
KNOWLEDGE MANAGEMENT SYSTEMS WITH REPUTATION
AND INTUITION
What for?
Juan Pablo Soto, Aurora Vizcaíno, Javier Portillo and Mario Piattini
Alarcos Research Group
Information Systems and Technologies Department, UCLM-Souluziona Research and Development Institute
University of Castilla – La Mancha, Spain
Paseo de la Universidad, 4 – 13071, Ciudad Real, Spain
Keywords: Knowledge management, multi-agent systems, communities of practice, reputation.
Abstract: Nowadays knowledge management is considering to be one of the more important processes by those
companies worried about their competitiveness. These companies focus their efforts on developing systems
that can be used to capture, store and reuse the knowledge generated by theirs employees. Nevertheless, all
this effort may be in vain if the system is not greatly used by the employees because the knowledge that
these systems have is often not valuable or on other occasions the knowledge sources do not provide the
necessary confidence to reuse the information. In an attempt to avoid this situation, we propose a multi-
agent architecture based on communities of practice and on the reputation concept with the purpose of
controlling the utility of information stored in a knowledge base.
1 INTRODUCTION
In recent years knowledge management is a topic of
special interest to organizations who are worried
about their employees’ learning and competitiveness
since a suitable management of this process can help
organizations to increment the collaboration of their
members and encourage the sharing of information
between them. The exchange of information among
employees in an organization represents an
important success factor in improving the
knowledge flow necessary for a suitable knowledge
management. An essential ingredient of knowledge
sharing information in organizations is that of
“community of practice”, by which we mean groups
of people with a common interest where each
member contributes knowledge about a common
domain (Wenger, 1998). This concept has become
more and more popular within the field of the
knowledge management where it is mainly used as a
knowledge management tool to support the
externalization of knowledge, both for reuse as well
as for purposes of innovation (Huysman & Wit,
2000). The importance of the concept of
communities of practice at an organizational level is
parallel to the growth in the interest of management
approaches such as organizational learning and
knowledge management. Communities of practice
enable their members to benefit from each other’s
knowledge. Most of the learning that takes place in
organizations occurs informally in communities of
practice (Lesser, 2000). An interesting fact is that
individuals are frequently more likely to use
knowledge built by their community team members
than those created by members outside their group
(Desouza, 2006). For these reasons, we consider the
modelling of communities of practices into
knowledge management systems an adequate
method by which to provide these systems with a
certain degree of control to measure the confidence
and quality of the information provided for each
member of the community.
In order to carry this out, we have designed a
multi-agent architecture in which agents try to
emulate humans’ rating knowledge sources with the
goal of fostering the use of knowledge bases where
intelligent agents provide “trustworthy knowledge”
to the employees and foster knowledge flow among
them.
The remainder of this work is organized as
follows. The next section presents two important
concepts that take place in the process of obtaining
498
Pablo Soto J., Vizcaíno A., Portillo J. and Piattini M. (2007).
KNOWLEDGE MANAGEMENT SYSTEMS WITH REPUTATION AND INTUITION - What for?.
In Proceedings of the Ninth International Conference on Enterprise Information Systems, pages 498-503
Copyright
c
SciTePress

information (trust and reputation). In section three
the multi-agent architecture proposed to manage
trustworthy knowledge bases is described. In section
four the reputation management used in the agents’
community is presented. In section five we illustrate
how the architecture and reputation management
have been used to implement a prototype which
detects and suggests trustworthy documents for
members in a community of practice. Finally in
section six conclusions are presented.
2 TRUST AND REPUTATION
The main goal of our work is to rate the credibility
of information sources and of knowledge. To do
this, we first need to define two important concepts:
trust and reputation. The former can be defined as
confidence in the ability and intention of an
information source to deliver correct information
(Barber & Kim, 2004) and the latter as the amount
of trust an agent has in an information source,
created through interactions with information
sources. There are other definitions for these
concepts (Gambetta, 1988; Marsh, 1994). However,
we have presented the most appropriate for our
research since the level of confidence in a source is
based on previous experience of this.
Figure 1: Reputation factors.
The reputation of an information source not only
serves as a means of belief revision in a situation of
uncertainty, but also serves as a social law that
obliges us to remain trustworthy to other people.
Therefore, people, in real life in general and in
companies in particular, prefer to exchange
knowledge with “trustworthy people” by which we
mean people they trust. People with a consistently
low reputation will eventually be isolated from the
community since others will rarely accept their
justifications or arguments and will limit their
interaction with them. It is for this reason that the
remainder of this paper deals solely with reputation.
However, if we attempt to imitate the behaviour of
the employees in a company when they are
exchanging and obtaining information we observe
that apart from the concept of reputation other
factors also influence. For this reason, in this paper
we argue that reputation is not a single notion but
one of multiple parts (see Figure 1). These are:
Position: employees often consider information
that comes from a boss as being more reliable
than that which comes from another employee
in the same (or a lower) position as him/her
(Wasserman & Glaskiewics, 1994). However,
this is not a universal truth and depends on the
situation. For instance in a collaborative
learning setting collaboration is more likely to
occur between people of a similar status than
between a boss and his/her employee or
between a teacher and pupils (Dillenbourg,
1999). Because of this, as will be explained
later, in our research this factor will be
calculated by taking into account a weight that
can strengthen this factor to a greater or to a
lesser degree.
Expertise: this term can be briefly defined as the
skill or knowledge of a person who knows a
great deal about a specific thing. This is an
important factor since people often trust in
experts more than in novice employees.
Moreover, tools such as expertise location
(Crowder et al, 2002) are being developed with
the goal of promoting the sharing of expertise
knowledge (Rodríguez-Elías et al, 2004).
Previous experience: People have greater trust
in those sources from which they have
previously obtained more “valuable
information”. Therefore, a factor that influences
the increasing or decreasing reputation of a
source is “previous experience” and this factor
can help us to detect trustworthy sources or
knowledge.
Intuition: When people do not have a previous
experience they often use their “intuition” to
decide whether or not they are going to trust
something. Other authors have called this issue
“indirect reputation or prior-derived reputation”
(Mui et al, 2002). In human societies, each of us
probably has different prior beliefs about the
trustworthiness of strangers we meet. Sexual or
racial discrimination might be a consequence of
such prior belief (Mui et al, 2002). We have
tried to model intuition according to the
similarity between the user profiles, the greater
the similarity between one agent and another,
the greater the intuition level.
Taking all these factors into account we have
defined an own “concept of reputation”. In
section four we shall describe how we use this
definition to rate knowledge and information
sources.
KNOWLEDGE MANAGEMENT SYSTEMS WITH REPUTATION AND INTUITION - What for?
499
3 A MULTIAGENT
ARCHITECTURE TO
DEVELOP TRUSTWORTHY
KNOWLEDGE BASES
When implementing a knowledge management
system we must consider the importance a
knowledge base has within that system. In this work
we have focused our attention on the difficulties of
controlling the quality of the contributions and the
“reputation” of contributors of a knowledge
management system. A knowledge management
system must store only useful knowledge for
employees. However, sometimes the knowledge
which is put into a knowledge base is not very
valuable. This decreases the trust that employees
have in their knowledge bases and reduces the
probability of people using it. In order to avoid this
situation we have developed a multi-agent
architecture in charge of monitoring and evaluating
the knowledge that is stored in a knowledge base.
To design this architecture we have taken into
account how people obtain information in their daily
lives and concretely how this exchange of
information takes place in communities of practice.
Bearing in mind the advantages of working with
groups of similar interests we have organized the
agents into communities of people who are
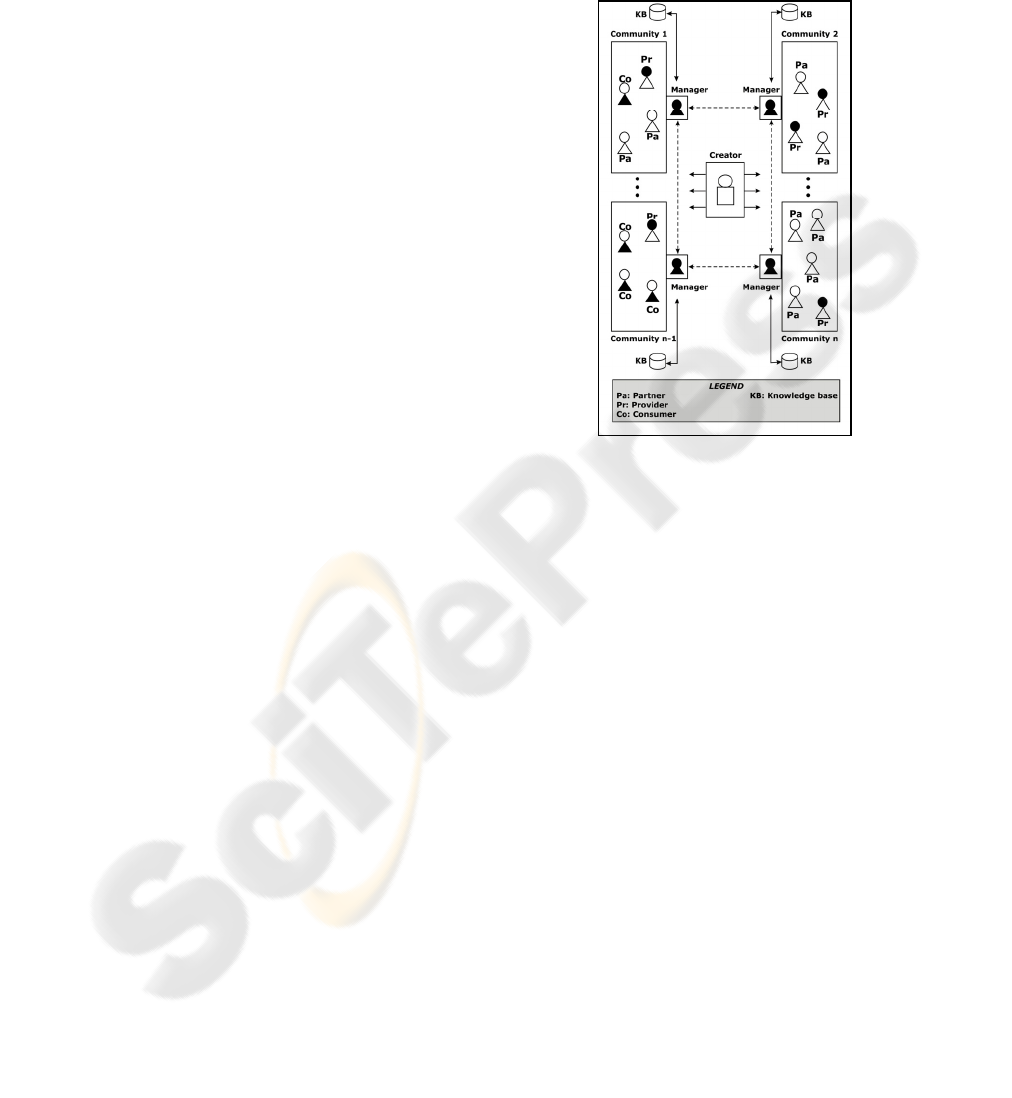
interested in similar topics. Thus, Figure 2 shows
different communities where there are two types of
agents: the User Agent and the Manager Agent. The
former is used to represent each person that may
consult or introduce knowledge in a knowledge
base.
The User Agent can assume three types of
behaviour or roles similar to the tasks that a person
may carry out in a knowledge base. Therefore, the
User Agent plays one role or another depending
upon whether the person that it represents carries out
one of the following actions:
The person contributes new knowledge to the
communities in which s/he is registered. In this
case the User Agent plays the role of Provider.
The person uses knowledge previously stored in
the community. Then, the User Agent will be
considered as a Consumer.
The person helps other users to achieve their
goals, for instance by giving an evaluation of
certain knowledge. In this case the role is of a
Partner. So, Figure 2 shows that in community
1 there are two User Agents playing the role of
Partner, one User Agent playing the role of
Consumer and another being a Provider.
The fact that this agent can act both as
consumers and also as providers of knowledge may
lead to better results because they aim to motivate
the active participation of the individual in the
learning process, which often results in the
development of creativity and critical thinking (Kan,
1999).
Figure 2: Multi-agent architecture.
The second type of agent within a community is
called the Manager Agent (represented in black in
Figure 2) which is in charge of managing and
controlling its community. In order to accomplish
this, the Manager Agent can perform the following
tasks:
Registering an agent in its community. It thus
controls how many agents there are and how
long the stay of each agent in that community is.
Registering the frequency of contribution of
each agent. This value is updated every time an
agent makes a contribution to the community.
Registering the number of times that an agent
gives feedback about other agents’ knowledge.
For instance, when an agent “A” uses
information from another agent “B”, the agent
A should rate this information. Monitoring how
often an agent gives feedback about other
agents’ information helps to detect whether
agents contribute to the creation of knowledge
flows in the community since it is as important
that an agent contributes with new information
as it is that another agent contributes by
evaluating the relevance or importance of this
information.
Registering the interactions between agents.
Every time an agent evaluates the contributions
of another agent the Manager Agent will
ICEIS 2007 - International Conference on Enterprise Information Systems
500

register this interaction. But this interaction is
only in one direction, which means, if agent A
consults information from agent B and evaluates
it, the Manager records that A knows B but that
does not means that B knows A because B does
not obtain any information about A.
Besides these agents there is another in charge of
initiating new agents and creating new communities.
This agent has two main roles: the “creator” role is
assumed when there is a petition (made by a User
Agent) to create a new Community and the
“initiator” role is assumed when the system is
initially launched. This agent, which is not included
in any of the communities, is located in the centre of
Figure 2, and is called the Creator Agent.
The following section describes how the agent
works in order to obtain reputation values.
4 REPUTATION MANAGEMENT
IN AGENTS’ COMMUNITIES
The idea of using reputation values has two
objectives. The first of them is that agents help
employees to discover the information that is most
relevant for them, thus, decreasing the overload of
information that employees often have and
strengthening the usage of knowledge bases in
companies. Another objective is to avoid the
situation of employees storing valueless information
in a knowledge base. In order to accomplish this
successfully, we need to manage reputation in such a
way that the agents can obtain reputation values that
can be used to maintain the quality of the
information in knowledge bases.
Bearing in mind that the reputation notion
described in section 2 is composed of position,
expertise, previous experiences and intuition, we
will describe the formulas used to measure the level
of reputation in agents’ communities.
For instance, the reputation of agent
j
in the eyes
of agent
s
is a collective measure defined by the
previously describe reputation factors in section two
and is computed as follows:
n
R
sj
= w
e
*E
j
+ w
p
*P
j
+ w
i
*I
j
+
(∑ QC
j
)/n
j=1
where R
sj
denotes the reputation value that
agent
s
has in agent
j
(each agent in the community
has an opinion about each of the other agent
members of the community).
E
j
is the value of expertise which is calculated
according to the degree of experience that a person
has in a domain.
P
j
is the value assigned to the position of a
person. This position is defined by the
organizational diagram of the enterprise. Therefore,
a value that determines the hierarchic level within
the organization can be assigned to each level of the
diagram.
I
j
is the value assigned to the intuition which is
calculated by comparing the users’ profiles of each
one.
In addition, previous experience should also be
calculated. We suppose that when an agent A
consults information from another agent B, the agent
A should evaluate how useful this information was.
This value is called QC
j
(Quality of j’s
Contribution). To attain the average value of an
agent’s contribution, we calculate the sum of all the
values assigned to their contributions and we divide
it between their total. In the expression n represents
the total number of evaluated contributions.
Finally, w
e
, w
p
and w
i
are weights with which the
Reputation value can be adjusted to the needs of the
organizations. For instance, if an enterprise
considers that all their employees have the same
category, then w
p
=0. The same could occur when the
organization does not take its account employees’
intuitions or expertise into account.
In this way, an agent can obtain a value related to
the reputation of another agent and decide to what
degree it is going to consider the information
obtained from this agent.
Moreover, when a user wants to join to a
community in which no member knows anything
about him/her, the reputation value assigned to the
user in the new community is calculated on the basis
of the reputation assigned from others communities
where the user is or was a member. For instance, an
User Agent called j, will ask each community
manager where he/she was previously a member to
consult each agent which knows him/her with the
goal of calculating the average value of his/her
reputation (R
Aj
). This is calculated as:
n
R
Aj
= (∑ R
ij
)/n
i=1
where n is the number agents who know j and R
ij
is the value of j’s reputation in the eyes of i. In the
case of being known in several communities the
average of the values R
Aj
will be calculated. Then,
the User Agent j presents this reputation value
(similar to when a person presents his/her
curriculum vitae when s/he wishes to join a
company) to the Manager Agent of the community
to which it is “applying”. This mechanism is similar
to the “word-of-mouth” propagation of information
for a human (Abdul-Rahman & Hailes, 2000).
KNOWLEDGE MANAGEMENT SYSTEMS WITH REPUTATION AND INTUITION - What for?
501

In the case of the user being new in the
community then this user is assigned a “new” label
in order for the situation to be identified.
Once the Community Manager has obtained a
Reputation value for j it is added to the community
member list.
In the following section, we will describe a
prototype developed to validate each of our
proposals.
5 PROTOTYPE
In order to evaluate the architecture and formulas to
manage reputation we have developed a prototype
system into which people can introduce documents
and where these documents can also be consulted by
other people. The goal of this prototype is for agents
software to help employees to discover the
information that may be useful to them thus
decreasing the overload of information that
employees often have and strengthening the use of
knowledge bases in companies. In addition, we try
to avoid the situation of employees storing valueless
information in the knowledge base.
The main feature of this system is that when a
person searches for knowledge in a community, and
after having used the knowledge obtained, that
person then has to evaluate the knowledge.
When a user wants to join to a new community
the person will use a “Register Menu” and choose a
community from all the available communities. In
this case the Manager Agent will ask whether there
are any agents that know new user in order to set a
reputation value on this person.
In addition, the prototype provides the options of
proposing new documents, using community
documents and updating reputation values,
proposing new topics in the community, etc. We
shall now describe only two situations, due to
limitations of space:
1) Proposing new documents. It is assumed that
any person is able to propose documents in those
communities where he/she is a member. To propose
a document a person must use the “Propose Menu”
and will have to configure the followings options:
Community: The person must select the
community to which s/he proposes to add a
document.
Topic: In each community there may be
different topics or areas and the user will choose
the one in which s/he intends to propose the
document.
Document: The proposed document.
Author: Indicates who the author of the
document is since a person may propose other
authors’ documents. In this case, the proposal is
considered as a contribution but not as the
proposer’s own contribution.
Knowledge Source: Where the knowledge came
from. It could have come from a partner, from
the person him/herself, from a web page, etc.
Once the user has chosen the options, the User
Agent takes the values and sends them to the
Manager Agent that is in charge of adding the new
document to the community document list and
modifying the frequency of contribution of this
agent in this community.
2) Using community documents and updating
reputation values. People can search for documents
in every community in which they are registered.
When a person searches for a document relating to a
topic his/her User Agent consults the Manager
Agent about which documents are related to their
search. Then, the Manager agent answers with a list
of documents. The User Agent sorts this list
according to the reputation value of the authors,
which is to say that the contributions with the best
reputations for this Agent are listed first. On the
other hand, when the user doesn’t know the
contributor then the User Agent consults the
Manager Agent about which members of the
community know the contributors. Thus, the User
Agent can consult the opinions that other agents
have about these contributors, thus taking advantage
of other agents’ experience. To do this the Manager
consults its interaction table and responds with a list
of the members who know the User Agent Then, this
User Agent contacts each of them. If nobody knows
the contributors then the information is listed, taking
their expertise and positions into account. In this
way the User Agent can detect how worthy a
document is, thus saving employees’ time, since
they do not need to review all the documents related
to a topic but only those considered most relevant by
the members of the community or by the person
him/herself according to previous experience with
the document or its authors.
Once the person has chosen a document, his/her
User Agent adds this document to its own document
list (list of consulted documents), and if the author
of the document is not known by the person because
it is the first time that s/he has worked with him/her,
then the Community Manager adds this relation to
the interaction table. This step is very important
since when the person evaluates the document
consulted, his/her User Agent will be able to assign
a QC for this document.
ICEIS 2007 - International Conference on Enterprise Information Systems
502

6 CONCLUSIONS
The main contribution of this paper is to add a
reputation concept to knowledge bases with the idea
of emulating people’s behaviour within communities
since according to literature the exchange of
knowledge is likely to take place in these
communities thanks to the trust that members have
in each other. Moreover, we have proposed a new
definition of “reputation” which considers aspects
that affect the degree of trust that a person has in
something (a knowledge source, a person, a piece of
knowledge). In this definition intuition, a concept
that according to (Mui et al, 2002) has not yet been
modelled by agent systems has been included.
Another important advantage of our approach is
that we use easy and generic formulas to measure
the reputation in knowledge management systems.
This is very important because our focus may be
useful in several situations.
In addition, this work has illustrated how the
architecture can be used to implement a prototype.
The main functionalities of this architecture are:
- Detecting information which is not particularly
useful in a knowledge base.
- Displaying useful information to employees
according to the user’s profiles.
- Detecting the most important knowledge
sources of a company. Since our approach rates
information as well as the contributor this could
also help companies to detect those employees
with more knowledge about a topic (expert
detection).
This architecture may also be useful in the
implementation of a recommender system as the
better evaluated information can be sent to interested
parties. For instance, our research group will use our
architecture to evaluate research papers and the best
valuated papers will be sent to the members of the
group who work on related topics. In addition the
architecture can be used to support virtual
communities, or to detect the most trustworthy
employees or with the best reputation.
All these situations provide organizations with a
better control of their knowledge bases which will
have more trustworthy knowledge and it is
consequently expected that employees will feel more
willing to use it.
ACKNOWLEDGEMENTS
This work is partially supported by the ENIGMAS
(PIB-05-058), and MECENAS (PBI06-0024)
project,. It is also supported by the ESFINGE project
(TIN2006-15175-C05-05) Ministerio de Educación
y Ciencia (Dirección General de Investigación)/
Fondos Europeos de Desarrollo Regional (FEDER)
in Spain
.
REFERENCES
Abdul-Rahman, A., Hailes, S., 2000, Supporting Trust in
Virtual Communities. 33rd Hawaii International
Conference on Systems Sciences (HICSS'00).
Barber, K., Kim, J., 2004, Belief Revision Process Based
on Trust: Simulation Experiments. 4th Workshop on
Deception, Fraud and Trust in Agent Societies.
Montreal Canada.
Crowder, R., Hughes, G., Hall, W., 2002, Approaches to
Locating Expertise Using Corporate Knowledge.
International Journal of Intelligent Systems in
Accounting Finance & Management, Vol. 11, pp. 185-
200.
Desouza, K., Awazu, Y., Baloh, P., 2006, Managing
Knowledge in Global Software Development Efforts:
Issues and Practices. IEEE Software, pp. 30-37.
Dillenbourg, P., 1999, Introduction: What Do You Mean
By "Collaborative Learning"?. Collaborative Learning
Cognitive and Computational Approaches.
Dillenbourg (Ed.). Elsevier Science.
Gambetta, D., 1988, Can We Trust Trust? In D. Gambetta,
editor, Trust: Making and Breaking Cooperative
Relations, pp. 213-237.
Huysman, M., Wit, D., 2000, Knowledge Sharing in
Practice. Kluwer Academic Publishers. Dordrecht.
Kan, G., 1999, Gnutella. Peer-to-Peer: Harnessing the
Power of Disruptive Technologies. O'Reilly, pp. 94-
122.
Lesser, E., 2000, Knowledge and Social Capital. In
Foundations and Applications. Boston: Butterworth
Heinemann.
Marsh, S., 1994, Formalising Trust as a Computational
Concept. PhD Thesis, University of Stirling.
Mui, L., Halberstadt, A., Mohtashemi, M., 2002, Notions
of Reputation in Multi-Agents Systems: A Review.
International Conference on Autonomous Agents and
Multi-Agents Systems (AAMAS'02), pp. 280-287.
Rodríguez-Elias, O., Martínez-García, A., Favela, J.,
Vizcaíno, A., Piattini, M., 2004, Understanding and
Supporting Knowledge Flows in a Community of
Software Developers. LNCS 3198, Springer, pp. 52-
66.
Wasserman, S., Glaskiewics, J., 1994, Advances in Social
Networks Analysis. Sage Publications.
Wenger, E., 1998, Communities of Practice: Learning
Meaning, and Identity, Cambridge U.K., Cambridge
University Press.
KNOWLEDGE MANAGEMENT SYSTEMS WITH REPUTATION AND INTUITION - What for?
503
