
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOA
Supporting Enterprise Collaboration Across Organisational Boundaries
Brahmananda Sapkota and Marten van Sinderen
Faculty of Electrical Engineering, Mathematics and Computer Science
University of Twente, Drienerlolaan 5, Enschede, The Netherlands
b.sapkota@utwente.nl, m.j.vansinderen@utwente.nl
Keywords:
Service Oriented Architecture, Enterprise Application Integration, Cross-organisational Collaboration, Busi-
ness Requirements, Business Processes, Business-IT alignment.
Abstract:
Service Oriented Architecture (SOA) has been widely recognized as an approach for flexible integration of
enterprise applications across organisational boundaries based on service abstractions and Internet standards.
Enterprise collaboration and application integration is driven by business requirements, which in turn are
translated to business models and expressed as business processes. For example, business processes can be
used to represent the coordination of several published services as well as the implementation of a composite
value-added service. In this way, enterprise functions are aggregated using multi-stage business processes
fulfilling the specific requirements of an enterprise. In order for enterprises to stay competitive in their re-
spective businesses, such solutions must evolve in a timely and appropriate way in response to changes in
market demands and opportunities that inevitably occur. Therefore, a mechanism is required for business-IT
alignment during the complete lifecycle of SOA-based enterprise collaboration and application integration. In
this paper, we discuss issues related to cross-organisational collaboration and how service-oriented principles
and architectures can be applied to address these issues.
1 INTRODUCTION
Service Oriented Architecture (Erl, 2005) has been
widely recognized as an approach for flexible integra-
tion of enterprise applications across organizational
boundaries based on service abstractions and Internet
standards. On-demand enterprise collaboration and
application integration is driven by business require-
ments, which in turn are translated to business mod-
els and expressed as business processes. For example,
business processes can be used to represent the coor-
dination of several published services as well as the
implementation of a composite value-added service.
In this way, enterprise functions are aggregated us-
ing multi-stage business processes fulfilling the spe-
cific requirements of an enterprise (van Sinderen and
Almeida, 2011). In order for enterprises to stay com-
petitive in their respective businesses, such solutions
must evolve in a timely and appropriate way in re-
sponse to changes in market demands and opportu-
nities that inevitably occur. Service Oriented Archi-
tecture (SOA) supports adaptation of such an evolu-
tion through the concept of service composition. The
composition of services is made possible because of
service discovery which allows to find and select the
suitable services. The service discovery thus plays a
central role in enterprise collaboration and application
integration.
One of the fundamental requirements for the ser-
vice discovery are service descriptions and service
registries. In general, service descriptions are used
for specifying: 1) what functionalities are offered by
the service to its users (i.e., the interface definition);
2) how the service is provided (i.e., the service bind-
ing); and 3) where the service can be accessed (i.e.,
the service endpoint information). The service reg-
istries are used to announce the offered services and
thus play crucial role for a successful on-demand en-
terprise collaboration and application integration. In
a typical scenario, service providers publish their ser-
vice descriptions to a publicly accessible service reg-
istry. The service users search over these registries
and find the information needed to use the required
services. This approach of publishing, finding and
using the services forms the so called SOA trian-
gular operational model which clearly separates the
34
Sapkota B. and van Sinderen M.
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOASupporting Enterprise Collaboration Across Organisational Boundaries.
DOI: 10.5220/0004458300340041
In Proceedings of the First International Symposium on Business Modeling and Software Design (BMSD 2011), pages 34-41
ISBN: 978-989-8425-68-3
Copyright
c
2011 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

role of service provider, service user and service reg-
istry (van Sinderen, 2009). SOA, thus, enables flexi-
ble on-demand enterprise collaboration and applica-
tion integration. Despite these sound principles of
SOA, a number of practical complexities still exists,
which are preventing enterprises to fully exploit the
potential benefits of SOA.
An on-demand collaboration can only be achieved
if 1) the participants required for the collaboration
can be found and 2) the participants can communi-
cate with each other. In the SOA based approach,
the former requirement is supported by publishing
the descriptions of the offered services and latter re-
quirement is supported by defining the messages be-
ing sent. This can be realised relatively easily by us-
ing pre-meditated message structures and function li-
braries, if the enterprises collaborate in closed envi-
ronment. If the autonomous enterprises are to col-
laborate, pre-meditated message structures or func-
tion libraries cannot be used. Therefore, semantics of
the information provided through the service descrip-
tions should be well defined and the service reposi-
tory should contain valid service descriptions. While
the initiatives around Semantic Web services have
defined formalisms such as WSMO (Roman et al.,
2006), OWL-S (Martin, 2004) and SAWSDL (Farrell
and Lausen, 2007), to semantically define service de-
scriptions, they cannot ensure that the published de-
scriptions correctly reflect the offered services at the
time of their discovery. Therefore, a mechanism is re-
quired for business-IT alignment during the complete
lifecycle of SOA-based enterprise collaboration and
application integration.
In this paper, we propose a Summary of Services
per Provider (SSP) description based approach for
service discovery and to ensure that the published de-
scriptions are valid. An SSP description provides a
means for describing the collection of services offered
by a single service provider. It specifies what type of
services are offered by a particular service provider.
In the proposed approach, we use Web Service Defini-
tion Language (Chinnici et al., 2007) as the language
for describing services and allow service providers
to store them in their local repository. We provide
a mechanism to generate SSP description based on
the Web Service Definition Language (WSDL) doc-
uments stored at the local service registry of the ser-
vice providers. These SSP descriptions are then pub-
lished to the public service registry. Though the ser-
vice provider still has to generate and publish these
descriptions, it can be automated. Through this sepa-
ration, we aim at reducing the registry updating bur-
den at the side of the service providers. The proposed
approach, therefore, follows the SOA triangular oper-
ational model except that SSP descriptions are pub-
lished to the service registry instead of publishing the
service descriptions.
The rest of the paper is structured as follows:
Some of the highly relevant existing works are dis-
cussed in Section 2. The service discovery challenges
are discussed in Section 3. The proposed solution is
presented in Section 4 and its use to support cross-
organisational collaboration is presented in Section 5.
Finally, the work presented in this paper is concluded
in Section 6 by highlighting possible future direc-
tions.
2 RELATED WORKS
The problem of guaranteeing correctness of the pub-
lished service descriptions and reducing the effort re-
quired for providing such guarantees is starting to at-
tract attention from the research communities. The
work presented in (K
¨
uster and K
¨
oning-Ries, 2007)
follows an approach similar to the one presented in
this paper. The focus of this work is to ensure that
the published service description indeed represents
the concrete service. In order to support this, an es-
timation step followed by a single execution step is
proposed. In the estimation step, additional informa-
tion than that is available in the service description
itself is gathered whereas in the execution step, the
actual invocation of service is performed.
A preference-based selection of highly config-
urable web services is presented in (Lamparter et al.,
2007). It focuses on defining algorithms required for
finding optimal configurations while selecting the ser-
vices. Unlike the work presented in this paper, their
work neither considers minimisation of the extra ef-
fort required to update the service registry when ser-
vice descriptions are changed nor maximising the cor-
rectness of the published service descriptions. To
address the problem due to changes in service de-
scriptions a RSS-based mechanism to announce such
changes is proposed in (Treiber and Dustdar, 2007).
The RSS-based approach is service provider depen-
dent because the changing information should come
from them.
Treating services from the economical point of
view, (Cardoso et al., 2009) defines universal service
description language. The proposed language is de-
fined to describe both the IT and non-IT services. In
the proposed language, provisions for defining dy-
namic information is poorly defined. The approach
presented in (Truong et al., 2010) defines mechanism
for identifying and reducing irrelevant information in
service composition and execution. This approach
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOA - Supporting Enterprise Collaboration Across
Organisational Boundaries
35

is target at increasing efficiency and correctness of
the composition and execution. This approach works
only after the services are discovered and does not
eliminate the possibility of discovering services with
incorrect information.
In contrast to many other traditional ap-
proaches, (Speiser and Harth, 2011) proposes a
LinkedData based approach for integrating data
providing services. Their approach is suitable for
sharing data which might change over time. In com-
parison to the work presented in this approach, their
approach requires the service providers to describe
the offered services using LinkedData principles and
does not support sharing of already existing service
descriptions which are described using WSDL. We
propose mechanisms to allow usage of WSDL while
still dealing with changing and state dependent data.
A crawl based approach for collecting, annotat-
ing and classifying public Web services has been pro-
posed in (AbuJarour et al., 2010) attempting to in-
crease the role of service registry in service-oriented
architecture by providing correct information. In their
approach, publicly available web service descriptions
are crawled, annotation information is gathered, Web
services are annotated and classified based on this in-
formation. Through such classification, authors aim
at supporting better discovery of services. In this di-
rection, the work presented in (Obrst et al., 2010)
aims at enabling rich discovery of Web services by
projecting weak semantics from structural specifica-
tions. These approaches, however, cannot guarantee
that the information required for service discovery is
gathered.
Combination of document classification and on-
tology alignment schemes is proposed in (CRASSO
et al., 2010) to semantically enrich Web services.
Though this scheme helps in efficiently discovering
required services, it does not tackle the problem of
outdated service descriptions. The work presented in
(da Silva et al., 2011) specifies mechanisms for run-
time discovery, selection and composition of seman-
tic services. The proposed approach supports seman-
tic descriptions of the services but lacks support for
dealing with outdated service descriptions.
3 SERVICE DISCOVERY
CHALLENGES
In an open environment, it is difficult to support on-
demand collaboration if the published service de-
scriptions are either outdated or provide ambiguous or
incorrect information. This difficulty escalates when
service descriptions contain limited information, ei-
ther because the service providers are unwilling to
share all the information or because the information
is state dependent (Treiber and Dustdar, 2007; K
¨
uster
and K
¨
oning-Ries, 2007), i.e., the information may
change as the service is invoked. This will result in
a poor discovery results.
The correctness problem arises due to the fact
that service registries are passive. If the function-
alities of the offered services are changed, service
providers should take the initiative to update the cor-
responding descriptions published in the service reg-
istry. In practice, the published descriptions are rarely
updated. Instead of publishing the service descrip-
tions to the service registries, they are published on
the Web (Michlmayr et al., 2007). Such a practice,
violates the original SOA model (i.e., the triangular
operational model) and consequently undermines the
role of service registries in SOA (AbuJarour et al.,
2010). This shift in practice is due to the lack of effi-
cient and elegant support to update the service registry
whenever a service description is updated. The latter
essentially requires an additional effort on part of the
service providers. It becomes more problematic be-
cause the existing service registries emerge and disap-
pear (Sabou and Pan, 2007) and cannot be fully relied
upon for service discovery. The results of the investi-
gation of Web services on the Web published in (Al-
Masri and Mahmoud, 2008) reveals that only around
63% of the discovered Web services are in fact ac-
tive. This lack of reliable service repositories makes
on-demand collaboration between autonomous enter-
prises difficult, if not impossible.
Besides these technical difficulties, there are other
reasons why public service registries have not been
successful so far. One of the reasons is that a consid-
erable amount of the published service descriptions
are unusable (Treiber and Dustdar, 2007). Some of
the information (e.g., the information that depends
on the change in state) which might be important
for discovery purposes cannot be included in the ser-
vice descriptions in a simple way. In addition, some
providers may not be willing to disclose informa-
tion related to nun-functional properties and the qual-
ity of service parameters because of the fear of bar-
gain or competition from other providers (K
¨
uster and
K
¨
oning-Ries, 2007). This contributes to the retrieval
of imprecise service descriptions leading to false pos-
itives and consequently reducing the usability and the
reliability of service registries.
The above mentioned problems could be resolved
if service providers are allowed to store their service
description locally and provide them with a tool that
extracts summary information from their repository,
builds an SSP description and publishes it to the ser-
BMSD 2011 - First International Symposium on Business Modeling and Software Design
36
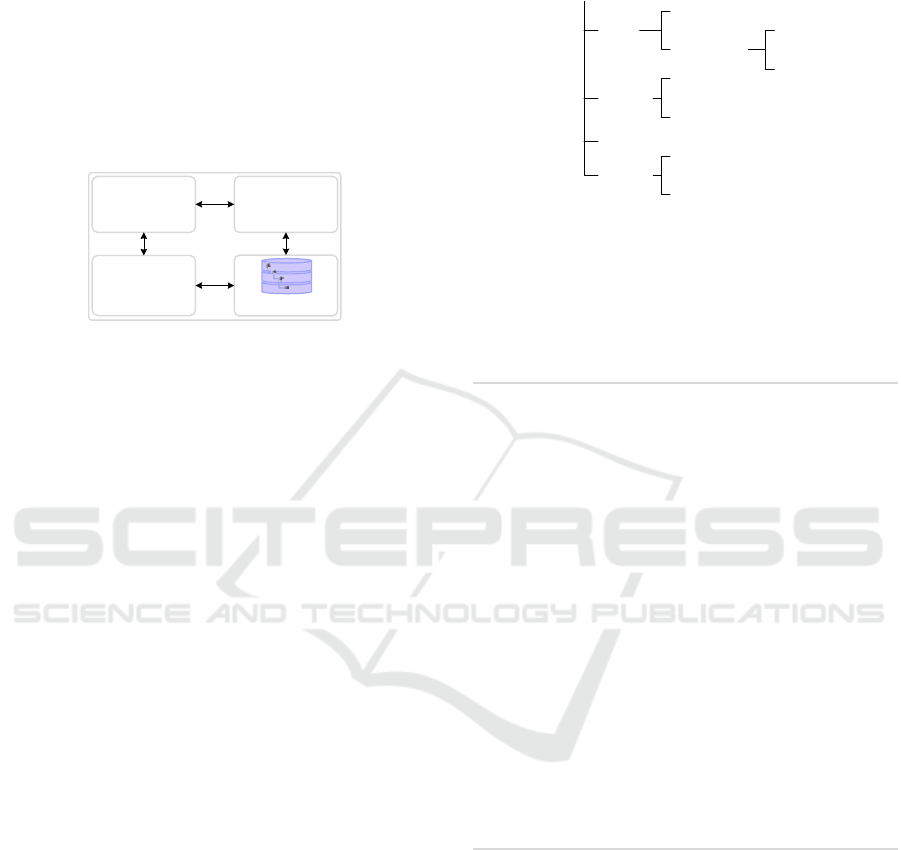
vice registry. The benefits of this approach are: 1)
service providers do not have to publish all the infor-
mation. It will also reduce the extra effort required for
maintaining and updating the service registry. Service
providers do not need to update service registry every
time the service description is updated, updates are
done locally. 2) service users can use these SSP de-
scriptions to find the potential providers, and finally
obtain the up-to-date information. Figure 1 shows the
overall architecture of this approach.
Service Providers
Registeries
Service Registry
Local Repository
Repository
Scanner
SSP Description
Generator
Publisher
Figure 1: Overall architecture.
4 SERVICE DISCOVERY
SOLUTIONS
We describe a mechanism to extract type information
from the WSDL files stored in the service provider’s
local repository and a mechanism to publish these in-
formation as SSP description to the service repository.
4.1 Generating Type Information
One of the purposes of using type information, in
the proposed approach, is to provide indication of
what type of services are offered by the service
providers. This kind of information serves the pur-
pose of guiding service requests towards the poten-
tial service providers. The type information based ap-
proaches are expected to help in narrowing down the
search space and allowing applications to deal with
the ever increasing number of Web services. We ex-
tract these information from service descriptions en-
coded in WSDL, which is a commonly used service
description language. A WSDL document is struc-
tured into four elements describing Service, Bindings,
Interface and Types definitions. A Service definition
specification specifies a collection of endpoints (i.e.,
URLs). The Bindings definition typically specifies
what data formats and communication protocols to
use when invoking the service. The operations, mes-
sage exchange patterns and mechanisms for fault han-
dling are specified in the Interface definition. The
data types used in messages and faults are specified
in the Types definition. Figure 2 shows some of these
parts pictorially where as the Listing 1 shows the type
and service definition parts of a WSDL document.
Description
Interface
Types
Element Declaration
Type Definition
Operation
Fault
Binding
Service
Input
Output
Interface
Endpoint
Figure 2: Pictorial representation of WSDL structure.
The data types specified in the Types definition es-
sentially model the domain knowledge and thus are
useful for extracting the necessary information for
generating SSP description from a given WSDL doc-
ument.
<wsdl:description
targetNamespace=”http://org.example.com/services/AvailabilityService/”
xmlns=”http://org.example.com/services/AvailabilityService/”
xmlns:wsdl=”http://www.w3.org/ns/wsdl”
xmlns:xsd=”http://www.w3.org/2001/XMLSchema”>
<wsdl:types>
<xsd:schema targetNamespace=”http://org.example.com/resources/
AvailabilityService”>
<xsd:element name=”ServiceRequest”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=”product” type=”xsd:string”/>
<xsd:element name=”date” type=”xsd:string”/>
<xsd:element name=”quantity” type=”xsd:float”/>
</xsd:sequence>
</xsd:complexType>
</xsd:element>
<xsd:element name=”ServiceResponse” type=”response”/> <xsd:element
name=”ServiceResponse” restriction=”xsd:boolean”/>
<xsd:simpleType name=”response”>
<xsd:restriction base=”xsd:boolean”/>
</xsd:simpleType>
</xsd:schema>
</wsdl:types>
<wsdl:interface name=”AvailabilityServiceInterface”>
<wsdl:operation name=”RequestOperation” pattern=”http://www.w3.org/ns/
wsdl/in−out”>
<wsdl:input element=”ServiceRequest”/>
<wsdl:output element=”ServiceResponse”/>
</wsdl:operation>
</wsdl:interface>
</wsdl:description>
Listing 1: Fragment of a WSDL document.
Given a WSDL document, we extract the Types
definitions and represent them as RDF (Klyne and
Carroll, 2004) triples. Representing those definitions
in RDF has several advantages. RDF provides an
abstract model for describing resources with proper-
ties, scoping them to a particular application domain
through RDF Schema (Hayes, 2004) and defining re-
lationships between these resources. In addition, stan-
dard RDF query language SPARQL (Prud’hommeaux
and Seaborne, 2007) can be used to provide flexi-
ble means to allow users to express their requests.
The RDF triples are generated based on the XML
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOA - Supporting Enterprise Collaboration Across
Organisational Boundaries
37

Schema to RDF Schema mappings approaches pre-
sented in (Thuy et al., 2008) and (CRASSO et al.,
2010). The resulting RDF triples are shown in List-
ing 2.
<rdfs:Class rdf:ID=”http://org.example.com/resources/AvailabilityService#
ServiceRequest”/>
<rdfs:Class rdf:ID=”http://org.example.com/resources/AvailabilityService#
ServiceResponse”/>
<rdf:Property rdf:about=”http://org.example.com/resources/AvailabilityService#
response”>
<rdfs:domain rdf:resource=”http://org.example.com/resources/
AvailabilityService#ServiceResponse”/>
<rdfs:range rdf:resource=”http://www.w3.org/2001/XMLSchema#boolean”/>
</rdf:Property>
<rdf:Property rdf:ID=”http://org.example.com/resources/AvailabilityService#
product”>
<rdfs:domain rdf:resource=”http://org.example.com/resources/
AvailabilityService#ServiceRequest”/>
<rdfs:range rdf:resource=”http://www.w3.org/2001/XMLSchema#string”/>
</rdf:Property>
<rdf:Property rdf:ID=”http://org.example.com/resources/AvailabilityService#date”
>
<rdfs:domain rdf:resource=”http://org.example.com/resources/
AvailabilityService#ServiceRequest”/>
<rdfs:range rdf:resource=”http://www.w3.org/2001/XMLSchema#string”/>
</rdf:Property>
<rdf:Property rdf:ID=”http://org.example.com/resources/AvailabilityService#
quantity”>
<rdfs:domain rdf:resource=”http://org.example.com/resources/
AvailabilityService#ServiceRequest”/>
<rdfs:range rdf:resource=”http://www.w3.org/2001/XMLSchema#int”/>
</rdf:Property>
Listing 2: RDF representation of extracted information.
In Listing 2, each triples are encoded in the form
<s, p, o> where s, p, and o are called the sub-
ject, predicate and the object respectively. In a triple,
a predicate is called the property of the triple and de-
notes the relationship between the subject and the ob-
ject that it connects. The subject always appears at the
left whereas the object appears at the right side of the
predicate in the triple.
4.2 SSP Description
An SSP description models the service provider as a
collection of services and enumerates all the offered
services. In particular, the SSP description specifies
the type of services that are offered by a particular ser-
vice provider. We use the information extracted from
the locally stored WSDL files to describe domain spe-
cific concepts and to avoid ambiguities between ser-
vices from different application domains. Using the
SSP description, functional properties of the offered
services are described collectively. These descrip-
tions provide information sufficient enough to filter
out the completely irrelevant service providers.
We define SSP description as <n, e, Q>, where n
is the URL of the service provider, e is the SPARQL
endpoint of the local repository and Q is the collec-
tion of (<p(s
t
, o
t
), f>) pairs, where s
t
and o
t
repre-
sents the type of the subject and object connected by
the predicate p whereas f represents the total num-
ber of occurrences of the predicate p together with
the s
t
and o
t
. The frequency of occurrences of sub-
ject and object type combination of each predicate is
measured to indicate the number of services from a
particular domain. We included the subject and ob-
ject types in the SSP description because they repre-
sent the domain and range of a predicate and hence is
useful to unambiguously select the required informa-
tion. The structure of the SSP description is defined
as RDF graph as shown in Listing 3.
<?xml version=‘‘1.0”?>
<rdf:RDF xmlns:ex=‘‘http://www.example.org/ontology#”
xmlns:ont=‘‘http://www.example.org/ns/ms−ontology#”
xmlns:xsd=‘‘http://www.w3.org/2001/XMLSchema#”
xmlns:rdf=‘‘http://www.w3.org/1999/02/22−rdf−syntax−ns#”>
<ont:Service rdf:about=‘‘http://www.example.org/provider/xyz”>
<ont:endPoint rdf:resource=‘‘http://www.example.org/services/abc”/>
<ex:name>
<rdf:Description>
<ex:subjectType rdf:resource=‘‘http://www.example.org/ontology#Hotel”/>
<ex:objectType rdf:resource=‘‘http://www.w3.org/2001/XMLSchema#string
”/>
<ex:count>435</ex:count>
</rdf:Description>
</ex:name>
<ex:product>
<rdf:Description>
<ex:subjectType rdf:resource=‘‘http://www.example.org/ontology#
Automobile”/>
<ex:objectType rdf:resource=‘‘http://www.example.org/ontology#Wheel”/>
<ex:count>1481</ex:count>
</rdf:Description>
</ex:product>
</ont:Service>
</rdf:RDF>
Listing 3: An example SSP description.
The number of instances of objects and subjects in
a repository is typically far larger than the number of
distinct predicates. Inclusion of the objects in the SSP
description is therefore likely to increase its size as
close to as the size of the repository. In order to avoid
such problems, the SSP description includes only the
subject and object types and not their instances. This
allows to select the relevant service provider based
on this type information. For example, if there are
a large number of printing service providers and only
few of them are providing book printing services it is
much more efficient to send a book printing service
requests only to those that provide the book printing
services. This type of SSP description will be helpful
in selecting the service providers in situations where
fine grained information is needed for answering the
service requests.
4.3 Finding Potential Service Providers
In order to find the required service we follow two
step discovery mechanism. In the first step, the dis-
covery request is sent to the service registry from
which a list of potential service providers are iden-
tified. In the second step, direct communication with
the potential service providers is established to find
the most appropriate service provider. The goal of
the first step is to reduce the search space whereas the
BMSD 2011 - First International Symposium on Business Modeling and Software Design
38
second step is intended to select the service provider
based on up-to-date information.
The major design goals of the proposed approach
is simplicity and extensibility. The SSP description is
essentially the collection of summary of the WSDL
files stored in the local repository of the providers
which simplifies the process of service description up-
dates. The service providers need to update only the
local repository. If the new service providers arise,
they can simply publish the SSP description to the ser-
vice registry.
We assume that the service providers employ the
mechanisms discussed above for extracting the infor-
mation needed for generating SSP descriptions. First,
the service requester initiates the lookup over SSP de-
scriptions and obtains a list of endpoints of the po-
tential partners. These endpoints are then queried to
obtain further information for selecting the potential
service providers.
4.4 Maintaining Freshness
The SSP descriptions are published to the service reg-
istry and hence can still pose the same problems as
with publishing the service descriptions if the do-
main information is changed. In order to ensure that
the SSP descriptions are still up-to-date, the service
repository requires a mechanism to reverse look up
the service providers local repository and synchro-
nize the information that is being provided through
the SSP descriptions.
5 ENTERPRISE
COLLABORATION
Let us now return to our original goal of facilitating
enterprise collaboration using SOA. We previously
concluded that the SOA architectural triangle with its
’publish-find-use’ paradigm is in principle very con-
venient to enterprises to utilize distributed capabilities
that may be under the control of different ownership
domains. The convenience stems from the loose cou-
pling of services - supporting flexible composition -
and the external-oriented representation of services -
allowing interactions between users and providers ir-
respective of their internal implementation. However,
we also concluded that the ’publish-find’ part of the
triangle has practical limitations, which so far has pre-
vented the successful uptake of public-registry/open-
discovery based enterprise collaboration. The main
limitations are: (a) it is hard to find and compose ser-
vices based on current service descriptions, since the
descriptions lack unambiguous and precise semantics;
(b) it is expensive and laborious to maintain service
descriptions, as the corresponding services continu-
ously evolve and therefore the descriptions require
frequent and manually managed updates; (c) trust is a
hindrance for publishing service descriptions and us-
ing services discovered with public registries.
We propose to leverage the publish-find-use
paradigm by using public descriptions that are au-
tomatically generated and semantically enhanced, as
described in Section 4. In the following, we first show
which interactions are necessary for enterprise collab-
oration using our approach, and subsequently discuss
the potential benefits of our approach.
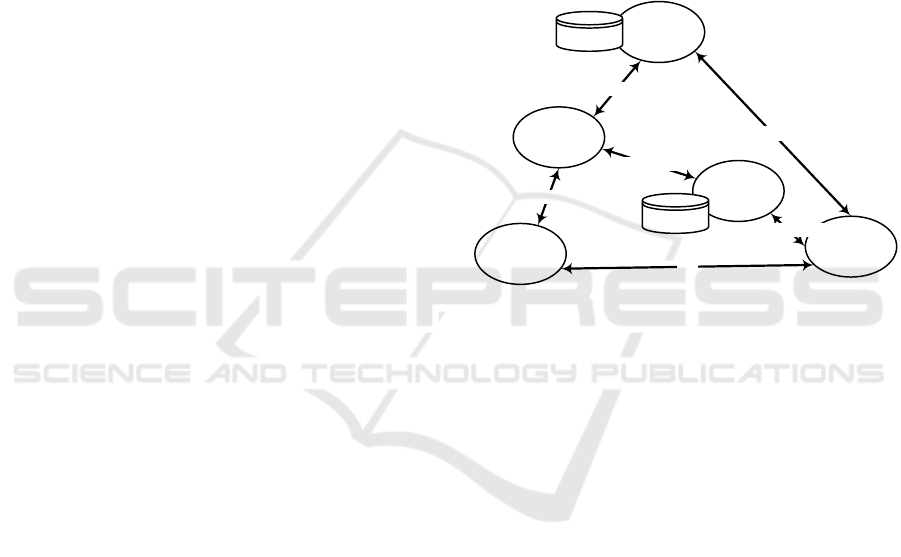
Service User
Public
Service
Registry
Service
Provider
Local
Service
Registry
Mediator
Find
Find Provider
Publish SSP Description
Store Service Description
Use
Find Service
Figure 3: Proposed service discovery approach.
Figure 3 illustrates the basic interactions:
1. A business organisation acting as a service
provider can publish relevant information on all
its services using a single keyword-based descrip-
tion (SSP) at a service broker that maintains a
public registry. If services offered by the business
organization evolve, the SSP is re-generated or in-
crementally updated, depending on the nature of
the change. The updated SSP can be pushed to
the service broker, in similar to the original pub-
lication, where it is used to replace the old SSP.
Alternatively, the service broker periodically asks
the service provider for updates.
2. A business organisation looking for partners that
can offer certain services can contact the service
broker and find SSPs based on keyword match-
ing. Although keyword matching can already be
reasonable efficient (Obrst et al., 2010), we can
further improve the recall and precision of service
discovery by exploiting the RDF-based semantics
of SSPs.
3. If an SSP fulfils the search criteria, the service
provider is contacted via the endpoint that is part
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOA - Supporting Enterprise Collaboration Across
Organisational Boundaries
39

of the SSP. Then the local repository of the service
provider is used to find available services. Both
step (2) and step (3) may be performed via an in-
termediary, making the two-step service discov-
ery transparent to the requesting business organi-
zation. For example, the service broker may take
the intermediary role. Possibly, the requested ser-
vices are not available as single services or are not
available from a single service provider. In that
case, the services have to be offered as a bundle or
must be composed. Again, an intermediary may
automate or support this process (da Silva et al.,
2011).
4. Once the (composed) services are found, the re-
questing business organization can start using
them, effectively entering collaborations with one
or more partner business organizations that are in-
volved in the offering of these services.
Comparing this with the enterprise collaboration
through public UDDI registries, we observe the fol-
lowing benefits:
• The SSP is based on extracting keywords from
WSDL type definitions, and represents these key-
words and their relationships with RDF. In this
way, the semantic properties of keywords can
be captured (CRASSO et al., 2010; Thuy et al.,
2008). This addresses the limitation (a) men-
tioned above.
• Since the extraction is automatic, the burden for
service providers to update descriptions is dramat-
ically lowered. Moreover, if the service broker is
able to poll for updates, the problem of ’disap-
pearing’ business organizations and ’ghost’ ser-
vices can be tackled. If a business organization
no longer supports its previously published ser-
vices, e.g. because it no longer exists, a poll for
updates by the service broker gets no reaction and
the service broker can decide to remove the SSP
from its registry. This addresses the limitation (b)
mentioned above.
• The two-step service discovery approach has the
advantage that it first determines the services
providers that offer potentially relevant services,
and then limits the search for services to those of
the selected service providers. Although we still
have to confirm this with experiments, we believe
that this approach has a better scalability than one-
level semantic search. Furthermore, by favoring
services from the same or a few providers, it is
more likely that these services are defined and im-
plemented in a consistent way, making search and
composition easier and more efficient (Forestiero
et al., 2010).
• In order to address limitation (c) mentioned
above, the local registry of a service provider
may be enhanced in two ways. First, the ser-
vice provider may monitor who wants to access
the local registry, and expose information on its
services depending on some trust classification
scheme (e.g., based on previous collaborations).
Secondly, the service provider may provide ad-
ditional information through the local registry,
which facilitates the (non-) selection of services.
For example, non-functional properties based on
resource availability or historical data may be
published, including information on trust, security
or privacy aspects.
• The implications for existing standards, most no-
tably UDDI, is minimal. Most of the interactions
described above can be supported with UDDI as
is.
6 CONCLUSIONS
Our research demonstrates how SSP descriptions al-
lows us to reduce maintainability cost at the service
providers side while still providing the relevant infor-
mation required for service discovery. This type of
approach has the ability to guarantee better service
results due to the separation of abridged service de-
scriptions and the actual detailed descriptions. Cur-
rent approaches either do not provide adequate sup-
port for publishing accurate information of the offered
services or the offered solutions are too restrictive in
terms of cost and time required for maintaining the
published descriptions. This is mainly because the
service descriptions are valid only at the time they are
created and subject to frequent change depending on
changes in market trends.
ACKNOWLEDGEMENTS
This material is based upon works jointly sup-
ported by the IOP GenCom U-Care project
(http://ucare.ewi.utwente.nl) sponsored by the
Dutch Ministry of Economic Affairs under contract
IGC0816 and by the DySCoTec project sponsored
by the Centre for Telematics and Information
Technology (CTIT), University of Twente, The
Netherlands.
BMSD 2011 - First International Symposium on Business Modeling and Software Design
40

REFERENCES
AbuJarour, M., Naumann, F., and Craculeac, M. (2010).
Collecting, Annotating, and Classifying Public Web
Services. In Proc. of International Conference on On
the Move to Meaningful Internet Systems, pages 256–
272.
Al-Masri, E. and Mahmoud, Q. H. (2008). Investigating
Web Services on the World Wide Web. In Proc. of the
World Wide Web Conference, pages 759–804.
Cardoso, J., Winkler, M., and Voigt, K. (2009). A Service
Description Language for the Internet of Services. In
Proc. of the International Symposium on Services Sci-
ence.
Chinnici, R., Moreau, J.-J., Ryman, A., and Weerawarana,
S. (2007). Web Services Description Language
(WSDL) Version 2.0.
CRASSO, M., ZUNINO, A., and CAMPO, M. (2010).
Combining Document Classification and Ontology
Alignment for Semantically Enriching Web Services.
New Generation Computing, 28:371–403.
da Silva, E. G., Pires, L. F., and van Sinderen, M. (2011).
Towards runtime discovery, selection and composi-
tion of semantic services. Computer Communications,
34(2):159–168.
Erl, T. (2005). Service-Oriented Architecture Concepts,
Technology, and Design. Prentice Hall Professional
Technical Reference.
Farrell, J. and Lausen, H. (2007). Semantic Annotations for
WSDL and XML Schema.
Forestiero, A., Mastroianni, C., Papuzzo, G., and Spez-
zano, G. (2010). A Proximity-Based Self-Organizing
Framework for Service Composition and Discovery.
In Proc. of the 10th IEEE/ACM International Confer-
ence on Cluster, Cloud and Grid Computing, pages
428–437.
Hayes, P., editor (2004). RDF Semantics. W3C Recom-
mendation.
Klyne, G. and Carroll, J. J., editors (2004). Resource De-
scription Framework: Concepts and Abstract Syntax.
W3C Recommendation.
K
¨
uster, U. and K
¨
oning-Ries, B. (2007). Supporting Dynam-
ics in Service Descriptions - The Key to Automatic
Service Usage. In Proc. of the 5th International Con-
ference on Service-Oriented Computing, pages 220–
232.
Lamparter, S., Ankolekar, A., and Grimm, S. (2007).
Preference-based Selection of Highly Configurable
Web Services. In Proc. of the 16th International Con-
ference on World Wide Web, pages 1013–1022.
Martin, D., editor (2004). OWL-S: Semantic Markup for
Web Services. W3C Member Submission.
Michlmayr, A., Rosenberg, F., Platzer, C., Treiber, M., and
Dustdar, S. (2007). Towards Recovering the Broken
SOA Triangle: A Software Engineering Perspective.
In Proc. of the 2nd International Workshop on Service
Oriented Software Engineering, pages 22–28.
Obrst, L., McCandless, D., and Bankston, M. (2010). En-
abling Rich Discovery of Web Services by Project-
ing Weak Semantics from Structural Specifications.
In Proc. of Semantic Technology for Intelligence, De-
fense, and Security.
Prud’hommeaux, E. and Seaborne, A., editors (2007).
SPARQL Query Language for RDF. W3C Candidate
Recommendation.
Roman, D., Lausen, H., and Keller, U., editors (2006). Web
Service Modeling Ontology (WSMO). WSMO Work-
ing Group.
Sabou, M. and Pan, J. (2007). Towards semantically en-
hanced Web service repositories. Web Semantics: Sci-
ence, Services and Agents on the World Wide Web,
5(2):142–150.
Speiser, S. and Harth, A. (2011). Integrating Linked Data
and Services with LIDS. In Proc. of the 8th Extended
Semantic Web Conference.
Thuy, P. T. T., Lee, Y.-K., Lee, S., and Jeong, B.-S. (2008).
Exploiting XML Schema for Interpreting XML Doc-
uments as RDF. In Proc. of the 2008 IEEE Interna-
tional Conference on Services Computing, pages 555–
558.
Treiber, M. and Dustdar, S. (2007). Active Web Service
Registries. IEEE Internet Computing, 11(5):66–71.
Truong, H.-L., Comerio, M., Maurino, A., Dustdar, S.,
Paoli, F. D., and Panziera, L. (2010). On Identifying
and Reducing Irrelevant Information in Service Com-
position and Execution. In Proc. of the International
Conference on Web Information Systems Engineering,
pages 52–66.
van Sinderen, M. (2009). From Service-Oriented Architec-
ture to Service-Oriented Enterprise. In Proc. of the
Third International Workshop on Enterprise Systems,
pages 3–16.
van Sinderen, M. and Almeida, J. P. A. (2011). Empow-
ering Enterprises through Next-Generation Enterprise
Computing. Enterprise Information Systems, 5(1):1–
8.
LEVERAGING THE PUBLISH-FIND-USE PARADIGM OF SOA - Supporting Enterprise Collaboration Across
Organisational Boundaries
41
