MULTI-MODAL PERSON DETECTION AND TRACKING FROM
A
MOBILE ROBOT IN A CROWDED ENVIRONMENT
A. A. Mekonnen
†‡
, F. Lerasle
†,‡
and I. Zuriarrain
¶
†
CNRS, LAAS, 7 Avenue du Colonel Roche, 31077 Toulouse Cedex 4, France
‡
Universit´e de Toulouse, UPS, INSA, INP, ISAE, LAAS, F-31077 Toulouse, France
¶
University of Mondragon, Goi Eskola Politeknikoa, Mondragon, Spain
Keywords:
Multi-person tracking, Multi-modal data fusion, MCMC particle filtering, Interactive robotics.
Abstract:
This paper addresses multi-modal person detection and tracking using a 2D SICK Laser Range Finder and a
visual camera from a mobile robot in a crowded and cluttered environment. A sequential approach in which
the laser data is segmented to filter human leg like structures to generate person hypothesis which are further
refined by a state of the art parts based visual person detector for final detection, is proposed. Based on
this detection routine, a Monte Carlo Markov Chain (MCMC) particle filtering strategy is utilized to track
multiple persons around the robot. Integration of the implemented multi-modal person detector and tracker
in our robotic platform and associated experiments are presented. Results obtained from all tests carried out
have been clearly reported proving the multi-modal approach outperforms its single sensor counterparts taking
detection, subsequent use, computation time, and precision into account. The work presented here will be used
to define navigational control laws for passer-by avoidance during a service robot’s person following activity.
1 INTRODUCTION
Currently, there is more demand to use robots in ev-
eryday life, a demand for their introduction into hu-
man all day environments. For this task, robots should
be able to interact with humans at a higher level with
more natural and effective interaction. One such inter-
action, the ability of a mobile robot to automatically
follow a person in public areas, is a key issue to effec-
tively interact with the surrounding world. Recently
various researchers have reported successful person
following activities from a mobile robot (Germa et al.,
2009), (Calisi et al., 2007), (Chen and Birchfield,
2007). A key point in person following task is safe
interaction as the workspace at any moment is shared
by humans and the robot. The robot should be capa-
ble of avoiding all passers-by in the environment in
a socially acceptable manner while carrying out the
activity. Some authors addressed this as static ob-
stacle avoidance considering people as static obsta-
cles e.g.(Calisi et al., 2007). We argue otherwise,
an effective collision avoidance not only has to cir-
cumvent static objects in the environment, but it also
has to take the dynamics of the persons in the sur-
rounding into account. This entails for perception of
the whereabouts and dynamics of humans sharing the
workspace. To the best of our knowledge, an assis-
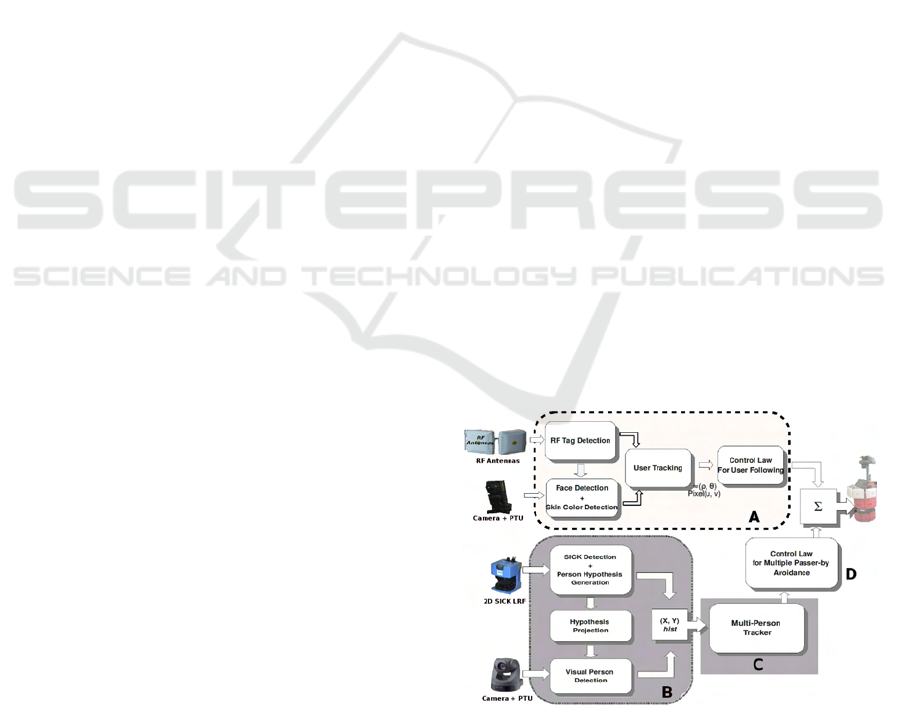
Figure 1: A block diagram of our complete envisaged sys-
t
em: Person Following with passer-by avoidance in a so-
cially acceptable manner.
tant robot capable of following a given person taking
the dynamics of the passers-by into consideration and
avoiding them in a socially acceptable way does not
yet exist (Fong et al., 2003).
A block diagram of our complete envisaged sys-
tem is shown in figure 1. The block diagram rep-
resents a person following activity with passer-by
avoidance in a socially acceptable manner (keeping a
social distance from surrounding persons while at the
same time taking their dynamics into consideration)
511
A. Mekonnen A., Lerasle F. and Zuriarrain I..
MULTI-MODAL PERSON DETECTION AND TRACKING FROM A MOBILE ROBOT IN A CROWDED ENVIRONMENT.
DOI: 10.5220/0003367705110520
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2011), pages 511-520
ISBN: 978-989-8425-47-8
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

by a service robot. The person following activity, the
area labeled ‘A’ in figure 1, has been successfully ad-
dressed in (Germa et al., 2009). The work presented
here addresses detection and tracking of multiple peo-
ple around the robot, the shaded areas: block ‘B’ and
‘C’ in figure 1, while the control law for passer-by
avoidance will be presented in future works. In a nut-
shell, the objective of the work presented in this pa-
per is detection and tracking of people in the robot
vicinity maintaining a correct trajectory of all tracked
people. It is aimed for defining control laws for so-
cially acceptable passer-by avoidance, during person
following activity, in a crowded public environment.
Automated person detection/tracking finds its ap-
plications in many areas including robotics, video-
surveillance, pedestrian protection systems, auto-
mated image and video indexing. Contrary to video-
surveillance applications where conventional back-
ground subtraction can be used, person detection is
more challenging in mobile robotics due to sensor
limitations, short fields of view and motion of embed-
ded sensors, and computationalrequirements for reac-
tive response acceptable by humans. All these chal-
lenges make successful person detections and track-
ing based on a single sensor very difficult. Sev-
eral works on person detection in the robotic com-
munity are based on vision and Laser Range Find-
ers (LRFs)(Schiele et al., 2009). Eventhough vision
based person detection yields a lot of information, de-
tections are very sensitive to illumination variation,
deformations, and partial occlusions on top of the as-
sociated high computational cost. Person detection
based on LRFs are computationally cheap and in-
sensitive to illumination. But their information con-
tent is not discriminative enough for robust detec-
tion unless used in a non-cluttered environment with
a priori learnt environment map which is not realis-
tic for crowded dynamic scenes. For real world sce-
narios, well established approaches combine inputs
from more than one sensory channel, a majority of the
works combining vision and Laser, e.g. (Zivkovic and
Kr¨ose, 2007) (Spinello et al., 2008). In this vein, we
propose a multi-modal person detector that uses a 2D
SICK Laser Range Finder (LRF) and a visual camera
for detecting multiple persons around the robot. A se-
quential approach in which the laser data is segmented
to filter human leg like structures to generate person
hypothesis which are further refined by a state-of-the-
art parts based visual person detector for final detec-
tion, is proposed. To be able to make spatio-temporal
analysis of the targets, we have also employed track-
ing based on the detections.
The literature in multi-target tracking contains dif-
ferent approaches, most commonly: Multiple Hy-
pothesis Tracker (MHT)(Reid, D., 1979), Joint Prob-
abilistic Data Association Filter (JPDAF)(Rasmussen
and Hager, 2001), centralized (Isard and Mac-
Cormick, 2001) and decentralized particle filters
(PFs) (Breitenstein et al., 2009), and MCMC PF
(Khan et al., 2005). MHT is computationally expen-
sive as the number of hypothesis grows exponentially
over time, while JPDAF is applicable to tracking a
fixed number of targets. The decentralized particle
filtering scheme, based on multiple independent PFs
per target, suffers from the “hijacking” problem since
whenever targets pass close to one another, the tar-
get with the best likelihood score takes the filters of
nearby targets. The centralized PF scheme, a parti-
cle filter with a joint state space of all targets, is not
viable for more than three or four targets due to the
associated computational requirement. A more ap-
pealing alternative in terms of performance and com-
putational requirement is the MCMC PF. MCMC PF
replaces the traditional importance sampling step in
joint PFs by an MCMC sampling step overcoming
the exponential complexity and leading to a more
tractable solution. For varying number of targets,
RJMCMC PF, an extension of MCMC to variable
dimensional state space, has been pioneered to per-
form successful tracking (Khan et al., 2005). The
MCMC PF frame work including RJMCMC PF has
been validated in video surveillance context solely on
visual data, e.g.(Smith et al., 2005). Inspired by this,
we have used RJMCMC PF for multi-person tracking
driven by our multi-modal detector with sensors em-
bedded on a robot. Implementation details along with
integration in our robotic platform, associated exper-
iments, and evaluation results are presented, proving
the proposed approach outperforms its single sensor
counterparts taking detection, subsequent use, com-
putation time, and precision into account.
This paper is structured as follows: section 2 dis-
cusses our multi-modal person detector implementa-
tion while section 3 presents our implementation of
the RJMCMC PF tracker. Integration of the devel-
oped functionalities in our robotic platform, associ-
ated experiments, results, and discussions are pre-
sented in section 4. Finally, section 5 summarizes the
presented work and highlights possible future investi-
gations.
2 MULTI-MODAL PERSON
DETECTOR
Our multi-modal person detector is based on a 2D
SICK Laser Range Finder and a visual camera.
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
512

2.1 SICK-based Detector
Recently, Laser Range Finders (LRFs) have become
attractive tools in the robotics area for environment
detection due to their accuracy and reliability. As the
LRFs rotate and acquire range data, they will have
distinct scan signatures corresponding to the shape of
an obstacle in the scan region. Detection of a person
from LRF information hence proceeds by trying to
detect shapes of a person in the scan data at the height
the scan is performed. In the context of this work, leg
detection will be considered as the laser scanner used
is positioned at a height of 38 cm above the ground.
Our robotic platform, Rackham (presented in
§4.1), has a SICK LMS200 2D laser range finder that
swipes an arc of 180
o
measuring the radial distance
of obstacles in a set angular resolution of 0.5
o
. The
detection makes use of geometric properties of leg
scans highlighted in (Xavier et al., 2005) with no a
priori environment map assumption. Though if a 2D
map of the environment, made of line segments, is
available, all points not lying on the map are filtered
to be considered further. The detection proceeds in
three steps:
Blob Segmentation. All sequential candidate scan
points that are close to each other are grouped to
make blobs of points. The grouping is done based on
the distance between consecutive points.
Blob Filtering. The blobs formed are filtered using
geometric properties outlined in (Xavier et al.,
2005). The filtering criteria used are Number of scan
points, Mid point distance, Mean Internal Angle
and Internal Angle Variance, and Sharp structure
removal. For details on these criteria, the reader is
referred to (Xavier et al., 2005).
Leg Formation. All the blobs that are not filtered out
by the above stated requirements are considered to be
legs. Each formed leg is then paired with a detected
leg in its vicinity (if there is one). The center of the
paired legs makes the position of the detected human.
This detection system has some drawbacks,
namely: false detection of table legs, chair legs, and
other narrow objects with circular pattern. People
standing with closed legs or wearing long skirts do
not yield appropriate leg signatures needed by the de-
tector, so are classified as negative instances resulting
in false-negatives. On top of these, it is not possi-
ble to know which leg detections correspond to which
person in the presence of multiple people, making as-
sociations of each legs in consecutive frames difficult.
This mode of detection is different from the combined
detector presented in §2.3 in that it makes use of all
the geometric properties strictly for leg detection.
2.2 Visual Detector
Recently, remarkable advances have been made in au-
tomated visual person detection, (Dalal and Triggs,
2005), (Laptev, 2006), and recently (Felzenszwalb
et al., 2010). For visual person detection, we have
used our complete C implementation of the state-of-
the-art person detector, Felzenszwalb’s person detec-
tor with discriminatively trained part based models.
The detector is based on mixtures of multi-scale de-
formable parts models that have the ability to repre-
sent a highly variable object class like that of a per-
son. The resulting person detector is efficient, accu-
rate, and has achieved state-of-the-art results in the
PASCAL VOC competition and the INRIA person
dataset
1
. Briefly speaking, the detector uses con-
trast sensitive and insensitive Histograms of Orienta-
tion Gradients (HOGs) with analytically reduced di-
mension as features. A person is modelled using a
star-structured part based model defined by a root fil-
ter and a set of parts filters with associated deforma-
tion models. Compared to full body detection ap-
proaches, (Dalal and Triggs, 2005), (Laptev, 2006),
this body parts based detector is more robust to partial
occlusions. The person model currently implemented
consists of mixtures of two models each of which
have one coarse root filter that approximately covers
an entire person and six high resolution parts filters
that cover smaller parts of the object. For details on
this person detector, the reader is referred to (Felzen-
szwalb et al., 2010).
In this work a person model trained with the Pas-
cal VOC 2008 dataset and provided with the Matlab
open source (Felzenszwalb et al., 2009) is used. Un-
fortunately, the C implementation of the person de-
tector takes about 4.6 seconds to detect persons on
a 320x240 image on a PIII 850 MHz computer with
6 levels in each octave of the feature pyramid. This
computation time is not acceptable for the task at
hand, navigation in a crowded environment, and en-
tails further improvements to speed the detection pro-
cess.
2.3 Combined Detector
The person detection from LRF suffer from false pos-
itives due to structures resembling that of a person leg,
mis-detections due to closed legs or long skirt, and do
not carry enough information to discriminate detec-
tions between multiple persons. On the other hand,
the visual person detector (Felzenszwalb et al., 2010)
is not readily applicable for the objective at hand due
to computation time requirement. To make use of the
1
See the URL http://pascal.inrialpes.fr/data/human/
MULTI-MODAL PERSON DETECTION AND TRACKING FROM A MOBILE ROBOT IN A CROWDED
ENVIRONMENT
513

two detectors in a complementary fashion, a multi-
modal detector is implemented. The block labelled
‘B’ in figure 1 shows a block diagram of the overall
multi-modal detector. Similar to (Cui et al., 2005)
and (Spinello et al., 2008), the proposed approach
is to define region of interests, henceforth referred as
person hypothesis, using the detections from the laser
scanner and then validate this by using the visual per-
son detector on these regions. For this, first the ge-
ometric criteria to detect persons from the 2D laser
scanner within the camera field of view region are re-
laxed to have a 100% person detection while at the
same time having many false positives. For every hy-
pothesis, a virtual rectangle conforming to an average
person height of 1.8 m with an aspect ratio of 4:11
(width:height) is positioned at the precise distance ob-
tained from the laser assuming a flat world. Then each
virtual rectangle is projected on to the image, thanks
to a complete calibrated camera system, defining a
rectangular search region on the image. The parts
based visual person detector is used to evaluate these
defined regions. All the regions confirmed to contain
persons are labelled as detections while those hypoth-
esis not confirmed by the visual detector are discarded
as false alarms. The main advantage of using the de-
fined region of interests is the reduced computation
time. Neither all the levels of the feature pyramid nor
model scores at all possible positions on the feature
pyramid need be computed. In the region outside the
camera field of view, detection is solely based on the
laser range finder as described in subsection 2.1. Note
that this mode of operation differs from the Laser only
based detection, explained in subsection 2.1, in the re-
gion within the camera field of view as loose geomet-
ric constraints are made use of for speeding the visual
person detector.
Finally, the multi-modal person detector provides
a list of detected targets with their precise locations,
(x, y), in the ground plane with respect to the robot,
and a normalized histogram of the image patch (if the
detection occurred within the field of view of the cam-
era) to the Multi-Person Tracker. Figure 2 shows a
typical instance of the multi-modal detector. Figure
2(a), shows the Human-Robot situation, 2(b) detected
persons by the multi-modal detector with bounding
boxes projected on the image plane, and 2(c) shows
the raw laser data (in blue) with the corresponding
person detections (in red) in the ground plane. The
shaded area in figure 2(c) is the camera field of view
whereas the robot is depicted as the red object in the
center of the arc.
(a) (b)
(c)
Figure 2: An instance of the multi-modal person detector
with Human-Robot situation.
3 MULTI-PERSON TRACKER
The Multi-Person Tracker (MPT) is concerned with
the problem of tracking a variable number of per-
sons, possibly interacting. Our aim here is to correctly
track and obtain trajectories of multiple persons in the
vicinity of the robot and within the field of view of the
utilized sensors based on the detector outputs.
3.1 Formalism
In object tracking in general, the primary goal is to de-
termine the posterior distribution P(X
t
|Z
1:t
) of a target
state X
t
at the current time t, given the observations
sequence Z
1:t
= {Z
1
, Z
2
, ..., Z
t
}. Under the Marko-
vian target motion assumption, the Bayes filter offers
a concise way to express the tracking problem. Par-
ticle Filters offer approximations of the Bayes filter
by propagating N number of particles over time to ap-
proximate the posterior P(X
t
|Z
1:t
) as a sum of Dirac
functions, such that: P(X
t
|Z
1:t
) ≈
1
N
∑
N
n=1
δ(X
t
− X
n
t
)
where X
n
t
denote the n
th
particle. In multi-target
tracking, the state encodes the configuration of the
tracked targets: X
n
t
= {I
n
t
, x
n
(t,i)
}, i ∈ {1, ..., I
n
t
}, where
I
n
t
is the number of tracked objects of hypothesis n at
time t, and x
n
(t,i)
is a vector encoding the state of ob-
ject i. In MCMCPF, the inefficient importance sam-
pling of a classical Particle Filters is replaced with a
more efficient MCMC sampling step. MCMC meth-
ods define a Markov Chain over the space configu-
ration X
n
t
such that the stationary distribution of the
chain is equal to the desired posterior.
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
514

Reversible Jump Monte Carlo Markov Chain
(RJMCMC) PF is an extension of MCMC PF that
accounts for the variability of the tracked targets by
defining a variable dimension state space. In this case,
the state space dimension is considered as a union of
several subspaces. Whenever a new person enters the
scene, the state “jumps” to a larger dimension sub-
space and there will be a “jump” to a lower dimen-
sion subspace whenever a tracked person leaves the
scene. An important point in RJMCMC is the re-
versibility of the proposals that vary the dimension-
ality of the state space exploration. Any jump be-
tween subspaces must have a corresponding reverse
jump to prevent the search chain from getting stuck
in local minimum. These moves that guide the state
space exploration are referred as proposal moves. A
common technique that simplifies both the transition
of the new proposed state hypothesis X
∗
from X and
evaluation of the acceptance ratio is, for the state tran-
sition model to consider only changes to a randomly
chosen subset of the state (in the case of multi-target
tracking, this translates into changing a single target
per iteration). In cases where interaction between dif-
ferent targets is likely to occur, an Interaction Model
should be included to maintain tracked target identity.
3.2 Implementation
Our RJMCMC PF tracker is driven by the multi-
modal detector described in §2. To handle the vari-
ability of the tracked targets three sets of proposal
moves are utilized in the RJMCMC PF: {Add, Up-
date, Remove}. A Markov Random Field is also used
to model the interactions amongst targets. The com-
plete principle of our tracker is presented in Algo-
rithm 1. Roughly, the algorithm iterates N+N
B
times
proposing new state based on the previous one. N
is the number of particles whereas N
B
represents the
number of burn-in iterations needed to converge to
stationary samples. Each subsection below gives an
overview of part of the algorithm in detail.
3.2.1 State Space
The state vector of a single hypothesis n at a certain
time t in our tracker is made of the joint state vec-
tors of the tracked persons (encodes the entire config-
uration): X
n
t
= {I
n
t
, x
n
t,i
, i ∈ 1, ..., I
n
t
}, where I
n
t
is the
number of tracked persons, N is the total number of
hypotheses (particles), and x
n
t
is the state vector of in-
dividual persons. Since our aim is to outline trajecto-
ries of persons around the robot, the tracking is done
on the ground plane. Hence, the state vector of an in-
dividual person is represents as (Id, x, y) in the ground
plane with respect to the robot. Formally, the i
th
state
Algorithm 1: RJMCMC Particle Filter.
Input: Particle set at time t − 1 : {X
n
t−1
}
N
n=1
Prediction: generate a prediction set at time
t : {X
n∗
t−1
}
N
n=1
according to the system dynamics
Q(X
n
t
|X
n
t−1
).
Init: X
0
t
= X
r∗
t
, r ∈ {1, ..., N}
1. for i = 0 to N + N
B
do
2. ⊲ Choose a move m ∈ {add, update, remove} ∼ q
m
.
3. if m == ’add’ then
4. ⊲ X
∗
= {X
i−1
t
, x
I
i−1
+1
}, with the new target x
p
=
x
I
i−1
+1
and I
i−1
representing the number of per-
sons hypothesized by X
i−1
t
5. else if m == ’remove’ then
6. ⊲ X
∗
= {X
i−1
t
\ x
p
} where p ∈ {1, ..., I
i−1
}
7. else if m == ’update’ then
8. ⊲ Randomly choose a tracked person from X
i−1
t
.
9. ⊲ Replace the person’s state in X
i−1
t
with a ran-
domly chosen state corresponding to this person
in the prediction set {X
n∗
t−1
}
N
n=1
, proposing X
∗
.
10. end if
11. ⊲ Compute Acceptance Ratio :
β = min(1,
π(X
∗
)Q
ind∗
(X
i−1
t
|X
∗
)Ψ(X
∗
)
π(X
i−1
t
)Q
ind
(X
∗
|X
i−1
t
)Ψ(X
i−1
t
)
)
where ind ∈ {add, update, remove} and ind
∗
denotes
the reverse operation.
12. if β ≥ 1 then
13. ⊲ X
i
t
= X
∗
14. else
15. ⊲ Accept X
i
t
= X
∗
with probability β or reject and
set X
i
t
= X
i−1
t
16. end if
17. end for
18. ⊲ Discard the first N
B
samples of the chain (burn-in).
19. ⊲ Compute the MAP estimate,
ˆ
X = E
p(X
t
|Z
1:t
)
[X
t
] =
argmax
X
i
t
[count(x
i
k
)]
Output: Particle Set at time t: X
n
t
n=N
B
+1,...,N
B
+N
and MAP
estimate,
ˆ
X.
vector of a single person in hypothesis n at time t is a
2D vector represented as: x
n
t,i
= {Id
i
, x
n
t,i
, y
n
t,i
}.
3.2.2 Proposal Moves
At each iteration of the RJMCMC PF, a proposal
move on only one randomly chosen dimension is pro-
posed. Recall that three sets of move are considered,
namely: m = {Add,U pdate, Remove}. The choice of
the proposal privileged in each iteration is determined
by q
m
, the jump move distribution. The probabilities
of Add, U pdate, and Remove are set to 0.2, 0.6, and
0.2 respectively. These proposal moves make use of
the proposal densities, Q(), associated with them. The
proposal densities make use of two masking maps:
a map made from detected targets, and a map made
from the tracked (MAP estimate) targets. Assuming
the number of detected persons at time t is M
t
, each
MULTI-MODAL PERSON DETECTION AND TRACKING FROM A MOBILE ROBOT IN A CROWDED
ENVIRONMENT
515

detection can be represented as p = (x, y) to make an
associated mask map as a Gaussian mixture with each
detection as a Gaussian having mean p and assumed
variance Σ (equation 1). Similarly, each tracked target
in the MAP estimate at t − 1 is used to make a mask-
ing map as a Gaussian mixture; ˆx
j
as mean values,
where j ∈ 1, .., N
t
and N
t
is total number of tracked
targets (equation 2).
S
d
t
(Z
t
) =
M
t
∑
j=0
N (; p
j
, Σ) (
1)
S
map
t
(
ˆ
X
t−1
) =
N
t
∑
j=0
N (; ˆx
j
, Σ) (2)
Add. The add move, randomly select a detected per-
son, x
p
, from the multi-modal detector and appends
its state vector on X
i−1
t
resulting in a proposal state
X
∗
. The proposal density driving the Add proposal,
when computing the acceptance ratio Q
Add
(X
∗
|X
i−1
t
),
is given in equation 3. The mask map from de-
tected targets is multiplied by a map derived from the
tracked targets mask map. This distribution will have
higher values whenever an add is proposed on loca-
tions conforming to detected targets that are not yet
being tracked.
Q
add
(X
∗
|X
i−1
t
) = S
d
t
(Z
t
) ∗ (1− S
map
t
(
ˆ
X
t−1
)) (3)
Figure 3 illustrates the derivation of Q
add
(X
∗
|X
i−1
t
) at
a certain time t. Figure 3(a) bottom shows an inverted
mask derived from the tracked targets at time t − 1
and figure 3(b) shows the detected targets. Finally, the
distribution Q
add
(X
∗
|X
i−1
t
) is derived by multiplying
both (figure 3(c) bottom). The derived distribution
shows higher values in the region near the detected
target that is not being tracked, favoring its addition.
The top figure in 3(c) shows the effect of the mask on
the actual video image and is presented here solely for
clarity purposes.
(a) (b) (c)
Figure 3: Derivation of Q
add
(X
∗
|X
i−1
t
) from tracked targets
and detection. White intensity value represents high value
whereas black is for low value.
Remove. The remove move, randomly selects a
tracked person from the particle being considered,
X
i−1
t
, and removesit, proposing a news state X
∗
. Con-
trary to the add move, the proposal density used when
computing the acceptance ratio, Q
Remove
(X
∗
|X
i−1
t
)
(equation 4), is given by the mask map from the
tracked targets multiplied by a map driven from the
detected targets. This density assures targets that
are not detected but are still being tracked have
higher values. Figure 4 depicts derivation of the
Q
Remove
(X
∗
|X
i−1
t
) distribution. A tracked target has
just left the scene but the tracker still has the per-
son in its state ( figure 4(a) bottom ). The detec-
tor returns one detection corresponding to the person
still in the scene (figure 4(b)). As illustrated, the fi-
nal Q
Remove
(X
∗
|X
i−1
t
), figure 4(c) bottom, shows high
values for the target which left the scene favoring its
removal. Figure 4(c) top illustrates the effect of the
mask on the video feed, all black meaning no target
in the camera field of view should be removed.
Q
remove
(X
∗
|X
i−1
t
) = (1− S
d
t
(Z
t
)) ∗ S
map
t
(
ˆ
X
t−1
) (4)
(a) (b) (c)
Figure 4: Illustration of Q
Remove
(X
∗
|X
i−1
t
) derivation. White
intensity value represents high value whereas black is for
low value.
Update. In the update proposal move, the state vec-
tor of a randomly chosen target is perturbed by a zero
mean normal distribution. The update proposal den-
sity, Q
update
(X
∗
|X
i−1
t
), is a normal distribution with
the position of the newly updated target as mean.
Hence, the acceptance ratio is influence by the like-
lihood evaluation and interaction amongst the targets.
3.2.3 Interaction Model
Similar to (Khan et al., 2005) and (Smith et al., 2005),
a Markov Random Field (MRF) is adopted to address
the interactions between nearby targets. The MRF is
defined on an undirected graph, with targets defining
the nodes of the graph, and links created at each time-
step between pairs of proximate targets. A pairwise
MRF where the cliques are restricted to the pairs of
nodes that are directly connected to the graph, is im-
plemented as part of our tracker. For a given state X,
the MRF model is given by equation 5. φ(x
i
, x
j
) eval-
uates to zero if two targets are in the same position,
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
516

penalizing fitting of two trackers to the same object
during overlap (interaction).
Ψ(X) = Π
i6= j
φ(x
i
, x
j
)
φ(x
i
, x
j
) = 1− exp(−(
d(x
i
, x
j
)
σ
)
2
) (5)
where d(x
i
, x
j
) is Euclidean distance, i, j ∈ {1, ..., N},
and N number of targets in X.
3.2.4 Observation Likelihood
The likelihood measure is derived from the 2D laser
range raw data. Every segmented blob is filtered to
keep blobs within a range of radius. This filters out
laser data pertaining to walls, thin table or chair legs,
and other wide structures. Then every filter blob is
represented as a Gaussian centered on the centroid of
the blob. The complete mixture of Gaussians makes
up the likelihood map for our tracker. Given a state
X, its likelihood is evaluated as the sum of likelihood
values on the position of each target averaged over the
number of targets (equation 6).
π(X
∗
) =
1
N
t
N
t
∑
i=0
s
lik
t
(Z
t
)|
(x
i
,y
i
)
s
lik
t
(Z
t
) =
N
b
∑
j=0
N (;Z
t, j
, Σ) (
6)
Where N
t
is the number of targets in X
∗
, and N
b
is the
number of blobs formed from the laser reading (Z
t
).
4 EXPERIMENTS
4.1 Robotic Platform
The target robotic platform, Rackham, is an iRobot
B21r mobile platform (figure 5). Its standard equip-
ment has been extended with one pan-tilt Sony EVI-
D70 camera, one digital camera mounted on a Di-
rected Perception pan tilt unit(PTU), one ELO touch
screen, a pair of loudspeakers, an optical fiber gyro-
scope, a Wireless Ethernet, and an RF system for de-
tecting RFID tags. It integrates two PCs (one mono-
CPU and one bi-CPUs PIII running at 850 MHz).
Rackham also has an LMS200 SICK Laser Range
Finder as its standard equipment. All these devices
give Rackham the ability to operate in public areas as
a service robot. The digital camera with the Directed
Perception PTU is dedicated for the person following
activity along with the RF system, whereas the Sony
EVI-D70 camera is used for the multi-person (passer-
by) detection and tracking. Rackham’s software ar-
Figure 5: Rackham with its onboarded sensors.
chitecture is based on the GenoM architecture for au-
tonomy (Alami et al., 1998). All its functionalities
have been embedded in modules created by GenoM
using C/C++ interface. Accordingly, the multi-modal
person detector and MCMC PF tracker described are
implemented as a GenoM modules.
4.2 Offline Evaluations
The offline evaluation corresponds to the evaluation
of both the multi-modal person detector and the RJM-
CMC PF tracker offline using real data acquired with
Rackham.
4.2.1 Multi-modal Detector Evaluations
In all the experiments, a 5 meter radius around the
robot is considered for detection and tracking. The
camera has a 45
o
field of view, leaving the rest of laser
scanner field of view, 135
o
, for laser only detection.
To evaluate the multi-modal person detector a dataset
containing a total of 2872 frames is used. To quantify
performance of the multi-modal person detector, two
measures namely True Positive Rate (TPR) and False
Positive Per Image (FPPI) are used.
• True Positive Rate (TPR): computes the ratio of
correctly detected targets to the total number of
targets present averaged over the entire dataset,
i.e.
1
J
t
∑
k, j
δ
k, j
where δ
k, j
= 1 if a target is detected
in frame k or 0 otherwise. J
t
is the total number
of targets present in the entire dataset.
• False Positive Per Image (FPPI): computes the
false positive occurrence per frame averaged over
the entire dataset, i.e.
1
K
∑
k, j
δ
k, j
where δ
k, j
= 1
if a target j is detected when there is actually no
target in frame k or 0 for correct detection. K is
the total number of frames in the entire dataset.
All the 2872 frames were hand labelled for (x, y) po-
sitions of persons on the ground plane based on the
MULTI-MODAL PERSON DETECTION AND TRACKING FROM A MOBILE ROBOT IN A CROWDED
ENVIRONMENT
517
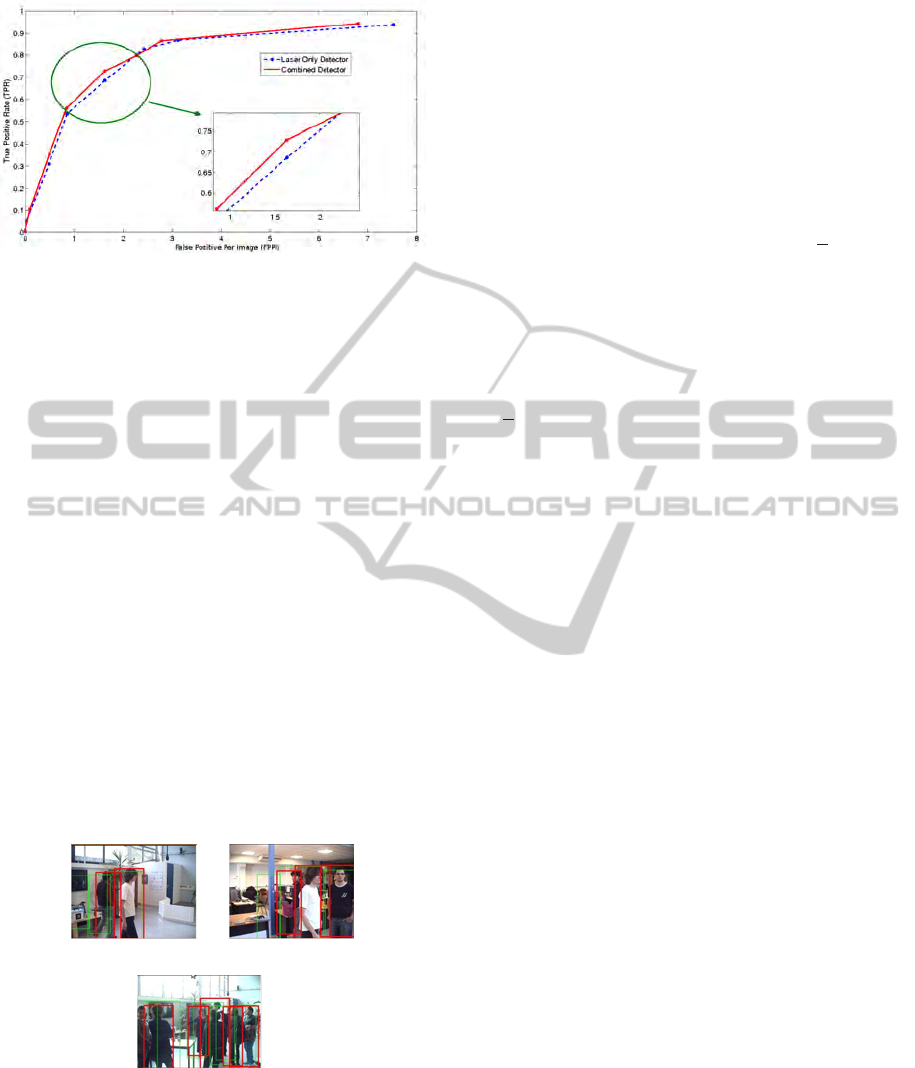
Figure 6: ROC curve (TPR Vs FPPI) comparing the per-
formance of both LRF only detector, and the multi-modal
detector.
laser data. A True Positive occurs whenever a detec-
tion is within 30 cm radius of the ground truth. A
Receiver Operator Curve (ROC), TPR vs FPPI ROC
graph shown in figure 6, is generated by relaxing
and/or straining the geometric constraints for leg de-
tection. To verify that the multi-modal detector is su-
perior than the Laser only based detector, the experi-
ment has also been done on the Laser only based de-
tector. Hence, the ROC curve is generated for the LRF
only based person detector (§2.1) and for the multi-
modal person detector (§2.3).
Looking at the ROC curve in figure 6, it can be
seen that, the addition of the visual detector improves
the overall detection performance. On top of this per-
formance improvement, a rich discriminative infor-
mation is obtained whenever a target is within the
field of view of the camera. Balancing True Detec-
tion with False Positive rate, the multi-modal person
detector is set to operate at a point with TPR = 0.72
and FPPI = 1.6. Sample detections obtained operat-
ing the detector at this point are shown in figure 7.
(a) (b)
(c)
Figure 7: Sample person detection with the multi-modal de-
tector.
4.2.2 Multi-person Tracker Evaluations
Similarly, to evaluate the performance of the MCM-
CPF multi-person tracker, two complete sequences
are used.
• Sequence I. A sequence of 785 frames containing
two moving targets.
• Sequence II. A sequence of 507 frames with two
moving targets but once in a while other targets
appear and disappear in the tracking area.
As a performance measure, the following three mea-
sures are computed.
• Tracking Success Rate (TSR): given by
1
J
t
∑
k, j
δ
k, j
where δ
k, j
= 1 if target j is tracked at time t, else
0. J
t
=
∑
k, j
j
k
, and j
k
represents the number of
persons in the tracking area at frame k.
• Ghost Rate (GR): computes the number of can-
didate targets over no target (ghosts) averaged
over the total number of targets in the dataset, i.e.
1
J
t
∑
k, j
δ
k, j
with δ
k, j
= 1 if tracked target j is a
ghost at frame k, else 0.
• Precision Error (PE): measures how precisely the
targets are tracked, as the sum of the squared er-
ror between tracker position estimate and ground
truth averaged over the entire sequence.
For each sequence, a hand labeled ground truth
with (x, y) position and unique Id for each person is
used. Similar to the detection, a person is considered
to be correctly tracked (True Success), if the track-
ing position is within a 30 cm radius of the ground
truth. All the Gaussians used to make associated dis-
tributions are constructed in polar form (ρ, θ) with
standard deviation of σ
ρ
= 30cm and σ
θ
= 0.157rad.
These values are set to account for a single walk (of
an average person) uncertainty. Whenever a target is
in the camera field of view, a histogram of the re-
gion subtended by the target is cached in memory.
This histogram is used to overcome discontinuities in
tracking when a tracked target is removed and initial-
ized as a new target due to subsequent misdetections.
It is also used to make association distinctions when-
ever targets come close by and some configuration
within the state sample another target’s state.
For evaluation, each sequence is run ten times to
account for the stochastic nature of the filter. Results
are reported as mean value and associated standard
deviation in table 1. The results show that our multi-
modal person tracker performs well on the two se-
quences used for evaluation, with a 73.3% True De-
tection on the first sequence. What should be high-
lighted here is that, the detector plus tracker makes
no use of a priori knowledge of the environment.
The environment the experiments were carried out is
a highly cluttered environment containing many arti-
facts that resemble the leg of a person and the field of
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
518

(a) (b) (c) (d) (e) (f) (g) (h)
Figure 9: A sequence of frames from online obstacle avoidance scenario based on the multi-modal person detector. The top
row shows Human-Robot situation, the middle user tracking for person following, and the third multi-modal person detections
on the ground plane.
Table 1: Results of the MCMCPF multi-tagged person
tracker.
MCMCPF Person Tracking Results
Seq. TSR GR PE (cm)
I 0.733± 0.074 1.221± 0.078 7.93± 0.68
II 0.62± 0.078 1.355± 0.297 8.37± 1.13
(a) (b)
(c)
Figure 8: Sample snap-shots taken from the multi-person
tracking on sequence I at the 35
th
, 51
th
, and 259
th
frames
respectively.
view of the camera is very narrow. The average po-
sition precision of the tracker is also less than 9cm.
An average Id switch per sequence of one for the first
sequence and two for the second has also been ob-
served.
Figure 8 shows sample snap-shots
2
taken from
tracking runs of sequence 1. The top row shows the
tracking on the video feed, the middle shows the par-
2
A video of the tracking sequence is available at
http://homepages.laas.fr/aamekonn/videos.htm
ticle swarm, and the bottom row shows the trajectory
of the tracked persons.
4.3 Online Robotic Evaluations
The online robotic evaluation corresponds to the ex-
periments carried out on Rackham. As mentioned
§4.1, the multi-modal detector and tracker are im-
plemented in C/C++ embedded in GenoM modules.
Both the detector and tracker run on the same com-
puter while the LRF scan data is acquired through
the second computer. The multi-modal detector alone
runs from 1.5f ps minimum to 4.5f ps maximum de-
pending on the number of hypothesis generated for
the visual detector. The rate at which the com-
bined system runs varies depending on the number of
tracked persons and number of hypothesis generated
by the laser for the visual detector. In our experiment,
an approximate minimum of 0.7 frames per second
was noted.
Recall the end goal is to realize a person following
service robot with passer-by avoidance. The Person
Following activity presented in (Germa et al., 2009)
and depicted in the shaded area in figure 1 is based on
an RFID system and a visual camera. A user (tagged
person) wearing an RFID tag is tracked and followed
by the robot irrespective of camera out of field of
view, or occlusions. To check the integration of both
systems, an experiment was carried out. In the ex-
periment a tagged person is followed while a simple
control law with rotative repulsive potential was used
to avoid passers-by based on the multi-modal detector
only. Figure 9 shows the a sequence of the video dur-
ing a person following with obstacle avoidance based
only on the multi-modal detector.
MULTI-MODAL PERSON DETECTION AND TRACKING FROM A MOBILE ROBOT IN A CROWDED
ENVIRONMENT
519

5 CONCLUSIONS
To conclude, this paper presented multi-modal per-
son detection and tracking from a mobile robot based
on LRF and vision intended for a socially accept-
able navigation in crowded scenes during a person
following activity. Though a person following sce-
nario is considered, the framework is applicable for
any service robot activity in a crowded public envi-
ronment where perception of the whereabouts and dy-
namics of the persons around is required. It has been
clearly shown that the multi-modal approach outper-
forms its single sensor counterparts taking detection,
subsequent use, computation time, and precision all
into account. Results obtained from offline and online
robotic experiments have also been clearly reported
asserting this statement.
Currently, investigations are on the way to use
a LadyBug2 spherical camera to improve the detec-
tion and tracking further taking advantage of its wide
field of view. Preliminary investigations are also un-
derway with navigational schemes that consider the
spatio-temporal information provided by our multi-
target tracker.
REFERENCES
Alami, R., Chatila, R., Fleury, S., Ghallab, M., and In-
grand, F. (1998). An architecture for autonomy. In
Int.Journal of Robotics Research (IJRR’98), 17:315–
337.
Breitenstein, M., Reichlin, F., Leibe, B., Koller-Meier,
E., and Van Gool, L. (2009). Robust tracking-by-
detection using a detector confidence particle filter. In
IEEE 12th Int. Conf. on Computer Vision (ICCV’09),
pages 1515 –1522.
Calisi, D., Iocchi, L., and Leone, G. R. (2007). Person fol-
lowing through appearance models and stereo vision
using a mobile robot. In Proceedings of Int. Workshop
on Robot Vision, pages 46–56.
Chen, Z. and Birchfield, S. T. (2007). Person following with
a mobile robot using binocular feature-based tracking.
In Proceedings of the IEEE/RSJ Int. Conf. on Intelli-
gent Robots and Systems (IROS’07).
Cui, J., Zha, H., Zhao, H., and Shibasaki, R. (2005). Track-
ing multiple people using laser and vision. In Proceed-
ings of the 2005 IEEE/RSJ Int. Conf. on Intelligent
Robots and Systems (IROS’05), pages pp.1301–1306.
Dalal, N. and Triggs, B. (2005). Histograms of oriented
gradients for human detection. In Proceedings of the
Int. Conf. on Computer Vision and Pattern Recogni-
tion (CVPR’05), pages 886–893.
Felzenszwalb, P. F., Girshick, R. B., and
McAllester, D. (2009). Discriminatively
trained deformable part models, release 3.
http://people.cs.uchicago.edu/ pff/latent-release3/.
Felzenszwalb, P. F., Girshick, R. B., McAllester, D. A.,
and Ramanan, D. (2010). Object detection with dis-
criminatively trained part-based models. IEEE Trans.
Pattern Anal. Mach. Intell. (TPAMI’10), 32(9):1627–
1645.
Fong, T. W., Nourbakhsh, I., and Dautenhahn, K. (2003).
A survey of socially interactive robots. Robotics and
Autonomous Systems.
Germa, T., Lerasle, F., Ouadah, N., Cadenat, V., and Devy,
M. (2009). Vision and RFID-based person tracking
in crowds from a mobile robot. In Proceedings of the
IEEE/RSJ Int. Conf. on Intelligent Robots and Systems
(IROS’09), pages 5591–5596. IEEE Press.
Isard, M. and MacCormick, J. (2001). Bramble: a bayesian
multiple-blob tracker. In Proceedings of 8th IEEE
Int. Conf. on Computer Vision (ICCV’01), volume 2,
pages 34 –41 vol.2.
Khan, Z., Balch, T., and Dellaert, F. (2005). Mcmc-based
particle filtering for tracking a variable number of in-
teracting targets. IEEE Trans. Pattern Anal. Mach. In-
tell. (TPAMI’05), 27(11):1805–1918.
Laptev, I. (2006). Improvements of object detection using
boosted histograms. In Proceedings of the British Ma-
chine Vision Conference (BMVC’06), pages 949–958.
Rasmussen, C. and Hager, G. D. (2001). Probabilistic
data association methods for tracking complex vi-
sual objects. IEEE Trans. Pattern Anal. Mach. In-
tell.(TPAMI’01), 23(6):560–576.
Reid, D. (1979). An algorithm for tracking multiple targets.
IEEE Transactions on Automatic Control, 24(6):843–
854.
Schiele, B., Andriluka, M., Majer, N., Roth, S., and Wojek,
C. (2009). Visual people detection: Different mod-
els, comparison and discussion. In Proceedings of the
IEEE ICRA 2009 Workshop on People Detection and
Tracking, pages 1–8.
Smith, K., Gatica-Perez, D., and Odobez, J.-M. (2005).
Using particles to track varying numbers of inter-
acting people. In Proceedings of the Int. Conf. on
Computer Vision and Pattern Recognition (CVPR’05),
pages 962–969, Washington, DC, USA. IEEE Com-
puter Society.
Spinello, L., Triebel, R., and Siegwart, R. (2008). Mul-
timodal people detection and tracking in crowded
scenes. In Proceedings of the 23rd National Confer-
ence on Artificial intelligence (AAAI’08), pages 1409–
1414. AAAI Press.
Xavier, J., Pacheco, M., Castro, D., and Ruano, A. (2005).
Fast line, arc/circle and leg detection from laser scan
data in a player driver. In Proceedings of the Int. Conf.
on Robotics and Automation (ICRA’05).
Zivkovic, Z. and Kr¨ose, B. (2007). Part based people detec-
tion using 2d range data and images. In Proceedings
of the 2007 IEEE/RSJ Int. Conf. on Intelligent Robots
and Systems (IROS’07).
VISAPP 2011 - International Conference on Computer Vision Theory and Applications
520
