
CONVERGENCE ANALYSIS
OF A MULTIAGENT COOPERATION MODEL
Markus Eberling and Hans Kleine B
¨
uning
Department of Computer Science, University of Paderborn, 33095 Paderborn, Germany
Keywords:
Cooperation, Multiagent systems, Value propagation, Imitation-based learning.
Abstract:
Cooperation between autonomous and rational agents is still a challenge. The problem even gets harder if the
agents follow different policies or if they are designed by different companies that have contradicting goals.
In such systems agents cannot rely on the cooperation willingness of the other agents. Mostly, the reason
for receiving cooperation is not observable as it is a result of the private decision process of the other agent.
We deal with a multiagent system where the agents decide with whom to cooperate on the basis of multiple
criteria. The system models these criteria with the help of rated propositions. Interaction in our system can
only occur between agents that are linked together in a network structure. The agents adapt their values to the
best performing neighbor and rewire their connections if they have uncooperative neighbors. We will present
an imitation-based learning mechanism and we will theoretically analyze the mechanism. This paper also
presents a worst case scenario in which the mechanism will fail.
1 INTRODUCTION
Agents in multiagent systems are designed to behave
rational and autonomous (Ferber, 1999; Wooldridge,
2009). Therefore, they have to decide with whom to
cooperate on their own. This process can be influ-
enced by different factors which may not be observ-
able for other agents. The problem is that the indi-
vidual rational choice may be different from the so-
cial rational choice. In this context an agent cannot
rely on receiving cooperation whenever it is needed.
However, cooperation is essential in many multiagent
systems if the agents should achieve a global goal.
Cooperation in everyday life can be found in
groups of humans or in companies that are organized
in a network structure besides other examples. In
most scenarios cooperation leads to higher benefit for
the whole group and to higher benefit for the indi-
viduals. Mostly, the group members have a common
goal but different motivations to join the group (Pen-
nington, 2002) or to stay in it (Buchanan and Huczyn-
ski, 1997). Companies build networks to achieve their
goals (Peitz, 2002) and moreover good supply chains
are helpful to produce qualitative products. Recip-
rocal behavior is one of the characteristics of such
networks (Sydow, 1992). Another aspect is altruism
which is on the one hand helping others without be-
ing payed for (Berkowitz and Macaulay, 1970) and
which can produce costs on the other hand (Krebs,
1982; Wisp
´
e, 1978). The decision to cooperate is of-
ten based on different criteria like kin selection or so-
cial cues.
We model the process of determining cooperation
partners with the help of propositions which are rated
by the agents. Based on the distances of these ratings
they determine the agents they are willing to cooper-
ate with. Each proposition leads to a criterium that
has to be fulfilled. If all criteria are fulfilled, the agent
will cooperate with an agent asking for help.
In (Eberling, 2009) and (Eberling and
Kleine B
¨
uning, 2010b) a local learning algo-
rithm was proposed that favors the determination
of cooperation partners. This paper will give a
convergence analysis of this approach. The agents
adapt to the best neighbor by imitating its proposition
ratings and reach high levels of cooperation. The
agents in the system only have local knowledge as
they are only aware of those agents they are linked
to. There exist similar models but most of them
lack theoretical analysis under which preconditions
convergence to cooperative behavior will emerge.
This paper will give a theoretical analysis of the
adaptation mechanism and will show that there are
examples where the system does not converge to
cooperation. However, it is claim that these examples
are very rare and that the assumptions that have to be
167
Eberling M. and Kleine Büning H..
CONVERGENCE ANALYSIS OF A MULTIAGENT COOPERATION MODEL.
DOI: 10.5220/0003139901670172
In Proceedings of the 3rd International Conference on Agents and Artificial Intelligence (ICAART-2011), pages 167-172
ISBN: 978-989-8425-41-6
Copyright
c
2011 SCITEPRESS (Science and Technology Publications, Lda.)

made for them are very specific as good results have
been observed in previous work.
In literature one can find similar models based on
observable markers such as tags which are evolved
over time. In the work of Riolo et al. coopera-
tion can only occur between two agents a and b if
|τ
a
−τ
b
| ≤ T
a
holds, where τ
a
is the tag value and T
a
is
a similarity threshold (Riolo et al., 2001). Hales also
made experiments based on this mechanism to deter-
mine cooperation (Hales, 2002; Hales, 2004). The
difference to our work is that on the one hand adap-
tation means copying the value and threshold as well
as the strategy of another agent. In our scenario the
agents are only allowed to imitate the values without
purely copying. Another aspect is that we will deal
with a set of such inequations that all have to be ful-
filled. Hales and Riolo et al. lack formal analysis why
the cooperation emerges but only give experimental
results. We will formally show different cases where
cooperation may and may not emerge.
De Weerdt et al. (de Weerdt et al., 2007) calculate
task allocations using a distributed algorithm in a so-
cial network. A social network is a graph where the
nodes represent the agents and the edges model possi-
ble interaction links. The tasks are assigned to agents
which have limited resources. They show that the
problem of finding an optimal task allocation, which
maximizes the social welfare, is NP-hard. In con-
trast to the work presented here, their model does not
consider cooperation costs and the agents also know
about all tasks before the decision process is started
which is also different to the work presented here.
Another difference is the static social network struc-
ture. In contrast, we analyze dynamic networks and
show that the challenges of those networks favors the
cooperation between the agents.
2 SCENARIO DESCRIPTION
In this section we describe the formal model used
in this paper. Due to page limitations we will only
describe the features of the model and omit the for-
mal definitions. They can be found in (Eberling and
Kleine B
¨
uning, 2010a). We will first define the basic
model and then describe the considered scenario.
The agents in our model are linked together and
form a so called interaction network IN. Basically,
the interaction network IN = (A,N ) is an undirected
graph with a finite set of agents A as the nodes and
a set of links N . The links between the agents
represents the neighborhood relationship. Therefore,
agents a and b are able to interact iff there exists an
edge between them in the interaction network, i.e.
{a,b} ∈ N . An interaction network is called dynamic
if the graph can change between successive simula-
tion steps. Note that due to the interaction network
the agents’ view of the system is local only.
In our system the agents have to fulfill different
jobs consisting of smaller tasks. Each task requires a
specific skill out of a skill set s
t
∈ S and leads to a non-
negative payoff q
t
∈ R
+
0
if the task is fulfilled. There-
fore, a task t can be modeled as a pair t = (s
t
,q
t
).
Let T be the finite set of all possible tasks. Then
J ⊆ Pow(T ) is the set of all jobs. Hence, a job j ∈ J
is a set of tasks j = {t
1
,...,t
n
} where t
min
≤ n ≤ t
max
with t
min
,t
max
∈ N denote the minimum and maximum
number of tasks a job consists of and n the number of
tasks. The payoff for a job is the sum of the tasks’
payoffs if it is fulfilled, i.e. if all tasks are fulfilled,
and zero otherwise.
The environment env the agents are situated in is
a tuple env = (S, P ,IN, J ) where S is a finite, non-
empty set of skills, P = {p
1
,..., p
m
} is a set of propo-
sitions, IN = (A,N ) is an interaction network and J
is a finite set of jobs. The set of propositions are a
mean to model the decision process to determine co-
operation partners based on many criteria. The agents
share the set of propositions that are part of the en-
vironment. These propositions can be opinions about
the overall world state or the evolution of the environ-
ment. As we do not concentrate on the modeling of
such propositions we do not provide a formal defini-
tion. A proposition p can represent anything like “The
road is clear” in the context of a taxi-driving agent or
“The color blue is prettier than black”. For our pur-
poses it is enough to know that there are propositions
that may influence the behavior of the agents. More
details can be found in (Eberling and Kleine B
¨
uning,
2010a).
An agent a ∈ A is a tuple a = (S
a
,N
a
,
C
a
,V
a
,Θ
a
) where S
a
⊆ S is the set of skills agent
a is equipped with, N
a
⊆ A is the agent’s neighbor-
hood defined by the interaction network, C
a
⊆ N
a
is
the set of neighbors, agent a is willing to cooperate
with, V
a
∈ [0,v
max
]
m
⊂ Q
m
is a vector giving values
to the propositions and finally Θ
a
∈ (0,Θ
max
]
m
⊂ Q
m
is a threshold vector. To keep the agents as simple
as possible, only the proposition-values are modeled
as observable properties. All other parts of the agents
(i.e. skills, thresholds and neighbors) are not visible to
other agents and constitute private knowledge. Based
on the values the agents give to the propositions their
cooperation partners are determined. The set of coop-
eration partners C
a
of agent a are all neighbors b ∈ N
a
for which the following holds:
∀p ∈ P : |V
a
(p)− V
b
(p)| ≤ Θ
a
(p) (1)
This means that for the cooperation partners the dis-
ICAART 2011 - 3rd International Conference on Agents and Artificial Intelligence
168

tances between the ratings for the propositions have
to be less or equal to the thresholds. We also define a
cooperation relation C ⊆ A × A based on the sets of
cooperation partners:
b ∈ C
a
⇔ (a, b) ∈ C (2)
According to this definition, it is easy to see that the
relation C is not symmetric in general.
As the agents should learn to select their cooper-
ation partners we endowed them with the possibility
of adaptation to other agents. This adaptation affects
the proposition values of the agents. They change
their values to imitate a better performing neighbor.
The intention for this is, that better performing agents
are believed to gain high performance based on bet-
ter values for the propositions. The adaptation step is
defined through Equation 3:
V
t+1
a
= V
t
a
+ η ·(V
t
a
∗
− V
t
a
) (3)
where a
∗
is the best performing agent out of agent
a’s neighborhood and η ∈ [0, 1] ⊂ Q is an exogenous
adaptation strength.
Algorithm 1: Simulation.
1: Initialize |A| agents and their neighborhoods ran-
domly
2: loop
3: Generate 10·|A| jobs and allocate them to ran-
domly chosen agents
4: for all agents a ∈ A do
5: E
a
← set of best agents of N
a
∪ {a}
6: if a /∈ E
a
then
7: a
∗
← best agent of N
a
8: V
a
← V
a
+ η ·(V
a
∗
− V
a
)
9: with probability P
N
: replace r uncoop-
erative neighbors by r randomly chosen
agents
10: end if
11: end for
12: end loop
Algorithm 1 describes our simulation which in-
corporates the adaptation mechanism. In each step
10 · |A| jobs are generated and assigned to randomly
chosen agents with uniform distribution (line 3). This
leads to an assignment of 10 jobs on average per
agent. The jobs are dynamically generated and sep-
arately assigned to the agents and processed sequen-
tially by the agents. This leads to a fundamental prop-
erty of our system: the agents are not able to reason
about the whole set of jobs and to select the most ben-
eficial ones. We decided to do this because we con-
centrate on the cooperation aspect and not on the as-
pect of most efficient task allocations as it is done in
a
a
bc
b
Figure 1: Simple MAS composed of two agents.
similar models (de Weerdt et al., 2007). Another rea-
son for this is that we want to concentrate on agents
that are as simple as possible.
The agents work on the jobs and every fulfilled
job is rewarded with the job’s payoff for the allo-
cated agent, only. Cooperative agents that helped oth-
ers to fulfill their jobs are punished with a payoff of
−0.25 · q
t
for every task they processed. Both, the un-
certainty about the next jobs as well as the coopera-
tion costs make it impossible to apply common coali-
tion formation techniques (Branzei et al., 2008) to our
considered system.
The second phase of the algorithm is the consid-
ered approach for imitation-based learning (lines 4-
11) and consists of two sub-phases. The first sub-
phase is the adaptation part. First, the best perform-
ing agents are determined locally (line 5) and these
agents build the elite set E
a
. If the agent is not in
this set, then it is said to be unsatisfied and adapts its
value-vector to the vector of the locally best perform-
ing agent (lines 7-8). The second sub-phase is called
social networking and effects the interaction network.
With some probability P
N
the agent replaces r unco-
operative agents with randomly chosen agents out of
A (line 9). For all settings with P
N
> 0 we have a
dynamic interaction network.
Note, that the agents are not able to sense the
threshold values of their neighbors. Therefore, they
are not able to compute which neighbor is not will-
ing to cooperate with them. But it is possible for the
agents to keep a history of previous behavior of their
neighbors. This can be used as an approximation of
the set of uncooperative neighbors which is not con-
sidered here.
3 CONVERGENCE ANALYSIS
In this section we analyze the convergence behavior
of our adaptation mechanism. To ease the analysis we
will only concentrate on static interaction networks
with very small agent sets.
3.1 The Simplest Scenario
Let us consider a very simple system composed of
two agents and a single proposition. For better read-
ability V denotes the rating of this single proposition
as a rational number instead of an one-dimensional
CONVERGENCE ANALYSIS OF A MULTIAGENT COOPERATION MODEL
169

vector. The system is illustrated in Figure 1. We de-
note with profit(a) the profit that an agent a earned in
one simulation step. In the scenario with two agents
the job phase can produce the following three differ-
ent profit distributions:
1. profit(a) = profit(b)
2. profit(a) > profit(b)
3. profit(a) < profit(b)
Case 1 is very simple since no adaptation takes
place. As case 2 and 3 are symmetric we will concen-
trate on case 2 in the remainder of this section. Then
agent b will always adapt to a by the adaptation rule
provided in Equation 3 which can be transformed to:
V
t+1
b
= V
0
b
· (1 −η)
t+1
+ η ·V
0
a
·
t
∑
i=0
(1 − η)
i
(4)
Lemma 1 . Let dist(a,b,t) be the distance of the
proposition ratings of two agents a and b in step t
with dist(a, b,t) =
V
t
a
− V
t
b
. In a scenario with just
two agents, the distance never increases, i.e. ∀t :
dist(a,b,t + 1) ≤ dist(a, b,t).
The proof can be found in (Eberling and
Kleine B
¨
uning, 2010a).
We now want to know how many steps are needed
until both agents are willing to cooperate with each
other, i.e. after how many steps a ∈ C
b
and b ∈ C
a
holds. As agent b adapts to agent a, only, we suppose
that agent a is less tolerant, i.e. Θ
a
< Θ
b
. This means
that agent a determines the number of steps needed,
since a ∈ C
b
will follow first. From the proof of
Lemma 1 (see (Eberling and Kleine B
¨
uning, 2010a))
we have:
dist(a,b,t) = (1 −η) · dist(a,b,t − 1) (5)
Through simple transformations we get:
dist(a,b,t) = (1 −η)
t
· dist(a,b,0) (6)
Thus, we are searching for the smallest t that satisfies
(1 − η)
t
· dist(a,b,0) ≤ Θ
a
. This is true for
t
0
=
ln(Θ
a
) − ln(dist(a,b,0))
ln(1 − η)
. (7)
Therefore after step t
0
a ∈ C
b
and b ∈ C
a
will hold.
We only considered case 2, where agent b adapts
to agent a in every step. If case 2 does not hold in
every simulation step, we will have to deal with in-
terleaved cases. If case 3 holds we have the symmet-
ric situation that will lead to the same result in the
end. However, case 1 can slow down the development
as no adaptation takes place, if both agents reach the
same profit. But eventually it will hold that case 2 or
3 will again occur and the process is continued. Al-
though we have seen good results in previous work,
we cannot ensure convergence in every setting.
a
a
bc
b
Figure 2: Simple MAS composed of three agents.
Lemma 2 . The adaptation cannot ensure conver-
gence. There are settings in which the system will fail.
Proof. Subsection 3.2 gives an example where the
adaptation does not converge.
3.2 A Simple Scenario without
Convergence
Consider the following very simple multiagent system
in Figure 2. We have three agents. For the agents
and the interaction network we consider the following
formal specification:
• IN = ({a,b,c},{{a,b},{b,c}})
• S = {1, 2,3, 4,5}
• t
min
= t
max
= 3 and q
t
= 1 for all tasks t
• S
a
= {1}, S
b
= {3}, S
c
= {5}
• P = {p
1
}
• V
a
= 0, V
b
= 50, V
c
= 100
• Θ
a
= 2, Θ
b
= 100, Θ
c
= 2
As we have only one proposition we will use
the simplified notation from the previous subsection.
Now, consider the following profit distribution:
profit(a) > profit(c) > profit(b), for odd t (8)
profit(c) > profit(a) > profit(b), for even t (9)
This profit distribution can be the result of the rel-
ative intolerant agents a and c and the very tolerant
agent b. This can lead to an alternating adaptation
of agent b to agent a in odd simulation steps and to
agent c in even simulation steps. As the agents a
and c only have a single neighbor, agent b, and this
agent is always the worst performing one, they never
adapt. Therefore, the length of the value-interval re-
mains constant.
If we set the adaptation strength η = 0.5 and let
agent b adapt in the alternating way as described
above, we can calculate the proposition value V
t
b
for
every time step t. The value of agent b changes in
every step and we observed in previous work that it
does not converge to a single value but it oscillates
between 33
1
3
and 66
2
3
(Eberling and Kleine B
¨
uning,
2010a). For both directions it holds that in every sim-
ulation step the minimal distance is 33
1
3
. Therefore,
agent b never receives help from the other two agents.
The only possibility for agent b to gain profit is the
ICAART 2011 - 3rd International Conference on Agents and Artificial Intelligence
170
fulfillment of a job containing three times skill 3. But
this situation is very rare because the probability of
getting such a job is 0.8% with the given parameters.
However, as agent b is very tolerant it always helps
the other two agents if they ask for help. That’s why
agent b is punished very often in contrast to the other
two agents.
However, this construction is very artificial. In
scenarios that have been considered in previous work
(Eberling, 2009; Eberling and Kleine B
¨
uning, 2010b)
this problem does not occur or at least it does not lead
to significant performance losses. We dealt with 1000
agents and neighborhood sizes of 15 to 20 agents in
a random network. Because of the results in (Eber-
ling, 2009; Eberling and Kleine B
¨
uning, 2010b), we
assume that in random networks the probability of
having situations without convergence is very low and
might be close to zero. One very strong assumption
we made in this subsection is, that agent b adapts to its
neighbors in an alternating way. If the agent adapts to
one neighbor only, we will get a similar convergence
behavior as in the scenario considered in subsection
3.1. Assume, that only the case occurs in which agent
a is the overall best agent. Then we can apply Equa-
tion 7 to calculate the time steps t
0
needed until agent
a and b will mutually cooperate, if the adaptation
strength is set to η = 0.5:
t
0
=
ln(2) − ln(50)
ln(0.5)
= 5 (10)
This means that after five adaptation steps it holds
that (a,b) ∈ C and (b,a) ∈ C . Especially it holds that
dist(a,b,t) ≤ Θ
a
for all t ≥ 5 which means that b will
receive cooperation from agent a and this lets agent
b perform better than agent c, after time step 5. As a
consequence c will adapt to b and the interval between
the values of agent a and agent c will diminish.
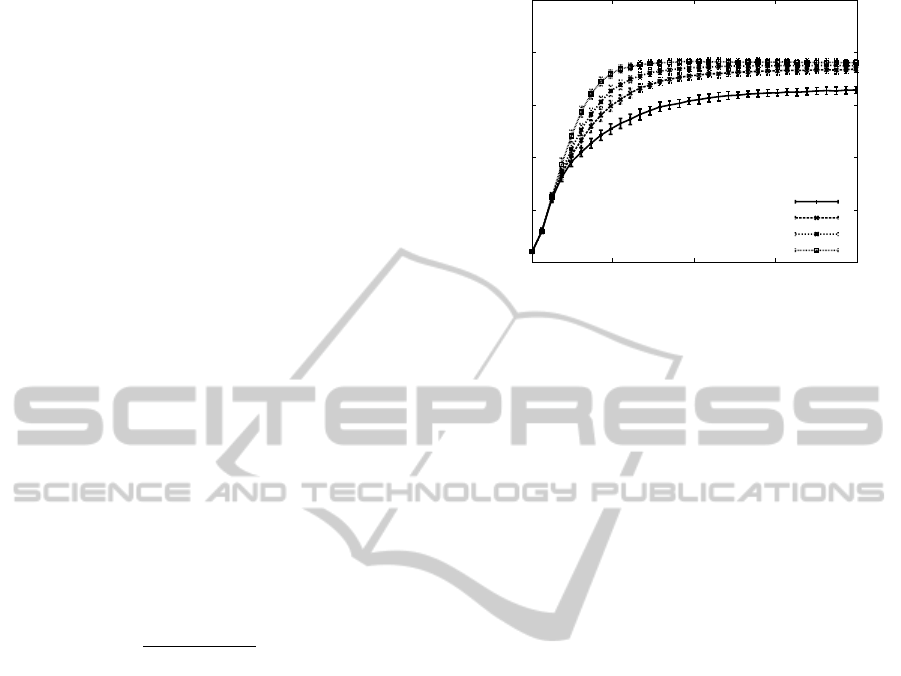
3.3 Empirical Analysis
Figure 3 shows some simulation results with 1000
agents over 200 simulation steps. The results are
means over 30 independent simulations. The jobs are
randomly generated and allocated with a uniform dis-
tribution. As can be seen the simulations reach high
cooperation rates for static scenarios (P
N
= 0.0) and
even better results for dynamic scenarios (P
N
> 0.0).
This shows that the non-converging behavior does not
take place in these scenarios or at least has no great in-
fluence on the performance. For detailed experimen-
tal analysis see (Eberling and Kleine B
¨
uning, 2010a).
0
0.2
0.4
0.6
0.8
1
50 100 150 200
Jobs Done Percentage
P
N
=0.00
P
N
=0.02
P
N
=0.04
P
N
=0.08
Figure 3: Percentage of completed jobs for 200 simulation
steps.
4 CONCLUSIONS AND FUTURE
WORK
Cooperation decisions in everyday life between hu-
mans are based on many criteria which may not be
observable by others. With the help of ratings for
propositions this process has been modeled in a multi-
agent system as a multidimensional decision process.
This paper analyzed the decision process and its abil-
ity to converge to cooperative behavior. The model
fits well to systems where the cooperation willingness
is not necessarily part of the designed agents. Com-
pared to other approaches towards self-organization
one can see that the agents in the presented model do
not need to be very complex and they do not require
much knowledge as only the values for the proposi-
tions have to be observable for the agents.
The local learning algorithm is able to produce
high rates of cooperation in the considered multiagent
systems. This paper has provided a theoretical analy-
sis and has shown that the considered approach does
not always lead to convergence to the intended behav-
ior. However, using randomly generated systems with
uniform distribution have not shown non-convergence
in previous experiments. The assumptions that had to
be made in the presented analysis are very specific
and do not seem to hold in uniformly at random gen-
erated scenarios. The question arises how this behav-
ior can be detected and avoided in a local way without
too much computational effort. This is left for future
work.
Additionally, the influence of other network struc-
tures and the convergence behavior in such systems
should be examined. Also the influence of trust mech-
anisms should be analyzed. In such settings different
trust mechanisms that favor the process of creating
cooperative structures should be analyzed.
CONVERGENCE ANALYSIS OF A MULTIAGENT COOPERATION MODEL
171

REFERENCES
Berkowitz, L. and Macaulay, J. (1970). Altruism and Help-
ing Behavior: Social Psychological Studies of Some
Antecedents and Consequences. Academic Press,
New York.
Branzei, R., Dimitrov, D., and Tijs, S. (2008). Models in co-
operative game theory. Springer Verlag, Heidelberg.
Buchanan, D. and Huczynski, A. (1997). Organisational
Behaviour: An Introductory Text. Prentice Hall, Lon-
don.
de Weerdt, M. M., Zhang, Y., and Klos, T. B. (2007). Dis-
tributed task allocation in social networks. In Huhns,
M. and Shehory, O., editors, Proceedings of the 6th
International Conference on Autonomous Agents and
Multiagent Systems, pages 488–495, Bradford, UK.
IFAAMAS, Research Publishing Services.
Eberling, M. (2009). Towards determining cooperation
based on multiple criteria. In Mertsching, B., Hund,
M., and Aziz, M. Z., editors, KI 2009, volume 5803 of
LNCS, pages 548–555, Heidelberg. Springer.
Eberling, M. and Kleine B
¨
uning, H. (2010a). Convergence
analysis of a multiagent cooperation model (extended
version). Technical Report TR–RI–10–321, Univer-
sity of Paderborn.
Eberling, M. and Kleine B
¨
uning, H. (2010b). Self-
adaptation strategies to favor cooperation. In Je-
drzejowicz, P., Nguyen, N. T., Howlett, R. J., and
Jain, L. C., editors, KES-AMSTA (1), volume 6070 of
LNCS, pages 223–232, Heidelberg. Springer.
Ferber, J. (1999). Multi-Agent Systems: An Introduction
to distributed artificial intelligence. Addison Wesley
Longman Inc., New York, USA.
Hales, D. (2002). Evolving specialisation, altruism, and
group-level optimisation using tags. In Sichman, J.,
Bousquet, F., and Davidsson, O., editors, MABS 2002,
volume 2581 of LNCS (LNAI), pages 26–35, Heidel-
berg. Springer.
Hales, D. (2004). The evolution of specialization in groups.
In Lindemann, G., Moldt, D., and Paolucci, M., ed-
itors, RASTA 2002, volume 2934 of LNCS (LNAI),
pages 228–239, Heidelberg. Springer.
Krebs, D. (1982). Psychological approaches to altruism: An
evaluation. Ethics, 92(3):447–458.
Peitz, U. (2002). Struktur und Entwicklung von Beziehun-
gen in Unternehmensnetzwerken. Deutscher Univer-
sit
¨
atsverlag, Wiesbaden.
Pennington, D. C. (2002). The Social Psychology of Behav-
ior in Small Groups. Psychology Press, New York.
Riolo, R. L., Cohan, M. D., and Axelrod, R. (2001). Evo-
lution of cooperation without reciprocity. Nature,
414:441–443.
Sydow, J. (1992). Strategische Netzwerke: Evolution und
Organisation. Gabler, Wiesbaden.
Wisp
´
e, L. (1978). Altruism, sympathy, and helping: Psy-
chological and sociological principles. Academic
Press, New York, New York.
Wooldridge, M. (2009). An Introduction to MultiAgent Sys-
tems - Second Edition. John Wiley & Sons, West Sus-
sex, UK.
ICAART 2011 - 3rd International Conference on Agents and Artificial Intelligence
172
