
Deep Learning with Sparse Prior
Application to Text Detection in the Wild
Adleni Mallek
1
, Fadoua Drira
1
, Rim Walha
1
, Adel M. Alimi
1
and Frank LeBourgeois
2
1
ReGIM-lab, University of Sfax, ENIS, BP 1173, 3038, Sfax, Tunisia
2
LIRIS, University of Lyon, INSA-Lyon, CNRS, UMR5205, F-69621, Lyon, France
{adleni.mallek.tn, fadoua.drira, rim.walha, adel.alimi}@ieee.org, franck.lebourgeois@insa-lyon.fr
Keywords:
PCANet, Deep Learning, Sparse Coding, Text Detection.
Abstract:
Text detection in the wild remains a very challenging task in computer vision. According to the state-of-the-
art, no text detector system, robust whatever the circumstances, exists up to date. For instance, the complexity
and the diversity of degradations in natural scenes make traditional text detection methods very limited and
inefficient. Recent studies reveal the performance of texture-based approaches especially including deep mod-
els. Indeed, the main strengthens of these models is the availability of a learning framework coupling feature
extraction and classifier. Therefore, this study focuses on developing a new texture-based approach for text
detection that takes advantage of deep learning models. In particular, we investigate sparse prior in the struc-
ture of PCANet; the convolution neural network known for its simplicity and rapidity and based on a cascaded
principal component analysis (PCA). The added-value of the sparse coding is the representation of each fea-
ture map via coupled dictionaries to migrate from one level-resolution to an adequate lower-resolution. The
specificity of the dictionary is the use of oriented patterns well-suited for textual pattern description. The
experimental study performed on the standard benchmark, ICDAR 2003, proves that the proposed method
achieves very promising results.
1 INTRODUCTION
Text in an image is a vital source of information
very useful mainly for understanding the content of
the image. Nowadays, a lot of studies are focusing
on text detection regarding various applications like
content-based image retrieval and document image
analysis. However, even though the tremendous work
done across this subject, text detection in the wild
remains a very challenging task in computer vision.
The study of the state-of-the-art ascertains that no text
detector system, robust whatever the circumstances,
exists up to date. The major difficulty is raised by
the widely use of digital cameras because the image
acquisition process in this case could introduce new
added distortions in terms of blur, noise, non-uniform
illumination and perspective degradations while tak-
ing into consideration the diversity of characters’ lay-
out (shape, size, position and color). Moreover, the
presence of background objects in natural scene im-
ages could be at the origin of many false-positive de-
tections. As illustration, we give in Figure 1 some
images extracted from the well-known ICDAR 2003
database. These images clearly illustrate the above
depicted challenges in text image detection in the
wild.
Figure 1: Extracts form the ICDAR 2003 dataset.
Faced with these different constraints, traditional
methods for text detection process have proven to be
insufficient. Thus, training a text detector, although it
is not a trivial task, represents the possible issue for a
good text detection. The state-of-the-art distinguishes
between two categories of text detection methods ac-
cording to the data taken into account (Ye and Doer-
mann, 2015): (1) connected component analysis and
(2) sliding window classification.
Mallek A., Drira F., Walha R., Alimi A. and LeBourgeois F.
Deep Learning with Sparse Prior - Application to Text Detection in the Wild.
DOI: 10.5220/0006129102430250
In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2017), pages 243-250
ISBN: 978-989-758-226-4
Copyright
c
2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
243

The first category includes bottom-up methods,
that proceed in general by a pre-processing step for
noise removal, then a segmentation step for charac-
ter regions extraction followed by a grouping step
for word detection. Stroke Width Transform (SWT)
(Epshtein et al., 2010; Neumann and Matas, 2013)
and Maximally Stable Extremal Regions (MSER)
(Neumann and Matas, 2012) are two representative
methods of this category for scene text detection. The
work of Gao et al. (Gao et al., 2014) introduces a
bottom-up visual saliency model utilizing color fea-
ture. The work of Yi et al. (Yi and Tian, 2011) uses
color features for the extraction of connected compo-
nents. Even though the simple implementation behind
this overall detection process and which explains its
popularity, it remains very sensitive to the size and
shape of characters, background noise and degraded
text patterns.
An alternative solution is sliding window based
methods characterized by the recourse to image
patches with different sizes on the image pyramid
and the application of text/non-text classifiers (Wang
et al., 2011; Lee et al., 2011). Thus, this solution in-
cludes top-down methods. In particular, these meth-
ods exploit predominant features (e.g. texture, edge
map...) of text regions characteristics to extract them
from the other object of the background. The classifi-
cation of text/non-text region could use either heuris-
tic methods (Garcia and Apostolidis, 2000; Zhong
et al., 1995) or machine learning methods (Lien-
hart and Wernicke, 2002). The efficiency of heuris-
tic methods relies on an adequate choice of features
and heuristic filters. In order to improve the ro-
bustness, machine learning methods investigate rel-
evant features over a given neighborhood accompa-
nied with robust classifier that is trained using ma-
chine learning techniques to distinguish textual re-
gions. For example, Anthimopoulos et al. (Anthi-
mopoulos et al., 2013) create hand-crafted features
specifically designed for text detection. These are
dynamically-normalized edge features which gener-
ate local binary patterns within the sliding window
image patch. Wang et al. (Wang et al., 2011) use
a classifier trained on the histogram of oriented gra-
dients features in a sliding window scenario to find
characters in an image, grouping them using a picto-
rial structures model for a fixed lexicon.
The main limitation of these methods is notice-
able for objects having similar structural texture to
texts. Moreover it remains not efficient in terms of
computation cost. Therefore, the focus of text detec-
tion system using machine learning tools is twofold:
(1) the choice of a robust learning tool with a low-
computational cost to perform an efficient classifica-
tion and (2) the choice of an adequate feature space
for a better description of the textual patterns.
Deep learning techniques have become recently
a popular trend in machine learning applications.
Their main strengthens is the availability of a learn-
ing framework coupling feature extraction and classi-
fication. Due to their efficiency, we focus on devel-
oping a new texture-based approach for text detection
which takes advantage of these techniques. In partic-
ular, we propose to deal with the structure of the sim-
ple convolution neural network PCANet with sparse
prior. The choice of this architecture is explained
by the improvement of some shortcomings of classic
convolution neural network including the high train-
ing computational cost time, special tuning parame-
ters and technical problems. Furthermore, the sparse
coding offers an automatic generation of sparse vec-
tors according to a dictionary to encode an input sig-
nal. The network stacked of multiple feature extrac-
tion stages, each of which comprises a convolutional
filter bank layer and a feature pooling layer, and a
non-linearity stage. For filter bank in each convolu-
tion layer, we present an unsupervised feature learn-
ing that can be automatically learned by PCA. The
feature maps are generated from the results of convo-
lution and are aggregated by pooling layer via sparse
prior taking benefit of coupled dictionaries to mi-
grate from one level-resolution to an adequate lower-
resolution level. The predefined dictionaries contain
patches of writing patterns extracted from a collection
of high-quality character images and thus describe the
specificities of writing. The non-linearity stage in-
volves binary hashing then concatenates block-wises
histogram to finally fed the results into a training clas-
sifier.
The remainder of the paper is organized as fol-
lows: Section 2 presents related works dealing with
deep learning based text detection methods in the
wild. Section 3 gives a description of our contribu-
tion; an emphasis is made to describe properly both
PCANet, the deep learning network architecture and
sparse coding representation for a better comprehen-
sion of the overall algorithm. After that, Section 4
gives experimental results for performance evaluation
of the proposed method within a comparative study
involving ICDAR 2003 well-known database. Sec-
tion 5 closes this study with overall conclusions and
suggestions for future research works.
2 RELATED WORKS
The efficiency of deep learning models has been no-
ticeable in various applications of computer vision
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
244

like image classification and object detection. In par-
ticular, text/non-text classification in natural images is
among the most extensively studied application in the
literature. If traditional approaches are based on hand-
engineering better sets of features (Srinivas et al.,
2016) which are very limited for highly challenging
textual scene images, recent studies investigate deep
learning, heavily based on convolutional deep neural
networks (ConvNet), to compute hierarchical features
or representations from raw images. Each neuron is
related to a feature where the subsequent layer takes a
broad view of the essential features from the previous
one (Krizhevsky et al., 2012; Girshick et al., 2014; Si-
monyan and Zisserman, 2015; Szegedy et al., 2015).
In general, a deep network architecture comprises
(1) a convolutional filter bank layer, (2) a nonlinear
processing layer, (3) and a feature pooling layer. For
each layer, the learning process could be achieved us-
ing one of the well-known learning techniques such
as restricted Boltzmann machines, regularized auto-
encoders (Ciresan et al., 2011) or their variations
(Socher et al., 2011), the PCANet... The latter rep-
resents a very simple deep learning network that can
offer a valuable baseline for reading complex deep
learning architectures suited for large-scale image ap-
plications (Chan et al., 2014).
The underlying assumption for feature design
is the use of text/non-text information for training.
Therefore, this information is very important to learn
a discriminative representation. The proposed deep
learning based methods of Wang et al. (Wang et al.,
2012), Jaderberg et al. (Jaderberg et al., 2014) and
Gupta et al. (Gupta et al., 2016) compute globally
image features that lead to insufficient and no generic
text/non-text representation. For a discriminative fea-
ture learning, He et al. (He et al., 2016) propose a
text CNN model that particularly involves text-related
specific characteristics such as text region mask, char-
acter label and binary text/non-text information.
Therefore, an efficient deep learning based text
detection method must encapsulate discriminative
text patterns and a deep architecture with a low-
computational cost.
3 CONTRIBUTIONS
This section details the proposed text detection sys-
tem which relies on the two most popular models of
machine learning: deep learning and sparse coding
representation. In fact, we propose to proceed by a
combination of the merits of the PCANet model and
the domain expertise of sparse coding to improve the
performance of the text detection system with a faster
training and adequate feature representation. There-
fore, we could learn in a simple and rapid manner the
most appropriate feature representation for text im-
age from data. Figure 2 illustrates an overview of the
proposed system. Further details are discussed in the
following subsections.
3.1 PCANet: Brief Review
PCANet is an example of a simplified deep learning
network. Therefore, it shares with ConvNet many of
its fundamental representation and functional proper-
ties. In particular, it represents a feature that auto-
matically learns from a given region of interest but
takes benefit of a more abstract expression of some
properties. The convolution filter bank is Principal
Component Analysis (PCA) filters. The non-linear
layer is the binary hashing (quantization). The pool-
ing layer is the block-wise histogram of the decimal
values of the binary vectors. Therefore, the struc-
ture of PCANet model contains the following steps :
patch-mean removal, PCA filter convolutions to pro-
duce a set of feature maps, binary quantization and
mapping, block-wise histograms, and an output clas-
sifiers (Chan et al., 2014).
Let us denote N the number of the input training
images
{
I
i
}
N
i=1
of size m ×n. For each image, we take
around each pixel a k
1
× k
2
patch. Then, the mean is
subtracted from each patch and the feature vector is
given. After that, the filter is defined for the next step
by taking into account the maximum eigenvalues. For
the second stage, the same process is repeated.
PCANet model includes a number of PCA stages
followed by an output stage. The number of these
stages can be varied, but a typical PCANet has two
stages. The work of (Chan et al., 2014) emphasized
that the two-stage PCANet model outperforms the
single stage in most cases. However, the increase of
the number of stages does not always improve the fi-
nal results performance. In particular, this study fo-
cuses on the two-stage PCANet model.
We note that the output stage contains the opera-
tions of binary hashing and block-wise histogram. A
step function is applied to generate binary values for
each patch and these values are converted to decimal
values using the binary hashing. The block-wise his-
togram operates on these decimal values to generate
the final output features. These features are then fed
into a trained classier like SVM. We suppose that the
number of filters in stage 1 after PCA application on
the N training images is F
1
and in stage 2 is F
2
.
Deep Learning with Sparse Prior - Application to Text Detection in the Wild
245

3.2 Sparse Coding: Brief Review
The goal of sparse coding is to automatically con-
struct sparse vectors from the training inputs Y . For
sparse representation, the following objective func-
tion is used to learn a dictionary D and jointly find
a sparse linear combination of the basis vectors by
minimizing the data reconstruction errors:
D = argmin
D,α
k
Y − Dα
k
2
2
+
k
α
k
1
(1)
where α is the sparse vectors that represent the train-
ing samples Y according to the dictionary D, and λ is a
constant that controls the sparsity penalty and fidelity
of the approximation to Y .
In the literature, we have noticed the recourse to
coupled sparse feature spaces: high-resolution and
low-resolution feature spaces mainly in patch-based
super-resolution tasks (Walha et al., 2015; Walha
et al., 2014; Yang et al., 2010). The given spaces
could be nominated as the observation space and the
latent space. Both of them must be tied by a mapping
function. The underlying assumption is to ensure a
collaborative learning between these two coupled dic-
tionaries in order to efficiently reconstruct the signal
in the latent feature space given the sparse represen-
tation of its corresponding signal in the observation
space.
Let us denote
n
Y
i
l
j
o
j=1,2
i=1...C
the patch pairs for the
level 1 (l
1
) and level 2 (l
2
) of each cluster i where C is
the total number of clusters. The coupled dictionaries
n
D
i
l
j
o
j=1,2
i=1...C
are thus defined as follows:
D
i
l
j
= argmin
D
i
l
j
,α
Y
i
l
j
− D
i
l
j
α
2
2
+
k
α
k
1
. (2)
3.3 Proposed PCANet with Sparse Prior
In this section, we propose an approach that combines
the simplicity and efficiency of PCANet architecture
and the domain expertise of sparse coding. The main
difference, in comparison with the PCANet model
described above, is that the feature maps, generated
from the results of convolution, are aggregated by
pooling layer via sparse prior. This is possible via the
use of coupled dictionaries to migrate from one level-
resolution to an adequate low-resolution level. In
this case, a correct selection of the training database
must be undertaken carefully for a successful learn-
ing process. Attracted by the competitive results of
the Walha et al. work (Walha et al., 2015), we choose
to proceed using its training database; even it has
been already collected to enhance the spatial resolu-
tion of textual images, we will adapt it to the con-
text of our study. In fact, this database is composed
of several patch images extracted around character
edges of high-quality images. These character im-
ages, generated using the graphic library FreeType,
encapsulates a variety of sizes, styles and fonts. The
high-resolution training set is composed by 124000
patch images. Figure 3 shows samples of the high-
resolution training set.
Algorithm 1: PCANet with sparse prior.
Input: Training patches (ICDAR 2003), Coupled
dictionaries level 1 and level 2.
1: Stage I: First feature extraction via PCA
1.a: First filter construction for layer 1 via PCA
application on the N training patches.
1.b: Convolution step: For each training patch,
extract L
1
feature maps by convoluting it with PCA
based filters bank.
2: Stage II: Feature pooling via sparse prior
2.a: Each feature map is represented via sparse
coding using coupled dictionaries to migrate from
one level-resolution to an adequate low-resolution
level.
3: Stage III: Second feature extraction via PCA
3.a: Second filter construction for layer 2 via PCA
application on the pooled features maps
3.b: Convolution Step: extract L
2
feature maps by
convoluting the output of the second stage with the
second PCA based filters bank.
4: Stage IV: Feature preparing for SVM classifier
4.a: Apply binary hashing
4.b: Concatenate block-wise histogram
Output: Learned Features, Learned SVM Classifier.
As output for the Stage I, we obtain NF
1
feature
maps where N is the number of the input image and
F
1
is the number of filter of the first stage. Firstly, we
extract l patches with a size of k
1
×k
2
of the i
th
image
that is vectorized into column vectors with a stride of
s pixels. Thus, we collect all patches extracted from
the same input image which forms a matrix with a size
T , denoted as
T = (k
1
k
2
) × ((
d
m − k
1
e
s
+ 1)(
d
n − k
2
e
s
+ 1)); (3)
X
i
= [x
i,1
,x
i,2
,...,x
i, j
,...,x
i,T
] ∈ ℜ
(k
1
×k
2
)T
(4)
where x
i j
∈ ℜ
k
1
×k
2
and j ∈ 1..l denotes the j
th
vec-
torized patch in I
i
.
In order to improve the features quality within a
neighborhood and removing the noise corresponding
to the small eigenvalues of the data covariance matrix,
we subtract the mean value of the corresponding patch
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
246
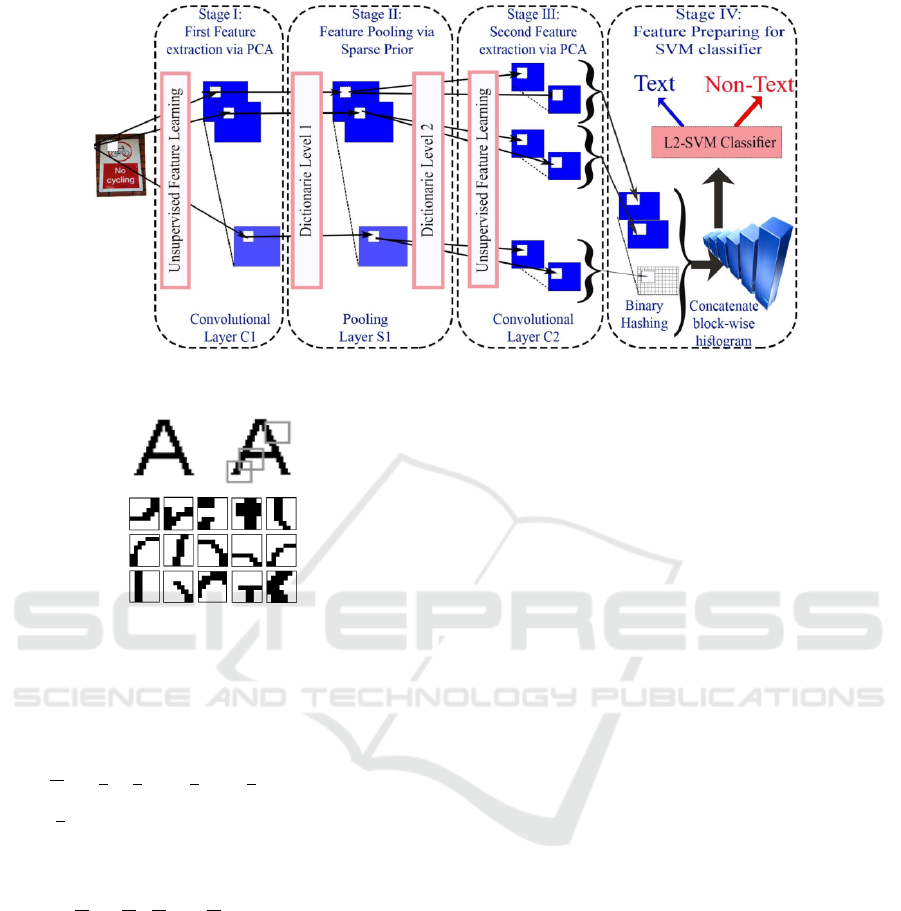
Figure 2: The four stage architecture of the proposed PCANet with sparse prior for text detection.
Figure 3: From top to down : Illustration of the selection
process of patch images from a character image and sam-
ples of the writing pattern from the training database (Walha
et al., 2015).
from each column vector in the matrix X
i
and obtain
the following matrix:
X
i
= [x
i,1
,x
i,2
,...,x
i, j
,...,x
i,T
] ∈ ℜ
(k
1
×k
2
)T
(5)
where x
i, j
is a mean-removed patch.
Once the same matrix is applied for all input im-
ages, we regroup them to form a large matrix defined
as:
X =
X
1
,X
2
,...,X
N
∈ ℜ
(k
1
×k
2
)N
mn
(6)
The eigenvectors associated with the most ener-
getic eigenvalues from the covariance matrix are then
extracted. The next step is performed on the matrix
XX
T
. Therefore, we take the convolutional filters that
form a matrix with F
1
principal eigenvectors of XX
T
.
The PCA filters that are learned can be expressed
as follows:
W
1
f
= mat
k
1
×k
2
(q
f
(XX
T
)) ∈ ℜ
k
1
k
2
,l = 1,2, ..., F
1
(7)
where mat
k
1
×k
2
(v) is a function that denotes the map-
ping relationship from vector v to a matrix W ∈ ℜ
k
1
k
2
,
and q
f
(XX
T
) designates the f
th
eigenvector of matrix
XX
T
. Lastly, all the principal eigenvectors of a matrix
keep the main variation of all the mean removed train-
ing patches and we obtain F
1
filters of size k1 × k2.
After that, we convolute each input image with the
learned filters to generate filter responses at each pixel
location and namely the filtering feature maps results.
Each feature map, extracted at corresponding location
in the image, represents particular features.
Let the f
th
filter output of the first stage be as fol-
lows:
I
f
i
= I
i
⊗W
1
f
,i = 1,2,...,N (8)
where ⊗ denotes 2D convolutional, and I
i
padded
with zeros before convolution.
For the Stage II, we apply a pooling layer via
sparse prior that represents the feature maps using
coupled dictionaries. This stage allows to recover a
patch of low-resolution level J
f
i
from an input patch
of one level resolution I
f
i
. Given the learned coupled
dictionaries {D
l
1
,D
l
2
} (Walha et al., 2015), sparse
coding generates sparse vectors to encode an input
patch I
f
i
from the dictionary D
l
1
. This can be mathe-
matically formulated as:
α = min
α
I
f
i
− D
l
1
α
2
2
(9)
where α is the sparse representation of I
f
i
over D
l
1
.
Then, we select only the representation
b
α that mini-
mizes the local reconstruction error according to the
appropriate dictionary
c
D
l
1
:
b
α = min
α
I
f
i
− D
l
1
α
2
2
(10)
The optimal solution
b
α is then applied to generate a
low-resolution level of patch J
f
i
from the correspond-
ing D
l
1
dictionary based on: J
f
i
= D
l
2
b
α.
In the case of the Stage III, we apply the same pro-
cess that is used in the first stage. Firstly, we collect
Deep Learning with Sparse Prior - Application to Text Detection in the Wild
247

all the overlapping patches of J
f
i
. Then, we join all
vectors extracted from which we subtract patch mean
to form a matrix denoted as
Y
i
=
y
i, f ,1
,y
i, f ,2
,...,y
i, f , j
,...,y
i, f ,T
∈ ℜ
(k
1
×k
2
)T
(11)
where y
i, j
is a mean-removed patch. We further col-
lect patches from all mean-removed patches in the f
th
filter output, and concatenate the matrix Y
f
i
denoted as
Y
f
=
h
Y
f
1
,Y
f
2
,...,Y
f
N
i
∈ ℜ
(k
1
×k
2
)N
mn
(12)
The PCA filters are learned and can be expressed
as follows:
W
2
f
= mat
k
1
×k
2
(q
f
(YY
T
)) ∈ ℜ
k
1
k
2
,l = 1,2, ..., F
2
(13)
For each input J
f
i
of the third stage, we take the
first L
2
main eigenvectors as PCA filters convolving
with W
2
f
for f = 1, 2, ...,F
2
V
f
i
= {J
f
i
⊗W
2
f
}
L
2
f =1
(14)
The number of features maps of the third stage is
F
1
NF
2
as output of the second feature extraction.
The stage IV is the output stage, we use binary
hashing and histogram statistics which build feature
maps to form final representation of the input image
as in PCANet (Chan et al., 2014). Each F
1
input fea-
ture maps to the second stage obtains F
2
feature maps
as outputs {J
f
i
⊗W
2
f
}
F
2
f =1
. We binarize these output
maps and apply {J
f
i
⊗W
2
f
}
F
2
f =1
, where H(.) is a Heav-
iside step function whose value is one for positive en-
tries and zero otherwise.
Around each pixel, we consider the vector of F
2
binary bits as a decimal number. This converts the F
2
outputs produced in the second stag back into a single
integer-valued image.
For each of F
1
integer valued images, we parti-
tion it into B blocks. We compute the histogram of
the decimal values in each block, and concatenate all
the B histograms into one vector. After this encoding
process, the feature of the input image I
i
becomes the
set of block-wise histograms. The local blocks can
be either overlapping or non-overlapping, depending
on applications. The output is then fed into a trained
classier.
4 EXPERIMENTAL RESULTS
4.1 Experimental Framework
4.1.1 Datasets and Evaluation Protocols
Our experiments were implemented with Matlab
2015 b platform, and run on a 64-bit Microsoft 10
machine powered by Intel(R) Core(TM) i7-4750HQ
CPU 2.00 GHz processor and 8 GB RAM.
In this section, we choose the dataset ICDAR 2003
with challenging text scene images for evaluating our
text detection method. This dataset proposed by S. M.
Lucas et al. contains 507 natural scene images in to-
tal; 258 images from the dataset are prepared for train-
ing and 249 images for testing. Most images vary in
size from 600 × 450 to 1280 × 960 and contain about
4 text regions on average for each image.
To evaluate the text detection, we used three im-
portant metrics in performance assessment: Precision
(P), Recall (R)and F-Measure (FM). Precision mea-
sure is the ratio between the successfully extracted
text regions (TP) and all detected regions (E). Re-
call measure represent the ratio of the successfully ex-
tracted text regions (TP) that should be in the ground
truth regions (T). The F-Measure is computing the
performance of algorithm, which combines the pre-
vious two measures. The metric formulas are given
by the following definitions:
P =
|
T P
|
/
|
E
|
(15)
R =
|
T P
|
/
|
T
|
(16)
FM =
2 × P × R
(P + R)
(17)
4.1.2 Experimental Setup
Our text detection system is based on PCANet archi-
tecture and on sparse coding representation. We use
samples of ICDAR 2003 dataset to learn PCA filters
with L
1
filters in the rst stage and L
1
groups in the
third stage; each group contains L
2
filters. To extract
the features, we adopted convolution layer that con-
voluate each input image 32 × 32 using patch size of
k1 ×k2 with the learned PCA-based filters to produce
a set of feature map. To train dictionary, the num-
ber of atoms varies between 128 and 1024. For the
classification layer, these outputs are fully connected
to train the network by back-propagating the L
2
-SVM
classication error.
For the experimental study, we choose the number
of filter as set L
1
= L
2
= 8 that is inspired from the
common setting of Gabor filters with 8 orientations.
The results are shown in Figure 4.
4.2 Performance Evaluation
In this section, we evaluate the performance of the
proposed system on the Robust Reading dataset IC-
DAR 2003. For text detection, we generate a 2-way
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
248
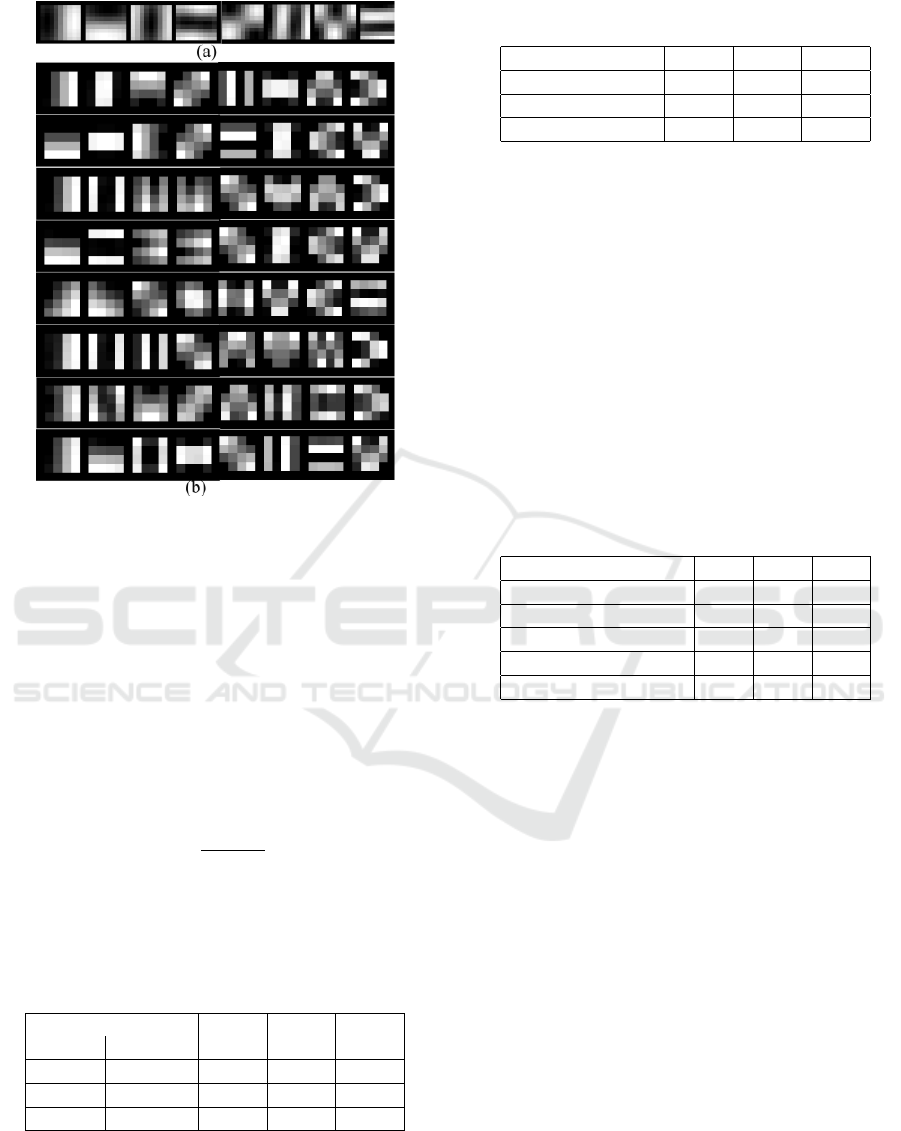
Figure 4: Filters learned on the ICDAR 2003 dataset. (a) 8
filters in the first stage;(b) There are 8 groups in the second
stage, and each group contains 8 filters, shown in a column.
text/no-text classication dataset by cropping patches
from this dataset.
4.2.1 Impact of the Patch Size
We study the influence of the different patch size y
1
varying between 7 and 11 pixels for the first stage. To
calculate the overlapping between adjacent patches
from the left to right input image and the patch size
y
2
of the third stage, we apply the following formula:
y
2
=
(y
1
+ 1)
2
. (18)
For ICDAR 2003 dataset, table 1 proves that the
best number of patch size is 7 and 4 for Stage I and
Stage II respectively.
Table 1: Impact of the patch size for Stage I and Stage II of
our proposition: Case study of ICDAR 2003 database.
Patch size
P R FM
Stage I Stage III
7 4 0.975 0.965 0.97
9 5 0.966 0.958 0.962
11 6 0.96 0.962 0.961
4.2.2 Impact of the Number of Atoms
In this subsection, the patch size is fixed to 7 × 7 for
stage I and 4 × 4 for stage III. We define the relation-
Table 2: Impact of the number of atoms for our proposition:
Case study of ICDAR 2003 database.
Number of atoms P R FM
128 0.97 0.962 0.966
256 0.975 0.965 0.97
512 0.976 0.96 0.968
ship between the classification performance and the
number of atoms. To generate the dictionary, we ap-
plied the K-means clustering algorithm patches. We
used the dictionary of Walha et al. (Walha et al., 2015)
to conduct both the two dictionaries generation such
as one level-resolution and low-resolution level. Ta-
ble 2 illustrates that the number of atoms equal to 256
gives better results than the other.
4.2.3 Comparative Methods Study
We compared our proposed text detection system
to the-state-of-the-art methods using the comparative
metrics already defined above.
Table 3: Comparisons of different methods of text detec-
tion: Case study of ICDAR 2003 database.
Algorithm P R FM
Epshtein et al. 0.73 0.60 0.66
Yi and Tian 0.71 0.62 0.62
Huang et al. 0.81 0.74 0.72
Basic PCANet 0.95 0.95 0.95
PCANet/Sparse prior 0.97 0.96 0.97
According to the different metrics such as Preci-
sion, Recall and F-Measure established for different
algorithms, including basic PCANet(without sparse
prior), modified PCANet (with sparse prior) and the
works of (Epshtein et al., 2010; Yi and Tian, 2011;
Huang et al., 2013), tested on the ICDAR 2003
dataset, table 3 shows that the modified variant of
PCANet with sparse prior achieves a better text de-
tection result.
5 CONCLUSIONS
We proposed a novel approach which takes the advan-
tage of unsupervised deep learning. More precisely,
we combine the simplicity and efficiency of PCANet
architecture and the domain expertise of sparse prior.
Our proposition provides competitive results com-
pared with state-of-the art methods but opens more
efficient prospects for other methods.
Further investigations will focus on the integration
of a dedicated feature to define automatically the fil-
ter numbers. The study of neighborhood for a given
Deep Learning with Sparse Prior - Application to Text Detection in the Wild
249

image block will be integrated to improve the overall
system detection performance.
REFERENCES
Anthimopoulos, M., Gatos, B., and Pratikakis, I. (2013).
Detection of artificial and scene text in images and
video frames. Pattern Anal. Appl., 16(3):431–446.
Chan, T. H., Jia, K., Gao, S., Lu, J., Zeng, Z., and Ma, Y.
(2014). Pcanet: A simple deep learning baseline for
image classification. IEEE Trans. on Image Process-
ing, 24(12):5017–5032.
Ciresan, D. C., Meier, U., Masci, J., Gambardella, L. M.,
and Schmidhuber, J. (2011). High performance neu-
ral networks for visual object classication. Technical
Report IDSIA-01-11.
Epshtein, B., Ofek, E., and Wexler, Y. (2010). Detect-
ing text in natural scenes with stroke width trans-
form. IEEE Computer Vision and Pattern Recogni-
tion, pages 2963–2970.
Gao, R., Uchida, S., Shahab, A., Shafait, F., and Frinken,
V. (2014). Visual saliency models for text detection in
real world. PLoS ONE, 9:114–539.
Garcia, C. and Apostolidis, X. (2000). Text detection and
segmentation in complex color images. In Proc. Int.
Conf. on Acoustics, Speech and Signal Processing,
pages 2326–2329.
Girshick, R., Donahue, J., Darrell, T., , and Malik, J. (2014).
Rich feature hierarchies for accurate object detection
and semantic segmentation. IEEE Computer Vision
and Pattern Recognition.
Gupta, A., Vedaldi, A., , and Zisserman, A. (2016). Syn-
thetic data for text localisation in natural image. IEEE
Computer Vision and Pattern Recognition.
He, T., Huang, W., Qiao, Y., and Yao, J. (2016). Text-
attentional convolutional neural network for scene
text detection. IEEE Trans. Image Processing, pages
2529–2541.
Huang, W., Lin, Z., Yang, J., and Wang, J. (2013). Text lo-
calization in natural images using stroke feature trans-
form and text covariance descriptors. IEEE Int. Conf.
on Computer Vision, pages 1241–1248.
Jaderberg, M., Vedaldi, A., and Zisserman, A. (2014). Deep
features for text spotting. European Conf. on Com-
puter Vision.
Krizhevsky, A., Sutskever, I., and Hinton, G. (2012). Im-
agenet classification with deep convolutional neural
networks. Neural Information Processing Systems.
Lee, J.-J., Lee, P.-H., Lee, S.-W., Yuille, A., and Koch, C.
(2011). Adaboost for text detection in natural scene.
In Int. Conf. on Document Analysis and Recognition,
pages 429–434.
Lienhart, R. and Wernicke, A. (2002). Localizing and seg-
menting text in images and videos. IEEE Trans. on
Circuits and Systems for Video Technology, 12:256–
268.
Neumann, L. and Matas, J. (2012). Real-time scene text
localization and recognition. IEEE Computer Vision
and Pattern Recognition, pages 3538–3545.
Neumann, L. and Matas, J. (2013). Scene text localization
and recognition with oriented stroke detection. IEEE
Int. Conf. on Computer Vision, pages 97–104.
Simonyan, K. and Zisserman, A. (2015). Very deep con-
volutional networks for large-scale image recognition.
Int. Conf. on Learning Representation.
Socher, R., Pennington, J., Huang, E., Ng, A., and Man-
ning, C. (2011). Semi-supervised recursive autoen-
coders for predicting sentiment distributions. In Conf.
on Empirical Methods in Natural Language Process-
ing, pages 151–161.
Srinivas, S., Sarvadevabhatla, R., Mopuri, K., Prabhu, N.,
Kruthiventi, S., and Radhakrishnan, V. (2016). A tax-
onomy of deep convolutional neural nets for computer
vision. Frontiers in Robotics and AI.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., and Reed, S.
(2015). Going deeper with convolutions. Computer
Vision and Pattern Recognition.
Walha, R., Drira, F., Lebourgeois, F., Garcia, C., and Alimi,
A. (2014). Sparse coding with a coupled dictionary
learning approach for textual image super-resolution.
Int. Conf. on Pattern Recognition, pages 4459–4464.
Walha, R., Drira, F., Lebourgeois, F., Garcia, C., and Al-
imi, A. (2015). Resolution enhancement of textual
images via multiple coupled dictionaries and adaptive
sparse representation selection. Int. Journal of Docu-
ment Analysis and Recognition, 18(1):87–107.
Wang, K., Babenko, B., and Belongie, S. (2011). End-to-
end scene text recognition. In Int. Conf. on Computer
Vision, pages 1457–1464.
Wang, T., Wu, D. J., Coates, A., and Ng, A. Y. (2012). End-
to-end text recognition with convolutional neural net-
works. Int. Conf. on Pattern Recognition, pages 3304–
3308.
Yang, J., Wright, J., Huang, T., and Ma, Y. (2010). Im-
age super-resolution via sparse representation. IEEE
Trans. Image Process, 19(11):2861–2873.
Ye, Q. and Doermann, D. (2015). Text detection and recog-
nition in imagery: A survey. IEEE Trans. on Pattern
Analysis and Machine Intelligence, 37(7):1480–1500.
Yi, C. and Tian, Y. (2011). string detection from natu-
ral scenes by structure-based partition and grouping.
IEEE Trans. on Image Processing, 20(9):2594–2605.
Zhong, Y., Karu, K., and Jain, A. (1995). Locating text
in complex color images. Pattern Recognition, pages
1523–1536.
VISAPP 2017 - International Conference on Computer Vision Theory and Applications
250
