
Leveraging Gabor Phase for Face Identification in Controlled Scenarios
Yang Zhong and Haibo Li
Department of Computing Science and Communication, KTH Royal Institute of Technology, 100 44, Stockholm, Sweden
Keywords:
Face Recognition, Controlled Scenario, HD Gabor Phase, Block Matching, Learning-free, Deep Learning.
Abstract:
Gabor features have been widely employed in solving face recognition problems in controlled scenarios. To
construct discriminative face features from the complex Gabor space, the amplitude information is commonly
preferred, while the other one — the phase — is not well utilized due to its spatial shift sensitivity. In this
paper, we address the problem of face recognition in controlled scenarios. Our focus is on the selection of
a suitable signal representation and the development of a better strategy for face feature construction. We
demonstrate that through our Block Matching scheme Gabor phase information is powerful enough to im-
prove the performance of face identification. Compared to state of the art Gabor filtering based approaches,
the proposed algorithm features much lower algorithmic complexity. This is mainly due to our Block Match-
ing enables the employment of high definition Gabor phase. Thus, a single-scale Gabor frequency band is
sufficient for discrimination. Furthermore, learning process is not involved in the facial feature construction,
which avoids the risk of building a database-dependent algorithm. Benchmark evaluations show that the pro-
posed learning-free algorithm outperforms state-of-the-art Gabor approaches and is even comparable to Deep
Learning solutions.
1 INTRODUCTION
Face recognition (FR) is a well established research
area and it has been studied for more than two decades
(Turk and Pentland, 1991; Belhumeur et al., 1997;
Wiskott et al., 1997; Ahonen et al., 2004; Zou et al.,
2007; Wright et al., 2009; Chan et al., 2013; Taigman
et al., 2013). Typically, face recognition works in two
essentially different modes: face verification or face
identification under either in controlled scenarios or
in the wild. Face verification performs 1:1 match-
ing and provides a binary decision to the claimed
identity. Face verification in controlled scenarios has
reached a rather high accuracy (Givens et al., 2013).
To tackle face verification in uncontrolled scenarios,
many approaches have been proposed for more ef-
fective alignment (Cao et al., 2014; Yi et al., 2013;
Chen et al., 2012), utilization of different types of fea-
ture representations (Lowe, 2004; Dalal and Triggs,
2005; Ahonen et al., 2004) and matching metric for
comparing faces (Hua and Akbarzadeh, 2009; Pinto
et al., 2009; Li et al., 2013). Driven by innovation
in Deep Learning approaches, face verification per-
formance has been greatly advanced in recent years.
By learning from big data, end-to-end artificial net-
works can outperform human on challenging verifica-
tion tasks, e.g., the Labeled Face in the Wild (Huang
et al., 2007), (Huang et al., 2012; Taigman et al.,
2013; Sun et al., 2013; Schroff et al., 2015).
In contrast, face identification is more difficult. It
performs 1:N matching to sort out the gallery images
based on pair wise similarity measurements. Obvi-
ously, the operating requirement of face identifica-
tion is vastly more demanding than operating merely
in verification: an identifier needs to be roughly N
times better than a verifier to achieve comparable
odds against making false matches (Daugman, 2006).
This is probably why progress in face identification
has been relatively insignificant over the last five
years. Though the proposed face identification ap-
proaches have become increasingly complex, recog-
nition performance according to the benchmark eval-
uations remained relatively constant (Xie et al., 2010;
Yang et al., 2013; Cament et al., 2014; Chai et al.,
2014). To make a breakthrough in face identification,
it seems we must revisit the foundation of face recog-
nition, and have a fresh look at the fundamental build-
ing blocks of face recognition.
A most fundamental building block of face recog-
nition is construction of features for measuring sim-
ilarity between two face images. The construction
of features consists of two steps: (1) the selection
of a suitable face representation; (2) feature extrac-
tion from the representation. There is a large collec-
Zhong, Y. and Li, H.
Leveraging Gabor Phase for Face Identification in Controlled Scenarios.
DOI: 10.5220/0005723700490058
In Proceedings of the 11th Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2016) - Volume 4: VISAPP, pages 49-58
ISBN: 978-989-758-175-5
Copyright
c
2016 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
49

tion of research papers on how to extract stable, local
or global discriminative features, e.g., the commonly
used SIFT (Lowe, 2004), HOG (Dalal and Triggs,
2005), and LBP (Ahonen et al., 2004). Recently, these
features have been criticized as “hand-crafted”. It has
been claimed that better features can be learned auto-
matically from big face data collections through Deep
Learning approaches as in (Huang et al., 2012; Taig-
man et al., 2013; Sun et al., 2013).
While Deep Learning solutions generally have
significant performance advantages over conventional
approaches, the dependence on access to very large
training datasets, the knowledge of designing deli-
cate hand-crafted artificial neural network and careful
engineering is considerable. This indicates that the
learned network could bias (or likely overfit) to the
training data; to adapt well to novel tasks, sufficient
data for fine tuning or even the construction of addi-
tional components in the learned architecture is often
a must (Parkhi et al., 2015) (we demonstrate this in the
last section). It also worth nothing that Deep Learn-
ing solutions are generally computational demanding:
typically the Convolutional Neural Networks (CNN)
involves millions of parameters. Thus, although we
believe a well tuned deep neural network is a most
effective FR solution (e.g., for FR in the wild), in
many scenarios where users are cooperative and envi-
ronments are controlled, it is often worth to consider
efficient and effective solutions depending on much
shallower networks. Considering this, it is tenable to
revisit one of the most widely adopted approaches,
Gabor transformation, which paved the way for face
representation in controlled scenarios.
The Gabor transformation enables the employ-
ment of rich low-level multi-scale features by trans-
forming images from pixel domain to the complex
Gabor space. In the complex Gabor transformed
space, one reasonable option for many state-of-the-art
approaches was to utilize the amplitude for face rep-
resentation and feature construction. This is because
the amplitude varies slowly with spatial shift, mak-
ing it robust to texture variations caused by dynamic
expressions and imprecise alignment. By construct-
ing LBP-type features mostly from the amplitude and
applying various learning techniques, many Gabor
based approaches have shown remarkable advantages
over pixel-featured based methods: the identification
rate in benchmark evaluations has benn found to be
improved by more than 20% (reaching around 90%)
thanks to the “blessing of dimensionality” (Givens
et al., 2013) ( but at the high cost of computational
efficiency (Mu et al., 2011; Chai et al., 2014)). Now
the question is how to achieve face identification rates
in the range from 90% to 95% or even higher. In this
paper we argue that leveraging Gabor phase could en-
able such performance improvement for face identifi-
cation.
The Gabor phase is robust to light change and
indeed has been well-known that phase is more im-
portant than amplitude for signal reconstruction (Op-
penheim and Lim, 1981). Gabor phase should have
played a more important role in face identification.
However, use of Gabor phase in face recognition is
far from common and it has often been unsuccess-
ful with worse or nearly the same performance as
the amplitude in comparative experiments (Gao et al.,
2006; Zhang et al., 2009; Xie et al., 2010; Cament
et al., 2014). This is largely due to two challenging
issues: (1) Gabor phase is a periodic function and
a hard quantization occurs for every period; (2) it is
very sensitive to spatial shift (Wiskott et al., 1997;
Zhang et al., 2009), which imposes a rigid require-
ment on face image alignment. The first issue was
partly solved by introducing the phase-quadrant de-
modulation technique (Daugman, 2004), but the sec-
ond issue is still far from being solved. The state-
of-the-art Gabor phase approach (LGXP (Xie et al.,
2010)) extracts varied LBP from the phase spectrum.
Since the combination of the phase and LBP is also
sensitive to spatial shift, the power of Gabor phase
was not demonstrated in face identification.
In this work, we propose a method that merely
leverages the power of Gabor phase to address the
problem of face identification in controlled scenarios.
We apply a slim filter bank of only two Gabor filters
to extract the Gabor phase information and perform
explicit matching on the quantized phase map via our
Block Matching scheme (Zhong and Li, 2014). Dif-
ferent from other elastic matching schemes, the Block
Matching scheme not only cancels the patch-wise
spatial shift in phase map but also simultaneously
evaluates the patch-wise utility during the learning-
free matching process. Combining the matching
scheme with phase codewords enables the exploit-
ment of high-difinition phase information (4 times
higher than (Xie et al., 2010)) from only 2 Gabor fil-
ters. Thus, the proposed approach can significantly
bring up the algorithmic efficiency without sacrificing
the recognition accuracy. Further more, it is totally
comparable to those state of the art Gabor solutions
and even CNN based solutions.
The disposition of our paper is as follows: we
first briefly review the related Gabor based and CNN
based solutions in Section 2; our approach is then de-
scribed in Section 3 followed by comparative experi-
ments presented in Section 4. We further compare the
performance between our approach and CNN archi-
tectures in Section 5, where we discuss our work as a
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
50

whole and offer our conclusions.
2 RELATED WORK
In this section, we first describe the Gabor representa-
tion and then review recent Gabor based face recogni-
tion methods utilizing the Gabor amplitude or phase
in different ways.
In state-of-the-art face identification methods
based on Gabor wavelet representations, there are two
steps to construct features for identification. The first
step is to use Gabor filters for an optimal image repre-
sentation. A Gabor face is obtained by filtering a face
image with the Gabor filter function, which is defined
as:
ψ
u,v
(z) =
k
k
u,v
k
2
σ
2
e
(−
k
k
u,v
k
2
k
z
k
2
/2σ
2
)
[e
ik
u,v
z
−e
−σ
2
/2
],
where u and v define the orientation and scale of the
Gabor kernels respectively, and the wave vector is de-
fined as:
k
u,v
= k
v
e
iφ
u
,
where k
v
= k
max
/ f
v
, φ
u
= uπ/8; k
max
is the maximum
frequency, σ is the relative width of the Gaussian en-
velop, and f is the spacing factor between kernels
in the frequency domain (Liu and Wechsler, 2002).
The discrete filter bank of 5 different spatial frequen-
cies (v ∈ [0,··· , 4]) and 8 orientations (u ∈ [0,··· , 7])
is mostly exploited to filter face images to facilitate
multi-scale analysis for face recognition.
From the Gabor face representation, we then need
to form face features for identification. The most pop-
ular way is to extract the LBP type patterns from the
complex Gabor transformed image. As in (Zhang
et al., 2005), the LGBP feature is extracted from the
amplitude spectrum. In (Zhang et al., 2007) and (Xie
et al., 2010), 4-ray phase-quadrant demodulator is ap-
plied to demodulate the phase from each of the com-
plex Gabor coefficients, and local binary phase de-
scriptors are subsequently generated from the demod-
ulated phase spectrum. Dimension reduction can also
be used for feature construction. As in (Xie et al.,
2010), FLD is applied to form local Gabor features.
Besides, face identification can be built on other types
of local representations, exemplified as GOM (Chai
et al., 2014) and SLF (Yang et al., 2013).
Fusing other features that are independent of the
local Gabor features can also lead to better perfor-
mance: (Tan and Triggs, 2007; Su et al., 2009; Zhang
et al., 2007) fuses the global (holistic) features with
local ones at feature level; (Xie et al., 2010) proposes
fusion of Gabor phase and amplitude on the score and
feature levels; (Chai et al., 2014) fuses real, imagi-
nary, amplitude and phase. Alternatively, attaching
an illumination normalization step and weighting the
local Gabor features is shown to be helpful as well
(Cament et al., 2014).
Another face representation trend is to utilize
comparatively and/or exclusively trained CNNs to
learn discriminative metrics and features.With re-
cently launched hardware platforms (Jia et al., 2014;
Vedaldi and Lenc, 2014) and especially public acces-
sible large-scale dataset (Yi et al., 2014), developing
deep learning based face recognition approaches be-
comes feasible with less resources. Many deep net-
work architectures have been proposed as in (Schroff
et al., 2015; Parkhi et al., 2015; Yi et al., 2014).
3 THE GABOR PHASE BLOCK
MATCHING APPROACH
In this section, we first introduce the philosophy of
our proposed approach in Subsection 3.1, and then
describe the signal representation selected for our ap-
proach and the details of the approach in Subsection
3.2.
3.1 Overview
Repeatable features extracted from small face por-
tions are known as good discriminative traits for iden-
tifying persons. In addition, such local features are
less likely to be influenced than the holistic features
by pose changes and facial expressions. Thus, it is
natural to divide face image into blocks and performs
similarity measurements between them.
Even if being different in how to construct local
features from either Gabor amplitude or phase rep-
resentation, state-of-the-art face recognition methods
do share a common implication: the spatially corre-
sponding patches/features are the best match (since
matching is only performed between spatially corre-
sponding features). This implication is hardly true
because of the movement of facial components, head
pose variablity and imprecise alignment, the spatially
corresponding patches easily become dislocated (see
Fig. 2 in (Zou et al., 2007)). In addition, matching
the spatially corresponding Gabor phase patches is
even worse than comparing Gabor amplitude patches
since phase is very sensitive to spatial shift of fa-
cial textures. To handle this problem, some solutions
deploy elastic matching strategy to allow each seg-
mented patch of one image to search the best match-
ing from spatially neighboring locations on the other
image. This has achieved better robustness to spatial
Leveraging Gabor Phase for Face Identification in Controlled Scenarios
51

shift of the textures as in (Lades et al., 1993; Wiskott
et al., 1997; Hua and Akbarzadeh, 2009; Zhong and
Li, 2014).
It is not surprising that different facial area
(blocks) have different utilities for identifying peo-
ple. For instance, patches containing eyes would
have higher discrimination power than other patches.
But, it is also straightforward that the discriminative
patches could locate at any position on the face when
matching faces. This is because the discriminative
features are totally matching-pair specific. For exam-
ple, patches from the cheek area with almost no tex-
ture would be useful only when matched to a cheek
patch has scar or a mole; it won’t contribute much
when matched to similar texture-less ones. Thus, to
improve discrimination, it is necessary to weight the
corresponding features based on their utility.
In this work, we show how to use the Blocking
Matching method (Zhong and Li, 2014) to construct
local face features and perform matching between
best-matching features. Our Block Matching scheme
explicitly handle spatial shift between two patches, so
that high-definition
1
Gabor phase information can be
maximally utilized and patch-wise utility is evaluated
on-line in the same matching process as well. We
demonstrate the combination of Gabor phase with the
Blocking Matching is powerful in handling the hard
factors, like light, pose, facial expressions, and aging
involved in face identification tasks.
3.2 Algorithm
The matching process of our Gabor Phase Block
Matching (GPBM) approach is illustrated in Fig.1 and
the details of the Block Matching searching scheme is
shown in Fig.2.
To match a gallery and a probe image, our GPBM
approach consists of two steps. In the first step, both
probe and gallery face images are filtered using a Ga-
bor filter bank (in the following we show that a single-
scale Gabor filter with two orientations is sufficient in
our approach). The filtered images are demodulated
by a Gray-coded Phase Shift Keying (PSK) demod-
ulator for smooth phase quantization. In the second
step, we divide phase images into non-overlapping
blocks. It is a natural choice to employ such a block
based approach since it is our way to construct fea-
tures. As mentioned in (Xie et al., 2010), the block
(patch) based strategy is an effective tool to handle
the so called “curse of dimensionality” and has been
proved to be an effective tool in face recognition.
1
Compared to approaches used quadratic phases, e.g., in
(Xie et al., 2010).
In our approach, the Block Matching method is
used to form features for identification. The demod-
ulated phase spectra are input to the Block Match-
ing method (Zhong and Li, 2014) to form features
and calculate the the pair wise distance between a
probe (pb) image and a gallery (gl) image. Specifi-
cally (Step 2 of Fig. 1), we first segment the probe
phase spectrum into N non-overlapping patches and
the patches {f
(pb)
n
}
N−1
0
are simply formed by the raw
phase codes of the patches. For each probe patch
f
(pb)
n
centered at image coordinate (x
n
,y
n
) (denoted
as f
(pb)
(x
n
,y
n
)), it searches its best matching block
within the corresponding search window and yields a
patch-wise distance vector d
n
denoted as:
d
n
= {d
i
n
},i ∈ [0, L −1] (1)
where L is the number of candidate gallery patches
within the (2R+1)×(2C +1) search window, i.e. L =
(2R +1) ·(2C +1) when applying full search method,
R and C stands for the searching offset in vertical and
horizontal directions respectively. Each element in d
n
is computed by performing an explicit matching over
the raw demodulated phase as:
d
i
n
=
XOR( f
(pb)
(x
n
,y
n
), f
(gl)
(x
i
,y
i
))
decimal
2
, (2)
where the patch-wise distance metric is the l2-norm
of element wise Humming distance in decimal and
f
(gl)
(x
i
,y
i
) denotes the patch that centered at image
coordinate (x
i
,y
i
) within the search window on the
gallery face image so that,
(
x
i
= x
n
+ ∆x, ∆x ∈ [−C,C]
y
i
= y
n
+ ∆y, ∆y ∈ [−R,R].
(3)
We then evaluate the patch-wise utility by apply-
ing linear regression to the matching distance values.
This is achieved by calculating the slope k
n
of the lin-
ear fitting of the first 5 ascendingly sorted values of d
n
for normalization of the patch wise distance for each
patch, such that the normalization factor s
n
is calcu-
lated as:
s
n
= k
n
/d
∗
n
, (4)
where d
∗
n
= min(d
n
). s
n
is then normalized by its l1-
norm as:
s
∗
n
= s
n
/
N−1
∑
n=0
s
n
. (5)
Finally, the distance between a matching pair of
probe and gallery face image is the weighted sum of
d
∗
n
as:
dist
(pb,gl)
=
N−1
∑
n=0
s
∗
n
·d
∗
n
. (6)
It is noteworthy that 1) feature extraction is not
carried out through the Block Matching process; 2)
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
52
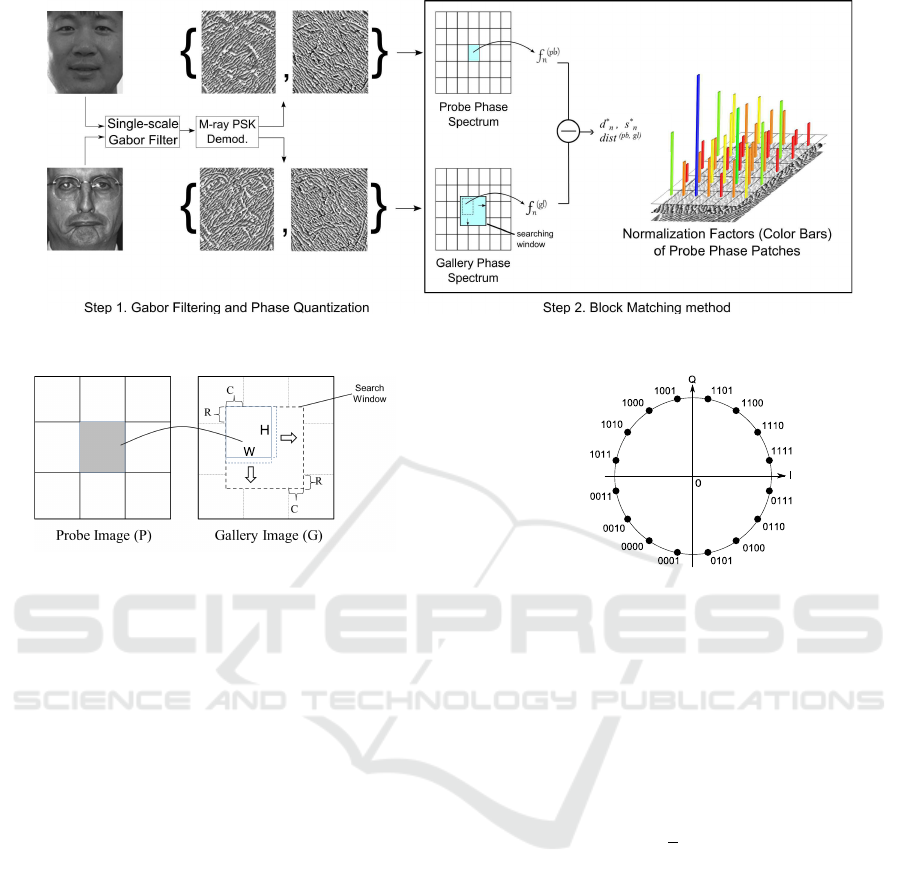
Figure 1: Gabor Phase Matching using the Block Matching Method.
Figure 2: Block Matching Scheme.
the patch-wsie utility evaluation process is realized
only based on the two matching images at hand and
learner is not involved.
4 EXPERIMENTS AND RESULTS
4.1 Database Selection
There are a variety of large-scale datasets available
for benchmark evaluation of different face recognition
approaches, such as the FERET (Phillips et al., 2000),
FRGC2.0(Phillips et al., 2005) and the LFW dataset.
Since we focus on face recognition in controlled sce-
narios in this paper, the FERET database — the most
commonly used face identification benchmark — is
selected to evaluate and compare our method with
state-of-the-art face identification approaches. In ad-
dition, the CMU-PIE (Sim et al., 2002) dataset is
selected to evaluate our GPBM against variations of
pose, expression and illumination.
4.2 Experimental Setup
Face images are first normalized (aligned) based on
the positions of both eyes as in (Xie et al., 2010).
A central facial area of 150 ×136 , which maintains
Figure 3: Phase codeword generator: 16-PSK demodulator
constellation.
the same height/width ratio (1.1 : 1) as in (Xie et al.,
2010; Zhang et al., 2010), is segmented from the face
image and used for our experiments.
Due to our Block Matching scheme, the Gabor
phase information with a higher definition can be uti-
lized in our approach. We found that a single-scale
Gabor filter pair with two orientations is sufficient
for face identification. In our implementation, the
selected Gabor filters have the following parameters:
v = 0, u ∈ {2, 6}, f =
√
2, k
max
= π/2, σ = 2π.
One can see that the chosen Gabor filters
have broad high-frequency coverage. These high-
frequency components correspond to facial texture
variations and are insensitive to the factors of lighting,
pose, and aging. Accordingly, to retain high phase
definition and to be tolerant to potential phase change
caused by texture shift, a Gray-coded 16-PSK demod-
ulator is used for phase demodulation and the constel-
lation is shown in Fig.3. Compared to the quadrature
phase demodulation used in (Zhang et al., 2007; Xie
et al., 2010), 4 times the phase information can be uti-
lized thanks to the employment of our block-matching
approach. With Gabor phase information, the block
matching approach is used to form features for face
identification.
Leveraging Gabor Phase for Face Identification in Controlled Scenarios
53

4.3 Evaluations on the CMU-PIE
Database
The CMU-PIE database contains 41368 images of 68
subjects. Images with Pose Label 05, 07, 09, 27, and
29 under 21 illuminations (Flash 2 to 22) of all the 68
persons are selected as the probe set.
When applying the blocking matching method,
the most important parameters are the block size (H
and W) and searching offset (R and C). We have con-
ducted a set of empirical tests over other datasets to
select suitable parameters. We found that it makes
sense to divide a central facial area into 5 ×7 batches,
which correspond to semantic facial macro features,
like eyes, nose, etc. Thus, for a facial area of 150 ×
136, a reasonable size of a block is 30 ×20. In our
implementation, we select the block size of 29 ×19
for convincing block searching (where we prefer the
block size with odd numbers). To have good cover-
age while keeping low computational complexity, the
searching offset is chosen as around
1
4
of the block
size and we select search offset of R = 7, C = 6 pixels
in our experiments. To test how sensitive the perfor-
mance is to the selected parameters, we selected the
first 2000 probe images on the CMU-PIE to evaluate
the performance with the chosen parameters and other
parameters randomly selected around them. The eval-
uation results are shown in Fig. 4. From the test re-
sults one can see that the performance is rather insen-
sitive to the selection of parameters. Thus, in our ex-
periments with both CMU-PIE and FERET databases
we used the chosen parameters.
Figure 4: Recognition rates under different parameters on
PIE.
We then conduct experiments on the CMU-PIE
probe set and compare our GPBM with G LBP and
G LDP (Zhang et al., 2010). The G LBP is the Ga-
bor version LBP and the G LDP is a type of im-
proved Gabor amplitude Local Binary Pattern. The
G LDP achieved equivalent performance as LGXP
(Gabor Phase pattern) on the FERET evaluations so it
is a good reference for comparison. The comparative
rank-1 recognition rates are listed in Table 1. It can
be seen that our method is at least 3% better than the
Table 1: Comparative rank-1 recognition rates of GPBM on
the CMU-PIE database.
Method Accuracy
G LBP
∗
71%
G LDP 2nd-order
∗
72%
G LDP 3rd-order
∗
79%
G LDP 4th-order
∗
74%
GPBM 82%
∗
The recognition rates are estimated from Fig. 12a in
(Zhang et al., 2010).
G LDP, even though LDP extract much more compli-
cated patterns than the LBP from the Gabor ampli-
tude space. Utilizing the Gabor phase in the Block
Matching scheme is more effective in dealing with
pose and illumination changes than LBP-type patterns
extracted from the Gabor amplitude space.
4.4 Evaluations on the FERET
Database
The FERET database contains 1196 frontal face im-
ages in the gallery set, 1195 images with different ex-
pressions in the probe set “Fa”, 194 images with illu-
mination variations in the probe set “Fc”, 722 images
taken in later time in the “Dup1” set, and 234 images
taken at least 1 year later than the gallery set form the
hardest “Dup2” set. We faithfully follow the evalua-
tion protocol of the FERET dataset. The results of our
GPBM with other approaches using Gabor-phase are
listed in Table 2.
From Table 2 one can see that in a fair compar-
ison, when only Gabor phase is utilized for match-
ing, our GPBM is almost 12% better than LGXP on
the hardest “Dup2”; even in unfavorable comparisons,
where pre-processing, training, and fusion methods
are exploited by LMGEW//LN+LGXP and S[LGBP
Mag+LGXP], our GPBM still excles. To our best
knowledge, the method S[LGBP Mag+LGXP] —
aided by the Gabor amplitude and training procedures
— is state-of-the-art Gabor phase based method in
terms of performance on the hardest FERET “Dup2”,
and our GPBM is entirely comparable.
We also further compare our GPBM with other
state-of-the-art approaches based on other techniques
on the FERET in Table 3. From the table one can see
that all these approaches are based on Gabor features,
which indicates the Gabor filter is a very effective tool
for signal representation. Our GPBM method outper-
forms all the other approaches on the hardest “Dup2”
set and it features three advantages: 1) it enables high
definition Gabor phase to be utilized for face identifi-
cation; 2) a single-scale Gabor filter with two orienta-
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
54

Table 2: Comparative rank-1 recognition rates of Gabor-phase based approaches on the FERET database.
Method Fb Fc Dup1 Dup2
LGBP Pha (Zhang et al., 2009) 93% 92% 65% 59%
LGBP Pha
weighted
(Zhang et al., 2009) 96% 94% 72% 69%
HGPP
weighted
(Zhang et al., 2007) 97.5% 99.5% 79.5% 77.8%
LGXP (Xie et al., 2010) 98% 100% 82% 83%
LGXP+BFLD (Xie et al., 2010) 99% 100% 92% 91%
S[LGBP Mag+LGXP] (Xie et al., 2010) 99% 100% 94% 93%
LMGEW//LN+LGXP (Cament et al., 2014) 99.9% 100% 94.7% 91.9%
GPBM 99.4% 100% 95.3% 94.9%
Table 3: Comparative Summary of Recent State-of-the-art Face Identification Approaches.
Methods Image Size Photometric Gabor Filter Gabor Feature Space Training Data Rank-1 Accuracy
Processing Scale × Orient. Independent on FERET Dup2
LGXP (Xie et al., 2010) 88 ×80 No 5 ×8 Phase No 83%
LGBP+LGXP (Xie et al., 2010) 88×80 No 5 ×8 Amplitude + Phase No 93%
GOM (Chai et al., 2014) 160 ×128 No 5 ×8 Amplitude + Phase No 93.1%
LN+LGXP (Cament et al., 2014) 251×203 Yes 5 ×8 Phase No 91.9%
LN+LGBP (Cament et al., 2014) 251 ×203 Yes 5 ×8 Amplitude No 93.6%
SLF-RKR l2 (Yang et al., 2013) 150 ×130 No 5 ×8 Amplitude No 94.4%
GPBM, ours 150 ×136 No 1 ×2 Phase(explicit matching) Yes 94.9%
tions is sufficient to generate an effective face image
representation, with 1/20 of the computational com-
plexity of other methods that utilized 40 Gabor filters;
3) further to this, it is not a learning-based face iden-
tification method and, therefore, promises good gen-
eralization.
The computational complexity is always a big
concern. From Table 4 in (Mu et al., 2011), un-
der the image size of 128 ×128 with a 5 ×8 Gabor
filter bank, the histogram extraction of LGBP takes
around 0.45 seconds, S[LGBP Mag+LGXP] takes
0.99 seconds. Extracting GOM feature takes 0.7 sec-
onds (Chai et al., 2014). However, the “feature ex-
traction” time in our method is 0 seconds since only
the raw phase is used for matching; the demodula-
tion is the only on-line computation of the probe face,
thus, it is extremely fast. Our Matlab implementation
executes the matching of a face pair in 0.05 second
in average (Gabor filtering included) on a 3.4GHz In-
tel CPU. We can therefore safely conclude that our
GPBM outperforms the best Gabor-phase based ap-
proach (S[LGBP Mag+LGXP]) in efficiency with a
big margin and we can also infer that the other meth-
ods in Table 3 could hardly be more efficient than our
GPBM due to higher image resolution, Gabor face
dimensions, and additional photometric processing.
Here we should mention that our GPBM needs to run
block matching. Right now, we used an “exhaustive
search” strategy. Since we have just a few blocks per
probe image, matching is still fast. In future work, we
could also incorporate fast-search strategies from the
video compression field to speed up face matching.
5 DISCUSSIONS AND
CONCLUSIONS
Before we conclude this paper, it would be inter-
esting to investigate “How good Deep Learning can
be in face recognition in controlled scenarios?”. To
answer this, we trained several CNNs with well-
known architectures of AlexNet (Krizhevsky et al.,
2012), VGG-net (Simonyan and Zisserman, 2014)
and Google’s InceptionNet (Szegedy et al., 2014) and
FaceNet (Schroff et al., 2015)), and evaluated them
on the most difficult probe set “Dup2” of FERET
database. For fair comparisons on different architec-
tures, layers after the last spatial pooling in our imple-
mentation of the InceptionNet and the FaceNet were
replaced by two concatenated Fully Connected (FC)
layers . We used WebFace dataset (Yi et al., 2014) to
train our networks and carefully fine tuned the trained
nets afterwords with FERET gallery images.
To illustrate how architecture choice affects recog-
nition performance, we investigated how the Rank-1
accuracy varies under different sizes of the FC lay-
ers. The results are enlisted in Table 4. We can see
that the architecture (length of FC) does influence the
recognition accuracy. On the one hand, explicitly in-
herit networks designed for other image classification
Leveraging Gabor Phase for Face Identification in Controlled Scenarios
55

Table 4: Rank-1 accuracy of several well-known CNN ar-
chitectures on FERET Dup2 (Input image size to CNNs is
120 ×120).
Archetectures
Length of the Last 2 FCs
FC-4096 FC-1024
AlexNet 91.9% 94.4%
VGG-13 layers 93.6% 94.9%
VGG-16 layers 93.2% 97.0%
InceptionNet 95.3% 98.7%
FaceNet 94.9% 98.3%
tasks may not perform well in novel face recognition
tasks (compare the left column to the right); investiga-
tions on suitable deep feature representations must be
made correspondingly ( here we found that FC −1024
is a good choice which is also verified by (Parkhi
et al., 2015)). On the other hand, the performance
strongly correlates to architecture in general: even
with FC −1024 the InceptionNet outperformed oth-
ers. While it is not astonishing that some CNNs out-
performed the proposed approach for almost 4%, we
can see that such advantage is not statistically signifi-
cant: the best CNN correctly identified 9 more probe
faces than our proposal which made 222 correct an-
swers out of 234 probes on the “Dup2” set. One can
expect even higher accuracy from better CNN solu-
tions, but under limited conditions where CNN based
solutions are not feasible (e.g., due to lack of train-
ing data) the proposed method is still a good alter-
native due to its comparable effectiveness and high
efficiency.
The Gabor based solutions share a common lim-
itation. They extract low level features from image
texture through a shallow filter bank (typically of 40
filter kernels). When it comes to matching faces with
dramatic texture changes, the features are not “deep”
enough to construct discriminative representations.
This makes Gabor based solutions unsuitable for face
recognition in uncontrolled scenarios where the CNN
solutions, which build high-level features from low
level Gabor-like filters, demonstrated overwhelming
advantages.
To conclude, we propose a plain approach to lever-
age the demodulated Gabor phase for face identifica-
tion based on the Block Matching method. The pro-
posed approach neither utilizes a large Gabor filter
bank nor a training process. It only depends on the
signal representation from a single-scale Gabor filter
pair to perform explicit matching over the raw Gabor
phase spectrum.
Comparative experiments show that: 1) our ap-
proach features the highest accuracy utilizing the Ga-
bor phase for face recognition; 2) our approach retains
very low computational complexity yet with compa-
rable performance to other state of the art methods
including Deep Learning methods when it works on
face recognition in controlled scenarios. Our experi-
ments demonstrate that our Block Matching method
is a powerful tool that can leverage the power of Ga-
bor phase to boost the face recognition performance.
REFERENCES
Ahonen, T., Hadid, A., and Pietikinen, M. (2004). Face
recognition with local binary patterns. In Pajdla, T.
and Matas, J., editors, Computer Vision - ECCV 2004,
volume 3021 of Lecture Notes in Computer Science,
pages 469–481. Springer Berlin Heidelberg.
Belhumeur, P. N., Hespanha, J. P., and Kriegman, D. (1997).
Eigenfaces vs. fisherfaces: Recognition using class
specific linear projection. Pattern Analysis and Ma-
chine Intelligence, IEEE Transactions on, 19(7):711–
720.
Cament, L. A., Castillo, L. E., Perez, J. P., Galdames, F. J.,
and Perez, C. A. (2014). Fusion of local normalization
and gabor entropy weighted features for face identifi-
cation. Pattern Recognition, 47(2):568–577.
Cao, X., Wei, Y., Wen, F., and Sun, J. (2014). Face align-
ment by explicit shape regression. International Jour-
nal of Computer Vision, 107(2):177–190.
Chai, Z., Sun, Z., Mendez-Vazquez, H., He, R., and Tan,
T. (2014). Gabor ordinal measures for face recogni-
tion. Information Forensics and Security, IEEE Trans-
actions on, 9(1):14–26.
Chan, C. H., Tahir, M. A., Kittler, J., and Pietikainen,
M. (2013). Multiscale local phase quantization for
robust component-based face recognition using ker-
nel fusion of multiple descriptors. Pattern Analy-
sis and Machine Intelligence, IEEE Transactions on,
35(5):1164–1177.
Chen, D., Cao, X., Wang, L., Wen, F., and Sun, J. (2012).
Bayesian face revisited: A joint formulation. In Com-
puter Vision–ECCV 2012, pages 566–579. Springer.
Dalal, N. and Triggs, B. (2005). Histograms of oriented gra-
dients for human detection. In Computer Vision and
Pattern Recognition, 2005. CVPR 2005. IEEE Com-
puter Society Conference on, volume 1, pages 886–
893. IEEE.
Daugman, J. (2004). How iris recognition works. Circuits
and Systems for Video Technology, IEEE Transactions
on, 14(1):21–30.
Daugman, J. (2006). Probing the uniqueness and random-
ness of iriscodes: Results from 200 billion iris pair
comparisons. Proceedings of the IEEE, 94(11):1927–
1935.
Gao, Y., Wang, Y., Zhu, X., Feng, X., and Zhou, X. (2006).
Weighted gabor features in unitary space for face
recognition. In Automatic Face and Gesture Recog-
nition, 2006. FGR 2006. 7th International Conference
on, pages 6–pp. IEEE.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
56

Givens, G. H., Beveridge, J. R., Lui, Y. M., Bolme, D. S.,
Draper, B. A., and Phillips, P. J. (2013). Biomet-
ric face recognition: from classical statistics to future
challenges. Wiley Interdisciplinary Reviews: Compu-
tational Statistics, 5(4):288–308.
Hua, G. and Akbarzadeh, A. (2009). A robust elastic and
partial matching metric for face recognition. In Com-
puter Vision, 2009 IEEE 12th International Confer-
ence on, pages 2082–2089. IEEE.
Huang, G., Lee, H., and Learned-Miller, E. (2012). Learn-
ing hierarchical representations for face verification
with convolutional deep belief networks. In Computer
Vision and Pattern Recognition (CVPR), 2012 IEEE
Conference on, pages 2518–2525.
Huang, G. B., Ramesh, M., Berg, T., and Learned-Miller,
E. (2007). Labeled faces in the wild: A database for
studying face recognition in unconstrained environ-
ments. Technical Report 07-49, University of Mas-
sachusetts, Amherst.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J.,
Girshick, R., Guadarrama, S., and Darrell, T. (2014).
Caffe: Convolutional architecture for fast feature em-
bedding. arXiv preprint arXiv:1408.5093.
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Im-
agenet classification with deep convolutional neural
networks. In Pereira, F., Burges, C., Bottou, L., and
Weinberger, K., editors, Advances in Neural Informa-
tion Processing Systems 25, pages 1097–1105. Curran
Associates, Inc.
Lades, M., Vorbruggen, J. C., Buhmann, J., Lange, J.,
von der Malsburg, C., Wurtz, R. P., and Konen, W.
(1993). Distortion invariant object recognition in the
dynamic link architecture. Computers, IEEE Transac-
tions on, 42(3):300–311.
Li, H., Hua, G., Lin, Z., Brandt, J., and Yang, J. (2013).
Probabilistic elastic matching for pose variant face
verification. In Computer Vision and Pattern Recogni-
tion (CVPR), 2013 IEEE Conference on, pages 3499–
3506. IEEE.
Liu, C. and Wechsler, H. (2002). Gabor feature based classi-
fication using the enhanced fisher linear discriminant
model for face recognition. Image processing, IEEE
Transactions on, 11(4):467–476.
Lowe, D. G. (2004). Distinctive image features from scale-
invariant keypoints. International journal of computer
vision, 60(2):91–110.
Mu, M., Ruan, Q., and Guo, S. (2011). Shift and gray
scale invariant features for palmprint identification us-
ing complex directional wavelet and local binary pat-
tern. Neurocomputing, 74(17):3351–3360.
Oppenheim, A. V. and Lim, J. S. (1981). The importance of
phase in signals. Proceedings of the IEEE, 69(5):529–
541.
Parkhi, O. M., Vedaldi, A., and Zisserman, A. (2015). Deep
face recognition. Proceedings of the British Machine
Vision Conference.
Phillips, P. J., Flynn, P. J., Scruggs, T., Bowyer, K. W.,
Chang, J., Hoffman, K., Marques, J., Min, J., and
Worek, W. (2005). Overview of the face recogni-
tion grand challenge. In Computer vision and pattern
recognition, 2005. CVPR 2005. IEEE computer soci-
ety conference on, volume 1, pages 947–954. IEEE.
Phillips, P. J., Moon, H., Rizvi, S. A., and Rauss, P. J.
(2000). The feret evaluation methodology for face-
recognition algorithms. Pattern Analysis and Machine
Intelligence, IEEE Transactions on, 22(10):1090–
1104.
Pinto, N., DiCarlo, J. J., and Cox, D. D. (2009). How far can
you get with a modern face recognition test set using
only simple features? In Computer Vision and Pattern
Recognition, 2009. CVPR 2009. IEEE Conference on,
pages 2591–2598. IEEE.
Schroff, F., Kalenichenko, D., and Philbin, J. (2015).
Facenet: A unified embedding for face recognition
and clustering. In Proceedings of the IEEE Confer-
ence on Computer Vision and Pattern Recognition,
pages 815–823.
Sim, T., Baker, S., and Bsat, M. (2002). The cmu pose,
illumination, and expression (pie) database. In Auto-
matic Face and Gesture Recognition, 2002. Proceed-
ings. Fifth IEEE International Conference on, pages
46–51. IEEE.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
CoRR, abs/1409.1556.
Su, Y., Shan, S., Chen, X., and Gao, W. (2009). Hierarchi-
cal ensemble of global and local classifiers for face
recognition. Image Processing, IEEE Transactions
on, 18(8):1885–1896.
Sun, Y., Wang, X., and Tang, X. (2013). Deep learning face
representation from predicting 10,000 classes. In Pro-
ceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 1891–1898.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S.,
Anguelov, D., Erhan, D., Vanhoucke, V., and Rabi-
novich, A. (2014). Going deeper with convolutions.
Computer Vision, 2014 IEEE 12th International Con-
ference on.
Taigman, Y., Yang, M., Ranzato, M., and Wolf, L. (2013).
Deepface: Closing the gap to human-level perfor-
mance in face verification. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 1701–1708.
Tan, X. and Triggs, B. (2007). Fusing gabor and lbp fea-
ture sets for kernel-based face recognition. In Analysis
and Modeling of Faces and Gestures, pages 235–249.
Springer.
Turk, M. A. and Pentland, A. P. (1991). Face recogni-
tion using eigenfaces. In Computer Vision and Pat-
tern Recognition, 1991. Proceedings CVPR’91., IEEE
Computer Society Conference on, pages 586–591.
IEEE.
Vedaldi, A. and Lenc, K. (2014). Matconvnet-
convolutional neural networks for matlab. arXiv
preprint arXiv:1412.4564.
Wiskott, L., Fellous, J.-M., Kuiger, N., and Von Der Mals-
burg, C. (1997). Face recognition by elastic bunch
graph matching. Pattern Analysis and Machine Intel-
ligence, IEEE Transactions on, 19(7):775–779.
Leveraging Gabor Phase for Face Identification in Controlled Scenarios
57

Wright, J., Yang, A. Y., Ganesh, A., Sastry, S. S., and Ma,
Y. (2009). Robust face recognition via sparse repre-
sentation. Pattern Analysis and Machine Intelligence,
IEEE Transactions on, 31(2):210–227.
Xie, S., Shan, S., Chen, X., and Chen, J. (2010). Fus-
ing local patterns of gabor magnitude and phase for
face recognition. Image Processing, IEEE Transac-
tions on, 19(5):1349–1361.
Yang, M., Zhang, L., Shiu, S.-K., and Zhang, D. (2013).
Robust kernel representation with statistical local fea-
tures for face recognition. Neural Networks and
Learning Systems, IEEE Transactions on, 24(6):900–
912.
Yi, D., Lei, Z., and Li, S. Z. (2013). Towards pose ro-
bust face recognition. In Computer Vision and Pat-
tern Recognition (CVPR), 2013 IEEE Conference on,
pages 3539–3545. IEEE.
Yi, D., Lei, Z., Liao, S., and Li, S. Z. (2014). Learn-
ing face representation from scratch. arXiv preprint
arXiv:1411.7923.
Zhang, B., Gao, Y., Zhao, S., and Liu, J. (2010). Lo-
cal derivative pattern versus local binary pattern: face
recognition with high-order local pattern descriptor.
Image Processing, IEEE Transactions on, 19(2):533–
544.
Zhang, B., Shan, S., Chen, X., and Gao, W. (2007). His-
togram of gabor phase patterns (hgpp): A novel object
representation approach for face recognition. Image
Processing, IEEE Transactions on, 16(1):57–68.
Zhang, W., Shan, S., Gao, W., Chen, X., and Zhang, H.
(2005). Local gabor binary pattern histogram se-
quence (lgbphs): A novel non-statistical model for
face representation and recognition. In Computer
Vision, 2005. ICCV 2005. Tenth IEEE International
Conference on, volume 1, pages 786–791. IEEE.
Zhang, W., Shan, S., Qing, L., Chen, X., and Gao, W.
(2009). Are gabor phases really useless for face recog-
nition? Pattern Analysis and Applications, 12(3):301–
307.
Zhong, Y. and Li, H. (2014). Is block matching an alterna-
tive tool to lbp for face recognition? In Image Pro-
cessing (ICIP), 2014 IEEE International Conference
on, pages 723–727.
Zou, J., Ji, Q., and Nagy, G. (2007). A comparative study
of local matching approach for face recognition. Im-
age Processing, IEEE Transactions on, 16(10):2617–
2628.
VISAPP 2016 - International Conference on Computer Vision Theory and Applications
58
