
COST-OPTIMAL STRONG PLANNING
IN NON-DETERMINISTIC DOMAINS
Giuseppe Della Penna, Fabio Mercorio
Dept. of Computer Science, University of L’Aquila, L’Aquila, Italy
Benedetto Intrigila
Dept. of Mathematics, University of Rome Tor Vergata, Rome, Italy
Daniele Magazzeni
Dept. of Sciences, University of Chieti-Pescara, Chieti and Pescara, Italy
Enrico Tronci
Dept. of Computer Science, University of Rome La Sapienza, Rome, Italy
Keywords:
Non-deterministic systems, Strong planning, Optimal planning.
Abstract:
Many real world domains present a non-deterministic behaviour, mostly due to unpredictable environmental
conditions. In this context, strong planning, i.e., finding a plan which is guaranteed to achieve the goal regard-
less of non-determinism, is a significant research challenge for both the planning and the control communities.
In particular, the problem of cost-optimal strong planning has not been addressed so far. In this paper we pro-
vide a formal description of the cost-optimal strong planning problem in non-deterministic finite state systems,
present an algorithm to solve it with good complexity bounds and formally prove the correctness and com-
pleteness of the proposed algorithm. Furthermore, we present experimental results showing the effectiveness
of the proposed approach on a meaningful case study.
1 INTRODUCTION
In recent years, a mutual interest between control the-
ory and AI planning communities has emerged, show-
ing that planning and control are closely related areas.
The use of sophisticated controllers as well as intel-
ligent planning strategies has become very common
in robotics, manufacturing processes, critical systems
and, in general, in hardware/software embedded sys-
tems (see, e.g., (Chesi and Hung, 2007)).
In particular, efforts made to deal with planning
in non-deterministic domains could be very helpful to
solve control problems for real-world appliances. In-
deed, many processes take place in an environment
that may have variable and unpredictable influences
on the action outcomes, which need to be taken into
account to design a correct and efficient control sys-
tem. In this context, strong planning, that is finding
automatically a plan which is guaranteed to achieve
the goal regardless of non-determinism, is a very in-
teresting research challenge.
To this aim, planning based on Markov Decision
Processes (MDP) has been proved very effective (see,
e.g., (Boutilier et al., 1999; Bonet and Geffner, 2005;
Yoon et al., 2002)), and, more recently, a variety
of techniques have been proposed to solve continu-
ous MDPs (see, e.g., (Meuleau et al., 2009; Mausam
and Weld, 2008; Mausam et al., 2007)). However,
MDP-based approaches deal with probabilistic distri-
butions taking into account the stochastic outcomes
of actions. Therefore, whether a solution provided by
MDP planning algorithms is strong depends on prob-
ability and cost distribution.
On the other hand, planning under partial observ-
ability works on a setting where only a subset of vari-
ables are observable, and looks for conditional plans
(see, e.g., (Bertoli et al., 2001; Bertoli et al., 2006;
Huang et al., 2007)), whilst in conformant planning
(Bonet and Geffner, 2000; Albore et al., 2010) no ob-
servation is available.
In this paper we focus on non-deterministic do-
mains with full observability. In our setting, as typi-
cally in the case of dynamic systems, the size of the
graph defining the dynamics of the system is exponen-
56
Della Penna G., Mercorio F., Intrigila B., Magazzeni D. and Tronci E..
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS.
DOI: 10.5220/0003448200560066
In Proceedings of the 8th International Conference on Informatics in Control, Automation and Robotics (ICINCO-2011), pages 56-66
ISBN: 978-989-8425-74-4
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

tial (state explosion) in the size of the input (i.e., the
code which implicitly describes the graph by means
of a next state function). As a result, classical algo-
rithms for explicit graphs cannot be used, and instead
suitable symbolic (e.g., (Burch et al., 1992)) or ex-
plicit (e.g., (Della Penna et al., 2004)) algorithms are
used to counteract state explosion. This is also the
typical situation for model checking problems.
Indeed, a key contribution to this field is described
in (Cimatti et al., 1998), where the authors present an
algorithm to find strong plans which has been imple-
mented in MBP, a planner based on symbolic model
checking. MBP produces a universal plan (Schop-
pers, 1987) which provides optimal solutions with
respect to the plan length (i.e., the worst execution
among the possible non-deterministic plan executions
is of minimum length). Moreover, the use of Ordered
Binary Decision Diagrams (OBDDs) together with
symbolic model checking techniques allows a com-
pact encoding of the state space and very efficient set
theoretical operations.
Our work is strictly based on (Cimatti et al., 1998),
however, there are the following main differences: (i)
we consider a cost function and present a novel tech-
nique to look for cost-optimal strong plans while pre-
serving a good complexity bound, and (ii) we use an
explicit approach rather than a symbolic one, so ex-
tending the class of problems on which strong plan-
ning can be applied to hybrid and/or nonlinear con-
tinuous domains, which are actually very common in
the practice. In fact, since representing addition and
comparison with OBDDs requires opposite variable
orderings and since this kind of problemsinvolveboth
such operations, OBDDs in our context tend to have
size exponential in the input size. On the other hand,
using an explicit approach allows us to expand “on
demand” the transition relation, generating and repre-
senting only the reachable states.
Note that the algorithm in (Cimatti et al., 1998)
could be adapted to support costs and devise cost-
optimal solutions only by ”unary encoding” the
weights, i.e., by replacing a transition of weight k with
k contiguous deterministic transitions. In this case,
however, its complexity, in the worst case, would be
exponentially higher than the one of the algorithm
presented in this paper.
Our synthesis problem could also be cast as a
strategy synthesis problem for a multistage game with
two players moving simultaneously (see, e.g., (Fu-
denberg and Tirole, 1991)), where the first player is
the controller, the second is the disturbance (caus-
ing the non-deterministic behaviours), and the game
rules are given by the plant dynamics. In this set-
ting, our control strategy could be seen as a minmax
strategy for the controller player. That is, in each
game state, the controller chooses the action that min-
imises the maximum cost (to reach the goal) that the
disturbance, with its (simultaneous) choice, may in-
flict to it. Such a game theoretic casting, however,
would be of little help from a computational point of
view, since in our setting the normal form of the game
would be intractable even for small systems. Indeed,
if the game has |S| states and, in each state, the con-
troller and the disturbance have at most |A | and |D|
actions available, respectively, then the game would
be represented by a graph with |S| nodes, each hav-
ing |A ||D| outgoing edges. Thus, even considering
simple plants, we would have very large graphs: for
example, in the case study presented in Section 4, we
have that |S| = 5 · 10
7
, |A | = 25 and |D| = 17, thus
representing explicitly such a problem would yield a
graph with 5· 10
7
nodes and more than 2·10
10
edges.
To the best of our knowledge, no tool based on game
theory techniques can handle games of such size.
The situation is exactly analogous to that for
model checking based analysis of Markov chains (e.g,
see (Kwiatkowska et al., 2004), (Della Penna et al.,
2006)). Of course, in principle, stationary distribu-
tions for Markovchains can be computed using classi-
cal numerical techniques (e.g., see (Behrends, 2000))
for Markov chains analysis. However, for dynamic
systems, our setting here, the number of states (eas-
ily beyond 10
10
) of the Markov chains to be analysed
rules out matrix based methods.
Finally, casting our problem as a Mixed Integer
Linear Programming (MILP) problem would be pos-
sible but, again, it would generate a MILP of size ex-
ponential in the input. Thus, to the best of our knowl-
edge, this is the first approach to cost-optimal strong
planning and no better solutions for this problem have
been devised so far, even in other computer science
fields.
In this paper we make the following contribu-
tions: we provide a formal description of cost-optimal
strong planning in non-deterministic finite state sys-
tems (NDFSS), then we present an algorithm for cost-
optimal strong planning on NDFSS, proving its cor-
rectness and completeness, and finally we show some
meaningful experimental results.
The paper is structured as follows. Section 2 in-
troduces the cost-optimal strong planning problem
together with all the required background notions.
Then, Section 3 describes an algorithm to solve this
problem and proves its correctness. Section 4 presents
a non-deterministic planning problem and shows the
solution obtained through our algorithm. Finally, Sec-
tion 5 outlines some concluding remarks.
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS
57

2 STATEMENT OF THE
PROBLEM
In this section we first introduce some background
notions about non-deterministic systems and non-
deterministic planning, then we define the concept of
cost-optimal strong plan and the corresponding plan-
ning problem.
2.1 Non-deterministic Finite State
Systems
We now introduce the formal definition of the non-
deterministic systems we are interested in.
Definition 1. A Non-Deterministic Finite State Sys-
tem (NDFSS) S is a 4-tuple (S,s
0
,A ,F), where: S
is a finite set of states, s
0
∈ S is the initial state, A
is a finite set of actions and F : S × A → 2
S
is the
non-deterministic transition function, that is F(s,a)
returns the set of states that can be reached from state
s via action a.
It is worth noting that we are restricting our at-
tention to NDFSS having a single initial state s
0
only
for the sake of simplicity. Indeed, if we are given a
NDFSS S
′
with a set of initial states I ⊆ S, we may
simply turn it into an equivalent NDFSS by adding a
dummy initial state connected to all the states in I by a
deterministic transition with fixed cost. The algorithm
given in Section 3 could then be trivially adapted to
return the set of cost-optimal strong plans for I.
The non-deterministic transition function implic-
itly defines a set of transitions between states which,
in turn, give raise to a set of trajectories as specified
in the following definitions.
Definition 2. Let S = {S,s
0
,A ,F} be an NDFSS. A
non-deterministic transition τ is a triple of the form
(s,a, F(s,a)) where s ∈ S and a ∈ A . A determin-
istic transition (or simply a transition) τ is a triple
of the form (s,a,s
′
) where s,s
′
∈ S, a ∈ A and s
′
∈
F(s,a). We say that τ = (s,a,s
′
) is in (s,a,F(s,a))
if s
′
∈ F(s,a). We denote with S
τ
the set of all the
transitions in S .
Definition 3. A trajectory π from a state s to a state s
′
is a sequence of transitions τ
0
,. .. ,τ
n
such that τ
0
has
the form (s,a,s
1
), for some s
1
and some a, τ
n
has the
form (s
n
,a
′
,s
′
), for some s
n
and some a
′
and for every
i = 0, ...,n−1 if τ
i
= (s
i
,a
i
,s
i+1
), for some s
i
,a
i
,s
i+1
,
then τ
i+1
= (s
i+1
,a
i+1
,s
i+2
), for some s
i+2
,a
i+1
. We
denote with |π| the length of π, given by the number
of transitions in the trajectory.
As usual we stipulate that the empty set of transi-
tions is a trajectory from any state to itself.
We now need to specify several notions concern-
ing non-deterministic transitions and trajectories.
Definition 4. Let S = {S,s
0
,A ,F} be an NDFSS
and Π be a set of non-deterministic transitions. We
say that a transition τ = (s,a,s
′
) is extracted from Π
if (s,a, F(s,a)) ∈ Π and (s,a,s
′
) is in (s,a,F(s,a)).
Similarly, we say that a trajectory π = τ
0
,. .. ,τ
n
is
extracted from Π if ∀i = 0...n,τ
i
= (s
i
,a
i
,s
′
i
) is in
(s
i
,a
i
,F(s
i
,a
i
)) and (s
i
,a
i
,F(s
i
,a
i
)) ∈ Π. Finally, we
say that a state s is in Π if there exists a transition
τ = (s,a,s
′
) extracted from Π.
Since we are interested in cost-optimal solutions,
we extend our setting with a cost function.
Definition 5. Let S = {S,s
0
,A ,F} be an NDFSS. A
cost function (also called weight function) for S is
a function W : S
τ
→ R
+
that assigns a cost to each
transition in S . Using the cost function for transi-
tions, we define the cost of the non-deterministic tran-
sition (s,a,F(s, a)), denoted by W (s,a), as follows:
W (s,a) = max
s
′
∈F(s,a)
W ((s,a, s
′
)).
It is worth noting that, for the sake of general-
ity, the definition of the cost function above allows
the transition cost to depend on both the correspond-
ing action and the source state. However, usually the
transition costs are bound to the corresponding action
only.
2.2 Cost-optimal Strong Plan
Now let S be a given NDFSS. In order to define the
cost-optimal strong planning problem for such a kind
of system, we assume that a non-empty set of goal
states G ⊂ S has been specified.
Definition 6. Let S = {S,s
0
,A ,F} be an NDFSS.
Then a Cost-Optimal Strong Planning Problem
(COSPP) is a triple P = (S ,W ,G) where G is the
set of the goal states and W : S
τ
→ R
+
is the cost
function associated to S .
In this setting, we aim to find a strong plan from
the initial state s
0
to G, that is a sequence of actions
that, starting from s
0
, leads the system to the goal
states, regardless of the non-deterministic outcome of
each action. Before formally describe such a solution,
we need the following definitions.
Definition 7. Let P = {{S,s
0
,A ,F},W ,G} be a
COSPP and s ∈ S. A deterministic plan p from s to
a goal g ∈ G is a trajectory π such that:
• either s ∈ G and |π| = 0;
• or π = τ
0
,τ
1
,. .. ,τ
n
, with τ
0
= (s,a, s
1
) and π
′
=
τ
1
,. .. ,τ
n
is a deterministic plan from s
1
to g.
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
58

Now we can formally define the cost-optimal
strong solutions we are interested in finding.
Definition 8. Let P = {{S,s
0
,A ,F},W ,G} be a
COSPP. Let s be a state in S. A strong plan from s
to G is a set P of non-deterministic transitions such
that either s ∈ G and P =
/
0 or s /∈ G and P satisfies
the following conditions:
1. there exists a natural number n
0
such that ev-
ery trajectory π that can be extracted from P has
length |π| ≤ n
0
;
2. every trajectory π starting from s which can be
extracted from P, can be extended to a determin-
istic plan π
′
from s to a goal s
g
∈ G such that π
′
is
extracted from P;
3. for every state s
′
such that s
′
/∈ G and s
′
is in P
there exists a trajectory π, extracted from P, start-
ing from s and ending in s
′
;
4. for every state s
′
such that s
′
/∈ G and s
′
is in P,
there exists exactly one non-deterministic transi-
tion in P of the form (s
′
,a, F(s
′
,a)), for some a ∈
A . We denote with P(s
′
) such non-deterministic
transition.
We have the following characterisation of plans.
Proposition 1. Let P = {S ,W ,G} be a COSPP.
P is a strong plan from s to G iff P is a set of
non-deterministic transitions such that either s ∈ G
and P =
/
0 or s /∈ G and there exists a unique
non-deterministic transition in P of the form τ =
(s,a, F(s,a)), for some a ∈ A , such that:
• either F(s,a) ⊆ G;
• or P\ {(s,a,F(s,a))} is the union of strong plans
P
i
from every state s
i
in F(s,a) to G.
Proof 1. Assume first that P is a strong plan from
s to G. If P is not empty, then there exists a unique
non-deterministic transition τ = (s,a,F(s,a)) ∈ P, for
some a. Let s
i
be an element of F(s,a). We define P
i
as
the set of non-deterministic transitions in P such that
P
i
contains some transitions of a deterministic plan
from s
i
.
Now observe that any sequence starting from s
i
can be completed in P to a deterministic plan with-
out using the node s. Indeed, no deterministic plan
extracted from P can return to the node s, since oth-
erwise there would be a cycle, contradicting the re-
quirement that every deterministic sequence in P is
bounded. It follows that P
i
is a subset of P\ {τ} and
is a strong plan from s
i
.
Moreover, let s
′
be any node in P\{τ}. Then there
exists a trajectory π from s to s
′
. By the uniqueness of
τ, the first transition of π is in τ and therefore has the
form (s,a,s
i
) for some s
i
, it follows that s
′
is in P
i
, and
that P\ {τ} =
S
s
i
∈F(s,a)
P
i
.
The other direction is easy and left to the reader.
By Proposition 1 we can define the cost of a plan
as follows:
Definition 9. The cost of a strong plan P from s to G,
denoted by W (P), is defined by recursion as follows:
• if P is empty then W (P) = 0;
• if P is composed only of the non-deterministic
transition (s,a,F(s,a)), for some a, then W (P) =
W (s,a);
• if P is composed of the non-deterministic tran-
sition (s,a,F(s,a)), for some a, and of plans
P
i
from every node s
i
in F(s,a) then W (P) =
max
s
i
∈F(s,a)
(W ((s,a,s
i
)) + W (P
i
)).
It is easy to see that the cost of a plan P is the
maximum cost of a deterministic plan extracted from
P.
Definition 10. Let P = {S ,W ,G} be a COSPP, with
S = {S,s
0
,A ,F}. Then a cost-optimal strong solution
of the COSPP P = {S ,W ,G} is a strong plan P from
s
0
to G such that the cost of P is minimal among the
strong plans from s
0
to G.
2.3 An Example of Cost-optimal Strong
Planning Problem
As an example of COSPP, let us consider the hurried
passenger problem. A passenger wants to arrive to
San Francisco airport (SFO) departing from one of
the Rome airports (CIA or FCO) and according to the
flight scheduling shown in Table 1. Moreover, there
is a bus on every hour that allow the passenger to go
from home to one of the Rome airports above in one
hour.
Table 1: Flight scheduling.
From To Flight #DepartArrive
Rome-FCO Paris-CDG A 08.00 09.00
Rome-FCO Berlin-BER E 08.00 10.00
Rome-CIA Amsterdam-AMS D 05.00 08.00
Paris-CDG San Francisco-SFOB 10.00 12.00 (GMT-7)
Paris-CDG San Francisco-SFOC 19.00 21.00 (GMT-7)
Berlin-BER San Francisco-SFOF 11.00 14.00 (GMT-7)
Berlin-BER Amsterdam-AMS I 12.00 13.00
Berlin-BER San Francisco-SFOG 12.00 15.00 (GMT-7)
Amsterdam-AMSSan Francisco-SFOH 15.00 20.00 (GMT-7)
The goal is to arrive to San Francisco as soon as
possible, and, however, no later than 21.00 local time.
We require the passenger to arrive at the airport at
least one hour before a flight departure. Moreover,
we assume that each flight may arrive at destination
later than the expected arrival time. The objective is
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS
59

to generate a strong plan (if any) that guarantees the
passenger to reach the San Francisco airport before
21.00 local time regardless of possible flight delays.
Table 2: COSPP for the hurried passenger problem.
S
home = s
0
, AMS = s
1
, AMS
d
= s
2
, CDG = s
3
, CDG
d
= s
4
, CIA = s
5
,
FCO = s
6
, BER = s
7
, BER
d
= s
8
. SFO
a
= s
9
, SFO
m
= s
10
, SFO
n
= s
11
.
A A, B, C, D, E, F, G, H, I, P, Q
F
F(s
0
,Q) = {s
6
}, F(s
0
,P) = {s
5
}
F(s
1
,H) = {s
9
}, F(s
2
,H) = {s
9
}
F(s
3
,B) = {s
9
,s
10
} , F(s
4
,C) = {s
9
,s
11
}
F(s
5
,D) = {s
1
,s
2
}
F(s
6
,A) = {s
3
,s
4
}, F(s
6
,E) = {s
7
,s
8
}
F(s
7
,F) = {s
9
}, F(s
8
,G) = {s
9
}, F(s
8
,I) = {s
1
,s
2
}
W
W (s
0
,Q, s
6
) = 1,W (s
0
,P,s
5
) = 1;
W (s
1
,H, s
9
) = 12,W (s
1
,H, s
9
) = 13;
W (s
2
,H, s
9
) = 11,W (s
2
,H, s
9
) = 12;
W (s
3
,B, s
10
) = 10,W (s
3
,B, s
9
) = 11;
W (s
4
,C,s
9
) = 18,W (s
4
,C,s
11
) = 19;
W (s
5
,D, s
1
) = 9,W (s
5
,D, s
2
) = 10 ;
W (s
6
,A, s
3
) = 2,W (s
6
,A, s
4
) = 3,
W (s
6
,E,s
7
) = 3,W (s
6
,E,s
8
) = 4;
W (s
7
,F,s
9
) = 11,W (s
7
,F,s
9
) = 12;
W (s
8
,G, s
9
) = 11,W (s
8
,G, s
9
) = 12,
W (s
8
,I, s
2
) = 3,W (s
8
,I, s
1
) = 2;
G s
9
,s
10
P
P(s
0
) = Q(17);P(s
5
) = D(22);P(s
6
) = E(16);P(s
7
) = F(12);
P(s
8
) = G(12);P(s
2
) = H(12);P(s
1
) = H(13), P(s
3
) = B(11)
The corresponding COSPP (according to Defi-
nitions 1,5 and 6) is reported in Table 2. Here
the actions correspond to the flights and the non-
determinism is given by the possible delay which, for
the sake of simplicity, we assume to be limited to one
hour for each flight. Note that the delay probabil-
ity distribution is uniform, i.e., each flight has equal
probability to arrive on time or with a 1-hour delay.
The cost of each transition (d, f,a) is W (d, f,a) =
(t(d)+t( f)+t(a)) where t(d) is the time spent at air-
port d waiting for the flight departure, t( f) is the du-
ration of the flight and t(a) is the time spent at airport
a waiting for the next flight (which could be zero).
Moreover, the special actions P and Q represent the
bus journey from home (state s
0
) to Rome-CIA and
Rome-FCO, respectively: for the sake of simplicity,
we do not consider delays on these actions, so the cor-
responding transitions are deterministic and have cost
1 (i.e., the bus journey takes an hour).
A graphical description of the problem is given
in Figure 1 where tagged nodes represent the arrival
time at the corresponding airport, while the edges are
labelled with the flight code.
The cost-optimal solution consists in flying from
Rome-FCO to Berlin-BER and then to San Francisco-
SFO. The total cost of the solution (considering all the
possible delays) is 17. Note that another strong solu-
tion would be flying from Rome-CIA to Amsterdam-
AMS and then to San Francisco-SFO, but its cost is
23. Finally, flying from Rome-FCO to Paris-CDG is
not a strong solution since in case of delay of flight
A it would be impossible to reach San Francisco on
time.
3 THE COST-OPTIMAL STRONG
PLANNING ALGORITHM
In this section we describe a procedure that looks for
a cost-optimal strong solution to a given COSPP. The
main algorithm (Procedure 4) consists of two subrou-
tines described in the following. All the procedures
make use of some auxiliary functions and sets : Cost,
Cand, ExtGoals, OldExtGoals and ∆ .
The cost function Cost(s) returns the minimum
cost of a strong plan from s to the goals calculated
so far. The algorithm updates this function every time
a better strong plan is found for s. Initially all the goal
states have a cost equal to zero, while the cost of the
other states is set to ∞.
The set of candidates (Cand) contains the pairs
(s,a) corresponding to all the states s which, at any
step, are recognised to have a plan starting with action
a, possibly of non minimum cost. The elements in the
set Cand can be partially ordered with respect to the
cost function Cost. Initially the set Cand is empty.
The set of extended goals (ExtGoals) contains all
the states s which, at any step, are recognised to have
a plan P of minimum cost. Initially the set ExtGoals
contains all the goal states in G. On the other hand,
the set of old extended goals ( OldExtGoals) con-
tains, at any step, the extended goals collected up to
the previous step: that is, the expression ExtGoals \
OldExtGoals represents the states that have been just
added to the extended goals.
Finally, each set ∆(s,a) in initialised with the
states reachable from s via action a, i.e., F(s,a),
which are consumed during the algorithm iterations.
In the following, we assume that all procedures
take as input the COSPP P = ((S,s
0
,A ,F),W ,G) as
well as the auxiliary sets and functions. The output is
a strong plan SP.
Note that, in the algorithms, some arithmetic op-
erations (i.e., min, max and sum) may involve infin-
ity. In this case, we assume the usual semantics, e.g.,
max(x,∞) = ∞ or x+ ∞ = ∞.
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
60

home
start
CIA
04.00
FCO
07.00
BER
10.00
BER
d
11.00
CDG
09.00
CDG
d
10.00
AMS
d
14.00
AMS
13.00
SFO
night
> 21
SFO
af t
13 − 21
SFO
morn
≤ 12
Q,1
P, 1
A,1+ 2
A,1 + 1
E,1+ 3
E,1+ 2
D,1 + 3+ 5
D,1 + 4+ 5
B,1 + 9
B,1 + 10
C, 9+9
C, 10+9
F,1+ 10
F,1+ 11
G,1 + 10
I, 1 +1
G,1 + 11
I, 1 +2
H, 2+ 10
H, 2+ 11
H, 1+ 11
H, 1+ 10
Figure 1: Graphical description of the COSPP for the hurried passenger problem.
3.1 The CandidateExtension Routine
The CANDIDATEEXTENSION routine (Procedure 1)
extends the set Cand of candidates. The function
Pre(s) returns all the transitions leading to s and is
applied to the extended goals found in the previous
iteration of the main algorithm. At any step, the set
∆(s,a) contains only the states reachable from s via
action a which have not been moved to the extended
goals yet. Thus, once ∆(s,a) is empty, s is guaranteed
to have a strong plan through action a, since all the
transitions in (s,a,F(s,a)) lead to an extended goal.
The pair (s,a) is then added to the set of candidates if
it improves the cost currently associated to s.
Procedure 1: CANDIDATEEXTENSION.
1: for all s
′
∈ (ExtGoals\ OldExtGoals) do
2: Pre(s
′
) ← {(s,a) ∈ S× A |s
′
∈ F(s, a)};
3: for all (s,a) ∈ Pre(s
′
) do
4: ∆(s,a) ← ∆(s,a) \ {s
′
};
5: if ∆(s,a) =
/
0 then
6: c
′
= max
¯s∈F(s,a)
(W (s, a, ¯s) +Cost( ¯s));
7: if c
′
< Cost(s) then
8: Cand ← Cand ∪ (s,a);
9: Cost(s) = c
′
;
10: end if
11: end if
12: end for
13: end for
3.2 The PlanExtension Routine
The effect of the PLANEXTENSION routine (Proce-
dure 2) is twofold. First, it selects the states in the
candidates set of minimum cost and moves them to
the set of extended goals. Indeed, the current solution
for such states cannot be improved, since there are no
actions which provide a strong solution with a lower
cost (see Proposition 2). Second, it inserts the new ex-
tended goals together with the associated action (i.e.,
the corresponding non-deterministic transition) in the
strong plan SP.
Procedure 2: PLANEXTENSION.
1: α ← min
(s,a)∈Cand
Cost(s);
2: for all (s,a) ∈ Cand|Cost(s) = α do
3: ExtGoals ← ExtGoals∪ {s};
4: Cand ← Cand \ {(s,a)};
5: SP ← SP∪ (s, a, F(s, a));
6: end for
Note that the extraction of the candidates with the
lowest cost (first two lines of Procedure 2) can be ac-
complished with a small complexity if we suppose
to have a structure costvector where each element
costvector[c] holds a list of references to the states
with cost c. Insertion in this structure is constant time,
whereas updates can be also accomplished in constant
time by re-inserting the state with updated cost with-
out removing the previous instance (i.e., creating a
duplicate with different cost). Indeed, the states with
minimum cost can be extracted from this structure as
shown by the MINCOSTCAND routine (Procedure 3).
The procedure takes as input the cost of the last
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS
61

Procedure 3: MINCOSTCAND.
Input: lastc, the cost of the last states returned
1: c ← lastc
2: loop
3: c ← c+ 1
4: AllCand
c
← costvector[c]
5: if AllCand
c
6=
/
0 then
6: Cand
c
←
/
0
7: for all s ∈ AllCand
c
do
8: if s 6∈ ExtGoals then
9: Cand
c
← Cand
c
∪ {s}
10: end if
11: end for
12: if Cand
c
6=
/
0 then
13: lastc ← c
14: return Cand
c
15: end if
16: end if
17: end loop
states returned, and scans the costvector starting from
the element corresponding to the next (higher) cost c
(for the sake of simplicity, in the pseudocode we sup-
pose it to be lastc+ 1, but in general it depends on the
approximation of the cost function). If costvector[c]
contains some states that are not yet in the extended
goals, the procedure returns them, otherwise it in-
creases c and loops. Thus, even if updates may create
duplicates of the same state in different elements of
costvector, since the algorithm always extracts first
the minimum cost instance of a state, and inserts it in
ExtGoals, all its further instances (with higher cost)
in costvector will be simply ignored.
3.3 The CostOptimalStrongPlan
Routine
Finally, the COSTOPTIMALSTRONGPLAN routine
(Procedure 4) initialises the cost value of each state
and the sets ∆, Cand, ExtGoals and OldExtGoals,
then iterates applying the subroutines described
above. In particular, the procedure loops until either
the initial state s
0
is included in the extended goals
(that is a strong solution has been found) or a fix point
is reached, since there are no new extended goals (in
this case there is no strong solution for s
0
). Note that,
as a collateral effect, the algorithm also finds all the
strong plans for the states in S having minimal cost
less or equal to the cost of s
0
. Thus, if s
0
does not
reach the goal (i.e., its cost is ∞), or if we explic-
itly remove the guard that stops the algorithm in this
case, the COSTOPTIMALSTRONGPLAN would actu-
ally calculate a cost-optimal strong universal plan.
Procedure 4: COSTOPTIMALSTRONGPLAN.
Input: a COSPP P = ((S,s
0
,A , F),W ,G)
Output: a cost-optimal strong plan SP
1: for all (s,a,s
′
) ∈ S
τ
do
2: if s ∈ G then
3: Cost(s) = 0;
4: else
5: Cost(s) = ∞;
6: ∆(s,a) = F(s,a);
7: end if
8: end for
9: Cand ←
/
0;
10: SP ←
/
0;
11: OldExtGoals ←
/
0;
12: ExtGoals ← G;
13: while (ExtGoals 6= OldExtGoals) do
14: if s
0
∈ ExtGoals then
15: return SP;
16: end if
17: CANDIDATEEXTENSION();
18: OldExtGoals ← ExtGoals;
19: PLANEXTENSION();
20: end while
21: return Fail;
3.4 Complexity of the Algorithm
Let m
′
be the number of transitions visited by the al-
gorithm, which is less or equal than the total number
of transitions in the graph, which mainly depends on
the degree of non-determinism of the system. More-
over, let c
′
be the number of different costs that a state
can be assigned to.
The CANDIDATEEXTENSION procedure removes
at least one state from a set ∆(s,a) in each iteration.
In other words, it consumes at least a transition of the
transition graph for each call. The cost of each execu-
tion is constant, thus the complexity of the procedure
is O(m
′
), since it is executed once for each visited
transition.
On the other hand, the MINCOSTCAND algo-
rithm, which is the core of the PLANEXTENSION pro-
cedure, scans the costvector exactly once, thus O(c
′
).
If a particular element costvector[c] does not have
states assigned, the algorithm does not perform any
other operation, otherwise it looks at each state with
cost c to see if it has been already used. Since the cost
of a state can be updated by CANDIDATEEXTENSION
(and thus the state itself duplicated in costvector) at
most once for each possible transition, the algorithm
performs this check O(m
′
) times. It follows that the
complexity of PLANEXTENSION is O(m
′
+ c
′
)
The overall complexity of COSTOPTIMAL-
STRONGPLAN is therefore O(m
′
+ c
′
). It is worth
noting that, if c
′
becomes too large, the costvector
could not fit in RAM, and the algorithm complexity
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
62

measure could be unacceptable. In this case, we may
employ a suitable sparse structure for costvector, e.g.,
a Fibonacci heap: indeed, with this kind of structure,
it is easy to see that the complexity would become
O(m
′
logm
′
), which does not depend on c
′
any more.
Note that in CANDIDATEEXTENSION we suppose
to use a precalculated Pre function. Otherwise, we
may apply an explicit state space exploration algo-
rithm to build it in O(|S
τ
|).
3.5 Correctness and Completeness of
the Algorithm
The algorithm given in Procedure 4 essentially it-
erates the two procedures CANDIDATEEXTENSION
and PLANEXTENSION until the desired state has a
plan or the fix point is reached. Let us indicate with
ExtGoals
k
and Cand
k
the contents of the ExtGoals
and Cand sets, respectively, at the k-th step of the
algorithm. Moreover, let us call Goals
k
the union
G∪ ExtGoals
k
.
Proposition 2. Let u
k
be the maximum cost of a state
in Goals
k
, that is u
k
= max
s∈Goals
k
Cost(s). Then, in
any step k ≥ 1 of the COSTOPTIMALSTRONGPLAN
algorithm, all the states with a plan of minimum cost
no greater than u
k
are in Goals
k
. That is ∀s ∈ S,
Cost(s) ≤ u
k
⇒ s ∈ Goals
k
Proof 2. At the first iteration of the algorithm (k = 1),
Goals
k
= ExtGoals
k
= G contains, by definition, all
the states with a plan having cost zero (i.e., the goals).
Now, let us assume by induction that the property
holds at step k. We shall prove that it still holds at
step k+ 1, i.e., the new elements inserted in Goals
k+1
do not falsify it.
To this aim, let α
k+1
be the minimum cost
of a candidate in Cand
k+1
, that is α
k+1
=
min
s∈Cand
k+1
Cost(s). We can simply prove that u
k
<
α
k+1
. Indeed, assume that u
k
≥ α
k+1
: then there ex-
ists a state s ∈ Cand
k+1
s.t. Cost(s) ≤ u
k
. However,
a state in Cand
k+1
cannot be in Goals
k
(since the al-
gorithm moves to the ExtGoals only states that are
already in Cand), and this contradicts the induction
hypothesis.
Note that the fact above implies that, at the end of
step k + 1, i.e., after the execution of PLANEXTEN-
SION, we have that u
k+1
= α
k+1
, since the algorithm
moves in Goals
k+1
all the candidates with cost α
k+1
,
which is greater than the previous maximum cost u
k
.
Now assume that the property to be proved is fal-
sified at step k + 1. This implies that there exist one
or more states s s.t. Cost(s) ≤ u
k+1
but s 6∈ Goals
k+1
.
Let us choose among these states the one with mini-
mum cost. Since we know that u
k+1
= α
k+1
, we can
also write that Cost(s) ≤ α
k+1
.
By induction hypothesis, since a state which is not
in Goals
k+1
could not also be in Goals
k
, we have that
u
k
< Cost(s). Let us consider a cost-optimal strong
plan for s. Such plan must contain at least one state
s
′
6∈ Goals
k
. Indeed, if all the states of such plan were
in Goals
k
, then s should be in Goals
k+1
. Let us choose
among these states the one with minimum cost.
We have two cases: if s
′
= s, then we have that, for
some suitable action a, F(s,a) ⊆ Goals
k
. This would
imply that s ∈ Cand
k+1
and, since Cost(s) ≤ α
k+1
, we
would have that Cost(s) = α
k+1
(recall that α
k+1
is
the minimum cost of a candidate in Cand
k+1
). But
in this case the algorithm would move s in Goals
k+1
,
contradicting the hypothesis.
Finally, if s 6= s
′
, then Cost(s
′
) < Cost(s) (by defi-
nition of cost of a plan). Again, since Cost(s) ≤ α
k+1
,
we have that Cost(s
′
) < α
k+1
, so s
′
6∈ Cand
k+1
. Thus
we also have that s
′
6∈ Goals
k+1
, and this contradicts
the hypothesis since s would not be the state with min-
imum cost s.t. Cost(s) ≤ α
k+1
and s 6∈ Goals
k+1
.
Thus, if a state enters in the extended goals (and
is therefore included in the strong optimal plan), then
its cost, i.e., the cost of the corresponding strong plan,
cannot be improved. This shows the algorithm cor-
rectness.
The algorithm completeness can be easily derived
from Proposition 2, too. To this aim, we can use the
following proposition.
Proposition 3. Let s ∈ S. If s has a cost-optimal
strong plan P, whose cost is not greater thanCost(s
0
),
then there exists k > 0 s.t. s ∈ ExtGoals
k
and
(s,a, F(s,a)) is added to SP.
Proof 3. The proof follows from Proposition 2. In-
deed, we have that the minimum cost of a candidate
α
k
′
is strictly increasing in each step of the algorithm
(otherwise, u
k
′
< α
k
′
+1
would not hold). Thus, the
process will eventually end with one of the following
conditions:
• the initial state s
0
is in ExtGoals
k
(if a strong plan
exists for such state): in this case, at step k all
the states whose cost is not greater than Cost(s
0
),
including s, are guaranteed to be in ExtGoals
k
,
too.
• there are no more candidate states that can be
reached from the (extended) goals: in this case,
since by hypothesis s has a strong plan, thus it can
reach the goal, it would be included in the last set
ExtGoals
k
.
Finally, the algorithm termination is guaranteed
by the arguments used in Proposition 3. Indeed, since
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS
63
the minimum cost of a candidate is strictly increasing,
the algorithm will eventually build the cost-optimal
strong plans for the states with highest cost: at this
point, no new candidates will be available, and the
process will terminate.
4 EXPERIMENTAL RESULTS
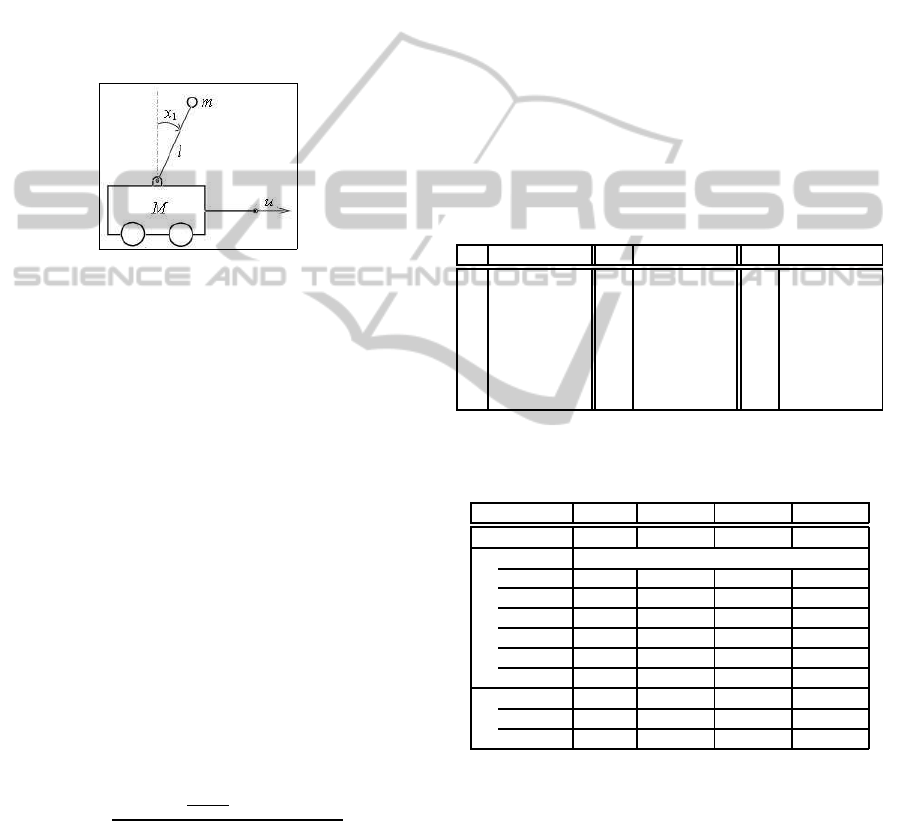
In this section we present a case study for the cost-
optimal strong planning algorithm, the inverted pen-
dulum on a cart, depicted in Figure 2.
Figure 2: Inverted pendulum on a cart.
Here the goal is to bring the pendulum to equilib-
rium using a minimum amount of force applied to the
cart. The non-determinismis givenby possible distur-
bances on the actuator that may result in a variation
of the force actually applied. Note that this appar-
ently simple case study is instead an important issue
in the controller design for many real-world systems.
Indeed, many control problems, e.g., in engineering
(i.e., the regulation of a steering antenna (Ilcev, 2009))
or robotics (Yokoi et al., 2003) can be reduced to an
inverted pendulum problem.
The pendulum state is described by two real vari-
ables:
• x
1
is the pendulum angle (w.r.t. the vertical axis)
with x
1
∈ [−1.5,1.5] rad;
• x
2
is the angular velocity with x
2
∈ [−8,8] rad/sec.
The continuous dynamics is described by a system
of differential equations:
˙x
1
= x
2
˙x
2
=
g
e
sin(x
1
)−[
cos(x
1
)
m
p
+m
c
][m
p
lx
2
2
sin(x
1
)+u]
4l/3−[m
p
/(m
p
+m
c
)]lcos
2
(x
1
)
where g
e
is the gravitational constant, m
p
= 0.1Kg
is the mass of the pole, m
c
= 0.9Kg is the mass
of the cart, l = 0.5m is the half-length of the pole
and u ∈ [−50, −46, .. .,46,50]N is the force applied
to the cart. Note that, due to disturbances, x
2
can
non-deterministically assume, with uniform probabil-
ity distribution, a value that differs from the expected
one by a small λ ∈ [−Λ,Λ] with steps of 0.01 rad/sec.
The actions that can be applied in each state of
the system correspond to the force applied to the cart,
i.e., A = [−50,−46, .. .,46,50]. In this setting, the
cost of a transition is given by the absolute value of
the applied force, i.e., for any s,s
′
, W (s,a, s
′
) = |a|.
Therefore, a plan of minimum cost minimises the en-
ergy consumption.
In order to solve this continuous non-deterministic
problem, we first had to approximate its continuous
behaviour, i.e., to find a suitable discretisation. To
this aim we exploited the discretise and validate ap-
proach implemented in the UPMurphi planner (Della
Penna et al., 2009b), applied to the deterministic
version of the problem, to devise such a discretisa-
tion. Then we applied the same discretisation to the
non-deterministic version of the problem and ran the
strong algorithm on the resulting NDFSS.
Table 3: Initial states for the inverted pendulum on a cart
problem.
# x
1
x
2
# x
1
x
2
# x
1
x
2
1 0.039 1.92 8 0.038 1.85 15 0.037 1.79
2 0.037 1.72 9 0.036 1.66 16 0.035 1.60
3 0.035 1.53 10 0.034 1.47 17 0.033 1.40
4 0.033 1.34 11 0.032 1.27 18 0.032 1.21
5 0.031 1.14 12 0.030 1.08 19 0.030 1.01
6 0.026 6.3 13 0.025 5.7 20 0.024 5.0
7 0.024 4.4 14 0.023 3.7 21 0.022 3.1
Table 4: Experimental results for the inverted pendulum on
a cart problem.
Instance 1 2 3 4
Λ 0.02 0.04 0.07 0.08
|S| 5· 10
7
|S
τ
| 6.25· 10
9
1.125· 10
10
1.875· 10
10
2.125· 10
10
Reach 11,439 11, 889 12,509 12,649
G Reach
τ
342,272 643,370 1,114,484 1,279, 010
|A | 25 25 25 25
max(δ(s)) 77 140 244 284
avg(δ(s)) 29.9 51.14 89.09 101.12
SP
size 1,146 1,198 698 —
max(C (s)) 75N 304N 180N —
time 10 18 13 7
In particular, we considered different instances of
the problem, taking into account disturbances of in-
creasing size, i.e., with Λ ∈ {0.02,0.04,0.07,0.08}.
For each instance, we applied the strong algorithm on
the sample set of initial states shownin Table 3, which
produced the results summarised in Table 4. Here,
for each problem instance, we report some statis-
tics about the corresponding graph G, i.e., total num-
ber of states (|S|), the total number of edges (|S
τ
|),
the number of reachable states and edges (Reach and
Reach
τ
, respectively), the number of actions (|A |) and
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
64

the average and maximum out degree (avg(δ(s)) and
max(δ(s)), respectively) of the states. Then, we sum-
marise the correspondingcost-optimal strong plan SP,
as devised by the algorithm, giving its size (i.e., the
number of plans that can be extracted from SP), the
maximum cost (max(C (s)) of a cost-optimal strong
plan that can be extracted from SP and the total plan
synthesis time (in minutes). The complete data set is
available online at (Della Penna et al., 2010).
Note that, as discussed in Section 1, the size of the
explicit graph representation of even a simple prob-
lem is huge: |S| = 5· 10
7
nodes and |S
τ
| = 6.25 · 10
9
edges in our best case. By visiting only the reachable
states, our algorithm succeeds in effectively counter-
acting state explosion.
We may note that, as expected, the greater the size
of disturbances, the bigger the number of transitions,
the smaller the number of states for which a strong
plan is found. In particular, for the fourth instance,
no strong plan exists. Moreover, the size of the re-
sulting strong plan could be effectively compressed
making use of Ordered Binary Decision Diagrams, as
described in (Della Penna et al., 2009a).
5 CONCLUSIONS AND FUTURE
WORK
In this paper we described an algorithm to solve
the cost-optimal strong planning problem in non-
deterministic finite state systems.
The presented approach extends the strong plan-
ning methodology given in (Cimatti et al., 1998) by
introducing the concept of cost, and thus generating
cost-optimal strong plans, and by exploiting explicit
algorithms to extend the class of solvable problems.
The devised algorithm has been formally proved
as correct and complete, and its complexity, if the
number of transitions in the system or the range of
possible transition costs are reasonable (to say, a bil-
lion of transitions or different costs), is dominated
by the number of (visited) transitions in the system
graph, which is a good bound for such kind of prob-
lem.
Finally, the proposed methodology has been illus-
trated through a case study based on the well known
inverted pendulum on a cart problem. Future work
will include an extensive experimentation on differ-
ent case studies. However, the first results are very
promising and show how the algorithm is effective
and scalable.
REFERENCES
Albore, A., Palacios, H., and Geffner, H. (2010). Compil-
ing uncertainty away in non-deterministic conformant
planning. In ECAI, pages 465–470.
Behrends, E. (2000). Introduction to Markov Chains.
Vieweg.
Bertoli, P., Cimatti, A., Roveri, M., and Traverso, P. (2001).
Planning in nondeterministic domains under partial
observability via symbolic model checking. In Proc.
17th IJCAI, pages 473–478. Morgan Kaufmann.
Bertoli, P., Cimatti, A., Roveri, M., and Traverso, P. (2006).
Strong planning under partial observability. Artif. In-
tell., 170:337–384.
Bonet, B. and Geffner, H. (2000). Planning with incom-
plete information as heuristic search in belief space.
In Chien, S., Kambhampati, S., and Knoblock, C., ed-
itors, Proc. 6th ICAPS, pages 52–61. AAAI Press.
Bonet, B. and Geffner, H. (2005). mGPT: A probabilistic
planner based on heuristic search. JAIR, 24:933–944.
Boutilier, C., Dean, T., and Hanks, S. (1999). Decision-
theoretic planning: Structural assumptions and com-
putational leverage. JAIR, 11:1–94.
Burch, J. R., Clarke, E. M., McMillan, K. L., Dill, D. L.,
and Hwang, L. J. (1992). Symbolic model checking:
10
20
states and beyond. Inf. Comput., 98(2):142–170.
Chesi, G. and Hung, Y. (2007). Global path-planning for
constrained and optimal visual servoing. IEEE Trans.
on Robotics, 23(5):1050–1060.
Cimatti, A., Roveri, M., and Traverso, P. (1998). Strong
planning in non-deterministic domains via model
checking. In AIPS, pages 36–43.
Della Penna, G., Intrigila, B., Lauri, N., and Magazzeni,
D. (2009a). Fast and compact encoding of numerical
controllers using obdds. In Informatics in Control, Au-
tomation and Robotics: Selected Papers from ICINCO
2008, pages 75–87. Springer.
Della Penna, G., Intrigila, B., Magazzeni, D., and Mercorio,
F. (2009b). UPMurphi: a tool for universal planning
on PDDL+ problems. In Proc. ICAPS 2009, pages
106–113. AAAI Press.
Della Penna, G., Intrigila, B., Magazzeni, D., and Mercorio,
F. (2010). Non-deterministic inverted pendulum on a
cart data set.
Della Penna, G., Intrigila, B., Melatti, I., Tronci, E., and
Venturini Zilli, M. (2004). Exploiting transition local-
ity in automatic verification of finite state concurrent
systems. STTT, 6(4):320–341.
Della Penna, G., Intrigila, B., Melatti, I., Tronci, E., and
Zilli, M. V. (2006). Finite horizon analysis of markov
chains with the murphi verifier. STTT, 8(4-5):397–
409.
Fudenberg, D. and Tirole, J. (1991). Game theory. MIT
Press.
Huang, W., Wen, Z., Jiang, Y., and Wu, L. (2007). Observa-
tion reduction for strong plans. In Proc. 20th IJCAI,
pages 1930–1935. Morgan Kaufmann.
COST-OPTIMAL STRONG PLANNING IN NON-DETERMINISTIC DOMAINS
65

Ilcev, S. D. (2009). Antenna systems for mobile satellite ap-
plications. In Microwave Telecommunication Technol-
ogy, 2009. CriMiCo 2009. 19th International Crimean
Conference, pages 393 –398.
Kwiatkowska, M. Z., Norman, G., and Parker, D. (2004).
Probabilistic symbolic model checking with prism: a
hybrid approach. STTT, 6(2):128–142.
Mausam, M., Bertoli, P., and Weld, D. S. (2007). A hy-
bridized planner for stochastic domains. In Proc. 20th
IJCAI, pages 1972–1978. Morgan Kaufmann.
Mausam, M. and Weld, D. S. (2008). Planning with durative
actions in stochastic domains. JAIR, 31:33–82.
Meuleau, N., Benazera, E., Brafman, R. I., Hansen, E. A.,
and Mausam, M. (2009). A heuristic search approach
to planning with continuous resources in stochastic
domains. J. Artif. Int. Res., 34:27–59.
Schoppers, M. (1987). Universal plans of reactive robots in
unpredictable environments. In Proc. IJCAI 1987.
Yokoi, K., Kanehiro, F., Kaneko, K., Fujiwara, K., Kajita,
S., and Hirukawa, H. (2003). Experimental study of
biped locomotion of humanoid robot hrp-1s. In Exper-
imental Robotics VIII, volume 5 of Springer Tracts in
Advanced Robotics, pages 75–84. Springer.
Yoon, S. W., Fern, A., and Givan, R. (2002). Inductive
policy selection for first-order MDPs. In UAI, pages
568–576.
ICINCO 2011 - 8th International Conference on Informatics in Control, Automation and Robotics
66
