
ADAPTATION BASED ON KNOWLEDGE MODELS FOR
DIAGNOSTIC SYSTEMS USING CASE-BASE REASONING
Brigitte Chebel Morello
1
, Mohamed Karim Haouchine
2
and Noureddine Zerhouni
1
1
Institute of Automatic Control and Micro-Mechatronic Systems, 24, Rue Alain Savary, 25000 Besançon, France
2
Em@systec sas, 18 Rue Alain Savary, 25000 Besançon, France
Keywords: Case-based reasoning, Adaptation, Adaptation-guided retrieval, Dependency relations, Hierarchical model,
Context model, Industrial diagnostic, Diagnostic help system, Industrial diagnostic.
Abstract: The adaptation phase is a key problem in the design of Case-Based Reasoning (CBR) systems. In most
cases, adaptation methods are application-specific. Our challenge in this work is to make a general
adaptation method for the field of industrial diagnostics. This paper is a contribution to fill this gap in the
field of fault diagnostic and repair assistance of equipment. Our adaptation algorithm relies on hierarchy
descriptors, an implied context model and dependencies between problems and solutions of the source
cases. In addition, we note that the first retrieved case is not necessarily the most adaptable case, and to take
into account this report we propose in our diagnostic problem an adaptation-guided retrieval step based on a
similarity measure associated with an adaptation measure. These two measures allow selecting the most
adaptable case among the retrieved cases. The two retrieval and adaptation phases are applied on real
industrial system called SISTRE (Supervised industrial system of Transfer of pallets).
1 INTRODUCTION
The objective of this study is to build an intelligent
application based on knowledge management for
industrial diagnosis and repair in a context of
maintenance services. It is targeted maintenance
operators to aid in their daily tasks. This decision
tool is developed within the framework of the
distributed e-maintenance platform. The platform
brings a major asset to maintenance interventions
and maintenance services in general by enabling
expertise via Internet to be went directly to the user
site. Our objective is to develop a case-based
reasoning system dedicated to industrial diagnosis in
order to solve a practical problem of an industry.
CBR is the technology of experience based
system, and is an approach to problem solving by
retrieving a similar past problem from the case base
by adapt it in the new context and by learning it.This
method is well suited to the diagnosis application
because fault diagnosis is one of domain based in the
experience of the human expertise, where problems
are recurrent and can be reuse.
(Althoff, 1996) thinks the CBR is the technology
of choice to implement a knowledge based system.
Moreover, CBR is frequently proposed as a
methodology for knowledge management
application. It presents expert knowledge as past and
concrete experiences easily understandable by
human users. Our objective is to solve diagnosis
problems by reusing cases in other contexts, by
adaptation phase of CBR. This phase is complex and
is usually designed for a specific application. Some
studies into “memory-based reasoning” (Kasif,
1995) avoid this step because the wealth of the case-
base can compensate for the adaptation phase
(Stanfill, 1986). However, other authors, like us,
develop this phase to enrich the case-base. In this
context the adaptation step is the core of CBR for
better exploiting the characteristics and strength of
the CBR (Chebel-morello, 2009), (Lieber, 2007).
Furthermore, prior works on adaptation were
dedicated to a given application. Our challenge in
this paper is to define a general adaptation method
on symbolic data in the field of industrial diagnostic.
In section 3 we develop an adaptation retrieval phase
folowing by the the adaptation phase. This method is
based on the dependencies between the problem and
the solution of a solved case and exploits two
knowledge models. Three relations of dependencies
are defined and exploited to adapt a retrieved case
within an adaptation algorithm described in the same
223
Chebel Morello B., Karim Haouchine M. and Zerhouni N..
ADAPTATION BASED ON KNOWLEDGE MODELS FOR DIAGNOSTIC SYSTEMS USING CASE-BASE REASONING.
DOI: 10.5220/0003666602230229
In Proceedings of the International Conference on Knowledge Management and Information Sharing (KMIS-2011), pages 223-229
ISBN: 978-989-8425-81-2
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

Section. The matching carried out at the time of the
retrieval, combined with dependency relations
between the problems and solutions, can adapt the
solution to the target problem.
This paper contains two contributions: the first
one relates to the establishment of two measures to
select the most easily adaptable among the retrieved
cases. A Retrieval Measure (RM) is combined with
an Adaptation Measure (AM) specifically defined
for diagnostic systems.
The second one is an adaptation algorithm,
dedicated to the diagnostic of industrial plants that
builds both on knowledge models and on the
dependency relations between problem and solution
descriptors.
The proposed approach will be applied
throughout this paper on a Supervised Industrial
System for pallets TRansfEr (SISTRE) (Rasovska,
2007). It represents a flexible production system and
it is composed of five robotized working stations
which are served by a transfer system of pallets
organized into double rings (internal and external).
Each station is equipped with pneumatic actuators
(pushers, pullers and indexers) and electric actuators
(stopper) as well as a certain number of inductive
sensors (proximity sensors). An inductive read/write
module allows to identify and locate each pallet and
to provide information relative to required operation
in a concrete station. The moving of the pallets is
ensured by friction on belts which are involved by
electric motors. Each pallet has a magnetic label that
is used like embarked memory. This memory can be
read in each working station thanks to magnetic
read/write modules (Balogh) and allows the
memorisation of the product assembly sequence.
These labels thus enable to track the pallet path
through the system. The feasibility of our approach
will be studied in Section 6 through 125 generic
cases.
2 CASE REPRESENTATION
2.1 The Diagnostic Case
The case base reflects the experiment by the link of
dysfunctional mode of component and the cause of
this fault, and the action of repair.
Indeed, this representation is based on the
standard definition of diagnostics which is the
following one (Maintenance terminology, 2001):
“they are the actions carried out for the detection of
breakdown, its localization and the identification of
the cause”. We exploit these three parts in the
formalization of the case, which, moreover, relies on
the knowledge models of the equipment to be
diagnosed. Thus, we have the localization and the
functional part in the problem space of case, the
detection part of the failure class and the
identification of the failing component in the
solution space of case.
A case is composed by Problem and Solution
part: Case= (ds1, ds2, dsi …., Ds1, Ds2, Ds3, Ds4).
The problem part is composed by two kinds of
descriptors: (i) the “localization” descriptors are
linked at a conceptual graph (see Figure2) where the
node is the value of the descriptor determined in this
part, and the solution is the failed zone. The failed
zones are composed of the components potentially
failed.
(ii) The “supervisor” descriptors are defined by
three attributes relating to the component value, its
state and its functional mode (Figure 3):
i
ds
= (
s
tate
i
ds
value
i
ds
FM
i
ds
,
).
A functional mode is an operating mode of a
component of the equipment. Abnormal operating
mode: corresponds to a system malfunction that is to
say there was a failure.
The solution part is composed by four
descriptors the first one Ds
1
, is relative at the class of
the fault component, the second Ds
2
is dedicated at:
the cause of failure, the next one describes Ds
3
: the
Repair action and the last one Ds
4
define the zone of
the failure.
Table 1: Generic structure of the case.
Example:
Let a specific component in equipment a puller. This
component can have two state linked at it position:
[front; back] and can have two functional modes
[normal, abnormal].
The descriptor associated at the puller in a diagnosis
case can write:
Table 2: Case example.
2.2 Models Associated with the Case
Moreover, the knowledge representation is based on
two models associated with the case-base, namely:
KMIS 2011 - International Conference on Knowledge Management and Information Sharing
224
the context model and the components taxonomy
model.
2.2.1 The Components Taxonomy Models
The equipment analysis determines sets of their
components. Every group of components is
regrouped by functional classes, and constitutes a
components' hierarchy which is common to the
source problem descriptors “ds” and source solution
“Ds”. The SISTRE hierarchical model of
components is described in Figure 1.
A case will have a formalization object and will
define a hierarchy of descriptors containing both
problem and solution descriptors (Haouchine, 2008).
Equipment (component)
Actuator
Magnetic sensor
Conveyor
Pneumatic
actuator
Electric
actuator
Balogh
Stopper
Brace
Belt
Motor
Pallet
D2
D9
D1
Balogh0
Balogh1
Puller
Pusher
Instance
Class
S2
S1
S5
Indexer
…
…
Detector
Speed
transmission
Figure 1: A part of the SISTRE’s components hierarchy.
The descriptors of the localization part are exploited
by a context model in two phases of the CBR. In the
elaboration phase, the user is asked a dynamic tree
of questions. Adaptation phase will select the correct
element to be substituted in the adaptation
algorithm.
In our study, the adaptation cost is quantified by
a measure called AM which taking account a crucial
descriptor related to the diagnostic: the functional
mode.
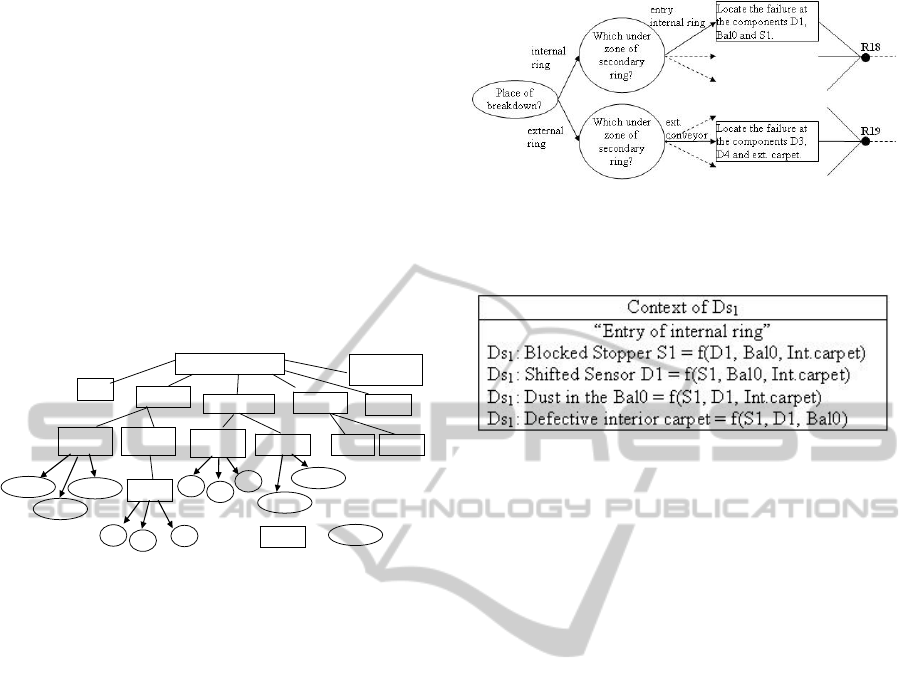
2.2.2 Context Model
The context model is a contextual graph allowing
the localization of components comprising a failure
and selection of concerned components compared to
the set. Therefore, the context model enables to
inform the “localization” descriptors in order to
determine the failure zone and the components
potentially failing. The course of a pallet will be
followed. Using a contextual graph, as shown on
Figure 2, components likely to be failing will be
localised.
Figure 2: A part of contextual graph of the equipment.
An example of a context model concerning the
descriptor “Ds
1
” is shown on Figure 3.
Figure 3: A context model of “Ds
1
” descriptor.
The context allows the localization of components
problems and the selection of the right descriptors
compared to all others. Therefore, these present
components
constitute the context in which the
failing component is identified. A dependency
relation is associated with these components.
2.3 The Diagnostic Case Base
We take inventory of 125 cases in SISTRE case base
the case problem part is composed of seven
descriptors. The first two descriptors define the
localization of the failure. This localization is
determined by “ds
1
: zone”, “ds
2
: palette site”.
Let us consider the example of case S1 in the
Table 3. This case represents a problem on the “D1
detector”. The localization part determines that there
is a failure on the entry of the principal ring. Then,
the supervisor part provides the components state
implied in this place. The S1 stopper is in “top”
position which has a “normal” functional mode. The
balogh0 has value “1”, which means that it must
enter the working area so that it can be treated by a
robot. Finally, the D1 sensor does not detect the
presence of the pallet which is in “abnormal” mode.
The solution part is made up of a class descriptor
of failing component, of a descriptor identifying the
failing component, of the repair action and of the
failure zone.
ADAPTATION BASED ON KNOWLEDGE MODELS FOR DIAGNOSTIC SYSTEMS USING CASE-BASE
REASONING
225
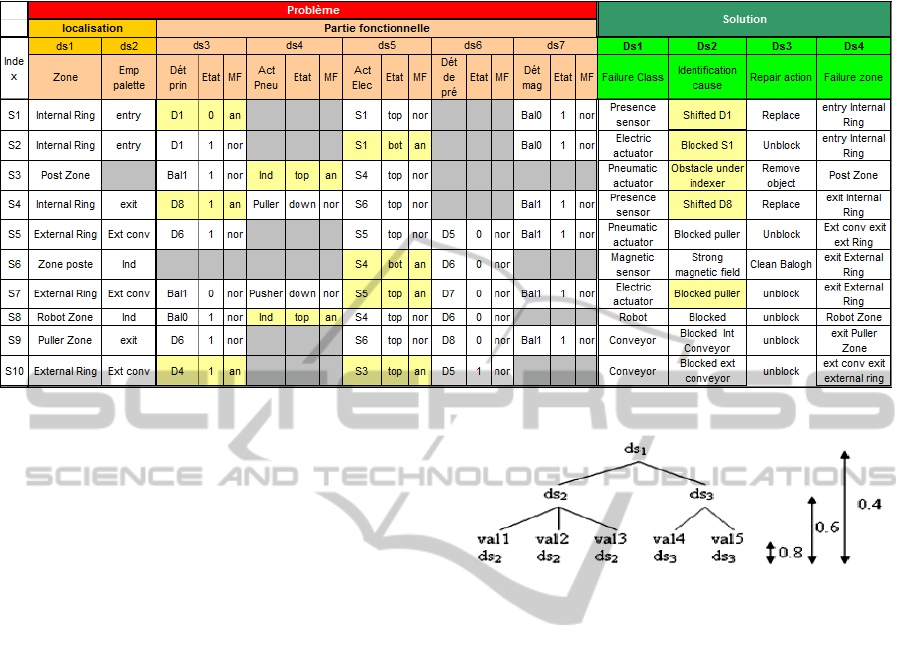
Table 3: A part of the SISTRE case base.
3 RETRIEVAL PHASE
There are two categories of retrieval phase: the first
to be called “simple retrieval" and the second
“combination retrieval/adaptation”. Our study is
focused on the second type. We note that the most
similar case is not always the best candidate for
adaptation (Smyth, 1995) Consequently we propose
an adaptation guided retrieval method applied at the
industrial diagnostic based on two measures the first
one of similarity the second one of adaptation.
3.1 Retrieval Measure
We propose four local similarity measures are
exploited: - For the value of
value
si
d
, which belongs
to the hierarchical model of descriptors, φvalue is
developed.
If
value
i
ds
=
value
i
dt
then φvalue = 1 (“dt” for target
descriptor)
If
value
i
ds
≠
value
i
dt
then
φ
value
= 0.8 if the value are in the identical level
value
ds
2
=val1 and
value
dt
2
=val2
φ
value
= 0.6 there is one level of differences
value
ds
1
=val1 and
value
dt
1
=val4
etc…(see Fig. 5).
Figure 4: Example of descriptor hierarchy.
- For the descriptor value
state
i
ds
and for the
functional, φ
state
and φ
FM
is calculated in the same
way.
If
state
i
ds
=
state
i
dt
then φstate = 1 and If
FM
i
ds
=
FM
i
dt
then φ
FM
= 1
If
state
i
ds
≠
state
i
dt
then φstate = 0 and If
FM
i
ds
=
FM
i
dt
then φ
FM
= 0
The similarity metric depends on the formalization
of the case. Note that all the descriptors are not all
inquire. The similarity measure will reflect the
presence of descriptors in the case.
To take into account presence and/or absence of
information in descriptors, a local similarity
φ
presence
is developed.
φ
presence
= 1 if component information is
present in
ds and dt descriptors
φ
presence
= 0, if not
The global similarity measure (1) is obtained by
aggregation of these functions on the whole set of
KMIS 2011 - International Conference on Knowledge Management and Information Sharing
226

descriptors. From this measure, a set of cases can be
selected.
∑
∑
=
=
×××
=
m
i
esence
i
m
i
FM
i
presence
i
state
i
value
i
M
R
1
Pr
1
ϕ
ϕϕϕϕ
(1)
Where m: represent the number of problem
descriptors.
The retrieval phase associates the RM measure
with a kNN algorithm in order to choose the set of
the most similar cases to the target case. In order to
select the most adaptable retrieved source case, we
have introduced a measure called “adaptation
measure" which will emphasize the functional mode
values of descriptors.
3.2 Adaptation Measure
The Adaptation Measure “AM” (2) takes into
account the source cases descriptors which are
different from case target and will be only linked to
the class and to the functional mode compared to the
solution descriptors. The adaptation measure is
conditioned by the functional mode value. Indeed, a
strong weight is affected to the dysfunctional mode
related to the failure.
∑
∑
=
=
+
⋅
=
n
i
value
i
state
i
MF
i
n
i
i
Class
i
M
A
1
.
1
).(
ϕϕϕ
λϕ
(2)
λi is the associated weight according to the
functional mode.
If FM = normal Æ λi = 20
If FM = normal/abnormal Æ λi = 21
If FM = abnormal Æ λi = 22
A weight is associated to the functional mode
because this last is considered as being important in
the determination of the failing component. The
number of different descriptors is determined by the
denominator in the equation (2).
The retrieved source case having the greatest
adaptation measure value among the retrieval source
cases will be the candidate chosen for the adaptation
step.
4 ADAPTATION PHASE
We propose an adaptation algorithm based on the
context model, on the dependency relations between
various problem and solution descriptors and on the
descriptors hierarchical model.
If the solution class of the best chosen source case is
similar to the problem class then the algorithm uses
the hierarchical model. If the class is different, then
the algorithm uses the contextual model to localise a
set of potential failure component and then uses the
hierarchical model.
4.1 Dependency Relations (DR)
The influence of a descriptor problem “ds” on the
solution descriptors “Ds” is expressed by a
dependency relation. A dependency relation is a
triplet (dsi, Dsj, DRij). DRij gives us the type of
relationship between the problem and the solution to
a given case. Three relation types are defined: DRij
⊂
(No relation, Low, High).
DRij = High: there is a high dependency
relation between dsi and Dsj descriptors.
Indeed, dsi descriptor is strongly relevant
1
compared to Dsj descriptor.
DRij = Low: there is a low dependency
relation, i.e., the descriptors are connected
thanks to the context which will be
characterized by a contextual model.
DRij = No relation: there is independence
between dsi and Dsj.
These dependency relations will be exploited in the
adaptation algorithm.
4.2 Adaptation Algorithm
The algorithm (algorithm 1) relies on the context
model, the descriptors hierarchical model and the
dependency relations. This algorithm adapts
descriptor by descriptor. The substitution's
adaptation, by generalization and by specialization
will be taken into account in the algorithm.
Three possible scenarios are treated differently by
the algorithm
DR = high and same class between problem
and solution descriptors.
DR = high and different class between problem
and solution descriptors
DR = Low
This algorithm deals with the adaptation of one
descriptor at a time. It is conditioned by the solution
1
A problem descriptor ds
i
is strongly relevant compared
to a solution descriptor Ds
j
when the value of ds
i
descriptor is crucial in the determination of Ds
j
value. The
change of ds
i
value is directly reflected on Ds
j
value.
ADAPTATION BASED ON KNOWLEDGE MODELS FOR DIAGNOSTIC SYSTEMS USING CASE-BASE
REASONING
227

descriptor class found at retrieval step. After the
retrieval phase which makes it possible to select a
retrieved case (
ret
i
ds
2
,
ret
j
Ds
3
) thanks to both RM and
AM measures, the adaptation phase engages. The
initialization step creates a list of couples having a
relation either high or
low. According to the nature
of the relation, the treatment differs. Consequently
the second step will depend on the DR values and
the classes of the descriptors
Algorithm 1: Adaptation Algorithm.
1. If by browsing through the list, a value of “DR
= high” is found then the couple is selected
and class of “
ret
j
Ds
” and “
ret
i
ds
”is compared. If
they have the same parent class, the influence
of this substitution will be considered in
“
ret
j
Ds
” to assign this new value to
ret
j
Dt
.,(on
the contrary, algorithm look at the context list
descriptors) and selects the “dti” descriptor
which belongs to the same parent class as
“
ret
j
Ds
”.We note that target descriptor “dt*”.
Then, the value of reminds will be determined
and which will be thereafter to be affected in
“Dtj”.
2. If in the list there is only the DR =low .the
algorithm selects the parent class of
ret
j
Ds
descriptor. Then, it identifies the dti descriptor
2
Retrieval descriptors problem.
3
Retrieval descriptors solution.
belonging to the same parent class as
ret
j
Ds
which will change status (dti Æ dt*). After
that, the relationship dt* will influence the
transformation of the
ret
j
Ds
solution which will
be affected thereafter to “Dtj”.
3. Finally, when all DR values are equal to “no
relation” then there is no adaptation.
5 VALIDATION & CONCLUSION
In this section we present two experiments (i) first
one concerns the need of adaptation phase in our
system, (ii) and second one studies the performance
of the adaptation algorithm. We used a leave-one-
out cross-validation method for the first two parts to
assess SISTRE's ability to accurately adapt retrieved
cases for a case base containing 125 cases
The need of adaptation:
Accuracy rate of diagnosis system with and
without adaptation phases are compared. The
results show that the proposed method with
adaptation selects the cases which are the best
adaptable ones by obtaining 88% of accuracy.
If the adaptation algorithm is powerful one can
get a good performance concerning the CBR
system applied to a limited number of cases.
However, we find bad results without the
adaptation, only 58.1% accuracy rate with the
retrieval step. These results show that in our
system this adaptation phase is essential to have
a good result.
Performance of adaptation algorithm: This
experiment is designed to study the accuracy of
the help diagnosis system; overall accuracy,
and more precisely the accuracy of only
retrieval cases.
Table 4: Results of the adaptation.
We note that the accuracy is 88% reflecting that
110 cases were adapted correctly to the set of 125
cases. This accuracy is computed using “Ds
2
” as the
component responsible for failure. The obtained
accuracy rate for which the adaptation measure is
well chosen and the adaptation algorithm is treated.
For this subset of cases, the accuracy rate is 91.66%.
KMIS 2011 - International Conference on Knowledge Management and Information Sharing
228

Within the study framework on technical
diagnostic and repair assistance system, an
adaptation-guided retrieval method has been
proposed. Our previous studies have enabled us to
formalize the case of a supervised industrial system
of pallets transfer (SISTRE). This formalization is
adapted to our method. In fact, we set up a
formalization of object of the cases, associated to the
descriptors hierarchical model. This model is
common to problem and solution descriptors of the
case-base cases and a model relating to the
application context. All steps depend on the cases
formalization and the associated knowledge models.
This modelling has influenced the proposed
similarity measure as well as the adaptation
measure. The latter is directly related to the
functional mode of the supervised components (an
attribute specific to the descriptor). The retrieval
phase is related to the adaptation phase using the
conjunction of similarity and adaptation measures.
This conjunction makes it possible to select among
the retrieved cases the most adaptable. The
adaptation phase will exploit the dependency
relations between the problem and the solution.
We are proved the feasibility of this diagnostic
help system. To build it in any type of industrial
equipment, two knowledge model need to be
elaborate.
To avoid the cost of the development of
knowledge models, we are currently working to use
these algorithms with models (functional events and
components models) developed in web-maintenance
platform. This model is defined in the domain
ontology of maintenance, in the context of
Semantic-maintenance and life cycle (SMAC)
Project.
ACKNOWLEDGEMENTS
This work was carried out and funded in the
framework of SMAC project (Semantic-
maintenance and life cycle), supported by European
program Interreg IV between France and
Switzerland
.
REFERENCES
Althoff K. D., Bartsch-Spörl B., 1996, Decision support
for case based application, Wirtschaftsinformatik,
ISSN 0937-6429, 1996, vol. 38, no1 pp. 8-16
Bridge, D., Ferguson, A., 2002, An expressive query
language for product recommender systems. Artificial
Intelligence Review 18(3-4), 269-307 (2002)
Chebel-Morello B., Haouchine M.-K., Zerhouni N., 2009.
A methodology to conceive a case based system of
industrial diagnosis. In World Congress of
Engineering Asset Management, WCEAM'09, Greece
Cordier A., 2008: Interactive and Opportunistic
Knowledge Acquisition in Case-Based Reasoning,
PhD thesis, Laboratoire d'InfoRmatique en Images et
Systèmes d'information, University of Lyon I,
November.
Haouchine, M. K., Chebel-Morello, B., Zerhouni, N.,
2008: Adaptation-Guided Retrieval for a Diagnostic
and Repair Help System Dedicated to a Pallets
Transfer. In 3rd European Workshop on Case-Based
Reasoning and Context-Awareness. 9th European
Conference on Case-Based Reasoning, ECCBR 2008,
Trier, Germany
Haouchine, M. K.: 2009 Rememoration guide par
l’adaptation et maintenance des systèmes de diagnostic
industriel par l’approche du raisonnement partir de
cas. PhD thesis, Automatic en Micro-Mecatrnoic
Department, Franche-Comt University
Kasif, S., Salzberg, S., Waltz, D., Rachlin, J., Aha, D.,
1995: Towards a Framework for Memory-Based R.
NECI Technical Report
Lieber, J., 2007: Application of the Revision Theory to
Adaptation in Case-Based Reasoning: the
Conservative Adaptation. In 7th International
Conference on Case-Based Reasoning - ICCBR'07,
4626, pp. 239-253.
Maintenance terminology. 2001 European standard, NF
EN 13306.
Rasovska, I., Chebel-Morello, B., Zerhouni, N., 2007: A
Case Elaboration M for a Diagnostic and Repair Help.
FLAIRS.
Smyth, B., Keane, M. T., 1998: Adaptation-guided
retrieval: Questioning the similarity assumption in
reasoning. Artificial Intelligence 102(2), 249-293.
Smyth, B., Keane, M. T 1995: Experiments on
Adaptation-Guided Retrieval in Case-Based Design.
In: Veloso, M., Aamodt, A.; (eds.): Proceedings of the
1st International Conference on Case-Based
Reasoning. LNAI, Vol. 1010, Springer, Berlin 313-
324.
Stanfill, C., Waltz, D., 1986: Towards memory-based
reasoning. Communications of the Association for
Computing Machinery, volume 29 pp. 1213-1228.
ADAPTATION BASED ON KNOWLEDGE MODELS FOR DIAGNOSTIC SYSTEMS USING CASE-BASE
REASONING
229
