NER models
but also contribute to optimizing the performance of
the whole system. The goal of this research project
is to develop and integrate a named entity recogni-
tion system into the RAGE ecosystem. The efficient
integration of a NER system into the RAGE ecosys-
tem will not only facilitate knowledge discovery (ef-
ficient extraction and analysis of named entities and
their interrelationships), but also, enable an automatic
classification of various text documents into existing
taxonomies found in the ecosystem. After review-
ing and comparing common systems and tools for
named entity recognition and document classification,
we present real-world use case scenarios and derive
features for training and managing NER models with
the Stanford NLP machine learning API. Then, the in-
tegration of our NER system together with the Drools
expert rule-based system is presented, allowing an au-
tomatic classification of text documents into different
taxonomy categories available in the knowledge man-
agement system. Finally, the results of a cognitive
walkthrough, that served as a qualitative evaluation
for optimizing the user interface and enabling a suit-
able system integration is shown.
2 STATE OF THE ART AND
RELATED WORK
2.1 RAGE
As stated earlier, the RAGE social platform includes
facilities for importing various text documents from
the Web (like Stack Exchange discussions) into its
ecosystem. These documents generally consist of a
title, a description and other metadata like tags, key-
words, etc. An integrated taxonomy management sys-
tem is also available for organizing and categorizing
the textual materials into hierarchical taxonomies of
the RAGE ecosystem. Taxonomy is the practice and
science of classifying things and concepts including
the principles underlining such classification (Sokal,
1963). It is used in RAGE to support faceted brows-
ing, which is a technique allowing users to drill down
their large number of search results, enabling faster
information retrieval.
However, it is hard to classify documents with
multiple taxonomies. The user can easily mix up one
with another while analyzing and classifying a doc-
ument into multiple hierarchical taxonomies. Each
document (including its metadata like title, descrip-
tion, tags) have to be analyzed each time manually to
be able to understand the context in which the docu-
ment is used, before making a proper classification
into the existing taxonomies. This process can be
very challenging and time consuming, especially with
multiple documents and various taxonomies having
complex hierarchical structures. To fulfill the require-
ments of the project, a very desirable goal would be
to develop and integrate a named entity recognition
system into the RAGE system that can automatically
recognize and classify various kinds of named entities
from the multiple social networks connected with the
ecosystem. Then, to apply an expert rule-based sys-
tem that will enable an automatic document classifica-
tion by reasoning about the extracted named entities,
the hierarchical taxonomies and other textual features
found in the existing RAGE documents.
2.2 Named Entity Recognition
Techniques
NER techniques generally include handcrafted rules
or statistical methods that rely on machine learning
(ML) (Nadeau and Sekine, 2007), or even a combi-
nation of those. A NER technique is denoted as rule-
based or handcrafted if all the parameters (including
rules) that are used to identify and categorize named
entities are defined manually by a human. Machine
learning based techniques will use a computer to esti-
mate those parameters automatically (Konkol, 2015).
Existing ML techniques include supervised learning
(parameter estimation is based on already annotated
data), semi-supervised learning (parameter estima-
tion uses only a small set of annotated data), and un-
supervised learning (does not use annotated data for
estimation). Most popular machine learning systems
are relying on Conditional Random Fields (CRF), the
state-of-the-art statistical modelling method for se-
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
109

quential text labelling (Sutton et al., 2007). CRF has
been widely used with machine learning to support
different NLP tasks, such as, part-of-speech tagging
(Gimpel et al., 2010), sentence splitting (Tomanek
et al., 2007) and NER (Ritter et al., 2011). Devel-
oping a machine learning-based NER system is how-
ever very challenges and requires a lot of data for
model training. Often, gazetteers (dictionaries of spe-
cific named entities) are introduced as additional fea-
tures to recognize unknown named entities - words
that were not used in the training process. Likewise,
regular expressions can be applied to optimize ML
models, because they detect more complex named en-
tities like compound words (Nagy et al., 2011).
Many factors can influence the performance of a
NER system, such as a) The language. Some NER
systems were developed for one specific language like
English. b) The named entity type. For instance, the
class of a datetime can be easily found if it only con-
tains absolute dates (2003; 6.2.2005, April 5, 2011),
but it can be difficult to detect relative dates (next Sat-
urday, in December). c) The domain of the processed
texts (corpora). If a classifier was trained using juris-
tic texts, it will be difficult for this same classifier to
deal with material originated from bioinformatics.
The standard measures for evaluating machine
NER systems are precision, recall and F1 for this
task. Recall is the ratio of correct annotated NEs to
the total number of correct NEs. Precision is the ratio
of correct annotated NEs to the total number (correct
and incorrect) of annotated NEs. F1 score is calcu-
lated from precision and recall and describes the bal-
ance between both measures. Most NER tools have
functions to calculate precision, recall and F1 from a
set of training and testing data.
2.2.1 Comparison of NER Tools
Many tools have been proposed in the literature for
named entity recognition. We need to review and
compare them to enable a suitable integration into our
target system. Therefore, we introduce the following
selection criteria: a) the chosen tool should not be
limited to a specific type of text or knowledge domain
b) should include a rich set of NLP features (includ-
ing NER, POS, Tokenization, Dependency Parsing,
Sentiment Analysis), c) must be stable, extendable,
distributed as opensource, and should have an active
community of developers.
Our solution is designed to classify a relatively
small amount of data. The RAGE contents have a
limited size and do not consist of many gigabytes of
data. Therefore, we prefer to achieve good results
with a high level of accuracy and do not need a very
fast classification process which often results in lower
accuracy.
Our tool comparison is based on the work of Pinto
(Pinto et al., 2016). According to our selection crite-
ria, we exclude from our comparison non-opensource
tools, tools without NER support, and those focus-
ing only on specific data. To compare state-of-the-art
tools, we added SpaCy, Spark NLP and Stanza to our
list, because these tools arose in the last view years
and may be relevant in our work. GATE ANNIE
1
is a more general solution for various NLP tasks. It
was first developed to help software engineers and re-
searchers working in NLP, but has been optimized
to a more powerful system with an integrated user
interface, which supports different data preprocess-
ing tasks and pipeline executions. GATE is dis-
tributed with an integrated information extraction sys-
tem called ANNIE that supports NER and many other
NLP tasks. ANNIE relies on the JAPE
2
specifica-
tion language, which provides finite state transduction
over annotations based on regular expressions. Using
the GATE interface, users can capture the provenance
of machine- and human-generated annotated data to
create new metrics for NLP tasks like named entity
recognition. Additional metrics for more specific sce-
narios can be added, but this requires an existing im-
plementation in the RAGE architecture, which intro-
duces the overhead of familiarization with the entire
GATE architecture. The Natural Language Toolkit
(NLTK)
3
is a Python library that supports most of the
common NLP tasks. It was launched in 2001 under
the Apache license. Each NLP task is performed by
an independent module and it is possible to train an
own model for NER. The main disadvantage is that it
lacks support for dependency parsing and an interface
for the standard Universal Dependencies
4
dataset is
missing. Apache OpenNLP
5
is written in Java and
based on machine learning. Launched in 2004 and
licensed under the Apache License, the software sup-
ports NER and many NLP tasks. But it lacks support
for dependency parsing. The Stanford CoreNLP
6
is a Java-based tool suite from Stanford University
that was launched in 2010. It supports all relevant
NLP tasks, including NER and dependency parsing.
CoreNLP can train new NER models independently
from the data types, languages, or domain. Its API in-
cludes more than 24 different annotators for text an-
notation, regular expressions and language process-
ing tasks. These annotators can be easily combined
1
https://gate.ac.uk/ie/annie.html
2
https://gate.ac.uk/sale/tao/splitch8.html
3
https://www.nltk.org/
4
https://universaldependencies.org/
5
https://opennlp.apache.org/
6
https://stanfordnlp.github.io/CoreNLP/
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
110

and executed sequentially in different pipelines. A
REST service interface is also available, which can
be used by other external systems for different NLP
tasks execution. Thus, CoreNLP may be easily in-
tegrated with a rule-based expert system to support
the automatic classification of documents in RAGE.
Finally, the training of NER models is very flexible
and customizable. CoreNLP includes nearly 100 pa-
rameters for CRF-based model training and perfor-
mance fine-tuning, including other options for adding
gazette lists that can recognize unknown named enti-
ties. CoreNLP is licensed under the GPLv3 and has
a very big active community. Thus, state-of-the-art
NLP methods and algorithms are permanently devel-
oped and integrated into the software. Stanza
7
is a
Python Library, developed by Stanford University as
a possible successor for CoreNLP. It was launched
in 2019 under the Apache license. Even the sys-
tem is rather new it supports many features needed
in our work, only sentiment analysis is missing. The
ML models trained by CoreNLP are not directly sup-
ported in Stanza and need to be trained again. Stanza
brings a client to connect to the CoreNLP server, so
it is possible to use CoreNLP features over this inter-
face, which increases the complexity. SpaCy
8
is one
of the newer systems for NLP that was launched in
2015. It is written in Python and was published under
the MIT license. It is used to produce software for
production usage, which should be easy to use and
fast. SpaCy supports most of the common NLP fea-
tures, including dependency parsing and features for
training custom models for NER. But it lacks sup-
port for sentiment analysis. The main disadvantage
for our purpose is, it focuses on fast classification,
which leads to a lower accuracy compared to other
systems. Spark NLP
9
is one of the most recent NLP
tools that was released in 2017. It is a library build
on top of Apache Spark and TensorFlow. It supports
Python, Java and Scala and focuses the usage in pro-
duction systems. It has more dependencies to get it
up and running compared to other systems, due to the
Apache Spark architecture. The supported NLP fea-
tures include all relevant features, including depen-
dency parsing and the training of a custom model for
NER. Due to its young age, the community is not as
big and active compared to others. On Stack Overflow
are just a few questions with the tag “johnsnowlabs-
spark-nlp” where “stanford-nlp” has over 3000. We
decided to use the Stanford CoreNLP suite for our
project. CoreNLP is the only NLP software which
met all our requirements. The competitors may be
7
https://stanfordnlp.github.io/stanza/
8
https://spacy.io/
9
https://nlp.johnsnowlabs.com/
better or faster in one or another subtask, but overall
CoreNLP seems to be the tool with the best mix of
all required features. Especially the rich feature set in
combination with an active and living community is
a huge advantage of Stanford CoreNLP, compared to
the other solutions.
2.3 Rule-based Expert Systems
Expert systems are rapidly growing technology of
Artificial Intelligence (AI) that use human expert
knowledge for complex problem-solving in fields like
Health, science, engineering, business and weather
forecasting (Koppich et al., 2009; Awan and Awais,
2011; Abu-Nasser, 2017). An expert system repre-
sents knowledge solicited by a human expert as data
or production rules within a computer program (Abu-
Nasser, 2017). These rules and data can be used to
solve complex problems. For instance, a rule-based
classification system can be applied to classify text
documents into organized groups by applying a set of
linguistic rules. The rules will instruct the system to
use semantically relevant elements of the document
and its contents to identify useful categories for auto-
matic classification (Blosseville et al., 1992).
Over the last decades, many expert systems have
been proposed but essentially all of them are ex-
pressed using IF THEN-like statements which con-
tain two parts: the conditions and the actions. In the
mathematical sense, a rule can be defined as X ==>
Y, where X is the set of conditions (or antecedent)
and Y is the set of actions (or the consequent). Rules
are used to represent and manipulate knowledge in
a declarative manner, while following the first-order
logic in an unambiguous, human-readable form, and
at the same time retaining machine interpretability.
Rule-based systems generally include a “production
memory” which contain a set of rules that are matched
against facts stored in the “working memory” of an
“inference engine” (Velickovski, 2016).
The C Language Integrated Production Sys-
tem (CLIPS) is a public domain software tool for
building expert systems. It was developed by the
NASA in 1985 (Velickovski, 2016). It has become
one of the most used RBES in the market because of
its efficiency and portability (Batista-Navarro et al.,
2010). CLIPS was written C, and for C program-
ming. But, it is now incorporating a complete object-
oriented language for writing expert systems, called
COOL. COOL combines the programming paradigms
of procedural, object-oriented and logical languages.
While CLIPS can separate the knowledge base (the
expert rules) from its inference logic, it is not that user
friendly in the formulation of rules like many other
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
111

systems (Velickovski, 2016).
Ten years after CLIPS, the Java expert System
Shell (JESS) was launched by Ernest Friedman-Hill
of Sandia National Lab (Velickovski, 2016) as a Java-
based implementation of the CLIPS system. It sup-
ports the development of rule-based expert systems
that can be tightly coupled to Java code and is often
referred to as an expert system shell (Friedman-Hill,
1997). JESS is compatible with the CLIPS rule lan-
guage, but a declarative language (called JessML) is
also available for specifying rules in XML. JESS is
free to use for educational and governmental purpose,
but it is not an opensource software. There is no free
source code under any available license
10
.
The Drools expert system is an opensource soft-
ware that was first developed by Bob McWhiter (in
2001), and later on, absorbed by the JBoss organi-
zation (in 2005). Drools is based on Java and its
rule definitions rely on IF...THEN statements which
are easier to understand than the syntax provided by
CLIPS and JESS. Drools rules can be also speci-
fied using a native XML format. The rule engine
essentially is based on the Rete algorithm (Forgy,
1989), however, extended to support object-oriented
programming in the rule formulation.
Drools is available under the Apache Software
Foundation’s opensource license. Because its easy
and far more readable rule syntax, Drools has been
widely used as an expert system in various domains
(Cavalcanti et al., 2014). Therefore, we chose Drools
to enable an automatic classification of text docu-
ments in the RAGE ecosystem.
3 SYSTEM DESIGN
Our system design relies on the user-centered de-
sign (UCD) approach by (Norman and Draper, 1986),
which has proved to be very successful in the opti-
mization of the product usefulness and usability (Vre-
denburg et al., 2002). Applying the UCD to design
a system includes: a) understanding the context in
which users may use the system, b) identifying and
specifying the users’ requirements, c) developing the
design solutions, and finally, d) evaluating the design
against users’ context and requirements.
Our system allows any user (experts or novice de-
velopers) to customize and train a machine learning-
based NER model in their domain of expertise. In
the target system, the user starts with a named entity
recognition definition, which is a set of parameters
and configuration steps to train a named entity recog-
10
https://jess.sandia.gov/jess/FAQ.shtml
Figure 1: SNERC Use Case.
nition model using machine learning. With the sup-
port of the system, the user can upload a text corpus,
define the named entity categories, and the named en-
tity names (including their related synonyms) based
on the requirements of the target domain. Then, he
or she can customize all the conditional random fields
and optimization parameters used to train a model us-
ing machine learning. The information about the NE
categories, the NE names, and their related synonyms
are used for the automatic annotation of the text cor-
pus, using the BIO annotation mechanism which is
integrated into our system. This is very useful be-
cause machine learning-based NER systems gener-
ally require a lot of annotated data for model train-
ing. However, while the system is able to suggest
a first annotation of the text corpus, which can then
be used for training and testing, it is necessary for
the user to customize the testing data to avoid overfit-
ting issues which may lead to very poor quality of the
trained model (Konkol, 2015). Once a NER model is
trained, the user can finally use it to construct flexible
rules (by referring to the extracted named entities in
the text) for automatic document classification in var-
ious domains. These rules are business rules and are
constructed using a rule-based expert system. They
will be used to represent and manipulate knowledge in
a declarative manner using a set of WHEN. . . THEN
statements in a human-readable form. The next sec-
tions will now provide an overview of relevant use
cases and describe the overall architecture of the sys-
tem.
3.1 Use Case
Our use case diagram in figure 1 describes all tasks for
a user to create a NER model definition, train a model,
manage it, and finally use the trained model to support
automated document classification in RAGE. We call
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
112

our system the Standford Named Entity Recognition
and Classification (SNER), as it relies on Standford
NLP for NER, and Drools for Document Classifica-
tion. Our actor is a registered and logged-in user in
KM-EP. There are four main actions:
“manage NER model definition” which includes:
1) uploading a data dump for use in the target domain,
2) defining the corresponding NE categories, names,
and synonyms, 3) customizing CRF and performance
parameters, 4) adding regular expressions to identify
complex named entities (like Java 11.0), 5) preparing
the NER model, which includes features for the au-
tomatic annotation of the text corpus and the splitting
of the annotated text into testing and training data. Fi-
nally, 6) training the NER model using CronJobs and
the Stanford NLP machine learning API.
“manage NER model” deals with the management
of the created NER models. This includes reviewing
the performance indicators like precision, recall and
F1. The NER models can be edited or deleted. An
upload of a pre-trained NER model is also possible.
“manage classifier parameter definition” deals
with adding, editing, or deleting business rules that
are used for classifying text documents into existing
taxonomies. To create new rules, the user can select
the taxonomies and NER models that are relevant for
its specific domain.
The “edit content” action describes the steps,
where a KM-EP content is edited and the automated
classification suggestion is retrieved, supervised and
saved.
3.2 System Requirements and Drools
Extensions for Automatic Document
Classification in RAGE
This section introduces our system requirements for
document classification in RAGE. It also presents our
feature extensions to create more complex rules based
on Linguistic Analysis, Syntactic Pattern Matching,
and Web Mining. Our features extensions will be
implemented as a proof-of-concept for the classifica-
tion of Stack Overflow discussions into RAGE tax-
onomies. Thus, we need to review the role of tax-
onomies in serious games to identify relevant tax-
onomies and validate our proof-of-concept. We can
refer to our previous study about (Tamla et al., 2019b)
to estimate which taxonomies may be relevant for
the domain of serious games. In this research, we
have applied the LDA statistical topic modelling to
automatically discover 30 topics about serious games
development, from which the following belong to
the most popular ones: Programming and Scripting
Language, 3D-Modeling, Game Design, Rendering,
Game Engines, Game Physics, Networking, Platform,
and Animation.
We can now review the current state-of-the-art in
taxonomies for serious games and select a list of tax-
onomies to be used in our proof-of-concept.
3.3 Serious Games-related Taxonomies
Taxonomies in serious games have many aspects and
dimensions. Most relevant taxonomies for our work
are related to 1) Game genre, 2) programming lan-
guages, 3) video game tools, 4) machine learning
algorithms, and 5) video game specification and im-
plementation bugs. Many researchers have proposed
different hierarchical taxonomies in the domain of
serious games. Their main objective was to eluci-
date the important characteristics of popular serious
games and to provide a tool through which future re-
search can examine their impact and ultimately con-
tribute to their development (RATAN and Ritterfeld,
2009). Our first classification taxonomy reflects the
game genre [GEN], as it is one the basic classifi-
cation schemes proposed by researchers in the clas-
sification of serious games (RATAN and Ritterfeld,
2009; Buchanan et al., 2011; De Lope and Medina-
Medina, 2017; Toftedahl and Henrik, 2019). A se-
rious game can be classified based on the market
[GEN/MAR](e.g. Education, HealthCare, Military),
the game type [GEN/TYPE](board-game, card-game,
simulation, role-playing game, toys, etc) or the plat-
form [GEN/PLA]in which the game runs (Browser,
Mobile, Console, PC) (RATAN and Ritterfeld, 2009).
Many Stack Overflow discussions are already tagged
with specific words like ”education”, “board-game”,
“simulation”, “console”. Therefore, we want to clas-
sify SG-related discussions in the game genre dimen-
sion. Second, our analysis of SG-related online dis-
cussions in Stack Overflow has revealed that devel-
opers of serious games are generally concerned with
finding ways to implement new features using a spe-
cific programming language (or scripting) language
[LANG]. So, a taxonomy in the programming lan-
guage dimension is essential. To classify program-
ming languages, we refer to Roy’s work (Van Roy
et al., 2009) and use the programming paradigm as
the main attribute in our work. We focus on serious
game development, where existing game engines and
tools for classic video game development are used,
and we want to classify the Stack Overflow posts
in this way. Third, (Toftedahl and Henrik, 2019)
proposed a lightweight taxonomy to standardize the
definition of common tools, development environ-
ments[TOOL/IDE], and game engines [TOOL/ENG]
that are used for game development. We can use
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
113

this taxonomy as a classification scheme for the Stack
Overflow posts. Fourth, another aspect is machine
learning [ML], the most trending aspect in serious
games development. Machine learning is one of the
main techniques used in reusable software compo-
nents (Van der Vegt et al., 2016) and for creating in-
telligent learning systems. For instance, pedagogical
systems use observational data to improve their adap-
tive ability, instead of relying on theoretical guide-
lines (Melo et al., 2018). This motivates us to inte-
grate a machine learning-based classification scheme
in our work. (Dasgupta and Nath, 2016) created such
a scheme and gave a brief overview of state-of-the-
art machine learning algorithms. We will use this in
our work for classifying posts in the machine learning
dimension. Our final dimension is regarding video
game bugs [BUG]. As shown in our study, one of
the main concerns of serious games developers (like
most of the software developers) is to find solutions
to fix their bugs, whether during the design or imple-
mentation of their games. (Lewis et al., 2010) devel-
oped in 2010 a taxonomy for video game bugs, which
differentiate between specification bugs [BUG/SPEC]
and implementation bugs [BUG/IMP]. A specifica-
tion bug is generally referring to a wrong requirement
in the game design document. This may refer to miss-
ing of critical information, conflicting requirements,
or incorrectly stated requirements. A bug in an im-
plementation is an error found in any asset (source
code, art, level design, etc.) that is created to make the
specification into a playable game (Varvaressos et al.,
2017). A failure in an implementation is generally a
deviation of the game’s operation from the original
game specification (Lewis et al., 2010).
3.4 Drools Extensions for Document
Classification
This section presents our Drools extensions that is rel-
evant to enable a flexible classification of text docu-
ments into the RAGE taxonomies. Our features ex-
tension rely on techniques for Linguistic Analysis,
Web Mining and Syntactic Pattern Matching. Our
classification system will be implemented as a stan-
dalone RESTful webservice so that it can be easily in-
tegrated within RAGE and any other external systems
that may need to classify documents into predefined
taxonomies.
3.4.1 Linguistic Analysis
We use the Stanford NLP API to support linguis-
tic analysis in our System. Stanford NLP supports
many NLP tasks like part-of-speech tagging (POS),
tokenization, and NER. By analyzing specific part-of-
speeches and recognizing various mentions of named
entities discussion sentences, we can analyze the syn-
tactic structure of each sentence. Then, we can refer
to the sentence components (subject, predicate, ob-
ject), the sentence form (whether it is affirmative(Liu
et al., 2018) or negative), and the sentence mood
(whether it is interrogative or declarative) to under-
stand the structure of each sentence and derive its
meaning. A similar approach was proposed by (Liu
et al., 2018) for the classification of Stack Overflow
discussions into software engineering-related facets,
but this approach relied on hand-crafted rules for rec-
ognizing named entities in discussion posts. Instead
of applying hand-crafted rules for NER, we will rely
on our NER system to extract SG-related named en-
tities (like game genres, programming languages, or
game engines) from the existing text documents. To
detect the sentence form and determine if a sentence is
positive or negative, we will rely on the StanfordNLP
Sentiment Analysis API
11
, as it includes a machine
learning-based API for this purpose. We will rely on
regular expressions to determine the sentence mood.
We will consider a sentence to be interrogative, if it
contains a question mark, or if it starts with an inter-
rogative word (what, how, why, etc.) (e.g. what is the
best way to record player’s orientation?), otherwise
the sentence is declarative. Using our linguistic anal-
ysis features, we can understand the meaning of each
individual sentence, and use this information to derive
the semantic of a document. Then, it becomes eas-
ier to group documents having similar semantic into a
single taxonomy.
3.4.2 Syntactic Pattern Matching
Research on web document mining has demonstrated
that certain lexico-syntactic patterns matched in texts
convey a specific relation (Liu and Chen-Chuan-
Chang, 2004). Liu’s study has revealed that many on-
line questions belonging to similar topics have similar
syntactic patterns. They found that many program-
ming languages usually appear after a preposition,
like with Java, in JavaScript. After carefully analyz-
ing the title and description of some SG-related topics
in Stack Overflow, we could easily observe similar
behaviour for game genres, game engines and tools,
such as for educational games, in Unity 3D, with
GameMaker, etc. Thus, the categories of a question
can be derived based on the syntactic patterns of its
sentences.
Table 1 shows the list of our syntactic patterns that
can be used to classify Stack Overflow discussions
11
https://nlp.stanford.edu/sentiment/index.html
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
114

Table 1: List of syntactic patterns.
Pattern Description
PA Entity or Term appears after a preposi-
tion
PB Entity or Term appears before a prepo-
sition
SG Entity or Term appears in the subject
group
PG Term appears in the predicate group
OG Entity or Term appears in the object
group
SA The sentence is affirmative
SI The sentence is interrogative
SP The sentence is positive
SN The sentence is negative
TT Term combination < term1 > <
term2 > appears in a sentence
TTSG Term combination < term1 > <
term2 > appears in the subject group
TTOB Term combination < term1 > <
term2 > appears in the object group
TTPB Term combination < term1 > <
term2 > appears before a preposition
into taxonomies of the RAGE system. Our syntactic
pattern definition is based on a rich set of terms, term
combinations, and standardized synonyms (Table 2),
that we observed in various Stack Overflow discus-
sions. Applying synonyms in our approach is very
important to automatically detect name variations in
text and enable a classification to perform better. For
instance, we can use a pattern that includes the term
“implement” and use the same pattern to identify texts
that include the term “develop” or “build”. To achieve
this goal, we will need to create a domain dictio-
nary with a set of semantic classes, each of which
includes a standardized term and its synonyms (Liu
et al., 2018).
For each parameter in our defined template shown
in Table 2, and for each taxonomy and category that
the template applies to, we will use a list of popu-
lar terms found in Stack Overflow to instantiate our
template and created a semantic class with each term.
We will rely on the WordNet API
12
to create seman-
tic classes of candidate synonyms using standardized
terms. When a new term is added, all its synonyms
should be identified using WordNet and then consid-
ered for inclusion. By combining different terms and
synonyms, we can discover a wide range of expres-
sions and term combinations and phrases used in the
majority of SG-related discussions. For instance, the
term combination < Best > < Way > can be used to
12
https://wordnet.princeton.edu/
identify posts containing the expressions: “best way“,
“best strategy“, “proper design“, “optimal solution“,
etc. This will allow us to have a more generic syntac-
tic pattern definition that can easily scale in different
domains compared to (Liu et al., 2018)’s system.
3.4.3 Document Structure Analysis
This feature is used to explore the structure of online
text documents. We can refer to specific HTML ele-
ments to find out if a document contains a code snip-
pets (< code > ... < /code >), bullet points (< ul >
... < /ul >), or even images (< img/ >). Explor-
ing the structure of online discussion can help us to
classify documents into specific taxonomies like Pro-
gramming Languages or Video Game Bugs. A qual-
ity study of Stack Overflow online discussion (Nasehi
et al., 2012) has revealed that explanations (generally
represented using bullet points in the question bodys)
accompanying code snippets are as important as the
snippets themselves. Also, existing survey research
on document structure analysis has demonstrated that
analyzing the hierarchy of physical components of a
web page can be very useful in indexing and retriev-
ing the information contained in this document (Mao
et al., 2003). For instance, if a Stack Overflow post,
contains the word “bug” in its title, and one or more
code snippets in its body, then it may be assigned
to the Implementation Category of the Video Game
Bug Taxonomy. Generally, such a discussion would
include sentences like “How to fix my bug in...” or
“How can I solve this issue... in my game” in its ti-
tle or description body. Similarly, if a bug discussion
includes terms like “requirement, design, or specifi-
cation” in its title (e.g. I want to fix ... in my specifi-
cation), with multiple bullet points in its description
body, then it may indicate that the user is seeking help
to solve an issue in a particular section of its design
specification. In this case, the discussion post may be
classified into the Specification Bug category of the
Video Game Bug Taxonomy.
Our features extensions are very flexible and can
be easily combined to construct even more complex
rules in the Drools language. There is also no limita-
tions for adding new extensions to classify text docu-
ments using our system.
3.5 System Architecture of SNERC
This section presents the system architecture of
SNERC. Based on our use cases, we have defined 5
main components which will want to describe here.
NER Model Definition Manager manages all the
necessary definitions and parameters for model train-
ing using machine learning. It includes 3 main
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
115

Table 2: Template for synonym detection in Stack Overflow.
Taxonomy Category Term Term synonyms
Programming Language < implement > implement, develop, code, create, construct, build, set
Specification Bug < speci f y > design, require, define, determine, redefine
Implementation Bug
Specification Bug
< error > error, bug, defect, exception, warning, mistake
Game Engine < con f igure > configure, setup, adjust, adapt, optimize
- < howto > How to, How do (I,we), How can (I,we), How should (I,we)
... Bug < f ix > fix, solve, remove, get rid of, eliminate
Table 3: Patterns for document structure analysis.
Pattern Description
LS Text contains multiple bullet points as
HTML list
CS Text contains one or multiple code
snippets
IM Text contains one or multiple images
followed by a text description
classes. The first two, Named Entity Category and
Named Entity, hold information about the domain-
specific named entities names and categories. The
third class, NERModelDefinition, is used to stored
data like the model name, text corpus, gazette lists,
and regex. We use the Stanford RegexNER API to
construct and store complex rules, as they can easily
be combined with already trained models.
NER Model Trainer is our second component that
is used to prepare a NER model. This includes the
automatic annotation of the domain text corpus (or
data dump) based on the previously defined NE cate-
gories, NE names and synonyms. Our system is also
able to split the annotated text corpus into testing and
training data. The testing data, however, needs to be
reviewed by a human expert and uploaded again to
avoid overfitting, and thus a realistic calculation of
precision, recall and F1 scores. When this is done, the
NER Model Trainer component can execute the task
for training a NER model using jobs and the Stan-
ford CoreNLP. As the NER Model Trainer is written
in Java and KM-EP is a PHP project, we designed it as
a separate REST service component. This has further
advantages. First, the service can be developed in-
dependently and does not affect KM-EP. Second, this
service can be used separately from KM-EP as it is
defined as a REST API. Other external systems will
just need to define the input data in a JSON format
and send them via an HTTP REST call to this ser-
vice. The NER Model Trainer has a class called NER
Model Definition which represents the corresponding
GUI components in KM-EP. The Trainer class is used
to control the training process.
Figure 2: Model of the conceptual architecture.
NER Model Manager. This component is very
straightforward since it only serves the storage of the
trained NER models into the KM-EP filesystem so
that they can be used by other systems like a linguis-
tic analyzer or our document classification system. If
a model is prepared with a NER Model Definition,
users can update the created testing and training data
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
116

Table 4: Pattern matching rules for matching Stack Overflow discussion posts.
Pattern Matching Taxonomy Categories Examples
PA LANG, GENRE, ... < How to > to do animation with < unity3d 5.2 >
(SG ||OG) && SA GENRE, ... An < Educational Game > for learning prog. language.
(TT && SI ) ||PA SPB It might be an issue in the < game > < design > spec.
PB && CS IMB I am using a nstimer and it has a < bug > with my game
loop < code >...< /code >
within the NER Model Manager to get better Preci-
sion, Recall and F1 scores. Also, the created Stanford
Regex NER rules can be edited and updated. It is also
possible to upload a StanfordNLP NER model that
was trained with another system and use it in KM-EP.
Figure 13 shows an example of a recognized named
entity with the NER Model Manager.
Classification Parameter Definition Manager. This
component is used to manage and store business rules
in KM-EP. To construct business rules that mention
named entities and can be used to classify documents
into existing taxonomy categories, the design of the
“Classification Parameter Definition Manager “ com-
ponent needs to include links to the “NER Model
Manager”, “Content Manager” and “Taxonomy Man-
ager” of KM-EP. We use the Simple Knowledge Or-
ganization System (SKOS) as the unique connection
between our business rules and the taxonomy cate-
gories found in KM-EP. Even each taxonomy cate-
gory in KM-EP has a SKOS persistent identifier rep-
resenting the category.
NER Classifier Server. The NER Classify Server
is our last component. It is developed as a stan-
dalone RestFul service to classify documents into tax-
onomies. To execute a document classification, the
NER Classify Server needs information about the
document (title, description, tags), the Drools rule,
and references about the NER models, so that named
entities can be used in the rule formulation. This in-
formation is sent to the server from KM-EP in a JSON
format. With the provided document data and the ref-
erences to the NER models, the server can now exe-
cute the NER, perform the synonym detection (with
WordNet), and execute Linguistic Analysis, and Syn-
tactic Pattern Matching on the Document structure
and content. This analysis is done in the “classify()”
method of a Java object, called Document. The anal-
ysis result is then stored into the properties of this ob-
ject and can be used during the execution of Drools
rules. The following code snippet shows the imple-
mentation of our Document.classify() method.
Server
Document
title
description
tags
...
classify()
LinguisticAnalyzer.check(sentence)
detectNamedEntities()
detectSynonyms()
appearsAfterPreposition()
appearsBeforePreposition()
isAffirmative()
appearsInSubject()
isSentencePostive()
DocumentStructureAnalyzer(text)
hasCodeSnippet()
hasBulletPoint()
hasImages()
3.5.1 System Service Implementation
To make the features of our implemented REST ser-
vices available to the various KM-EP components, we
created two new services in KM-EP. These services
are used as an adaptor between KM-EP and its ob-
jects and our developed REST services. Each service
bundles the features of the corresponding REST ser-
vice and is connected with the KM-EP PHP API. The
big advantage of relying on this service-based archi-
tecture is that, if we decide to change or update our
REST APIs, we will only need to change the KM-
EP services and leave their underline implementations
untouched.
NER Model Trainer Service. The NER Model
Trainer Service of KM-EP is used to connect with
the NER Model Trainer REST service. As already
discussed in the previous sections, this component
includes the creation of a NER Model preview, the
preparation of a NER Model and model training. Be-
cause the NER Models are created using the NER
Model Trainer component, they need to be down-
loaded from there into KM-EP and deleted after-
wards.
Classifier Service. The Classifier Service of KM-EP
is used for the communication between KM-EP and
the NER Classify Server REST service. To handle
the automatic document classification, we first need
to manage the NER Models using the NER Classify
Server. Then, the Classifier Service of KM-EP can
trigger the execution of the operation for adding or
deleting NER Models by calling the NER Classify
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
117
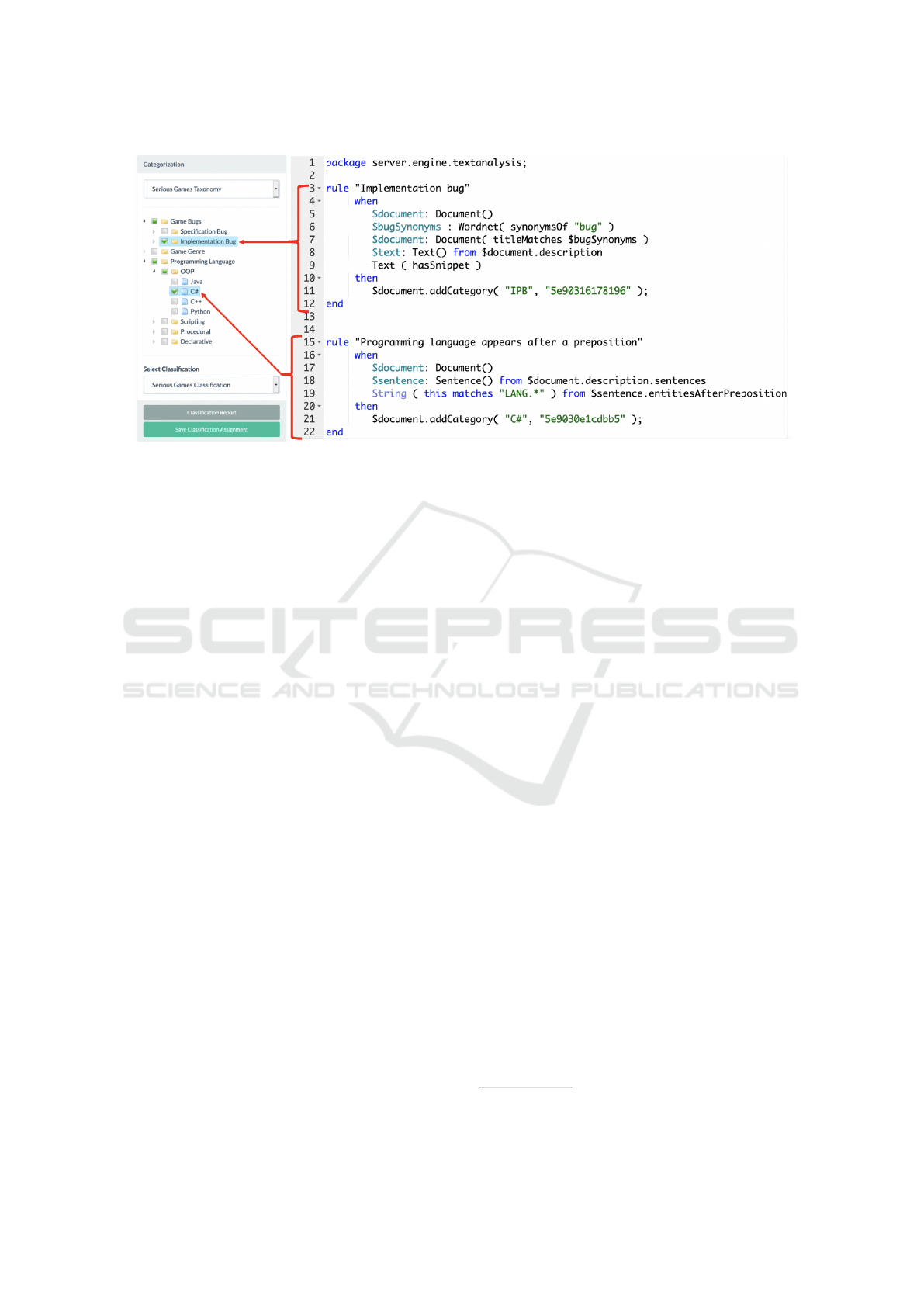
Figure 3: Selected categories and their rules.
Server. Furthermore, the Classifier Service will be
able to trigger the automatic classification of docu-
ments to be suggested to the user.
3.6 Proof-of-Concept
After presenting our major use cases and showing
details about our implemented components, we can
now present a common use case scenario where Stack
Overflow discussions about SG topics can be classi-
fied in RAGE.
With an existing NER model in the system, a classi-
fication parameter definition can be created with the
Classification Parameter Definition Manager compo-
nent to classify discussion texts into taxonomies of the
system. For instance, there may be a Stack Overflow
post like this in RAGE:
• Title: “bug in my game loop”
• Keywords: “cocoa-touch, nstimer”
• Description: “I am making a game on xcode 5. I
am using a nstimer in C# and there may be a bug
in my game loop. Can you help me please. All
help is great. < code >...< /code >”
According to our previous definition, we can
create Drools rules to automatically classify this
document into Video Game Bug and Programming
Language taxonomies. First, we will start with
the creation of a “Classification Parameter Defini-
tion”, where we select the desired taxonomy and
NER models for named entity extraction. Then,
we will construct our classification rules using the
WHEN...THEN syntax provided by Drools. Based
on the selected taxonomy, the NER models, and our
rich set of features extensions, we can easily refer
to specific named entities (like C# (LANG), cocoa-
touch (TOOL)) in our rule definitions and perform
Linguistic Analysis, Web Mining, and Syntactic Pat-
tern Matching based on the structure and content of
our document. Figure 3 shows an example of such
classification rules in the Drools language.
• Lines 6-7 (of rule 1) refer to our WordNet integra-
tion to detect if the term “bug” (or one of its syn-
onyms) is included in the discussion title. Line 9
analyzes the document structure to identify if the
post description includes a code snippet. Because
both conditions are true, the document is automat-
ically assigned to the Implementation Bug of the
Video Game Bug taxonomy.
• Line 19 (of rule 2) checks the syntax of the post
description to identify if a named entity of type
LANG appears after a preposition. Since it is true,
the post is assigned to the C# category of the Pro-
gramming Language taxonomy.
To make it easier for the user to test the created
rules, we implemented a form to test the developed
rules. The user can input some text, execute the clas-
sification parameter definition and see a classification
report with the results of the annotation and classi-
fication process. There is also a visualization of the
NLP features detected by Stanford CoreNLP which
is based on CoreNLP Brat
13
. The reports include the
following information:
A list of persistent identifiers of the detected cat-
egories, an area for the detected sentences with the
results of the Stanford CoreNLP features, represen-
tation of detected Parts-of-Speech, detected NEs,
13
https://github.com/stanfordnlp/CoreNLP/tree/master/
src/edu/stanford/nlp/pipeline/demo
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
118

detected basic dependencies and the detected sen-
timent. For further analysis the original Stanford
CoreNLP output is also available in JSON format in
the GUI.
4 EVALUATION OF SNERC
After we implemented SNERC, it is needed to prove
the usability of the system. There are several evalu-
ation methods available to perform this task. Auto-
mated and formal methods are testing a system with
a computer program, based on a formal specification,
or with formal models. As it is difficult to create such
a specification or model, we will not use one of these
methods. Other methods like empirical methods in-
volve a crowd of potential users of the system, which
will perform common tasks in it. Such an evaluation
is very resource-intensive and therefore not appropri-
ate to our purpose. Informal methods are based on the
knowledge and experience of the evaluating persons.
It is known, that these methods create good results
and detect many problems in a given system. On the
other hand, they are not very difficult or expensive
to implement, so they may be a good approach for
our project. One of these informal inspection methods
is the “Cognitive Walkthrough” (Polson et al., 1992),
where a group of experts simulates a potential user of
the system. The group navigates the system and tries
to perform the typical steps to achieve the results a
user tries to get. Potential problems and defects are
documented and solved. Afterwards, the cognitive
walkthrough may be repeated. We chose the cogni-
tive walkthrough as an appropriate evaluation method
for our system.
Our evaluation was performed in two steps. First,
we performed a cognitive walkthrough in a collabora-
tive meeting with three experienced experts: Expert 1
is a very experienced professor and since many years
Char of Area of Multimedia and Internet Application
in the Department of Mathematics and Computer Sci-
ence at FernUniversit
¨
at in Hagen. Expert 2 is a PhD,
significantly responsible for the concept and design of
KM-EP. Expert 3 is a PhD student, researching in the
area of serious games and named entity recognition.
First, the menu structure of SNERC was navigated
exploratively, to simulate the navigation of a poten-
tial user in the system. Then each SNERC compo-
nent was tested. Finally, the creation of an automated
classification was evaluated. Within these steps, there
were overall eight defects detected, which needed to
be fixed. Then, a second evaluation was performed.
We extended the expert group by two new evaluators:
Expert 4 is a PhD student, researching in the medical
area and emerging named entity recognition. Expert
5 is a PhD student, researching in the area of advanced
visual interfaces and artificial intelligence.
Within the second cognitive walkthrough all typi-
cal steps where performed, as a potential user would
do it. There were no further defects detected. Expert
4 pointed to the problem of unrealistic performance
indicators due to overfitting. This could be disproved
with the possibility to supervise and edit the automat-
ically generated testing data within the NER Model
Manager. A further note was, SNERC may not be
suitable to deal with huge data sets, because of its
web-based GUI architecture. As KM-EP does not
deal with such huge data sets this is not a real problem
for our approach.
We saw the informal evaluation method lead to
many results with a limited amount of time and re-
sources. Nevertheless, an empirical evaluation with
a bigger group of potential users should be done, to
prove the usability and robustness of the system fur-
ther.
5 CONCLUSIONS
In this research, we presented our integration of a
named entity recognition and document classification
tool into an innovative Knowledge Management Sys-
tem for Applied Gaming. Presentation of real-word
use case scenarios for NER and automatic document
classification has been highlighted and we saw, that it
is possible to support users with the process of doc-
ument classification through the use of named entity
recognition in combination with a rule-based expert
system. Our system has been successfully integrated
and has been validated with a Cognitive Walkthrough.
A future evaluation with a bigger group of potential
users may help to gather further insights about the us-
age, usability and error handling of the system. Also,
it should be analyzed if newer NLP tools evolved and
may be suitable for out system. The use of standard
tools for the management of the created ML models
should also be taken into account.
REFERENCES
Abu-Nasser, B. (2017). Medical expert systems survey. In-
ternational Journal of Engineering and Information
Systems (IJEAIS), 1(7):218–224.
Awan, M. S. K. and Awais, M. M. (2011). Predicting
weather events using fuzzy rule based system. Applied
Soft Computing, 11(1):56–63.
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
119

Batista-Navarro, R. T. B., Bandojo, D. A., Gatapia, M.
A. J. K., Santos, R. N. C., Marcelo, A. B., Pan-
ganiban, L. C. R., and Naval, P. C. (2010). ESP:
An expert system for poisoning diagnosis and man-
agement. Informatics for Health and Social Care,
35(2):53–63. Publisher: Taylor & Francis eprint:
https://doi.org/10.3109/17538157.2010.490624.
Blosseville, M.-J., Hebrail, G., Monteil, M.-G., and Penot,
N. (1992). Automatic document classification: nat-
ural language processing, statistical analysis, and ex-
pert system techniques used together. In Proceedings
of the 15th annual international ACM SIGIR confer-
ence on Research and development in information re-
trieval, pages 51–58.
Buchanan, L., Wolanczyk, F., and Zinghini, F. (2011).
Blending bloom’s taxonomy and serious game design.
In Proceedings of the International Conference on Se-
curity and Management (SAM), page 1. The Steering
Committee of The World Congress in Computer Sci-
ence, Computer . . . .
Cavalcanti, Y. C., Machado, I. d. C., Neto, P. A. d. M. S.,
de Almeida, E. S., and Meira, S. R. d. L. (2014). Com-
bining rule-based and information retrieval techniques
to assign software change requests. In Proceedings of
the 29th ACM/IEEE international conference on Au-
tomated software engineering, ASE ’14, pages 325–
330. Association for Computing Machinery.
Dasgupta, A. and Nath, A. (2016). Classification of ma-
chine learning algorithms. International Journal of
Innovative research in Advanced ngineering, 3(3).
David R. and Sandra L. (2005). Serious games: Games that
educate, train, and inform. ACM.
De Lope, R. P. and Medina-Medina, N. (2017). A com-
prehensive taxonomy for serious games. Journal of
Educational Computing Research, 55(5):629–672.
Forgy, C. L. (1989). Rete: A fast algorithm for the many
pattern/many object pattern match problem. In Read-
ings in Artificial Intelligence and Databases, pages
547–559. Elsevier.
Friedman-Hill, E. J. (1997). Jess, the java expert system
shell. Technical report, Sandia Labs., Livermore, CA
(United States).
Gimpel, K., Schneider, N., O’Connor, B., Das, D., Mills,
D., and Eisenstein, J., editors (2010). Part-of-speech
tagging for twitter: Annotation, features, and experi-
ments.
K, X., Zhou, Z., Hao, T., and Liu, W. (2017). A bidirectional
lstm and conditional random fields approach to med-
ical named entity recognition. International Confer-
ence on Advanced Intelligent Systems and Informat-
ics.
Konkol, I. M. (2015). Named entity recognition. Phd, PhD
thesis, University of West Bohemia.
Koppich, G., Yeng, M., and Ormond, L. (2009). Docu-
ment management system rule-based automation. US
Patent 7,532,340.
Lewis, C., Whitehead, J., and Wardrip-Fruin, N. (2010).
What went wrong: a taxonomy of video game bugs.
In Proceedings of the fifth international conference on
the foundations of digital games, pages 108–115.
Liu, B. and Chen-Chuan-Chang, K. (2004). Special is-
sue on web content mining. Acm Sigkdd explorations
newsletter, 6(2):1–4.
Liu, M., Peng, X., Jiang, Q., Marcus, A., Yang, J., and
Zhao, W. (2018). Searching stackoverflow questions
with multi-faceted categorization. In Proceedings of
the Tenth Asia-Pacific Symposium on Internetware,
pages 1–10.
Mao, S., Rosenfeld, A., and Kanungo, T. (2003). Document
structure analysis algorithms: a literature survey. In
Document Recognition and Retrieval X, volume 5010,
pages 197–207. International Society for Optics and
Photonics.
Melo, F., Mascarenhas, S., and Paiva, A. (2018). A tu-
torial on machine learning for interactive pedagogi-
cal systems. International Journal of Serious Games,
5(3):79–112.
Nadeau, D. and Sekine, S. (2007). A survey of named entity
recognition and classification. Lingvisticae Investiga-
tiones, 30:3–26.
Nagy, I., Berend, G., and Vincze, V. (2011). Noun com-
pound and named entity recognition and their usabil-
ity in keyphrase extraction. In Proceedings of the In-
ternational Conference Recent Advances in Natural
Language Processing 2011, pages 162–169.
Nasehi, S. M., Sillito, J., Maurer, F., and Burns, C., editors
(2012). What makes a good code example?: A study
of programming Q&A in StackOverflow. IEEE.
Newman, D., Chemudugunta, C., Smyth, P., and Steyvers,
M. (2006). Analyzing entities and topics in news
articles using statistical topic models. International
conference on intelligence and security informatics.
Springer.
Norman, D. A. and Draper, S. W. (1986). User Cen-
tered System Design; New Perspectives on Human-
Computer Interaction. L. Erlbaum Associates Inc.
Pinto, A., Gonc¸alo Oliveira, H., and Oliveira Alves, A.
(2016). Comparing the Performance of Different NLP
Toolkits in Formal and Social Media Text. In 5th Sym-
posium on Languages, Applications and Technolo-
gies (SLATE’16), page 16 pages. Artwork Size: 16
pages Medium: application/pdf Publisher: Schloss
Dagstuhl - Leibniz-Zentrum fuer Informatik GmbH,
Wadern/Saarbruecken, Germany.
Polson, P. G., Lewis, C., Rieman, J., and Wharton, C.
(1992). Cognitive walkthroughs: a method for theory-
based evaluation of user interfaces. International
Journal of man-machine studies, 36(5):741–773.
RATAN, R. A. and Ritterfeld, U. (2009). Classifying se-
rious games. In Serious games, pages 32–46. Rout-
ledge.
Ritter, A., Clark, S., and Etzioni, O., editors (2011). Named
entity recognition in tweets: an experimental study.
Sokal, R. R. (1963). The principles and practice of numeri-
cal taxonomy. Taxon, pages 190–199.
Sutton, C., McCallum, A., and Rohanimanesh, K. (2007).
Dynamic conditional random fields: Factorized prob-
abilistic models for labeling and segmenting sequence
data. Journal of Machine Learning Research, 8:693–
723.
KEOD 2020 - 12th International Conference on Knowledge Engineering and Ontology Development
120

Tamla, P., B
¨
ohm, T., Hemmje, M., and Fuchs, M., editors
(2019a). Named Entity Recognition supporting Se-
rious Games Development in Stack Overflow Social
Content. International Journal of Games Based Learn-
ing.
Tamla, P., B
¨
ohm, T., Nawroth, C., Hemmje, M., and Fuchs,
M., editors (2019b). What do serious games devel-
opers search online? A study of GameDev Stack-
exchange, volume VOL. 2348 of PROCEEDINGS
OF THE 5TH COLLABORATIVE EUROPEAN RE-
SEARCH CONFERENCE (CERC 2019). CEUR-
WS.ORG.
Toftedahl, M. and Henrik, E., editors (2019). A Taxonomy of
Game Engines and the Tools that Drive the Industry,
DIGRA INTERNATIONAL CONFERENCE 2019:
GAME, PLAY AND THE EMERGING LUDO-MIX.
Tomanek, K., Wermter, J., and Hahn, U. (2007). Sen-
tence and token splitting based on conditional ran-
dom fields. In Proceedings of the 10th Conference of
the Pacific Association for Computational Linguistics,
volume 49, page 57. Melbourne, Australia.
Van der Vegt, W., Nyamsuren, E., and Westera, W. (2016).
Rage reusable game software components and their
integration into serious game engines. In Interna-
tional Conference on Software Reuse, pages 165–180.
Springer.
Van Roy, P. et al. (2009). Programming paradigms for
dummies: What every programmer should know.
New computational paradigms for computer music,
104:616–621.
Varvaressos, S., Lavoie, K., Gaboury, S., and Hall
´
e, S.
(2017). Automated bug finding in video games: A
case study for runtime monitoring. Computers in En-
tertainment (CIE), 15(1):1–28.
Velickovski, F. (2016). Clinical decision support for screen-
ing, diagnosis and assessment of respiratory diseases:
chronic obstructive pulmonary disease as a use case.
PhD thesis, University of Girona. Accepted: 2017-11-
27T07:51:26Z Publisher: Universitat de Girona.
Vredenburg, K., Mao, J.-Y., Smith, P. W., and Carey, T.
(2002). A survey of user-centered design practice. In
Proceedings of the SIGCHI conference on Human fac-
tors in computing systems, pages 471–478.
Ye, D., Xing, Z., Foo, C. Y., Ang, Z. Q., Li, J., and
Kapre, N., editors (2016). Software-specific named
entity recognition in software engineering social con-
tent. IEEE.
Supporting Named Entity Recognition and Document Classification in a Knowledge Management System for Applied Gaming
121
