
Dynamic Feature Selection and Coarse-To-Fine Search
for Content-Based Image Retrieval
J. You, Q. Li, K. H. Cheung
1
and Prabir Bhattacharya
2
1
Department of Computing, The Hong Kong Polytechnic University, KLN, Hong Kong
2
Institute for Information Systems Engineering, Concordia University
Montreal, Quebec, H3G 1T7, Canada
A
bstract. We present a new approach to content-based image retrieval by ad-
dressing three primary issues: image indexing, similarity measure, and search
methods. The proposed algorithms include: an image data warehousing structure
for dynamic image indexing; a statistically based feature selection procedure to
form flexible similarity measures in terms of the dominant image features; and
a feature component code to facilitate query processing and guide the search for
the best matching. The experimental results demonstrate the feasibility and effec-
tiveness of the proposed method.
1 Introduction
The generation of large on-line collections of images has resulted in a need for new
methods which can 1) find all images similar to a given image; 2) identify images
containing a specified object; 3) determine the derivatives of the original input image;
and 4) recognize images represented by specified colors, textures or shapes. In general,
image retrieval (IR) approaches fall into two categories: attribute-based methods and
content-based methods. Attribute-based methods represent image contents using text
and structured fields. Examples of such methods include Kodak Picture Exchange Sys-
tem (KPX) and PressLink library. However, the scope of applications of such methods
is limited because it is difficult to describe image details such as irregular shapes and
jumbled textures in text.
Content-based image retrieval (CBIR) requires an integration of research in com-
puter vision, image understanding, artificial intelligence and databases to address the
problem of information retrieval from large collections of images and video frames. The
developments in this area are surveyed in [1], [2], [3], [4]. The CBIR approach is based
on the integration of feature-extraction and object-recognition during the management
of image databases to overcome the limitation of attribute-based retrieval. Traditionally
designing a CBIR technique involves three primary issues: image feature extraction
and representation, similarity measures, and image indexing and searching. Currently a
large proportion of research into CBIR is centered on issues such as which image fea-
tures are extracted, the level of abstraction manifested in the features, and the degree of
desired domain independence. Examples of CBIR systems include QBIC, Virage, Pho-
tobook, CANDID, Garlic, MetaSEEK, WebSeek and C-BIRD. Although the existing
You J., Li Q., H. Cheung K. and Bhattacharya P. (2005).
Dynamic Feature Selection and Coarse-To-Fine Search for Content-Based Image Retrieval.
In Proceedings of the 5th International Workshop on Pattern Recognition in Information Systems, pages 81-93
DOI: 10.5220/0002566800810093
Copyright
c
SciTePress

techniques resolve the design issues in various ways [2], they have the following lim-
itations: 1) the selection of image feature(s) for indexing and matching is pre-defined
and lacks flexibility; 2) the multiple features are not integrated for similarity measures;
3) the search for the best matching is computationally expensive and somewhat domain
dependent for object recognition by features. It is thus of significant interest to develop
a general methodology for effective image feature extraction, indexing, searching and
integration.
Liang and Kuo [5] proposed a wavelet-based system, WaveGuide, which integrated
a set of image features including texture, color and shape in the wavelet domain for im-
age description and indexing. Although the system successfully handled the two compo-
nents of data representation and content description in a unified framework, it adopted a
fixed image feature selection scheme and applied pre-defined criteria for similarity mea-
sures. The recent MARS (Multimedia Analysis and Retrieval System) project [6] aims
to bridge the gap between the low-level features to high-level semantic concepts such
as complex objects and scenes by utilizing image understanding techniques. However,
the selection of features and indexing structure are fixed in MARS.
To achieve flexibility and multiple feature integration, we propose to construct a
decision tree for the retrieval task where a statistically based feature selection criterion
is used to guide the selection and integration of the most relevant features for similarity
measurement in a hierarchical structure.
Furthermore, we introduce a data warehousing structure and a feature component
code scheme to facilitate dynamic image indexing, multiple feature integration, flexible
similarity measures and guided search.
This paper is organized in the following sections. Section 2 presents a dynamic
image indexing scheme which embraces multiple features in conjunction with the sta-
tistically based feature selection scheme and the feature component codes for large
collection of images based on the proposed image data warehousing structure. Section
3 describes a coarse-to-fine search algorithm for image retrieval. The comprehensive
experimental results are reported in Section 4. Finally the conclusions are summarized
in Section 5.
2 Dynamic Image Indexing
2.1 Image Data Warehouse and Multi-dimensional Feature Cube
Unlike the traditional image databases which focus on only image data (content), the
proposed image data warehouse extends its capacity for data mapping and summariza-
tion. By mapping different image features to the data warehouse and generating sum-
mary tables based on the dimension data, the retrieval for similar feature data is guided
by directing a query to the right tables for fast searching. This search is much faster as
the size of these tables and the number of feature components is much smaller. Further,
as these tables are materialized views, information stored in them is pre-computed. The
reference to different summary tables will result in the selection of different indexing
schemes and similarity measurement. Thus, the use of the data warehouse will facili-
tate dynamic indexing to speed up the retrieval task. Fig. 1 illustrates the hierarchy of
multi-dimensional data cubes.
82

.
.
.
Summarized
Feature
Tables
.
.
.
Summarized
Feature
Tables
.
.
.
Summarized
Feature
Tables
M
U
L
T
I
M
E
D
I
A
SOURCE
E
M
T
I
V
I
S
U
A
L
SOURCE
T
I
M
E
I
M
A
G
E
SOURCE
T
I
M
E
(Shape)(Color) (Texture)
FEATURE REPRESENTATION
PHASE 1
PHASE 2
PHASE 3
Fig.1. A hierarchy of multi-dimensional data cubes
In our proposed image data warehouse system, the fact table defines the image con-
tent with three major image features: color, texture and shape. For each image feature,
the representation of the particular item is further described in the subsequent dimen-
sion table. Each of the fields in the current dimension table can be considered as facts
at a lower level and the details are summarized in the associated dimension table. Fig. 2
shows an example of such multi-level dimension tables for the representation of shape
feature, where Level 1 describes the major fields of an image content (fact table), Level
2 shows the further description of shape feature details in a corresponding dimension
table at a lower level (dimension table) and Level 3 lists the further details of the subse-
quent moment information for shape feature measurement at the next lower level. Note
that the amount of information stored in one of the lower tables is much less than in
the original fact table, which makes it easier to handle. For other image features such
as color, texture and salient feature points, the corresponding dimension tables can be
constructed in a similar manner.
With the proposed hierarchies of the image data warehousing structure, a multi-
dimensional feature cube can be used to visualize the image data warehouse and its
OLAP (On-line Analytical Processing) data, where the cells hold the quantifying im-
age feature components (often referred to as facts), while the qualifying feature indices
describe the axes of the cube and can be used for addressing individual feature com-
ponents or groups of multiple features. The proposed multi-dimensional structure of
the image feature cube offers flexibility to access and manipulate the image data from
different perspectives. Such a structure allows quick data summarization at different
levels for dynamic image indexing and multiple feature integration. The statistical data
resulting from the OLAP operation is used to discover the hidden patterns or implicit
knowledge to speed up the task of CBIR. For example, a statistically based feature se-
lection criterion can be adopted to determine the importance of individual features in
indexing and similarity measurement. A comparison of our proposed approach with
the existing techniques is summarized in Table 1 and more details are reported in the
following sections.
2.2 Dynamic Feature Selection and Multiple Feature Integration
Most of the existing CBIR systems pre-define the features for the retrieval task in a
conventional database structure. In this paper, we propose to use a statistically based
83

CategoryImage ID
image #1
Color Texture Shape
texture dimension table
texture dimension table
image #2
image #N
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Moment DescriptionB-spline Description Salient Points
B-spline coefficients
B-spline coefficients
. . . . . .
moment feature vector
moment feature vector
. . . . . .
feature point list
feature point list
. . . . . .
Image ID
image #1
image #2
. . . . . .
LEVEL 1: The major fields of an image content (fact table)
LEVEL 2: The major fields of shape feature description (dimension table)
LEVEL 3: The data fields of invariant moments (dimension table)
(Order 0)
Invariant MomentInvariant Moment Invariant Moment
(Order 1) (Order 2)
moment measurement
moment measurement moment measurement
moment measurement moment measurement
moment measurement
. . . . . . . . . . . . . . . . . .
image #1
image #2
. . . . . .
Image ID
feature component code
feature component code
feature component code
texture dimension tablecolor dimension table
color dimension table
color dimension table
shape dimension table
shape dimension table
shape dimension table
Fig.2. A hierarchy of multi-level dimension tables for shape representation
feature selection criterion to determine the most appropriate feature dimension table for
dynamic feature selection and indexing.
Recently feature selection criteria based on statistical measures have been exten-
sively studied. These include the Chi-square criterion, Asymmetrical Tau and Symmet-
rical Tau [9]. A comprehensive description and comparison of these criteria is given
in [9]. In this paper, we extend the use of the Symmetrical Tau criterion [9] to guide
the selection and combination of multiple image features for content-based image re-
trieval within the framework of image data warehousing structure. The key features
of our approach include: 1) apply Symmetrical Tau criterion to determine the impor-
tance of each individual image features; 2) use partitioning and aggregation technique
to generate the most appropriate feature dimension table for dynamic image indexing;
3) adopt a flexible similarity measurement to integrate multiple features with different
weights. In addition, we apply a training procedure to determine the most appropriate
weights for multiple feature integration. Instead of using individual features to calcu-
late the corresponding Tau as initially defined, we use the combined feature vector to
obtain the relevant Tau. Such a process is iteratively repeated by dynamically adjusting
the weights associated with each feature component. A higher weight is assigned to
the component for strong emphasis and a lower weight reflects less emphasis on the
non-relevant component. The set of weights with the maximum Tau is used to combine
multiple features for similarity measures. More specifically, we conduct the calculation
throughout the following major steps: 1) Identify all of the individual features to be used
for retrieval and obtain their feature vectors. For n features f
i
(i = 0, 1, ..., n − 1), there
will be n individual feature vectors V
i
(i = 0, 1, ..., n − 1). 2) Apply Gaussian normal-
84
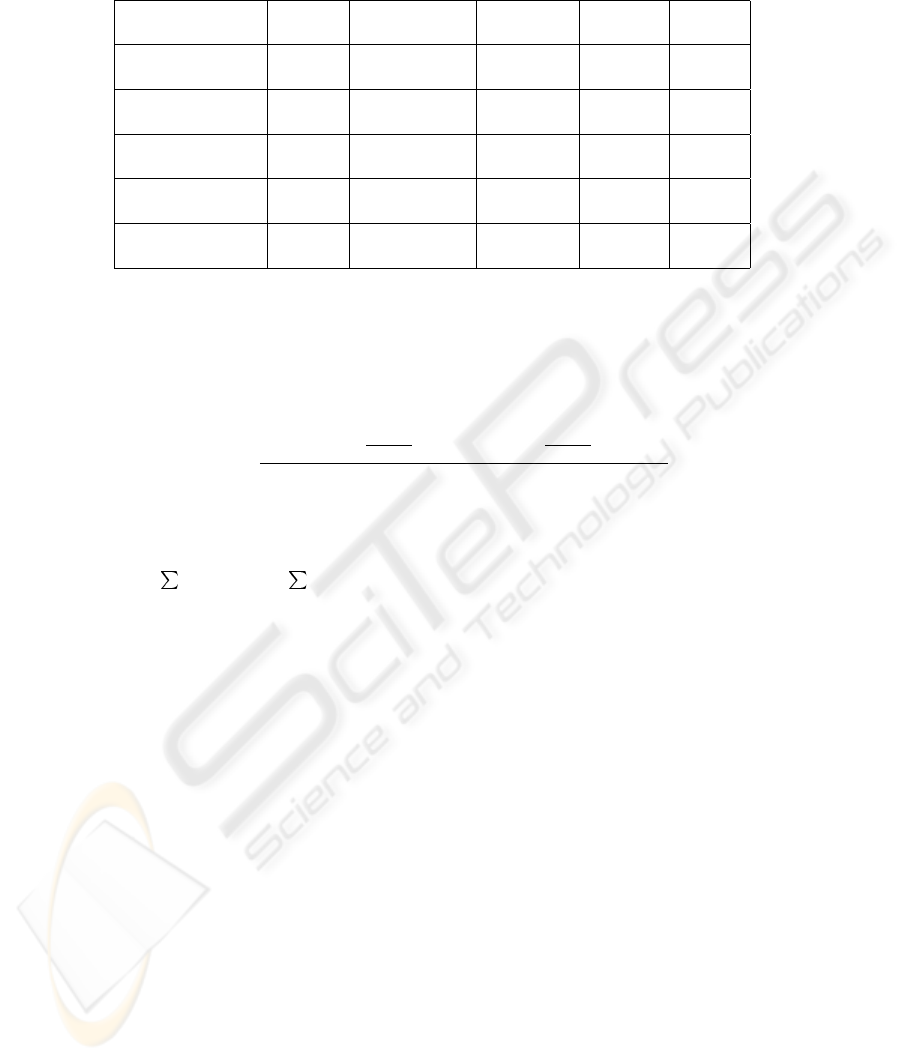
Table 1. Comparison of different CBIR systems
Name of System Data Similarity Search Query
the System Structure Representation Measurement Method Process
QBIC [7] single image pre-defined one-to-one user
database modeling measures comparison interactive
Garlic [8] multiple image&text fuzzy set object user
databases features technique oriented interactive
MARS [6] traditional image/video fixed hierarchical user
database features measurement structure interactive
WaveGuide [5] traditional wavelet-based fixed weighted user
database multiple features measurement ranking interactive
Mediahouse data multiple flexible hierarchical user
(proposed approach) warehouse features measurement search interactive
ization to the above feature vectors. 3) Initialize a set of weights α
i
(i = 0, 1, ..., n − 1)
and obtain its corresponding combined feature vector V
c
=
P
n−1
i=0
α
i
V
i
. 4) Calculate
the corresponding Tau using the following formula:
T au =
P
J
j=1
P
I
i=1
P (ij)
2
P (+j)
+
P
I
i=1
P
J
j=1
P (ij)
2
P (i+)
− SUM
2 − SUM
(1)
where the contingency table has I rows and J columns; P (ij) is the probability that a
variable belongs both to row category and to column category j; P(i+) and P(+j) are
the marginal probabilities in row category i and column category j, respectively, and
SU M =
I
i=1
P (i+)
2
+
J
j=1
P (+j)
2
. 5) Adjust the set of weights, and obtain a new
combined feature vector V’
c
and calculate the corresponding Tau. 6) Repeat Step 5 for
all of the given adjustment weight sets. 7) Find the maximum value of Tau from the
sequences of Tau obtained in the previous stage. 8) Choose the combined feature with
the maximum Tau value.
3 Coarse-to-Fine Search
We propose a coarse-to-fine search scheme in conjunction with feature component code
and selective matching criteria to speed up the process in a hierarchical fashion. Our ap-
proach is characterized as follows: 1) we use image feature component code to identify
the major feature components in an image; 2) we apply statistically based feature se-
lection criterion to rank the importance of each feature component and access to the
corresponding feature dimension table to group the potential candidates at coarse level;
3) we use different similarity measurements to conduct matching at the fine level. Our
proposed system will support two types of queries: a) to pose a query by image sample,
and b) to use a simple sketch as a query.
In the case of query by image sample, the search follows multiple feature extraction
and image similarity measurement described in the previous sections. Based on the
nature of the query image, the user can add additional component weights during the
85

combination of image features for image similarity measurement.In the case of query
by a simple sketch provided a user, we will apply a B-spline based curve matching
scheme to identify the most suitable candidates from the image database. In the case
of a query by sample image, we will use the proposed image component code to guide
the search for the most appropriate candidates in terms of color, texture and shape from
data warehouse at a coarse level and apply image matching at fine level for the final
output. A fractional discrimination function is used to identify object boundaries for
coarse-to-fine matching.
3.1 Feature Component Code
In this paper, we adopt a general wavelet based scheme for image feature extraction
and representation. Three features – color, texture and shape are considered and each is
associated with an individual feature vector. To organize the index structure with these
features to facilitate image query, we propose a three-bit feature component code to
characterize the status of each individual image, where the left bit C represents color
status (1 for a color image and 0 for a black and white image), the middle bit T rep-
resents texture status (1 for a texture image and 0 for a non-texture image), and the
right bit S represents shape status (1 for an image with clear objects and 0 for an image
without any objects).
Fig. 3 shows four image samples representing an outdoor scene, a texture, a sketch,
and a textured object respectively. The component code will facilitate the hierarchical
structure of indexing and searching. Each individual image is classified into different
image groups according to its component code. Within each group, images are further
ranked with respect to their individual feature vectors or measurements. The relevant
data is pre-processed and stored in the corresponding summary tables in the warehouse
structure. The search process will start with the image group which has the same compo-
nent code as the query image, which speeds up the processing by filtering out irrelevant
images from the image collection.
(a) code 001 (b) code 010 (c) code 001 (d) code 011
Fig.3. Image feature component coding
3.2 A Multi-level Curve Matching Scheme
To avoid the blind searching for the best fit between the template pattern and all of the
sample patterns stored in the image data warehouse, a guided search strategy is essential
to reduce computation burden. In a conventional data warehouse, various methods of
partitioning have been developed to improve the efficiency for query processing. Most
of the existing methods fall into two major categories – horizontal partitioning and
86

vertical partitioning. In general, the way in which a fact table will be split up depends on
the type of a query. In this paper, we adopted partitioning along a dimension to facilitate
a coarse-to-fine curve matching scheme for similar shape retrieval. As illustrated in
Fig. 2, B-spline curve and invariant moments coefficients are associates with the shape
feature in two dimensions and can be further partitioned into a lower level.
The initial search for the best similar shape matching starts with the dimension
of invariant moments. The similarity measurement is based on the comparison of the
Cosine distance of the proposed shape moment feature vectors for different samples
after Gaussian normalization. The candidates with small distance differences will be
considered for fine matching based on 2D polygonal arc matching and B-spline curve
matching. The goal here is to match and recognize shape curves for the final retrieval
output. The curve candidates which are selected from the 2D polygonal arc match will
be further compared based on their B-spline models. Traditionally the judgment is made
by the comparison of their control points, where the ordered corner points from bound-
ary tracing are used. The sample is allocated to the class with minimum difference
distance. However, the problem with this approach is that it cannot handle occluded
curves although it is straightforward to estimate the residual errors for similarity mea-
surements. Based on [10], we are able to use the Hausdorff distance algorithm to search
for portions, or partial hidden objects [11]. In the work reported here, we further extend
our previous research by using contour corner points as a basis for curve matching in
terms of the Hausdorff distance. It aims to reduce the computation required for a re-
liable match and be able to find partially hidden curves. The Hausdorff distance is a
non-linear operator which determines the degree of the mismatch between a model and
an object by measuring the distance of the point of a model that is farthest from any
point of an object and vice versa. Therefore, it can be used for object recognition by
comparing two images which are superimposed on one another. For the curve match-
ing, set A and B contain the contour points of two curves respectively; and the best
matching occurs when its Hausdorff distance is minimal. To speed up the searching for
the best fit between the two given curves, once again, we adopt a hierarchical scheme.
The Hausdorff distance at coarse level is determined by the B-spline control points of
each curve, and the more neighboring contour points are considered to determine the
Hausdorff distance at a fine level.
4 Experimental Results
4.1 System Description
Our MediaHouse system applies data warehousing technique to handle important is-
sues of CBIR for a large collection of image samples from different sources. The 6,228
images used in our experiments include 3,834 palmprint samples of size 384 × 284 for
the case study of personal identification via palmprint retrieval, 1,266 face images of
size 384 × 284 for the case study of face recognition based on similar shape retrieval,
and 1,128 natural images collected from various websites and public domains. The pre-
processing includes: 1) wavelet transforms of image samples; 2) multiple image feature
representation with respect to color, texture and shape; 3) generation of feature dimen-
sion tables. The Oracle data warehousing tool is used for data analysis and processing.
87
The operation of our system includes two basic phases: dynamic feature selection and
integrated similarity measures for phase I; and hierarchical search for the best match for
phase II. Our system supports query-by-example which compares the target image with
the possible candidates in the image data warehouse throughout the proposed guided
search procedure. Fig. 4 shows the diagram of the system structure.
Loading
Extraction
Transformation
Cleaning
DB1
DB2
DBn
Distributed
Multimedia
Databases
Data Marts
Inputs Outputs
Data
Multimedia
Multimedia Data Warehouse
OLAP Server
Decision Support
Data Mining
Q
U
E
R
Y
O
C
E
S
S
O
R
P
R
Modeling
Integration
Training
Fig.4. System structure of MediaHouse image data warehouse
4.2 Dynamic Feature Selection and Multi-level Similarity Measures
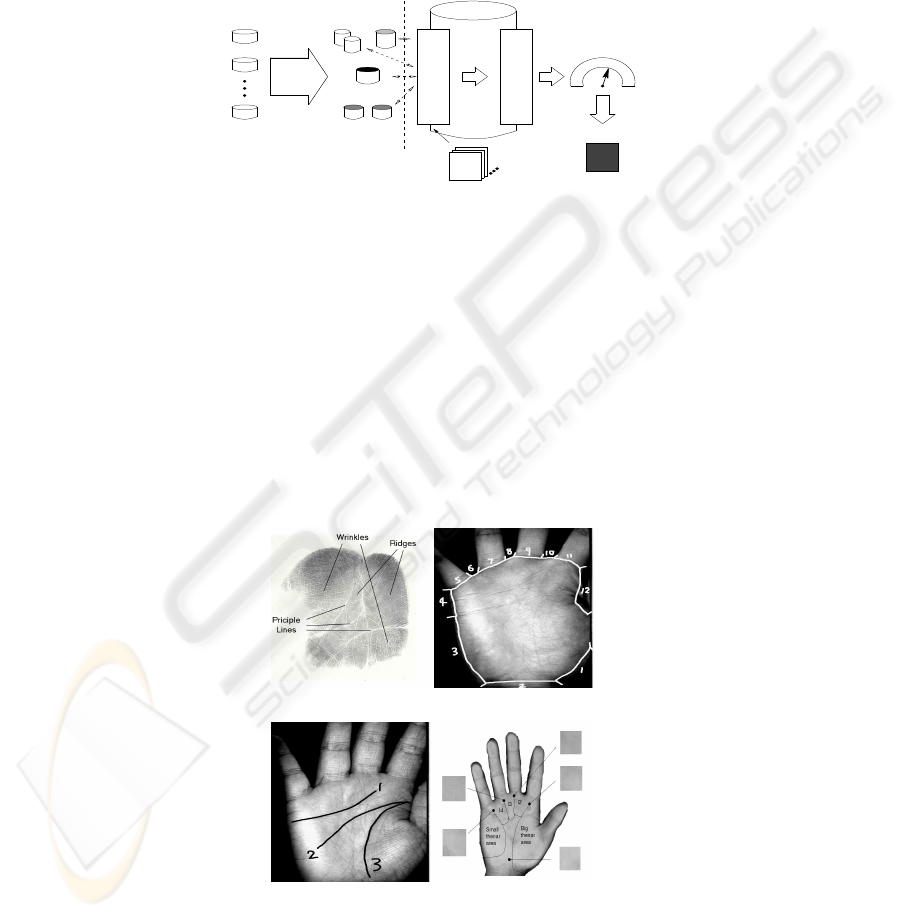
The dynamic selection of image features is demonstrated by multi-level palmprint fea-
ture extraction for personal identification and verification (see our previous work [12]).
The experiment is carried out in two stages. In stage one, the global palmprint features
are extracted at coarse level and candidate samples are selected for further process-
ing. In stage two, the regional palmprint features are detected and a hierarchical image
matching is performed for the final retrieval. Fig. 5 illustrates the multi-level extraction
of palmprint features.
(a) palm (b) palm-boundary
(c) palm-line (d) palm-region
Fig.5. Multi-level feature extraction
88

In our system, we consider multiple palmprint features and adopt different simi-
larity measures in a hierarchical manner to facilitate a coarse-to-fine palmprint match-
ing scheme for personal identification. Four palmprint features are extracted – Level-1
global geometry feature, Level-2 global texture energy, Level-3 local “interest” lines,
and Level-4 local texture feature vector. More specifically, the palm boundary segments
are used as Level-1 global geometry feature and they can be extracted by a boundary
tracking algorithm. The ‘tuned’ mask based texture energy measurement is used for
Level-2 global texture feature representation [12]. The dominant feature lines such as
principal lines, wrinkles, ridges in palmprint are extracted as Level-3 local ‘interest’
feature lines. A 2D Gabor phase coding is used to form Level-4 local texture feature
vector. We begin initial searching for the best similar palmprint matching group with
Level-1 global geometry feature. Our similarity measurement method is based on the
comparison of the boundary segment with respect to its length and tangent for different
samples. The candidates with small distance differences will be considered for further
coarse-level selection by global texture measurement. The selected candidates will be
subjected to fine matching based on 2D polygonal arc matching and comparison of local
texture feature vector.
The proposed fine matching algorithm starts with 2D polygonal arc matching by
using a subgroup of the unit quaternions. For palmprint samples which consist of the
best matched arcs will go through the final fine matching in terms of their local texture
feature vectors. The final matching is based on the comparison of local texture feature
vectors via 2D Gabor coding. The best match is the candidate with the least normalized
Hamming distance.
The palmprint image samples used for the testing are size of 384× 284 with the res-
olution of 75 dpi and 256 gray scales. In our palmprint image database, 3834 palmprint
images from 193 individuals are stored. These palmprint samples are collected from
both female and male adults with the age range from 18 to 50. A series of experiments
have been carried out to verify the high performance of the proposed algorithms.
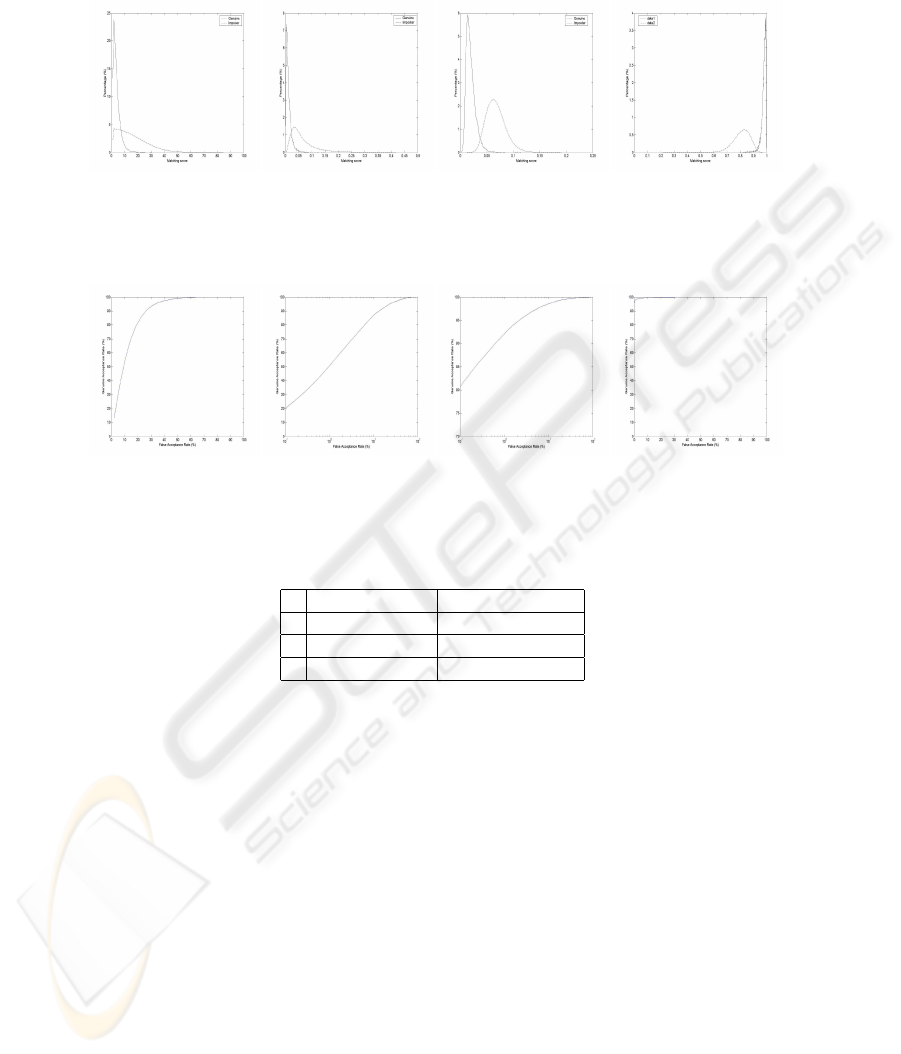
The verification accuracies at different levels are shown in Fig 6. Fig 6 A-1,A-2,
A-3 and A-4 present the probability distributions of genuine and imposter at different
feature levels. The corresponding receiver operating curves (ROC), being a plot of
genuine acceptance rate against false acceptance rate for all possible operating points
are demonstrated in Fig 6 B-1, B-2, B-3 and B-4. Based on ROCs, we conclude that
Level-4 local texture feature performs better than our hierarchical palmprint approach
when the false acceptance rate is large, such as 5%. However, a biometric system should
always operate in the condition of low false acceptance rate. Therefore, our hierarchical
palmprint approach is better than fine-texture with low false acceptance rates. The false
rejection and correct rejection rates of the first three levels are given in Table 2. The
improvement of system efficiency by the use of hierarchical scheme is illustrated in
Fig. 7 of system performance.
4.3 Multi-level Similar Shape Retrieval
The problem of similar-shape retrieval concerns retrieving or selecting all shapes or
images that are visually similar to the query shape or the query image’s shape. The
proposed coarse-to-fine curve matching approach is demonstrated in the test of face
89
A. Genuine and imposter distributions for different features
(a) Level-1 (b) Level-2 (c) Level-3 (d) Level-4
B. Receiver operator curve (ROC) distributions for different features
(e) Level-1 (f) Level-2 (g) Level-3 (h) Level-4
Fig.6. Palmprint verification test using multi-level features
Table 2. The system performance of accuracy
False Reject Rate Correct Reject Rate
T
a
1.69% 92.47%
T
b
1.10% 86.62%
T
c
0.73% 79.27%
recognition for personal identification. At the coarse level, a fractional discrimination
function is used to identify the region of the interest of an individual’s face. At fine curve
matching level, the active contour tracing algorithm is applied to detect the boundaries
of interest face regions for the final matching. Fig. 8 illustrates the tracing of face curves
for face recognition. Fig. 8(a) is an original image, Fig. 8(b) shows the boundaries of
interest regions on the face and Fig. 8(c) presents the curve segments for hierarchical
face recognition by curve matching.
To verify the effectiveness of our approach, a series of tests are carried out in a data-
base of 1,266 face collections from different individuals under various conditions such
as uneven lighting, moderate tilting and partial sheltering. Fig. 9 shows the detected
regions of different individuals detected by the proposed algorithm and Table 3 lists the
correctness rate of the coarse-level detection.
To show the robustness of the proposed algorithm for face detection invariant of per-
spective view, partial distortion and occlusion, the fine-level curve matching is applied
90
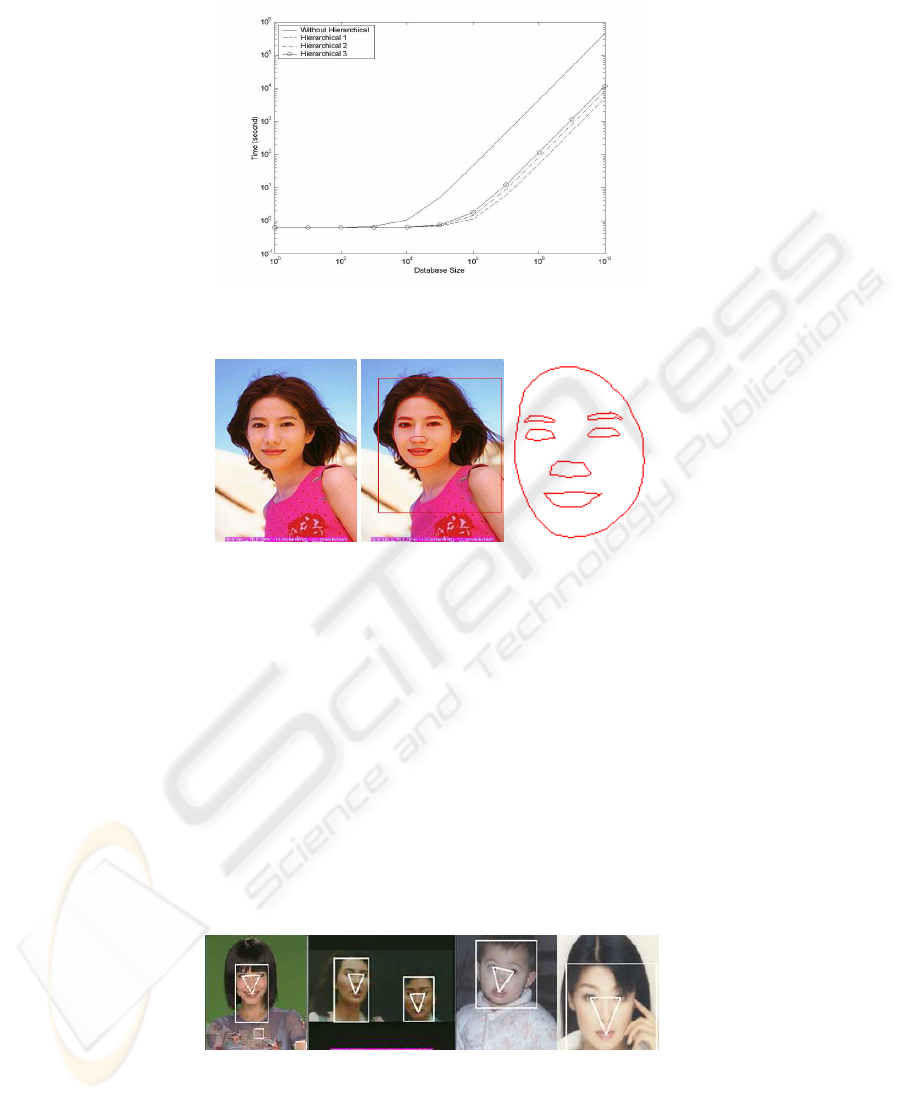
Fig.7. The system performance
(a) original image (b) boundary detection (c) face curves
Fig.8. Face curve extraction
to face images with different orientations and expressions. Fig. 10 illustrates face sam-
ples of the same person at various perspective views and Table 4 summarizes the testing
result for 100 testing cases. Fig. 11 shows face samples of the same person at different
conditions such as face expression, partial occlusion and distortion. The testing result
for 100 cases is listed in Table 5.
5 Conclusion
Image feature extraction, indexing and search are essential issues in content-based im-
age retrieval. In contrast to the existing techniques which mostly apply a fixed mecha-
nism for feature extraction and indexing, we have proposed a statistically based feature
Fig.9. The detection of face region of interest
91

Table 3. Performance of face detection at coarse-level
Face Condition Correct Detection Rate
unevenness of lighting 98%
multiple faces 95%
moderate tilt of faces 97%
partial sheltering 85%
Fig.10. The face samples at different orientations
selection scheme for dynamic multiple feature extraction and integration within the im-
age data warehousing structure. This method is characterized as a flexible but simple
approach to extract multiple features for similarity measures. In addition, the introduc-
tion of fractional discrimination function is powerful for multi-level feature extraction
and the proposal of image feature component code facilitates guided search for the best
matching. The experimental results provide the basis for the further development of
an effective and efficient content-based image retrieval system. For future research, it
would be of considerable interest to investigate the following issues. Firstly, we would
like to develop a comprehensive interactive query interface with the full support of user
feedback. Secondly, we would like to include more image samples of diversity in our
image data warehouse and apply data mining techniques for image understanding and
feature clustering. Thirdly, we would like to develop a general scheme for performance
evaluation in terms of accuracy and efficiency in addition to the current measurement
of precision and recall.
Acknowledgment
The support from the Hong Kong Polytechnic University Research Grants is greatly
appreciated.
Table 4. Performance of face recognition at different orientations
Viewing Perspective Correct Classification Rate
−20
0
(vertical) 84%
−10
0
(vertical) 86%
+10
0
(vertical) 86%
+20
0
(vertical) 83%
−20
0
(horizontal) 85%
−10
0
(horizontal) 87%
+10
0
(horizontal) 87%
+20
0
(horizontal) 84%
92

Fig.11. The face samples at different conditions
Table 5. Performance of face classification with different conditions
Face Condition Correct Classification Rate
partial occlusion 77%
various expressions 81%
wearing glasses 82%
References
1. Antani, S., Kasturi, R., Jain, R.: A survey on the use of pattern recognition methods for
abstraction, indexing and retrieval of images and video. Patt. Recog. 35 (2002) 945–965
2. Smeulders, A., Santini, M., Gupta, A., Jain, R.: Content-based image retrieval at the end of
the early years. IEEE Trans. Patt. Anal. Machine Intell. PAMI-22 (2000) 1349–1380
3. Rui, R., Huang, T., Chang, S.: Image retrieval: current techniques, promising directions, and
open issues. J. Visual Communication and Image Representation 10 (1999) 39–72
4. Shapiro, L., Stockman, G.: Computer Vision. 2nd edn. Prentice-Hall, Englewood Cliffs, NJ,
N.J. (2001)
5. Liang, K., Kuo, C.: Waveguide: A joint wavelet-based image representation and description
system. IEEE Trans. on Image Processing 10 (1999) 39–72
6. Huang, T., Naphade, M.: Mars (multimedia analysis and retrieval system): A test bed for
video indexing, browsing, searching, filtering, and summarization. In: Proc. 2000 IEEE Int.
Workshop on Multimedia Data Storage, Retrieval, Integration and Applications, Hong Kong
(2000) 1–7
7. Flickner, M., Sawhney, H., Niblack, W., Ashley, J.: Query by image and video content: The
qbic system. IEEE Computer 28 (1995) 23–32
8. Cody, W., Haas, L., Niblack, W., Arya, M., Carey, M., Fagin, R., Flickner, M., Lee, D.,
Petkovic, D., Schwarz, P., Thomas, J., Williams, J., Wimmers, E.: Querying multimedia data
from multiple repositories by content: the garlic project. In: Proc. of IFIP 3rd Working Conf.
on Visual Database Syst. (VDB-3). (1995)
9. Zhou, X., Dillon, T.: A statistical-heuristic feature selection criterion for decision tree induc-
tion. IEEE Trans. Patt. Anal. Machine Intell. PAMI-13 (1991) 834–841
10. Huttenlocher, D., Klanderman, G., Rucklidge, W.: Comparing images using the hausdorff
distance. IEEE Trans. Patt. Anal. Machine Intell. PAMI-15 (1993) 850–863
11. You, J., Bhattacharya, P.: A wavelet-based coarse-to-fine image matching scheme in a paral-
lel virtual machine environment. IEEE Trans. on Image Processing 9 (2000) 1547–1559
12. You, J., Li, W., Zhang, D.: Hierarchical palmprint identification via multiple feature extrac-
tion. Patt. Recog. 35 (2002) 847–859
93
