
Upper Body Detection and Feature Set Evaluation for Body Pose
Classification
Laurent Fitte-Duval, Alhayat Ali Mekonnen and Fr´ed´eric Lerasle
CNRS, LAAS, 7, Avenue du Colonel Roche, F-31400 Toulouse, France
Universit´e de Toulouse, UPS, LAAS, F-31400 Toulouse, France
Keywords:
Upper Body Detection, Body Pose Classification, Fast Feature Pyramid, Sparse Classification, Aggregated
Channel Features, Feature Evaluation
Abstract:
This work investigates some visual functionalities required in Human-Robot Interaction (HRI) to evaluate
the intention of a person to interact with another agent (robot or human). Analyzing the upper part of the
human body which includes the head and the shoulders, we obtain essential cues on the person’s intention.
We propose a fast and efficient upper body detector and an approach to estimate the upper body pose in 2D
images. The upper body detector derived from a state-of-the-art pedestrian detector identifies people using
Aggregated Channel Features (ACF) and fast feature pyramid whereas the upper body pose classifier uses a
sparse representation technique to recognize their shoulder orientation. The proposed detector exhibits state-
of-the-art result on a public dataset in terms of both detection performance and frame rate. We also present
an evaluation of different feature set combinations for pose classification using upper body images and report
promising results despite the associated challenges.
1 INTRODUCTION
In Human Robot Interaction (HRI), one of the fun-
damental requirements is the correct detection and
localization of human agents in the vicinity of the
robot. The robot should be able to perceivethe where-
abouts of human agents in order to coordinate with
them seamlessly. Depending on the exact applica-
tion, the interaction space can vary from few centime-
ters to several meters. This proximity, in turn, intro-
duces constraints about the field of view of the cam-
eras mounted on the robot for instance. Usually, in
close interaction the majority of cameras mounted on
a robot can only see parts of the person, specifically
the part above the thigh (figure 1), and any person de-
tection mechanism adopted should take this into con-
sideration.
In HRI, person detection relies on either classical
RGB cameras, e.g., (Mekonnen et al., 2011), or RGB-
D cameras that can provide 3D data like the Kinect
sensor (Jafari et al., 2014). Due to physical, economi-
cal, and design constraints classical RGB cameras are
predominantly found on robots. Hence, in this pa-
per we will focus on perceptions based on 2D RGB
images. The most popular approach for human de-
tection in HRI is using a pedestrian detector that has
been trained on full body annotated people dataset,
e.g., (Doll´ar et al., 2012). Unfortunately, these detec-
tors fail to detect people in presence of partial occlu-
sions, specifically partial occlusions of the legs. But,
by focusing on the upper part of the body, principally
the head and the shoulders, it is possible to identify
the presence of humans in the image under these cir-
cumstances. The approach, referred as upper body
detection, is similar to a pedestrian detection but fo-
cuses on a smaller area which is less variable than the
complete human body and is less exposed to the prob-
lem of occlusion (Li et al., 2009; Zeng and Ma, 2010).
Figure 1 illustrates this point: given a typical Human-
Robot (H/R) situation depicted on the left, the best
pedestrian detector fails to correctly detect the two
persons in front of the robot (bottom right) whereas
our proposed upper body detector handles it perfectly
(top right).
After identifying the human agents, we need to
characterize their global behavior and their degree of
intentionality to interact with the robot or with an-
other human agent. Generally, the analysis of these
cues is related to the head cues (Katzenmaier et al.,
2004; Sheikhi and Odobez, 2012). The head cue in-
dicates the direction of the person’s visual point of
interest and eventually the recipient of the person’s
439
Fitte-Duval L., Mekonnen A. and Lerasle F..
Upper Body Detection and Feature Set Evaluation for Body Pose Classification.
DOI: 10.5220/0005313104390446
In Proceedings of the 10th International Conference on Computer Vision Theory and Applications (VISAPP-2015), pages 439-446
ISBN: 978-989-758-090-1
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

Figure 1: Output of our proposed detector (top right) and
state-of-art pedestrian detector (Doll´ar et al., 2014), bottom
right, in an HRI context.
speech if there is a discussion (Bazzani et al., 2013).
But the estimation of orientations from both indica-
tors, the head and the body, helps to know its posture
or the direction of its movement in addition to its vi-
sual point of interest (Chen et al., 2011).
In this vein, we propose to estimate the orienta-
tion (body pose) of people using upper body cues.
We present an extensive evaluation of different fea-
ture sets to identify the best feature set that can cap-
ture required discriminative cues for upper body pose
classification. Given different scenarios as those pic-
tured in Fig. 2, the upper body pose allows to differ-
entiate a situation where two agents interact amongst
each other without paying attention to the robot (left)
from a situation where the agent is facing the robot
forward for a possible interaction (right).
Figure 2: Output of our pose classifier in several interaction
scenarios. The protruding arrows indicate pose orientation.
Related Works. Many researchers have investi-
gated 2D upper body detection for human detection,
e.g., (Li et al., 2009; Zeng and Ma, 2010; Eichner
et al., 2012). The most frequent features used in
these works are the Histogram of Oriented Gradient
(HOG) (Dalal and Triggs, 2005) features which cap-
ture gradient distribution in the image. To date, these
are the most discriminant features and the best results
are achieved by approaches that use some variants of
HOG (Doll´ar et al., 2012). Some works further im-
prove the detection performance by considering het-
erogeneous pool of features, for example, combining
Local Binary Pattern (LBP) and HOG features (Zeng
and Ma, 2010; Hu et al., 2014).
Some recent advances on pedestrian detection fo-
cus on feature representation introducingthe notion of
Integral Channel Features (ICF) (Doll´ar et al., 2012).
This representation takes advantage of the fast com-
putation using integral image and combines differ-
ent type of heterogeneous features to obtain outper-
forming detection results in comparison to state-of-
the-art detectors based on HOG features. Doll´ar et
al. (2014) propose an alternative representation of
the channel features called Aggregated Channel Fea-
tures (ACF) which slightly improves these perfor-
mances. Both ICF and ACF are quite appealing as
they have recorded outstanding performance both in
terms of detection and computation time. Combined
with a cascade classifiers configuration (Bourdev and
Brandt, 2005) and an efficient multiscale represen-
tation using approximation of rescaled features for
the detection process, this approach produces one of
the fastest state-of-the-art pedestrian detector (Doll´ar
et al., 2014).
Upper body pose estimation has also been inves-
tigated by various researchers, e.g, (Eichner et al.,
2012; Weinrich et al., 2012). These works use dif-
ferent methods to retrieve an articulated model of a
good configuration on a single image or on a sequence
of images. To avoid the complexity associated with
articulated models some works have investigated us-
ing data obtained from global pedestrian detection for
pose classification in video surveillance context (An-
driluka et al., 2010; Chen et al., 2011; Baltieri et al.,
2012). These works use the same HOG features com-
puted at several scales with different classifiers simi-
lar to those used in the detection process to attribute
one of the possible direction to the observed pedes-
trian, for examples, SVMs (Andriluka et al., 2010),
or random trees (Baltieri et al., 2012). The original
approach of Chen et al. (2012), which is adopted in
this work, uses sparse representation technique. This
approach has proved robust to occlusion and data cor-
ruption.
Contributions. This paper makes two core contri-
butions: (1) it presents an upper body detector based
on 2D RGB image using Aggregate Channel Features
(ACF) and soft cascade classifier that leads to state-
of-the-art results in terms of both detection perfor-
mance and frame rate; and (2) it presents a detailed
comparative evaluation of various feature sets for up-
per body based pose classification using a sparse rep-
resentation technique.
This paper is structured as follows: It begins with
an overview of the framework in section 2. Sections 3
and 4 detail the approach used for upper body detec-
tion and pose classification respectively. All experi-
ments carried out and associated results are presented
in section 5. Finally, the paper ends with concluding
remarks in section 6.
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
440

Upper Body
Detector
Body Pose
Classification
Figure 3: Adopted complete perceptual framework.
2 FRAMEWORK OVERVIEW
Figure 3 depicts a concise summary of the framework
adopted in this work that highlights the two core com-
ponents: upper body detector and body pose classifi-
cation. As stated in section 1, given a sequence of
RGB images, we are interested to detect people in the
image stream and correctly classify their body poses.
The upper body detector finds people in the image by
using a sliding window approach which exhaustively
scans the image at all possible locations and scales
applying the trained model. This step is computation-
ally intensive and is the main bottleneck that inhibits
achieving high frame rates. Taking this into account,
we use the ACF feature set combined with soft cas-
cade classifier, which have been proven to lead to su-
perior detection and speed, for detection. This block
passes all detected upper bodies to the upper body
pose classification block.
The body pose classification block determines the
orientation of the provided upper body data. For this
we have also adopted a proven technique based on
sparse representation. We evaluate a plethora of fea-
ture sets including classical and multiscale ACF and
HOG features and their combinations but only retain
the feature set that leads to the best result for actual
applications. Finally, this block provides orientation
information for the detected upper bodies.
3 UPPER BODY DETECTOR
We present the key processes used in the detection
framework: the feature representation, the classifica-
tion algorithm structure and the algorithm for multi-
scale feature representation.
3.1 Aggregated Channel Features
Aggregated Channel Features (ACF) differs from In-
tegral Channel Features (ICF) by using pixel lookups
as features instead of sums over rectangular re-
gions (Doll´ar et al., 2014). A channel C is a repre-
sentation of an image I where the pixels are obtained
applying a feature generation function Ω. So several
channels C = Ω(I) can be defined using different fea-
ture transformations. The channel features used in
this work are:
Gray and Color. The gray-scale is the simplest color
channel of an image as C = I. For our detection mod-
ule, we use the three LUV color channels which have
proved informative for person detection (Doll´ar et al.,
2012).
Gradient Magnitude. A non-linear transformation
which captures edge strength.
Gradient Oriented Histogram. It consists of a
histogram indexed by six gradient orientations (one
channel per orientation bin) and weighted by the gra-
dient magnitude. Normalizing the histogram using
the gradient magnitude allows to approximate the
HOG features.
Local Binary Pattern. We introduce this new chan-
nel feature in addition of the previous already used in
the work in (Doll´ar et al., 2014). The Local Binary
Pattern (LBP) is one of the best texture descriptor in
the literature. We use an efficient implementation of
the gray-scale and rotation invariant LBP descriptor
inspired by the works of Ojala et al., (2002).
Once, all the channels C = Ω(I) have been com-
puted, the channels are further divided into blocks.
The pixels in each block are summed and the result-
ing lower resolution channels are smoothed to make
up the ACF. Then, the ACF obtained are used to train
a soft cascaded boosted tree (section 3.2). Figure 4
illustrates the different channels used in our work and
the steps to generate the aggregated channels.
3.2 Soft Cascade
Boosting is a classification method that consists
of combining weighted weak classifiers to create a
strong classifier. The soft cascade classifier is a
boosted classifier variant proposed by Zhang and Vi-
ola (2008) and used for pedestrian detection success-
fully in (Doll´ar et al., 2014). Unlike a classical cas-
cade which has apredefined number of distinct stages,
the soft cascade has a single stage with many weak
classifiers. Rejection thresholds that make the “soft”
cascades are calculated for each weak classifier in a
process called cascade calibration that allows reorder-
ing of the “soft” stages to improve the classification
accuracy. Its main strength is that it considers the in-
formation of each stage in the global process contrary
to the classical attentional cascade which trained each
stage individually. It also allows optimization of de-
tection rate and execution time.
3.3 Fast Feature Pyramids
A feature pyramid is a multiscale representation of
an image where channels C
s
= Ω(I
s
) are computed at
UpperBodyDetectionandFeatureSetEvaluationforBodyPoseClassification
441

Figure 4: Aggregated Channel Features computation.
every scale s for the corresponding rescaled image I
s
.
The scales are organized per octave of 8 scales evenly
sampled in log-space between one given scale and the
next scale with half its value. Instead of generating
each scale computing C
s
= Ω(I
s
), a feature channel
scaling approximation is used :
C
s
= R(C,s) · s
λ
Ω
(1)
where R(C,s) denotes C re-sampled by s and λ
Ω
, a
lambda coefficient specific to the channel transforma-
tion Ω in order to scale the feature channel C using
a power law. An iterative method can be deduced
to efficiently generate a feature pyramid approximat-
ing channel features at intermediate scales s using the
computed channel features at the closest scale s
′
as
C
s
= R(C, s/s
′
) · (s/s
′
)
λ
Ω
. The best compromise con-
sists to compute one scale per octave and approximate
the 7 others.
This approach, pioneered by Dollar et al. (2014),
combined with the presented ACF features and soft
cascade classifier enables efficient sliding window
based detection implementation. This leads to fast
and highly accurate detector as will be shown in sec-
tion 5.
4 UPPER BODY POSE
CLASSIFICATION
The objective of this modality is to estimate the ori-
entation of a person’s upper body with respect to the
camera. The adopted body pose classification ap-
proach has initially been applied for pedestrian direc-
tion estimation (Chen et al., 2011).
4.1 Upper Body Pose Representation
Tackling the upper body pose determination as a clas-
sification problem–rather than a regression problem
due to limited training dataset–and in accordance with
the literature, we consider eight evenly spaced direc-
Figure 5: The eight upper body pose classes.
tions in steps of 45 degrees (N, NE, E, SE, S, SW, W,
NW) as the possible orientations, figure 5.
In the state-of-the-art work of (Chen et al., 2011),
a multi-level HOG feature is generated to extract in-
formation from the human bounding box. Three dif-
ferent levels are generated using different cell sizes
(respectively 8× 8, 16×16 and 32× 32 ) and the gra-
dient orientation is quantized in 9 bins. In this work,
we propose to usethe ACFfeatures representationin a
sparse representation for pose classification. We also
take advantage of the fast feature pyramid framework
introduced in section 3.3 to generate multiscale ACF
at three different levels similar to those used on the
multi-level HOG feature representation. So we gen-
erate aggregated channels at three scales without ap-
proximating intermediate scales in the octave.
4.2 Classification by Sparse
Representation
The upper body pose classification method adopted is
the same as in (Chen et al., 2011) inspired by the work
in face recognition in (Wright et al., 2009). We gen-
erate F = [F
1
,F
2
,...,F
k
], the training set matrix with
F
i
(1 < i < k) ∈ R
m×n
i
, the matrix associated to the
pose label i composed of n
i
feature vectors of size m.
A new feature vector y can be expressed as a linear
combination of the training features:
y = a
1
F
1
+ a
2
F
2
+ ... + a
k
F
k
= Fa
0
(2)
where F = [F
1
,F
2
,...,F
k
] and a
0
= [a
1
,a
2
,...,a
k
]
T
are
the concatenation of the coefficient vectors associated
to each class. The coefficients of a
0
obtained by solv-
ing the equation Fa = y are non-zero coefficients if
they are related to the actual pose of the new feature
vector demontrasting the sparsity of this decomposi-
tion. An easy way to solve this problem is to use the
l
1
-minimization approach:
a* = argminkak
1
subject to Fa = y, (3)
which can be solved using the pseudoinverse of F.
Giving this decomposition, for each class we can cal-
culate its pose probability ρ
k
(y) as :
ρ
k
(y) =
∑
a
∗
i
/ka∗k
1
, (4)
Then classifying y consists of finding the maximal
pose probability defined by:
class(y) = maxρ
k
(y) (5)
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
442

5 EXPERIMENTS AND RESULTS
In this section, the different experimental considera-
tions and carried out evaluations along with obtained
results are presented in detail.
5.1 Features Set Considerations
The ACF features are primarily used in both the de-
tection and body pose classification modules. Utiliz-
ing the same family of features is advantageous as it
avoids further computational overhead in the global
process. To see the effects of different channels on the
detector and pose classifier modules, we evaluate dif-
ferent constituent channel feature combinations listed
below:
• Magnitude gradient and six channels of histogram
of oriented gradients (GM+HOG or a),
• Color channels, magnitude gradient, and his-
togram of oriented gradients (Clr+GM+HOG or
b),
• Color channels, magnitude gradient, histogram
of oriented gradients, and local binary pattern
(Clr+GM+HOG+LBP or c),
• Magnitude gradient, histogram of oriented gradi-
ents, and local binary pattern (GM+HOG+LBP or
d),
In the body pose classifier, the gray-scale channel is
used instead of the 3 LUV color channels because cur-
rent publicly available training sets for pose classifi-
cation are mainly composed of gray-scale images.
5.2 Dataset and Implementation
Specifications
In both modules, the upper body windows considered
are cropped square windows from standard pedestrian
windows–the same width and a third of their height
from top (Fig. 5). Hence, a 64× 64 base window di-
mension is adopted. It has been observed than using a
square window with a third of the pedestrian window
rather than half leads to marginal loss in overall de-
tection performance on public datasets, but it is able
to detect head and shoulders in situations where the
person is close to the robot.
5.2.1 Upper Body Detector
Dataset. To train the upper body detector, we use
the INRIA Dataset (Dalal and Triggs, 2005). The
dataset contains 614 positive images containing 1237
annotated pedestrians in various situations including
crowds. The negative samples are randomly selected
from the 1218 people-free images. As in (Ferrari
et al., 2008), the training set is augmented by per-
turbing the positive samples applying slight rotations
(3 rotations in steps of 3
o
) and mirror reflections.
The positive training set is hence augmented 6 times
consisting in total around 7000 samples. Introduc-
ing these variations allows better generalization of the
classifier.
To test the trained detector, we use the InriaLite
dataset, a subset of the INRIA person dataset con-
taining 145 outdoor images with 219 persons in to-
tal, most of them entirely visible and viewed approx-
imately from the front or from the back.
Detector Training. The training of the soft cas-
cade used 2048 depth-two trees in four bootstrapping
rounds where the misclassified negative samples are
reused in the training process.
5.2.2 Upper Body Pose Classifier
Dataset. To train and test the body pose classifier,
we use the TUD Multiview Pedestrians dataset (An-
driluka et al., 2010). The dataset contains 400 to 749
annotated pedestrians in each class. It also contains
a total of 248 validation and 248 test annotated im-
ages which, in this work, are used for test purposes
resulting in combined 496 test instances.
Pose Classification Training. As presented in sec-
tion 4.2, the training matrix F depends of the number
of training samples per class n
i
and the dimensional-
ity m of the feature vector which is varied through our
feature evaluation process. The parameters affecting
m are specific to the features used. For the ACF, it
depends of the number of channels which varies be-
tween 7 and 9 in the classification module and of the
block size which divides the channels in blocks during
the summation step. Here, we use a fixed block size of
4×4 pixels. To make sure that the body pose classifier
does not over-fit, we test a classifier trained with dif-
fering samples, n
i
, of equal sizes per each class varied
between 200 and 400. Finally, the classifier is trained
using the whole training set (variable number of sam-
ples per class).
5.3 Evaluation Metrics
Detection Evaluation. The detection evaluation pro-
tocol used is the same as in the PASCAL Visual Ob-
ject Classes Challenge (Everingham et al., 2010). The
detection system returns a series of detected windows
after analyzing the image. These windows are ob-
tained after multiscale detection and non-maximum
suppression which avoid the accumulation of nearby
windows around a person. Given a detected bounding
UpperBodyDetectionandFeatureSetEvaluationforBodyPoseClassification
443
box (BB
dt
) and a ground truth bounding box (BB
gt
),
we consider the detection as correct if the overlap be-
tween the two windows exceed 50%:
overlap =
BB
dt
∩ BB
gt
BB
dt
∪ BB
gt
> 0.5 (6)
The non assigned BB
dt
and BB
gt
are counted respec-
tively as false positives and false negatives. The com-
parison of the detectors is realized as in (Doll´ar et al.,
2012), plotting the log-averagemiss rate (MR) against
the false positives per image (FPPI).
Pose Classification Evaluation. The classifica-
tion is evaluated using confusion matrices where the
columns corresponded to the predicted classes while
each row corresponds to the ground truth classes.
Concentrated detections along the diagonal indicate
preferred performance. We can extract the classifica-
tion accuracy per class considering the exact instances
of the class normalized by all the classified instances
for this same class. Then we can average the accu-
racy for all the classes which is our first performance
criteria, accuracy 1 (acc.1). We consider a second cri-
teria, accuracy 2 (acc.2), where the predictions to one
of the two adjacent classes are considered as correct
as in (Andriluka et al., 2010).
5.4 Results
Upper Body Detection. To compare the perfor-
mance of the proposed upper body detector variants
(using different constituent channel features) with no-
table approaches in the literature, we evaluated three
others upper body detectors including the OpenCV
implementation of the Viola and Jones detector (Vi-
ola and Jones, 2001), our implementation of the Dalal
and Triggs (2005) HOG-SVM detector, and the De-
formable Parts Model (DPM) based detector pro-
posed by the Calvin group (Eichner et al., 2012). All
detectors are trained with identical training set.
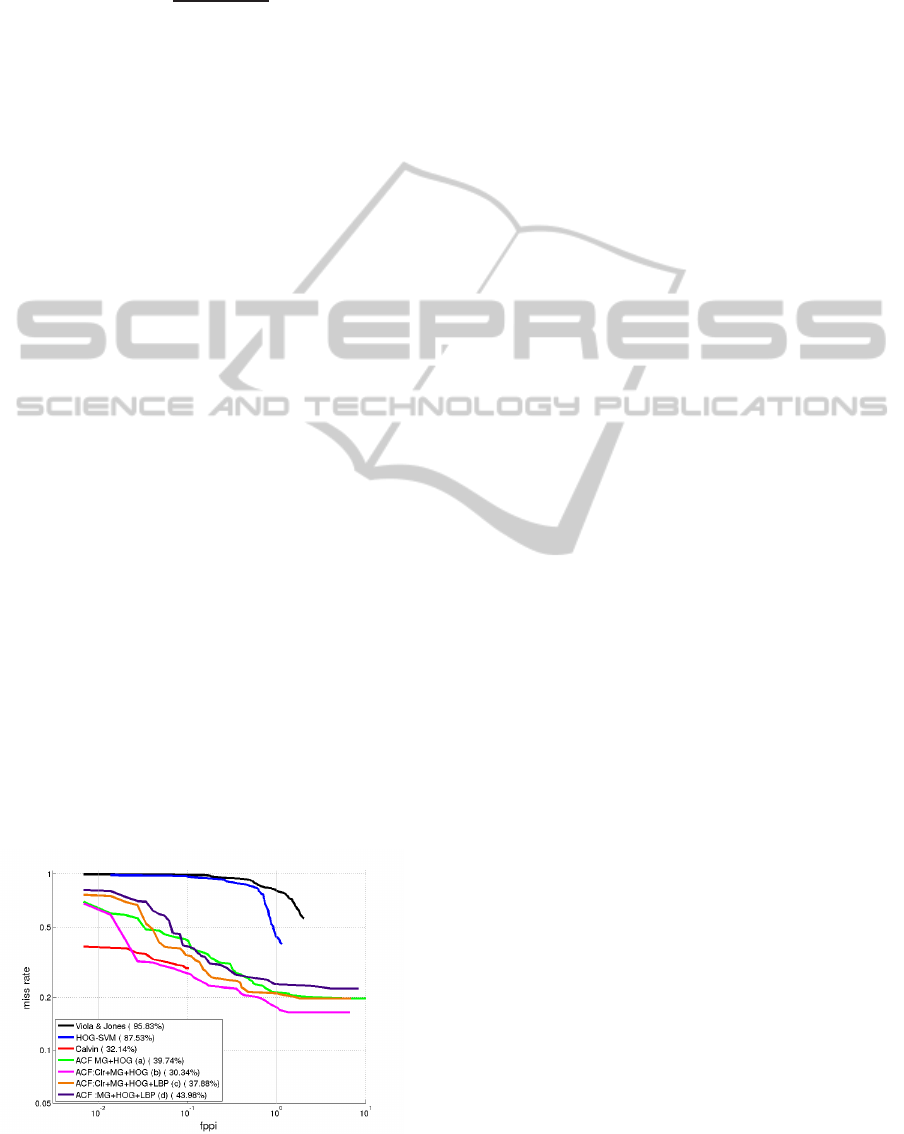
As can be seen from the results depicted in fig-
ure 6, all the ACF based detectors outperform the
Figure 6: Log-average miss rate on InriaLite dataset.
HOG-SVM and Viola and Jones based upper body de-
tectors significantly.
The best results are obtained by the original com-
bination of ACF combining the color, the magnitude
gradient, and the histogram of oriented gradient chan-
nels which also outperforms the Calvin detector–the
best upper body detector in the literature–achieving a
30.34% log-averge miss rate. This detector records a
0.18 Miss Rate at an average of 1 FPPI which can
be further ameliorated by using a filtering mecha-
nism. The combination of magnitude gradient and
histogram of oriented gradients is the simplest chan-
nel combination used but also illustrates how infor-
mative the gradient orientation features are. Adding
only the LBP channel decrease the performances of
the detector whereas using all the channel features
presented improves it relatively but overall it tends to
over-fit the detector due to the increased number of
feature sets. Computationally, with unoptimized Mat-
lab based code, all the ACF based detectors run at ap-
proximately 12.5 fps on 640× 480 images on an Intel
core i7 machine using a single thread. This is suffi-
cient for most real time robotic application require-
ments and is much higher than the 0.63 fps achieved
by the Calvin detector.
Upper Body Pose Classification. The upper body
pose classifier is evaluated using the combined 496
annotated samples from the TUD multiview pedes-
trian dataset. We generate classification matrices for
each type of features (11 in total) and consider the two
accuracies: acc.1 and acc.2. We evaluate the perfor-
mance of the proposed approach based on ACF along
with their multiscale variants and compare it with
the approach using multi-level HOG features (Chen
et al., 2011). Corresponding results are shown in fig-
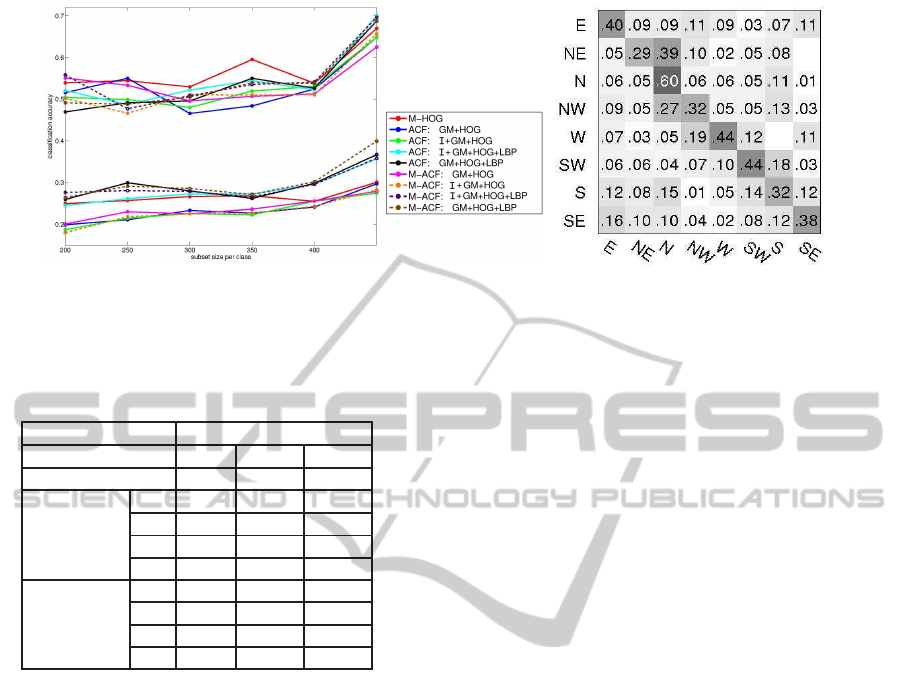
ures 7(a) and 7(b). Figure 7(a) shows the variations in
the performancesof the classifiers on the test set as the
data used for training is varied from 200 to 400 sam-
ples per class. The results confirm that as the training
dataset is increased, there is no observed over-fitting.
And indeed, the best results are obtained when using
all the data in the training set (which corresponds to
extreme data points in the plot). The confusion matrix
depicted in figure 7(b) corresponds to the best classi-
fier which is the multiscale ACF: GM+HOG+LBP.
Table 1 shows the dimensionality and the the accu-
racies obtained for the upper body pose classification
with the different combination of ACF using multi-
scale computation or not, in addition of the multi-
level HOG features. The combination of magnitude
gradient and histogram of oriented gradients results
are close to those using the multi-level HOG features
as we could expect because they use similar infor-
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
444
(a) (b)
Figure 7: (a) Classification accuracy for upper bodies, acc1 (lower curves), acc2 (upper curves), plotted as a function of the
amount of samples per each class; the extreme data points correspond to using the whole training set. (b) Confusion matrix
for upper body pose estimation using multiscale ACF: GM+HOG+LBP.
Table 1: Upper body pose classification.
upper body (64x64)
Approach dim. acc. 1 acc. 2
Multi-level HOG 756 0.3 0.67
Aggregated (a) 1792 0.3 0.65
Channel (b) 2048 0.27 0.65
Features (c) 2304 0.36 0.7
(d) 2048 0.37 0.69
Multiscale (a) 2352 0.28 0.63
Aggregated (b) 2688 0.28 0.66
Channel (c) 3024 0.36 0.7
Features (d) 2688 0.4 0.7
mations. But, contrary to the detection module, the
improvement of the results is given by the texture in-
formation from the LBP channel whereas the addi-
tion of the grayscale color channel decrease the re-
sults. Then the utilization of the multiscale informa-
tion keeps improving the accuracies. The best ex-
act precision is also obtained by the multiscale ACF:
GM+HOG+LBP.
The classification matrix is quite full with a con-
centration of the scores on the diagonal. Some er-
rors come from misclassified estimations for adjacent
classes. The North-East and North-West orientations
are often confused with North orientation for exam-
ple. These errors are considered in the second ac-
curacy criteria. This criteria has the same order of
magnitude around 66 per cent of the estimates what-
ever the kind of features used. We can also quote the
fact that the best pose estimation is the North orien-
tation when the face is not visible whereas the score
are lower for the other orientations when the face is
visible. Even the symmetric confusions are less vis-
ible because of all the weak estimations along one
orientation. These estimations allows to have a first
idea of the context in the image but would need to be
improved. Sample correct/incorrect classification and
pose estimates are shown in figure 8.
6 CONCLUSIONS
In this work, we presented two important percep-
tual components using 2D images–upper body de-
tection and upper body pose classification–that have
pertinent applications in machine perception of hu-
mans. The presented upper body detector based on
ACF features results in state-of-the-art detection re-
sult improving the previous best detector by a 2% av-
erage miss rate while improving computation speed
20x. We also presented upper body pose classification
based on sparse representation using single scale and
multiscale ACF features. Generally, the pose classifi-
cation results showed comparable accuracy compared
to the best approach in the literature. The results were
further improved by the addition of the LBP channel
features in the ACF framework leading to a 70% ac-
curacy (acc.2), outperforming the best approach in
the literature. Hence, the implemented perceptual
functionalities based on ACF lead to state-of-the-art
performance taking both accuracy and speed into ac-
count. In future works, the presented functionalities
will be coupled with stochastic filtering approach to
further improve the results and will be ported on our
mobile robot platforms for human intention detection.
ACKNOWLEDGEMENTS
This work has been funded by ROMEO2 (http://
www.projetromeo.com/) and RIDDLE projects –
BPIFrance in the framework of the Structuring
Projects of Competitiveness Clusters (PSPC), and a
UpperBodyDetectionandFeatureSetEvaluationforBodyPoseClassification
445

(a) (b)
Figure 8: Some illustrations of upper body detections from the Inrialite dataset (a), and pose estimations from the TUD
Multiview Pedestrians Set (b).
grant from the French National Research Agency un-
der grant number ANR-12-CORD-0003 respectively.
REFERENCES
Andriluka, M., Roth, S., and Schiele, B. (2010). Monocular
3d pose estimation and tracking by detection. In IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 623–630.
Baltieri, D., Vezzani, R., and Cucchiara, R. (2012). People
orientation recognition by mixtures of wrapped distri-
butions on random trees. In European Conference in
Computer Vision (ECCV), pages 270–283.
Bazzani, L., Cristani, M., Tosato, D., Farenzena, M.,
Paggetti, G., Menegaz, G., and Murino, V. (2013).
Social interactions by visual focus of attention in
a three-dimensional environment. Expert Systems,
30(2):115–127.
Bourdev, L. and Brandt, J. (2005). Robust object detection
via soft cascade. In IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 236–
243.
Chen, C., Heili, A., and Odobez, J.-M. (2011). Combined
estimation of location and body pose in surveillance
video. In IEEE Advanced Video and Signal-Based
Surveillance (AVSS), pages 5–10.
Dalal, N. and Triggs, B. (2005). Histograms of oriented
gradients for human detection. In IEEE Conference
onComputer Vision and Pattern Recognition (CVPR),
volume 1, pages 886–893.
Doll´ar, P., Appel, R., Belongie, S., and Perona, P. (2014).
Fast feature pyramids for object detection. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 36(8):1532–1545.
Doll´ar, P., Wojek, C., Schiele, B., and Perona, P. (2012).
Pedestrian detection: An evaluation of the state of the
art. IEEE Transactions on Pattern Analysis and Ma-
chine Intelligence, 34(4):743–761.
Eichner, M., Marin-Jimenez, M., Zisserman, A., and Fer-
rari, V. (2012). 2D articulated human pose estimation
and retrieval in (almost) unconstrained still images.
International Journal of Computer Vision, 99(2):190–
214.
Everingham, M., Van Gool, L., Williams, C. K., Winn, J.,
and Zisserman, A. (2010). The pascal visual object
classes (voc) challenge. International journal of com-
puter vision, 88(2):303–338.
Ferrari, V., Marin-Jimenez, M., and Zisserman, A. (2008).
Progressive search space reduction for human pose es-
timation. In IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), pages 1–8.
Hu, R., Wang, R., Shan, S., and Chen, X. (2014). Ro-
bust head-shoulder detection using a two-stage cas-
cade framework. In International Conference on Pat-
tern Recognition (ICPR).
Jafari, O. H., Mitzel, D., and Leibek, B. (2014). Real-time
RGB-D based people detection and tracking for mo-
bile robots and head-worn cameras. In International
Conference on Robotics and Automation (ICRA’14).
Katzenmaier, M., Stiefelhagen, R., and Schultz, T. (2004).
Identifying the addressee in human-human-robot in-
teractions based on head pose and speech. In Interna-
tional Conference on Multimodal Interfaces (ICMI),
pages 144–151.
Li, M., Zhang, Z., Huang, K., and Tan, T. (2009). Rapid and
robust human detection and tracking based on omega-
shape features. In International Conference on Image
Processing (ICIP), pages 2545–2548.
Mekonnen, A. A., Lerasle, F., and Zuriarrain, I. (2011).
Multi-modal person detection and tracking from a mo-
bile robot in a crowded environment. In International
Conference on Computer Vision Theory and Applica-
tions (VISAPP’11), pages 511–520.
Sheikhi, S. and Odobez, J.-M. (2012). Recognizing the vi-
sual focus of attention for human robot interaction.
In Human Behavior Understanding, pages 99–112.
Springer.
Viola, P. and Jones, M. (2001). Rapid object detection using
a boosted cascade of simple features. In IEEE Con-
ference on Computer Vision and Pattern Recognition
(CVPR), volume 1, pages I–511.
Weinrich, C., Vollmer, C., and Gross, H.-M. (2012). Es-
timation of human upper body orientation for mobile
robotics using an svm decision tree on monocular im-
ages. In IEEE/RSJ International Conference on Intel-
ligent Robots and Systems (IROS), pages 2147–2152.
Wright, J., Yang, A. Y., Ganesh, A., Sastry, S. S., and Ma,
Y. (2009). Robust face recognition via sparse repre-
sentation. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 31(2):210–227.
Zeng, C. and Ma, H. (2010). Robust head-shoulder detec-
tion by pca-based multilevel HOG-LBP detector for
people counting. In International Conference on Pat-
tern Recognition (ICPR), pages 2069–2072.
VISAPP2015-InternationalConferenceonComputerVisionTheoryandApplications
446
