
Making Cloud-based Systems Elasticity Testing Reproducible
Michel Albonico
1,3
, Jean-Marie Mottu
1
, Gerson Sunye
1
and Frederico Alvares
2
1
AtlanModels Team (Inria, IMT-A, LS2N), France
2
Ascola Team (Inria, IMT-A, LS2N), France
3
Federal Technological University of Parana, Francisco Beltr
˜
ao, Brazil
Keywords:
Cloud Computing, Elasticity, Elasticity Testing, Controllability, Reproducibility.
Abstract:
Elastic Cloud infrastructures are capable of dynamically varying computational resources at large scale, which
is error-prone by nature. Elasticity-related errors are detected thanks to tests that should run deterministically
many times all along the development. However, elasticity testing reproduction requires several features not
supported natively by the main cloud providers, such as Amazon EC2. We identify three requirements that we
claim to be indispensable to ensure elasticity testing reproducibility: to control the elasticity behavior, to select
specific resources to be unallocated, and coordinate events parallel to elasticity. In this paper, we propose an
approach fulfilling those requirements and making the elasticity testing reproducible. Experimental results
show that our approach successfully reproduces elasticity-related bugs that need the requirements we claim in
this paper.
1 INTRODUCTION
Elasticity is one of the main reasons that makes cloud
computing an emerging trend. It allows to vary (al-
locate or deallocate) system resources according to
demand (Herbst et al., 2013; Bersani et al., 2014).
Therefore, Cloud-Based Systems (CBS) must adapt
themselves to resource variations.
Due to their scalability nature, CBS adaptations
may be complex and error-prone (Herbst et al., 2013).
This is the case, for instance, of bug 2164 that affects
Apache ZooKeeper (Hunt et al., 2010), a coordination
service for large-scale systems. According to the bug
report, the election of a new leader never ends when
the leader leaves a system with three nodes. This
happens when the resource hosting the leader node
is deallocated.
Furthermore, some bug reproductions require
more than adaptation tasks. This is the case of Mon-
goDB NoSQL database bug 7974, where elasticity
and consequently, adaptation tasks, happen in paral-
lel with other events. In that case, even though adap-
tation tasks are still a requirement, they are not the
unique cause of the bug.
Reproducing bugs several times is necessary to di-
agnose and to correct them. That is, bugs reported in a
CBS bug tracking should be corrected by developers,
who need to reproduce them, at first. Moreover, dur-
ing the development, regression tests should be run
regularly (Engstrom et al., 2010), requiring the de-
sign of efficient and deterministic tests. Making CBS
testing reproducible is then an important concern.
To verify the existence of elasticity-related bugs
in the real-world, we analyze MongoDB’s bug track-
ing, a popular CBS. In the bug tracking we identify
a total of 43 bugs that involve elasticity. Since these
bugs occur in real-world, testers must manage elas-
ticity when writing and running their tests. However,
writing and executing tests considering the reproduc-
tion of elasticity-related bugs is complex. Besides the
typical difficulty of writing test scenarios and oracles,
it requires to deterministically manage the elasticity
and parallel events.
The management of elasticity involves driving
the system through a sequence of resource changes,
which is possible by varying the workload accord-
ingly (Albonico et al., 2016). In addition, tester
should also manage parameters that cannot be na-
tively controlled. For instance, resource changes are
managed by the cloud provider according to its own
policy. This prevents the tester to choose which re-
source must be deallocated, a requirement for 19 of
the 43 MongoDB’s elasticity-related bugs. The coor-
dination of events in parallel to elasticity (17/43 bugs)
is also an important parameter, which among others
needs a precise monitoring of resources.
Albonico, M., Mottu, J-M., Sunyé, G. and Alvares, F.
Making Cloud-based Systems Elasticity Testing Reproducible.
DOI: 10.5220/0006308905230530
In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), pages 495-502
ISBN: 978-989-758-243-1
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
495
In this paper, we present an approach for elasticity
testing that allows the tester to reproduce tests con-
cerned with elasticity-related bugs. We control the
elastic behavior by sending satisfactory workload to
CBS that drives it through a sequence of resource al-
locations and deallocations. Our approach also pro-
vides two original contributions: the deallocation of
specific resources, and the coordination of events in
parallel with elasticity. The two original contribu-
tions are required to reproduce 30 of the 43 elasticity-
related bugs of MongoDB, i. e., ≈70 %. In the paper,
we also present a prototype for the approach.
To support our claims and to validate our ap-
proach, we select 1 representative bug, and conducted
a set of experiments on Amazon EC2. The selected
bug requires our approach to satisfy all the require-
ments we identified. Experiment results show that
our approach reproduces real-world elasticity-related
bugs fulfilling all the requirements.
The remainder of this paper is organized as fol-
lows. In the next section, we remind the major as-
pects of cloud computing elasticity. Section 3 details
the requirements we claim be necessary for elasticity
testing. Section 4 introduces the testing approach we
propose. The experiment and its results are described
in Section 5. Section 6 discusses threats to validity.
Finally, Section 7 concludes.
2 CLOUD COMPUTING
ELASTICITY
This section provides the definitions of the main con-
cepts related to Cloud Computing Elasticity that are
required for the good understanding of our approach.
2.1 Typical Elastic Behavior
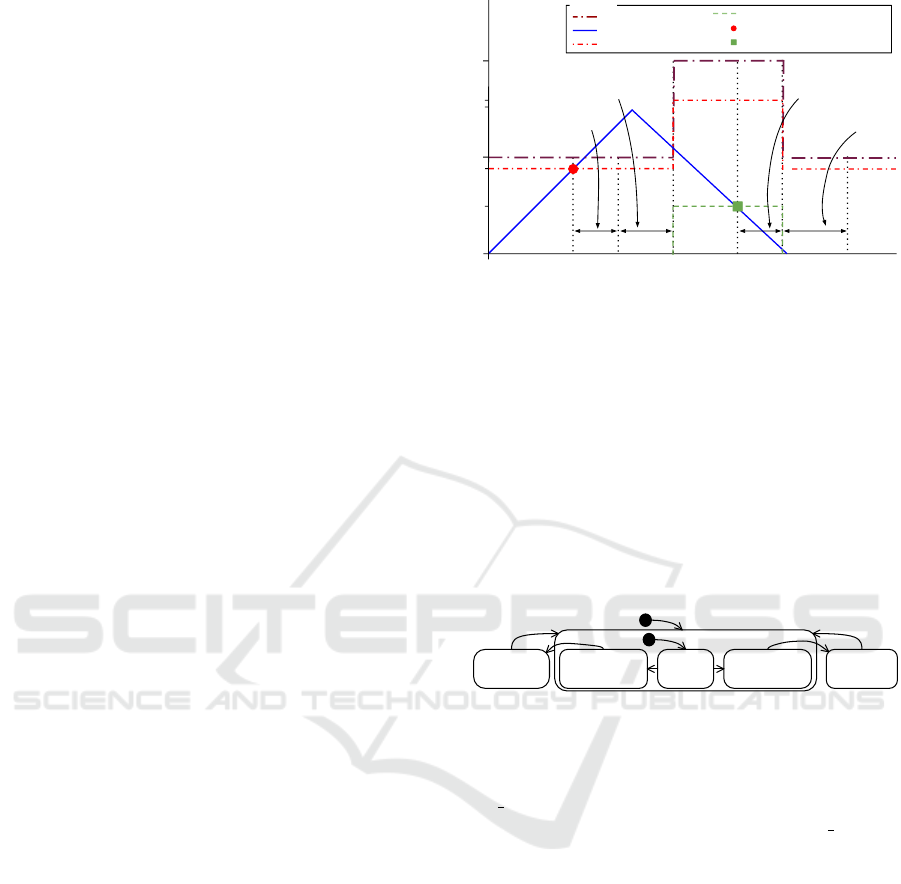
Figure 1 presents the typical behavior of elastic cloud
computing applications (Albonico et al., 2016). In
this figure, the resource demand (continuous line)
varies over time, increasing from 0 to 1.5 then de-
creasing to 0. A resource demand of 1.5 means that
the application demands 50 % more resources than the
current allocated ones.
When the resource demand exceeds the scale-out
threshold and remains higher during the scale-out re-
action time, the cloud elasticity controller assigns a
new resource. The new resource becomes available
after a scale-out time, the time the cloud infrastruc-
ture spends to allocate it. Once the resource is avail-
able, the threshold values are updated accordingly. It
is similar considering the scale-in, respectively. Ex-
cept that, as soon as the scale-in begins, the threshold
1.5
Resource Allocation
Resource Demand
Scale-out Threshold
Scale-in Threshold
Scale-out Threshold Breaching
Scale-in Threshold Breaching
Time (s)
Resource
(Processors)
2
1
0.4
0.8
1.6
scale-out reaction time
scale-out time
scale-in reaction time
scale-in time
Legend
Figure 1: Typical Elastic Behavior.
values are updated and the resource is no longer avail-
able. Nonetheless, the infrastructure needs a scale-in
time to release the resource.
2.2 Elasticity States
When an application is deployed on a cloud infras-
tructure, workload fluctuations lead to resource vari-
ations (elasticity). These variations drive the applica-
tion to new, elasticity-related, states. Figure 2 depicts
the runtime lifecycle of an application running on a
cloud infrastructure.
ready (ry)
scaling
-out (so)
steady
(ry_s)
si reaction
(ry_sir)
scaling
-in (si)
so reaction
(ry_sor)
Figure 2: Elasticity States.
At the beginning the application is at the ready
state (ry), when the resource configuration is steady
(ry s substate). Then, if the application is exposed
for a certain time (scale-out reaction time, ry sor sub-
state) to a pressure that breaches the scale-out thresh-
old, the cloud elasticity controller starts adding a new
resource. At this point, the application moves to the
scaling-out state (so) and remains in this state while
the resource is added. After a scaling-out, the appli-
cation returns to the ready state. It is similar with the
scaling-in state (si), respectively.
2.3 Elasticity Control
We can categorize elasticity control approaches in
two groups: (i) direct resource management, and (ii)
generation of adequate workload.
The first and simplest one (i) interacts directly
with the cloud infrastructure, asking for resource al-
location and deallocation. The second one (ii) con-
sists in generating adequate workload variations that
drive CBS throughout elasticity states, as previously
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
496
explained in Section 1. It is more complex since re-
quires a preliminary step for profiling the CBS re-
source usage, and calculating the workload variations
that trigger the elasticity states.
3 REQUIREMENTS FOR
ELASTICITY TESTING
REPRODUCTION
In this paper, we consider three requirements for re-
producing elasticity testing: elasticity control, selec-
tive elasticity, and events scheduling.
Elasticity Control is the ability to reproduce a spe-
cific elastic behavior. Elasticity-related bugs may oc-
cur after a specific sequence of resource allocations
and deallocations. Logically, all the 43 elasticity-
related bugs of MongoDB should satisfy this require-
ment.
Analyzing elasticity-related bugs, we identify two
other requirements: selective elasticity, and event
scheduling. Those requirements are necessary to re-
produce 30 of the 43 selected bugs.
Selective Elasticity is the necessity to specify pre-
cisely which resource must be deallocated. The repro-
duction of some elasticity-related bugs requires a de-
terministic management of elasticity changes. For in-
stance, deallocating a resource associated to the mas-
ter component of a cloud-based system. From the se-
lected bugs, 19 require selective elasticity.
Event Scheduling is the necessity to synchronize
elasticity changes with parallel events. We consider
as an event any interaction or stimulus to CBS, such
as forcing a data increment or to simulate infrastruc-
ture failures. The reproduction of 17 of MongoDB
elasticity-related bugs requires event scheduling.
Table 1 shows the number of bugs that should
meet those requirements in order to be reproducible.
As already said, all the bugs require elasticity con-
trol.A total of 30 bugs (70 %) should meet require-
ments besides elasticity, where 6 bugs need all the
requirements. Finally, 13 bugs only need elasticity
control (30 %) .
Table 1: Requirements for Bug Reproductions.
Elasticity
Control
Selective
Elasticity
Event
Scheduling All
Only
Elasticity
Control
Quantity 43 19 17 6 13
4 ELASTICITY TESTING
APPROACH
In this section, we present the overall architecture of
our approach as well as the aspects on the prototype
implementation.
4.1 Architecture Overview
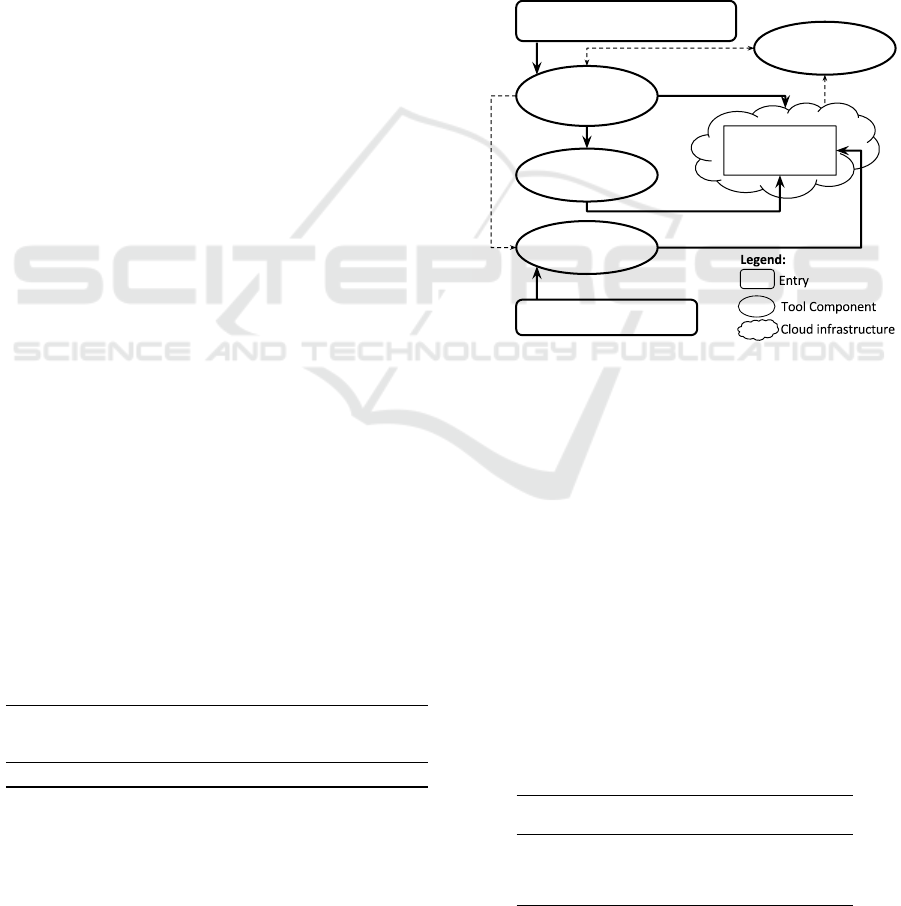
Figure 3 depicts the overall architecture of our ap-
proach. The architecture has four main components:
Elasticity Controller Mock (ECM), Workload Gener-
ator (WG), Event Scheduler (ES), and Cloud Monitor
(CM).
Elasticity
Controller
Mock
Event
Scheduler
E = {ec1=(s
1
,W
1
),ec
2
, …, ec
n
}
SER = {(ec
i
, ser
i
), …}
Events Schedule
Workload
Generator
W
j
Cloud
System
Workload
Current Elasticity State
Event Execution
Resource Variation
Cloud
Monitor
Figure 3: Overall Architecture.
The ECM simulates the behavior of the cloud
provider elasticity controller, allocating and deal-
locating determined resources, according to testing
needs. It also asks the WG to generate the workload
accordingly, reproducing a realistic scenario. The
role of the ES is to schedule and execute a sequence
of events in parallel with the other components. Fi-
nally, the CM monitors the cloud system, gathering
information that helps orchestrating the behavior of
the three other components, ensuring the sequence
of elasticity states, and their synchronization with the
events.
Table 2 summarizes the requirements that each
component helps in ensuring, as we detail in this sec-
tion.
Table 2: Requirements Ensured by the Architecture’s Com-
ponents.
COMPONENT
Elasticity
Control
Selective
Elasticity
Event
Scheduling
ECM YES YES YES
WG YES NO NO
ES NO NO YES
CM YES YES NO
Making Cloud-based Systems Elasticity Testing Reproducible
497

4.1.1 Elasticity Controller Mock
The ECM is designed to reproduce the elastic behav-
ior. By default, ECM requires as input a sequence of
elasticity changes, denoted by E = {ec
1
, ec
2
, ..., ec
n
},
where each ec is a pair that corresponds to an elas-
ticity change. Elasticity change pairs are composed
of a required elasticity state (s
i
) and a workload (W
i
),
ec
i
=
h
s
i
, W
i
i
where 1 ≤ i ≤ n. A workload is charac-
terized by an intensity (i. e., amount of operations per
second), and a workload type (i. e., set of transactions
sent to the cloud system).
ECM reads elasticity change pairs sequentially.
For each pair, ECM requests resource changes to meet
elasticity state s
i
and requests the Workload Genera-
tor to apply the workload W
i
. Indeed, we have to send
the corresponding workload to prevent cloud infras-
tructure to provoke unexpected resource variations.
In particular, it could deallocate a resource that ECM
just allocated, because the workload has remained low
and under the scale-in threshold.
Instead of waiting for the cloud computing infras-
tructures for elasticity changes, it directly requests
to change the resource allocation (elasticity control).
Based on both, required elasticity state and workload
(elasticity change pair), ECM anticipates the resource
changes. To be sure CBS enters the expected elas-
ticity state, ECM queries the Cloud Monitor, which
periodically monitors the cloud infrastructure.
The ECM may also lead to a precise resource
deallocation (selective elasticity). Typically, elastic-
ity changes are transparent to the tester, managed by
the cloud provider. To set up the selective elastic-
ity, ECM requires a secondary input, i. e., Selective
Elasticity Requests (SER). SER is denoted by SER =
{(ec
1
, ser
1
), ..., (ec
n
, ser
n
)}, where ec
i
∈ E, and ser
i
refers to a selective elasticity request. A selective
elasticity request is a reference to an algorithm (freely
written by tester) that gets a resource’s ID. When ec
i
is performed by ECM, the algorithm referred by ser
i
is executed, and the resource with the returned ID is
deallocated by ECM.
ECM helps in ensuring all of elasticity testing re-
quirements. As earlier explained in this section, it de-
terministically requests resource variations (elasticity
control and selective elasticity), and helps on ensur-
ing the event scheduling providing information of the
current elasticity state to the Event Scheduler.
4.1.2 Workload Generator
The Workload Generator is responsible for generat-
ing the workload (W ). We base it on Albonico et
al. work (Albonico et al., 2016), which takes into
account a threshold-based elasticity (see Figure 1),
where resource change demand occurs when a thresh-
old is breached for a while (reaction time). Therefore,
a workload should result in either threshold breached
(for scaling states) or not breached (for ready state),
during the necessary time. To ensure this, the Work-
load Generator keeps the workload constant, either
breaching a threshold or not, until a new request ar-
rives.
Considering a scale-out threshold is set as 60% of
CPU usage, the workload should result in a CPU us-
age higher than 60% to request a scale-out. In that
case, if 1 operation A hypothetically uses 1% of CPU,
it would be necessary at least 61 operations A to re-
quest the scale-out. On the other hand, less than 61
operations would not breach the scale-out threshold,
keeping the resource steady.
The Workload Generator contributes with the
Elasticity Controller Mock to the elasticity control re-
quirement.
4.1.3 Event Scheduler
The Event Scheduler input is a map associating sets of
events to elasticity changes (ec
i
), i. e., the set of events
that should be sent to the cloud system when a given
elasticity change is managed by the ECM. Table 3 ab-
stracts an input where four events are associated to
two elasticity changes.
Table 3: Events Schedule.
Elasticity Change Event ID Execution Order Wait Time
ec
1
e1 1 0 s
e2 2 10 s
e3 2 0 s
ec
2
e2 1 0 s
e4 2 0 s
Periodically, the Event Scheduler polls the ECM
for the current elasticity change, executing the events
associated to it. For instance, when the ECM manages
the elasticity change ec
1
, it executes the events e
1
, e
2
,
and e
3
. Events have execution orders, which define
priorities among events associated to the same state:
event e
1
is executed before events e
2
and e
3
. Events
with the same execution order are executed in paral-
lel (e. g., e
2
and e
3
). Events are also associated to a
wait time, used to delay the beginning of an event. In
Table 3, event e
2
has a wait time of 10 s (starting 10 s
after e
3
, but nonetheless executed in parallel). This
delay may be useful, for instance, to add a server to
the server list a few seconds after the ready state be-
gins, waiting for data synchronization to be finished.
The Event Scheduler ensures the event scheduling
requirement.
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
498

4.1.4 Cloud Monitor
Cloud Monitor helps ECM to ensure elasticity control
and selective elasticity. It periodically requests cur-
rent elasticity state and stores it in order to respond
to the ECM queries, necessary for elasticity control.
It also executes the selective elasticity algorithm of
SER, responding to ECM with the ID of the found
resources.
4.2 Prototype Implementation
Each component of the testing approach architecture
is implemented in Java and communicate with each
other through Java RMI. Currently, we only support
Amazon EC2 interactions, though one could adapt
our prototype to interact with other cloud providers.
4.2.1 Elasticity Controller Mock
The elasticity changes are described in a property file.
The entries are set as
h
key, value
i
pairs, as presented
in Listing 1. The key corresponds to the elasticity
change name, while the value corresponds to the elas-
ticity change pair. The first part of the value is the
elasticity state, and the second part is the workload,
divided into intensity and type.
Listing 1: Example of Elasticity Controller Mock Input File
(Elasticity Changes).
ec1=ready, (1000,write)
ec2=scaling−out, (2000,read/write)
...
ec4=scaling−in, (1500,read)
As previously explained, for each entry, the ECM
sends the workload parameters to the Workload Gen-
erator and deterministically requests the specified
resource change. Resource changes are requested
through the cloud provider API, which enables re-
source allocation and deallocation, general infrastruc-
ture settings, and monitoring tasks. Before perform-
ing an elasticity change, the ECM asks the Cloud
Monitor whether the previous elasticity state was
reached. Cloud Monitor uses the Selenium
1
auto-
mated browser to gather pertinent information from
cloud provider’s dashboard Web page.
We use Java annotations to set up selective elastic-
ity requests (SER), as illustrated in Listing 2. A Java
method implements the code that identifies a specific
resource and returns its identifier as a String type. It
is annotated with metadata that specifies its name and
associated elasticity change.
1
http://www.seleniumhq.org/
Listing 2: Selective Elasticity Input File.
@Selection{name=”ser1”, elasticity change=”ec4”}
public String select1() {
... //code to find a resource ID
return resourceID; }
4.2.2 Workload Generator
The WG generates the workload according to the pa-
rameters received from the ECM (i. e., workload type
and intensity), whereas the workload is cyclically gen-
erated until new parameters arrive. It uses existing
benchmark tools, setting the workload parameters in
the command line.
For instance, YCSB benchmark tool allows three
parameters related to the workload: the preset work-
load profile, the number of operations, and the num-
ber of threads. The preset workload profile refers to
the workload type, while the multiplication of the two
last parameters results in the workload intensity.
4.2.3 Event Scheduler
Event schedule is set in a Java file, where each event
is an annotated method, such as the example illus-
trated in Listing 3. Java methods are annotated with
the event identifier, the related elasticity change, the
order, and the waiting time. EC periodically polls the
ECM to obtain the current elasticity change. Then, it
uses Java Reflection to execute the Java methods re-
lated to it.
Listing 3: Example of Event Scheduler Input File.
@Event{id=”e1”,elasticity change=”ec1”,
order=”1”, wait=”0”}
public void event1() { ... }
4.3 Prototype Execution
Before executing our approach’s prototype, testers
must deploy the CBS, which is done using an exist-
ing approach based on a Domain Specific Language
(DSL) by Thiery et al. (Thiery et al., 2014). The DSL
enables us to abstract the deployment complexities in-
herent to CBS. Information in deployment file, such
as cloud provider’s credentials and Virtual Machine’s
configuration, are then used by the components of our
prototype. However, since the deployment of CBS is
not a contribution of our approach, we do not further
explain it in this paper.
To execute our approach’s prototype, testers write
the input files: E, SER, and ES files. These files as
well as the deployment file are passed to the prototype
as command line parameters. Then, all the execution
is automatically orchestrated.
Making Cloud-based Systems Elasticity Testing Reproducible
499

5 EXPERIMENTS
This section presents the experiment where we at-
tempt to reproduce the MongoDB bug 7974. We be-
lieve that the bug is representative, since it needs all
the requirements we claim in this paper in order to
be identified. The experiments consists in attempt-
ing to reproduce the bugs in two ways: using our ap-
proach, and relying on the cloud computing infras-
tructure. Then, we compare both approaches to verify
whether the requirements that we identify in this pa-
per are met.
5.1 Experimental Environment
5.1.1 Case Study
MongoDB
2
is a NoSQL document database. Mon-
goDB has three different components: the configu-
ration server, MongoS and MongoD. The configura-
tion server stores metadata and configuration settings.
While MongoS instances are query routers, which en-
sure load balance, MongoD instances store and pro-
cess data.
To generate the workload for the experiment with
MongoDB, we use the Yahoo Cloud Serving Bench-
mark (YCSB) (Cooper et al., 2010).
5.1.2 Cloud Computing Infrastructure
All the experiments are conducted on the commer-
cial cloud provider Amazon Elastic Cloud Compute
(EC2), where we set scale-out and scale-in thresh-
olds as 60 % and 20 % of CPU usage, respectively.
MongoS instance is deployed on a large machine
(m3.large), while the other instances are deployed on
medium machines (m3.medium).
5.1.3 Requirements for Bug Reproduction
This bug affects the MongoDB versions 2.2.0 and
2.2.2, when a secondary component of a MongoDB
replica set
3
is deallocated. Indeed, in a MongoDB
replica set, one of the components is elected as pri-
mary member, which works as a coordinator, while
the others remain as secondary members.
To reproduce this bug, we must follow a specific
elastic behavior: initialization of a replica set with
three members, deallocation of a secondary member,
and allocation of a new secondary member. There-
fore, the second step of the elastic behavior requires
the deallocation of a precise resource, one of the
2
https://www.mongodb.org/
3
https://docs.mongodb.com/replica-set
secondary members. The bug reproduction also re-
quires two events synchronized to elasticity changes.
Right after the secondary member deallocation, we
must create a unique index, and after the last step of
the elastic behavior, we must add a document in the
replica set.
In conclusion, the reproduction of this bug needs
to meet all the requirements that we consider in this
paper: elasticity control, selective elasticity, and event
scheduling.
5.2 Bug Reproduction
In this section, we describe the use of our approach to
reproduce the selected bug, and compare the results to
reproduction attempts without our approach. We do
not explain in details the setup of reproductions with-
out our approach but we assume one can manage the
control elasticity and meet this requirement. Indeed,
elasticity is a native feature of cloud computing in-
frastructures, and we just drive CBS through required
elastic behavior using Albonico et al. approach (Al-
bonico et al., 2016).
For the reproduction of MongoDB bug 7974 using
our approach, we first manually create the MongoDB
replica set, composed by three nodes. Then, we set up
the following sequence of elasticity changes, which
should drive MongoDB through the required elastic
behavior:
E =
h
ry
1
,
h
4500, r
ii
,
h
si
1
,
h
1500, r
ii
,
h
ry
2
,
h
3000, r
ii
,
h
so
1
,
h
4500, r
ii
,
h
ry
3
,
h
4500, r
ii
Since we must deallocate a secondary member of
MongoDB replica set at elasticity change ec
2
, it is as-
sociated to a selective elasticity request (SER). The
SER queries MongoDB replica set’s members, using
MongoDB shell method db.isMaster, until finding a
member that is secondary.
In parallel to the elasticity changes, we set up two
events, e1 and e2, which respectively create a unique
index, and insert a new document in the replica set.
The e1 is associated to elasticity change ec
3
, a ready
state that follows the scaling-in state where a sec-
ondary member is deallocated. The e2 is associated to
elasticity change ec
5
, the last ready state. Both events
are scheduled without waiting time.
Table 4: MongoDB-7974 Event Schedule.
Elasticity Change Event ID Execution Sequence Wait Time
ec
3
e1 1 0 s
ec
5
e2 1 0 s
We repeat the bug reproduction for three times.
After each execution, we look for the expression ”du-
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
500

plicate key error index” in the log files. If the expres-
sion is found, we consider the bug is reproduced.
Table 5 shows the result of all the three executions,
either using our approach or not. All the attempts us-
ing our approach reproduce the bug, while none of the
attempts without our approach do it.
Table 5: MongoDB-7974 Bug Reproduction Results.
Reproduction Reproduced Not Reproduced
With Our Approach 3 0
Without Our Approach 0 3
For the executions without our approach, we force
MongoDB to elect the intermediate node (in the or-
der of allocation) as primary member
4
, what can oc-
casionally occur in a real situation. In this scenario,
regardless of the scale-in settings, cloud computing
infrastructure always deallocate a secondary member,
since Amazon EC2 only allows to deallocated the old-
est or newest nodes. Despite in this experiment we
force a selective elasticity, in a real situation without
using our approach the resource selection would not
be deterministic. For instance, the newest or oldest
node could be elected as a primary member. Even
though cloud computing infrastructures reproduces
the required elastic behavior, this bug still needs the
event executions, which must be correctly synchro-
nized. This is the why the bug cannot be reproduced
without our approach.
6 RELATED WORK
Several research efforts are related to our approach
in terms of elasticity control, selective elasticity, and
events scheduling. The work of Gambi et al. (Gambi
et al., 2013b; Gambi et al., 2013a) addresses elastic-
ity testing. The authors predict elasticity state transi-
tion based on workload variations and test whether
cloud infrastructures react accordingly. However,
they do not focus on controlling elasticity and cannot
drive cloud application throughout different elasticity
states.
Banzai et al. (Banzai et al., 2010) propose D-
Cloud, a virtual machine environment specialized in
fault injection. Like our approach, D-Cloud is able
to control the test environment and allows testers to
specify test scenarios. Test scenarios are specified
in terms of fault injection and not on elasticity and
events (as in our approach).
Yin et al. (Yin et al., 2013) propose CTPV, a Cloud
Testing Platform Based on Virtualization. The core
of CTPV is the private virtualization resource pool.
4
https://docs.mongodb.com/force-primary
The resource pool mimics cloud infrastructures en-
vironments, which in part is similar to our elasticity
controller. CTPV differs from our approach in two
points: (i) it does not use real cloud infrastructures
and (ii) it uses an elasticity controller that does not
anticipate resource demand reaction.
Vasar et al. (Vasar et al., 2012) propose a frame-
work to monitor and test cloud computing web appli-
cations. Their framework replaces the cloud elasticity
controller, predicting the resource demand based on
past workload. Contrary to our approach, they do not
allow to control a specific sequence of elasticity states
or events.
Li et al. (Li et al., 2014) propose Reprolite, a tool
that reproduces cloud system bugs quickly. Similarly
to our approach, Reprolite allows for the execution of
parallel events on the cloud system and on the envi-
ronment, but does not focus on elasticity, one of our
main contributions.
7 CONCLUSION
In this paper, we proposed an approach to reproduce
elasticity testing in a deterministic manner. This ap-
proach is based on three main features: elasticity con-
trol, selective elasticity, and event scheduling. We use
our approach to successfully reproduce a bug of Mon-
goDB, a popular open source system. Indeed, the bug
cannot be deterministically reproduced with state-of-
the-art approaches.
As testing is not only about reproducing existing
bugs, but also diagnosing them, a likely evolution for
our approach is to generate different test scenarios
combining elasticity state transitions, workload vari-
ations, selective elasticity, and event scheduling. An-
other feature we plan to investigate as future work is
the speediness of test executions. Deterministic re-
source allocation can accelerate state transitions and
thus optimize the number of executions per period of
time, and/or reduce execution costs. This is particu-
larly important when testing cloud systems: to per-
form our three experiments, we used ≈45 machine-
hours in Amazon EC2 . Finally, we also plan to apply
model-driven engineering to create an unified high-
level language. In the current implementation, the
writing of test cases involves a mix of shell scripts,
Java classes, and configuration files, which are not
very suitable for users.
Making Cloud-based Systems Elasticity Testing Reproducible
501

REFERENCES
Albonico, M., Mottu, J.-M., and Suny
´
e, G. (2016). Con-
trolling the Elasticity of Web Applications on Cloud
Computing. In The 31st SAC 2016, Pisa, Italy.
ACM/SIGAPP.
Banzai, T., Koizumi, H., Kanbayashi, R., Imada, T.,
Hanawa, T., and Sato, M. (2010). D-Cloud: De-
sign of a Software Testing Environment for Reliable
Distributed Systems Using Cloud Computing Tech-
nology. In Proceedings of CCGRID’10, Washington,
USA.
Bersani, M. M., Bianculli, D., Dustdar, S., Gambi, A.,
Ghezzi, C., and Krsti
´
c, S. (2014). Towards the For-
malization of Properties of Cloud-based Elastic Sys-
tems. In Proceedings of PESOS 2014, New York, NY,
USA. ACM.
Cooper, B. F., Silberstein, A., Tam, E., Ramakrishnan, R.,
and Sears, R. (2010). Benchmarking Cloud Serving
Systems with YCSB. In Proceedings of SoCC’10,
New York, NY, USA. ACM.
Engstrom, E., Runeson, P., and Skoglund, M. (2010). A sys-
tematic review on regression test selection techniques.
Information and Software Technology, 52(1):14–30.
Gambi, A., Hummer, W., and Dustdar, S. (2013a). Auto-
mated testing of cloud-based elastic systems with AU-
ToCLES. In The proceedings of ASE’13, pages 714–
717. IEEE/ACM.
Gambi, A., Hummer, W., Truong, H.-L., and Dustdar, S.
(2013b). Testing Elastic Computing Systems. IEEE
Internet Computing, 17(6):76–82.
Herbst, N. R., Kounev, S., and Reussner, R. (2013). Elas-
ticity in Cloud Computing: What It Is, and What It Is
Not. ICAC.
Hunt, P., Konar, M., Junqueira, F. P., and Reed, B. (2010).
Zookeeper: Wait-free coordination for internet-scale
systems. In 2010 USENIX, Boston, MA, USA, 2010.
Li, K., Joshi, P., Gupta, A., and Ganai, M. K. (2014). Re-
proLite: A Lightweight Tool to Quickly Reproduce
Hard System Bugs. In Proceedings of SOCC’14, New
York, NY, USA.
Thiery, A., Cerqueus, T., Thorpe, C., Sunye, G., and Mur-
phy, J. (2014). A DSL for Deployment and Testing in
the Cloud. In Proc. of the IEEE ICSTW 2014, pages
376–382.
Vasar, M., Srirama, S. N., and Dumas, M. (2012). Frame-
work for Monitoring and Testing Web Application
Scalability on the Cloud. In Proc. of WICSA/ECSA
Companion, NY, USA.
Yin, L., Zeng, J., Liu, F., and Li, B. (2013). CTPV: A Cloud
Testing Platform Based on Virtualization. In The pro-
ceedings of SOSE’13.
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
502
