
TEXTURE BASED IMAGE INDEXING AND RETRIEVAL
N. Gnaneswara Rao
1
and V. Vijaya Kumar
2
1
Associate Professor, Dept of CSE, Gudlavalleru Engg. College, Gudlavalleru, A.P., India
2
Professor & Head, Dept of CSE ,RGM College of Engg & Technology, Nandyal, A.P., India
Keywords: Texture, Content based Image Retrieval.
Abstract: The Content Based Image Retrieval (CBIR) has been an active research area. Given a collection of images it
is to retrieve the images based on a query image, which is specified by content. The present method uses a
new technique based on wavelet transformations by which a feature vector characterizing texture of the
images is constructed. Our method derives 10 feature vectors for each image characterizing the texture of
sub image from only three iterations of wavelet transforms. A clustering method ROCK is modified and
used to cluster the group of images based on feature vectors of sub images of database by considering the
minimum Euclidean distance. This modified ROCK is used to minimize searching process. Our experiments
are conducted on a variety of garments images and successful matching results are obtained.
1 INTRODUCTION
With the steady growth of computer power, rapidly
declining cost of storage and ever-increasing access
to the Internet, digital acquisition of information has
become increasingly popular in recent years. Digital
information is preferable to analog formats because
of convenient sharing and distribution properties.
This trend has motivated research in image
databases, which were nearly ignored by traditional
computer systems due to the enormous amount of
data necessary to represent images and the difficulty
of automatically analyzing images. Currently,
storage is less of an issue since huge storage
capacity is available at low cost. However, effective
indexing and searching of large-scale image
databases remains as a challenge for computer
systems.
The Content Based Image Retrieval System
CBIR ( Antani et al., 2002), (Kherfi and Ziou,
2004) is a system, which retrieves the images from
an image collection where the retrieval is based on a
query, which is specified by content and not by
index or address. Alternatively, if given a collection
of images the function of CBIR is to retrieve the
images based on a query, which is specified by
content and not by index or address. The query
image is an image in which a user is interested and
wants to find similar images from the image
collection. The CBIR system retrieves relevant
images from an image collection based on automatic
derived features. The derived features include
primitive features like texture, color and shape. The
features may also be logical features like identity of
objects shown, abstract features like significance of
some scene depicted etc.There are many general-
purpose image search engines. In the commercial
domain, IBM QBIC (Faloutsos et al., 1994),
(ICASSPW, 1993) is one of the earliest developed
systems. Recently, additional systems have been
developed at IBM T.J. Watson (Smith and Li, 2000),
VIRAGE (Grupta and Rain, 1997), NEC AMORE
(Mukherjea et al., 1999), Bell Laboratory (Natsev et
al., 1999), Interpix (Yahoo), Excalibur, and
Scour.net. In the academic domain, MIT Photobook
(Pentland et al., 1994), (Picard and Kabir, 1993) is
one of the earliest. Berkeley Blobworld (Carson et
al., 1999), Columbia VisualSEEK and Web SEEK
(Smith and Chang, 1997), CMU Informedia
(Stevens et al., 1994), UCSB NeTra (Ma and
Manjunath, 1997), UCSD, Stanford (EMD (Rubner
et al., 1997), WBIIS (Wang et al., 1998) are some of
the recent systems. The proposed CBIR system can
be extended at the other primitive feature vectors
like, color and shape.
The present method implemented basically by
three steps. First, for each image in the image
collection, a feature vector characterizing texture of
the image is computed based on the Wavelet
transformation method. The Wavelet
177
Gnaneswara Rao N. and Vijaya Kumar V. (2007).
TEXTURE BASED IMAGE INDEXING AND RETRIEVAL.
In Proceedings of the Second International Conference on Computer Vision Theory and Applications, pages 177-181
DOI: 10.5220/0002065801770181
Copyright
c
SciTePress

transformations are used because they capture the
local level texture features quite efficiently. Where
10 feature vectors are stored in a feature database,
Second, using clustering algorithm to construct
indexed image database based on the texture feature
vectors obtained from wavelet transformation, and
finally, given a query image, its feature vector is
computed, compared to the feature vectors in the
feature database, and images most similar to the
query image are returned to the user. Every care has
been taken to ensure that the features and the
similarity measure used to compare two feature
vectors are efficient enough to match similar images
and to discriminate dissimilar ones. The main aim of
this approach is that not even a single relevant image
should be missed in the output as well as to
minimize the number of irrelevant images.
The steps involved in the methodology are listed
below:
• Wavelet transformation is used for feature
extraction.
• Precomputing the texture feature vectors
for all the images in the database using haar
wavelet.
• Clustering the images based on feature
vectors using modified ROCK clustering
algorithm.
• Computing the feature vector of the query
image as and when presented.
• Comparing query image with indexed data
base, identifying the closest cluster for the
query image and retrieves those images.
• Presenting the result as the thumbnail set of
images.
2 EXTRACTION OF FEATURE
VECTOR
Texture is another important property of images.
Various texture representations have been
investigated in pattern recognition and computer
vision. Basically, texture representation methods can
be classified into two categories: structural and
statistical. Structural methods, including
morphological operator and adjacency graph,
describe texture by identifying structural primitives
and their placement rules. They tend to be most
effective when applied to textures that are very
regular. Statistical methods, including Fourier power
spectra, co-occurrence matrices, shift-invariant
principal component analysis (SPCA), Tamura
feature, Wold decomposition, Markov random field,
fractal model, and multi-resolution filtering
techniques such as Gabor and wavelet transform,
characterize texture by the statistical distribution of
the image intensity.
The Extraction of feature vector is the most
crucial step in the whole CBIR system. This is
because these feature vectors are used in all the
subsequent modules of the system. It is to be
realized that the image itself plays no part in the
following modules. It is the feature vectors that are
dealt with. The quality of the output drastically
improves as the feature vectors that are used are
made more effective in representing the image. The
fact that the quality of the output is a true reflection
of the quality of the feature vector is very much
evident in our experiments.
The Feature vector generation (Natsev et al., 1999),
(Wang et al., 1998) has been tried in two different
ways. One way was to use wavelets (Daubechies,
1992), (Meyer, 1993), (Natsev et al., 1999) to
compute energies whose values were classified.
Haar Wavelets
The Wavelets are useful for hierarchically
decomposing functions in ways that are both
efficient and theoretically sound. Broadly speaking,
a wavelet representation of a function consists of a
coarse overall approximation together with detail
coefficients that influence the function at various
scaled (Kherfi and Ziou, 2004). The wavelet
transform has excellent energy compaction and de-
correlation properties, which can be used to
effectively generate compact representations that
exploit the structure of data. By using wavelet sub
band decomposition, and storing only the most
important sub bands (that is, the top coefficients),
we can compute fixed-size low-dimensional feature
vectors independent of resolution, image size and
dithering effects. Also, wavelets are robust with
respect to color intensity shifts, and can capture both
texture and shape information efficiently.
Furthermore, wavelet transforms can be computed in
linear time, thus allowing for very fast algorithms.
In this paper, we compute feature vectors using
Haar wavelets because they are the fastest to
compute and have been found to perform well in
practice (Natsev et al., 1999), (ICASSPW, 1993).
Haar wavelets enable us to speed up the wavelet
computation phase for thousands of sliding windows
of varying sizes in an image. They also facilitate the
development of efficient incremental algorithms for
computing wavelet transforms for larger windows in
terms of the ones for smaller windows. One
disadvantage of Haar wavelets is that it tends to
produce large number of signatures for all windows
in image. We proposed the modified the Haar
wavelet transformation overcomes that reducing
signatures only calculating 10 for the image in our
VISAPP 2007 - International Conference on Computer Vision Theory and Applications
178
method.
In our feature vector computation process, we
applied Wavelet Transformations only three times to
get 10 sub images of input image in the following
way.
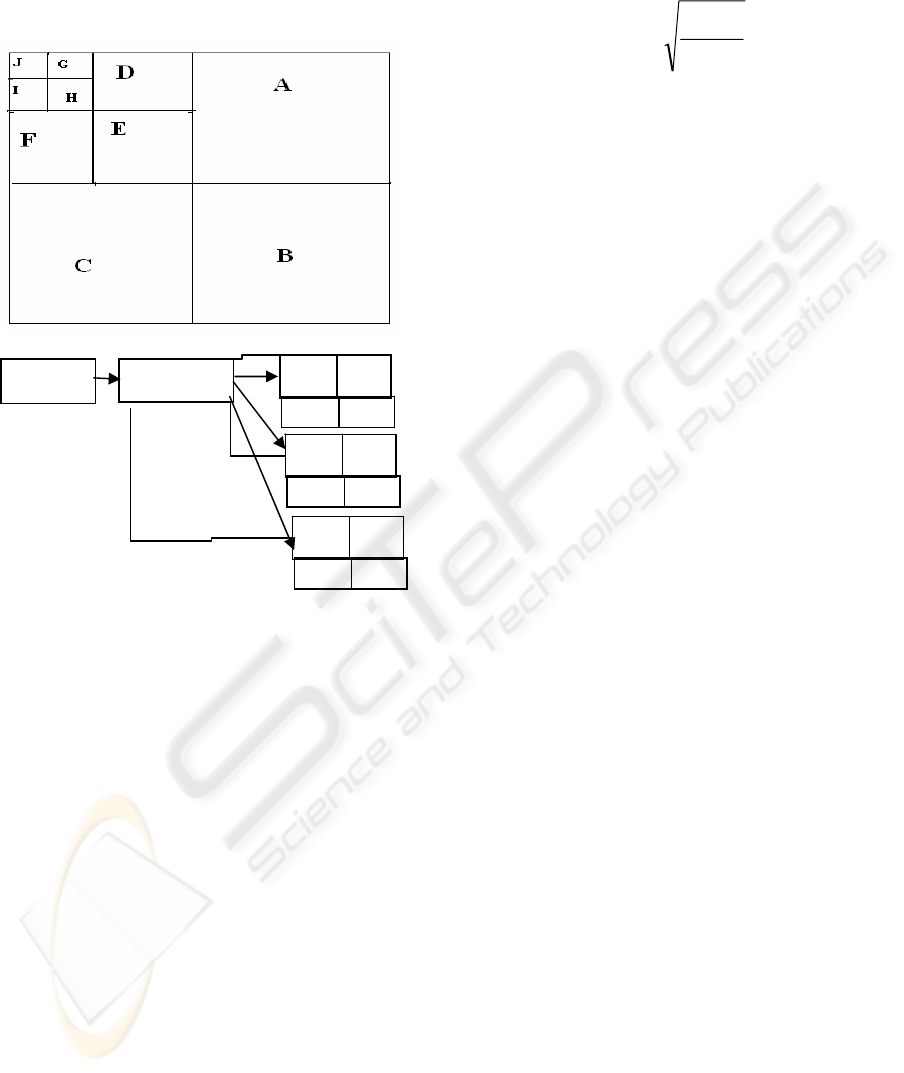
In each iteration Ii
2...4
images are saved and Ii
1
sub
image is again subjected to wavelet Transformation
instead of entire image for three iterations, by which
10 sub images of input image are obtained. Sub
image I
11
is further divided into sub images I
21
... I
24
in the second iteration. The sub image I
21
is further
divided into I
31
I
32
I
33
I
34
in the third iteration. All
sub images are normalized to maintain the uniform
size.
Algorithm for calculating wavelet signatures
1. Let I be the image of size w×w
2. Divide the image I into four bands I
1
,I
2
,I
3
,I
4
based on Haar wavelet of size w/2×w/2
3. Compute Signatures f
r
for I
2
,I
3
,I
4
4. Now take the image I
1
and divide it into 4
bands namely I
11
,I
12
,I
13
,I
14
of size w/4×w/4
5. Compute signatures f
r
for I
12
,I
13
,I
14
6. Again take the I
11
and divide it into 4 bands
namely I
111
,I
112
,I
113
,I
114
of size w/8×w/8.
7. Now we obtain 10 signatures then stop the
process.
The texture feature vectors (signatures) are
computed from sub image as follows,
ji
c
f
ij
r
×
=
∑
2
Where f
r
is the computed 1-d texture feature
vector(signature) of the sub image, C
ij
is the
representation of the intensity value of all elements
of
sub image and i × j is the size of the sub image.
3 INDEXING OF IMAGES
Another important issue in content-based image
retrieval is effective indexing (Antani et al., 2002),
(Wang et al., 1998) and fast searching of images
based on visual features. Because the feature vectors
of images tend to have high dimensionality and
therefore are not well suited to traditional indexing
structures, dimension reduction is usually used
before setting up an efficient indexing scheme.
The basis of the clustering method in indexed
image data base is that, the images belonging to the
same cluster are similar or relevant to each other
when compared to images belonging to different
clusters. We clustered the images using modified
ROCK (Guha, 1999).The modified ROCK allow us
to minimize the undesirable results of the ROCK
algorithm. The feature vector of each image is a
vector of size 10.The Euclidean distance measure is
used to measure the similarity between feature
vectors of query image and indexed database image.
In the present method we calculated representative
Feature vector of Cluster (F
C
) as the minimum
Euclidean distance, which resulted in good cluster-
matching results. The representative feature vector
of cluster(F
C
) is computed from the following
equation.
F
ci
= min|F
i
-∑F
j
|
Where j =1,2,….n and j ≠ i, and i=1,2,..n.
F
ci.
denotes representative feature vector of cluster
i,and F
i
,F
j
represents feature vector of the given
cluster.
Query by example allows the user to formulate a
query by providing an example image. The system
converts the example image into an internal
representation of features. Images stored in the
database with similar features are then searched.
Query by example can be further classified into
query by external image example, if the query image
is not in the database, and query by internal image
example, if otherwise. For query by internal image,
Input image
Haar Wavelet
Transformation
I11 I12
I13 I14
I11 I12
I13 I14
I31 I32
I33 I34
I11 I12
I13 I14
I11 I12
I13 I14
I11 I12
I13 I14
I11 I12
I13 I14
I11 I12
I13 I14
I21 I22
I23 I24
TEXTURE BASED IMAGE INDEXING AND RETRIEVAL
179

all relationships between images can be pre-
computed. The main advantage of query by example
is that the user is not required to provide an explicit
description of the target, which is instead computed
by the system. It is suitable for applications where
the target is an image of the same object or set of
objects under different viewing conditions. Most of
the current systems provide this form of querying.
4 RESULTS
As a case study the proposed method is applied on
the following Garments images. Figure 1 shows the
query image. Table1 shows the feature vector values
or feature vectors of sub images of fig.2.
Figure 1: Query image.
Figure 2: Sub Images of figure 1.
Table 1: Feature vectors of figure 2.
Sub image number 10-digit feature vector or FV
I
A
92.889603
I
B
45.284988
I
C
568.128662
I
D
23.954145
I
E
54.004360
I
F
75.862289
I
J
25.402018
I
G
20.730150
I
H
20.200342
I
I
23.954145
The clustered images from the database, are shown
in figure 3. The figure 3 clearly represents matching
images with the original (query) image and it has
removed all nonrelevant images.
Figure 3: Clustered Image Set.
Choice of the Image-Collection
The reason behind choosing such an image
collection is that such garments provide us a wide
variety of texture, color and Texture. These three
constitute the primitive features of an image. As
mentioned earlier, our CBIR system operates on
level-1 of feature extraction and thus this appeared
to be the most convincing collection to test the
system.
The downloaded images were subjected to
further treatment to suit our system. The images
were scaled to a size of 300 * 300 (width, height in
terms of pixels) and were converted to 256-color
Bitmap images in Gray scale format.
VISAPP 2007 - International Conference on Computer Vision Theory and Applications
180

5 CONCLUSION
By deriving ten feature vectors or feature vectors
from wavelet transformation in three iterations
reduces overall time complexity than previous
methods. The new method proposed in our study for
clustering effectively minimizes the undesirable
results and gives a good matching pattern, that will
be having zero or a minimum set of nonrelevant
images.
REFERENCES
Sameer Antani, Rangachar Kasturi, and Ramesh Jain. A
Survey on the Use of Pattern Recognition Methods for
Abstraction, Indexing and Retrieval of Images and
Video. Pattern Recognition,35:945–965, 2002.
I. Daubechies, Ten Lectures on Wavelets, Capital City
Press, 1992.
Faloutsos, R. Barber, M. Flickner, J. Hafner, W. Niblack,
D. Petkovic, W. Equitz, ``Efficient and effective
querying by image content,'' Journal of Intelligent
Information Systems: Integrating Artificial
Intelligence and Database Technologies, vol. 3, no. 3-
4, pp. 231-62, July 1994.
Gupta, R. Jain, "Visual information retrieval,'' Comm.
Assoc. Comp. Mach., vol. 40, no. 5, pp. 70-79, May
1997
Guha S.,Rastogi R., and Shim K.ROCK: A robust
clustering algorithm for categorical attributes. In
proceedingConclusions of the IEEE International
Conference on data engineering,Sydney,March 1999.
W. Y. Ma, B. Manjunath, ''NaTra: A toolbox for
navigating large image databases'', Proc. IEEE Int.
Conf. Image Processing, pp. 568-71, 1997.
Y. Meyer, Wavelets AlgoConclusion rithms and
Applications, SIAM, Philadelphia, 1993.
S. Mukherjea, K. Hirata, Y. Hara, “AMORE: a World
Wide Web image retrieval engine,” World Wide Web,
vol. 2, no. 3, pp. 115-32, Baltzer, 1999.
A. Natsev, R. Rastogi, K. Shim, ``WALRUS: A similarity
retrieval algorithm for image databases,'' SIGMOD,
Philadelphia, PA, 1999.
ICASSPW. Niblack, R. Barber, W. Equitz, M. Flickner, E.
Glasman, D. Petkovic, P. Yanker, C. Faloutsos, G.
Taubin, ``The QBIC project: querying images by
content using color, texture, and Texture,'' Proc. SPIE
- Int. Soc. Opt. Eng., in Storage and Retrieval for
Image and Video Database, vol. 1908, pp. 173-87, San
Jose, February, 1993.
A. Pentland, R. W. Picard, S. Sclaroff, `Photobook: tools
for content-based manipulation of image databases,''
SPIE Storage and Retrieval Image and Video
Databases II, vol. 2185, pp. 34-47, San Jose, February
7-8, 1994.
R. W. Picard, T. Kabir, ``Finding similar patterns in large
image databases,'' IEEE, Minneapolis, vol. V, pp. 161-
64, 1993.
Y. Rubner, L. J. Guibas, C. Tomasi, ``The earth mover's
distance, Shimulti-dimensional scaling, and color-
based image retrieval,'' Proceedings of the ARPA
Image Understanding Workshop, pp. 661-668, New
Orleans, LA, May 1997.
Carson, M. Thomas, S. Belongie, J. M. Hellerstein, J.
Malik, ``Blob world: a system for region-based image
indexing and retrieval,'' Third Int. Conf. on Visual
Information Systems, D. P. Huijsmans, A. W.M.
Smeulders (eds.), Springer, Amsterdam, The
Netherlands, June 2-4, 1999.
J. R. Smith, S. -F. Chang, “An image and video search
engine for the World-Wide Web,'' Storage and
Retrieval for Image and Video Databases V (Sethi, I K
and Jain, R C, eds), Proc SPIE 3022, pp. 84-95, 1997.
J. R. Smith, C. S. Li, ''Image classification and querying
using composite region templates,'' Journal of
Computer Vision and Image Understanding, 2000, to
appear.
S. Stevens, M. Christel, H. Wactlar, “Informedia:
improving access to digital video,'' Interactions, vol. 1,
no. 4, pp. 67-71, 1994.
J. Z. Wang, G. Wiederhold, O.Firschein, X. W. Sha,
``Content-based image indexing and searching using
Daubechies' wavelets,'' International Journal of
Digital Libraries, vol. 1, no. 4, pp. 311-328, 1998.
M. L. Kherfi and D. Ziou, universit´e de sherbrooke, A.
Bernardi, Laboratoires Universitaires Bell,” Image
Retrieval from the World Wide Web: Issues,
Techniques, and Systems In ,ACM Computing
Surveys, Vol. 36, No. 1, March 2004, pp. 35–67.
TEXTURE BASED IMAGE INDEXING AND RETRIEVAL
181
