
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
Anna Kobusi
´
nska, Jerzy Brzezi
´
nski and Kamil Pawulczuk
1
Institute of Computing Science, Pozna
´
n University of Technology, Piotrowo 3, Pozna
´
n, Poland
Keywords:
IoT, Big Data, Fingerprinting, Web Tracking, Security.
Abstract:
Device fingerprinting is a modern technique of using available information to distinguish devices. Finger-
printing can be used as a replacement for storing user identifiers in cookies or local storage. In this paper we
discover features and corresponding optimal implementations that may enrich and improve an open-source
fingerprinting library Fingerprintjs2 that is daily consumed by hundreds of websites. As a result, the paper
provides a noticeable progress in the analysis of fingerprinting solutions.
1 INTRODUCTION
Many on-line business models are based on the neces-
sity of distinguishing one web visitor from another.
Thus, web tracking becomes essential to the World
Wide Web. HTTP cookies (RFC, 2016),(Cahn et al.,
2016) are heavily consumed for this purpose. Once a
web page is requested, a cookie containing a unique
identifier is stored on the users computer. Such prac-
tice is fundamental for many websites to ensure a high
level of usability. At the same time, it is exploited
by advertising companies to track user interests and
hence, increase the probability of purchase by serving
personalized offers. Yet, this mechanism has been re-
cently under high public attention. Due to the contin-
uous rise of privacy awareness in society, many peo-
ple tend to either block or regularly remove cookies
from their computers. Forthcoming laws and direc-
tives became a danger for future usage of this stor-
age type. For these reasons, many other alternatives
were considered. Various additional storage-based
techniques are daily utilized, thanks to the success-
ful adoption of HTML5 specification (HTML5, 2016)
that introduced additional APIs e.g. localStorage or
indexedDB.
However, the past decade brought more advanced
invention, something that does not leave any data
on the user computer — e-fingerprinting. And it is
even more powerful than human fingerprinting. When
properly executed, the process may stay unnoticeable.
By collecting many small pieces of information about
the specific device, one can try to distinguish one from
another. Nowadays, it is very unlikely that, having a
set of random users, their devices, installed software
or its setting will not differ in any way. Large compe-
tition of hardware producers, daily software updates
caused by the need of addressing the latest security
threats, or high personalization trends are just a few
of the reasons for the devices to differ. That brings an
opportunity for fingerprinting. Information such as
User-Agent header, screen resolution, hardware fin-
gerprint (e.g. audio, canvas) or approximate location
based on IP address, once combined together, hold
invaluable identification properties. Such data is eas-
ily obtainable from JavaScript. Once the user opens
a web page having a fingerprinting script attached, a
user identifier can be generated. Simple queries to
various APIs yield dozens of values which can be con-
sidered as fingerprinting features. The simplest solu-
tion to get the final user identifier (out of the features
vector), is to apply a hash function to all of the infor-
mation concatenated into one string. If none of the
fingerprints have changed over different visits of the
user, such hash is not going to differ between con-
secutive executions of the algorithm. Therefore, it
could be treated as an identifier in the same way as
cookie identifiers. Depending on the type of used fin-
gerprinting method, such identifier should be called
a device, browser or user fingerprint. Nevertheless,
device and browser terms are often considered equal
due to a small boundary laying in between.
Such fingerprinting scripts are already in use. Fin-
gerprintjs2 (Fingerprints2, 2016) is an open-source
fingerprinting solution which follows exactly the sce-
nario described above. It is used by many, primar-
ily with aim of blocking abusive users. Augur (Au-
gur, 2016) is a commercial solution providing de-
vice recognition based on a similar concept. Many
Kobusi
´
nska, A., Brzezi
´
nski, J. and Pawulczuk, K.
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods.
DOI: 10.5220/0006375701670177
In Proceedings of the 2nd International Conference on Internet of Things, Big Data and Security (IoTBDS 2017), pages 167-177
ISBN: 978-989-758-245-5
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
167

advertising-related companies have already incorpo-
rated basic fingerprinting routines into their cookie
syncing scripts, which are the backbone of their busi-
nesses. All the examples are collecting fingerprints
and generating final identifiers on the client side. The
most advanced solutions will send the data to the
server which will do the job of putting all the infor-
mation together.
As the need for additional storageless techniques
appeared, various of fingerprinting studies have
started. Most of them are focused on evaluating an-
other idea which could be turned into additional fin-
gerprint. They usually discuss the issues related to
diversity and stability. These are the primary chal-
lenges each solution has to face. It is important to
collect as many independent fingerprints as possible
so the samples are diverse enough to provide unique
device recognition. On the other hand, due to the con-
siderable speed of evolution of the software, hardware
and their settings, fingerprints are changing equally,
on daily basis. Such changes have to be tracked down
and controlled by additional mechanisms, or unstable
features have to be classified and excluded from the
process.
Stability and diversity are the most important cri-
teria for all of the fingerprint usages, yet many busi-
nesses are restricted with additional conditions which
this work focuses on. The length of execution code,
execution time and the length of the final fingerprint
are crucial limitations of any real-time fingerprint-
ing solutions. So far, despite a noticeable need of
many companies that are trying to implement early
solutions, they were not addressed by other theoret-
ical studies. Thus, this study aims on implementing
various methods of fingerprint collection and compar-
ing them accordingly to the most restrictive needs. In
the paper, a wide discussion of available fingerprint-
ing methods was conducted. A set of most promising
ones was chosen for evaluation and has been imple-
mented within a fingerprinting environment. Devel-
oped script has been executed on thousands of differ-
ent user browsers in order to collect real fingerprinting
data. This data has been a subject of excessive anal-
ysis. As a result of cost-benefit evaluation, a set of
features and respective optimal fingerprinting imple-
mentations has been chosen.
The paper is organized as follows. Section 2 de-
scribes the topic background: explains web tracking
and available methods, introduces the term of finger-
printing, its usages and challenges. Section 3 dis-
cusses the literature of the topic. Section 4 presents
the architecture developed for the purpose of anal-
ysis of various fingerprint features. Next, Section
5 presents the obtained results and their discussion,
while the last Section brings final conclusions and
proposes the further steps.
2 DEVICE FINGERPRINTING
BACKGROUND
Web tracking is commonly known as assigning a
unique and possibly stable identifier to each user vis-
iting a website. The general purpose is to connect
future page views of the same person or device with
historical ones. Most of all, it allows to serve person-
alized content and restore the visitors context. The
most common way of categorizing tracking is to di-
vide it regarding whether it uses any of the storage
mechanisms on the client side, i.e. storage-based and
storageless techniques.
2.1 Storage-based Techniques
A well known representative of this group are HTTP
cookies (Cahn et al., 2016). According to Web Tech-
nology Survey statistics (Persistent, 2016), they are
actively used on over 50% of websites globally. Half
of them are persistent, meaning they remain on a vis-
itors computer after closing the browser (until they
expire or until deleted manually). Their rising pop-
ularity, brought up to the public the topics of pri-
vacy in the web and dramatically raised the aware-
ness among people. Recent directives of the European
Union, known as Cookie law (Low, 2016), require
each website taking advantage of this mechanism to
openly notify it. Thus, HTTP cookies are being in-
creasingly deleted by privacy-conscious users. Ad-
ditionally, some browser maintainers are starting to
support this movement, e.g. Safari is blocking third-
party cookies by default to protect unwary customers.
All of that made cookies relatively unreliable. Fortu-
nately, there are many alternatives.
High attention is recently directed towards Web
Storage API, which was introduced in the newest
HTML specification. It is already widely adopted
by browsers and offers similar to cookies method of
storing data, but for larger amounts. Usually, when
the user requests a cookie removal, this storage is not
cleared out, so the data still remains. Therefore, web
Storage is considered as modern cookies substitute for
storing user identifiers more persistently.
ETags are identifiers set by a web server to spe-
cific versions of resources found under URLs (Fet-
terly et al., 2003). Whenever a modification of the
content occurs, a new tag is being assigned and sent
together with the requested file. By exploiting this
functionality aimed at cache validation, one can serve
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
168

different ETags for each file request and thus, identify
users. Browser cache could be used similarly by serv-
ing files containing variable definitions of unique ids
— they shall be read on the client side and attached to
each further request. Local Shared Objects, known as
Flash cookies, are another place to store data, same as
Silverlights Isolated Storage, Internet Explorers user-
Data storage or HTML5 indexed database.
There are plenty of examples that could be ex-
ploited to serve as user identifiers storage, however
most of them are having poor browser support or their
reputation is infamous — knowing the history, reck-
less usage could end up with a law suit. A final so-
lution for storage-based tracking is a JavaScript Ev-
ercookie (Kamkar, 2016). This script produces ex-
tremely persistent cookies in the browser, using all
possible methods at the same time. Whenever any of
the identifiers from a particular source is removed, it
is recreated using the remaining ones.
2.2 Storage-less Techniques
One category of methods which are not employing
any storage are state-based techniques, also known as
history stealing. Considered as attacks, they are rather
not visible across the web. CSS history knocking
exploits the browser feature of marking visited links
with different color (usually purple instead of blue).
With JavaScript, one can write into HTML DOM
some hyper-links and test their CSS properties to de-
termine whether the user has recently visited them.
This attack has its origins in the past decade. Over
time, browser maintainers were working to prevent
exploiting similar features — some queries for com-
puted hyper-link styles are being lied with false in-
formation about their appearance. Therefore, various
timing attacks were invented to detect when browsers
are trying to mislead. The battle between browsers
and attackers is still in place today, in the name of
users privacy.
Attribute-based and setting-based methods are
second half of storageless techniques. They are of-
ten referred to as fingerprinting (device, browser or
user fingerprinting) (Yen et al., 2012), (Acar et al.,
2013). Focusing on collecting as many small pieces
of information as possible and then putting them to-
gether is giving reasonably unique device identifica-
tion. Various categories of fingerprints could be de-
termined: low-level fingerprinting: hardware (CPU
or GPU measuring) and network fingerprinting (com-
paring TCP/ICMP/AJAX clock skew); information-
based fingerprinting: collecting available information
e.g. User-Agent, JavaScript properties; behavioral
/ biometric fingerprinting: measuring mouse move-
ment, typing, etc. On the other hand, fingerprint-
ing could be divided into two categories according
to the execution mode: passive (collection of already
available data), active (measuring, tracking or active
querying in purpose of collecting additional informa-
tion).
While storage-based techniques are relatively easy
to be noticed, fingerprinting is bringing the worst-
class scenario for user privacy. It has the insidious
property of not leaving any persistent evidence of de-
vice identification process that has occurred. There-
fore, it has slightly wider applications. Some of the
most important (Webkit2016, 2016) are: identifying
users on devices previously used for fraud, establish-
ing a unique visitor count, advertising networks at-
tempting to establish a unique click-through count,
advertising networks attempting to profile users to in-
crease ad relevance, profiling the behavior of unregis-
tered users, linking the visits of users when they are
both registered and unregistered and identify the user
when visiting the site without authenticating.
2.3 Fingerprinting Obstacles
A primary obstacle the fingerprinting algorithm has to
deal with is stability. Over time, the users browser or
device is upgraded, which causes some fingerprints
to change its value. Ideally, one should approach
this problem by tracking the changes in certain ways.
Once the browsers is updated, the User-Agent header
is upgraded to a higher browser version string. Some
of the installed add-ons are no longer supported and
therefore temporarily or permanently disabled. This
is one of the examples of fingerprints evolution. Such
changes are mostly deterministic, so machine learn-
ing algorithms could make an effect in following them
(Yen et al., 2009), (Boda et al., 2011). Still, any ab-
normal user action, e.g. disabling cookies due to pri-
vacy awareness raised, installing a new font or change
of device location, would bring unpredictable shift
which is hard to deal with. Only if the adjustment
is not serious, it is likely to be still detected.
All the information about particular device col-
lected within fingerprinting, needs to be as unique as
possible. There are many machines sharing the same
configuration and having similar setting which finger-
print may be identical. Therefore, it is crucial to col-
lect many and diversified fingerprints.
Measuring fingerprints diversity can be done with
a mathematical tool — entropy. A distribution of a set
of fingerprints is having 20 bits of entropy if randomly
picked value is only shared with one among each 2
20
devices. Entropy is defined as follows:
H(X) = −
∑
i=1..n
P(x
i
) ∗ log
2
P(x
i
),
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
169
where X = (x
1
, x
2
, ..., x
n
) is a set of observed fea-
tures, where P(x
i
) describes discrete probability dis-
tribution. If a website is regularly visited by a set X of
different browsers with equal probability, the entropy
is going to reach its maximum and could be estimated
as H(X) ≈ log
2
|X|.
3 RELATED WORK
In 2010, EFF published a reference study (Eckersley.,
2010) on browser fingerprinting. Relatively simple
script has been developed and used to collect over
470,000 samples, among which 18 bits of entropy
was observed. In total, 83.6% of unique users were
recognized. According to the study, fingerprints were
changing quite rapidly (chance for a change of at least
one during primary 24 hours reached 37.4% while af-
ter 15 days raised to 80%), however it was relatively
easy to track. Using basic string similarity algorithm,
99.1% of modifications were tracked (false-positives
rate was 0.86%). Forged User-Agent header was not
enough to mislead the detection.
For a couple of years, Princeton University, coop-
erating with Catholic University of Leuven, has been
conducting relevant and valuable studies in the field
of privacy on the web. Published in 2014 paper (Acar
et al., 2014), presenting the problem of canvas fin-
gerprinting, cookie re-spawning and syncing, brought
serious media attention to these topics. Partially be-
cause of it, the score of 5.5% crawled sites exploiting
canvas fingerprinting in 2014 dropped down to 1.6%
in 2016. Cookie syncing analysis showed, that only
around a quarter of third-party scripts is respecting
users not willing to be tracked (who have used either
opt-out cookies or set Do Not Track header). Created
for the purpose of conducting privacy studies on large
scale, OpenWPM web privacy measurement frame-
work is regularly used for analysis of over a million
top websites. According to recent results, tracking
is especially popular among websites serving news.
Scripts coming from particular companies that were
present on over 10% of analyzed sites were only from
the biggest players: Facebook, Google and Twitter.
Nevertheless, browser add-ons such as Ghostery or
uBlock Origin are dealing with those scripts quite ef-
fectively, except of very sophisticated and advanced
ones that are hard to classify (same for fingerprinting
only around 60-70% of scripts is blocked). Canvas
fingerprinting of fonts were observed on 0.3% of web-
sites while IP NAT address fingerprinting with we-
bRTC API or audio fingerprinting were present only
on about 0.06% of sites (Englehardt and Narayanan.,
2016).
There are also plenty of websites aimed at raising
awareness of tracking among Internet users. Many
on-line fingerprinting tools (Frontier, 2016), (Cross-
browser, 2016), (Kurent, 2016), (Tillmann, 2016),
exposing various browser features, have been devel-
oped — collected fingerprints are a subject of anal-
ysis for many similar studies. Moreover, some addi-
tional websites aimed at helping users to adjust their
browsers protection are present (BrowserSpy, 2016),
(Checklist, 2016).
4 EMPIRICAL EVALUATION
Analysis environment consists of three parts: finger-
printing script, back-end service and analysis tools.
To overcome the limitation of collecting fingerprints
from a single dedicated web page, a script that can
be attached to any website was created (which in fact
is the target scenario of its usage). However, in-
stead of the machine that serves particular domain
to process the fingerprint, it shall be sent to another
server that is responsible for data collection. Such
solution implies many technological issues that had
to be addressed. They are discussed in this section
altogether with a description of the setup. General
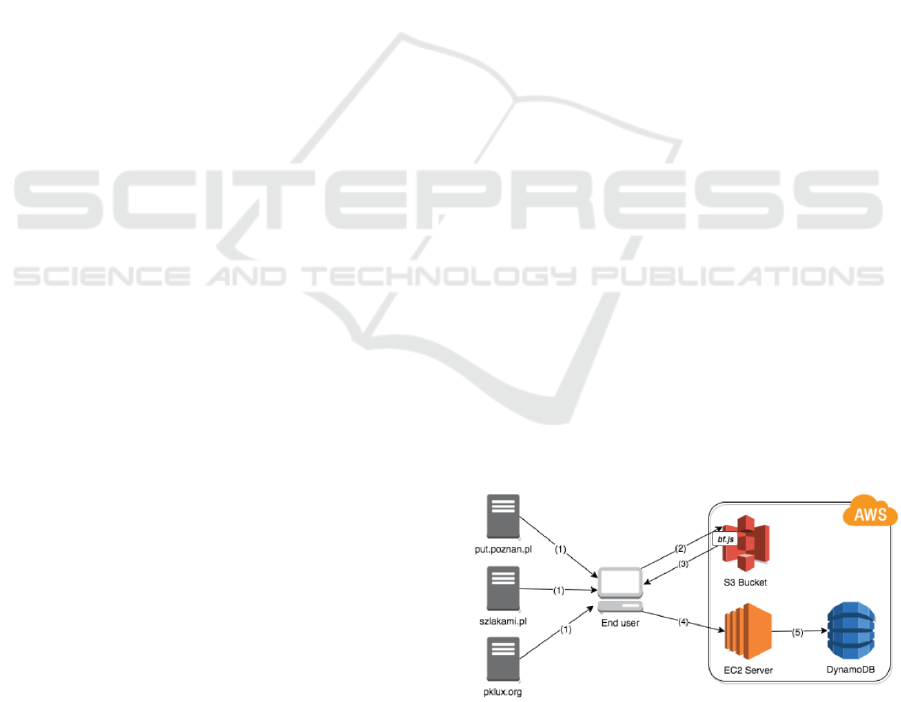
process of gathering fingerprint samples is presented
in Figure 1. The script was exposed within Ama-
zon S3 Bucket and could be linked to any website.
When a user entered one of the collaborating web
pages, the script was downloaded and executed as
one of the assets. The outcome was sent directly
to the study server (Amazon EC2), which processed
the data, appended backend-side fingerprints (HTTP
request headers) and eventually, stored it into Dy-
namoDB database for further analysis. The statistics
were generated with analysis tool that fetched the data
directly from Amazon.
Figure 1: Fingerprinting process scheme.
Fingerprinting script called bf.js has been devel-
oped. Once triggered, it collects all implemented fin-
gerprints and sends them to the server, where they are
stored in the database.
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
170

While creating fingerprinting framework, commu-
nication with the server was the first issue to be ad-
dressed. For security reasons, browsers restrict cross-
origin HTTP requests initiated by scripts. Yet, there
are certain exceptions that could be exploited. For
example, a request for an image containing the data
as GET parameter could be sent. Due to the character
limitation of URL parameters 1 , none of the solutions
are applicable up to the size of 100 KB — the average
size of a fingerprint obtained within bf.js. Therefore,
CORS-enabled AJAX requests were used for transfer-
ring the data to the server. Within CORS, additional
preflight HTTP request (by specification) is triggered
before the actual request is made. This was a sup-
plementary cost in performance that has to be kept in
mind while evaluating the overall fingerprinting over-
head.
As the script was going to be most likely linked on
all of the sub-pages of the host website, each time the
user would navigate or refresh the page, the finger-
printing process would be started. To prevent that, a
cookie mechanism was implemented. Once the fin-
gerprinting completed, it blocked its execution for
next 3 minutes. Such suspension allowed to track
long-term stability of fingerprints and at the same
time, prevented flooding of the database with identical
ones. This solution, as well as usage of WebStorage
API during fingerprinting, brought the necessity to in-
form the users about usage of storage mechanisms, in
accordance to European Union cookie law.
Amazon Web Services were used as a back-end
infrastructure for the whole solution. Their first and
foremost goal was to provide high-availability and
high-performance static files server for bf.js. As the
number of study participants was unpredictable and
any website could join the study at any time (by link-
ing the script), the machine should be provisioned for
high demand and easily scalable. Instead of creating
virtual machine running Apache, Nginx or another
type of server, Amazon dedicated solution for serv-
ing static files was utilized. S3 Bucket container is
a space for files which is a part of Amazon content
delivery infrastructure. It is used as assets server by
Amazon itself, the same way it was used within this
work.
Next element, constituted of EC2 service, pro-
vided endpoints for data collection. Created
t2.medium virtual machine instance was running
Amazon Linux RMI and Apache server. The latter
served as a proxy to core functionality. It handled
AJAX requests, initiated by bf.js, and through WSGI
module executed its processing implemented in the
Flask framework. Flask is a Python micro-framework
suitable for applications exposing small functional-
ity. Two endpoints were necessary to handle interac-
tions, one for GET requests and one for POST. The
first was a debugging routine which could be used
to send exception message if such occurred on the
client side. The second was gathering the fingerprints
transfered as JSON payload of POST requests. It was
also responsible for assigning unique cookie identi-
fiers (for the purpose of tracking fingerprints stabil-
ity), extracting and appending HTTP request headers
to the dataset and finally, connecting to the database
instance to dump the data. DynamoDB, an Amazons
distributed NoSQL solution, ensuring performance
and high scalability, was used. Since the size of fin-
gerprints (and therefore the requests) was substantial,
it was provisioned with 15 MB / s throughput. In case
it would not be enough for incoming traffic, it could
be easily increased in a similar way the t2.medium
instance could be upgraded. Fortunately, during the
whole data collection period, there was no necessity
to update any of the configuration.
In order to collect a reasonable number of fin-
gerprints, bf.js had to be linked to a minimal num-
ber of websites such that combined together visitors
traffic was analysis-considerable. A study page e-
fingerprint.me had been created in order to find sup-
porters. It provided all the essential information about
the work, simultaneously trying to persuade websites
administrators to get involved. Obviously, it was not
an easy task since foreign script execution may cause
a serious damage. Therefore, hosts that have taken
part in the study were mostly found as colleagues of
the author, except of those, who accepted the petition
with a privilege of attaching the script as a local re-
source (to protect from script modification), after re-
viewing it. The data have been collected from 7 par-
ticipating websites during approximate period of one
month. In total 15042 records from 5038 users were
obtained.
5 RESULTS
The evaluation environment described in the previous
section allowed to obtain a reasonable number of sam-
ples for further analysis. In total, 15042 samples were
collected (of the total size 1.36 GB).
5.1 Evaluation Criteria and Data
Representation
Except of identification of the best possible finger-
printing implementations of certain features, each at-
tribute has been analyzed according to the following
criteria:
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
171

Diversity — basic criterion for each fingerprint-
ing study, a measure of how diverse is a set of samples
calculated independently for each attribute as entropy.
Additionally, a number of distinct and unique values
in the dataset was counted.
Stability — second cannon criterion states how
often a fingerprint is changing its value over the time.
Four characteristics were calculated for each method:
total number of changes, average time distance be-
tween the changes, number of devices for which at
least one alternation was observed, average percent-
age ratio of how many samples have been modified
for these devices.
Length of Execution Code — as the number
of collected fingerprints increases, as well as li-
braries necessary for processing, size of the execu-
tion code becomes a limitation for some real-time-
oriented businesses. Thus, length of minified code
for each method implemented in bf.js was included.
Advanced fingerprints rely on time-consuming pro-
cessing that makes another limitation. Thus, execu-
tion time has been measured for each method inde-
pendently so the average time could be calculated.
Length of the Fingerprint — in scenario when
all the results are transfered to the server unchanged,
their overall size is a shortcoming. Average length of
sent data was computed as the last criterion.
Before the analysis, some essential data prepro-
cessing was executed. Out of 15042 samples two pro-
cessing sets were prepared:
• data unique — a set of unique samples used as
the base for all of the criteria evaluation, except
of stability. It was created by filtering the sam-
ples by user cookie-based identifiers. For each
user, only the earliest observed sample was taken.
8350 entries were removed so 6692 samples pre-
served. Yet, some cookies could have been re-
moved in the meantime so their identical finger-
prints could be stored under many cookie–ids. An
important assumption has been taken — in such
a small dataset with large number of fingerprint-
ing methods, it is very unlikely that many colli-
sions (two different devices having all of the fin-
gerprints identical) could occurred. Hence, a sub-
sequent filtering to remove identical fingerprints
from the dataset was conducted. In total 1654 du-
plicates were dismissed, resulting in 5038 sam-
ples. Considerable number of recognized dupli-
cates confirms that cookies are being frequently
removed by some users.
• data recurrent — a set of 8146 samples con-
structed by filtering out all user entries from
which only a single record was collected. In other
words, the data for which stability over time could
be evaluated was preserved in this dataset.
This evaluation, having 5000 samples, could achieve
at best log
2
5000 ≈ 12.3bits.
5.2 Discussion
The number of possible features to be fingerprinted
is immense. This work is focused on browser fin-
gerprinting. Fingerprints have been divided into
two categories, based on the source of information:
JavaScript code executed within the client browser
or HTTP headers obtained on the server side. It is
important to note that browser fingerprinting do not
have any explicit law interpretations. Some of the fin-
gerprints are having questionable reputation and thus,
are denounced within specific societies. This study
does not focus on the legal issues. Any possible us-
age of poor reputation-wise fingerprints was not in-
tended. All the collected samples were gathered for
educational purposes.
There are many properties exposed within
JavaScript APIs (e.g. window, navigator) bringing
valuable information. Most of the fingerprinting so-
lutions available, are checking those values in true-
false dimension only. However, it is not correct ap-
proach since different browser versions may handle
them quite unexpectedly, for instance, returning false,
null or 0 as the negative value. Treating it all as false,
would be a rejection of precious data that is aimed to
be collected. Moreover, another additional piece of
information can be obtained by slightly more detailed
querying — by adding vendor prefixes. Some proper-
ties used to be prefixed with webkit, moz, ms or o re-
spectively for Chrome, Firefox, Internet Explorer and
Opera browsers, prior the final standard was created.
Due to them, developers were able to control incon-
sistencies between the browsers. Prefixes for certain
properties are still working, even though they are of-
ten marked as deprecated. Such checks were included
in the evaluation.
Canvas Fingerprinting. Canvas is an HTML el-
ement used to draw basic 2D graphics on a web page.
Since this fingerprint was very popular within past
years, many different ways of implementation were
discovered. In this paper 12 canvas fingerprint tests
were collected to answer the question which proper-
ties are the most valuable. As a result, the following
conclusions were drawn:
• The canvas size (width and height) is having con-
siderable impact on the entropy. While all the
drawn elements are bigger, number of unique fin-
gerprints is significantly larger and the entropy in-
creases.
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
172

• Tests for blending and winding support improved
the overall result.
• The smile icon rendering test achieved a surpris-
ingly high score of entropy. The most common
values in the dataset were following (some of
them seem to be identical while there are small
differences when compared binary)
• Surprisingly, the usage of fake (fallback) font has
lower entropy than the usage of widely- accessi-
ble Arial font, even though it registered a larger
number of uniques and distinct values.
• Adding a number to a text increased overall diver-
sity. As the test for special characters was not im-
plemented in a proper way (as extension instead
of method replacement), the result does not allow
to draw any particular conclusions.
The most advanced canvas test (canvas-advanced)
obtained 8.08 bits of entropy. It is a significant score,
however other criteria must be considered. Appar-
ently, it is quite unstable (90 changes each 4.5 days),
time consuming (0.2s) and its length is the high-
est from all collected fingerprints (21KB). Individual
tests imply that the ”smile” icon (canvas-fontSmiles)
is the primary source of instability and, at the same
time, of entropy. The bigger the canvas and drawn el-
ements are, the higher the entropy, instability and ex-
ecution time. The only stable element seem to be the
font drawing (canvas-basic, canvas-font*). Notwith-
standing, the average fingerprint size of 21KB is too
large for most. Luckily, the usage of a hash function
can solve this issue if additional uniqueness deterio-
ration is acceptable.
Cookies and Web Storage API Support.
Browsers are exposing cookie support setting via nav-
igator.cookieEnabled property. Cookies, local and
session storage were tested both using JavaScript
properties (e.g. navigator.cookieEnabled indicating
the setting) and with active evaluation with the fol-
lowing scenario: get storage handle, write some data
into it, probe it for saved data existence, remove the
data. If the check for saved content failed or an excep-
tion was raised, storage mechanism could be consid-
ered as disabled. The results reveal that such method
was successful in detecting a few ”lied” situations for
local and session storage, while for cookies, property
value was always providing the same answer. Un-
fortunately, even though storage fingerprints are sta-
ble and execution low-cost, their small entropy make
them relatively irrelevant. It it also worth noticing,
that only 2 distinct values were observed for cookies
test while larger studies collected up to 7 configura-
tions. It confirms that small amount of collected data
does not allow to draw widely applicable conclusions.
CPU Class. This property is presumably present
only in Firefox and Internet Explorer (under oscpu
and cpuClass endpoint), while in Chrome it is a part
of appVersion. In 95% of cases navigator.cpuClass
did not return any value. 259 devices returned x86,
40 yielded ARM and x64 was observed twice, all re-
sulting in 0.25 bits of information. oscpu property
returned much more interesting results, the ratio of
empty values was 72%. Unexpectedly, it does not
only concern CPU architecture but also OS version,
making the entropy higher (1.76). Since both fin-
gerprints were stable and their execution cost was
negligible, such consideration in independence makes
them a good choice for any algorithm.
Do Not Track (DNT) Header. Users are able to
set “Do Not Track flag, indicating whether they wish
to not be tracked. Sadly, there is no public law to
respect this setting. IE 10 was released with DNT
header set to true by default — it brought a huge con-
troversy. From that time, all of the browsers are not
adding this flag unless the user explicitly wishes oth-
erwise. This fingerprint was collected in JavaScript
using two different objects: navigator and window.
The obtained results were exclusive and they did not
cover with the back-end side values. The fact that it
is not clear what is the real user setting does not pre-
vent these attributes from being useful in the finger-
printing process, due to relatively high entropies in
comparison to small numbers of distinct values (2 or
3). Paradoxically, a feature that was created to protect
privacy proved to be a valuable addition for this study.
Fonts Fingerprinting. The complete list of fonts
installed in the system can make another complex fin-
gerprint. Browsers do not provide a way to retrieve
it without usage of external plug-ins (Adobe Flash of
Java), however there are hacks to obtain a partial col-
lection. Among two methods of fingerprinting fonts,
canvas and CSS, the more efficient one was intended
to be uncovered. In a very early stage of the sam-
ple collection, it was already clear that CSS-based
method is much more attractive than canvas prob-
ing. Because canvas tests were affecting overall pro-
cessing time substantially, they were entirely removed
from bf.js script. The comparison of the observations
of each method is the following:
• Average execution time of canvas-based font
probing was roughly three times slower.
• CSS detection slightly outranks canvas but in both
methods efficiency is almost complete (assessed
with manual verification).
• CSS probing for foreign fonts containing excep-
tional characters (e.g. Japanese alphabet), even
though there were not included in the test string,
detected the font while canvas method did not.
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
173

The author suspects that CSS methods ”reserves”
the space (maximal height) for any character sup-
ported by a font, also if they are not printed.
• In some browsers discrepancies of 1 pixel were
observed. Therefore, the tests were improved to
meet this margin of error.
• Usage of a test string containing full alphabet
or the one chosen for fonts entropy assessment
(adfgjlmrsuvwwwwz7901) increased the detec-
tion rate in comparison to the string proposed in
other studies (based on m and w letters).
• Test string size of 70 pixels produced almost iden-
tical results as 180 or 200 pixels.
• monospace font was slightly more effective than
sans-serif, both for CSS and canvas tests.
• The only drawback of CSS method remains the
fact that it requires to be executed in users DOM
which brings a danger of influencing website ap-
pearance (canvas works in the background).
There were two additional observations which remain
unsolved. Firstly, for unknown reasons, drawing with
monospace as fallback font was on average 10 times
faster than drawing using sans-serif. The author did
not find any confirmed explanation for this fact. It
is suspected that monospace tests could have been
optimized after sans-serif checks were run, although
no particular execution order was assured. Secondly,
drawing strings of size 200 pixels were twice faster
than 70 pixels in CSS-based tests. The same possible
explanation applies.
Another important aspect of fonts evaluation is de-
termining a subset to be used for probing. A font
that is not supported for each user nor is present in
all the samples, will not allow to distinguish devices.
Maximum entropy (1 bit) is reached when a font is
present in exactly half of the data. Yet, choosing only
such fonts will not maximize the output since many
sets are strongly dependent. Therefore, an excessive
list of 821 fonts was prepared and for all of them, a
sample was collected. An iterative entropy maximiza-
tion algorithm was executed in order to find optimal
collection. To achieve 6 bits result, in the best sce-
nario the following 9 fonts were used (ordered from
the most valuable): Open Sans, Brush Script MT, Es-
trangelo Edessa, Gadugi, Roman, Papyrus, MT Ex-
tra, Wingdings, Segoe UI Semibold. Above 8 bits,
the number of fonts required to improve the entropy
increases drastically. After reaching 9 bits the re-
maining 746 elements almost did not improved the
result. It shows how important choosing the right col-
lection is. It is essential not only for the diversity
but also for the code execution time (3.5s) and stabil-
ity (187 changes, 6 days), as this fingerprint achieved
the worst results in both categories. Reducing the set
of fonts from 821 to 100 would decrease the aver-
age time necessary for probing to around 0.4s which
may be acceptable in certain usages. Stability metrics
should improve as well, although fontJs-sans-70px-
65 test probing for only 65 fonts still presents alarm-
ingly high instability (132 changes each 7 days). A
short investigation revealed three main categories of
changes that have occurred: (1) single font installa-
tion, (2) a large set of fonts changing the status from
absent to present, (3) single font fluctuations. The
first two categories may denote that the user has in-
stalled an additional font or a new software. Unfor-
tunately, there is nothing that can be done to prevent
them. Yet, often status changes of a particular font
are quite unlikely to be caused by a user action. Thus,
the latter category suggests either a field for detection
algorithm improvement or necessity to investigate the
cause in a deeper manner.
Language Setting. Exposed by navigator ob-
ject language property, is supposed to return user pre-
ferred language, in a format described by RFC speci-
fication, e.g. en-US, pl-PL or de-Latin- CH 1992 [29].
4 methods of obtaining language were implemented.
Broadly supported (99.9%) navigator.language prop-
erty presented 2.1 bits of information. Remaining
tests returned a result in only 5% of cases and as their
values were mostly equal, they barely achieved any
entropy. Yet, thanks to a decent stability and low cost
execution all of the features are worth taking them
into consideration.
Platform Fingerprint.navigator.platform repre-
sents the platform on which the execution takes place.
The set of possible values is not closed and the repre-
sentation may differ from browser to browser. Ex-
ample values are: Linux aarch64, MacIntel, iPhone,
Nokia Series 40 or PlayStation 4. This fingerprint has
changed its value only once, so it is one of the most
stable. 16 distinct values with 3 uniques were found
in the dataset (1.57 entropy).
Screen Properties. window.screen object may be
used to yield properties such as device screen color
depth, resolution and available resolution. The latter
is representing the space that may be consumed by
system applications (without menu bars). In terms of
fingerprinting resolutions, depending on which value
is greater (width or height), the screen orientation is
additionally determined. Again, by using it, some fin-
gerprinting solutions are incorrectly creating another
artificial fingerprint. On the other hand, orientation
may be dangerous considering stability, as the users
may change it quite often. Among both screenCol-
orDepth and screenPixelRatio tests, stable but rather
similar values were collected, providing 0.74 and 0.82
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
174

bits of entropy. However, screen dimensions method
yielded surprisingly diverse (5.76 bits) and unstable
results (90 changes, on average every 3 days). Insta-
bility was not expected since the test did not take into
account the screen orientation. It was analyzed what
entropy loss it implied — it was only 0.25 bits. Both
methods frequently yielded different values for the
same users, although window.screen.availHeight and
availWidth prevailed the final result. Some changes
were marginal (e.g. 404 pixels to 401 pixels) and
their cause should be further investigated. Yet, many
changes appear to be a switch to entirely new reso-
lution of the same device or to an external display
(rarely since color depth and pixel ratio didnt change).
Timezone. Utilizing JavaScript Date object, one
can request an offset which shall represent user
system timezone setting within 15 minutes slots.
Browsers may yield here quite unexpected numbers
4 , which, properly interpreted, could make a valu-
able fingerprint. Timezone fingerprint results with 22
distinct and 7 unique values scored only 0.74 bits of
entropy. Yet, this fingerprint is also very stable and
execution low-cost so worth a consideration.
Touch Support Detection. The evaluation of 6
detection methods suggests, that the three could be
used redundantly as they are all marked by the same
devices as touch-enabled (25% of the dataset, 0.75
entropy). touchSup-maxPoints test and the second
part of Modernizr library [34] check method returned
false for all of the devices. As Internet Explorer
property, msPointer marked additional devices as sup-
ported (0.24 bits), an ideal solution could make use of
a combination of these features.
WebGL Fingerprints. WebGL JavaScript API
allows to draw on three dimensional canvas in the
browser and used properly, makes another example
of hardware fingerprinting. Images obtained with this
technology can be translated into text the same way as
for canvas fingerprinting, and therefore easily com-
pared. Additionally, a variety of settings that may
extend the fingerprint, can be accessed within getPa-
rameter and getShaderPrecisionFormat methods. Be-
sides collecting WebGL drawing fingerprint, 10 cate-
gories of properties were collected. Their high en-
tropy makes them valuable, yet many samples have
changed over the time (on average after 36 hours). As
most of the tests manifested a similar performance,
they do not allow to draw any conclusions indepen-
dently. Additional evaluation was executed to asses
the attributes together. By combining drawing fin-
gerprint with all properties, only 6.31 bits of entropy
were achieved. In total 73 values have changed within
a relatively short period of time, namely 27 hours.
As for the cost of 0.4 seconds of execution time, the
great length of code (6KB) and the final sample size
of 5KB, this study does not allow to conclude that
WebGL features are a necessary addition to any fin-
gerprinting algorithm.
5.3 Summary
A selection of the most efficient features that could
make the client-side production fingerprinting algo-
rithm is conducted. Additionally, some important ob-
servations useful in creating a more advanced solution
that utilizes a server-side logic (and HTTP-based fin-
gerprints) are summarized.
Client-side Solution. Weighting the expectations
from an optimal fingerprinting script, the following
key points were summed up to serve as the criteria of
the final selection:
• The script should not fingerprint any of the fea-
tures classified as unstable.
• As many features as possible should be employed
to ensure maximal diversity. Even if the finger-
print independent entropy is barely recognizable,
but all the other criteria are matched, such feature
should be included in the algorithm (the number
of samples collected within this study is not sig-
nificant enough to come up with a conclusion of
permanent attribute rejection).
• Execution time of the script should not exceed
0.5s on average — many of the usages are aimed
on blocking abusive users which should be exe-
cuted as soon as they enter a website.
• A size of the final code bundle should be mini-
mized to reduce the download time and save the
bandwidth on mobile devices.
A few of the implemented tests have been concluded
to need an improvement in order to match the crite-
ria. Thus, with the purpose of measuring the charac-
teristics of the algorithm created from an optimal set
of implementations, the dataset was translated into a
form of a results yielded by improved fingerprinting
methods.
The only issue was a lack of the real world execu-
tion time data — an estimation had been made based
on the old methods performances. The result achieved
by all fingerprinting methods together, implemented
in bf.js, were compared with the fingerprinting effi-
ciency of an algorithm utilizing only selected features.
Obtained with the first solution entropy is extraor-
dinarily satisfactory, in fact almost ideal as for the
available dataset. Yet, bf.js could not be used in a
production environment since it was not built with
such intention — its execution time is exceedingly
high (3.9s) and instability (a change observed each
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
175

3.5 days) leaves much to be desired. Nonetheless,
the production solution, while matching all the ex-
pectations listed previously, achieved likewise high
diversity — only 0.3 less bits of entropy. The execu-
tion time of 0.4s is excellent, the number of changes
dropped by a half and the average time distance of a
change improved by almost 3 days, which is highly
more acceptable.
Server-based Solutions. 6 days of fingerprint sta-
bility achieved with the proposed production solution
is far behind cookie-based identifiers that are able to
last for years. The need for more advanced techniques
is a natural way of improving the process of finger-
print creation. This work has employed certain as-
pects of a potential server-based solution, thus few
conclusions that could be useful in creating such were
summarized.
The primary obstacle is the transfer of data ob-
tained in the browser to the server. Length of cer-
tain fingerprints (e.g. canvas, webGL) proved to be
unacceptable, thus the author suggests compressing
the data by applying a hashing algorithm before the
transfer. Locality preserving hash could be utilized
in case the server logic would implement a tracking
of value changes — it would allow to measure the
change extent. By having such hashes for the most
expensive fingerprints and implementing translation
and compression methods for the remaining ones (e.g.
true/false setting sent as one bit of information, map-
ping of common phrases to shorter symbols), the ne-
cessity to use CORS POST request could be possi-
bly reduced. Because CORS introduces a noticeable
connection overhead, having a fingerprint compressed
enough to fit a GET parameter would significantly ad-
vance the networking performance.
To improve the JavaScript code execution time, its
length and the size of transfered data, some finger-
prints could be processed on the back-end side instead
in the users browser, e.g. User-Agent accessible from
HTTP request headers holds identical information as
the value returned by JavaScript API — server could
utilize parsing libraries to extract meaningful data.
6 CONCLUSIONS
Fingerprinting, as a mechanism used in security and
advertisement, plays an important role in web track-
ing. This work proves that this storage-less technique
is really demanding and it requires a lot of effort to
develop an efficient fingerprinting algorithm. The re-
sulting solution presented satisfactory performance in
terms of diversity, execution time and the length of the
code bundle, yet demonstrated a need for improve-
ment of its stability, which is essential in most of the
usages.
Except for the benefits coming from conducting
the first evaluation of different fingerprint implemen-
tations and producing an optimal set of features, this
work allows to draw many additional conclusions.
Analysis of existing solutions revealed some miscon-
ceptions that they introduce — creating artificial fin-
gerprints like browser tempering is only exacerbat-
ing the overall efficiency. Some of the fingerprints
(ad-block extension detection, flash-based) have been
found to be unstable between regular browsing and
private-mode, something that should not make a dif-
ference to a respectable algorithm. An instability of
certain fingerprints was observed and discussed alto-
gether with potential causes and possible improve-
ments. Finally, this work proves the superiority of
CSS-based font probing over canvas-based solutions
and allows to select a reference set of fonts providing
the best detection performance. Additionally, some
important objectives of an advanced server solution
were pointed out.
The outcome of this research provides a notice-
able progress in the analysis of fingerprinting solu-
tions. The discovered features and corresponding op-
timal implementations will enrich and improve an
open-source fingerprinting library Fingerprintjs2.
This study was not able to evaluate many addi-
tional features to be fingerprinted, therefore an anal-
ysis of remaining ideas could take place. Certain
test outcomes did not allow to perform their full as-
sessment, thus continuation of their evaluation could
bring important findings in terms of their usability.
Importantly, a short period of data collection, result-
ing in a decent but limited dataset, did not allow to
conclude reliably in a few aspects — following re-
search should be conducted in the long-term to elimi-
nate such concerns. Device fingerprinting proves to
be a powerful technique, yet leaving a large room
for improvement. Further researches have to be con-
ducted in order to decrease the efficiency distance
with well-known storage-based methods.
REFERENCES
Acar, G., Eubank, C., Englehardt, S., Juarez, M.,
Narayanan, A., and Diaz., C. (2014). The web never
forgets: Persistent tracking mechanisms in the wild.
technical report, princeton university, ku leuven.
Acar, G., Juarez, M., Nikiforakis, N., Diaz, C., G
¨
urses,
S., Piessens, F., and Preneel, B. (2013). Fpdetective:
dusting the web for fingerprinters. In Proceedings of
the 2013 ACM SIGSAC conference on Computer &
communications security, pages 1129–1140. ACM.
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
176

Augur (2016). Augur, a set of apis and tools that instantly
enables businesses to recognize devices, and con-
sumers across devices. [on-line] https://www.augur.io/
(retrieved: 08/2016).
Boda, K., F
¨
oldes,
´
A. M., Guly
´
as, G. G., and Imre, S. (2011).
User tracking on the web via cross-browser finger-
printing. In Nordic Conference on Secure IT Systems,
pages 31–46. Springer.
BrowserSpy (2016). Browserspy on-line ngerprinting
test tool. [on-line] http://browserspy.dk/ (retrieved:
08/2016).
Cahn, A., Alfeld, S., Barford, P., and Muthukrishnan, S.
(2016). An empirical study of web cookies. In
Proceedings of the 25th International Conference on
World Wide Web, WWW ’16, pages 891–901.
Checklist, S. (2016). Web browser security checklist.
[on-line] https://www.browserleaks.com/ (retrieved:
08/2016).
Cross-browser (2016). Cross-browser ngerprinting test 2.0.
[on-line] https://fingerprint.pet-portal.eu/ (retrieved:
08/2016).
Eckersley., P. (2010). How unique is your web browser? in
international symposium on privacy enhancing tech-
nologies symposium, pages 118. springer, 2010.
Englehardt, S. and Narayanan., A. (2016). On-line tracking:
A 1-million-site measurement and analysis. technical
report, princeton university.
Fetterly, D., Manasse, M., Najork, M., and Wiener, J.
(2003). A large-scale study of the evolution of web
pages. In Proceedings of the 12th International Con-
ference on World Wide Web, WWW ’03, pages 669–
678. ACM.
Fingerprints2 (2016). Fingerprintjs2 - mod-
ern browser ngerprinting library. [on-line]
https://github.com/valve/fingerprintjs2.
Frontier, E. (2016). On-line ngerprinting test conducted
by electronic frontier foundation. [on-line] https:
//panopticlick.eff.org/ (retrieved: 08/2016).
HTML5 (2016). HTML5, a vocabulary and associated
apis for html and xhtml. http://aiweb.techfak. uni-
bielefeld.de/content/bworld-robot-control-software/
adsfdf afdfds afsddfs adfd adfdf adfsdfs adfsdsf
afsddfs. [on-line] https://www.w3.org/tr/html5/
(retrieved: 08/2016).
Kamkar, S. (2016). Evercookie virtually irrevocable persis-
tent cookies. [on-line] http://samy.pl/evercookie/ (re-
trieved: 08/2016).
Kurent, A. (2016). Crossbrowser device
ngerprinting diploma thesis. [on-line]
http://fingerprinting.comyr.com/ (retrieved: 08/2016).
Low, C. (2016). Cookie law explained. [on-line]
https://www.cookielaw.org/the-cookie-law/ (re-
trieved:08/2016).
Persistent (2016). Usage of persistent cookies for websites.
[on-line] https://w3techs.com/technologies/details/ce-
persistentcookies/all/all (retrieved: 08/2016).
RFC (2016). RFC 6265 specication. http
state management mechanism. [on-line]
https://tools.ietf.org/html/rfc6265 (Retrieved:
08/2016).
Tillmann, H. (2016). Browser ngerprinting test by henning
tillmann. [on-line] http://bfp.henning-tillmann.de/ (re-
trieved: 08/2016).
Webkit2016 (2016). Fingerprinting in webkit. [on-line]
https://trac.webkit.org/wiki/fingerprinting.
Yen, T.-F., Huang, X., Monrose, F., and Reiter, M. K.
(2009). Browser fingerprinting from coarse traffic
summaries: Techniques and implications. In Inter-
national Conference on Detection of Intrusions and
Malware, and Vulnerability Assessment, pages 157–
175. Springer.
Yen, T.-F., Xie, Y., Yu, F., Yu, R. P., and Abadi, M. (2012).
Host fingerprinting and tracking on the web: Privacy
and security implications. In NDSS.
Device Fingerprinting: Analysis of Chosen Fingerprinting Methods
177
