
Ontology-quality Evaluation Methodology for Enhancing Semantic
Searches and Recommendations: A Case Study
Paula Pe
˜
na
1 a
, Raquel Trillo-Lado
2 b
, Rafael del Hoyo
1 c
,
Mar
´
ıa del Carmen Rodr
´
ıguez-Hern
´
andez
1 d
and David Abad
´
ıa
1 e
1
Technological Institute of Aragon (ITAINNOVA), Mar
´
ıa de Luna 7, Zaragoza, Spain
2
University of Zaragoza, Zaragoza, Spain
Keywords:
Quality Ontology Modelling, ESCO Ontology, Information Retrieval, Ontology Quality Evaluation.
Abstract:
In the big data era, there exist an increasing demand of models and tools to evaluate quality of data used in
decision-making and search processes, as decision based on wrong and poor data quality can lead to enormous
loss. Thus, data has become an asset and the most powerful enabler of any organization. In this context,
ontologies and semantic techniques have gained importance in order to represent data sources and metadata
during the last decades. In this paper, we describe our work-in-progress concerning to the generation of
models that encourage data quality through the use of ontologies. In particular, we present a use case where
an enriched ontological model of ESCO (European Skills, Competences, Qualifications and Occupations)
is used to improve the effectiveness of a search and recommendation system. In more detail, we focus on
how ESCO is enriched by following METHONTOLOGY methodology and 101 methodological guidelines.
We also provide the design of a search and recommendation system oriented to labour market that exploits
the enhanced ontology to suggest qualifications required by job seekers and employees to reach a specific
occupation position and different training itineraries to get those recommended qualifications.
1 INTRODUCTION
The progressive emergence of numerous and signifi-
cant technological changes in the Information Tech-
nology (IT) industry has been the driver for the large
amount of data generated and accumulated at an un-
precedented speed. Data has become the main asset
and the most powerful enabler for any type of organi-
zation or institution to make operational, tactical and
strategic decisions. For this reason, data quality is
seen as a key element, not only to be able to generate
value, knowledge and competitive advantage, but also
to prevent adverse consequences from being incurred
by decisions based on wrong data or with inadequate
levels of quality.
In recent years, research works have been carried
out with a great diversity of approaches on the issue
of data quality (Cai and Zhu, 2015; Taleb et al., 2018).
a
https://orcid.org/0000-0001-5750-6238
b
https://orcid.org/0000-0001-6008-1138
c
https://orcid.org/0000-0003-2755-5500
d
https://orcid.org/0000-0002-0062-9525
e
https://orcid.org/0000-0002-6005-3863
Due to the evolution of the big data and its new char-
acteristics, in the state-of-the-art, there is a lack of
data-quality methods to reach optimal solutions that
consider the continuously growing data volume with a
reasonable time and cost. In addition, there are no ma-
ture models to assess data quality to support decision-
making and address problems at the business level.
In the meantime, in a world overflowing with un-
structured data, semantic technologies are presented
as an effective tool for understanding, storing, relat-
ing, sharing, searching and finding information. The
use of these technologies are a suitable means for in-
telligent analysis of big data based on artificial intelli-
gence (AI) techniques and value generation. Explor-
ing the connection between data quality and semantic
technologies in this era of big data and data-driven
decision making is a broad field of research.
In this context, we describe our work-in-progress
concerning the generation of models that foster data
quality through the use of ontologies. These models
can be used for the intelligent analysis and data man-
agement, and value extraction and decision making
with large volumes of data from diverse sources and
with a variety of uses of those data in business and
Peña, P., Trillo-Lado, R., Hoyo, R., Rodríguez-Hernández, M. and Abadía, D.
Ontology-quality Evaluation Methodology for Enhancing Semantic Searches and Recommendations: A Case Study.
DOI: 10.5220/0010143602770284
In Proceedings of the 16th International Conference on Web Information Systems and Technologies (WEBIST 2020), pages 277-284
ISBN: 978-989-758-478-7
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
277

institutional contexts. In particular, we focus on how
improving the data model that describes the informa-
tion used by a search and recommendation system ori-
ented to labour market and enhances the performance
of the system.
We propose to introduce an enhanced ESCO on-
tology
1
in a dynamic information retrieval system ori-
ented to labour market: different training itineraries
are suggested to job seekers and employees who want
to reach a specific occupation position. We postulate
that improving the quality of the ontologies used im-
proves the efficiency or performance of the systems.
Thus, a proposal for a new approach and metrics to
evaluate how the quality of the recommended results
depends on the built ontology quality is outlined.
This paper is organized as follows. Section 2
presents related work on ontology engineering and
quality evaluation. Section 3 describes the purpose
and motivation of our work through a use case and
the high-level information retrieval system architec-
ture used. An ontological enhancing methodology is
detailed and the quality evaluation approach to work
on is outlined in Section 4. Finally, Section 5 presents
conclusions and highlights lines of future work.
2 RELATED WORK
Semantic technologies are presented as an important
means in unstructured information management pro-
cesses (understanding, sharing, searching, etc.), but
also for intelligent analysis of big data based on AI
techniques and value creation. In this context, ontolo-
gies play a critical role to provide a shared formal rep-
resentation of knowledge regarding naming and defi-
nition of types, and properties and interrelationships
of entities that exist in a particular domain of dis-
course (Gruber, 1993). In this section, we discuss re-
lated work on existing ontology-engineering method-
ologies and quality assessment of built ontologies.
2.1 Ontology Engineering
Many ontology engineering methodologies (OEM)
have been proposed to build ontologies over the last
decades, although there is no a standard method or
widely used guidelines. The available methodologies
have either been initially proposed or emerged from
experiences and insights achieved during ontology
development for different projects. A critical analy-
sis and comparison of these methodologies is carried
out in (Iqbal et al., 2013).
1
https://ec.europa.eu/esco/portal/home
In this paper, we do not propose another ontol-
ogy development methodology, but an approach that
facilitates the integration and enhancement of exist-
ing ontologies in order to improve the performance of
systems. We pursue to analyze how the quality of on-
tologies influence the effectiveness of the system and
the achievement of the business goals of an enterprise
or institution. Hence, we consider the METHONTOL-
OGY methodology (Fern
´
andez-L
´
opez et al., 1997)
and 101 method guidelines (Noy and McGuinness,
2001) to enhance the ESCO ontology and evaluate
how it impacts on the performance of the application
system.
The use of ontologies for describing data sources
has been exponentially increasing in the last decades,
especially in the context of the semantic web. On-
tology alignments are required in order to integrate
the information from several data sources and manage
heterogeneity. Ontology matching consists of find-
ing correspondences between semantically related en-
tities from different ontologies and purposes (Shvaiko
and Euzenat, 2013).
Along the time, a wide range of ontology match-
ing techniques, systems and tools have been pro-
posed. Some of the more recent ones are SAMBO,
Falcon, DSsim, RiMOM, ASMOV, Anchor-Flood and
AgreementMaker which have appeared to cover gaps
from previous works (Otero-Cerdeira et al., 2015;
Bellahsene et al., 2011; Gal and Shvaiko, 2009; Choi
et al., 2006; Zimmermann et al., 2006; Bouquet et al.,
2005). Besides, while the current research focuses
mainly on fully automatic matching tools, the user in-
volvement and collaborative interaction become new
challenges for ontology matching (Shvaiko and Eu-
zenat, 2013). In this paper, we pursue to evaluate the
quality of the results obtained by existing automatic
matching tools and techniques. In addition, we will
assess the results of the search and recommendation
system that includes the enhanced ontology.
2.2 Ontology Quality Assessment
Although a significant amount of research has been
conducted about ontology-building processes, there
are no mature models to assess ontology quality.
Nowadays, ensuring that ontologies are well de-
signed, structured and contain all essential elements,
remains a major concern and a challenging task.
Different approaches, aspects, criteria and tools
have emerged with the aim to prove ontology correct-
ness and quality. Regarding scopes, domains and on-
tologies purposes, attempts based on logical or rule,
evolution, metric or feature, application, data-driven,
evaluation by humans, the Gold standard and task
WEBIST 2020 - 16th International Conference on Web Information Systems and Technologies
278

have been proposed (Mishra and Jain, 2020). As a
result, various quality metrics and criteria such as ac-
curacy or correctness, adaptability, clarity, complete-
ness or competency, computational efficiency, con-
ciseness, consistency or coherence and organizational
fitness, have been proposed in recent years to cover
a larger range of quality attributes (Vrande
ˇ
ci
´
c, 2009).
Some of which are now widely accepted and imple-
mented in frameworks and tools for ontological eval-
uation. Examples of these are OntoClean, (Guarino
and Welty, 2004), ODEval (Corcho et al., 2004), On-
toQA, (Tartir et al., 2005), OQuaRE (Duque-Ramos
et al., 2013), OntoQualitas (Rico et al., 2014) and
(Zaveri et al., 2015; Abi
´
an et al., 2018).
3 PURPOSE AND MOTIVATION
In this section, we describe a case study that illustrates
the motivation of our article, which is in the context of
a European research project
2
. In addition, we present
a high-level view of the architecture designed to fa-
cilitate the retrieval and recommendation of relevant
information for the construction sector.
3.1 Case Study: DETECTA
This section describes our ongoing work regard-
ing the development of a new dynamic information
retrieval and recommendation system (called DE-
TECTA) for the detection of qualification needs of job
seekers and employees in the construction sector. We
aim at scenarios where the DETECTA platform sug-
gests different training itineraries to users who want
to achieve a specific occupation position, by consider-
ing the user’s profile, desired occupation and external
information sources (see Figure 1).
For example, a job seeker or employee from the
construction sector has experience in occupations
such as house builder, stonemason and kitchen unit
installer (mentioned in her/him resume), and now
he/she wants to work in the carpenter or construc-
tion painter occupations, but he/she does not have the
required studies (skills and competences) to perform
them. Based on the current user scenario (the start-
ing point and the desired point that he/she wants to
achieve), the system would be able to suggest a train-
ing itinerary to obtain the required certificates.
DETECTA is also interesting for different types
of enterprises and entities in order to suggest train-
ing itineraries to their employees, by considering their
2
http://www.e-detecta.eu/web/
Figure 1: Overview of the user training itinerary retrieval
and recommendation process.
target roles, skills and responsibilities along with the
business strategic goals.
DETECTA considers a set of data sources related
to training and job offers and trend analysis on the
construction field (e.g, public European and regional
web portals, interviews, newspaper articles, reports,
social networks, etc.). Moreover, new data sources
can be added dynamically to the system. Initially, we
focus on external data sources that provide relevant
information (e.g., professional certificates, unregu-
lated certificates, training courses, job offers, etc.) for
the countries Spain, France, Ireland and Belgium. In
addition, the system exploits existing ontologies. For
example, the ESCO ontology (Smedt et al., 2015) that
includes concepts such as occupations, skills, qualifi-
cations, etc.
3.2 Training Itinerary Retrieval and
Recommendation Architecture
The architecture of DETECTA has been designed to
facilitate the retrieval and recommendation of training
itineraries required by users (job seekers, employees
or enterprise manages) in order to achieve their target
occupations (see a high-level view in Figure 2). The
proposed architecture is composed of the following
layers:
• Data Access Layer. It provides the access in an
abstract way to the information stored in an ontol-
ogy and the Solr database to feed the DETECTA
system. Moreover, in order to model the domain
of the search or recommendation system, these
data are described and annotated by means of an
enhanced version of the ESCO ontology (Smedt
et al., 2015). It was enriched with information ex-
tracted from external data sources, by using the
Ontology-quality Evaluation Methodology for Enhancing Semantic Searches and Recommendations: A Case Study
279

Figure 2: Overview of the training itinerary retrieval system architecture.
Crawler Manager module (see Section 4 for more
details). Specifically, we use the EURES (EURo-
pean Employment Services) European Job Mo-
bility Portal
3
to extract information about job of-
fers. Regarding training offers, we exploit dif-
ferent web portals (e.g., FUNDAE
4
and SEPE
5
for Spain, R
´
eseau des CARIF OREF for France
6
,
Dorifor for Belgium
7
, and Further Education &
Training Course for Ireland
8
) to extract informa-
tion related to professional certificates, unregu-
lated certificates and training centers. The Ontol-
ogy Manager module is used to access the infor-
mation stored in the ESCO ontology. Concern-
ing job-trend analysis, relevant and specific con-
text sites are considered in order to detect period-
ical reports and social networks (e.g. CECE
9
) to
be analysed by using Natural Language Process-
ing (NLP) techniques. Finally, the User Profile
Manager and Company Profile Manager modules
are responsible for managing (inserting, modify-
ing and removing) the information of the users’
profiles, stored in a Solr database.
• Logic Layer. It contains the main modules
of the DETECTA system, which will be imple-
mented through the software development tool
Moriarty (Pe
˜
na et al., 2016). The User-based
Search Engine module supports a keyword-based
information retrieval model. First, the query intro-
duced by the user in the system (through the view
layer) is pre-processed, by using different analyz-
ers (e.g., lower filter, stop filter, ASCII filter, etc.).
Then, the system retrieves the K occupations most
3
https://ec.europa.eu
4
https://www.fundae.es
5
https://sede.sepe.gob.es
6
https://reseau.intercariforef.org
7
https://www.fetchcourses.ie
8
https://www.dorifor.be
9
https://www.cece.eu/home
similar to the user’s query (or desired occupation),
by considering occupation alternative labels (e.g.,
synonyms). For this analysis, the system uses the
Ontology Manager module (contained in the data
access layer) to access the occupations stored in
the ESCO ontology. The system seeks the pro-
fessional and unregulated certificates related to
retrieved occupations, discarding those that have
been obtained by him/her in the past (contained in
the user’s profile). Both occupations and certifi-
cates are related through common skills and com-
petences. Finally, the system presents to the user a
list of certificates required to perform the desired
occupation. The user-based search can be multi-
target as the user can choose several targets as de-
sired occupation position. In this case, DETECTA
suggests a training itinerary with the aggregated
information, by enabling to point out incremen-
tal training needs in order to achieve the desired
occupation. This multi-target suggestion can also
apply to the enterprise level by matching common
and incremental training needs for the employees,
by using the Company-based Search Engine mod-
ule. In addition, the system administration and
the programming of crawler web services (e.g.,
frequency, date and hour of execution of the ser-
vices, as well as the type of process to apply: syn-
chronous or asynchronous) is also possible thanks
to the Administrator Manager module.
• View Layer. It shows the main components of the
graphical user interface (GUI). Through this inter-
face, both the user (job seeker, employee) or com-
pany manager can include, modify and remove in-
formation in their profile (e.g., personal informa-
tion, skills, education and working experience). In
addition, they can submit queries about desired
occupations to perform in the construction sec-
tor and receive recommendations about possible
training itineraries. The results of the search can
WEBIST 2020 - 16th International Conference on Web Information Systems and Technologies
280

be presented to users through a graph or a ranked
list. From both alternatives, users can filter certifi-
cates by his/her location, as well as navigate over
the ontology, which contains information related
to the retrieved certificates (e.g., courses, train-
ing centers, jobs, occupations, skills, and possi-
ble equivalence at European level). Administra-
tors can manage permissions and schedule the ex-
ecution of maintenance services, such as crawlers
to pick job offers and training courses up.
In this paper, we focus on the main components of
the Data Access Layer. The information contained
in external data sources is heterogeneous and chang-
ing over time. A deep analysis and pre-processing of
the considered data sources is needed to extend the
design of the ESCO ontology and automatically pop-
ulate it with relevant information, used by the DE-
TECTA system. Moreover, the results obtained from
the system could be strongly influenced by the quality
of the considered and enhanced ontology.
4 ONTOLOGICAL ENRICHMENT
AND QUALITY ASSESSMENT
In this section, firstly, we describe the methodology
to build the extended version of the ESCO ontology.
Then, we present the outlines of a new approach to
evaluate how the quality of results obtained from the
DETECTA system depends on the quality of the built
ontological model.
4.1 The ESCO Ontology
The state-of-the-art on domain ontologies related to
jobs, occupation, competences, skills, training and
qualifications were analyzed. After that, the ESCO
ontology was selected as core of the data model for
the DETECTA system. A brief description and the
criteria used to adopt it are detailed in the following.
The ESCO (European Skills, Competences, Qual-
ifications and Occupations) ontology model uses rel-
evant concepts and relationships to model the labour
market and education and training programmes. It
is also enriched with a multilingual European clas-
sification of professional occupations, competences
and qualifications, which is available in 27 languages
and provides descriptions of 2.942 different occupa-
tions and 13.485 skills. As new emerging occupa-
tions and skills are regularly requested by employ-
ers and changes in curricula and in terminology, it
is under continuous improvement. The most recent
version of ESCO Classification v1.0.5 was published
in May 2020. Other popular domain ontologies and
models such as HRM (G
´
omez-P
´
erez et al., 2007),
International Standard Classification of Occupations
(ISCO)
10
, EQF
11
, Fields of Education and Training
(FoET)
12
and Statistical Classification of Economic
Activities in the European Community (NACE)
13
,
etc. were considered. Nevertheless, ESCO was se-
lected because most of these ontologies and models
were integrated in it and ESCO is a current active
project.
4.2 Enrichment Proposed Methodology
For the purpose of this work, in the process of enrich-
ing the ESCO ontological model, the methodologi-
cal guidelines contained in METHONTOLOGY and
101 method have been followed. From a closer in-
sight, these OEMs (Iqbal et al., 2013) recommend a
life cycle as well as keeping the reusability perspec-
tive in mind to improve standardization and data qual-
ity. These methodologies follow an evolving proto-
type model, their natures are application independent
and provide at least some details about the used tech-
niques and activities.
The enhanced ontology has been created using
this iterative and incremental development process,
which emphasizes the construction of a robust con-
ceptual model, and the clear and concise determi-
nation of requirements of the ontology to be built.
Phases and activities were defined as shown below:
• Planning: establishment of the activities required
to obtain the expected result.
• Specification: definition of the domain, scope and
granularity of the ontology to be improved with
the semantics of new resources. Requirements de-
termination for enhancing the ontology.
• Conceptualization: definition of a conceptual
model, which describes the problem and its so-
lution in terms of the vocabulary of the domain
identified in the specification.
• Formalization: transformation of the conceptual
model into a formal model.
• Implementation: codification of the ontology in a
formal language such as RDF or OWL. Prot
´
eg
´
e
ontology editor has been used.
• Evaluation: verification and validation of the ex-
tended ontology through tests that allow its subse-
quent update, refinement or correction of errors.
10
http://www.ilo.org/public/english
11
https://europa.eu/europass/en
12
http://uis.unesco.org/en
13
https://ec.europa.eu/eurostat
Ontology-quality Evaluation Methodology for Enhancing Semantic Searches and Recommendations: A Case Study
281

• Dissemination: dissemination of work done and
the process to be followed to adapt the new ontol-
ogy.
The ontology with a set of individuals constitutes a
knowledge model. As a key-element of ontologies,
classes describe concepts in a domain. Our ontol-
ogy is constructed based on standard RDF model 1.2
ESCO ontology, FOAF vocabulary, vCard Ontology,
The Organization Ontology and OWL Time Ontology.
The main classes are shown in Figure 3 and described
as follows:
• Person: information on a basic user.
• JobProfile: information about the users’ job pro-
files (personal skills, education and certificates
obtained and previous work occupation).
• Certificate: information related to “Professional”
and “Non-Regulated” certificates.
• TrainingCenter: information on the companies
that give the courses required to obtain a certifi-
cate (either professional or non-regulated). It is
an Organization subclass.
• TrainingModule: information on the modules
contained in a course.
• CompetenceUnit: information about the compe-
tence units of a training module.
• Job: information on job offers. In this case for the
countries of Spain, France, Belgium and Ireland.
• Employer: information about companies offering
job offers. It is an Organization subclass.
• Sector: classification of the different sectors asso-
ciated with the companies that offer work.
To model the DETECTA domain, the ontology uses
other main ESCO classes such as Occupation, Skill,
Qualification, Organization and AwardingBody (Or-
ganization subclass). Basic relationships are defined
in the ontology. Each user is related to a job pro-
file. Each certificate is associated with a qualification
level, a professional family, a professional area, and a
type of modality (professional, not-regulated), as well
as one or more occupations, training centers, content
modules and competence units. Relevant information
on how to associate a professional certificate with a
European Supplement is also provided.
The ontology is populated with information intro-
duced by users using a web application (person and
job profile), periodically updated information (certifi-
cate, training center, modules, competence units, job,
employer, sector, occupation, skills and qualification)
through the crawlers implemented (see Section 3),
and public RDF or SKOS datasets for countries, re-
gions and cities (e.g. NUTS), language level, driving
license, etc.
4.3 Quality Evaluation Approach
The aim of our approach is to demonstrate that the
quality and customization of search and recommen-
dation results can be improved through the genera-
tion and use of ontologies. In particular, our pur-
pose is showing that the quality of the underlying on-
tologies influences the performance of the quality ob-
tained from the system. In our case, the knowledge
domain is focused on recommending different train-
ing itineraries based on the user’s profile as a start-
ing point, the desired occupation to be reached and
data from external sources (e.g., job offers, training
courses, certificates, etc.).
Since our ontology has been built by hand on the
foundation of the ESCO ontology model, reusing on-
tologies and vocabularies for the representation of
certain concepts, adding new concepts and relation-
ships to fill gaps of knowledge and gather a richer
domain representation, and using external sources to
populate the ontology, there is a need to evaluate the
resulting ontology to ensure it meets certain quality
criteria. The quality of this ontology will certainly
affect the effectiveness of the DETECTA system.
In this context, our approach to address the on-
tology quality evaluation is using existing evalua-
tion tools (e.g., OOPs, OntoQA, OntoMetric, On-
toCheck, etc.), based on different metrics, dimensions
and methodologies. This will allow checking, iden-
tifying and improving general errors that could have
been committed during ontology building (e.g., lack
of domain or range in the properties, fusion of differ-
ent concepts in the same class, etc.). Then, we pro-
pose to evaluate the quality of the ontological model
built by hand (in our case, the enriched ontologi-
cal model of ESCO) regarding the resulting ontology
generated through existing automatic matching tools
and techniques, and taking as a starting point the same
ontologies of origin. In addition, the performance of
the automatic matching tools will be also evaluated
by considering the results obtained from the search
and recommendation system, where the enhanced on-
tology is used. Moreover, it could be evaluated how
other existing ontologies of the analyzed application
domain (e.g., HRM), as input from these automatic
matching tools, can influence the performance of the
system.
In order to evaluate ontology quality, dimensions
and metrics will be adopted according to the classifi-
cation presented in (Zaveri et al., 2015), such as ac-
curacy, consistency, completeness, relevancy, etc. In
addition, within our ontology-quality evaluation ap-
proach, we propose new metrics (e.g., metrics related
to reputation systems) that can envision the develop-
WEBIST 2020 - 16th International Conference on Web Information Systems and Technologies
282
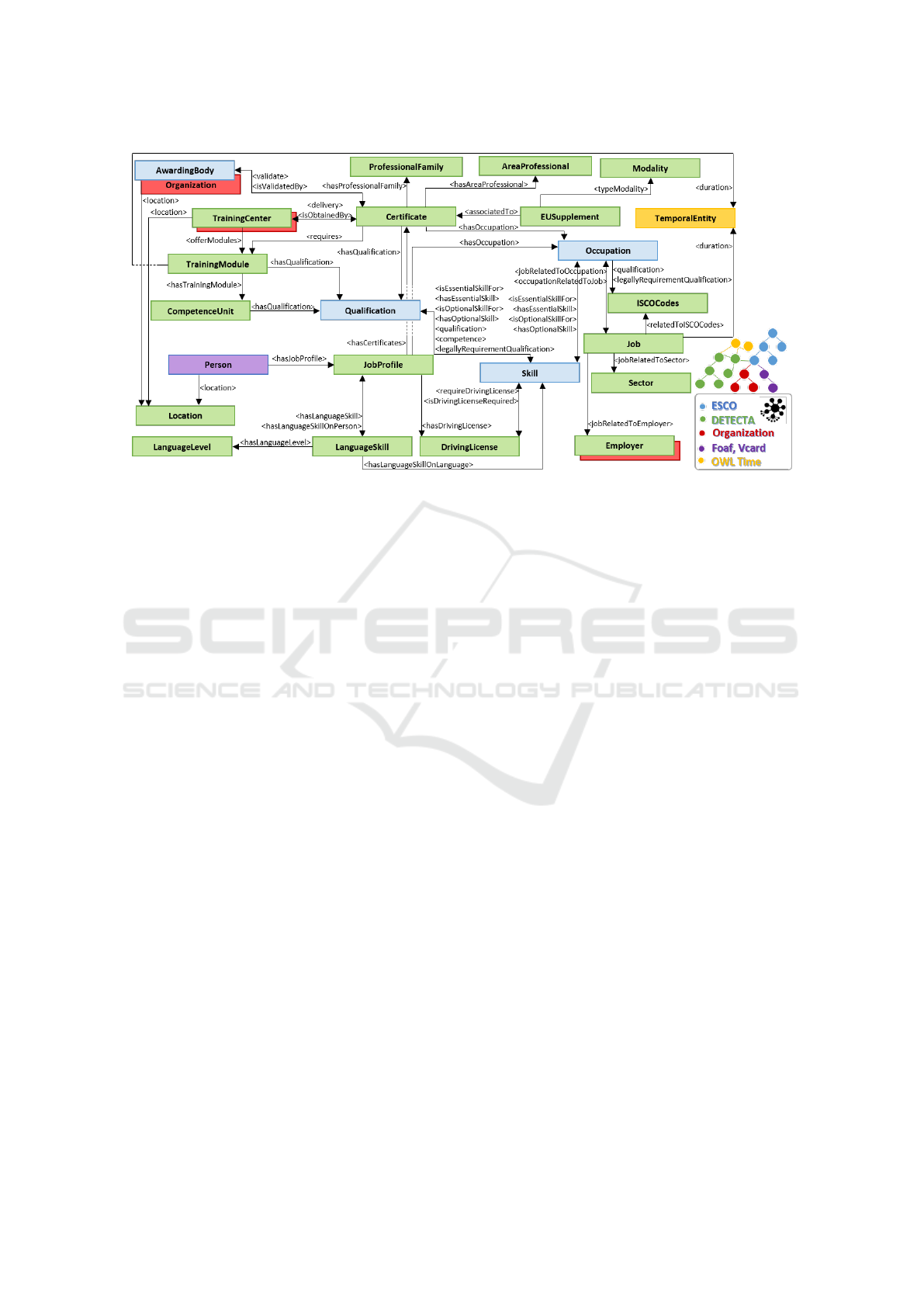
Figure 3: Main classes and relationships of the built enriched ontology.
ment of new models that promote quality, by analyz-
ing the context and factors that affect quality in real
problems in organizational or institutional domains
for better decision making and achievement of results.
Effectiveness and best results rely on the high-quality
ontology, and although in some cases the manual con-
struction of a quality ontology is not feasible, it is an
aspect to take into account in systems that turn out to
be critical.
5 CONCLUSIONS AND FUTURE
WORK
In recent years, a large amount of data has been gen-
erated and stored at increasing speed as a result of
the digital transformation and the appearance of the
big data and its new features. How to provide qual-
ity results become a critical issue and an important
key to support decision-making and to address prob-
lems at the business level. In this paper, we presented
our work-in-progress related to the methodology fol-
lowed to build an enriched version of the ESCO on-
tology, based on standards to enable higher quality
results in a real-life scenario related to labour mar-
ket as a case study. In this context, the DETECTA
search and recommendation system can take advan-
tage of ontologies capabilities. Furthermore, we out-
lined a new approach to evaluate how the performance
of the search and recommendation system depends on
the quality of the built ontological model.
Our next steps involve the implementation of the
designed DETECTA architecture, the use of existing
evaluation tools to address the improvement of the
hand built ontology, and the evaluation of the enriched
ontology model regarding the resulting ontology, gen-
erated through automatic matching tools. In addi-
tion, the evaluation of the search and recommenda-
tion system performance where the built ontology is
used, the adoption of relevant quality dimension and
criteria for the evaluation, and the proposal of new
metrics to foster higher quality and better results in
the analyzed context. As future work, we would like
to further research the generation of models that pro-
mote data quality through the use of semantic tech-
nologies, based on systems with large data volumes
and from heterogeneous sources for different business
and institutional domains. Thus, these models could
be used for intelligent data analysis and management,
value extraction and decision making.
ACKNOWLEDGEMENTS
This work has been supported by the IODIDE (Inte-
gration and Development of Big Data and Electrical
Systems) ITAINNOVA research group, and the DE-
TECTA (EACEA/04/2017 call, 591843-EPP-1-2017-
1-ES-EPPKA2-SSA-N) and TIN2016-78011-C4-3-R
(AEI/FEDER, UE) projects.
REFERENCES
Abi
´
an, D., Guerra, F., Romanos, J. M., and Trillo-Lado,
R. (2018). Wikidata and DBpedia: A comparative
Ontology-quality Evaluation Methodology for Enhancing Semantic Searches and Recommendations: A Case Study
283

study. In Szyma
´
nski, J. and Velegrakis, Y., edi-
tors, Semantic Keyword-Based Search on Structured
Data Sources (IKC), volume 10546, pages 142–154.
Springer, Berlin, Heidelberg. Lecture Notes in Com-
puter Science (LNCS).
Bellahsene, Z., Bonifati, A., and Rahm, E. (2011). Schema
Matching and Mapping. Data-Centric Systems and
Applications (DCSA). Springer, Berlin, Heidelberg.
Bouquet, P., Ehrig, M., Euzenat, J., Franconi, E., Hitzler,
P., Krotzsch, M., Serafini, L., Stamu, G., Sure, Y.,
and Tessaris, S. (2005). Specification of a common
framework for characterizing alignment. Deliverable
D2.2.1, Knowledge web NoE, Wright State Univer-
sity, Ohio (USA).
Cai, L. and Zhu, Y. (2015). The challenges of data quality
and data quality assessment in the Big Data era. Data
Science Journal, 14(2):1–10.
Choi, N., Song, I.-Y., and Han, H. (2006). A survey on
ontology mapping. ACM SIGMOD Record, 35(3):34–
41.
Corcho,
´
O., G
´
omez-P
´
erez, A., Gonz
´
alez-Cabero, R., and
Su
´
arez-Figueroa, M. C. (2004). ODEval: A tool for
evaluating RDF(S), DAML+OIL, and OWL concept
taxonomies. In Bramer, M. and Devedzic, V., edi-
tors, First International Conference on Artificial Intel-
ligence Applications and Innovations (AIAI), volume
154 of IFIP International Federation for Informa-
tion Processing (IFIPAICT), pages 369–382. Springer,
Boston (USA).
Duque-Ramos, A., Fern
´
andez-Breis, J. T., Iniesta, M., Du-
montier, M., Aranguren, M. E., Schulz, S., Aussenac-
Gilles, N., and Stevens, R. (2013). Evaluation of the
OQuaRE framework for ontology quality. Expert Sys-
tems with Applications, 40(7):2696–2703.
Fern
´
andez-L
´
opez, M., G
´
omez-P
´
erez, A., and Juristo, N.
(1997). METHONTOLOGY: From ontological art to-
wards ontological engineering. In AAAI-97 Spring
Symposium Series, pages 33–40. American Asocia-
tion for Artificial Intelligence.
Gal, A. and Shvaiko, P. (2009). Advances in ontology
matching. In Dillon, T. S., Chang, E., Meersman, R.,
and Sycara, K., editors, Advances in Web Semantics I:
Ontologies, Web Services and Applied Semantic Web,
volume 4891 of Lecture Notes in Computer Science
(LNCS), pages 176–198. Springer, Berlin, Heidelberg.
G
´
omez-P
´
erez, A., Ram
´
ırez, J., and Villaz
´
on-Terrazas, B.
(2007). An ontology for modelling Human Resources
Management based on standards. In Apolloni, B.,
Howlett, R. J., and Jain, L., editors, International
Conference on Knowledge-Based and Intelligent In-
formation and Engineering Systems (KES), volume
4692, pages 534–541. Springer, Berlin, Heidelberg.
Lecture Notes in Computer Science (LNCS).
Gruber, T. R. (1993). A translation approach to portable
ontology specifications. Knowledge Acquisition,
5(2):199–220.
Guarino, N. and Welty, C. A. (2004). An overview of Onto-
Clean. In Staab, S. and Studer, R., editors, Handbook
on Ontologies, International Handbooks on Informa-
tion Systems (INFOSYS), pages 151–171. Springer,
Berlin, Heidelberg.
Iqbal, R., Murad, M. A. A., Mustapha, A., and Sharef,
N. M. (2013). Analysis of ontology engineering
methodologies: A literature review. Research Jour-
nal of Applied Sciences, Engineering and Technology,
6(16):2993–3000.
Mishra, S. and Jain, S. (2020). Ontologies as a semantic
model in IoT. International Journal of Computers and
Applications, 42(3):233–243.
Noy, N. F. and McGuinness, D. L. (2001). Ontology de-
velopment 101: A guide to creating your first ontol-
ogy. Technical Report KSL-01-05, Stanford Univer-
sity, California (USA).
Otero-Cerdeira, L., Rodr
´
ıguez-Mart
´
ınez, F. J., and G
´
omez-
Rodr
´
ıguez, A. (2015). Ontology matching: A lit-
erature review. Expert Systems with Applications,
42(2):949–971.
Pe
˜
na, P., Del Hoyo, R., Vea-Murgu
´
ıa, J., Rodrig
´
alvarez, V.,
Calvo, J., and Mart
´
ın, J. (2016). Moriarty: Improving
‘time to market’in big data and artificial intelligence
applications. International Journal of Design & Na-
ture and Ecodynamics, 11(3):230–238.
Rico, M., Caliusco, M. L., Chiotti, O., and Galli, M. R.
(2014). OntoQualitas: A framework for ontology
quality assessment in information interchanges be-
tween heterogeneous systems. Computers in Industry,
65(9):1291–1300.
Shvaiko, P. and Euzenat, J. (2013). Ontology match-
ing: State of the art and future challenges. IEEE
Transactions on Knowledge and Data Engineering,
25(1):158–176.
Smedt, J. D., le Vrang, M., and Papantoniou, A. (2015).
ESCO: Towards a Semantic Web for the European la-
bor market. In Second International Workshop on Se-
mantic and Dynamic Web Processes (ICWS), volume
140. CEUR Workshop Proceedings.
Taleb, I., Serhani, M. A., and Dssouli, R. (2018). Big
Data quality: A survey. In 2018 IEEE International
Congress on Big Data (BigData Congress), pages
166–173. IEEE.
Tartir, S., Arpinar, I. B., Moore, M., Sheth, A. P.,
and Aleman-Meza, B. (2005). OntoQA: Metric-
based ontology quality analysis. In IEEE Work-
shop on Knowledge Acquisition from Distributed,
Autonomous, Semantically Heterogeneous Data and
Knowledge Sources at Fifth IEEE International Con-
ference on Data Mining (ICDM), pages 45–53.
Vrande
ˇ
ci
´
c, D. (2009). Ontology evaluation. In Staab, S.
and Studer, R., editors, Handbook on Ontologies, In-
ternational Handbooks on Information Systems (IN-
FOSYS), pages 293–313. Springer, Berlin, Heidel-
berg.
Zaveri, A., Rula, A., Maurino, A., Pietrobon, R., Lehmann,
J., and Auer, S. (2015). Quality assessment for Linked
Data: A survey. Semantic Web, 7(1):63–93.
Zimmermann, A., Krotzsch, M., Euzenat, J., and Hitzler, P.
(2006). Formalizing ontology alignment and its oper-
ations with category theory. In Fourth International
Conference on Formal Ontology in Information Sys-
tems (FOIS), pages 277–288. hal-00825949.
WEBIST 2020 - 16th International Conference on Web Information Systems and Technologies
284
