
AN ONTOLOGY-BASED APPROACH TO PROVIDE
PERSONALIZED RECOMMENDATIONS USING A
STOCHASTIC ALGORITHM
Romain Picot-Clémente, Christophe Cruz and Christophe Nicolle
LE2I Laboratory, University of Bourgogne, Dijon, France
Keywords: Recommender systems, Information filtering, Semantic web, Adaptive hypermedia systems, User
modelling, Stochastic processes.
Abstract: The use of personalized recommender systems to assist users in the selection of products is becoming more
and more popular and wide-spread. The purpose of a recommender system is to provide the most suitable
items from an knowledge base, according the user knowledge, tastes, interests, ... These items are generally
proposed as ordered lists. In this article, we propose to combine works from adaptive hypermedia systems,
semantic web and combinatory to create a new kind of recommender systems suggesting combinations of
items corresponding to the user.
1 INTRODUCTION
In the first years after its creation, Web was the same
for everybody. Websites was presenting the same
information and the same links to each visitor,
without taking into account their goals and their
knowledge.
Given the important growth of the number of
available information, the diversity of users and the
complexity of Web applications, researchers started
to question the "one-size-fits-all" approach.
Therefore researches have emerged to answer these
problems, to propose a Web where the appearance,
the behaviour, the resources would be ideally
adapted to each individual. This Web would offer a
different experience to each user. This Web is called
the Adaptive Web.
A first step to reach the Adaptive Web is to
reason on local adaptation problems.
This adaptation to users is currently widely
found into the so-called domain of recommender
systems (Tintarev and Masthoff, 2007) (Mcsherry,
2005). These systems have the role to provide
recommendations to users. This domain has become
important since the mid-year 90. It is yet a big
domain of research due to its richness in terms of
problem to solve, and given the great number of
possible applications to deal with information
overload and provide adaptive recommendations.
Recommender systems allow companies to filter
information, and then to recommend products to
their customers, according their preferences.
Recommending products or services can consolidate
relations between the seller and the customer, and
thus, enhance the benefits (Zhang and Jiao, 2007).
Many systems developed as TrustWalker (Jamali
and Ester, 2009) emphasize the current interest of
recommendation.
Content-based (CB) and collaborative filtering
(CF) methods are two of the main approaches used
to form recommendations. Hybrid techniques
integrating these two different approaches have also
been proposed. The CB method has been developed
basing on the textual filtering model described in
(Oard, 1997). Generally, in CB systems, the user
profile is inferred automatically from documents'
content that the user has seen and rated. The profiles
and domain documents are then used as input of a
classification algorithm. The documents which are
similar (in content) to the user profile are considered
interesting and are recommended to the user.
CF systems (Goldberg, 1992) are an alternative
to CB systems. The basic idea is to go beyond the
experience of an individual user profile and instead
to use the experiences of a population or community
of users. These systems are designed with the
assumption that a good way to find interesting
content is to find people with similar tastes and to
659
Picot-Clémente R., Cruz C. and Nicolle C..
AN ONTOLOGY-BASED APPROACH TO PROVIDE PERSONALIZED RECOMMENDATIONS USING A STOCHASTIC ALGORITHM.
DOI: 10.5220/0003478506590665
In Proceedings of the 7th International Conference on Web Information Systems and Technologies (SWAT-2011), pages 659-665
ISBN: 978-989-8425-51-5
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

propose items they like. Typically, each user is
associated to a set of nearest-neighbour users,
comparing profiles’ information. With this method,
objects are recommended basing on similarities of
users rather than the similarities of objects.
Both CF and CB systems have strengths and
weaknesses. In CF systems, the main problem is that
the new objects with no rate cannot be
recommended. CB systems suffer from deficiencies
in the way of selecting items for recommendation.
Indeed, the objects are recommended if the user has
seen and liked similar objects in the past.
Consequently, a variety of hybrid systems have
recently been developed:
Some use other users’ ratings as additional
features in a CB system.
Some use CB methods for the creation of bots
producing additional data for “pseudo-users”.
These data are combined with real users’ data
using CF methods.
Others use CB predictions to “fill out” the
probable user-items’ ratings in order to allow
CF techniques to produce more accurate
recommendations.
In this paper, we propose a content-based
recommender system. Its architecture is inspired
from adaptive hypermedia researches. Unlike most
recommender systems which provide a list of items
to users, we suggest to generate combinations of
items corresponding to them. A first part will
explain what an adaptive hypermedia system is.
Then, our proposition is presented. The final part
shows a application to tourism domain.
2 ADAPTIVE HYPERMEDIA
SYSTEMS
The research domain of adaptive hypermedia has
been very prolific these 10 last years. Some systems
(Cristea and Mooij, 2003) (Henze, 2000) have been
developed, giving principally solutions for e-
Learning which is considered as the first application
domain. Each system brings its own architecture and
methods. Moreover, few attempts have been made to
define reference models (De Bra et al., 1999)
(Hendrix and Cristea, 2008) but without success
because of being not enough generic to take account
of the new trends and innovations. Nevertheless,
most of the systems and models are based on a set of
layers, also called models, which separate clearly the
different tasks. Then, we can see that there are at
least three models in common, necessary and
sufficient to achieve adaptive hypermedia systems
according Brusilovsky (Brusilovsky, 2001). It needs
to primarily be a hypermedia system based on a
domain. The domain model is a representation of the
knowledge on a given subject the creator wants to
deliver. It describes how the domain is organized
and interconnected. The second model is called a
user model which is a representation of the user
within the system. It models all user information
which may require the system to provide an
adaptation. The last model is the adaptation model.
It performs all the adaptive algorithms based on
other models to provide an adaptation to the user.
Beyond the use of domain, user and adaptation
models, the trend is to use additional models like
presentation, goals, context or other models. This
allows to better identify the different performed
tasks and to facilitate the construction of adaptive
hypermedia systems. Nevertheless, there is no
generic model integrating them for the moment.
Methods to model domain/user (adaptation
principles are also described):
Keywords vectors: A popular method to
represent domain and user model used by a lot
of systems is the keywords vectors space
representation (Liberman, 1995) (Kamba et
al., 2007). This method considers that each
document and user profile is described by a
set of weighted keywords vectors. At the
adaptation model, the weights are used to
calculate the similarity degree between two
vectors and then to propose relevant document
to the user. The keywords representation is
popular because of its simplicity and its
efficiency. Nevertheless, the main drawback is
that a lot of information is lost during the
representation phase.
Semantic networks: In semantic networks,
each node represents a concept. Minio and
Tasso (Minio and Tasso, 1996) present a
semantic networks based approach where each
node contains a particular word of a corpus
and arcs are created following the co-
occurrences of the words from connected
nodes into the documents. Each domain
document is represented like that. In simple
systems using only one semantic network to
model the user, each node contains only one
keyword. The keywords are extracted from
pages which the user gives its taste. Then,
they are treated to keep only the most relevant
ones and are weighted in order to remove
those with a weight lesser than a predefined
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
660

threshold. The selected keywords are then
added to the semantic network where each
node represents a keyword and each arc their
co-occurrence into the documents. With this
method, it is possible to evaluate the relevance
of a document compared to the user profile.
Indeed, it suffices to construct a semantic
network of a document and compare it to the
semantic network of the user to classify it to
interesting, uninteresting or indifferent
documents.
Ontology: This approach is similar to the
semantic network approach in the sense that
both are represented using nodes and relations
between nodes. Nevertheless, in concepts
based profiles, nodes represent abstract
subjects and not word or set of words.
Moreover, links are not only co-occurrence
relations between words, they have several
significations. The use of ontology can keep a
maximum of information. In QuickStep
(Middleton at al., 2002), the ontology is used
for the research domain and has been created
by domain experts. The ontology concepts are
represented as vectors of article examples. The
users’ papers from their publication list are
modelled as characteristic’ vectors and are
linked to concepts using the nearest neighbour
algorithm. These concepts are then used to
form a user profile. Each concept is weighted
by the number of papers linked to it.
Recommendations are then made from the
correlations between the current interests of
the user to topics and papers that are related to
these topics. In (Cantador and Castells, 2006)
and (Sieg et al., 2007), a predefined ontology
is used to model the domain. User profiles are
represented with a set of weighted concepts
where weight represents the user’s interest for
a concept. Its interests are determined by
analyzing its behaviour.
Three types of adaptation have been highlighted
in the researches on adaptive hypermedia systems:
content, navigation and presentation adaptation. The
content adaptation consists in hiding/showing or
highlighting some information. The adaptation
model makes the decision of which content has to be
adapted and how to display it. The navigation
adaptation consists in modifying the link structure
suggesting links or forcing the user to follow a
destination. There is URLs’ adaptation or
destinations adaptation. In the first, the adaptation
model provides destination links to the presentation
model; these links are displayed at the page
generation. Whereas, in the second one, the
adaptation model provides links without fixed
destination to the presentation model; the destination
is decided by the adaptation model when the link is
accessed by the user. The presentation adaptation
consists in insisting (or not) on the content parts or
on the links. It consists also in adapting the
preferences setting to the device or the page. The
adaptation model process makes the decision of
which content or links to insist in following the
presentation context.
Even if recommender systems are often
differentiated from adaptive hypermedia systems, a
lot of similarity between these two types of systems
can be highlighted. Indeed, the recommender
systems provide recommendations using different
algorithms, as it is done in the adaptation model.
Moreover, we can see that they model also users’
tastes and domain’s items, as it is done in adaptive
hypermedia systems with the user model and domain
model. Nevertheless, recommender systems perform
only adaptation of the content whereas adaptive
hypermedia systems realize two more adaptation
types. Following these observations, a
recommendation system appears to be a constrained
adaptive hypermedia system. Thus, it seems clear
that recommender systems can be defined as a
subset of adaptive hypermedia systems, whatever its
type (CB or CF).
The use of an adaptive hypermedia architecture
for the creation of recommender systems is
interesting because we can clearly define the tasks
associated with each part of the application, and it
gives the opportunity to evolve the system adding
modules and/or other types of adaptation without
difficult modifications of parts already implemented.
For instance, a CB recommender system could be
improved with features of CF systems, adding a
group model where clusters of users can be defined.
For the creation of our CB recommender system,
we base on adaptive hypermedia architecture.
Beyond the use of the three main ones (domain, user
and adaptation model), a goal model has been added.
It allows the modelling of users’ goals. A description
of the proposition is explained in the following part.
3 PROPOSITION
This section describes the architecture of the
proposed recommender system based on an adaptive
hypermedia architecture. This system aims to
generate a combination of necessary items for the
purpose of the application according the items types
AN ONTOLOGY-BASED APPROACH TO PROVIDE PERSONALIZED RECOMMENDATIONS USING A
STOCHASTIC ALGORITHM
661
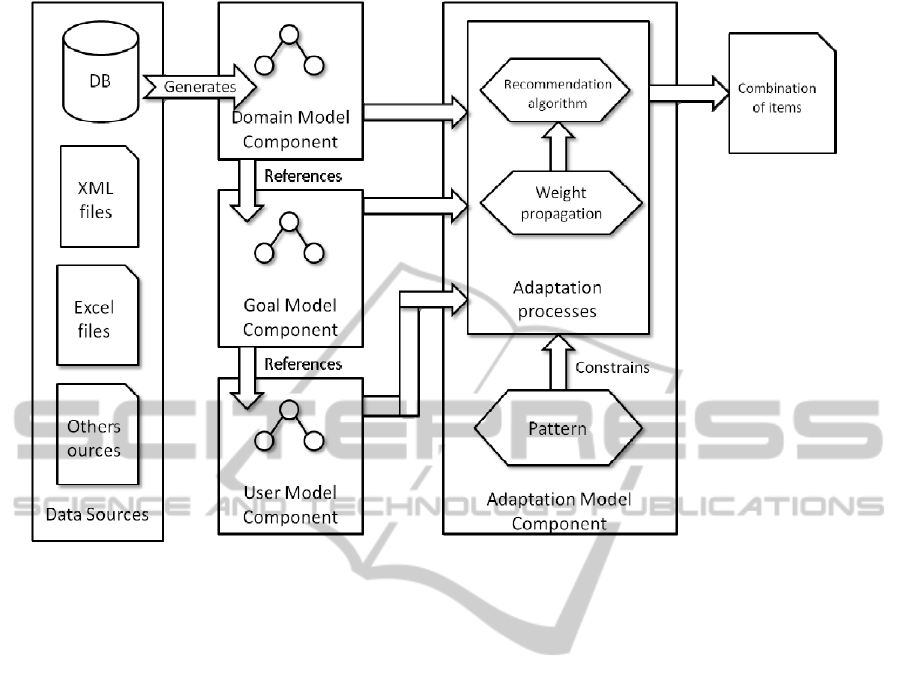
Figure 1: The components of the architecture.
and constraints (semantics, localization, ...). An item
is a piece of information provided by the
information system transformed into the
recommender system. The architecture of the system
is composed of four components: The domain model
component, the goal model component, the user
model component, the adaptation model component
(Figure. 1).
3.1 The Domain Model Component
To fully express the knowledge of a domain, the
domain model component uses an OWL ontology.
An item will be an individual of this domain
ontology which is generated from data provided by
data sources like relational databases, XML
documents, Excel files, etc. Actually, the ontology is
enriched by the schema of the data sources and
populated by the data of the sources. This
construction is carried out using expert’s knowledge.
Three steps have been identified to achieve this goal.
The first step consists in using the database as a
starting point for the basis of the domain ontology.
The second step consists in enriching this basic
ontology by domain experts adding new axioms
usually not present in the data source. Usually, this
process comprises the addition of semantic links
between concepts which are often unqualified in the
relational schema. Moreover, the hierarchical
structure of concepts is refined with the help of
professionals. The last step consists in populating
the ontology with instances selected from the data
source.
The ontology creation process is partly manual
and automatic. The first step and the second step
require the investment of domain experts. The third
step is automatic and, fortunately, it is the only one
that is brought to be repeated regularly to update the
data of the ontology. The structural part of the
ontology which is set up by the first two steps will
not often be changed.
3.2 The Goal Model Component
Our objective is to use the domain ontology within a
specific user-centered application. In this context, an
adjustment of the ontology must be made to adapt it
to the usage and, especially, to the user modeling.
Hence, the domain ontology is enriched with goal
concepts. These concepts define the user possible
objectives into the system.
A goal concept is composed of first order logic
rules. A rule makes a link between individuals of the
ontology and the related goal. Each rule has a weight
representing the importance of it within a goal
concept.
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
662

For example, we could have the goal
"culturalActivity " defined by the weighted rules:
- (Cinema(x) ^ haveCulturalAspect(x,y) ->
culturalActivity (x), 5)
- (Theater(x) ^ haveCulturalAspect(x,y) ->
culturalActivity (x), 9)
- (Museum(x) ^ haveCulturalAspect(x,y) ->
culturalActivity (x), 10)
The set of the goal concepts is called the goal
model.
3.3 The User Model Component
From there, we have an ontology oriented to a
particular application by a set of goal concepts. We
have now to model the user within the system in
order to offer an adapted environment. The user is
modeled in two distinct parts. The first one concerns
the characteristics that are independent of the
domain, also called the static part. This may be the
age, size, gender, etc. They are simply modeled
using <attribute, value> vectors. The second part
represents the user features directly related to the
domain. It consists of goal concepts, representing the
goals of the user with weights which allow the
position of a discriminating index in terms of
preferences. This part is said dynamic and is an
overlay on the domain model. Together, these two
parts represent the user model and the instantiation
of this model represents a profile of a user.
For instance, a user profile can be: User1 (<age,
20>, <gender, male>, …) (<physicalActivity,5>,
<culturalActivity,1>, …)
3.4 The Adaption Model Component
This component is responsible to provide a
combination of items regarding the domain
ontology. This set of item is adapted to the user
profile which is an instance of the user model. In
order to enclose the solution to provide, a pattern of
combination is defined. The pattern constrains the
elements to be returned to the user by filtering to the
type, the number, the item order or the
geolocalisation for example.
Using the goals weights into the user profile and the
weighted connections between the individuals and
goal concepts, the weights are combined linearly to
be propagated to the individuals.
For instance, if a goal is weighted of 3 in a
profile and is constituted of two rules with the
respective weights 5 and 1, then the individuals
linked to the goal by these rules receive the
respective weights
)53(15
×
and
)13(3 ×
which can
be cumulated if individuals are associated to the two
goals at once.
This weight propagation into the ontology is not
done with the whole ontology. Indeed, it is not
necessary to weight individuals which cannot be
involved in the final solution. Only individuals that
instantiate a concept from the domain model
specified into the pattern of combination are
weighted. In other words, the individuals which the
type (the concept) is not reflected in the pattern are
not weighted. Thus, we have a subset of weighted
individuals from the domain ontology. We now wish
to find a "good" combination of these individuals
depending on the pattern. The notion of quality of a
combination is defined by one or more relevance
functions that will take into account the individual
weights and other attributes (geographic coordinates,
volume, etc.).
For example, we could have this pattern <
(Activity, Activity, Activity, Activity), 1km > which
constrains the combination to have 4 activities in a
neighborhood of 1km.
The purpose consists then in optimizing the
relevance function, in order to find the optimal
solution. Searching an optimal solution means
browsing the set of possible solutions and returns the
best one. However, the number of possible solutions
grows very rapidly according to the number of
individuals, and it becomes quickly impossible to
find the best solution in a reasonable time. Thus, to
resolve this problem, a stochastic algorithm is used.
This latter takes as input all the weighted individuals
and the pattern of combination to provide. This
algorithm will return “good” items approaching the
best one. However, the results will depend on the
type of the used stochastic algorithm which optimize
the time for real-time application. Finally, the user is
offered a combination of items supposed to
correspond to their profile. The adaptation model is
composed of all these processes.
4 TOURISM APPLICATION
This modeling is being applied to the tourism
domain in the region of Côte-d’Or in France for the
company Côte-d’Or Tourisme. The aim is to create a
tourism application that should provide a
combination of tourism products from Côte-d’Or
according to a user profile. At the beginning, a
domain ontology has been created with all the
concepts and the individuals related to the
application domain. This ontology was supplied
from a database composed of more than 4000
AN ONTOLOGY-BASED APPROACH TO PROVIDE PERSONALIZED RECOMMENDATIONS USING A
STOCHASTIC ALGORITHM
663

tourism products. Then, a goal model has been
defined using goal concepts like “Week end”,
“Going out with friends”, “with a baby”, etc. This
knowledge was generated from the specialists of the
domain represented by people working for the
company Côte-d’Or Tourisme.
An empirical pattern is defined to determine
what kind of combination the adaptation model has
to return. The relevance function giving the
relevance of a combination is based on the interest
weights and the coordinates of the tourism products,
because it is not relevant to propose an activity in
the morning and a restaurant for lunch with a
distance of more than 50 kilometers. The traveling
time required to reach the restaurant after the
activity ending is inappropriate.
A variance threshold needs to be set in order to
define the maximum preferred variance between the
individuals coordinates. This variance characterized
the value dispersion regarding the average, in this
case the threshold. Subsets in this pattern are
possible. For instance, we can define a pattern like
“Accommodation, Restaurant1, Activity,
Restaurant2” in which “Hotel and Restaurant1” are
the first subset, and “Activity and Restaurant2” the
second subset. In addition, a variance threshold is
defined for each one. Thereby, the system can use
more complex patterns for the combinations.
The variance of a combination is defined as
follow:
2
22
11 1
00 0
11 1
var( )
NN N
ix ix iy iy
ii i
CCCCC
NN N
−− −
== =
⎛⎞
⎛⎞⎛⎞
=−+−
⎜⎟
⎜⎟⎜⎟
⎜⎟
⎝⎠⎝⎠
⎝⎠
∑∑ ∑
(1)
where C is a combination, N the number of
elements into the combination, C
i
the i
th
element of
the combination, and C
ix
and C
iy
the x and y
coordinates of the i
th
element.
The weight of a combination is defined as
follow:
∑
−
=
=
1
0
1
)(
N
i
iweight
C
N
Cweight
(2)
where C
iweight
is the weight of the i
th
element.
Using the variance and the weight function, the
relevance of a combination is:
1
0
var( )
1var()
()
()
Cj
L
Cj
j
CG
G
C
Energy C E E
weight C Threshold Threshold
−
=
⎛⎞
⎛⎞
⎛⎞
⎜⎟
⎜⎟
=× +
⎜⎟
⎜⎟
⎜⎟
⎝⎠
⎝⎠
⎝⎠
∑
(3)
where E(X) is the integer part of X, Threshold
C
is the variance threshold of the geographic
coordinates for the combination C,
Cj
G
Threshold
is
the variance threshold of the geographic coordinates
for the j
th
subset of C, and L the number avec
subsets.
Then, a stochastic algorithm is performed. We
use a simulated annealing algorithm (Kirkpatrick et
al., 1983) which try to optimise the relevance
function, so that it can provide a combination of
tourism products matching the user interests and
with close coordinates.
5 BENCHMARK
Some tests of the algorithm for the generation of
combinations have been done on a set of four
thousand tourism products. In these tests, the
average time required for the generation of a
combination of six products was around 3 seconds.
But, this time depends on the different parameters
(temperature decrease rate, the number of iteration
per level of temperature) necessary to perform the
simulated annealing algorithm. For example, the
faster is the temperature decrease and the lower is
the number of iterations, the faster is the generation,
but the worse is the resulting combination. In any
case, this time is better than the time required to find
the best combination by browsing all the
possibilities. For example, in our test, finding the
best combination needed around 3 hours against 3
seconds using the simulated annealing algorithm.
These times are only given to have orders of
magnitude, more tests need to be performed to have
exacts results and to prove the interest of our
proposition. Nevertheless, given these few results,
the algorithm seems to give a relevant solution
according a predefined relevance function with a
lesser cost (in terms of time) than calculating the
optimal solution.
6 CONCLUSIONS
This paper presents a new content based
recommender system. The idea consists in taking
advantages of the semantic Web technologies, the
properties of adaptive hypermedia systems, and in
combining them with combinatory algorithms in
order to provide recommendations, adapted
combinations of items. The simulated annealing
algorithm is used in order to solve the problem of
the polynomial time search required to generate a
combination of tourism products. It gives a solution
which approaches the best solution in a short time.
The few results seem to be good considering the
time required to obtain them and comparing to the
best solutions. Nevertheless, for the future, we need
WEBIST 2011 - 7th International Conference on Web Information Systems and Technologies
664

to make more tests and benchmarks to quantify more
precisely the relevance of our system. Moreover, we
could improve the quality of the propositions by
taking into account some group of users as it is done
in collaborative filtering recommender systems. It is
possible by adding a group model into the
architecture. Thus, the recommender system would
become a hybrid recommender system.
ACKNOWLEDGEMENTS
This research is done in collaboration with Côte-
d’Or Tourisme, a company which aims to promote
tourism in its region.
REFERENCES
Brusilovsky, P. 2001. Adaptive hypermedia, User
modeling and user-adapted interaction, 2001 –
Springer.
Cantador, I. and Castells, P. 2006. A multilayered
ontology-based user profiles and semantic social
networks for recommender systems. In 2
nd
International Workshop on Web Personalisation
Recommender Systems and Intelligent User Interfaces
in Conjunction with 7th International Conference in
Adaptive Hypermedia.
Sieg, A., Mobasher, B. and Burke, R. 2007. Leaning
Ontology-Based User Profiles: A Semantic Approach
to Personalized Web Search. In IEEE Intelligent
Informatics Bulletin, vol.8, no. 1.
Cristea, A. and De Mooij, A. 2003. LAOS: Layered
WWW AHS authoring model and their corresponding
algebraic operators, Proceedings of World Wide Web
International Conference, New York, NY: ACM.
De Bra, P., Houben, G-J. and Wu, H. 1999. AHAM: A
dexter-based reference model for adaptive
hypermedia, in Hypertext’99: Proceedings of the 10th
ACMConference on Hypertext and Hypermedia:
Returning to our Diverse Roots, New York, pp.147-
156.
Goldberg, D., Nichols, D., Oki, B. M. and Terry, D. 1992.
Using collaborative filtering to weave an information
tapestry. Communications of the Association for
Computing Machinery, 35(12):61–70.
Hendrix, M. and Cristea, 2008. A. Meta-levels of
adaptation in education, Proceedings of 11th IASTED
International Conference on Computers and Advanced
Technology in Education, V. Uskov (Ed.), IASTED.
Henze, N. 2000. Adaptive hyperbooks: Adaptation for
project-based learning resources. PhD Dissertation,
University of Hannover.
Jamali, M. and Ester, M. 2009. TrustWalker : a Random
Walk Model for Combining Trust-Based and Item-
Based Recommendation. In KDD ’09 : Proceedings of
the 15th ACM SIGKDD international conference on
Knowledge discovery and data mining, New York,
NY, USA, pp. 397–406. ACM.
Kamba, T., Sakagami, H. and Koseki, Y. 2007.
Antagonomy: A Personalized Newspaper on the
World Wide Web, Int’l J. Human-Computer Studies.
Kirkpatrick, S., Gelatt C. D. and Vecchi, M. P. 1983
Optimization by simulated annealing, Science 220
(4598), 671-680.
Liberman, H. 1995. Letizia: An Agent that Assists Web
Browsing. In Proceedings of the Fourteenth
International Joint Conference on Artificial
Intelligence (IJCAI-95), pp 924--929, Morgan
Kaufmann publishers Inc, Montreal, Canada.
Middleton, S., Alani, H., Shadbolt, N. and De Roure, D.
2002. Exploiting synergy between ontologies and
recommender systems. In Proceedings of the WWW
international workshop on the semantic web, v. 55 of
CEUR workshop proceedings, Maui, HW, USA.
Minio, M. and Tasso, C. 1996. User Modeling for
Information Filtering on INTERNET Services:
Exploiting an Extended Version of the UMT Shell. In
UM96 Workshop on User Modeling for Information
Filtering on the WWW; Kailua-Kona, Hawaii, January
2-5.
Mcsherry, D. 2005. Explanation in recommender systems.
Artificial Intelligence Review, 24(2):179 – 197, 2005.
Oard, D. 1997. The State of the Art in Text Filtering User
Modeling and User Adapted Interaction, 7(3)141-178.
Tintarev, N. and Masthoff, J. 2007. A survey of
explanations in recommender systems,
ICDE'07
Workshop on Recommender System.
Zhang, Y. Y. and Jiao, J. X. 2007. An associative
classification-based recommendation system for
personalization in B2C e-commerce application,
Expert Systems with Applications 33 (1) 357–367.
AN ONTOLOGY-BASED APPROACH TO PROVIDE PERSONALIZED RECOMMENDATIONS USING A
STOCHASTIC ALGORITHM
665
