
A Multi-criteria Approach for Large-object Cloud Storage
Uwe Hohenstein
1
, Michael C. Jaeger
1
and Spyridon V. Gogouvitis
2
1
Corporate Technology, Siemens AG Munich, Germany
2
Mobility Management, Siemens AG Munich, Germany
Keywords:
Cloud Storage, Federation, Multi-criteria.
Abstract:
In the area of storage, various services and products are available from several providers. Each product pos-
sesses particular advantages of its own. For example, some systems are offered as cloud services, while others
can be installed on premises, some store redundantly to achieve high reliability while others are less reliable
but cheaper. In order to benefit from the offerings at a broader scale, e.g., to use specific features in some
cases while trying to reduce costs in others, a federation is beneficial to use several storage tools with their
individual virtues in parallel in applications. The major task of a federation in this context is to handle the
heterogeneity of involved systems. This work focuses on storing large objects, i.e., storage systems for videos,
database archives, virtual machine images etc. A metadata-based approach is proposed that uses the metadata
associated with objects and containers as a fundamental concept to set up and manage a federation and to con-
trol storage locations. The overall goal is to relieve applications from the burden to find appropriate storage
systems. Here a multi-criteria approach comes into play. We show how to extend the object storage developed
by the VISION Cloud project to support federation of various storage systems in the discussed sense.
1 INTRODUCTION
The National Institute of Standards and Technology
(NIST) states that ”Cloud computing is a model for
enabling ubiquitous, convenient, on-demand network
access to a shared pool of configurable computing
resources (e.g., networks, servers, storage, applica-
tions, and services) that can be rapidly provisioned
and released with minimal management effort or ser-
vice provider interaction” (Mell and Grance, 2011).
Hence, cloud computing represents a provisioning
paradigm for resources in first place.
Cloud storage is certainly one important cloud re-
source that benefits from the major characteristics of
cloud computing (Fox et al., 2009) such as
• virtually unlimited storage space,
• no upfront commitment for investments into hard-
ware and software licenses, and
• pay per use for the occupied storage.
The term cloud storage is mostly associated with
the recent technology of Not only SQL databases
(NoSQL, 2017), which attained a lot of popularity.
Implied by an adaptation to distributed systems and
cloud computing environments, NoSQL databases
follow a different approach than the traditional fix-
schema based model provided by relational database
servers. They heavily rely on distributing data across
several computers and prefer a schema-less storage of
data with a relaxed consistency concept. Certainly,
the settled technology of relational databases - if de-
ployed in a cloud - is also a kind of cloud storage.
There are corresponding offerings from major Cloud
providers. And finally, Blob stores represent a further
type of storage that should be mentioned.
Hence, we notice an increasing heterogeneity
of storage technologies even within the same cate-
gory, with further differences from vendor to ven-
dor, whether deployed on-premises or in the cloud,
whether used as Platform-as-a-Service (PaaS) or as a
special Virtual Machine on the IaaS level. Each indi-
vidual cloud storage has virtues of its own.
To benefit at a broader scale, a combination of
storage solutions seems to be useful. Some impor-
tant aspects in this context are in the sense of polyglot
persistence (Sandalage and Fowler, 2012):
• to use the most appropriate storage technology for
each specific problem;
• to reduce costs by using a public cloud, by choos-
ing an appropriate cloud provider, particularly un-
der consideration of the various and complex price
schemes and underlying factors such as price/GB,
data transfer or number of transactions;
Hohenstein, U., Jaeger, M. and Gogouvitis, S.
A Multi-criteria Approach for Large-object Cloud Storage.
DOI: 10.5220/0006432100750086
In Proceedings of the 6th International Conference on Data Science, Technology and Applications (DATA 2017), pages 75-86
ISBN: 978-989-758-255-4
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
75

• to take into account access time and latency, e.g.,
to use fast but expensive storage only when really
needed but slow and cheap storage in other cases;
• to consider the differences between on-premises
and cloud solutions with certain limitations, e.g.,
the maximal database size, a reduced features set;
• to use a hybrid cloud for security and confiden-
tiality issues, i.e., keeping confidential data in a
private cloud while taking benefit from the public
cloud for non-confidential data;
• to shard data in general, e.g., according to geo-
graphic locations, costs etc.
These points are fully interleaved and demand
for a multi-criteria approach. Therefore a model
is needed that captures the necessary information
and creates associations between all involved entities.
This information can be used to find an optimal data
placement solution for an overall benefit.
In this paper, we base our work upon a metadata-
based approach for a cloud storage scheme de-
veloped by the European funded VISION Cloud
project (Kolodner et al., 2011)(Kolodner (2) et al.,
2012). VISION Cloud aimed at developing next
generation technologies for storing large objects like
videos and virtual machine images, accompanied by
a content-centric access to storage. Following the
CDMI proposal (CDMI, 2010), the approach relies
upon objects and containers and offers first-class sup-
port for metadata for these storage entities.
VISION Cloud has implemented a simple federa-
tion approach that provides some basic access to sev-
eral storage solutions. We extend the original federa-
tion approach to tackle the needs of a multi-criteria
storage solution that attempts to combine different
storage technologies. Indeed, having a federation,
it is possible to benefit from the advantages of vari-
ous storage solutions, private, on-premise and public
clouds, access speed, best price offerings etc. while
the same way avoiding the disadvantages of a single
storage. A federation approach can provide a unified
and location-independent access interface, i.e., trans-
parency for data sources, while leaving the federation
participants autonomous.
The remainder of this work is structured as fol-
lows: Section 2 explains the VISION Cloud software
that is relevant and extended in this work: the concept,
especially of using metadata, the storage interfaces,
and the storage architecture. The original cloud fed-
eration approach of VISION Cloud is also presented.
We explain an extended federation approach, partic-
ularly the architectural setup, in Section 3, and con-
tinue with technical details in Section 4. Section 5
is concerned with related work. This work ends with
Section 6 providing conclusions and future work.
2 THE VISION CLOUD PROJECT
VISION Cloud (Kolodner et al., 2011) was an EU
co-funded project for the development of metadata-
centric cloud storage solutions. The project developed
a storage system and several domain applications
where the handling of rich metadata provides new in-
novations. Domains targeted by VISION Cloud were
telecommunication, broadcasting and media, health
care, and IT application management.
These domains share the need for an appropri-
ate object storage system. The telecommunication,
the broadcasting, and media domains envisage the
storage of videos, the health care domain applica-
tion stores high resolutions diagnostics images, and
the IT application management stores virtual ma-
chine images. They all share the need for grow-
ing storage capacity and large storage consumption
per object. The images of virtual machines in a
data center grow bigger. The media domain is mov-
ing to Ultra High-Definition and 4K resolution con-
tent. And in the telecommunication domain, shar-
ing of video messages turns into a trend as the mar-
ket share of high-resolution camera equipped hand-
sets grows (VISION-Cloud, 2011). All these domains
in VISION Cloud benefit from an object storage de-
veloped in the project and serve as a proof-of-concept:
They require an increasing need of large capacity for
the expectation to store a vast number of large objects
and the ability to maintain rich metadata sets in order
to navigate and retrieve stored content.
Pursuing a metadata-centric approach, VISION
Cloud stresses the ability to represent the type and for-
mat of the stored objects. With such an awareness of
the storage, functionality can be triggered depending
on the execution context and the currently processed
storage object. The automation based on the aware-
ness also contributes to the ability to deal with a high
number of objects stored in an autonomous manner.
2.1 The VISION Concept of Metadata
Classic approaches that handle large objects basically
organize files in a hierarchical structure in order to al-
low navigating through the hierarchy and finally find-
ing a particular item. However, it can be quite dif-
ficult to set up a hierarchy in an appropriate manner
that provides flexible search options with acceptable
access performance and intuitive categories for ever
increasing amounts of data. Moreover, such a hierar-
chy has usually to be organized manually and is thus
prone to outdated or wrongly applied placements. In
addition, the problem arises how to maintain a hierar-
chy changes in a distributed environment.
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
76

One of the goals of VISION Cloud was to enhance
the object storage with rich metadata handling capa-
bilities. Looking at the cloud storage offerings that
existed from the popular vendors at project start, VI-
SION Cloud decided to focus on the storage and re-
trieval of objects based on metadata and the ability
to perform autonomous actions on the storage node
based on metadata (Kolodner et al., 2011).
The content can be accessed based upon using
metadata. A lot of useful metadata is technical, such
as the file format or the image compression algorithm.
Looking at some video sharing plaforms, some obvi-
ous metadata is also already available such as the title,
the author of the video, a description, the date of up-
load, or a rating provided by users who have watched
the content. Of course, such (existing) metadata could
be easily added during import, as one of the VISION
Cloud demonstrators has shown (Jaeger et al., 2012).
Besides objects, metadata can be also attached to con-
tainers, which hold several different objects. Using
container metadata also enables storage handling in-
formation for the objects inside.
In addition to such types of metadata that requires
just the import of objects, the VISION Cloud ob-
ject storage has the ability to derive metadata from
processing storage objects. VISION Cloud uses so
called storlets (Kolodner (2) et al., 2012): Storlets
are software modules, similar to stored procedures
or triggers in traditional databases, which contain ex-
ecutable code to process uploaded storage objects.
They can analyze storage object, e.g., deriving meta-
data to be attached to objects. Hence, one applica-
tion of storlets is to run speech-to-text analyzers on
video content in order to store the text resulting from
the audio track as metadata. Then indexing can pro-
vide search terms as additional metadata attached to
video content. Such an approach improves the abil-
ity to navigate across a large number of video objects
drastically.
From a technical perspective, VISION Cloud uses
a key-value objects tree in a dedicated storage for
keeping the metadata only, along with a further ba-
sic object storage for the large objects themselves. It
is the special ability of VISION Cloud to efficiently
keep both the storage objects and their metadata in
synchronization when considering the node-based ar-
chitecture and envisaging horizontal scaling.
2.2 The VISION Content Centric
Interface
Applications deal with metadata in VISION Cloud by
using the so-called Content Centric Interface (CCI),
an interface that maintains and allows for querying
metadata. The content-centric approach relieves a
user from establishing hierarchies in order to organize
a high number of storage objects. VISION Cloud fol-
lows the Cloud Data Management Interface (CDMI,
2010) specification. CDMI standardizes the interface
to object storage systems in general. However, the
concept of the previously mentioned storlet, for exam-
ple, is a CDMI extension not covered by the standard
at the time of developing the VISION Cloud.
CDMI defines a standard for accessing and storing
objects in a cloud specifying the typical CRUD (Cre-
ate, Retrieve, Update, Delete) operations in a REST
style (Fielding and Taylor, 2002) using HTTP(S). The
user can organize storage objects using containers.
Containers can be compared to the concept of buckets
in other storage solutions.
In VISION Cloud, a container enables not only
the organization of storage objects, it allows also to
efficiently design queries and handle objects in gen-
eral. The following REST examples give an impres-
sion about the CDMI-based interface of VISION:
• PUT /CCS/MyTenant/MyContainer creates a
new container for a specific tenant MyTenant.
• PUT /CCS/MyTenant/MyContainer/MyObject
then stores an object MyOb ject in this container.
The payload of a HTTP PUT request contains the
metadata describing an object. To distinguish a con-
tainer from an object, the type of data for this request
is indicated in the HTTP Content-Type header field
(cdmi-container). For example, a full request for
creating a new container looks as in Figure 1:
Example: PUT /CCS/MyTenant/MyContainer
X-CDMI-Specification-Version: 1.0
Content-Type: application/cdmi-container
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Accept: application/cdmi-container
{ metadata : { content : video, format : mpeg3 } }
Figure 1: HTTP PUT request.
2.3 VISION Cloud Architecture
The general VISION Cloud architecture was pre-
sented in previous work (Kolodner et al., 2011). Thus,
we here focus on the storage and the metadata han-
dling. Figure 2 outlines the structure of layering: The
foundation is the object storage, which includes the
ability to store and manage the metadata. For ex-
ample, replication of storage objects with their meta-
data across nodes is handled by this layer. On top of
this layer, every node has the Content Centric Service
(CCS) deployed, which offers higher services such
as a relationship concept. The Content Centric Stor-
age implements the CCI. It extends CDMI by adding
A Multi-criteria Approach for Large-object Cloud Storage
77
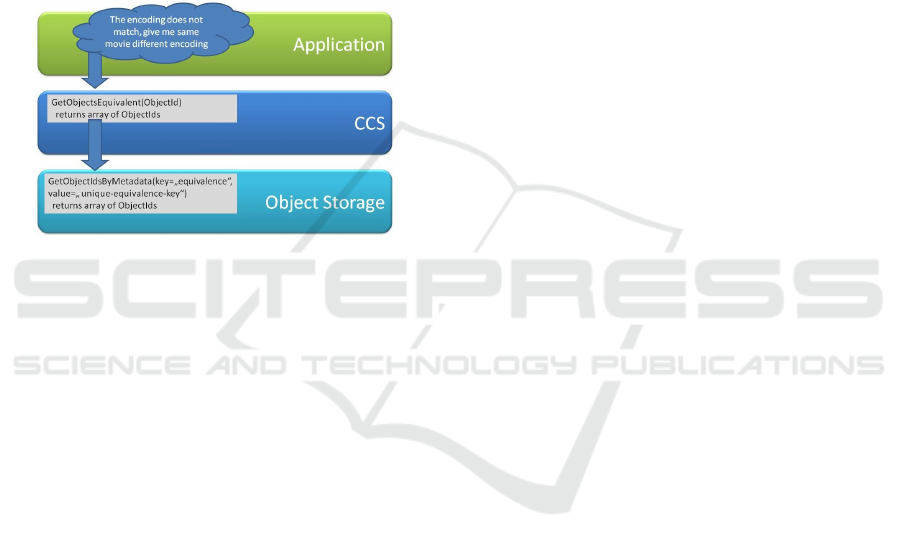
some additional operations in order to provide rich
metadata handling for applications. The application,
depicted on the top of the two other layers in Figure 2,
accesses the storage via the CCS.
Being a cloud service implementation, the VI-
SION cloud storage software was designed to run on
common appliance dimensions allowing one to de-
ploy a massive number of parallel nodes in a data cen-
ter in order to enable horizontal scaling. An applica-
tion is principally able to access several nodes with
CCS and underlying object storage stacks deployed.
In fact, the distribution over nodes is transparent to
the user and facilitated by load balancing in a VISION
Cloud storage system.
Figure 2: VISION architecture.
As an example, assume the application has a ref-
erence of an object and would like to find similar
objects in the storage. This is a popular use case
when it comes to different media encoding types for
different end devices. The provider might store me-
dia content optimized for hand held devices or smart
phones along with media content optimized for high-
definition displays. The application uses the CCS to
query for objects similar to the object already known.
The similarity is a metadata feature that was provided
especially as part of the ability to maintain relations
between objects as metadata. The CCS defines how to
encode relations by using key-value metadata on the
object storage and decodes the relation-based query
from the application into an internal metadata for-
mat which is not aware of relations. A corresponding
query is sent to the underlying object storage.
The underlying object storage was developed as
part of the VISION Cloud project. It provides a num-
ber of innovations in addition to the handling of meta-
data, e.g., execution of storlets or resiliency of storage
items. If an application uses only the metadata han-
dling features and not the storlets, i.e, only the basic
features for storing and managing objects, the CCS
can work also with other storage systems that are ca-
pable of storing metadata attached to objects and con-
tainers. The CCS uses an adapter concept to separate
the integration of different storage servers. Therefore
by implementing an adapter, other storage implemen-
tations can be integrated with CCS as well, given that
the metadata handling requirements are provided in
addition to a plain object storage. As part of the VI-
SION Cloud project, the open source CouchDB doc-
ument database was also integrated with the CCS.
Using a specific storage adapter, the CCS connects
to a storage server’s IP and port number, either refer-
ring to a single storage server or to a load balancer
within a cluster implementation. Technically, the ob-
ject storage and the CCS could reside on different
machines or nodes. Also, a client could access the
object storage directly, not using the CCS metadata
handling capabilities. In the basic setup of VISION
Cloud nodes, the CCS is deployed on every storage
node, which is a (potentially virtual) server running
a VISION Cloud node software stack. This avoids
increased request response times resulting from the
connections between different network nodes. More-
over, the CCS is capable of avoiding node manage-
ment functionality and keeping track of the current
status of object nodes. This enables a horizontal scal-
ing of VISION Cloud storage nodes in general.
The request handling of CCS does not (need to)
support sessions. As such, it can be easily deployed
on the storage node as a module. The CCS can also
work with storage system on different machines.
2.4 Basic VISION Cloud Support for
Federations
Cloud federation aims at providing an access inter-
face so that a transparency of data sources in differ-
ent storage clouds of different provisioning modes is
provided. At the same time it leaves the federation
participants autonomous. Clients are able to leverage
a federation with a unified view of storage and data
services across several systems and providers.
In general, such a federation has to tackle hetero-
geneity of the units to be combined. In the context
of storage federation, there are several types of het-
erogeneity. At first and most obvious, each cloud
provider has management concepts and Application
Programming Interfaces (APIs) of its own, which may
be proprietary or may implement industry specifica-
tions, e.g., (CDMI, 2010). And then at the next lower
level, the federation has to take into account the het-
erogeneity of data models of the cloud providers. In
fact, the implementation of the content-centric storage
service of VISION Cloud helps to handle heterogene-
ity by means of adapters, thus allowing one to wrap
heterogeneous units, each with a CCS interface. An
instance of a VISION Cloud CCS sits on top of a sin-
gle storage system. Moreover, the CCS architecture
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
78

supports multiple cloud providers and underlying
storage system types, as long as a storage adapter
is provided. Currently, CCS adapters are available
for the proprietary VISION Cloud storage service or
CouchDB.
The CCS communicates with the object storage
using an IP connection. This means that the CCS can
have several storage servers beneath with a load bal-
ancer in front. Hence, the VISION Cloud decision
was to put CCS on top of these (homogeneous) cluster
solutions due to several benefits. CCS is just a bridge
between the load balancer and the client. All scalabil-
ity, elasticity, replication, duplication, and partition-
ing is done by the storage system itself. Therefore,
there is no need for CCS to re-implement features that
are already available in numerous cloud storage im-
plementations. In fact, current storage system types
usually have a built-in cluster implementation already.
For instance, the open source project CouchDB has
an elastic cluster implementation named BigCouch.
MongoDB as another open source example, has vari-
ous strategies for deploying clusters of MongoDB in-
stances. To our knowledge and published material by
the vendors, we can assume that these cloud systems
are able to deal with millions of customers and tens
of thousands of servers located in many data centers
around the world. Hence, the CCS does not have to
manage all the distribution, scalability, load balanc-
ing, and elasticity. This would have tremendously in-
creased the complexity of CCS.
The basic federation functionality of VISION
Cloud allows the CCS to actually distribute requests
between multiple storage nodes. Depending on meta-
data, the CCS can route storage requests to different
storage services. This appears similar to the features
of a load balancer. Although the CSS does not repre-
sent a load balancer, the role of the CCS in the soft-
ware stack could be useful to service similar purpose:
In fact, the CCS can distribute requests over different
storage nodes not based on the classic load balancing
algorithms for distributing load, but based on qual-
ity characteristics and provided capabilities that are
matched with the available storage clouds.
Moreover, VISION Cloud was designed with se-
curity in mind and provides fine granular access con-
trol lists (ACLs). ACLs are attachable to tenants, con-
tainers, and objects.
2.5 Use of Federations
The basic VISION Cloud federations features have
been used and slightly extended in two federation sce-
narios. The approaches are briefly presented now.
2.5.1 On-boarding Federation
The first scenario is a so-called on-boarding federa-
tion (Vernik et al., 2013). The purpose of this scenario
is to migrate data from one storage system to another,
the target. One important feature of the on-boarding
federation is to allow accessing all the data via the
target cloud while the migration is in progress, i.e.,
while data is being transferred in the background. The
on-boarding scenario helps to avoid a vendor lock-
in, which is the second among top ten obstacles for
growth in cloud computing according to (Fox et al.,
2009). With on-boarding being enabled to move data
without operational downtime, a client becomes inde-
pendent of a single cloud storage provider.
To set up on-boarding, an administrator has to cre-
ate and maintain a federation of the two involved stor-
age systems. A federation is always defined between
two containers: The administrator has to send a ”fed-
eration configuration”, which describes the federation
to the target container, because the target container
will initiate a pull mechanism.
"federationinfo": {
// information about remote cloud
"eu.visioncloud.federation.status": "0",
"eu.visioncloud.federation.job_start_time": "1381393258.3",
"eu.visioncloud.federation.remote_cloud_type": "S3",
"eu.visioncloud.federation.remote_container_name":
"example_S3_bucket",
"eu.visioncloud.federation.remote_region": "EU_WEST",
"eu.visioncloud.federation.type": "sharding",
"eu.visioncloud.federation.is_active": "true",
"eu.visioncloud.federation.local_cloud_port": "80",
// credentials to access remote cloud
"eu.visioncloud.federation.remote_s3_access_key":
"AFAIK3344key",
"eu.visioncloud.federation.remote_s3_secret_key":
"TGIF5566key",
"eu.visioncloud.federation.status_time": "1381393337.72" }
Figure 3: Sample payload.
The payload in Figure 3 describes a typical fed-
eration configuration in VISION Cloud. The data is
required for accessing a member’s cloud storage, i.e.,
the remote storage to be moved to the target cloud,
here for an Amazon S3 member. With this configura-
tion request, a link between the clouds is created.
A new REST service, the federation service, pro-
vides the basic CRUD operations to configure and
handle federations. This federation service is de-
ployed along with the CCS. PUT creates a new fed-
eration instance by passing an id in the Uniform Re-
source Identifier (URI) and the federation configura-
tion in the body. GET gives access to a specific fed-
eration instance and returns the federation progress or
statistical data. A federation configuration can be
A Multi-criteria Approach for Large-object Cloud Storage
79

deleted by DELETE. For details please refer to the
project deliverable (VISION-Cloud, 2012).
After the administrator has configured the federa-
tion, the objects of federated containers will be trans-
ferred in the background to the container in the target
cloud. If a client asks for the contents of the container,
all objects from all containers in the federation will be
returned. Thus, objects that have not been on-boarded
yet will be fetched from the remote source, too.
A special on-boarding handler of the federa-
tion service intercepts GET-requests from the client
and redirects them to the remote system for non-
transferred containers and schedules the background
jobs for copying data from the remote cloud.
2.5.2 Hybrid Cloud
Going further, we demonstrated in (Hohenstein et al.,
2014) how to set up a hybrid cloud scenario. A hy-
brid cloud uses both a public and a private cloud. The
motivation for hybrid clouds is often to keep critical
or privacy data on private servers. One reason might
be regulatory certifications or legal restrictions forc-
ing one to store material that is legally relevant or
subject to possible confiscation on premises. How-
ever, non-critical data could be routed to more effi-
cient cloud offerings from external providers, which
might be cheaper and offer better extensibility. The
idea is to control the location of objects according to
metadata.
The federation again occurs at container level: A
logical container can be split across physical public
and private cloud containers. Every logical container
has to know its physical locations. To this end, we
make the two cloud containers aware of each other by
a PUT request with the payload of Figure 4, which
has to be sent to the federation service of vision-tb-
1. An analogous PUT request is implicitly sent to the
second cloud, however, with an ”inverted” payload.
https://vision-tb-1.myserver.net:8080/MyTenant/vision1
{ "target_cloud_url" : "vision-tb-2.myserver.net",
"target_cloud_port" : "8080",
"target_container_name" : "logicalContainer",
"local_container_name" : "logicalContainer",
"local_cloud_url" : "vision-tb-1.myserver.net",
"local_cloud_port" : "8080",
"type" : "sharding",
"private_cloud" : "vision1",
"public_cloud" : "vision2" }
Figure 4: Federation payload.
This configuration contains information regard-
ing the private and public cloud types, URLs,
users, authorization information etc. Due to
private/public cloud, vision-tb-1 will be the pri-
vate cloud and vision-tb-2 the public cloud. Such a
specification is needed for any container (here logi-
calContainer) to act as a shard.
Clients are enabled to distribute data over the
clouds and are provided with a unified view of the
data that resides in both the private and public cloud.
The hybrid cloud setup is completely transparent for
the clients of a container, and the clienst might even
not be aware where the data resides. Data CRUD op-
erations are performed in a sharded way; The possi-
bility to determine data confidentiality is given to the
client by a metadata item that indicates data confiden-
tiality. In order to store confidential data, one need to
perform the request in Figure 5.
PUT vision-tb-1.cloudapp.net:8080/CCS/siemens
/logicalContainer/newObject
{ "confidential" : "true" }
Figure 5: PUT request for storing confidential data.
PUT requests are handled as follows by a new
ShardService in the CCS. The metadata of the ob-
ject is checked for an item indicating confidentiality
such as confidential : true|false. The approach bene-
fits from the ability of the CCS to connect to multiple
object storage nodes at the same time using the basic
federation component of VISION Cloud. The shard-
ing is performed in the CCS based on metadata val-
ues. According to the metadata of the container, the
connection information is determined for both clouds.
The ShardService decides to store newObject in the
private cloud.
Every GET request to a federated container is sent
to all clouds participating in the federation unless con-
fidentiality is part of the query. The results of requests
are combined, and the result is sent back to the client.
Each federated cloud can be an access point to the
federation, i.e., can accept requests. Hence, there is
no additional interface to which object creation oper-
ations and queries need to be submitted. A request
can be sent to any shard in any cloud. Access to the
container can be via the public and private cloud store,
accesses are delegated to the right location.
The basic federation service of VISION Cloud (cf.
2.5.1) is not used for the hybrid cloud setup. Instead,
the service has been technically implemented in the
CCS that provides the content-centric storage func-
tions. In fact, in order to enable the hybrid cloud in
the CCS, several extensions have been made to the
CCS: A new ShardService has been added to CCS the
task of which is to intercept requests to the CCS and
decide where to forward the request. The ShardSer-
vice implements a reduced CDMI interface and plays
the key role to shard in hybrid environments.
To sum up, the development of the VISION Cloud
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
80

project mainly provides important mechanisms that
can be used as a base for federations:
1. Metadata concept. All objects are allowed to con-
tain user-definable metadata entries. Those key-
value pairs can be used in several ways to query
for objects inside the cloud storage system. A
schema can be employed for these metadata en-
tries to require the existence of certain metadata
fields and hence to enforce a certain metadata
schema.
2. Adapters for storage clouds. VISION Cloud in-
cludes an additional layer that abstracts from the
underlying storage and thus makes it possible to
integrate cloud storage systems, e.g a blob storage
service of some larger public cloud offering.
3 MULTI-CRITERIA STORAGE
APPROACH
In the previous Section 2, we have considered an on-
boarding and a hybrid cloud setup where the location
of objects is determined according to metadata. Being
able to work with several cloud storage systems in a
sharded manner offers further opportunities which are
explained in this section.
3.1 The Approach and Concept
The goal is to extend the existing VISION Cloud fed-
eration approach to offer a more flexible solution for
a so named multi-criteria storage. The term multi-
criteria refers to the ability of the approach to orga-
nize the storage in shards based on multiple criteria at
the same time.
This work uses the concept of federation (Vernik
et al., 2013) to define a heterogeneous cloud setup in-
volving different cloud storage systems with various
properties and benefits. The metadata processing fa-
cilities are used to let clients specify storage criteria
to be satisfied. The metadata processing takes places
in the Content Centric Service component of VISION
Cloud (Jaeger et al., 2012), using the management
models and their associations.
Let us assume several cloud storage systems (CSs)
named CS
1
, CS
2
, CS
3
etc. Each CS
i
possesses specific
properties and advantages with regard to privacy, ac-
cess speed, availability SLAs and other characteristics
following a resource model (cf. 3.2.2).
The definition of CS properties requires an admin-
istrative PUT request to the federation admin service
of a VISION Cloud installation with a payload that
describes the capabilities of any added CS
i
. These
properties are for the whole CSs, not for a specific
container or object. The payload is then automat-
ically distributed to all the members of the federa-
tion. At this point, the difference to the previously
described VISION Cloud federation approaches be-
comes obvious: instead of federating containers, the
multi-criteria approach spans across several contain-
ers globally. The extension of the federation con-
cept intends to use different cloud storages in dif-
ferent provisioning modes. Referencing a classical
example, data with higher demands in terms of pri-
vacy should be routed to locally hosted cloud storage
systems, while data subject to less critical could be
stored in a public cloud offering. As another example,
cloud storage providers have special features such as
reduced resilience. Storage with reduced redundancy
can be used to store data that is temporarily required,
in such a cheaper cloud storage offering.
Technically, the intended goal is to establish meta-
data conventions that provide rules for processing ob-
ject or containers metadata in order to take routing
decisions to the according storage. Thus, CCI opera-
tions obtain a higher level of abstraction since hiding
the various underlying storage systems. The behavior
of existing CCI operations is affected as follows:
• To Create a New Container. A PUT request can
be sent to the CCI of any CS
i
specifying the de-
sired properties according to a criteria model (cf.
3.2.1): The receiving CS
i
decides where to create
the container in order to satisfy the specified prop-
erties. Usually, there will be one CS
i
, however,
several CSs might be suitable and chosen for stor-
ing data, e.g., for sharding data, load balancing, or
achieving higher availability by redundancy. Any
CS
i
is able to handle requests by involving other
CSs, if necessary. The container keeps metadata
about its properties and a mapping to its list of
further containers in other storage systems.
• To Create a New Object (in a Container).
Again, a PUT request can be sent to the CCI of
any CS
i
. We decided to allow for specifying cri-
teria not only for a container but also an object.
Thus, the container criteria lead to a default stor-
age location for all its objects, which can be over-
ridden on a per-object basis. This principle sup-
ports use cases where a ”logical” container should
store images, however, some of them are confi-
dential (e.g., non-anonymous press images) while
others are non-confidential (e.g., anonymous ver-
sions of the same press images), leading to differ-
ent CS
i
. Some objects are rarely accessed while
others are used frequently. Some of them are rel-
evant on the long term while other images could
be easily recovered (i.e., thumbnails of original
A Multi-criteria Approach for Large-object Cloud Storage
81

images) and thus do not require high reliability.
The CS
i
takes the same decisions as above to de-
termine the appropriate CS(s).
• To Retrieve a Particular Object in a Container.
If a client wants to get an object, each CS must be
able to retrieve the object even it is not available
on its CS. In that case, the object’s metadata is not
available with such a request. Therefore, every
CS
i
must determine the possible object locations
from the globally propagated properties. Anyway,
querying the CS’s is performed in parallel.
Please note VISION cloud deployment sets up a
federation admin service/interface for each cloud stor-
age. In general, all different cloud storage nodes pro-
vide the same service interfaces.
3.2 Requirements and Resource Model
One of the main benefits of a federation approach is
that data can be placed optimally on different storage
systems according to user and system specified func-
tional and non-functional requirements. In order to
achieve this goal, properly capturing the application
requirements is needed as well as an accurate descrip-
tion of the underlying physical resources. Therefore
the VISION Cloud management models (Gogouvitis
et al., 2012), requirements and resource model, come
into play in federation scenarios.
3.2.1 Requirements Model
In order for an application to run effectively over a
cloud infrastructure, the customer should be able to
specify requirements, which will be used by the in-
frastructure to drive the data access operations of the
application. To this end, a requirements model is
necessary to capture the requirements emerging from
application attributes modeling and the ones deriv-
ing directly from the user needs. In addition, such
a model defines structures to describe lower level re-
quirements for the service offerings of the cloud as
well as resource requirements that are used for the re-
source provisioning. More specifically the following
models have been developed:
• User Requirements Model. This model captures
the user requirements in a formalized way. They
can be high level requirements characterizing the
application data or describing the needed storage
service and can be translated to low-level storage
characteristics. Examples of parameters described
are metrics like number of users, durability and
availability requirements.
• Resource Requirements Model. This model aims
at specifying the resource requirements for the op-
eration of the cloud service. This structure will
be utilized during resource provisioning and will
keep the desired resources for meeting the con-
straints specified by the application.
Criteria that can be specified for creating contain-
ers or objects (and which determines the placement in
a storage system) are for instance:
• Confidentiality (private vs. public cloud, high-
secure data center)
• Storage cost (at certain levels)
• Reliability
• Access speed (fast disk access and low latency
due to geo-location)
• Load balancing or replication properties
By using these two types of models, a user of a
cloud storage system is able to define his strategy re-
garding placement of data and criteria-based provi-
sioning. There are important issues, being combin-
able and ranked with a percentage.
3.2.2 Resource Model
The purpose of the resource model is to describe in a
uniform way different features of storage systems that
make up a federation. The resource models consists
among others of properties such as:
• Public/private cloud
• Cloud provider and type (e.g., Amazon S3 Blob
Store)
• Price scheme for storage, basically per GB/month,
number of transactions, data transfer etc.
• Redundancy factor
• Disk access properties (e.g., SSD)
• Latency of data center for locations
4 TECHNICAL ASPECTS OF
MAPPING APPROACH
Indeed, the usage-related criteria must be mapped to
the physical storage properties by relating the con-
cepts of the requirements and resource models. Then,
it is possible to map high-level requirements, de-
scribed as metadata, to low level resource require-
ments and to finally find storage systems that can ful-
fill the specified user criteria.
As the general approach of VISION Cloud was
to implement the CDMI, a user of the system should
perform the configuration of the system using the
same REST/JSON-based approach as CDMI does. As
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
82
such, the already federation service provides some
configuration calls that are extended by a PUT opera-
tion to let an administrator submit configurations. All
users of the interface can use generic REST clients
as well as implement their own front end using these
REST calls.
Inside the federation service, one important task is
to map the criteria specified by users to the technical
parameters of storage systems in such a way that a
storage system fitting best to the criteria will be found.
To this end, we implemented an appropriate mapping
approach. The basic idea is as follows:
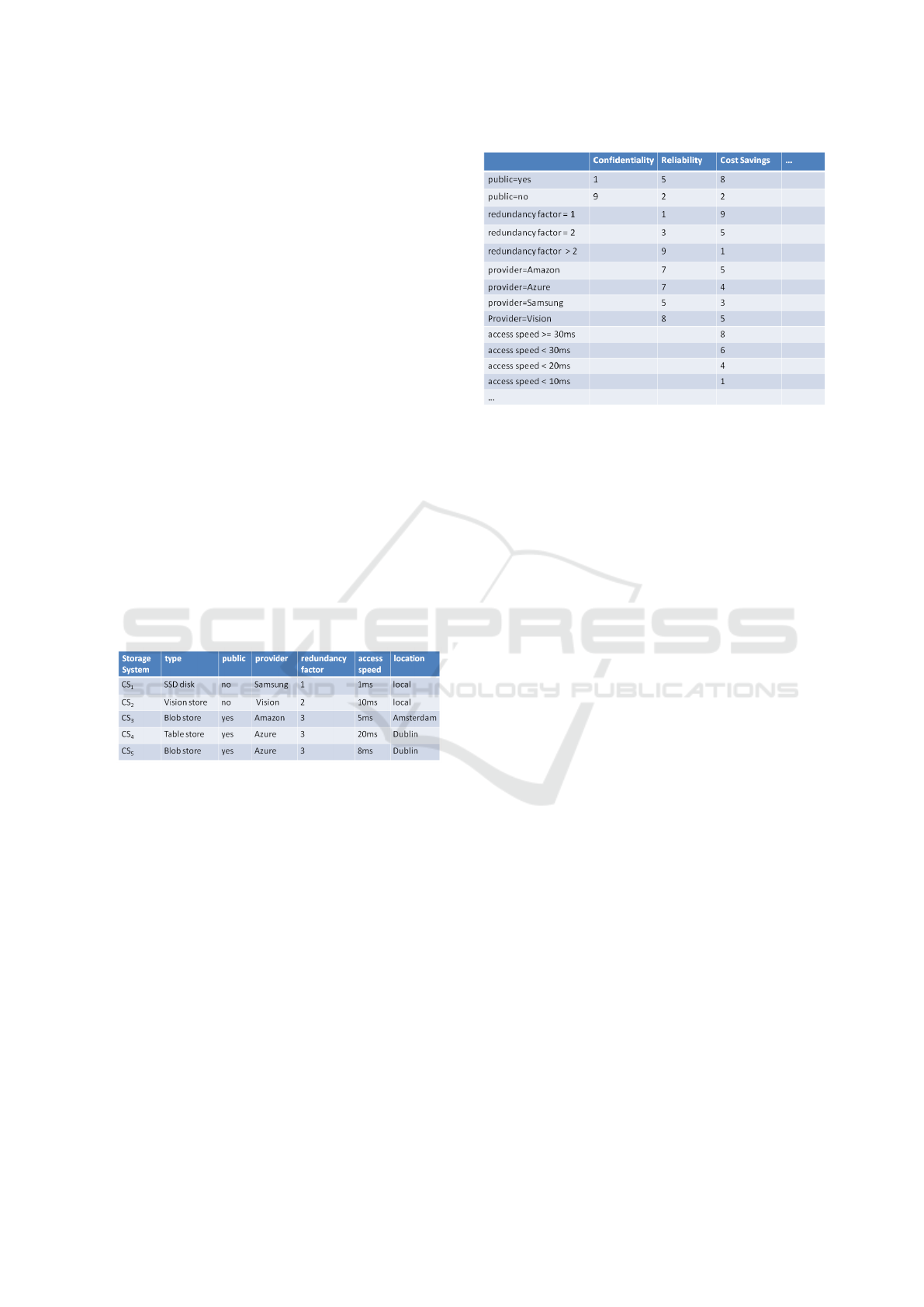
• Each storage system is described by certain cat-
egories according to the resource model: pub-
lic/private, a redundancy factor, its location, ac-
cess speed, latency etc. (cf. Figure 6). The pay-
load of Figure 4 obtains the properties of every
newly added CS.
• If a user request to create a container or object
with associated metadata requirements arrives at
the CCS, the CCS asks the federation service for
the federation information. The request contains
metadata according to the requirements model –
independently of the physical resource model of
CSs. The federation returns the referring storage
location(s) accordingly. All the metadata is part
of a request, similar to Figure 5.
Figure 6: Table RESOURCE – storage system properties.
The basis for recommending appropriate Storage
Systems (CSs) for given user requirements is first a
list of storage systems (cf. Figure 6) with their prop-
erties. The task of producing a recommendation is of-
ten formulated in knowledge-based systems as a tuple
(R,E). R corresponds to the set of user requirements
and E is the set of elements that form the knowledge
base. In our case, the elements E are the features of
the resource model, i.e., entries in Table 6.
The solution for a task (R,E) is a set S ⊆ E that
has to satisfy the following condition:
∀ e
i
∈ S : e
i
∈ σ
(R)
(E)
σ
(R)
(E) is a selection on those elements in E that
satisfy R. As an example, if the user requirements are
defined by the concrete set R = { r
1
: access speed
≤ 15; r
2
: public = yes }, then obviously only CS
5
satisfies the requirement R.
We now propose a procedure that allows recom-
Figure 7: Table MAP – mapping table.
mending appropriate storage systems. To determine
a ranking, we apply a schema that forms the basis
for a Multi-Attribute Utility Theory (MAUT). Using
this theory, resource requirements can be assessed and
ranked according to the dimensions of a particular in-
terest. Dimensions of interest are in our case user re-
quirements such as reliability or cost.
To set up a MAUT schema, the properties of the
storage systems are assigned to the dimensions of in-
terest in a first step ending up in a matrix. Each entry
of the matrix contains a value that defines the rele-
vance for the related dimension by associating a cer-
tain weight. The larger the value is, the more con-
tributes the property to the dimension of interest. Fig-
ure 7 presents a sample mapping matrix. The matrix
should be understood as follows. The first line (’pub-
lic=yes’) specifies that a public infrastructure as a re-
source requirement contributes to
• confidentiality (second column) with a weight of
1, thus being quite low;
• reliability with a medium weight of 5;
• cost savings with a high weight of 8 etc.
Similarly, ’private=no’ contributes to confidential-
ity with a weight of 9, to reliability with a weight of
2, to cost savings with a weight of 2 etc.
The redundancy factor has impact on the reliabil-
ity (increasing with the factor), to the costs (decreas-
ingly) etc., but not on confidentiality.
A user U then formulates his requirements, which
represent his preferences in a request. Finding ade-
quate storage systems implies that these requirements
have to be satisfied. Moreover, a user can rank each
of its features with a percentage, i.e., a user has the
possibility to define a WEIGHT(U,d) for each dimen-
sion d of interest in a request. For instance, a user U
can specify a weight of 50% for the dimension ”Con-
A Multi-criteria Approach for Large-object Cloud Storage
83

fidentiality” and weights of 30% for the dimension
”Reliability” and 20% for the dimension ”Cost Sav-
ings”. The storage CS
i
with the highest overall value
is suited best to satisfy the demands.
In order to formalize the approach, we assume a
function MAP : Properties x Values x Dimensions →
Int that represents the mapping table. For instance,
MAP(public, y, Reliablity) refers to the value 5 in the
first line in Figure 7.
Another function RESOURCE :
StorageSystemsxProperties → Values corresponds
to Figure 6.
The following formula then computes the rele-
vance of a storage system in a weighted manner using
those functions:
Relevance(U, CS
i
) = Σ
d∈Dimensions
(Σ
p∈Properties
MAP(p, RESOURCE(CS
i
, p), d) × WEIGHT (U, d))
Using this formula, we can calculate for each CS
i
a value for each dimension and obtain the resulting
table in Figure 8 for our example. That is, CS
2
hav-
ing a value of 10.4 is best suited for the given set of
requirements whilst CS
3
and CS
5
with a value of 7.7
are the worst options.
Figure 8: Sample calculation.
Due to the logic applied to the generation of a
recommendation, it might happen that a given set of
requirements leads to an empty set of recommenda-
tions: σ
(R)
(E) =
/
0. In such a case, it is not very help-
ful to inform the user only about such a conflict, but
also to give him a hint about what requirement should
be relaxed in order to obtain a recommendation.
A set of conflicts is a set SoC ⊆ R such that
σ
SoC
(E) 6=
/
0. SoC is maximal in the sense that no
other conflict SoC’ fulfilling σ
SoC
0
(E) 6=
/
0 ∧ SoC’ ⊃
SoC exists. A set of conflicts SoC refers to a cer-
tain elements e ∈ E under consideration of a set R of
requirements. SoC gives a concrete hint about what
condition to relax.
5 RELATED WORK
Even if cloud federation is a research topic, the ba-
sic concepts and architectures of data storage feder-
ations have already been discussed many years ago
within the area of federated database management
systems (Sheth and Larson, 1990). Sheth and Larson
define a federated database system as a ”collection
of cooperating but autonomous component database
systems” including a ”software that provides con-
trolled and coordinated manipulation of the compo-
nent database system”. (Sheth and Larson, 1990) de-
scribes a five-layer reference architecture for feder-
ated database systems. According to the definition,
the federated database layer sits on top of the con-
tributing component database systems.
One possible characterization of federated sys-
tems can be done according to the dimensions of dis-
tribution, heterogeneity, and autonomy. One can also
differentiate between tightly coupled systems (where
administrators create and maintain a federation in ad-
vance) and loosely coupled systems (where users cre-
ate and maintain a federation on the fly).
Based upon Google App Engine, Bunch et
al. (Bunch et al., 2010) present a unified API to sev-
eral data stores of different open source distributed
database technologies. Such a unified API repre-
sents a fundamental building block for working with
cloud storage as well as on-premises NoSQL database
servers. However, the implementation provides ac-
cess only to a single storage system at a time. Hence
compared to our CCS solution, the main focus is on
portability and not on a federated access.
Redundant Array of Cloud Storage (RACS) is
a cloud storage system proposed by Abu Libdeh
et al. (Abu-Libdeh et al., 2010). RACS can be
seen as a proxy tier on top of several cloud stor-
age providers, and offers a concurrent use of differ-
ent storage providers or systems. Adapters for three
different storage interfaces are discussed in the pa-
per, however, the approach can be expanded to further
storage interfaces. Using erasure coding and distribu-
tion, the contents of a single PUT request are split
into parts and distributed over the participating stor-
age providers similar to a RAID system. Any opera-
tion has to wait until the slowest provider has com-
pleted the request. While this approach splits data
across storage systems, our approach routes a PUT
request to the best suited storage system.
Brantner et al. (Brantner et al., 2008) build a
database system on top of Amazon’s S3 cloud stor-
age with the intention to include support for multiple
cloud storage providers in the future. In fact, Amazon
S3 is also one of storage layer options that VISION
supports.
There is a lot of ongoing work in the area of multi-
cloud APIs and libraries. Their goal is also to enable
a unified access to multiple different cloud storage
systems. Among them, Apache Libcloud (Libcloud,
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
84

2017), Smestorage (SmeStorage, 2017) and Delta-
cloud (Deltacloud, 2017) should be mentioned. They
provide unified access to different storage systems,
and protect the user from API changes. However,
only basic CRUD methods are supported, mostly
lacking of query functionality. Moreover, they have
administration features such as stopping and running
storage instances.
Further notable approaches can be found in the
area of Content Delivery Networks (CDN). A con-
tent delivery network consists of a network of servers
around the world which maintain copies of the same,
merely static data. When a user accesses the stor-
age, the CDN infrastructure delivers the website from
the closest servers. However, Broberg et al. (Broberg
et al., 2009) state that storage providers have emerged
recently as a genuine alternative to CDNs. Moreover,
they propose a system called Meta CDN that makes
use of several cloud storage providers. Hence, it is
not really a storage system. As CDNs in general,
Meta CDN mostly focuses on read performance and
neglects write performance, too. Anyway, the system
provides cheaper solution by using cloud storage.
There are also a couple of hybrid cloud solutions
in the literature. Most of them focus on transferring
data from private to public, not providing a unified
view to hybrid storages. For instance, Nasuni (Na-
suni, 2017) is a form of network attached storage,
which moves the user’s on-premise data to a cloud
storage provider. Hence, this hybrid cloud approach
gather and encrypt the data from on-premise stor-
age, afterwards sending the encrypted data to a public
cloud at either Microsoft Azure or Amazon Web Ser-
vices. Furthermore, a user has the option to distribute
data over multiple stores. Compared to our multi-
level sharding approach, Nasuni is a migration ap-
proach that eventually moved data to the public cloud.
Another example is Nimbula (Nimbula, 2017),
which provides a service allowing the migration of
existing private cloud applications to the public cloud
using an API that permits the management of all re-
sources. CloudSwitch (CloudSwitch, 2017) has also
developed a hybrid cloud that allows an application to
migrate its data to a public cloud.
A hybrid cloud option has been developed by Nir-
vanix (Nirvanix, 2017), however, based upon propri-
etary Nirvanix products and thus limiting usage due
to a danger of vendor lock. Nirvanix offers a private
cloud on premises to their customers, and enables data
transfer to the public Nirvanix Cloud Storage Net-
work. Other public cloud platforms than Nirvanix are
not supported. Due to our adapter approach, VISION
is not limited to a specific public cloud service.
As a general observation that can be made, most
commercial federated and hybrid cloud storage solu-
tions do provide a range of offerings to satisfy vari-
ous customers demands, but pose the risk of a vendor
lock-in due to the use of own infrastructure.
The MetaStorage (Bermbach et al., 2011) system
seems to be most comparable to our approach since
it is a federated cloud storage system that is able to
integrate different cloud storage providers. MetaStor-
age uses a distributed hash table service to replicate
data over diverse storage services by providing a uni-
fied view between the participating storage services
or nodes.
6 CONCLUSION AND FUTURE
WORK
In this paper, we presented a multi-level federation
approach for storing large objects like videos. The
approach is based upon the metadata idea of the VI-
SION Cloud project. Our approach provides a uni-
form interface for accessing data. The key idea is to
use metadata for controlling data placement behav-
ior at a higher semantic level by specifying require-
ments instead of physical properties. As a technical
basis, we benefit from the VISION Cloud software
stack (VISION-Cloud, 2011) where such a metadata
concept is an integral part for handling storage en-
tities. We show in detail how well-suited VISION
Cloud and its storage system architecture is to sup-
port new scenarios such as using several storage tech-
nologies with different properties for different pur-
poses in parallel, e.g., handling confidential and non-
confidential data, the first kept in an on-premise data
store, the later stored in a public cloud.
In this respect, the overall approach allows for
adding various further sharding strategies, such as
region-based, load balancing, or storage space balanc-
ing, redundancy level control etc.
In our future work, we are evaluating the ap-
proach. Furthermore, several points have not been
tackled so far and are subject to future work. For in-
stance, changing or adding properties of a storage sys-
tem might lead to a redistribution, maybe taking ben-
efit from on-board federation/migration. Similarly,
adding a new storage system node also affects the dis-
tribution to storage systems. And finally, we think of
extending the approach to a self-learning system that
uses information about the user’s satisfaction to adopt
the mapping table between users’ requirements and
the properties of the storage system.
A Multi-criteria Approach for Large-object Cloud Storage
85

ACKNOWLEDGEMENTS
The research leading to the results presented in
this paper has received funding from the European
Union’s Seventh Framework Programme (FP7 2007-
2013) Project VISION Cloud under grant agreement
number 217019.
REFERENCES
Abu-Libdeh, H., Princehouse, L., and Weatherspoon, H.
(2010). Racs: a case for cloud storage diversity.
In Proceedings of the 1st ACM symposium on Cloud
computing, SoCC ’10, pages 229–240, New York, NY,
USA. ACM.
Bermbach, D., Klems, M., Tai, S., and Menzel, M. (2011).
Metastorage: A federated cloud storage system to
manage consistency-latency tradeoffs. In Proceed-
ings of the 2011 IEEE 4th International Conference
on Cloud Computing, CLOUD ’11, pages 452–459,
Washington, DC, USA. IEEE Computer Society.
Brantner, M., Florescu, D., Graf, D., Kossmann, D., and
Kraska, T. (2008). Building a database on s3. In
Proceedings of the 2008 ACM SIGMOD international
conference on Management of data, page 251.
Broberg, J., Buyya, R., and Tari, Z. (2009). Service-oriented
computing — icsoc 2008 workshops. chapter Creat-
ing a ‘Cloud Storage’ Mashup for High Performance,
Low Cost Content Delivery, pages 178–183. Springer-
Verlag, Berlin, Heidelberg.
Bunch, C. et al. (2010). An evaluation of distributed data-
stores using the appscale cloud platform. In Proceed-
ings of the 2010 IEEE 3rd International Conference
on Cloud Computing, CLOUD ’10, pages 305–312,
Washington, DC, USA. IEEE Computer Society.
CDMI (2010). Cloud data management interface version
1.0. At: http://snia.cloudfour.com/sites/default/files
/CDMI SNIA Architecture v1.0.pdf. [retrieved:
March, 2017].
CloudSwitch (2017). Cloudswitch. At: http://www.
cloudswitch.com. [retrieved: March, 2017].
Deltacloud (2017). Deltacloud. At: http://deltacloud.
apache.org/. [retrieved: March, 2017].
Fielding, R. T. and Taylor, R. N. (2002). Principled design
of the modern web architecture. ACM Transactions on
Internet Technologies, 2(2):115–150.
Fox, A. et al. (2009). Above the clouds: A berkeley view
of cloud computing. Dept. Electrical Eng. and Com-
put. Sciences, University of California, Berkeley, Rep.
UCB/EECS, 28.
Gogouvitis, S. V., Katsaros, G., Kyriazis, D., Voulodimos,
A., Talyansky, R., and Varvarigou, T. (2012). Re-
trieving, storing, correlating and distributing infor-
mation for cloud management. In Vanmechelen, K.,
Altmann, J., and Rana, O. F., editors, Economics of
Grids, Clouds, Systems, and Services, volume 7714 of
Lecture Notes in Computer Science, pages 114–124.
Hohenstein, U., Jaeger, M., Dippl, S., Bahar, E., Vernik,
G., and Kolodner, E. (2014). An approach for hy-
brid clouds using vision cloud federation. In 5th Int.
Conf. on Cloud Computing, GRIDs, and Virtualization
(Cloud Computing), Venice 2014, pages 100–107.
Jaeger, M. C., Messina, A., Lorenz, M., Gogouvitis, S. V.,
Kyriazis, D., Kolodner, E. K., Suk, X., and Bahar,
E. (2012). Cloud-based content centric storage for
large systems. In Federated Conference on Computer
Science and Information Systems - FedCSIS 2012,
Wroclaw, Poland, 9-12 September 2012, Proceedings,
pages 987–994.
Kolodner, E. et al. (2011). A cloud environment for data-
intensive storage services. In CloudCom, pages 357–
366.
Kolodner (2), E. et al. (2012). Data intensive storage ser-
vices on clouds: Limitations, challenges and enablers.
In Petcu, D. and Vazquez-Poletti, J. L., editors, Euro-
pean Research Activities in Cloud Computing, pages
68–96. Cambridge Scholars Publishing.
Libcloud (2017). Apache libcloud: a unified interface to
the cloud. At: http://libcloud.apache.org/. [retrieved:
March, 2017].
Mell, P. and Grance, T. (2011). The nist definition of
cloud computing (draft). NIST special publication,
800(145):7.
Nasuni (2017). Nasuni. At: http://www.nasuni.com/. [re-
trieved: March, 2017].
Nimbula (2017). Nimbula. At: http://en.wikipedia.
org/wiki/Nimbula. [retrieved: March, 2017].
Nirvanix (2017). Nirvanix. At: http://www.nirvanix.com/
products-services/cloudcomplete-hybrid-cloud-
storage/index.aspx. [retrieved: March, 2017].
NoSQL (2017). Nosql databases. At: http://nosql-
database.org. [retrieved: March, 2017].
Sandalage, P. and Fowler, M. (2012). Nosql distilled: a brief
guide to the emerging world of polyglot persistence.
Pearson Education.
Sheth, A. and Larson, J. (1990). Federated database sys-
tems for managing distributed, heterogeneous, and au-
tonomous databases. ACM Computing Surveys, (22
(3):183–236.
SmeStorage (2017). Smestorage. At:
https://code.google.com/p/smestorage/. [retrieved:
March, 2017].
Vernik, G. et al. (2013). Data on-boarding in federated
storage clouds. In Proceedings of the 2013 IEEE
Sixth International Conference on Cloud Computing,
CLOUD ’13, pages 244–251, Washington, DC, USA.
IEEE Computer Society.
VISION-Cloud (2011). Vision cloud project consor-
tium, high level architectural specification release 1.0,
vision cloud project deliverable d10.2, june 2011.
At: http://www.visioncloud.com. [retrieved: March,
2017].
VISION-Cloud (2012). Vision cloud project consor-
tium: Data access layer: Design and open speci-
fication release 2.0, deliverable d30.3b, sept 2012.
At: http://www.visioncloud.com/. [retrieved: March,
2017].
DATA 2017 - 6th International Conference on Data Science, Technology and Applications
86
