
ESTIMATION OF IMPLICIT USER INFLUENCE
FROM PROXY LOGS
An Empirical Study on the Effects of Time Difference and Popularity
Tomonobu Ozaki
1
and Minoru Etho
1,2
1
Cybermedia Center, Osaka University, 1-32 Machikaneyama, Toyonaka, Osaka 560-0043, Japan
2
NTT DOCOMO R&D Center, 3-6 Hikarino-oka, Yokosuka, Kanagawa 239-8536, Japan
Keywords:
User influence, Proxy logs, Web usage mining.
Abstract:
In this paper, we propose a framework for estimating implicit user influence from proxy logs. For the esti-
mation, we employ a vector representation of user interactions obtained from log data by taking account of
popularity of web pages and difference of access time to them. One of the key issues for successful estimation
is how to model the popularity and time difference. Since appropriate models depend on application domains,
we propose various models of them. We confirm the effectiveness of the proposed framework by conducting
experiments on web page recommendation and community discovery for real proxy logs.
1 INTRODUCTION
Browsing behavior of users on the web is influenced
implicitly and explicitly by others. Estimation of the
degree of user influence from log data is one of critical
tasks for wide variety of applications such as recom-
mendation, viral marketing and community discov-
ery. In this paper,we consider a problem of estimating
implicit user influence from proxy logs.
A user modeling from the aspect of interaction is
required to estimate user influence. We will explain
the necessity to model interactions by using a very
simple example. In the proxy log shown in Figure 1,
while three users
x
,
y
and
z
accessed to the web pages
A.html
and
B.html
in common, we can guess that the
degree of influence among them is not equal. While
y
always accesses the same web pages just after
x
’s
accesses, the access time of
z
is completely different
from those of
x
and
y
. Thus, we can easily expect that
the behavior of
x
gives significant impact on that of
y
,
and the degree of influence of
x
on
y
is high. Besides
the difference of access time, popularity of web page
is a promising indicator of user interaction. Since all
users except
z
accessed to
A.html
in a short period
of time, we can judge that their browsing behaviors
on
A.html
might be caused by not user influence but
by global one. This very simple example shows that
taking account of page popularity and time difference
is one of key issues for accurate modeling of user in-
teraction and for estimation of user influence.
UID URL Time
x http://xxx/A.html 2011-04-01 10:01:40
y http://xxx/A.html 2011-04-01 10:02:21
z http://xxx/B.html 2011-04-01 10:02:48
m http://xxx/A.html 2011-04-01 10:08:06
n http://xxx/A.html 2011-04-01 10:10:15
··· ··· ···
x http://xxx/B.html 2011-04-01 15:12:59
y http://xxx/B.html 2011-04-01 15:14:01
··· ··· ···
z http://xxx/A.html 2011-04-01 20:09:10
··· ··· ···
Figure 1: An example of proxy log.
In this paper, we propose a model of user inter-
actions based on the page popularity and time dif-
ference, and develop methods for estimating implicit
user influence. In the area of social network analysis,
many sophisticated methods for estimating user influ-
ence have been proposed, most of which assume link
formation representing user interactions. However,
we cannot always expect precise link information in
case of proxy logs. So, we prepare two methods for
the estimation: one does not require link information,
and the other works with additional (incomplete) in-
formation.
While we focus on the user influence in this paper,
the property of homophily(McPherson et al., 2001)
250
Ozaki T. and Etho M..
ESTIMATION OF IMPLICIT USER INFLUENCE FROM PROXY LOGS - An Empirical Study on the Effects of Time Difference and Popularity.
DOI: 10.5220/0003659702420247
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval (KDIR-2011), pages 242-247
ISBN: 978-989-8425-79-9
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

will also give significant impact on user behavior. Ho-
mophily is the tendency of users to have similar be-
haviors with ones having similar characteristics. In
this paper, we drive a rough effect of homophily from
log data by using a simple model, and compare it with
the effect of influence. In addition, we consider the
mixture of homophily and influence.
The effectiveness of the proposed framework is
evaluated empirically by conducting experiments on
web page recommendation and community discovery.
2 MODELING THE DEGREE OF
INFLUENCE
A proxy log L consists of a set of triplets l = (u, p,t)
which indicates that a user u visited or accessed a web
page p at time t. We use notations U
L
= {u|(u, p,t) ∈
L } and P
L
= {p|(u, p,t) ∈ L } to denote a set of all
users and web pages in L , respectively.
Our purpose in this paper is to estimate the degree
of influence from a user x to other user y for every
ordered pair hx,yi ∈ U
L
× U
L
of users in L .
2.1 Representation of Interactions
For an ordered pair hx,yi of users, we employ an inter-
action vector to represent interactions from x to y on
each web page p (see Figure 2). The value of dimen-
sion p in an interaction vector is denoted as V
y
x
(p).
user pair p
1
··· p
|P
L
|
hu
1
,u
2
i V
u
2
u
1
(p
1
) ··· V
u
2
u
1
(p
|P
L
|
)
··· ··· ··· ···
hu
1
,u
|U
L
|
i V
u
|U
L
|
u
1
(p
1
) ··· V
u
|U
L
|
u
1
(p
|P
L
|
)
··· ··· ··· ···
hu
|U
L
|−1
,u
|U
L
|
i V
u
|U
L
|
u
|U
L
|−1
(p
1
) ··· V
u
|U
L
|
u
|U
L
|−1
(p
|P
L
|
)
Figure 2: Vector representation of interactions.
To make V
y
x
(p) reflect significance of interaction,
we formulate V
y
x
(p) in the exponential waiting time
model(Gomez Rodriguez et al., 2010) with the con-
sideration of importance of p. In the formulation, we
give high value to V
y
x
(p) if p is important and y’s ac-
cess time to p is close to that of x. In other words, we
regard that x affects y significantly if y follows x’s be-
havior on important web pages. The formal definition
is given below:
V
y
x
(p) =
I
y
x
(p) · exp(−∆
y
x
(p)/α)
( min
(x,p,t
x
)∈L
(t
x
) < min
(y,p,t
y
)∈L
(t
y
))
0 (otherwise)
where α is a parameter, I
y
x
(p) denotes an importance
of p with respect to hx,yi, and ∆
y
x
(p) denotes a differ-
ence of timestamps when x and y visited p.
Various models of I
y
x
(p) and ∆
y
x
(p) in V
y
x
(p) can
be considered. In this paper, we examine four models
of I
y
x
(p) and two of ∆
y
x
(p).
The first model of I
y
x
(p) is the inverse document
frequency (IDF) of p, defined formally as:
idf(p) = log
|U
L
|
|{z|(z, p,t
′
) ∈ L }|
.
In this setting, web pages accessed by fewer users
have higher importance.
The second model of I
y
x
(p) is restricted version of
IDF. Only triplets before y’s first access to p are used
in calculating IDF.
r idf(y, p) = log
|U
L
|
|{z|(z, p,t
′
) ∈ L ,t
′
≤ min
(y,p,t)∈L
(t)}|
r idf(y, p) reflects a context on p and y by consid-
ering the access time of y to p. It gives high value to
early adopters of p.
As the third model of I
y
x
(p), we consider the term
frequency - inverse document frequency (tf-idf) de-
fined below. In this case, I
y
x
(p) depends on x and p.
tfidf(x, p) =
|{(x, p,t) ∈ L }|
|{(x, p
′
,t
′
) ∈ L }|
× id f(p)
Finally, as the fourth model, we prepare a constant
function, i.e. I
y
x
(p) = 1.
Capturing the time difference on a web page p be-
tween two users x and y is not trivial since users visit
the same web pages several times. To reflect a situa-
tion in which y visits p by the influence of x, it is rea-
sonable to use the y’s first access to p and x’s access
just before y’s first access. On the other hand, if we
assume that x’s interest in p decreases with time and
thus x’s effect on p also decreases, using the first ac-
cesses of y and x is another reasonable candidate. To
model the aboveideas, two models of time difference,
denoted as LtoF
y
x
(p) and FtoF
y
x
(p), are defined:
LtoF
y
x
(p) = min
(y,p,t
y
)∈L
(t
y
) − max
(x,p,t
x
)∈L
p
y
(t
x
)
FtoF
y
x
(p) = min
(y,p,t
y
)∈L
(t
y
) − min
(x,p,t
x
)∈L
(t
x
)
where L
p
y
= {(z, p,t
z
) ∈ L |t
z
< min
(y,p,t
y
)∈L
(t
y
)} rep-
resents a set of triplets in L whose time stamp is ear-
lier than y’s first access to p.
2.2 Estimation of User Influence
For every ordered pair hx,yi of users, an interac-
tion vector can be obtained by instantiating I
y
x
(p) and
ESTIMATION OF IMPLICIT USER INFLUENCE FROM PROXY LOGS - An Empirical Study on the Effects of Time
Difference and Popularity
251

∆
y
x
(p) for all web pages p ∈ P
L
. Then, the vectors
will be used to estimate a user influence. In this paper,
we propose two methods for estimating user influence
from a set of interaction vectors.
The first method is very simple. We estimate the
degree of influence from x to y, denoted as w
σ
(x,y),
as the summation of elements in a vector on hx,yi:
w
σ
(x,y) =
∑
p∈P
L
V
y
x
(p).
In addition, if necessary, we use a normalized influ-
ence w
′
σ
(x,y) = w
σ
(x,y)/max
z∈U
L
(w
σ
(z,y)). As ex-
plained before, V
y
x
(p) indicates the degree of signifi-
cance on the interaction from x to y on p. Thus, the es-
timation by summation gives high degree of influence
to hx,yi if there are many significant interactions be-
tween two users. The idea behind this estimation is re-
lated to the traditional similarity measures which give
high similarity to the pair of vectors having manyhigh
value elements in common. In case of w
σ
(x,y), the
information on “high value elements in common” be-
tween x and y is already encoded in calculatingV
y
x
(p)
since V
y
x
(p) reflects the significance of interactions.
The second proposed method to estimate user in-
fluences is application of supervised learning. While
it is difficult to observe interactions and influences
directly in general, we prepare a class information
c : U
L
× U
L
→ {0,1} by using additional information
which indicates whether or not a user pair has a lot of
chances of interactions: c(x,y) = 1 means that there
is a high possibility of interaction and thus we regard
that x influences y significantly, while c(x,y) = 0 cor-
responds to the opposite situation.
A model which estimates the probability that
c(x,y) = 1 can be obtained by applying a supervised
learning to a set of interaction vectors with class in-
formation, i.e.
{(hV
y
x
(p
1
),··· ,V
y
x
(p
|P
L
|
)i, c(x,y) )|x, y ∈ U
L
}.
We regard this probability as the degree of influ-
ence from x to y and denote it as w
L
(x,y). Similar
to the case of w
σ
, we use the normalized influence
w
′
L
(x,y) = w
L
(x,y)/max
z∈U
L
(w
L
(z,y)) if necessary.
The property of homophily(McPherson et al.,
2001) also gives significant impact on user behavior.
In this paper, we regard that the cosine similarity of
user behavior
w
C
(x,y) =
∑
p∈P
L
tfidf(x, p) · tfidf(y, p)
q
∑
p∈P
L
tfidf(x, p)
2
q
∑
p∈P
L
tfidf(y, p)
2
roughly represents homophily effects and use it as a
baseline method. In addition, we consider a mixture
of homophily and influence:
w
λ
I
(x,y) = λ
w
C
(x,y)
max
z∈U
L
(w
C
(z,y))
+ (1 − λ)w
′
I
(x,y)
where λ is a mixture parameter and I ∈ {σ,L}.
3 EXPERIMENTS
The proposed framework is evaluated by tasks of web
page recommendation and community discovery.
3.1 Datasets
After the application of standard data cleaning, three
datasets L
1
, L
2
and L
3
are prepared from a proxy
server log recorded in Osaka University from April
to June 2010. In addition, as a simple abstraction for
better estimation, all parameters in URL (string after
“?”) are deleted.
L
1
: It contains about 308,000 records of 99 students
who belong to a certain department on sciences.
L
2
: It contains about 258,000 records of 151 students
who belong to a certain department on arts.
L
3
: It contains about 242,000 records of 157 students
participating in a certain project.
We prepare class information for L
1
and L
2
based
on the physical location of computers determined by
IP address recorded in the original proxy log. We
judge c(x, y) = 1 if there exists at least one situation in
which two students x and y use two computers located
adjacent to each other at the same time. As a result,
the numbers of user pairs hx,yi judged as c(x,y) = 1
become 786 in L
1
and 776 in L
2
, respectively. We
prepare class information for L
3
by using ‘group in-
formation’ obtained by a questionnaire. The students
in L
3
consists of six groups having 50, 50, 26, 13, 10,
and 8 members, respectively. We judge c(x,y) = 1 if
x and y belong to the same group.
3.2 Web Page Recommendation
3.2.1 Estimation of User Influence
We prepare six settings on α for the exponential wait-
ing time model, denotes as D
5
, D
10
, D
20
, H
75
, H
150
and H
300
, respectively. In case of D
a
(a= {5,10, 20}),
we abstract timestamps at the level of “day” and set
the parameter α to a. On the other hand, H
a
(a =
{75, 150, 300}) denotes the abstraction of timestamps
at the level of “hour”. While D
10
corresponds to the
situation in which the effect of page importance de-
creases to about 0.5 in a week, H
150
cuts down the
effect to about 0.3 in the same period.
By considering all the combinations of I
y
x
(p),
∆
y
x
(p) and α, 48(= 4× 2 × 6) sets of interaction vec-
tors are obtained for each datasets. From each set
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
252

Table 1: Number of records for web page recommendation.
|P
i,1
| |A
i,1
| |P
i,2
| |A
i,2
|
i = 1 38,827 140,421 104,221 88,303
i = 2 25,347 35,079 21,367 38,663
i = 3 25,962 61,432 30,171 67,276
of interaction vectors, we derive w
σ
by summation
and w
L
by supervised learning of LibSVM(Chang and
Lin, 2001). Parameters for SVM learning were deter-
mined by the grid search. We employ w
C
as a base-
line. The mixtures w
λ
σ
and w
λ
L
are also obtained by
setting λ = 0, 0.05, 0.1,· ·· ,0.95, 1, respectively.
3.2.2 Evaluation Metrics
For each L
i
(i = {1, 2,3}), two pairs of datasets L
i, j
=
(P
i, j
,A
i, j
)( j = {1,2}) are prepared from the same
proxy server log recorded in July 2010. While P
i, j
is a set of records of students in L
i
for one week, A
i, j
is a set of records for two weeks just after P
i, j
. P
i, j
and
A
i, j
are used for producing a recommendation set and
an answer set, respectively. Different from L
i
, we do
not apply the abstraction of URL to L
i, j
. The numbers
of records are summarized in Table 1.
For each user x, a set of web pages to which x does
not access in P
i, j
is produced as a recommendation set
P
i, j
(x) = {p|(z, p,t) ∈ P
i, j
,z 6= x} \ {p|(x, p,t) ∈ P
i, j
}.
Each web page p in the recommendation set has the
score v(p, x) =
∑
z∈{z6=x| (z,p,t)∈P
i, j
}
w(z,x) of weighted
voting according to a user influence w. We sort P
i, j
(x)
in descending order of the scores. On the other hand,
we define the answer set as
A
i, j
(x) = {p|(x, p,t) ∈ A
i, j
,(x, p,t
′
) 6∈ P
i, j
} ∩ P
i, j
(x).
We believe that recommendation of minor web
pages is worth more than that of major ones. To re-
flect such consideration, we put a weight w(p) on a
web page p based on inverse document frequency, i.e.
w(p) = log
|U
P
i, j
|/|{z|(z, p,t
′
) ∈ P
i, j
}|
.
We employ the macro average of weighted pre-
cision@k taken over users as an evaluation criterion.
The weighted precision@k for a user x is defined as :
p@k(x) =
∑
p∈P
i, j
(x)
I(x, p, k) · w(p) /
∑
p∈P
i, j
(x)
w(p)
where I(x, p, k) is an indicator function which be-
comes 1 if p is in A
i, j
(x) and it also locates within
the k-th place in P
i, j
(x). Otherwise, I(x, p,k) = 0.
As another evaluation criterion, mean average pre-
cision (MAP) is employed:
MAP =
1
|U
A
i, j
|
∑
x∈U
A
i, j
1
|A
i, j
|
∑
p∈A
i, j
(x)
p@k(x, p)(x)
where k(x, p) is the rank of p in P
i, j
(x).
3.2.3 Results
Table 2 shows the best values of MAP among all the
combinations of parameters. The best values within
each L
i, j
are marked by underline. We can observe
that the proposed methods outperform the baseline
(w
C
). In addition, the mixtures of homophily and in-
fluence (w
λ
σ
and w
λ
L
) take the first place in all cases.
In comparison with the results by summation (w
σ
and
w
λ
σ
), results by supervised learning (w
L
and w
λ
L
) are
better in all cases of L
3, j
. On the other hand, such
tendency is not recognized in L
1, j
and L
2, j
.
Table 2: Best values of MAP.
MAP L
1,1
L
1,2
L
2,1
L
2,2
L
3,1
L
3,2
w
C
0.231 0.162 0.167 0.269 0.210 0.293
w
σ
0.250 0.198 0.191 0.299 0.240 0.308
w
L
0.253 0.191 0.166 0.303 0.242 0.311
w
λ
σ
0.260 0.198 0.194 0.306 0.243 0.321
w
λ
L
0.260 0.194 0.170 0.310 0.253 0.330
We show the average values of MAP and preci-
sion@k (k = {5,10}) for w
σ
and w
L
taken over 48
combinations of parameters in Table 3. In the table,
all average MAP values except w
L
for L
2,1
and w
σ
for L
3,2
outperform those of baseline method. Simi-
lar to MAP, average values of precision@k tend to be
higher than corresponding values of baseline method.
While w
L
is clearly better than w
σ
in L
2,2
, L
3,1
and
L
3,2
, w
L
is worse in others, especially in L
2,1
.
From the results, we simply conclude that: (1)the
proposed methods perform well under appropriate pa-
rameter settings, (2)the mixture of homophily and
influence gains the result of recommendation, and
(3)the quality of class information has an impact on
user influence obtained by supervised learning.
Table 3: Average values of MAP and precision@k.
MAP L
1,1
L
1,2
L
2,1
L
2,2
L
3,1
L
3,2
w
C
0.231 0.162 0.167 0.269 0.210 0.293
w
σ
0.241 0.180 0.173 0.281 0.218 0.287
w
L
0.245 0.188 0.157 0.299 0.235 0.305
precision@5
w
C
0.436 0.337 0.152 0.343 0.310 0.387
w
σ
0.440 0.369 0.162 0.348 0.334 0.385
w
L
0.422 0.358 0.111 0.357 0.342 0.410
precision@10
w
C
0.310 0.230 0.134 0.219 0.246 0.310
w
σ
0.347 0.251 0.150 0.239 0.262 0.307
w
L
0.348 0.233 0.124 0.250 0.271 0.339
In order to assess the effects of parameters, we
compare the MAP values in all datasets obtained by
different models of page importance I
y
x
(p) under the
ESTIMATION OF IMPLICIT USER INFLUENCE FROM PROXY LOGS - An Empirical Study on the Effects of Time
Difference and Popularity
253
same settings other than I
y
x
(p). For each proposed
methods w
σ
and w
L
, we have 72 comparisons in to-
tal because of two of time differences, six of αs and
six of datasets. The ratio of taking the best value is
summarized in Table 4. We apply the same compar-
isons to ∆
y
x
(p) and α. The results on ∆
y
x
(p) and α are
obtained from 144 and 48 comparisons, respectively.
While tfidf and const drive better results in w
σ
, r idf is
the best in w
L
. H
300
clearly outperforms others in w
σ
.
LtoF is better than FtoF in both w
σ
and w
L
. Since the
winning rates are not uniform, we can recognize that
different models givesignificant impact on the results.
Table 4: Winning rates of different models in MAP.
w
σ
w
L
w
σ
w
L
idf 0.153 0.139 D
5
0.000 0.083
r idf 0.125 0.347 D
10
0.063 0.083
tfidf 0.347 0.181 D
20
0.313 0.250
const 0.375 0.333 H
75
0.104 0.229
FtoF 0.222 0.333 H
150
0.104 0.146
LtoF 0.778 0.667 H
300
0.417 0.208
A similar analysis is also applied to a mixture pa-
rameter λ in w
λ
σ
and w
λ
L
. The results are shown in
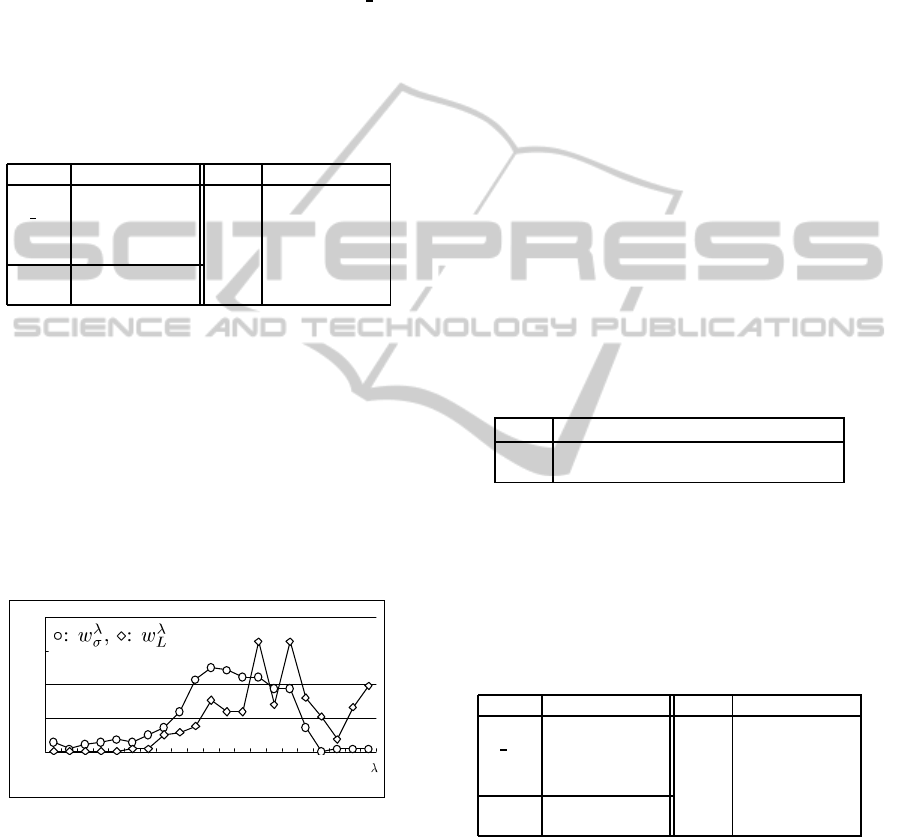
Figure 3. The value of λ between 0.5 and 0.55 and
that between 0.65 and 0.75 seem to be promising for
w
λ
σ
and w
λ
L
, respectively. Compared with w
λ
σ
, the peak
of w
λ
L
exists at the higher value of λ. In other words,
w
λ
L
requires large effect of homophily to get better re-
sults on web page recommendation. We believe that
unreliability of class information of L
1
and L
2
causes
these results.
0
0.05
0.1
0.15
0.2
0
0
.1
0
.2
0
.3
0
.4
0.
5
0.
6
0.7
0
.8
0
.9
1
0
0.05
0.1
0.15
0.2
0
0
.1
0
.2
0
.3
0
.4
0.
5
0.
6
0.7
0
.8
0
.9
1
Figure 3: Winning rates of different λs in MAP.
3.3 Community Discovery
We conduct experiments on community discovery by
using the dataset L
3
.
As the same as the experiments on web page rec-
ommendation, we prepare 48 of w
σ
s for each combi-
nation of parameters. On the other hand, we employ
a cross-validation like method to derive w
L
. In the
method, a set of interaction vectors is divided into five
pieces and the influence w
L
(x,y) in one piece is esti-
mate by using a model build from other four pieces.
A community structure having maximal modular-
ity(Newman and Girvan, 2004) is discovered by us-
ing the igraph library(Csardi and Nepusz, 2006). By
using the group information obtained by a question-
naire as a correct answer, we evaluate the discovered
community structure based on normalized mutual in-
formation (NMI)(Danon et al., 2005). The range of
NMI is from 0 to 1, and high value indicates that the
predicted structure is similar to the answer.
The best and average values of NMI over all the
combinations of parameters are shown in Table 5. In
the results, we observe that the proposed methods out-
perform the baseline method w
C
. Especially, the best
value of w
L
is significant. But it is not surprising since
we use class information to prepare w
L
even if a cross-
validation like method is applied. Different from the
results in web page recommendation, the mixtures w
λ
σ
and w
λ
L
become worse than w
σ
and w
L
. We believe
that the normalization process causes these results. In
fact, the best values of NMI in the normalized influ-
ences w
′
σ
and w
′
L
are 0.145 and 0.217, respectively.
Table 5: Best and average values of NMI.
w
C
w
σ
w
λ
σ
w
L
w
λ
L
Best 0.150 0.227 0.150 0.426 0.235
Avg. 0.150 0.165 0.127 0.266 0.156
The effects of parameters are assessed in Table 6.
In the table, FtoF drives better results in w
L
and H
75
significantly outperforms others in w
σ
and w
L
. While
w
σ
and w
L
have the same tendency on ∆
y
x
(p) and α,
the results on I
y
x
(p) is quite different between them.
Table 6: Winning rates of different models in NMI.
w
σ
w
L
w
σ
w
L
idf 0.000 0.083 D
5
0.000 0.000
r idf 0.000 0.333 D
10
0.000 0.188
tfidf 0.750 0.000 D
20
0.000 0.000
const 0.250 0.583 H
75
0.875 0.500
FtoF 0.521 0.667 H
150
0.125 0.250
LtoF 0.479 0.333 H
300
0.000 0.063
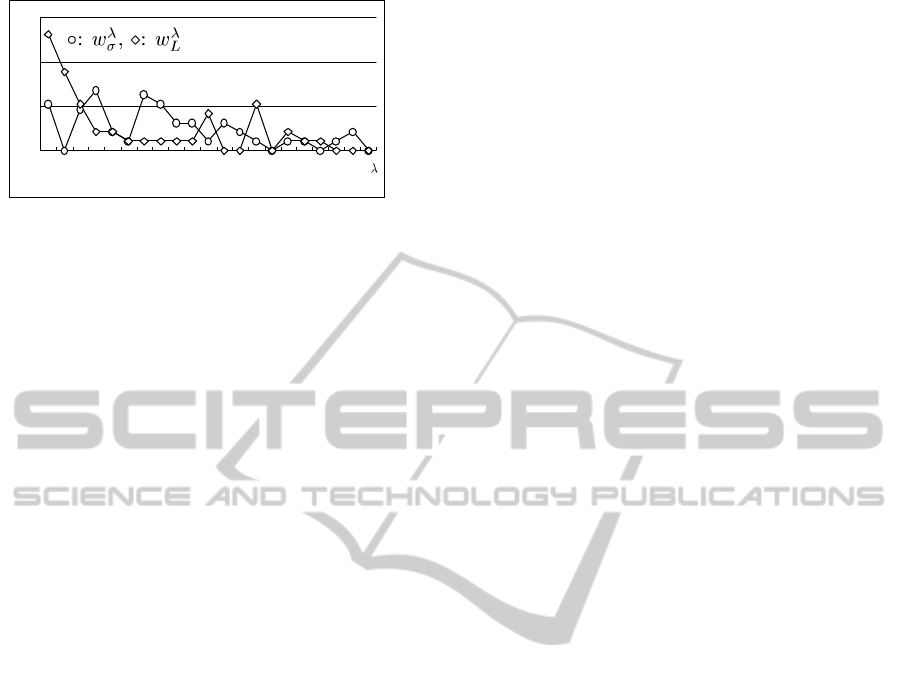
Figure 4 shows the results of comparisons on a
mixture parameter λ. We can observe that small λs
get better results in w
λ
L
due to the supervised learn-
ing. The peak of w
λ
σ
is also small relatively. These
results suggests that the effect of influence is domi-
nant than that of homophily on community discovery
in this dataset.
The parameter effects are completely different
from the tasks of web page recommendation and that
KDIR 2011 - International Conference on Knowledge Discovery and Information Retrieval
254
0
0.1
0.2
0.3
0
0.1
0.2
0.
3
0
.
4
0.
5
0
.
6
0
.
7
0.8
0.
9
1
0
0.1
0.2
0.3
0
0.1
0.2
0.
3
0
.
4
0.
5
0
.
6
0
.
7
0.8
0.
9
1
Figure 4: Winning rates of different λs in NMI.
of community discovery. Thus, we can confirm that
the appropriate parameter setting heavily depends on
application domain.
4 RELATED WORK
Estimation of user influence attracts much attention
in the area of social network analysis, and many so-
phisticated models are proposed, e.g. (Goyal et al.,
2010; Kimura et al., 2009). However, it is difficult to
apply them directly to proxy logs not having precise
information to construct accurate user networks.
Several methods for estimating user influence
without explicit network information have been de-
veloped recently. In (Gomez Rodriguez et al., 2010),
an algorithm named ‘netinf’ is proposed which esti-
mates hidden network structures from a set of infor-
mation cascades obtained from (proxy) log data. Net-
inf estimates directed unweighted networks of users
by adopting the exponential waiting time model on
information diffusion while it assumes that the de-
gree of user influences are the same among any user
pairs. As an extension of netinf, a convex program-
ming based method for inferring directed weighted
network structures from cascade data has been pro-
posed in (Myers and Leskovec, 2010). While these
two methods employ the exponential waiting time
model for reflecting information on time difference,
they do not consider the importance of contents at all.
A probabilistic model for user adoption behaviors
has been proposed in (Au Yeung and Iwata, 2010).
By using the model, user influence as well as influ-
ences of popularity and recency of contents are esti-
mated from log data. The model requires a parameter
specifying the length of period in which a user affects
others. In other words, behaviors outside of the pe-
riod are regarded to give no effect. On the other hand,
the effects of behaviors decrease gradually with time
in our proposal.
5 CONCLUSIONS
In this paper, we propose a framework for estimat-
ing implicit user influence from proxy logs. We
model user interactions as vectors by taking account
of the difference of access time and importance of
web pages, and use the vectors to estimate the influ-
ence. The proposed methods are evaluated empiri-
cally by using three real datasets in the tasks of web
page recommendation and community discovery.
For future work, detailed assessments of obtained
user influences are necessary. In addition, we plan to
investigate further experiments with large-scale proxy
logs having different characteristics as well as pre-
cise comparisons with related techniques on estimat-
ing user influence.
REFERENCES
Au Yeung, C.-m. and Iwata, T. (2010). Capturing implicit
user influence in online social sharing. In Proceedings
of the 21st ACM Conference on Hypertext and Hyper-
media, pages 245–254.
Chang, C.-C. and Lin, C.-J. (2001). LIBSVM: a library
for support vector machines. Software available at
http://www.csie.ntu.edu.tw/˜cjlin/libsvm
.
Csardi, G. and Nepusz, T. (2006). The igraph software
package for complex network research. InterJournal,
Complex Systems:1695.
Danon, L., D´ıaz-Guilera, A., Duch, J., and Arenas, A.
(2005). Comparing community structure identifica-
tion. Journal of Statistical Mechanics: Theory and
Experiment, 2005(9):P09008.
Gomez Rodriguez, M., Leskovec, J., and Krause, A. (2010).
Inferring networks of diffusion and influence. In
Proceedings of the 16th ACM SIGKDD International
Conference on Knowledge Discovery and Data Min-
ing, pages 1019–1028.
Goyal, A., Bonchi, F., and Lakshmanan, L. V. (2010).
Learning influence probabilities in social networks. In
Proceedings of the third ACM International Confer-
ence on Web Search and Data Mining, pages 241–250.
Kimura, M., Saito, K., and Motoda, H. (2009). Efficient
estimation of influence functions for sis model on so-
cial networks. In Proceedings of the 21st International
Joint Conference Artificial Intelligence, pages 2046–
2051.
McPherson, M., Lovin, L. S., and Cook, J. M. (2001). Birds
of a Feather: Homophily in Social Networks. Annual
Review of Sociology, 27(1):415–444.
Myers, S. and Leskovec, J. (2010). On the convexity of
latent social network inference. In Advances in Neu-
ral Information Processing Systems 23, NIPS, pages
1741–1749.
Newman, M. E. J. and Girvan, M. (2004). Finding and eval-
uating community structure in networks. Physical Re-
view E, 69(2):026113.
ESTIMATION OF IMPLICIT USER INFLUENCE FROM PROXY LOGS - An Empirical Study on the Effects of Time
Difference and Popularity
255
