
A Frequency-domain-based Pattern Mining
for Credit Card Fraud Detection
Roberto Saia and Salvatore Carta
Dipartimento di Matematica e Informatica, Universit
`
a di Cagliari, Italy
Keywords:
Business Intelligence, Fraud Detection, Pattern Mining, Fourier, Metrics.
Abstract:
Nowadays, the prevention of credit card fraud represents a crucial task, since almost all the operators in the
E-commerce environment accept payments made through credit cards, aware of that some of them could be
fraudulent. The development of approaches able to face effectively this problem represents a hard challenge
due to several problems. The most important among them are the heterogeneity and the imbalanced class
distribution of data, problems that lead toward a reduction of the effectiveness of the most used techniques,
making it difficult to define effective models able to evaluate the new transactions. This paper proposes a new
strategy able to face the aforementioned problems based on a model defined by using the Discrete Fourier
Transform conversion in order to exploit frequency patterns, instead of the canonical ones, in the evaluation
process. Such approach presents some advantages, since it allows us to face the imbalanced class distribution
and the cold-start issues by involving only the past legitimate transactions, reducing the data heterogeneity
problem thanks to the frequency-domain-based data representation, which results less influenced by the data
variation. A practical implementation of the proposed approach is given by presenting an algorithm able to
classify a new transaction as reliable or unreliable on the basis of the aforementioned strategy.
1 INTRODUCTION
Studies conducted by American Association of Fraud
Examiners
1
show that the financial frauds represent
the 10-15% of the entire fraud cases, by involving
the 75-80% of the entire financial value, with an es-
timated average loss per fraud case of 2 million of
dollars, in the USA alone. Fraud represents one of
the major issues related to the use of credit cards, an
important aspect considering the exponential growth
of the E-commerce transactions. For these reasons,
the research of effective approaches able to detect the
frauds has become a crucial task, because it allows the
involved operators to eliminate, or at least reduce, the
economic losses.
Since the fraudulent transactions are typically less
than the legitimate ones, the data distribution is highly
unbalanced and this reduces the effectiveness of many
machine learning strategies Japkowicz and Stephen
(2002). Such problem is worsened by the scarcity
of information that characterizes a typical financial
transaction, a scenario that leads toward an overlap-
ping of the classes of expense of a user Holte et al.
1
http://www.acfe.com
(1989).
There are many state-of-the-art techniques de-
signed to perform the fraud detection task, for in-
stance, those that exploit the Data Mining Lek
et al. (2001), the Artificial Intelligence Hoffman and
Tessendorf (2005), the Fuzzy Logic Lenard and Alam
(2005), the Machine Learning Whiting et al. (2012),
and the Genetic Programming Assis et al. (2010) tech-
niques.
Almost all the aforementioned techniques mainly
rely on the detection of outliers in the transactions un-
der analysis, a basic approach that could lead toward
many wrong classifications (i.e., reliable transactions
classified as unreliable). Most of these wrong classifi-
cations happen due to the absence of extensive criteria
during the evaluation process, since many techniques
are not able to manage some non-numeric transac-
tion features during the evaluation process, e.g., one
of the most performing approaches, such as Random
Forests, is not able to manage types of data that in-
volve a large number of categories.
The idea behind this paper is a new representation
of the data obtained by using the Fourier transforma-
tion Duhamel and Vetterli (1990) in order to move a
time series (the sequence of discrete-time data given
386
Saia, R. and Carta, S.
A Frequency-domain-based Pattern Mining for Credit Card Fraud Detection.
DOI: 10.5220/0006361403860391
In Proceedings of the 2nd International Conference on Internet of Things, Big Data and Security (IoTBDS 2017), pages 386-391
ISBN: 978-989-758-245-5
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

by the feature values of a transaction ) in the fre-
quency domain, allowing us to analyze the data from
a new point of view.
It should be observed that the proposed evalua-
tion process involves only the past legitimate transac-
tions, presenting some advantages: first, it operates in
a proactive way, by facing the imbalanced class distri-
bution and the cold-start (i.e., scarcity or total absence
of fraudulent transaction cases) problems; second, it
reduces the problems related to the data heterogene-
ity, since the data representation in the frequency do-
main is more stable than the canonical one, in terms
of capability of recognizing a peculiar pattern, regard-
less of the value assumed by the transaction features.
The contributions of this paper are as follows:
(i) definition of the time series to use in the Fourier
process, on the basis of the past legitimate trans-
actions;
(i) formalization of the comparison process between
the time series of an unevaluated transaction and
those of the past legitimate transactions, in terms
of difference between their frequency magnitude;
(i) formulation of an algorithm, based on the previ-
ous comparison process, able to classify a new
transaction as reliable or unreliable.
The remainder of the paper is organized as fol-
lows: Section 2 introduces the background and related
work; Section 3 provides a formal notation, makes
some assumptions, and defines the faced problem;
Section 4 describes the steps necessary to define the
proposed approach; Section 5 gives some concluding
remarks.
2 BACKGROUND AND RELATED
WORK
Many studies consider the frauds as the biggest prob-
lem in the E-commerce environment. The challenge
faced by the fraud detection techniques is the classifi-
cation of a financial transaction as reliable or unreli-
able, on the basis of the analysis of its features (e.g.,
description, date, total amount, etc.).
The study presented in Assis et al. (2010) indi-
cates how in the fraud detection field there is a lack of
public real-world datasets, configuring a relevant is-
sue for those who deal with the research and develop-
ment of new and more effective fraud detection tech-
niques. This scenario mainly depends on the restric-
tive policies adopted by the financial operators, which
for competitive or legal reasons do not provide in-
formation about their business activities. These poli-
cies are also adopted because the financial data are
composed by real information about their customers,
which even anonymized may reveal potential vulner-
abilities related to the E-commerce infrastructure.
Supervised and Unsupervised Approaches. In
Phua et al. (2010) it is underlined how the unsuper-
vised fraud detection strategies are still a very big
challenge in the field of E-commerce. In spite of
the fact that every supervised strategy in fraud detec-
tion needs a reliable training set, the work proposed
in Bolton and Hand (2002) takes in consideration the
possibility to adopt an unsupervised approach during
the fraud detection process, when no dataset of refer-
ence containing an adequate number of transactions
(legitimate and non-legitimate) is available.
Data Heterogeneity. Pattern recognition can be
considered an important branch of the machine learn-
ing field. Its main task is the detection of patterns
and regularities in a data stream, in order to define
an evaluation model to exploit in a large number of
real-world applications Garibotto et al. (2013). One
of the most critical problems related to the pattern
recognition tasks is the data heterogeneity. Litera-
ture describes the data heterogeneity issue as the in-
compatibility among similar features resulting in the
same data being represented differently in different
datasets Chatterjee and Segev (1991).
Data Unbalance. One of the most important
problems that makes the definition of effective models
for the fraud detection difficult is the imbalanced class
distribution of data Japkowicz and Stephen (2002);
He and Garcia (2009). This issue is given by the fact
that the data used in order to train the models are char-
acterized by a small number of default cases and a
big number of non-default ones, a distribution of data
that limits the performance of the classification tech-
niques Japkowicz and Stephen (2002); Brown and
Mues (2012).
Cold Start. The cold start problem Donmez et al.
(2007) arises when there is not enough information to
train a reliable model about a domain. In the context
of the fraud detection, such scenario appears when the
data used to train the model are not representative of
all classes of data Attenberg and Provost (2010) (i.e.,
default and non-default cases).
Detection Models. The static approach Pozzolo
et al. (2014) represents a canonical way to operate in
order to detect fraudulent events in a stream of trans-
actions. This approach divides the data stream into
blocks of the same size, and the user model is trained
by using a certain number of initial and contiguous
blocks of the sequence, which are used to infer the
future blocks. The updating approach Wang et al.
(2003), instead, when a new block appears, trains the
user model by using a certain number of latest and
contiguous blocks of the sequence, then the model can
A Frequency-domain-based Pattern Mining for Credit Card Fraud Detection
387

Frequency
Time
Magnitude
f
1
f
2
f
...
f
X
Figure 1: Time and Frequency Domains.
be used to infer the future blocks, or it can be aggre-
gated into a big model composed by several models.
In another strategy, based on the so-called forgetting
approach Gao et al. (2007), a user model is defined
at each new block, by using a small number of non
fraudulent transactions, extracted from the last two
blocks, but by keeping all previous fraudulent ones.
Also in this case, the model can be used to infer the
future blocks, or it can be aggregated into a big model
composed by several models.
The main disadvantages related to these ap-
proaches of user modeling are: the incapacity to track
the changes in the users behavior, in the case of the
static approach; the ineffectiveness to operate in the
context of small classes, in the case of the updating
approach; the computational complexity in the case
of the forgetting approach. However, regardless of
the used approach, the problem of the heterogeneity
and unbalance of the data still remains unaltered.
Discrete Fourier Transform. The basic idea be-
hind the approach proposed in this paper is to move
the process of evaluation of the new transactions (time
series) from their canonical time domain to the fre-
quency one, in order to obtain a representative pattern
composed by their frequency components, as shown
in Figure 1. This operation is performed by recurring
to the Discrete Fourier Transform (DFT ), whose for-
malization is reported in Equation 1, where i is the
imaginary unit.
F
n
def
=
N−1
∑
k=0
f
k
· e
−2πink/N
, n ∈ Z (1)
As result we obtain a set of sinusoidal functions,
each corresponding to a particular frequency compo-
nent. It is possible to return to the original time do-
main by using the inverse Fourier transform shown in
Equation 2.
f
k
=
1
N
N−1
∑
n=0
F
n
· e
2πikn/N
, n ∈ Z (2)
3 PRELIMINARIES
Formal notation, assumptions, and problem definition
are stated in the following:
3.1 Formal Notation
Given a set of classified transactions T =
{t
1
,t
2
,. ..,t
N
}, and a set of features V = {v
1
,v
2
,
.. .,v
M
} that compose each t ∈ T , we denote as
T
+
⊆ T the subset of legitimate transactions, and
as T
−
⊆ T the subset of fraudulent ones. We also
denote as
ˆ
T = {
ˆ
t
1
,
ˆ
t
2
,. ..,
ˆ
t
U
} a set of unclassified
transactions. It should be observed that a trans-
action only can belong to one class c ∈ C, where
C = {reliable,unreliable}. Finally, we denote as
F = { f
1
, f
2
,. .. , f
X
} the frequency components of
each transaction obtained through the DFT process.
3.2 Assumptions
A periodic wave is characterized by a frequency f
and a wavelength λ (i.e., the distance in the medium
between the beginning and end of a cycle λ =
w
f
0
,
where w stands for the wave velocity), which are de-
fined by the repeating pattern, the non-periodic waves
that we take into account during the Discrete Fourier
Transform process do not have a frequency and a
wavelength. Their fundamental period T is the pe-
riod where the wave values were taken and sr denotes
their number over this time (i.e., the acquisition fre-
quency).
Assuming that the time interval between the ac-
quisitions is equal, on the basis of the previous defi-
nitions applied in the context of this paper, the con-
sidered non-periodic wave is given by the sequence
of values v
1
,v
2
,. .. ,v
M
with v ∈ V , which composes
each transaction t ∈ T
+
(i.e., the past legitimate trans-
actions) and
ˆ
t ∈
ˆ
T (i.e., the unevaluated transactions),
and that representing the time series taken into ac-
count. Their fundamental period T starts with v
1
and
it ends with v
M
, thus we have that sr = |V |; the sample
interval si is instead given by the fundamental period
T divided by the number of acquisition, i.e., si =
T
|V |
.
We compute the Discrete Fourier Transform of
each time series t ∈ T
+
and
ˆ
t ∈
ˆ
T , by converting their
representation from the time domain to the frequency
one. The obtained frequency-domain representation
provides information about the signal’s magnitude
and phase at each frequency. For this reason, the out-
put (denoted as x) of the DFT computation is a series
of complex numbers composed by a real part x
r
and
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
388

an imaginary part x
i
, thus x = (x
r
+ ix
i
). We can ob-
tain the x magnitude by using |x| =
q
(x
2
r
+ x
2
i
) and
the x phase by using ϕ(x) = arctan
x
i
x
r
, although in
the context of this paper we take into account only the
frequency magnitude.
3.3 Problem Definition
On the basis of a process of comparison (denoted as
Θ) performed between the frequency patterns of the
time series related to the set T
+
and to the set
ˆ
T ,
the goal of the proposed approach is to classify each
transaction
ˆ
t ∈
ˆ
T as reliable or unreliable.
Given a function evaluation(
ˆ
t,Θ) created to eval-
uate the correctness of the
ˆ
t classification, which re-
turns a boolean value β (0=misclassification, 1=cor-
rect classification), we can formalize our objective
as the maximization of the results sum, as shown in
Equation 3.
max
0≤β≤|
ˆ
T |
β =
|
ˆ
T |
∑
u=1
evaluation(
ˆ
t
u
,Θ) (3)
4 PROPOSED APPROACH
The implementation of our approach is carried out
through the following steps:
• Data Definition: definition of the time series in
terms of sequence of transaction features;
• Data Evaluation: comparison of the frequency
patterns of two transactions, made by processing
the related time series;
• Data Classification: presentation of the algo-
rithm able to classify a new transaction as reliable
or unreliable, on the basis of the previous compar-
ison process.
In the following, we provide a detailed description of
each of these steps.
4.1 Data Definition
In the first step of our approach we define the time se-
ries to use in the Discrete Fourier Transform process.
Formally, a time series represents a series of data
points stored by following the time order and usually
it is a sequence captured at successive equally spaced
points in time, thus it can be considered a sequence of
discrete-time data.
In the context of the proposed approach, the time
series taken into account are defined by using the set
of features V that compose each transaction in the T
+
and
ˆ
T sets, as shown in Equation 4, by following the
criterion reported in Equation 5.
T
+
=
v
1,1
v
1,2
.. . v
1,M
v
2,1
v
2,2
.. . v
2,M
.
.
.
.
.
.
.
.
.
.
.
.
v
N,1
v
N,2
.. . v
N,M
ˆ
T =
v
1,1
v
1,2
.. . v
1,M
v
2,1
v
2,2
.. . v
2,M
.
.
.
.
.
.
.
.
.
.
.
.
v
U,1
v
U,2
.. . v
U,M
(4)
(v
1,1
,v
1,2
,. .. , v
1,M
),(v
2,1
,v
2,2
,. .. , v
2,M
),· ·· , (v
N,1
,v
N,2
,. .. , v
N,M
)
(v
1,1
,v
1,2
,. .. , v
1,M
),(v
2,1
,v
2,2
,. .. , v
2,M
),· ·· , (v
U,1
,v
U,2
,. .. , v
U,M
)
(5)
The time series related to an item
ˆ
t ∈
ˆ
T will be
compared to the time series related to all the items
t ∈ T
+
, by following the criteria explained in the next
steps.
4.2 Data Evaluation
The frequency domain representation allows us to
perform a transaction analysis in terms of the magni-
tude assumed by each frequency component that char-
acterizes the transaction, allowing us to detect some
patterns in the features that are not discoverable oth-
erwise. As preliminary work, we compared the two
different representation of a transaction (i.e., these ob-
tained in the time and frequency domains), observing
some interesting properties for the context taken into
account in this paper, which are described in the fol-
lowing:
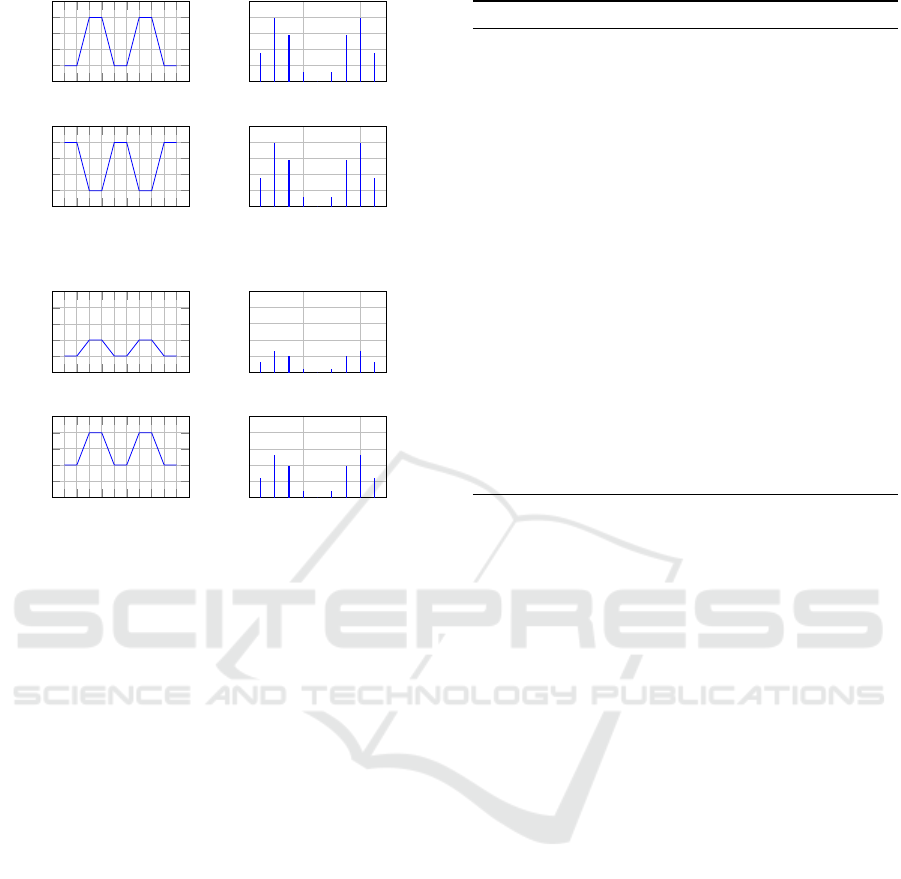
• The phase invariance property shown in Figure 2
proves that also in case of translation
2
between
transactions, a specific pattern still exists in the
frequency domain. In other words, by working
in the frequency domain we can detect a specific
pattern, also when it shifts along the features that
compose a transaction.
• The amplitude correlation property shown in FIg-
ure 3 evidences that a direct correlation exists be-
tween the feature values in the time domain and
the magnitudes assumed by the frequency com-
ponents in the frequency domain. It grants that
our approach is able to differentiate the transac-
tions on the basis of the values assumed by the
transaction features.
Practically, the process of analysis is performed
by moving the time series of the transactions to com-
pare from their time domain to the frequency one, by
recurring to the DFT introduced in Section 2.
The process of comparison between a transaction
ˆ
t ∈
ˆ
T to evaluate and a past legitimate transaction
t ∈ T + is performed by measuring the difference ∆
between the magnitude | f | of each component f ∈ F
2
A translation in time domain corresponds to a change
in phase in the frequency domain.
A Frequency-domain-based Pattern Mining for Credit Card Fraud Detection
389
1 2 3 4
5 6
7 8 9 10
1.0
2.0
3.0
4.0
Time (Series)
Value
1 2 3 4
5 6
7 8 9 10
1.0
2.0
3.0
4.0
Time (Series)
Value
0.2 0.4
2.0
4.0
6.0
8.0
Frequency (Hz)
Magnitude
0.2 0.4
2.0
4.0
6.0
8.0
Frequency (Hz)
Magnitude
Figure 2: Phase Invariance Property.
1 2 3 4
5 6
7 8 9 10
1.0
2.0
3.0
4.0
Time (Series)
Value
1 2 3 4
5 6
7 8 9 10
1.0
2.0
3.0
4.0
Time (Series)
Value
0.2 0.4
2.0
4.0
6.0
8.0
Frequency (Hz)
Magnitude
0.2 0.4
2.0
4.0
6.0
8.0
Frequency (Hz)
Magnitude
Figure 3: Amplitude Correlation Property.
in the frequency components of the involved transac-
tions.
It is shown in the Equation 6, where f
1
x
and f
2
x
denote, respectively, the same frequency component
of an item t ∈ T
+
and an item
ˆ
t ∈
ˆ
T .
∆ =
| f
1
x
| − | f
2
x
|
, with | f
1
x
| ≥ | f
2
x
| (6)
It should be noted that, as described in Section 4.3,
for each transaction
ˆ
t ∈
ˆ
T to evaluate, the aforemen-
tioned process is repeated by comparing it to each
transaction t ∈ T
+
. This allows us to evaluate the vari-
ation ∆ in the context of all the legitimate past cases.
4.3 Data Classification
The proposed approach is based on the Algorithm 1.
It takes as input the set T
+
of past legitimate trans-
actions and a transaction
ˆ
t to evaluate. It returns a
boolean value that indicates the classification of the
transaction
ˆ
t (true=reliable or false=unreliable).
From step 1 to step 21 we process the unevaluated
transaction
ˆ
t, by starting with the extraction of its time
series (step 2), which is processed at step 3 in order to
get the frequency components. From the step 4 to step
14 we instead process each non-default transaction t ∈
T
+
, by performing the extraction of the time series
(step 5) and by obtaining its frequency components
(step 6). The steps from 7 to 13 verify if the
Algorithm 1: Transaction classification.
Input: T
+
=Legitimate past transactions,
ˆ
t=Unevaluated transaction
Output: β=Classification of the transaction
ˆ
t
1: procedure TRANSACTIONCLASSIFICATION(T
+
,
ˆ
t)
2: ts1 ← getTimeseries(
ˆ
t)
3: F
1
← getDFT (ts1)
4: for each t in T
+
do
5: ts2 ← getTimeseries(t)
6: F
2
← getDFT (ts2)
7: for each f in F do
8: if (|F
2
( f )| − |F
1
( f )| ∈ getVariationRange(T
+
, f ) then
9: reliable ← reliable + 1
10: else
11: unreliable ← unreliable + 1
12: end if
13: end for
14: end for
15: if reliable > unreliable then
16: β ← true
17: else
18: β ← f alse
19: end if
20: return β
21: end procedure
difference between the magnitude of each frequency
components f ∈ F of the non-default transactions and
the correspondent component of the current transac-
tion, is within the interval given by the minimum and
maximum variation measured in the set T
+
, by com-
paring all magnitudes of the current frequency com-
ponent f . On the basis of the result of this operation
we increase the reliable value (when the difference is
within the interval) or the unreliable one (otherwise)
(steps 9 and 11). The reliable and unreliable values
will determine the classification of the transaction un-
der evaluation (steps from 15 to 19), and the result is
returned by the algorithm at the step 20.
5 CONCLUSIONS
Fraud detection techniques cover a crucial role in
many financial contexts, since they are able to reduce
the losses due to fraud, suffered directly by the traders
or indirectly by the credit card issuers.
This paper introduces a novel fraud detection ap-
proach aimed to classify the new transactions as re-
liable or unreliable by evaluating their characteris-
tics (pattern) in the frequency domain instead of the
canonical one. It is performed through the Fourier
transformation, defining our model by only using the
past legitimate user transactions.
Such approach allows us to avoid the data unbal-
ance problem that affects the canonical classification
approaches, because it only uses a class of data dur-
ing the process of definition of the model, allowing
IoTBDS 2017 - 2nd International Conference on Internet of Things, Big Data and Security
390

us to operate in a proactive way, by also reducing the
cold-start problem.
Even the problems related to the data heterogene-
ity are reduced thanks to the adoption of a more sta-
ble model (based on the frequency components) able
to recognize peculiar patterns in the transaction fea-
tures, regardless of the value assumed by them.
Future work would be oriented to the implementa-
tion of the proposed approach in a real-world context,
by comparing its performance to those of the most
widely used state-of-the-art approaches.
ACKNOWLEDGEMENTS
This research is partially funded by Regione Sardegna
under project “Next generation Open Mobile Apps
Development” (NOMAD), “Pacchetti Integrati di
Agevolazione” (PIA) - Industria Artigianato e Servizi
- Annualit
`
a 2013.
REFERENCES
Assis, C., Pereira, A. M., de Arruda Pereira, M., and Car-
rano, E. G. (2010). Using genetic programming to
detect fraud in electronic transactions. In Prazeres,
C. V. S., Sampaio, P. N. M., Santanch
`
e, A., Santos, C.
A. S., and Goularte, R., editors, A Comprehensive Sur-
vey of Data Mining-based Fraud Detection Research,
volume abs/1009.6119, pages 337–340.
Attenberg, J. and Provost, F. J. (2010). Inactive learn-
ing?: difficulties employing active learning in prac-
tice. SIGKDD Explorations, 12(2):36–41.
Bolton, R. J. and Hand, D. J. (2002). Statistical fraud de-
tection: A review. Statistical Science, pages 235–249.
Brown, I. and Mues, C. (2012). An experimental compari-
son of classification algorithms for imbalanced credit
scoring data sets. Expert Syst. Appl., 39(3):3446–
3453.
Chatterjee, A. and Segev, A. (1991). Data manipulation
in heterogeneous databases. ACM SIGMOD Record,
20(4):64–68.
Donmez, P., Carbonell, J. G., and Bennett, P. N. (2007).
Dual strategy active learning. In ECML, volume 4701
of Lecture Notes in Computer Science, pages 116–
127. Springer.
Duhamel, P. and Vetterli, M. (1990). Fast fourier trans-
forms: a tutorial review and a state of the art. Signal
processing, 19(4):259–299.
Gao, J., Fan, W., Han, J., and Yu, P. S. (2007). A general
framework for mining concept-drifting data streams
with skewed distributions. In Proceedings of the Sev-
enth SIAM International Conference on Data Min-
ing, April 26-28, 2007, Minneapolis, Minnesota, USA,
pages 3–14. SIAM.
Garibotto, G., Murrieri, P., Capra, A., Muro, S. D.,
Petillo, U., Flammini, F., Esposito, M., Pragliola, C.,
Leo, G. D., Lengu, R., Mazzino, N., Paolillo, A.,
D’Urso, M., Vertucci, R., Narducci, F., Ricciardi, S.,
Casanova, A., Fenu, G., Mizio, M. D., Savastano, M.,
Capua, M. D., and Ferone, A. (2013). White paper on
industrial applications of computer vision and pattern
recognition. In ICIAP (2), volume 8157 of Lecture
Notes in Computer Science, pages 721–730. Springer.
He, H. and Garcia, E. A. (2009). Learning from imbalanced
data. IEEE Trans. Knowl. Data Eng., 21(9):1263–
1284.
Hoffman, A. J. and Tessendorf, R. E. (2005). Artificial in-
telligence based fraud agent to identify supply chain
irregularities. In Hamza, M. H., editor, IASTED In-
ternational Conference on Artificial Intelligence and
Applications, part of the 23rd Multi-Conference on
Applied Informatics, Innsbruck, Austria, February 14-
16, 2005, pages 743–750. IASTED/ACTA Press.
Holte, R. C., Acker, L., and Porter, B. W. (1989). Concept
learning and the problem of small disjuncts. In Srid-
haran, N. S., editor, Proceedings of the 11th Interna-
tional Joint Conference on Artificial Intelligence. De-
troit, MI, USA, August 1989, pages 813–818. Morgan
Kaufmann.
Japkowicz, N. and Stephen, S. (2002). The class imbal-
ance problem: A systematic study. Intell. Data Anal.,
6(5):429–449.
Lek, M., Anandarajah, B., Cerpa, N., and Jamieson, R.
(2001). Data mining prototype for detecting e-
commerce fraud. In Smithson, S., Gricar, J., Pod-
logar, M., and Avgerinou, S., editors, Proceedings of
the 9th European Conference on Information Systems,
Global Co-operation in the New Millennium, ECIS
2001, Bled, Slovenia, June 27-29, 2001, pages 160–
165.
Lenard, M. J. and Alam, P. (2005). Application of fuzzy
logic fraud detection. In Khosrow-Pour, M., editor,
Encyclopedia of Information Science and Technology
(5 Volumes), pages 135–139. Idea Group.
Phua, C., Lee, V. C. S., Smith-Miles, K., and Gayler, R. W.
(2010). A comprehensive survey of data mining-based
fraud detection research. CoRR, abs/1009.6119.
Pozzolo, A. D., Caelen, O., Borgne, Y. L., Waterschoot, S.,
and Bontempi, G. (2014). Learned lessons in credit
card fraud detection from a practitioner perspective.
Expert Syst. Appl., 41(10):4915–4928.
Wang, H., Fan, W., Yu, P. S., and Han, J. (2003). Mining
concept-drifting data streams using ensemble classi-
fiers. In Getoor, L., Senator, T. E., Domingos, P. M.,
and Faloutsos, C., editors, Proceedings of the Ninth
ACM SIGKDD International Conference on Knowl-
edge Discovery and Data Mining, Washington, DC,
USA, August 24 - 27, 2003, pages 226–235. ACM.
Whiting, D. G., Hansen, J. V., McDonald, J. B., Albrecht,
C. C., and Albrecht, W. S. (2012). Machine learning
methods for detecting patterns of management fraud.
Computational Intelligence, 28(4):505–527.
A Frequency-domain-based Pattern Mining for Credit Card Fraud Detection
391
