
Towards Modeling Monitoring of Smart Traffic Services
in a Large-scale Distributed System
Andreea Buga and Sorana Tania Nemes
,
Christian Doppler Laboratory for Client-Centric Cloud Computing, Johannes Kepler University,
Softwarepark 35, Hagenberg im M
¨
uhlkreis, Austria
Keywords:
Formal Modeling, Monitoring Service, Traffic Surveillance, Abstract State Machines.
Abstract:
Smart traffic solutions have become an important component of today’s cities, due to their aim of improving
the quality of the life of inhabitants and reducing the time spent in transportation. They are deployed across
large distributed systems and require a robust infrastructure. Their complex structure has been addressed
numerous times in practice, but rarely in a formal manner. We propose in this paper a formal modeling
approach for monitoring traffic systems and identifying possible failures of traffic sensors. Ensuring a safe
and robust deployment and execution of services implies having a clear view on the system status, which is
analysed by the monitoring framework. Our work focuses on availability aspects and makes use of the Abstract
State Machines modeling technique for specifying the solution. The framework is defined as an Abstract State
Machine agent and simulated in the ASMETA tool.
1 INTRODUCTION
Design and development of large-scale distributed
systems (LDSs) have been widely researched in the
last years due to the continuously growing storage and
processing demands in information systems’ area. We
address in our research project the aspects related to
monitoring nodes composing an LDS, with a practical
example of traffic monitoring services. We consider
monitoring to represent acquiring data about the sta-
tus of the nodes and other information offered by their
internal sensors.
The main goal of our work is to construct a formal
specification for the monitoring services, through us-
ing algorithms specific to distributed systems. Build-
ing a formal model evolves from natural-language
use cases and user stories and focuses on capturing
correctly functional and non-functional requirements.
We started from examining traffic systems and elabo-
rating the requirements, from which we built the for-
mal model.
In order to ensure that such systems deliver reli-
able and correct data to the users within an admissi-
ble period of time, we need to observe possible fail-
ures that might occur either at node level or during
communication. Interpreting information and assess-
ing the state of the system and also of the traffic is,
therefore, essential. The solution we propose is a
formal model for a monitoring framework deployed
along the LDS, with components replicated at node-
level. We use Abstract State Machine(ASM) method
for elaborating the specifications.
In comparison with previous proposals in the area
of monitoring smart traffic systems, we are now fo-
cusing on identifying failures of sensor nodes and as-
signing a robust diagnosis through collaboration of
several monitors.
The remainder of the paper is structured as fol-
lows. In section II we define the problem state-
ment and the motivation. Section III familiarizes the
reader with the necessary concepts and introduces the
ground model for the monitors, that we refine to a
pseudo-code-like/AsmetaL characterization, and sim-
ulate. Section IV explores previous meaningful work
carried out in the area, after which the paper is con-
cluded in Section V.
2 PROBLEM STATEMENT
LDSs have become a necessary paradigm for ensuring
the needed capabilities of nowadays services. Exist-
ing traffic surveillance solutions for smart cities ben-
efit of the evolution of distributed systems methods
capture a huge amount of data. Cloud computing is
a successful example of an LDS, which can offer a
Buga, A. and Nemes, S.
Towards Modeling Monitoring of Smart Traffic Services in a Large-scale Distributed System.
DOI: 10.5220/0006303704830490
In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), pages 455-462
ISBN: 978-989-758-243-1
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
455

robust infrastructure for traffic monitoring.
We aim to define a model for the smart surveil-
lance of traffic and identify possible issues that might
occur inside the system. We propose a framework
for monitoring the availability of the sensors, named
throughout the paper as nodes. We are interested also
in collecting the data offered by the nodes and inter-
pret it to understand the current situation of the traffic.
The monitoring framework ensures the availability of
the smart traffic services.
Monitoring is essential for understanding the per-
formance and evolution of the system. Tradition-
ally, it implies collecting data from running services
and assessing system performance in terms of service
availability, failures and anomalies. The heterogene-
ity and distribution of the sensors of a traffic system
over a wide geographical area has introduced a high
complexity for the monitoring solutions. The use of
a formal model covers the system analysis and design
phases of software development and leads to a pro-
posal which can be verified for its intended properties.
Model-driven engineering allows the stake-
holders to contribute at defining specific concepts
and entities. Natural language requirements, Unified
Modeling Language (UML) use cases, agile user sto-
ries are captured in models who are part of the soft-
ware development process. In the design phase func-
tional and non-functional properties are proposed and
validated. Spotting errors later in the development
process leads to higher costs for software projects.
The specification needs to encompass the behavior
of the monitors and abstract away from complex de-
tails. We favored the use of the ASM method in front
of other modeling techniques as, UML or Business
Process Model and Notation (BPMN), due to its abil-
ity to model multi-agent systems and to easily refine
specifications by replacing an action through multi-
ple parallel actions. In comparison with UML, ASMs
provide a more rigorous abstraction, that allows veri-
fication through model checking.
3 SYSTEM OVERVIEW
Traffic surveillance solutions consist of a large num-
ber of sensors deployed and communicating across
an LDS. The proposed monitoring framework is part
of an architecture model concerned with coordinating
numerous heterogeneous components. The architec-
ture of the whole system is expressed as an abstract
machine model as depicted in Fig. 1. The moni-
toring component is closely related to the execution
layer from where it extracts information and the adap-
tation layer, which uses information from it to bring
the system to a proper state. The diagnosis established
by the monitor focuses on three main aspects: failure
detection, assessment of availability and diagnosis of
network problems (failure of the communication pro-
cesses).
The ASM relies also on local storage for saving
important events and data. Monitoring information
is saved in terms of low- and high-level metrics in
the data storage, while meaningful operations (adap-
tation events, identification of problems) are stored in
the event database. A meta storage is used for sav-
ing additional information as for instance functions to
aggregate low-level metrics.
Robustness of the proposal is achieved by employ-
ing redundant monitors that can take over the tasks in
case of the misbehavior of running elements. There-
fore, each traffic sensor is assigned a set of monitors
to assess its status. The evaluation is carried out in a
collaborative way. When one of the monitors exhibits
a random behavior, it is stopped by the middleware
and replaced.
Moreover, the interaction of the monitoring and
adaptation layers enables the system to perform re-
configuration plans whenever any of the sensors faces
a problem. The monitoring framework submits the
collected data to the adapter whenever a problem oc-
curs. Afterwards, a plan to restore the system to a
normal working state is proposed and the monitors
perform a new evaluation that can indicate if the adap-
tation processes have been efficient.
3.1 Background on ASM
Our research focused on elaborating formal models
for monitoring the smart traffic solutions in terms of
ASMs, which allow capturing the requirements in ab-
stract specifications that can further be implemented.
The method offers system descriptions that can
be easily understood by the clients, as well as de-
velopers. ASMs have already been used in indus-
trial projects, in proofs of correctness of programming
languages (B
¨
orger and Stark, 2003) and in modeling
client-cloud interaction (Arcaini et al., 2016).
One of the main artefacts of ASMs is the ground
model, which reflects system’s requirements. It is ad-
vanced, through incremental refinements, to a written
specification, that can be simulated and validated be-
fore deployment.
Basic ASMs contain transition rules expressed as
if Condition then Updates, where the Condition is an
arbitrary predicate logic formula and the Updates are
defined as a set of assignments f(t
1
, ..., t
n
) := t. For
an update to be carried out successfully, consistency
must be ensured, meaning that for each location only
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
456

Middleware Component
Service
Interface
Dynamic
Deployment
Service
Monitor
Request
Handler
Abstract
Machine
Communication
Handler
Rollback
Engine
Restart
Engine
Optimizer
Abstract Machine
Adaptation
Layer
Monitoring &
Assessment Layer
Execution
Layer
Failure
Detection
Availability
Assessment
Network
Diagnosis
Event
Storage
Alternative
Meta Storage
Data Storage
Figure 1: Structure of the Middleware and its internal Abstract Machine.
one value has to be assigned (B
¨
orger and Stark, 2003).
LDSs usually rely on multiagents ASMs, which
better reflect their modular organization. Each agent
executes its own rules in parallel on its local states.
Each monitor component is represented in our pro-
gram as an ASM agent. The system we describe is
asynchronous, and hence it cannot ensure a global
state, but rather a stable local view of each monitor.
Constants in ASMs are expressed as static func-
tions, while variables are expressed as dynamic func-
tions. A classification of the dynamic functions de-
pends on the agent who is allowed to operate on them.
For instance, controlled functions can be modified
only by the agent and read by the environment, while
monitored ones can be written only by the environ-
ment and read internally by the agent. It is worth men-
tioning, that from the perspective of an agent, the en-
vironment is represented by the other agents. Shared
functions can be modified by both the agent and the
environment. A more exhaustive description of the
ASM method and functions is given by (B
¨
orger and
Stark, 2003).
We make use of ASMETA framework, a toolset
tailored for defining and simulating ASM models. We
are interested at this step in defining, simulating and
observing their behavior at runtime. (Gargantini et al.,
2008).
3.2 System Requirements
As mentioned in the previous subsection, ASMs me-
diate the translation of requirements to specifications.
At design phase, we had into consideration the fol-
lowing list of requirements:
• [R. 1. ]Each node of the system is assigned a set
of monitors;
• [R. 2. ]Monitoring is carried out at different levels
of the system and follows and hierarchical struc-
ture;
• [R. 3. ]After monitoring is started, availability of
a node is checked through heartbeat requests;
• [R. 4. ]The framework must detect problems of a
node based on the data collected;
• [R. 5. ]The monitor must disseminate the infor-
mation locally and gossip about detected prob-
lems;
• [R. 6. ]Data collected are processed and temporar-
ily stored;
• [R. 7. ]The monitoring processes run continu-
ously in the background of execution of normal
services;
• [R. 8. ]The trust in the assessment of a monitor
decreases with the number of incorrect diagnoses
it made;
• [R. 9. ]When a monitor is considered untrustwor-
thy, the middleware will stop the activity of the
monitor;
3.3 ASM Ground Model
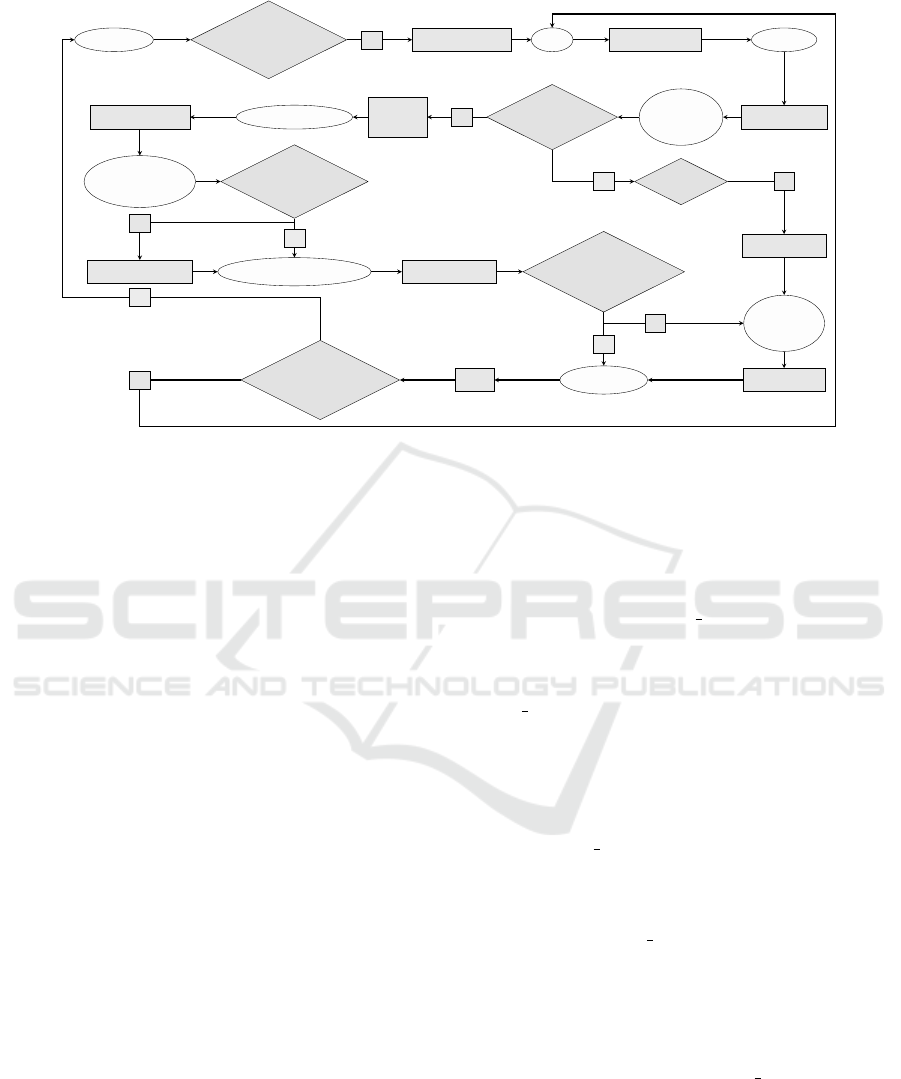
As illustrated in Fig. 2, we encompassed all the re-
quirements previously listed in the control state di-
agram of the local monitor assigned to a node. We
complete the diagram with sequences of the ASM
rules elaborated in AsmetaL language, which is part
of the ASMETA framework for modeling various
services and prototyping (Riccobene and Scandurra,
2014).
In equivalence with the control state diagram,
the monitoring agent can be in one of the following
states:
en um dom ai n St ate = { I NA C TI V E | ID LE | A CT I VE |
WA I T _RE S PON S E | C O LL E C T_ D A TA | R ET R I EV E _ INF O |
AS S I G N_ D I AGN O S IS | LO G _DA TA | R EP O R T_P R O BL E M };
Towards Modeling Monitoring of Smart Traffic Services in a Large-scale Distributed System
457
Inactive
Monitor deployed
Yes
Assign to node
Idle
Start monitor Active
Send request
Wait for
response
Reply arrived
Yes
No Timeout Yes
Stop request
Process
response
Collect dataGather metrics
Retrieve
information
Repository
available
Yes
No
Query database Assign diagnosis Interpret data
Problem discovered
Yes
No
Report
problem
Gossip issue
Log data
Log
Monitor
trustworthy
Yes
No
Figure 2: ASM ground model for the monitor.
In the initial phase of the execution, the monitor is
in INACTIVE state. It awaits for its deployment in the
system, which is carried out by the middleware and
modeled as a monitored boolean function:
mo n ito r ed m o n ito r D ep l o y ed : Mo n it o r - > Bo o le a n
After its deployment in the system, the monitor
has to be assigned to a node. This process is currently
randomly binding a monitor to a sensor. In order to
ensure fairness, we aim to refine this process so that a
new monitor is distributed to the node with the small-
est number of monitors. The monitors designated to a
node are stored in the nodeMonitors list.
ru le r _ as s i gn T o Nod e ( $mon in M o ni t or ) =
if ( a s si g ne d ( $m on )) t he n
sk ip
el se
ch oos e $n in No de wi th true do
par
as s ig n ed ( $ mo n ) := t ru e
no d e Mo n i to r s ($n ) := a ppe nd ( nod e Mon i tor s ( $n ) ,
$m on )
en dpa r
en di f
Once the monitor is appointed to a node, it reaches
the IDLE state, from where the monitoring process
starts and it moves to the ACTIVE state. Sending a re-
quest implies creating a Heartbeat instance and send-
ing it to the node to discover latency and availability.
ru le r _se n d Re q u es t ( $mon in M on i to r ) =
ex ten d He a rtb e at w it h $h do
seq
he a r tbe a t Sta t u s ( $h ) := S UBM I TT E D
he a rtb e at s ( $mon ) := a ppe nd ( h e art b ea t s ( $m on ) ,
$h )
en dse q
Subsequently to submitting the request, the mon-
itor advances to the WAIT RESPONSE state. The
guard Reply arrived verifies if a response to the
heartbeat is acknowledged. If the monitor records
a response, it inspects it and moves to the COL-
LECT DATA state. The measurements are stored in a
set of < key, value > pairs, where the key is the unique
string identifier of the metric and the value is filled by
the monitor. The pairs are stored in the local repos-
itory at every monitoring cycle. The monitor gath-
ers all the available data from the node and moves to
the RETRIEVE INFORMATION state. At this point it
checks if it can access the local repository and if so, it
queries the database. In case it is not possible to ob-
tain information from the local storage, the monitor
moves to the ASSIGN DIAGNOSIS state directly.
The rule for interpreting the data is in charge with
processing the collected metrics and evaluating the
current state of the sensor node. When a problem
is identified, as well as in the case the heartbeat re-
ply takes longer than an accepted maximum delay,
the monitor moves to the REPORT PROBLEM state.
From there gossip communication is triggered and the
other monitors assigned to the current node submit
their own assessment. The diagnosis set by the ma-
jority of the nodes is the one taken into consideration.
We left the gossip rule abstract for the moment, as
there are various gossip protocols that can be used by
different systems. After establishing a diagnosis by
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
458

consulting with the other counterparts, the decision is
locally logged and the confidence degree of the mon-
itor is calculated after the following formula:
con f Degree(mon) = con f Degree(mon)−
c(mon) · penalty ·
|diagnoses| − |similar diagnoses|
numberO f Diagnoses
(1)
where the initial confidence degree of a monitor is:
function confDegree($m in Monitor) = 100
and
c(mon) =
(
0, if the diagnosis was correct
1, otherwise.
As it can be noticed, the confidence degree is a strictly
monotonically decreasing function in order to prevent
the case the confidence degree is increased by false
positive diagnosis. A diagnosis is considered cor-
rect if it matches the decision adopted by the major-
ity of the monitors. In case of a false diagnosis, the
confidence degree of a monitor is influenced by the
marginality of its assessment. For instance, if the di-
agnosis is shared by more counterparts, then the con-
fidence degree decreases with a smaller value. The
value of the penalty constant depends on how critical
a mistaken diagnosis is for the system and is defined
at the initialization of the system. If the confidence
degree value of a monitor is above a set threshold, it
starts a new monitoring cycle. Otherwise, it will move
to the INACTIVE state and wait for the middleware to
take an action.
fu n ct i on is M oni t o rTr u s t wo r t h y ( $m on i n M on i to r ) =
if ( gt ( con f ( $mon ), m in C on f )) t he n
tr ue
el se
fa ls e
en di f
Monitors are also components of the LDS and they
can be affected by failures and unavailability prob-
lems just like any other node of the system. Using the
confidence measure for evaluating the correctness of
a monitor we aim to mitigate the failures of the mon-
itoring solution itself.
Monitoring processes produce a high volume of
data, which needs to be processed for assessing the
evaluation. In order to avoid data cluttering and load-
ing the local storage, we proposed a data degradation
approach. Hence, the information which is older than
a specific date are considered irrelevant and are re-
moved from the repository.
3.4 Relevant Monitoring Metrics
Basic monitoring data does not offer a complete view
over the system. Having a delayed response does not
give extra information about probable network con-
gestion or overloaded sensors. Unsuccessful data log-
ging does not reveal problems related to the storage,
and so on. Combining basic data into higher-level
metrics provides a better understanding of the state
of the node, helps in establishing a better diagnosis
and finding proper adaptation measures.
The monitoring framework detects abnormal run-
time situations of sensors of the smart traffic system.
The tasks executed by such nodes have to be taken
over by another suitable components. We describe a
composed metric characterizing the process transfer
effort (PTE), which is of interest in case the adaptation
component decides that a node needs to be replaced
with another candidate. The metric comprises infor-
mation about the candidate node (availability, perfor-
mance and reliability), which need to be defined in
their turn from other basic data as available storage,
memory consumption and network bandwidth. Due
to privacy issues and different security policies, it
needs to be established if a new node can take over
the data of the faulty component. If a task cannot be
moved due to legislation issues, the value of the PTE
for the new node is set to ∞.
if !canBeLegallyTransferred(i, t) then
pte(i, t) = ∞
end if
For a node i, among k eligible candidates for a task
t we propose the following metric:
pte(i,t) =
1
bdwidth(t)
·
per f (i)
max(per f (k))
·
reliab(i)
100
, (2)
where bdwith(t) refers to the bandwidth available
for submitting task t, perf(i) represents the perfor-
mance of the node i, max(perf(k)) is the maximum
value of performance from all the available k candi-
dates. Reliab(i) refers to the reliability of the node
candidate i. The PTE gives information about the best
node candidate to move a traffic surveillance task to.
It evaluates a node according to the performance perf
relatively to other nodes, its absolute reliability and
the absolute bandwidth of the communication estab-
lished for submitting the task. The lower the PTE, the
most suitable the competitor node.
Node work capacity describes an overview of the
percentage of available resources. This metric is im-
portant for understanding the behavior of the node
when sending new requests. High consumption of re-
sources leads to undesired delays which sometimes
might be interpreted as being caused by network com-
munication issues. Resources refer to storage, CPU
and memory of a sensor. A high usage value of any of
the resources leads to a significantly smaller capacity
Towards Modeling Monitoring of Smart Traffic Services in a Large-scale Distributed System
459

for taking new tasks. For a node i, the work capacity
is equal to the percentage of resources left available
after withdrawing the current efforts:
workCapacity(i) =
100
3
· (3 −
cpuUsage(i)
100
−
memoryUsage(i)
100
−
storageUsage(i)
100
) (3)
As mentioned before, the latency of a node i to
respond to a request r is introduced either by its
overloading or by network infrastructure problems.
Knowing that the bandwidth is small, reduces the sus-
picions that there might be problems with the node
and the other way around. For sensor networks, the
connection between nodes is susceptible to different
issues, reason for which it is important to include it in
the assessment of the status of the node.
delay(r, i) = (100−workCapacity(i))·
1
bdwidth(r)
(4)
We defined the metrics also inside the rule desig-
nated to interpret the data. It works on the assumption
that the structure of the measurement list is known.
We temporarily made use of simple comparisons for
evaluating the state of the system but we aim to ad-
vance this function so that it can make use of more
complex statistic analysis methods.
ru le r _ in t e rpr e t Da t a ( $mo n in Mo n it o r ) =
seq
wo r k Ca p a ci t y ( $m on ) := 10 0 .0 * ( it or (3) - se con d
( at ( dat a Col l e ct e d ( $m on ) , 1 n ) ) /1 00. 0 -
se con d ( at ( da ta C o ll e c ted ( $ mo n ) , 3n ) ) / 10 0 .0
- seco nd ( at ( dat a C ol l e ct e d ( $m on ) , 4 n ) )
/1 0 0. 0 ) / 3.0
de la y ( $m on ) := (1 0 0. 0 - w o rk C a pa c i ty ( $ mo n ) ) /
se con d ( at ( da ta C o ll e c ted ( $ mo n ) , 2n ) )
if (( de la y ( $m on ) > 2. 0) o r ( w ork C apa c ity ( $ mo n )
< 30. 0) or ( s e co nd ( at ( dat a C ol l e ct e d ( $m on ) ,
6n)) < 40 .0 ) ) t he n
par
di a gno s is ( $mon ) := " Crit i ca l "
pr o b l em D i s co v e r ed ( $ mo n ) := true
en dpa r
el se
di a gno s is ( $mon ) := " Nor m al f u nc t i on i n g "
en di f
as s e s se d D i ag n o s is ( $ mo n ) := ap pe n d (
as s e s se d D i ag n o s is ( $ mo n ) , d i ag n osi s ( $m on ))
en dse q
The initial set of data to be collected by the monitor
contains the following metrics: latency expressed in
milliseconds needed by a node to reply to a request,
CPU, memory and storage usage represented in the
percentage of used resource, bandwidth expressed in
Mb/s, the cost of a node to perform a task and its per-
formance expressed as a percentage of the actual effi-
ciency in report to the capabilities of a node. The list
of metrics is yet to be completed with other relevant
functions which provide insights on the status of the
traffic sensors and their execution.
3.5 Simulation of the Model
We verified through simulation if the monitor model
passes through the states as expressed in the control
state diagram and if monitors are able to identify pos-
sible problems of a sensor node. We used AsmetaS
1
tool to simulate the execution of the model. The sim-
ulation consisted in following a specific scenario for
execution. Different configurations trigger a differ-
ent workflow. For compactness, we took into con-
sideration a monitor and a smaller set of metrics for
comparison and analysis, and left aside the collabo-
rative diagnosis. The set of metrics and the values of
the measurement are initialized in the function data-
Collected. We present in Listing 1 an excerpt of the
simulation of our model and we can notice that af-
ter passing through the state of ASSIGN DIAGNOSIS
the monitor correctly evaluates the node as being in a
Critical execution mode. The evaluation is carried out
by analysing the rule for interpreting the data, which
specifies that in the case of a performance value be-
low 40.0, the monitor assesses that the node is in a
Critical state.
fu n ct i on da ta C o lle c t ed ( $ mo n in Mo n it o r ) =
sw itc h ( $ mo n )
ca se mo n1 : [( " La ten cy " , 5.0) , (" CPU Us ag e " ,
84 .0 ) , (" B an d wi d th " , 1 50 . 0) , ( " Memo ry U sa ge
", 50 .0 ) , (" St o ra g e U sag e " , 4 4. 0) , (" C os t " ,
4. 0) , (" P erf o rma n ce " , 2 0. 0) ]
en d swi t ch
4 RELATED WORK
LDSs, especially grids and clouds, are in the focus
of researchers due to their high computing capacities
and resources. Modeling properties of such systems
imposes, nonetheless, some restrictions as researchers
need to abstract away from several details that might
impede proper verification.
Modeling cloud systems has been proposed by the
MODA-Cloud project in order to obtain self-adaptive
multi-cloud applications. It relies on CloudML lan-
guage, an extension of UML, for modeling the run-
time processes and specifying the data, QoS mod-
els and monitoring operation rules (Bergmayr et al.,
1
http://asmeta.sourceforge.net/download/asmetas.html
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
460

Listing 1: Excerpt of simulating the monitor agent.
IN I TI A L S TA T E : Mo ni t or ={ mo n1 }
No de ={ n1 , n2 }
In ser t a bo o le a n co n st a nt for mo n i t or D e plo y e d ( mon1
): tru e
< Sta te 0 ( m o ni t or e d )>
mo n i tor D e plo y e d ( mon1 )= tru e
</ S ta te 0 ( m o nit o re d ) >
< Sta te 1 ( c o nt r oll e d ) >
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= IDL E
</ S ta te 1 ( c o n tr o lle d )>
< Sta te 2 ( c o nt r oll e d ) >
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= AC TI VE
</ S ta te 2 ( c o n tr o lle d )>
< Sta te 3 ( c o nt r oll e d ) >
He a rtb e at ={ Hea r tb e at !1}
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
he a r tbe a t Sta t u s ( He a rtb e at ! 1) = SUB M IT T ED
he a rtb e at s ( mon1 ) =[ He ar t be a t !1]
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= WA I T _R E S PO N S E
</ S ta te 3 ( c o n tr o lle d )>
In ser t a bo o le a n co n st a nt for re p l yA r r iv e d : tru e
< Sta te 3 ( m o ni t or e d )>
re p l yA r r iv e d = tr ue
</ S ta te 3 ( m o nit o re d ) >
< Sta te 4 ( c o nt r oll e d ) >
He a rtb e at ={ Hea r tb e at !1}
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
he a r tbe a t Sta t u s ( He a rtb e at ! 1) = SUC C ES S F UL
he a rtb e at s ( mon1 ) =[ He ar t be a t !1]
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= CO L LEC T _DA T A
</ S ta te 4 ( c o n tr o lle d )>
< Sta te 5 ( c o nt r oll e d ) >
He a rtb e at ={ Hea r tb e at !1}
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
he a r tbe a t Sta t u s ( He a rtb e at ! 1) = SUC C ES S F UL
he a rtb e at s ( mon1 ) =[ He ar t be a t !1]
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= RE T R IE V E _I N F O
</ S ta te 5 ( c o n tr o lle d )>
In ser t a bo o le a n co n st a nt for rep o s ito r y A va i l a bl e (
mo n1 ):
fa ls e
< Sta te 5 ( m o ni t or e d )>
rep o s ito r y Ava i l a bl e ( m on 1 ) = fal se
</ S ta te 5 ( m o nit o re d ) >
< Sta te 6 ( c o nt r oll e d ) >
He a rtb e at ={ Hea r tb e at !1}
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s ig n ed ( m on 1 ) = tru e
he a r tbe a t Sta t u s ( He a rtb e at ! 1) = SUC C ES S F UL
he a rtb e at s ( mon1 ) =[ He ar t be a t !1]
no d e Mo n i to r s (n2 ) =[ m on 1 ]
st at e ( mo n1 )= AS S I GN_ D I AGN O S IS
</ S ta te 6 ( c o n tr o lle d )>
< Sta te 7 ( c o nt r oll e d ) >
He a rtb e at ={ Hea r tb e at !1}
Mo n it o r ={ m on 1 }
No de ={ n1 , n2 }
as s e s se d D i ag n o s is ( m on 1 ) =[" C ri t ic a l "]
as s ig n ed ( m on 1 ) = tru e
de la y ( mo n1 ) = 0 .39 5 5 5 55 5 5 5 555 5 5 55
di a gno s is ( m on 1 ) = " Cr it i ca l "
he a r tbe a t Sta t u s ( He a rtb e at ! 1) = SUC C ES S F UL
he a rtb e at s ( mon1 ) =[ He ar t be a t !1]
no d e Mo n i to r s (n2 ) =[ m on 1 ]
ou t Me s s =" P r ob l em d i sco v er e d "
pr o b l em D i s co v e r ed ( m on 1 ) = tru e
st at e ( mo n1 )= RE P O RT _ P ROB L E M
wo r k Ca p a ci t y ( mo n1 ) = 4 0 .66 6 6 666 6 6 666 6 7
</ S ta te 7 ( c o n tr o lle d )>
... . . . . . ... . . . . ... . . . . . ... . . . . . ... . . . . . ... . . . . . ..
2015). The ASM method we used allows a more rig-
urous elaboration of specification in comparison with
UML.
Traffic control systems have been formally mod-
eled in terms of Petri Nets from the point of view of
safety (List and Cetin, 2004). We shift the attention
towards formally modeling failure detection inside a
traffic system and focus on availability of the traffic
sensors.
A solution for modeling monitoring smart traffic
solutions using smart agent and emphasizing on self-
* properties has been proposed by (Haesevoets et al.,
2009). The authors present the organization of the
system and formally express the roles of the agents
and their capabilities.
The necessity of modeling and validating criti-
cal systems has been reported also by (Gl
¨
asser et al.,
2008), which focuses on capturing the security of
aviation processes with the aid of ASMs and proba-
bilistic modeling techniques reported also by (Arcaini
et al., 2015), where authors describe a medical system
in a formal approach through the aid of AsmetaL.
Previous approaches of using ASMs in express-
ing grid services propose the description of job man-
agement and service execution in (A. Bianchi, 2011),
work that was further extended by (Bianchi et al.,
Towards Modeling Monitoring of Smart Traffic Services in a Large-scale Distributed System
461

2013). Specification of grids in terms of ASMs has
been proposed also by (Nemeth and Sunderam, 2002),
with a focus in underlining differences between grids
and normal distributed systems. Our work can be con-
sidered an extension of these projects with a focus on
monitoring components which are responsible of ser-
vice execution and detecting possible failures that can
occur at node level.
5 CONCLUSIONS
The use of formal models before starting the develop-
ment of a software system leads to more robust solu-
tions. Being able to design a model according to the
natural language specifications is very well supported
by the ASM technique through its ground models and
transition rules. We presented in the current paper
a formal approach for defining a monitoring frame-
work for a smart traffic system deployed in an LDS.
We started from the requirements and elaborated the
ground model and specific transition rules. One can
easily infer from the structure the complete workflow
of the system.
The work stays at the ground of future valida-
tion and verification of the specifications, which will
help the practitioners to construct robust and reliable
smart traffic solutions and their intrinsic monitoring
services. As a future work, we intend to further refine
the proposed model and investigate it through valida-
tion and model-checking until we obtain a prototype.
By these means, issues faced by such real-time sys-
tems, like complexity and failures, can be overcome.
REFERENCES
A. Bianchi, L. Manelli, S. P. (2011). A Distributed Ab-
stract State Machine for Grid Systems: A Prelimi-
nary Study. In P. Ivnyi, B. T., editor, Proceedings of
the Second International Conference on Parallel, Dis-
tributed, Grid and Cloud Computing for Engineering.
Civil-Comp Press.
Arcaini, P., Bonfanti, S., Gargantini, A., Mashkoor, A., and
Riccobene, E. (2015). Formal validation and verifi-
cation of a medical software critical component. In
2015 ACM/IEEE International Conference on Formal
Methods and Models for Codesign (MEMOCODE),
pages 80–89.
Arcaini, P., Holom, R.-M., and Riccobene, E. (2016). Asm-
based formal design of an adaptivity component for a
cloud system. Form. Asp. Comput., 28(4):567–595.
Bergmayr, A., Rossini, A., Ferry, N., Horn, G., Orue-
Echevarria, L., Solberg, A., and Wimmer, M. (2015).
The Evolution of CloudML and its Manifestations.
In Proceedings of the 3rd International Workshop
on Model-Driven Engineering on and for the Cloud
(CloudMDE), pages 1–6, Ottawa, Canada.
Bianchi, A., Manelli, L., and Pizzutilo, S. (2013). An ASM-
based Model for Grid Job Management. Informatica
(Slovenia), 37(3):295–306.
B
¨
orger, E. and Stark, R. F. (2003). Abstract State Machines:
A Method for High-Level System Design and Analysis.
Springer-Verlag New York, Inc., Secaucus, NJ, USA.
Gargantini, A., Riccobene, E., and Scandurra, P. (2008). A
metamodel-based language and a simulation engine
for Abstract State Machines. j-jucs, 14(12):1949–
1983.
Gl
¨
asser, U., Rastkar, S., and Vajihollahi, M. (2008). Mod-
eling and Validation of Aviation Security, pages 337–
355. Springer Berlin Heidelberg, Berlin, Heidelberg.
Haesevoets, R., Weyns, D., Holvoet, T., and Joosen,
W. (2009). A formal model for self-adaptive and
self-healing organizations. In 2009 ICSE Work-
shop on Software Engineering for Adaptive and Self-
Managing Systems, pages 116–125.
List, G. F. and Cetin, M. (2004). Modeling traffic signal
control using Petri nets. IEEE Transactions on Intel-
ligent Transportation Systems, 5(3):177–187.
Nemeth, Z. N. and Sunderam, V. (2002). A formal frame-
work for defining grid systems. In Cluster Comput-
ing and the Grid, 2002. 2nd IEEE/ACM International
Symposium on, pages 202–202.
Riccobene, E. and Scandurra, P. (2014). A formal frame-
work for service modeling and prototyping. Formal
Aspects of Computing, 26(6):1077–1113.
CLOSER 2017 - 7th International Conference on Cloud Computing and Services Science
462
