
Estimating the Functionality of Mashup Applications for Assisted,
Capability-centered End User Development
Carsten Radeck, Gregor Blichmann and Klaus Meißner
Faculty of Computer Science, Technische Universit
¨
at Dresden, Dresden, Germany
Keywords:
Mashup, End User Development, Capability, Capability Estimation, Assistance.
Abstract:
The mashup paradigm allows end users to build their own web applications consisting of several components
in order to fulfill specific needs. Thereby, communicating on a non-technical level with non-programmers as
end users is crucial. It is also necessary to assist them, for instance, by explaining inter-widget communication
and by helping to understand a mashup’s functionality. However, prevalent mashup approaches provide no
or limited concepts for these aspects. In this paper, we present our proposal for estimating and formalizing
the functionality of mashup compositions based on capabilities of components and their communication links.
It is the foundation for our end-user-development approach comprising several assistance mechanisms, like
presenting the functionality of mashups and recommended composition steps. The concepts are implemented
and evaluated by means of example applications and an expert evaluation.
1 INTRODUCTION
Powered by the growth of available web resources
and application programming interfaces, the mashup
paradigm enables loosely coupled components to be
re-used in a broad variety of application scenarios
to fulfill the long tail of user needs. Recently, uni-
versal composition approaches allow for platform-
independent modeling of composite web applica-
tion (CWA) and uniformly describing and composing
components spanning all application layers, ranging
from data and logic services to user interface widgets.
The mashup paradigm and end-user development
complement each other quite well. It is, however,
still very cumbersome for end-users, especially as
non-programmers are the target group, to develop
and even use CWA. Challenging tasks in CWA de-
velopment and usage, posing tough requirements to
mashup platforms, are amongst others: (1) express-
ing goals or requirements towards the mashup in a
non-technical manner, (2) understanding what sin-
gle components are capable of and what functional-
ity they provide in interplay, (3) being aware of inter-
widget communication, as shown by (Chudnovskyy
et al., 2013), (4) adding or removing whole “func-
tional blocks” rather than several technical elements
like components and connections, and (5) understand-
ing what functionality recommendations will provide
in context of the current task.
Our platform adheres to universal composition
and strives for enabling domain experts without pro-
gramming skills to build and use situation-specific
mashups. Non-programmers can extend or manipu-
late a running application to get instant feedback on
their actions and are guided by recommendations on
composition patterns (Radeck et al., 2012). We se-
mantically annotate components with the functional-
ity they provide in terms of capabilities. Based on
this, the capabilities of whole composition models are
estimated. This allows our mashup environment to of-
fer a set of assistance features which we illustrate with
the help of two scenarios.
Scenario 1: Non-programmer Bob uses an exist-
ing mashup for travel planning recommended by a
friend. It consists of two maps, a route calculator, a
weather widget and two widgets for searching points
of interest and hotels. Since he is neither familiar with
the overall application nor the components utilized,
Bob faces several understanding problems of what the
mashup provides and what not. For instance, Bob is
not sure why there are two maps, if the location in a
map has effect in other components, and if so, which
kind of effect, and how to find hotels near the target
location. While normally he would have to explore
the mashup manually in a try&error style, the plat-
form supports Bob in gaining insight. First, there is
an overview panel displaying the mashup functional-
ity, possibly composed of several sub-functionalities.
Radeck, C., Blichmann, G. and Meißner, K.
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development.
In Proceedings of the 12th International Conference on Web Information Systems and Technologies (WEBIST 2016) - Volume 2, pages 109-120
ISBN: 978-989-758-186-1
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
109

It allows Bob to inspect what tasks he can solve with
the application and gets aware of the components that
partake. This way, Bob understands that one map
serves for selecting the start location, while the other
is used to select the target location for the route. Fur-
thermore, Bob can start animations explaining neces-
sary steps and interactions he has to perform, e. g., to
see a list of routes. Bob activates a mode animating
the actual data flow. Thus, Bob gets aware of data
transfer between map and weather widget, which are
positioned far away from each other on the screen.
Additionally, Bob is assisted in identifying capabili-
ties of a component and how these are reflected on the
component UI. So, Bob understands that he can move
a marker or type the location name in an input field
of the map in order to select a location. After using
the mashup for a while, the platform recommends ex-
tensions useful regarding the functionality it already
provides. All recommendations are visualized by dis-
playing the functionality they would offer.
Scenario 2: Knowledge-worker Alice has good
domain knowledge, but no programming skills, and
requires an enterprise search CWA for finding experts
within her company for a certain topic. In a wizard-
style dialog Alice is asked by the mashup platform to
answer questions or define criteria in order to derive
her goals in form of domains concepts and activities
or tasks to be performed on those. Thereby, Alice
gets advice on existing, similar, alternative and com-
plementary concepts as well as tasks. During this iter-
ative procedure, mashups that semantically match her
requirements at least partially are identified based on
a classification of the provided functionality and are
previewed to her. Since a hierarchical functionality
description is supported, mashups that offer “search
experts” on highest level can be considered possible
candidates although on lower levels of the capability
model and especially comparing the underlying com-
position models there may be differences. Facilitating
this, Alice can decide which optional functionalities
she needs or does not need, implicitly selecting a can-
didate. After finishing a certain subtask in the selected
mashup, she removes it from the application. Neces-
sary changes according to the technical composition
model are done transparently. Finally, she shares an-
other sub-task with the responsible colleague Horst.
In order to implement the scenarios, to provide
the mentioned features, and to tackle the challenges
stated above, there are at least the following founda-
tional requirements:
• The functionality of composition fragments has to
be described. The notion composition fragment
refers to arbitrary partial composition models like
components, patterns and whole applications. In
order to allow for automation at least some for-
malism is required. To further ease understand-
ing, there should be a link between capabilities
and actual UI-parts which serve to provide them.
• While capabilities of components can be statically
defined, it is far from trivial to estimate the func-
tionality of component interplay in an arbitrary
composition fragment. Such a description should
be derived semi-automatically, i. e., automatic es-
timation complemented with learning techniques
and feedback for validation to increase quality.
While most mashup approaches support users with
recommendations, assisting the understanding of the
mashup at hand or presenting recommendations by
the functionality they provide is neglected so far. Es-
timating which functionality a user wants to achieve
with his current mashup is out of scope, too. In or-
der to allow for such features, basic concepts like a
proper model and derivation algorithms are currently
missing.
Thus, the contributions of this paper are twofold.
First, we introduce a model for light-weight func-
tional semantics – capabilities – of composition frag-
ments, which also allows to establish a link between
semantic and UI layer. Based on this, we present,
evaluate and show the practicability of an algorithm
for estimating a composition fragment’s capabilities.
These concepts are the basis for our capability-
centered End User Development (EUD) approach.
Several development and assistance tools and mech-
anisms rely on knowledge about a composition frag-
ment’s capabilities, provided by component capabil-
ities and inter-component communication, and their
relation to component UIs, e. g., in order to calculate
and present recommendations and to explain the ap-
plication functionality.
The remaining paper is structured as follows. In
Section 2 we discuss related work. Next, we intro-
duce our overall approach for assisted CWA develop-
ment and usage in Section 3. Modeling foundations
of our concepts are subject of Section 4. Based on
this, an algorithm for estimating a composition frag-
ment’s functionality is described in Section 5. Then
we evaluate our concepts in Section 6. Finally, Sec-
tion 7 concludes the paper and outlines future work.
2 RELATED WORK
In the mashup domain, recent approaches feature
a tightly interwoven development and usage as a
commonality with capability-centered mashup EUD.
Within the OMELETTE project (Chudnovskyy et al.,
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
110
2012) a live development mashup environment has
been created, which features a recommender system
and a user assistant for expressing goals. Patterns
reflect composition knowledge and recommendations
are based on patterns and are visualized by incorpo-
rated components and textual description which has
to be provided manually. There is no model for func-
tional semantics. Similarly, PEUDOM (Matera et al.,
2013) allows to manipulate mashups during usage
and offers a recommender system, but there is noth-
ing similar to our capability model and algorithm.
SMASHAKER (Bianchini et al., 2010) utilizes se-
mantic component annotation and based on this a rec-
ommender system. Part of those annotations are cate-
gories which describe functionality, however, less ex-
pressive than capabilities. And deriving category an-
notations of whole mashups is not supported. In Nat-
uralMash (Aghaee and Pautasso, 2014) restricted nat-
ural language is used to describe and define mashup
functionality and a link between text fragments and
corresponding UI parts is provided, too. We uti-
lize a formal, semantic model to describe function-
ality, which we also use to derive natural language
sentences. For instance, we previously developed
CapView (Radeck et al., 2013), an overlay view that
allows to explore and manipulate the mashup’s func-
tionality, and abstract the composition procedure to
coupling capabilities. However, CapView does not
support composite capabilities, for which we provide
the foundation in this article. DEMISA (Tietz et al.,
2013) proposes a top-down procedure to build mash-
ups. Mashup developers first define a semantic task
model, which is transformed semi-automatically into
a CWA then. As already stated, our capability model
is influenced by task models, but dedicated to CWA.
Further, we also enable the bottom-up approach, i. e.
from CWAs to capability graphs, with our algorithm.
A tagging-based approach to annotate compo-
nents and discover and compose them to applications
is described in (Bouillet et al., 2008). Tag taxonomies
are utilized to avoid unambiguity and allow more flex-
ible matching. However, the model is less formal
and expressive. Further, the application functional-
ity equals all annotations of a flow, while we estimate
subordinate capabilities, i. e., a hierarchical structure.
(Bai et al., 2012) describe an ontology-based
model of mashups and their functionality. It shares
some similarity with ours, however, functionality is
not semantically backed but rather free-text. Further,
an algorithm to instantiate such models from exist-
ing mashups is provided. It uses lexical analysis of
functionality only, and no hierarchical structuring and
sub-sequencing takes place.
3 OVERALL APPROACH
Now we briefly outline our overall approach and re-
late the concepts we describe in this paper to it.
Adhering to universal composition, the CRUISE
platform follows a model-driven composition ap-
proach to create and execute presentation-oriented
CWA. Thereby, components of the data, business
logic and UI layer are basically black-boxes and share
a generic component model. The latter character-
izes components by means of several abstractions:
events and operations with typed parameters, typed
properties, and capabilities. The Semantic Mashup
Component Description Language (SMCDL) serves
as a declarative language implementing the compo-
nent model. It features semantic annotations to clar-
ify the meaning of component interfaces and capa-
bilities (Radeck et al., 2013). Based on the com-
ponent model, the declarative Mashup Composition
Model (MCM) describes all aspects of a CWA, like
components to be integrated, views with their layout
and transitions between them, and event-based com-
munication including mediation techniques to resolve
interface heterogeneity.
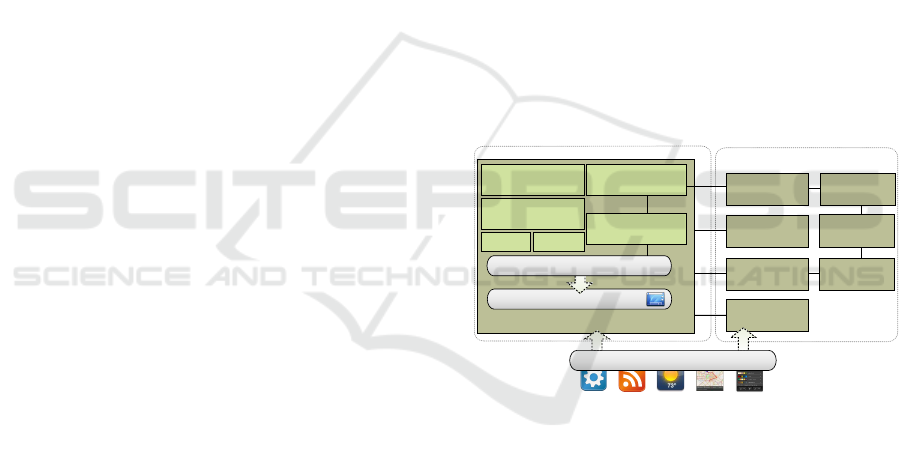
Mashup Runtime Environment
Pattern
Repository
Context
Service
Application
Repository
Component
Repository
CapView LiveView
Requirements
Composer
Explanation
Mode
Adaptation
System
management and services
bind
composite web application
composition model (MCM)
composition and usage
register
universal description (SMCDL)
Meta Data
Indexer
Functionality
Analyzer
Pattern
Miner
Recommendation
System
Figure 1: Architectural overview of our platform.
A fundamental characteristic of our approach is
that run time and development time of a CWA are
strongly interwoven. End users – in our case domain
experts which know their problem and possible so-
lutions in terms of domain tasks to perform, but fail
to map such solutions on technical mashup compo-
sitions – can seemingly switch between editing and
using the application. Thereby, they are not bothered
with composition model concepts. Instead, commu-
nication with users takes place on capability level and
necessary mappings of composition steps to compo-
sition model changes are handled transparently.
To this end, a mashup runtime environment
(MRE) is equipped with a set of tools and mecha-
nisms, see Figure 1. For instance, the recommenda-
tion system covers the whole recommendation loop,
starting from identifying when recommendations may
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development
111

be necessary (triggers), querying recommendations
from a pattern repository, and displaying candidate
patterns to the end user. The latter is done utilizing
capabilities of patterns and is contextualized with re-
spect to the CWA at hand. Optionally, the user can de-
fine functional and quality requirements in a require-
ments composer. Furthermore, an MRE provides dif-
ferent views on the current CWA: In the live view,
mainly intended for usage, only component UIs are
visible to the user, while there are overlay views, like
CapView, that display component and composition
model details and mainly serve for development pur-
poses. In addition, an MRE offers tools explaining the
functional interplay of components in a textual and vi-
sual manner, like the explanation mode.
Components are registered at the component
repository using SMCDL descriptors and can be
queried. Analogously, composition models of CWAs
are managed on server-side in a repository separated
from a concrete MRE. There are also modules at-
tached to repositories that analyze the persisted items.
For instance, composition models are classified re-
garding the approximate capabilities they provide by
the meta data index, which uses the functionality an-
alyzer. The same holds for patterns which are de-
tected by pattern miners using semantic technologies
exploiting component interface annotations or using
statistical analysis methods. In any case the pattern
functionality in terms of capabilities is derived, too.
Required models, algorithms and applications of such
a functional classification is in scope of this paper.
The following platform features build up on the
derivation of capabilities of composition fragments,
i. e., mashup applications and patterns:
• Explanation of CWA functionality (single compo-
nents and especially the interplay of components);
• Awareness for inter-widget communication;
• Entering functional requirements towards compo-
sition fragments;
• Calculating composition fragment recommenda-
tions and presenting them based on the function-
ality they provide;
• Composition steps on whole functionality blocks
rather than single technical concepts like compo-
nents and channels;
We argue that utilizing capabilities is beneficial for
all those use cases and ease communication with the
end user. In order to enable such features, it is obvi-
ously necessary to model and estimate capabilities of
composition fragments. In the following sections, we
introduce our solutions to this end.
4 MODELLING ASPECTS
Based on our previous work (Radeck et al., 2013) and
research on task models, we developed a model for
capabilities, shown in Figure 2. The main idea and
assumption is that components serve to solve tasks,
and that a composition of components can fulfill more
complex tasks accordingly. The proposed model is
more lightweight than traditional task models, uses
semantic annotations and is dedicated to CWA since
it is possible to establish links to UI elements.
Capabilities describe functional and, tough re-
stricted, behavioral semantics of a composition frag-
ment, i. e. what it is able to do or which functionality
it provides, like displaying a location or searching ho-
tels. To this end, capabilities essentially are tuples
(activity, entity) – denoted activity entity from
now on – and express which activity or task is per-
formed on or with which domain object, e. g. search
hotel. References to concepts like classes, proper-
ties and individuals described in Web Ontology Lan-
guage (OWL) ontologies back the description with
formal semantics. There are optional attributes to ad-
dress activity and entity more precisely: In case the
entity is an OWL property e. g. hasName, entity con-
text can define the domain, e. g. person; similarly, an
activity modifier can clarify the activity without the
need to blow up ontologies with individuals or sub
concepts, e. g. sort with activity modifier hasName
instead of declaring an individual sortByName in the
ontology. Optionally, a capability belongs to a do-
main or a certain topic. In order to achieve a capa-
bility, it may be necessary for the user to partake and
interact with the component UI or not. Thus, UI and
system capabilities are distinguished.
Our model allows to build composite capabilities
i. e. establish hierarchical structures. The relation of
children of a composite capability is expressed with
the help of a connective. Currently, we support par-
allel and sequential relations. In case of sequences,
capabilities are chained to define the order using the
relation next and previous. As an example, it is pos-
sible to describe the capability search route as a
sequence of select start, select destination,
search route and display route.
Relating capabilities with requirements allows to
state that the provision of a capability depends on cer-
tain parameters and conditions of the user, usage or
execution context. For instance, the capability take
picture requires access to a camera within the run-
time environment context.
A concept particular for UI capabilities are view
bindings. They link the semantic layer and the user
interface of the according component. Basically, a
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
112
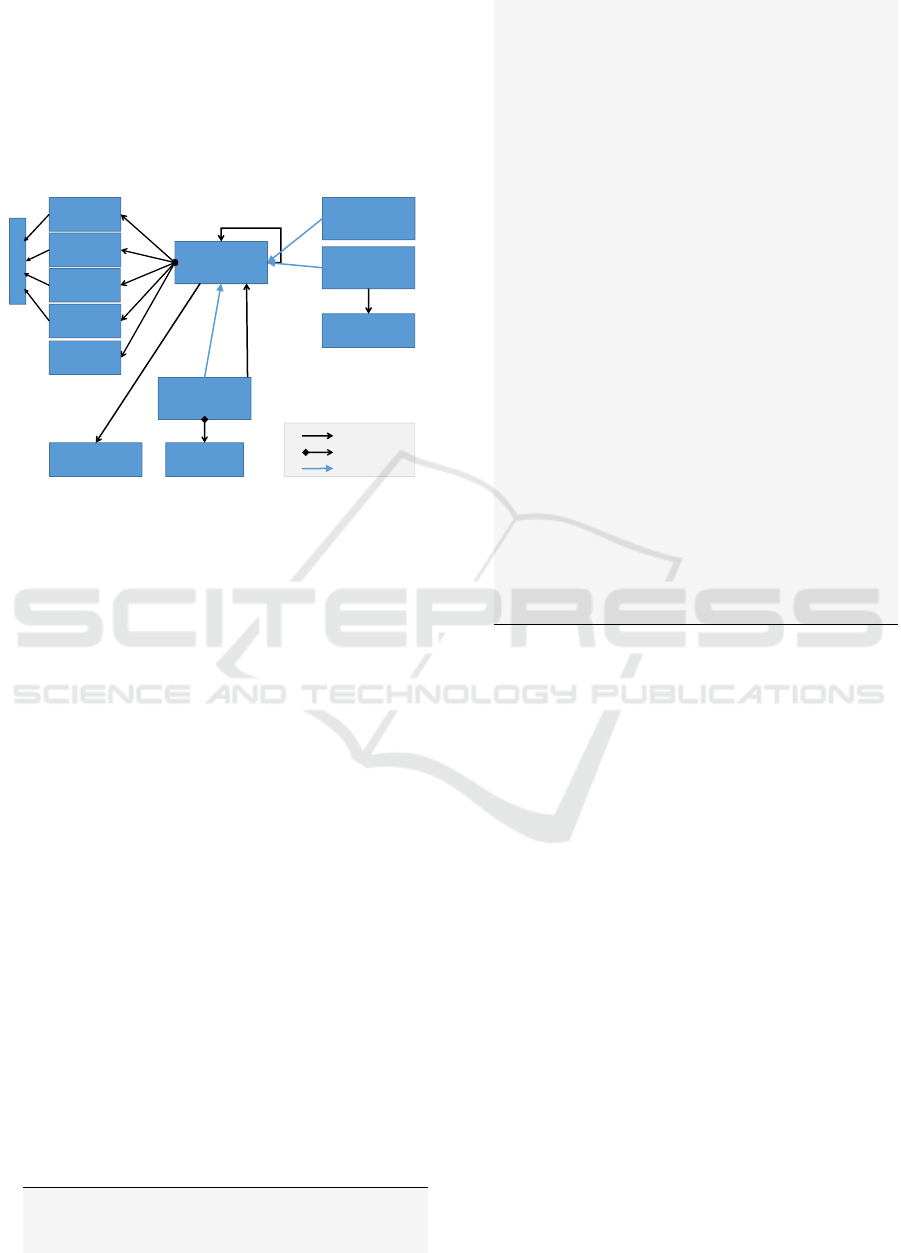
view binding describes interaction steps via atomic,
parallel or sequential operations. These point to UI el-
ements using a selector language, e. g. CSS selectors,
and define the interaction technique, like click and
sweep. In case a capability has multiple view bind-
ings, they are considered alternative, for instance, if it
is possible to select a location via typing something in
a text field or double clicking a map.
Capability
Entity
Activity
UICapability
System
Capability
ViewBinding
*
Requirement
*
Composite
Capability
Connective
2…*
next/previous
1
Association
Aggregation
Inheritance
rdf:Resource
children
Activity
Modifier
Entity
Context
Domain
0..1
0..1
0..1
Figure 2: Schematic overview of the capability metamodel
All composition fragments, i. e. components, ap-
plications and patterns, can carry capabilities.
Capabilities of components are statically anno-
tated by component developers in the corresponding
SMCDL descriptor. Listing 1 shows an excerpt from
a map component’s descriptor. Most concepts of the
capability metamodel are reflected by XML elements
and attributes. Thereby, capabilities can be located
at two positions: at level of the whole component
(see Listing 1 lines 2–15), where especially UI ca-
pabilities are annotated, and at interface level (lines
22–24), where only system capabilities occur that are
exclusively achieved when invoking an operation or
setting a component property. It is not necessary to
declare composite capabilities in order to reduce an-
notation effort for component developers. However,
capabilities can and should be linked via causes and
causedBy (see e. g. line 6) with other capabilities.
This reflects causality and is a replacement that en-
ables to derive composite capabilities afterwards. Sin-
gle entries in causes and multiple ones connected via
and map to a sequences, multiple or-ed entries are
mapped to a parallel composite capability. Details on
this step are provided in Section 5.2.
Events and properties reference existing capabil-
ities via causedBy (and causes in case of properties)
rather than declaring new ones, see line 19.
1 < component id = " ... " name = " M ap " >
2 < c a p a b i lity id = " capDispLoc " ac tivity = "
act:Dis p l a y " en tity = " g e o : L o c a tion " >
3 < v i e wbinding >
4 < a tomi c o p e r a t i on elem e n t = " d iv [ id $= ’ _map ’] " / >
5 </ viewb i n d i n g >
6 < c a u s e d B y > c a p I n p L o c or ca p 0 2 or ca p I n p L o c D e t < /
cause d B y >
7 </ capability >
8 < c a p a b i lity i d = " c a p 02 " a c t i v i t y = " a c t : S e l e c t "
en t i t y = " geo: L o c a t i o n " >
9 < v i e wbinding >
10 < a tomi c o p e r a t i on ele m e n t = " in p u t [ id $= ’
ma p T e x t Field ’] " i n tera c t i o n T e ch = "
i:T y p e O p e r a tion " / >
11 </ viewb i n d i n g >
12 < v i e wbinding >
13 < a tomi c o p e r a t i on ele m e n t = " d iv [ id $= ’
gMapCu r r e n t L o c a t i o n I con ’] "
int e r a c t i o n Tech = " i :DragNDr o p " / >
14 </ viewb i n d i n g >
15 </ capability > . ..
16 < i n t e r f a c e >
17 < e v ent name = " l o c a t i o nSel e c t e d " >
18 < p a r a m e t e r name = " l oc " type = " g e o : L o c a t i o n " / >
19 < c a u s e d B y > c a p 02 < / c a u s e d B y >
20 </ e v e nt >
21 < o p e r a t i o n name = " sh o w L o c a t i o n " >
22 < c a p a b i lity en t i t y = " g e o:Loca t i o n " ac t i v i t y = "
act:Input " id = " c a p I n p L o c " >
23 < c a u s es > c a p D i s p L o c </ caus e s >
24 </ capability >
25 < p a r a m e t e r name = " l oc " type = " g e o : L o c a t i o n " / >
26 </ operation > ...
Listing 1: Excerpt of a map’s SMCDL descriptor.
While the implementation of our capability meta-
model in SMCDL has its specificities, CWA and pat-
terns are directly equipped with arbitrarily structured
capabilities. Since components are the atomic build-
ing blocks, capabilities of patterns and mashups result
of the statically declared capabilities of components
and especially how these are connected via commu-
nication channels. Thus, capabilities of patterns and
CWA are not predefined and consequently have to be
derived for each composition fragment. Our solution
for that is presented next.
5 CLASSIFICATION
ALGORITHM
In this section we go into details on our algorithm for
estimating the capabilities of an arbitrary, valid com-
position fragment.
5.1 Foundation
As a prerequisite we briefly describe some basic con-
cepts and foundations of the algorithm in this section.
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development
113
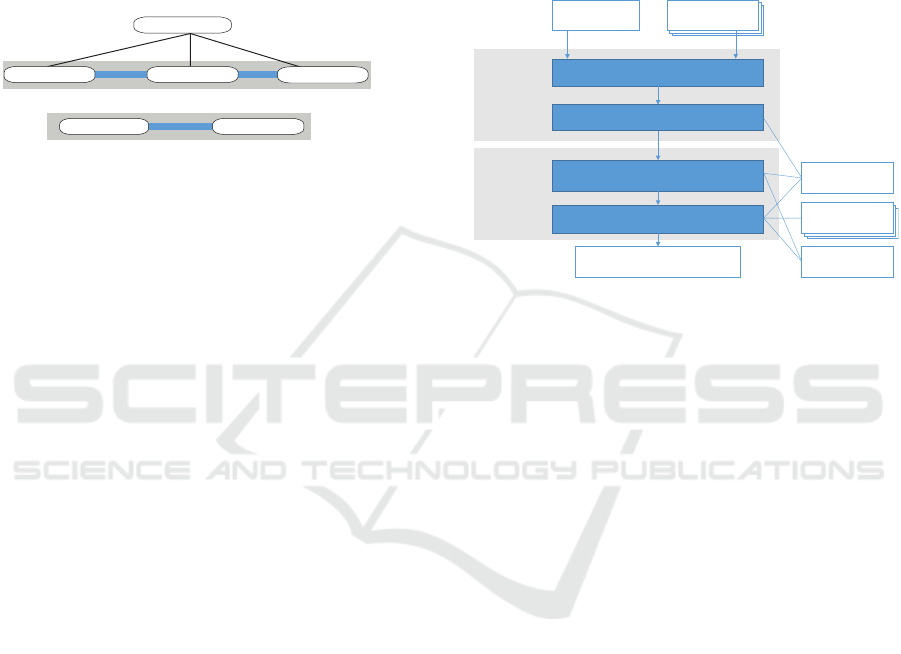
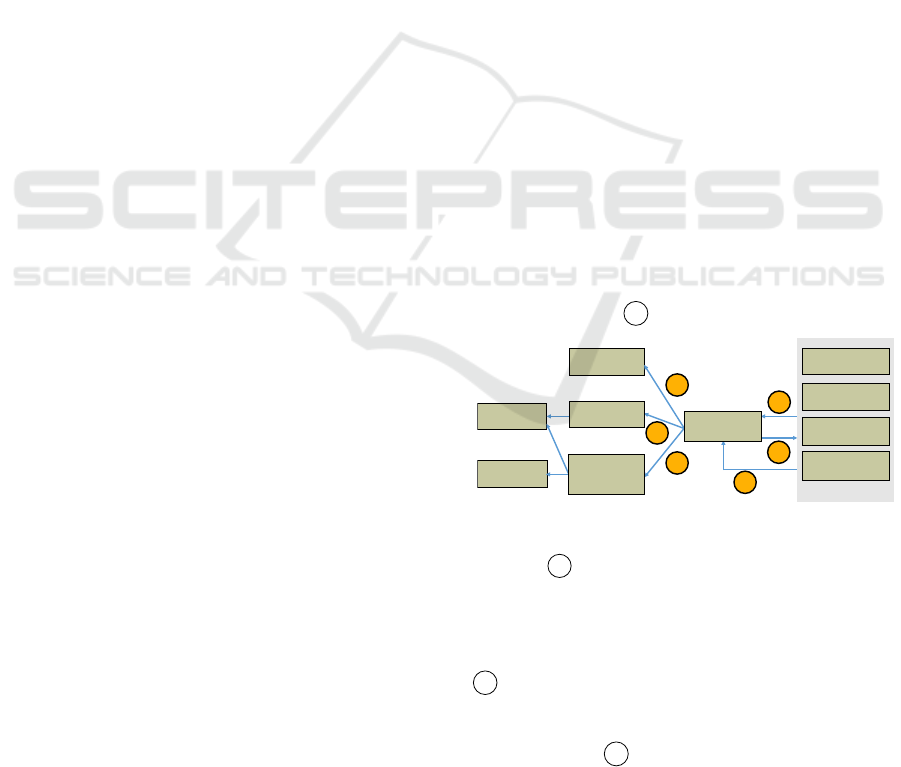
A capability graph is a set of capability nodes and
directed edges called capability links, see Figure 3.
It may be cyclic and represents the capabilities of a
composition fragment since for each communication
channel and causes or causedBy relation a capabil-
ity link is created between nodes encapsulating the
coupled capabilities. Each capability link comprises
a start and a target capability node and stores selected
composition model information, e. g. mediation tech-
niques applied on a channel.
Activity Entity
>
--> -->
-->
}
hierarchy
graph
capability
link
composite capability
node
atomic capability node
parent-child-relation
capability chain
Activity Entity Activity Entity
Activity Entity
Activity Entity Activity Entity
Figure 3: Schematic example of a capability graph.
Besides the dataflow or causality-oriented graph
built from atomic capabilities and links between them,
there is an overlay structure, the hierarchy graph. It is
created from deriving composite capabilities with the
help of our algorithm.
In case a capability graph consists of multiple iso-
lated subgraphs which are coherent in themselves,
these are called capability chains.
As mentioned earlier, entities refer to OWL con-
cepts. The latter can be related in different ways us-
ing OWL properties, like subClassOf and defining
range and domain. When deriving a composite capa-
bility it is necessary to identify an entity as expres-
sive as possible, which we call dominant entity. Due
to space limitation we only can give a brief overview
on how we determine a dominant entity. It is calcu-
lated by analyzing the semantic entity annotations of
all direct child capabilities of the composite capabil-
ity at stake, denoted as set E. Thereby, we utilize
inheritance (subClassOf, subPropertyOf) to iden-
tify coarse grained concepts subsuming other entities.
Further, we assume that a class C
1
aggregates or sub-
sumes C
2
if there are OWL properties with domain
C
1
and range C
2
. In this step we skip symmetric and
inverse properties. A concept is dominant if it sub-
sumes all e ∈ E. Such a concept does not have to be
element of E. Lets consider a simple example: The
entities location and route are given and the ontol-
ogy states that each route has OWL ObjectProper-
ties hasStart and hasDestination, both with range
location. Then route is the dominant entity.
5.2 Detailed Procedure
Basic ideas and assumptions of our algorithm can be
summarized as follows. The core functionality of a
CWA is achieved by components and their interplay
based on capability links. Through transitive con-
nections more complex functional relations are estab-
lished within a CWA. Facilitating semantic informa-
tion of capabilities, heuristics and learned data, com-
posite capabilities can be estimated and describe func-
tionality of whole composition fragments.
Figure 4 shows the essential workflow of our al-
gorithm, which is explained in detail in the following.
Domain
Domain
Composion
Model
Acvity
Ontology
Domain
Ontology
Domain
Domain
Component
Descripon
Analyze
Composion
model
Calculate Capability Links
Calculate Capability Chains
Determine Hierarchy per
Capability Chain
Esmate Acvity, Enty etc. of
composite Capabilies
Analyze
Capability
Chains
Learned DataSet of Capabilies
I
II
Figure 4: Inputs, main steps and outputs of the algorithm.
Phase I. Given a composition model representing
the composition fragment, a main goal of the first
phase is to calculate capability links by analyzing
MCM as well as SMCDLs of included components.
In a preparation step, information about compo-
nents and their annotations are gathered, for instance,
references in element causes are resolved to actual ca-
pabilities and for each component property, a capabil-
ity with activity set and an entity according to the
property type is created.
Then all communication channels in the composi-
tion model are considered. We assume that a channel
has exactly one publisher and one subscriber interface
element, and more complex communication patterns
are build on top of such “atomic” channels. For all
combinations of relevant capabilities of publisher and
subscriber a capability link is created. Subsequently,
those capability links are completed by following the
intra-component relations causes and causedBy and
creating additional capability links for each of them.
Optionally, if requested by the client or if there
are no capability links so far, the capability graph
is extended by intra-component capability nodes and
links. Thereby, only capabilities that are not yet part
of the capability graph and which can be performed
by users, i. e. no capabilities at operation level and
none exclusively caused by operation calls, are con-
sidered. As described above, capability links are es-
tablished based on the relations causes and causedBy.
Capability chains, i. e. functionality blocks of a
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
114
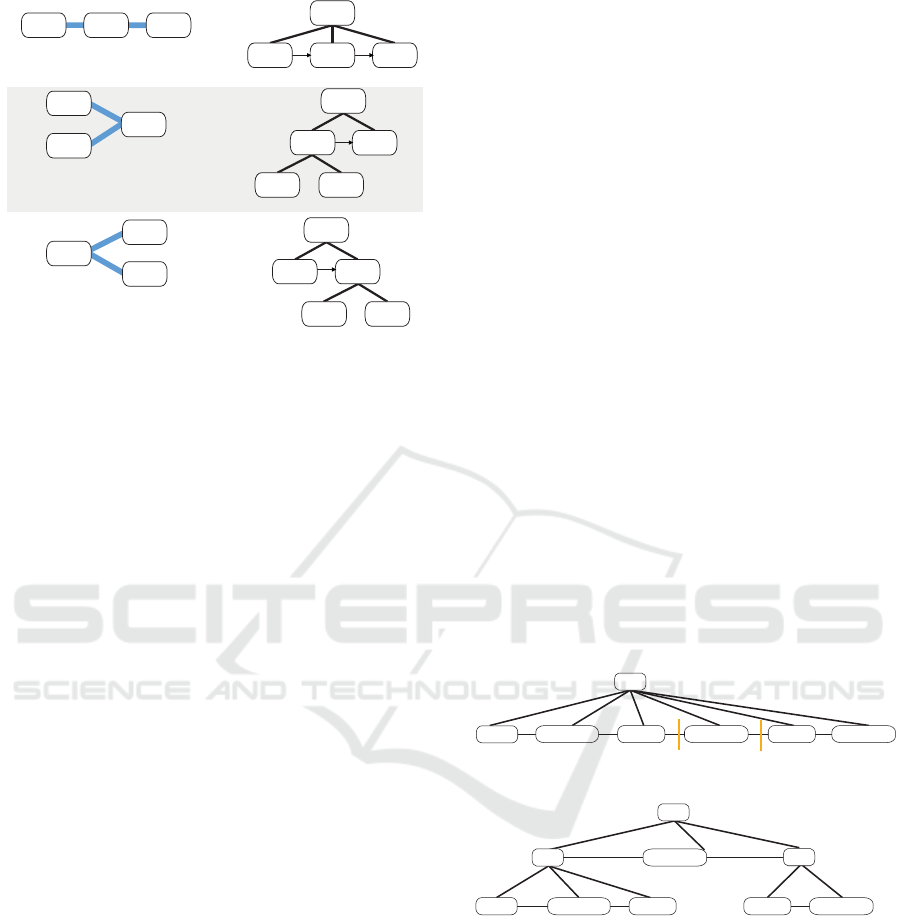
>
A B C
A B C
A
B
C
A
B
C
(1)
(2)
(3)
A
C
B
>
A
CB
>
||
||
D
D
Figure 5: Supported graph patterns for hierarchically struc-
turing composite capabilities.
CWA, are identified then. Beginning at capability
nodes with outgoing links only, capability links are
followed until either another chain or a capability
node without outgoing links is reached. In the first
case, both chains are merged.
Phase II. In this phase the algorithm strives for de-
termining a hierarchy graph per capability chain. To
this end, certain graph structures, inspired by work-
flow patterns (van der Aalst et al., 2003), are iden-
tified in a capability chain. Each structure has a well
defined effect on the resulting hierarchy graph leading
to the creation of composite nodes, see Figure 5.
(1) Sequence If there are two or more capability
nodes connected in a line pattern and all nodes
have max. 1 in and max. 1 outgoing link, they
are assigned as children to a composite capability
node with sequence connective.
(2) Synchronization Converge several capability
links in a capability node, the latter is a synchro-
nization point. In the resulting overlay hierarchy,
all sources (A and B in Figure 5) are grouped to a
parallel composite node (D), which is source in a
sequence with the target node (C).
(3) Parallel split In this case, a capability node has
multiple outgoing capability links. The target
nodes (B and C in Figure 5) are assigned to a
parallel composite node (D), which is in sequence
with the source node (A), this time as target node.
These rules are applied to create composite capabili-
ties forming the hierarchy graph whereby (2) and (3)
are higher prioritized than (1).
As described in Section 3, the MCM allows to de-
fine different views on a CWA, affecting the visibility
of UI components and, from an end-user-perspective,
consequently the accessibility of corresponding UI
capabilities. Thus, rules (2) and (3) are adapted: In
case the underlying components of D’s child capabil-
ity nodes do not occur in the same view, the connec-
tive of D is set to sequential, otherwise parallel. The
order in a sequence corresponds to the view order.
Next, sub sequencing takes place. In this central
step, child nodes of sequence nodes are analyzed re-
garding their activity concept in order to detect poten-
tial subdivisions. According to a system-theoretical
paradigm, we assume that functionality essentially
consists of inputting something, transforming it and
outputting a result. Based on this, we define the fol-
lowing rules determining potential borders between
sub functionalities in a sequence of capability nodes.
Further, we classify activities or actions according to
the superclasses input, transform, output in our
activity ontology (Tietz et al., 2013). Let act
i
denote
the superclass of the activity of the i-th capability in a
sequence. Then a potential border is after capability i
• if act
i
= output and act
i+1
6= output or
• if act
i
= transform and act
i+1
= input
In case all resulting sequences would have more
than one child, the hierarchy graph is adapted ac-
cordingly. Please refer to Figure 6 for an example,
where the sequence in the upper part is analyzed ac-
cordingly, and the resulting structure is shown below.
Potential borders are depicted in orange.
Input
Transform Output
InputTransform Transform
>
Input
Transform Output
Input
Transform
Transform
>
>
>
Figure 6: Exemplified sub sequencing approach.
The intermediate result at this point is a hierarchy
graph per capability chain whose composite capabil-
ity nodes are not semantically annotated yet. All hier-
archy graphs are assigned as children to the root node.
Thus, semantic annotations are estimated next. To
this end, composite capability nodes are arranged in
layers according to the distance from the root. Then,
the procedure begins on the lowest layer and performs
for each composite capability node c
comp
a number of
steps. All child nodes cap
children
are analyzed to try
to estimate the most likely capability for c
comp
. Exter-
nal knowledge for this is provided by ontologies used
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development
115
to annotate activity and entity concepts, as well as
learned data from previous runs in shape of confirmed
capability graphs. First, a look up for known solutions
in learned data is performed by graph matching. If
there exists an identical case, c
comp
is set accordingly.
Otherwise the estimation proceeds and calculates for
every entity concept, which is annotated in cap
children
,
a rating that is influenced by the following factors.
• Activity rating r
a
is defined as the maximum of
all weights w
a
for activity concepts an entity oc-
curs with. Given the superclass of an activity con-
cept we propose the following order w
trans f orm
>
w
out put
> w
input
. If there are multiple activities
with the same w
a
, learned knowledge is incorpo-
rated, by looking for similar constellations of ca-
pabilities and increasing w
a
of the activity chosen
in such cases.
• Structural rating r
s
states the relevance of an entity
with respect to its position and role in capability
and hierarchy graph. This comprises factors like:
– Position within a sequence, whereby entities lo-
cated at the end are rated higher.
– Entities of composite nodes are rated higher.
– Entities of capability nodes partaking in capa-
bility links derived from communication chan-
nels, are considered more important.
• Frequency rating r
f
denotes the relative frequency
of an entity with the set under investigation.
• Semantic rating r
sem
expresses, if an entity is
dominant regarding the set under investigation.
The overall rating for an entity is defined as
rating
entity
= r
a
+ r
s
+ r
f
+ r
sem
If there are multiple entities with the same rating, we
determine if one of them is the dominant entity with
respect to that set, and increase the rating. Further-
more, we incorporate learned knowledge by looking
for a capability node where the children are equipped
with the same annotations. If a similar case exists, we
set that entity’s rating to the highest value since we
consider the data as validated.
Finally a composite capability cap
result
is created
with the best rated entity, the corresponding activity
and its activity modifier. In addition, the domain of
cap
result
is derived. We use the ontology defining the
entity concept of cap
result
and expect it to provide
rdfs:label annotations, which serve as a brief do-
main descriptor. In some cases we also set cap
result
’s
entity context: We check if the child capability node
carrying the best rated entity is connected via a capa-
bility link to the previous node cap
p
and if this link
originates from a communication channel which uses
projection for mediating source and target interface,
e. g., Event → hasName. Then, the parent nodes en-
tity context is set to the entity of cap
p
. This enables to
distinguish slightly different capabilities, like search
article by name of an event or a location.
Additionally, a confidence value is calculated and
attached to cap
result
. It is proportional to the distance
of the highest and second highest rating
entity
. In order
to increase the plausibility of the overall result, the hi-
erarchy graphs root node is removed if its confidence
value is below a threshold c
min
, leading to several ca-
pability nodes as a result.
6 EVALUATION
In this section, we go into detail on the prototype we
developed and how we validated our algorithm.
6.1 Implementation
We implemented the algorithm and a set of clients
as part of the CRUISE platform. In the following,
the conceptual architecture and some implementation
details are presented utilizing Figure 7. The algo-
rithm is situated on server-side and encapsulated in
a dedicated package, to which the Functionality
Analyzer is the central access point to. Therefore,
it provides several interfaces, e. g., as SOAP web ser-
vice. The Functionality Analyzer orchestrates
several other modules and performs pre-processing
steps like format transformations in order to answer
incoming requests A .
Meta Data
Indexer
Pattern
Miner
Composition
Analyzer
Entity
Knowledge
Activity
Knowledge
A
B
C
E
D
Recommendation
Manager
F
Functionality
Analyzer
Clients
Mashup Runtime
Environment
Grouping
Analyzer
Composite
Capability
Analyzer
Figure 7: Architectural overview of our prototype.
Then B , the Composition Analyzer is respon-
sible for analyzing the given composition fragment
in terms of a composition model and the SMCDL
component descriptors. The resulting capability links
are handed over to the Grouping Analyzer in step
C which derives capability chains and the capa-
bility hierarchy. The latter is enriched with se-
mantic annotations by the Composite Capability
Analyzer then
D . It utilizes semantic knowledge
from the modules Activity Knowledge and Entity
Knowledge, which manage ontologies and provide
access to reasoning facilities and to answer queries.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
116
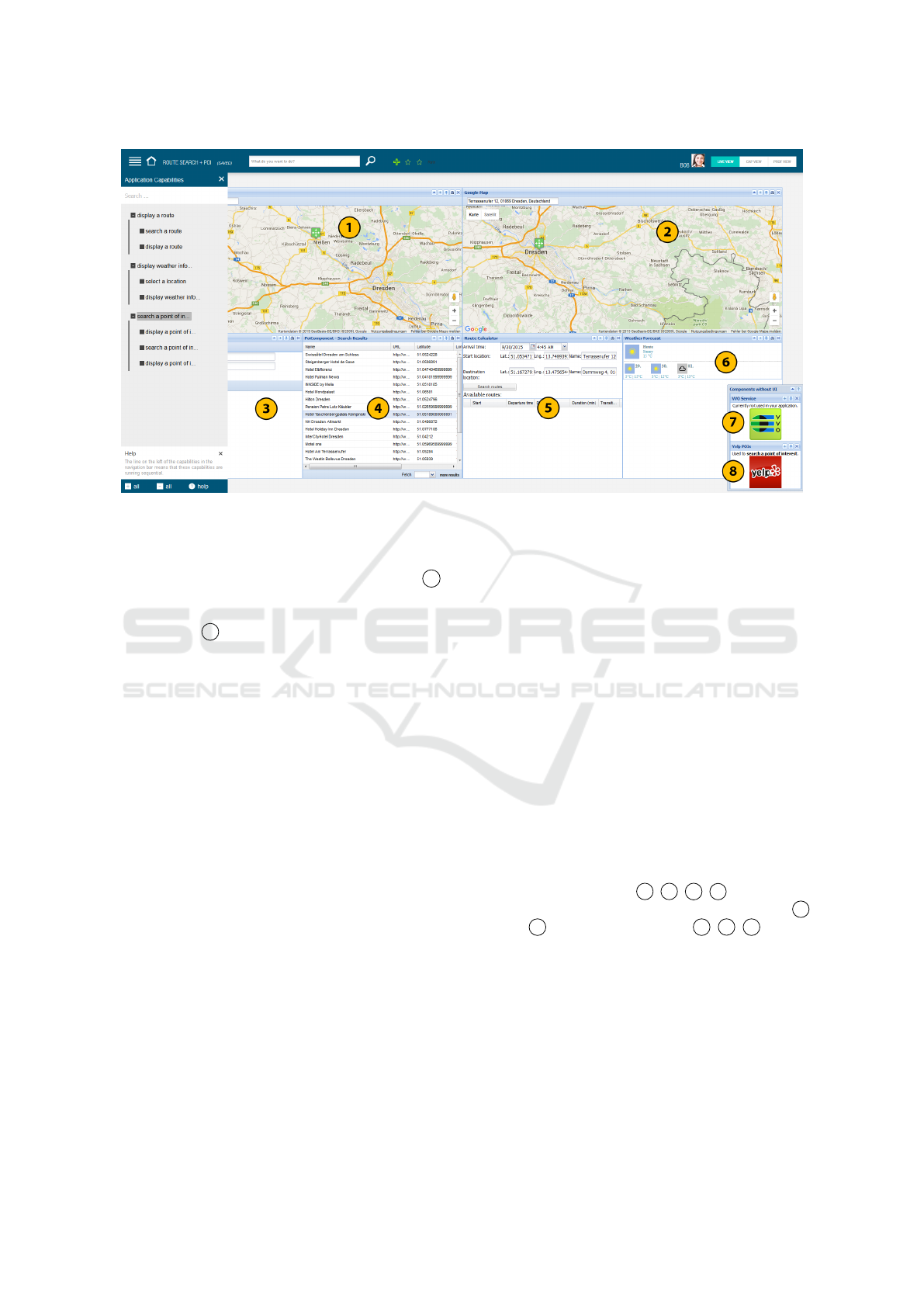
Figure 8: Screenshot of a mashup in our test bed.
For these tasks, our prototype employs the framework
Apache Jena in both modules. Finally, results are de-
livered to the client after some post-processing E .
User feedback on algorithm results is transfered from
an MRE to the server side and stored as confirmed
solutions, see F .
There are several clients to be considered. The
Recommendation Manager requires the algorithm for
calculating recommendations paying attention to ca-
pabilities required by the user or already part of a
mashup. Further, within our repositories for appli-
cations and components, the Meta Data Indexer and
Pattern Miners use the Functionality Analzyer to
derive the capabilities of persisted mashups or newly
identified composition patterns. An MRE provides
several tools for understanding and developing mash-
ups. On the left-hand side of Figure 8 there is for in-
stance a widget visualizing capabilities of the current
application. Results of the algorithm are also used to
present capabilities by generating short natural lan-
guage sentences (Radeck et al., 2013) when giving
recommendations, e. g., in the CapView and a recom-
mendation menu, and when composing functional re-
quirements in a wizard. Additionally, we are currently
working on mechanisms interactively explaining ap-
plication capabilities to users.
6.2 Experiments
In order to validate the prototypical implementation
of the proposed algorithm, i. e., to test if it works as
expected, we defined test cases with increasing com-
plexity in terms of number of components N
co
, chan-
nels N
ch
and capability links N
l
. Our test bed consists
of the following types of composition fragments (CF):
• CF comprising a single component.
• CF with two non-connected components.
• CF with two components that are connected via
one channel, e. g. map and weather widget. We
also varied the connection on composition model
level to test if the result is semantically the same,
for instance, both components can be coupled via
event and operation or via properties.
• CF from different application domains with 2-7
components and 1-7 channels, for instance, travel
planning, POI search, news scenario, appointment
scheduling, hotel search. Again we tested struc-
tural variations if applicable.
• CF consisting of separate capability chains, e. g.,
the mashup shown in Figure 8 allowing to search
routes (components 1 , 2 , 5 , 7 ), to display
weather information at the destination ( 2
and 6 ) and to search POIs ( 3 , 4 , 8 )
Based on the test bed described above, we were also
interested in the performance of our research proto-
type to show the practicability and applicability. To
this end, we measured the average calculation time
needed by our algorithm to process increasingly com-
plex composition fragments. For each data set we per-
formed 100 runs in a single thread in order to lower
the impact of outliers. The test system features an In-
tel i7-4900 with 2.8 GHz and 32 GB RAM. Table 1
shows the results in case of local calls.
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development
117

Table 1: Benchmark results.
Test case N
co
N
ch
N
l
T
∅
News scenario 2 1 1 181 ms
Appointment app 4 2 2 280 ms
Travel planning 8 7 12 458 ms
The results indicate that calculation time increases
proportional to the structural complexity of the in-
putted composition fragment. Even for rather com-
plex mashups, the calculation time is far below one
second, which we consider good performance taking
into account the prototypical character of our imple-
mentation. Further, none of our use cases poses hard
time constraints with particularly low response time.
6.3 Expert Evaluation
Methodology. In order to validate both our capabil-
ity model and the estimation algorithm, we conducted
an expert evaluation. Seven computer scientists or
master students, which work in and have contributed
to the area of mashups or service-oriented architec-
tures, participated. All participants have profound
knowledge about using and building component-
based applications. We sketched nine mashups of our
test bed with increasing complexity on paper, like the
CWA depicted in Figure 8. Thereby, components,
their capabilities and capability links were schemat-
ically represented. If required, a short introduction to
our capability model was given. Further, we showed
live mashups in our platform if necessary to avoid
misinterpretations. Then, the experts were asked to
answer the following questions for one CWA at a time
by sketching capability graphs on paper. Explanations
and thoughts were noted by the interviewer.
Q1 How would you describe the overall functionality
the CWA provides in terms of capabilities?
Q2 Would you decompose those capabilities? If yes,
how?
Our main goal was to show that the proposed capabil-
ity model is well suited to describe functionality and
that our algorithm is able to derive adequate capability
model instances for composition fragments covering
a broad variety of cases. To this end, we then com-
pared the capability models our experts would assign
with the output of our algorithm.
Results and Discussion. Experts were in nearly all
cases able to express what they wanted using our ca-
pability model. Often they qualified activities or enti-
ties, e. g., “search article for location”, which is map-
pable to activity modifier and entity context. Repeat-
edly the following suggestions were made. It is possi-
ble to use one capability, e. g. select location, as
source for multiple capability links or to provide sev-
eral sources in multiple components. Some experts
remarked that in the latter case, a distinction of those
capabilities should be possible, since there are several
instances e. g. of location. We agree, and required in-
formation are only implicitly part of our model, given
by ID and corresponding components of capabilities.
Thus, it is mainly a matter of properly analyzing and
presenting the model in a front-end. Additionally, few
experts suggested to allow optional capabilities.
Regarding Q1 the results are promising. We cal-
culated a matching degree for activities and entities.
We considered semantically similar concepts as 50%
match, e.g. show and display. In case, experts
derived additional hierarchy levels, we matched the
layer comparable to the algorithmic result. An entity
match of 96.83 % and an activity match of 80.16 %
lead to an overall accuracy of 88.49 % in our test.
There was no consensus about if transform or
output activities are more important. However, in
all cases at least 5 of 7 experts decided for the first,
which confirms our prioritization. In case there are
multiple capabilities with the same type of activity in
sequence, e. g., search song → search article, 6
of 7 experts prioritized entity article when deriving
a parent capability. That is consistent with our heuris-
tics, which pay attention to flow direction.
We did not incorporate learned data in order to
validate the base concepts and heuristics of our al-
gorithm. Due to this, in more complex scenarios, our
algorithm was not able to derive a meaningful root ca-
pability like experts did. For instance, for the CWA in
Figure 8 our prototype calculates three composite ca-
pabilities. Though this is in line with what experts de-
rived, 6 of 7 experts additionally defined plan trip
or similar as additional parent capability. In the test
case “appointment app”, our prototype derives edit
as activity of the root capability based on annotated
concepts, while experts often used similar terms, like
manage or plan, based on assumptions and additional
knowledge. Deriving such capabilities is far from
trivial, especially in a generic automatic way, in some
cases even for experts. Combining community and
semantic knowledge seems the most promising solu-
tion. However, semantics-based heuristics enable to
avoid cold start problems in case there are no feed-
back, training or learned data available.
Regarding Q2 results showed, that the capability
graphs experts drew were in principle similar to our
concept. However, it becomes evident that experts
tend to subsume capabilities and leave them out. For
instance, some experts stated, that it is clear to them
that to search something implies to input search cri-
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
118

teria first. Due to the multitude of use cases our algo-
rithm keeps such capabilities. It is up to the concrete
client to apply filters if necessary. In the most com-
plex scenario, experts struggled to structure the hier-
archy up to the leaves, while the upper hierarchy lay-
ers were without difficulty. This underpins the neces-
sity of an automated approach. We observed, that ex-
perts created sub-sequences similarly to our concept,
although not in every case our algorithm would do.
However, this mainly leads to flatter hierarchies rather
than different semantics. Regarding the importance
of non-linked component capabilities opinions dif-
fered. Some experts ignored them, others subsumed
or grouped them in a composite capability, e. g., with
activity display.
In general, we noticed that experts were influ-
enced by experiences with web applications and con-
sequently assumed functionalities when reading com-
ponent names, even if there was no adequate ca-
pability presented. The same holds for incomplete
annotations like missing links, which were assumed
by experts. This underpins the crucial role of care-
ful semantic component annotations. Annotating
is a potentially cumbersome and error prone task.
Thus, component developers should be provided with
proper tooling. Also the quality of ontologies used
for annotation has a strong impact on the results.
Therefore, well accepted ontologies should be uti-
lized. However, we argue that mashup platforms
benefit from semantic annotations — we have indi-
cated some use cases throughout this paper. Further,
based on our proposal, annotations of composition
fragments can be derived without explicit modeling
of developers or users.
7 CONCLUSIONS
Mashup development and usage are still cumbersome
tasks for non-programmers, for instance, when it
comes to understanding the composite nature of the
functionality of unfamiliar CWA. Our model-driven
mashup platform strives for capability-centered EUD,
which basic characteristics are interwoven runtime
and development time, capabilities as description of
functionality of composition fragments, and a palette
of EUD tools building up on capabilities as commu-
nication means with end users. This novel approach
aims to overcome limitations of current mashup plat-
forms. Therein, knowledge about the capabilities of
arbitrary (parts of) composition models is a central as-
pect. We use it, e. g., to present recommendations and
explain application functionality. Even with seman-
tically annotated components it is far from trivial to
derive the functionality of a set of connected compo-
nents. We introduce our capability metamodel which
allows to describe functional semantics of composi-
tion fragments. Based on this, we propose an algo-
rithm for estimating capabilities of a given composi-
tion fragment which analyzes annotations of compo-
nents and the communication channels between them.
Future work includes backend extensions, e. g.
completion of causes relations, and frontend concepts
for capability-centered mashup EUD, like implement-
ing and evaluating the explanation mode.
ACKNOWLEDGEMENTS
The work of Carsten Radeck is funded by the Euro-
pean Union and the Free State of Saxony within the
EFRE program. Gregor Blichmann is funded by the
German Federal Ministry of Economic Affairs and
Energy (ref. no. 01MU13001D).
REFERENCES
Aghaee, S. and Pautasso, C. (2014). End-user development
of mashups with naturalmash. Journal of Visual Lan-
guages & Computing, 25(4):414 – 432.
Bai, L., Ye, D., and Wei, J. (2012). A goal decomposition
approach for automatic mashup development. In van
Sinderen, M., Johnson, P., Xu, X., and Doumeingts,
G., editors, Enterprise Interoperability, volume 122
of Lecture Notes in Business Information Processing,
pages 20–33. Springer Berlin Heidelberg.
Bianchini, D., De Antonellis, V., and Melchiori, M. (2010).
A recommendation system for semantic mashup de-
sign. In Database and Expert Systems Applications
(DEXA), 2010 Workshop on, pages 159 –163.
Bouillet, E., Feblowitz, M., Liu, Z., Ranganathan, A., and
Riabov, A. (2008). A tag-based approach for the de-
sign and composition of information processing appli-
cations. SIGPLAN Not., 43(10):585–602.
Chudnovskyy, O., Nestler, T., Gaedke, M., Daniel, F.,
Fern
´
andez-Villamor, J. I., Chepegin, V., Fornas, J. A.,
Wilson, S., K
¨
ogler, C., and Chang, H. (2012). End-
user-oriented telco mashups: The omelette approach.
In Proceedings of the 21st International Conference
on World Wide Web, WWW ’12 Companion, pages
235–238, New York, NY, USA. ACM.
Chudnovskyy, O., Pietschmann, S., Niederhausen, M.,
Chepegin, V., Griffiths, D., and Gaedke, M. (2013).
Awareness and control for inter-widget communica-
tion: Challenges and solutions. In Daniel, F., Dolog,
P., and Li, Q., editors, Web Engineering, volume 7977
of Lecture Notes in Computer Science, pages 114–
122. Springer Berlin Heidelberg.
Matera, M., Picozzi, M., Pini, M., and Tonazzo, M. (2013).
Peudom: A mashup platform for the end user devel-
Estimating the Functionality of Mashup Applications for Assisted, Capability-centered End User Development
119

opment of common information spaces. In Daniel,
F., Dolog, P., and Li, Q., editors, Web Engineering,
volume 7977 of Lecture Notes in Computer Science,
pages 494–497. Springer Berlin Heidelberg.
Radeck, C., Blichmann, G., and Meißner, K. (2013).
Capview – functionality-aware visual mashup devel-
opment for non-programmers. In Daniel, F., Dolog, P.,
and Li, Q., editors, Web Engineering, volume 7977 of
Lecture Notes in Computer Science, pages 140–155.
Springer Berlin Heidelberg.
Radeck, C., Lorz, A., Blichmann, G., and Meißner, K.
(2012). Hybrid Recommendation of Composition
Knowledge for End User Development of Mashups.
In ICIW 2012, The Seventh International Conference
on Internet and Web Applications and Services, pages
30–33.
Tietz, V., Mroß, O., R
¨
umpel, A., Radeck, C., and Meißner,
K. (2013). A requirements model for composite and
distributed web mashups. In Proc. of the 8th Intl.
Conf. on Internet and Web Applications and Services
(ICIW 2013). XPS.
van der Aalst, W., ter Hofstede, A., Kiepuszewski, B., and
Barros, A. (2003). Workflow patterns. Distributed and
Parallel Databases, 14(1):5–51.
WEBIST 2016 - 12th International Conference on Web Information Systems and Technologies
120
