
A Knowledge Base Guided Approach for Process Modeling in
Complex Business Domain
Roberto Paiano and Adriana Caione
Department of Engineering for Innovation, University of Salento, 73100 Lecce, Italy
Keywords: Knowledge Base, Business Process Management, Compliance, Natural Language Text.
Abstract: The business process analysis requires an in-depth knowledge of factors such as the activities carried out;
the actors involved; the domain or business context in which the activities are performed; the internal
company structure; the current regulatory framework. This involves the employment and the collaboration
of different professionals, such as business experts, domain experts and legal experts, along with a
considerable effort in terms of time and resources. For the purpose of an efficient and effective management
of business processes, it is also important to ensure the compliance with the company context and the
flexibility with regard to changes that may occur within the company or at the legislative level. This paper
shows a methodological and architectural approach guided by a knowledge base that describes the
application domain. It is populated iteratively with the information extracted from the analysis of
documents, regulations and requirements. The knowledge base is then used by the process designer as a
guide for business process modelling and management.
1 INTRODUCTION
Business process modelling and management is a
discipline that aims to increase the efficiency and
effectiveness of the activities carried out in the
companies. Indeed, it analyses the processes, which
is the company way of working, and identifies, by
comparison with the best practices in the same
context, the strengths and the weaknesses. It follows
a business process reorganization and reengineering.
The analysis of business processes requires an
in-depth knowledge of some aspects such as the
activities carried out in the company; the actors
involved; the domain or business context in which
the activities are performed; the internal company
structure; the current regulatory framework. This
implies the interaction and the collaboration of
different professionals, such as business experts,
domain experts and legal experts, along with a
considerable effort in terms of time, about 60% of
the total time spent to manage the processes (Herbst
and Karagiannis, 1999).
For the purpose of an efficient and effective
business process management, it is also important to
ensure compliance with the company context and
flexibility with regard to changes that may occur
within the company or at legislative level.
As reported verbatim in (Sadiq and Governatori,
2015) “The ever-increasing obligations of regulatory
compliance are presenting a new breed of challenges
for organizations across several industry sectors.
Aligning control objectives that stem from
regulations and legislation with business objectives
devised for improved business performance is a
foremost challenge”. Indeed, a prompt response to
changes and the compliance with the company
context could be the reason of improvement in the
competitive position compared to other companies
in the same sector.
In view of these consideration, there is the need
of methods and technologies able to facilitate and
speed up the acquisition phase of the information
related to the company context, identify and model
business processes and ensure the process
compliance with the company operational context,
even in the faces of changes.
Most of such business information, about 85%
(Blumberg and Atre, 2003), is stored in an
unstructured way, in text documents and the amount
of available unstructured sources is continuously
growing. But how these sources can be used for
defining and modelling business processes?
In this paper we propose a methodological and
architectural solution that falls in research
Paiano, R. and Caione, A.
A Knowledge Base Guided Approach for Process Modeling in Complex Business Domain.
DOI: 10.5220/0005974801690176
In Proceedings of the 11th International Joint Conference on Software Technologies (ICSOFT 2016) - Volume 1: ICSOFT-EA, pages 169-176
ISBN: 978-989-758-194-6
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
169

disciplines such as knowledge management
(Tiwana, 2000), process mining (Van Der Aalst,
2011) and business process management. It is based
on an approach guided by a knowledge base realized
by the help of domain and legal experts. This
knowledge base describes the entire company
domain in the form of concepts and relationships
among them. The idea is to populate, iteratively, the
knowledge base with the information extracted from
unstructured sources, and to use the knowledge base
for business process modelling, ensuring the
compliance with the company context and
facilitating the process adaptation to changes.
The purpose is to make the process design
experts as autonomous as possible during business
process management phases.
The paper is organized as follows. In Section 2
we describe the background of this research work.
Section 3 shows how the literature faces problems
similar to those analysed here. Section 4 describes
the methodology and the phases that characterize it.
Section 5 shows the approach from the architectural
point of view and of the components that
characterize it. Finally, Section 6 includes some
conclusions.
2 BACKGROUND
The contribution described in this paper represents a
continuation of the research work (Caione et al.,
2015a) which results in a methodological and
architectural solution able of managing the entire
business process life cycle in complex business
domain, from process modelling to process running
on an automatically generated web application
prototype.
First it is important to consider and know the
operational context in which the company takes
place in order to proceed with the definition of the
activities and business processes. To this end it is
essential a strong interaction between different
professionals. Because of a different cultural
background, they should use a common dictionary to
allow the knowledge sharing and transfer. In this
regard, in (Guido et al., 2015) the authors suggest
some guidelines addressed to legal experts in order
to schematize the texts of laws and regulations and
to simplify the understanding to the process design
experts who will model the processes in accordance
with the existing laws. The output of the guidelines
is a set of schemes that could provide support for
domain knowledge base modelling. The knowledge
base is actually the result of a careful analysis of the
operational context, the detection of the main
concepts that characterize it along with the
identification, reuse and merge of one or more
existing knowledge bases able to describe the entire
reference domain. In (Paiano et al., 2015) the
authors propose a knowledge model structured into
two ontological levels:
Enterprise Domain Ontologies (EDO) that
“model the entities (i.e., human resources, tasks,
processes, objectives, etc.) that represent the
organizational environment from a general
perspective. Because of their general purpose,
these ontologies have been defined extending
and combining ontologies (i.e. reference
ontologies) already existing at the state of the
art”;
Application Domain Ontologies (ADO) that
“model domain specific concepts and they
support the classification of entities represented
through the EDO. The regulations represent a
typical example of ADO because they are
application specific”.
This model is useful during the design phase of new
business processes compliant with the reference
domain and during the management of expected
and/or unexpected events.
With regard to the definition and management of
business processes, in the literature there are several
workflow management systems that support the
business and IT expert during the process planning,
execution and management. A survey is given in
(Caione et al., 2015b) in which the authors describe
five open source workflow management systems:
Intalio BPMS (www.intalio.com);
BonitaSoft (http://it.bonitasoft.com);
jBPM (www.jbpm.org);
Activiti BPMN 2.0 (www.activiti.org);
Camunda (www.camunda.com)
These solutions are compared on the basis of eight
key aspects:
process editor oriented to business and/or IT
experts;
APIs availability for business and/or IT experts;
connectors availability;
BPMN 2.0 compliance;
fast prototyping;
prototyped application customization;
process monitoring;
engine source code customization.
Particular attention is paid to the requirements of
extending the solution in order to allow the
integration and the interaction with the domain
knowledge base.
ICSOFT-EA 2016 - 11th International Conference on Software Engineering and Applications
170

From the analysis and the obtained results, jBPM
has proved to be the most suitable system from the
point of view of the requirement fulfilment.
The processes are modelled using the standard
Business Process Model Notation (BPMN) also
available in version 2.0 (OMG, 2011). It includes
four categories of elements necessary for the design
of a process:
flow Objects (Activities, Events and Gateways),
swimlanes (Pools and Lanes);
artifacts (e.g. Data Objects, Text Annotations or
Groups);
connecting objects (Sequence Flows, Message
Flows and Associations).
Typically, a process design reflects the analysis of
the operating context and of the company
requirement that is carried out through interviews,
meetings, etc., then transcribed into text form, along
with the understanding of structured and
unstructured documents.
The methodological and architectural approach
described in this paper, shows the use of these
guidelines, knowledge bases and tools. We have also
done a scouting on the state of art of software
solutions able to map the information contained in
unstructured documents with the concepts of a
previously modelled knowledge base, the tool
named OwlExporter was identified (Witte et al.,
2010).
It is an extension of the General Architecture for
Text Engineering (GATE) framework (Bontcheva et
al., 2004). It includes support for the semantic
language Ontology Web Language – Description
Logic (OWL-DL), the automatic population of a
knowledge base and the integration of information
taken from Natural Language Processing (NLP) in
order to make a more accurate reasoning.
Being the tool dependent on a specific
knowledge base, for the purposes of this work it will
have to be extended and customized for the specific
reference domain in order to better support the
process designers in the business process modelling
phase.
3 RELATED WORKS
Recently there is a considerable attention to the
identification and generation of process models from
content written in natural language.
An interesting solution is described in (Friedrich
et al., 2011). In the paper the authors present an
automatic approach for the generation of process
designs according to the BPMN standard and
starting from texts written in natural language.
Verbatim, they "combine an extensive set of tools
from natural language processing (NLP) in an
innovative way and augment it with an anaphora
resolution mechanism". The approach involves three
steps:
Sentence Level Analysis, through which it is
possible to extract actors and actions (verb +
object) and connect the actors to the actions;
Text Level Analysis, through which it is possible
to analyse the sentences taking into account their
mutual relationships. The end result is the
creation of flows of activities describing how the
activities interact with each other;
Process Model Generation, the information
extracted in the previous steps and stored in a
template are transformed into processes
according to the BPMN standard.
Another solution, validated on a case study in the
archaeological field, is described in (Viorica Epure
et al., 2015). It is called TextProcessMiner and
consists of the generation and analysis of process
activity logs starting from text documents in an
attempt to define the process instance model. The
solution is "fully unsupervised and uses natural
language processing techniques with a focus on the
verb semantics" and is divided into three
components:
TextCleaner, “responsible for cleaning the
methodology section and preparing the text
which will be mined”;
ActivityMiner, “responsible for mining the
activities from the text”;
ActivityRelationshipMiner, “responsible for
mining the relationships between the activities,
thus discovering the process instance”.
Lastly, we quote the paper (Brandão et al., 2015)
where the authors propose a solution able to solve
the problem of subjectivity related to the business
expert vision. It also facilitates the process
management, the reuse, the maintenance and the
understanding. The idea is to automatically identify
particular elements in business processes through the
analysis of the process event log. Within the
business process models, as defined by the authors,
"elements can be scattered (repeated) within
different processes, making it difficult to handle
changes, analyze process for improvements, or
check crosscutting impacts". These elements are
called aspects.
Some of the above mentioned solutions use
knowledge bases to define a set of useful rules in
order to analyse natural language texts. In this paper,
A Knowledge Base Guided Approach for Process Modeling in Complex Business Domain
171

the knowledge base plays a crucial role since it
describes the entire reference domain in terms of
concepts and relationships and it is integrated into
the business process management system to support
the business expert and the process designer during
the modelling, the reuse and the maintenance phases
of processes. Therefore, the option of automatically
populating the knowledge base from the information
contained in analysis and requirement documents
could support the business experts and process
designers, reducing their knowledge gap and the
time spent in the analysis of the operational context.
An attempt similar to that described in this paper,
though with different aims and tools, is shown in
(Rashwan et al., 2013) which illustrates an automatic
requirement classification system, based on support
vector machines. It automatically categorizes
requirement sentences into different Non-Functional
Requirements knowledge base concepts.
4 METHODOLOGY
The methodology adopted in this work consists of
three main phases that can be summarized as
follows:
knowledge acquisition about the company
domain. The output of this phase is a knowledge
base that summarizes the context in the form of
concepts and semantic relationships among
them;
information mapping, which aims to
automatically populate the knowledge base,
defined in the previous step, through the
information contained in the analysis, regulatory
and business requirement documents;
business process modelling, the final result of
which is the BPMN representation of the
business processes modelled by the process
designer through the information contained in the
populated knowledge base.
In the following we describe in detail these phases.
4.1 Knowledge Acquisition about
Company Domain
In recent years, the use of knowledge bases has seen
a strong increase as a result of the spread of
semantic information systems. The design of these
systems is an activity demanding from the
standpoint of time and human resources. This led to
the definition of methodologies with the attempt to
standardize the construction of knowledge bases and
to achieve a result in a common semantic language,
in order to ensure the knowledge base sharing and
reuse even in different domains.
There are numerous methods in the literature for
the creation and the management of knowledge
bases, among them Methontology (Fernández-López
et al., 1997), Skeletal Methodology (Uschold and
King, 1995), Grüninger and Fox (1995), to name but
a few. They provide a valuable support to
knowledge engineers and carefully describe the
steps to be followed during the phases of modelling,
implementation and maintenance of the knowledge
bases.
Our approach inherits what realized in (Paiano et
al., 2015). The authors chose the methodology of
Grüninger and Fox, both because it is based on a
complete existing technique, Methontology, which
describes the entire knowledge base creation life
cycle, both because it extends this methodology and
focuses on the creation of knowledge bases from the
the information related to the application domain.
Added to this is the importance of the research
and the reuse of existing knowledge bases or parts of
them as additional support for the knowledge
engineer.
We combine the above mentioned work with
some helpful guidelines with the attempt of
schematizing complex domains such as those that
provide laws and regulations (Guido et al., 2015).
The end result is an abstract representation of the
application domain in a standard semantic language.
This representation organizes the company
knowledge in both ADO and EDO levels, briefly
described in the Background section.
Although there are tools that can semi-
automatically generate knowledge bases starting
from textual documents such as Ontogen (Fortuna et
al., 2007), Text2Onto (Philipp and Völker, 2005),
etc. For our purposes, they are not sufficiently
accurate to describe complex domains such as
business and regulatory ones. Therefore, from our
point of view, it is preferable that the construction of
such knowledge bases is guided by domain experts,
legal experts and business experts.
4.2 Mapping of the Information
Written in Natural Language
The implemented knowledge base, in order to be
helpful during the business process modelling phase,
should also contain the actual data extracted from
the analysis documents, regulatory and requirement
texts written in natural language.
Having built a solid knowledge base, it is
possible to use tools that, starting from documents
ICSOFT-EA 2016 - 11th International Conference on Software Engineering and Applications
172

written in natural language, instantiate the concepts
of the knowledge base. Among the tools we name
OwlExporter (Witte et al., 2010).
The main characteristics of this tool are:
instance creation, using the entities contained in
the text;
creation of the relations between concepts, using
the information and relationships in the text;
coreference chains creation, leveraging the
concept of equality for the same entities that are
positioned in different parts of the text.
We have extended and customized this tool with the
idea of modelling business processes in complex
domains.
To this end, the pipeline and the source code
have been modified in order to overcome a
limitation which did not allow the processing of
complex texts.
Subsequently we have defined a lookup list of
entities and some JAPE transducers, that are files
containing some rules to further identify
patterns/entities from the text and to generate
annotations that will have to be matched with the
concepts and properties defined in the knowledge
base.
The benefit of automatically populating a
knowledge base from text, is to have a
categorization of the information contained in the
documents on the basis of the concepts modelled in
the knowledge base and, therefore, the possibility to
make queries and inference in order to extract
implicit knowledge.
Furthermore, taking advantage of the concepts
and instances contained in the knowledge base, it is
possible to enrich the model comparing the
information present in text documents with the
instances of the knowledge base.
4.3 Business Process Modelling
Since we have on the one hand a knowledge base
that schematises the application domain in terms of
concepts, instances and semantic relationships, and
on the other a business process management system,
the business expert and the process design are
facilitated in the design of the business activities.
More to the point, the interaction with the
knowledge base allows to fill the gap of the
knowledge expert in terms of the application
domain, speeds the information retrieval and
facilitates the adjustment of the processes if changes
happen in the application domain.
Our approach organises the business process
modelling into two main phases, as shown in Figure
1, Planning Time and Design Time.
In order to have a greater understanding of these
phases, it is good to define the concept of sub-
process template and the motivations of its use. It is
a block of BPMN elements, or a portion of process
that can not be executed by workflow engines, but
can be composed with other elements or portions to
derive executable business processes.
Figure 1: Business Process Modelling - Planning Time and
Design Time.
Planning Time - In this phase the process designer
uses an editor called Business Process Editor to
model the sub-process templates in BPMN standard
notation.
The editor allows the process designer to query
the domain knowledge base through an interface
named Knowledge Base (KB) Explorer. The
interaction is useful to semantically characterize the
sub-process template elements, establishing a
semantic relationship between the elements of the
sub-process templates and the knowledge base
concepts; to get some suggestions about the design
(the names of the process tasks, the input and output
parameters, etc.); to facilitate the management of
domain changes.
Design Time - In this phase the process designer
models the business processes that can be executed
within the workflow engines. To this end it may use
the previously defined templates, connecting them
according to three possible options:
sequential adding: the connection in sequence of
the activities that constitute the sub-process
templates used;
parallel adding: the connection in parallel of the
activities that constitute the sub-process
templates. This can be done using the parallel
A Knowledge Base Guided Approach for Process Modeling in Complex Business Domain
173
gateway of the BPMN notation;
conditional adding: connection with branching of
the sub-process template activity flow. This is
applicable using all of the BPMN gateway types.
It is clear that the events and the redundant tasks
must be eliminated or merged.
At the end of the process composition and
modelling, the business designer must enter the
execution parameters, inputs and outputs to the
tasks, in order to make the processes executable. The
integration of such information may be done
querying the knowledge base.
The business model thus obtained is stored in
two different ways: in a format executable by
workflow engines (.bpmn extension); in a semantic
format so that it is sent to the knowledge base and
stored in it (.owl extension).
This makes easier to ensure the compliance of
the processes modelled with respect to the
application domain. A change in the domain, results
in a change in the knowledge base and, as a
consequence to a notification to the process designer
who will have to adapt the processes on which the
change has impact.
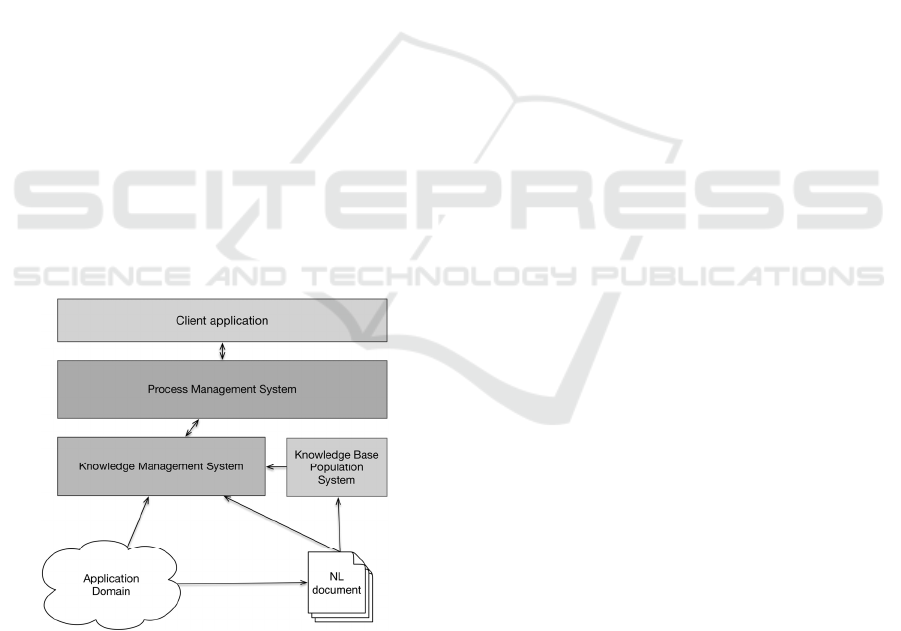
5 ARCHITECTURAL SOLUTION
The proposed architectural solution (Figure 2)
includes three main components.
Figure 2: Architectural solution.
Knowledge Management System. It is responsible
for the management of the domain knowledge
base. It stores the concepts and the semantic
relationships and allows to make inferences and
queries. The access to the knowledge base is
realized, on the client side, using the interface
KB Explorer. The process designer can start a
search for concepts entering free text or
keywords. The interaction occurs through
Representational State Transfer (REST) and
Simple Object Access Protocol (SOAP) calls.
Knowledge Base Population System. It is
responsible for the knowledge base population
with the information contained in unstructured
documents. It customizes and extends the
OwlExporter tool for the specific domain and is
based on GATE NLP framework that allows to
work with the knowledge bases using integrated
models.
The system is characterized by two knowledge
bases. The first models the concepts and the
relationships relevant for the particular domain.
The second knowledge base is a basic NLP
knowledge model independent from the domain
that contains the concepts commonly used in
language engineering, such as Document,
Sentence, Noun, Predicate, etc.
Process Management System. It is responsible
for the business process modelling through the
composition of sub-process templates and it is
responsible for the entire management of the
modelled processes using the features offered by
the Knowledge Management System. The
Business Process System extends the jBPM
modelling editor for the features of sub-process
template definition, composition, saving of the
executable processes in a standard format and in
a format compatible with the knowledge base,
access to read and insert information to and in
the knowledge and management of domain
changes.
5.1 Process Management System
In this section we describe in more detail the main
modules that constitute the core component of the
architecture, the Process Management System.
The component conforms with the business 1
Knowledge Management System component
manages the domain knowledge base, result of the
knowledge acquisition about company domain phase
of the methodology. The Knowledge Base
Population System component allows the mapping
of the information written in natural language phase
of the methodology in order to automatically
populate the knowledge base with instances
extracted from documents.
Architectural details for the these two
components are provided in the papers (Paiano et al.,
2015) and (Witte et al., 2010), respectively.
ICSOFT-EA 2016 - 11th International Conference on Software Engineering and Applications
174

5.1.1 Knowledge Base Explorer
The KB Explorer module allows the interaction with
the knowledge base and the collection of the
concepts contained in it. The designer can retrieve
the concepts stored in the knowledge base by
performing one of the following search methods: by
free text; by keywords; by concepts related to the
results of a previous search.
This tool is integrated into the Business Process
Editor and can be used:
to insert one or more references to the knowledge
base concepts, when creating a sub-process
template or a process;
to characterize a specific BPMN element of the
model with one or more knowledge base
concepts, during the design of a process;
to insert the input and output parameters
connected to the knowledge base concepts,
during the concretization of the process.
The concepts used in the models can assume
different states:
active, when the concept is valid and can be used
to semantically describe an entire process or an
element of it;
deleted, when the concept has been removed
from the knowledge base;
replaced, when the concept has been modified in
the knowledge base because of some domain
changes.
The change in status is indicated by events from the
knowledge base.
5.1.2 Business Process Editor
The Business Process Editor is a standalone
application extending the Eclipse-based editor of
jBPM.
The necessity to update the source code is
dictated by the following features:
creating a new model, that is a process or a sub-
process template. The wizard, then, allows the
process designer to use the KB Explorer in order
to select the concepts that will characterize the
design.
opening an existing model to view it and/or to
make changes in it. The user can also update the
concepts of the model.
modelling of a business process. In this activity
the process designer uses the tools, the graphic
elements, the palette and the properties of the
jBPM Eclipse-based editor. However, extensions
are needed to allow the process designer to
connect the process elements with the concepts
extracted from the knowledge base and to insert
the task execution parameters.
saving the model. The model is saved in a format
executable by the jBPM workflow engine and it
can be exported in the corresponding semantic
representation. This semantic file is sent to the
knowledge base, transparently to the designer.
management of changes in the application
domain. The process designer can check for
changes in the knowledge base, can see the
changed concepts and, then, he can update the
respective templates and/or processes.
execution parameters entry. They are parameters
functional to execute a process. The definition of
the input and output parameters, through the
knowledge base, is obtained by invoking the KB
Explorer module.
process recomposer. This is a useful feature for
events for the management of which is not
possible to identify a perfectly compatible
process. After the selection of an event, the
system suggests to the user a list of processes
and/or sub-process templates semantically
related to the event. The user can select one or
more processes and/or sub-process templates
among those proposed in order to insert and
connect them into the process that will handle the
event.
6 CONCLUSIONS AND FUTURE
WORKS
This paper presents a methodological and
architectural approach for business process
modelling, starting from the analysis and the
requirements of complex application domains.
Compared to the related works, where business
processes are obtained from documents written in
natural language, here a domain knowledge base
plays a central role in the business process
modelling phase. Indeed, it summarizes in terms of
concepts and relationships the application context
and it is integrated into a business process
management system. In this way the process
designer can proceed with the design of business
processes autonomously, without the need to interact
with domain and legal experts but with the
possibility to extract the required information from
the knowledge base.
Moreover, the use of an automatic knowledge
base populating system from text, constantly
A Knowledge Base Guided Approach for Process Modeling in Complex Business Domain
175

enriches this model and simplifies the reading and
the understanding of analysis and requirement
documents along with of more generally texts
describing the application domain.
Interesting is the possibility to define some
business-process templates that could be reused and
merged during the final process modelling phase.
These templates could be also semantically
characterized, tagging them and their elements with
the concepts of the knowledge base.
Finally, it is important to emphasize the
flexibility of the system with respect to the domain,
and consequently knowledge base, changes. The
proposed system, in effect, notifies to the process
designers the occurrence of such events and the
processes on which these events may have impact.
In the future it is expected to increase the level of
the system automation through the iterative use of
the system itself. We plan also to show some
examples and usage scenarios of the methodology
and the system on which to make evaluations and
comparisons of the obtained results with those
arising from the employ of a traditional approach,
that is without the use of a knowledge base, but with
the iterative interaction with the domain, legal and
business experts.
REFERENCES
Blumberg, R., Atre, S., 2003. The problem with
unstructured data. DM REVIEW, 13(42-49), 62.
Bontcheva, K., Tablan, V., Maynard, D., Cunningham, H.,
2004. Evolving GATE to meet new challenges in
language engineering. Natural Language Engineering,
10(3-4), 349-373.
Brandão, B. C. P., Santoro, F., Azevedo, L. G., 2015.
Towards Aspects Identification in Business Process
Through Process Mining. In Proceedings of the
annual conference on Brazilian Symposium on
Information Systems: Information Systems: A
Computer Socio-Technical Perspective-Volume 1 (p.
99). Brazilian Computer Society.
Caione, A., Guido, A. L., Martella, A., Paiano, R.,
Pandurino, A., 2015a. Knowledge base support for
dynamic information system management.
Information Systems and e-Business Management, 1-
44.
Caione, A., Guido, A.L., Paiano, R., Pandurino, A., 2105b.
A Survey of Open Source Workflow Management
System. International Journal of Emerging Trends &
Technology in Computer Science, ISSN: 2278-6856
VOL. 4, pp.22-26.
Fernández-López, M., Gómez-Pérez, A., Juristo, N., 1997.
Methontology: from ontological art towards
ontological engineering.
Fortuna, B., Grobelnik, M., Mladenic, D., 2007. Ontogen:
Semi-automatic ontology editor (pp. 309-318).
Springer Berlin Heidelberg.
Friedrich, F., Mendling, J., Puhlmann, F., 2011. Process
model generation from natural language text. In
Advanced Information Systems Engineering (pp. 482-
496). Springer Berlin Heidelberg.
Guido, A. L., Paiano, R., Pandurino, A., 2015. From laws
to business process: reducing the skill gap between
legal professional and business process analyst. In
Internet Technologies and Applications (ITA), 2015
(pp. 23-28). IEEE.
Grüninger, M., Fox, M. S., 1995. Methodology for the
Design and Evaluation of Ontologies.
Herbst, J., Karagiannis, D., 1999. An inductive approach
to the acquisition and adaptation of workflow models.
In Proceedings of the IJCAI (Vol. 99, pp. 52-57).
OMG, O., 2011. Business Process Model and Notation
(BPMN) Version 2.0. Object Management Group.
Paiano, R., Pandurino, A., Guido, A.L., Ritrovato, P.,
D’Apice, C., Laria, G., 2015. An Approach to
Integrated Management System Exploiting
Knowledge Base to Support Business Processes
Management. In Italian chapter of association for
information systems (ItAIS).
Philipp, C., Völker, J., 2005. Text2Onto-A Framework for
Ontology Learning and Data-driven Change
Discovery. In Proceedings of the 10th International
Conference on Applications of Natural Language to
Information Systems-NLDB (Vol. 5, pp. 15-17).
Rashwan, A., Ormandjieva, O., Witte R., 2013. Ontology-
Based Classification of Non-Functional Require-
ments in Software Specifications: A new Corpus and
SVM- Based Classifier. In The 37th Annual
International Computer Software & Applications
Conference (COMPSAC 2013), (pp. 381–386). IEEE.
Sadiq, S., Governatori, G., 2015. Managing regulatory
compliance in business processes. In Handbook on
Business Process Management 2 (pp. 265-288).
Springer Berlin Heidelberg.
Tiwana, A., 2000. The knowledge management toolkit:
practical techniques for building a knowledge
management system. Prentice Hall PTR.
Uschold, M., King, M., 1995. Towards a methodology for
building ontologies (pp. 15-30). Edinburgh: Artificial
Intelligence Applications Institute, University of
Edinburgh.
Van Der Aalst, W., 2011. Process mining: discovery,
conformance and enhancement of business processes.
Springer Science & Business Media.
Viorica Epure, E., Martin-Rodilla, P., Hug, C., Deneckere,
R., Salinesi, C., 2015. Automatic process model
discovery from textual methodologies. In Research
Challenges in Information Science (RCIS), 2015 IEEE
9th International Conference on (pp. 19-30). IEEE.
Witte, R., Khamis, N., Rilling, J., 2010. Flexible Ontology
Population from Text: The OwlExporter. In LREC
(Vol. 2010, pp. 3845-3850).
ICSOFT-EA 2016 - 11th International Conference on Software Engineering and Applications
176
