
ESTIMATING PATTERNS CONSEQUENCES FOR THE
ARCHITECTURAL DESIGN OF E-BUSINESS APPLICATIONS
Feras T. Dabous
1
, Fethi A. Rabhi
1
, Hairong Yu
1
, and Tariq Al-Naeem
2
1
School of Information Systems, Technology and Management
2
School of Computer Science and Engineering
The University of New South Wales, 2052 Sydney NSW, Australia
Keywords:
Patterns, Legacy Systems, Development Methodology, e-Business Applications, e-Finance.
Abstract:
Quality attributes estimations at early stages of the design process play an important role in the success of
e-business applications that support the automation of essential Business Processes (BPs). In many domains,
these applications may utilise functionalities that are embedded in a number of monolithic and heterogeneous
legacy systems. In previous work, we have identified a range of patterns that capture best practices for the
architectural design of such applications with the presence of legacy functionality. In this paper, we present
and discuss quantitative patterns’ consequences models to systematically estimate two quality attributes that
are the development and maintenance efforts. A real life case study in the domain of e-finance and in particular
capital markets trading is used in this paper to validate these models.
1 INTRODUCTION
The concept of e-business applications has emerged
as an acronym of distributed applications that utilize
the Internet as a medium for coordinating the interac-
tions among different distributed components. Each
component may correspond to an activity that imple-
ments part of an organisations business logic. In this
research, we consider e-business application domains
that can be improved by developing or utilising cor-
responding business logic and functionality that may
span across different organisational legacy systems.
In many domains such as e-finance, these applications
are business process intensive and therefore we alter-
natively use the term Business Process (BP) to corre-
spond to an e-business application.
Legacy systems are valuable assets within organ-
isations many of which are expensive, reliable and
efficient in supporting businesses. As these systems
evolve, they become complex and hard to adapt to
new business requirements (Umar, 1997). However,
such systems can play an important role in automat-
ing new BPs. Current modern development methods
usually do not provide tools, techniques, or guidelines
on how to utilise legacy functionality (van den Heuvel
et al., 2002). In (Dabous, 2005), we have identified a
number of architectural patterns that address the ar-
chitectural design of BPs by utilising legacy systems
functionalities that correspond to some activities of
BPs. Each of these patterns has consequences that
are described in terms of quality attributes estimations
that impact the selection of the appropriate pattern as
an architectural solution for a given problem context.
This papers contribution is to present and discuss two
consequence models that are development and main-
tenance efforts validated on a real life case study in
the domain of e-finance.
2 BASIC ASSUMPTIONS
This section presents the basic assumptions made in
this paper and introduces the concepts such as func-
tionality, legacy systems and BPs. The assumptions
model used in this research is based on several archi-
tectural analysis and benchmarking studies such as
(Rabhi et al., 2003) that have been conducted on a
number of legacy systems.
2.1 Review of notation
A functionality in the context of this research refers to
an identified autonomous task that resides within an
“encapsulating entity”. A functionality corresponds
to an activity within a BP which performs a specific
job (i.e. in part of the business logic). A functionality
248
T. Dabous F., A. Rabhi F., Yu H. and Al-Naeem T. (2005).
ESTIMATING PATTERNS CONSEQUENCES FOR THE ARCHITECTURAL DESIGN OF E-BUSINESS APPLICATIONS.
In Proceedings of the Seventh International Conference on Enterprise Information Systems, pages 248-254
DOI: 10.5220/0002553702480254
Copyright
c
SciTePress

can be either automated or non-automated. If auto-
mated then the encapsulating entity can be a legacy
system. On the other hand, if not automated then the
encapsulating entity can be a human process. We use
the notion F
all
= {f
i
: i = 1..|F
all
|} to represent the set
of all functionalities (automated and not automated)
that belong to a particular domain. The definition of
the set F
all
does not tell anything about the automa-
tion of any functionality. We also use the concept
of “equivalent functionalities” to refer to a group of
functionalities that have similar business logic each
of which resides in a different encapsulating entity.
We use the notion Q = {q
i
: i = 1..|Q|} to represent the
set of all groups of equivalent functionalities. Each
q
i
⊆ F
all
is the ı
th
set of a number of equivalent func-
tionalities such that |q
i
| ≥ 1 and q
a
∩ q
b
= φ : a 6= b and
q
i=1
q
i
= F
all
(see figure 1).
Two assumptions related to the legacy systems are
made. The first one is that each legacy system is
owned by one company within the domain of study
and their development teams are not related to the
BPs development team. The second one is that the
development team for the BPs can only interact with
these legacy systems through their defined interfaces
(e.g. in the form of APIs) and has no access permis-
sion to the corresponding source code. Therefore, we
assume that different functionalities within the same
legacy system have similar interfacing mechanism.
We use the notation F
au
⊆ F
all
to represent the
set of all automated functionalities contained in the
legacy systems of a particular domain. Let LG = {l
i
:
i = 1..|LG|} be the set of key legacy systems identi-
fied in that particular domain. Every l
i
⊆ F
au
and
l
a
∩ l
b
= φ when a 6= b . It is also important to note
that in practice there is no instance of two equivalent
functionalities within the same legacy system mean-
ing that if f
x
∈ l
i
and, f
y
∈ l
i
then {f
x
, f
y
} * q∀q ∈ Q (see
figure 1).
We also consider a fixed number of BPs in a par-
ticular domain referred to by the set BP = {bp
i
: i =
1..|BP |}. We assume that these BPs may have ac-
tivities that correspond to existing functionalities in
the legacy systems. The business logic of each bp
i
is expressed in terms of an activity diagram whose
nodes are the activities (i.e. functionalities) and the
arcs determines the execution flow between the func-
tionalities. We use the function activities(bp) ⊆ F
all
to identify the set of functionalities that are required
by the BP bp (i.e. it returns the set of all nodes in
a bp’s activity diagram) and therefore the set of non-
automated activities for bp are referred to by {f : f ∈
(F
all
− F
au
), f ∈ activ ities(bp)}. A bp is said to by
fully-automated if activities(bp) ⊆ F
au
, non-automated
if activities(bp) ⊆ (F
all
− F
au
). and semi automated
otherwise.
In the context of this research we assume that
every f ∈ F
all
has at least one corresponding bp ∈
BP such that f ∈ activities(bp). In other words,
b
i=1
activ ities(bp
i
) = F
all
.
2.2 Common architectural
description
We use a common architectural description for the
purpose of facilitating a unified presentation the archi-
tectural patterns. This allows all pattern solutions to
be expressed in a uniform way and their consequences
estimated in a systematic way. An architecture is de-
scribed in terms of a set Comp = {X
i
: i = 1..|Comp|}
whose entries are architectural components each of
which may correspond to a different software archi-
tectural entity. Components communicate with each
other according to the BPs description. The features
for each X
i
∈ Comp are modelled by the following
functions:
1. tasks(X
i
): is a function that identifies the set of
tasks that are encapsulated in the component X
i
.
These tasks can be one of three types. The first one
is the implementation of a functionality f ∈ F
all
that is denoted by C(f). The second one is the im-
plementation of a wrapper for a functionality f that
is denoted by CW (f). It is used when X
i
corre-
sponds to a ‘basic service’ that wraps an f ∈ F
au
.
The third one is the implemention of the business
logic choreography of a BP bp denoted by CBL(bp).
It is used when X
i
corresponds to a ‘composite ser-
vice’ x ∈ (BP ∪ Q).
2. connectT o(X
i
) ⊆ Comp: is a function that returns the
set of components that X
i
invokes while executing
its business logic.
3. invokedBy(X
i
) ⊆ Comp: is a function that returns the
set of components that invoke X
i
.
4. access(X
i
): a function that returns the access
method that is used by other X
j
∈ Comp to invoke
X
i
. We use a set AC of identified access meth-
ods. There are three categories of access meth-
ods that we consider: (1) service-oriented (SO) that
presumes the existence of accessible interfaces by
means of remote invocation using XML based pro-
tocols such as SOAP, (2) legacy-oriented that pre-
sumes the existing of APIs for local invocations
whereas extra code is required to make these APIs
available for remote invocations by means of binary
protocols that ranges from TCP/IP to RPC based
protocols, and (3) ‘nil’ (when X
i
is not required for
invocation by any other X
j
∈ Comp.).
2.3 Proposed architectural patterns
In (Dabous, 2005), we have identified a number of ar-
chitectural patterns for e-business applications using a
process of combining matched design strategies. The
work in this paper is based on five identified patterns
briefly described as follows:
ESTIMATING PATTERNS CONSEQUENCES FOR THE ARCHITECTURAL DESIGN OF E-BUSINESS
APPLICATIONS
249

Reuse+MinCoordinate (Pt1). This pattern con-
siders accessing the required functionalities across
domain legacy systems by direct invocation through
the native APIs of these systems. On the other hand,
each BP implements locally the activities that have
no corresponding functionality in these systems.
Reuse+Automate+MinCoordinate (Pt2). This pat-
tern considers accessing the required functionalities
across enterprise systems by direct invocation through
their native APIs. It also considers implementing all
activities of BPs that have no corresponding imple-
mentation in any of the existing systems as shared
e-services with advertised service-based interfaces.
Reuse+Wrap+Automate+MinCoordinate (Pt3).
This pattern considers providing unified e-services
to all functionalities embedded in legacy systems by
developing wrappers. It also considers implementing
all activities of BPs that have no corresponding
implementation in any of the existing systems as
shared e-services.
Reuse+Wrap+MinCoordinate(Pt4). This pattern
considers providing unified e-services to every
functionality across all legacy systems by developing
wrappers. On the other hand, each BP implements
locally the activities that have no corresponding
functionality in any of the existing systems.
Migrate+MinCoordinate (Pt5). This pattern con-
siders replacing existing systems with new ones. This
involves migrating the implementation of required
functionalities into unified e-services. To minimize
redundancy, each group of equivalent functionalities
is replaced with a single program code that as an e-
service. For more details on the identification process
of these patterns and their detailed architectural
descriptions, see (Dabous, 2005).
3 CONSEQUENCES MODELS
Patterns consequences are typically discussed in
terms of a number of quality attributes. In this paper,
we only consider two quality models that estimate the
patterns consequences. These qualities are develop-
ment effort (devE) and maintenance effort (maintE).
Each model can be applied to any of the identified pat-
terns whose solution is formalised using the shared
architectural description. The quantitative estimates
generated by these models are for the purpose of com-
parison between the different patterns. Therefore,
quality factors that are shared among all patterns and
not affected by the architecture of any particular pat-
tern are negligible and not being considered.
The two consequences models presented in this
section utilise the following input values:
1. An estimate of the devE for each f ∈ F
all
that is
denoted by the functions F devE(f ) : f ∈ F
all
. This
estimation corresponds to the effort of developing
the code for a functionality as if it is built from
the scratch regardless of being a functionality in a
legacy system. We consider Person Months (PM)
as a measurement for this estimation.
2. An estimate of the devE for each access method
ac ∈ AC that is denoted by the functions
AcDevE(ac). This estimation corresponds to the ef-
fort of developing a code to access a component
that has an ac access method. We also consider
PM as a measurement for this estimation.
3. The probability for initiating a code maintenance
request. There are two parts for such probability
denoted by the function modP rob(X
i
, C(f)) : C(f ) ∈
tasks(X
i
). The first one is for the code of a func-
tionality that is in a legacy system (i.e. X
i
∈ XLG).
The latter one is for the code of a new functional-
ity (i.e. X
i
/∈ XLG). Associated with each proba-
bility is the percentage of the code to be modified
denoted by the function modP erc(X
i
, C(f)). In the
first case, when X
i
∈ XLG, this percentage is equal
to 100%. This is based on an assumption made in
the problem context that the development team for
the BPs do not have rights to access permission to
the legacy code.
Methods for obtaining such values from the domain
problem context are discussed in (Dabous, 2005).
3.1 Development effort
The overall development effort (devE) for any pattern
solution encompasses the development effort associ-
ated with all tasks in all components of the resulting
architecture. Considering the three types of tasks that
can appear in any of the Comp components, we can
identify a generic development effort model as fol-
lows:
dev E(Comp) =
X
i
∈Comp
t∈tasks(X
i
)
XdevE(X
i
, t) (1)
In the above model, XdevE(X
i
, t) corresponds to the
development effort for a task t that is in the compo-
nent X
i
(i.e. t ∈ tasks(X
i
)). Each of the three task
types is estimated differently as follows:
XDevE(X
i
, C(f)) is nil when C(f ) is a task within a
component that corresponds to a legacy system (i.e.
X
i
∈ XLG). This is logically consequence of the
fact that f ∈ F
au
is a functionality that is already
encapsulated within a legacy system that is accessed
through its advertised API. Otherwise, when C(f ) is a
task within a component that does not correspond to a
legacy system (i.e. X
i
/∈ XLG)), the XDevE(X
i
, C(f)) is
estimated by considering the value of the input func-
tion F devE(f) that uses known cost estimation mod-
els such as COCOMO or experience as discussed later
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
250

in this section. Therefore:
XDevE(X
i
, C(f)) =
0 X
i
∈ XLG
F devE(f) X
i
/∈ XLG
(2)
The XdevE(X
i
, CW (f)) : f ∈ F
au
is estimated as
the effort of developing a wrapper to another com-
ponent that encapsulates f . On the other hand,
XdevE(X
i
, CBL(bp)) : bp ∈ BP is estimated only by the
effort of developing accesses ∀x ∈ conT o(X
i
). We ar-
gue that the effort incurred in developing the business
logic itself for bp can be dropped because this effort is
similar across all patterns for a given business process
and this is not needed when using the estimations for
comparable purposes. Therefore, we can represent
both XdevE(X
i
, CW (f)) and XdevE(X
i
, CBL(bp)) with
the same model as follows:
XdevE(X
i
, t) ≤
X
y
∈ConT o(X
i
)
AcDevE(access(X
y
)), t = CBL() or CW ()
(3)
The application of (3) across all components in the
architecture shows that the histogram of the usage for
AcDevE(ac) calls can be relatively high. Therefore,
we used the operator “≤” in the above model to em-
phasize the fact that repeating alike effort by the de-
velopment team certainly enhance the learning curve
and therefore the effort is decreased as the number of
repetitions increases. In other words, each type of ac-
cess method ac across all components in Comp (e.g.
‘so’, ‘api1’, ‘api2’, ‘api3’) is accessed by a number
of other components in Comp. We assume that the
different accesses of each type have similar develop-
ment effort. Therefore, we have utilised the cumu-
lative average-time learning model for this purpose.
In order to apply this model, we first need to find
the number of accesses (i.e. invocations) across all
components in Comp to the components with the sim-
ilar access method. This is determined by the func-
tion noAccesses(ac) that iterates through all compo-
nents with ‘ac’ access while counting the total number
of links to these components. Therefore, when apply-
ing the learning model then the average effort of de-
veloping an access to a componentt that has ac access
method is expressed by the functions avgAcDevE(ac).
This is determined as follows:
av gAcDevE(ac) = AcDevE(ac) ∗ noAccesses(ac)
log(lc)/log(2)
s.t: lc : the learning curve (e.g. 95%)
(4)
When considering the learning model, then the model
in (3) is refined as follows:
XdevE(X
i
, t) =
X
y
∈ConT o(X
i
)
av gAc DevE(access(X
y
)), t = CBL() or CW ()
(5)
3.2 Maintenance effort
The maintenance effort (maintE) that we consider is
an estimation of the effort that is spent on maintaining
the implemented code and deployed architecture. We
emphasize the following three assumptions that have
been considered in the maintenance model in this sec-
tion. The first one is that the development team does
not have the access rights to change or maintain the
actual code for any of the legacy systems functional-
ities. As stated in the problem context, they can only
access these functionalities through there advertised
APIs. Therefore, maintaining any of these function-
alities would require the development team to code it
from scratch. The second one is that the maintenance
of each of the new functionalities code that has been
developed is maintained by directly modifying por-
tions of the code. The last one is that the maintenance
effort for the BPs logic code is insignificant because it
is constant across all alternative patterns and therefore
would not have an impact when comparing the esti-
mations of maintenance across all patterns. The same
is also applicable for the wrappers code because their
maintenance is attached with the maintenance of the
functionality code that is wrapped. Based on these as-
sumptions, most of the maintenance effort is incurred
due to the changes that are required on functionali-
ties codes. It should be noted in our model that the
expected effort of introducing new BPs corresponds
to the development effort and has been discussed as a
DevE prediction model in (Dabous, 2005). A model
for estimating the maintE can be derived based on the
following generic model that caters for the mainte-
nance of all tasks across all components in the archi-
tecture.
maintE(Comp) =
X
i
∈Comp
t∈tasks(X
i
)
XmaintE(X
i
, t)
(6)
Based on the last assumption above, both
XmaintE(X
i
, CBL()) and XmaintE(X
i
, CW ()) are
insignificant. Therefore, the model can be estimated
by the following refinement.
maintE(Comp) =
X
i
∈Comp
C(f )∈tasks(X
i
)
XmaintE(X
i
, C(f))
(7)
The value for XmaintE(X
i
, C(f)) is affected by X
i
be-
ing in XLG or not. Therefore, we start with dis-
cussing each case. In the first case, when X
i
∈ XLG,
there is a probability estimated by modP rob(X
i
, C(f))
that the whole code for f (i.e. modP erc(X
i
, C(f))=1) is
required to be replaced incurring a minimum effort es-
timated by F devE(f). The code maintenance approach
that we consider is to create and add a new compo-
nent X
j
to the architecture where C(f ) ∈ tasks(X
j
) and
access(X
i
) is the unified access method targeted by the
code maintenance model (e.g. ‘so’ in the case study).
Therefore, an extra effort denoted by the function
linksE(X
i
, f ) is added to the total XmaintE(X
i
, C(f))
that corresponds to changing all invocations of f to
the new X
j
component. Such extra effort is not ap-
plicable when the legacy functionality has a wrap-
ESTIMATING PATTERNS CONSEQUENCES FOR THE ARCHITECTURAL DESIGN OF E-BUSINESS
APPLICATIONS
251
per component because the new functionality would
have the same access as that wrapper and therefore
replacing C(f) instead of CW (f ) task. As a result,
the overall XmaintE(X
i
, C(f)) : X
i
∈ XLG is estimated
as the modP rob(X
i
, C(f)) fraction of the total of both
F DevE(f) and the linksE(X
i
, f ). That is:
XmaintE(X
i
, C(f)) =
modP rob(X
i
, C(f)) ∗
F DevE(f) + linksE(X
i
, f )
(8)
In the second case, when X
i
/∈ XLG, it is differ-
ent from the previous case in two aspects. The first
one is that a modP erc(X
i
, C(f)) fraction of F devE(f ) is
modified because the source code is totally owned by
the development team (recall that modP erc(X
i
, C(f)) :
X
i
∈ XLG =1). Consequently, the latter aspect is that
linksE(X
i
, f ) is always nil since there is no need to cre-
ate and add a new component to the architecture. That
is:
XmaintE(X
i
, C(f)) =
modP rob(X
i
, C(f)) ∗ modP erc(X
i
, C(f)) ∗ F DevE(f )
(9)
The two cases above can be combined in the follow-
ing model while considering whether X
i
is in XLG or
not when implementing it.
XmaintE(X
i
, C(f)) = modP rob(X
i
, C(f))∗
modP erc(X
i
, C(f)) ∗ F DevE(f ) + linksE(X
i
, f )
(10)
Such that linksE(X
i
, f ) is identified by the following
algorithm:
linksE(Xi, f): C(f)∈tasks(Xi) {
Let totEffort = 0; /
*
the total accumulated effort
*
/;
If (Xi/∈XLG) Then return totEffort;
If (y ∈ invBy(Xi): CW(f) /∈ tasks(y)) Then
For every y ∈ invBy(Xi) Do
If (CW(f) ∈ tasks(y)) Then Continue
If(f∈activities(bp): CBL(bp)∈tasks(y)) Then
totEffort += avgAcDevE( ac);
return totEffort;}
4 CASE STUDY
LG
F
all
F
au
f1:TeSim1
FATE
f3:RealTimeSim1
f2:CurrDaySim1
XSTREAM
f10:Realtime3
f11:TE3
f9:CurrDay3
AUDIT
f12:VisualModel4
SMARTS
f4:CalibRun2
f5:RealTimeAlerts2
f6:IntraDay2
f7:InterDay2
f8:Analytic2
Q5
Q8
Q7
Q6
f7:InterDay2
f4:CalibRun2
f12:VisualModel4
f5:RealTimeAlerts2
Q1
f6:IntraDay2
f9:CurrDay3
f2:CurrDaySim1
Q2
f3:RealTimeSim1
f10:Realtime3
Q3
f1:TeSim1
f11:TE3
f13:BAnalytic
Q4
f8:Analytic2
Q9
f15:MktEventDetect
Q12
f14:Regulator
Q11
f16:StrategyCnrl
Q10
f17:OrderExeMgt
Figure 1: Case study problem context illustrated
f6 f9
f8
f12
BP2: Visualization
Today in Days
Mkt=asx
Mkt=asx
Old in Days
f9
f7
f6
Mkt =ASXsim
f8
f13
Metrics=smarts
Metrics=Beta
BP1: ASX Trading Data Processing
Mkt =rASX
Old in Days
f2
Today in Days
BP3: Surveillance
f4
f5
f14
Alert raised
BP4: Trade Strategy
formalisation
f15
Event detected
f16
Ctrl msg
f17
Event=trade
else
BP5: Trade Strategy exection
f15
Event
detected
f16
Ctrl msg
f17
f3
f10
Subscriber event
triggered
Subscriber event
triggered
f11
Order
palcement
Event=trade
else
Mkt= ASXsim
Mkt= ASX
Mkt= ASXsim Mkt= ASX
f1
Figure 2: Activity diagrams of the BPs
4.1 Selected application domain
Within the e-finance domain, we focus on capital
markets which are places where financial instruments
such as equities, options and futures are traded (Har-
ris, 2003). The trading cycle in capital markets com-
prises a a number of phases which are: pre- trade an-
alytics, trading, post-trade analytics, settlement and
registry. At each phase of this cycle, one or more
legacy systems may be involved. Therefore, a vast
number of BPs exist within this domain involving a
number of activities that span through different stages
of the trading cycle. Many of these activities can
be automated by utilising functionalities of existing
legacy systems. The automation of these BPs is chal-
lenging for two reasons. The first one is that it may
involve a number of legacy systems that are owned by
different companies. The latter one is that these BPs
are normally used by business users who are not tied
to any of these companies (e.g. finance researchers).
The case study presented in this paper corresponds
to one problem context that comprises four legacy
systems encapsulating 12 automated functionalities,
five non-automated functionalities and five BPs that
leverages the 17 functionalities in conducting the
business logic. We focus on four legacy systems that
have been customised around Australian Stock Ex-
change (ASX) practices. Theses systems are FATE,
SMARTS, XSTREAM, and AUDIT Explorer. Each
of these systems supports a number of functionalities
accessible through APIs. In this paper, we consider a
few functionalities in each system that are shown in
figure 1. These functionalities have been reported in
(Yu et al., 2004; Dabous et al., 2003). We also con-
sider five BPs in this paper which are: ASX trading
data processing, visualisation of ASX trading data,
reporting surveillance alerts, trading strategy formal-
isation, and trading strategy execution. Figure 2 il-
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
252

Access() = nil
CBL(BP1)
Access() =nil
CBL(BP2)
Access() = nil
CBL(BP3)
Access() = nil
CBL(BP4)
Access() = nil
CBL(BP5)
Access= SO
C(f9)
C(f6)C(f2)
SO
C(f10)
C(f3)
SO
C(f11)
C(f1)
SO
C(f13)
C(f8)
SO
C(f7)
SO
C(f4)
SO
C(f5)
SO
C(f12)
SO
C(f14)
SO
C(f16)
SO
C(f17)
SO
C(f15)
Pt5
XLG
Access() =nil
CBL(BP2)
SO
CW(f1)
SO
CW(f2)
SO
CW(f3)
SO
CW(f4)
SO
CW(f5)
SO
CW(f6)
SO
CW(f7)
SO
CW(f8)
SO
CW(f9)
SO
CW(f10)
SO
CW(f11)
SO
CW(f12)
Access() = API4
C(f12)
Access() = API3
C(f11)
C(f10)
C(f9)
Access() = API2
C(f4)
C(f8)
C(f7)C(f6)
C(f5)
Access() = API1
C(f3)
C(f2)C(f1)
Access() = nil
CBL(BP4)
C(f17)
C(f16)
C(f15)
Access() = nil
CBL(BP5)
C(f17)
C(f16)
C(f15)
Access() = nil
CBL(BP3
)
C(f14)
Access() = nil
CBL(BP1)
C(f13)
Pt4
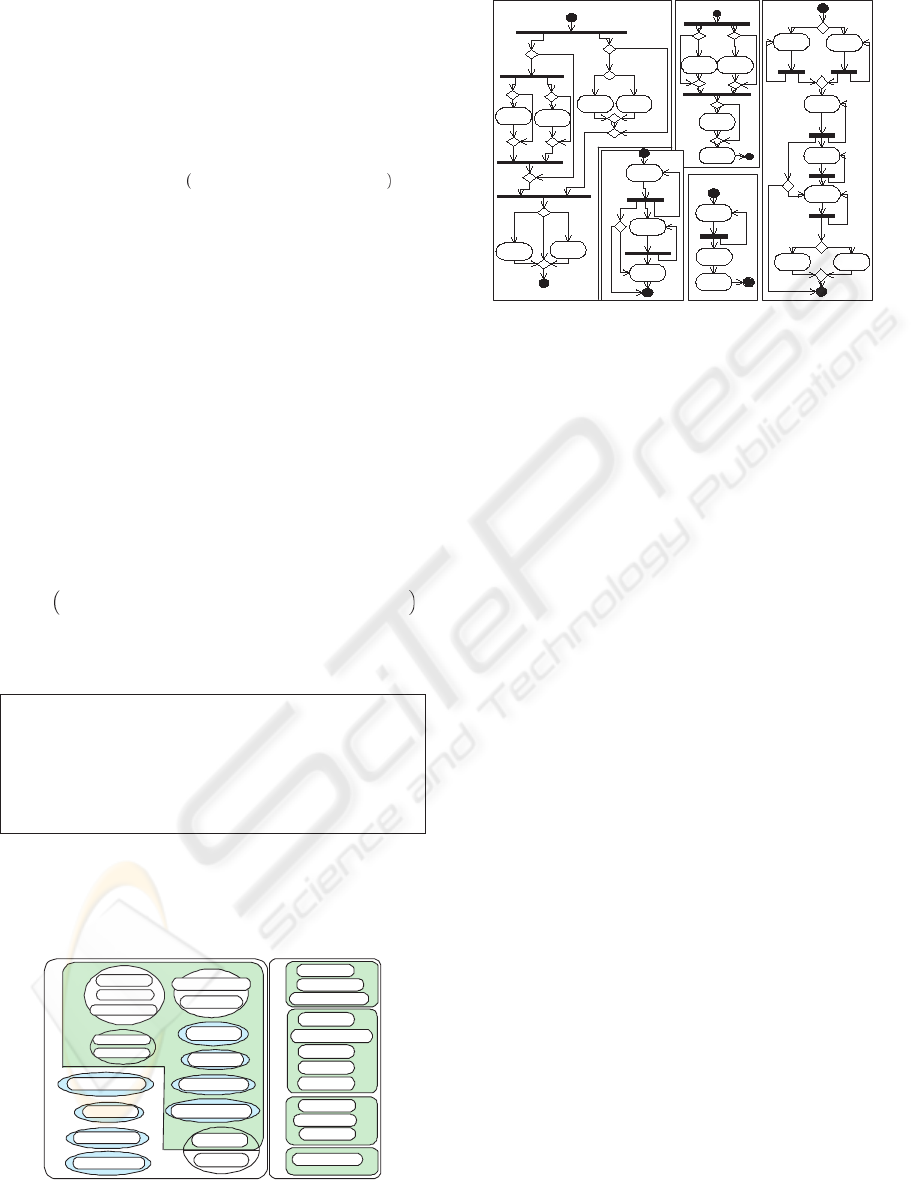
Figure 3: Pt4 and Pt5 applied on the case study
lustrates the workflow for each of these BPs as activ-
ity diagrams. More details about the functionalities,
legacy systems, and the BPs that are used in this case
study are discussed in (Dabous, 2005).
4.2 Consequences estimations
The resulting architectures are determined by apply-
ing each proposed pattern described in section 2.3 on
this case study. Graphical representations are shown
for Pt4 and Pt5 in figure 3. Table 1 presents the in-
put data that is required by development and mainte-
nance models. The columns of this table corresponds
to required values as discussed in the beginning of
section 3. Other predefined estimations that are re-
quired by the consequences models relate to the de-
velopment effort of accessing a give X
i
∈ Comp in
particular AcDevE(access) (see equation (4)). We re-
fer to the access methods used by an X
i
∈ XLG that
correspond to FATE, SMARTS, XSTREAM, and AU-
DIT systems as ‘api1’, ‘api2’, ‘api3’, and ‘api4’ re-
spectively whereas ‘so’ access method is used as the
targeted unified access method for X
i
/∈ XLG. The
AcDevE(ac) are 7.3, 7.3, 5.4, 3.5, 0.6 PMs for the five
access methods respectively that are computed based
on COCOMO model. By applying the model in l (1),
the devE estimations for the five patterns are 93.58,
76.58, 117.53, 115.32, and 403.73 respectively. And
by applying the model in (10), the maintE estimations
for the five patterns are 48.35, 47.69, 38.50, 40.86,
and 24.21 respectively.
4.3 Discussion
Any change to the problem context may result in dif-
ferent estimations for the consequences models. Such
Table 1: Case study input data
f FdevE(f) modProb() modProb() modPerc()
X
i
∈ XLG X
i
/∈XLG X
i
/∈XLG
f
1
25.4 10% 10% 50%
f
2
5.6 10% 10% 50%
f
3
7.5 10% 10% 50%
f
4
60.7 7% 10% 50%
f
5
19.3 7% 10% 50%
f
6
13.3 7% 10% 50%
f
7
4.2 7% 10% 50%
f
8
16.3 7% 10% 50%
f
9
30.5 12% 10% 50%
f
10
39.8 12% 10% 50%
f
11
134.5 12% 10% 50%
f
12
15.9 15% 10% 50%
f
13
6.3 - 10% 50%
f
14
5 - 10% 50%
f
15
6.3 - 10% 50%
f
16
2.9 - 10% 50%
f
17
3.7 - 10% 50%
changes can be changes applied to the set of func-
tionalities, legacy systems, functionalities develop-
ment effort, functionalities/legacy system modifica-
tion probabilities, development effort of building in-
teraction to an access method for a legacy system, etc.
Nominating the best architectural pattern for a given
problem context is not trivial when having a large set
of alternative patterns together with a number of dif-
ferent quality models (i.e. patterns consequences) and
a number of stakeholders with different preferences
for qualities that are often conflicting. We have in-
vestigated a number of patterns selection methods in
(Dabous, 2005). We demonstrate the application the
Simple Additive Weighting (SAW) method (Hwang
and Yoon, 1981) by considering the two quality mod-
els reported in this paper and the latency estimation
reported in (Dabous, 2005). We only consider pref-
erences weights provided by the development team
which are 0.34, 0.33, 0.33 for the three models re-
spectively. The application of SAW generates scaled
values that are 0.65, 0.56, 0.41, 0.50, and 0.34 for
the five patterns respectively. This output would sug-
gest that the best ranking pattern is Pt1, followed by
Pt2, Pt4, Pt3, and finally Pt5. The BP development
team has been consulted on these results and a pos-
itive feedback has been received in supporting these
results. The justification of these results is explained
based on the fact that the number of identified BPs
is relatively very small and therefore, Pt1 and Pt2 are
most favourable. However, the development team has
leveraged Pt4 then Pt3 based on the fact that more BPs
are likely to be introduced and these two patterns can
utilise service-oriented paradigm where high modu-
larity and interoperability are achieved. The pattern
ESTIMATING PATTERNS CONSEQUENCES FOR THE ARCHITECTURAL DESIGN OF E-BUSINESS
APPLICATIONS
253

selection method is expected to push forward towards
Pt3 and Pt4 once the consequences models are ex-
tended to cope with such quality attributes.
5 CONCLUSIONS
E-business applications often involve a number of
BPs that may require utilising legacy functionality
in order to be automated. Previous work has pre-
sented a number of alternative patterns that can be
utilized in such situations. In this paper, we presented
two models to estimate the development and main-
tenance efforts as possible pattern consequences to
help designers choose the appropriate pattern within
a given problem context. We have validated these
models by a real life case study derived from the e-
finance domain. In (Dabous, 2005), we described a
process of determining more patterns based on prac-
tices. As the number of patterns increases with the
presence of multiple stakeholders with different and
often conflicting preferences of qualities, the prob-
lem of determining the appropriate pattern to adapt
becomes more difficult. In (Al-Naeem et al., 2005),
we have leveraged Multiple-Attribute Decision Mak-
ing (MADM) methods for this purpose. A simple
tool has been developed to systematically generate es-
timates for the quality models and to rank patterns
with accordance to their appropriateness for a given
problem context. Our current research direction is to
address consequences models for a number of other
quality attributes. We are also investigating extending
the tool support to systematically generate the archi-
tectures for all the patterns and estimations for other
quality attributes.
REFERENCES
Al-Naeem, T., Dabous, F. T., Rabhi, F. A., and Benatal-
lah, B. (2005). Quantitative evaluation of enterprise
integration patterns. In 7th Int. Conf. on Enterprise
Information Systems (ICEIS05), USA.
Dabous, F. T. (2005). Pattern-Based Approach for the Ar-
chitectural Design of e-Business Applications. Phd
thesis, School of Information Systems, Technology
and Management, The University of New South
Wales, Australia. (to be submitted in Apr 2005).
Dabous, F. T., Rabhi, F. A., and Yu, H. (2003). Perfor-
mance issues in integrating a capital market surveil-
lance system. In Proceedings of the 4th International
Conference on Web Information Systems engineering
(WISE03), Rome, Italy.
Harris, L. (2003). Trading and Exchanges: Market Mi-
crostructure for Practitioners. Oxford University
Press.
Hwang, L. and Yoon, K. (1981). Multiple criteria decision
making. Lec. Notes in Economics and Mathematical
Systms.
Rabhi, F. A., Dabous, F. T., Chu, R. Y., and Tan, G. E.
(2003). SMARTS benchmarking, prototyping & per-
formance prediction. Technical Report CRCPA5005,
Capital Market Cooperative Research Center (CM-
CRC).
Umar, A. (1997). Application (Re)Engineering: Build-
ing Web-Based Applications and Dealing With Legacy
systems. Prentice Hall.
van den Heuvel, W.-J., van Hillegersberg, J., and Papa-
zoglou, M. (2002). A methodology to support web-
services development using legacy systems. In IFIP
TC8 / WG8.1 Working conference on Engineering In-
formation Systems in the Internet Context.
Yu, H., Rabhi, F. A., and Dabous, F. T. (2004). An ex-
change service for financial markets. In 6th Int. Conf.
on Enterprise Information Systems (ICEIS04), Porto,
Portugal.
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
254
