
FROM 3D POINT CLOUDS TO SEMANTIC OBJECTS
An Ontology-based Detection Approach
Helmi Ben Hmida
1,2
, Christophe Cruz
2
, Frank Boochs
1
and Christophe Nicolle
2
1
Institut i3mainz, am Fachbereich 1 - Geoinformatik und Vermessung
Fachhochschule Mainz, Lucy-Hillebrand-Str. 2, 55128, Mainz, Germany
2
Laboratoire Le2i, UMR-5158 CNRS, Dep. Informatique IUT Dijon
7, Boulevard Docteur Petitjean, BP 17867, 21078, Dijon Cedex, France
Keywords: Geometric analysis, Topologic analysis, 3D processing algorithm, Semantic web, Knowledge modelling,
Ontology, 3D scene reconstruction, Object identification.
Abstract: This paper presents a knowledge-based detection of objects approach using the OWL ontology language,
the Semantic Web Rule Language, and 3D processing built-ins aiming at combining geometrical analysis of
3D point clouds and specialist’s knowledge. This combination allows the detection and the annotation of
objects contained in point clouds. The context of the study is the detection of railway objects such as
signals, technical cupboards, electric poles, etc. Thus, the resulting enriched and populated ontology, that
contains the annotations of objects in the point clouds, is used to feed a GIS systems or an IFC file for
architecture purposes.
1 INTRODUCTION
As object reconstruction is an important task for
many applications, considerable effort has already
been invested to reduce the impact of time
consuming, manual activities and to substitute them
by numerical algorithms. Actually, the automatic
processing of 3D point clouds can be very fast and
efficient, but often relies on significant interaction of
the user for controlling algorithms and verifying the
results. Alternatively, the manual processing is
intelligent and very precise since a human person
uses its own knowledge for detecting and identifying
objects in point clouds, but it is very time-
consuming and consequently inefficient and
expensive. In this context, we aim at inserting
business knowledge in automatic detection and
reconstruction algorithms in order to make the point
cloud processing more efficient and reliable.
Consequently, the WiDOP project (knowledge
based detection of objects in point clouds) aims at
making a step forward. The goal is to develop
efficient and intelligent methods for an automated
processing of terrestrial laser scanner data. In
contrast to existing approaches, the project consists
in using prior knowledge about the context and the
objects. This knowledge is extracted from databases,
CAD plans, Geographic Information Systems (GIS),
or domain experts. Therefore, this knowledge is the
basis for a selective knowledge-oriented detection.
The following paper is structured into section 2
which gives an overview of actual existing strategies
for reconstruction processes, section 3 explains the
general adopted architecture and the related
ontology structure, section 4 describe the domain
knowledge modelling, section 5 highlight the
annotation process, section 6 gives first results for a
real example and section 7 concludes and shows
next planned steps.
2 BACKGROUND
This section is composed of two parts. This first part
deals with the detection strategies described in the
literature for geometric modelling and object
recognition. The second part presents the knowledge
modelling which of value for our strategy.
2.1 Detection Strategies
Today, scene model creation process is largely a
manual procedure, which is time-consuming and
subjective. While there is a clear need for
255
Ben Hmida H., Cruz C., Boochs F. and Nicolle C..
FROM 3D POINT CLOUDS TO SEMANTIC OBJECTS - An Ontology-based Detection Approach.
DOI: 10.5220/0003660002550260
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development (KEOD-2011), pages 255-260
ISBN: 978-989-8425-80-5
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

automated, or even semi-automated methods to ease
the creation of as-built scene, research on the subject
is still in the very early stages. This survey shows
that many of the existing methods for geometric
modelling and object recognition can be important
for the process automation. Within the literature,
three main strategies are described where the first
one is based on human interaction with provided
software’s for point clouds classifications and
annotations. While the second strategy relies more
on the automatic data processing without any human
interaction by using different segmentation
techniques for features extraction. Finally, new
techniques present an improvement compared with
the cited ones by integrating semantic networks to
guide the reconstruction process.
2.1.1 Manual Supported Strategy
Actually, tools used for 3D reconstruction of objects
are still largely relying on human interaction. Here
the user might be supported in his construction
activity, but object interpretation, selection and
extraction of measurements has to be done
manually. That's why this processing is the most
time consuming way to come from a data set to
extracted objects (Leica Cyclone: 3D Point Cloud
Processing Software).
2.1.2 Semi-automatic and Automatic
Strategy
These methods present a real optimization within the
process compared of the manual ones. Within the
current section, we will not expose the problematic
from the automatism point of view, but these
methods are based on two main parts, geometry
extraction and annotation.
Basically, geometry extraction presents the
process of constructing a simplified representation
of a 3D shape such as a Signal or an Electric born
like in our case. The representation of geometric
shapes has been studied extensively, (Campbell &
Flynn, 2001). Once geometric elements are detected
and stored via a specific presentation, the second
core of the object detection and scene reconstruction
is object recognition, In fact, it presents the process
of labelling a set of data points or geometric
primitives extracted from the data with a named
object or object class. Whereas the geometry
modelling task would find a set of points to be a
vertical Bounding Box, the recognition task would
label that Box as a Signal. Object recognition
algorithms may label object instances of an exact
shape, or they may recognize classes of objects.
Research on recognition of specific building
components is still in its early stages. Methods in
this category are typically shape-based ones. They
aim at segmenting a scene into planar regions, for
example, and then use features derived from the
segments to recognize objects. This approach was
carried out by Rusu et al. by using heuristics to
detect walls, floors, ceilings, and cabinets in a
kitchen environment, (Rusu, 2008). A similar
approach was proposed by Pu and Vosselman to
model building façades, (Pu, 2009). One of the
challenges of recognition in the building context is
that many of the objects to be recognized are very
similar to objects of little relevance. Some
researchers have proposed qualifying the spatial
relationships between objects or geometric
primitives to reduce the ambiguity of recognition
results. Such approaches generate semantic labels of
geometric primitives, and test the validities of these
labels with a spatial relationship knowledge base.
Usually, such a knowledge model is represented by a
semantic network, (Nuchter, 2008). For instance, a
semantic net may specify the relationships between
entities such as “floors are orthogonal to walls and
doors, and parallel with ceilings”. Such validity
checking approaches provide ways to integrate
domain knowledge into the object recognition
process. Another approach for recognition is to first
detect objects that are easily recognizable, and then
use the context of these initial detections to facilitate
recognition of more challenging structures. For
example, Pu and Vosselman use characteristic
features, such as size, orientation, and relationships
to other prominent objects, to detect walls and roofs
(Pu, 2009). Then, a second stage detects windows
within each of the detected walls.
One strategy for reducing the search space of
object recognition algorithms is to utilize knowledge
about a specific facility, such as a CAD model or
floor plan of the original design. For instance, Yue et
al. overlay a design model of a facility with the as-
built point cloud to guide the process of identifying
which data points belong to specific objects and to
detect differences between the as-built and as-
designed condition (Yue, 2006). In such cases,
object recognition problem is simplified to be a
matching problem between the scene model entities
and the data points. Another similar approach is
presented in (Osche, 2008).
From the above mentioned works, we can deduce
that the problematic of 3D object detections and
scene reconstructions including standard algorithm
and semantic networks can produce first results.
Moreover such strategies suffer from the lack of
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
256

flexibility, efficiency and are in general hard coded.
Thus, the context and the algorithm which are part
of knowledge that are required to be used in
recognition process have to be modelled.
2.2 Knowledge Modelling
In recent years, formal ontology has been suggested
as a solution to the problem of 3D objects
reconstruction from 3D point clouds (Cruz et al.,
2007). In this area, ontology structure was defined as
a formal representation of knowledge by a set of
concepts within a domain, and the relationships
between those concepts. It is used to reason about
the entities within that domain, and may be used to
describe the domain. Conventionally, ontology
presents a "formal, explicit specification of a shared
conceptualization" (Gruber, 2005). Ontology
provides a shared vocabulary, which can be used to
model a domain. Through technologies known as
Semantic Web, most precisely the Ontology Web
Language (OWL) (MacGuiness and Harmelen,
2004), researcher are able to share and extends
knowledge through the scientific community. The
basic strength of formal ontology is their ability to
reason in a logical way based on Description Logics
DL. Lots of reasoners exist nowadays like Pellet
(Sirin et al., 2007), (Tasrkov and Harrocks, 2006)
and KAON (U. Hustadt, 2010). Despite the richness
of OWL's set of relational properties, the axioms
does not cover the full range of expressive
possibilities for object relationships that we might
find, since it is useful to declare relationship in term
of conditions or even rules. These rules are used
through different rules languages to enhance the
knowledge possess in an ontology. Some of the
evolved languages are related to the semantic web
rule language (SWRL) and advanced Jena rules
(Carroll et al., 2004). SWRL is a proposal as
a Semantic Web rules language, combining
sublanguages of the OWL Web Ontology Language
with the Rule Markup Language (Horrocks et al.,
2004). In addition, SWRL language specifies also a
library for mathematical built-ins functions which
can be applied to individuals. It includes numerical
comparison, simple arithmetic and string
manipulation.
In this project, domain ontologies are used to
define the concepts, and the necessary and sufficient
conditions that define the concepts. These conditions
are of value, because they are used to populate new
concepts. For instance, the concept
“Horizontal_BoudinBox” can be specialized into
“Wall” if it contains a “Window”. Consequently, the
concept “Wall” will be populated with all
“Horizontal_BoudinBox” if they are linked to a
“Window” or “OpeningElement” object (Vanland,
2008). In addition, the rules are used to compute
more complex results such as the topological
relationships between objects. For instance, the
intersection of two objects is used to determine if a
part of an object is inside of another object. The
ontology is than enriched with this new relationship.
The topological relation built-ins are not defined in
the SWRL language. Consequently, the language
was extended.
3 APPROACH OVERVIEW
This paper presents a knowledge based detection
approach using the OWL ontology language, the
Semantic Web Rule Language, and 3D processing
built-ins aiming at combining geometrical analysis
of 3D point clouds and specialist’s knowledge. This
combination allows the detection and the annotation
of objects contained in point clouds. The field of the
Deutsch Bahn railway scene is treated for object
detection. The objective of the system consists in
creating, from a set of point cloud files, from an
ontology that contains knowledge about the DB
railway objects, and from the knowledge about 3D
processing algorithms, an automatic process that
produces as output a set of tagged elements
contained in the point clouds.
The process enriches and populates the ontology
with individuals and relationships between these
new individuals. To represent these objects, a
VRML file (VRML Virtual Reality Modeling
Language, 1995) is generated. The resulting
ontology contains enough knowledge to feed a GIS
system, and to generate IFC file (IFC Model, 2008)
for CAD software, but this is out of the scope the
paper. The processing steps can be detailed within
the schema of Figure 1, where three main steps aim
at detecting and identifying objects.
(3) From 3D point clouds to geometric elements.
(4) From geometry to topologic relations.
(5) From geometric and/or topologic relations to
semantic elements annotation.
As intermediate steps, the different geometries
within a specific 3D point clouds are detected and
stored within the ontology structure. Once done, the
existent topological relations between the detected
geometries are qualified and then stored within the
same knowledge base. Finally, detected geometries
are annotated semantically, based on existing
FROM 3D POINT CLOUDS TO SEMANTIC OBJECTS - An Ontology-based Detection Approach
257

knowledge’s related to the geometric characteristics
and topologic relations.
Figure 1: Sequence of the object detection application.
4 DOMAIN KNOWLEDGE
MODELLING
The domain ontology presents the core of WiDOP
project and provides a knowledge base to the created
application. The global schema of the modelled
ontology structure offers a suitable framework to
characterize the different Deutsche Bahn elements
from the 3D processing point of view.
The created knowledge base related to the
Deutsche Bahn scene has been inspired next to our
discussion with the domain expert and next to our
study based on the official Web site for the German
rail way specification ”http://stellwerke.de”. The
input ontology contains knowledge about the DB
railway objects and knowledge about 3D processing
algorithms. Consequently, the knowledge base is
divided into two layers, the layer of DB object
description and the layer of the algorithmic
description.
The sub-layer of scene knowledge is composed
by three main classes which are the Scene, the
domain concepts and the characteristics. In case of
Deutsche Bahn scene, this might comprise a list such
as: {Signals, Mast, Schalanlage, etc.}. Besides, the
importance of the other classes cannot be ignored.
The sub-layer of the geometrical knowledge
formulates the basic geometrical elements used
within the prototype. Actually, the annotation
elements step processes bounding boxes. Other
geometries especially lines and planes are more used
to characterize domain concepts elements by a list of
geometries. This information is used to create useful
descriptions that facilitate the object detection
process. The sub-layer of the topologic knowledge
represents topological relationships between scene
elements. For instance, a topological relation
between a distant signal and a main one can be
defined, as both have to be distant of 1 Km. The
qualification of topologic relations into the semantic
framework is done by means of topological Built-Ins
called “3DSWRL_Topologic_Built-Ins”. Further,
the object properties are also used to link an object
to others by a topologic relation. In general there are
a set of object properties in the ontology which have
their specialized properties for the specialized
activities, Figure 2.
Figure 2: Topologic rules.
Finally, the 3D processing algorithmic layer
contains all relevant aspects related to the 3D
processing algorithms. It´s integration into the
semantic framework is done by means of special
Built-Ins called “Processing Built-Ins”. They
manage the interaction between above mentioned
layers. In addition, it contains algorithm definitions,
properties, and geometries related to the each
defined algorithms.
An importance achievement is the detection and
the identification of objects which has linear
structure such as signal, indicator column, and
electric pole, etc., through utilizing their geometric
properties.
Figure 3
demonstrates the general layout
schema of the ontology.
Figure 3: Ontology general schema overview
The next section introduces an overview of the
approach undertaken in the WiDOP project to detect
and annotate semantically the different Deutsch
Bahn objects.
5 SEMANTIC ANNOTATION
PROCESS
It presents the process of affecting a semantic label
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
258

to the different geometries based on SWRL rules
and composed by three basic steps.
5.1 Point Cloud to Geometry
The first step aims at the geometric elements
detection. Thus, Semantic Web Rule Language
within extended built-ins for complex 3D processing
are used in order to detect geometry (e.g. Table 1).
Once done, the detected elements are used to
populate the ontology.
The “3Dswrlb:VerticalElementDetection” built-
ins aims at the detection of vertical elements.
The prototype of the designed Built-in is:
3D_swrlb_Processing:
VerticalElementDetection(?Vert, ?Dir)
where the first parameter presents the target object
class, and the last one presents the point clouds
directory defined within the created scene. Table 1
show the mapping between the 3D processing built-
ins, which are computer and translated to predicate,
and the corresponding class.
Table 1: 3D processing built-Ins mapping process.
Processing Built-Ins Correspondent class
3D_swrlb_Processing:
VerticalElementDetection(?V
ert,?Dir)
Vertical_BoundingBox(?x)
5.2 Geometries to Topology
Once geometries are detected, the second step, aims
at verifying certain topology properties between
detected geometries. Thus, 3D_Topologic built-ins
have been added in order to extend the SWRL
language. Topological rules are used to define
constrains between different elements. After parsing
the topologic built-ins and its execution, the result is
used to enrich the ontology with relationships
between individuals that verify the rules. Similarly
to the 3D processing built-ins, our engine translates
the rules with topological built-ins to standard rules,
Table 2.
Table 2: Example of topologic built-ins.
Processing Built-Ins
Correspondent object
property
3D_swrlb_Topology:Intersect(
?x, ?y)
Intersect (?x,?y)
5.3 Geometry and/or Topology to
Semantic
After the geometry and the topological relation de-
detection, swrl rules aim at qualifying and
annotating the different detected geometries. The
following example shows how a rule specifies the
class of a VerticalElement which is of type Mast
regarding its altitude. The altitude is highly relevant
only for this element.
3DProcessing_swrlb:VerticalElementDetec
tion(?Vert, ?dir) ^ altitude (?x, ?alt)
^swrlb:moreThan (?alt, 6) → Mast
(?Vert)
In case where geometric knowledge is not sufficient,
the topologic relationships between detected
geometries are helpful to manage the annotation
process. The following example shows how
semantic information about existing objects is used
conjunctly with topological relationships in order to
define the class of another object.
Mast (?vert1) ^ VerticalBB (?Vert2) ^
hasDistanceFrom (?vert1,?vert2, 50) →
Mast(?vert2)
6 CASE STUDY
For the demonstration of our system, 500 m from the
scanned point clouds related to Deutsch Bahn scene
in the city of Nürnberg was extracted. The whole
scene has been scanned using a terrestrial laser
scanner fixed within a train, resulting in a large point
cloud representing the surfaces of the scene objects.
Different swrl rules are processed. First, all
vertical elements will be searched in the area of
interest, and then topological relations between
detected geometries are qualified. To do, useful
topologies for geometry annotation are tested.
Topologic Built-Ins like
isConnected, touch,
Perpendicular, isDistantfrom are created. As
result, relations found between geometric elements
are propagated into the ontology, serving as an
improved knowledge base for further processing and
decision steps.
The last step consists in annotating the different
geometries. Vertical elements of certain
characteristics can be annotated directly. In more
sophisticated cases, the combination of semantic
information and topologic ones can deduce more
robust results by minimizing the false acceptation
rate. Finally, based on a list of SWRL rules, most of
detected geometries are annotated. In this example,
among 67 elements are classified as Masts, 21
SchaltAnlage, 34 basic signals and finally, 155
secondary signals, Figure 4.
FROM 3D POINT CLOUDS TO SEMANTIC OBJECTS - An Ontology-based Detection Approach
259
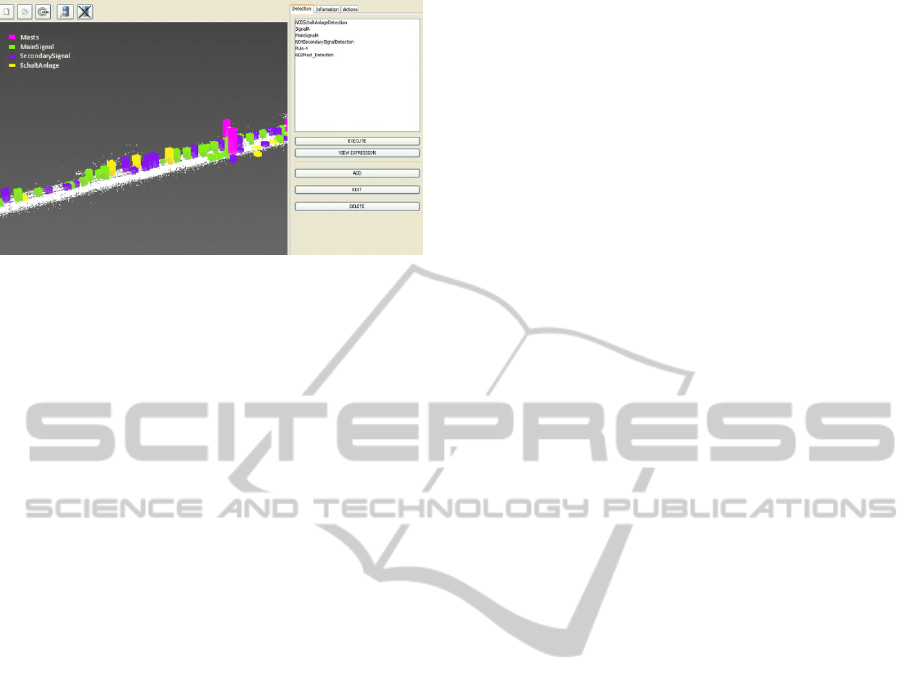
Figure 4: Detected and annotated elements visaliazation
within VRML language.
7 CONCLUSIONS
We have proposed a new solution to perform the
detection of objects from technical survey within the
laser scanner technology. The solution performs the
detection of objects in 3D point clouds by using
available knowledge about a specific domain (DB).
This prior knowledge modelled within ontology
SWRL rules are used to control the 3D processing
execution, the topologic qualification and finally to
annotate the detected elements in order to enrich the
ontology and to drive the detection of new objects.
Future work will include the integration of new
knowledge’s that can intervene within the annotation
process like the number of detected lines within each
bounding box and the update of the general platform
architecture, by ensure more communication
between the scene knowledge within the 3D
processing.
ACKNOWLEDGEMENTS
This paper presents work performed in the
framework of research project funded by the
German ministry of research and education under
contract No. 1758X09. The authors cordially thank
for this funding. Special thinks also for Hung
Truong for his contribution.
REFERENCES
VRML Virtual Reality Modeling Language. (1995, 04 17).
Retrieved from W3C: http://www.w3.org/
MarkUp/VRML/
Campbell, R. J., & Flynn, P. J. (2001). A survey of free-
form object representation and recognition techniques.
Computer Vision and Image Understanding, 81, pp.
166-210.
Carroll, J. J., Dickinson, I., Dollin, C., Reynolds, D.,
Seaborne, A., & Wilkinson, K. (2004). Jena:
implementing the semantic web recommendations.
Proceedings of the 13th international World Wide
Web conference on Alternate track papers & posters,
(pp. 74-83).
Cruz, C., Marzani, F., & Boochs, F. (2007). Ontology-
driven 3D reconstruction of architectural objects.
VISAPP (Special Sessions), pp. 47-54.
Gruber, T. (2005). What is an Ontology. Retrieved from
www-ksl.stanford.edu/kst/what-is-an-ontology.html.
Horrocks, I., Patel-Schneider, P. F., Boley, H., Tabet, S.,
Grosof, B., & Dean, M. (2004). SWRL: A semantic
web rule language combining OWL and RuleML.
W3C Member submission, 21.
Leica Cyclone: 3D Point Cloud Processing Software.
(n.d.). Retrieved 05 09, 2011, from Leica:
http://hds.leica-geosystems.com/en/Leica-
Cyclone_6515.htm
McGuinness, D. L., & Harmelen, F. v. (2004, February
10). OWL Web Ontologgy Language: Overview.
Retrieved December 2, 2009, from W3C
Recommendation: http://www.w3.org/TR/owl-
features/
Nuchter, A. a. (2008). Towards semantic maps for mobile
robots. Robotics and Autonomous Systems, pp. 915-
926.
Osche, F. a. (2008). Automated retrieval of 3D CAD
model objects in construction range images.
Automation in Construction, pp. 499-512.
Pu, S. a. (2009). Knowledge based reconstruction of
building models from terrestrial laser scanning data.
ISPRS Journal of Photogrammetry and Remote
Sensing, pp. 575-584.
Vanlande, R., N. (2008). IFC and building lifecycle
management. Automation in Construction, 18, pp. 70-
78.
Rusu, R. a. (2008). Towards 3D Point cloud based object
maps for household environments. Robotics and
Autonomous Systems, pp. 927-941.
Sirin, E., Parsia, B., Grau, B. C., Kalyanpur, A., & Katz,
Y. (2007). Pellet: A practical owl-dl reasoner. Web
Semantics: science, services and agents on the World
Wide Web, 5, 51-53.
Tsarkov, D., & Horrocks, I. (2006). FaCT++ description
logic reasoner: System description. Automated Rea-
soning, pp. 292-297.
Hustadt U., B. M. (2010). Retrieved from KAON2:
http://kaon2.semanticweb.org/
Yue, K. A. (2006). The ASDMCon project: The challenge
of detecting defects on construction sites., (p. IEEE
Computer Society).
KEOD 2011 - International Conference on Knowledge Engineering and Ontology Development
260
