
HYBRID INFRASTRUCTURE AS A SERVICE
A Cloud-oriented Provisioning Model for Virtual Hosts and Accelerators in
Hybrid Computing Environments
Thomas Grosser, Gerald Heim, Wolfgang Rosenstiel
University of T¨ubingen, Computer Engineering Department, T¨ubingen, Germany
Utz Bacher, Einar Lueck
IBM Deutschland Research & Development GmbH, Ehningen, Germany
Keywords:
Hybrid computing, Hybrid infrastructure, HyIaaS, Mainframe, Accelerators, Logical system modeling.
Abstract:
State of the art cloud environments lack a model allowing the cloud provider to leverage heterogeneous re-
sources to most efficiently service workloads. In this paper, we argue that it is mandatory to enable cloud
providers to leverage heterogeneous resources, especially accelerators, to optimize the workloads that are
hosted in accordance with the business model. For that we propose a hybrid provisioning model that builds on
top of and integrates into state of the art model-driven provisioning approaches. We explain how this model
can be used henceforth to handle the combinatoric explosion of accelerators, fabrics, and libraries and discuss
how example workloads benefit from the exploitation of our model.
1 INTRODUCTION
Large data centers consist of many machines and var-
ious architectures. Virtualization is widely used to en-
able abstraction from hardware and provide isolation
of systems and its data, as well as driving utilization
of resources to achieve cost-effective data process-
ing. Moreover, special-purpose hardware becomes
popular to increase processing efficiency. The cloud
paradigm has been accepted by data centers for fine-
grained billing of customers. We propose to extend
the cloud provisioning model towards heterogeneous
collections of resources, which delivers Hybrid In-
frastructure as a Service (HyIaaS for short). This
leverages cost-effectiveness across all involved sys-
tems and special-purpose resources. In hybrid infras-
tructure services, accelerator resources can be shared,
thereby increasing utilization of such attachments.
Accelerator sharing is abstracted in the infrastructure,
so that accelerator software runtime components do
not need to be aware of any level of virtualization.
Business data is typically processed by robust,
centralized systems, implemented on server farms or
mainframes. Especially mainframes come with so-
phisticated reliability, availability, and serviceability
capabilities (RAS). The strengths of such systems are
efficient processing of transactional, data-intensive,
and I/O-intensive workloads. On the other hand, com-
pute and data-intensive workloads in the field of high
performance computing (HPC) demand for additional
compute resources. In order to move to hybrid sys-
tems, additional management functionality must be
incorporated. As an example, the latest Mainframe
IBM zEnterprise (IBM, 2010b) is extended with racks
full of blades, which can be used as accelerators
or appliances. The Unified Resource Manager run-
ning on the Mainframe provides common manage-
ment across the system complex. Moreover, the first
supercomputer to reach a peak performance of over
one petaflops was the supercomputer built by IBM at
the Los Alamos National Laboratory (LANL) (Koch,
2008). This setup is also a hybrid system, consisting
of two different processor architectures. In this paper,
we envision that cloud-oriented hybrid infrastructure
provisioning services will become common practice
in the future. Thereby, we discuss multi-tenant access
and a consolidated programmer’s view that allows ab-
straction from the underlyinginterconnect in a hetero-
geneous data center. With upcoming implementations
of the proposed model it will be possible to evaluate
the feasibility of our approach.
170
Grosser T., Heim G., Rosenstiel W., Bacher U. and Lueck E..
HYBRID INFRASTRUCTURE AS A SERVICE - A Cloud-oriented Provisioning Model for Virtual Hosts and Accelerators in Hybrid Computing
Environments.
DOI: 10.5220/0003391001700175
In Proceedings of the 1st International Conference on Cloud Computing and Services Science (CLOSER-2011), pages 170-175
ISBN: 978-989-8425-52-2
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

2 RELATED WORK
In the course of hybrid system exploration we are
working on two applications, which are outlined in
this section, and will be used later in this paper to ex-
emplify the application of the proposed model. The
first application under investigation implements ac-
celeration of compute-intensive tasks for insurance
product calculations (Grosser et al., 2009). Compute-
intensivetasks are executed by network-attached IBM
POWER blades. Acceleration is achieved through
leveraging parallelism and calculating insurance al-
gorithms by just-in-time compiled code snippets on
the attached blades. Requirements towards availabil-
ity are met by tightly controlling execution from the
host’s off-loading facility.
The second application scenario focuses on nu-
meric and data-intensive calculations of seismic mod-
eling problems. Seismic algorithms are parallelized
on various types of accelerators, each having its
advantages and disadvantages (Clapp et al., 2010).
FPGAs can be exploited efficiently, by implement-
ing pipeline-based stream processing architectures.
Besides FPGAs, we also investigate in CPU SIMD
processing, threads, MPI, and OpenCL. By using
OpenCL we are moreover able to evaluate multiple
architectures, like different types of CPUs and GPUs.
The focus of this application is to have a broad range
of accelerators and programming environments, in or-
der to evaluate different compositions of a hybrid sys-
tem and its resulting performance.
3 PROBLEM STATEMENT
In the cloud computing anatomy there are three lay-
ers to deliver infrastructure, platform, and software as
a service, i.e. IaaS, PaaS, and SaaS, respectively (Va-
quero et al., 2008). To service infrastructure, phys-
ical deployment methods are used to implement the
established cloud services. Infrastructure deployment
methods are realized using model-based approaches,
which enable abstraction from the underlying hard-
ware. Today, no cloud provisioning models exist for
offering multiple adapted accelerator environments
1
:
complexity is imposed on the administrator to build
workload optimized solutions based on resources of
various types and architectures. A composite system
built from host resources, connectivity, and accelera-
tor resources needs to be provisioned as a single entity
in order to establish hybrid infrastructure. Abstrac-
tion of the physics allows for both accelerator sharing
1
Meanwhile, Amazon EC2 offers Nvidia-based GPU com-
pute racks (http://aws.amazon.com/ec2/hpc-applications/).
and flexibility of the cloud service provider. Isolation
needs to be ensured to create a multi-tenancy capable
landscape.
Table 1 lists the manifoldness of an arbitrary het-
erogeneous data center. The table allows to create any
combination of host, accelerator, fabric, including the
desired programming platform.
Table 1: Each possible combination imposes challenges to
handle hosts and interrelationships to multiple accelerators.
In addition, the used library must be adapted to the under-
lying system and interconnect.
Host Accelerator Fabric Library
i386 Cell/B.E. Ethernet OpenCL
x86 64 GPGPU InfiniBand MPI
s390 Cluster PCIe DaCS/ALF
POWER FPGA/DRP Myrinet SOAP
Itanium DataPower Quadrics CUDA
Manufacturers develop all kinds of multi-core
and many-core accelerators, each having its targeted
application domain. This includes, among others,
multi-core CPUs, GPGPUs, Cell/B.E., and FPGAs.
Arising standards for heterogeneous computing, like
OpenCL, enable to use GPGPUs for number crunch-
ing. An OpenCL implementation is provided, among
others, for Nvidia GPUs (NVIDIA, 2010), Cell/B.E.,
and POWER (IBM, 2010a). OpenCL enables easy
parallelization over a device’s compute units, exploit-
ing data-parallel computing power. In order to scale
an accelerated application, multiple devices must be
incorporated, thus additional management function-
ality is needed in the host code to queue opera-
tions efficiently. As another example, some appli-
cation domains fit efficiently onto FPGAs, eventu-
ally forming appliances. Multiple access to these re-
sources must also be shared. Regarding the fabric,
in HPC, InfiniBand may be preferred over Ethernet.
Traditional Ethernet networking allows to send mes-
sages, while InfiniBand channel adapters also provide
RDMA capabilities. Also, Ethernet adapters may be
equipped with RDMA capabilities to reduce commu-
nication overhead, though. Unlike networking, PCIe
is an attachment approach where devices are accessi-
ble through the memory-mapped PCI address space.
Thus, the use of PCIe-attached accelerators is differ-
ent from network-attached ones. From an infrastruc-
ture point of view, there is a variety of available hosts,
available accelerators, fabrics, programming environ-
ments, frameworks, and libraries. In the following
sections, we introduce the model and discuss how ex-
ample workloads benefit from hybrid infrastructure.
HYBRID INFRASTRUCTURE AS A SERVICE - A Cloud-oriented Provisioning Model for Virtual Hosts and
Accelerators in Hybrid Computing Environments
171
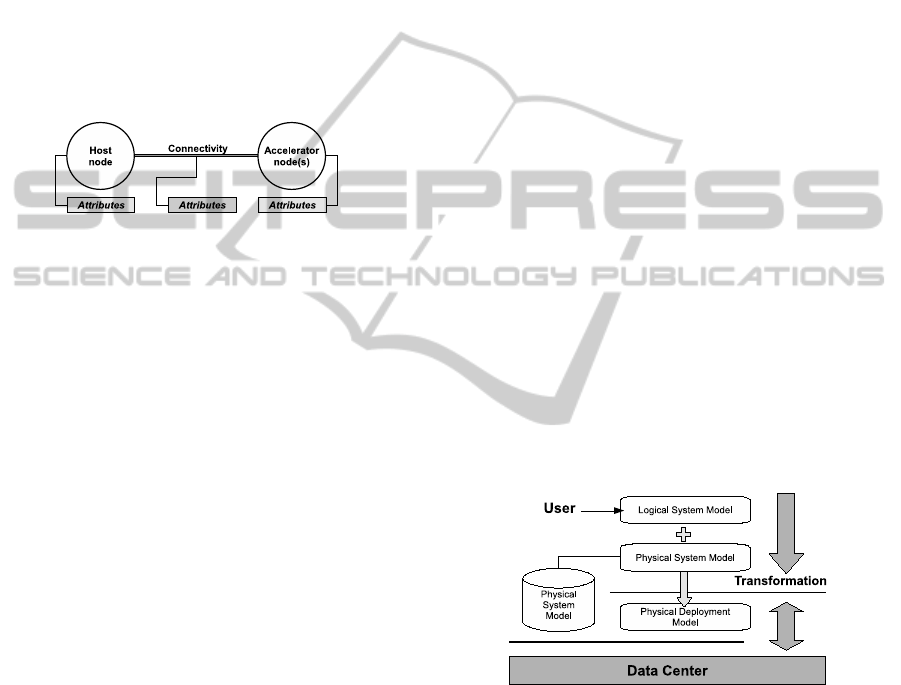
4 HYBRID PROVISIONING
MODEL
To achieve abstraction from the underlying hetero-
geneous data center, an object-relationship model is
used to define a logical system structure. By us-
ing this, host systems, compute nodes, and acceler-
ators are specified, including additional information
on their interrelationship. That is, in the logical view
the system is modeled consisting of hosts, accelera-
tors, and the connection. This enables to model con-
nectivity requirements between two nodes. Using this
representation, it is possible to create arbitrary logical
configurations of a hybrid system.
Figure 1: The logical system structure is built using an
object-relationship model.
The object-relationship model in figure 1 enables
cloud providers to implement the attributes according
to their particular business model. A cloud provider
with a very simple and homogeneous data center
could for example focus on a model that allows a
customer to specify attributes like number of CPUs,
memory, number of GPGPUs and required through-
put, regarding the interconnect. In contrast, another
cloud provider with a more advanced heterogeneous
data center allows the customer to specify the host
architecture including a specific accelerator architec-
ture, thereby offering various attributes. Attributes are
used to operate on multiple levels, i.e. to reflect physi-
cal attributes, business goals, deployment constraints,
and performance requirements.
The use of a model as abstraction allows trans-
formations to generate physical deployment config-
urations. In this section, we study model-based ap-
proaches that are used to deploy physical systems us-
ing automated processes. Based on this, we propose
a model flow to handle hybrid systems. To service
Hybrid Infrastructure as a Service, we claim that ac-
celerator resources are connected to the host system
and appear as fabric-attached devices in the infras-
tructure system. The idea is to provide a single re-
liable node instead of multiple individual nodes. To
accommodate multiple users, an accelerator sharing
model is discussed which allows to handle different
types of accelerators. According to our hybrid appli-
cation scenarios, considerations regarding the runtime
management are introduced as well.
4.1 libvirt on Linux
The model proposed in this section is intended to be
integrated as part of
libvirt
(Coulson et al., 2010)
on Linux-based systems in the future. We aim to use
libvirt
as part of our hybrid managementprototype,
as it allows to manage virtual machines, virtual net-
works, and storage. Adding extensions to
libvirt
may enable creation, attachment, and operation sup-
port of accelerators, forming hybrid infrastructure.
4.2 Prerequisites
Physical deployment is an automated process to ser-
vice connectivity, security, and performance. Model-
based approaches are used to service physical topol-
ogy designs according to transformation rules and
constraints. There are several approaches that can be
adapted to setup infrastructure in constrained environ-
ments (Eilam et al., 2004). The underlying object-
relationship model shown in figure 1 is used to repre-
sent logical resources including the components’ rela-
tionships. The flow depicted in figure 2 represents the
transformation process to a physical deployment. The
user provides a Logical System Model that is trans-
formed to a Physical Deployment Model by using an
Physical System Model, which represents hardware
available in the data center. At each stage of the trans-
formation the model incorporates attributes represent-
ing business goals and configuration dependencies.
Figure 2: The physical deployment includes VM creation,
network deployment, etc.
Using model-based approaches it is also possible
to define platform services and applications by sep-
arating business logic and IT deployment. Transfor-
mation rules are then used to create platform-specific
models from platform-independent models. Targeted
applications are service-oriented architectures with
Web service interfaces (Koehler et al., 2003). More-
over, frameworks for enhanced autonomic manage-
ment of distributed applications are enabled using
similar techniques (Dearle et al., 2004). The opti-
mal use of hardware in large heterogeneous data cen-
CLOSER 2011 - International Conference on Cloud Computing and Services Science
172
ters leads to distributed service management (Adams
et al., 2008). The proposed architecture uses de-
tailed knowledge about available resources including
resource interrelationships to achieve sharing. To im-
plement a refinement process, the deployment is grad-
ually improved as the system communicates the cur-
rent status of the physical resources back into the
logical model to adjust further deployment configu-
rations. As in other model-based approaches, rules
and constraints are used during transformation which
are denoted as attributes in figure 1.
As model-based approaches are used to imple-
ment various services, such models can also be de-
fined to provision cloud-oriented infrastructure. The
hardware of large heterogeneous data centers can be
shared to multiple users, thus improving overall uti-
lization of few specialized hardware. In order to fur-
ther move from heterogeneous to managed hybrid in-
frastructure deployment, it is crucial to define models
specific to accelerator management. This includes an
accelerator runtime, which can be serviced as part of
the hybrid infrastructure. The runtime is part of a soft-
ware stack to query, allocate, and operate accelerator
engines. Out-of-band monitoring may be used by the
cloud service provider to obtain capacity and utiliza-
tion data with respect to all resources in the hybrid
environment. According to user-specified goals, the
deployment of shared accelerator resources is config-
ured autonomously.
4.3 Proposed Hybrid Model Flow
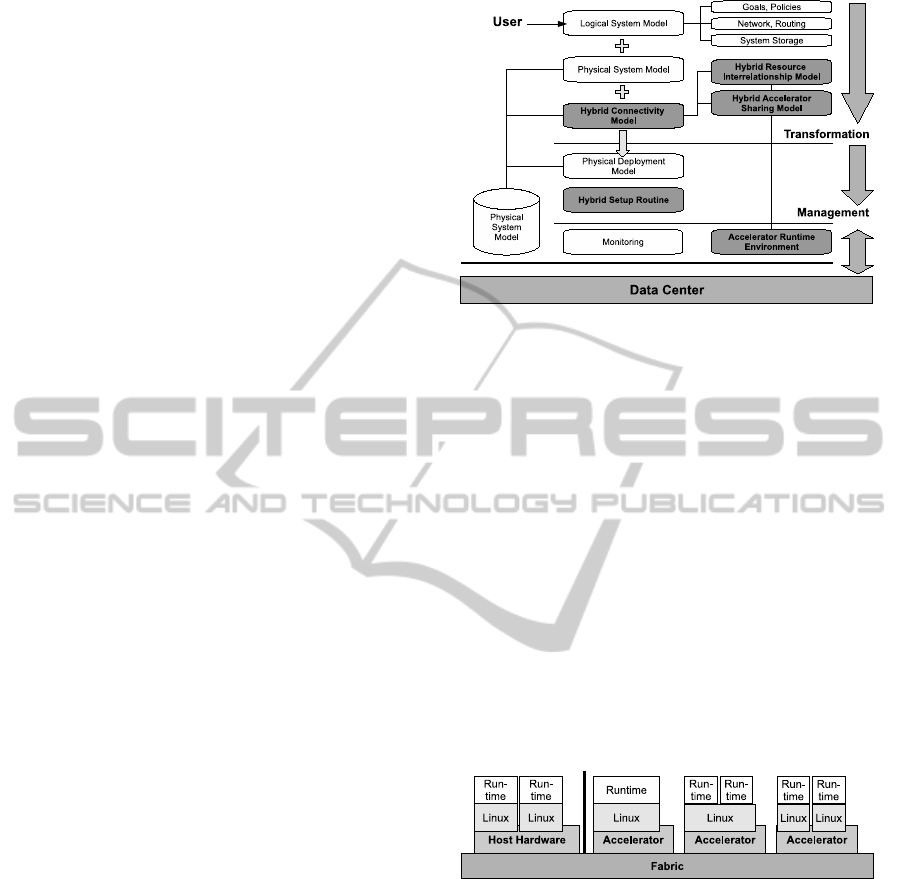
In contrast to figure 2, the HyIaaS deployment flow
uses additional models and methods (shaded gray), as
depicted in figure 3. The transformation requires an
additional Hybrid Connectivity Model in order to re-
flect available fabrics in the data center. Attributes
include bandwidth and latency allowing implementa-
tion of Quality of Service. Besides the physical de-
ployment, a Hybrid Setup Routine is created, which
initializes and configures involved resources, i.e. cre-
ates the host node and enables connectivity to desig-
nated accelerators. As soon as the fabric is shared
between accelerator instances, isolation of the logi-
cal connectivity is included (e.g. via virtual LANs) to
avoid interference of other host or accelerator nodes.
Another essential part of our flow is the Resource
Interrelationship Model, which can define limitations
and constraints used to set up the runtime environ-
ment or select connectivity and acceleration resources
by meeting performance requirements. In the remain-
der of this section, the Accelerator Sharing Model and
Accelerator Runtime Environment will be described
more detailed.
Figure 3: Hybrid Infrastructure as a Service flow.
4.4 Accelerator Sharing Model
While virtualization can improve overall resource
utilization, the variety of accelerator architectures
imposes several challenges on sharing and multi-
tenancy. Figure 4 depicts three accelerators, each of-
fering hardware resource abstraction at different lev-
els. Virtualization offers entire virtual sets of ac-
celerator hardware, each instance running the entire
accelerator-resident software service stack. An exam-
ple for this level of virtualization is a Linux-based
accelerator framework running on general purpose
CPUs virtualized by a hypervisor. Not all sorts of
accelerators exhibit such mature virtualization capa-
bilities. Therefore accelerator sharing can also be
achieved on other levels by means of multi-tenancy
in the accelerator-resident software service stack.
Figure 4: Sharing of accelerators at different level.
In correlation to figure 4 the schemes for acceler-
ator abstraction and sharing include:
• Fully virtualized, using a hypervisor
• Time sharing, scheduling
• Queuing, with ordering and blocking
• Exclusive use of the accelerator
The sharing technique imposes implications to ef-
ficient data handling. This includes data and cache
locality, scheduling, and connectivity to achieve ad-
equate performance and utilization. Multi-tenancy
of the accelerator service requires proper abstrac-
tion, which allows for isolation between different con-
HYBRID INFRASTRUCTURE AS A SERVICE - A Cloud-oriented Provisioning Model for Virtual Hosts and
Accelerators in Hybrid Computing Environments
173

sumers of virtual accelerators. Selection of the shar-
ing technique can be performed by the transformation
process of the HyIaaS flow. It may be guided by per-
formance requirements as stated in the logical system
model defined by the user. Selection of the accelera-
tor architecture can be made an attribute of the logi-
cal system model, or can be determined as part of the
transformation process, again guided by definitions of
the user.
4.5 Accelerator Runtime Environment
Figure 5 shows the individual layers of the HyIaaS
model, with the accelerator runtime as top layer. The
accelerator runtime environment can be provided by
the cloud service provider as part of a pre-deployed
image. It depends on the architecture and attach-
ment type of the accelerator and offers a well-defined
set of interfaces. Each combination of accelerator,
fabric and API may result in a different implemen-
tation of the accelerator runtime environment, and
some combinations may not exist at all. The API of-
fered by the accelerator runtime also defines the in-
terface that applications have to use to consume ac-
celerator resources, and is therefore specified as part
of the logical system model. In most cases, the user
will start out with a desired API and derive lower
levels of the system model from that. Use of fu-
ture software as well as applicability to future accel-
erator architectures suggest the use of de-facto stan-
dards like OpenCL, rather than vendor-proprietary
programming paradigms. Quality of Service im-
provements like redundant execution, job retry, and
accelerator failover, can be implemented efficiently in
the runtime environment, if not offered by the under-
lying fabric and accelerator infrastructure.
Figure 5: Essential functionality for the Hybrid Infrastruc-
ture as a Service model.
5 APPLICATION OF THE MODEL
In this section, we outline how the applications stated
in section 2 can be represented using the proposed
cloud-oriented hybrid infrastructure model.
5.1 Insurance Calculations
The insurance application is used for both batch and
interactive processing. While acceleration of batch
processing results in shorter batch windows and ben-
efits from higher batch throughput in off-shift hours,
the interactive processing of insurance calculations
has requirements to handle workload peaks and must
be able to return results with low latency. In both
cases, hybrid infrastructure can enable workload op-
timized processing and improves the capacity of the
overall solution. In the logical system model for this
application, the host system and multiple CPUs as
accelerators, connected through an IP-capable fabric,
are defined. To scale out according to workloads, the
logical system defines a 1 : n correlation of host and
accelerators. In order to guarantee low-latency re-
sults, the network topology must be adapted to avoid
bottlenecks. As this application is run on a main-
frame, the acceleration has to incorporate RAS ca-
pabilities which are specified in the logical system
and result in deployment of an appropriate acceler-
ator runtime environment. In this case, the accelera-
tor communicates with a host-side session manager to
dispatch individual tasks.
5.2 Seismic Processing
The seismic application exhibits more degrees of free-
dom for selecting accelerators. The host application
itself started out as cluster application, working on
large amounts of seismic data. In order to achieve
maximum compute throughput, the workload is dis-
tributed to several nodes, which also applies to the
hybrid environment. The targeted accelerator can be
a combination of the following: a cluster of homo-
geneous nodes, a cluster of OpenCL-enabled nodes
(CPUs and GPUs), or a cluster of specialized FPGA
accelerators. Besides FPGAs and GPGPUs (Clapp
et al., 2010), the Cell/B.E. processor may also be con-
sidered (Perrone, 2009). For maximum bandwidth,
InfiniBand may be favored over Ethernet, which is ex-
pressed by performance attributes in the logical sys-
tem structure. In any of these combinations, the trans-
formation has to find a suitable network topology by
evaluating the resource interrelationship model, at-
tach appropriate accelerators, and establish the proper
runtime environment. So, hybrid infrastructure has
to support selecting the right runtime with regard to
the specified accelerator, fabric, and API. Assum-
ing OpenCL is used as acceleration method, the run-
CLOSER 2011 - International Conference on Cloud Computing and Services Science
174

time may be extended to transparently switch to other
OpenCL-enabled nodes.
6 CURRENT AND FUTURE
WORK
In the course of our current work, we started to im-
plement the proposed model on Linux-based systems
using
kvm
as hypervisor and
libvirt
as infrastruc-
ture provisioning engine. By using
libvirt
, the sys-
tem description is provided as XML. To implement
the flow of our model, hybrid infrastructure XML
descriptions have to be defined and integrated into
libvirt
. In the current work, we ported libvirt to
s390
in order to enable the basic flow as depicted in
figure 2. Using the application scenarios described in
the previous sections, we address the proposed flow
shown in figure 3. That way, the provided hybrid in-
frastructure can, for example, be modified or extended
by accelerator elements as well as networking or de-
vice structures.
7 CONCLUSIONS
In this paper we propose a model to enable cloud pro-
visioning of accelerator resources in heterogeneous
data centers. This will allow cloud users to con-
sume composite systems equipped with accelerator
resources, instead of having to deal with a multiplic-
ity of nodes and orchestration thereof. According to
our proposal, the user specifies his requirements via
a logical system structure, consisting of nodes, accel-
erators, and fabrics. The model flow allows produc-
ing a transformation engine, which maps the logical
system structure to the actual hardware of the data
center, fulfilling the user’s requirements specified as
model attributes. We introduce sharing of acceler-
ators and multi-tenancy, which requires appropriate
isolation at the accelerator entity as well as in the fab-
ric. A runtime software stack allows for using the ac-
celerator from the host, thereby abstracting from the
environment’s actual implementation. Such use of ac-
celerator resources attached to host nodes results in a
cloud paradigm to combine the advantages of work-
load optimized systems with the data center’s com-
mercial model: applications can improve compute ef-
ficiency through the use of accelerators, and the cloud
provider can achieve high utilization and offer a cost-
competitive environment.
REFERENCES
Adams, R., Rivaldo, R., Germoglio, G., Santos, F., Chen,
Y., and Milojicic, D. S. (2008). Improving distributed
service management using Service Modeling Lan-
guage (SML). Salvador, Bahia. IEEE.
Clapp, R. G., Fu, H., and Lindtjorn, O. (2010). Selecting
the right hardware for reverse time migration (in High-
performance computing). In Leading Edge, pages 48–
58, Tulsa, OK.
Coulson, D., Berrange, D., Veillard, D., Lalancette, C.,
Stump, L., and Jorm, D. (2010). libvirt 0.7.5: Ap-
plication Development Guide. URL: http://libvirt.org/
guide/pdf/.
Dearle, A., Kirby, G. N., and McCarthy, A. J. (2004).
A Framework for Constraint-Based Deployment and
Autonomic Management of Distributed Applications.
Autonomic Computing, International Conference on.
Eilam, T., Kalantar, M., Konstantinou, E., Pacifici, G.,
Eilam, T., Kalantar, M., Konstantinou, E., and Paci-
fici, G. (2004). Model-Based Automation of Service
Deployment in a Constrained Environment. Research
report, IBM.
Grosser, T., Schmid, A. C., Deuling, M., Nguyen, H.-N.,
and Rosenstiel, W. (2009). Off-loading Compute In-
tensive Tasks for Insurance Products Using a Just-in-
Time Compiler on a Hybrid System. In CASCON ’09,
pages 231–246, New York, NY, USA. ACM.
IBM (2010a). OpenCL Development Kit for Linux on
Power. URL: http://www.alphaworks.ibm.com/tech/
opencl.
IBM (2010b). The IBM zEnterprise System – A new di-
mension in computing URL: http://www-01.ibm.com/
common/ssi/rep ca/9/877/ENUSZG10-0249/ENUSZ
G10-0249.PDF.
Koch, K. (2008). Roadrunner Platform Overview. URL:
http://www.lanl.gov/orgs/hpc/roadrunner/pdfs/Koch -
Roadrunner Overview/RR Seminar - System Over-
view .pdf.
Koehler, J., Hauser, R., Kapoor, S., Wu, F. Y., and Ku-
maran, S. (2003). A Model-Driven Transformation
Method. In EDOC ’03, Washington, DC, USA. IEEE
Computer Society.
NVIDIA (2010). Developer Zone – OpenCL. URL:
http://developer.nvidia.com/object/opencl.html.
Perrone, M. (2009). Finding Oil with Cells: Seismic Imag-
ing Using a Cluster of Cell Processors. URL: https://
www.sharcnet.ca/my/documents/show/44.
Vaquero, L. M., Rodero-Merino, L., Caceres, J., and Lind-
ner, M. (2008). A break in the clouds: towards a cloud
definition. SIGCOMM Comput. Commun. Rev., 39.
HYBRID INFRASTRUCTURE AS A SERVICE - A Cloud-oriented Provisioning Model for Virtual Hosts and
Accelerators in Hybrid Computing Environments
175
