
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS
USING A FIELD MULTIPLIER
Saptarsi Das
1
, Keshavan Varadarajan
1
, Ganesh Garga
2
, Rajdeep Mondal
1
,
Ranjani Narayan
2
and S. K. Nandy
1
1
CAD Lab, Indian Institute of Science, Bangalore, India
2
Morphing Machines Pvt. Ltd., Bangalore, India
Keywords:
Elliptic Curve Cryptography, Binary Fields, Flexible Reduction, Polynomial Multiplication.
Abstract:
Flexibility in implementation of the underlying field algebra kernels often dictates the life-span of an Elliptic
Curve Cryptography solution. The systems/methods designed to realize binary field arithmetic operations can
be tuned either for performance or for flexibility. Usually flexibility of these solutions adversely affects their
performance. For solutions to reduction operation this adverse effect is particularly prominent. Therefore it is
a non-trivial task to design a flexible reduction method/system without compromising performance. In this pa-
per we present a method for flexible reduction. The proposed reduction technique is based on the well-known
repeated multiplication technique and Barrett reduction. This technique is particularly appealing in the context
of coarse-grain programmable architectures where performance of any kernel is heavily influenced by granu-
larity of operations. In this context we propose a design of a polynomial multiplier based on the well-known
Interleaved Galois Field multiplier to accelerate the underlying multi-word polynomial multiplications. We
show that this modified IGF multiplier offers a significant improvement in throughput over a purely software
realization or a hybrid software-hardware implementation using a conventional polynomial multiplier.
1 INTRODUCTION
Proliferation of various kinds of threats has lead to
an increased interest in cryptographic solutions for
communication equipments. Thus strong cryptogra-
phy has emerged as an indispensable part of different
communication protocols. One of the strongest de-
terrents of such threats is the class of Elliptic curve
cryptography (ECC) algorithms. Due to ever increas-
ing threat level, the key-length applied to these algo-
rithms keeps on increasing with time. In order to cope
with such growing need for stronger security the ideal
approach would be to design ”future-proof”solutions.
Quantitatively, the life-span of such a solution can be
evaluated by measuring its flexibility to support var-
ious key lengths. The ECC algorithms are designed
based on algebraic properties of finite fields. The na-
ture of arithmetic involved in these algorithms makes
it difficult to build arbitrarily flexible solutions with-
out compromising on performance. The two funda-
mental operations involved in finite field arithmetic
are addition and multiplication. Binary fields (finite
fields of the form GF(2
m
)) are especially popular due
to the ease of implementation of addition and sub-
traction (which are equivalent to one another) over
them. However, multiplication is a relatively expen-
sive operation. Unlike addition or subtraction, multi-
plication of two polynomials from a finite field may
produce a polynomial whose degree exceeds the or-
der of the finite field. In order to translate such a re-
sult to an equivalent canonical form within the order
of the finite field, a reduction operation is performed.
Flexibility in polynomial multiplication can be easily
achieved. However, supporting flexible reduction ef-
ficiently over arbitrarily large binary fields and for any
irreducible polynomial requires special attention.
In this paper we investigate the case of flexible re-
duction and analyze different possible solutions. In
section 2 we discuss the nature of the reduction oper-
ation and show that a software-hardware hybrid so-
lution is best suited for flexible reduction over any
binary field using any irreducible polynomial. We
identify the possibility of using a hardware assist in
the form of a field multiplier for improving the per-
formance of such a hybrid technique. In this context
we present the design of a Modified Interleaved Ga-
50
Das S., Varadarajan K., Garga G., Mondal R., Narayan R. and Nandy S..
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS USING A FIELD MULTIPLIER.
DOI: 10.5220/0003447500500058
In Proceedings of the International Conference on Security and Cryptography (SECRYPT-2011), pages 50-58
ISBN: 978-989-8425-71-3
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

lois Field (MIGF) multiplier as an accelerator for the
well-known Repeated Multiplication Method of re-
duction. In section 3 we present the improvement in
performance achieved through the use of MIGF mul-
tiplier. We compute the increase in hardware com-
plexity of the said multiplier which is offset by the
improvement in performance of the reduction opera-
tion. In section 4 we present the synthesis results of
a 32-bit MIGF multiplier and evaluate the improve-
ment in performance of reduction operation over five
NIST recommended irreducible polynomials. Finally
we conclude the paper with a short summary.
2 REDUCTION OVER BINARY
FIELDS: THE BASIC
OPERATIONS INVOLVED AND
THEIR REALIZATION
The reduction operation is a modulo operation of a
polynomial with an irreducible polynomial that gen-
erates the finite field under consideration. Section 2.1
presents a brief mathematical background of reduc-
tion operation, various ways of implementing it and
the associated implications. In section 2.2 we com-
pare two algorithms for reduction operation and iden-
tify polynomial multiplications as the core computa-
tions in them. In section 2.3 we analyze the multipli-
cation operations involved in reduction. In section 2.4
we present the design of a MIGF multiplier that can
be used for efficient implementation of the aforemen-
tioned polynomial multiplications.
2.1 Mathematical Background of
Reduction Operation
Elements of a binary field are usually represented as
polynomials over the base field GF(2) i.e. the degree
of the polynomials is determined by the order of the
field and the coefficients belong to GF(2). Multipli-
cation of such elements is governed by the addition
and multiplication rules over GF(2). For instance,
let us consider two elements A(x) and B(x) belonging
to the binary field GF(2
m
). These polynomials can
be represented as a string of m symbols, where each
symbol is 0 or 1. Therefore they are equivalent to two
m-bit long binary strings. Equation 1 shows the two
polynomials and their product C(x).
A(x) = Σ
m−1
i=0
a
i
x
i
B(x) = Σ
m−1
i=0
b
i
x
i
C(x) = A(x) × B(x) (1)
= Σ
2m−2
i=0
c
i
x
i
;wherec
k
= Σ
i+ j=k
a
i
b
j
As is apparent from equation 1, the result C(x) is al-
most twice as long as the input polynomials. C(x) has
a unique equivalent canonical representation among
the set of polynomials of degree m−1. Though, math-
ematically both the representations are equivalent, ef-
ficient utilization of computation resources necessi-
tates conversion from the 2m−1-bit representation to
the m-bit representation. This conversion often re-
ferred to as reduction operation is based on an irre-
ducible polynomial that generates the binary field of
interest. The reduction operation is based on the fact
that a polynomial C(x) belonging to a finite field is
equivalent to the polynomial modulo an irreducible
polynomial P(x) that generates the finite field.
C(x) ≡ C(x) mod P(x) (2)
From equation 2 it is clear that the reduced polyno-
mial can be computed by traditional long division
technique for polynomials. But this method is iter-
ative in nature and requires up to m− 1 iterations.
At this point let us digress a little and consider
the aspect of flexibility regarding reduction opera-
tion over finite fields. There are two major factors
that govern flexibility of a reduction method: the or-
der of the finite field and the irreducible polynomial
that generates the finite field. A flexible reduction
method/system should be capable of operating over
finite fields of arbitrarily large order. Such a solution
should also be versatile enough to handle all possible
irreducible polynomial for any given field order. A
purely hardware approach (Peter et al., 2007; Saqib
et al., 2004) to support arbitrarily flexible reduction
cannot be employed since a hardware solution cannot
be used for finite field beyond a certain range. More-
over supporting all possible irreducible polynomials
even upto a specified field order will immensely in-
crease the complexity of the hardware. A purely soft-
ware implementation is capable of delivering the de-
sired flexibility, but poor performance of such an im-
plementation may make it highly inefficient over very
large fields. In order to cope with this, it is neces-
sary to develop hybrid solutions. In a hybrid solution
the data-path of the core computations are realized as
fast hardware kernels and the control-path to invoke
and cascade the hardware kernels is realized using a
thin layer of software. Such coexistence of hardware
and software necessitates some kind of a protocol to
govern the communication between the two domains.
One of the most important aspects of such a proto-
col is the data-granularity of the hardware kernels.
Data-granularity determines the amount of data that
can be processed by the individual hardware kernels
at any time. In architecture terminology, this granu-
larity translates to word-length. Transport latency of
data and metadata in such hybrid systems is strongly
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS USING A FIELD MULTIPLIER
51

dependent on data-granularity. In order to minimize
(or even hide) the transport latency, it is preferable to
deploy coarse-grain hardware kernels in hybrid sys-
tems. However, it should be noted that, higher granu-
larity implies increased complexity of the hardware
kernels. Therefore it is essential to find a balance
in hardware complexity versus data-granularity to de-
sign optimized hybrid systems.
With this background let us get back to the case
of reduction operation. As mentioned before reduc-
tion involves a series of basic arithmetic and logical
operations. The order of the finite field influences the
implementation of these basic operations on a coarse-
grain hybrid system. As mentioned before, an ele-
ment of GF(2
m
) can be represented as an m-bit wide
binary string. Let the word length of a certain coarse-
grain system be w. If m 6 w, then the number can be
represented within a single word. In such a situation,
it is feasible to develop a m× m multiplier and reduc-
tion operation can be integrated with the multiplier
itself. Such a multiplier requires three inputs to oper-
ate, two numbers to be multiplied and an irreducible
polynomial for reduction of the product. Equation
3 describes multiplication of A(x) and B(x) belong-
ing to GF(2
m
), which is generated by the irreducible
polynomial P(x).
C(x) = (A(x) × B(x)) mod P(x)
= (A(x) × (Σ
m−1
i=0
b
i
x
i
)) mod P(x)
= Σ
m−1
i=0
b
i
(A(x)x
i
mod P(x)) (3)
Equation 3 describes the operation of a traditional
shift-and-add multiplier. Note that, the shifted multi-
plicands of the form A(x)x
i
are reduced at each stage.
So the m − 1 iterations of the modulo operation are
embedded in each stage of the multiplier.
On the other hand, if m > w, the element of
the finite field can be represented using ⌈
m
w
⌉ words.
Therefore the direct multiplication-and-reduction ap-
proach cannot be applied. Under such circumstances,
it becomes imperative to employ a software algo-
rithm to break the m-bit operations into w-bit oper-
ations. Multiplication of two m-bit polynomials pro-
duces a 2m − 1-bit result which needs to be reduced
separately. Algorithms such as the Karatsuba-Ofman
(Karatsuba and Ofman, 1963) algorithm can be ap-
plied iteratively to perform the aforementioned multi-
plications. The 2m−1-bit result can be reducedby the
Repeated Multiplication Reduction (RMR) method
(Eberle et al., 2003; Satoh and Takano, 2003). The
RMR method and Barrett Reduction (Barrett, 1987)
method are the most suitable techniques for flexible
reduction. A brief description of the RMR method is
reproduced here from (Eberle et al., 2003). Let C
0
(x)
be the product of two polynomials of degree less than
m. The degree of C
0
(x) is less than 2m− 1 and it can
be split into two parts as shown in equation 4.
C
0
(x) = C
h,0
(x)x
m
+ C
l,0
(x) (4)
The RMR method is an iterative technique and the
subsequent polynomials are computed by the equa-
tion 5.
C
j+1
(x) = C
h, j
(x)(P(x) − x
m
) + C
l, j
(x)
until C
h, j+1
(x) = 0 ⇔ deg(C
j+1
(x)) 6 m− 1 (5)
The RMR method requires m iterations and each it-
eration involves multiplication of C
h, j
(x) with P(x) −
x
m
. This polynomial multiplication can be realized as
a set of m left shift operations. However, the most
commonly used irreducible polynomials are usually
trinomials and pentanomials. This implies, each of
the multiplication involves no more than five left shift
operations. Moreover deg(P(x) − x
m
) <
m
2
. For
such classes of polynomials, the RMR method con-
verges after only two iterations (Peter et al., 2007). In
(Knezevic et al., 2008) the authors have presented an
adaptation of the famous Barrett Reduction method
for binary fields. In section 2.2 we analyze the RMR
and Barrett reduction method and establish an equiv-
alence between the two.
2.2 Barrett Reduction and the RMR
Method
We reproduce the adaptation of Barrett reduction
from (Knezevic et al., 2008) to compare with the
RMR method for irreducible polynomials with the
following property: deg(P(x) − x
m
) <
m
2
. Let us
consider the RMR method first. Let C
0
(x) be the
product of two polynomials that needs to be reduced.
P(x) = x
m
+ x
k
+ ··· + x
p
+ 1 be the irreducible poly-
nomial. Note that, for the RMR method to converge
within two iterations, k should be less than
m
2
. Using
equation 5 we reduce the polynomial C
0
(x) as shown
in equation 6.
C
0
(x) = C
h,0
(x)x
m
+ C
l,0
(x)
C
1
(x) = C
h,0
(x)(P(x) − x
m
) + C
l,0
(x)
= C
h,1
(x)x
m
+ C
l,1
(x)
whereC
h,1
(x) = C
h,0
(x)(P(x) − x
m
)divx
m
and C
l,1
(x) = C
h,0
(x)(P(x) − x
m
)modx
m
+C
l,0
(x)
C
2
(x) = C
h,1
(x)(P(x) − x
m
) + C
l,1
(x)
(6)
Clearly, deg(C
h,1
(x)) 6 k and therefore deg(C
2
(x)) <
m. Now, let us consider the Barrett Reduction method
SECRYPT 2011 - International Conference on Security and Cryptography
52

for the same irreducible polynomial. Barrett Reduc-
tion involves computation of three quotients Q
1
(x),
Q
2
(x) and Q
3
(x) along with two remaindersR
1
(x) and
R
2
(x) as shown in equation 7. The final result is given
by the remainder polynomial R(x).
Q
1
(x) = C
0
(x) div x
m
= C
h,0
(x)
Q
2
(x) = Q
1
(x)P(x)
Q
3
(x) = Q
2
(x) div x
m
= C
h,0
(x)(x
m
+ x
k
+ ··· + x
p
+ 1) div x
m
= C
h,0
(x) +C
h,1
(x)
R
1
(x) = C
0
(x) mod x
m
= C
l,0
(x)
R
2
(x) = Q
3
(x)P(x) mod x
m
= Q
3
(x)(x
k
+ ··· + x
p
+ 1) mod x
m
= C
h,0
(x)(x
k
+ ··· + x
p
+ 1)modx
m
+ C
h,1
(x)(x
k
+ ··· + x
p
+ 1)modx
m
R(x) = R
1
(x) + R
2
(x)
= C
h,1
(x)(P(x) − x
m
) +C
l,1
(x) (7)
From equations 6 and 7 it is evident that both the
methods are equivalent and both of them require mul-
tiplication of m-bit polynomials. Note that, the mod-
ulo and division operations in the two methods trans-
late to partitioning of the polynomials into lower and
higher half and therefore do not require any arithmetic
operation. In section 2.3 we present a method for per-
forming the aforementioned multiplications in order
to achieve arbitrary flexibility in reduction.
2.3 Multiplication Operations in
Reduction
From equations 6 and 7 we observe that multiplica-
tions of the form C(x)(x
k
+ ··· + x
p
+ 1) form the
core of the computations. Therefore it is necessary
to accelerate these multiplications in order to perform
fast reduction. It should also be noted that the only
other operations involved in reduction are addition
over GF(2
m
). Since there is no carry involved in ad-
dition, addition of two m-bit polynomials which span
more than one word in a w-bit architecture can be re-
alized as ⌈
m
w
⌉ w-bit XOR operations. Multiplication
on the other hand requires multi-word shift and ac-
cumulation of results. Consider the two polynomials
C(x) and P
′
(x) of degree m and k respectively. These
polynomials can be represented in a w-bit architecture
as a collection of m
c
and m
p
w-bit words respectively.
Equation 8 shows the representation.
C(x) = Σ
m
c
−1
i=0
C
i
(x)x
iw
where m
c
=
l
m
w
m
P
′
(x) = Σ
m
p
−1
j=0
P
′
j
(x)x
jw
where m
p
=
k
w
(8)
C
i
(x)x
iw
and P
j
(x)x
jw
denote the i-th and j-th words
of the polynomials C(x) and P
′
(x) respectively. The
product of these two polynomials can be computed as
follows:
C
′
(x) = C(x)P
′
(x)
= Σ
m
p
−1
j=0
C(x)P
′
j
(x)x
jw
= Σ
m
p
−1
j=0
(Σ
m
c
−1
i=0
C
i
(x)x
iw
P
′
j
(x)x
jw
) (9)
A closer look at equation 9 reveals that computa-
tion of C
i
(x)P
′
j
(x) involves computations of the form
C
i
(x)x
r
. Each of the individual words like C
′
i, j
(x) (re-
fer to figure 1) in the product of the entire polynomial
C(x) and x
r
can be computed as follows:
C
′
i, j
= (C
i
≪ r | C
i−1
≫ (w− r)) (10)
The individual words like C
′
i, j
(x) in the product of
C(x) and P
′
j
(x) can be expressed as given by equation
11.
C
′
i, j
= ⊕
w−1
r=0
(C
i
≪ r | C
i−1
≫ (w− r))p
′
j,r
(11)
Note that, p
′
j,r
x
r
denotes the r-th term in the j-th word
of the polynomial P
′
(x) in equation 11. The opera-
tions of equation 11 can be repeated for each of the
words in P
′
(x) to compute the final result. Note that
the product of C(x) and each of the words in P
′
(x)
is m
c
+ 1 word wide. Henceforward we will refer to
products of C(x) with the individual words of P
′
(x)
as “partial products”. It should be noted that these
m
c
+ 1 word wide partial products need to be aligned
to proper word boundaries before they can be added
together to produce the final result. Figure 1 shows
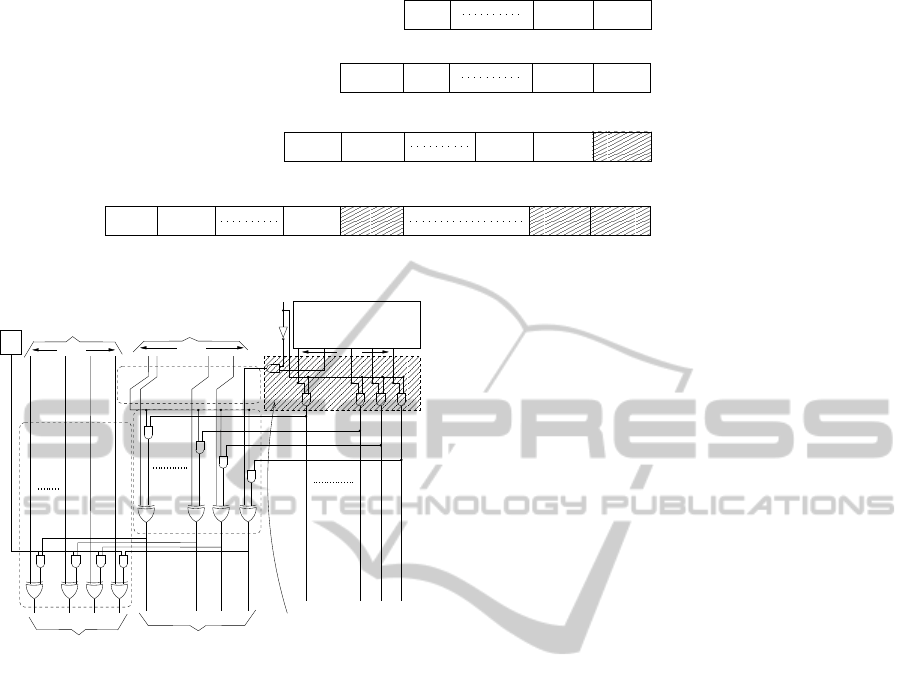
how the partial products are aligned.
2.4 A Modified Interleaved Galois Field
Multiplier as a Hardware Assist for
Reduction
The discussion in section 2.3 makes it clear that a re-
duction method is only as fast as the underlying multi-
plication operations. Therefore it is obviousthat poly-
nomial multiplication kernels are the candidates for
acceleration in a crypto-system. The simplest way of
accelerating a w × w polynomial multiplication is to
introduce a w-bit polynomial multiplier that produces
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS USING A FIELD MULTIPLIER
53
c
C
p
m −1,m −1
p
C
c
m ,m −1
C
0,m −1
p
C(x)P’ (x)x
m −1
p
(m −1)w
p
m −1,1
C
c
m ,1
C
c
C(x)P’ (x)x
1
w
C
1,1
C
0,1
c
C
m −1,0
C
c
m ,0
0
C(x)P’ (x)
C
C
1,0
0,0
C
m −1
c
1
C
C
0
C(x)
Figure 1: Arrangement of Partial Products.
w bit
(w−r) bit
w bit
Extra Logic Introduced
Accumulated result
w bit
Shift Operation
Multiplicand
after (r−1) stages
Multiplier[r]
Accumulated result
after (r−1) stages
Select
Mode
Irreducible Polynomial/
Multiplicand
Lower Word of
Operation
Accumulation
Reduction Operation
Multiplicand after
after r stages
after r stages
Figure 2: One stage of the Modified IGF Multiplier.
2w-bit results. Therefore each word in the input poly-
nomial C(x) produces a pair of words and these pairs
need to be added (i.e. XORed) with proper alignment
to compute a partial product.
In this section we propose a technique for combin-
ing the addition operations with the polynomial mul-
tiplications. Instead of considering one word of the
polynomial C(x) we focus on one word of the partial
product (i.e. C
′
i, j
(x)). It is evident from equation 11
that to produceC
′
i, j
(x) two words from the polynomial
C(x) and one word from P
′
(x) are necessary. Thus
the intended operation can be described as a 2w × w
polynomial multiplication that produces a w-bit re-
sult. In this section we show that an Interleaved Ga-
lois Field (IGF) Multiplier (Hinkelmann et al., 2009)
can be modified to support this type of multiplica-
tions. In a shift-and-add IGF multiplier, the multi-
plicand operand is successively left shifted and the
multiplier operand is used to selectively accumulate
the results of the left shift operations. The IGF mul-
tiplier always produces a reduced result. Reduction
over large fields however, requires support for multi-
plication of polynomials where the result is kept unre-
duced. This can be achieved by setting the irreducible
polynomial to all zeros. This is achieved by mask-
ing the irreducible polynomial input to each stage of
the multiplier with a one bit control signal (Mode Se-
lect signal in figure 2). In order to emulate the oper-
ations described in equation 11 the MIGF multiplier
inserts the (w− r)-th bit from the second multiplicand
operand to the LSB of the first multiplicand at the r-th
stage of the multiplier. This is enabled by introducing
a single AND gate that drives the LSB of the shifted
polynomial. As can be seen from figure 2, we use the
inverted control signal to mask the (w−r)-th bit from
the second multiplicand operand. This added hard-
ware (shown inside the shaded rectangle in figure 2)
enables the multiplier to perform two-word shift op-
erations successively which in turn alleviates the need
for adding the individual products of the multiplier to
form the partial product. In the section 3 we discuss
the reduction in instruction-count of the reduction op-
eration using this MIGF multiplier and the flexibility
that this technique offers.
3 PERFORMANCE AND
FLEXIBILITY OF THE
PROPOSED REDUCTION
TECHNIQUE
In this section we analyze the reduction method de-
scribed in section 2.3 to evaluate the improvement in
performance of the method with an MIGF multiplier
as a hardware assist. We also show that this technique
is arbitrarily flexible in terms of field order and choice
of irreducible polynomial.
3.1 Performance Improvement due to
use of Modified IGF Multiplier
In this section we analyze the benefits of using
the MIGF multiplier for multiplication of C(x) with
SECRYPT 2011 - International Conference on Security and Cryptography
54

P
′
(x). We proceed by first considering the case of
multiplication of the entire C(x) polynomial with just
one word of P
′
(x) and continue the analysis to com-
plete multiplication of C(x) with entire P
′
(x).
3.1.1 Multiplying C(x) with One Word of P
′
(x)
From equation 10 it is evident that each m
c
-word shift
operation corresponding to a single term in the poly-
nomial P
′
(x) translates to 2m
c
shift operations and
m
c
− 1 logical concatenations. Note that the concate-
nations can be conveniently expressed as either logi-
cal OR operations or logical XOR operations. There-
fore the total number of logical operations necessary
to produce the result of the multi-word multiplication
as described in equation 11 is determined by the num-
ber of terms other than 1, present in the word of the
irreducible polynomial P
′
j
(x). Assuming there are p
terms present in P
′
j
(x), the number of logical shifts is
2m
c
p and the number of concatenation operations is
(m
c
− 1)p. Note that these operations are required to
produce the shifted polynomials of the form C(x)x
r
for different values of r < w. In order to accumu-
late these shifted polynomials of the form C(x)x
r
it
is necessary to perform at most p
′
− 1 logical XOR
operation for each word of the shifted polynomials
where p
′
is total the number of terms present in P
′
j
(x)
(including a 1 if any). Since the shifted polynomi-
als span across (m
c
+ 1) words, the total number of
XORs necessary is (m
c
+1)(p
′
−1) to accumulate the
shifted polynomials. Thus the total number of basic
logic operations necessary to compute C(x)x
r
is 2m
c
p
shift operations and (m
c
−1)p+(m
c
+1)(p
′
−1) log-
ical XORs. Using a polynomial multiplier to produce
the partial product requires m
c
multiplications and
m
c
− 1 XOR operations. Using the MIGF multiplier
for this operation requires m
c
+ 1 two-word multipli-
cations i.e one extra multiplication for m
c
− 1 XOR
operations. Thus we have reduced the total number
of arithmetic and logical operations by approximately
4p times, when compared to a purely software real-
ization.
3.1.2 Multiplying C(x) with Entire P
′
(x)
So far we have considered multiplication of the poly-
nomial C(x) with one word of the irreducible poly-
nomial P
′
(x). With the analysis of the previous para-
graph as the basis let us compute the number of oper-
ations involved in realizing the entire multiplication
operation described in equation 9. The number of
shift operations involved is determined by the num-
ber of terms with distinct indices present in the poly-
nomial P
′
(x). In a w-bit architecture C(x)x
tw+r
is
computed by simply appending t words filled with
zeros to the right of C(x)x
r
. Therefore the terms of
P
′
(x) with indices tw + r are equivalent to one an-
other. Assuming that there are p terms with distinct
indices present in the irreducible polynomial, the to-
tal number of shift operations necessary is given by
2m
c
p. The number of concatenation operations is
(m
c
− 1)p. However, the total number of XOR opera-
tions required for accumulation of these shifted poly-
nomials is determined by the number of terms (with
distinct and equivalent indices) present in P
′
(x). In
order to calculate the total number XOR operations
for accumulation it is necessary to examine the candi-
dates for accumulation. Let us denote the number of
terms present in P
′
j
(x) by p
j
. Therefore the accumu-
lation of the shifted polynomials of the form C(x)x
r
,
produced by these p
j
terms require (p
j
− 1)(m
c
+ 1)
XOR operations. It should be noted that if p
j
= 0 for
any particular word P
′
j
(x), no XOR operation is nec-
essary. For simplicity let us assume p
j
> 0 for all j.
Total number of basic arithmetic-logic instructions to
produce all the polynomials of the form C(x)P
′
j
(x) is
shown in equation 12
#SHIFT = 2m
c
p
#XOR = (m
c
− 1)p+ Σ
m
p
−1
j=0
(m
c
+ 1)(p
j
− 1)
(12)
It should be noted that, the number of XOR operations
required to add results produced by different words of
the polynomial P
′
(x) remains unaltered irrespective
of whether the MIGF multiplier is used or not. Thus
we have intentionally not considered such XOR op-
erations in counting the total number of XOR opera-
tions.
Using the MIGF multiplier reduces the number of
operation required to perform the same set of oper-
ations. Note that, an intelligent sequencing of mul-
tiplication operations is necessary to minimize the
number of multiplications. Sequencing of multipli-
cation operation can be done by examining the irre-
ducible polynomial. A set of m
c
+ 1 multiplications
are necessary to produce a term like C(x)P
′
j
(x). How-
ever, it should be noted that this set of multiplica-
tions need to be performed for words of the polyno-
mial P
′
(x), with at least one term present. Therefore
the maximum number of such multiplications neces-
sary is (m
c
+ 1)m
p
. Clearly (m
c
+ 1)m
p
< 2m
c
p +
(m
c
− 1)p + Σ
m
p
−1
j=0
(m
c
+ 1)(p
j
− 1). Let us take this
comparison a little further by making a set of assump-
tions. Let us assume that on an average p
′
terms are
present in each of the words that constitute the irre-
ducible polynomial. In that case the total number of
basic arithmetic-logic operations involvedcan be sim-
plified to 2m
c
p+(m
c
+1)(p
′
−1)m
p
. Using a conven-
tional w× w polynomial multiplier will require m
c
m
p
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS USING A FIELD MULTIPLIER
55

multiplications and (m
c
− 1)m
p
additional XOR op-
erations. Using the MIGF multiplier brings down the
total number of operations to (m
c
+ 1)m
p
. Assum-
ing m
c
is large enough so that m
c
≈ m
c
+ 1 the re-
duction in operation count is 2p/m
p
+ (p
′
− 1) times
when compared to a purely software realization and
2× compared to hybrid realization using a conven-
tional polynomial multiplier.
3.2 Flexibility of the Reduction Method
In this section we will analyze the flexibility of the
reduction method. As discussed in section 2.3 the re-
duction operation is realized as series of polynomial
multiplications. The number of individual multiplica-
tion operationsis determined by two factors: the order
of the finite field in consideration (2
m
) and the word-
length of the architecture (w). The RMR method of
reduction is flexible by nature, since it does not im-
pose any restriction on the order of the finite field or
the nature of the irreducible polynomial P(x). The
Barrett reduction method, which is be shown to be
a special case of RMR method imposes the restric-
tion deg(P(x) − x
m
) <
m
2
on the irreducible polyno-
mial P(x), in order to improve performance. The el-
liptic curves suggested by NIST follow this restriction
and therefore only two iterations of multiplications
are sufficient for the result to converge. We evaluated
the decrease in number of instructions brought about
by usage of an MIGF multiplier as a hardware as-
sist for multi-word multiplication in section 3.1. This
analysis is completely general in nature and we have
not made any assumption regarding the nature of the
irreducible polynomial. Therefore the speed-up we
computed applies in general to reduction with any ar-
bitrary irreducible polynomial.
3.3 Hardware Complexity of the
Modified IGF Multiplier
As shown in figure 2, we introduced a set of two-input
AND gates in each stage of the MIGF Multiplier to
enable two-word shift operations. In a w-bit instance
of the multiplier, two sets of w two input AND gates
are introduced. The first set of w two input AND gates
are used for masking the irreducible polynomial input
to the multiplier to zero. The second set of w two in-
put AND gates are used for enabling two-word shift
operation. This increase in hardware complexity is
compensated by the significant reduction in the num-
ber of operations brought about by using this multi-
plier as a hardware assist for reduction.
Table 1: Synthesis Results of a IGF Multiplier and an MIGF
Multiplier.
Type of Multi-
plier
Area in µm
2
Max. Operating
Freq. in MHz
IGF 42228 270
Multiplier
MIGF 42255 256
Multiplier
Table 2: NIST recommended Irreducible Polynomials.
Size Recommended Irreducible Polynomial
163 x
163
+ x
7
+ x
6
+ x
3
+ 1
233 x
233
+ x
74
+ 1
283 x
283
+ x
12
+ x
7
+ x
5
+ 1
409 x
409
+ x
87
+ 1
571 x
571
+ x
10
+ x
5
+ x
2
+ 1
4 RESULTS
In this section we present the synthesis results of a 32-
bit MIGF multiplier and evaluate the improvement in
performance of reduction operations over the NIST
curves using the MIGF multiplier.
4.1 Synthesis Results of a 32-bit
Modified IGF Multiplier
We implemented a 32-bit instance of an MIGF multi-
plier using verilog HDL and synthesized with Faraday
Tech 90nm standard performance library, using Syn-
opsys Design Vision. We compared the increase in
area and drop in maximum operating frequency (due
to addition of 2×32 extra two input AND gates) with
a IGF multiplier synthesized using same parameters.
The comparison is presented in table 1. Since these
results are not post-layout results, they are not accu-
rate, but are indicative of the fact that increase in hard-
ware complexity of the IGF multiplier for enabling
2w× w multiplication, is marginal.
4.2 Performance Improvement of
Reduction over NIST Curves
Table 2 lists the NIST recommended irreducible poly-
nomials over binary fields of different orders. We
evaluate the improvement in performance of reduc-
tion operation over these fields using a 32-bit MIGF
multiplier. Note that each of the polynomials ad-
here to the restriction deg(P(x) − x
m
) <
m
2
. Therefore
only two iterations of multiplications are sufficient for
completion of the reduction operation.
SECRYPT 2011 - International Conference on Security and Cryptography
56

Let us consider the first polynomial in the list
x
163
+ x
7
+ x
6
+ x
3
+ 1. Since deg(P(x) − x
163
) < 31,
all the terms in P
′
(x) fit within one 32-bit word. Be-
low we evaluate the number of operations involved
in the two iterations of reduction using the aforemen-
tioned polynomial.
• Iteration One:
P
′
(x) = x
7
+ x
6
+ x
3
+ 1
Number of words in C
h,0
(x) is m
c
=
163
32
= 6
Number of words in P
′
(x) is m
p
=
7
32
= 1
Number of terms present in P
′
(x) other than 1 is
p = 3
Total number of terms present in P
′
(x) is p
′
= 4
#SHIFT = 2m
c
p = 36
#XOR = (m
c
− 1)p+ (m
c
+ 1)(p
′
− 1) = 36
#Multiplications using a conventional Polyno-
mial Multiplier is m
c
= 6
#XOR using a conventional Polynomial Multi-
plier is (m
c
− 1) = 5
#Multiplications using an MIGF Multiplier is
given by m
c
+ 1 = 7
• Iteration Two:
Number of words in C
h,1
(x) is m
c
=
7
32
= 1
Number of words in P
′
(x) is m
p
=
7
32
= 1
#SHIFT = 2m
c
p = 6
#XOR = (m
c
− 1)p+ (m
c
+ 1)(p
′
− 1) = 6
#Multiplications using a conventional Polyno-
mial Multiplier is m
c
= 1
#XOR using a conventional Polynomial Multi-
plier is (m
c
− 1) = 0
#Multiplications using an MIGF Multiplier is
given by m
c
+ 1 = 2
Now let us consider the second polynomial x
233
+
x
74
+ 1 from table 2. Clearly (P(x)−x
233
) spans mul-
tiple words in a 32-bit environment. Below we evalu-
ate the number of operations involved in the two iter-
ations of reduction using the aforementioned polyno-
mial.
• Iteration One:
P
′
(x) = x
74
+ 1
Number of words in C
h,0
(x) is m
c
=
233
32
= 8
Number of words in P
′
(x) with at least one non-
zero term is m
p
= 2
Number of distinct terms present in P
′
(x) other
than 1 is p = 1
Total number of terms present in individual words
of P
′
(x) is p
′
0
= 1 and p
′
1
= 1
#SHIFT = 2m
c
p = 16
#XOR = (m
c
− 1)p+ Σ
j
(m
c
+ 1)(p
′
j
− 1) = 14
#Multiplications using a conventional Polyno-
mial Multiplier is m
c
m
p
= 16
#XOR using a conventional Polynomial Multi-
plier is (m
c
− 1)m
p
= 14
Table 3: Number of Operations involved in reduction over
various NIST curves using three different techniques.
Size ITRERATION I ITERATION II
163
SW
#SHIFT 36 #SHIFT 6
#XOR 36 #XOR 6
POLY
#MULT 6 #MULT 1
#XOR 5 #XOR 0
MIGF #MULT 7 #MULT 2
233
SW
#SHIFT 16 #SHIFT 6
#XOR 6 #XOR 2
POLY
#MULT 16 #MULT 6
#XOR 14 #XOR 4
MIGF #MULT 18 #MULT 8
283
SW
#SHIFT 54 #SHIFT 6
#XOR 54 #XOR 6
POLY
#MULT 9 #MULT 1
#XOR 8 #XOR 0
MIGF #MULT 10 #MULT 2
409
SW
#SHIFT 26 #SHIFT 6
#XOR 12 #XOR 2
POLY
#MULT 26 #MULT 6
#XOR 24 #XOR 4
MIGF #MULT 28 #MULT 8
571
SW
#SHIFT 108 #SHIFT 6
#XOR 108 #XOR 6
POLY
#MULT 18 #MULT 1
#XOR 17 #XOR 0
MIGF #MULT 19 #MULT 2
#Multiplications using an MIGF Multiplier is
given by (m
c
+ 1)m
p
= 18
• Iteration Two:
Number of words in C
h,1
(x) is m
c
=
74
32
= 3
Number of words in P
′
(x) with at least one non-
zero term is m
p
= 2
#SHIFT = 2m
c
p = 6
#XOR = (m
c
− 1)p+ Σ
j
(m
c
+ 1)(p
′
j
− 1) = 2
#Multiplications using a conventional Polyno-
mial Multiplier is m
c
m
p
= 6
#XOR using a conventional Polynomial Multi-
plier is (m
c
− 1)m
p
= 4
#Multiplications using an MIGF Multiplier is
given by (m
c
+ 1)m
p
= 8
Similarly we evaluated the number of operations
in each of the iterations of reduction operation over
the NIST curves. The numbers of operations are listed
in table 3. The fields SW, POLY and MIGF refer to
implementation of reduction using pure software al-
gorithm, a conventional polynomial multiplier and an
MIGF multiplier respectively. From table 3 it is evi-
dent that total number of operations is the least when
using an MIGF multiplier as hardware accelerator for
reduction.
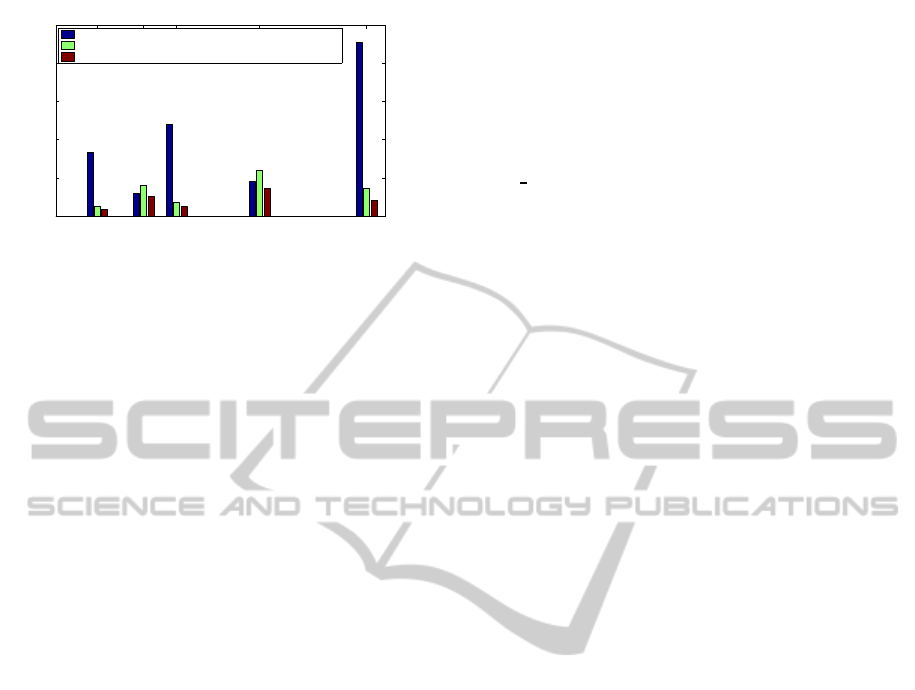
We present the instruction count in reduction over
the various NIST curves using the three differenttech-
niques in figure 3. It is evident form figure 3 that
the advantage of using hardware assists for reduc-
A METHOD FOR FLEXIBLE REDUCTION OVER BINARY FIELDS USING A FIELD MULTIPLIER
57
163 233 283 409 571
0
50
100
150
200
250
Size
Instruction Count
Instruction Count of Reduction Operation
Software Implementation
Hybrid Implementation Using Conventional Polynomial Multiplier
Hybrid Implementation Using Modified IGF Multiplier
Figure 3: Instruction count of Reduction Operation in three
different implementations.
tion is prominent when the there are large number
of terms present in the irreducible polynomial. This
is attributed to the fact that hardware assists in the
form of multipliers combine a number of shift and
XOR operations into a single multiplication. If there
are less number of terms present in P
′
(x), the effects
of this combination is less prominent. In fact, as in
the case of the two polynomials x
409
+ x
87
+ 1 and
x
233
+ x
74
+ 1, the hybrid technique using a polyno-
mial multiplier may perform worse than a simple soft-
ware realization for certain irreducible polynomials.
However, the absence of XOR operations in form-
ing the partial products makes the proposed technique
(using an MIGF multiplier) perform better than both
the other techniques, for all the NIST polynomials.
5 CONCLUSIONS
In the context of efficient realization of elliptic Curve
Cryptography algorithms, we recognized the impor-
tance of an efficient and flexible solution for reduction
operations over binary fields. In this paper we pre-
sented a method for flexible reduction. The method
is especially suitable for coarse-grained platforms
where, granularity of data and operations play a major
role in the computations. We identified that efficiency
of the underlying polynomial multiplication opera-
tions determines the speed of reduction algorithms
like the Repeated Multiplication Reduction method or
the Barrett Reduction method. In this context we pro-
posed a design of a polynomial multiplier based on
the well-known Interleaved Galois Field (IGF) mul-
tiplier. This MIGF multiplier is shown to achieve a
significant improvement in throughput over a purely
software realization or a hybrid implementation using
a conventional polynomial multiplier.
REFERENCES
Barrett, P. (1987). Implementing the rivest shamir and adle-
man public key encryption algorithm on a standard
digital signal processor. In Odlyzko, A., editor, Ad-
vances in Cryptology CRYPTO 86, volume 263 of
Lecture Notes in Computer Science, pages 311–323.
Springer Berlin / Heidelberg. 10.1007/3-540-47721-
7 24.
Eberle, H., Gura, N., Shantz, S. C., and Gupta, V. (2003).
A cryptographic processor for arbitrary elliptic curves
over GF(2
m
). Technical report, Mountain View, CA,
USA.
Hinkelmann, H., Zipf, P., Li, J., Liu, G., and Glesner, M.
(2009). On the design of reconfigurable multipliers
for integer and galois field multiplication. Micropro-
cessors and Microsystems - Embedded Hardware De-
sign, 33(1):2–12.
Karatsuba, A. and Ofman, Y. (1963). Multiplication of
multidigit numbers on automata. Soviet Physics—
Doklady, 7(7):595–596.
Knezevic, M., Sakiyama, K., Fan, J., and Verbauwhede, I.
(2008). Modular reduction in GF(2
n
) without pre-
computational phase. In von zur Gathen, J., Ima˜na,
J. L., and C¸etin Kaya Koc¸, editors, WAIFI, volume
5130 of Lecture Notes in Computer Science, pages
77–87. Springer.
Peter, S., Langend¨orfer, P., and Piotrowski, K. (2007). Flex-
ible hardware reduction for elliptic curve cryptogra-
phy in GF(2
m
). In Lauwereins, R. and Madsen, J.,
editors, DATE, pages 1259–1264. ACM.
Saqib, N. A., Rodriguez-Henriquez, F., and Diaz-Pirez, A.
(2004). A parallel architecture for fast computation of
elliptic curve scalar multiplication over GF(2
m
). Par-
allel and Distributed Processing Symposium, Interna-
tional, 4:144a.
Satoh, A. and Takano, K. (2003). A scalable dual-field ellip-
tic curve cryptographic processor. IEEE Transactions
on Computers, 52:449–460.
SECRYPT 2011 - International Conference on Security and Cryptography
58
