
Process Mining Monitoring for Map Reduce Applications in the Cloud
Federico Chesani, Anna Ciampolini, Daniela Loreti and Paola Mello
DISI - Department of Computer Science and Engineering, University of Bologna, Viale del Risorgimento 2, Bologna, Italy
Keywords:
Business Process Management, Map Reduce, Monitoring, Cloud Computing, Autonomic System.
Abstract:
The adoption of mobile devices and sensors, and the Internet of Things trend, are making available a huge
quantity of information that needs to be analyzed. Distributed architectures, such as Map Reduce, are indeed
providing technical answers to the challenge of processing these big data. Due to the distributed nature of
these solutions, it can be difficult to guarantee the Quality of Service: e.g., it might be not possible to ensure
that processing tasks are performed within a temporal deadline, due to specificities of the infrastructure or pro-
cessed data itself. However, relaying on cloud infrastructures, distributed applications for data processing can
easily be provided with additional resources, such as the dynamic provisioning of computational nodes. In this
paper, we focus on the step of monitoring Map Reduce applications, to detect situations where resources are
needed to meet the deadlines. To this end, we exploit some techniques and tools developed in the research field
of Business Process Management: in particular, we focus on declarative languages and tools for monitoring
the execution of business process. We introduce a distributed architecture where a logic-based monitor is able
to detect possible delays, and trigger recovery actions such as the dynamic provisioning of further resources.
1 INTRODUCTION
The exponential increase in the use of mobile devices,
the wide-spread employment of sensors across vari-
ous domains and, in general, the trending evolution
towards an “Internet of everything”, is constantly cre-
ating large volumes of data that must be processed to
extract knowledge. This pressing need for fast anal-
ysis of large amount of data calls the attention of the
research community and fosters new challenges in the
big data research area (Chen et al., 2014b). Since
data-intensive applications are usually costly in terms
of CPU and memory utilization, a lot of work has
been done to simplify the distribution of computa-
tional load among several physical or virtual nodes
and take advantage of parallelism.
Map Reduce programming model (Dean and Ghe-
mawat, 2008) has gained significant attraction for
this purpose. The programs implemented according
to this model can be automatically split into smaller
tasks, parallelized and easily executed on a distributed
infrastructure. Furthermore, data-intensive applica-
tions requires a high degree of elasticity in resource
provisioning, especially if we deal with deadline con-
strained applications. Therefore, most of the cur-
rent platforms for Map Reduce and distributed com-
putation in general (Apache Hadoop, 2015; Apache
Spark, 2015) allow to scale the infrastructure at exe-
cution time.
If we assume that the performance of the over-
all computing architecture is stable and a minimum
Quality of Service (QoS) is guaranteed, Map Reduce
parallelization model makes relatively simple to esti-
mate a job execution time by on-line checking the ex-
ecution time of each task in which the application has
been split – as suggested in the work (Mattess et al.,
2013). This estimation can be compared to the dead-
line and used to predict the need for scaling the archi-
tecture.
Nevertheless, the initial assumptions are not al-
ways satisfied and the execution time can differ from
what is expected depending on either architectural
factors (e.g., the variability in the performance of the
machines involved in the computation or the fluctua-
tion of the bandwidth between the nodes), or domain-
specific factors (e.g., a task is slowed down due to the
input data content or location). This unpredictable be-
havior could be run-time corrected if the execution re-
layed on an elastic set of computational resources as
that provided by cloud computing systems. Offering
“the illusion of infinite computing resources available
on demand” (Armbrust et al., 2009), cloud computing
is the ideal enabler for tasks characterized by a large
and variable need for computational power.
Cloud computing is indeed knowing a wide suc-
cess in a plethora of different applicative domains,
Chesani, F., Ciampolini, A., Loreti, D. and Mello, P.
Process Mining Monitoring for Map Reduce Applications in the Cloud.
In Proceedings of the 6th International Conference on Cloud Computing and Services Science (CLOSER 2016) - Volume 1, pages 95-105
ISBN: 978-989-758-182-3
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
95

thanks to the maturity of standards and implemen-
tations. Usually, the cloud is the preferred choice
for applications that must comply to a set of contract
terms and functional and non-functional requirements
specified by a service level agreement (SLA). The
complexity of the resulting overall system, as well
as the dynamism and flexibility of the involved pro-
cesses, often require an on-line operational support
checking compliance. Such monitor should detect
when the overall system deviates from the expected
behavior, and raise an alert notification immediately,
possibly suggesting/executing specific recovery ac-
tions. This run-time monitoring/verification aspect –
i.e., the capability of determining during the execu-
tion if the system exhibits some particular behavior,
possibly compliance with the process model we have
in mind – is still matter of an intense research effort in
the emergent Process Mining area. As pointed out in
(Van Der Aalst et al., 2012), applying Process Min-
ing techniques in such an online setting creates ad-
ditional challenges in terms of computing power and
data quality.
Starting point for Process Mining is an event log.
We assume that in the architecture going to be ana-
lyzed it is possible to sequentially record events. Each
event refers to an activity (i.e., a well-defined step in
some process/task) and it is related to a particular pro-
cess instance. Note that, in case of a distributed com-
putation, we also need extra information such as, for
instance, the resource/node executing, initiating and
finishing the process/task, the timestamp of the event,
or other data elements.
While, in an cloud architecture, several tools ex-
ist for performing a generic, low-level monitoring
task (Ceilometer, 2015; Amazon Cloud Watch, 2015),
we also advocate the use of an application-/process-
oriented monitoring tool in the context of Process
Mining in order to run-time check the conformance of
the overall system. Essentially, the goal of this work
is to apply the well-known Process Mining techniques
to the monitoring of complex distributed applications,
such as Map Reduce in a cloud environment.
Since Map Reduce applications typically oper-
ate in dynamic, complex and interconnected environ-
ments demanding high flexibility, a detailed and com-
plete description of their behavior seems to be very
difficult, while the elicitation of the (minimal) set
of behavioral constraints/properties that must be re-
spected to correctly execute the process (and that can-
not be directly incorporated at design time into the
system) can be more realistic and useful. Therefore,
in this context, we will adopt a verification framework
based on constraints, called MOBUCON EC (Monitor-
ing business constraints with Event Calculus (Montali
et al., 2013b)), able to dynamically monitor streams
of events characterizing the process executions (i.e.,
running cases) and check whether the constraints of
interest are currently satisfied or not. MOBUCON is
an extension of the constraint-based Declare language
(Pesic and van der Aalst, 2006) and is data aware.
This allows us to specify properties of the system
to be monitored involving time constraints and task
data. The Event Calculus (EC) formalization has been
proven a successful choice for dealing with runtime
verification and monitoring, thanks to its high expres-
siveness and the existence of reactive, incremental
reasoners (Montali et al., 2013b).
This work presents an on-line monitoring system
to check the compliance of each node of a distributed
infrastructure for data processing running on a cloud
environment. The resulting information is used for
taking scaling decisions and dynamically recovering
from critical situations with a best effort approach (by
means of an underlying previously implemented in-
frastructure layer). This could be considered as a first
step towards a Map Reduce engine with autonomic
features either in run-time detecting undesired task
behaviors, or in handling such events with dynamic
provisioning of computational resources in a cloud
scenario.
The paper is organized as follows. In Section 2,
after introducing the applicative scenario based on the
Map Reduce model, we present the overall architec-
ture, describing the main components and their rela-
tionships. A special emphasis is given to the monitor-
ing block, based on declarative constraints. Section
3 presents the use case scenario, based on the exe-
cution of a well-known benchmark over the popular
Map Reduce platform Hadoop. This section also in-
cludes the experimental results demonstrating the po-
tential of our approach. Related work and Conclu-
sions follow.
2 SYSTEM CONTEXT AND
SPECIFICATIONS
In this section, we propose a framework architecture
to online detect user-defined critical situations in a
Map Reduce environment and autonomously react by
providing or removing resources according to high-
level rules definable in declarative language.
2.1 Applicative Scenario
Map Reduce is a programming model able to sim-
plify the complexity of parallelization. Following this
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
96
approach, the input data-set is partitioned into an ar-
bitrary number of parts, each exclusively processed
by a different computing task, the mapper. Each
mapper produces intermediate results (in the form of
key/value pairs) that are collected and processed by
other tasks, called reducers, in charge of calculating
the final results by merging the values associated to
the same key. The most important feature of MapRe-
duce is that programs implemented according to this
model are intrinsically parallelizable.
In this scenario, the estimation of the execution
time can be crucial to check deadline or detect bottle-
necks but the time to execute each mapper or reducer
task can vary depending on different factors – e.g., the
content of the block of input data analyzed, the perfor-
mance of the machine on which the task is executed,
the location of the input data (local to the task or on
another machine), the bandwidth between the phys-
ical nodes of the distributed infrastructure. For this
reason, the prediction of the execution time for Map
Reduce applications is not a trivial task.
Since elasticity is so crucial in the data-intensive
scenario, all the main platforms that implement the
Map Reduce model offer application scale-up/-down
as a feature, making relatively simple to add (or re-
move) computational nodes to the distributed infras-
tructure while performing a data-intensive analysis.
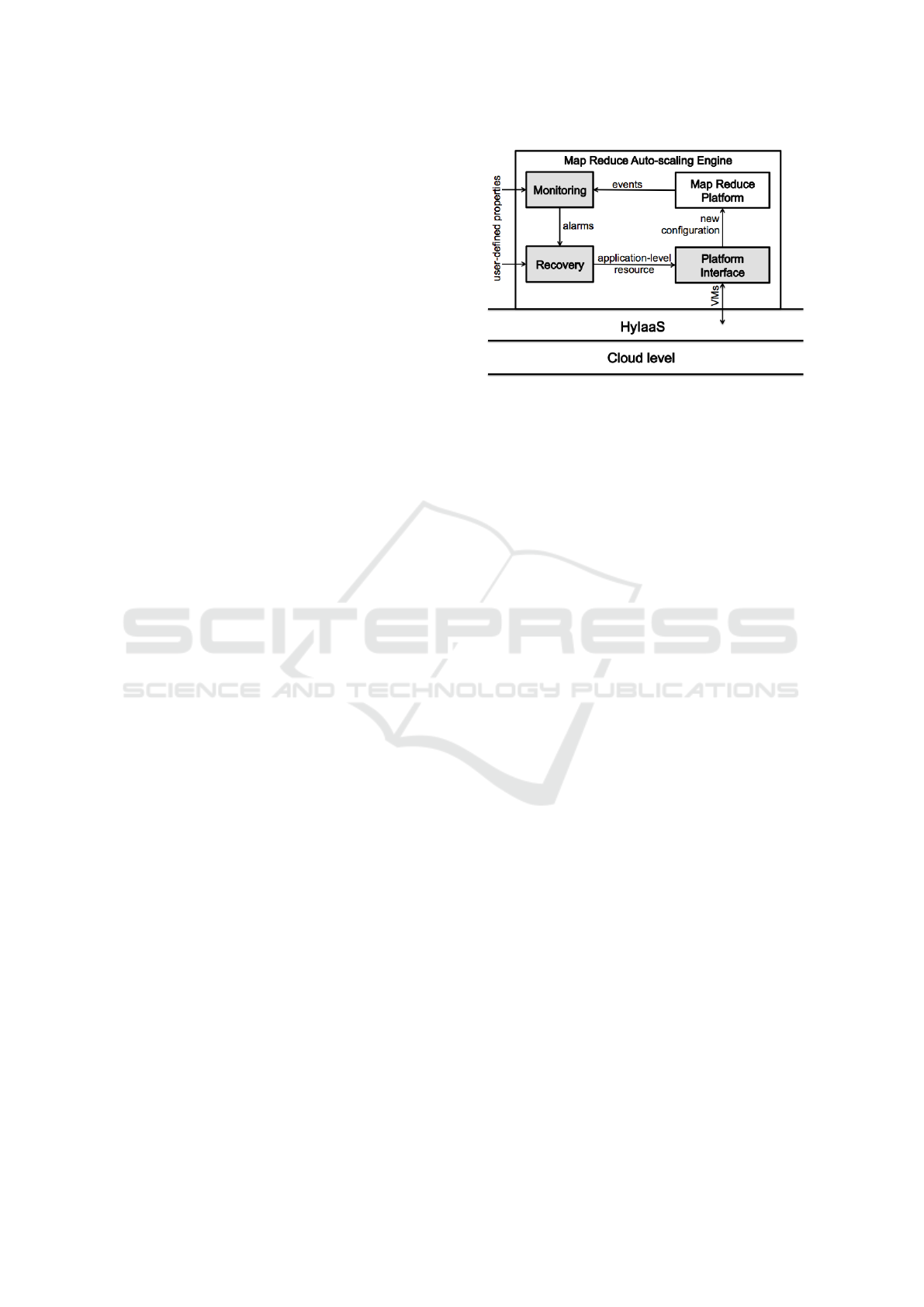
2.2 Framework Architecture
The main component of the proposed architecture is
Map Reduce Auto-scaling Engine. This application-
level software consists of three main subcomponents
(grey blocks in Figure 1): the Monitoring, Recov-
ery and Platform Interface. These elements interacts
with the Map Reduce platform to detect and react to
anomalous sequences of events in the execution flow.
The Monitoring component takes as input a high-
level specification of the system properties describ-
ing the expected behavior of a Map Reduce work-
flow and the on-line sequence of events from the Map
Reduce platform’s log. Given these input data, the
Monitoring component is able to rise alerts whenever
the execution flow violates user-defined constraints.
The alarms are evaluated by the Recovery compo-
nent in order to estimate how many computational
nodes must be provisioned (or de-provisioned) to face
the critical condition according to user-defined rules
taken as input.
Finally, the Platform Interface is in charge of
translating the requests for new Map Reduce nodes
into virtual machine (VM) provisioning requests to
the infrastructure manager. The Platform Interface is
also responsible for the installation of Map Reduce-
Figure 1: Framework architecture.
specific software on the newly provided virtual ma-
chines (VMs). The output of this subcomponent is a
new configuration of the computing cluster with a dif-
ferent number of working nodes.
As shown in Figure 1, Map Reduce Auto-scaling
Engine relays on a lower level component called Hy-
brid Infrastructure as a Service (HyIaaS) for the provi-
sioning of VMs (Loreti and Ciampolini, 2015). This
layer encapsulates the cloud functionality and inter-
acts with different infrastructures to realize a hybrid
cloud: if the resources of a private (company-owned)
on-premise cloud are no longer enough, HyIaaS redi-
rects the scale-up request to an off-premise public
cloud. Therefore, thanks to HyIaaS, the resulting
cluster of VMs for Map Reduce computation can be
composed by VMs physically deployed on different
clouds. Further details about HyIaaS can be found in
(Loreti and Ciampolini, 2015).
The hybrid nature of the resulting cluster is often
very useful (especially if the on-premise cloud has
limited capacity) but can also further exacerbate the
problem of Map Reduce performance prediction. If
part of the computing nodes is available through a
higher latency, the execution time can be substantially
afflicted by the allocation of the tasks and the amount
of information they trade with each other. Despite the
complexity of the scenario, we want the monitoring
system to offer a simple interface for the elicitation of
the properties to be respected. Nonetheless, it should
be able to rapidly identify critical situations. To this
end, we apply the MOBUCON framework to the mon-
itoring component and benefit from the application of
well-known Process Mining techniques to our envi-
ronment.
Process Mining Monitoring for Map Reduce Applications in the Cloud
97

2.3 Monitoring the System Execution
w.r.t. Declarative Constraints
Monitoring complex processes such as Map Reduce
approaches in dynamic and hybrid clouds has two
fundamental requirements: on one hand, there is the
need of a language expressive enough to capture the
complexity of the process and to represent the key
properties that should be monitored. Of course, for
practical applications, such language should come al-
ready equipped with sound algorithms and reasoning
tools. On the other hand, any monitor must produce
results in a timely fashion, being the analysis carried
out on the fly, typically during the system execution.
Declarative languages are one of the solutions
proposed in the field of Business Process Manage-
ment to answer the above requirements. In particu-
lar, they have been adopted to model business rules
and loosely-structured processes, mediating between
support and flexibility.
Among the many proposals, we focused on the
Declare language (Pesic and van der Aalst, 2006), a
graphical, declarative language for the specification
of activities and constraints. The Declare language
has been extended with temporal deadlines and data-
aware constructs in (Montali et al., 2013b; Montali
et al., 2013a), where also the MOBUCON tool has
been presented, together with some figures about its
performances in a run-time context.
Declare is a graphical language focused on activ-
ities (representing atomic units of work), and con-
straints, which model expectations about the (non)
execution of activities. Constraints range from classi-
cal sequence patterns to loose relations, prohibitions
and cardinality constraints. They are grouped into
four families: (i) existence constraints, used to con-
strain the number of times an activity must/can be ex-
ecuted; (ii) choice constraints, requiring the execution
of some activities selecting them among a set of avail-
able alternatives; (iii) relation constraints, expecting
the execution of some activity when some other activ-
ity has been executed; (iv) negation constraints, for-
bidding the execution of some activity when some
other activity has been executed. Tab. 1 shows few
simple Declare constraints.
The Declare language provides a number of ad-
vantages: being inherently declarative and open, it
supports the modeler in the elicitation of the (min-
imal) set of behavioral constraints that must be re-
spected by the process execution. Acceptable execu-
tion courses are not explicitly enumerated, but rather,
they are implicitly defined by the execution traces that
comply with all the constraints. In this sense, Declare
is indeed a notable example of flexibility by design.
Table 1: Some Declare constraints.
0
a
1..∗
b
Absence The target activity a cannot
be executed
Existence Activity b must be exe-
cuted at least once
a •−−−I b
Response Every time the source ac-
tivity a is executed, the target activity
b must be executed after a
a −−−I• b
Precedence Every time the source
activity b is executed, a must have
been executed before
a •−−−Ik b
Negation response Every time the
source activity a is executed, b can-
not be executed afterwards
Moreover, Declare (and its extensions) supports tem-
poral deadlines and data-aware constraints, thus mak-
ing it a powerful modeling tool. The MOBUCON tool
fully supports the Declare language; moreover, being
based on a Java implementation of the EC formal-
ism (Kowalski and Sergot, 1986), it provides a further
level of adaptability: the system modeler can directly
exploit the EC – as in (Bragaglia et al., 2012) – or the
Java layer underneath for a fully customizable moni-
toring. Finally, MOBUCON and the extended Declare
support both atomic and non-atomic activities.
3 USE CASE SCENARIO
The architecture shown in Figure 1 has been imple-
mented and analyzed using a testbed framework. In
particular, a simulation approach has been adopted to
create specific situations, and to verify the run-time
behavior of the whole architecture. To this end, syn-
thetic data has been generated, with the aim of stress-
ing the Map Reduce implementation.
3.1 Testbed Architecture and Data
The Map Reduce model is implemented and sup-
ported by several platforms. In this work we opted
for Apache Hadoop (Apache Hadoop, 2015), one of
the most used and popular frameworks for distributed
computing. Hadoop is an open source implemen-
tation consisting of two components: Hadoop Dis-
tributed File System (HDFS) and Map Reduce Run-
time. The input files for Map Reduce jobs are split
into fixed size blocks (default is 64 MB) and stored in
HDFS. Map Reduce runtime follows a master-worker
architecture. The master (Job-Tracker) assigns tasks
to the worker nodes. Each worker node runs a Task-
Tracker daemon that manages the currently assigned
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
98

task. Each worker node can have up to a predefined
number of mappers and reducers simultaneously run-
ning. This concurrent execution is controlled through
the concept of slot: a virtual container that can host a
running task. The user can specify the number s
w
of
slots for each worker w. This number should reflect
the maximum number of processes that the worker
can concurrently run (e.g., on a dual core with hyper-
threading s
w
is suggested to be 4). The Job-Tracker
will assign to each worker a number n
w
of tasks to be
concurrently executed, such that the relation n
w
≤ s
w
is always guaranteed.
We define S as the total number of slots in the
MapReduce platform:
S =
∑
w
s
w
(1)
The value in Eq. 1 also addresses the total number
of tasks that the platform can concurrently execute.
For the sake of simplicity, we start focusing only
on map phase deadlines because all the map tasks usu-
ally operates on similar volumes of data and we can
assume that in a normal execution they will require
similar amount of time – as also suggested by (Matt-
ess et al., 2013). The deadline t
M
for each mapper can
be evaluated as:
t
M
=
D
M
· S
M
(2)
Where D
M
is the deadline for the execution of the
map phase and M is the total number of mapper to be
launched. Conversely, the amount of data processed
by the reduce phase is unknown until all the mappers
have completed, thus complicating the estimation of
a deadline for each reducer.
Our Hadoop testbed is composed of 4 VMs: 1
master and 3 worker nodes. Each VM has 2 VCPUs,
4GB RAM and 20GB disk. At the cloud level we
use 5 physical machines, each one with a Intel Core
Duo CPU (3.06 GHz), 4GB RAM and 225GB HDD.
Since a dual core machine (without hyperthreading)
can concurrently execute at most two tasks, we as-
signed two slots to each worker. Our Map Reduce
platform can therefore execute up to six concurrent
tasks (S = 6).
As for the task type, we opted for a word count
job, often used as a benchmark for assessing perfor-
mances of a Map Reduce implementation. In our sce-
nario we prepared a collection of 20 input files of
5MB each. Consequently, Hadoop Map Reduce Run-
time launches M = 20 mappers to analyze the input
data. In this testbed, we would like to complete the
map phase in D
M
= 200 seconds, so every map task
should not exceed one minute execution.
According to the default Hadoop configuration,
the output of all these mappers is analyzed by a sin-
gle reducer. In order to emulate the critical condition
of some tasks showing an anomalous behavior, we ar-
tificially modified 8 input files, so has to simulate a
dramatic increase of the time required to complete the
task. The mappers analyzing these blocks resulted to
be 6 times slower than the normal ones.
Note that, as other MapReduce platforms, Hadoop
has a fault tolerance mechanism to detect the slow
tasks and relaunch them from the beginning on other
– possibly more performing – workers. This solu-
tion is useful in case the problem is caused by ar-
chitectural factors (poor performance or bandwidth
saturation on the original worker), but is likely to be
counter-productive when the execution slow down is
related to the content of the data blocks involved. In
that case indeed, the problem will occur again on the
new worker. The only way to speed up the compu-
tation is by assigning to the newly provided workers
other pending tasks in the queue, thus to increase the
value of S for the MapReduce platform.
3.2 Properties to be Monitored
In this work we mainly focus on time-constrained data
insight: the aim is to identify as soon as possible the
critical situation of the Map Reduce execution going
to complete after a predefined deadline. Practically
speaking, this correspond to situations where the total
execution time of the Map Reduce is expected to stay
within some (business-related) deadline: e.g., banks
and financial bodies require to perform analyses of
financial transactions during night hours, and to pro-
vide outcomes at the next work shift.
The MOBUCON framework already provides a
model of activities execution, where a number of
properties to be monitored are already directly sup-
ported. In particular, a support for non-atomic ac-
tivities execution is proposed within the MOBUCON
framework, where for each start of execution of a spe-
cific ID, a subsequent end of execution (with same ID)
is expected. This feature has been particularly use-
ful during the verification of our testbed, to identify a
number of exceptions and worker faults due to prob-
lems and issues not directly related to the Map Re-
duce approach. For example, during our experiments
we ignored fault events generated by power shortages
of some of the PC composing the cloud. The out-of-
the-box support offered by MOBUCON was exploited
to identify these situations and rule them out.
To detect problematic mappers, we decided to
monitor a very simple Declare property between the
start and the end of the elaboration of each mapper.
Process Mining Monitoring for Map Reduce Applications in the Cloud
99

Map start
(0..60)
•−−−−−I Map end
Figure 2: Declare Response constraint, with a metric tem-
poral deadline.
Declare augmented with metric temporal deadlines as
in (Montali et al., 2013b) was exploited to this end,
and the constraint shown in Figure 2 illustrates the
Response constraint we specified in MOBUCON. It
simply states that after an event Map start, a corre-
sponding event Map end should be observed, within
zero and 60 seconds
1
. Notice that MOBUCON cor-
relates different events on the basis of the case: i.e.,
it requires that every observed event belongs to a spe-
cific case, identified by a single case ID. To fulfill such
requirement, we fed the MOBUCON monitor with the
events logged by the Hadoop stack, and exploited the
Map identifier (assigned by Hadoop to each mapper)
as a case ID. This automatically ensures that each
Map start event is indeed matched with the corre-
sponding Map end event.
The constraint shown in Figure 2 allows us to de-
tect mappers that are taking too much time to compute
their task. The deadline set to 60 seconds has been
chosen on the basis of the total completion time we
want to respect while analyzing the simulation data.
Naturally, some knowledge about the application do-
main is required to properly set such deadline. Map-
pers that violate the deadline are those that, unfortu-
nately, were assigned a long task. This indeed would
not be a problem for a single mapper. However, it
could become a problem if a considerable number of
mappers gets stuck on long tasks, as this might un-
dermine the completion of the whole bunch of data
within a certain deadline. Note that, if the user doesn’t
have any knowledge of the volume of data to be pro-
cessed – and consequently, the number of map tasks
to be launched is not known a priori –, this method-
ology allow him to still detect anomalies in the data
that can require additional resources to speed up the
computation. For example, the deadline for each map
task can be computed at execution time by taking into
account the average completion time for each com-
pleted mapper. The same approach can be used for
the runtime estimation of the reduce phase deadline
compliance.
Besides supporting the monitoring of Declare
constraints, MOBUCON supports also the definition
of user-specific properties. We exploited this fea-
ture and expressed a further property by means of
1
MOBUCON accepts deadlines at different time units. In
this paper we opted for expressing the time unit in terms
of seconds, although depending on the application domain
minutes or milliseconds might be better choices.
the EC language. The property, that we named
long execution maps, aims to capture all the mappers
that have already violated the deadline, and that are
still active (i.e., a start event has been seen for that
mapper, and no end event has yet been observed).
Such definition is given in terms of an EC axiom:
initiates(
deadline expired(A, ID),
status(i(ID, long execution maps), too long),
T
) ←
holds at(status(i(ID, waiting task), pend), T ),
holds at(status(i(ID, A), active), T ).
We do not provide here all the details about the ax-
iom – the interested reader can refer to (Kowalski and
Sergot, 1986) for an introduction to EC. Intuitively,
the axiom specifies that at any time instant T , the
happening of the event deadline expired(A, ID) ini-
tiates the property long execution maps with value
too long for the mapper ID, if that mapper was still
active and there was a constraint waiting task still not
fulfilled. The waiting task constraint is indeed the re-
sponse constraint we discussed in Figure 2.
With the long execution maps property we can
determine within the MOBUCON monitor which are
the mappers that got stuck on some task. However, to
establish if a problem occur to the overall system, we
should aggregate this information, and consider for
each time instant how many mappers are stuck w.r.t.
the total number of available mappers. Exploiting the
MOBUCON feature of supporting also a healthiness
function, we provided the following function:
System health = 1 −
#long execution maps
#total maps available
(3)
In other words, the system health is expressed as
the fraction of mappers that are not busy with a long
task, over the total number of launched mappers. The
lower the value, the higher the risk that the overall
Hadoop framework gets stuck and violates some busi-
ness deadline. In order to make the health function
more responsive, we can define a window of map task
to be considered in the computation of system health.
3.3 The Output from MOBUCON
Monitor
In Figure 3, we show what happens when we analyze
a word count execution on the Hadoop architecture
described in Section 3.1, with respect to the proper-
ties discussed in Section 3.2. Note that, as we focus
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
100
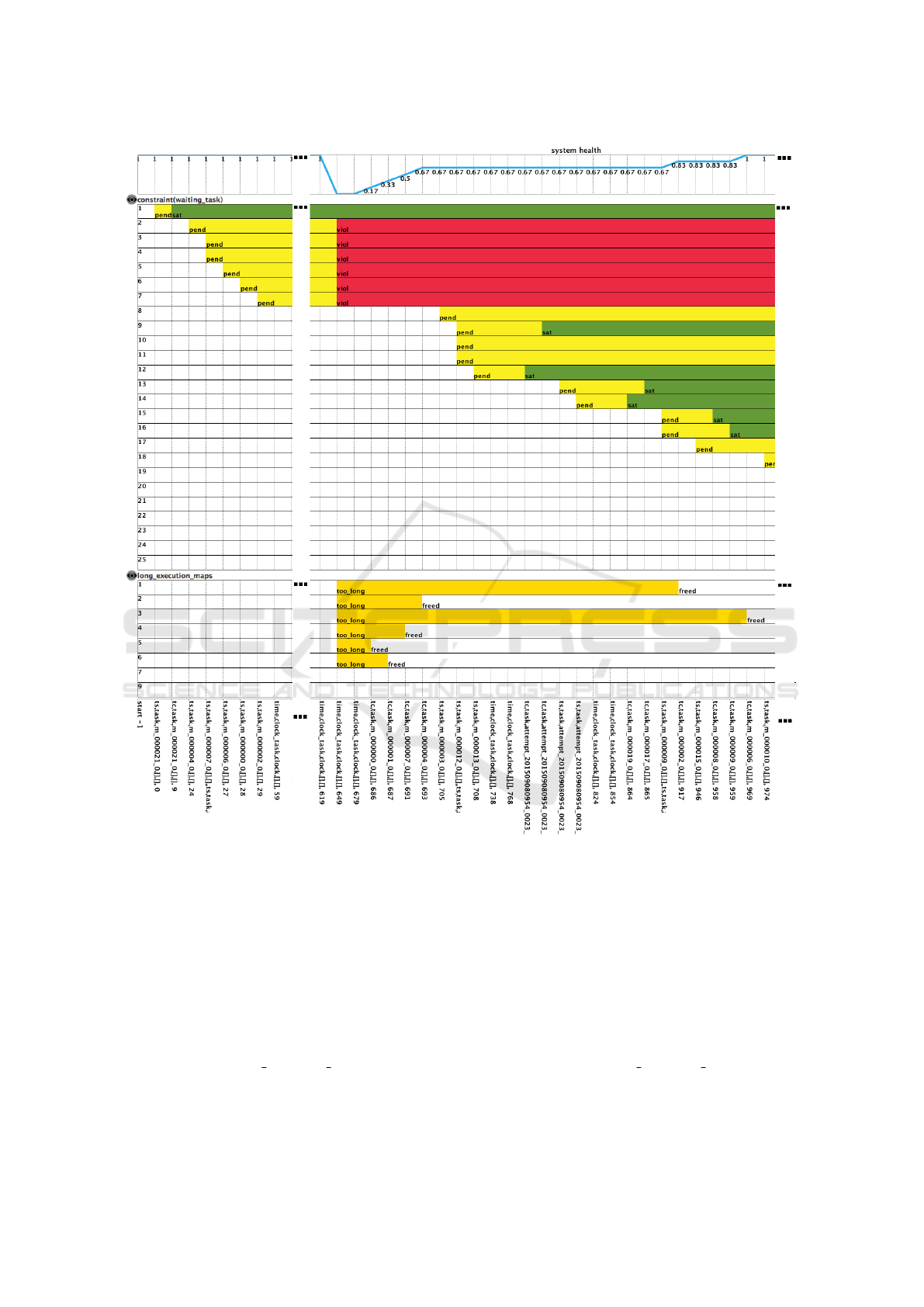
Figure 3: The output of the MOBUCON monitor for the execution of word count job on the given testbed.
on the performance of the system when data-specific
factors slow down the computation, the declarative se-
mantic employed and the results of the following eval-
uation are independent from the specific MapReduce-
encoded problem (e.g., word count, terasort, inverted
index etc.).
Figure 3 is composed of four strips, representing
the evolution of different properties during the exe-
cution. From top to bottom of the figure we have:
the health function, graphical representation of the
Declare constraint, long execution maps property and
description of the events occurred in each time inter-
val. In the latter in particular (bottom part of Figure
3), the observed events has starting labels ts or tc to
represent the start and the completion of a task, re-
spectively. There are also a number of events starting
with the label time: these events represent the ticking
of a reference clock, used by MOBUCON to establish
when deadlines are expired.
The health function on top of Figure 3 is the one
defined in Eq. 3: indeed, the system healthiness dra-
matically decreased when six over seven of the first
mappers launched in our testbed got stuck in a long
execution task. The long execution maps strip (third
strip from the top in Figure 3) further clarifies the in-
tervals during which the long map tasks exceed their
Process Mining Monitoring for Map Reduce Applications in the Cloud
101
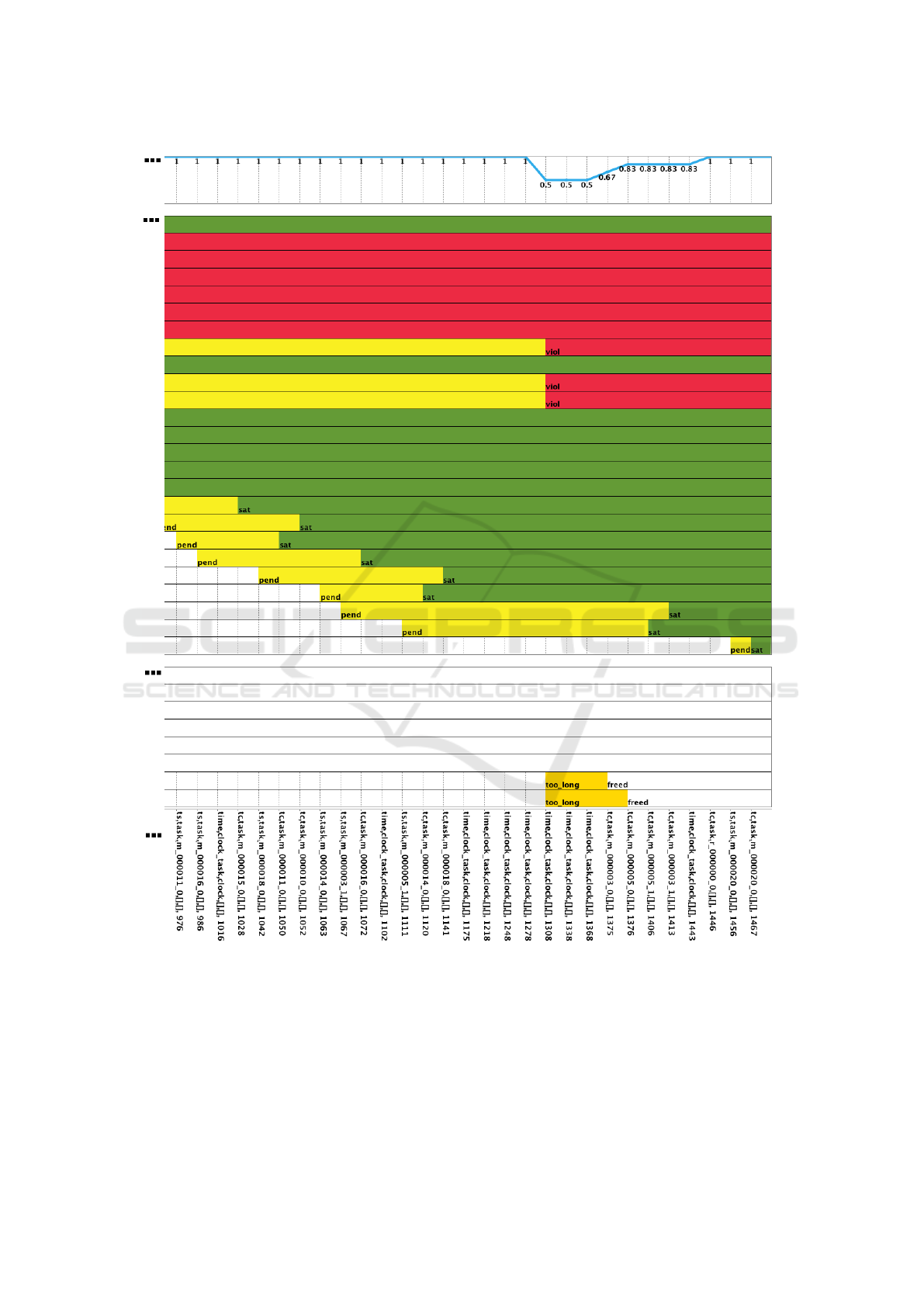
Figure 4: Output of the MOBUCON monitor subsequent to Figure 3.
time deadline.
Finally, the Declare response constraint strip (sec-
ond strip from the top in Figure 3) shows the status
of each mapper: when the mapper is executing, the
status is named pending and it is indicated with a yel-
low bar. As soon as there is information about the
violation of a deadline (because of a tick event from
the reference clock), the horizontal bar representing
the status switched from pending to violated, and the
color is changed from bright yellow to red. Notice
that once violated (red color), the response constraint
remains as such: indeed, this is a consequence of
the Declare semantics where no compensation mech-
anisms are considered.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
102

For reasons of space, we provide in Figure 4 the
evolution of our test (subsequent to what shown in
Figure 3). As expected, the total number of mapper
violating the deadline constraint is 8, as we provided
8 modified files in the input dataset. MOBUCON is
therefore able to suddenly and efficiently identify any
anomaly in the Hadoop execution (according to sim-
ple user-defined constraints).
The health function values in the output of
MOBUCON monitor can be used to determine when
a recovery action is needed. The intervention can be
dynamically triggered by a simple threshold mecha-
nism over the health function or by a more complex
user-defined policy (e.g., implementing an hysteresis
cycle), possibly specified with a declarative approach.
Once the number of additional Hadoop workers
needed is determined, Map Reduce Auto-scaling En-
gine relays on HyIaaS for the provisioning of VMs
over a single public cloud or federated hybrid envi-
ronment.
During the evaluation depicted in Figure 3 and 4,
85 events are processed by the MOBUCON monitor
in 285 milliseconds (worst case over 10 evaluations).
Thanks to the high expressiveness of the adopted
declarative language, the user can define complex
constraints, thus increasing the computational cost of
the runtime monitoring. We are aware that, under this
condition, the system can suffer a penalty in the exe-
cution time and the described method can show lim-
its when dealing with fast monitored tasks (i.e., the
time between task start and task end events is too
short for the Monitoring component to evaluate the
compliance). Nevertheless, in the envisioned MapRe-
duce scenario, the average duration time is in general
higher than the time required by MOBUCON to check
the constraints. Furthermore, since the recovery ac-
tion to provide additional workers is intrinsically time
consuming (tens of minutes), the Monitoring compo-
nent is not requested to be responsive in the order of
sub-seconds. Therefore, we can state that the time to
detect anomalies shown in Figure 3 and 4 is accept-
able for the envisioned scenario.
4 RELATED WORK
Cloud computing is currently used for a wide and het-
erogeneous range of tasks. It is particularly useful as
elastic provider of virtual resources, able to contribute
to heavy computing tasks.
Data-intensive applications are an example of re-
source demanding tasks. A widely adopted pro-
gramming model for this scenario is MapReduce
(Dean and Ghemawat, 2008), whose execution can
be supported by platforms such as Hadoop (Apache
Hadoop, 2015), possibly in a cloud computing infras-
tructure. We tested our system with MapReduce ap-
plications, choosing Hadoop as execution engine.
Recently, a lot of work has focused on cloud
computing for the execution of big data applications:
as pointed out in (Collins, 2014), the relationship
between big data and the cloud is very tight, be-
cause collecting and analyzing huge and variable vol-
umes of data require infrastructures able to dynam-
ically adapt their size and their computing power
to the application needs. The work (Chen et al.,
2014a) presents an accurate model for optimal re-
source provisioning useful to operate MapReduce ap-
plications in public clouds. Similarly, (Palanisamy
et al., 2015) deals with optimizing the allocation of
VMs executing MapReduce jobs in order to mini-
mize the infrastructure cost in a cloud datacenter. In
the same single-cloud scenario, the work (Rizvandi
et al., 2013) focuses on the automatic estimation of
MapReduce configuration parameters, while (Verma
et al., 2011) proposes a resource allocation algorithm
able to estimate the amount of resources required to
meet MapReduce-specific performance goals. How-
ever, these models were not intended to address the
challenges of the hybrid cloud scenario, which is a
possible target environment for the provisioning of
additional VMs in our system thanks to the underly-
ing HyIaaS layer.
More similarly to our approach, cloud bursting
techniques has been adopted for scaling MapReduce
applications in the work(Mattess et al., 2013), which
presents an online provisioning policy to meet a dead-
line for the Map phase. Differently from our ap-
proach, (Mattess et al., 2013) focuses on the predic-
tion of the execution time for the Map phase with
a traditional approach to monitoring, which intro-
duces complexity in the implementation and tuning,
whereas our solution can benefit from a simple enun-
ciation of the system properties relaying on Declare
language.
Also the work presented in (Kailasam et al., 2014)
deals with cloud monitoring/management for big data
applications. It proposes an extension of the MapRe-
duce model to avoid the shortcomings of high laten-
cies in inter-cloud data transfer: the computation in-
side the on-premise cloud follows the batch MapRe-
duce model, while in the public cloud a stream pro-
cessing platform called Storm is used. The resulting
system shows significant benefits. Differently from
(Kailasam et al., 2014), we chose to keep complete
transparency and uniformity with respect to the allo-
cation of the working nodes and their configuration.
As regards the use of EC for verification and mon-
Process Mining Monitoring for Map Reduce Applications in the Cloud
103

itoring, several examples can be found in letterature
in different application domains but we are not aware
of any work applying it to the monitoring of MapRe-
duce jobs in a cloud environment. EC has been used
in various fields to verify the compliance of a sys-
tem to user-defined behavioral properties. For exam-
ple, (Spanoudakis and Mahbub, 2006), (Farrel et al.,
2005) exploit ad-hoc event processing algorithms to
manipulate events and fluents, written in JAVA. Dif-
ferently from MOBUCON they do not have an under-
lying formal basis, and they cannot take advantage of
the expressiveness and computational power of logic
programming.
Several authors – (Giannakopoulou and Havelund,
2001), (Bauer et al., 2011) – have investigated the use
of temporal logics – Linear Temporal Logic (LTL)
in particular – as a declarative language for specify-
ing properties to be verified at runtime. Neverthe-
less, these approaches lack the support of quantitative
time constraints, non-atomic activities with identifier-
based correlation, and data-aware conditions. These
characteristics – supported by MOBUCON – are in-
stead very important in our application domain.
5 CONCLUSIONS
This work present a framework architecture that en-
capsulates an application level platform for data-
processing. The system lends the Map Reduce in-
frastructure the ability to autonomously check the
execution, detecting bottlenecks and constraint vio-
lations through Business Process Management tech-
niques with a best effort approach.
Focusing on activities and constraints, the use of
Declare language has shown significant advantages
in the monitoring system implementation and cus-
tomization.
Although this work represents just a first step to-
wards an auto-scaling engine for Map Reduce, its
declarative approach to the monitoring issue shows
promising results, both regarding the reactivity to crit-
ical conditions and the simplification in monitoring
constraint definition.
For the future, we plan to employ the defined
framework architecture to test various diagnosis and
recovery policies and verify the efficacy of the over-
all auto-scaling engine in a wider scenario (i.e., with
a higher number of Map Reduce workers involved).
Finally, particular attention will be given to the
hybrid cloud scenario, where the HyIaaS component
is employed to transparently perform VM provision-
ing either on an on-premise internal or an off-premise
public cloud. In case of a hybrid deploy, several ad-
ditional constraints will need to be taken into account
(e.g., the limited inter-cloud bandwidth), thus further
complicating the implemented monitoring and recov-
ery policies. Nevertheless, we believe that a declara-
tive approach to the problem can contribute to signif-
icantly simplify the implementation of the solution.
REFERENCES
Amazon Cloud Watch (2015). Amazon cloud monitor
system. https://aws.amazon.com/it/cloudwatch/. Web
Page, last visited in Dec. 2015.
Apache Hadoop (2015). Apache software foundation.
https://hadoop.apache.org/. Web Page, last visited in
Dec. 2015.
Apache Spark (2015). Apache software foundation.
http://spark.apache.org. Web Page, last visited in
Dec. 2015.
Armbrust, M., Fox, O., and R., G. (2009). Above the
clouds: A berkeley view of cloud computing. Techni-
cal report, Electrical Engineering and Computer Sci-
ences University of California at Berkeley.
Bauer, A., Leucker, M., and Schallhart, C. (2011). Runtime
verification for ltl and tltl. ACM Trans. Softw. Eng.
Methodol., 20(4):14:1–14:64.
Bragaglia, S., Chesani, F., Mello, P., Montali, M., and Tor-
roni, P. (2012). Reactive event calculus for monitoring
global computing applications. In Logic Programs,
Norms and Action. Springer.
Ceilometer, O. (2015). the openstack monitoring module.
https://wiki.openstack.org/wiki/ceilometer.
Chen, K., Powers, J., Guo, S., and Tian, F. (2014a). Cresp:
Towards optimal resource provisioning for mapreduce
computing in public clouds. Parallel and Distributed
Systems, IEEE Transactions on, 25(6):1403–1412.
Chen, M., Mao, S., and Liu, Y. (2014b). Big data: A
survey. Mobile Networks and Applications, Volume
19(2):171–209.
Collins, E. (2014). Intersection of the cloud and big data.
Cloud Computing, IEEE, 1(1):84–85.
Dean, J. and Ghemawat, S. (2008). Mapreduce: Simpli-
fied data processing on large clusters. Commun. ACM,
51(1):107–113.
Farrel, A., Sergot, M., Sall
`
e, M., and Bartolini, C. (2005).
Using the event calculus for tracking the normative
state of contracts. International Journal of Coopera-
tive Information Systems, 14(02n03):99–129.
Giannakopoulou, D. and Havelund, K. (2001). Automata-
based verification of temporal properties on running
programs. In Automated Software Engineering, 2001.
(ASE 2001). Proceedings. 16th Annual International
Conference on, pages 412–416.
Kailasam, S., Dhawalia, P., Balaji, S., Iyer, G., and Dha-
ranipragada, J. (2014). Extending mapreduce across
clouds with bstream. Cloud Computing, IEEE Trans-
actions on, 2(3):362–376.
CLOSER 2016 - 6th International Conference on Cloud Computing and Services Science
104

Kowalski, R. A. and Sergot, M. J. (1986). A Logic-Based
Calculus of Events. New Generation Computing.
Loreti, D. and Ciampolini, A. (2015). A hybrid cloud in-
frastructure fo big data applications. In Proceedings
of IEEE International Conferences on High Perfor-
mance Computing and Communications.
Mattess, M., Calheiros, R., and Buyya, R. (2013). Scaling
mapreduce applications across hybrid clouds to meet
soft deadlines. In Advanced Information Networking
and Applications (AINA), 2013 IEEE 27th Interna-
tional Conference on, pages 629–636.
Montali, M., Chesani, F., Mello, P., and Maggi, F. M.
(2013a). Towards data-aware constraints in declare.
In Shin, S. Y. and Maldonado, J. C., editors, Proceed-
ings of the 28th Annual ACM Symposium on Applied
Computing, SAC ’13, Coimbra, Portugal, March 18-
22, 2013, pages 1391–1396. ACM.
Montali, M., Maggi, F. M., Chesani, F., Mello, P., and
van der Aalst, W. M. P. (2013b). Monitoring busi-
ness constraints with the event calculus. ACM TIST,
5(1):17.
Palanisamy, B., Singh, A., and Liu, L. (2015). Cost-
effective resource provisioning for mapreduce in a
cloud. Parallel and Distributed Systems, IEEE Trans-
actions on, 26(5):1265–1279.
Pesic, M. and van der Aalst, W. M. P. (2006). A Declar-
ative Approach for Flexible Business Processes Man-
agement.
Rizvandi, N. B., Taheri, J., Moraveji, R., and Zomaya,
A. Y. (2013). A study on using uncertain time se-
ries matching algorithms for mapreduce applications.
Concurrency and Computation: Practice and Experi-
ence, 25(12):1699–1718.
Spanoudakis, G. and Mahbub, K. (2006). Non-intrusive
monitoring of service-based systems. Interna-
tional Journal of Cooperative Information Systems,
15(03):325–358.
Van Der Aalst, W., Adriansyah, A., de Medeiros, A. K. A.,
and Arcieri, F. (2012). Process mining manifesto. In
Business Process Management Workshops. Springer
Berlin Heidelberg.
Verma, A., Cherkasova, L., and Campbell, R. H. (2011). Re-
source Provisioning Framework for MapReduce Jobs
with Performance Goals, volume 7049 of Lecture
Notes in Computer Science, pages 165–186. Springer
Berlin Heidelberg.
Process Mining Monitoring for Map Reduce Applications in the Cloud
105
