
A MULTI-VIEWS REPOSITORY FOR MULTI-STRUCTURED
DOCUMENTS
Karim Djemal
IRIT, SIG/D2S2 Team, Paul Sabatier University 118 Route de Narbonne, 31062 Toulouse, France
Keywords: Document repositories, meta-model, multi-views, multi-structured document.
Abstract: The diversity of use of digital documents has created new interests on archiving, storing and accessing the
digital documents. These documents can have several structures and different interpretations of these
structures. This paper presents an approach to process the multi-structured documents through repositories.
So, we present the repository meta-model based on views. Integrating various views in a document
repository allows a complete vision and a better targeted exploitation of these documents.
1 INTRODUCTION
The recent growing of digital documents and in
particular the audio-visual ones has created new
interests on archiving, storing and accessing the
information extracted from these documents. Thus,
document repositories were used to allow an easy
and efficient exploitation of documentary
information. Indeed, the document storage provides
a detailed description of the structure as well as
contents of each document stored in the repository.
This description is used to represent
immaterialized documents and to gather documents
that have the same structure in order to lead to
possible analysis. These documents can have several
structures and different interpretations of these
structures. So, each document can have several
views. These views are generally related to a
particular case of use of a document. Moreover, in
the literature, a “view” can have two meanings. It
can focus on a certain aspect of the studied entity
and in this case it presents a vision corner, or it can
include all the aspects of the entity within an
interpretation and in this case it presents an opinion.
In every instance, the view concept introduces a use
or an interpretation dimension which allows to give
semantics to the various structures.
This paper presents an approach to process the
multi-structured documents through repository. The
use of the views is a way of managing these
documents. Integrating various views in a document
repository allows a complete vision and a better
targeted exploitation of the documents.
This paper is organized in two sections. The first
one describes related works regarding a modeling
muti-structured document and metadata usage for
media description. The second section exposes our
approach to process the multi-structured documents
within a repository. We start by introducing our
proposal that includes a modeling a multi-view
repository. Afterwards, we show an example of the
instantiation of our meta-model.
2 RELATED WORK
A document repository contains the document (i.e.
granules of it) as well as the associated structures
and content information. Indeed, to exploit the
information extracted from these documents, it is
necessary to represent and store these documents
according to appropriate models. This information
can be of complex nature (e.g. image, audio, video).
Metadata are proposed in the literature to describe
this information.
2.1 Modeling Multi-structured
Documents
A lot of work has been done in the perspective of
modeling multi-structured documents. These works
can be classified into two categories.
(1) Work that uses conceptual graphs (made up
by concepts) in order to represent the various
structures. These concepts are already defined.
EMIR² (Mechkour M., 1995) and EMIR² extended
544
Djemal K. (2007).
A MULTI-VIEWS REPOSITORY FOR MULTI-STRUCTURED DOCUMENTS.
In Proceedings of the Ninth International Conference on Enterprise Information Systems - DISI, pages 544-548
DOI: 10.5220/0002381505440548
Copyright
c
SciTePress

models (Charhad M. et Quénot G., 2004) join this
category of models. They represent the document
like set of concept, which are connected in the shape
of graph, thus forming a different structure.
EMIR² model presents an image description
according a set view (facet). It combines various
interpretations image in order to build a complete
image content description. This model is based on
conceptual graph to conceive these views. These
facets are classified according two description
levels:
• The logical level collects all views describing the
image contents: structural, symbolic and spatial
views,
• The physical level presents the perceptual view. It
describes the low level characteristic of image.
EMIR² model was extended to include audio-
visual documents. (Charhad M. et Quénot G., 2004)
proposed to add two facets: a temporal one and an
event one. These two facets characterize the specific
dynamic aspect of this kind of documents. Temporal
facet presents the temporal aspect of video
documents. It permits to order and synchronize a
dynamic content of these documents. Event facet
describes several events produced in audio-visual
documents. These events describe actions occurring
in a video sequence.
(2) Work which represent the structures through
elements and metadata which compose to them.
These elements and these metadata are not already
defined. Two types of structures arise: an
arborescent structures representing the documents:
case of the model of (Mbarki M. et al., 2005), and
the graph structures representing the documents:
case of the ISDN and MSDM models.
Within the framework realized within ISDN,
(Abascal R. et al., 2003) proposed a generic model
to manage the multi- structures documents. ISDN
model defines, in a generic way, a multi-structured
document specifying the relations between the
various structures detected in the same document.
(Chatti N. et al., 2006) extend this model to describe
these relations. They propose a model called
MSDM. This model organizes the various document
structures and attaches them to a base structure.
The objective in these works is the modeling of
multiple documents structures; and this is
accomplished by allowing on the one hand, the
integration of the structure as a whole, and on the
other hand, the representation and handling of multi-
structured documents.
As part of treatment of multimedia documents,
(Mbarki M. et al., 2005) present a model which
exploits two document structures; the logical and the
semantic, and that offers a dichotomy between these
two structures. Each document can have a logical
structure composed by elements and their attributes
and also it can have a semantic structure composed
of components and metadata which describe them.
Although it treats documents multi-media
integrating of the complex data, this meta-model
allows to manage only two structures of the same
document simultaneously.
2.2 Metadata for a Semantic Access to
Contents
Above, we have shown the possibility of structuring
a document in various ways. In this part, we browse
a particular structure: the semantic one. This
structure offers a semantic access to the data through
the metadata which it uses. Indeed, metadata (i.e.,
data about data) can be used to describe several
aspects of content (e.g. formats, semantics, etc.).
(Jokela S., 2001). In our works, we are interested in
the semantic aspect offered by these metadata. So,
by accessing these metadata, we can exploit
semantics of a document by retrieving, interrogating
and analyzing the contents.
In the literature, there are several metadata
languages providing semantics of documents. In the
following part, we show three languages: RDF,
Dublin Core and MPEG7. These languages are
based on XML syntax for the document description.
RDF (Resource Description Framework)
provides a generic model for metadata. Coded on a
triplet (resource, property and value), RDF
implements a mechanism to share, exchange and use
semantic information (W3C, 2004).
Dublin Core (Hunter J., et al., 1999)
being a
descriptive diagram of metadata, it is designed to
express metadata on Web and to cover a wide
spectrum of application. While being simple (usable
by non expert) and flexible (possible to extend it),
Dublin core offers, in the initial version fifteen
descriptive properties (e.g. “Title”, “Subject”,
“Description”, “Date”, “Type”, “Format”,
“Language”, “Relation”, “Coverage”, etc.).
These elements were extended to describe audio-
visual document. This suggested extension
concerned mainly three elements: “Format” (to
specify physical characteristics), “Relation” (to
describe the hierarchical relationship of structure.)
and “Coverage” (to locate the spatio-temporal
segments to be described).
MPEG 7 (Multimedia Content Description
Interface) (Manjunath B.S., et al., 2002) is a
standard description, based on multi-media
document metadata. It provides set descriptors (D)
describing physical characteristics of the audiovisual
objects (texture, movement, etc.), set of description
A MULTI-VIEWS REPOSITORY FOR MULTI-STRUCTURED DOCUMENTS
545

diagram (DS), an extensible DDL (Data Definition
Language) and tools system. For example, MPEG 7
proposes tools for the content description according
two aspects; structural one and conceptual one, like
it proposes tools for the content management.
MPEG 7 and extended Dublin Core offer an
overall description of the audio-visual documents.
Dublin Core focuses on the bibliographical
description of the data and it does not describe low
level information. MPEG 7 standardizes descriptors
of very low levels, although, it offers a mechanism
of descriptors extension to generate high levels
descriptors. RDF is characterized by the description
of the resources and relations between them. Today,
RDF seems to be the suitable language that can be
coupled with our proposition including views
management and their representation
3 MULTI-STRUCTURED
DOCUMENT REPOSITORY
3.1 Meta-Model
In this section, we expose our approach; we show
and exploit the multiple-views associated with a
document, within a repository.
In order to take account of the multi-structured
documents in repository, we propose a meta-model
with multi-views (cf. Figure 1). This meta-model
presents, in particular, the views that are associated
to the same document. These views are developed
by the elements and the associated metadata. In
addition, certain views will be brought to exploit the
relations between metadata or between the elements
to have a specific characteristic.
This meta-model presents two aspects; a generic
one, and specific one. In a first level, we treat the
specific aspect of a document. More precisely, each
document has a declaration, with its own physical
and logical specific structure. The physical structure
describes physical parameters of a document. As for
the specific logical structure, it translates the
organization of a document into several levels. It is
composed of set specific elements which can be
described by specific metadata. The specific logical
structure then describes the role and the nature of
each specific element like their hierarchies. This
specific logical structure is attached to a generic
logical structure. And, this generic logical structure
is made up of generic elements which can be
described by generic metadata. Logical structure
could be interpreted according to several views i.e.
elements and metadata which compose it. These
views express a different point of view; they can
then show the structural, semantic, spatial or
temporal aspect of a logical structure.
• Structural view: built by the generic elements, it
presents the structural aspect relating to a
document making it possible to focus on its
logical organization.
• Semantic view: only composed of metadata
which describe certain elements. This view
allows thus, the exploitation of certain complex
elements (e.g. an image, a video sequence, etc.)
while accessing their contents.
• Temporal view: composed by elements and
metadata as well as the relations which could
exist between the elements or between the
metadata. This view allows to have a structure
with temporal character with an aim of having
certain individual uses in the exploitation phase.
• Spatial view: like the temporal view it is
composed by elements, metadata and relations.
This view focuses on the spatial characteristics of
certain elements and metadata (e.g. for a
geometrical form, we can associate the nature and
the coordinates) like on the relations (e.g. the
positioning of these geometrical forms or objects
between them).
Allen relations (Allen J., 1991) allow to structure
the contents of a video sequence based on temporal
information. Indeed, Allen identifies a complete set
of temporal relations that can to exist between two
intervals. He introduced thirteen relations among
which twelve are asymmetric (“Before”, “Meets”,
“Overlaps”, “starts”, “During”, “Finished” and.
“Equal”).
The spatial view is described primarily by the
three relations: topological, directional and distance
defined in (Charhad M. et Quénot G., 2004).
• The topological relations are described by the
positions between objects: in front of, behind, etc.
• The directional relations show a particular
orientation between the objects: right, left, above
and below.
• The third type of relations is based on distance:
near and far.
ICEIS 2007 - International Conference on Enterprise Information Systems
546
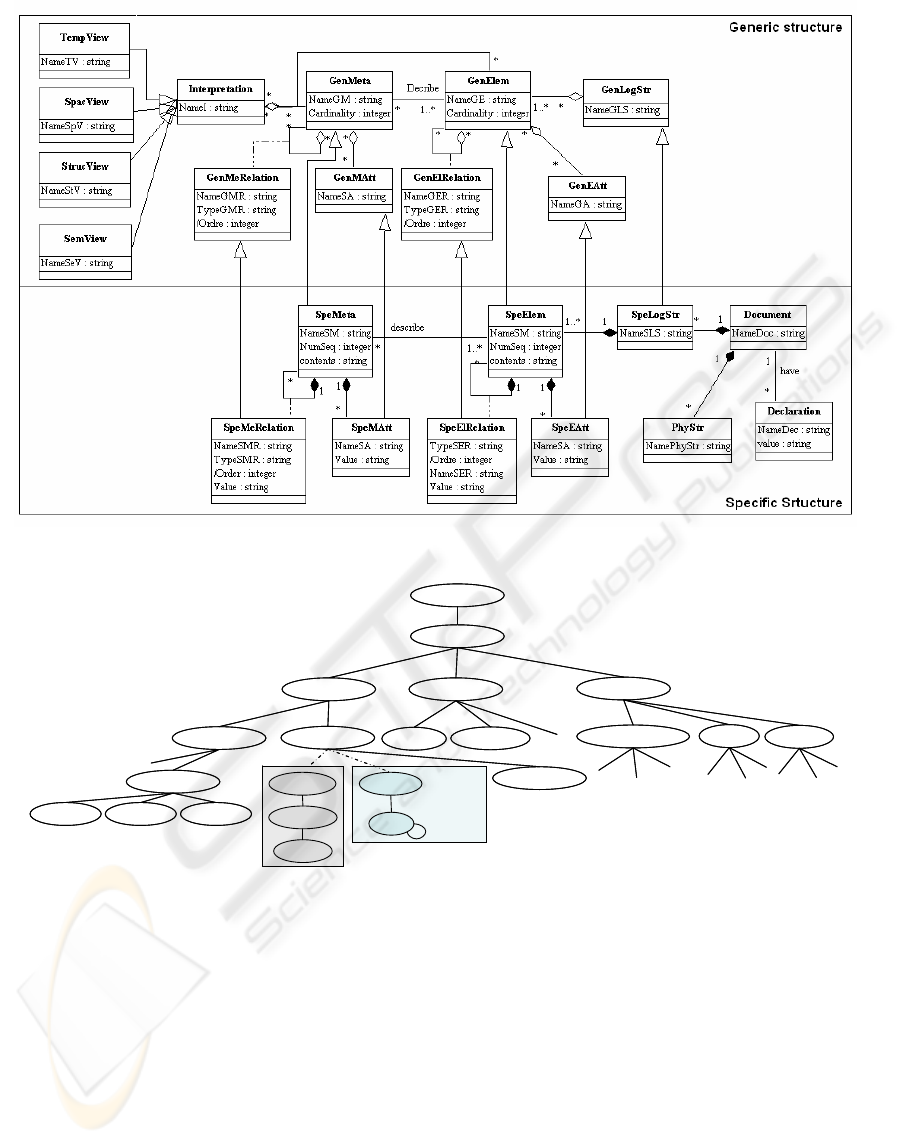
Figure 1: Meta-model of multi-structured document repository
Frame
Zone
SpatialRelation
+
DVD
Title
Preface Chapter
Bonus
Start-End
advertisement
Photo
Interview
Region
Region-text
Coordinate
Frame key
+
+
*
?
?
*
*
+
*
*
…
Coordinate
Face
SkinColorShape
?
Paragraph
Text
+
Word
+
?
?
Frame
Zone
SpatialRelation
+
DVD
Title
Preface Chapter
Bonus
Start-End
advertisement
Photo
Interview
Region
Region-text
Coordinate
Frame key
+
+
*
?
?
*
*
+
*
*
…
Coordinate
Face
SkinColorShape
?
Paragraph
Text
+
Word
+
?
Paragraph
Text
+
Word
+
?
?
Figure 2: Generic structure of a DVD.
This meta-model allows to take into account
various interpretations of the logical structures
through the views. Indeed, the same element or the
same metadata can belong to different views. This
meta-model then allows the overlapping between
views and consequently between structures. So, this
solution also enables to store the contents of a
document only once and each view can refer it. In
consequently, it allows to eliminate the possible
redundancies due to multiples storage from various
elementary information.
These multi-views also permit to structure the
document description on several abstraction levels.
We will have then, the structural view in the low
level, then the semantic view and finally both views;
a temporal one and spatial one.
3.2 Example of Repository Content
To validate our meta-model, we propose to treat a
DVD example. Indeed, by observing a collection of
DVD we could extract a generic structure common
to these DVDs. The Figure 2 shows this generic
structure. Indeed, a DVD is composed of one or
more titles. These titles can contain a preface, a
possibly bonus or set of the chapters. The chapters
represent index on film. They are characterized by
their start and their end, and by their key frames.
A MULTI-VIEWS REPOSITORY FOR MULTI-STRUCTURED DOCUMENTS
547
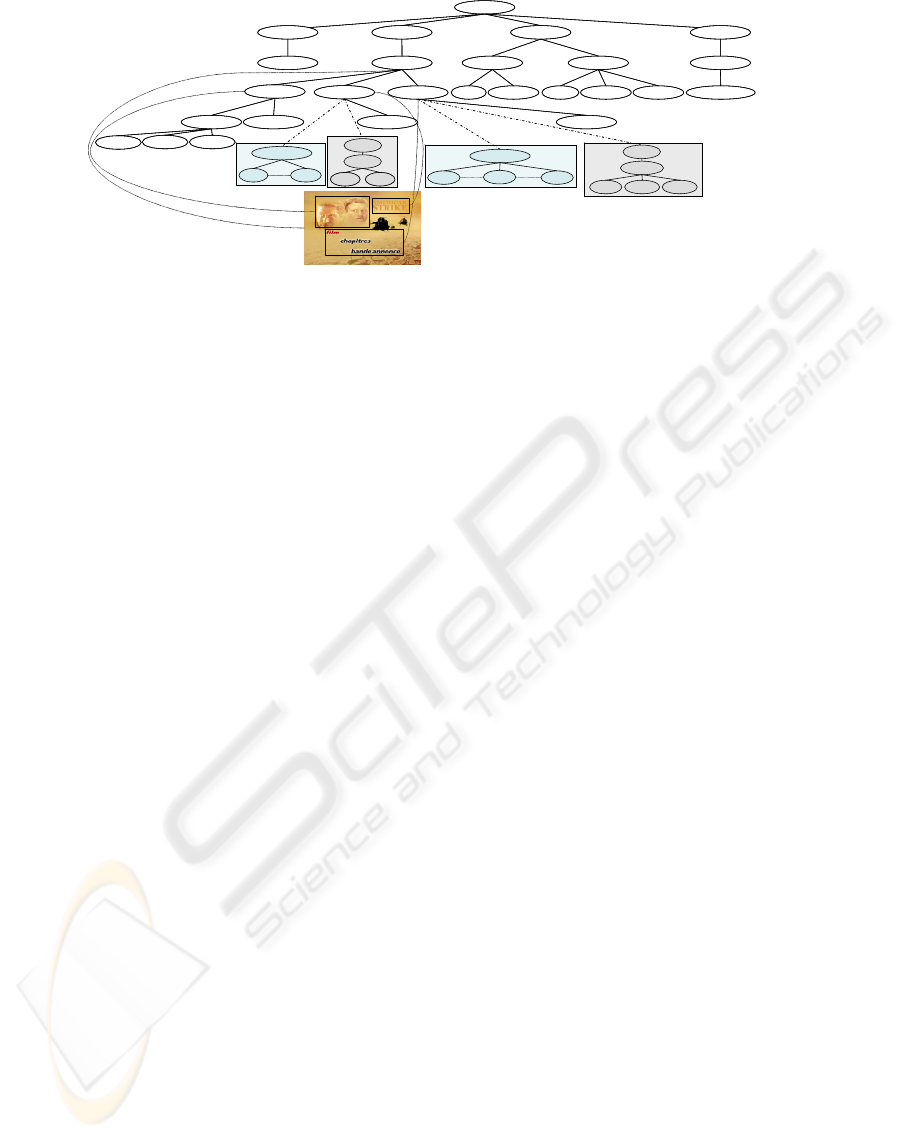
Figure 3: Specific structure of a DVD.
In our example, we develop in particular
"Prefaces" element. This element can be composed
of "region" and\or "text-region". This fragment is
characterized by its coordinates. These coordinates
depend on the region form (e.g. for a rectangular
region, we define the Cartesian coordinates of the
high left corner of the rectangle, as well as its width
and its height). We present two different views
associated to this element. Indeed, a text-region can
be interpreted in two different ways. According to
the use, a user can interpret it as an image and text.
So, there will be two possible structural views
"Frame Str" and "Text Str" to describe same
elementary information.
4 CONCLUSION
We have presented in this article some related works
of multi-structured documents, as well as of the
metadata. After that, we show our approach. We
present a meta-model of document repository and an
example of repository content.
This paper proposes an approach of multi-
structured documents management within document
repository. The meta-model suggested allow jointly
to manage several structures associated to the same
document. On the one hand, our meta-model, unlike
to the Mbarki’s and the MSDN model, can manage
various interpretations of each structure. On anther
hand, our meta-model allows to store each document
fragment only once and each document structure
refers to this fragment, differently to MDSM model.
Indeed, each structure represents a view different
from the document and each view is made up of
several fragments (elements and metadata). These
fragments can pertain to more than view
simultaneously. Consequently, this méta-model
allows the overlapping between the views.
We aim, in our next work, to validate this
approach by a prototype and to show a possible use
cases of this repository.
REFERENCES
Abascal R., Beigbeder M., Benel A., Calabretto S.,
Chabbat B., Champin P.A., Chatti N., Jouve D., Prie
Y. and Rumpler B., 2003. Modéliser la structuration
multiple des documents. In Actes de la Conférence
H2PTM Hypertexte et Hypermédia -Créer du sens à
l’ère du numérique, Ed. Hermès, Paris, pp. 253-258.
Allen J., 1991, Time and time again: The many ways to
represent time. In International Journal of Intelligent
Systems.
Charhad M. and Quénot G., 2004. Semantic Video
Content Indexing and Retrieval using Conceptual
Graphs. In ICTTA, Damascus, Syria, 19-23.
Chatti N., Calabretto S. and Pinon J.M., 2006. MultiX: an
XML-based formalism to encode multi-structured
documents. In Proceedings of Extreme Markup
Languages 2006, Montréal, Canada.
Hunter J. and Armstrong L., 1999. A Comparison of
Schemas for Video Metadata Representation, In
WWW8, Toronto.
Jokela, S., 2001. Metadata enhanced content management
in media companies, In Dissertation for PhD, Helsinki
University of Technology, Espoo, Finland.
Manjunath B.S., Salembier P., and Sikora T., 2002.
Introduction to MPEG-7: Multimedia Content
Description Interface, Wiley.
Mbarki M., Soulé-Dupuy, C. and Vallés-Parlangeau, N.,
20805. Modeling and Flexible exploitation of Audio
Documents. In the proceeding of IEEE International
Conference on Signal-Image Technology & Internet
Based Systems. Yaoundé, Cameroon 216-223.
Mechkour M., 1995. A multifacet formal image model for
information retrieval. In MIRO final workshop.
W3C, 2004. Consortium RDF Primer,
http://www.w3c.org/TR/rdf-primer/.
Title
Word1 Word 2
Text
Item1 Item2
Items
Item3
Text
Zone3
Zone4
Under
Frame2
Zone5
Under
Frame1
Zone1 Zone2
under
DVD
Title 1 Title 2 Title 3 Title 4
Preface MenuPage Chapter 1 Chapter 2 Bonus
StartEnd StartEndKeyFrame1 advertisement
Region
TextRegion
TextRegion
CoordinateCoordinate Coordinate
KeyFrame2 KeyFrame3
Coordinate
Face
SkinColor
Shape
Title
Word1 Word 2
Text
Title
Word1 Word 2Word1 Word 2
Text
Item1 Item2
Items
Item3
Text
Item1 Item2
Items
Item3
Text
Zone3
Zone4
Under
Frame2
Zone5
Under
Zone3
Zone4
Under
Frame2
Zone5
Under
Frame1
Zone1 Zone2
under
Frame1
Zone1 Zone2
under
DVD
Title 1 Title 2 Title 3 Title 4
Preface MenuPage Chapter 1 Chapter 2 Bonus
StartEnd StartEndKeyFrame1 advertisement
Region
TextRegion
TextRegion
CoordinateCoordinate Coordinate
KeyFrame2 KeyFrame3
Coordinate
Face
SkinColor
Shape
ICEIS 2007 - International Conference on Enterprise Information Systems
548
