
A Container-centric Methodology for Benchmarking Workflow
Management Systems
Vincenzo Ferme
1
, Ana Ivanchikj
1
, Cesare Pautasso
1
, Marigianna Skouradaki
2
and Frank Leymann
2
1
Faculty of Informatics, University of Lugano (USI), Lugano, Switzerland
2
Institute of Architecture of Application Systems, University of Stuttgart, Stuttgart, Germany
Keywords:
Benchmarking, Docker Containers, Workflow Management Systems, Cloud Applications.
Abstract:
Trusted benchmarks should provide reproducible results obtained following a transparent and well-defined
process. In this paper, we show how Containers, originally developed to ease the automated deployment of
Cloud application components, can be used in the context of a benchmarking methodology. The proposed
methodology focuses on Workflow Management Systems (WfMSs), a critical service orchestration middle-
ware, which can be characterized by its architectural complexity, for which Docker Containers offer a highly
suitable approach. The contributions of our work are: 1) a new benchmarking approach taking full advantage
of containerization technologies; and 2) the formalization of the interaction process with the WfMS vendors
described clearly in a written agreement. Thus, we take advantage of emerging Cloud technologies to address
technical challenges, ensuring the performance measurements can be trusted. We also make the benchmarking
process transparent, automated, and repeatable so that WfMS vendors can join the benchmarking effort.
1 INTRODUCTION
Performance benchmarking contributes to the con-
stant improvement of technology by clearly posi-
tioning the standards in measuring and assessing
performance. Benchmark results conducted un-
der the umbrella of research are recognized as a
great contribution to software evolution (Sim et al.,
2003). For example, the well-known and estab-
lished benchmark, TPC-C (Transaction Processing
Council (TPC), 1997) had a meritorious contribu-
tion to the performance of Database Management
Systems (DBMSs), which improved from 54 trans-
actions/minute in 1992 to over 10 million transac-
tions/minute in 2010. The importance of benchmark-
ing is also recognized by the emergence of organi-
sations, such as the Transaction Processing Perfor-
mance Council (TPC)
1
and the Standard Performance
Evaluation Corporation (SPEC)
2
, that are responsible
for ensuring the integrity of the benchmarking pro-
cess and results. They maintain steering committees,
involving both industry and academic partners.
Widely accepted and trustworthy benchmarks
should demonstrate relevance, portability, scalability,
1
https://www.tpc.org/
2
https://www.spec.org/
simplicity, vendor-neutrality, accessibility, repeatabil-
ity, efficiency, and affordability (Gray, 1992; Hup-
pler, 2009; Sim et al., 2003). These requirements im-
pose significant technical challenges (Pautasso et al.,
2015) regarding the automation of the benchmark-
ing process, in order to facilitate efficiency and scal-
ability, i.e., the benchmarking of different systems;
the repeatability of tests under the same initial con-
ditions; the reduction of noise from the environment,
etc. Benchmarks also often face logistic challenges,
since many vendors
3
use software licence agreements
to tightly control how benchmark results, obtained us-
ing their products, are published. Addressing such
challenges is only possible with a carefully designed
methodology to manage the entire benchmarking pro-
cess, from the deployment of the targeted system,
through its testing, and up till the publishing of the
results.
In this paper, we propose a methodology for
benchmarking the performance of Workflow Manage-
ment Systems (WfMSs). As defined by the Workflow
Management Coalition (WfMC), a WfMS is “a sys-
tem that completely defines, manages and executes
3
Like Oracle: http://www.oracle.com/technetwork/
licenses/standard-license-152015.html and Microsoft:
http://contracts.onecle.com/aristotle-international/
microsoft-eula.shtml
74
Ferme, V., Ivanchikj, A., Pautasso, C., Skouradaki, M. and Leymann, F.
A Container-centric Methodology for Benchmarking Workflow Management Systems.
In Proceedings of the 6th International Conference on Cloud Computing and Services Science (CLOSER 2016) - Volume 2, pages 74-84
ISBN: 978-989-758-182-3
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

Figure 1: Benchmarking Input/Process/Output (IPO) Model.
‘workflows’ through the execution of software whose
order of execution is driven by a computer represen-
tation of the workflow logic” (Hollingsworth, 1995).
The WfMSs can use different languages to execute
the modeled workflows (e.g., WS-BPEL, BPMN 2.0).
Even though the proposed methodology is not limited
to any specific execution language, we use the Busi-
ness Process Model and Notation (BPMN) 2.0 (Jor-
dan and Evdemon, 2011) as a use case for describing
its feasibility. There are several reasons behind such
decision: the growing usage of BPMN 2.0 and the
WfMSs that support it (Skouradaki et al., 2015) (e.g.,
Camunda, Activiti, jBPM, Bonita BPM
4
), the ISO
standardization (ISO/IEC 19510:2013) of the lan-
guage and above all the fact that BPMN 2.0 supports
a superset of the elements supported by BPEL (Ley-
mann, 2011).
Our methodology aims to offer solutions to the
aforementioned: 1) technical challenges by defin-
ing a benchmarking framework which benefits from
the emerging containerization technology, initially
used for deployment of Cloud applications (Turnbull,
2014); and 2) logistic challenges by formalising the
interaction between the conductor of the benchmark-
ing process (hereinafter the BenchFlow team) and the
vendors of the WfMSs which are being benchmarked.
We believe that such formalisation will foster ven-
dor collaboration and public access to the benchmark-
ing results. In our approach, we treat the WfMSs as
a black-box, as the proposed methodology is appli-
cable to any WfMS released in a Docker container.
Our current goal is to benchmark the performance of
the WfMSs under different load and observe their be-
haviour in normal conditions (e.g., we do not inject
fault during the workload execution). Furthermore,
we assume that the execution bottlenecks lie with the
WfMS, and not with the external services invoked
during the process instance execution. We ensure this
assumption holds when designing the workload, or
when running the experiments.
Our work is conducted under the scope of the
BenchFlow project
5
which has the aim of defining a
standard way to assess and compare WfMSs perfor-
mance (Skouradaki et al., 2015).
The remainder of the paper is organized as fol-
4
More detailed list is provided at: https://en.
wikipedia.org/wiki/List of BPMN 2.0 engines
5
http://benchflow.inf.usi.ch
lows: Section 2 introduces the benchmarking frame-
work, Section 3 presents the process of formal in-
teraction with WfMS vendors and the used artifacts,
Section 4 examines the related work, and Section 5
concludes and presents the planned future work.
2 BENCHMARKING PROCESS
To ensure benchmark’s transparency and repeatabil-
ity, it is crucial to clearly define the benchmarking
process, its input and output artifacts, as well as the
implementation of the benchmarking framework.
2.1 Benchmarking
Input/Process/Output Model
Regardless of the targeted System Under Test (SUT),
the benchmarking process always uses as an input
a workload, i.e, an instance of the workload model,
whose parameters are influenced by the test type. It
is a good practice to explore SUT performance using
different SUT configurations and different computa-
tional resources. The output of the benchmarking pro-
cess is the data for calculating different metrics and/or
Key Performance Indicators (KPIs). Such data should
be recorded only after a warm-up period, necessary to
remove system initialization bias. Before the data can
be used for computing metrics and KPIs, it must be
validated, by running the same tests multiple times,
to ensure that the standard deviation in the results is
below a predefined limit. In the following subsections
we define the elements of the Input/Process/Output
(IPO) model (Fig. 1) in the WfMSs context.
2.1.1 Workload Model
The parameters of the workflow model (workload
mix, load functions, and test data) vary depending on
the objective of the test type (e.g., load test, stress test,
soak test (Molyneaux, 2014)). The interactions be-
tween the parameters of the workload model are pre-
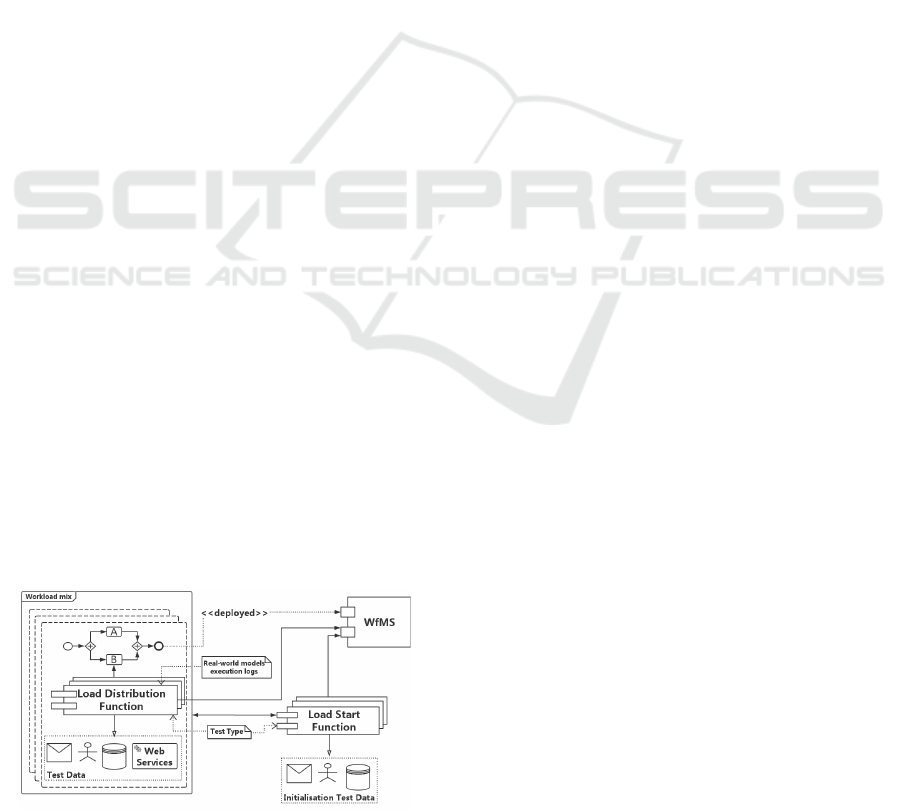
sented in Fig. 2.
The workload mix is the mix of process models
to be deployed during a given test. Each process
model defines the activities, the order in which they
are performed, as well as any external interactions.
A Container-centric Methodology for Benchmarking Workflow Management Systems
75
It is crucial for benchmark’s validity that the work-
load mix is representative of real-world models and
the set of language constructs that they use. Collect-
ing and synthesizing real-world models is one of the
challenges faced when benchmarking WfMS perfor-
mance, to be addressed by static and dynamic analy-
sis of real-world model collections (Pautasso et al.,
2015). Given the fact that the workflow execution
languages are very rich and complex, the constructs
included in the workload mix models need to be care-
fully selected. They should: 1) stress the performance
of the WfMS; 2) be supported by the WfMS (Geiger
et al., 2015); 3) be frequently used in real-world pro-
cesses; and 4) be in-line with the targeted perfor-
mance tests and KPIs. To make sure that our work-
load mix is representative, we will follow the itera-
tive approach for its development and evaluation (Sk-
ouradaki et al., 2015). Since each WfMS uses dif-
ferent serialization of executable process models, ev-
ery time we add a new WfMS to the framework, our
workload mix needs to be adapted to a compatible ex-
ecutable format.
The load functions describe how the workload is
issued to the SUT. For example, in the case of Online
Transaction Processing (OLTP) systems, the work-
load mix consists of transactions against a database
(DB) and a load function describes the number of
queries that will be executed against the DB per time
unit (Transaction Processing Council (TPC), 1997;
Transaction Processing Performance Council, 2007).
In more complex examples, such as the session-based
application systems, the workload mix is defined
through different types of transactions, and different
roles of users that execute these transactions. In these
systems, the load functions are more complex as they
have to describe the behavior of the users, i.e., the
frequency and sequence in which they execute dif-
ferent types of transactions (van Hoorn et al., 2014).
The workload model for benchmarking WfMSs can
be seen as an extension of the workload model for
session-based applications, since the WfMS executes
blocks of language constructs as transactions which
can be compensated in case of an error. When
Figure 2: Workload Model Parameters’ Interactions.
benchmarking WfMSs we distinguish two types of
load functions: 1) Load Start Functions - determined
based on the performance test type, they define how
often process instances are being initiated during the
test. Even though a Load Start Function needs to be
defined for each process model in the workload mix,
it is possible that multiple or all process models share
the same Load Start Function; 2) Load Distribution
Functions - contain rules to define the distribution of
the executed paths of a given process model in the
workload mix and the distribution of the interactions.
Examples of such interactions are the completion of
a human (user or manual) task and the call of an ex-
ternal Web service. The rules will be derived from
the analysis of real-world execution logs and based
on the test type. There is mutual dependency between
all the instances of a given process model, and the
Load Start Function for that process model, marked
with bidirectional arrow in Fig. 2. Namely the Load
Start Function determines the number of instances for
a given process model in the workload mix, but at the
same time, the Load Start Function needs to know the
process model to be able to generate the test data nec-
essary to instantiate a process instance.
The test data are used as an input for starting a
process instance, or during the execution of the pro-
cess instance as part of the performance test. They
depend on the definition of the load functions and can
refer to, for example, results of evaluating gateway
rules, messages for invoking Web services, persistent
data required for completing a task, the number of
users, etc.
To summarise: the workload applied to the SUT
is determined by the load functions, used to generate
process instances of all the process models included
in the workload mix. The process instances are in-
stantiated and executed using the test data selected in
accordance with the load functions. For instance, we
could use the process model shown in Fig. 2 as a sim-
plistic workload mix. Consider Task A a human task
and Task B a Web service task. We can define the
Load Start Function, such that, 100 process instances
are started with the initialization event and then exe-
cuted by the WfMS. The test data in this case, would
be the input data that the users are entering into the
WfMS for Task A. The Load Distribution Function
would define users’ think times, and the time it takes
for the Web service to complete.
2.1.2 System Under Test
The SUT refers to the system that is being tested for
performance. In our case a WfMS which, accord-
ing to the WfMC (Hollingsworth, 1995), includes the
Workflow Enactment Service (WES) and any envi-
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
76

Table 1: Summary of Core and Non-core APIs to be imple-
mented by the WfMS.
Functionality Min Response Data
Core APIs
Initialisation
APIs
Deploy a process Deployed process ID
Start a process instance Process instance ID
Non-core APIs
User APIs Create a user User ID
Create a group of users User group ID
Access pending tasks Pending tasks IDs
Claim a task*
Complete a task
Event APIs Access pending events Pending events IDs
Issue events
Web service
APIs
Map tasks to Web
service endpoints
*Optional depending on the WfMS implementation
ronments and systems required for its proper func-
tioning, e.g., application servers, virtual machines
(e.g., Java Virtual Machine) and DBMSs. The WES
is a complex middleware component which, in addi-
tion to handling the execution of the process models,
interacts with users, external applications, and Web
services. This kind of SUT offers a large set of con-
figuration options and deployment alternatives. The
DBMS configuration as well as the WES configura-
tions (e.g., the granularity level of history logging,
the DB connection options, the order of asynchronous
jobs acquisition), may affect its performance. More-
over, WfMSs often offer a wide range of deployment
alternatives (e.g., standalone, in a clustered deploy-
ment, behind a load balancer in an elastic cloud in-
frastructure) and target different versions of applica-
tion server stacks (e.g., Apache Tomcat, JBoss).
To add a WfMS in the benchmark, we require the
availability of certain Core and Non-core APIs. A
summary of the same is presented in Table 1.
The Core APIs are Initialisation APIs necessary
for automatic issuing of the simplest workload to the
SUT in order to test SUT’s performance. They in-
clude: 1) deploy a process and return as a response an
identifier of the deployed process (PdID); and 2) start
a process instance by using the PdID and return as a
response the new instance identifier (PiID).
Depending on the execution language of the
WfMS and the constructs that it supports, other Non-
core APIs might be necessary for testing more com-
plex workloads. For instance, if we are targeting
BPMN 2.0 WfMSs we might also require the follow-
ing APIs:
For applying workloads involving human tasks,
the following User APIs are necessary: 1) create
a user and return the identifier of the created user
(UsID); 2) create a group of users, return the cre-
ated group identifier (UgID), and enable adding users
by using their UsIDs; 3) pending user/manual tasks:
access all the pending user/manual task instances of
a given user/manual task identified by its id (Jordan
and Evdemon, 2011, sec. 8.2.1) as specified in the
model serialization. We want to obtain all the pend-
ing tasks with the given id of all the process instances
(PiIDs) of a given deployed process (PdID). The API
has to respond with data, enabling the creation of a
collection that maps the process instances to the list
of their pending tasks <PiID, UtIDs> and <PiID,
MtIDs>; 4) claim a user/manual task identified by
UtID/MtID, if tasks are not automatically assigned by
the WfMS; and 5) complete a user/manual task iden-
tified by UtID/MtID by submitting the data required
to complete the task.
To issue a workload containing process mod-
els with catching external events, the following
Event APIs are necessary: 1) pending catching
events/receive tasks: access the pending catching
event/receive task instances of a given event/task
identified by its id (Jordan and Evdemon, 2011, sec.
8.2.1) specified in the model serialization. We want
to obtain all the pending catching events/receive tasks
with the given id of all the process instances (Pi-
IDs) of a given deployed process (PdID). The API
has to respond with data enabling the creation of a
collection that maps the process instances to the list
of their pending catching events/receive tasks <PiID,
CeIDs> and <PiID, RtIDs>; and 2) issue an event to
a pending catching event/receive task identified by us-
ing CeID/RtID. We require the APIs to accept the data
necessary to correlate the issued event to the correct
process instance, e.g., a correlation key.
Finally, to be able to issue a workload defining in-
teraction with Web services and/or containing throw-
ing events, the WfMS has to support a binding mech-
anism to map each Web service task/throwing event
to the corresponding Web service/throwing event end-
point. The WfMS should preferably allow to specify
the mapping in the serialized version of the model,
so that the binding can be added before deploying the
process.
Since many WfMSs are offered as a service, it is
safe to assume that many WfMSs expose, what we
call, the Core APIs. In our experience with systems
we have evaluated so far (e.g., Activiti, Bonita BPM,
Camunda, Imixs Workflow, jBPM), they support not
only the core APIs, but also the non-core APIs. The
exact API may differ among systems, however the
necessary API features were always present.
2.1.3 Metrics and Key Performance Indicators
The output of the performance testing is collected
and later used to calculate a set of metrics and KPIs.
A Container-centric Methodology for Benchmarking Workflow Management Systems
77

To make performance testing meaningful, they must
be carefully selected in order to capture the differ-
ences among configurations and systems. A metric
is defined as a “quantitative measure of the degree
to which a system, component or process possesses
a given attribute” (Fenton and Bieman, 2014). A KPI
on the other hand is a “a set of measures” (Parmenter,
2010, ch. 1) which focus on the critical aspects of
SUT’s performance. As opposed to metrics, the num-
ber of KPIs should be limited, in order to clearly
focus the improvement efforts. We propose group-
ing the metrics and KPIs in three different levels,
based on the requirements of their expected users: 1)
Engine-level: to help end-users select the most suit-
able WfMS as per their performance requirements; 2)
Process-level: suitable for WfMS vendors to position
and evaluate their offerings in different use-case sce-
narios; and 3) Feature-level: fine-grained measures
allowing WfMS developers to deal with system’s in-
ternal complexity and to explore its bottlenecks. For
each level, we enumerate a non-exhaustive set of met-
rics to be calculated using process execution, environ-
ment monitoring and resource utilization data. Which
metrics will be calculated when running a specific
performance test, will depend on the objective of the
test. To increase transparency, a detailed definition of
each of the used metrics will be provided to the WfMS
vendors, together with the benchmark results.
The Engine-level metrics measure the WfMS per-
formance based on the execution of the entire test
workload. Most metrics defined in the literature
for assessing WfMS performance, refer to this level
and include throughput, latency, resource utilization
(e.g., RAM, CPU, disk and network utilization) (R
¨
ock
et al., 2014). In addition to these metrics, we pro-
pose to also add metrics for assessing the scalabil-
ity, the capacity (Jain, 1991, p. 123), and the flexi-
bility of the SUT. For example, response time (ms)
- what is the time it takes for the SUT to respond to
the service request (Barbacci et al., 1995, ch. 3), en-
durance - can the SUT sustain a typical production
load (Molyneaux, 2014, p. 51), flexibility to spike -
how does the SUT react to a sudden increase of the
load (Molyneaux, 2014, ch. 3).
The Process-level metrics measure the WfMS per-
formance based on the execution of instances of a spe-
cific process model in the test workload. The resource
utilization metric is interesting at the process-level as
well, to analyse how much resource consumption is
needed per single process instance execution. We also
propose metrics for the duration of a process instance,
and the delay introduced by the WfMS in executing
the process instance. The delay is computed as a dif-
ference between the actual and the expected duration
of the process instance, where the expected duration
is determined as the aggregation of the expected du-
ration of the constructs included in the executed path
of the process instance.
Different languages can support different concepts
(e.g., time, parallelism, control and data flow), thus
impacting the design of the WfMSs executing them.
The Feature-level fine-grained metrics are necessary
to determine the impact of specific language con-
structs or patterns on WfMS performance, and to iso-
late possible sources of performance issues. We pro-
pose measuring the resource usage, the duration, and
the delay, for each language construct as well as for
frequently used patterns
6
. For instance, in BPMN 2.0,
such constructs can include user task, timer event,
exclusive gateway, etc. The ultimate goal is to help
developers determine the performance bottlenecks of
their WfMS, so that they can work on removing them,
and thus improving the WfMS performance in gen-
eral. We have used some of the mentioned metrics to
evaluate the BenchFlow framework in (Ferme et al.,
2015).
However, being able to calculate the above men-
tioned metrics imposes certain requirements on the
granularity and the type of data to be saved in the
DBMS. The DBMS persists and recovers the process
instance execution status and history. The most im-
portant data to be recorded are the following times-
tamps: start time and end time of each executed pro-
cess instance (identified by its PiID); as well as start
time and end time of specific language constructs that
are part of the process instances, e.g., activities or
events identified by their id with a possibility to map
them to the process instance they belong to. The
timestamps should preferably have a precision up to
milliseconds.
2.2 Benchmarking Framework
Implementation
The goal of the benchmarking framework is twofold:
1) to make our research publicly available, and fos-
ter collaboration; and 2) to enable reproducibility and
full transparency in the benchmarking process. To do
so we have released the framework as open source
7
.
The second goal is very important for inducing WfMS
vendors to join our efforts, since it enables them to
verify the benchmark results and use the framework
with their own infrastructure.
The framework builds on: 1) Faban (Faban,
2014), an established and tested “performance work-
6
http://www.workflowpatterns.com
7
https://github.com/benchflow
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
78

Figure 3: Framework Deployment View.
load creation and execution framework”, to de-
sign the load drivers and issue the load; and 2)
lightweight software containerization technologies,
precisely Docker (Turnbull, 2014) in the current ver-
sion of the framework, in order to obtain, from the
vendors, a ready to use setup of the WfMSs to be
tested. We have decided to adopt Docker since it
is a widely used and accepted containerization solu-
tion (Merkel, 2014). Moreover, if carefully config-
ured, it has proved to have a negligible impact on the
performance of the containerized application (Felter
et al., 2014). The benefits of using containerization
technologies are: 1) avoiding the highly error-prone
task of installing the WfMS that can lead to a non op-
timal setup impacting its performance results; 2) en-
suring the reproducibility of the benchmark results by
saving system’s initial status (Boettiger, 2014); and 3)
collecting detailed resources usage statistics for each
Container by means of the Docker stats API.
The architecture of the framework has been de-
scribed in details in (Ferme et al., 2015), while Fig. 3
presents the framework components and their deploy-
ment. Each of the framework’s components is de-
ployed inside a different Container. Although we
use Docker as a containerization technology, the pro-
posed methodology and framework can be applied
to any other containerization technology as well. To
scale with the amount of performance tests to be in-
cluded in the benchmark, in order to provide for a
reliable comparison of WfMSs, we integrate the de-
ployment of the WfMS in the setup of the perfor-
mance test. We do so by using a SUT Deployment
Descriptor and by extending the Faban Master in
the Benchmark Master. The SUT Deployment De-
scriptor defines the servers on which to deploy the
WfMS’s Containers. The Benchmark Master auto-
matically deploys the SUT as well as the workload,
and all the related entities defined in the load func-
tions, i.e., the Load Start Functions, users and appli-
cations which are simulated by means of Faban Driver
Agents; and the Web services which are simulated
by using techniques for automatic testbed generation,
e.g., (Juszczyk et al., 2008). The main deployment
requirement for a reliable benchmark is to isolate, as
much as possible, the WES from other components,
by deploying them on different physical machines on
the same local network, with the purpose of minimis-
ing the possible noise introduced by their concurrent
execution on the same machine (e.g., the DBMS run-
ning on the same machine as the WES). To do so,
the framework enables the user to select the servers
where to deploy the different components of the SUT,
so that there are enough computational resources to
generate a load that stresses the WfMS performance,
and enough computational resources for the WES to
sustain that load. For example, less powerful servers
can be used to run the WES, while the load func-
tions and the DBMS can be assigned to more power-
ful servers. While enhancing the reliability of the ob-
tained results, deploying the components on different
A Container-centric Methodology for Benchmarking Workflow Management Systems
79

physical machines adds network costs to the systems.
We mitigate these costs by connecting the different
servers on a high performance local network.
The framework also deals with the asynchronous
execution of process models, by gathering perfor-
mance data directly from the DB used by the WES.
Data cannot be gathered from the client side since the
starting of a new process instance from the Core API
is done in an asynchronous way. This means that the
Core API call to the WfMS finishes as soon as the in-
stance is created, and the Load Start Function is only
aware of the start time of a process instance, while the
end time needs to be obtained directly from the DB.
By using measurements collected from all the WfMS
Containers, the framework ensures that the conditions
of the environments that host the WfMS are suitable
for benchmark execution (e.g., there are neither inter-
ferences from other running applications nor bottle-
necks in the underlying hardware). This safeguards
the reliability of the environment in which the perfor-
mance tests are executed.
3 FORMAL INTERACTION AND
ARTIFACTS
Although a carefully designed framework can lead to
a benchmark that systematically satisfies the afore-
mentioned desired properties, its industry acceptance
is not always a straightforward process. To address
this issue, in addition to the technical framework, as
part of our methodology, we also propose a process
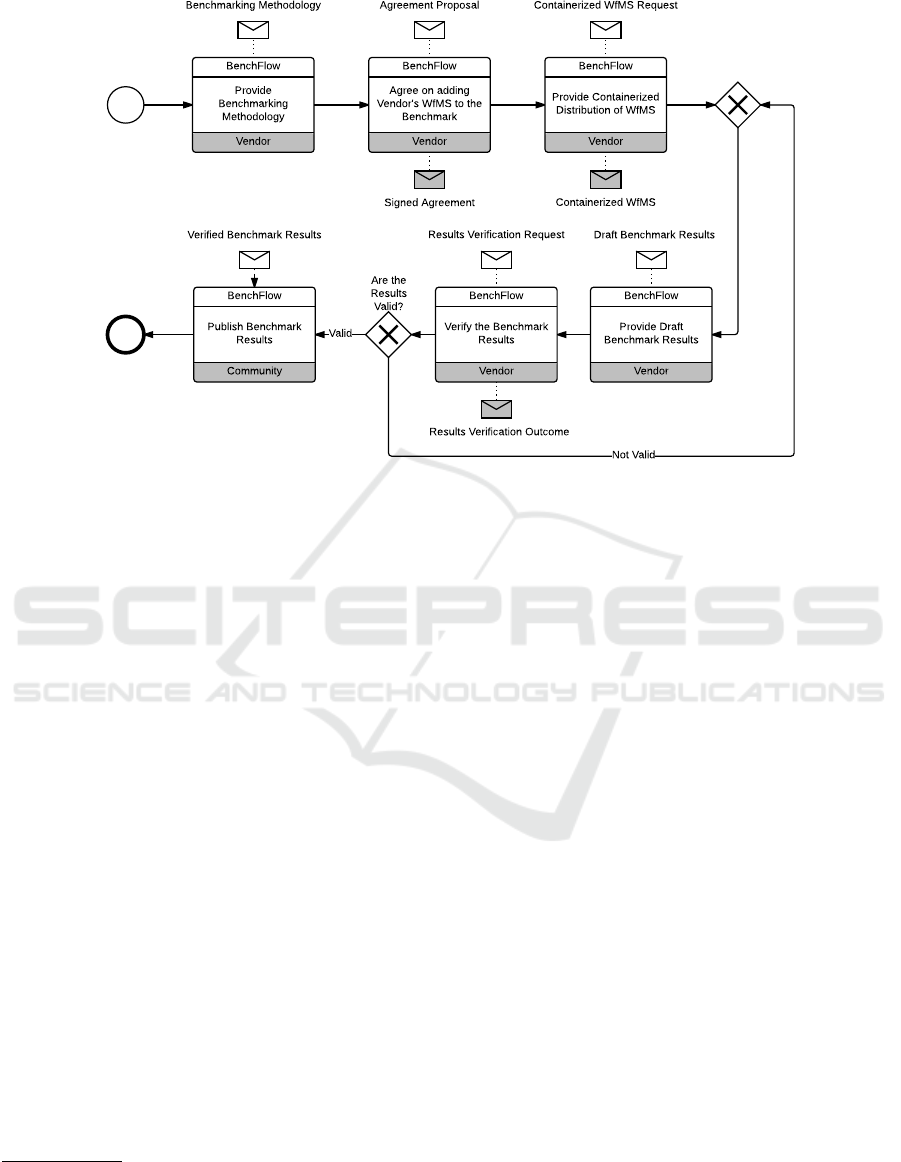
of formal interaction with WfMS vendors (Fig. 4).
Its main purpose is to enhance the transparency of
the overall benchmarking process, while promoting
the engagement of WfMS vendors. The interaction
can be initiated either by the BenchFlow team or by
the WfMS vendor. Fig. 4 depicts only the desired
path. If the vendor decides not to participate in the
benchmark, we can still run tests on its WfMS and
publish only anonymised results in research papers,
provided it is not prohibited by its licence agreement.
The rest of this section describes in detail the artifacts
exchanged or produced during the benchmarking pro-
cess.
3.1 Agreement with Vendors
After the vendor becomes familiar with the proposed
benchmarking methodology, its WfMS can only be
included in the benchmark after a written agreement
is signed. The agreement precisely defines the rights
and obligations of both parties: the vendor and the
BenchFlow team. The main concerns the vendor
needs to agree on are:
• defining which versions of the WfMS will be in-
cluded in the benchmark. Such versions need to
be a production stable release of the system and
provide at least the Core APIs described in Sub-
section 2.1.2.
• providing the BenchFlow team with a container-
ized WfMS for each version to be included in
the benchmark, or providing WfMS’s installa-
tion guide and configuration details to enable
the BenchFlow team to prepare the containerized
WfMS;
• making the containerized WfMS publicly avail-
able on a Container registry or providing the
BenchFlow team access to a private registry.
• authorizing the BenchFlow team to publish the
obtained results on its website and in research pa-
pers using WfMS’s name, after the vendor has
verified their correctness.
The framework will be publicly available for free
use for non commercial purposes, however with lim-
ited analytics functionalities. Full analytics and dif-
ferent workload models will be available to vendors
which sign the agreement and include their WfMS
in the benchmark. Thus they would benefit from de-
tailed insights to possible causes of performance bot-
tlenecks, and performance comparisons to competi-
tors’ products or to previous versions of their own
product. Namely they could integrate the benchmark-
ing framework in their performance regression testing
framework, in addition to their continuous improve-
ment efforts.
3.2 Containerized WfMS
As discussed in Section 2.2, we deploy the WfMS
components in different Containers. To isolate the
WES from other components, to access relevant data,
and to formalize WfMS configuration parameters,
we define some requirements for the containerized
WfMS. The vendor should provide at least two sep-
arate Containers, one for the WES and one for the
DBMS. Separate Containers can be provided for other
WfMS components as well (e.g., load balancers,
workload predictors and autonomic controllers) de-
pending on the WfMS’s architecture. The DBMS
Container can refer to an existing publicly available
Container distributions. The containerized WfMS
should be publicly available (e.g., at the Docker Hub
registry
8
), or the Benchflow team should be granted
access to a private registry used by the vendor. The
same applies to the Containers’ definition file, i.e., the
8
https://hub.docker.com/
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
80
Vendor
BenchFlow
Provide
Benchmarking
Methodology
Vendor
BenchFlow
Agree on adding
Vendor's WfMS to the
Benchmark
Benchmarking Methodology Agreement Proposal
Signed Agreement
Vendor
BenchFlow
Provide Containerized
Distribution of WfMS
Containerized WfMS Request
Containerized WfMS
Vendor
BenchFlow
Verify the Benchmark
Results
Results Verification Outcome
Results Verification Request
Vendor
BenchFlow
Provide Draft
Benchmark Results
Draft Benchmark ResultsVerified Benchmark Results
Not Valid
Are the
Results
Valid?
Community
BenchFlow
Publish Benchmark
Results
Valid
Figure 4: Benchmarking Methodology Choreography.
Dockerfile (Turnbull, 2014, ch. 4). While private reg-
istries are a solution that can work with vendors of
closed-source systems, they impact the reproducibil-
ity of the results. For each WfMS version to be in-
cluded in the benchmark, there must be a default con-
figuration, i.e., the configuration in which the WfMS
Containers start without modifying any configuration
parameters, except the ones required in order to cor-
rectly start the WfMS, e.g., the database connection.
However, if vendors want to benchmark the perfor-
mance of their WfMS with different configurations,
for example, the configuration provided to users as
a “getting started” configuration, or production-grade
configurations for real-life usage, they can also pro-
vide different configurations. To do that, the Con-
tainers must allow to issue the WfMS configurations
through additional environment variables
9
, and/or by
specifying the volumes to be exposed
10
in order to
access the configuration files. Exposing the volumes
allows to access the files defined inside the Contain-
ers, on the host operating system. Precisely, the WES
Container has to, at least, enable the configuration of:
1) the used DB, i.e., DB driver, url, username and
password for connection; 2) the WES itself; and 3) the
logging level of the WES, and the application stack
layers on which it may depend on. Alternatively, in-
stead of providing configuration details, the vendors
9
https://docs.docker.com/reference/run/
#env-environment-variables
10
https://docs.docker.com/userguide/dockervolumes/
#mount-a-host-directory-as-a-data-volume
can provide different Containers for different config-
urations. However, even in that case enabling the DB
configuration is required.
In order to access relevant data, all WfMS Con-
tainers have to specify the volumes to access the
WfMS log files, and to access all the data useful to
setup the system. For instance, if the WfMS defines
examples as part of the deployment, we may want
to remove those examples by overriding the volume
containing them. Moreover, the WES Container (or
the DBMS Container) has to create the WfMS’s DB
and populate it with data required to run the WfMS.
The vendors need to provide authentication configu-
ration details of the WfMS components (e.g., the user
with admin privileges for the DBMS). Alternatively
the vendor may simply provide the files needed to cre-
ate and populate the DB.
3.3 Draft Benchmark Results
The draft benchmark results delivered to the WfMS
vendor consist of two important sets of information:
1) information necessary for replicating the perfor-
mance tests, i.e., input and configuration data. They
include description of the type of tests that have been
run accompanied by all the necessary input for run-
ning them, i.e., the parameters of the workload model
and the workload as described in Subsection 2.1.1.
They also include data regarding the environment set-
up and deployment, and WfMS configuration; and 2)
information and data regarding the metrics and KPIs
calculated with the framework, both in terms of pre-
A Container-centric Methodology for Benchmarking Workflow Management Systems
81

cise definition of their calculation and purpose, as
well as, in terms of the results of their calculation and
possible interpretation of the same. If the calculation
of certain metrics/KPIs is not possible, due to lack of
data or system support of given language constructs,
the status of the metric calculation attempt will be
provided in the draft results, together with an expla-
nation of its meaning. The raw performance data, as
obtained during the execution, will also be included
in the draft results, to enable WfMS vendors to calcu-
late additional metrics not provided in the framework,
should it be necessary.
If the WfMS vendors have agreed on including
different versions or configurations of their product in
the benchmark, they would receive draft benchmark
results for each version/configuration. This would
enable them, for example, to draw conclusions on
how different configurations impact the performance
of their product and, if necessary, change their de-
fault configuration with a better performing one. They
could also control benchmark’s website for published
results from other WfMS vendors to understand their
product’s market position.
3.4 Verified Benchmark Results
After receiving the draft benchmark results, the ven-
dors can validate their correctness by replicating the
tests and comparing the obtained results. Ideally, no
significant differences should be noticed in the results
when replicating the tests using the same environment
and workload the BenchFlow team had used to per-
form the initial tests. However, should such differ-
ences be identified, the vendor has to report them to
the BenchFlow team who is obliged, by the agree-
ment, not to publish results unless they have been ver-
ified for correctness by the vendor. Iterative approach
will be followed, as evident in Fig. 4, until the results
have been verified and thus authorised for publishing
at benchmark’s website and in research papers. Rea-
sonable time for verification of draft results will be
defined in the agreement as per discussion with the
vendors.
4 RELATED WORK
To the best of our knowledge, this is the first work
proposing a Container-centric benchmarking frame-
work, and providing a full methodology for bench-
marking WfMSs. There have been various efforts to
outline structured frameworks for the description of
benchmarking methodologies applied to diverse ap-
plications and environments. Iosup et al. introduce
a generic approach for Cloud benchmarking, dis-
cuss the challenges in benchmarking Cloud environ-
ments, and summarize experiences in the field (Iosup
et al., 2014). They also propose a benchmarking tool,
SkyMark, for workloads based on the MapReduce
model (Dean and Ghemawat, 2008). Baruwal Chhetri
et al. propose Smart CloudBench (Chhetri et al.,
2015), a platform for automated performance bench-
marking of the Cloud. Both of these references pro-
pose Infrastructure-as-a-Service (IaaS) benchmark,
thus they do not deal with the challenges introduced
by benchmarking applications (e.g., the need of an
agreement with vendors). Puri presents the challenges
in benchmarking applications, and acknowledges that
the benchmarking process requires extensive planning
and thus a well defined methodology (Puri, 2008).
While the aim of the mentioned papers is similar to
ours, i.e., to formalize a benchmarking process for
emerging technologies and attract industry attention
to give feedback and share experiences, the focus is
different. In our work we focus on benchmarking a
precise middleware, the WfMS.
SPEC and TPC propose a different approach in
benchmarking software systems. Their approach can
be seen as complementary to the one proposed by us,
since it allows the vendors to execute the benchmarks
on their own hardware and send back the results. The
SPEC/TPC committees verify internally the correct-
ness of the results before publication on their website.
Their approach has demonstrated to be effective when
a standard benchmark is well defined. Currently we
are working on defining such a standard benchmark
for WfMSs, thus at this phase, we believe that feed-
back from different vendors through validation of in-
ternally calculated results, might be more effective.
The need to benchmark WfMSs is frequently dis-
cussed in literature (Wetzstein et al., 2009; Russell
et al., 2007). Gillmann et al. compare the perfor-
mance of a commercial WfMS with the one devel-
oped by the authors, by using a simple e-commerce
workflow (Gillmann et al., 2000). The benchmark
measures the throughput of each of the systems as
well as the impact of the DB work that is forwarded
to a dedicated server. Bianculli et al. propose a
more systematic approach in the SOABench (Bian-
culli et al., 2010b), where they tackle the automatic
generation, execution and analysis of testbeds for
testing the service-oriented middleware performance.
That framework is used to compare the response time
of several Web Services Business Process Execu-
tion Language (WS-BPEL) WfMSs, i.e., ActiveVOS,
jBPM, and Apache ODE (Bianculli et al., 2010a),
when using a different number of clients and differ-
ent think times between subsequent requests. The re-
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
82

sults have pointed to some scalability limitations of
the tested systems.
The limitations of the above projects, and other
work in the area (R
¨
ock et al., 2014; Skouradaki et al.,
2015; Daniel et al., 2011) lie in the fact that: 1)
they target a small number of WfMSs; 2) their work-
load mix consists of simple, non-representative pro-
cesses; 3) their performance tests are limited to, e.g.,
response time, or load testing; 4) the performance
metrics and KPIs used are not focused on WfMS,
but on software systems in general; and 5) they fo-
cus on benchmarking framework architecture, while
ignoring the methodological issues discussed in this
paper. Thus they do not satisfy the requirements of
standard benchmarks, but can be seen more as cus-
tom benchmarks. Our methodology aims at address-
ing these limitations, while being applicable on dif-
ferent industry use cases.
There are many commercial and open-source per-
formance framework solutions (Molyneaux, 2014),
some dedicated to generic web applications (Fa-
ban, 2014; The Apache Software Foundation, 2015;
SmartBear, a), and others to specific middleware per-
formance testing (Li et al., 2009; SmartBear, b).
However, none of them refers specifically to WfMSs.
Hence, this paper aims at filling that gap by offering
an open-source solution.
5 CONCLUSION AND FUTURE
WORK
Benchmarking is a widely accepted approach to as-
sess the current state of a technology and drive its per-
formance improvement (Sim et al., 2003), provided
that it meets the main requirements of relevance, trust-
worthiness, and reproducibility. To address these re-
quirements, in this paper, we propose a framework
which takes advantage of Docker Containers and Fa-
ban. They enable the automatic and reliable bench-
marking of different WfMSs, as long as the latter ex-
pose suitable APIs for process model deployment, in-
stance execution, and monitoring. The actual perfor-
mance metrics are collected and processed offline, af-
ter the workload has been completely issued in accor-
dance with the corresponding workload model. By
exploiting containerization technologies, we also deal
with some of the logistic challenges in handling the
interaction with WfMSs vendors. To enhance the
transparency, our methodology: 1) clearly defines the
interaction between the BenchFlow team and the ven-
dors, and formalises it by means of a written agree-
ment; 2) allows the vendors to provide configured
WfMS Containers for each version to be included in
the benchmark, as well as for each configuration al-
ternative; 3) defines a verification process in which
the vendors can access the draft benchmark results,
as well as all the configuration parameters for auto-
matic execution of the tests, in order to validate their
correctness.
We have started applying the methodology with
two open-source WfMSs (Ferme et al., 2015), which
is driving the further development of the complete
benchmarking framework that will be released as an
open-source. This will enable interested vendors to
apply the framework following the methodology de-
fined in this paper to obtain their performance bench-
mark results. Only then we will be able to provide
a full validation of proposed methodology’s capabil-
ities for real-world benchmarking and a definition of
KPIs capable of rightfully reflecting the differences
in performance. For the time being, the approach de-
scribed in this paper has been approved as sound by
the management of the Activiti BPM Platform
11
.
ACKNOWLEDGEMENTS
This work is funded by the Swiss National Sci-
ence Foundation and the German Research Founda-
tion with the BenchFlow project (DACH Grant Nr.
200021E-145062/1).
REFERENCES
Barbacci, M., Klein, M., et al. (1995). Quality at-
tributes. Technical report, Software Engineering In-
stitute, Carnegie Mellon University, Pittsburgh, PA.
Bianculli, D., Binder, W., and Drago, M. L. (2010a).
SOABench: Performance evaluation of service-
oriented middleware made easy. In Proc. of the ICSE
’10, pages 301–302.
Bianculli, D., Binder, W., et al. (2010b). Automated perfor-
mance assessment for service-oriented middleware: A
case study on BPEL engines. In Proc. of the WWW
’10, pages 141–150.
Boettiger, C. (2014). An introduction to Docker for repro-
ducible research, with examples from the R environ-
ment. ACM SIGOPS Operating Systems Review, Spe-
cial Issue on Repeatability and Sharing of Experimen-
tal Artifacts, 49(1):71–79.
Chhetri, M. B., Chichin, S., et al. (2015). Smart Cloud-
Bench – a framework for evaluating Cloud infras-
tructure performance. Information Systems Frontiers,
pages 1–16.
Daniel, F., Pozzi, G., and Zhang, Y. (2011). Workflow en-
gine performance evaluation by a black-box approach.
11
http://activiti.org
A Container-centric Methodology for Benchmarking Workflow Management Systems
83

In Proc. of the International Conference on Informat-
ics Engineering & Information Science (ICIEIS ’11),
ICIEIS ’11, pages 189–203. Springer.
Dean, J. and Ghemawat, S. (2008). MapReduce: Simplified
data processing on large clusters. Communications of
the ACM, 51(1):107–113.
Faban (2014). Faban. http://faban.org.
Felter, W., Ferreira, A., Rajamony, R., and Rubio, J. (2014).
An updated performance comparison of virtual ma-
chines and linux containers. Technical report, IBM.
Fenton, N. and Bieman, J. (2014). Software metrics: a rig-
orous and practical approach. CRC Press, 3rd edition.
Ferme, V., Ivanchikj, A., and Pautasso, C. (2015). A frame-
work for benchmarking BPMN 2.0 workflow manage-
ment systems. In Proc. of the 13th International Con-
ference on Business Process Management, BPM ’15.
Springer.
Geiger, M., Harrer, S., et al. (2015). BPMN conformance in
open source engines. In Proc. of the SOSE 2015, San
Francisco Bay, CA, USA. IEEE.
Gillmann, M., Mindermann, R., et al. (2000). Benchmark-
ing and configuration of workflow management sys-
tems. In Proc. of the CoopIS ’00, pages 186–197.
Gray, J. (1992). The Benchmark Handbook for Database
and Transaction Systems. Morgan Kaufmann, 2nd
edition.
Hollingsworth, D. (1995). Workflow management coalition
the workflow reference model. Workflow Management
Coalition, 68.
Huppler, K. (2009). The art of building a good bench-
mark. In Performance Evaluation and Benchmarking
(TPCTC 2009), pages 18–30. Springer.
Iosup, A., Prodan, R., et al. (2014). IaaS Cloud bench-
marking: Approaches, challenges, and experience.
In Cloud Computing for Data-Intensive Applications,
pages 83 –104. Springer New York.
Jain, R. K. (1991). The art of computer systems perfor-
mance analysis: techniques for experimental design,
measurement, simulation and modeling. Wiley, NY.
Jordan, D. and Evdemon, J. (2011). Business Pro-
cess Model And Notation (BPMN) version 2.0.
Object Management Group. http://www.omg.org/
spec/BPMN/2.0/.
Juszczyk, L., Truong, H.-L., et al. (2008). GENESIS - a
framework for automatic generation and steering of
testbeds of complex Web Services. In Proc. of the
ICECCS 2008, pages 131–140.
Leymann, F. (2011). BPEL vs. BPMN 2.0: Should you
care? In Proc. of the BPMN ’10, volume 67, pages
8–13. Springer.
Li, X., Huai, J., et al. (2009). SOArMetrics: A toolkit for
testing and evaluating SOA middleware. In Proc. of
SERVICES-1 ’09, pages 163–170.
Merkel, D. (2014). Docker: Lightweight linux containers
for consistent development and deployment. Linux J.,
2014(239).
Molyneaux, I. (2014). The Art of Application Performance
Testing: From Strategy to Tools. O’Reilly Media, Inc.,
2nd edition.
Parmenter, D. (2010). Key Performance Indicators (KPI):
developing, implementing, and using winning KPIs.
John Wiley & Sons.
Pautasso, C., Ferme, V., et al. (2015). Towards workflow
benchmarking: Open research challenges. In Proc. of
the BTW 2015, pages 331–350.
Puri, S. (2008). Recommendations for performance
benchmarking. http://www.infosys.com/consulting/
architecture-services/white-papers/Documents/
performance-benchmarking-recommendations.pdf.
R
¨
ock, C., Harrer, S., et al. (2014). Performance bench-
marking of BPEL engines: A comparison framework,
status quo evaluation and challenges. In Proc. of the
SEKE 2014, pages 31–34.
Russell, N., van der Aalst, W. M., and Hofstede, A. (2007).
All that glitters is not gold: Selecting the right tool for
your BPM needs. Cutter IT Journal, 20(11):31–38.
Sim, S. E., Easterbrook, S., et al. (2003). Using bench-
marking to advance research: A challenge to software
engineering. In Proc. of the ICSE ’03, pages 74–83.
Skouradaki, M., Roller, D. H., et al. (2015). On the road to
benchmarking BPMN 2.0 workflow engines. In Proc.
of the ICPE ’15, pages 301–304.
SmartBear. LoadUI. http://www.loadui.org/.
SmartBear. SoapUI. http://http://www.soapui.org.
The Apache Software Foundation (2015). JMeter.
http://jmeter.apache.org.
Transaction Processing Council (TPC) (1997). TPC Bench-
mark C (Online Transaction Processing Benchmark)
Version 5.11.
Transaction Processing Performance Council (2007). TPC-
E. http://www.tpc.org/tpce.
Turnbull, J. (2014). The Docker Book: Containerization is
the new virtualization.
van Hoorn, A., Vøgele, C., et al. (2014). Automatic extrac-
tion of probabilistic workload specifications for load
testing session-based application systems. In Proc. of
the VALUETOOLS 2014, pages 139–146. ICST.
Wetzstein, B., Leitner, P., et al. (2009). Monitoring and
analyzing influential factors of business process per-
formance. In Proc. of EDOC ’09, pages 141–150.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
84
